These platforms allow advertisers to spoof links with unverified ‘vanity URLs’, laundering trust in their systems, while simultaneously deflecting blame onto advertisers when these mechanisms are exploited for fraudulent purposes.
I believe that this status quo must be abolished. Commercial entities that maintain advertising systems that systemically enable link fraud must contend with their net-negative impact on society.
What are vanity URLs and what is link fraud?
URL spoofing is the act of presenting an internet address that appears to lead to one destination but actually leads to another, unexpected, location. URL spoofing is commonly referred to as “vanity URLs” or “display URLs” by the adtech industry when provided as a first-class feature on adtech platforms.
Link fraud is the use of URL spoofing to achieve financial gain or other illicit objectives. It is a staple practice in spam emails and scam websites, where links may appear legitimate but lead to harmful content.
Examples of preventable link fraud
Link fraud is commonly used on popular websites to hijack ecommerce and software downloads. People that don’t block ads can get convincing link fraud whenever they search for web browsers[1][2], videoconferencing apps[3], password managers[4], task management apps[5], authenticators[6], software development tools[7], open source image editors[8], and cryptocurrency wallet managers[9]. People are more likely to input their sensitive account information when they see valid links to trusted sites on ‘trustworthy’ search engines.
An industry-wide lack of effective technical protections allows scam operations to scale up such that it becomes practical to farm low-value targets en-masse. There are instances where scammers use link fraud just to collect media streaming provider credentials[10], likely for resale.
This compilation thread on X includes all of the examples below.

Google Search
- See this compilation of reports on X by Germán Fernández.
- See this post on X by Eric Lawrence about a spoofed YouTube ad.
- See this post on X by Karl Emil Nikka about a spoofed Bitwarden ad.
- See this post on X by Scott Chacon about a spoofed Todoist ad.
- See this post on X by nixCraft about a spoofed ad for GNU Image Manipulation Program.
- See this post on X by Samruddhi Mokal about a spoofed Disney+ ad.
- See this article on BleepingComputer by Bill Toulas about a spoofed Google Authenticator ad.
- See this post on X by Ryan Chenkie about a spoofed Homebrew package manager ad.
- See this post on X by Radiant.
- See this post on X by Robby Russell.
- See this post on X by Ronin.
- See this post on X by Phantom.
- See this post on X by Trader Joe XYZ.
- See this post on X by winston.
- See this post on X by vrypan.eth.
- See this post on X by Rabby Wallet.
- See this post on X by Grills.
- See this post on X by John Macleod.
- See this post on X by Ian Lim.
- See this post on X by betaplux.
- See this post on X by MacCallister Higgins.
- See this post on X by Scott Redgate.
- See this post on X by (22)c.
Microsoft Bing
- See this Forbes article by Jason Evangelho and my analysis of the incident on X. I reproduced the issue at the time and triaged the root cause to be uncontrolled use of vanity URLs.
- See this post on X by Ti Zhao.
- See this post on X by sedat kapanoğlu.
- See this post on X by Steve
 Trout.
Trout. - See this post on X by 0xngmi. Note: DuckDuckGo uses Bing Ads and largely sources results from Bing.
X (Twitter)
- See this post on X by Justin.
- See this post on X by Colin Fraser.
- See this post on X by Logan Williams.
- See this post on X by Dan Morley.
I’ve also personally witnessed link fraud twice on X but didn’t screenshot it.
Culprits
Google, Microsoft, and X all appear to have similarly ineffective enforcement methods and policies for vanity URL control on their advertising platforms.
I suspect that Facebook and Reddit also have similar limitations as they also allow link spoofing for ads, although I haven’t sufficiently confirmed a lack of effective domain ownership verification.
Implicit regulatory capture
Adtech companies play the victim by claiming that fraudsters and scammers are ‘abusing’ their unverified vanity URL systems. These companies should not be able to get away with creating systems that enable link fraud and then pretend to tie their hands behind their back when asked to combat the issue. They have created systems for trust-laundered URL spoofing, and then disclaimed ethical or legal responsibility for the fundamental technical failures of these systems.
It is not possible to automatically prevent link fraud in systems that allow for unverified URL spoofing to occur. If adtech providers do not perform domain ownership verification on vanity URLs, advertisers are technically free to commit fraud as they please.
How did we get here?
The adtech industry may excuse these practices as an unavoidable consequence of the complexity of online advertising. However, this overlooks the responsibility that these companies bear for prioritizing profit over user safety and the integrity of their platforms.
Corporate greed has gotten so out-of-control that companies such as Google, Microsoft, and Brave now all deeply integrate advertising technologies at the browser-level, with some effects ranging from battery drain to personal interest tracking, and even taking a cut of the value of your attention.
National security risks
The risk of malvertising and fraud through adtech platforms has become so concerning and prevalent that the FBI now recommends all citizens install ad blockers. Interestingly, some of the FBI’s advice for checking ad authenticity is inadequate in practice. The FBI suggests “Before clicking on an advertisement, check the URL to make sure the site is authentic. A malicious domain name may be similar to the intended URL but with typos or a misplaced letter.” — this is useless advice in the face of unverified vanity URLs. Instead of asking private citizens to block an entire ‘legal’ industry, the FBI should be investigating adtech platforms for systemically enabling link fraud.
Intelligence agencies such as the NSA and CIA also use adblockers in order to keep their personnel safe from malware threats. I anticipate that the US federal government may start requiring adblockers on all federal employee devices at some point in the future.
What can be done? Verification & enforcement
Companies are generally mandated by law to provide true statements to consumers where technically possible. Unverified vanity URLs as a first-class feature flies in the face of these requirements.
Adtech providers should validate ownership of the domain names used within vanity URLs, or alternatively vanity URLs should be banned entirely. Validating domain ownership can easily be done through automated or manual processes where domain name owners place unique keys in their domain name’s DNS records.
A common, yet fundamentally flawed ‘verification’ mechanism that adtech platforms such as Google Ads employ is the use of sampled URL resolution, which involves visiting a website at given points in time from one or more given computers. This technique can easily be bypassed with dynamic redirection software to hide fraud and malware from URL scanning servers.
Petition your elected government officials to let them know that big tech is willingly ignoring their role in the rise of effective link fraud, spurred by their support of unverified vanity URLs. The United States FTC should investigate companies that knowingly enable link fraud through unverified vanity URL systems that are fundamentally impossible to audit.
On a personal level, you can install an adblocker such as uBlock Origin to block advertising, which has a nice added side effect of increasing web browsing privacy and performance.
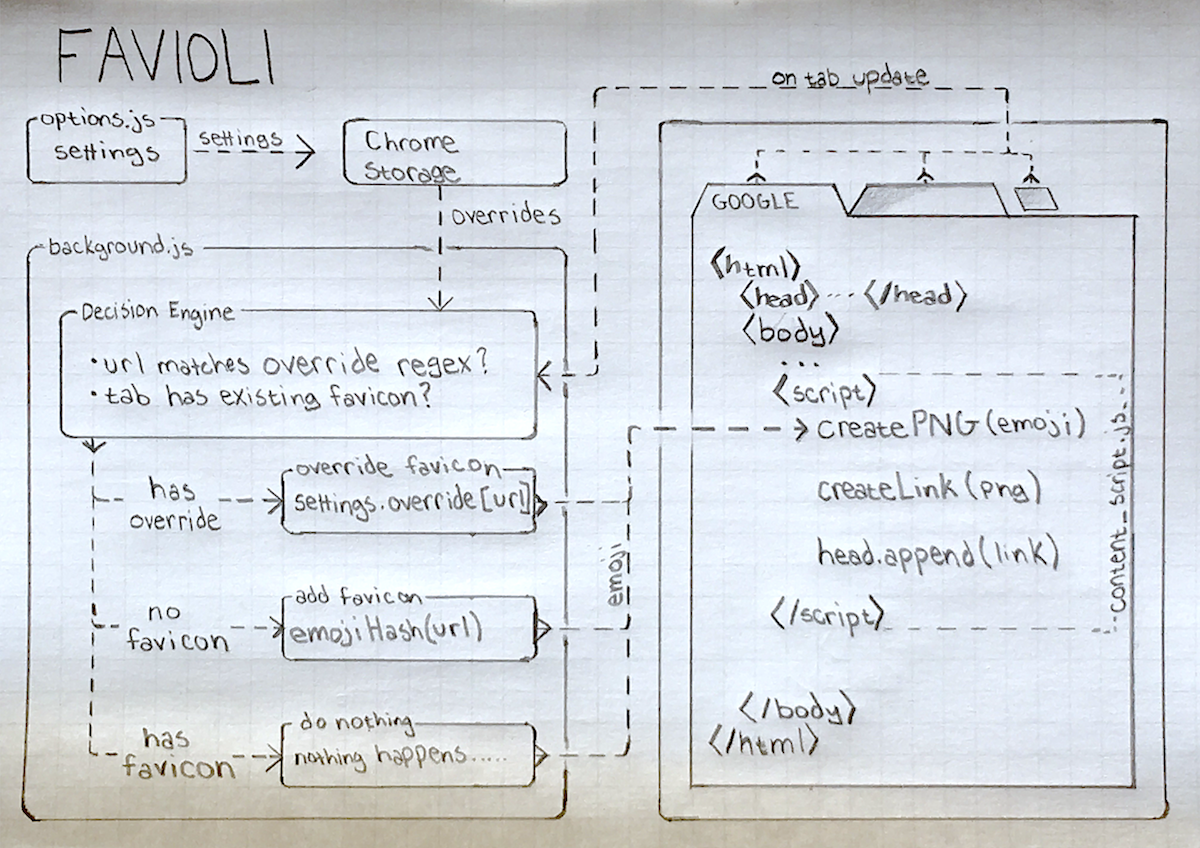
]]> Favioli is a productivity extension that makes it easier to recognize tabs within Chrome.
Favioli is a productivity extension that makes it easier to recognize tabs within Chrome.
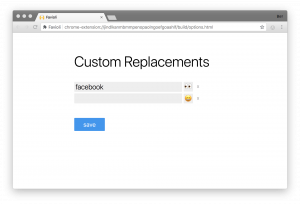
 emojis for 404/500 page responses,
emojis for 404/500 page responses,  for non-https sites or something like that. These would be configured in settings, but could be a fun way to interact with the web.
for non-https sites or something like that. These would be configured in settings, but could be a fun way to interact with the web.

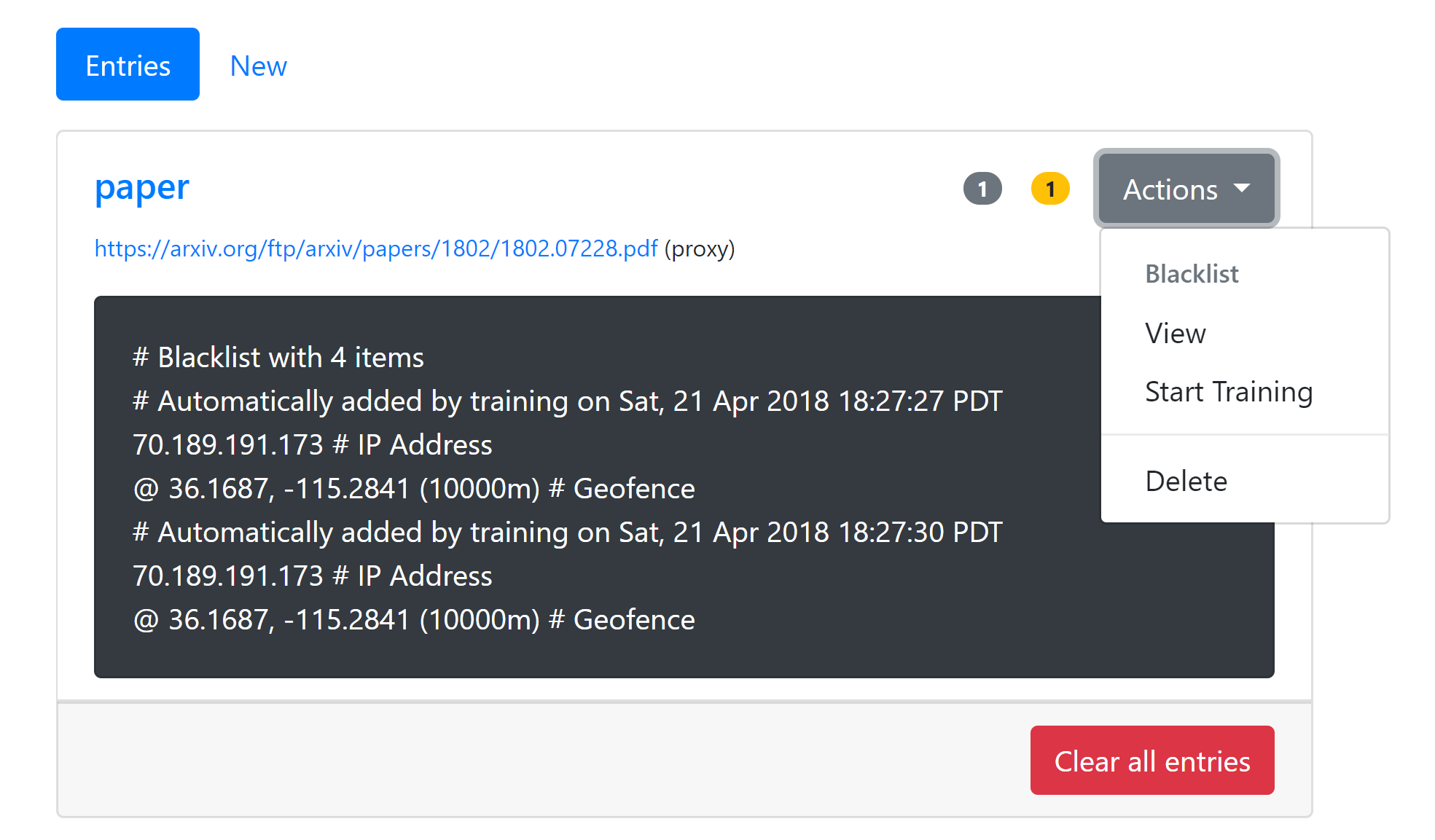
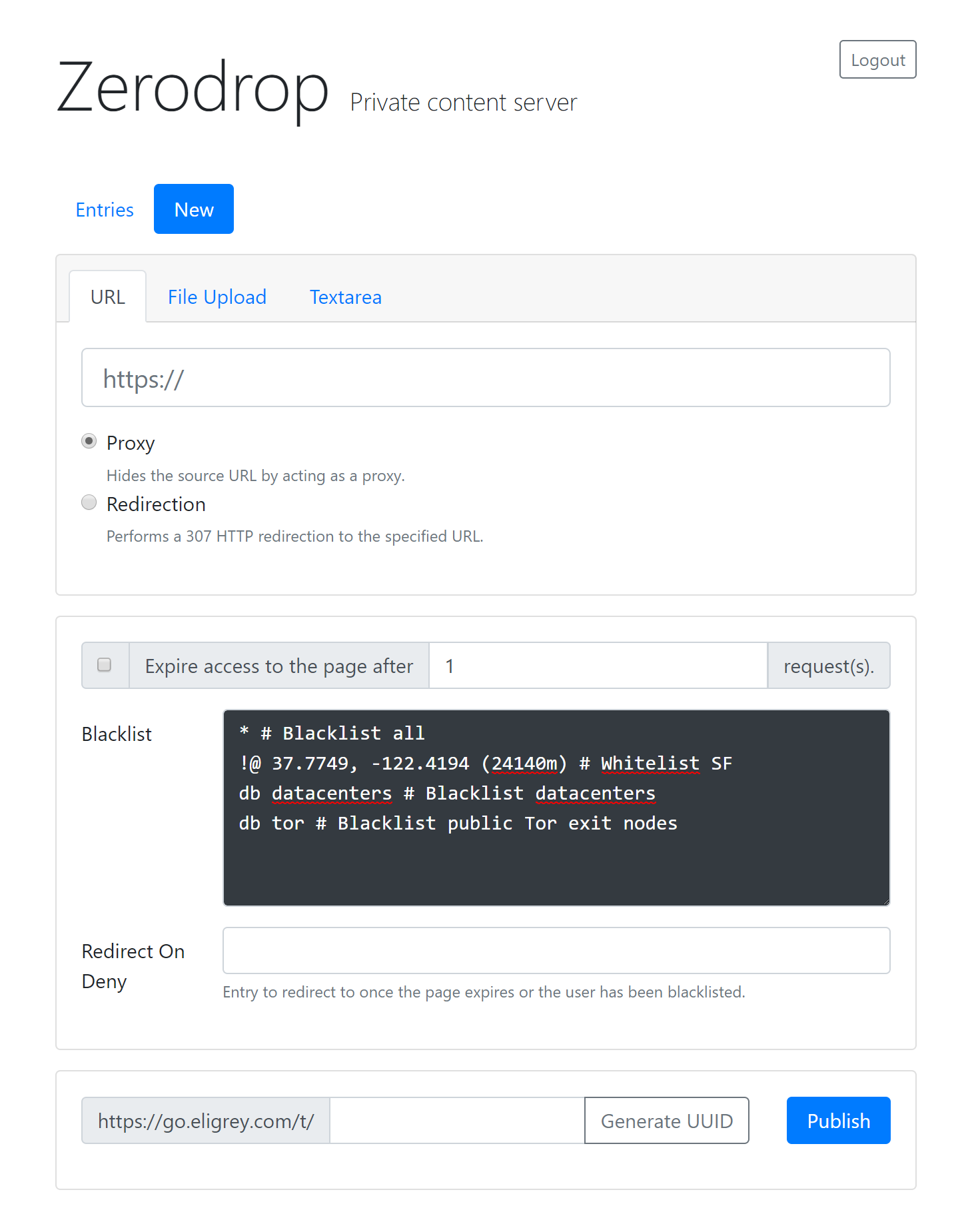
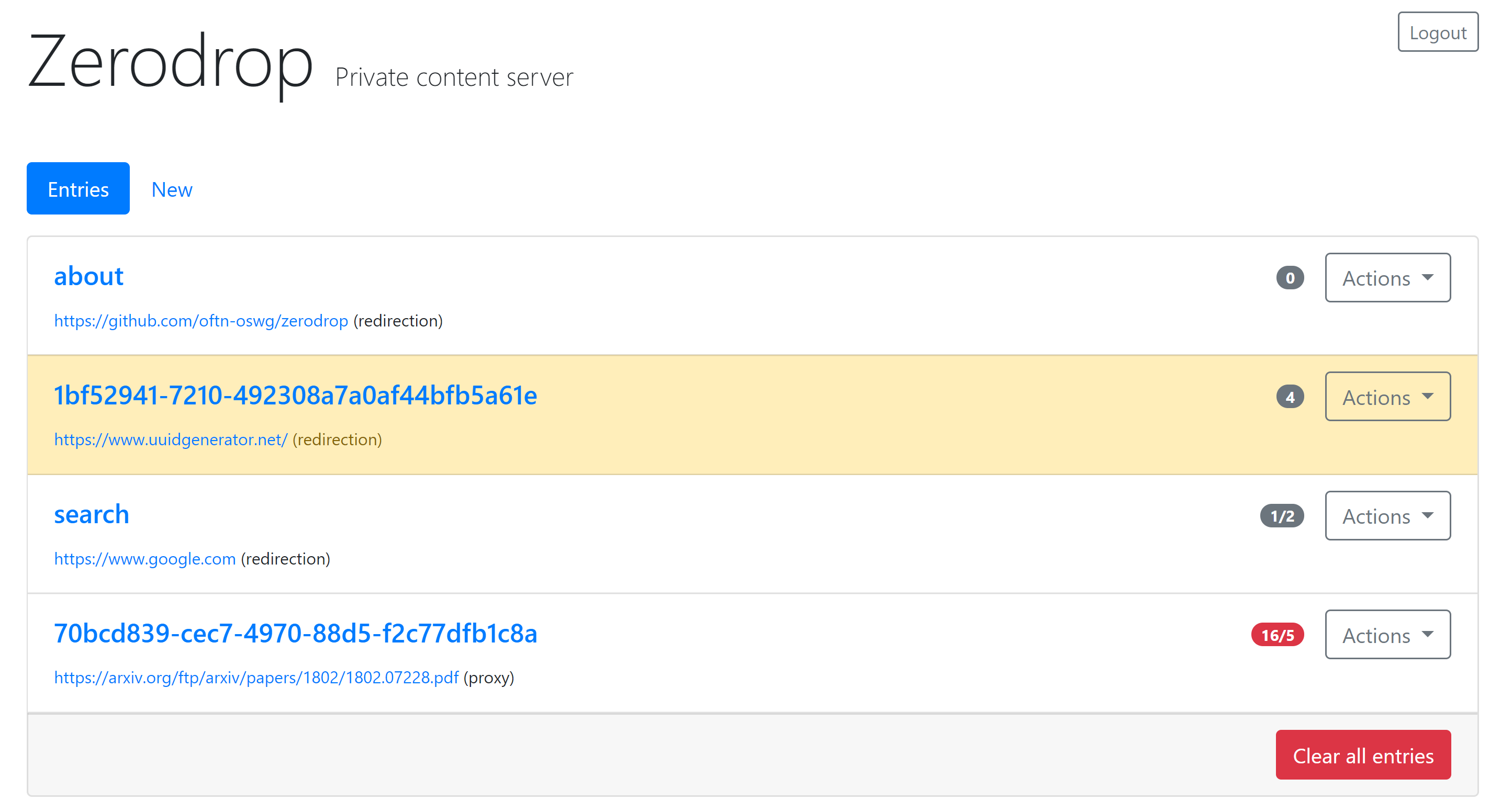
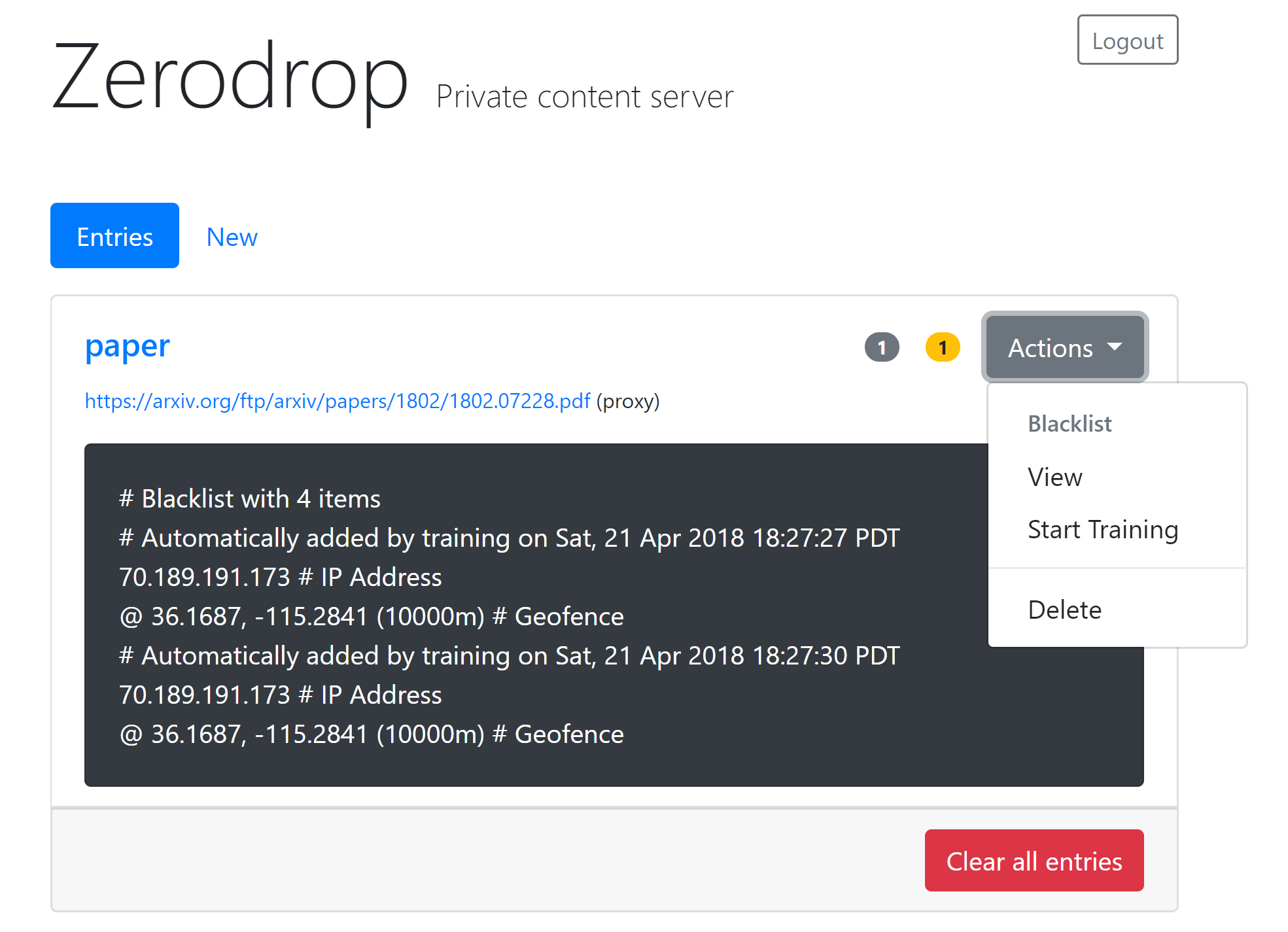
 ” internal identifier. When triggered, Zerodrop will attempt to delete all traces of itself from the host system. External navigation to “
” internal identifier. When triggered, Zerodrop will attempt to delete all traces of itself from the host system. External navigation to “
_/¯")
{kind=link}