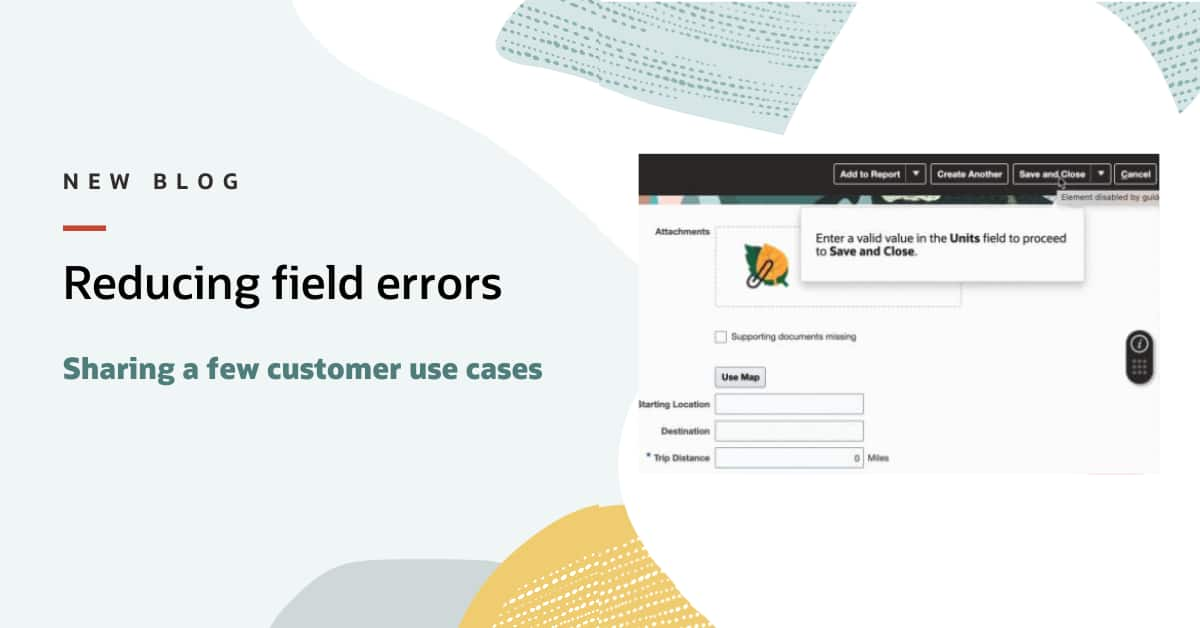
Accessibility Policy
Skip to content
Oracle
Oracle Blogs
Search
Exit Search Field
Clear Search Field
Menu
Blogs Home
RSS
Oracle Blogs
Your source for the latest news, product updates, and industry insights
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
Our Vision of Trusted Autonomy in a People-Agent Workforce
Rich Clayton
5 minute read
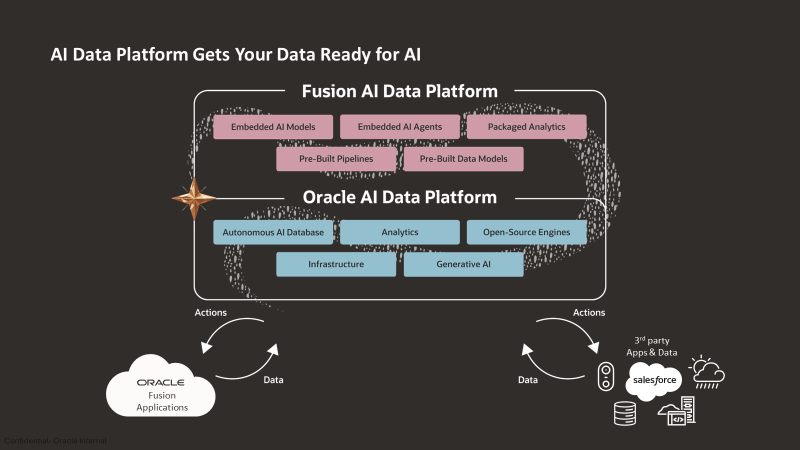
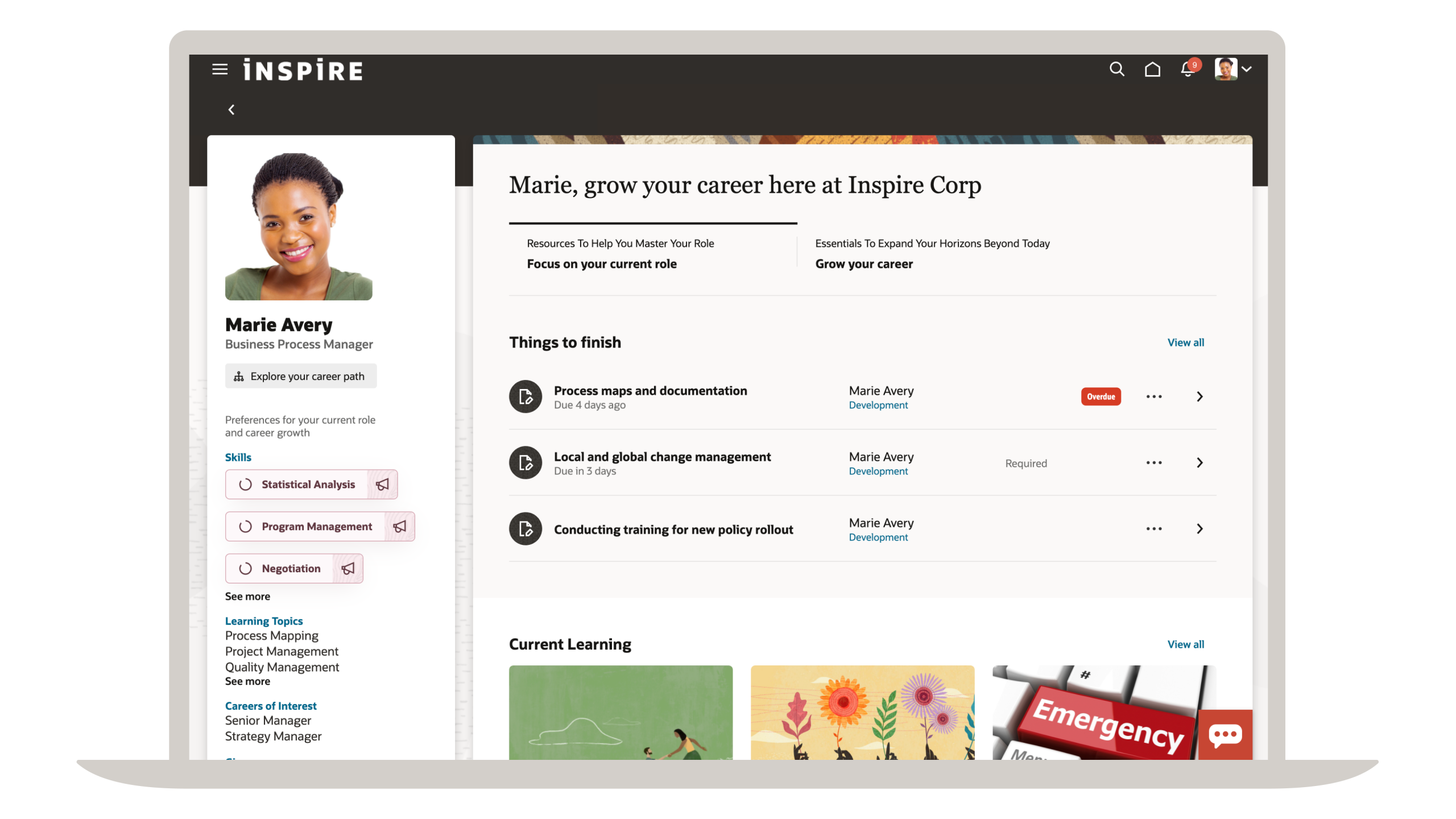
Introducing Oracle Fusion AI Data Platform: Where Trusted Business Data Meets AI-Powered Action
Yaldah Hakim Rashid
7 minute read
Learning Never Stops for Top AI Talent – Join Oracle Race to Certification 2025 Today
Damien Carey
4 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Oracle Cloud Infrastructure Blog
See all
OCI Secure Desktops Unveils Major Feature Updates: Non-Persistent ...
Vijay Sai Virup Chitrapu
2 minute read
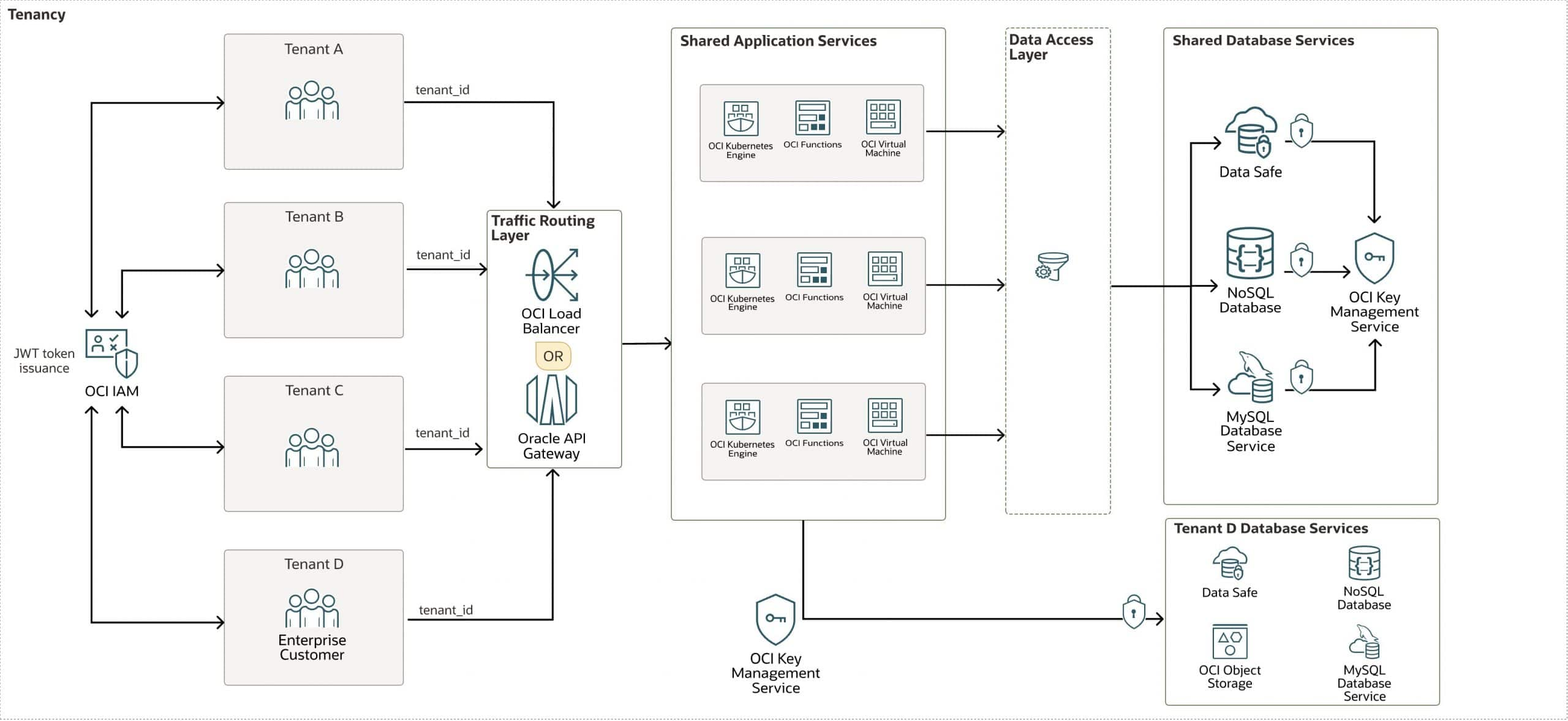
How to SaaSify Applications on OCI
Gururaj Mohan
7 minute read
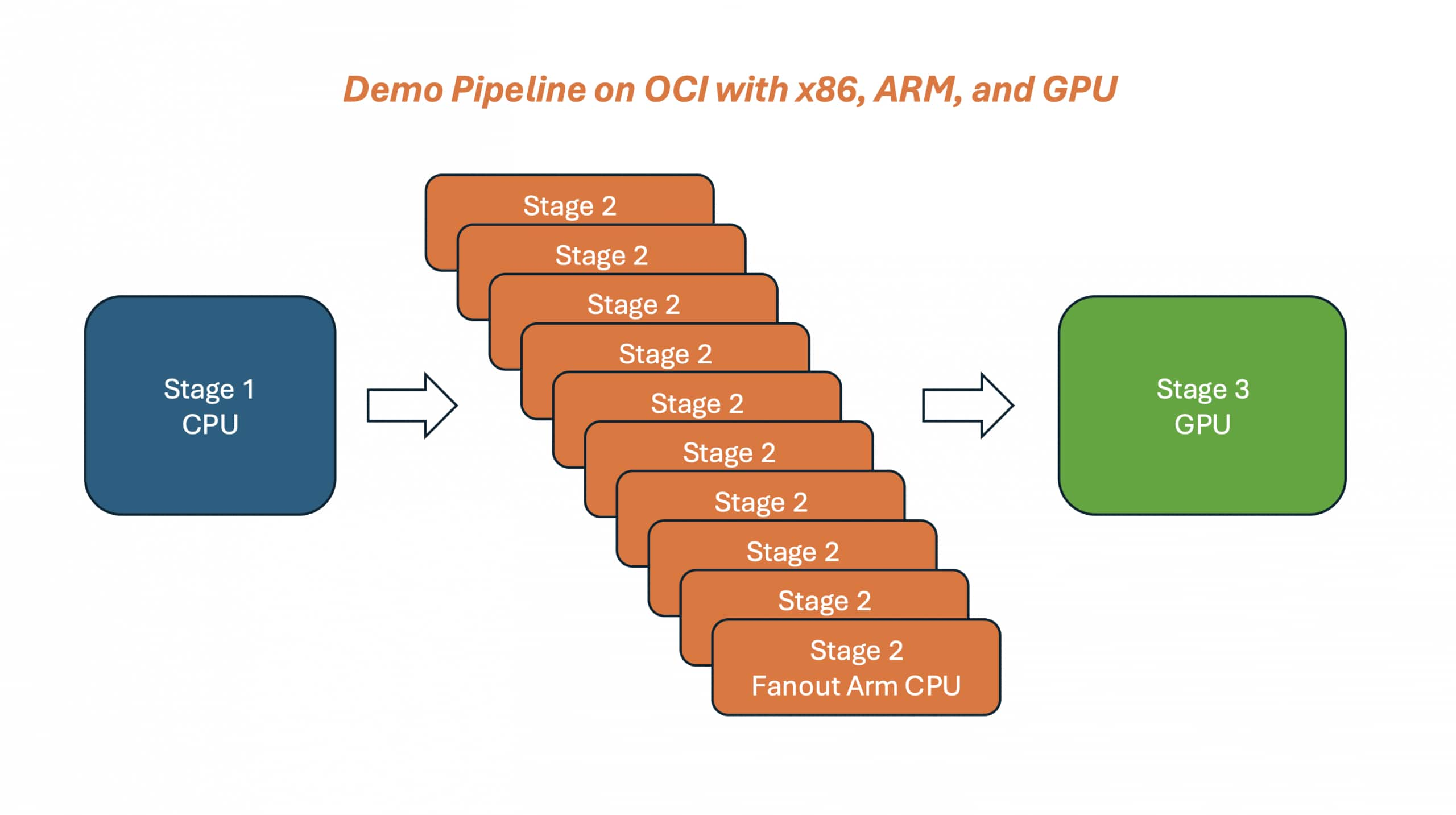
Run Nextflow with Mixed x86 + Arm + GPU Heterogeneous Computing on OCI
Leo Li
6 minute read
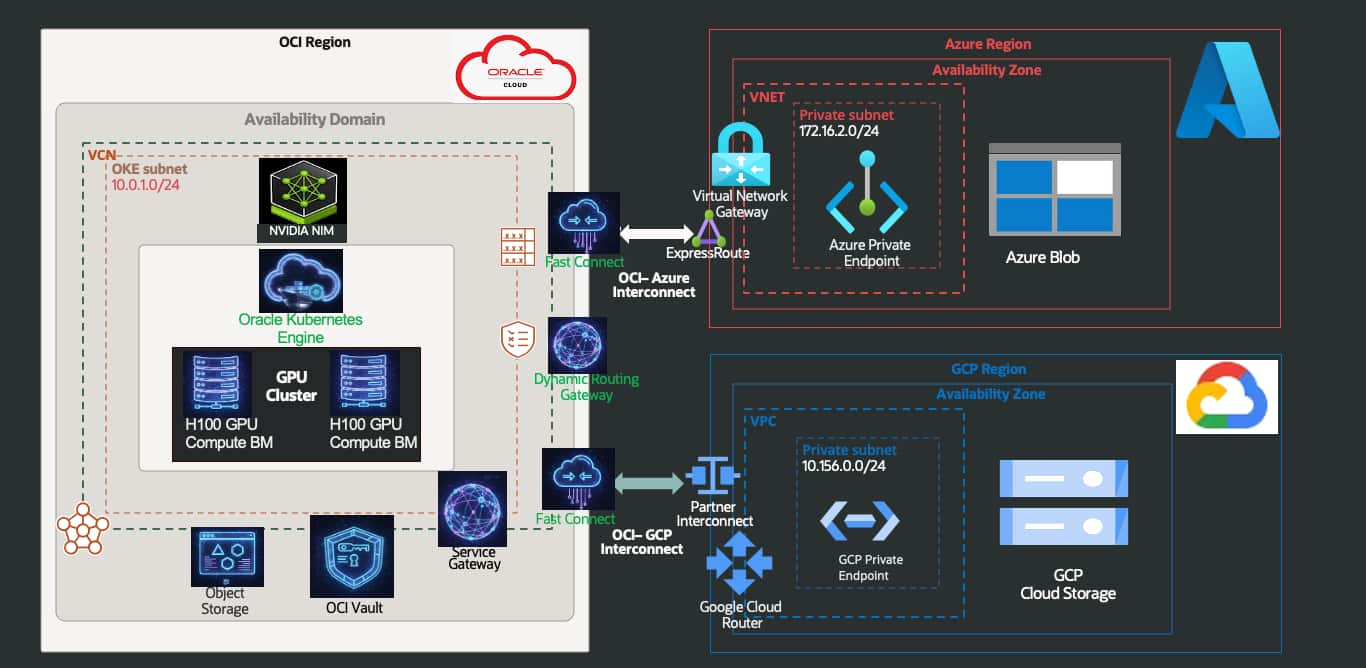
Run Your NVIDIA RAG on OCI with Secure Access to Data from Azure and ...
Niranjan Mohapatra
Eli Schilling
Ritika Gupta
3 minute read
Do more with less: Making the most of block volumes
Natraj Mani
6 minute read
OCI CKS Roundup: What’s new in Containers, Kubernetes, and Serverless
Jordan Spore
4 minute read
Empowering warfighters at the tactical edge with the Oracle Defense ...
Greg Magram
5 minute read
Oracle Linux 7 (x86_64) enters Extended Support—what it means for ...
Jordan Spore
4 minute read
The Fusion Insider Blog
See all
New—more SCM and CX agents for Fusion Apps
Fusion Development
4 minute read
26A roadmaps—new AI agents for ERP, HCM, SCM, and CX
Fusion Development
3 minute read
This agent takes the hassle out of electronic invoicing
Fusion Development
4 minute read
Talk to your data (instead of building custom reports)
Fusion Development
4 minute read
This agent smooths hiring for candidates and recruiters
Fusion Development
4 minute read
Top 10 stories—your guide to what’s hot in AI
Fusion Development
3 minute read
New—AI-powered homepage for Fusion Apps
Fusion Development
3 minute read
Quarterly updates made easy
Fusion Development
5 minute read
Database Insider Blog
See all
DZ Bank Accelerates Modernization and Data Protection with Oracle ...
Dana Serb
3 minute read
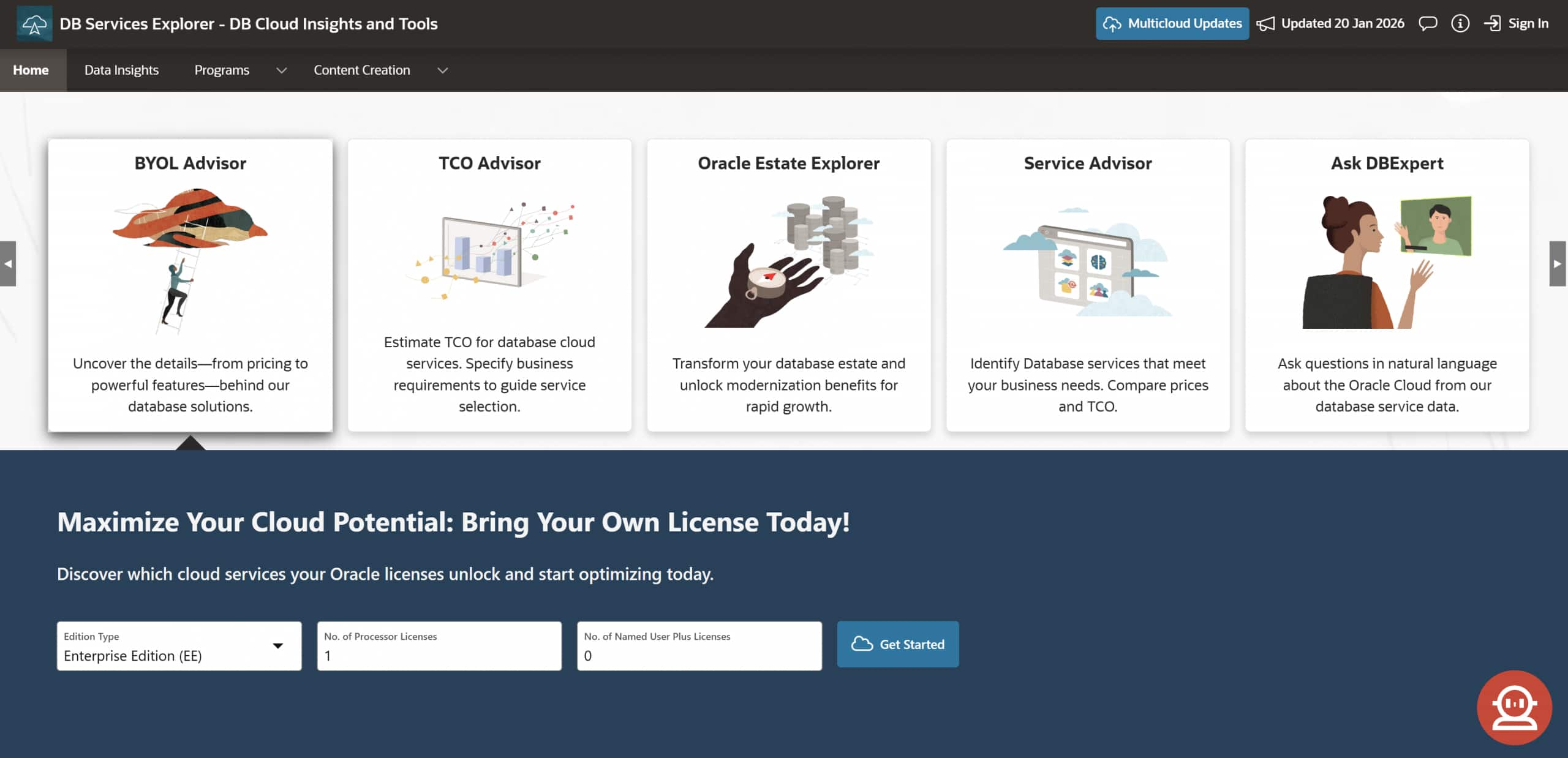
Unlock Cloud Value Instantly with DB Services Explorer’s BYOL Advisor
Tim Pirog
Regina Ruiz
3 minute read
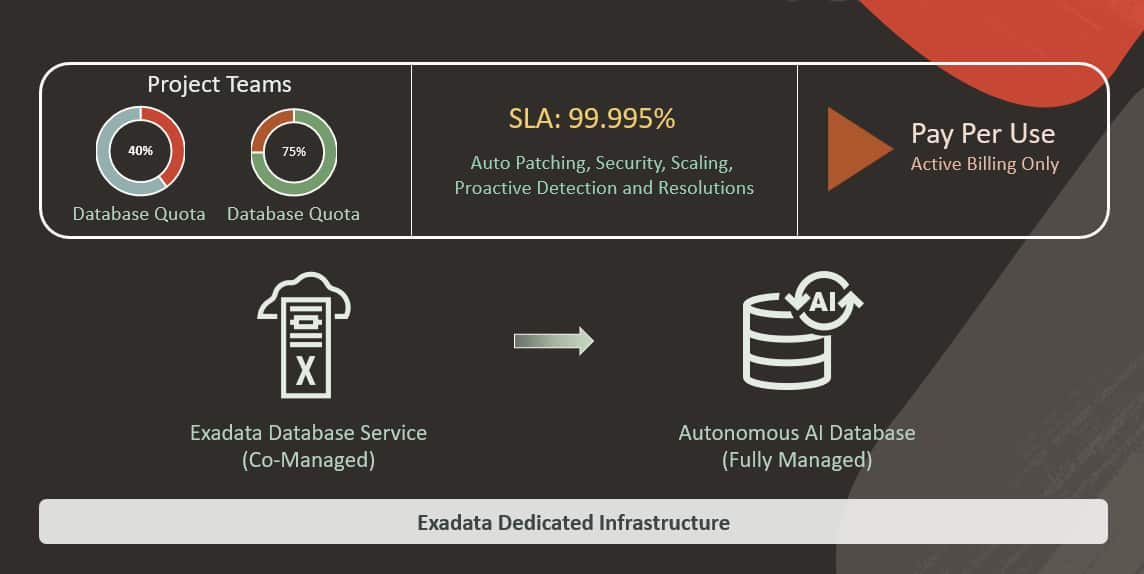
The Evolution of Exadata: Bridging Co-managed Power and Autonomous ...
Simon Law
4 minute read
DZ Bank Accelerates Modernization and Data Protection with Oracle ...
Dana Serb
3 minute read
Eliminating Kafka Brokers with Oracle Transactional Event Queues for ...
Nithin Thekkupadam Narayanan
3 minute read
GA of Oracle AI Database 26ai for Linux x86-64 on-premises platforms
William Hardie
2 minute read
Oracle AI Database 26ai achieves Common Criteria certification and ...
Vipin Samar
3 minute read
Both is better – Oracle AI Database 26ai adds hybrid-mode ...
Russ Lowenthal
3 minute read
Modern Finance Blog
See all
Workday is not an ERP solution—and that’s an issue
Charles Homs
7 minute read
How Oracle closes its books twice as fast as SAP and Workday
Charles Homs
6 minute read
3 reasons why EDM is the right solution for the right time
kevinblack
5 minute read
Ready for the future? Oracle Cloud EPM is the smart alternative to ...
Nick Stankovic
5 minute read
How Enterprise Data Management (EDM) can reduce finance’s ...
Nick Stankovic
5 minute read
Exploring the benefits of replacing SAP BFC with Oracle Cloud EPM ...
Nick Stankovic
6 minute read
Shift your perspective: Turn your enterprise data into valuable ...
Rahul Kamath
4 minute read
Oracle is a Continued Leader in Three Gartner Magic Quadrant Reports ...
Jennifer Toomey
3 minute read
Customer Experience Blog
See all
Oracle Named a Leader for the 9th Consecutive Year in the 2026 ...
Omar Shams
4 minute read
It’s Not About the Dot. It’s About the Direction.
Matthew Westover
4 minute read
NetApp’s Quote-to-Cash Transformation: Applying AI Across the Revenue ...
Omar Shams
2 minute read
Will AI Amplify Your Organizational Silos or Remove Them Entirely?
Rob Pinkerton
4 minute read
Go Behind the Scenes on Oracle’s Own Transformation
Kari Gallagher
2 minute read
How Oracle Uses AI in Fusion Sales to Boost Seller Performance and ...
Alicia Silverman
2 minute read
The Power of Connection: Turning Effort into Reward at TriNet
Elizabeth Shaheen
4 minute read
Introducing the Oracle B2C Service Cloud (RightNow) to Fusion Service ...
Nicole James
2 minute read
Developers Blog
See all
Comparing File Systems and Databases for Effective AI Agent Memory ...
Richmond Alake
34 minute read
HA App Dev: A Developer’s Journey to High Availability
Irina Granat
Richard Exley
5 minute read
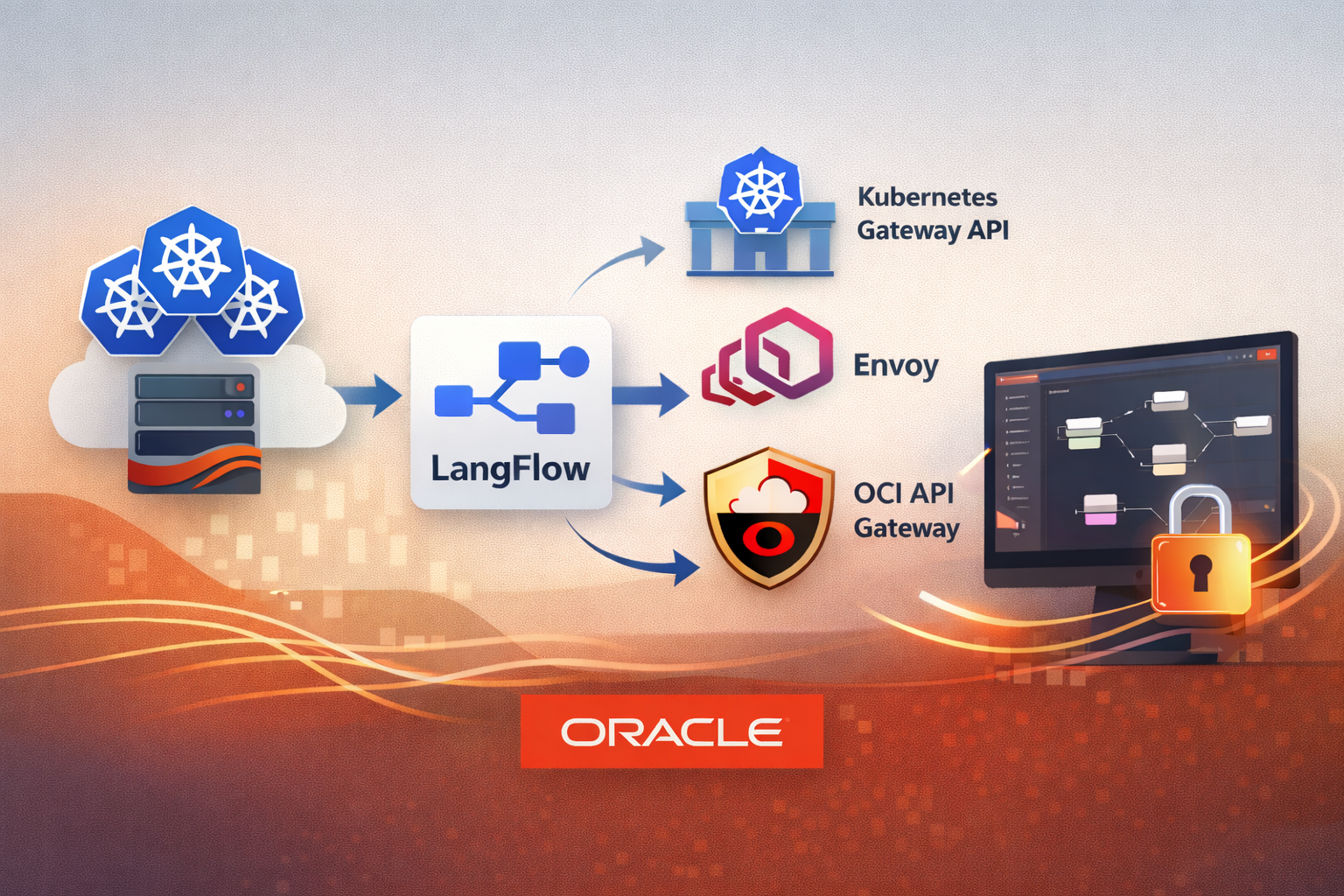
Deploying LangFlow on OCI Kubernetes Engine (OKE) and exposing the UI ...
Joao Tarla
11 minute read
Say hello to the all new server-side JavaScript LiveLab
Martin Bach
2 minute read
Building a Reactive Spring WebFlux (R2DBC) Application with Oracle ...
Sathishkumar Rangaraj
5 minute read
Authorising Pods in OKE to Access GCP Resources Using OpenID Connect ...
Fernando Harris
5 minute read
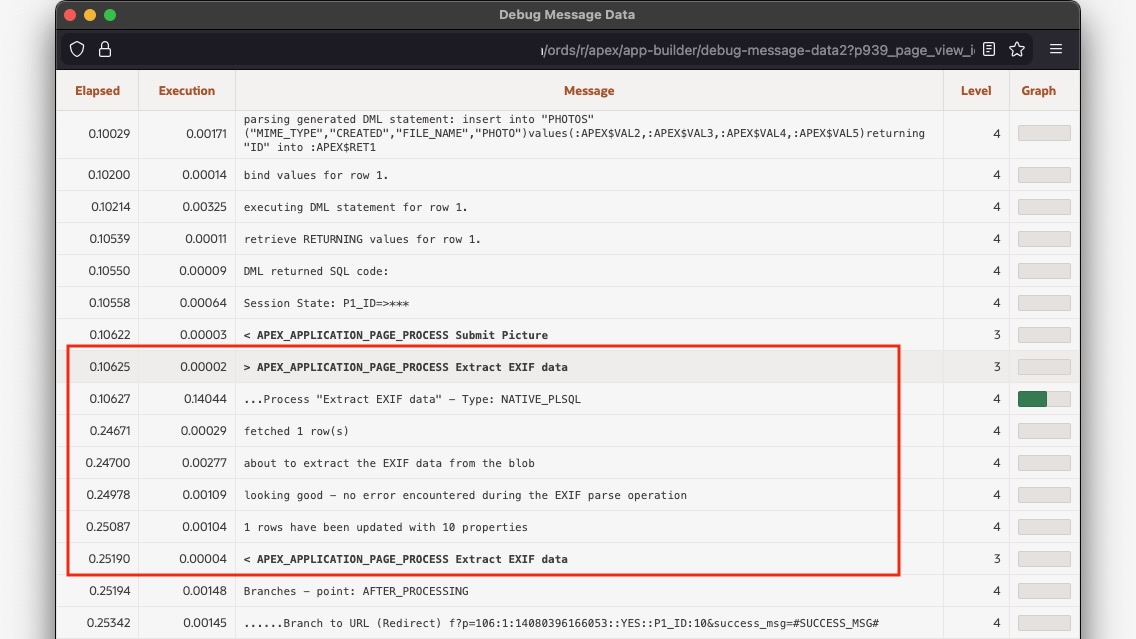
Using the MLE PL/SQL Foreign Function Interface in APEX
Martin Bach
3 minute read
Oracle AI Database Operator for Kubernetes v2.0.0
Kuassi Mensah
3 minute read
Modern Marketing Blog
See all
Alt Text: Best Practices & Evolving Concerns
Chad S. White
Lauren Castady
8 minute read
The Bridge to an Omnichannel Digital Marketing Future: 3 Foundational ...
Chad S. White
4 minute read
Welcome Email Best Practices: Making a Great First Impression
Chad S. White
8 minute read
Using AI Subject Line & Copywriting Tools Successfully
Tommy Hummel
Chad S. White
5 minute read
Key Lead Nurturing Campaigns by Industry
Jessica Stamer
Kaitlin Reno
Cristal Foster
4 minute read
The AI ROI Killer Lurking in Your Architecture: Data Access Charges
Patrick Maxwell
4 minute read
Lead Nurture Campaigns Every B2B Brand Needs
Jessica Stamer
Kaitlin Reno
Cristal Foster
5 minute read
Why Your AI Solutions May Not Be Working as Expected
Patrick Maxwell
Kaiti Gary
6 minute read
Java Blog
See all
Release of the New Java Card Development Kit Version 25.1
Nicolas Ponsini
2 minute read
JDK 25.0.1, 21.0.9, 17.0.17, 11.0.29, and 8u471 Have Been Released
Raymond Gallardo
1 minute read
Unlock Powerful Insights with Java Management Service: Introducing ...
Aurelio Garcia-Ribeyro
3 minute read
The Arrival of Java 25
Sharat Chander
14 minute read
Detaching GraalVM from the Java Ecosystem Train
Donald Smith
2 minute read
Announcing Graal Dev Kit for Micronaut 4.9.1
Sachin Pikle
3 minute read
JDK 24.0.2, 21.0.8, 17.0.16, 11.0.28, and 8u461 Have Been Released
Raymond Gallardo
1 minute read
Simplifying Java Runtime Setup in OCI Cloud Shell with the Java ...
Sanju Nair
3 minute read
AI & Data Science Blog
See all
Announcing AI-powered generative extraction in OCI Document ...
Guy Fogel
2 minute read
Beyond Perception: Building Grounded, Agentic AI at GRAIL-V@CVPR 2026
Amit Agarwal
Hitesh Laxmichand Patel
2 minute read
Evaluating language models with OCI Data Science and Generative AI
Rui Romanini
10 minute read
Vision and Multimodal AI Now Available in OCI Generative AI ...
Federico Kamelhar
4 minute read
Quantifying AI Success: An Analysis of Generative AI Usage in Fusion ...
Christian Rodriguez Jacobs
4 minute read
Agentic AI in the Enterprise: How Oracle Is Powering the Next Wave of ...
Abdul Rafae Mohammed
Aby Joy
5 minute read
Accelerating Enterprise Gen AI applications development on OCI with ...
Amar Gowda
Dennis Kennetz
4 minute read
Expand your global customer reach with OCI Speech AI multilingual ...
Michael Zhang
2 minute read
Oracle Careers Blog
See all
Oracle introduces paid change of station leave for United States ...
Oracle Careers Editorial Team
4 minute read
Actions and insights from the Oracle Career Development Expo
Oracle Careers Editorial Team
4 minute read
Telco to Tech: Abdullah’s path to Oracle SaaS success
Oracle Careers Editorial Team
4 minute read
Top tips to prepare for an interview
Oracle Careers Editorial Team
2 minute read
Oracle Opportunities in Nashville: Building a Thriving Tech Career
Oracle Careers Editorial Team
3 minute read
Forbes: Oracle named one of the world’s best employers
Oracle Careers Editorial Team
3 minute read
Navigating Your Job Search: How to Use AI and Stand Out at Oracle
Oracle Careers Editorial Team
4 minute read
Unlock your future: Oracle’s Abilene data center is your next big ...
Oracle Careers Editorial Team
3 minute read
Analytics Blog
See all
The Oracle Analytics Cloud AI Ecosystem: Shaping the Future of ...
Ravi Bhuma
8 minute read
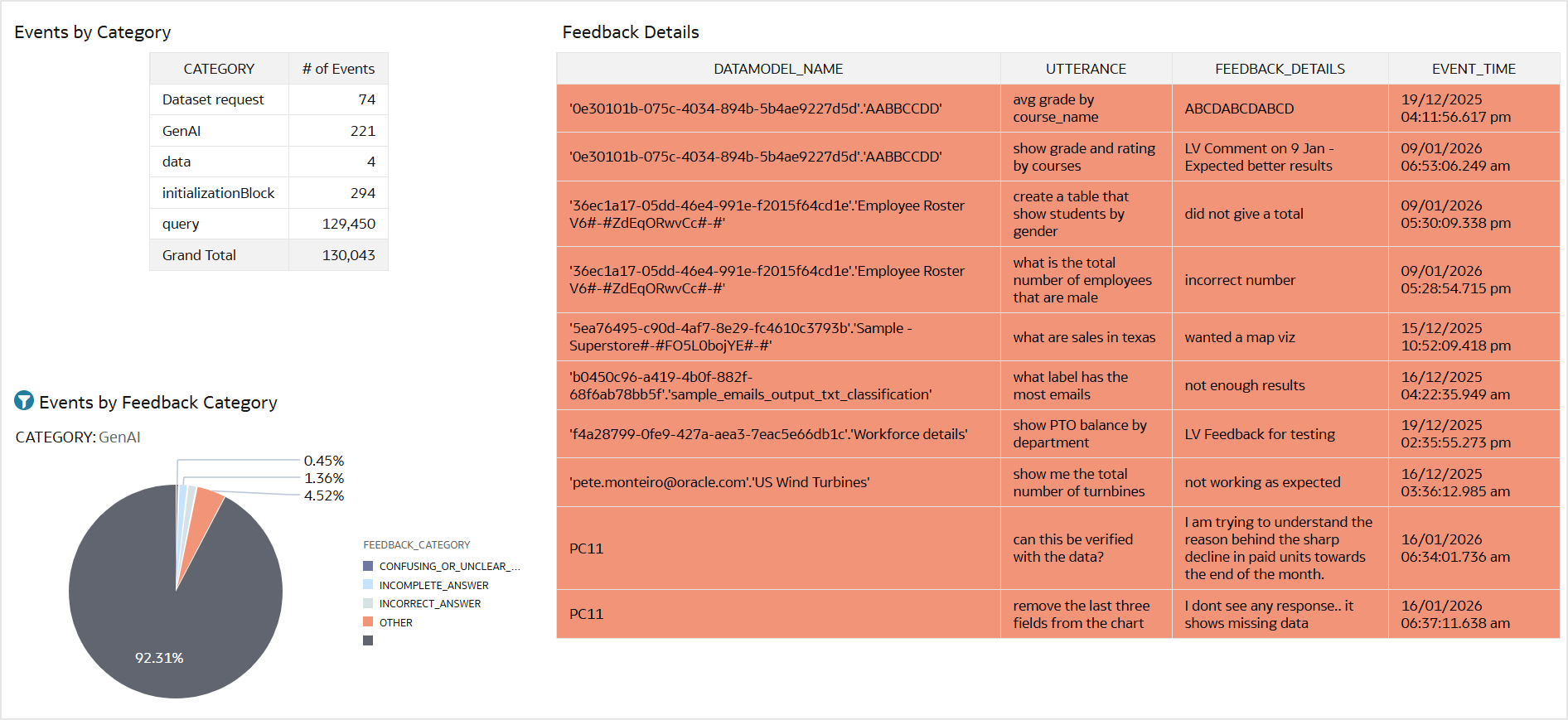
Analyze Oracle Analytics Cloud AI Assistant User Feedback Using ...
Prasenjit Thakur
8 minute read
Unlocking Oracle Analytics Cloud Diagnostics with Oracle Cloud ...
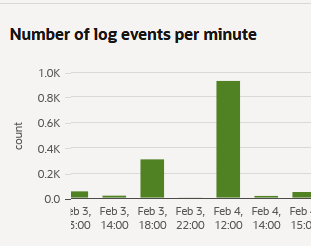
Pete Monteiro
7 minute read
“AI is like oxygen” – an AI expert’s view on Oracle AI Data ...
Emily Cikovsky
Nick Whitehead
7 minute read
CentraCare puts the focus on people with analytics
Emily Cikovsky
Nick Whitehead
6 minute read
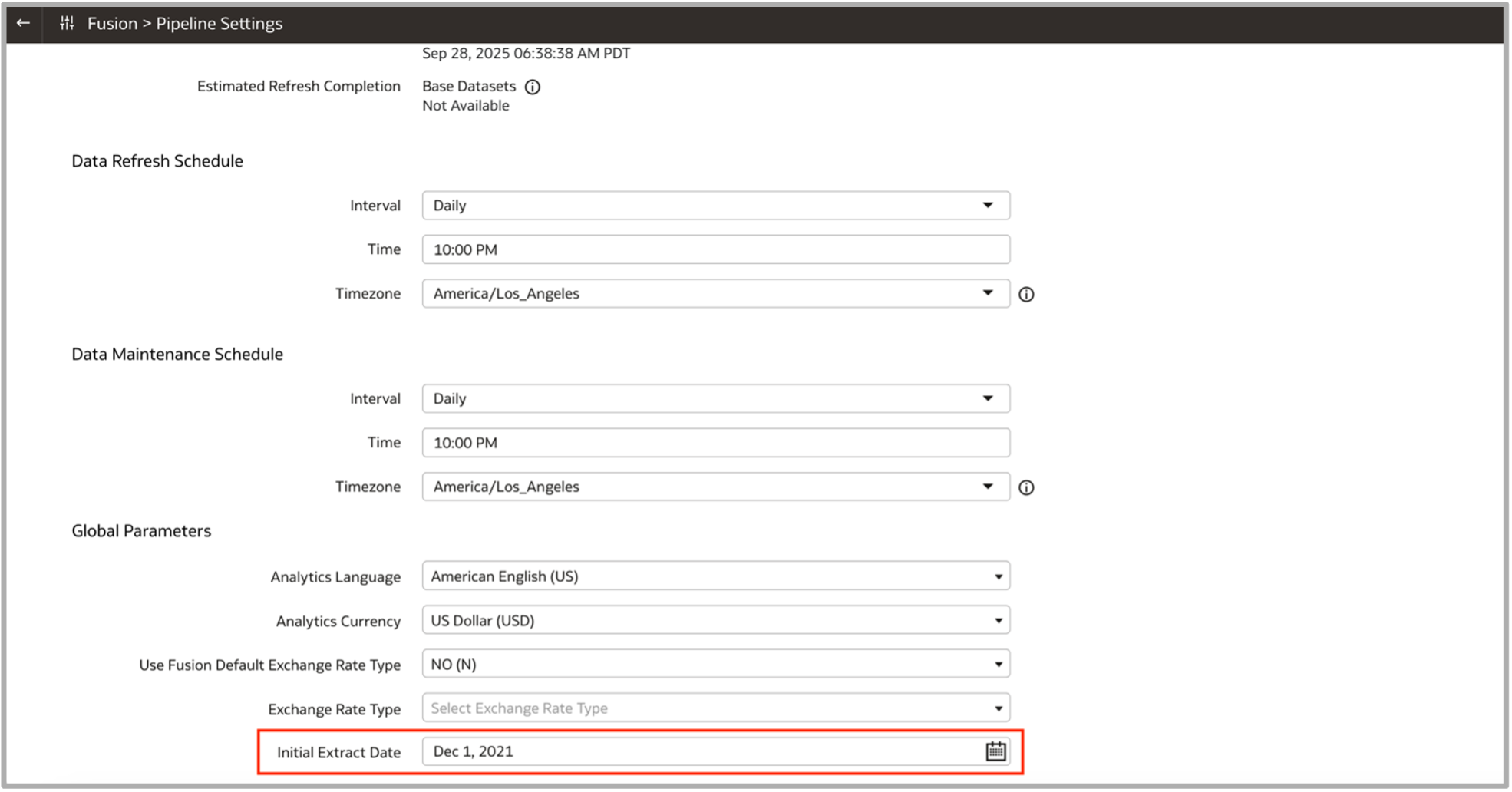
Unlock the Full Potential of the Oracle Fusion AI Data Platform ...
Krithika Raghavan
7 minute read
e& gains better insight into its people
Emily Cikovsky
Nick Whitehead
5 minute read
Oracle Analytics January 2026 Update
Alexandria Toothman
6 minute read
Human Capital Management Blog
See all
Transforming Workplace Safety: Oracle’s Workforce Health and ...
Glen Walton
3 minute read
Oracle’s global first payroll approach – simplifying global payroll ...
Felicia Cheek
4 minute read
Pay Transparency: Redefining Equity with Oracle Skills
Dave O'Meara
3 minute read
Oracle Cloud HCM vs. Workday: 5 things to know
Jeff Wilson
12 minute read
Help achieve cost reductions with Oracle Workforce Health and Safety
Jeff Wilson
6 minute read
Coaching with Clarity: Changing the Game in Learning and Growth!
Chris Havrilla
5 minute read
Modern HR leaders are driving innovation in finance
Guest Author
3 minute read
HCM is the glue that holds manufacturing together
Guest Author
3 minute read
Sustainability Blog
See all
Oracle’s Sustainability Journey: Celebrating our progress and ...
Scott Twaddle
4 minute read
OCI Carbon Emissions Analysis – Introducing more accurate power-based ...
Ronak Shah
2 minute read
Remembering Jon Chorley
Jennifer Thompson
4 minute read
Enhancing grid resilience with AI
Jennifer Thompson
3 minute read
AI for Good: How Oracle AI can help solve complex sustainability ...
Jennifer Thompson
5 minute read
Inspiring women in technology: Spotlight on Elena Avesani
Elena Avesani
6 minute read
2025 ESG Regulatory Outlook: Resilience through Strategic Reporting ...
Jennifer Thompson
6 minute read
Industry Series: The opportunities for financial institutions to ...
Caroline Firer
Saloni Ramakrishna
Alexandra Villain Lecompte
7 minute read
Security Blog
See all
January 2026 Critical Patch Update Released
Integrated Cyber Center (ICC)
1 minute read
Preparing for Post Quantum Cryptography
ERIC BELMON
10 minute read
Security Plans for AI Systems
Nancy Kramer
Betina Tagle
4 minute read
October 2025 Critical Patch Update Released
Integrated Cyber Center (ICC)
1 minute read
Security Alert CVE-2025-61884 Released
Rob Duhart
1 minute read
Apply Oracle Security Alert CVE-2025-61882 for Oracle E-Business ...
Rob Duhart
1 minute read
Using Generative Artificial Intelligence (GenAI) to Advance Security
Daniel Southern
Nancy Kramer
3 minute read
July 2025 Critical Patch Update Released
Eric Maurice
1 minute read
Supply Chain Management Blog
See all
Elevating Order Management With Release 26A – Three Themes ...
Marc J Fitten
4 minute read
Less Routine, More Inspiration – Oracle Supply Chain Planning Update ...
Marc J Fitten
3 minute read
Smarter and Faster: Top 5 Enhancements in Oracle Fusion ...
Lucia Ligamari
3 minute read
Unlocking Next-Level Productivity: Top 5 Must-See Oracle PLM 26A ...
Lucia Ligamari
3 minute read
Optimizing Process Manufacturing with Oracle: Enhanced Capabilities ...
Joan Lim
2 minute read
Modernizing Logistics Operations with Oracle: AI Agents, Mobile, and ...
Joan Lim
3 minute read
Workday is not an ERP solution—and that’s an issue
Charles Homs
7 minute read
5 supply chain management success factors every CPG company needs to ...
Erin Sun
5 minute read
Social Impact Blog
See all
Walking with Nzeli: 35 years of conservation through the eyes of one ...
Oracle Social Impact
5 minute read
Local action, global difference: Oracle CloudWorld Tour brings ...
Oracle Social Impact
4 minute read
On International Volunteer Day, Oracle Volunteers share how ...
Oracle Social Impact
4 minute read
Celebrating a year of service with Oracle Volunteers
Oracle Social Impact
2 minute read
Oracle and d.tech: a philosophy of learning in action
Colleen Cassity
8 minute read
Earth Day 2024: Plastics vs. the Planet with Colleen Cassity, Vice ...
Oracle Social Impact
10 minute read
Oracle Social Impact and the positive feedback loop of caring for ...
Oracle Social Impact
7 minute read
Building a water resilient future through our philanthropy
Erin Davis
Rhia Birak
4 minute read
Oracle University Blog
See all
User adoption isn’t a one time event – why leaders rely ...
Chris Supangat
3 minute read
How Oracle Guided Learning helps you to reduce user errors – ...
Chris Supangat
3 minute read
AI Skills for a New Era: Why Certification Sets You and Your ...
Damien Carey
2 minute read
Oracle Cloud Success Navigator 25.2.2: Continued Enhancements for an ...
Rachel Bennett
3 minute read
From Curiosity to Career Growth: An Oracle AI Certification Journey
Lois Houston
7 minute read
How to master Selectors: A guide to picking the perfect web element
Chris Supangat
7 minute read
OGL Insider: AI Assistant for Steps
Prakash Arumugapandian
5 minute read
OGL Insider: Guide Break Assistance
Lokesh Reddy
6 minute read
Oracle Academy
See all
The Ministry of Information, Communication, Technology and Innovation ...
Danny Gooris
2 minute read
Oracle Academy presents at Nigeria Education Conference and Awards ...
Danny Gooris
2 minute read
Tech Chat podcast announces the Oracle Academy Community: Member ...
Lorilyn Owens
3 minute read
Oracle Academy collaborates with Aditya University, India, to host a ...
Damian Haas
2 minute read
Oracle Academy collaborates with and presents at ACM – India Chapter ...
Damian Haas
3 minute read
Oracle Academy presents honor at the inaugural Stripe Young Scientist ...
Danny Gooris
2 minute read
Empowering educators: Highlights from Oracle Academy Day in Budapest
Danny Gooris
2 minute read
We congratulate the middle and high school student winners of the ...
Danny Gooris
4 minute read
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers