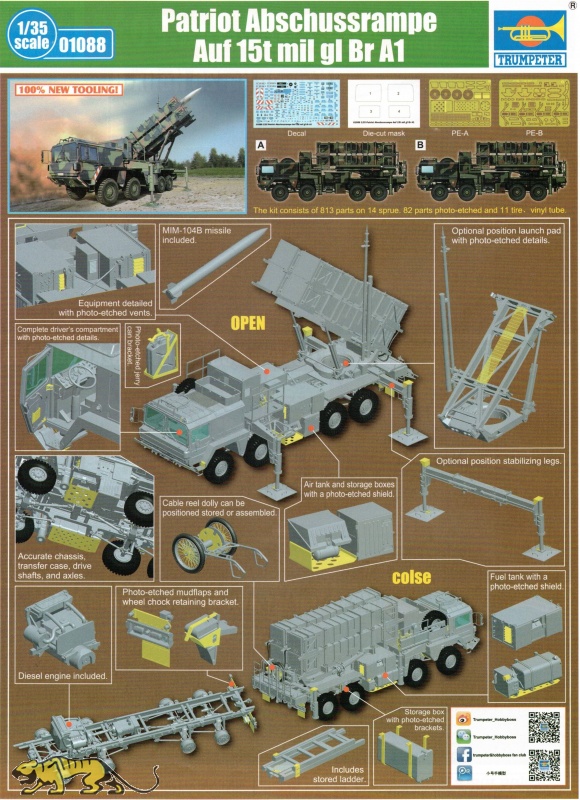
Patriot Abschussrampe Auf 15t Mil Gl Br A1
lieferbar - in 1-2 Werktagen bei dir
57 €
inkl. MwSt. zzgl.
Versandkosten
Artikelbeschreibung












Verwandte Produkte zu diesem Artikel
 Smartphone Selfie Stick Bluetooth Stativ Teleskop Stange17 €
Smartphone Selfie Stick Bluetooth Stativ Teleskop Stange17 € LADYSON Ersatzbildschirm Für Sony Xperia XZ1 Compact/Mini LCD Display17 €
LADYSON Ersatzbildschirm Für Sony Xperia XZ1 Compact/Mini LCD Display17 € Spiegelglas Links Rechts Heizbar Plan Für Nissan Micra Renault Clio Megane Coach5 €
Spiegelglas Links Rechts Heizbar Plan Für Nissan Micra Renault Clio Megane Coach5 € Hydraulikaggregat Einfachwirkend 380/400V, Motorleistung - 1,5kW, Pumpe204 €
Hydraulikaggregat Einfachwirkend 380/400V, Motorleistung - 1,5kW, Pumpe204 € UPP 36V 48V 52V Ebike Akku LG Li-Ionen-Zelle Hailong Batterie Für 0114 €
UPP 36V 48V 52V Ebike Akku LG Li-Ionen-Zelle Hailong Batterie Für 0114 €/images/67838/678383380.jpg?$spa_ambiente$) Matratze 160x200 Kaltschaum 7 Zonen PEARL HR Bett Konturschnitt H4 16 Cm Neu 61029614158 €
Matratze 160x200 Kaltschaum 7 Zonen PEARL HR Bett Konturschnitt H4 16 Cm Neu 61029614158 €





/images/67838/678383380.jpg?$spa_ambiente$&fmt=auto)
Empfehlungen für dich
 Drive Belt For Ski-Doo GTX 380 F 2005-2006 / GTX 550 F 2005-200921 €
Drive Belt For Ski-Doo GTX 380 F 2005-2006 / GTX 550 F 2005-200921 € Siemens Synchropower Staubsauger (2025) Zum Bestpreis69 €
Siemens Synchropower Staubsauger (2025) Zum Bestpreis69 € 36W Honeywell Ersatz Lse Lighting Kompatible UV-Ersatzlampe, 36 W, Für Honeywell Uc100E1030 UV Leuchtmittel15 €
36W Honeywell Ersatz Lse Lighting Kompatible UV-Ersatzlampe, 36 W, Für Honeywell Uc100E1030 UV Leuchtmittel15 € XXL Damen Schal Stola Halstuch Kopftuch Bunt Uni Plissee Frühjahr 20233.99 €
XXL Damen Schal Stola Halstuch Kopftuch Bunt Uni Plissee Frühjahr 20233.99 € MG PRIME Autolack Sprühdosen Set Für Mitsubishi P19 Red Metallic23 €
MG PRIME Autolack Sprühdosen Set Für Mitsubishi P19 Red Metallic23 € BOSCH Zahnriemensatz Wasserpumpe Für Audi A2 A3 Seat Skoda VW 1.4 1.9 TDI 40470239 €
BOSCH Zahnriemensatz Wasserpumpe Für Audi A2 A3 Seat Skoda VW 1.4 1.9 TDI 40470239 € Suchergebnis Auf Für: Fototapete Kinderzimmer Tiere17 €
Suchergebnis Auf Für: Fototapete Kinderzimmer Tiere17 € Sony Fernbedienung Ersatz Fernbedienung Für Sony TV - Plug & Play4 €
Sony Fernbedienung Ersatz Fernbedienung Für Sony TV - Plug & Play4 €







