And I can certainly understand the logic behind it - using Virtualization we could get so much more mileage out of our instances and theoretically drop the AWS costs even further down (more on that logic later).
The short answer to that question is: No. It is not possible to run any kind of Virtualization software inside an AWS Instance.
A word about Virtualization, and it’s prerequisites
Before we jump into the full answer, let’s first have a quick refresher on Virtualization, Emulation and the difference between them.
Virtualization is about taking an existing system architecture (like an Intel-based server) and enabling multiple instances of operating systems to run on it simultaneously while “playing nice” with each other.
Emulation, on the other hand, is taking an existing system architecture (like the aforementioned Intel-based server) and pretending that it is something completely different - like a Power processor running a Mac or a shiny new iPad.
The thing to keep in mind is that Virtualization doesn’t enable you to run on the given hardware anything which you couldn’t just run natively. In a nutshell: Virtualization is about running more of the same whereas Emulation is about running something else.
For further reading, please see Link, Link.
Peering under the hood of an AWS Instance
Modern Virtualization engines are hardware-assisted - meaning that they are relying on hardware support of the CPU (in the form of Instruction Sets) to do some of the heavy lifting associated to avoid slowing down the execution by performing the processing in software.
In Intel and AMD processors these Instruction Sets are called VT and AMD-V accordingly and unsurprisingly - are required by Hyper-V , VMware and Xen.
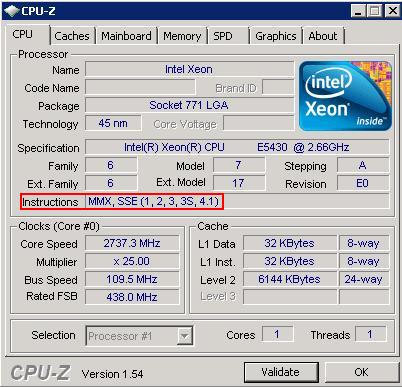
Armed with the knowledge of what to look for, Let’s review the available CPU Instruction Sets on a Windows Instance as displayed by the excellent tool CPU-Z:
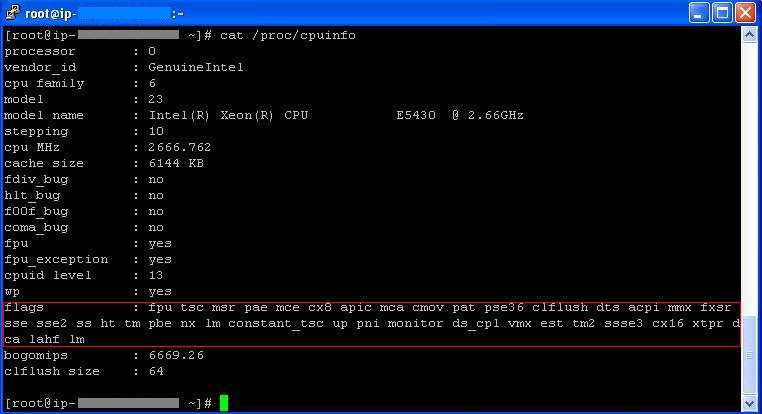
Likewise, Here are the CPU Instruction Sets in a Linux Instance:
Conclusion
As we’ve seen both in Windows and in Linux Instances, no Instruction Sets are available to the instance even though they are supported by the underlying processor (Intel E5430 in our case).
Although running a hypervisor inside another hypervisor (also known as cascading) is possible in different circumstances and under strict limitations - I can certainly understand AWS for not allowing this feature due to security concerns (opening this kind of interaction between an Instance and the underlying Hypervisor can be dangerous) as well as operational (think about how adding another layer of IP multiplexing will effect the AWS network management).
Plus, from a service offering perspective: if customers want more machines they should just launch new ones and pay for them accordingly rather then stress their existing one to their limit and strain the AWS servers to the point of abuse.
Although we’ve established that Virtualization is generally not possible, Emulation is still a viable option (with all of it’s numerous drawbacks) - the only reason I can think of to run Emulation in AWS is to run applications that were written to non-Intel processors (such as Power).
Here is a guide on how to run QEMU in AWS.
Final Thoughts
I would like to ask why are we trying to enter the adventure of owning and operating Virtualization hypervisors (with all of the attached costs and labor) when we already have the ability to launch as many virtual machines as we want for “free” from AWS?
Sure, EC2 Instances cost money - but the ability to launch more and more machines is there right from the gate with no maintenance cost.
After all, having someone taking care of our server infrastructure (storage, servers, switches, hypervisors, etc.) for no up-front cost is the whole point of Cloud Computing? - turning down this “hypervisor outsourcing” may save a few cents, but pulls us back towards the business of operating our own server infrastructure and erodes the benefits we already receive from the Cloud.
]]>