
Ben Fry in ‘Visualizing Data‘:
Graphs can be a powerful way to represent relationships between data, but they are also a very abstract concept, which means that they run the danger of meaning something only to the creator of the graph. Often, simply showing the structure of the data says very little about what it actually means, even though it’s a perfectly accurate means of representing the data. Everything looks like a graph, but almost nothing should ever be drawn as one.
There is a tendency when using graphs to become smitten with one’s own data. Even though a graph of a few hundred nodes quickly becomes unreadable, it is often satisfying for the creator because the resulting figure is elegant and complex and may be subjectively beautiful, and the notion that the creator’s data is “complex” fits just fine with the creator’s own interpretation of it. Graphs have a tendency of making a data set look sophisticated and important, without having solved the problem of enlightening the viewer.

Ben Fry is entirely correct.
I suggest two excuses for this indulgence: if the visuals are meaningful only to the creator of the graph, then let’s make everyone a graph curator. And if the things the data attempts to describe — for example, 14 million books and the world they in turn describe — are complex and beautiful and under-appreciated in their complexity and interconnectedness, … then perhaps it is ok to indulge ourselves. When do graphs become maps?
I report here on some experiments that stem from two collaborations around Linked Data. All the visuals in the post are views of bibliographic data, based on similarity measures derrived from book / subject keyword associations, with visualization and a little additional analysis using Gephi. Click-through to Flickr to see larger versions of any image. You can’t always see the inter-node links, but the presentation is based on graph layout tools.
Firstly, in my ongoing work in the NoTube project, we have been working with TV-related data, ranging from ‘social Web’ activity streams, user profiles, TV archive catalogues and classification systems like Lonclass. Secondly, over the summer I have been working with the Library Innovation Lab at Harvard, looking at ways of opening up bibliographic catalogues to the Web as Linked Data, and at ways of cross-linking Web materials (e.g. video materials) to a Webbified notion of ‘bookshelf‘.
In NoTube we have been making use of the Apache Mahout toolkit, which provided us with software for collaborative filtering recommendations, clustering and automatic classification. We’ve barely scratched the surface of what it can do, but here show some initial results applying Mahout to a 100,000 record subset of Harvard’s 14 million entry catalogue. Mahout is built to scale, and the experiments here use datasets that are tiny from Mahout’s perspective.
In NoTube, we used Mahout to compute similarity measures between each pair of items in a catalogue of BBC TV programmes for which we had privileged access to subjective viewer ratings. This was a sparse matrix of around 20,000 viewers, 12,500 broadcast items, with around 1.2 million ratings linking viewer to item. From these, after a few rather-too-casual tests using Mahout’s evaluation measure system, we picked its most promising similarity measure for our data (LogLikelihoodSimilarity or Tanimoto), and then for the most similar items, simply dumped out a huge data file that contained pairs of item numbers, plus a weight.
There are many many smarter things we could’ve tried, but in the spirit of ‘minimal viable product‘, we didn’t try them yet. These include making use of additional metadata published by the BBC in RDF, so we can help out Mahout by letting it know that when Alice loves item_62 and Bob loves item_82127, we also via RDF also knew that they are both in the same TV series and Brand. Why use fancy machine learning to rediscover things we already know, and that have been shared in the Web as data? We could make smarter use of metadata here. Secondly we could have used data-derrived or publisher-supplied metadata to explore whether different Mahout techniques work better for different segments of the content (factual vs fiction) or even, as we have also some demographic data, different groups of users.
Anyway, Mahout gave us item-to-item similarity measures for TV. Libby has written already about how we used these in ‘second screen’ (or ‘N-th’ screen, aka N-Screen) prototypes showing the impact that new Web standards might make on tired and outdated notions of “TV remote control”.
What if your remote control could personalise a view of some content collection? What if it could show you similar things based on your viewing behavior, and that of others? What if you could explore the ever-growing space of TV content using simple drag-and-drop metaphors, sending items to your TV or to your friends with simple tablet-based interfaces?
So that’s what we’ve been up to in NoTube. There are prototypes using BBC content (sadly not viewable by everyone due to rights restrictions), but also some experiments with TV materials from the Internet Archive, and some explorations that look at TED’s video collection as an example of Web-based content that (via ted.com and YouTube) are more generally viewable. Since every item in the BBC’s Archive is catalogued using a library-based classification system (Lonclass, itself based on UDC) the topic of cross-referencing books and TV has cropped up a few times.

Meanwhile, in (the digital Public Library of) America, … the Harvard Library Innovation Lab team have a huge and fantastic dataset describing 14 million bibliographic records. I’m not sure exactly how many are ‘books’; libraries hold all kinds of objects these days. With the Harvard folk I’ve been trying to help figure out how we could cross-reference their records with other “Webby” sources, such as online video materials. Again using TED as an example, because it is high quality but with very different metadata from the library records. So we’ve been looking at various tricks and techniques that could help us associate book records with those. So for example, we can find tags for their videos on the TED site, but also on delicious, and on youtube. However taggers and librarians tend to describe things quite differently. Tags like “todo”, “inspirational”, “design”, “development” or “science” don’t help us pin-point the exact library shelf where a viewer might go to read more on the topic. Or conversely, they don’t help the library sites understand where within their online catalogues they could embed useful and engaging “related link” pointers off to TED.com or YouTube.
So we turned to other sources. Matching TED speaker names against Wikipedia allows us to find more information about many TED speakers. For example the Tim Berners-Lee entry, which in its Linked Data form helpfully tells us that this TED speaker is in the categories ‘Japan_Prize_laureates’, ‘English_inventors’, ‘1955_births’, ‘Internet_pioneers’. All good to know, but it’s hard to tell which categories tell us most about our speaker or video. At least now we’re in the Linked Data space, we can navigate around to Freebase, VIAF and a growing Web of data-sources. It should be possible at least to associate TimBL’s TED talks with library records for his book (so we annotate one bibliographic entry, from 14 million! …can’t we map areas, not items?).

Can we do better? What if we also associated Tim’s two TED talk videos with other things in the library that had the same subject classifications or keywords as his book? What if we could build links between the two collections based not only on published authorship, but on topical information (tags, full text analysis of TED talk transcripts). Can we plan for a world where libraries have access not only to MARC records, but also full text of each of millions of books?
I’ve been exploring some of these ideas with David Weinberger, Paul Deschner and Matt Phillips at Harvard, and in NoTube with Libby Miller, Vicky Buser and others.
Yesterday I took the time to make some visual sanity check of the bibliographic data as processed into a ‘similarity space’ in some Mahout experiments. This is a messy first pass at everything, but I figured it is better to blog something and look for collaborations and feedback, than to chase perfection. For me, the big story is in linking TV materials to the gigantic back-story of context, discussion and debate curated by the world’s libraries. If we can imagine a view of our TV content catalogues, and our libraries, as visual maps, with items clustered by similarity, then NoTube has shown that we can build these into the smartphones and tablets that are increasingly being used as TV remote controls.
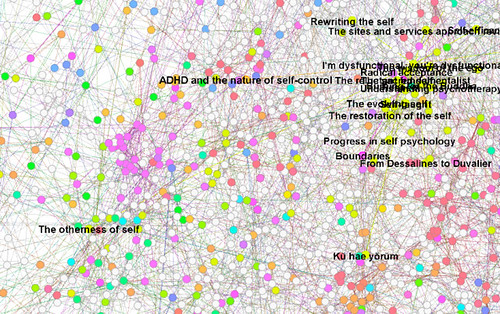
And if the device you’re using to pause/play/stop or rewind your TV also has access to these vast archives as they open up as Linked Data (as well as GPS location data and your Facebook password), all kinds of possibilities arise for linked, annotated and fact-checked TV, as well as for showing a path for libraries to continue to serve as maps of the entertainment, intellectual and scientific terrain around us.
A brief technical description. Everything you see here was made with Gephi, Mahout and experimental data from the Library Innovation Lab at Harvard, plus a few scripts to glue it all together.
Mahout was given 100,000 extracts from the Harvard collection. Just main and sub-title, a local ID, and a list of topical phrases (mostly drawn from Library of Congress Subject Headings, with some local extensions). I don’t do anything clever with these or their sub-structure or their library-documented inter-relationships. They are treated as atomic codes, and flattened into long pseudo-words such as ‘occupational_diseases_prevention_control’ or ‘french_literature_16th_century_history_and_criticism’,
‘motion_pictures_political_aspects’, ‘songs_high_voice_with_lute’, ‘dance_music_czechoslovakia’, ‘communism_and_culture_soviet_union’. All of human life is there.
David Weinberger has been calling this gigantic scope our problem of the ‘Taxonomy of Everything’, and the label fits. By mushing phrases into fake words, I get to re-use some Mahout tools and avoid writing code. The result is a matrix of 100,000 bibliographic entities, by 27684 unique topical codes. Initially I made the simple test of feeding this as input to Mahout’s K-Means clustering implementation. Manually inspecting the most popular topical codes for each cluster (both where k=12 to put all books in 12 clusters, or k=1000 for more fine-grained groupings), I was impressed by the initial results.
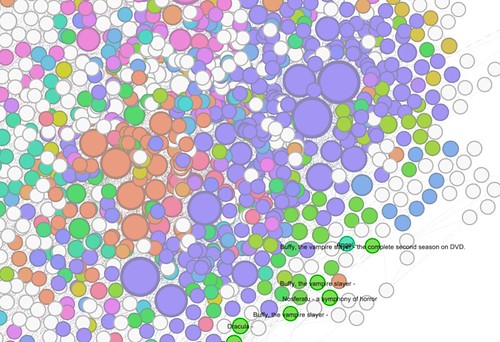
I only have these in crude text-file form. See hv/_k1000.txt and hv/_twelve.txt (plus dictionary, see big file
_harv_dict.txt ).
For example, in the 1000-cluster version, we get: ‘medical_policy_united_states’, ‘health_care_reform_united_states’, ‘health_policy_united_states’, ‘medical_care_united_states’,
‘delivery_of_health_care_united_states’, ‘medical_economics_united_states’, ‘politics_united_states’, ‘health_services_accessibility_united_states’, ‘insurance_health_united_states’, ‘economics_medical_united_states’.
Or another cluster: ‘brain_physiology’, ‘biological_rhythms’, ‘oscillations’.
How about: ‘museums_collection_management’, ‘museums_history’, ‘archives’, ‘museums_acquisitions’, ‘collectors_and_collecting_history’?
Another, conceptually nearby (but that proximity isn’t visible through this simple clustering approach), ‘art_thefts’, ‘theft_from_museums’, ‘archaeological_thefts’, ‘art_museums’, ‘cultural_property_protection_law_and_legislation’, …
Ok, I am cherry picking. There is some nonsense in there too, but suprisingly little. And probably some associations that might cause offense. But it shows that the tooling is capable (by looking at book/topic associations) at picking out similarities that are significant. Maybe all of this is also available in LCSH SKOS form already, but I doubt it. (A side-goal here is to publish these clusters for re-use elsewhere…).

So, what if we take this, and instead compute (a bit like we did in NoTube from ratings data) similarity measures between books?

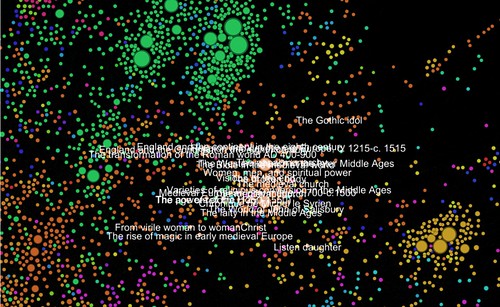
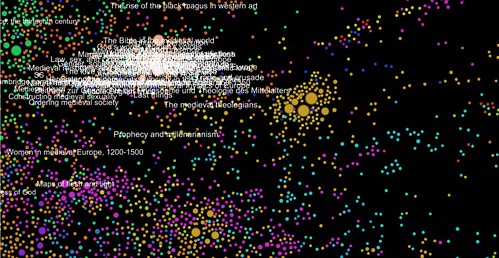
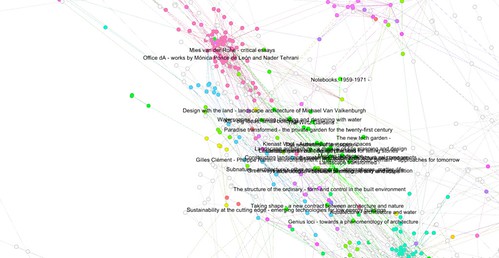
I tried that, without using much of Mahout’s sophistication. I used its ‘rowsimilarityjob’ facility and generated similarity measures for each book, then threw out most of the similarities except the top 5, later the top 3, from each book. From this point, I moved things over into the Gephi toolkit (“photoshop for graphs”), as I wanted to see how things looked.

First results shown here. Nodes are books, links are strong similarity measures. Node labels are titles, or sometimes title + subtitle. Some (the black-background ones) use Gephi’s “modularity detection” analysis of the link graph. Others (white background) I imported the 1000 clusters from the earlier Mahout experiments. I tried various of the metrics in Gephi and mapped these to node size. This might fairly be called ‘playing around’ at this stage, but there is at least a pipeline from raw data (eventually Linked Data I hope) through Mahout to Gephi and some visual maps of literature.

What does all this show?
That if we can find a way to open up bibliographic datasets, there are solid opensource tools out there that can give new ways of exploring the items described in the data. That those tools (e.g. Mahout, Gephi) provide many different ways of computing similarity, clustering, and presenting. There is no single ‘right answer’ for how to present literature or TV archive content as a visual map, clustering “like with like”, or arranging neighbourhoods. And there is also no restriction that we must work dataset-by-dataset, either. Why not use what we know from movie/TV recommendations to arrange the similarity space for books? Or vice-versa?
I must emphasise (to return to Ben Fry’s opening remark) that this is a proof-of-concept. It shows some potential, but it is neither a user interface, nor particularly informative. Gephi as a tool for making such visualizations is powerful, but it too is not a viable interface for navigating TV content. However these tools do give us a glimpse of what is hidden in giant and dull-sounding databases, and some hints for how patterns extracted from these collections could help guide us through literature, TV or more.
Next steps? There are many things that could be tried; more than I could attempt. I’d like to get some variant of these 2D maps onto ipad/android tablets, loaded with TV content. I’d like to continue exploring the bridges between content (eg. TED) and library materials, on tablets and PCs. I’d like to look at Mahout’s “collocated terms” extraction tools in more details. These allow us to pull out recurring phrases (e.g. “Zero Sum”, “climate change”, “golden rule”, “high school”, “black holes” were found in TED transcripts). I’ve also tried extracting bi-gram phrases from book titles using the same utility. Such tools offer some prospect of bulk-creating links not just between single items in collections, but between neighbourhood regions in maps such as those shown here. The cross-links will never be perfect, but then what’s a little serendipity between friends?
As full text access to book data looms, and TV archives are finding their way online, we’ll need to find ways of combining user interface, bibliographic and data science skills if we’re really going to make the most of the treasures that are being shared in the Web. Since I’ve only fragments of each, I’m always drawn back to think of this in terms of collaborative work.
A few years ago, Netflix had the vision and cash to pretty much buy the attention of the entire machine learning community for a measly million dollars. Researchers love to have substantive datasets to work with, and the (now retracted) Netflix dataset is still widely sought after. Without a budget to match Netflix’, could we still somehow offer prizes to help get such attention directed towards analysis and exploitation of linked TV and library data? We could offer free access to the world’s literature via a global network of libraries? Except everyone gets that for free already. Maybe we don’t need prizes.
Nearby in the Web: NoTube N-Screen, Flickr slideshow
]]>









{kind=link}
{kind=link}