Open Source HackerPushing the boundaries of free technology2023-02-11T09:12:11Zhttps://opensourcehacker.com/feed/atom/Mikko Ohtamaahttp://opensourcehacker.com<![CDATA[The State of Python in Blockchain 2023 report]]>https://opensourcehacker.com/?p=31242023-02-11T09:12:11Z2023-02-10T10:07:06ZContinue reading →]]>
I have been co-authoring the report The state of Python in the blockchain 2023. The report overviews the modern blockchain development ecosystem for Python developers. Despite turbulences in the markets, we see the year-over-year growth of developer numbers. The demand for Python developers in the industry is growing: Last year, we organised PyChain 2022 conference, where we got 1200 signups.
Python-based open-source solutions lead in two categories: ETL (extract, transform, load) and security and auditing (static linting, formal verification). Python is also heavily used in development and devops toolchains (smart contract compilation) and integration (RPC clients).
If you are a Python developer and looking for opportunities in the blockchain ecosystem, take a look, and you may find a lot of interesting projects that are hiring. The report is also good to read if you just want to understand what’s happening in the blockchain industry without all the noise of market news.
The audience of this post is software developers who are looking to build scalable software-as-a-service solutions and are interested in Svelte, Python and TimescaleDB technologies. Developers who are interested in Web3, Ethereum, cryptocurrency and blockchain technologies will also find this post useful.
What are Trading Strategy protocol and algorithmic trading?
Trading Strategy is a new service for algorithmic and technical trading of cryptocurrencies on decentralised exchange (DEXes).
Algorithmic trading is a derivative of technical analysis; taking trading positions based on pure mathematics and data. Algorithmic trading is part of quantitative finance, the opposite of value investing where trading decisions are made based on fundamentals. Algorithmic trading provides a systematic approach to trading compared to methods based on trader intuition or instinct. Whereas technical analysis often aids humans to take trading positions, in its purest form in algorithmic trading a trading program follows a set of trading rules and independently executes trades on the market 24/7.
Today, Trading Strategy offers market data feeds for Uniswap compatible exchanges across three different blockchains (Ethereum, Binance Smart Chain, Polygon). We expect to cover all major decentralised exchanges and exchange types on all major blockchains by the end of the year.
Our mission is to make algorithmic by developing and investing in algorithmic trading strategies easy. Although serving the market data is the first step, Trading Strategy is going to grow beyond the information service website. During the course of 2022, the service will be decentralised, so that the whole software solution, strategy and trade execution will be runnable anyone independently (so-called operating a node).
Trading Strategy chose modern architecture and the best components of 2021 for its software development, making its codebase high in technical wealth.
Technical wealth is the opposite of technical debt. As Trading Strategy was able to start as a clean slate project, we had the privilege to pick the latest technologies and build our architecture around these. This enables us to build faster and do changes more dynamically. As an example, a lot of out of the box features offered by TimescaleDB would have taken us months if we had built them ourselves.
The decentralised finance (DeFi) industry itself is high in technical wealth compared to traditional finance (TradFi). This is due to the use of public ledger (open data), free-as-in-speech codebases (open source) and permissionless public blockchains (open access). This is the opposite of the traditional financial services that are built around closed networks, private APIs and exclusive access. Privileged and siloed software development leads to high maintenance cost long term, as there are no people who are able to work with the code. For references, see this blog post on legacy investment bank software and Google’s woes about maintaining their own Linux kernel with 9000+ in-house patches. Writing financial applications for DeFi is 10x – 100x more developer productive than writing them for TradFi.
What is a Web3?
From the software developer point of view, Web3 refers to backend-free services. No logins or registrations are needed. The user data is not processed and stored on a private server, but a public blockchain where the business logic is wired together using smart contracts. Any transaction, or a “POST request” in the traditional parlay, is initiated by users themselves, using their private key on their locally stored wallet application.
In this kind of model, there are no sysadmin fraud risks, no data loss risks or data liability risks with user identity information. The user is in 100% control. It is a fairer world where users have more control over the revenue streams they generate. Big IT like Facebook and Google have fewer unfair monetization opportunities on user data.
Only some services are a good fit for Web3. At the moment Web3 works best for pseudonymous and public data use cases. This is almost all finance, provenance (NFTs), public social media like Twitter and discussion forums and eCommerce.
Web3 is still early: though most pieces have been figured out in computer science theory, the implementation is still under development. For example, doing database-like traffic (ThreadDB) and storage (Arweave, Storj) can be still considered “alpha” today.
Software stack overview
Below is a walkthrough of how the HTTP requesting of Trading Strategy website is set up. Because Trading Strategy application is eventually going to be a Web3-like oracle node in a distributed network, everything built API first. There are no internal APIs – the website uses the same public market data APIs as everyone else.
Trading Strategy Oracle is a process that indexes blockchain data: DEX trading data, tokens and so on. Oracle and web processes communicate over TimescaleDB. Oracle is responsible for tasks like generating OHLCV candle data, generating liquidity maps and fetching US dollar reference prices. Oracle processes connect to various blockchain GoEthereum nodes that are part of the P2P network for the respective Ethereum Virtual Machine based blockchains.
We considered React for Trading Strategy . React is the de facto frontend framework choice of the cryptocurrency industry. However, even with our extensive experience in React, we chose Svelte because we believe Svelte is the framework of the future. Svelte offers reactivity with ahead-of-time compiled virtual DOM free approach. Svelte components are very maintanable single files, containing normal HTML template and normal CSS code instead of bastardized “styles-in-JS” or domain-specific templating approaches. Writing reactive logic in Svelte is easier than in other frameworks, due to its elegant design making the most developer-friendly frontend framework.
SvelteKit takes the developer experience of Svelte even further, by introducing the concepts of file-system based routing, simple server-side rendering and integrated web server (Vite). With SvelteKit’s batteries included approach an application developer spends less time on plumbing, boilerplate code and debugging async reactivity mess This all translates to better efficiency: the codebase is easier to read and maintain due to standardized coding conventions across open source libraries, components are faster to develop and new developers pick up the pace faster.
We also use components outside Svelte. We use uPlot for charting. Though the TradingView is the most popular JS framework for technical trading, we are puritans that go with 100% open-source approach as we are building for long term. uPlot was the charting library with an open-source license. For our number heavy tables we use DataTable library. For Web3 integration, we use web3.js through svelte-web3.
Backend: Why did we choose Python, Pyramid and SQLAlchemy?
For developers who know several programming languages, Python is superior choice for the backend. Writing Python programs takes fewer keystrokes. Python is the most readable of all programming languages. Optional typing support is a great way to make the code more static when the team grows.
There is a forever battle with sync vs. async. There is greater maintenance efficiency with colored function free, linear threaded, Python code. Our workloads are computationally sensitive, not IO sensitive, so using async IO would cause more headaches and we would get no benefits out of it.
We chose Pyramid and SQLAlchemy because we are doing API first backend and complex databasing with our special workload. Trading Strategy currently features tracking of 800k trading pairs (NASDAQ has only 3000). This is not your run of the mill CRUD and admin UI application. For this kind of use case, Pyramid and SQLALchemy are the choice today. This framework combo offers powerful tooling to cover advanced use cases without sacrificing developer productivity or being completely outside of an average backend developer skillset.
We chose TimescaleDB, because they are based on PostgreSQL. During the last 20 years, PostgreSQL has overtaken as the most advanced open-source database. PostgreSQL has the most vibrant database ecosystem on this planet. Tuning PostgreSQL is well-known: there are multiple products and companies to support in-house development.
TimescaleDB team has been the most responsive of any projects we have seen during the 25 years of open-source involvement. Their proactivity and helpfulness give us an assurance that TimescaleDB is serious about building an open-source community. All of our StackOveflow questions and Github issue reports, no matter how bad or novice has gone unanswered. We are pretty sure if one were to ask something offtopic, like making a coffee, and tagging with “timescaledb” it would still a receive perfect answer.
Why did we launch on Ethereum mainnet, Binance Smart Chain and Polygon?
When we started to build Trading Strategy early 2021, the layer 1 blockchains were not still on such rampage as they are today. Polygon and Binance Smart Chain were the layer 1 top dogs and no layer two was live yet. Ther chains had user adoption and active DEXes like PancakeSwap and QuickSwap. Today we have more competition with the likes of Avalanche, Fantom, Aurora and Telos EVM. Also we have non-EVM based solid solutions like NEAR, Elrond and Solana. We expect to integrate all of them during the source of 2022.
Ethereum mainnet has the best developer community. However, the Ethereum mainnet transaction costs are prohibitively expensive for the unforeseeable future, and thus it is unsuitable for our active trading strategies.
What challenges do we see?
Developing the means failing and retrying a few times, as your first guess is not always right one. We have some good lessons from 2021.
SvelteKit is still in beta. Some of the aspects of it are still under development and may not have complete documentation or supporting material like tutorial blog posts. We had to figure out a lot of aspects ourselves, especially what comes to SvelteKit server-side rendering speed and tuning. We feel the benefits of SvelteKit developer productivity greatly outweighs some learning curve and contributions to the documentation we had to do ourselves.
Svelte is new, thus it still does not have Svelte-native feature-rich charting libraries like uPlot and Datatables. They do not integrate to SvelteKit server-side rendering flow, making it not possible to serve pre-rendered pages.
Hosting Polygon and Binance Smart Chain nodes is tough. Both blockchain teams have issues with developer communications. There are no adequate manuals for running your own node. The expectation of using bug-ridden third-party API services goes against the blockchain ethos
We are currently hiring for frontend (Svelte), backend (Python/PostgreSQL) and quant research (Jupytere Notebook/Pandas) positions. If you are interested to work with cryptocurrencies and algorithmic trading please email us careers@tradingstrategy.ai.
]]>0Mikko Ohtamaahttp://opensourcehacker.com<![CDATA[Building a cryptocurrency site with Svelte, Python and TimescaleDB]]>https://opensourcehacker.com/?p=31112022-01-07T11:59:23Z2022-01-07T11:59:23ZContinue reading →]]>
The audience of this post is software developers who are looking to build scalable software-as-a-service solutions and are interested in Svelte, Python and TimescaleDB technologies. Developers who are interested in Web3, Ethereum, cryptocurrency and blockchain technologies will also find this post useful.
What are Trading Strategy protocol and algorithmic trading?
Trading Strategy is a new service for algorithmic and technical trading of cryptocurrencies on decentralised exchange (DEXes).
Algorithmic trading is a derivative of technical analysis; taking trading positions based on pure mathematics and data. Algorithmic trading is part of quantitative finance, the opposite of value investing where trading decisions are made based on fundamentals. Algorithmic trading provides a systematic approach to trading compared to methods based on trader intuition or instinct. Whereas technical analysis often aids humans to take trading positions, in its purest form in algorithmic trading a trading program follows a set of trading rules and independently executes trades on the market 24/7.
Today, Trading Strategy offers market data feeds for Uniswap compatible exchanges across three different blockchains (Ethereum, Binance Smart Chain, Polygon). We expect to cover all major decentralised exchanges and exchange types on all major blockchains by the end of the year.
Our mission is to make algorithmic by developing and investing in algorithmic trading strategies easy. Although serving the market data is the first step, Trading Strategy is going to grow beyond the information service website. During the course of 2022, the service will be decentralised, so that the whole software solution, strategy and trade execution will be runnable anyone independently (so-called operating a node).
Trading Strategy chose modern architecture and the best components of 2021 for its software development, making its codebase high in technical wealth.
Technical wealth is the opposite of technical debt. As Trading Strategy was able to start as a clean slate project, we had the privilege to pick the latest technologies and build our architecture around these. This enables us to build faster and do changes more dynamically. As an example, a lot of out of the box features offered by TimescaleDB would have taken us months if we had built them ourselves.
The decentralised finance (DeFi) industry itself is high in technical wealth compared to traditional finance (TradFi). This is due to the use of public ledger (open data), free-as-in-speech codebases (open source) and permissionless public blockchains (open access). This is the opposite of the traditional financial services that are built around closed networks, private APIs and exclusive access. Privileged and siloed software development leads to high maintenance cost long term, as there are no people who are able to work with the code. For references, see this blog post on legacy investment bank software and Google’s woes about maintaining their own Linux kernel with 9000+ in-house patches. Writing financial applications for DeFi is 10x – 100x more developer productive than writing them for TradFi.
What is a Web3?
From the software developer point of view, Web3 refers to backend-free services. No logins or registrations are needed. The user data is not processed and stored on a private server, but a public blockchain where the business logic is wired together using smart contracts. Any transaction, or a “POST request” in the traditional parlay, is initiated by users themselves, using their private key on their locally stored wallet application.
In this kind of model, there are no sysadmin fraud risks, no data loss risks or data liability risks with user identity information. The user is in 100% control. It is a fairer world where users have more control over the revenue streams they generate. Big IT like Facebook and Google have fewer unfair monetization opportunities on user data.
Only some services are a good fit for Web3. At the moment Web3 works best for pseudonymous and public data use cases. This is almost all finance, provenance (NFTs), public social media like Twitter and discussion forums and eCommerce.
Web3 is still early: though most pieces have been figured out in computer science theory, the implementation is still under development. For example, doing database-like traffic (ThreadDB) and storage (Arweave, Storj) can be still considered “alpha” today.
Software stack overview
Below is a walkthrough of how the HTTP requesting of Trading Strategy website is set up. Because Trading Strategy application is eventually going to be a Web3-like oracle node in a distributed network, everything built API first. There are no internal APIs – the website uses the same public market data APIs as everyone else.
Trading Strategy Oracle is a process that indexes blockchain data: DEX trading data, tokens and so on. Oracle and web processes communicate over TimescaleDB. Oracle is responsible for tasks like generating OHLCV candle data, generating liquidity maps and fetching US dollar reference prices. Oracle processes connect to various blockchain GoEthereum nodes that are part of the P2P network for the respective Ethereum Virtual Machine based blockchains.
We considered React for Trading Strategy . React is the de facto frontend framework choice of the cryptocurrency industry. However, even with our extensive experience in React, we chose Svelte because we believe Svelte is the framework of the future. Svelte offers reactivity with ahead-of-time compiled virtual DOM free approach. Svelte components are very maintanable single files, containing normal HTML template and normal CSS code instead of bastardized “styles-in-JS” or domain-specific templating approaches. Writing reactive logic in Svelte is easier than in other frameworks, due to its elegant design making the most developer-friendly frontend framework.
SvelteKit takes the developer experience of Svelte even further, by introducing the concepts of file-system based routing, simple server-side rendering and integrated web server (Vite). With SvelteKit’s batteries included approach an application developer spends less time on plumbing, boilerplate code and debugging async reactivity mess This all translates to better efficiency: the codebase is easier to read and maintain due to standardized coding conventions across open source libraries, components are faster to develop and new developers pick up the pace faster.
We also use components outside Svelte. We use uPlot for charting. Though the TradingView is the most popular JS framework for technical trading, we are puritans that go with 100% open-source approach as we are building for long term. uPlot was the charting library with an open-source license. For our number heavy tables we use DataTable library. For Web3 integration, we use web3.js through svelte-web3.
Backend: Why did we choose Python, Pyramid and SQLAlchemy?
For developers who know several programming languages, Python is superior choice for the backend. Writing Python programs takes fewer keystrokes. Python is the most readable of all programming languages. Optional typing support is a great way to make the code more static when the team grows.
There is a forever battle with sync vs. async. There is greater maintenance efficiency with colored function free, linear threaded, Python code. Our workloads are computationally sensitive, not IO sensitive, so using async IO would cause more headaches and we would get no benefits out of it.
We chose Pyramid and SQLAlchemy because we are doing API first backend and complex databasing with our special workload. Trading Strategy currently features tracking of 800k trading pairs (NASDAQ has only 3000). This is not your run of the mill CRUD and admin UI application. For this kind of use case, Pyramid and SQLALchemy are the choice today. This framework combo offers powerful tooling to cover advanced use cases without sacrificing developer productivity or being completely outside of an average backend developer skillset.
We chose TimescaleDB, because they are based on PostgreSQL. During the last 20 years, PostgreSQL has overtaken as the most advanced open-source database. PostgreSQL has the most vibrant database ecosystem on this planet. Tuning PostgreSQL is well-known: there are multiple products and companies to support in-house development.
TimescaleDB team has been the most responsive of any projects we have seen during the 25 years of open-source involvement. Their proactivity and helpfulness give us an assurance that TimescaleDB is serious about building an open-source community. All of our StackOveflow questions and Github issue reports, no matter how bad or novice has gone unanswered. We are pretty sure if one were to ask something offtopic, like making a coffee, and tagging with “timescaledb” it would still a receive perfect answer.
Why did we launch on Ethereum mainnet, Binance Smart Chain and Polygon?
When we started to build Trading Strategy early 2021, the layer 1 blockchains were not still on such rampage as they are today. Polygon and Binance Smart Chain were the layer 1 top dogs and no layer two was live yet. Ther chains had user adoption and active DEXes like PancakeSwap and QuickSwap. Today we have more competition with the likes of Avalanche, Fantom, Aurora and Telos EVM. Also we have non-EVM based solid solutions like NEAR, Elrond and Solana. We expect to integrate all of them during the source of 2022.
Ethereum mainnet has the best developer community. However, the Ethereum mainnet transaction costs are prohibitively expensive for the unforeseeable future, and thus it is unsuitable for our active trading strategies.
What challenges do we see?
Developing the means failing and retrying a few times, as your first guess is not always right one. We have some good lessons from 2021.
SvelteKit is still in beta. Some of the aspects of it are still under development and may not have complete documentation or supporting material like tutorial blog posts. We had to figure out a lot of aspects ourselves, especially what comes to SvelteKit server-side rendering speed and tuning. We feel the benefits of SvelteKit developer productivity greatly outweighs some learning curve and contributions to the documentation we had to do ourselves.
Svelte is new, thus it still does not have Svelte-native feature-rich charting libraries like uPlot and Datatables. They do not integrate to SvelteKit server-side rendering flow, making it not possible to serve pre-rendered pages.
Hosting Polygon and Binance Smart Chain nodes is tough. Both blockchain teams have issues with developer communications. There are no adequate manuals for running your own node. The expectation of using bug-ridden third-party API services goes against the blockchain ethos
We are currently hiring for frontend (Svelte), backend (Python/PostgreSQL) and quant research (Jupytere Notebook/Pandas) positions. If you are interested to work with cryptocurrencies and algorithmic trading please email us careers@tradingstrategy.ai.
]]>0Mikko Ohtamaahttp://opensourcehacker.com<![CDATA[Simple loop parallelization in Python]]>https://opensourcehacker.com/?p=31022017-01-30T11:04:57Z2017-01-30T11:04:57ZContinue reading →]]>Sometimes you are programming a loop to run over tasks that could be easily parallelized. Usual suspects include loads that wait IO like calls to third party API services.
Since Python 3.2, there have been easy tool for this kind of jobs. concurrent.futures standard library module provides thread and multiprocess pools for executing tasks parallel. For older Python versions, a backport library exists.
Consider a loop that waits RPC traffic and the RPC has a wide enough pipe to handle multiple calls simultaneously:
def import_all(contract: Contract, fname: str):
"""Import all entries from a given CSV file."""
for row in read_csv(fname):
# This functions performs multiple RPC calls
# with wait between calls
import_invoicing_address(contract, row)
You can create a thread pool that runs tasks on N worker threads. Tasks are wrapped in futures that call the worker function. Each thread keeps consuming tasks from the queue until all of work is done.
import concurrent.futures
def import_all_pooled(contract: Contract, fname: str, workers=32):
"""Parallerized CSV import."""
# Run the futures within this thread pool
with concurrent.futures.ThreadPoolExecutor(max_workers=workers) as executor:
# Stream incoming data and build futures.
# The execution of futures beings right away and the executor
# does not wait the loop to be completed.
futures = [executor.submit(import_invoicing_address, contract, row) for row in read_csv(fname)]
# This print may be slightly delayed, as futures start executing as soon as the pool begins to fill,
# eating your CPU time
print("Executing total", len(futures), "jobs")
# Wait the executor to complete each future, give 180 seconds for each job
for idx, future in enumerate(concurrent.futures.as_completed(futures, timeout=180.0)):
res = future.result() # This will also raise any exceptions
print("Processed job", idx, "result", res)
If the work is not CPU intensive then Python’s infamous Global Interpreter Global will not become an issue either.
]]>1Mikko Ohtamaahttp://opensourcehacker.com<![CDATA[Deform 2.0]]>https://opensourcehacker.com/?p=30972016-10-25T23:22:39Z2016-10-25T23:22:39ZContinue reading →]]>Deform 2.0 has been released.
"""Self-contained Deform demo example."""
from __future__ import print_function
from pyramid.config import Configurator
from pyramid.session import UnencryptedCookieSessionFactoryConfig
from pyramid.httpexceptions import HTTPFound
import colander
import deform
class ExampleSchema(deform.schema.CSRFSchema):
name = colander.SchemaNode(
colander.String(),
title="Name")
age = colander.SchemaNode(
colander.Int(),
default=18,
title="Age",
description="Your age in years")
def mini_example(request):
"""Sample Deform form with validation."""
schema = ExampleSchema().bind(request=request)
# Create a styled button with some extra Bootstrap 3 CSS classes
process_btn = deform.form.Button(name='process', title="Process")
form = deform.form.Form(schema, buttons=(process_btn,))
# User submitted this form
if request.method == "POST":
if 'process' in request.POST:
try:
appstruct = form.validate(request.POST.items())
# Save form data from appstruct
print("Your name:", appstruct["name"])
print("Your age:", appstruct["age"])
# Thank user and take him/her to the next page
request.session.flash('Thank you for the submission.')
# Redirect to the page shows after succesful form submission
return HTTPFound("/")
except deform.exception.ValidationFailure as e:
# Render a form version where errors are visible next to the fields,
# and the submitted values are posted back
rendered_form = e.render()
else:
# Render a form with initial default values
rendered_form = form.render()
return {
# This is just rendered HTML in a string
# and can be embedded in any template language
"rendered_form": rendered_form,
}
def main(global_config, **settings):
"""pserve entry point"""
session_factory = UnencryptedCookieSessionFactoryConfig('seekrit!')
config = Configurator(settings=settings, session_factory=session_factory)
config.include('pyramid_chameleon')
deform.renderer.configure_zpt_renderer()
config.add_static_view('static_deform', 'deform:static')
config.add_route('mini_example', path='/')
config.add_view(mini_example, route_name="mini_example", renderer="templates/mini.pt")
return config.make_wsgi_app()
This library is actively developed and maintained. Deform 2.x branch has been used in production on several sites for more than two years. Automatic test suite has 100% Python code coverage and 500+ tests.
Python standard library provides logging module as a de facto solution for libraries and applications to log their behavior. logging is extensively used by Websauna, Pyramid, SQLAlchemy and other Python packages.
Python logging subsystem can be configured using external configuration file and the logging configuration format is specified in Python standard library.
Python logger can be individually turned on, off and their verbosity adjusted on per module basis. For example by default, Websauna development server sets SQLALchemy logging level to INFO instead of DEBUG to avoid flooding the console with verbose SQL logs. However if you are debugging issues related to a database you might want to set the SQLAlchemy logging back to INFO.
Logging is preferred diagnose method over print statements cluttered around source code.. Well designed logging calls can be left in the source code and later turned back on if the problems must be diagnosed further.
Python logging output can be directed to console, file, rotating file, syslog, remote server, email, etc.
import logging
logger = logging.getLogger(__name__)
def my_view(request):
logger.debug("my_view got request: %s", request)
logger.info("my_view got request: %s", request)
logger.error("my_view got request: %s and BAD STUFF HAPPENS", request)
try:
raise RuntimeError("OH NOES")
except Exception as e:
# Let's log full traceback even when we ignore this exception
# and it's not risen again
logger.exception(e)
This names a logger based on a module so you can switch logger on/off on module basis.
Pass logged objects to logging.Logger.debug() and co. as full and let the logger handle the string formatting. This allows intelligent display of logged objects when using non-console logging solutions like Sentry.
Use logging.Logger.exception() to report exceptions. This will record the full traceback of the exception and not just the error message.
Please note that although this logging pattern is common, it’s not a universal solution. For example if you are creating third party APIs, you might want to pass the logger to a class instance of an API, so that the API consumer can take over the logger setup and there is no inversion of control.
Websauna defines development web server log levels in its core development.ini. Your Websauna application inherits settings from this file and can override them for each logger in the conf/development.ini file of your application.
For example to set SQLAlchemy and transaction logging level to more verbose you can do:
]]>0Mikko Ohtamaahttp://opensourcehacker.com<![CDATA[Why source code editors cannot do beautiful soft wraps?]]>https://opensourcehacker.com/?p=30772015-12-22T07:35:22Z2015-12-22T07:35:22ZContinue reading →]]>Again it surfaced that recommending 80 character line lengths, or any hard line lengths, might not be a good idea for the source code layout.
Without making any coherent line of thought:
People have different screen widths and you can drag to resize your window
My text processor was able to soft wrap sentences back in 1989. Why my source code editor cannot do the same and still retain readable code despite being 200 MB monster of Java code. Writing a logic to lay out readable code with soft word wrapping such not be such a hard task.
]]>2Mikko Ohtamaahttp://opensourcehacker.com<![CDATA[Twitter bot using Google Spreadsheets in Python]]>https://opensourcehacker.com/?p=30692015-10-14T17:26:31Z2015-10-14T17:26:31ZContinue reading →]]>This blog posts shows how to build a Twitter bot using Google Spreadsheets as data source in Python.
The service presented here was originally created for a friend of mine who works in Megacorp Inc. They have a marketing intelligence department that is filling out stalked information about potential customers. This information stored in Google Spreadsheet. Every day a new spreadsheet arrives to a folder. Then my friend proceeds to go through all of the leads in the spreadsheet, check who have a Twitter account and harass them in Twitter about Megacorp Inc. products.
To make my friend jobless I decided to replace his tedious workflow with a Python script. Python is a programming language for making simple tasks simple, eliminating the feeling of repeating yourself with as little lines as possible. So it is a good weapon of choice for crushing middle class labor force participation.
The bot sends two tweets to every Twitter user. Timing between tweets and the second tweet is randomized, just to make sure that no one could not figure out in a blink of an eye that they are actually communicating with a bot.
The ingredients of this Twitter bot are
Python 3.4+ – a snake programming language loved by everyone
gspread – a Python client for Google Spreadsheets making reading and manipulating data less painful
ZODB – An ACID compliant transaction database for native Python objects
The script is pretty much self-contained, around 200 lines of Python code and 3 hours of work.
1. Authenticating for third party services
The bot uses OAuth protocol to authenticate itself against Google services (Google Drive, Google Spreadsheet) and Twitter. In OAuth, you arrive to a service provider web site through your normal web browser. If you are not yet logged in the service asks you log in. Then you get this page where it asks authorize the app. Twitter authentication is done in a separate script run tweepyauth.py which asks you enter the pin number shown on Twitter website. Google API client does things different and spins up a local web server running in a localhost port. When you authorize on Google services it redirects you back to the local webserver and the script grabs the authentication token from there.
The script stores authentication tokens in JSON files You can run the script on your local computer first to generate JSON files and then move it to the server where a web browser for authentication is not possibly available.
2. Maintaining persistent state
The bot needs to maintain a state. It needs to process a new spreadsheet every day. But on some days the bot might not be running. Thus, it needs to remember already processed spreadsheets. Sometimes the spreadsheets may contain duplicate entries of the same Twitter handle and we don’t want to harass this Twitter user over and over again. Some data cleaning is applied to the column contents, as it might be raw Twitter handle, HTTP or HTTPS URL to a Twitter user – those marketing intelligence people are not very strict on what they spill in to their spreadsheets.
The state is maintained using a ZODB. ZODB is a transaction database, very robust. It is mature, probably older than some of the blog post readers, having multigigabyte deployments running factories around the world. It can run in-process like SQLite and doesn’t need other software running on the machine. It doesn’t need any ORM as it uses native Python objects. Thus, to make your application persistent you just stick your Python objects to ZODB root. Everything inside a transaction context manager is written to the disk or nothing is written to the disk.
As a side note using Google Spreadsheets over their REST API is painfully slow. If you need to process larger amounts of data it might be more efficient to download the data locally as CSV export and do it from there.
3. Usage instructions
This code is exemplary. You can’t use it as you do not have correct data or access to data. Use it to inspire your imagination. However if you were to use it would happen like this:
Run tweepyauth.py to get Twitter tokens stored in twitter_oauth.json.
Run bot once on your local computer and authenticate it against Google services and write client_secrets.json.
See that the bot starts working.
Move the whole stuff to a server.
Leave it running in a loop on Bash prompt forever: $ while true; do python chirper.py; sleep
4. Source code
chirper.py
"""
Installation:
pip install --upgrade oauth2client gspread google-api-python-client ZODB zodbpickle tweepy iso8601
"""
import time
import datetime
import json
import httplib2
import os
import sys
# Authorize server-to-server interactions from Google Compute Engine.
from apiclient import discovery
import oauth2client
from oauth2client import client
from oauth2client import tools
# ZODB
import ZODB
import ZODB.FileStorage
import BTrees.OOBTree
from persistent.mapping import PersistentMapping
import random
import transaction
# Date parsing
import iso8601
# https://github.com/burnash/gspread
import gspread
# Twitter client
import tweepy
try:
import argparse
flags = argparse.ArgumentParser(parents=[tools.argparser]).parse_args()
except ImportError:
flags = None
# We need permissions to drive list files, drive read files, spreadsheet manipulation
SCOPES = ['https://www.googleapis.com/auth/devstorage.read_write', 'https://www.googleapis.com/auth/drive.metadata.readonly', 'https://spreadsheets.google.com/feeds']
CLIENT_SECRET_FILE = 'client_secrets.json'
APPLICATION_NAME = 'MEGACORP SPREADSHEET SCRAPER BOT'
OAUTH_DATABASE = "oauth_authorization.json"
FIRST_TWEET_CHOICES = [
"WE AT MEGACORP THINK YOU MIGHT LIKE US - http://megacorp.example.com",
]
SECOND_TWEET_CHOICES = [
"AS WELL, WE ARE PROBABLY CHEAPER THAN COMPETITORCORP INC. http://megacorp.example.com/prices",
"AS WELL, OUR FEATURE SET IS LONGER THAN MISSISSIPPI http://megacorp.example.com/features",
"AS WELL, OUR CEO IS VERY HANDSOME http://megacorp.example.com/team",
]
# Make sure our text is edited correctly
for tweet in FIRST_TWEET_CHOICES + SECOND_TWEET_CHOICES:
assert len(tweet) < 140
# How many tweets can be send in one run... limit for testing / debugging
MAX_TWEET_COUNT = 10
# https://developers.google.com/drive/web/quickstart/python
def get_google_credentials():
"""Gets valid user credentials from storage.
If nothing has been stored, or if the stored credentials are invalid,
the OAuth2 flow is completed to obtain the new credentials.
Returns:
Credentials, the obtained credential.
"""
credential_path = os.path.join(os.getcwd(), OAUTH_DATABASE)
store = oauth2client.file.Storage(credential_path)
credentials = store.get()
if not credentials or credentials.invalid:
flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES)
flow.user_agent = APPLICATION_NAME
if flags:
credentials = tools.run_flow(flow, store, flags)
else: # Needed only for compatability with Python 2.6
credentials = tools.run(flow, store)
print('Storing credentials to ' + credential_path)
return credentials
def get_tweepy():
"""Create a Tweepy client instance."""
creds = json.load(open("twitter_oauth.json", "rt"))
auth = tweepy.OAuthHandler(creds["consumer_key"], creds["consumer_secret"])
auth.set_access_token(creds["access_token"], creds["access_token_secret"])
api = tweepy.API(auth)
return api
def get_database():
"""Get or create a ZODB database where we store information about processed spreadsheets and sent tweets."""
storage = ZODB.FileStorage.FileStorage('chirper.data.fs')
db = ZODB.DB(storage)
connection = db.open()
root = connection.root
# Initialize root data structure if not present yet
with transaction.manager:
if not hasattr(root, "files"):
root.files = BTrees.OOBTree.BTree()
if not hasattr(root, "twitter_handles"):
# Format of {added: datetime, imported: datetime, sheet: str, first_tweet_at: datetime, second_tweet_at: datetime}
root.twitter_handles = BTrees.OOBTree.BTree()
return root
def extract_twitter_handles(spread, sheet_id, column_id="L"):
"""Process one spreadsheet and return Twitter handles in it."""
twitter_url_prefix = ["https://twitter.com/", "http://twitter.com/"]
worksheet = spread.open_by_key(sheet_id).sheet1
col_index = ord(column_id) - ord("A") + 1
# Painfully slow, 2600 records = 3+ min.
start = time.time()
print("Fetching data from sheet {}".format(sheet_id))
twitter_urls = worksheet.col_values(col_index)
print("Fetched everything in {} seconds".format(time.time() - start))
valid_handles = []
# Cell contents are URLs (possibly) pointing to a Twitter
# Extract the Twitter handle from these urls if they exist
for cell_content in twitter_urls:
if not cell_content:
continue
# Twitter handle as it
if "://" not in cell_content:
valid_handles.append(cell_content.strip())
continue
# One cell can contain multiple URLs, comma separated
urls = [url.strip() for url in cell_content.split(",")]
for url in urls:
for prefix in twitter_url_prefix:
if url.startswith(prefix):
handle = url[len(prefix):]
# Clean old style fragment URLs e.g #!/foobar
if handle.startswith("#!/"):
handle = handle[len("#!/"):]
valid_handles.append(handle)
return valid_handles
def watch_files(http, title_match=None, folder_id=None) -> list:
"""Check all Google Drive files which match certain file pattern.
Drive API:
https://developers.google.com/drive/web/search-parameters
:return: Iterable GDrive file list
"""
service = discovery.build('drive', 'v2', http=http)
if folder_id:
results = service.files().list(q="'{}' in parents".format(folder_id)).execute()
elif title_match:
results = service.files().list(q="title contains '{}'".format(title_match)).execute()
else:
raise RuntimeError("Unknown criteria")
return results["items"]
def scan_for_new_spreadsheets(http, db):
"""Check Google Drive for new spreadsheets.
1. Use Google Drive API to list all files matching our spreadsheet criteria
2. If the file is not seen before add it to our list of files to process
"""
# First discover new spreadsheets
discovered = False
for file in watch_files(http, folder_id="0BytechWnbrJVTlNqbGpWZllaYW8"):
title = file["title"]
last_char = title[-1]
# It's .csv, photos, etc. misc files
if not last_char.isdigit():
continue
with transaction.manager:
file_id = file["id"]
if file_id not in db.files:
print("Discovered file {}: {}".format(file["title"], file_id))
db.files[file_id] = PersistentMapping(file)
discovered = True
if not discovered:
print("No new spreadsheets available")
def extract_twitter_handles_from_spreadsheets(spread, db):
"""Extract new Twitter handles from spreadsheets.
1. Go through all spreadsheets we know.
2. If the spreadsheet is not marked as processed extract Twitter handles out of it
3. If any of the Twitter handles is unseen before add it to the database with empty record
"""
# Then extract Twitter handles from the files we know about
for file_id, file_data in db.files.items():
spreadsheet_creation_date = iso8601.parse_date(file_data["createdDate"])
print("Processing {} created at {}".format(file_data["title"], spreadsheet_creation_date))
# Check the processing flag on the file
if not file_data.get("processed"):
handles = extract_twitter_handles(spread, file_id)
# Using this transaction lock we write all the handles to the database once or none of them
with transaction.manager:
for handle in handles:
# If we have not seen this
if handle not in db.twitter_handles:
print("Importing Twitter handle {}".format(handle))
db.twitter_handles[handle] = PersistentMapping({"added": spreadsheet_creation_date, "imported": datetime.datetime.utcnow(), "sheet": file_id})
file_data["processed"] = True
def send_tweet(twitter, msg):
"""Send a Tweet.
"""
try:
twitter.update_status(status=msg)
except tweepy.error.TweepError as e:
try:
# {"errors":[{"code":187,"message":"Status is a duplicate."}]}
resp = json.loads(e.response.text)
if resp.get("errors"):
if resp["errors"][0]["code"] == 187:
print("Was duplicate {}".format(msg))
time.sleep(10 + random.randint(0, 10))
return
except:
pass
raise RuntimeError("Twitter doesn't like us: {}".format(e.response.text or str(e))) from e
# Throttle down the bot
time.sleep(30 + random.randint(0, 90))
def tweet_everything(twitter, db):
"""Run through all users and check if we need to Tweet to them. """
tweet_count = 0
for handle_id, handle_data in db.twitter_handles.items():
with transaction.manager:
# Check if we had not sent the first Tweet yet and send it
if not handle_data.get("first_tweet_at"):
tweet = "@{} {}".format(handle_id, random.choice(FIRST_TWEET_CHOICES))
print("Tweeting {} at {}".format(tweet, datetime.datetime.utcnow()))
send_tweet(twitter, tweet)
handle_data["first_tweet_at"] = datetime.datetime.utcnow()
tweet_count += 1
# Check if we had not sent the first Tweet yet and send it
elif not handle_data.get("second_tweet_at"):
tweet = "@{} {}".format(handle_id, random.choice(SECOND_TWEET_CHOICES))
print("Tweeting {} at {}".format(tweet, datetime.datetime.utcnow()))
send_tweet(twitter, tweet)
handle_data["second_tweet_at"] = datetime.datetime.utcnow()
tweet_count += 1
if tweet_count >= MAX_TWEET_COUNT:
# Testing limiter - don't spam too much if our test run is out of control
break
def main():
script_name = sys.argv[1] if sys.argv[0] == "python" else sys.argv[0]
print("Starting {} at {} UTC".format(script_name, datetime.datetime.utcnow()))
# open database
db = get_database()
# get OAuth permissions from Google for Drive client and Spreadsheet client
credentials = get_google_credentials()
http = credentials.authorize(httplib2.Http())
spread = gspread.authorize(credentials)
twitter = get_tweepy()
# Do action
scan_for_new_spreadsheets(http, db)
extract_twitter_handles_from_spreadsheets(spread, db)
tweet_everything(twitter, db)
main()
tweepyauth.py
import json
import webbrowser
import tweepy
"""
Query the user for their consumer key/secret
then attempt to fetch a valid access token.
"""
if __name__ == "__main__":
consumer_key = input('Consumer key: ').strip()
consumer_secret = input('Consumer secret: ').strip()
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
# Open authorization URL in browser
webbrowser.open(auth.get_authorization_url())
# Ask user for verifier pin
pin = input('Verification pin number from twitter.com: ').strip()
# Get access token
access_token, access_token_secret = auth.get_access_token(verifier=pin)
data = dict(consumer_key=consumer_key, consumer_secret=consumer_secret, access_token=access_token, access_token_secret=access_token_secret)
with open("twitter_oauth.json", "wt") as f:
json.dump(data, f)
]]>0Mikko Ohtamaahttp://opensourcehacker.com<![CDATA[PyCharm vs. Sublime Text]]>https://opensourcehacker.com/?p=30482015-05-02T12:44:54Z2015-05-02T12:41:59ZContinue reading →]]>This blog post is about comparing two popular development tools and text editors, Sublime Text and PyCharm to each other. This blog post is written from the perspective of professional software development or if the programming is what you do for living.
I have been developing Python for a decade now in various environments. Few weeks ago, I decided to make a shift from Sublime Text 3 to PyCharm as my primary tool for typing in code on OSX. I tried PyCharm long time ago and I was dissatisfied – PyCharm is built on Java software stack and UI issues, alongside “Java software bloat”, were major turn off for me by the time. But the times change, hardware gets more powerful and it was time for me to reconsider my decision.
Sublime Text is a commercial programmer’s text editor being in development since 2008. Its major selling points are speed, powerful code text editing features (multicursor), cross platform support, customizations and plugin ecosystem. Currently Sublime Text version 3 is in beta. Though the development slowed down in one point, as Sublime Text has been mostly one man show, new Sublime Text builds roll out now regularly. Sublime Text costs 70 USD. Unless you purchase a license you’ll be notified by a nagging dialog.
PyCharm is a child of JetBrains IntelliJ IDEA family of editors. First PyCharm was released 2010, but the IDE codebase goes all way back to IntelliJ IDEA which was released as far back as 2001 – I remember doing Java development on IntelliJ in 2004. PyCharm is developed by Czech company JetBrains, having over 400 employees. PyCharm shares most of the features with other IDEA family IDEs, which means it has robust HTML, JavaScript and CSS support. PyCharm license costs 199 EUR / year (professional), 99 EUR / year (individual) and there is also free community edition. The community edition is 100% open source.
Though Sublime Text is not an IDE per se, many Python and JavaScript developers I know use it as “development platform”. This is possible because active Sublime Text community provides tools to optimize your development workflow – namely to support autocomplete, syntax highlighting and background linting and various programming languages.
2. Feature highlights both in Sublime Text and PyCharm
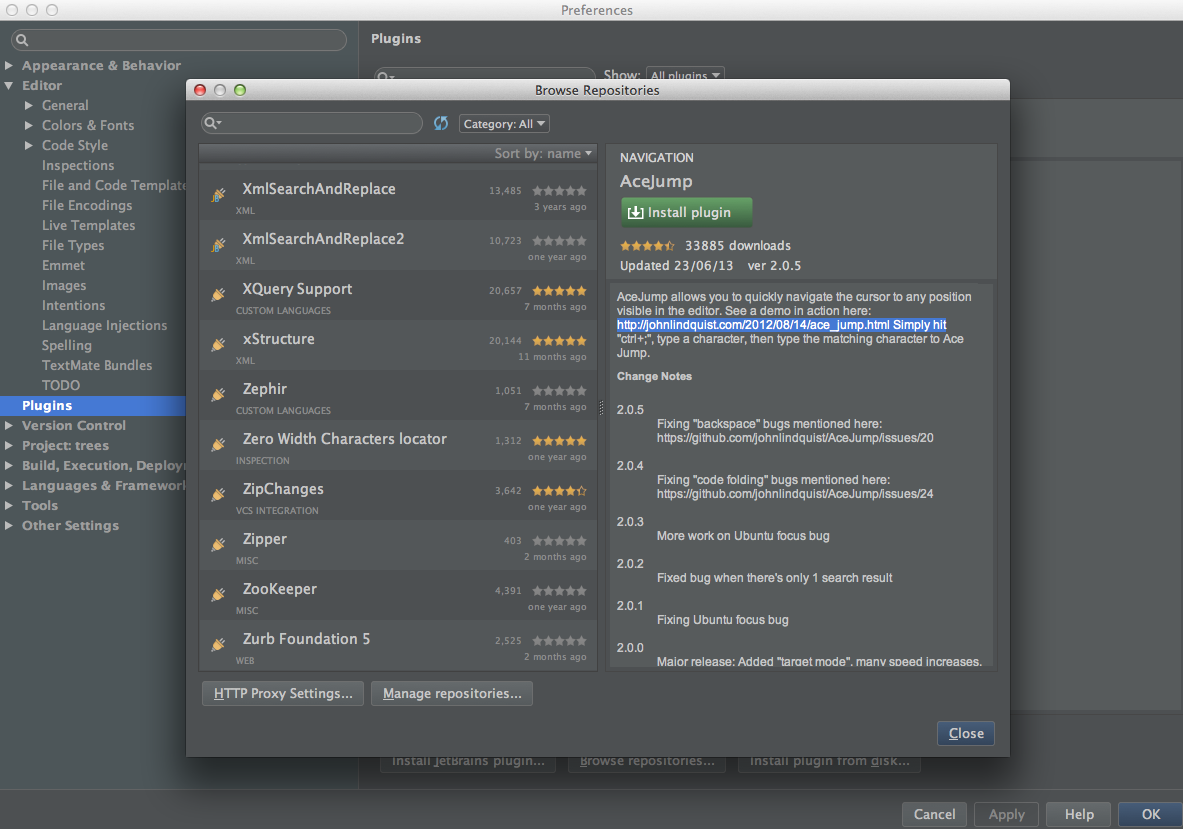
Sublime Text and PyCharm have integrated plugin manager. Sublime Text Package Control is not built in, making the initial adoption more hassle. On the other hand I found PyCharm’s plugin installer to be more cumbersome to use – more clicks. Reminds me of those Windows EXE installers.
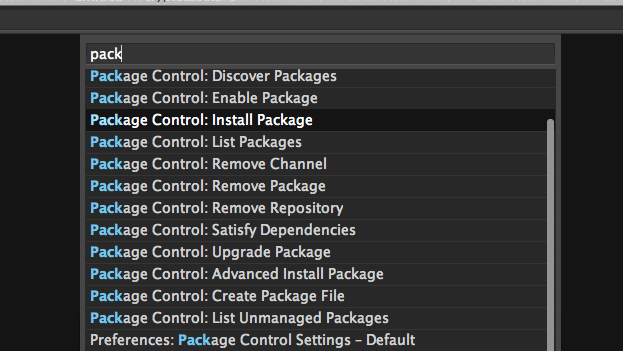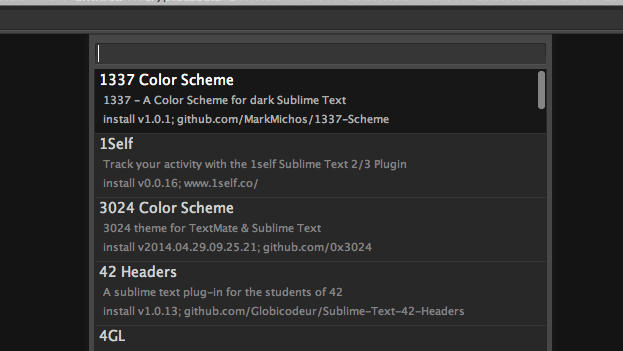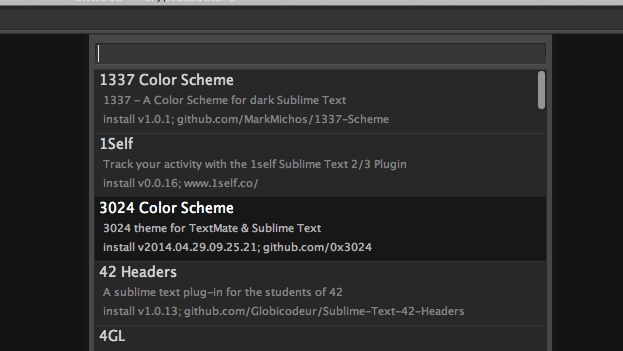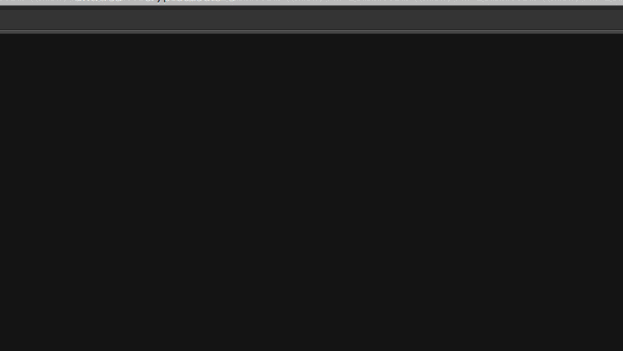
Installing a new plugin in Sublime Text is only few keystrokes
The text editors are good for Python editing and have e.g. indention guidelines and fast toggle soft text wrap options.
3. Sublime Text pros
Sublime Text beats PyCharm in few points and I miss these features in PyCharm, though some of them can be replaced using PyCharm alternatives.
Sublime Text’s Go To Anywhere is more powerful. Press CMD+T and type in few letters of package and module name. Go To Anywhere finds the suitable match. PyCharm Navigate -> File or Navigate -> Symbol are not as powerful as their heuristics seem to need more typing to get where you want.
Jumping to cryptoassets.core.backend.base in Sublime Text
Whereas PyCharm has a scrollbar with color hints to highlight next TODO / warning / error place, Sublime Text has a minimap. Scrolling around with the minimap is more powerful as your eyes see the structure of the file unfolding.
Sublime Text minimap shows outline of the file in visual
Sublime Text user interface is OpenGL accelerated and it runs smoothly 60 FPS all the time, making it pleasant for the eye and for typing. PyCharm is slower, though the difference is not so noticeable anymore after you pour in enough money to your hardware.
The Sublime Text plugin community is more vibrant. There are more plugins available, they get more support. For example if you need to do polyglot programming in rare languages, like R, Erlang or Haskell, there is guaranteed to be good Sublime Text support. Also if you write documentation in Restructured Text or Markdown PyCharm did not have such good plugins as one gets for Sublime Text.
Restructured Text syntax highlighting in Sublime Text
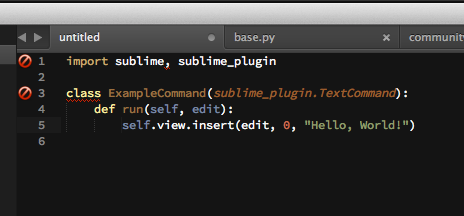
As this blog post is mostly about Python development, one cannot dismiss the fact that Sublime Text plugins are self-contained Python modules – not cumbersome Java projects. It is very easy to write them, though Sublime Text plugin API is somewhat limited. There is even a menu entry New plugin. This might be one of the fact explaining why the Sublime Text plugin ecosystem is so healthy.
Creating Sublime Text plugin
4. PyCharm pros
PyCharm is big. The editor has history since 2001, it comes tons of features out of the box. It is very polished and it does most of the features very well – after all selling IDEs is the main business for JetBrains – for example compared IBM’s Eclipse whereas IBM’s main business is sell IBM services. With PyCharm you need to spent little time to tune up your programming environment or hunt plugins for your basic development needs (Python, JavaScript, HTML, CSS).
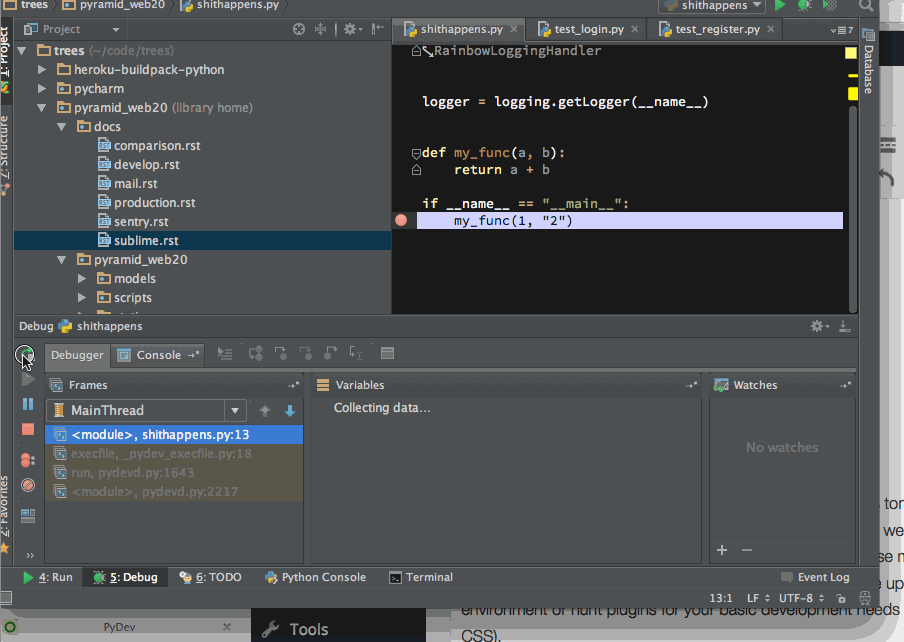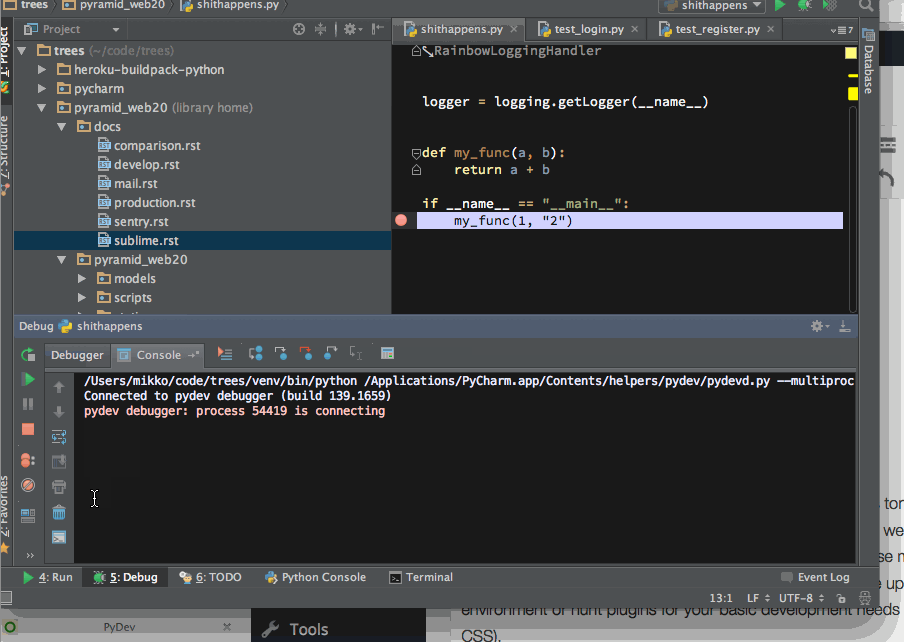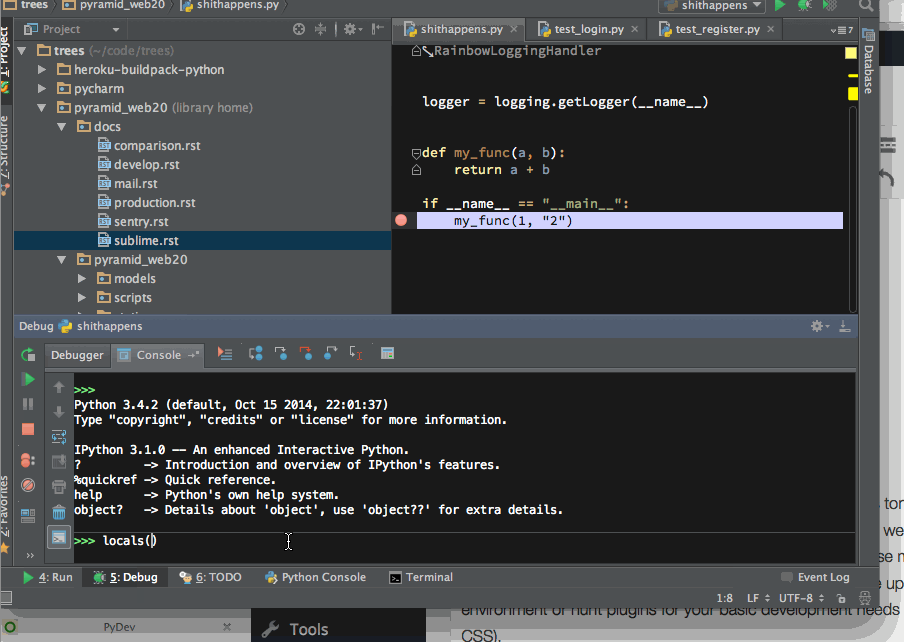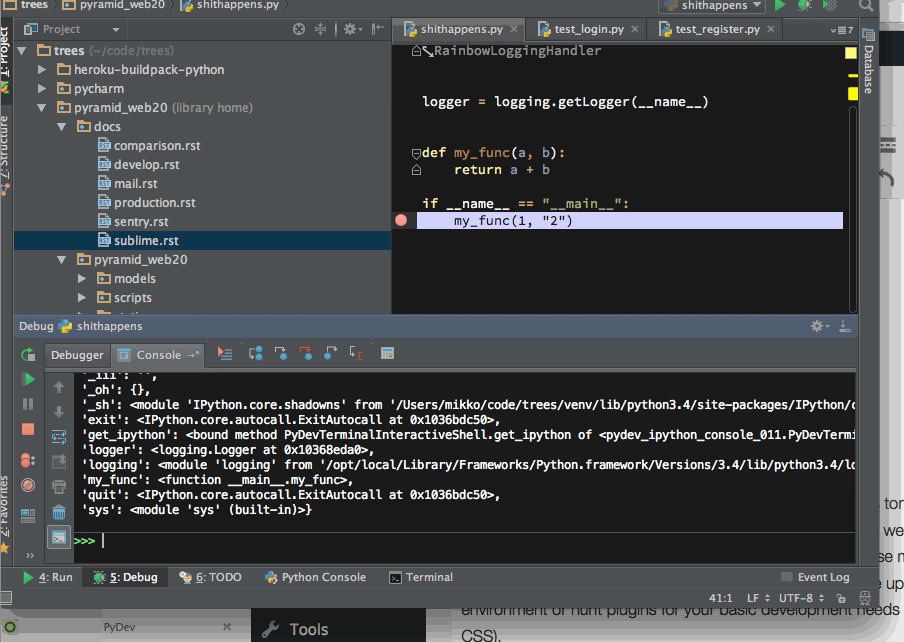
PyCharm comes with an integrated debugger. You can double click to set breakpoints in your editor and then run your application to stop on the line. But you still don’t lose the ability of drop into an interactive IPython shell when hit to the breakpoint:
Dropping into IPython session after PyCharm stops in a Python breakpoint
Though I did find the PyCharm debugger slowing down the application too much. For example, when running a Pyramid website application inside the debugger the automatic restart cycle became too slow. You had to wait each restart more than ten seconds. This kills the basic web development flow: edit – save – refresh. Maybe there is a way to speed up the debugger for large projects – please somebody tell me?
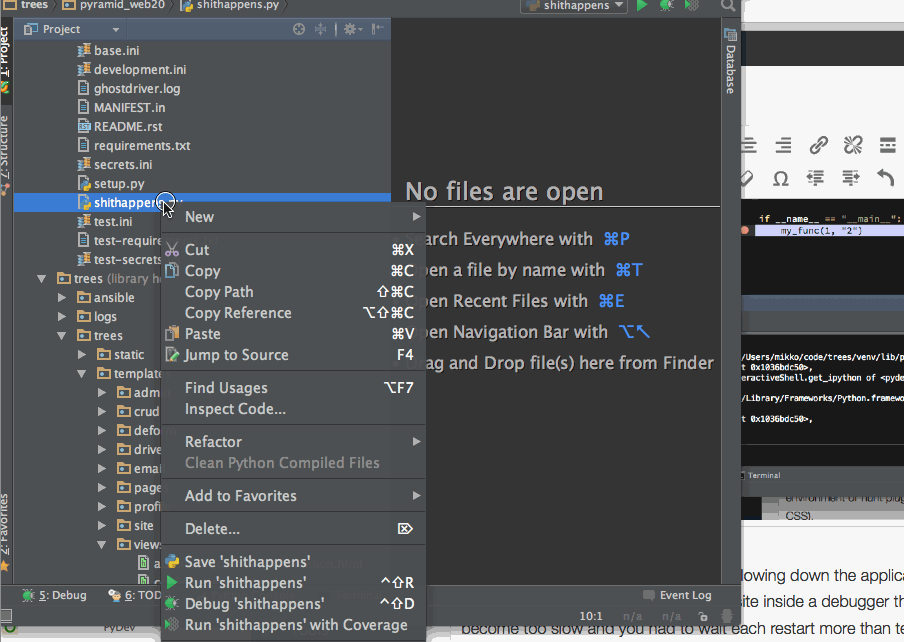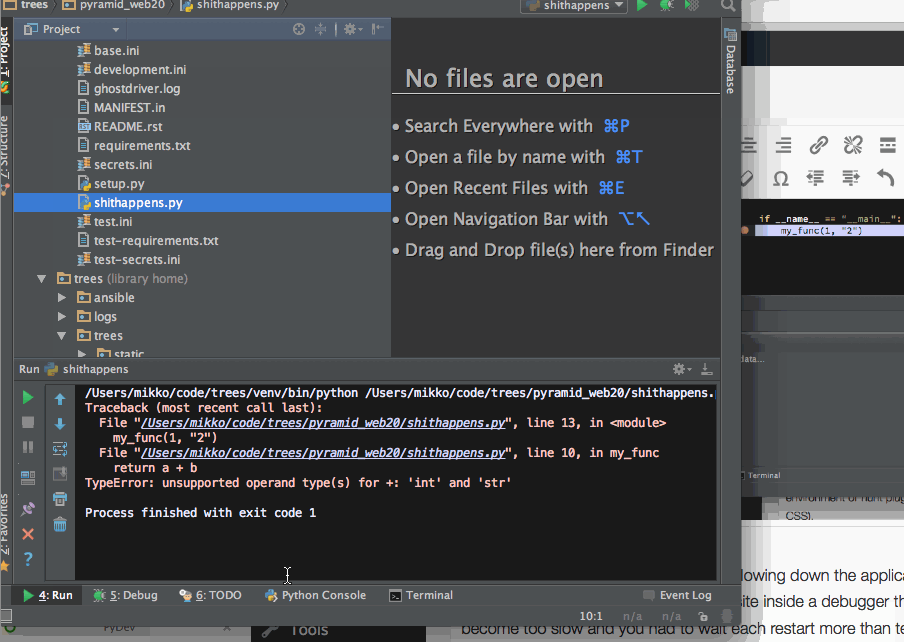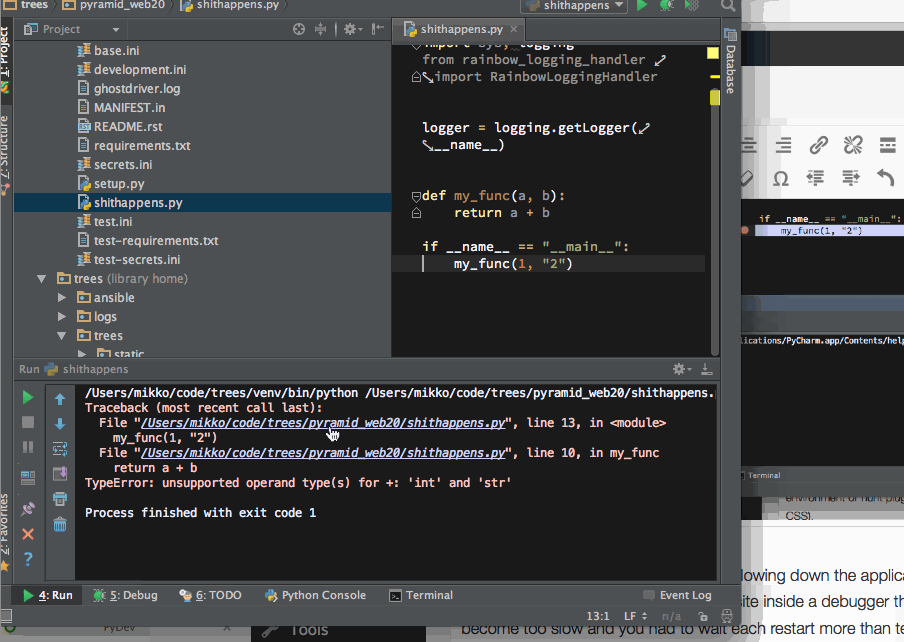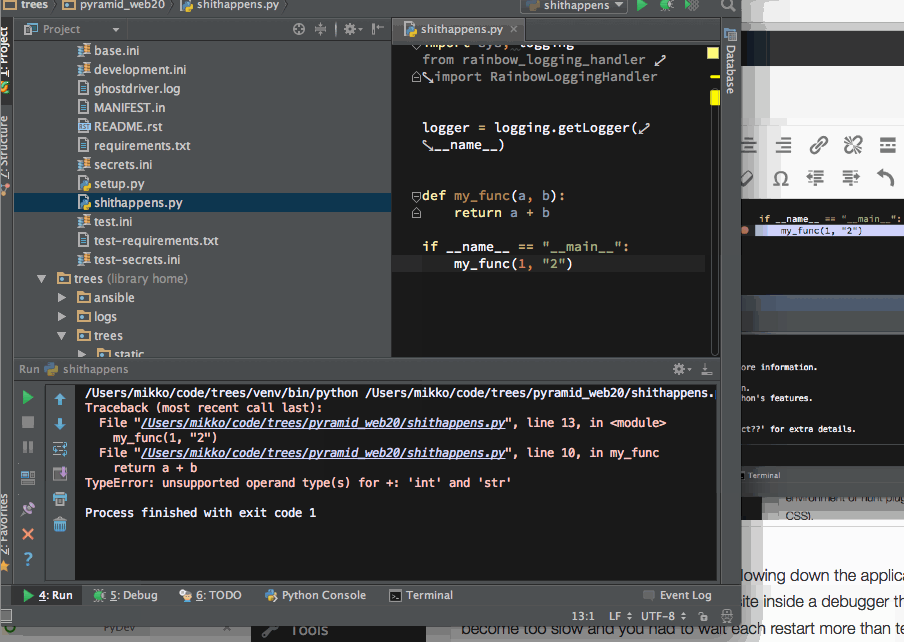
Then the major reason why I switched over – due to limitations in Sublime Text plugin API one simply could not get run output where one can click Python traceback and is taken where the error happened.
Click Python traceback to navigate around the codebase and find the error root cause
I found this lovely navigation bar a quick fix to navigate around to related modules – partially compensates the lack of powerful Go To Anywhere as in Sublime Text:
PyCharm shows the path to the current file as interactive navigation bar
Autocomplete, autoimport and other code intel and refactoring tools work better in PyCharm. With Sublime Text you need to play around with a lot of plugins to get decent autocomplete. Sublime Text plugins have their own, incompatible settings and need a lot of manual package installation (pip install flake8, etc). In PyCharm I just hit alt+enter on a missing symbol and it got added as the import at the beginning of the file. Though I could not change it to format the import as I want – one import statement per one line.
PyCharm does background spellchecking of written text and Python docstrings. It’s very handy if you want to write high quality software with meaningful comments and API descriptions.
PyCharm has more robust integrated version control support (Git, SVN). Though Sublime Text has plugins for this, Sublime Text plugin API offers only very limited UI interaction and you cannot, for example, color files in the project explorer based on their edit status.
PyCharm has Power save mode. It disables background tasks like code intel which are CPU drainage for large projects. This makes digital nomading much more fun when you are fighting over the single available power plug in a hostel on a remote island.
PyCharm has integrated unit test runner. But it did not work for my py.test and splinter browser tests, as it seems to behave differently than virtualenv’ed tests launched from command line.
5. Conclusion and the future
After few weeks I found myself using PyCharm for the most of my programming needs. The key pain points PyCharm solved for me where robust code intel tools, better Python application run and debug support, with traceback clicking. The development efficiency gained from these features is enough to migrate over, even though there are features I miss in Sublime Text. However, these editors sync files perfectly and I can always alt+tab switch to Sublime Text when I need to write some Restructured Text or Markdown.
I am looking forward for the upcoming contender Github’s atom.io editor which has the ease and flexibility of Sublime Text plugin system, but with better features, UI integration and big development-oriented company backing it up. Atom team is still working on getting the basic architecture together, so it might be few years until we see robust Python tools on Atom. I’d guess HTML, CSS and JavaScript support get there sooner, as they are building the Atom itself on CoffeeScript.
]]>17Mikko Ohtamaahttp://opensourcehacker.com<![CDATA[Inspecting thread dumps of hung Python processes and test runs]]>https://opensourcehacker.com/?p=30442015-04-16T20:39:24Z2015-04-16T20:39:24ZContinue reading →]]>Sometimes, moderately complex Python applications with several threads tend to hang on exit. The application refuses to quit and just idles there waiting for something. Often this is because if any of the Python threads are alive when the process tries to exit it will wait any alive thread to terminate, unless Thread.daemon is set to true.
In the past, it use to be little painful to figure out which thread and function causes the application to hang, but no longer! Since Python 3.3 CPython interpreter comes with a faulthandler module. faulthandler is a mechanism to tell the Python interpreter to dump the stack trace of every thread upon receiving an external UNIX signal.
Here is an example how to figure out why the unit test run, executed with pytest, does not exit cleanly. All tests finish, but the test suite refuses to quit.
First we run the tests and set a special environment variable PYTHONFAULTHANDLER telling CPython interpreter to activate the fault handler. This environment variable works regardless how your Python application is started (you run python command, you run a script directly, etc.)
PYTHONFAULTHANDLER=true py.test
And then the test suite has finished, printing out the last dot… but nothing happens despite our ferocious sipping of coffee.
Use the following command to send SIGABRT signal to the suspended process.
kill -SIGABRT %1
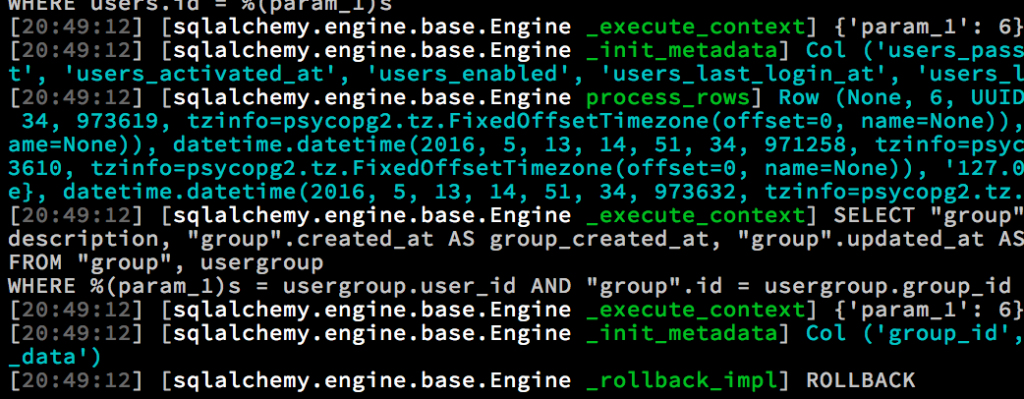
Voilá – you get the traceback. In this case, it instantly tells SQLAlchemy is waiting for something and most likely the database has deadlocked due to open conflicting transactions.
Fatal Python error: Aborted
Thread 0x0000000103538000 (most recent call first):
File "/opt/local/Library/Fra% meworks/Python.framework/Versions/3.4/lib/python3.4/socketserver.py", line 154 in _eintr_retry
File "/opt/local/Library/Frameworks/Python.framework/Versions/3.4/lib/python3.4/socketserver.py", line 236 in serve_forever
File "/Users/mikko/code/trees/pyramid_web20/pyramid_web20/tests/functional.py", line 40 in run
File "/opt/local/Library/Frameworks/Python.framework/Versions/3.4/lib/python3.4/threading.py", line 921 in _bootstrap_inner
File "/opt/local/Library/Frameworks/Python.framework/Versions/3.4/lib/python3.4/threading.py", line 889 in _bootstrap
Current thread 0x00007fff75128310 (most recent call first):
File "/Users/mikko/code/trees/venv/lib/python3.4/site-packages/SQLAlchemy-1.0.0b5-py3.4-macosx-10.9-x86_64.egg/sqlalchemy/engine/default.py", line 442 in do_execute
...
File "/Users/mikko/code/trees/venv/lib/python3.4/site-packages/SQLAlchemy-1.0.0b5-py3.4-macosx-10.9-x86_64.egg/sqlalchemy/sql/schema.py", line 3638 in drop_all
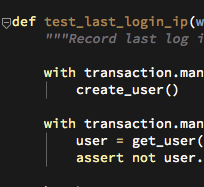
File "/Users/mikko/code/trees/pyramid_web20/pyramid_web20/tests/conftest.py", line 124 in teardown
...
File "/Users/mikko/code/trees/venv/lib/python3.4/site-packages/_pytest/config.py", line 41 in main
File "/Users/mikko/code/trees/venv/bin/py.test", line 9 in <module>
 Subscribe to RSS feed
Subscribe to RSS feed  Follow me on Twitter
Follow me on Twitter
 Follow me on Facebook
Follow me on Facebook  Follow me Google+
Follow me Google+